Elasticsearch数据搜索原理
Elasticsearch 是一个开源的、基于 Lucene 的分布式搜索和分析引擎,设计用于云计算环境中,能够实现实时的、可扩展的搜索、分析和探索全文和结构化数据。它具有高度的可扩展性,可以在短时间内搜索和分析大量数据。
Elasticsearch 不仅仅是一个全文搜索引擎,它还提供了分布式的多用户能力,实时的分析,以及对复杂搜索语句的处理能力,使其在众多场景下,如企业搜索,日志和事件数据分析等,都有广泛的应用。
本文将向你详细介绍什么是倒排索引、以及 Elasticsearch 查询、相关性评分和搜索优化的相关原理。
文章目录
- 1、倒排索引
- 1.1、为什么需要倒排索引
- 1.2、为什么叫倒排索引
- 1.3、倒排索引的结构
- 2、数据查询过程
- 2.1、数据查询处理原理
- 2.2、解析查询语句
- 2.3、生成查询计划
- 2.4、执行查询
- 2.5、生成查询结果
- 3、相关性评分
- 3.1、相关性评分的作用
- 3.2、TF-IDF 原理
- 3.3、其他评分规则
- 4、搜索功能
- 4.1、全文搜索
- 4.2、多值搜索
- 4.3、模糊搜索
- 4.4、范围搜索
- 4.5、聚合搜索
- 5、搜索优化
- 5.1、索引优化
- 5.2、查询优化
- 5.3、使用doc_values优化排序和聚合
- 5.4、使用routing优化分片
- 5.5、其他优化
1、倒排索引
1.1、为什么需要倒排索引
倒排索引,也是索引。索引,初衷都是为了快速检索到你要的数据。
每种数据库都有自己要解决的问题(或者说擅长的领域),对应的就有自己的数据结构,而不同的使用场景和数据结构,需要用不同的索引,才能起到最大化加快查询的目的。
对 Mysql 来说,是 B+ 树,对 Elasticsearch 和 Lucene 来说,是倒排索引。
Elasticsearch 是建立在全文搜索引擎库 Lucene 基础上的搜索引擎,它隐藏了 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API,不过掩盖不了它底层也是 Lucene 的事实。Elasticsearch 的倒排索引,其实就是 Lucene 的倒排索引。
1.2、为什么叫倒排索引
“倒排索引”(Inverted Index)的概念是从"正向索引"(Forward Index)中衍生出来的。
在"正向索引"中,我们从文档出发,记录下每个文档中出现的词项,这样就可以知道每个文档包含哪些词项。而在"倒排索引"中,我们从词项出发,记录下每个词项出现在哪些文档中,这样就可以知道每个词项被哪些文档包含。
正向索引:document -> to -> words
倒排索引:word -> to -> documents
因此,“倒排索引"可以看作是"正向索引"的逆操作,所以被称为"倒排”。在全文搜索中,"倒排索引"是非常重要的数据结构,因为它可以让我们快速找到包含特定词项的所有文档。
1.3、倒排索引的结构
倒排索引作为一种数据结构,用于存储一种映射关系,即从词项到出现该词项的文档的映射。它是全文搜索引擎的核心组成部分,如 Elasticsearch、Lucene 等。
在倒排索引中,每个唯一的词项都有一个相关的倒排列表,这个列表中包含了所有包含该词项的文档的 ID。这样,当我们搜索一个词项时,搜索引擎只需要查找倒排索引,就可以快速找到所有包含这个词项的文档。
例如,假设我们有以下三个文档:
1. 文档1:I love coding
2. 文档2:I love reading
3. 文档3:I love both
对这些文档建立倒排索引后,我们会得到以下的映射关系:
- I:文档1,文档2,文档3
- love:文档1,文档2,文档3
- coding:文档1
- reading:文档2
- both:文档3
所以,当我们搜索"love"时,搜索引擎会在倒排索引中找到"love",然后返回所有包含"love"的文档,即文档1,文档2 和文档3。
2、数据查询过程
2.1、数据查询处理原理
在 Elasticsearch 中,查询处理主要包括以下步骤:
- 解析查询语句:首先,Elasticsearch 会解析用户的查询请求,将其转换为内部的查询表示。这个过程包括解析查询语句的语法、解析查询参数、验证查询语句的合法性等。
- 生成查询计划:解析查询语句后,Elasticsearch 会生成一个查询计划。查询计划描述了如何在倒排索引上执行查询,包括哪些词项需要查询、如何组合词项的查询结果等。
- 执行查询:有了查询计划后,Elasticsearch 就可以在倒排索引上执行查询了。这个过程包括查找词项的倒排列表、计算文档和查询的相关性、生成候选结果集等。
- 生成查询结果:最后,Elasticsearch 会根据候选结果集和查询参数,生成最终的查询结果。这个过程包括排序候选结果、生成摘要、分页等。
2.2、解析查询语句
在 Elasticsearch 中,解析查询语句是查询处理的第一步。这个过程主要包括以下步骤:
- 解析 JSON:Elasticsearch 的查询语句通常以 JSON 格式提供。首先,Elasticsearch 会解析 JSON,将其转换为内部的数据结构。
{"query": {"match": {"field_name": "query_value"}}
}
- 解析查询类型:查询语句中通常会指定查询类型(包括 Match 查询用于基本的全文搜索,Term 查询用于精确匹配,Range 查询用于范围搜索,Bool 查询用于逻辑组合多个查询条件,Phrase 查询用于短语搜索,Wildcard 查询用于通配符搜索,Prefix 查询用于前缀搜索,以及 Fuzzy 查询用于模糊搜索等)。Elasticsearch 会解析查询类型,并根据查询类型选择相应的查询处理器。
- 解析查询参数:查询语句中还会包含一些查询参数,如字段名、查询值、模糊匹配的阈值等。Elasticsearch 会解析这些查询参数,并将它们传递给查询处理器。
- 验证查询语句:最后,Elasticsearch 会验证查询语句的合法性。例如,检查字段名是否存在,检查查询值的类型是否与字段类型匹配等。如果查询语句不合法,Elasticsearch 会返回一个错误。
2.3、生成查询计划
在 Elasticsearch 中,生成查询计划的过程包括确定查询类型(如 match、term、range 等),确定要查询的字段和值,然后根据这些信息生成查询计划,描述了如何在倒排索引上执行查询,包括哪些词项需要查询以及如何组合词项的查询结果。
2.4、执行查询
在 Elasticsearch 中,执行查询是查询处理过程的关键步骤。这个过程主要包括以下步骤:
-
查找词项:根据查询计划,Elasticsearch 会在倒排索引中查找每个词项的倒排列表。
-
计算相关性:Elasticsearch 会计算每个文档和查询的相关性。这通常通过一个名为 TF-IDF 的算法来完成。
-
生成候选结果集:Elasticsearch 会根据相关性的计算结果,生成一个候选结果集。这个结果集包含了所有可能满足查询条件的文档。
2.5、生成查询结果
在 Elasticsearch 中,生成查询结果是查询处理过程的最后一步。这个过程主要包括以下步骤:
-
排序:Elasticsearch 会根据每个文档和查询的相关性,对候选结果集进行排序。
-
生成摘要:为了方便用户查看查询结果,Elasticsearch 会为每个文档生成一个摘要。摘要通常包括文档的一部分内容和查询词项的位置。
-
分页:如果查询请求中指定了分页参数,Elasticsearch 会根据这些参数,从排序后的结果集中提取出一个页面的结果。
-
返回结果:最后,Elasticsearch 会将查询结果返回给用户。查询结果通常以 JSON 格式提供,包括总的命中数、查询时间、每个文档的 ID、摘要等信息。
以上就是 Elasticsearch 生成查询结果的基本过程。需要注意的是,这个过程可能会受到查询语句的复杂性、数据量的大小、集群的状态等因素的影响。
3、相关性评分
3.1、相关性评分的作用
在 Elasticsearch 中,相关性评分(也称为评分或得分)是用来衡量一个文档与查询条件的匹配程度的。它是由 Elasticsearch 的查询模块根据 TF-IDF 算法或其他相关性算法计算出来的一个数值。
相关性评分的作用主要体现在以下几个方面:
-
排序:在返回查询结果时,Elasticsearch 会根据相关性评分对结果进行排序。评分越高的文档,被认为与查询条件的匹配程度越高,因此会被排在更前面。****
-
筛选:在某些情况下,你可能只关心那些与查询条件高度匹配的文档。这时,你可以设置一个评分阈值,只返回评分高于这个阈值的文档。
-
调优:通过理解和调整相关性评分的计算方式,你可以优化查询的效果,使其更符合你的需求。例如,你可以通过设置字段的权重,影响其在评分计算中的重要性。
需要注意的是,相关性评分并不是一个绝对的值,它的大小并不能直接反映出文档的质量或重要性。它只是表示了文档与特定查询条件的匹配程度。同一个文档对于不同的查询条件,可能会有不同的评分。
3.2、TF-IDF 原理
TF-IDF(词频-逆文档频率)算法用于评估一个词对于一个文件集或语料库中的某个文件的重要程度。它的工作原理如下:
-
Term Frequency (TF):衡量一个词在文档中出现的频率。计算方法通常是将文档中某个词出现的次数除以文档中所有词的总数。TF 值越高,表示该词在文档中的重要性越高。
-
Inverse Document Frequency (IDF):衡量一个词是否常见。计算方法是将语料库中的文档总数除以包含该词的文档数的对数。IDF 值越高,表示该词的信息量越大,对于区分文档的重要性越高。
-
TF-IDF 值计算:将 TF 值和 IDF 值相乘,得到最终的 TF-IDF 值。TF-IDF 值越高,表示该词对于某个文档的重要性越高。
在 Elasticsearch 中,对于每个查询词,会计算它在文档中的 TF 值和在整个语料库中的 IDF 值,然后将这两个值相乘,得到最终的 TF-IDF 值。查询结果按照 TF-IDF 值的大小进行排序,TF-IDF 值越大,表示文档和查询的相关性越高。
TF-IDF 算法的目标是通过考虑词频和词的普遍性来确定词的重要性,从而提高信息检索的准确性和相关性。
3.3、其他评分规则
除了基于 TF-IDF 的相关性评分外,Elasticsearch 还提供了其他的评分规则,以满足不同的搜索需求。以下是一些常见的评分规则:
- Constant Score:这种评分规则会给所有的文档赋予相同的评分。它通常用于过滤操作,因为在过滤操作中,我们只关心文档是否满足条件,而不关心文档的相关性。
- Boolean/Disjunction Max Score:这种评分规则会计算每个查询条件的评分,然后取最高的评分作为最终的评分。它通常用于多条件查询,因为在多条件查询中,我们通常关心的是文档满足任何一个条件的程度。
- Function Score:这种评分规则允许你自定义评分函数,以实现复杂的评分逻辑。你可以基于文档的字段值、查询参数、脚本等因素,计算出一个评分。
以上只是 Elasticsearch 评分规则的一部分,实际上 Elasticsearch 还提供了更多的评分规则,如 script_score、field_value_factor、decay functions 等,可以满足各种复杂的搜索需求。
4、搜索功能
Elasticsearch 提供了一些高级搜索功能,如全文搜索、模糊搜索、范围搜索、聚合搜索等。
4.1、全文搜索
Elasticsearch 最基本且核心的功能就是全文搜索。全文搜索是指对大量文本数据进行搜索,找出包含指定词项的文档。Elasticsearch 使用倒排索引这种数据结构来实现高效的全文搜索。
全文搜索的工作原理主要基于倒排索引。倒排索引是一种数据结构,它将所有的词项(Term)映射到出现这些词项的文档列表。当执行全文搜索时,Elasticsearch 会根据查询的词项找到对应的文档列表,然后根据一定的评分规则(如 TF-IDF)计算每个文档的相关性得分,并按得分排序返回结果。
Elasticsearch 的全文搜索支持多种查询类型,如 match 查询、multi_match 查询、query_string 查询等。这些查询类型可以满足各种复杂的搜索需求,如单词搜索、短语搜索、布尔搜索等。
4.2、多值搜索
在 Elasticsearch 中,如果你需要对多个值进行搜索,可以使用 terms 查询。terms 查询允许你指定一个字段和多个值,Elasticsearch 会返回所有字段值在这些值中的文档。
terms 查询的工作原理是将每个值都转换为一个 term 查询,然后将这些 term 查询以 OR 的方式进行组合。这意味着只要文档的字段值匹配了任何一个值,就会被认为满足查询条件。
例如,如果你执行一个 terms 查询,查找颜色为 “红色” 或 “蓝色” 的商品,Elasticsearch 会首先在倒排索引中查找 “红色” 和 “蓝色” 这两个词项的倒排列表,然后将这两个列表进行合并,得到最终的结果。
需要注意的是,terms 查询只适用于精确值的匹配,不适用于全文搜索。如果你需要对多个词项进行全文搜索,可以使用 multi_match 查询或 query_string 查询。
4.3、模糊搜索
Elasticsearch 的模糊搜索是一种能够处理拼写错误和近似搜索的功能。
模糊搜索的实现主要基于编辑距离(Levenshtein distance)算法,该算法可以计算两个词项之间的差异程度。编辑距离是通过计算从一个词项变换到另一个词项所需的最少单字符编辑操作(如插入、删除、替换)的数量来衡量差异程度。
在 Elasticsearch 中,可以使用 fuzzy 查询来进行模糊搜索。fuzzy 查询允许你指定一个 fuzziness 参数,该参数决定了允许的最大编辑距离。例如,fuzziness 参数设置为 1,那么就可以匹配出与查询词项编辑距离在 1 以内的所有词项。
模糊搜索非常适合处理用户输入错误的情况,可以提高搜索的容错性,从而提升用户体验。
4.4、范围搜索
Elasticsearch 的范围搜索允许你查找字段值在指定范围内的文档。
范围搜索在 Elasticsearch 中主要通过 range 查询来实现。在 range 查询中,你可以为字段指定一个上界和一个下界,Elasticsearch 会返回所有字段值在这个范围内的文档。
例如,你可以查找价格在 10 到 20 之间的所有商品,或者查找发布日期在过去一周内的所有文章。
range 查询支持数值字段、日期字段、IP 地址字段等多种类型的字段。对于日期字段,你还可以使用日期数学表达式来指定范围,如 now-1d 表示从现在开始的过去一天。
此外,range 查询还支持开闭区间的设置,你可以通过 gte(大于等于)、gt(大于)、lte(小于等于)、lt(小于)等参数来控制区间的开闭。
范围搜索是 Elasticsearch 中非常常用的一种搜索方式,它可以满足各种基于范围的过滤和查询需求。
4.5、聚合搜索
Elasticsearch 的聚合搜索是一种强大的数据分析工具,它允许你在搜索结果上进行各种统计分析。
聚合搜索在 Elasticsearch 中主要通过聚合(Aggregations)功能来实现。聚合功能提供了一组用于数据分析的操作符,如 min、max、avg、sum、count 等,你可以使用这些操作符来对搜索结果进行统计分析。
例如,你可以使用 avg 聚合来计算所有商品的平均价格,或者使用 histogram 聚合来统计每个价格区间的商品数量。
此外,聚合功能还支持嵌套聚合,你可以在一个聚合的基础上进行另一个聚合。这使得你可以实现复杂的数据分析需求,如分组统计、多级分组统计等。
聚合搜索是 Elasticsearch 中非常强大的一种功能,它可以满足各种复杂的数据分析需求。
5、搜索优化
5.1、索引优化
在 Elasticsearch 中,优化索引结构是提高搜索性能的重要手段。以下是一些常见的索引优化策略:
-
合理设置分片数量:每个索引都可以分为多个分片,每个分片是索引数据的一个独立部分。分片的数量会影响 Elasticsearch 的并行处理能力,但是过多的分片会增加集群的管理负担,可能会降低性能。因此,需要根据数据量、硬件资源等因素,合理设置分片的数量。
-
使用合适的字段类型:Elasticsearch 支持多种字段类型,不同的字段类型有不同的索引和搜索性能。例如,对于需要全文搜索的字段,应该使用
text类型,因为text类型会对字段值进行分词处理,适合全文搜索;对于需要精确匹配的字段,应该使用keyword类型,因为keyword类型不会对字段值进行分词处理,适合精确匹配。 -
禁用不需要搜索的字段的索引:如果一个字段不需要被搜索,那么就没有必要为它建立索引。你可以在映射中将这个字段的
index参数设置为false,这样 Elasticsearch 就不会为这个字段建立索引,可以节省存储空间,提高索引和搜索性能。 -
优化文档结构:尽量避免使用嵌套类型(nested type),因为嵌套类型会增加索引的复杂性和存储开销。如果需要在数组字段上进行搜索,可以考虑使用
flattened类型。
以上只是优化 Elasticsearch 索引结构的一部分方法,实际上还有很多其他的优化技术和策略,如使用 doc_values 优化排序和聚合、使用 routing 优化分片访问等。
5.2、查询优化
在 Elasticsearch 中,优化查询语句是提高搜索性能的重要手段。以下是一些常见的查询优化策略:
-
避免使用高开销的查询:某些类型的查询,如
wildcard、regexp、fuzzy等,由于需要对大量的词项进行匹配,所以开销较大。在性能敏感的场景下,应尽量避免使用这些查询。 -
优先使用 filter:在 Elasticsearch 中,
filter和query都可以用来过滤文档,但是filter的结果可以被缓存,下次执行相同的filter时可以直接使用缓存,从而提高性能。因此,对于那些不需要计算相关性得分的过滤条件,应优先使用filter。 -
避免深度分页:深度分页指的是获取结果的后面几页,如第 1000 页。深度分页需要 Elasticsearch 对前面所有的结果进行排序,开销较大。如果需要处理大量的结果,应考虑使用
scrollAPI 或search_after参数。 -
减少返回的字段:默认情况下,Elasticsearch 会返回文档的所有字段。如果只需要文档的部分字段,可以使用
_source参数来指定返回的字段,这样可以减少网络传输的数据量,提高性能。
以上只是优化 Elasticsearch 查询语句的一部分方法,实际上还有很多其他的优化技术和策略,如使用 bool 查询的 must、should、filter、must_not 来优化布尔逻辑,使用 constant_score 查询来优化静态得分等。
5.3、使用doc_values优化排序和聚合
在 Elasticsearch 中,doc_values 是一种在磁盘上的列式存储,它可以用来快速、高效地执行排序、聚合等操作。
当你对一个字段进行排序或聚合时,Elasticsearch 需要访问该字段的所有值。如果这些值存储在文档中,那么 Elasticsearch 就需要从磁盘中加载每个文档,这可能会非常慢。而 doc_values 则将字段的值存储在磁盘的一个单独的区域,Elasticsearch 可以直接访问这些值,无需加载文档,因此可以大大提高性能。
默认情况下,Elasticsearch 会为所有的 keyword 类型和数值类型的字段启用 doc_values。如果你有一个 text 类型的字段,也需要进行排序或聚合,那么你可以为该字段添加一个 keyword 类型的子字段,并启用 doc_values。
需要注意的是,虽然 doc_values 可以提高排序和聚合的性能,但它也会占用额外的磁盘空间。因此,对于不需要排序或聚合的字段,你可以在映射中将 doc_values 设置为 false,以节省磁盘空间。
5.4、使用routing优化分片
在 Elasticsearch 中,routing 参数可以用来控制文档存储到哪个分片,以及搜索请求路由到哪个分片。通过合理的路由策略,可以显著提高搜索性能。
默认情况下,Elasticsearch 会根据文档的 ID 来决定将文档存储到哪个分片,搜索请求会路由到所有的分片。这种策略可以保证数据的均匀分布,但在某些情况下,可能并不高效。
例如,如果你的索引包含了多个用户的数据,每次搜索请求只涉及到一个用户的数据,那么默认的路由策略就会导致很多无效的搜索,因为大部分分片并不包含该用户的数据。
这时,你可以使用 routing 参数来优化分片访问。你可以将用户 ID 作为 routing 参数的值,这样同一个用户的所有文档就会被存储到同一个分片,搜索请求也只会路由到该分片。这样可以大大减少无效的搜索,提高搜索性能。
需要注意的是,虽然 routing 参数可以提高搜索性能,但如果使用不当,也可能导致数据分布不均,影响集群的稳定性。因此,在使用 routing 参数时,需要充分考虑数据的分布情况。
5.5、其他优化
除上述两种,还可以考虑:
- 使用缓存:Elasticsearch 提供了查询结果缓存和字段数据缓存,可以提高重复查询的性能。需要注意的是,缓存并不总是有益的,如果查询模式具有很高的随机性,缓存可能会降低性能。
- 硬件优化:提升硬件性能也可以提高搜索性能,如增加内存可以提高缓存效果,使用 SSD 可以提高 IO 性能等。
相关文章:

Elasticsearch数据搜索原理
Elasticsearch 是一个开源的、基于 Lucene 的分布式搜索和分析引擎,设计用于云计算环境中,能够实现实时的、可扩展的搜索、分析和探索全文和结构化数据。它具有高度的可扩展性,可以在短时间内搜索和分析大量数据。 Elasticsearch 不仅仅是一个…...
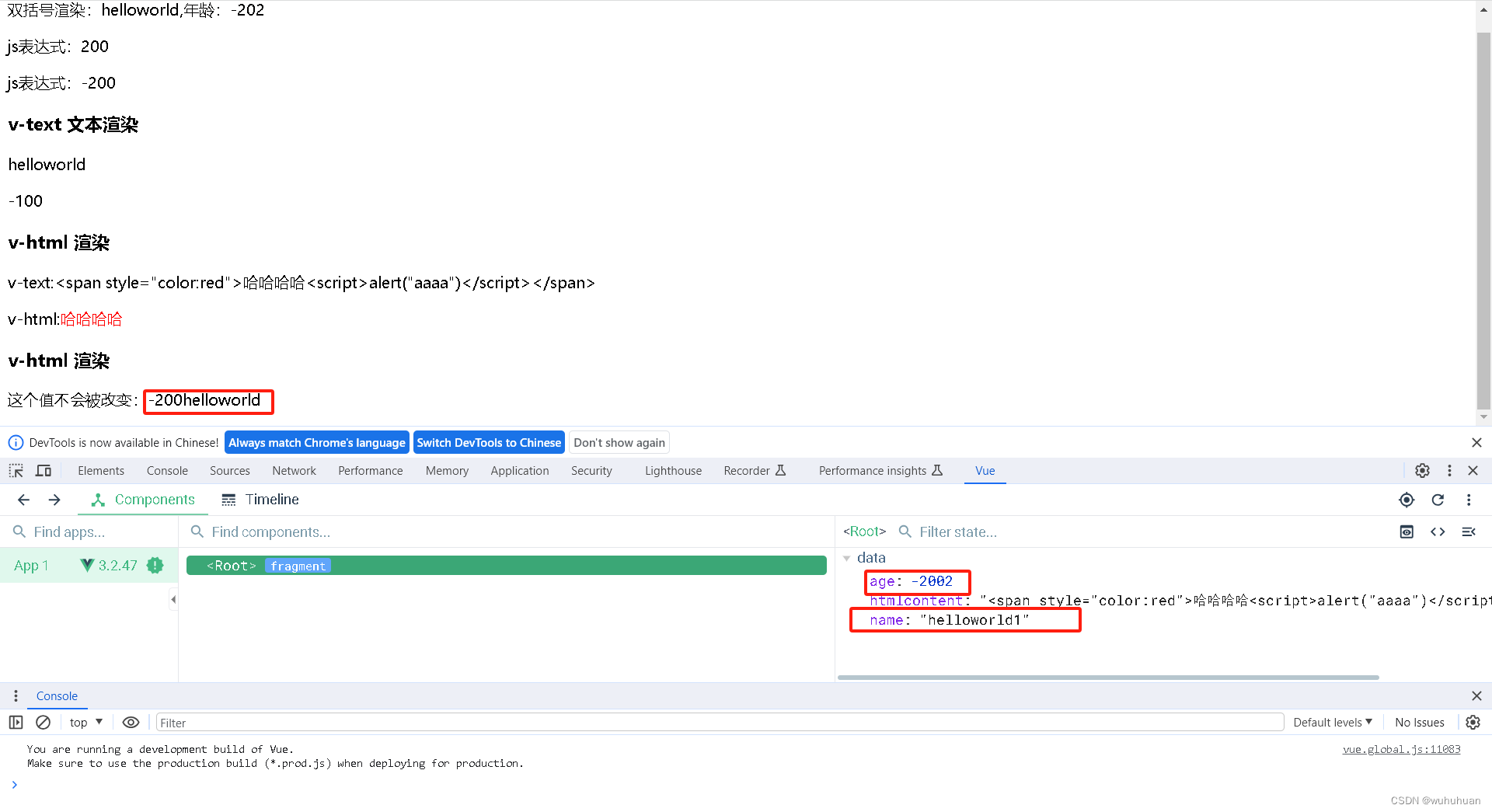
vue模版语法-{{}}/v-text/v-html/v-once
一、{{}}双括号:用于文本渲染 1、 {{变量名}}:data中返回对象的变量名 2、{{js表达式}}:可以直接进行js表达式处理 3、注意:双大括号中不要写等式书写 二、v-text 指令,用于文本渲染 1、为了解决双大括号渲染数据出现闪烁问题 三、v-cloak …...

前端埋点上传
没事看看: 从用户行为到数据:数据采集全景解析 | 人人都是产品经理 搭建前端监控,采集用户行为的 N 种姿势-前端监控设备 创业公司做数据分析(三)用户行为数据采集系统-CSDN博客...
)
第11章 Redis(一)
11.1 谈谈你对Redis的理解 难度:★★★ 重点:★★ 白话解析 对Redis的理解无非从三个方面去说一说:背景,是什么,特性。 背景:数据直接存磁盘太慢了,虽然MySQL用到了BufferPool等缓存,但是为了保证数据不丢失,MySQL采用的RedoLog依然要直接写磁盘。所以,数据的存储就…...

freertos信号量之二值信号量
freertos信号量之二值信号量 简介例程 简介 FreeRTOS的二值信号量(Binary Semaphore)是用于实现进程间同步和临界资源保护的重要工具。以下是一些二值信号量的常用函数及其说明: 1)xSemaphoreCreateBinary() 创建一个二值信号量…...
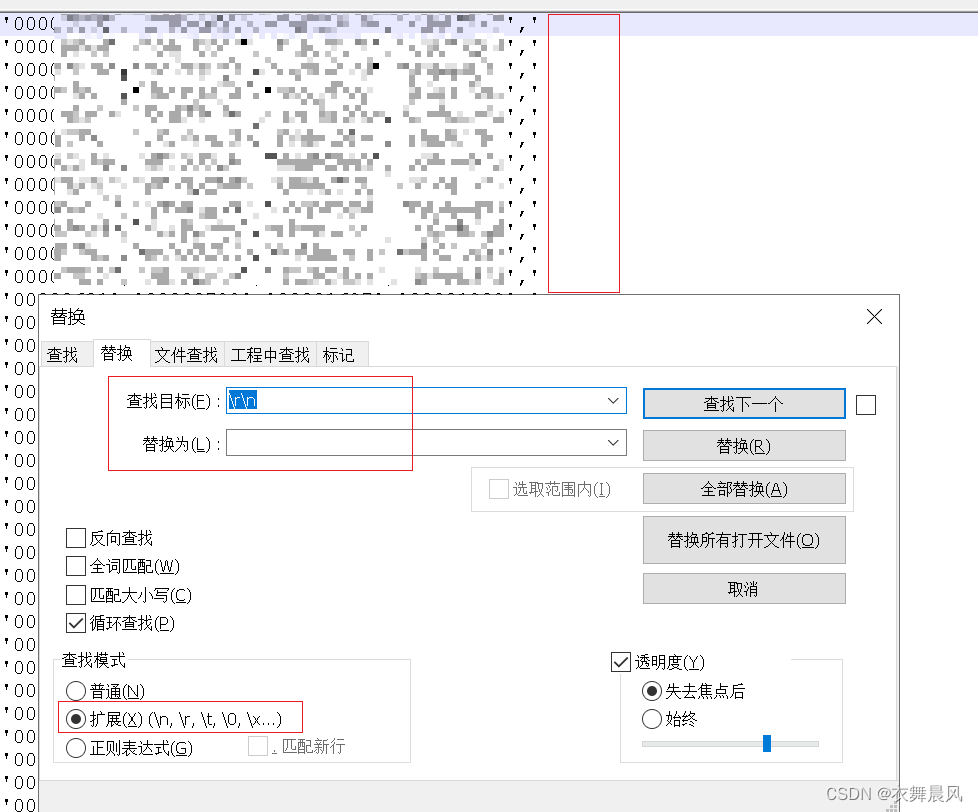
notepad++ 如何去除换行
选中下方的“扩展” “查找目标”输入:\r\n,替换为:空白 最后全部替换。...

PPT NO.2 插入透明校徽
插入透明校徽: ①先下载一个校徽: ②用矢量网站转换一下,这个免费的,很多其他的要钱钱: 位图转矢量图,JPG转矢量,PNG转矢量,GIF转矢量,BMP转矢量 - 在线工具 - 字客网 (fontke.com) 转换完了如下: 打…...

Linux系统部署PostgreSQL 单机数据库
安装方式 1 安装包方式 (Packages and Installers) 支持的操作系统包括 liunxMacosWindowsBSDSolaris 2 源码安装 (Source code) 下载源码包 通过下载地址PostgreSQL: File Browser 可以看到有各个版本的源码目录 选择13.1…...

好用的办公摸鱼神器
http://t.chaojizhu.cn/fawork/Down?uid180819...

手写Java序列化工具
一、思考 假设给一个java bean,让你按照 json 的格式打印出来,你会怎么做? 比如这个java bean 长这样,并且创建了一个叫宝儿姐的朋友 package com.test;public class User {private String name;private Integer age;private Bi…...

mysql面试题26:MySQL中什么是MVCC,它的底层原理是什么
该文章专注于面试,面试只要回答关键点即可,不需要对框架有非常深入的回答,如果你想应付面试,是足够了,抓住关键点 面试官:什么是MVCC,它的底层原理是什么? MVCC(Multi-Version Concurrency Control)是一种并发控制机制,用于在数据库中实现并发事务的隔离性和一致性…...

SQL进阶 - SQL的编程规范
性能优化是一个很有趣的探索方向,将耗时耗资源的查询优化下来也是一件很有成就感的事情,但既然编程是一种沟通手段,那每一个数据开发者就都有义务保证写出的代码逻辑清晰,具有很好的可读性。 目录 引子 小试牛刀 答案 引言 …...
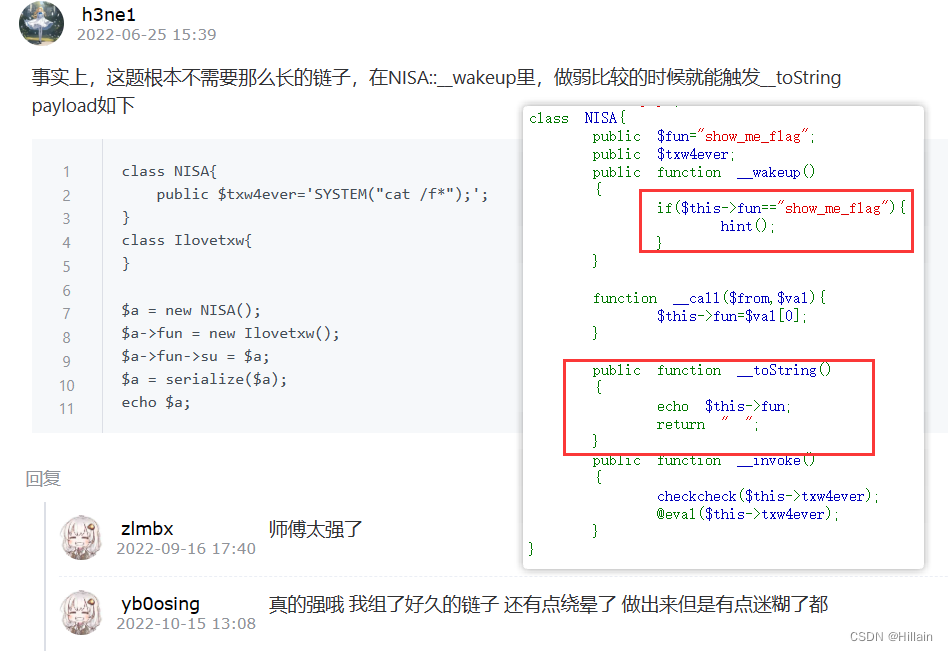
[NISACTF 2022]babyserialize - 反序列化+waf绕过【*】
[NISACTF 2022]babyserialize 一、解题过程二、思考总结(一)、关于题目的小细节(二)、关于弱类型比较技巧 一、解题过程 题目代码: <?php include "waf.php"; class NISA{public $fun"show_me_fl…...
docker部署Vaultwarden密码共享管理系统
Vaultwarden是一个开源的密码管理器,它是Bitwarden密码管理器的自托管版本。它提供了类似于Bitwarden的功能,允许用户安全地存储和管理密码、敏感数据和身份信息。 Vaultwarden的主要特点包括: 1. 安全的数据存储:Vaultwarden使…...

低代码开发技术选型
低代码的技术路径 低代码开发低代码开发优势低代码的技术路径1.表格驱动2.表单驱动3.数据模型4.领域模型 低代码的核心能力企业级低代码开发平台的11项关键能力低代码平台的流程引擎选型低代码平台的流程设计器选型低代码平台的表单设计器选型低代码平台的Vue.js 框架选型 低代…...
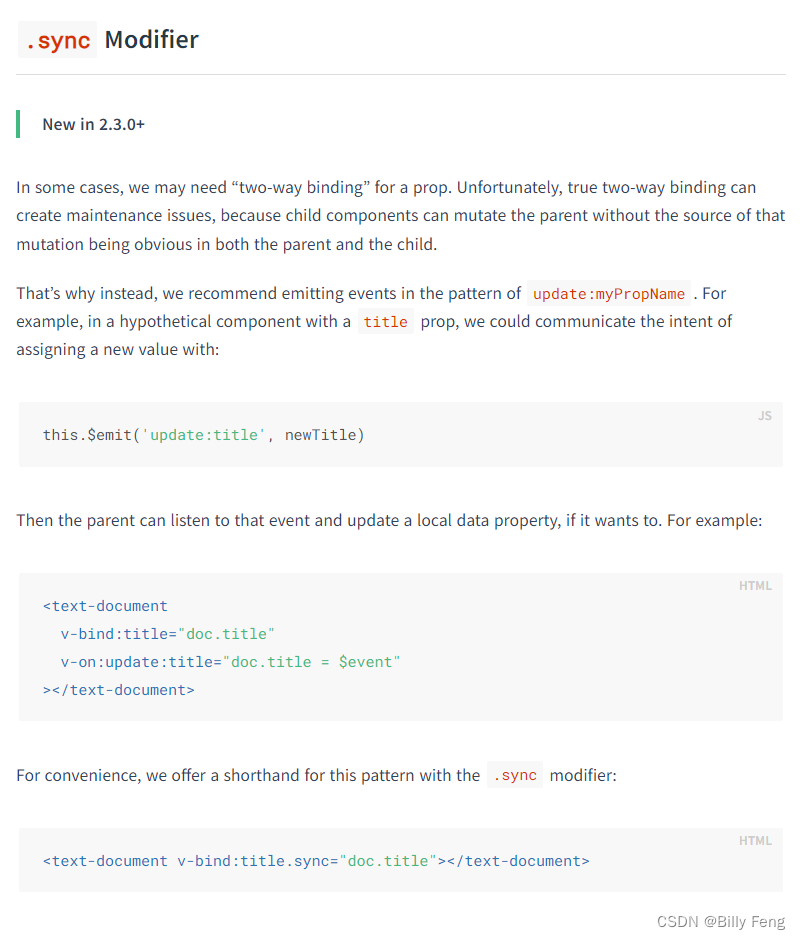
在vue2中,v-model和.sync的区别
最近在封装一个弹窗组件时,用了比较复杂的逻辑去做显示和隐藏的逻辑,在查看同事的代码之后,才知道还有更简单的方法,自己已经忘了一些API. popup组件里统一的template: <div v-ifisShowPopup> // 弹窗内容 <…...

nginx 配置
一、nginx安装 下载地址:http://nginx.org/en/download.html,和Keepalived搭配使用,防止nginx挂掉 二、nginx配置 ########### 每个指令必须有分号结束。################# #user administrator administrators; #配置用户或者组…...
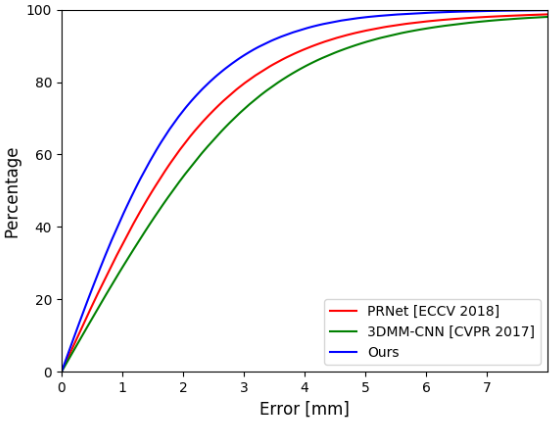
【计算机视觉|人脸建模】学习从图像中回归3D面部形状和表情而无需3D监督
本系列博文为深度学习/计算机视觉论文笔记,转载请注明出处 标题:Learning to Regress 3D Face Shape and Expression from an Image without 3D Supervision 链接:[1905.06817] Learning to Regress 3D Face Shape and Expression from an I…...
Linux系统之部署h5ai目录列表程序
Linux系统之部署h5ai目录列表程序 一、h5ai介绍1.1 h5ai简介1.2 h5ai特点 二、本地环境介绍2.1 本地环境规划2.2 本次实践介绍 三、检查本地环境3.1 检查本地操作系统版本3.2 检查系统内核版本 四、安装httpd软件4.1 检查yum仓库4.2 安装httpd软件4.3 启动httpd服务4.4 查看htt…...
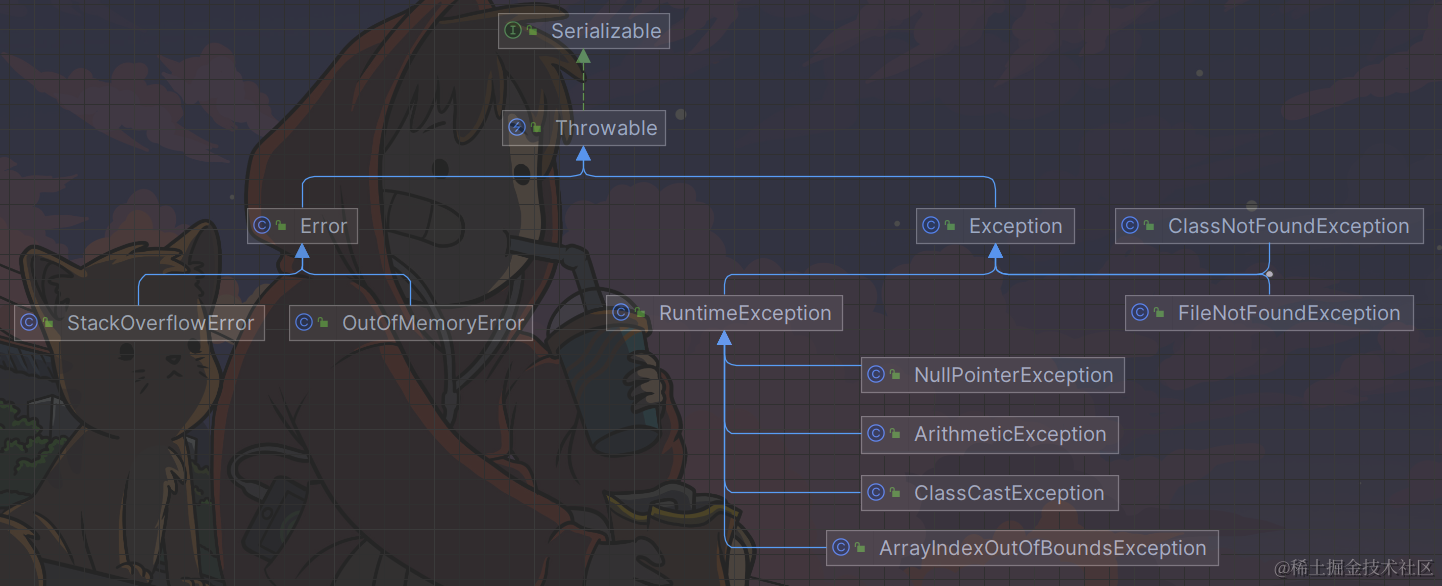
Java-Exception
目录 异常概念ErrorException 体系图常见运行时异常NullPointerExceptionArithmeticExceptionArrayIndexOutOfBoundExceptionClassCastExceptionNumberFormatException 常见的编译异常异常处理机制自定义异常throw和throws对比 异常是Java编程中的常见问题,了解如何…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

安宝特方案丨XRSOP人员作业标准化管理平台:AR智慧点检验收套件
在选煤厂、化工厂、钢铁厂等过程生产型企业,其生产设备的运行效率和非计划停机对工业制造效益有较大影响。 随着企业自动化和智能化建设的推进,需提前预防假检、错检、漏检,推动智慧生产运维系统数据的流动和现场赋能应用。同时,…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

基于Java Swing的电子通讯录设计与实现:附系统托盘功能代码详解
JAVASQL电子通讯录带系统托盘 一、系统概述 本电子通讯录系统采用Java Swing开发桌面应用,结合SQLite数据库实现联系人管理功能,并集成系统托盘功能提升用户体验。系统支持联系人的增删改查、分组管理、搜索过滤等功能,同时可以最小化到系统…...