【多级缓存】
文章目录
- 1. JVM进程缓存
- 2. Lua语法
- 3. 实现多级缓存
- 3.1 反向代理流程
- 3.2 OpenResty快速入门
- 4. 查询Tomcat
- 4.1 发送http请求的API
- 4.2 封装http工具
- 4.3 基于ID负载均衡
- 4.4 流程小结
- 5. Redis缓存查询
- 5.1 实现Redis查询
- 6. Nginx本地缓存
- 6.1 本地缓存API
- 6.2 实现本地缓存查询
- 7. 缓存同步
- 7.1 数据同步策略
- 7.2 安装Canal
- 8. 总结
传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库,如图: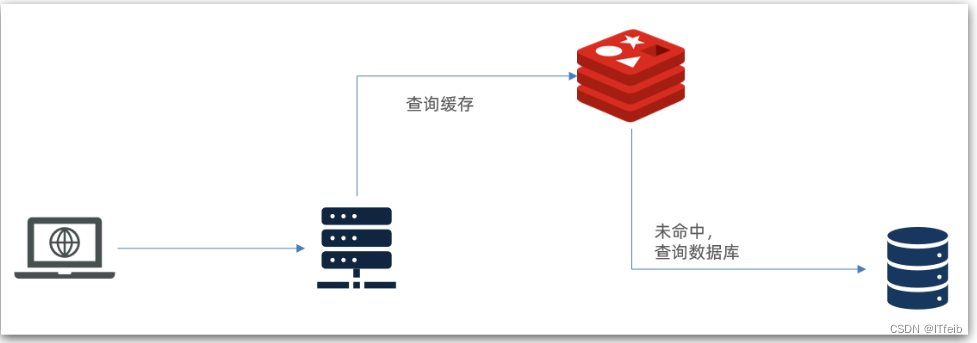
存在下面的问题:
-
请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
-
Redis缓存失效时,会对数据库产生冲击
多级缓存就是充分利用请求处理的每个环节,分别添加缓存,减轻Tomcat压力,提升服务性能
在多级缓存架构中,Nginx内部需要编写本地缓存查询、Redis查询、Tomcat查询的业务逻辑,因此这样的nginx服务不再是一个反向代理服务器,而是一个编写业务的Web服务器了。

可见,多级缓存的关键有两个:
- 一个是在nginx中编写业务,实现nginx本地缓存、Redis、Tomcat的查询
- 另一个就是在Tomcat中实现JVM进程缓存
- Nginx编程则会用到OpenResty框架结合Lua这样的语言。
1. JVM进程缓存
案例:
需求:利用Caffeine实现下列需求:
- 给根据id查询商品的业务添加缓存,缓存未命中时查询数据库
- 给根据id查询商品库存的业务添加缓存,缓存未命中时查询数据库
- 缓存初始大小为100
- 缓存上限为10000
首先,我们需要定义两个Caffeine的缓存对象,分别保存商品、库存的缓存数据。
在item-service的com.heima.item.config包下定义CaffeineConfig类:

然后,修改item-service中的com.heima.item.web包下的ItemController类,添加缓存逻辑:

2. Lua语法
Nginx编程需要用到Lua语言,因此学习Lua的基本语法。
Lua中支持的常见数据类型包括:

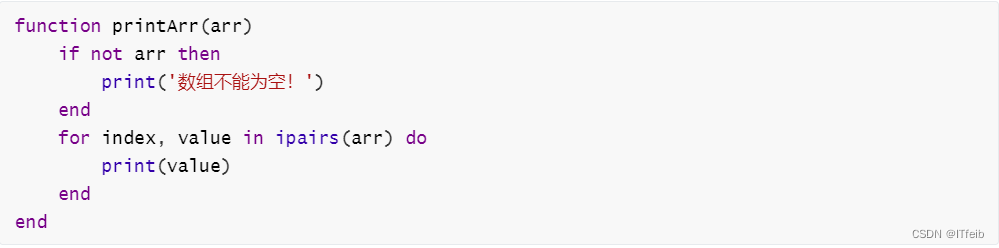
需求:自定义一个函数,可以打印table,当参数为nil时,打印错误信息
3. 实现多级缓存
多级缓存的实现离不开Nginx编程,而Nginx编程又离不开OpenResty。
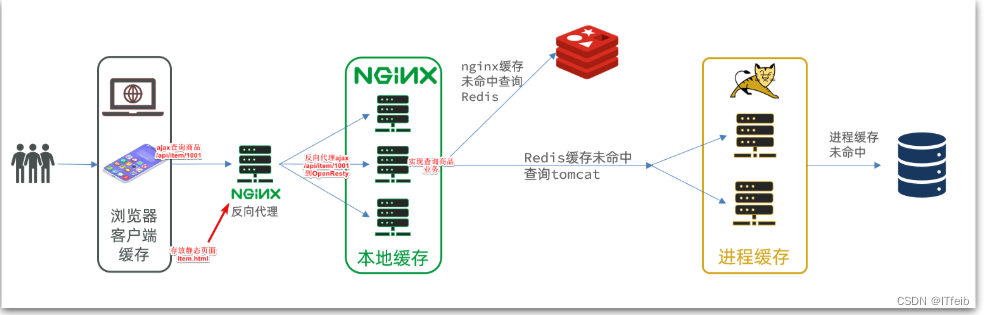
- windows上的nginx用来做反向代理服务,将前端的查询商品的ajax请求代理到OpenResty集群
- OpenResty集群用来编写多级缓存业务
3.1 反向代理流程
现在,商品详情页使用的是假的商品数据。不过在浏览器中,可以看到页面有发起ajax请求查询真实商品数据。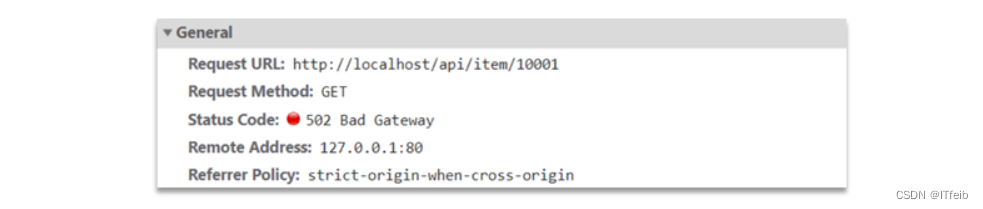
请求地址是localhost,端口是80,就被windows上安装的Nginx服务给接收到了。然后代理给了OpenResty集群:
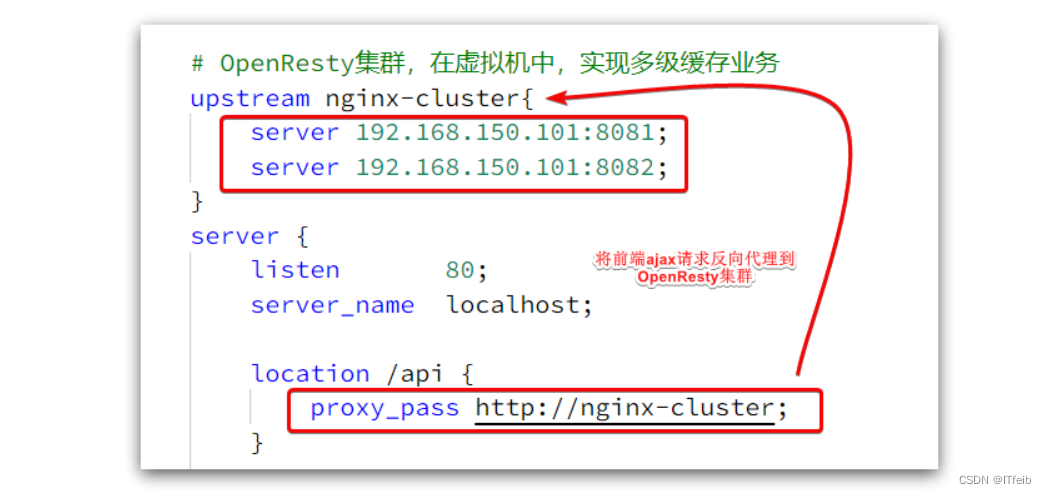
3.2 OpenResty快速入门
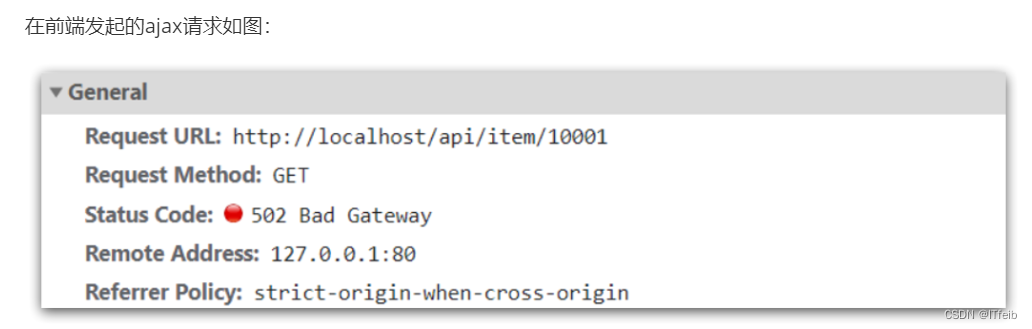
可以看到商品id是以路径占位符方式传递的,因此可以利用正则表达式匹配的方式来获取ID
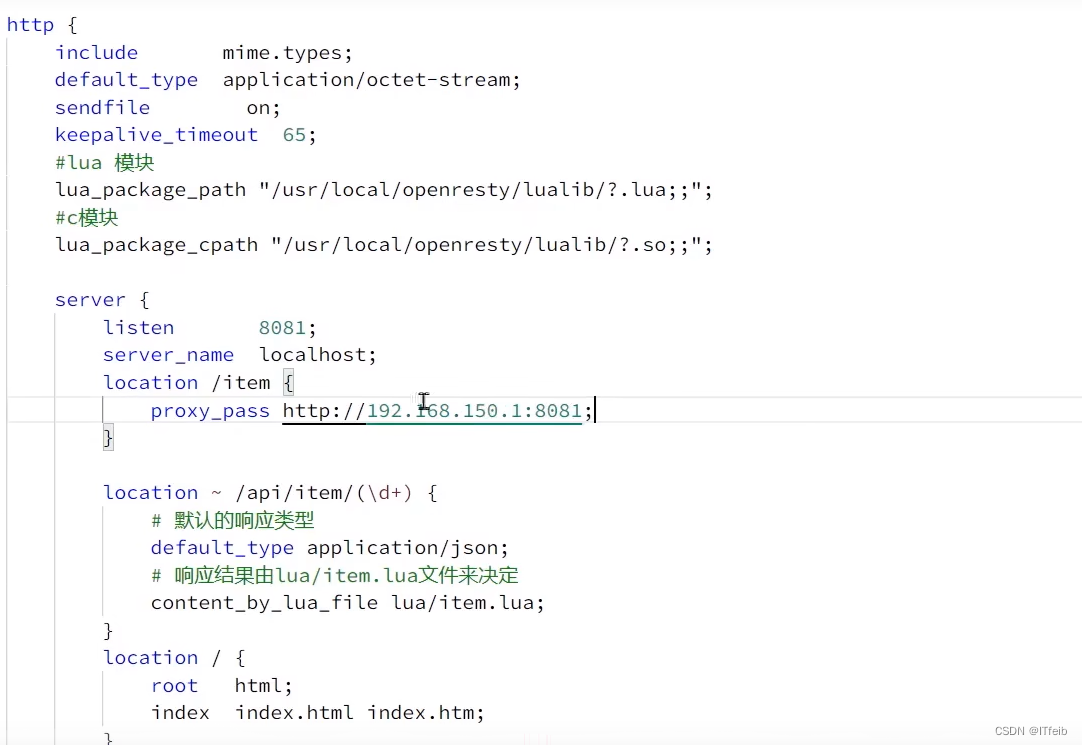
OpenResty的很多功能都依赖于其目录下的Lua库,需要在nginx.conf中指定依赖库的目录,并导入依赖:
1)添加对OpenResty的Lua模块的加载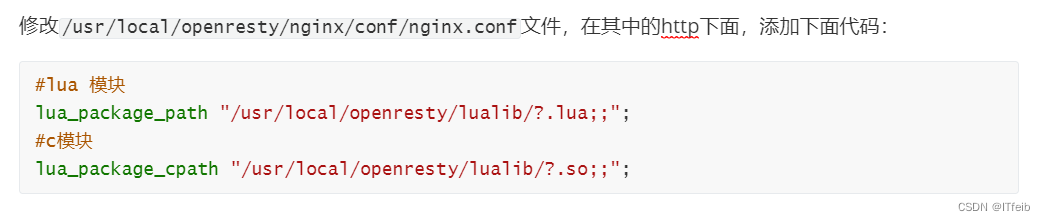
2)获取商品id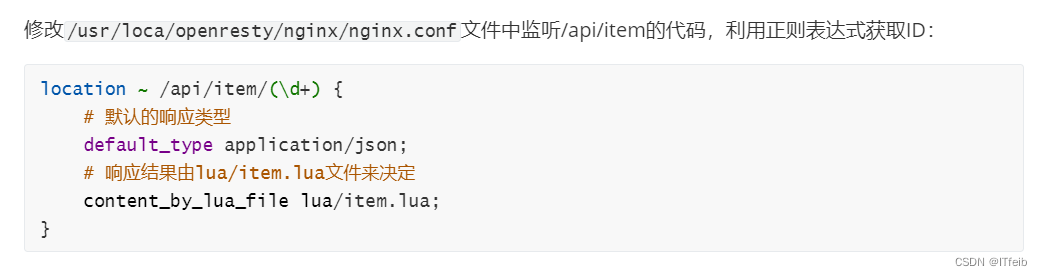
3)编写item.lua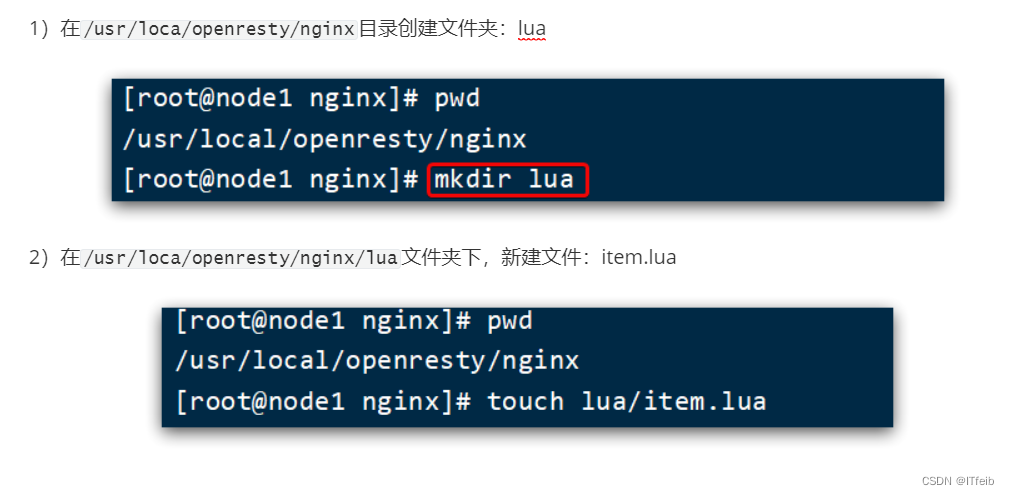

4. 查询Tomcat
4.1 发送http请求的API
nginx提供了内部API用以发送http请求:
返回的响应内容包括:
- resp.status:响应状态码
- resp.header:响应头,是一个table
- resp.body:响应体,就是响应数据
注意:这里的path是路径,并不包含IP和端口。这个请求会被nginx内部的server监听并处理。但是我们希望这个请求发送到Tomcat服务器,所以还需要编写一个server来对这个路径做反向代理: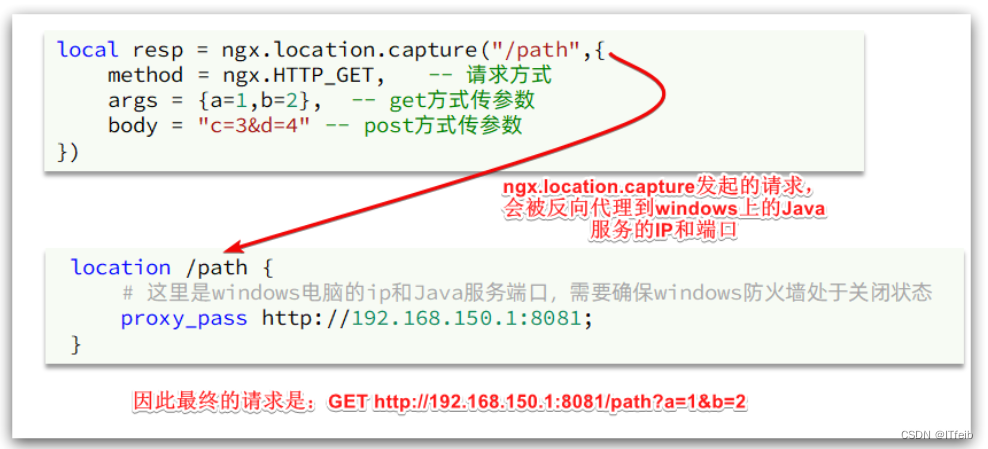
4.2 封装http工具
1)添加反向代理,到windows的Java服务
因为item-service中的接口都是/item开头,所以我们监听/item路径,代理到windows上的tomcat服务。
以后,只要我们调用ngx.location.capture("/item"),就一定能发送请求到windows的tomcat服务。
2)封装工具类
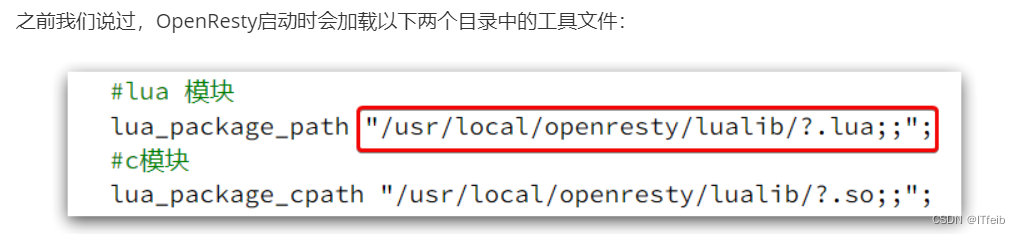
所以,自定义的http工具也需要放到这个目录下。
在/usr/local/openresty/lualib目录下,新建一个common.lua文件:内容如下:

这个工具将read_http函数封装到_M这个table类型的变量中,并且返回,这类似于导出。
使用的时候,可以利用require('common')来导入该函数库,这里的common是函数库的文件名。
3)实现商品查询
最后,我们修改/usr/local/openresty/lua/item.lua文件,利用刚刚封装的函数库实现对tomcat的查询:
这里查询到的结果是json字符串,并且包含商品、库存两个json字符串,页面最终需要的是把两个json拼接为一个json:
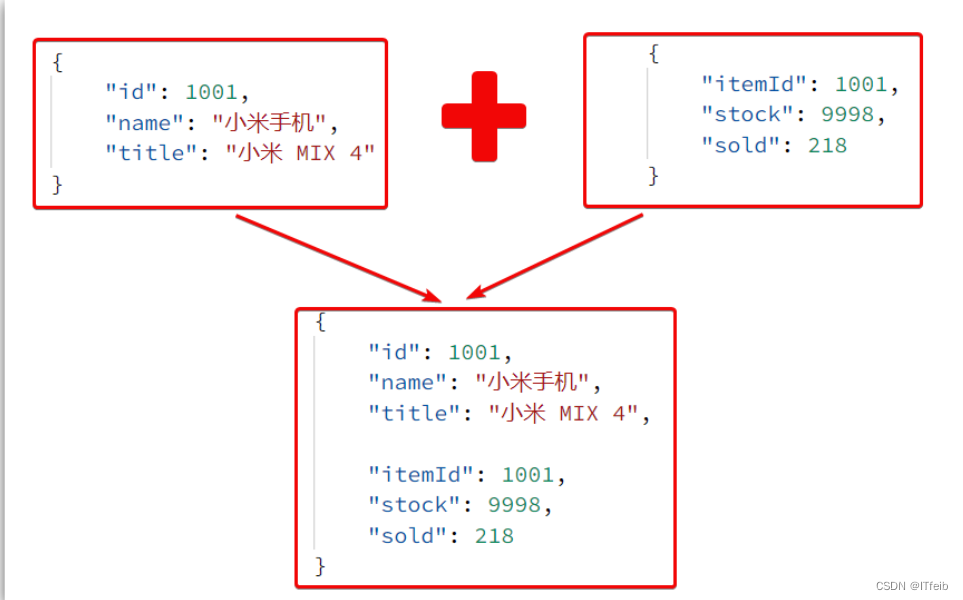
这就需要我们先把JSON变为lua的table,完成数据整合后,再转为JSON。
OpenResty提供了一个cjson的模块用来处理JSON的序列化和反序列化。
下面,我们修改之前的item.lua中的业务,添加json处理功能:
4.3 基于ID负载均衡
刚才的代码中,我们的tomcat是单机部署。而实际开发中,tomcat一定是集群模式:
因此,OpenResty需要对tomcat集群做负载均衡。
而默认的负载均衡规则是轮询模式,当我们查询/item/10001时:
- 第一次会访问8081端口的tomcat服务,在该服务内部就形成了JVM进程缓存
- 第二次会访问8082端口的tomcat服务,该服务内部没有JVM缓存(因为JVM缓存无法共享),会查询数据库
如果能让同一个商品,每次查询时都访问同一个tomcat服务,那么JVM缓存就一定能生效了。
也就是说,我们需要根据商品id做负载均衡,而不是轮询。
nginx根据请求路径做hash运算,把得到的数值对tomcat服务的数量取余,余数是几,就访问第几个服务,实现负载均衡。
实现:
修改/usr/local/openresty/nginx/conf/nginx.conf文件,实现基于ID做负载均衡。
首先,定义tomcat集群,并设置基于路径做负载均衡: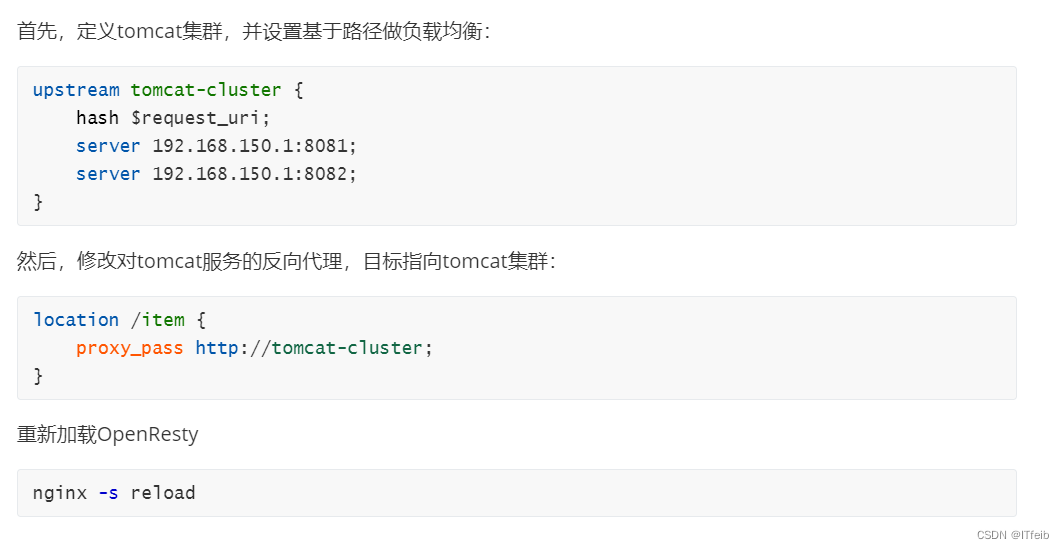
4.4 流程小结
首先进来的localhost:80会由Nginx拦截代理到openresty,openresty会将路径为/api/item/(***)这样的路径解析出访问的商品id,之后通过将/item这样的路径代理发送到windows电脑中的Tomcat服务器查询,当tomcat中线程缓存有则返回,没有则去数据库查询。
5. Redis缓存查询
冷启动:服务刚刚启动时,Redis中并没有缓存,如果所有商品数据都在第一次查询时添加缓存,可能会给数据库带来较大压力。
缓存预热:在实际开发中,我们可以利用大数据统计用户访问的热点数据,在项目启动时将这些热点数据提前查询并保存到Redis中。
我们数据量较少,并且没有数据统计相关功能,目前可以在启动时将所有数据都放入缓存中。
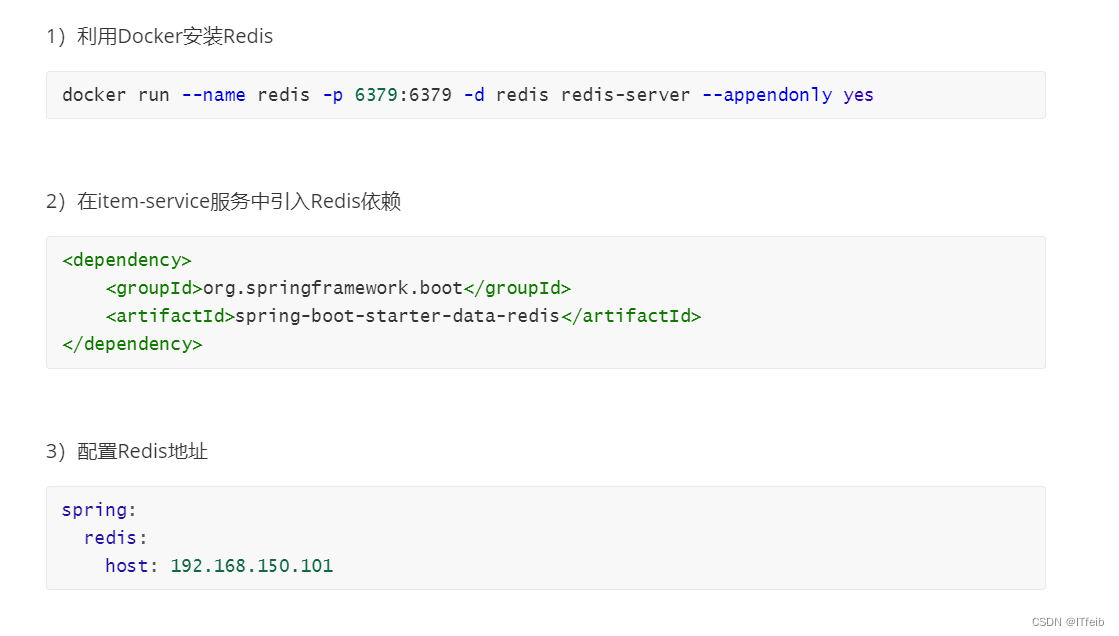
4)编写初始化类
缓存预热需要在项目启动时完成,并且必须是拿到RedisTemplate之后。
这里我们利用InitializingBean接口来实现,因为InitializingBean可以在对象被Spring创建并且成员变量全部注入后执行。
现在,Redis缓存已经准备就绪,我们可以再OpenResty中实现查询Redis的逻辑了。如下图红框所示: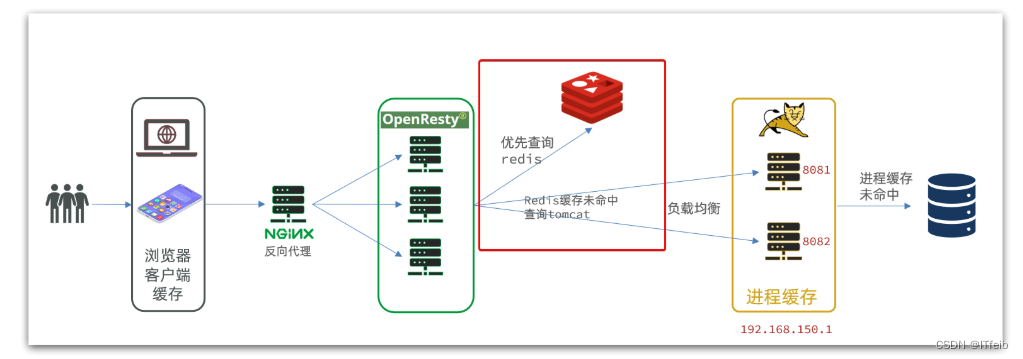
当请求进入OpenResty之后:
- 优先查询Redis缓存
- 如果Redis缓存未命中,再查询Tomcat
封装Redis工具:
OpenResty提供了操作Redis的模块,我们只要引入该模块就能直接使用。但是为了方便,我们将Redis操作封装到之前的common.lua工具库中。
修改/usr/local/openresty/lualib/common.lua文件:
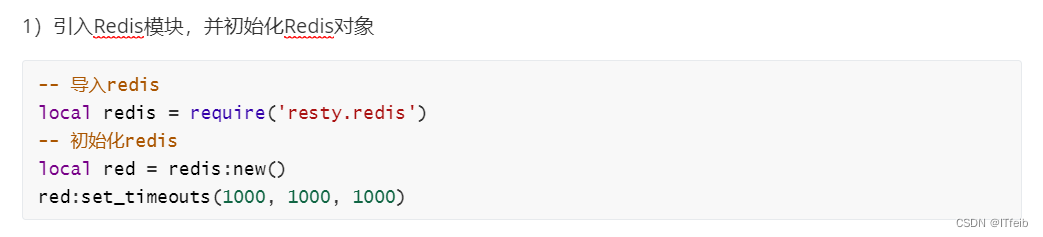



完整的common.lua:
-- 导入redis
local redis = require('resty.redis')
-- 初始化redis
local red = redis:new()
red:set_timeouts(1000, 1000, 1000)-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒local pool_size = 100 --连接池大小local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)if not ok thenngx.log(ngx.ERR, "放入redis连接池失败: ", err)end
end-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, key)-- 获取一个连接local ok, err = red:connect(ip, port)if not ok thenngx.log(ngx.ERR, "连接redis失败 : ", err)return nilend-- 查询redislocal resp, err = red:get(key)-- 查询失败处理if not resp thenngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)end--得到的数据为空处理if resp == ngx.null thenresp = nilngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)endclose_redis(red)return resp
end-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)local resp = ngx.location.capture(path,{method = ngx.HTTP_GET,args = params,})if not resp then-- 记录错误信息,返回404ngx.log(ngx.ERR, "http查询失败, path: ", path , ", args: ", args)ngx.exit(404)endreturn resp.body
end
-- 将方法导出
local _M = { read_http = read_http,read_redis = read_redis
}
return _M
5.1 实现Redis查询
接下来,我们就可以去修改item.lua文件,实现对Redis的查询了。
查询逻辑是:
- 根据id查询Redis
- 如果查询失败则继续查询Tomcat
- 将查询结果返回
1)修改/usr/local/openresty/lua/item.lua文件,添加一个查询函数:

2)而后修改商品查询、库存查询的业务: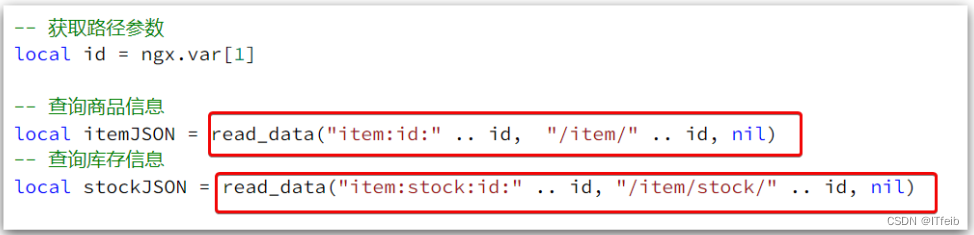
6. Nginx本地缓存
现在,整个多级缓存中只差最后一环,也就是nginx的本地缓存了。如图:
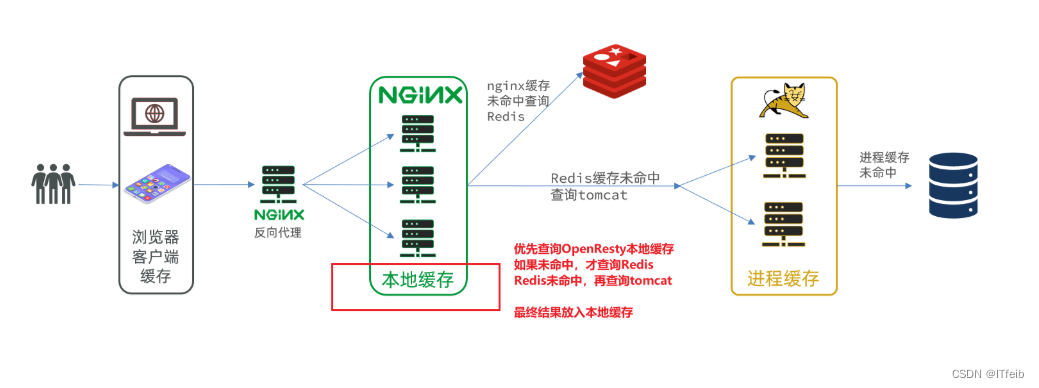
6.1 本地缓存API
OpenResty为Nginx提供了shard dict的功能,可以在nginx的多个worker之间共享数据,实现缓存功能。
1)开启共享字典,在nginx.conf的http下添加配置:
2)操作共享字典:
6.2 实现本地缓存查询
1)修改/usr/local/openresty/lua/item.lua文件,修改read_data查询函数,添加本地缓存逻辑:
2)修改item.lua中查询商品和库存的业务,实现最新的read_data函数:
其实就是多了缓存时间参数,过期后nginx缓存会自动删除,下次访问即可更新缓存。
3)完整的item.lua文件:
-- 导入common函数库
local common = require('common')
local read_http = common.read_http
local read_redis = common.read_redis
-- 导入cjson库
local cjson = require('cjson')
-- 导入共享词典,本地缓存
local item_cache = ngx.shared.item_cache-- 封装查询函数
function read_data(key, expire, path, params)-- 查询本地缓存local val = item_cache:get(key)if not val thenngx.log(ngx.ERR, "本地缓存查询失败,尝试查询Redis, key: ", key)-- 查询redisval = read_redis("127.0.0.1", 6379, key)-- 判断查询结果if not val thenngx.log(ngx.ERR, "redis查询失败,尝试查询http, key: ", key)-- redis查询失败,去查询httpval = read_http(path, params)endend-- 查询成功,把数据写入本地缓存item_cache:set(key, val, expire)-- 返回数据return val
end-- 获取路径参数
local id = ngx.var[1]-- 查询商品信息
local itemJSON = read_data("item:id:" .. id, 1800, "/item/" .. id, nil)
-- 查询库存信息
local stockJSON = read_data("item:stock:id:" .. id, 60, "/item/stock/" .. id, nil)-- JSON转化为lua的table
local item = cjson.decode(itemJSON)
local stock = cjson.decode(stockJSON)
-- 组合数据
item.stock = stock.stock
item.sold = stock.sold-- 把item序列化为json 返回结果
ngx.say(cjson.encode(item))
7. 缓存同步
大多数情况下,浏览器查询到的都是缓存数据,如果缓存数据与数据库数据存在较大差异,可能会产生比较严重的后果。
所以我们必须保证数据库数据、缓存数据的一致性,这就是缓存与数据库的同步。
7.1 数据同步策略
缓存数据同步的常见方式有三种:
设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新
- 优势:简单、方便
- 缺点:时效性差,缓存过期之前可能不一致
- 场景:更新频率较低,时效性要求低的业务
同步双写:在修改数据库的同时,直接修改缓存
- 优势:时效性强,缓存与数据库强一致
- 缺点:有代码侵入,耦合度高;
- 场景:对一致性、时效性要求较高的缓存数据
异步通知:修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
- 优势:低耦合,可以同时通知多个缓存服务
- 缺点:时效性一般,可能存在中间不一致状态
- 场景:时效性要求一般,有多个服务需要同步
而异步实现又可以基于MQ或者Canal来实现:
1)基于MQ的异步通知: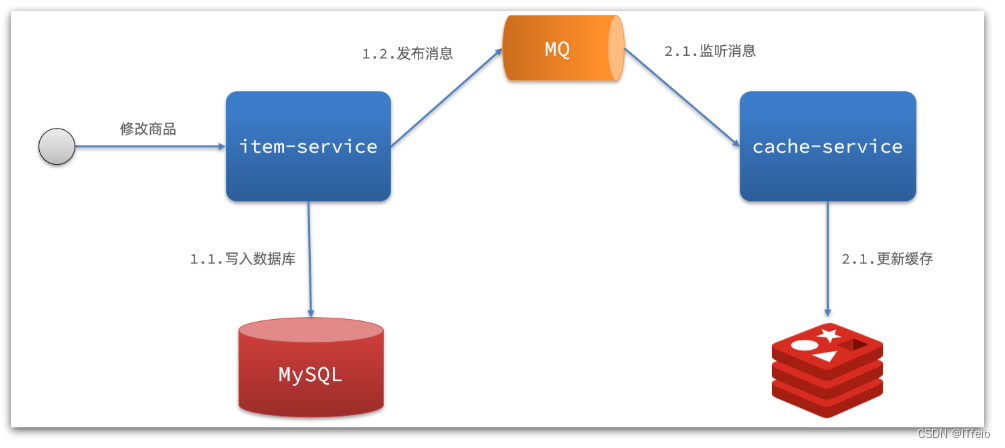
解读:
- 商品服务完成对数据的修改后,只需要发送一条消息到MQ中。
- 缓存服务监听MQ消息,然后完成对缓存的更新,依然有少量的代码侵入。
2)基于Canal的通知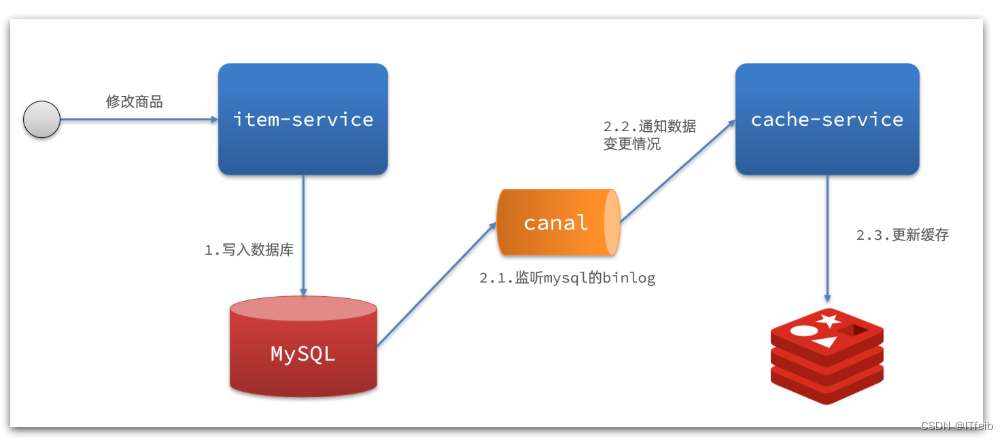
解读:
- 商品服务完成商品修改后,业务直接结束,没有任何代码侵入
- Canal监听MySQL变化,当发现变化后,立即通知缓存服务
- 缓存服务接收到canal通知,更新缓存,代码零侵入
7.2 安装Canal
Canal是基于mysql的主从同步来实现的,MySQL主从同步的原理如下: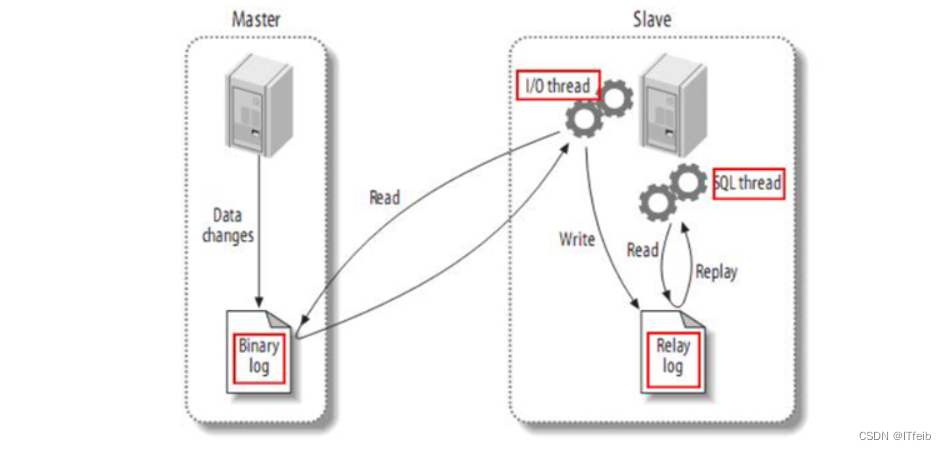
- 1)MySQL master 将数据变更写入二进制日志( binary log),其中记录的数据叫做binary log events
- 2)MySQL slave 将 master 的 binary log events拷贝到它的中继日志(relay log)
- 3)MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
而Canal就是把自己伪装成MySQL的一个slave节点,从而监听master的binary log变化。再把得到的变化信息通知给Canal的客户端,进而完成与数据库的同步。
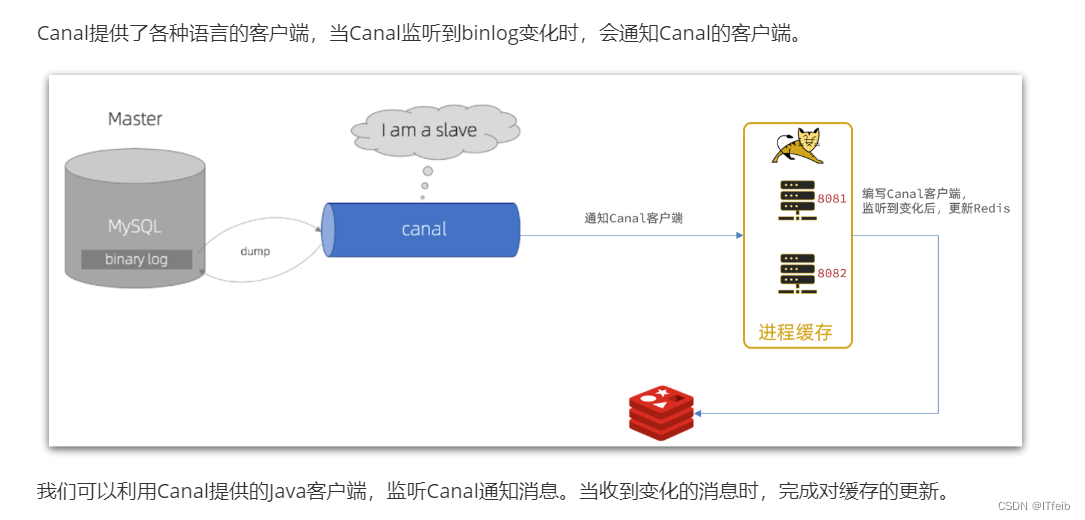
步骤:
- 引入依赖

- 编写配置:

- 修改Item实体类:通过@Id、@Column、@Transient注解完成Item与数据库表字段的映射:

- 编写监听器:
通过实现EntryHandler<T>接口编写监听器,监听Canal消息。注意两点:
- 实现类通过
@CanalTable("tb_item")指定监听的表信息 - EntryHandler的泛型是与表对应的实体类
package com.heima.item.canal;import com.github.benmanes.caffeine.cache.Cache;
import com.heima.item.config.RedisHandler;
import com.heima.item.pojo.Item;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import top.javatool.canal.client.annotation.CanalTable;
import top.javatool.canal.client.handler.EntryHandler;@CanalTable("tb_item")
@Component
public class ItemHandler implements EntryHandler<Item> {@Autowiredprivate RedisHandler redisHandler;@Autowiredprivate Cache<Long, Item> itemCache;@Overridepublic void insert(Item item) {// 写数据到JVM进程缓存itemCache.put(item.getId(), item);// 写数据到redisredisHandler.saveItem(item);}@Overridepublic void update(Item before, Item after) {// 写数据到JVM进程缓存itemCache.put(after.getId(), after);// 写数据到redisredisHandler.saveItem(after);}@Overridepublic void delete(Item item) {// 删除数据到JVM进程缓存itemCache.invalidate(item.getId());// 删除数据到redisredisHandler.deleteItemById(item.getId());}
}
在这里对Redis的操作都封装到了RedisHandler这个对象中,是我们之前做缓存预热时编写的一个类,内容如下:
package com.heima.item.config;import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.heima.item.pojo.Item;
import com.heima.item.pojo.ItemStock;
import com.heima.item.service.IItemService;
import com.heima.item.service.IItemStockService;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.StringRedisTemplate;
import org.springframework.stereotype.Component;import java.util.List;@Component
public class RedisHandler implements InitializingBean {@Autowiredprivate StringRedisTemplate redisTemplate;@Autowiredprivate IItemService itemService;@Autowiredprivate IItemStockService stockService;private static final ObjectMapper MAPPER = new ObjectMapper();@Overridepublic void afterPropertiesSet() throws Exception {// 初始化缓存// 1.查询商品信息List<Item> itemList = itemService.list();// 2.放入缓存for (Item item : itemList) {// 2.1.item序列化为JSONString json = MAPPER.writeValueAsString(item);// 2.2.存入redisredisTemplate.opsForValue().set("item:id:" + item.getId(), json);}// 3.查询商品库存信息List<ItemStock> stockList = stockService.list();// 4.放入缓存for (ItemStock stock : stockList) {// 2.1.item序列化为JSONString json = MAPPER.writeValueAsString(stock);// 2.2.存入redisredisTemplate.opsForValue().set("item:stock:id:" + stock.getId(), json);}}public void saveItem(Item item) {try {String json = MAPPER.writeValueAsString(item);redisTemplate.opsForValue().set("item:id:" + item.getId(), json);} catch (JsonProcessingException e) {throw new RuntimeException(e);}}public void deleteItemById(Long id) {redisTemplate.delete("item:id:" + id);}
}
8. 总结
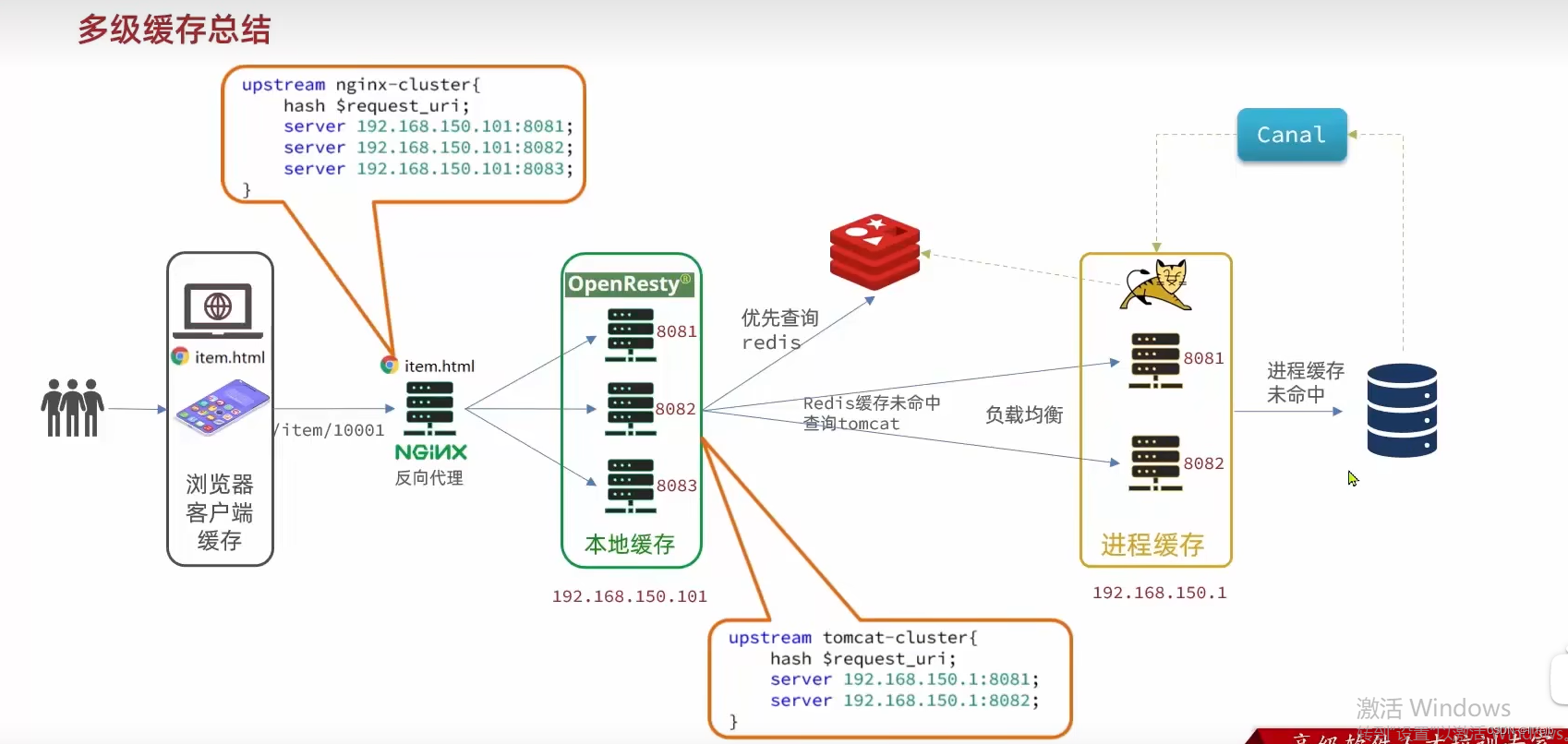
首先用户发一个请求,先经过Nginx(此处Nginx作为静态资源服务器与反向代理服务器)返回一个静态资源,经过浏览器渲染给呈现出来,但是上面的数据都是假的,此时前端会发一些ajax请求后端数据,先吧请求发送给Nginx,因为Nginx中有本地缓存,所以还是将请求路由(这里类似于redis的槽),确保同一个请求路由到同一个Nginx服务器,当Nginx接收到请求时,首先会查看本地缓存有没有,没有的话先在redis缓存中找,当redis中也没有的话才访问Tomcat,此时Tomcat会先在JVM进程缓存中去找,再没有的话才去数据库查,然后针对缓存同步来说的话,用canal监听mysql的binlog日志,其实canal就是伪装成一个slave节点,当监听到binlog变换时,通知给java客户端,然后在程序中进行缓存同步的操作。其实canal在代码中的话就是实现EntryHandler<>这个接口重写里面的insert、update、delete方法,将redis和jvm进程缓存进行更新操作。
相关文章:
【多级缓存】
文章目录 1. JVM进程缓存2. Lua语法3. 实现多级缓存3.1 反向代理流程3.2 OpenResty快速入门 4. 查询Tomcat4.1 发送http请求的API4.2 封装http工具4.3 基于ID负载均衡4.4 流程小结 5. Redis缓存查询5.1 实现Redis查询 6. Nginx本地缓存6.1 本地缓存API6.2 实现本地缓存查询 7. …...
第五课 树与图
文章目录 第五课 树与图lc94.二叉树的中序遍历--简单题目描述代码展示 lc589.N叉树的层序遍历--中等题目描述代码展示 lc297.二叉树的序列化和反序列化--困难题目描述代码展示 lc105.从前序与中序遍历序列构造二叉树--中等题目描述代码展示 lc106.从中序与后序遍历序列构造二叉…...

2023-10-07 事业-代号z-副业-CQ私服-调研与分析
摘要: CQ作为一款运营了20年的游戏, 流传出的私服可以说是层出不穷, 到了现在我其实对这款游戏的长线运营的前景很悲观. 但是作为商业的一部分, 对其做谨慎的分析还是很有必要的. 传奇调研的来源: 一. 各种售卖私服的网站 传奇服务端版本库-传奇手游源码「免费下载」传奇GM论…...
合并不同门店数据-上下合并
项目背景:线下超市分店,统计产品的销售数量和销售额,并用透视表计算求和 merge()函数可以根据链接键横向连接两张不同表,concat()函数可以上下合并和左右合并2种不同的合并方式。merge()函数只能横向连接两张表,而con…...

学习记忆——数学篇——案例——算术——整除特点
理解记忆法 对于数的整除特征大家都比较熟悉:比如4看后两位(因为100是4的倍数),8看后三位(因为1000是8的倍数),5末尾是0或5,3与9看各位数字和等等,今天重点研究一下3,9,…...

PHP8中的魔术方法-PHP8知识详解
在PHP 8中,魔术方法是一种特殊的方法,它们以两个下划线(__)开头。魔术方法允许您定义类的行为,例如创建对象、调用其他方法或访问和修改类的属性。以下是一些常见的魔术方法: __construct(): 类的构造函数…...

[图论]哈尔滨工业大学(哈工大 HIT)学习笔记23-31
视频来源:4.1.1 背景_哔哩哔哩_bilibili 目录 1. 哈密顿图 1.1. 背景 1.2. 哈氏图 2. 邻接矩阵/邻接表 3. 关联矩阵 3.1. 定义 4. 带权图 1. 哈密顿图 1.1. 背景 (1)以地球为建模,从一个大城市开始遍历其他大城市并且返回…...

Nginx+Keepalived实现服务高可用
Nginx 和 Keepalived 是常用于构建高可用性(High Availability)架构的工具。Nginx 是一款高性能的Web服务器和反向代理服务器,而Keepalived则提供了对Nginx服务的健康状态监测和故障切换功能。 下载Nginx 在服务器1和服务器2分别下载nginx …...
picodet onnx转其它芯片支持格式时遇到
文章目录 报错信息解决方法两模型精度对比 报错信息 报错信息为: Upsample(resize) Resize_0 not support attribute coordinate_transformation_mode:half_pixel. 解决方法 整个模型转换过程是:paddle 动态模型转成静态,再用paddle2onnx…...

【学习笔记】CF704B Ant Man
智商不够啊,咋想到贪心的😅 非常经典的贪心模型🤔 首先,从小到大将每个 i i i插入到排列中,用 D P DP DP记录还有多少个位置可以插入,可以通过钦定新插入的位置左右两边是否继续插入数来提前计算贡献。注…...

SQLines数据迁移工具
Data and Analytics Platform Migration - SQLines Tools SQLines提供的工具可以帮助您在不同的数据库平台之间传输数据、转换数据库模式(DDL)、视图、存储过程、包、用户定义函数(udf)、触发器、SQL查询和SQL脚本。 SQLines SQL Converter OverviewCommand LineConfigurati…...
)
pkl文件与打开(使用numpy和pickle)
文章目录 1. 什么是pkl文件2. 如何打开?Reference 1. 什么是pkl文件 1)python中有一种存储方式,可以存储为.pkl文件。 2)该存储方式,可以将python项目过程中用到的一些暂时变量、或者需要提取、暂存的字符串、列表、…...

3d渲染农场全面升级,好用的渲染平台值得了解
什么是渲染农场? 渲染农场是专门从事 3D 渲染的大型机器集合,称为渲染节点,这些机器组合在一起执行一项任务(渲染 3D 帧和动画)。通过将渲染工作分配给数百台机器,可以显着减少渲染时间,从而使…...

1.5 JAVA程序运行的机制
**1.5 Java程序的运行机制** --- **简介:** Java程序的运行涉及两个主要步骤:编译和运行。这种机制确保了Java的跨平台特性。 **主要内容:** 1. **Java程序的执行过程**: - **编译**:首先,扩展名为.jav…...

基于FPGA的拔河游戏设计
基于FPGA的拔河游戏机 设计内容: (1)拔河游戏机需要11个发光二极管排成一行,开机 后只有中间一个亮点,作为拔河的中间线。 游戏双方 各持一个按键,迅速且不断地按动产生脉冲,哪方按 得快,亮点就向哪方移动, 每按一次,亮点移动一次。 移到任一方二极管的终端,该方就…...
关联规则挖掘(下):数据分析 | 数据挖掘 | 十大算法之一
⭐️⭐️⭐️⭐️⭐️欢迎来到我的博客⭐️⭐️⭐️⭐️⭐️ 🐴作者:秋无之地 🐴简介:CSDN爬虫、后端、大数据领域创作者。目前从事python爬虫、后端和大数据等相关工作,主要擅长领域有:爬虫、后端、大数据…...

8、【Qlib】【主要组件】预测模型:模型训练和预测
8、【主要组件】预测模型:模型训练和预测 简介基本类Example简介 预测模型(Forecast Model)旨在对股票做出预测评分。用户可以通过 qrun 在自动化工作流中使用预测模型。 由于 Qlib 中的组件设计成了松耦合方式,预测模型也可以作为一个独立模块使用。 基本类 Qlib 提供了…...

kettle安装
kettle安装 安装java环境 mkdir /data/java ln -s /data/java/ /opt/ cd /opt/javatar zxvf jdk-8u171-linux-x64.tar.gz#java export JAVA_HOME/opt/java/jdk1.8.0_171 export JRE_HOME$JAVA_HOME/jre export CLASSPATH$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH export PATH$J…...

基于生物地理学优化的BP神经网络(分类应用) - 附代码
基于生物地理学优化的BP神经网络(分类应用) - 附代码 文章目录 基于生物地理学优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.生物地理学优化BP神经网络3.1 BP神经网络参数设置3.2 生物地理学算法应用 4…...
第二证券:买基金1w一个月能赚多少?
跟着经济的开展和出资观念的改动,越来越多的人开始出资基金,购买基金已成为普遍且盛行的出资方式之一。在这个商场中,人们最重视的问题莫过于“买基金1w一个月能赚多少?”本文将从多个角度分析这一问题,协助出资者更全…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

云原生玩法三问:构建自定义开发环境
云原生玩法三问:构建自定义开发环境 引言 临时运维一个古董项目,无文档,无环境,无交接人,俗称三无。 运行设备的环境老,本地环境版本高,ssh不过去。正好最近对 腾讯出品的云原生 cnb 感兴趣&…...

网站指纹识别
网站指纹识别 网站的最基本组成:服务器(操作系统)、中间件(web容器)、脚本语言、数据厍 为什么要了解这些?举个例子:发现了一个文件读取漏洞,我们需要读/etc/passwd,如…...

mac 安装homebrew (nvm 及git)
mac 安装nvm 及git 万恶之源 mac 安装这些东西离不开Xcode。及homebrew 一、先说安装git步骤 通用: 方法一:使用 Homebrew 安装 Git(推荐) 步骤如下:打开终端(Terminal.app) 1.安装 Homebrew…...

论文阅读笔记——Muffin: Testing Deep Learning Libraries via Neural Architecture Fuzzing
Muffin 论文 现有方法 CRADLE 和 LEMON,依赖模型推理阶段输出进行差分测试,但在训练阶段是不可行的,因为训练阶段直到最后才有固定输出,中间过程是不断变化的。API 库覆盖低,因为各个 API 都是在各种具体场景下使用。…...