Python-Scrapy框架(框架学习)
一、概述
Scrapy是一个用于爬取网站数据的Python框架,可以用来抓取web站点并从页面中提取结构化的数据。
基本组件:
-
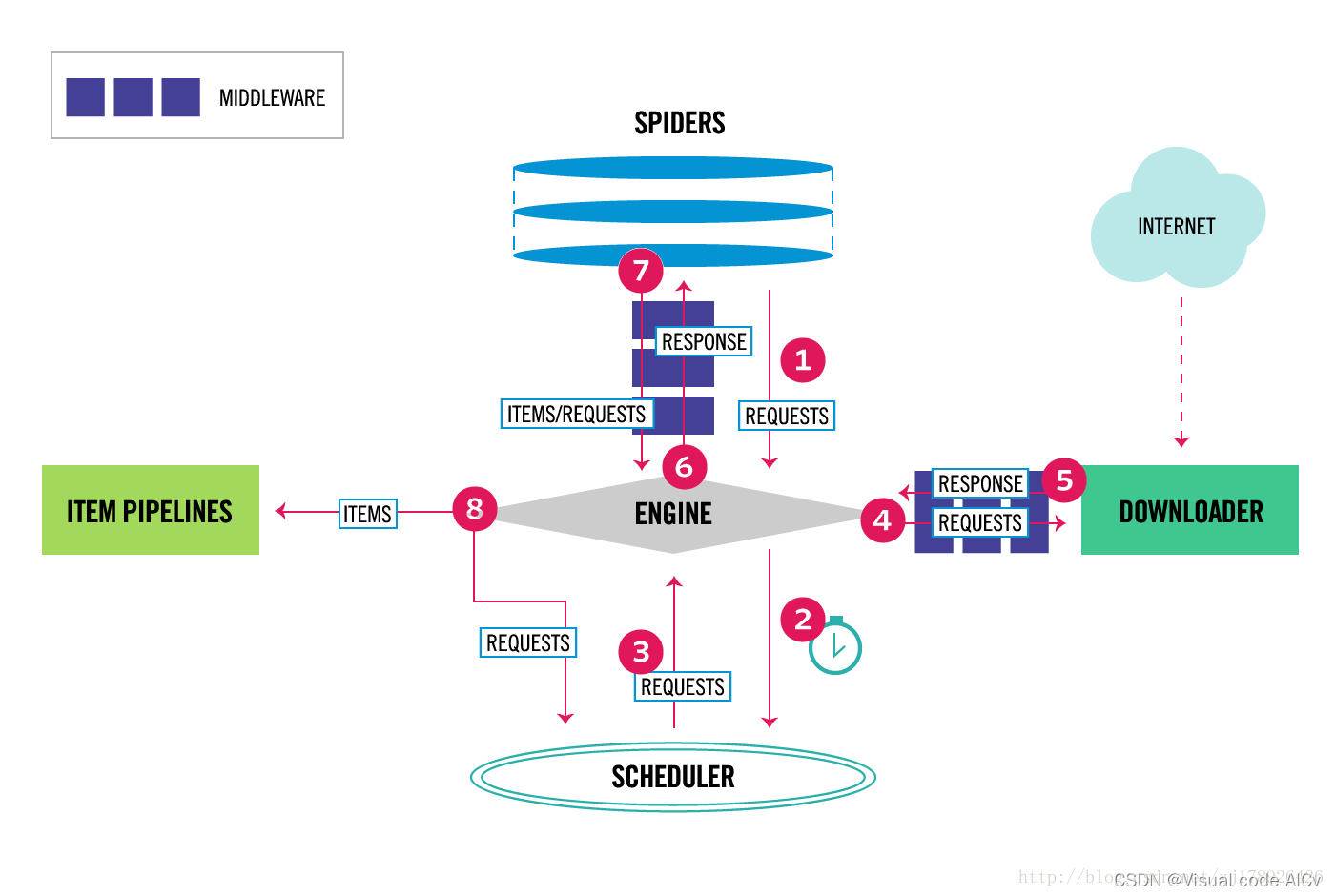
引擎(Engine):负责控制整个爬虫的流程,包括调度请求、处理请求和响应等。
-
调度器(Scheduler):负责接收引擎发送的请求,并将其按照一定的策略进行调度,生成待下载的请求。
-
下载器(Downloader):负责下载请求对应的网页,可以使用多种下载器,例如基于Twisted的异步下载器和基于requests的同步下载器。
-
中间件(Middleware):负责对请求和响应进行预处理和后处理,可以用于添加请求头、处理cookies等操作。
-
爬虫(Spider):负责定义如何解析网页和提取数据的规则,包括起始URL、请求构造、响应解析和数据提取等。
-
项目管道(Item Pipeline):负责处理爬虫从网页中提取的数据,并进行后续的处理,例如数据清洗、数据存储等。
数据处理流程:
-
引擎从爬虫中获取起始URL,并生成对应的请求。
-
引擎将请求发送到调度器,调度器将获取到的URL存储在队列中,按照一定的策略进行调度,并生成待下载的请求。
-
引擎从调度器中获取接下来需要爬取的页面。
-
引擎将待下载的请求通过下载中间件发送到下载器。
-
下载器下载网页,并将响应返回给引擎。
-
引擎将响应通过爬虫中间件发送给爬虫,爬虫根据定义的规则对响应进行解析,并提取出需要的数据。
-
爬虫将提取的数据发送给项目管道,项目管道对数据进行处理,并进行后续的存储或其他操作。
-
引擎根据配置的规则继续生成新的请求,并重复上述步骤,直到没有新的请求或达到指定的停止条件。
下面是Scrapy框架的运行流程
二、基本使用方法
2.1 创建&管理Scrapy项目
2.1.1 Scrapy命令行
Scrapy自带一套命令行工具用于管理和运行Scrapy项目。
-
创建一个新的Scrapy项目:
scrapy startproject <project_name> -
在项目中创建一个新的Spider:
scrapy genspider <spider_name> <website_url> -
运行Spider并将结果保存为JSON或其他格式:
scrapy crawl <spider> -o <output_file>.json -
列出可用的Spider:
scrapy list -
检查Spider是否正确工作:
scrapy check <spider_name> -
运行Scrapy Shell来交互式地测试和调试Spider:
scrapy shell <website_url> -
查看Scrapy信息:
scrapy version
2.1.2 Pycharm
创建Scrapy项目:
1. 在Pycharm中创建一个“纯python”项目
注:demo1是项目名
2.在pycharm内使用命令行工具创建Scrapy项目
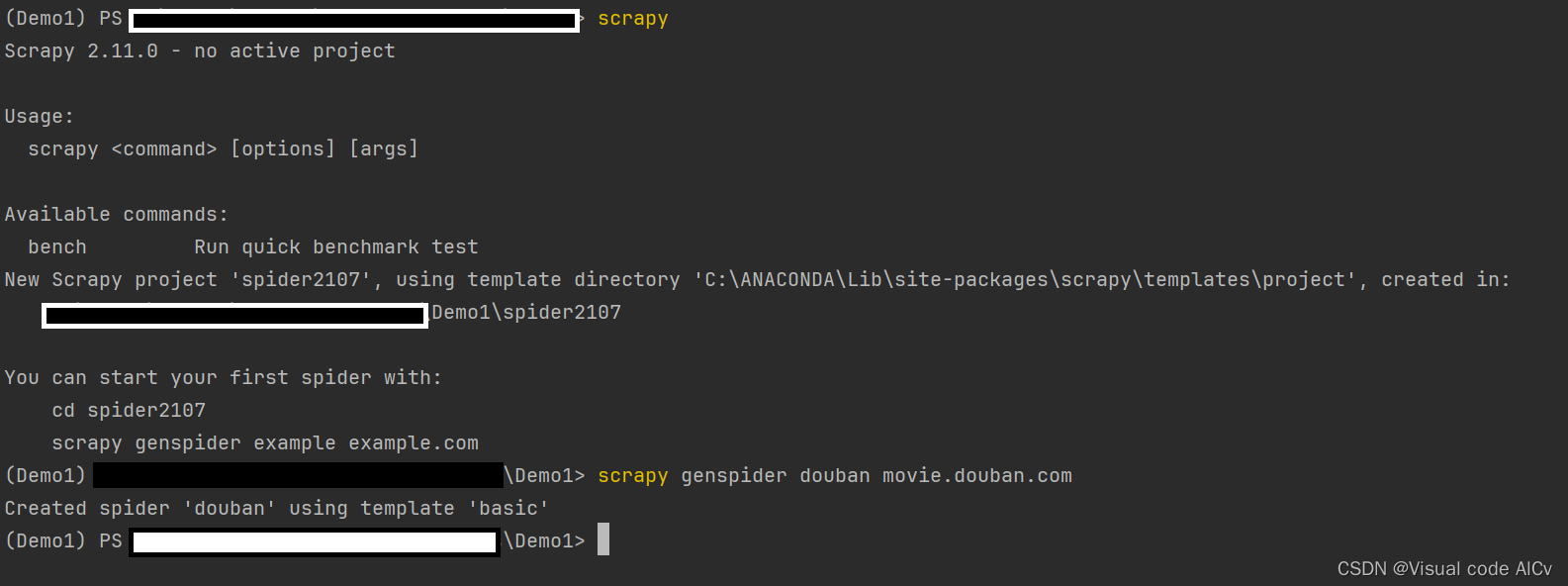
创建spider程序的命令行
scrapy genspider douban movie.douban.com
# douban为爬虫名称
# movie.douban.com为爬虫的作用域创建的目录
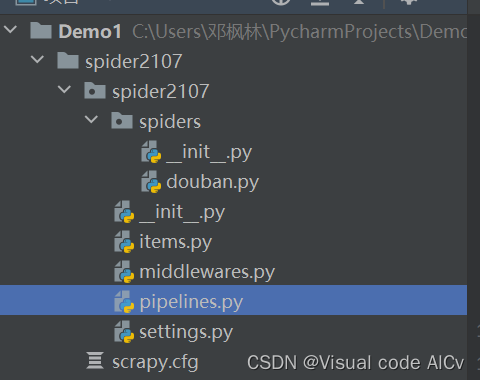
这些文件分别是:
- scrapy.cfg: 项目的配置文件。
- spider2107/: 项目的Python模块,将会从这里引用代码。
- spider2107/items.py: 项目的目标文件。
- spider2107/pipelines.py: 项目的管道文件。
- spider2107/settings.py: 项目的设置文件。
- spider2107/spiders: 存储爬虫代码目录。
新建虚拟环境:
文件 ——>设置项目设置 ——>新项目的设置
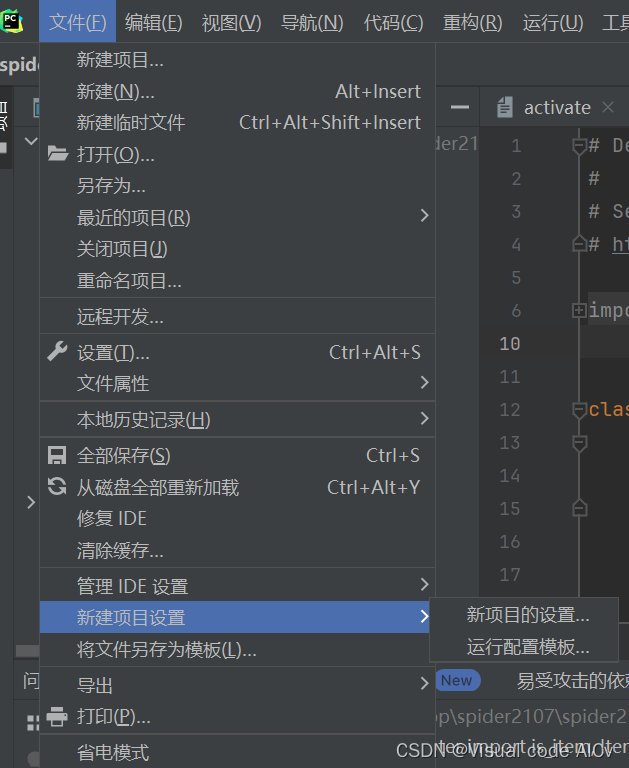
选择python解释器 ——>添加解释器 ——>Virtualenv环境 ——>在项目文件夹下添加envs (虚拟环境)——>确定
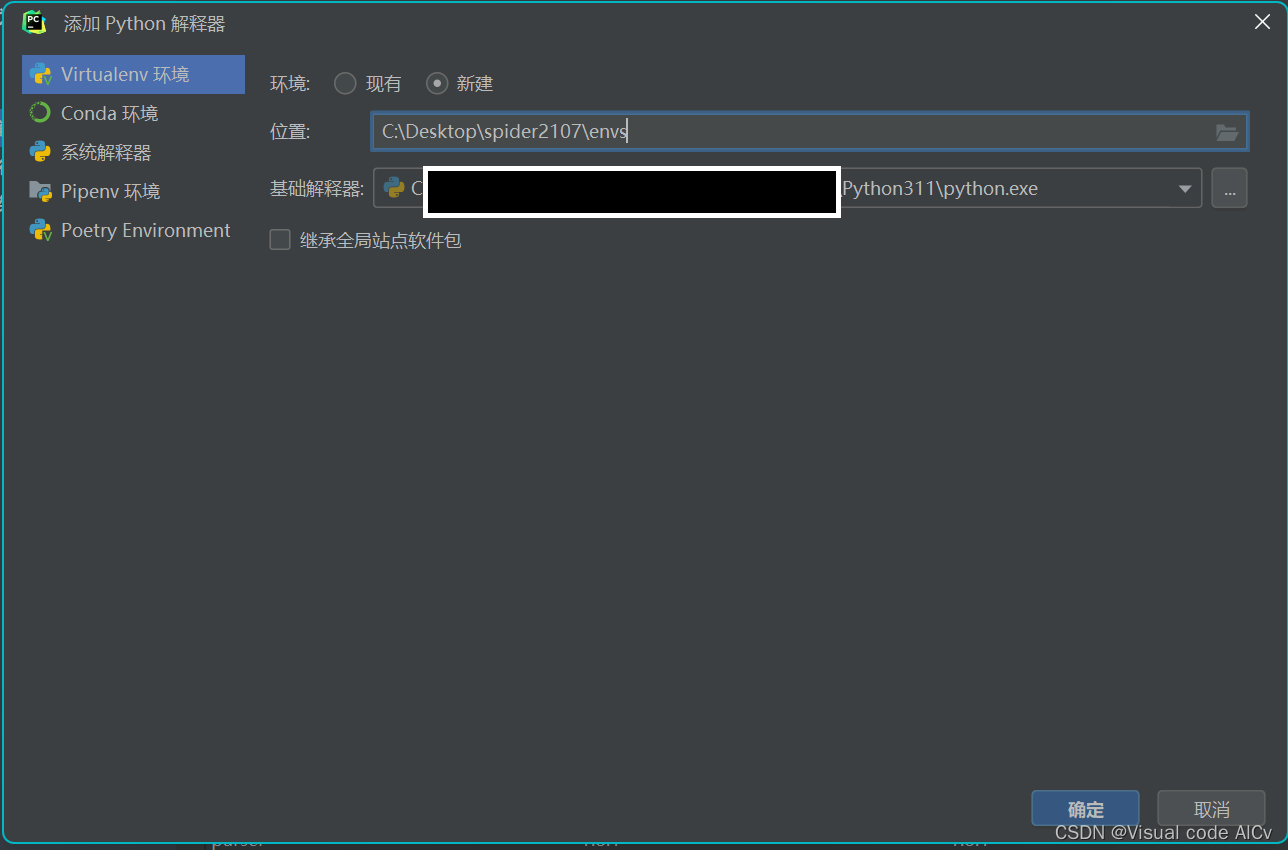
激活虚拟环境(Virtualenv环境)
env\Script\activate注:如果显示无法加载模块,可以先等一段时间,当pycharm新建索引到env文件夹时在运行这段命令
在pycharm中打开终端
使用pip下载scrapy
pip install scrapy创建spider程序
scrapy genspider <spidername><domain>写好程序后会scrapy会出现一个crawl的执行选项可用于执行spider
scrapy crawl <spidername>相关文章:
Python-Scrapy框架(框架学习)
一、概述 Scrapy是一个用于爬取网站数据的Python框架,可以用来抓取web站点并从页面中提取结构化的数据。 基本组件: 引擎(Engine):负责控制整个爬虫的流程,包括调度请求、处理请求和响应等。 调度器(Scheduler):负责…...

flink生成水位线记录方式--基于特殊记录的水位线生成器
背景 在flink基于事件的时间处理中,水位线记录的生成是一个很重要的环节,本文就来记录下几种水位线记录的生成方式的其中一种:基于特殊记录的水位线生成器 基于特殊记录的水位线生成器 我们发送的事件中,如果带有某条特殊记录的…...

Arcgis日常天坑问题(1)——将Revit模型转为slpk数据卡住不前
这段时间碰到这么一个问题,revit模型在arcgis pro里导出slpk的时候,卡在98%一直不动,大约有两个小时。 首先想到的是revit模型过大,接近300M。然后各种减小模型测试,还是一样的问题,大概花了两天的时间&am…...
JavaWeb:上传文件
1.建普通maven项目,或者maven项目,这里以普通maven为例,区别的jar包的导入方式啦 到中央仓库下载哦 2.结构 3.写fileservlet public class FileServlet extends HttpServlet {Overrideprotected void doPost(HttpServletRequest req, HttpSe…...

STM32 大小端与字节对齐使用记录
大小端 串口数据包解析 MDK stm32 小段模式 接收到的数据包: DD 03 00 1B 11 59 00 00 00 00 17 70 00 00 2F 39 00 00 00 00 00 03 23 64 00 0E 02 0B 6E 0B 84 FC EA 77 其中数据内容为: DD 03 00 1B 11 59 //电压mV 00 00 00 00 17 70 …...

RabbitMQ中basic**方法汇总与参数解释
当使用RabbitMQ进行消息传递时,Channel对象提供了一组称为"basic方法"的方法,用于执行最基本的消息传递操作。在本篇博客中,我们将详细介绍这些方法,包括示例和参数解释。 1. basicPublish 方法 basicPublish 方法用于…...

linux之/etc/default/useradd文件
/etc/default/useradd文件是在使用useradd添加用户时,一个需要调用的默认的配置文件之一,可以使用命令"useradd -D"进行修改。 useradd用法: [rootcentos79-3 mail]# useradd --help Usage: useradd [options] LOGINuseradd -Dus…...

3.primitive主数据类型和引用 认识变量
3.1 声明变量 Java注重类型。它不会让你做出把长颈鹿类型变量装进兔子类型变量中这种诡异又危险的举动——如果有人对长颈鹿调用“跳跃”这个方法会发生什么样的悲剧?并且它也不会让你将浮点数类型变量放进整数类型的变量中,除非你先跟编译器确认过数字…...

【群智能算法改进】一种改进的光学显微镜算法 IOMA算法[1]【Matlab代码#60】
文章目录 【获取资源请见文章第5节:资源获取】1. 光学显微镜算法(OMA)1.1 物镜放大倍数1.2 目镜放大倍数 2. 改进后的IOMA算法2.1 透镜成像折射方向学习 3. 部分代码展示4. 仿真结果展示5. 资源获取说明 【获取资源请见文章第5节:…...
第三课-软件升级-Stable Diffusion教程
前言: 虽然第二课已经安装好了 SD,但你可能在其它地方课程中,会发现很多人用的和你的界面差距很大。这篇文章会讲一些容易忽略或者常常需要做的操作,不一定要完全照做,以后再回过头看看也可以。 1.控制类型 问题:为什么别人有“控制类型”部分,而我没有?如下红色方框…...

【C++】设计模式之——建造者
建造者模式概念模拟实现建造者模式代码实现 建造者模式 首先先大体了解一下,建造者模式是什么意思,它是怎么实现的? 首先,建造者模式是一种创建型设计模式再一个它是使用多个简单的对象一步一步的搭建出一个复杂的对象它可以将一个…...
)
【C++】基础语句(学习笔记)
一、分支 1、三种基本结构 顺序结构分支结构循环结构 2、if与switch对比 1)使用场景 switch只支持常量值固定相等的分支判断if可以判断区间范围用switch能做的,用if都能做 2)性能比较 分支少时,差别不是很大。分支多时&…...

大厂秋招真题【DP】米哈游20230924秋招T2-米小游与魔法少女-奇运
米哈游20230924秋招T2-米小游与魔法少女-奇运 题目描述与示例 题目描述 米小游都快保底了还没抽到希儿,好生气哦!只能打会活动再拿点水晶。 米小游和世界第一可爱的魔法少女 TeRiRi 正在打 BOSS,BOSS 的血量为h,当 BOSS 血量小…...
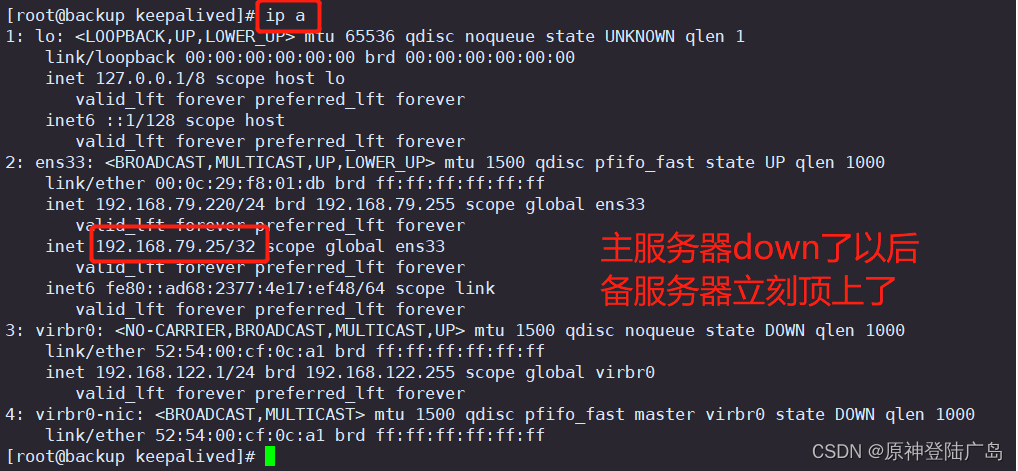
LVS+Keepalived 高可用集群负载均衡
一.keepalived介绍 1.1.Keepalived实现原理 由多台路由器组成一个热备组,通过共用的虚拟IP地址对外提供服务。 每个热备组内同时只有一台主路由器提供服务,其他路由器处于冗余状态。 若当前在线的路由器失效,则其他路由器会根据设置…...

Qt QList类和QLinkedList类 详解
一、QList 类 对于不同的数据类型,QList<T>采取不同的存储策略,存储策略如下: 如果T 是一个指针类型或指针大小的基本类型(该基本类型占有的字节数和指针类型占有的字节数相同),QList<T>将数值直接存储在它的数组当…...

Mac安装GYM遇到的一些坑
以下是遇到的一些问题 安装GitHub上说的直接 pip install gym成功了,但是运行实例报错没安装gym[classic_control],所以就全安装一下[all] 安装GitHub上说的直接 pip install gym成功了,但是运行实例报错没安装gym[classic_control]ÿ…...
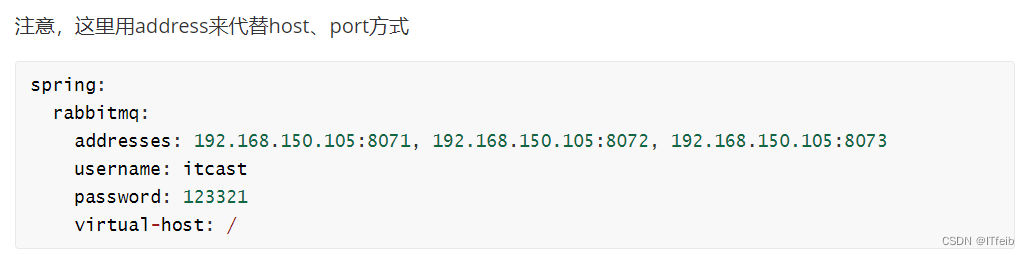
【高级rabbitmq】
文章目录 1. 消息丢失问题1.1 发送者消息丢失1.2 MQ消息丢失1.3 消费者消息丢失1.3.1 消费失败重试机制 总结 2. 死信交换机2.1 TTL 3. 惰性队列3.1 总结: 4. MQ集群 消息队列在使用过程中,面临着很多实际问题需要思考: 1. 消息丢失问题 1.1…...
数百个下载能够传播 Rootkit 的恶意 NPM 软件包
供应链安全公司 ReversingLabs 警告称,最近观察到的一次恶意活动依靠拼写错误来诱骗用户下载恶意 NPM 软件包,该软件包会通过 rootkit 感染他们的系统。 该恶意软件包名为“node-hide-console-windows”,旨在模仿 NPM 存储库上合法的“node-…...

SpringBoot的error用全局异常去处理
记录一下使用SpringBoot2.0.5的error用全局异常去处理 在使用springboot时,当访问的http地址或者说是请求地址输错后,会返回一个页面,如下: 这是因为请求的地址不存在,默认会显示error页面 但我们实际需要一个接口&a…...
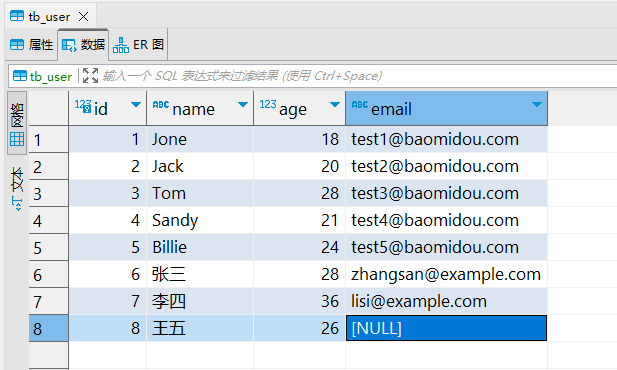
MyBatisPlus(十一)包含查询:in
说明 包含查询,对应SQL语句中的 in 语句,查询参数包含在入参列表之内的数据。 in Testvoid inNonEmptyList() {// 非空列表,作为参数List<Integer> ages Stream.of(18, 20, 22).collect(Collectors.toList());in(ages);}Testvoid in…...

LeetCode 热题 100 之 160. 相交链表 206. 反转链表 234. 回文链表 141. 环形链表 142. 环形链表 II
160. 相交链表 206. 反转链表 234. 回文链表 141. 环形链表 142. 环形链表 II 160. 相交链表 public class Solution {public ListNode getIntersectionNode(ListNode headA, ListNode headB) {if (headA null || headB null) return null;ListNode pA headA, pB headB;whi…...
)
Windows CMD高效操作指南(从入门到精通)
1. 为什么你需要掌握CMD命令? 每次看到别人在黑色窗口里敲几行代码就能完成文件整理、批量重命名、网络故障排查,你是不是觉得特别神奇?其实这就是Windows自带的CMD命令行工具。虽然现在有图形化界面,但CMD在处理批量操作、自动化…...

Qwen2.5-VL-7B-Instruct开源可部署优势:完全离线运行,无外网依赖保障安全
Qwen2.5-VL-7B-Instruct开源可部署优势:完全离线运行,无外网依赖保障安全 1. 项目概述 Qwen2.5-VL-7B-Instruct是一款强大的多模态视觉-语言模型,能够同时处理图像和文本输入,生成高质量的文本输出。这个开源模型最突出的特点是…...
升级docker)
WSL2(Linux)升级docker
一、确认升级前的版本可以看到是28.2.2docker -v二、备份、停止服务在升级 Docker 之前,建议备份重要的容器和数据,以防止意外情况。升级过程中,确保 Docker 服务已停止,以避免出现问题:sudo systemctl stop docker 三…...
)
我让AI开发一个完整项目,结果离谱了(全流程实测)
最近我做了一个“有点离谱”的实验:👉 不写一行代码,让AI帮我开发一个完整项目。结果是:项目真的跑起来了功能基本完整甚至代码结构还不错但同时也出现了一些“很真实的问题”。这篇文章,我把整个过程完整复盘给你看&a…...
)
OpenClaw - Personal AI Assistant (个人 AI 助理)
OpenClaw - Personal AI Assistant {个人 AI 助理} 1. OpenClaw - Personal AI Assistant2. OpenClaw2.1. Docs2.2. Mattermost 3. ConclusionsReferences OpenClaw (formerly Clawdbot, Moltbot, and Molty) is a free and open-source autonomous artificial intelligence ag…...
预测控制附matlab代码)
【数据驱动】基于深度学习LSTM模型的建筑温控系统(地源热泵 GSHP)预测控制附matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、建模仿真、程序设计、完整代码获取、论文复现及科研仿真。🍎 往期回顾关注个人主页:Matlab科研工作室👇 关注我领取海量matlab电子书和…...

STM32G474 IAP实战:基于Ymodem协议的远程固件升级全流程解析
1. STM32G474 IAP技术核心解析 第一次接触STM32G474的IAP功能时,我被它精巧的设计思路惊艳到了。简单来说,IAP就是在不拆机、不借助烧录器的情况下,通过串口等通信接口直接更新单片机程序。这就像给手机OTA升级系统一样方便,但实现…...

LittleFS大规模部署终极指南:如何高效管理数千设备上的嵌入式文件系统
LittleFS大规模部署终极指南:如何高效管理数千设备上的嵌入式文件系统 【免费下载链接】littlefs 项目地址: https://gitcode.com/gh_mirrors/litt/littlefs 在当今物联网和嵌入式设备爆炸式增长的时代,如何在数千台设备上高效部署和管理嵌入式文…...
)
QNAP TS-231P实战:用Docker快速搭建Aria2下载服务器(含远程访问技巧)
QNAP TS-231P实战:用Docker容器化部署Aria2全功能下载中心 在数字化资源日益丰富的今天,一个稳定高效的下载解决方案已成为许多技术爱好者的刚需。QNAP TS-231P作为一款高性价比的NAS设备,结合Docker的轻量化容器技术,能够快速搭…...