聊聊MySQL的聚簇索引和非聚簇索引
文章目录
- 1. 索引的分类
- 1. 存储结构维度
- 2. 功能维度
- 3. 列数维度
- 4. 存储方式维度
- 5. 更新方式维度
- 2. 聚簇索引
- 2.1 什么是聚簇索引
- 2.2 聚簇索引的工作原理
- 3. 非聚簇索引(MySQL官方文档称为`Secondary Indexes`)
- 3.1 什么是非聚簇索引
- 3.2 非聚簇索引的工作原理
- 4. 聚簇索引与非聚簇索引的区别

MySQL的聚簇索引和非聚簇索引翻译为中文也叫聚集索引,非聚集索引。英文有两种叫法
Clustered index、
non-Clustered index 。MySQL官方对
非聚集索引称之为
Secondary Indexes。所以遇到
Secondary Indexes 和
non-Clustered index等价。
MySQL官方文档介绍在 《15.6.2.1 Clustered and Secondary Indexes》https://dev.mysql.com/doc/refman/8.0/en/innodb-index-types.html
1. 索引的分类
在了解聚簇索引和非聚簇索引之前,我们先对数据库索引的分类进行一个了解,不然繁杂的概念和分类会使得搞混,通常我们可以听到B-Tree索引、全文索引 、复合索引、 聚簇索引 、静态索引,其实这些描述都是站在不同维度的描述,B-Tree索引是站在存储结构的维度,全文索引是站在功能维度描述,所以我们先了解一下不同维度的索引描述。
以下是常见的一些维度:
1. 存储结构维度
| 索引类型 | 描述 | 适用场景 |
|---|---|---|
| B-Tree索引 | 基于平衡多路搜索树的索引结构,维护数据有序性 | 范围查询、排序操作 |
| Hash索引 | 基于哈希表的索引结构,适合等值查询 | 等值查询 |
| R-Tree索引 | 适用于存储和查询空间数据的树形结构 | 地理空间数据的查询 |
| Bitmap索引 | 适用于低基数列的索引,占用空间小且查询效率高 | 低基数列(不同值的数目较少)的索引 |
2. 功能维度
| 索引类型 | 描述 | 适用场景 |
|---|---|---|
| 普通索引 | 基本的索引类型,无任何限制 | 通用 |
| 唯一索引 | 类似于普通索引,要求索引列的值必须唯一,通常用于主键 | 确保索引列的唯一性 |
| 全文索引 | 用于全文搜索 | 全文搜索 |
| 空间索引 | 用于地理空间数据的索引 | 地理空间数据的查询 |
3. 列数维度
| 索引类型 | 描述 |
|---|---|
| 单列索引 | 仅包含一个字段的索引 |
| 复合索引 | 包含多个字段的索引,可以是普通索引、唯一索引等 |
这些索引类型的选择取决于需要索引的列的组合和查询需求。复合索引可以更好地支持涉及多个列的查询,但需要权衡索引的大小和维护成本。
4. 存储方式维度
聚簇索引将数据行直接存储在索引中,因此范围查询和排序操作效率较高,而非聚簇索引则需要通过指针访问数据行。选择适当的索引类型取决于数据访问模式和查询需求。
| 索引类型 | 描述 |
|---|---|
| 聚簇索引 | 数据行存储在索引中,数据行的物理顺序与索引中的键值顺序一致 |
| 非聚簇索引 | 索引中的键值顺序与数据行的物理顺序不一致,索引中包含指向数据行的指针 |
5. 更新方式维度
| 索引类型 | 描述 |
|---|---|
| 静态索引 | 仅在数据被插入、删除或更新时更新索引 |
| 动态索引 | 在查询时实时更新索引 |
静态索引在数据被修改时才更新,因此可能存在索引与实际数据不一致的情况。它适用于数据变动较少的场景,可以提高插入、删除和更新操作的性能。动态索引则在查询时实时更新,确保索引与实际数据保持一致,适用于频繁变动的数据环境,但可能对写入操作的性能有一定影响。选择适当的索引类型应考虑数据变动频率和查询性能需求。
本章我们着重了解聚簇索引和非聚簇索引的工作原理
2. 聚簇索引
2.1 什么是聚簇索引
聚簇索引是一种特殊类型的索引,在存储引擎中,数据记录实际的存放方式会根据聚簇索引来组织。一个表中只能有一个聚簇索引,但可以有多个非聚簇索引。
在许多数据库系统中,聚簇索引通常就是主键索引。例如:
-
在MySQL的InnoDB引擎中,聚簇索引默认是主键,如果没有定义主键,MySQL会选择一个非空唯一索引代替,如果没有非空唯一索引,MySQL会自动创建一个隐藏的聚簇索引。
-
在SQL Server中,也可以选择用哪个列作为聚簇索引,但一般推荐使用主键。
-
在Oracle中,可以明确指定创建聚簇索引。
虽然聚簇索引在很多情况下被设置为主键,但并不意味着聚簇索引一定是主键。聚簇索引应该选择最能代表数据存储特征的那一列或几列,例如,如果一个表的数据经常按照某一列的顺序进行查找,那么这一列就非常适合做聚簇索引。
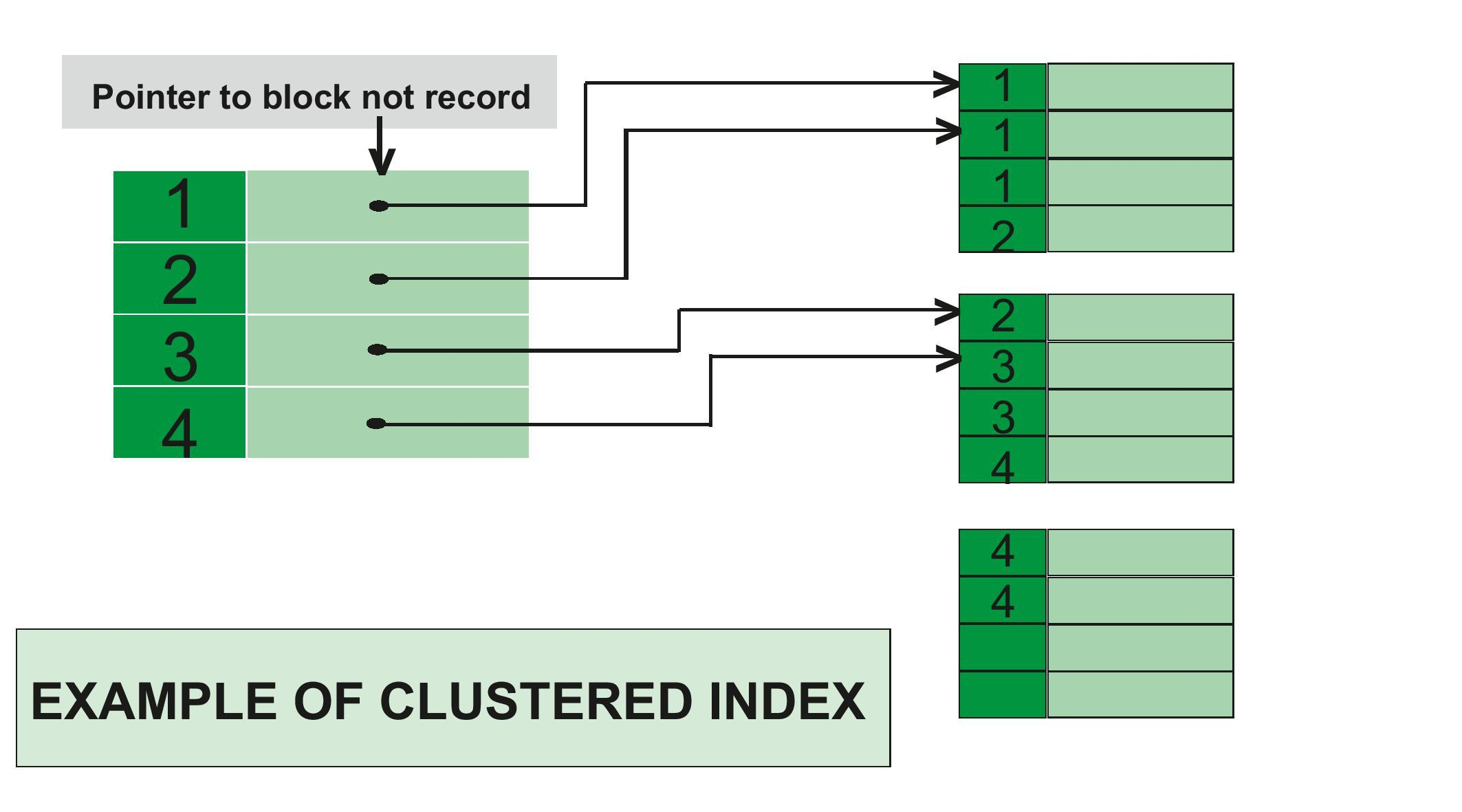
2.2 聚簇索引的工作原理
MySQL 8中的聚簇索引原理与之前版本类似,主要的工作原理是基于B+树数据结构进行排序和检索操作。
对于MySQL的InnoDB存储引擎,聚簇索引是按照主键的顺序来存储数据的。这意味着每个表只能有一个聚簇索引,如果没有明确指定主键,InnoDB会自动选择一个能作为主键的列或者自行生成一个。
以下是聚簇索引的工作原理:
-
查询操作:当执行查询操作时,InnoDB引擎会利用B+树的特性,从根节点开始,通过比较索引的键值找到对应的叶子节点(数据页),从而快速找到需要的数据。因为索引的键值和数据是在一起的,所以查询效率非常高。
-
插入和删除操作:当进行插入或删除操作时,InnoDB引擎需要找到对应的索引键值,然后在对应的位置插入新的数据或删除旧的数据。因为数据是按照键的顺序存储的,所以插入和删除操作可能会引发数据的移动,尤其是在插入时如果插入的数据键值在当前键值范围内则可能会触发数据页的分裂。
-
更新操作:当进行更新操作时,如果更新的是非索引列,那么只需定位到数据页并进行更新即可;但是如果更新的是索引列,那么可能会引发数据的移动,因为要保持数据的有序性。
设计聚簇索引时要尽可能选择稳定且不频繁变动的列作为主键,这样可以减少因为插入、删除和更新操作引发的数据移动,提高数据库的性能。
聚簇索引可以提高大多数查询操作的性能,因为它们为数据提供了更线性的访问路径,数据存储在页面中。此外,由于具有相似索引键值的行存储在一起,使用聚簇索引时,顺序检测预取更高效。
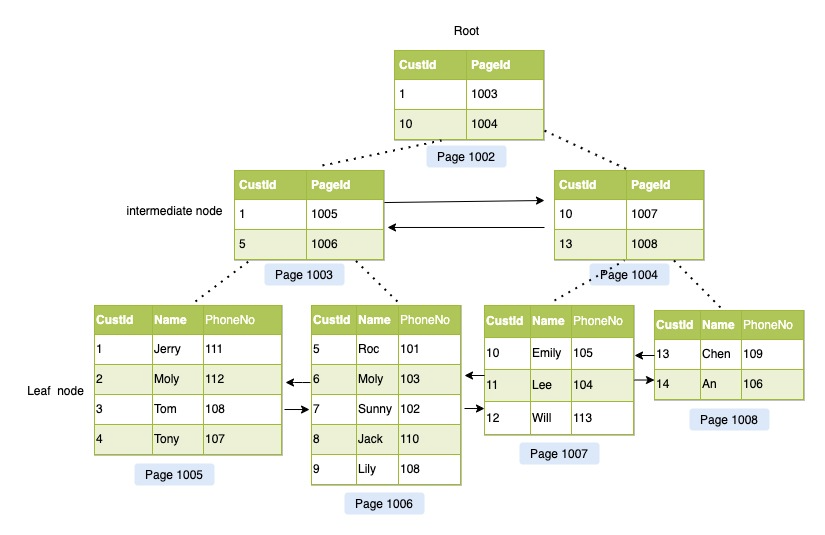
示例
假设我们有一个学生信息表,我们可以通过以下SQL语句创建这个表,并且设置id为主键,也就是聚簇索引:
CREATE TABLE students (id INT PRIMARY KEY,name VARCHAR(100),age INT
);
假设我们现在要查询id为100的学生的信息,我们可以通过以下SQL语句进行查询:
SELECT * FROM students WHERE id = 100;
在执行这个查询操作时,因为id是聚簇索引,所以MySQL会通过B+树的检索算法,从根节点开始,比较索引的键值,找到对应的叶子节点(数据页),然后读取该数据页,找到id为100的学生的信息,这个过程的效率非常高。
同样地,如果我们要更新id为100的学生的年龄,我们可以通过以下SQL语句进行更新:
UPDATE students SET age = 20 WHERE id = 100;
在执行这个更新操作时,MySQL也会先通过聚簇索引找到id为100的学生的信息,然后直接在数据页上进行更新操作。如果更新的是非索引列(在这个例子中,是age列),那么更新操作的效率也是非常高的。
如果更新的是索引列,那么可能会引发数据的移动,因为要保持数据的有序性。例如,如果我们要改变id为100的学生的id,那么可能就会引发数据的移动,因此,设计聚簇索引时,我们应该尽可能选择稳定且不频繁变动的列作为主键。
3. 非聚簇索引(MySQL官方文档称为Secondary Indexes)
MySQL官方文档介绍在《15.6.2.1 Clustered and Secondary Indexes》
3.1 什么是非聚簇索引
非聚簇索引,也被称为二级索引或辅助索引,它的工作方式与聚簇索引有所不同。在非聚簇索引中,索引的逻辑顺序与磁盘上行的物理存储顺序不同。换句话说,非聚簇索引的逻辑顺序是索引的键值顺序,但是这个顺序并不等于数据在磁盘上的物理存储顺序。
在非聚簇索引中,每一个索引条目都包含了键值和一个指向该键值对应的数据行的指针。这个指针通常是数据行的物理地址或者是一个指向数据行的其他种类的标识符。
一个表可以有多个非聚簇索引。当查询不包含聚簇索引的列时,数据库系统会使用非聚簇索引来提高查询性能。
比如在一个员工表中,聚簇索引可能会基于员工的ID进行设置,而非聚簇索引可能会基于员工的姓名或者部门来设置。这样当查询姓名或者部门时,数据库系统就可以直接利用非聚簇索引进行查找,而不需要扫描整张表,从而提高了查询效率。
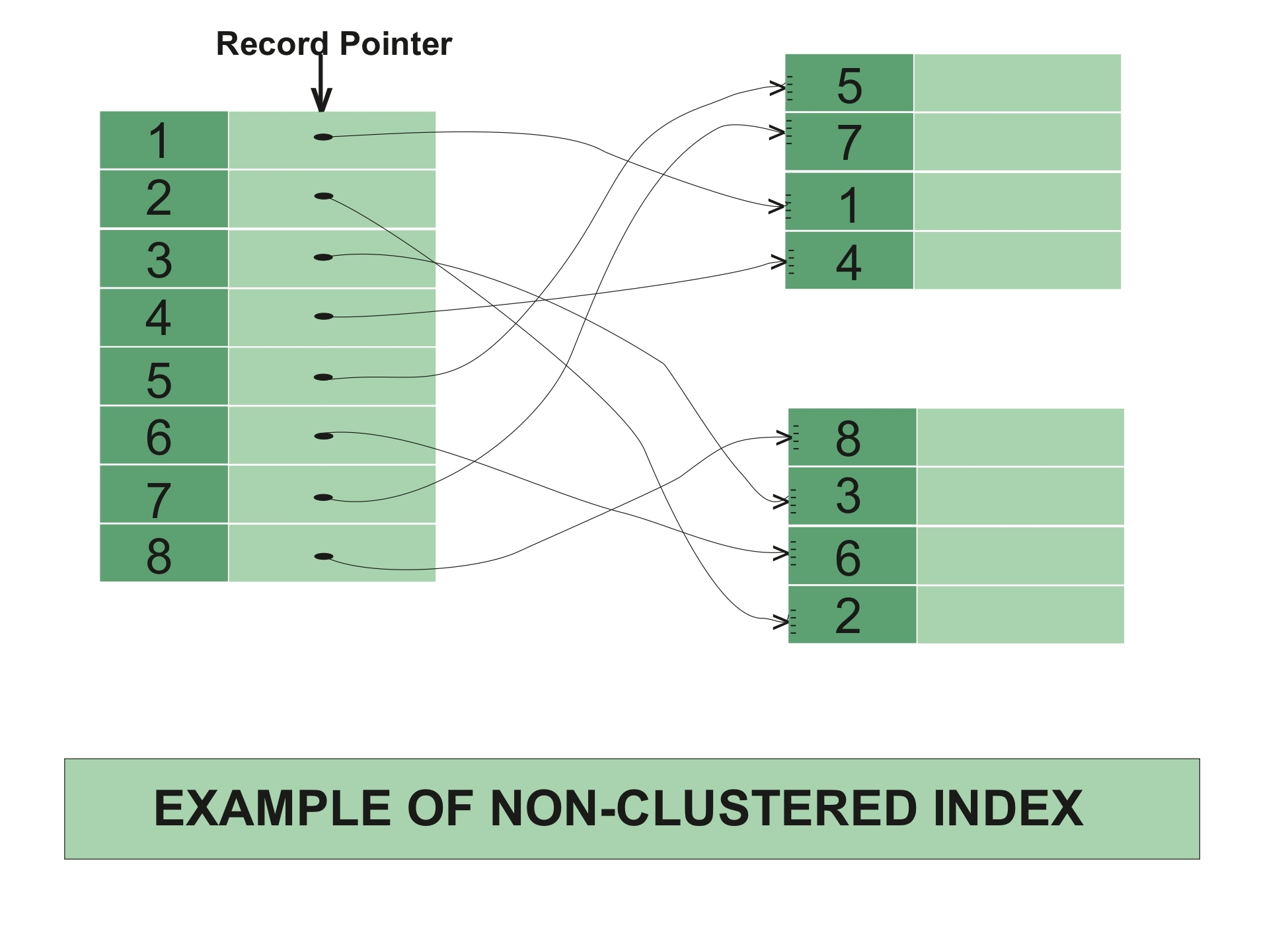
3.2 非聚簇索引的工作原理
非聚簇索引的工作原理与聚簇索引有些不同。非聚簇索引(也称为二级索引或辅助索引)并不会影响表中数据的物理存储顺序,而是创建一个单独的数据结构(通常是B+树)来存储索引列的值和对应的行指针。如上图示例。
非聚簇索引的工作原理:
-
查询操作:当执行查询操作时,数据库会从非聚簇索引的B+树的根节点开始,通过比较索引的键值找到对应的叶子节点。这个叶子节点包含了键值和一个指向该键值对应的数据行的指针。数据库通过这个指针找到实际的数据行。这个过程通常需要两次磁盘I/O操作,第一次是在索引上进行查找,第二次是通过找到的指针去数据文件中获取实际的数据行。
-
插入和删除操作:当进行插入或删除操作时,数据库需要同时在索引结构和数据文件中进行操作。首先,数据库会在索引结构中插入或删除对应的键值和行指针,然后在数据文件中插入或删除实际的数据行。
-
更新操作:当进行更新操作时,如果更新的是非索引列,那么数据库只需要在数据文件中更新对应的数据行即可;如果更新的是索引列,那么数据库需要同时在索引结构和数据文件中进行更新操作。
4. 聚簇索引与非聚簇索引的区别
| 聚簇索引 | 非聚簇索引 | |
|---|---|---|
| 查询速度 | 通常较快,因为可以直接定位到数据 | 较慢,因为需要先定位到索引,然后再通过索引找到数据 |
| 内存使用 | 使用的内存较少,因为数据和索引在一起 | 使用的内存较多,因为数据和索引是分开的 |
| 数据存储 | 聚簇索引就是主数据,数据按照索引排序 | 非聚簇索引是数据的一份索引,数据的物理排序与索引无关 |
| 索引数量 | 一个表只能有一个聚簇索引 | 一个表可以有多个非聚簇索引 |
| 数据存储能力 | 聚簇索引存储数据本身 | 非聚簇索引存储数据的指针,并不存储数据本身 |
| 存储内容 | 聚簇索引存储实际的数据行 | 非聚簇索引存储索引列和行指针 |
| 叶节点内容 | 在聚簇索引中,叶节点就是实际的数据 | 在非聚簇索引中,叶节点不是实际的数据,而只包含索引和行指针 |
| 数据顺序 | 在聚簇索引中,数据物理存储的顺序与索引的顺序一致 | 在非聚簇索引中,数据的物理存储顺序与索引顺序无关 |
| 索引类型 | 聚簇索引是一种将表记录物理排序以匹配索引的索引类型 | 非聚簇索引是一种索引的逻辑顺序与数据在磁盘上的物理存储顺序无关的索引类型 |
| 索引大小 | 主聚簇索引的大小一般较大 | 相对而言,非聚簇索引的大小较小 |
相关文章:
聊聊MySQL的聚簇索引和非聚簇索引
文章目录 1. 索引的分类1. 存储结构维度2. 功能维度3. 列数维度4. 存储方式维度5. 更新方式维度 2. 聚簇索引2.1 什么是聚簇索引2.2 聚簇索引的工作原理 3. 非聚簇索引(MySQL官方文档称为Secondary Indexes)3.1 什么是非聚簇索引3.2 非聚簇索引的工作原理…...

python之subprocess模块详解
介绍 subprocess是Python 2.4中新增的一个模块,它允许你生成新的进程,连接到它们的 input/output/error 管道,并获取它们的返回(状态)码。 这个模块的目的在于替换几个旧的模块和方法。 那么我们到底该用哪个模块、哪个…...

第10讲:Vue组件的定义与注册
定义组件 1. 在程序的 components 目录下新建一个名为 Child.vue 的文件 2. 在文件内键入如下代码 <template><div>Child</div> </template> <script> export default {name: Child } </script>新建的 Child .vue 文件即为我们定义的组件…...
Pycharm操作git仓库 合并等
菜单 Git CommitPushUpdate ProjectPullFetchMergreRebase 查询 查询分支 查询本地所有分支 # 查询本地分支 git branch# 查询远程分支 git branch -rPycharm查看当前分支 步骤: Git->Branches 哈喽,大家好,我是[有勇气的牛排]&…...
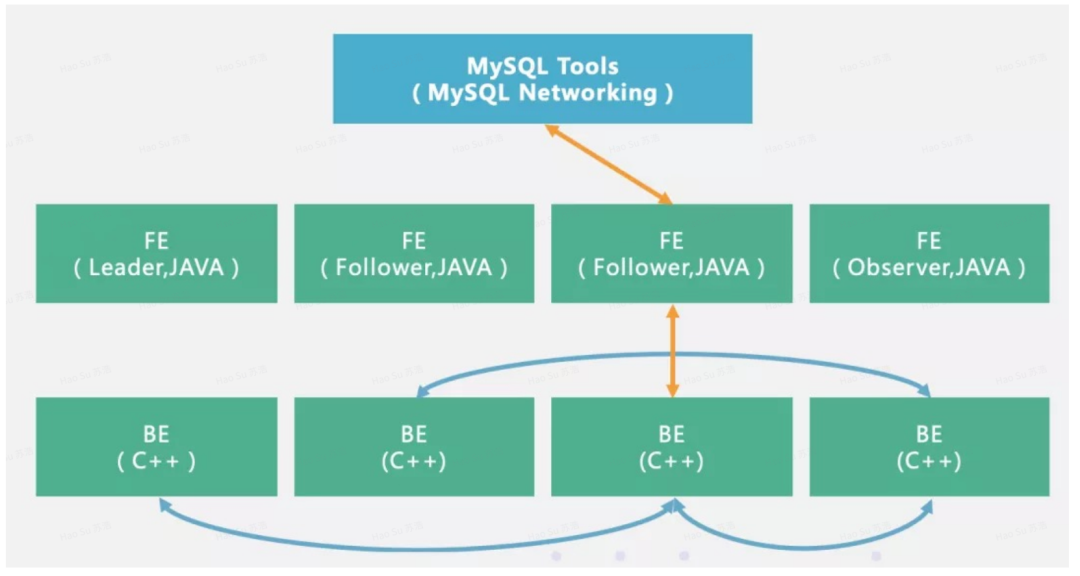
Flink+Doris 实时数仓
Flink+Doris 实时数仓 Doris基本原理 Doris基本架构非常简单,只有FE(Frontend)、BE(Backend)两种角色,不依赖任何外部组件,对部署和运维非常友好。架构图如下 可以 看到Doris 的数仓架构十分简洁,不依赖 Hadoop 生态组件,构建及运维成本较低。 FE(Frontend)以 Java 语…...
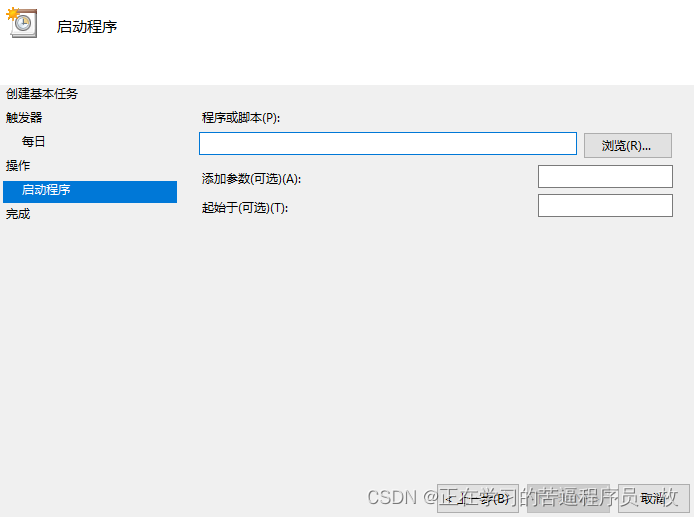
windows 任务计划自动提交 笔记到github 、gitee
一、必须有个git仓库托管到git上。 这个就不用说了,自己在github或者码云上新建一个仓库就行了。 二、创建自动提交脚本 这个bat脚本是在windows环境下使用的。 注意:windows定时任务下 调用自动提交git前,必须先进入该git仓库目录&#x…...

闭包和装饰器
#闭包的作用 #全局变量有被修改的风险,代码在命名空间上不够干净整洁 #第一种,不使用闭包的场景 account_amount0 def atm(num,depositTrue):global account_amountif deposit:account_amountnumprint(f"存款:{num},账户余额…...

注册器模式
注册器模式 注册器模式(Registry Pattern)是一种设计模式,用于管理和维护对象的注册和检索。它允许您在运行时注册对象,并通过一个唯一的标识符或名称来检索这些对象。这种模式通常用于构建可扩展的、松耦合的系统,其…...

5SpringMVC处理Ajax请求携带的JSON格式(“key“:value)的请求参数
SpringMVC处理Ajax 参考文章数据交换的常见格式,如JSON格式和XML格式 请求参数的携带方式 浏览器发送到服务器的请求参数有namevalue&...(键值对)和{key:value,...}(json对象)两种格式 URL请求会将请求参数以键值对的格式拼接到请求地址后面,form表单的GET和POST请求会…...
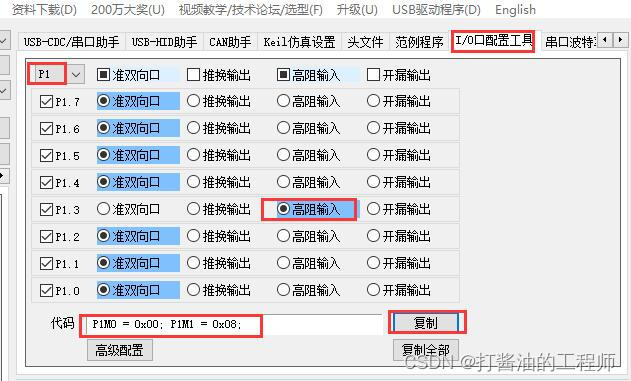
学习笔记|ADC|NTC原理|测温程序|STC32G单片机视频开发教程(冲哥)|第十九集:ADC应用之NTC
文章目录 1.NTC的原理开发板上的NTC 2.NTC的测温程序编写3.实战小练总结课后练习 1.NTC的原理 NTC(Negative Temperature Coefficient)是指随温度上升电阻呈指数关系减小、具有负温度系数的热敏电阻现象和材料。该材料是利用锰、铜、硅、钴、铁、镍、锌…...

Redisson 集成SpringBoot 详解
一、引入依赖 <dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId><version>3.23.5</version></dependency> redison-spring-boot-starter依赖于与最新版本的spring-boot兼容…...

C# 下载模板文件 Excel
后端代码 [HttpGet("DownloadExcel")]public async Task<dynamic> DownloadExcel(string tmplName){var _fileName "导入表模板.xlsx";var filePath "Files\DownLoad\";var NewFile Path.Combine(filePath, tmplName);var stream new…...
如何做好sop流程图?sop流程图用什么软件做?
5.如何做好sop流程图?sop流程图用什么软件做? 建立标准作业程序sop已经成为企业进步和发展的必经之路,不过,很多刚刚开始着手搭建sop的企业并不知道要如何操作,对于如何做sop流程图、用什么软件做sop流程图等问题充满…...

JAVA编程题-求矩阵螺旋值
螺旋类 package entity; /*** 打印数组螺旋值类*/ public class Spiral { // 数组行private int row; // 数组列private int col; // 行列数private int size; // 当前行索引private int rowIndex; // 当前列索引private int colIndex; // 行开始索引private int rowStart; //…...
Python--入门
标识符 标识符由字母,数字,下划线_组成 第一个字符不能是数字,必须是字母或下划线 标识符区分大小写 关键字 关键字即保留字,定义标识符时不能使用关键字,python中的关键字如下图 注释 python中的单行注释用 # 多行注…...
STM32复习笔记(二):GPIO
目录 (一)Demo流程 (二)工程配置 (三)代码部分 (四)外部中断(EXTI) (一)Demo流程 首先,板子上有4个按键,…...
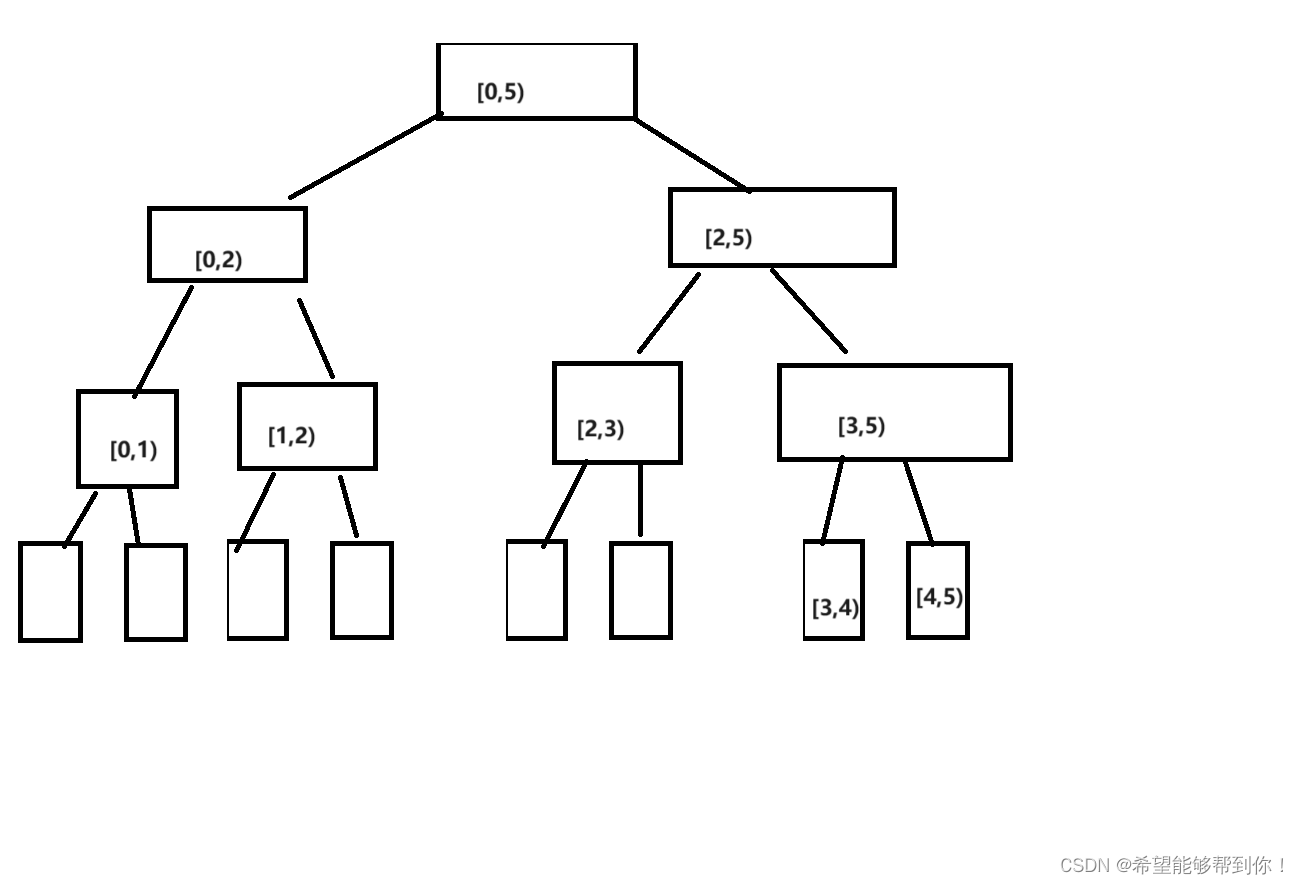
POJ 3264 Balanced Lineup 线段树 / 平方分割
一、题目大意 给出一个长度为 n(n<50000) 数组 arr,进行Q次查询(Q<200000),每次查询的内容为数组arr在 [L , R] 的切片的极差(最大元素 - 最小元素) 二、解题思路 1、线段树 区间极差…...

element-plus自动引入组件报错,例如collapse、loading
element-plus自动引入组件,例如collapse、loading,使用时报错,报错信息如下图所示: 解决办法:vite-config.ts改变vue的引入顺序,将vue放在第一个...
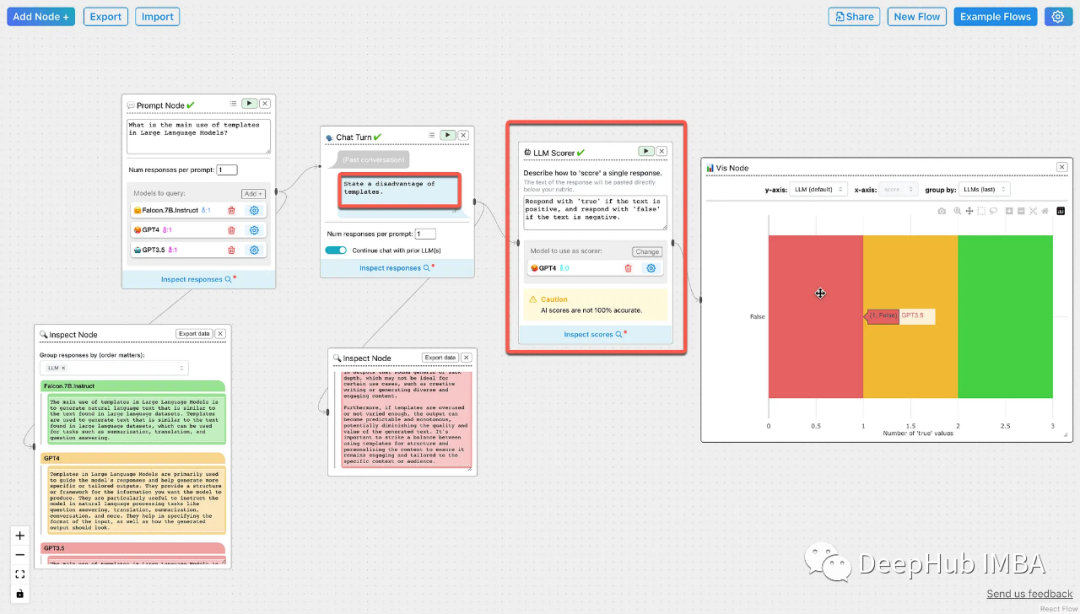
ChainForge:衡量Prompt性能和模型稳健性的GUI工具包
ChainForge是一个用于构建评估逻辑来衡量模型选择,提示模板和执行生成过程的GUI工具包。ChainForge可以安装在本地,也可以从chrome浏览器运行。 ChainForge可以通过聊天节点对多个对话可以使用不同的llm并行运行。可以对聊天消息进行模板化,并…...

队列--二叉树层序遍历
/*1/ \2 3/\ /\4 5 6 7利用LinkedListQueue1. 头 [1] 尾12.头 [2 3] 尾1 23.头 [3 4 5] 尾1 24.头 [4 5 6 7] 尾1 2 35.头 [] 尾1 2 3 4 5 6 7*/ 代码: class Solution {public List<List<Integer>> levelOrder(TreeNode root) {List<List&l…...

Qwen3智能字幕系统Typora文档生成功能
Qwen3智能字幕系统Typora文档生成功能 1. 引言 写技术文档是每个开发者和内容创作者的日常任务,但传统的文档编写方式往往效率低下。想象一下这样的场景:你刚看完一段重要的技术视频,需要把其中的关键内容整理成文档。通常的做法是一边暂停…...

Janus-Pro-7B C语言项目辅助:代码审查与注释生成
Janus-Pro-7B C语言项目辅助:代码审查与注释生成 1. 引言 如果你写过C语言,尤其是那种嵌入式或者系统级的项目,肯定有过这样的体验:接手一个几千上万行的老项目,打开一看,函数名是proc_data,变…...

Qwen3-VL-30B新手入门指南:从零开始,轻松搭建你的图文对话机器人
Qwen3-VL-30B新手入门指南:从零开始,轻松搭建你的图文对话机器人 你是不是经常遇到这样的情况:看到一张复杂的图表,想快速理解其中的数据趋势;收到一张产品设计图,需要生成详细的文字描述;或者…...

立创开源全志H616卡片电脑:4层双贴DDR3L内存,Ubuntu/Debian/Android TV多系统实战
立创开源全志H616卡片电脑:4层双贴DDR3L内存,Ubuntu/Debian/Android TV多系统实战 最近在立创开源平台上看到一款基于全志H616的卡片电脑设计,硬件设计上用了4层板和双贴DDR3L内存,性能实测内存频率能跑到1056MHz,而且…...

UForm源码解析:揭秘Attention机制与MLP模块的高效实现原理
UForm源码解析:揭秘Attention机制与MLP模块的高效实现原理 【免费下载链接】uform Multi-Modal AI library for Multi-Lingual Text, Image, and Video Search, Recommendations, and other Vision-Language tasks, up to 5x faster than OpenAI CLIP 🖼…...

Janus-Pro-7B保姆级部署教程:GPU显存优化与WebUI快速启动
Janus-Pro-7B保姆级部署教程:GPU显存优化与WebUI快速启动 本文详细讲解如何快速部署Janus-Pro-7B多模态AI模型,重点介绍GPU显存优化技巧和三种启动方式,让你10分钟内完成从零到可用的完整部署。 1. 环境准备与模型介绍 Janus-Pro-7B是一个强…...

【杂谈】结构体的内存对齐与位段
目录 一、结构体内存对齐问题(节省时间) 1.什么是内存对齐 2.需要使用内存对齐的原因 3.内存对齐的规则 4.举例 5.小结 二、结构体实现位段操作(节省空间) 1.位域简介与使用原因 2.位域的定义与使用时的注意事项 3.举例 …...

光伏MPPT电导增量法仿真模型及配套视频
光伏MPPT-电导增量法-仿真模型,有配套video光伏系统里MPPT算法就像个"追光者",得实时捕捉最大功率点。电导增量法(Incremental Conductance)这招挺有意思,它不像扰动观测法(PBO)那样无…...

NVIDIA Profile Inspector NVAPI_ACCESS_DENIED错误全方位解决指南
NVIDIA Profile Inspector NVAPI_ACCESS_DENIED错误全方位解决指南 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 🔍 问题定位 在使用NVIDIA Profile Inspector(简称NPI&#…...

解锁AMD Ryzen潜能:SMUDebugTool硬件调试完全指南
解锁AMD Ryzen潜能:SMUDebugTool硬件调试完全指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcod…...