【C++】string的模拟实现
文章目录
- 1. string的模拟实现
- 1.构造函数
- 使用new开辟空间
- 优化成全缺省的构造函数
- 2. C_str
- 3. operator[]
- 4.拷贝构造
- 浅拷贝
- 深拷贝
- 5. 赋值
- 三种情况
- 6. 迭代器
- 7.比较(ASCII值)大小
- 8. reserve(扩容)
- 9. push_back(尾插字符)
- 10. append(尾插字符串)
- 11. +=(字符/字符串)
- 12. insert
- 在pos位置前插入字符ch
- 在pos位置前插入字符串str
- 13 .resize
- 14. erase
- 15. 流插入<<
- 16. 流提取 >>
- 2. 整体代码
string底层是一个字符数组
为了跟库里的string区别,所以定义了一个命名空间 将string类包含
1. string的模拟实现
1.构造函数
#pragma once
#include<iostream>
using namespace std;
namespace yzq
{class string{public:string()//无参构造函数//初始化列表:_str(nullptr),_size(0),_capaicty(0){}string(const char*str)//带参构造函数:_str(str),_size(strlen(str)),_capaicty(strlen(str)){}private:char* _str;size_t _size;size_t _capaicty;};void test(){string s1;string s2("hello world");}
}
若写成两个构造函数,一个设置成无参,一个设置成带参,若调用如上的带参构造函数就会报错,将str传给_str,属于权限放大,
为了解决这个问题,可以将_str改为const char*类型,但是无法修改_str所指向的内容,调用operator[]函数就会报错
使用new开辟空间

因为后续要考虑扩容等问题,所以最好是new一块空间
而无参的构造函数为了保持析构都用delete[],所以使用new[]
优化成全缺省的构造函数
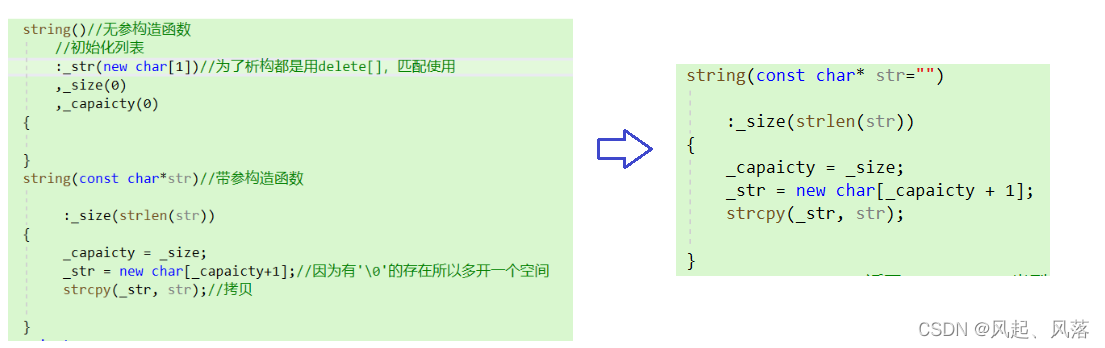
- 不可以将缺省值设置成nullptr,strlen(str)对于str指针解引用,遇到’\0’终止,解引用NULL会报错
- 将缺省值设置成一个空字符串,结尾默认为’\0’
string(const char* str="")//构造函数:_size(strlen(str)){if (_size == 0){_capaicty = 3;}else{_capaicty = _size;}_str = new char[_capaicty + 1];strcpy(_str, str);}
2. C_str
const char* C_str()//返回const char*类型的指针 {return _str;}
返回const char*类型的指针相当于返回字符串
3. operator[]
char& operator[](size_t pos)//operator[]{return _str[pos];}char& operator[](size_t pos)const //函数重载{return _str[pos];}
- 由于可能存在 string与const string类型所以设置成两个函数构成函数重载

调用函数print 需要使用operator[ ]const
而正常遍历 s[i] ,需要调用 operator [ ]
4.拷贝构造
浅拷贝
拷贝构造函数如果不写编译器会自动生成,对于内置类型完成值拷贝或者浅拷贝

- 若使用编译器自动生成的拷贝构造就会报错
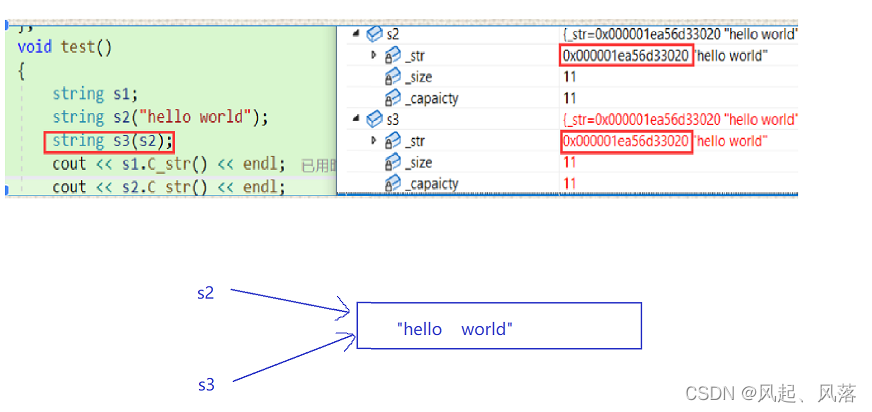
s2与s3发生浅拷贝,导致两个指针都指向同一块空间,一个修改会影响另一个,会析构两次空间
深拷贝

创建一块同样大小的空间,并将原来的数据拷贝下来,这样就是s2与s3指向各自的空间,一个被修改也不会影响另一个
string(const string& s)//拷贝构造:_size(s._size),_capaicty(s._capaicty){_str = new char[_capaicty + 1];//开辟一块空间strcpy(_str, s._str);//将s2拷贝给s1}
5. 赋值
赋值运算符也是默认成员函数,如果不写会进行浅拷贝/值拷贝
三种情况
- 正常赋值会存在以下是那种情况
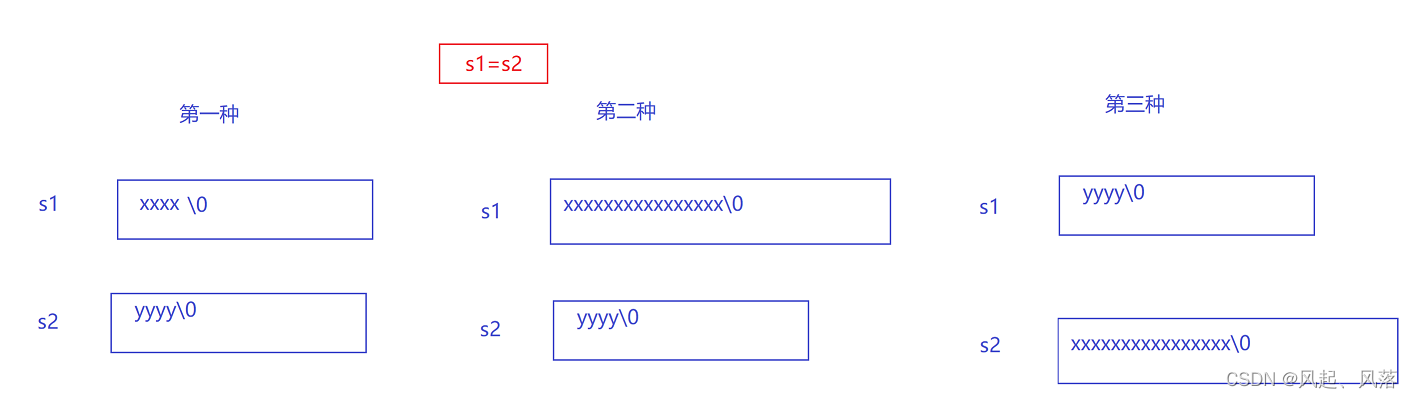
- 若为第一种两者空间大小相同,则进行值拷贝
- 若为第二种s1的空间远大于s2的空间,进行值拷贝会浪费空间,所以系统会按照第三种做法执行
- 若为第三种,s1的空间太小,需要new开辟一块空间,将旧空间销毁,将s2拷贝到新开辟的空间
- 编译器不会这样处理,直接将旧空间释放,再去开新空间,并将值拷贝过来
string& operator=(const string& s)//赋值 s1=s3{if (this != &s)//排除赋值本身的情况{char* tmp = new char[s._capaicty + 1];strcpy(tmp, s._str);delete[] _str;_str = tmp;_size = s._size;_capaicty = s._capaicty;}return *this;}
若释放旧空间,如果new失败了,则破坏原有空间
所以使用一个临时变量tmp接收开辟的空间,
如果new成功将tmp传给_str,若new失败也不会破坏s1空间
6. 迭代器
typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}iterator begin()const //指针指向的内容不能被修改{return _str;}iterator end()const{return _str + _size;}

使用typedef 分别将用iterator代替 char*
const_iterator代替 const char*
7.比较(ASCII值)大小
bool operator==(const string& s)const //s1==s2{return strcmp(_str, s._str)==0;}bool operator<(const string& s)const //s1<s2{return strcmp(_str, s._str) < 0;}bool operator<=(const string& s)const //s1<=s2{return *this < s || *this == s;}bool operator>(const string& s)const //s1>s2{return !(*this <= s);}bool operator>=(const string& s)const //s1>=s2{//复用return *this > s || *this == s;}bool operator!=(const string& s)const //s1!=s2{return !(*this == s);}
- 通过C语言函数strcmp,比较字符串从头开始字符的ASCII值,再通过复用来实现剩下的
- 如果不小心在复用时将const修饰的传给非const成员就会报错,所以括号外面加上const,修饰this指针
8. reserve(扩容)
void reserve(size_t n)//开辟空间{if (n > _capacity)//防止缩容的问题{char* tmp = new char[n + 1];//多开一个'\0'strcpy(tmp, _str);delete[]_str;_str = tmp;_capacity = n;//计算有效}}
reserve主要实现类似扩容的操作
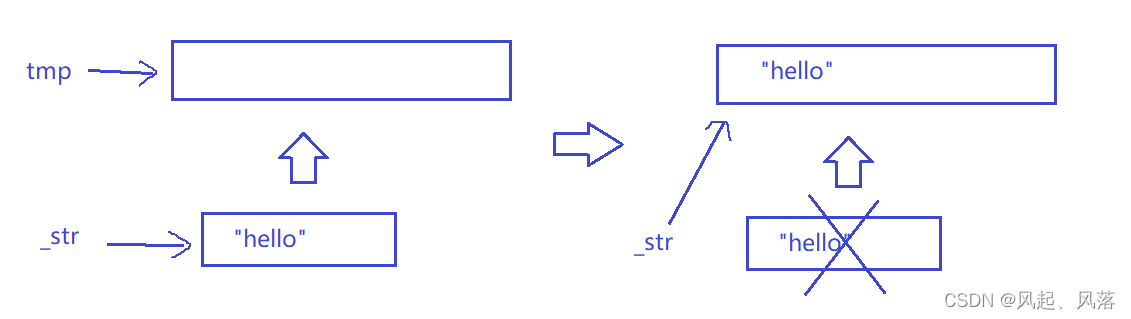
为了防止new失败,所以使用临时变量tmp指向new出来的空间,若new成功,释放旧空间,并将_str指向新空间
9. push_back(尾插字符)
void push_back(char ch)//尾插字符{if (_size + 1 > _capaicty){reserve(2 * _capaicty);//开辟2倍空间}_str[_size] = ch;_size++;}
- 通过reserve进行类似扩容的操作,再将ch赋值给当前最后一个字符
10. append(尾插字符串)
void append(const char* str)//尾插 字符串{ int len = strlen(str);if (_size + len > _capaicty){reserve(_size + len);}strcpy(_str + _size, str);//在原来的字符串后拷贝字符串_size += len;}
通过reserve类似扩容的操作,扩大了字符串长度的空间,并且在原字符串’\0’的位置开始拷贝str字符串
11. +=(字符/字符串)
string& operator+=(char ch)//+= 字符{push_back(ch);return *this;}string& operator+=(const char* str)//+= 字符串 函数重载{append(str);return *this;}
使用使用上面实现好的push_back和append
12. insert
在pos位置前插入字符ch
void insert(size_t pos, char ch)//在pos位置前插入字符ch{if (_size + 1 > _capacity)//扩容{reserve(2 * _capacity);}size_t end = _size + 1;//'\0'的下一个位置while (end > pos){//把前面传给后面_str[end] = _str[end - 1];end--;}_str[pos] = ch;_size++;}
由于pos与end都是size_t类型,没有负数
所以当while循环条件设置为end>=pos并且pos=0时,end–,end变为负数,计算的是其补码,所以一直成立,无法结束循环
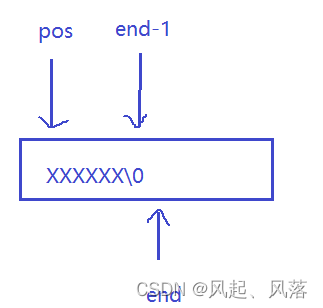
把前面的传给后面的,当end下标为1时,end-1的下标为0,循环结束
在pos位置前插入字符串str
void insert(size_t pos, const char* str)//在pos位置前插入字符串str{int len = strlen(str);if (_size + len > _capacity)//扩容{reserve(_size + len);}size_t end = _size + len;while (end > pos+len-1){//把前面传给后面_str[end] = _str[end-len];end--;}strncpy(_str + pos, str, len);//拷贝len个字节,不包含'\0'_size += len;}
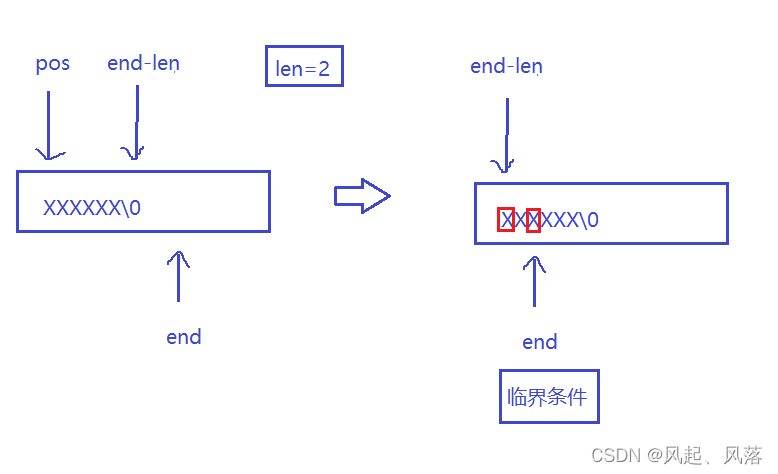
临界条件为保证最后一次下标end减去len,在下标为0的位置上,所以取边界为pos+len
end>pos+len-1 ,最后一次取值即为pos+len
使用strncpy函数,不包含’\0’,将str拷贝给_str+pos下标位置开始的len个字符
13 .resize
void resize(size_t n,char ch)//开辟空间+初始化{if (n <= _size)//删除数据保留前n个{_size = n;_str[n] = '\0';}else //n>_size{if (n >_capacity)//扩容{reserve(n);}int i = _size;while (i < n)//剩余空间初始化为ch{_str[i] = ch;i++;}_size = n;_str[_size] = '\0';}}

分为三种情况
n<size 删除数据
size<n<capacity 剩余空间初始化
n>capacity 扩容+初始化
14. erase
- pos位置开始删除len个数据
static const size_t npos = -1;string& erase(size_t pos = 0, size_t len = npos)//从pos位置开始删除len个数据{if (len==npos||pos+len>=_size){//全部删除_str[pos] = '\0';_size = pos;}else{strcpy(_str + pos, _str +pos+len);//包含'\0'_size -= len;}return *this;}
- pos处于下标为2的位置上,共有两种情况

- 当pos+len<总长度时,使用strcpy函数拷贝,从而覆盖删除要被删除的字符

- 当pos+len大于总长度或者len等于npos时,剩余长度全部删除
15. 流插入<<
- 流插入重载必须实现为友元函数么?
- 不对,使用友元函数是为了在类外面调用类的私有的成员变量,若不需要调用则不用友元函数
ostream& operator<<(ostream& out, const string&s){int i = 0;for (i = 0; i < s.size(); i++){out << s[i] << " ";}return out;}
实现流插入不可以调用C_str(),因为C_str()返回的是一个字符串,遇见’\0’就会结束,但若打印结果有好几个’\0’,则遇见第一个就会结束,不符合预期
16. 流提取 >>
输入多个值,C++规定 空格/换行是值与值之间的区分
istream& operator>>(istream& in, string& s)//>>{//错误写法char ch;in >> ch;while (ch != ' ' && ch != '\n'){s += ch;in >> ch;}return in;}
- 上述代码在循环中无法找到空格/换行,导致循环无法停止
- 输入的数据在缓冲区中,使用循环在缓冲区中提取数据,但是空格/换行不在缓冲区中,因为认为它是多个值之间的间隔
- 使用get就不会认为空格/换行是多个值之间的间隔,若遇见空格/换行就会存储缓冲区中等待提取
istream& operator>>(istream& in, string& s)//>>{s.clear();char ch = in.get();char buf[128];size_t index = 0;while (ch != ' ' && ch != '\n'){buf[index++] = ch;if (index == 127)//为了防止频繁扩容{buf[127] = '\0';s += buf;index = 0;}ch = in.get();}if (index != 0){buf[index] = '\0';s += buf;}return in;}
- 当需要输入的string对象中有值存在时,需要先使用clear清空,再输入新的数据
- 为了避免频繁扩容,使用一个128的字符数组接收,若输入的数据比128小,跳出循环将数组中的数据传给string类s,若输入的数据比128大,则将字符数组整体传给string类s,再正常扩容
2. 整体代码
#define _CRT_SECURE_NO_WARNINGS
#include<iostream>
using namespace std;
namespace yzq
{class string{public://string()//无参构造函数// //初始化列表// :_str(new char[1])//为了析构都是用delete[],匹配使用// ,_size(0)// ,_capaicty(0)//{// _str[0] = '\0';//}//string(const char*str)//带参构造函数// // :_size(strlen(str))//{// _capaicty = _size;// _str = new char[_capaicty+1];//因为有'\0'的存在所以多开一个空间// strcpy(_str, str);//拷贝//}typedef char* iterator;typedef const char* const_iterator;iterator begin(){return _str;}iterator end(){return _str + _size;}iterator begin()const {return _str;}iterator end()const{return _str + _size;}string(const char* str="")//构造函数:_size(strlen(str)){if (_size == 0){_capacity = 3;}else{_capacity = _size;}_str = new char[_capacity + 1];strcpy(_str, str);}string(const string& s)//拷贝构造:_size(s._size),_capacity(s._capacity){//深拷贝_str = new char[_capacity + 1];//开辟一块空间strcpy(_str, s._str);//将s2的值传给s1}string& operator=(const string& s)//赋值 s1=s3{if (this != &s)//排除赋值本身的情况{char* tmp = new char[s._capacity + 1];strcpy(tmp, s._str);delete[] _str;_str = tmp;_size = s._size;_capacity = s._capacity;}return *this;}size_t size()const{return _size;}const char* C_str()//返回const char*类型的指针 {return _str;}char& operator[](size_t pos)//operator[]{return _str[pos];}char& operator[](size_t pos)const //函数重载{return _str[pos];}bool operator==(const string& s)const //s1==s2{return strcmp(_str, s._str)==0;}bool operator<(const string& s)const //s1<s2{return strcmp(_str, s._str) < 0;}bool operator<=(const string& s)const //s1<=s2{return *this < s || *this == s;}bool operator>(const string& s)const //s1>s2{return !(*this <= s);}bool operator>=(const string& s)const //s1>=s2{//复用return *this > s || *this == s;}bool operator!=(const string& s)const //s1!=s2{return !(*this == s);}void reserve(size_t n)//开辟空间{if (n > _capacity)//防止缩容的问题{char* tmp = new char[n + 1];//多开一个'\0'strcpy(tmp, _str);delete[]_str;_str = tmp;_capacity = n;//计算有效}}void resize(size_t n,char ch)//开辟空间+初始化{if (n <= _size)//删除数据保留前n个{_size = n;_str[n] = '\0';}else //n>_size{if (n >_capacity)//扩容{reserve(n);}int i = _size;while (i < n){_str[i] = ch;i++;}_size = n;_str[_size] = '\0';}}void push_back(char ch)//尾插字符{if (_size + 1 > _capacity){reserve(2 * _capacity);//开辟2倍空间}_str[_size] = ch;_size++;//ch是一个字符,所以用单独处理'\0'_str[_size] = '\0';}void append(const char* str)//尾插 字符串{ int len = strlen(str);if (_size + len > _capacity){reserve(_size + len);}strcpy(_str + _size, str);//在原来的字符串后拷贝字符串_size += len;//str是一个字符串,本身带'\0'}string& operator+=(char ch)//+= 字符{push_back(ch);return *this;}string& operator+=(const char* str)//+= 字符串 函数重载{append(str);return *this;}string& insert(size_t pos, char ch)//在pos位置前插入字符ch{if (_size + 1 > _capacity)//扩容{reserve(2 * _capacity);}size_t end = _size + 1;while (end > pos){//把前面传给后面_str[end] = _str[end - 1];end--;}_str[pos] = ch;_size++;return *this;}string& insert(size_t pos, const char* str)//在pos位置前插入字符串str{int len = strlen(str);if (_size + len > _capacity)//扩容{reserve(_size + len);}size_t end = _size + len;while (end > pos+len-1){//把前面传给后面_str[end] = _str[end-len];end--;}strncpy(_str + pos, str, len);//拷贝len个字节,不包含'\0'_size += len;return *this;}static const size_t npos = -1;string& erase(size_t pos = 0, size_t len = npos)//从pos位置开始删除len个数据{if (len==npos||pos+len>=_size){//全部删除_str[pos] = '\0';_size = pos;}else{strcpy(_str + pos, _str +pos+len);//包含'\0'_size -= len;}return *this;}void swap(string &s)//交换{std::swap(_str, s._str);std::swap(_capacity, s._capacity);std::swap(_size, s._size);}size_t find(char c, size_t pos =0){int i = 0;for (i = pos; i < size(); i++){if (_str[i] == c){return i;}}return npos; }size_t find(const char* str, size_t pos = 0)//从pos位置开始找子串{char*p=strstr(_str+pos, str);if (p == nullptr){return npos;}else{return p - _str;//指针相减为个数}}void clear()//清空{_str[0] = '\0';}~string()//析构{delete[]_str;_str = nullptr;_size = 0;_capacity = 0;}private:char* _str;size_t _size;size_t _capacity;};ostream& operator<<(ostream& out, const string&s)//<<{int i = 0;for (i = 0; i < s.size(); i++){out << s[i];}return out;}istream& operator>>(istream& in, string& s)//>>{s.clear();char ch = in.get();char buf[128];size_t index = 0;while (ch != ' ' && ch != '\n'){buf[index++] = ch;if (index == 127)//为了防止频繁扩容{buf[127] = '\0';s += buf;index = 0;}ch = in.get();}if (index != 0){buf[index] = '\0';s += buf;}return in;}void print(const string& s){string::const_iterator it = s.begin();while (it != s.end()){cout << *it << " ";it++;}cout << endl;}void test(){string s1;cin >> s1;cout << s1;}
}相关文章:
【C++】string的模拟实现
文章目录1. string的模拟实现1.构造函数使用new开辟空间优化成全缺省的构造函数2. C_str3. operator[]4.拷贝构造浅拷贝深拷贝5. 赋值三种情况6. 迭代器7.比较(ASCII值)大小8. reserve(扩容)9. push_back(尾插字符)10. append(尾插字符串)11. (字符/字符串)12. insert在pos位置…...
前端借助Canvas实现压缩base64图片两种方法
一、具体代码 1、利用canvas压缩图片方法一 // 第一种压缩图片方法(图片base64,图片类型,压缩比例,回调函数)// 图片类型是指 image/png、image/jpeg、image/webp(仅Chrome支持)// 该方法对以上三种图片类型都适用 压缩结果的图片base64与原类型相同// …...
用ChatGPT生成Excel公式,太方便了
ChatGPT 自去年 11 月 30 日 OpenAI 重磅推出以来,这款 AI 聊天机器人迅速成为 AI 界的「当红炸子鸡」。一经发布,不少网友更是痴迷到通宵熬夜和它对话聊天,就为了探究 ChatGPT 的应用天花板在哪里,经过试探不少人发现,…...
【Kubernetes 企业项目实战】09、Rancher 2.6 管理 k8s-v1.23 及以上版本高可用集群
目录 一、Rancher 介绍 1.1Rancher简介 1.2 Rancher 和 k8s 的区别 1.3 Rancher 企业使用案例 二、安装 Rancher 2.1 初始化环境 2.2 安装 Rancher 2.3 登录 Rancher 平台 三、通过 Rancher 管理已存在的 k8s 集群 3.1 配置 rancher 3.2 导入 k8s 四、通过 Ranc…...
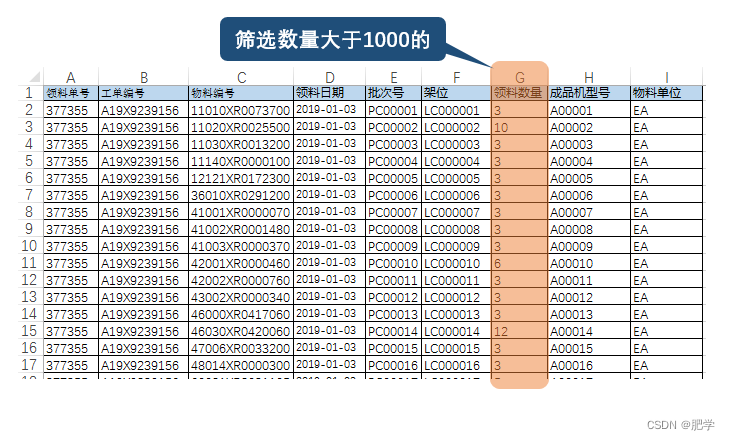
在Excel中按条件筛选数据并存入新的表
案例 老板想要看去年每月领料数量大于1000的数据。手动筛选并复制粘贴出来,需要重复操作12次,实在太麻烦了,还是让Python来做吧。磨刀不误砍柴工,先整理一下思路: 1读取原表,将数量大于1000的数据所对应的行整行提取(如同在excel表中按数字筛选大于1000的) 2将提取的数…...

【面试题】MySQL索引相关知识点
1.什么是索引 索引是存储引擎快速查找记录的一种数据结构,就类似书的目录,通过目录可以快速的查找到想要查找的内容 2.索引的特点 特点:索引是基于数据引擎的,不同的数据引擎实现索引的方式不一定相同 好处:通过索引…...
MySQL索引类型及原理?一文读懂
一、什么是MySQL索引? MySQL索引是一种数据结构,用于提高数据库查询的性能。它类似于一本书的目录,通过在表中存储指向数据行的引用,使得查询数据的速度更快。 在MySQL中,索引通常是在表上定义的,它们可以…...
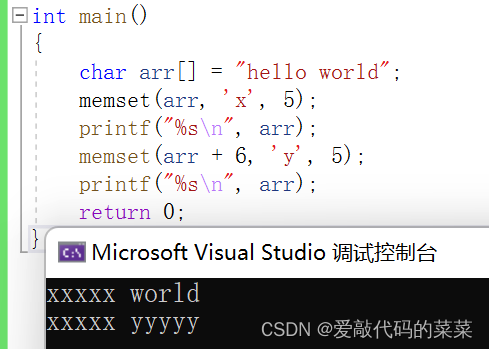
【C语言】字符分类函数+内存函数
目录 1.字符函数 1.1字符分类函数 1.2.字符转换函数 //统一字符串中的大小写 2.内存处理函数 2.1内存拷贝函数memcpy //模拟实现memcpy 2.2内存移动函数memmove //模拟实现memmove 2.3内存比较函数memcmp 2.4内存设置函数memset 1.字符函数 1.1字符分类函数 头文…...

高通平台开发系列讲解(SIM卡篇)SIM卡基础概念
文章目录 一、SIM卡基本定义二、卡的类型三、SIM卡的作用三、SIM卡基本硬件结构四、SIM卡的内部物理单元五、卡文件系统沉淀、分享、成长,让自己和他人都能有所收获!😄 📢本篇文章将介绍SIM的相关组件。 一、SIM卡基本定义 SIM卡是一种智能卡(ICC Card/UICC Card) SIM…...

记录一次ubuntu下配置ssh登录出现的问题
现象描述: 1. 配置完服务器端公钥和本地的私钥之后,ssh登录始终会让输入密码,用ssh -vvv rootip 查看发现发送密钥之后就没反应了。 本机debug info: debug1: Trying private key: C:\Users\wangc/.ssh/id_xxxx (私钥文件) debug3…...

深度剖析数据在内存中的存储(下)(适合初学者)
上篇讲解了整形在内存中的存储方式,这篇文章就来继续讲解浮点数在内存中的存储方式。 上篇地址: (5条消息) 深度剖析数据在内存中的存储(上)_陈大大陈的博客-CSDN博客 目录: 3.浮点型在内存中的存储 3.1.浮点数的…...
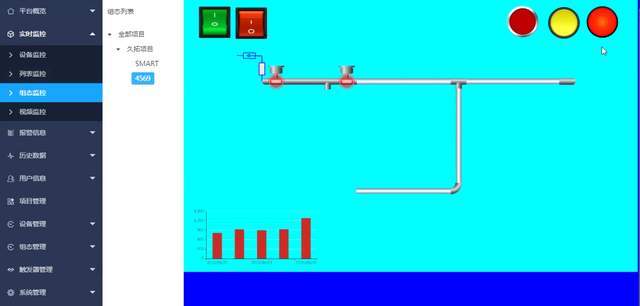
智慧物联网系统源码:一个用于数据的收集、处理、可视化、设备管理、设备预警、报警的平台
项目简介: 一个用于数据的收集、处理、可视化、设备管理、设备预警、报警的平台,通过平台将所有设备连接起来,为上层应用提供设备的管理、数据收集、远程控制等核心物联网功能。 支持支持远程对设备进行实时监控、故障排查、远程控制&#…...

2023年,拥有软考证书在这些地区可以领取福利补贴
众所周知,软考的含金量很高,比如可以入户、领取技能补贴、抵扣个税、以考代评、招投标加分,入专家库… 今天小编给大家收集了拥有软考证书可以领取软考福利的地区,希望对大家有所帮助! 【深圳】 入户 ①核准类入户:…...

使用Unity在材质球上实现绘画:详细解释每一行Shader代码!
在Unity中实现在材质球上绘画可以使用下面这个步骤:创建一个基础的材质球:在Unity的项目面板中创建一个新材质球,然后将其分配给您要绘画的对象。创建一个Shader:为了实现在材质球上绘画,您需要使用一种特殊的Shader。…...

Tesseract 4.0训练字库并且识别训练后的图片
各个工具下载链接在文章底部! 重要!!自己先创建一个空文件夹(名字随意),用来保存训练后的模型 ,还需要在里面创建一个 名称为tessdata 的文件夹 ,必须叫这个名 可以先使用下载后的进行测试训练(只需要把ja…...

ChatGPT热潮背后,金融行业大模型应用路在何方?——金融行业大模型应用探索
ChatGPT近两个月以来不断引爆热点,对人工智能应用发展的热潮前所未有地高涨,ChatGPT所代表的大模型在语义理解、多轮交互、内容生成中所展现的突出能力令人惊喜。而人工智能技术在金融行业的落地应用仍然面临挑战,虽然已经让大量宝贵的人力从…...

【怎么预防sql注入,以及还有预防其他的什么网络攻击】
SQL注入是一种常见的Web攻击,通过在Web应用程序中注入恶意SQL语句来获取或修改数据库中的数据。为了防止SQL注入,开发者可以采取以下措施: 1、使用参数化查询(Prepared Statement)或存储过程(Stored Proce…...

2023年全国最新机动车签字授权人精选真题及答案4
百分百题库提供机动车签字授权人考试试题、机动车签字授权人考试预测题、机动车签字授权人考试真题、机动车签字授权人证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 11.使用转化炉原理测量氮氧化物的排气分析仪进行排气污…...
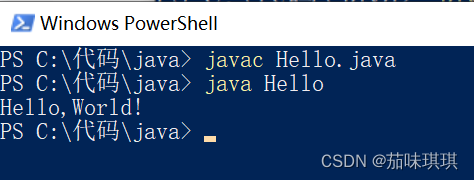
【Java】用记事本实现“HelloWorld”输出
【在进行以下操作前需要下载好JDK并配置好对应的环境变量】 一、在任意文件夹中创建一个新的文本文档文件并写入以下代码 public class Hello{public static void main (String[] args){System.out.print("Hello,World!");} } 二、修改文件名称及文件类型为 Hello.j…...

我希望早点知道的关于成长的建议
人上了年纪,往往在诸如更加闭塞,更加固执这些缺点之外,再多出来一个缺点:那就是动不动就爱给别人建议。我当然也未能免俗。有时候会听到同样悲观且固执的过来人告诉我,这些建议说了和没说效果都一样,人们在…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...

Vue 3 + WebSocket 实战:公司通知实时推送功能详解
📢 Vue 3 WebSocket 实战:公司通知实时推送功能详解 📌 收藏 点赞 关注,项目中要用到推送功能时就不怕找不到了! 实时通知是企业系统中常见的功能,比如:管理员发布通知后,所有用户…...

LUA+Reids实现库存秒杀预扣减 记录流水 以及自己的思考
目录 lua脚本 记录流水 记录流水的作用 流水什么时候删除 我们在做库存扣减的时候,显示基于Lua脚本和Redis实现的预扣减 这样可以在秒杀扣减的时候保证操作的原子性和高效性 lua脚本 // ... 已有代码 ...Overridepublic InventoryResponse decrease(Inventor…...
深入理解 C++ 左值右值、std::move 与函数重载中的参数传递
在 C 编程中,左值和右值的概念以及std::move的使用,常常让开发者感到困惑。特别是在函数重载场景下,如何合理利用这些特性来优化代码性能、确保语义正确,更是一个值得深入探讨的话题。 在开始之前,先提出几个问题&…...
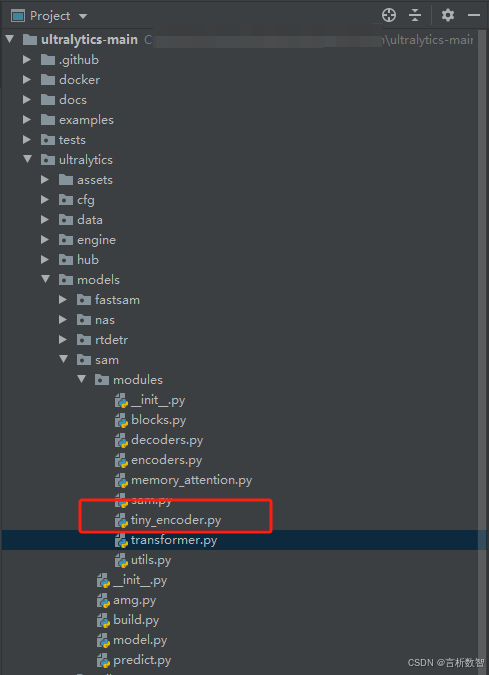
开源项目实战学习之YOLO11:12.6 ultralytics-models-tiny_encoder.py
👉 欢迎关注,了解更多精彩内容 👉 欢迎关注,了解更多精彩内容 👉 欢迎关注,了解更多精彩内容 ultralytics-models-sam 1.sam-modules-tiny_encoder.py2.数据处理流程3.代码架构图(类层次与依赖)blocks.py: 定义模型中的各种模块结构 ,如卷积块、残差块等基础构建…...

win11部署suna
参考链接 项目链接 沙盒链接 数据库链接 本文介绍 本文只为项目的辅助,手把手太麻烦 执行步骤 1.下载代码 git clone https://github.com/kortix-ai/suna.git cd suna2.配置环境(在Anaconda Prompt上执行) python setup.py3.运行代码 …...

K8S认证|CKS题库+答案| 8. 沙箱运行容器 gVisor
目录 8. 沙箱运行容器 gVisor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、官网找模板 3)、创建 RuntimeClass 4)、 将命名空间为 server 下的 Pod 引用 RuntimeClass 5)…...