Java中栈实现怎么选?Stack、Deque、ArrayDeque、LinkedList(含常用Api积累)
目录
Java中的Stack类
不用Stack有以下两点原因
1、从性能上来说应该使用Deque代替Stack。
2、Stack从Vector继承是个历史遗留问题,JDK官方已建议优先使用Deque的实现类来代替Stack。
该用ArrayDeque还是LinkedList?
ArrayDeque与LinkList区别:
ArrayDeque:
LinkList:
结论
API积累
Deque中常用方法:
把Deque当栈用的时候:
把Deque当队列用的时候:
从上面(头部)插入:
从上面(头部)出来/观察:
从下面(尾部)插入:
从下面(尾部)出来/观察:
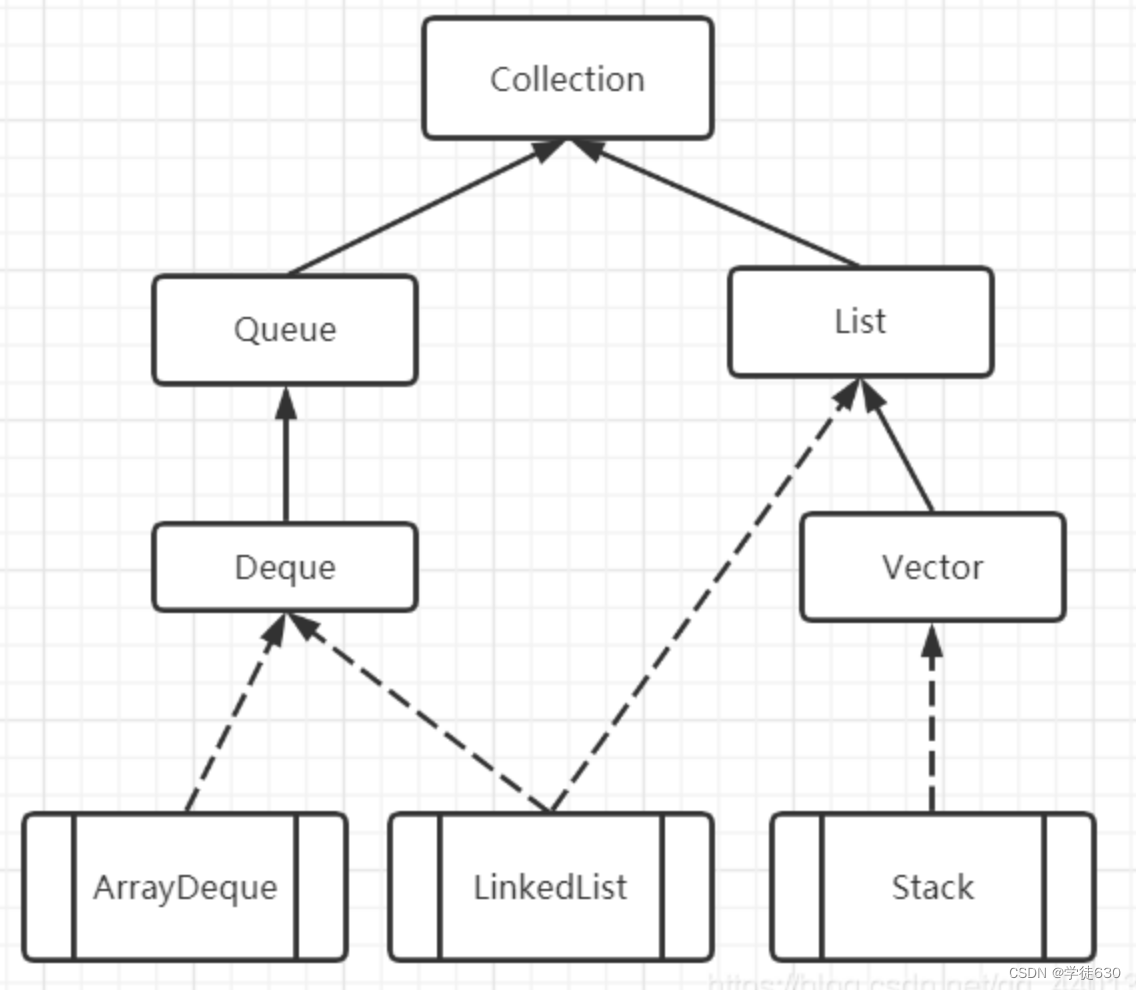
Java中的Stack类
Java中Stack类从Vector类继承,底层是用数组实现的线程安全的栈。栈是一种后进先出(LIFO)的容器,常用的操作push/pop/peek。
不过Java中用来表达栈的功能(push/pop/peek),更适用的是使用双端队列接口Deque,并用实现类ArrayDeque / LinkedList来进行初始化。
Deque<Integer> stack = new ArrayDeque<>();
Deque<Integer> stack = new LinkedList<>();
不用Stack有以下两点原因
1、从性能上来说应该使用Deque代替Stack。
Stack和Vector都是线程安全的,其实多数情况下并不需要做到线程安全,因此没有必要使用Stack。毕竟保证线程安全需要上锁,有额外的系统开销。
2、Stack从Vector继承是个历史遗留问题,JDK官方已建议优先使用Deque的实现类来代替Stack。
Stack从Vector继承的一个副作用是,暴露了
set/get方法,可以进行随机位置的访问,这与Stack只能从尾巴上进行增减的本意相悖。此外,Deque在转成ArrayList或者stream的时候保持了“后进先出”的语义,而Stack因为是从Vector继承,没有这个语义。
Stack<Integer> stack = new Stack<>(); Deque<Integer> deque = new ArrayDeque<>();stack.push(1); stack.push(2); deque.push(1); deque.push(2);System.out.println(new ArrayList<>(stack)); // [1,2] List<Integer> list1 = stack.stream().collect(Collectors.toList());//[1,2]// deque转成ArrayList或stream时保留了“后进先出”的语义 System.out.println(new ArrayList<>(deque)); // [2,1] List<Integer> list2 = deque.stream().collect(Collectors.toList());//[2,1]
该用ArrayDeque还是LinkedList?
ArrayDeque和LinkedList这两者底层,一个采用数组存储,一个采用链表存储;
ArrayDeque与LinkList区别:
ArrayDeque:
- 数组结构
- 插入元素不能为null
- 无法确定数据量时,后期扩容会影响效率
LinkList:
- 链表结构
- 插入元素能为null
- 无法确定数据量时,有更好表现
PS:这两者既可当成栈(仅支持在尾部加入或移除元素)使用;也可当成双端队列使用,即可以在队列的两端(头或尾)将元素加入或移除。
单次加入/移除元素的平均时间复杂度均为O(1)。
那么问题来了,在用作栈时到底用ArrayDeque好还是LinkedList好呢?
注意到ArrayDeque源码注释中有一句话:
This class is likely to be faster than {@link Stack} when used as a stack,
and faster than {@link LinkedList} when used as a queue.
ArrayDeque用作栈时比Stack快没有疑问,用作队列的时候似乎也会比LinkedList快!
笔者经过50W数据量的测试,发现两者性能基本接近,ArrayDeque平均耗时在18-24ms,LinkedList耗时平均在20-28ms。
如果数据量上升到100W的话,ArrayDeque的优势会更明显。
结论:ArrayDeque会略胜一筹,不过差别通常可以忽略
public static void main(String[] args) {int length = 500000;int max = length;// 生成一个长度为length,值从1~max的随机数组int[] data = new RandomIntArray(length,1,length,max).next();int loopCount = 10;long t1, t2;t1 = System.currentTimeMillis();for (int i = 0; i < loopCount; i++) {// testArrayDeque(data);testLinkedList(data);}t2 = System.currentTimeMillis();// 测试loopCount次取平均结果System.out.println("timeTaken: " + String.format("%.1f", (t2-t1)/(double)loopCount));
}public static void testArrayDeque(int[] data) {int length = data.length;Deque<Integer> stack = new ArrayDeque<>();for (int i = 0; i < length/2; i++) {stack.push(data[i]);stack.push(data[i+1]);stack.pop();stack.push(stack.peek()+1);}
}public static void testLinkedList(int[] data) {int length = data.length;Deque<Integer> stack = new LinkedList<>();for (int i = 0; i < length/2; i++) {stack.push(data[i]);stack.push(data[i+1]);stack.pop();stack.push(stack.peek()+1);}
}
结论
ArrayDeque会略胜一筹,不过差别通常可以忽略。
经过性能对比,笔者更倾向于使用ArrayDeque来表达Java中的栈功能。
API积累
Deque中常用方法:
以这2个为基础整出来的Deque除了结构不一样,方法都一样的。
把Deque当栈用的时候:
| 入栈 | push(E e) |
| 出栈 | poll() / pop() 后者在栈空的时候会抛出异常,前者返回null |
| 查看栈顶 | peek() 为空时返回null |
把Deque当队列用的时候:
| 入队 | offer(E e) |
| 出队 | poll() 为空时返回null |
| 查看队首 | peek() 为空时返回null |
有些时候需要进行一些骚操作的时候(比如取得栈底元素,取得队尾元素),这些常规操作就不能满足了。
下面就是Deque中一些更详细的方法。
从上面(头部)插入:
| 方法名 | 作用 |
|---|---|
| void addFirst(E e) | 将指定的元素插入此双端队列的前面 ,空间不足抛异常 |
| boolean offerFirst(E e) | 将指定的元素插入此双端队列的前面 ,空间不足插入失败返回回false |
| void push(E e) | 将指定的元素插入此双端队列的前面 ,空间不足抛异常 |
从上面(头部)出来/观察:
| 方法名 | 作用 |
|---|---|
| E removeFirst() | 检索并删除第一个元素,为空时抛出异常 |
| E remove() | 和removeFirst一样 检索并删除第一个元素,为空时抛出异常 |
| E pop() | 和removeFirst一样 检索并删除第一个元素,为空时抛出异常 |
| E pollFirst() | 检索并删除第一个元素 ,为空时返回null |
| E poll() | 和pollFirst一样 检索并删除第一个元素 ,为空时返回null |
| E getFirst() | 只看看第一个元素 ,不出来,为空就抛异常 |
| E element() | 和getFirst一样 只看看第一个元素 ,不出来,为空就抛异常 |
| E peekFirst() | 只看看第一个元素 ,不出来,为空时返回null |
| E peek() | 和peekFirst一样 只看看第一个元素 ,不出来,为空时返回null |
从下面(尾部)插入:
| 方法名 | 作用 |
|---|---|
| void addLast(E e) | 将指定的元素插入此双端队列的后面 ,空间不足抛异常 |
| boolean offerLast(E e) | 将指定的元素插入此双端队列的后面,空间不足返回false |
| boolean add(E e) | 将指定的元素插入此双端队列的后面,空间不足抛异常 |
| boolean offer(E e) | 将指定的元素插入此双端队列的后面,空间不足返回false |
从下面(尾部)出来/观察:
| 方法名 | 作用 |
|---|---|
| E removeLast() | 检索并删除最后一个元素,为空时抛出异常 |
| E pollLast() | 检索并删除最后一个元素 ,为空时返回null |
| E getLast() | 只看看最后一个元素 ,不出来,为空就抛异常 |
| E peekLast() | 只看看最后一个元素 ,不出来,为空时返回null |
相关文章:
Java中栈实现怎么选?Stack、Deque、ArrayDeque、LinkedList(含常用Api积累)
目录 Java中的Stack类 不用Stack有以下两点原因 1、从性能上来说应该使用Deque代替Stack。 2、Stack从Vector继承是个历史遗留问题,JDK官方已建议优先使用Deque的实现类来代替Stack。 该用ArrayDeque还是LinkedList? ArrayDeque与LinkList区别࿱…...
雷达分辨率单元、单向/双向雷达方程、天气雷达方程简介
一、点状目标 如果两个点状目标在一个分辨率单元中,经典脉冲雷达只能看到一个目标。 点状目标 二、雷达距离分辨率 对于简单的键控开/关脉冲调制: 对于使用脉冲内调制的雷达,距离分辨率取决于压缩脉冲的脉冲持续时间。脉冲压缩比(PCR)取决于传输带宽BWtx,即距离分辨率取…...
RabbitMQ之Fanout(扇形) Exchange解读
目录 基本介绍 适用场景 springboot代码演示 演示架构 工程概述 RabbitConfig配置类:创建队列及交换机并进行绑定 MessageService业务类:发送消息及接收消息 主启动类RabbitMq01Application:实现ApplicationRunner接口 基本介绍 Fa…...

Redisson—分布式集合详述
7.1. 映射(Map) 基于Redis的Redisson的分布式映射结构的RMap Java对象实现了java.util.concurrent.ConcurrentMap接口和java.util.Map接口。与HashMap不同的是,RMap保持了元素的插入顺序。该对象的最大容量受Redis限制,最大元素数…...

开发做前端好还是后端好?这是个问题!
前言 随着互联网的快速发展,越来越多的人选择从事Web开发行业,而Web开发涉及到前端和后端两个方面,相信许多人都曾经对这两个方面进行过探究。而且编程世界就像一座大城市,前端开发和后端开发就像城市的两个不同街区。作为初学者&…...

运行huggingface Kosmos2报错 nameerror: name ‘kosmos2tokenizer‘ is not defined
尝试运行huggingface上的Kosmos,https://huggingface.co/ydshieh/kosmos-2-patch14-224失败,报错: nameerror: name kosmos2tokenizer is not defined查看报错代码: vi /root/.cache/huggingface/modules/transformers_modules/ydshieh/kosmos-2-patch14-224/48e3edebaeb…...

吃鸡玩家必备神器!一站式提升战斗力、分享干货!
大家好,我是吃鸡玩家。在这个视频中,我要分享一个让你瞬间提高战斗力的神器,同时让你享受到顶级游戏作战干货的盛宴!让我们一起来了解吧! 首先,我们推荐绝地求生作图工具。通过这款工具,你可以轻…...

【maven】idea中基于maven-webapp骨架创建的web.xml问题
IDEA中基于maven-webapp骨架创建的web工程,默认的web.xml是这样的。 <!DOCTYPE web-app PUBLIC"-//Sun Microsystems, Inc.//DTD Web Application 2.3//EN""http://java.sun.com/dtd/web-app_2_3.dtd" ><web-app><display-name…...

【算法题】2034. 股票价格波动
插: 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 坚持不懈,越努力越幸运,大家一起学习鸭~~~ 题目: 给你一支股票价格的数据流。数据流…...

APSIM模型】作物模型应用案例
APSIM (Agricultural Production Systems sIMulator)模型是世界知名的作物生长模拟模型之一。APSIM模型有Classic和Next Generation两个系列模型,能模拟几十种农作物、牧草和树木的土壤-植物-大气过程,被广泛应用于精细农业、水肥管理、气候变化、粮食安…...

io_uring之liburing库安装
手动编译和安装 liburing: 1.首先,从 liburing 的 GitHub 仓库中获取源代码。您可以使用以下命令克隆仓库: git clone https://github.com/axboe/liburing.git2.进入 liburing 目录: cd liburing3.运行configure ./configure …...
Python WebSocket自动化测试:构建高效接口测试框架!
为了更高效地进行WebSocket接口的自动化测试,我们可以搭建一个专门的测试框架。本文将介绍如何使用Python构建一个高效的WebSocket接口测试框架,并重点关注以下四个方面的内容:运行测试文件封装、报告和日志的封装、数据驱动测试以及测试用例…...
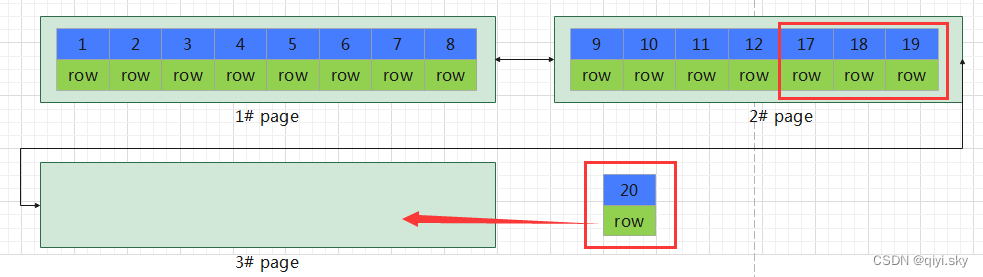
MySQL数据库——SQL优化(1)-介绍、插入数据、主键优化
目录 介绍 插入数据 Insert 大批量插入数据 主键优化 数据组织方式 页分裂 页合并 索引设计原则 介绍 SQL优化将分为下面几个部分进行学习: 插入数据主键优化order by优化group by优化limit优化count优化update优化 首先就先来看第一方面, 插…...

Flink---10、处理函数(基本处理函数、按键分区处理函数、窗口处理函数、应用案例TopN、侧输出流)
星光下的赶路人star的个人主页 我的敌手就是我自己,我要他美好到能使我满意的程度 文章目录 1、处理函数1.1 基本处理函数(ProcessFunction)1.1.1 处理函数的功能和使用1.1.2 ProcessFunction解析1.1.3 处理函数的分类 1.2 按键分区处理函数&…...

多种方案教你彻底解决mac npm install -g后仍然不行怎么办sudo: xxx: command not found
问题概述 某些时候我们成功执行了npm install -g xxx,但是执行完成以后,使用我们全局新安装的包依然不行,如何解决呢? 解决方案1: step1: 查看npm 全局文件安装地址 XXXCN_CXXXMD6M ~ % npm list -g …...

斐波那契数列 JS
问题: 给出一个数字,找出它是斐波那契数列中的第几个数 斐波那契数列 [1, 1, 2, 3, 5, 8, 13, ...],后一个数字是前两个数字之和 输入的数字大于等于 2 如果输入数字不存于斐波那契数列中,返回 -1 function demo(num) {//初始数据…...

IP 地址的分类
IP地址是用于标识计算机或设备在互联网上的位置的一种地址。IP地址通常根据其范围和用途分为不同的分类,主要包括以下几种: IPv4地址(Internet Protocol version 4): IPv4地址是32位二进制数,通常以点分十…...
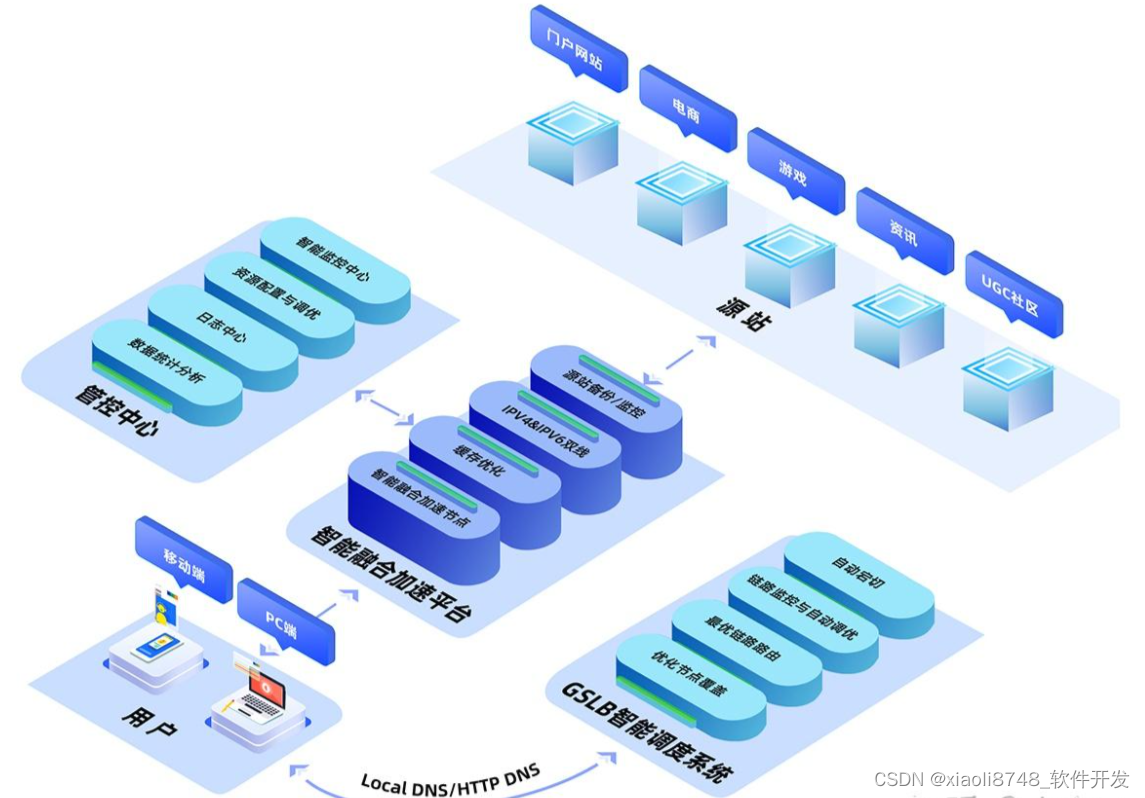
CDN网络基础入门:CDN原理及架构
背景 互联网业务的繁荣让各类门户网站、短视频、剧集观看、在线教育等内容生态快速发展,互联网流量呈现爆发式增长,自然也面临着海量内容分发效率上的挑战,那么作为终端用户,我们获取资源的体验是否有提升呢? 答案是…...
李沐深度学习记录2:10多层感知机
一.简要知识记录 x.numel():看向量或矩阵里元素个数 A.sum():向量或矩阵求和,axis参数可对某维度求和,keepdims参数设置是否保持维度不变 A.cumsum:axis参数设置沿某一维度计算矩阵累计和x*y:向量的按元素乘法 torch.…...

Python标准库中内置装饰器@staticmethod@classmethod
装饰器是Python中强大而灵活的功能,用于修改或增强函数或方法的行为。装饰器本质上是一个函数,它接受另一个函数作为参数,并返回一个新的函数,通常用于在不修改原始函数代码的情况下添加额外的功能或行为。这种技术称为元编程&…...

MCU工程迁移实战:从STM32到MSPM0L1306的完整指南
1. 项目概述:从零理解MCU工程迁移最近在折腾TI的MSPM0系列MCU,特别是MSPM0L1306这颗芯片。很多朋友拿到新的开发板或者从旧项目切换到新平台时,最头疼的就是“迁移工程”这一步。这不仅仅是把代码从一个文件夹复制到另一个文件夹那么简单&…...

56、CAN总线RC低通滤波器截止频率计算与实战
CAN总线RC低通滤波器截止频率计算与实战 一、一个让我熬夜三天的CAN通信故障 去年做某车载ECU项目,CAN总线在电机启动瞬间频繁丢帧。示波器抓波形,CAN_H对地毛刺高达8V,持续时间约200ns。团队里有人提议“加磁珠”,有人喊“上共模扼流圈”。我翻出TI的AN-2298应用笔记,发…...

FanControl终极指南:5分钟让你的Windows风扇控制既智能又安静
FanControl终极指南:5分钟让你的Windows风扇控制既智能又安静 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tren…...

Inter字体终极指南:从零开始掌握现代界面设计的免费开源字体方案
Inter字体终极指南:从零开始掌握现代界面设计的免费开源字体方案 【免费下载链接】inter The Inter font family 项目地址: https://gitcode.com/gh_mirrors/in/inter Inter字体是一款专为计算机屏幕精心设计的开源无衬线字体系统,凭借其卓越的可…...

免费本地语音识别的终极解决方案:3步实现完全离线实时语音转文字
免费本地语音识别的终极解决方案:3步实现完全离线实时语音转文字 【免费下载链接】TMSpeech 腾讯会议摸鱼工具 项目地址: https://gitcode.com/gh_mirrors/tm/TMSpeech 在数字化办公和在线学习日益普及的今天,你是否还在为云端语音识别服务的隐私…...

全息三维空间孪生,全域无感精准智位:数字孪生·视频孪生·无感定位 行业地位核心优势
在全域空间数字化、实景虚实融合与空间智能快速演进的产业周期中,镜像视界(浙江)科技有限公司持续深耕视频原生三维重构、时空AI像素解算、全域无感精准定位、跨镜轨迹智能推演底层核心领域,依托八大自主可控核心引擎构筑全栈技术…...

湿敏电阻HR202/CM-R的两种驱动方案详解:IO充放电法 vs. 交流方波AD采样
湿敏电阻HR202/CM-R的两种驱动方案深度解析:从原理到实战选择 在环境监测和智能家居领域,湿敏电阻作为成本效益突出的湿度传感方案,其驱动电路的设计直接影响测量精度和系统稳定性。HR202和CM-R作为市面上常见的湿敏电阻型号,工程…...

零代码脚本神器:熊猫精灵脚本助手V3.6.4 --Ai找图找色多窗口驱动点击键鼠录制适合游戏自动化办公操作
🛠️ 软件核心定位熊猫精灵脚本助手V3.6.4是一款零代码可视化的自动化工具,主打后台多窗口异步操作,无需编程基础就能实现复杂的自动化流程,覆盖办公、游戏、模拟器、手机投屏等多场景需求,兼容Win7及以上系统…...

Tycoon2FA 利用 OAuth 设备码钓鱼劫持 Microsoft 365 账户的机理与防御
摘要 以 Tycoon2FA 为代表的钓鱼即服务平台正采用基于 OAuth 2.0 设备码流程的新型钓鱼攻击,针对 Microsoft 365 账户实施高隐蔽性劫持。该攻击不窃取明文口令与传统双因素验证码,而是诱导用户在微软官方认证页面完成设备授权,使攻击者获取合…...

Whisky深度评测:如何在Apple Silicon Mac上构建Windows应用运行沙箱
Whisky深度评测:如何在Apple Silicon Mac上构建Windows应用运行沙箱 【免费下载链接】Whisky A modern Wine wrapper for macOS built with SwiftUI 项目地址: https://gitcode.com/gh_mirrors/wh/Whisky 随着Apple Silicon芯片在Mac产品线中的全面普及&…...