计算机竞赛 行人重识别(person reid) - 机器视觉 深度学习 opencv python
文章目录
- 0 前言
- 1 技术背景
- 2 技术介绍
- 3 重识别技术实现
- 3.1 数据集
- 3.2 Person REID
- 3.2.1 算法原理
- 3.2.2 算法流程图
- 4 实现效果
- 5 部分代码
- 6 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 深度学习行人重识别(person reid)系统
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:5分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 技术背景
行人重识别技术,是智能视频监控系统的关键技术之一,其研宄是针对特定目标行人的视频检索识别问题。行人再识别是一种自动的目标判定识别技术,它综合地运用了计算机视觉技术、机器学习、视频处理、图像分析、模式识别等多种相关技术于监控系统中,其主要描述的是在多个无重叠视域的摄像头监控环境之下,通过相关算法判断在某个镜头下出现过的感兴趣的目标人物是否在其他摄像头下再次出现。
2 技术介绍
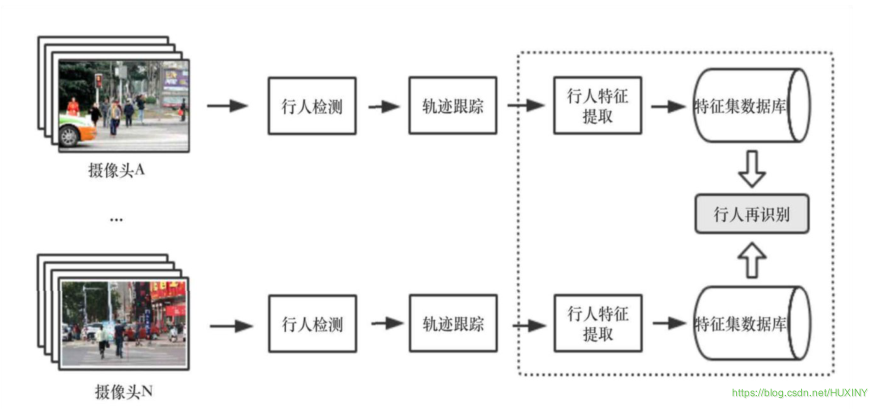
在视频监控系统中,行人再识别任务的整体框架如下图所示:
—个监控系统由多个视域不相交的监控摄像头组成,摄像机的位置可以随时更改,同时也可以随时增加或减少摄像机。不两监控摄像头所摄取的画面、视角等各不相同。在这样的监控系统中,对行人的动向监测是,至关重要的。
对行人的监控主要基于以下三个基本的模块:
-
行人检测:
行人检测的目标是在图片中定位到行人的具体位置。这一步骤仅涉及到对于静止的单张图片的处理,而没有动态的处理,没有时间序列上的相关分析。 -
行人轨迹跟踪:
行人轨迹跟踪的主要任务是在一段时间内提供目标任务的位置移动信息。与行人检测不同,轨迹跟踪与时间序列紧密相关。行人轨迹跟踪是在行人检测的基础上进行的。 -
行人再识别:
行人再识别任务的目标是在没有相重合视域的摄像头或摄像机网络内的不同背景下的许多行人中中识别某个特定行人。行人再识别的
在此基础上,用训练出的模型进行学习从而判断得出某个摄像头下的行人与另一摄像头下的目标人物为同一个人。在智能视频监控系统中的行人再识别任务具有非常广阔的应用前景。行人再识别的应用与行人检测、目标跟踪、行人行为分析、敏感事件检测等等都有着紧密的联系,这些分析处理技术对于公安部门的刑侦工作和城市安防建设工作有着重要的意义。
3 重识别技术实现
3.1 数据集
目前行人再识别的研究需要大量的行人数据集。行人再识别的数据集主要是通过在不同区域假设无重叠视域的多个摄像头来采集拍摄有行人图像的视频,然后对视频提取帧,对于视频帧图像采用人工标注或算法识别的方式进行人体检测及标注来完成的。行人再识别数据集中包含了跨背景、跨时间、不同拍摄角度下、各种不同姿势的行人图片,如下图所示。

3.2 Person REID
3.2.1 算法原理
给定N个不同的行人从不同的拍摄视角的无重叠视域摄像机捕获的图像集合,行人再识别的任务是学习一个模型,该模型可以尽可能减小行人姿势和背景、光照等因素带来的影响,从而更好地对行人进行整体上的描述,更准确地对不同行人图像之间的相似度进行衡量。
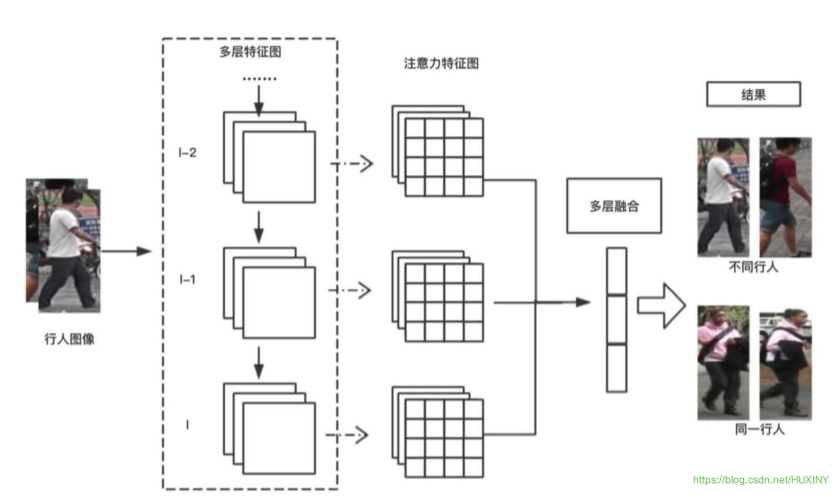
我这里使用注意力相关的特征的卷积神经网络。该基础卷积神经网络架构可以由任何卷积神经网络模型代替,例如,VGG-19,ResNet-101。
该算法的核心模块在于注意力学习模型。
3.2.2 算法流程图
4 实现效果
在多行人场景下,对特定行人进行寻找

5 部分代码
import argparseimport timefrom sys import platformfrom models import *from utils.datasets import *from utils.utils import *from reid.data import make_data_loaderfrom reid.data.transforms import build_transformsfrom reid.modeling import build_modelfrom reid.config import cfg as reidCfgdef detect(cfg,data,weights,images='data/samples', # input folderoutput='output', # output folderfourcc='mp4v', # video codecimg_size=416,conf_thres=0.5,nms_thres=0.5,dist_thres=1.0,save_txt=False,save_images=True):# Initializedevice = torch_utils.select_device(force_cpu=False)torch.backends.cudnn.benchmark = False # set False for reproducible resultsif os.path.exists(output):shutil.rmtree(output) # delete output folderos.makedirs(output) # make new output folder############# 行人重识别模型初始化 #############query_loader, num_query = make_data_loader(reidCfg)reidModel = build_model(reidCfg, num_classes=10126)reidModel.load_param(reidCfg.TEST.WEIGHT)reidModel.to(device).eval()query_feats = []query_pids = []for i, batch in enumerate(query_loader):with torch.no_grad():img, pid, camid = batchimg = img.to(device)feat = reidModel(img) # 一共2张待查询图片,每张图片特征向量2048 torch.Size([2, 2048])query_feats.append(feat)query_pids.extend(np.asarray(pid)) # extend() 函数用于在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表)。query_feats = torch.cat(query_feats, dim=0) # torch.Size([2, 2048])print("The query feature is normalized")query_feats = torch.nn.functional.normalize(query_feats, dim=1, p=2) # 计算出查询图片的特征向量############# 行人检测模型初始化 #############model = Darknet(cfg, img_size)# Load weightsif weights.endswith('.pt'): # pytorch formatmodel.load_state_dict(torch.load(weights, map_location=device)['model'])else: # darknet format_ = load_darknet_weights(model, weights)# Eval modemodel.to(device).eval()# Half precisionopt.half = opt.half and device.type != 'cpu' # half precision only supported on CUDAif opt.half:model.half()# Set Dataloadervid_path, vid_writer = None, Noneif opt.webcam:save_images = Falsedataloader = LoadWebcam(img_size=img_size, half=opt.half)else:dataloader = LoadImages(images, img_size=img_size, half=opt.half)# Get classes and colors# parse_data_cfg(data)['names']:得到类别名称文件路径 names=data/coco.namesclasses = load_classes(parse_data_cfg(data)['names']) # 得到类别名列表: ['person', 'bicycle'...]colors = [[random.randint(0, 255) for _ in range(3)] for _ in range(len(classes))] # 对于每种类别随机使用一种颜色画框# Run inferencet0 = time.time()for i, (path, img, im0, vid_cap) in enumerate(dataloader):t = time.time()# if i < 500 or i % 5 == 0:# continuesave_path = str(Path(output) / Path(path).name) # 保存的路径# Get detections shape: (3, 416, 320)img = torch.from_numpy(img).unsqueeze(0).to(device) # torch.Size([1, 3, 416, 320])pred, _ = model(img) # 经过处理的网络预测,和原始的det = non_max_suppression(pred.float(), conf_thres, nms_thres)[0] # torch.Size([5, 7])if det is not None and len(det) > 0:# Rescale boxes from 416 to true image size 映射到原图det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()# Print results to screen image 1/3 data\samples\000493.jpg: 288x416 5 persons, Done. (0.869s)print('%gx%g ' % img.shape[2:], end='') # print image size '288x416'for c in det[:, -1].unique(): # 对图片的所有类进行遍历循环n = (det[:, -1] == c).sum() # 得到了当前类别的个数,也可以用来统计数目if classes[int(c)] == 'person':print('%g %ss' % (n, classes[int(c)]), end=', ') # 打印个数和类别'5 persons'# Draw bounding boxes and labels of detections# (x1y1x2y2, obj_conf, class_conf, class_pred)count = 0gallery_img = []gallery_loc = []for *xyxy, conf, cls_conf, cls in det: # 对于最后的预测框进行遍历# *xyxy: 对于原图来说的左上角右下角坐标: [tensor(349.), tensor(26.), tensor(468.), tensor(341.)]if save_txt: # Write to filewith open(save_path + '.txt', 'a') as file:file.write(('%g ' * 6 + '\n') % (*xyxy, cls, conf))# Add bbox to the imagelabel = '%s %.2f' % (classes[int(cls)], conf) # 'person 1.00'if classes[int(cls)] == 'person':#plot_one_bo x(xyxy, im0, label=label, color=colors[int(cls)])xmin = int(xyxy[0])ymin = int(xyxy[1])xmax = int(xyxy[2])ymax = int(xyxy[3])w = xmax - xmin # 233h = ymax - ymin # 602# 如果检测到的行人太小了,感觉意义也不大# 这里需要根据实际情况稍微设置下if w*h > 500:gallery_loc.append((xmin, ymin, xmax, ymax))crop_img = im0[ymin:ymax, xmin:xmax] # HWC (602, 233, 3)crop_img = Image.fromarray(cv2.cvtColor(crop_img, cv2.COLOR_BGR2RGB)) # PIL: (233, 602)crop_img = build_transforms(reidCfg)(crop_img).unsqueeze(0) # torch.Size([1, 3, 256, 128])gallery_img.append(crop_img)if gallery_img:gallery_img = torch.cat(gallery_img, dim=0) # torch.Size([7, 3, 256, 128])gallery_img = gallery_img.to(device)gallery_feats = reidModel(gallery_img) # torch.Size([7, 2048])print("The gallery feature is normalized")gallery_feats = torch.nn.functional.normalize(gallery_feats, dim=1, p=2) # 计算出查询图片的特征向量# m: 2# n: 7m, n = query_feats.shape[0], gallery_feats.shape[0]distmat = torch.pow(query_feats, 2).sum(dim=1, keepdim=True).expand(m, n) + \torch.pow(gallery_feats, 2).sum(dim=1, keepdim=True).expand(n, m).t()# out=(beta∗M)+(alpha∗mat1@mat2)# qf^2 + gf^2 - 2 * qf@gf.t()# distmat - 2 * qf@gf.t()# distmat: qf^2 + gf^2# qf: torch.Size([2, 2048])# gf: torch.Size([7, 2048])distmat.addmm_(1, -2, query_feats, gallery_feats.t())# distmat = (qf - gf)^2# distmat = np.array([[1.79536, 2.00926, 0.52790, 1.98851, 2.15138, 1.75929, 1.99410],# [1.78843, 1.96036, 0.53674, 1.98929, 1.99490, 1.84878, 1.98575]])distmat = distmat.cpu().numpy() # : (3, 12)distmat = distmat.sum(axis=0) / len(query_feats) # 平均一下query中同一行人的多个结果index = distmat.argmin()if distmat[index] < dist_thres:print('距离:%s'%distmat[index])plot_one_box(gallery_loc[index], im0, label='find!', color=colors[int(cls)])# cv2.imshow('person search', im0)# cv2.waitKey()print('Done. (%.3fs)' % (time.time() - t))if opt.webcam: # Show live webcamcv2.imshow(weights, im0)if save_images: # Save image with detectionsif dataloader.mode == 'images':cv2.imwrite(save_path, im0)else:if vid_path != save_path: # new videovid_path = save_pathif isinstance(vid_writer, cv2.VideoWriter):vid_writer.release() # release previous video writerfps = vid_cap.get(cv2.CAP_PROP_FPS)width = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))height = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))vid_writer = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*fourcc), fps, (width, height))vid_writer.write(im0)if save_images:print('Results saved to %s' % os.getcwd() + os.sep + output)if platform == 'darwin': # macosos.system('open ' + output + ' ' + save_path)print('Done. (%.3fs)' % (time.time() - t0))if __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--cfg', type=str, default='cfg/yolov3.cfg', help="模型配置文件路径")parser.add_argument('--data', type=str, default='data/coco.data', help="数据集配置文件所在路径")parser.add_argument('--weights', type=str, default='weights/yolov3.weights', help='模型权重文件路径')parser.add_argument('--images', type=str, default='data/samples', help='需要进行检测的图片文件夹')parser.add_argument('-q', '--query', default=r'query', help='查询图片的读取路径.')parser.add_argument('--img-size', type=int, default=416, help='输入分辨率大小')parser.add_argument('--conf-thres', type=float, default=0.1, help='物体置信度阈值')parser.add_argument('--nms-thres', type=float, default=0.4, help='NMS阈值')parser.add_argument('--dist_thres', type=float, default=1.0, help='行人图片距离阈值,小于这个距离,就认为是该行人')parser.add_argument('--fourcc', type=str, default='mp4v', help='fourcc output video codec (verify ffmpeg support)')parser.add_argument('--output', type=str, default='output', help='检测后的图片或视频保存的路径')parser.add_argument('--half', default=False, help='是否采用半精度FP16进行推理')parser.add_argument('--webcam', default=False, help='是否使用摄像头进行检测')opt = parser.parse_args()print(opt)with torch.no_grad():detect(opt.cfg,opt.data,opt.weights,images=opt.images,img_size=opt.img_size,conf_thres=opt.conf_thres,nms_thres=opt.nms_thres,dist_thres=opt.dist_thres,fourcc=opt.fourcc,output=opt.output)6 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
计算机竞赛 行人重识别(person reid) - 机器视觉 深度学习 opencv python
文章目录 0 前言1 技术背景2 技术介绍3 重识别技术实现3.1 数据集3.2 Person REID3.2.1 算法原理3.2.2 算法流程图 4 实现效果5 部分代码6 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 深度学习行人重识别(person reid)系统 该项目…...

在线图片转BASE64、在线BASE64转图片
图片转BASE64、BASE64转图片...

什么是RPA?一文了解RPA发展与进程!
RPA(Robotic Process Automation,机器人流程自动化)是一种通过软件机器人模拟人类在计算机上执行重复性任务的技术。RPA的核心理念是将规则、过程和数据“机器人化”,从而实现对业务流程的自动化。RPA技术可以显著提高企业的工作效…...
【云备份项目】【Linux】:环境搭建(g++、json库、bundle库、httplib库)
文章目录 1. g 升级到 7.3 版本2. 安装 jsoncpp 库3. 下载 bundle 数据压缩库4. 下载 httplib 库从 Win 传输文件到 Linux解压缩 1. g 升级到 7.3 版本 🔗链接跳转 2. 安装 jsoncpp 库 🔗链接跳转 3. 下载 bundle 数据压缩库 安装 git 工具 sudo yum…...

工信部教考中心:什么是《研发效能(DevOps)工程师》认证,拿到证书之后有什么作用!(下篇)丨IDCF
拿到证书有什么用? 提高职业竞争力:通过学习认证培训课程可以提升专业技能,了解项目或产品研发全生命周期的核心原则,掌握端到端的研发效能提升方法与实践,包括组织与协作、产品设计与运营、开发与交付、测试与安全、…...
Linux进程相关管理(ps、top、kill)
目录 一、概念 二、查看进程 1、ps命令查看进程 1)ps显示某个时间点的程序运行情况 2)查看指定的进程信息 2、top命令查看进程 1)信息统计区: 2)进程信息区 3)交互式命令 三、信号控制进程 四、…...
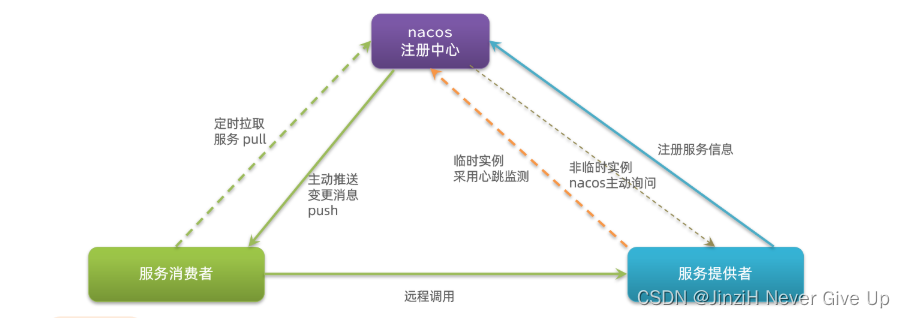
微服务技术栈-Ribbon负载均衡和Nacos注册中心
文章目录 前言一、Ribbon负载均衡1.LoadBalancerInterceptor(负载均衡拦截器)2.负载均衡策略IRule 二、Nacos注册中心1.Nacos简介2.搭建Nacos注册中心3.服务分级存储模型4.环境隔离5.Nacos与Eureka的区别 总结 前言 在上面那个文章中介绍了微服务架构的…...

知识图谱和大语言模型的共存之道
源自:开放知识图谱 “人工智能技术与咨询” 发布 导 读 01 知识图谱和大语言模型的历史 图1 图2 图3 图4 图5 02 知识图谱和大语言模型作为知识库的优缺点 图6 图7 表1 表2 图8 图9 03 知识图谱和大语言模型双知识平台融合 图10 图11 04 总结与展望 声明:公众号转…...

enum, sizeof, typedef
枚举类型enum enum 是 C 语言中的一种自定义类型enum 值是可以根据需要自定义的整型值第一个定义的 enum 值默认为 0默认情况下的 enum 值在前一个定义值得基础上加 1enum 类型的变量只能取定义时得离散值 void code() {enum Color{GREEN, // 0RED 2, // 2BLUE, …...

(二)激光线扫描-相机标定
1. 何为相机标定? 当相机拍摄照片时,我们看到的图像通常与我们实际看到的不完全相同。这是由相机镜头引起的,而且发生的频率比我们想象的要高。 这种图像的改变就是我们所说的畸变。一般来说,畸变是指直线在图像中出现弯曲或弯曲。 这种畸变我们可以通过相机标定来进行解…...

pytorch 数据载入
在PyTorch中,数据载入是训练深度学习模型的重要一环。 本文将介绍三种常用的数据载入方式:Dataset、DataLoader、以及自定义的数据加载器。 使用 Dataset 载入数据 方法: from torch.utils.data import Datasetclass CustomDataset(Dataset…...
angular 在vscode 下的hello world
Angulai 是google 公司开发的前端开发框架。Angular 使用 typescript 作为编程语言。typescript 是Javascript 的一个超集,提升了某些功能。本文介绍运行我的第一个angular 程序。 前面部分参考: Angular TypeScript Tutorial in Visual Studio Code 一…...

Django、Nginx、uWSGI详解及配置示例
一、Django、Nginx、uWSGI的概念、联系与区别 Django、Nginx 和 uWSGI 都是用于构建和运行 Web 应用程序的软件,这三个软件的概念如下: Django:Django 是一个基于 Python 的开源 Web 框架,它提供了一套完整的工具和组件…...
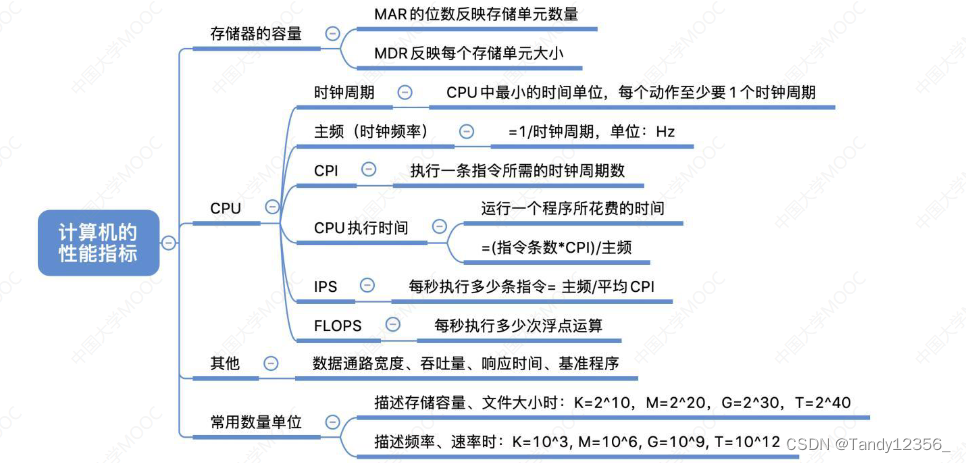
王道考研计算机组成原理——计算机硬件的基础知识
计算机组成原理的基本概念 计算机硬件的针脚都是用来传递信息,传递数据用的: 服务程序包含一些调试程序: 计算机硬件的基本组成 控制器通过电信号来协调其他部件的工作,同时负责解析存储器里存放的程序指令,然后指挥…...

[晕事]今天做了件晕事21;设置代理访问网站的时候需注意的问题
今天在家上班,设置好VPN,通过代理来访问公司内部的一个系统浏览器的反应如下: Hmmm… can’t reach this page ***.com refused to connect. 这个返回的错误,非常的具有迷惑性,提示的意思:拒绝链接…...

Go通过reflect.Value修改值
到目前为止,反射还只是程序中变量的另一种读取方式。然而,在本节中我们将重点讨论如何通过反射机制来修改变量。 回想一下,Go语言中类似x、x.f[1]和*p形式的表达式都可以表示变量,但是其它如x 1和f(2)则不是变量。一个变量就是一…...

【MySql】4- 实践篇(二)
文章目录 1. SQL 语句为什么变“慢”了1.1 什么情况会引发数据库的 flush 过程呢?1.2 四种情况性能分析1.3 InnoDB 刷脏页的控制策略 2. 数据库表的空间回收2.1 innodb_file_per_table参数2.2 数据删除流程2.3 重建表2.4 Online 和 inplace 3. count(*) 语句怎样实现…...

获取多个接口的数据并进行处理,使用Promise.all来等待所有接口请求完成
Promise.all (等待机制) 方法 它调用了多个函数,这些函数返回了Promise对象,每个Promise对象代表了一个异步操作。 然后,使用Promise.all将这多个Promise对象包装成一个新的Promise对象,它会等待所有的Promise都完成(或…...
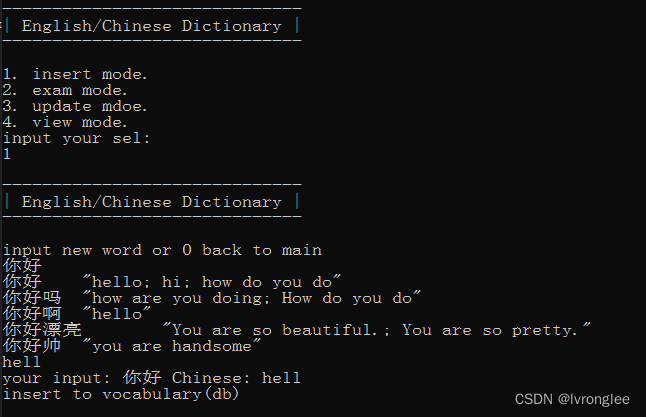
利用C++开发一个迷你的英文单词录入和测试小程序-升级版本
我们现在有了一个本地sqlite3的迷你英文单词小测试工具,需求就跟工作当中一样是不断变更的。这里虚构两个场景,并且一步一步的完成最终升级后的小demo。 场景:数据不依赖本地sqlite3,需要支持远程访问,用目前的restfu…...
实现手撸神经网络230902)
用c动态数组(实现权重矩阵可视化)实现手撸神经网络230902
变量即内存、指针使用的架构原理: 1、用结构struct记录 网络架构,如 float*** ws 为权重矩阵的指针(指针地址); 2、用 = (float*)malloc (Num * sizeof(float)) 给 具体变量分配内存; 3、用 = (float**)malloc( Num* sizeof(float*) ) 给 指向 具体变量(一维数组)的…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

React第五十七节 Router中RouterProvider使用详解及注意事项
前言 在 React Router v6.4 中,RouterProvider 是一个核心组件,用于提供基于数据路由(data routers)的新型路由方案。 它替代了传统的 <BrowserRouter>,支持更强大的数据加载和操作功能(如 loader 和…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...

什么?连接服务器也能可视化显示界面?:基于X11 Forwarding + CentOS + MobaXterm实战指南
文章目录 什么是X11?环境准备实战步骤1️⃣ 服务器端配置(CentOS)2️⃣ 客户端配置(MobaXterm)3️⃣ 验证X11 Forwarding4️⃣ 运行自定义GUI程序(Python示例)5️⃣ 成功效果
ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...