竞赛选题 深度学习 opencv python 实现中国交通标志识别
文章目录
- 0 前言
- 1 yolov5实现中国交通标志检测
- 2.算法原理
- 2.1 算法简介
- 2.2网络架构
- 2.3 关键代码
- 3 数据集处理
- 3.1 VOC格式介绍
- 3.2 将中国交通标志检测数据集CCTSDB数据转换成VOC数据格式
- 3.3 手动标注数据集
- 4 模型训练
- 5 实现效果
- 5.1 视频效果
- 6 最后
0 前言
🔥 优质竞赛项目系列,今天要分享的是
🚩 基于深度学习的中国交通标志识别算法研究与实现
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:4分
- 工作量:4分
- 创新点:3分
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 yolov5实现中国交通标志检测
整个互联网基本没有国内交通标志识别的开源项目(都是国外的),今天学长分享一个中国版本的实时交通标志识别项目,非常适合作为毕业设计~
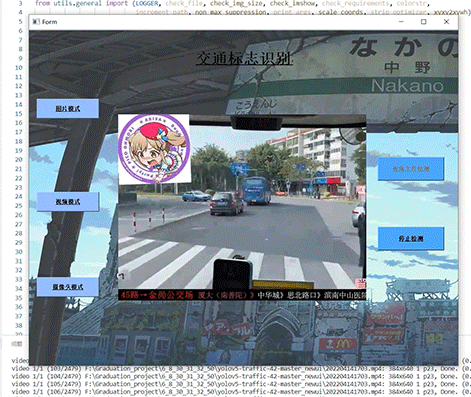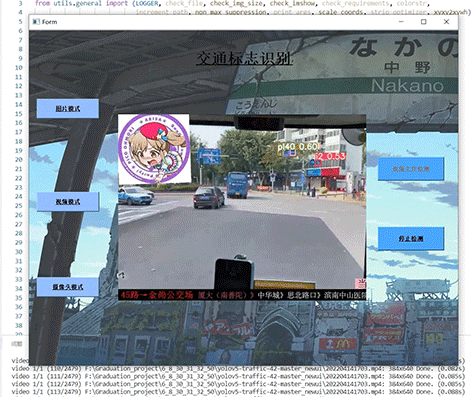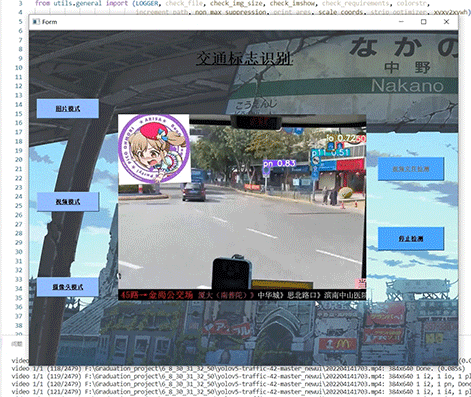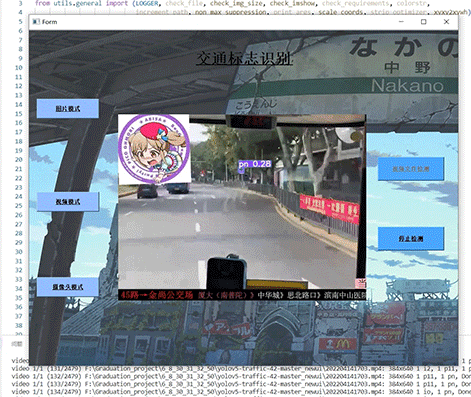
2.算法原理
2.1 算法简介
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
基准网络:融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
Neck网络:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构;
Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
2.2网络架构
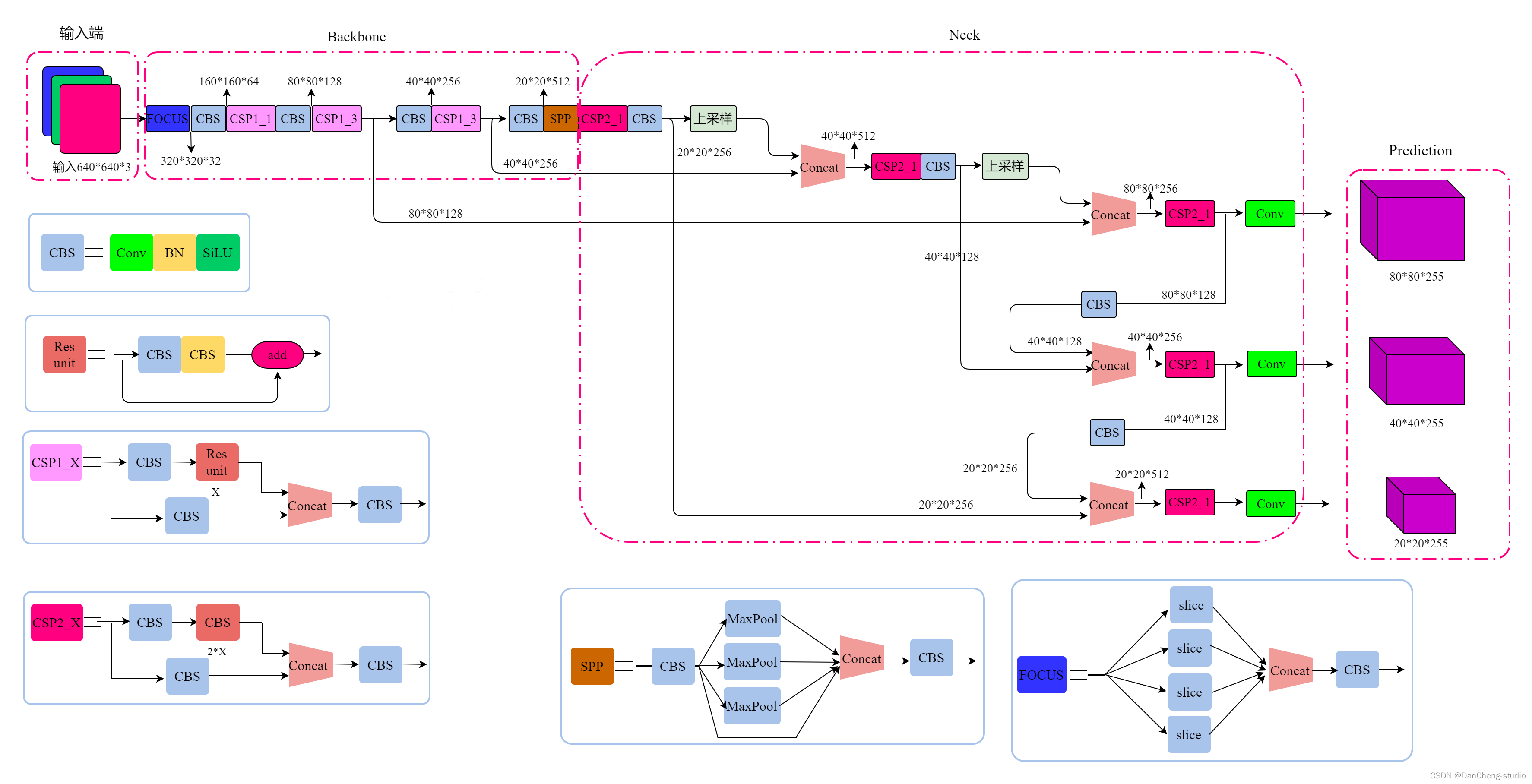
上图展示了YOLOv5目标检测算法的整体框图。对于一个目标检测算法而言,我们通常可以将其划分为4个通用的模块,具体包括:输入端、基准网络、Neck网络与Head输出端,对应于上图中的4个红色模块。YOLOv5算法具有4个版本,具体包括:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四种,本文重点讲解YOLOv5s,其它的版本都在该版本的基础上对网络进行加深与加宽。
- 输入端-输入端表示输入的图片。该网络的输入图像大小为608*608,该阶段通常包含一个图像预处理阶段,即将输入图像缩放到网络的输入大小,并进行归一化等操作。在网络训练阶段,YOLOv5使用Mosaic数据增强操作提升模型的训练速度和网络的精度;并提出了一种自适应锚框计算与自适应图片缩放方法。
- 基准网络-基准网络通常是一些性能优异的分类器种的网络,该模块用来提取一些通用的特征表示。YOLOv5中不仅使用了CSPDarknet53结构,而且使用了Focus结构作为基准网络。
- Neck网络-Neck网络通常位于基准网络和头网络的中间位置,利用它可以进一步提升特征的多样性及鲁棒性。虽然YOLOv5同样用到了SPP模块、FPN+PAN模块,但是实现的细节有些不同。
- Head输出端-Head用来完成目标检测结果的输出。针对不同的检测算法,输出端的分支个数不尽相同,通常包含一个分类分支和一个回归分支。YOLOv4利用GIOU_Loss来代替Smooth L1 Loss函数,从而进一步提升算法的检测精度。
2.3 关键代码
class Detect(nn.Module):stride = None # strides computed during buildonnx_dynamic = False # ONNX export parameterdef __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layersuper().__init__()self.nc = nc # number of classesself.no = nc + 5 # number of outputs per anchorself.nl = len(anchors) # number of detection layersself.na = len(anchors[0]) // 2 # number of anchorsself.grid = [torch.zeros(1)] * self.nl # init gridself.anchor_grid = [torch.zeros(1)] * self.nl # init anchor gridself.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na, 1) for x in ch) # output convself.inplace = inplace # use in-place ops (e.g. slice assignment)def forward(self, x):z = [] # inference outputfor i in range(self.nl):x[i] = self.m[i](x[i]) # convbs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()if not self.training: # inferenceif self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)y = x[i].sigmoid()if self.inplace:y[..., 0:2] = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xyy[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # whelse: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953xy = (y[..., 0:2] * 2 - 0.5 + self.grid[i]) * self.stride[i] # xywh = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # why = torch.cat((xy, wh, y[..., 4:]), -1)z.append(y.view(bs, -1, self.no))return x if self.training else (torch.cat(z, 1), x)def _make_grid(self, nx=20, ny=20, i=0):d = self.anchors[i].deviceif check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibilityyv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)], indexing='ij')else:yv, xv = torch.meshgrid([torch.arange(ny).to(d), torch.arange(nx).to(d)])grid = torch.stack((xv, yv), 2).expand((1, self.na, ny, nx, 2)).float()anchor_grid = (self.anchors[i].clone() * self.stride[i]) \.view((1, self.na, 1, 1, 2)).expand((1, self.na, ny, nx, 2)).float()return grid, anchor_gridclass Model(nn.Module):def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classessuper().__init__()if isinstance(cfg, dict):self.yaml = cfg # model dictelse: # is *.yamlimport yaml # for torch hubself.yaml_file = Path(cfg).namewith open(cfg, encoding='ascii', errors='ignore') as f:self.yaml = yaml.safe_load(f) # model dict# Define modelch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channelsif nc and nc != self.yaml['nc']:LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")self.yaml['nc'] = nc # override yaml valueif anchors:LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')self.yaml['anchors'] = round(anchors) # override yaml valueself.model, self.save = parse_model(deepcopy(self.yaml), ch=[ch]) # model, savelistself.names = [str(i) for i in range(self.yaml['nc'])] # default namesself.inplace = self.yaml.get('inplace', True)# Build strides, anchorsm = self.model[-1] # Detect()if isinstance(m, Detect):s = 256 # 2x min stridem.inplace = self.inplacem.stride = torch.tensor([s / x.shape[-2] for x in self.forward(torch.zeros(1, ch, s, s))]) # forwardm.anchors /= m.stride.view(-1, 1, 1)check_anchor_order(m)self.stride = m.strideself._initialize_biases() # only run once# Init weights, biasesinitialize_weights(self)self.info()LOGGER.info('')def forward(self, x, augment=False, profile=False, visualize=False):if augment:return self._forward_augment(x) # augmented inference, Nonereturn self._forward_once(x, profile, visualize) # single-scale inference, traindef _forward_augment(self, x):img_size = x.shape[-2:] # height, widths = [1, 0.83, 0.67] # scalesf = [None, 3, None] # flips (2-ud, 3-lr)y = [] # outputsfor si, fi in zip(s, f):xi = scale_img(x.flip(fi) if fi else x, si, gs=int(self.stride.max()))yi = self._forward_once(xi)[0] # forward# cv2.imwrite(f'img_{si}.jpg', 255 * xi[0].cpu().numpy().transpose((1, 2, 0))[:, :, ::-1]) # saveyi = self._descale_pred(yi, fi, si, img_size)y.append(yi)y = self._clip_augmented(y) # clip augmented tailsreturn torch.cat(y, 1), None # augmented inference, traindef _forward_once(self, x, profile=False, visualize=False):y, dt = [], [] # outputsfor m in self.model:if m.f != -1: # if not from previous layerx = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layersif profile:self._profile_one_layer(m, x, dt)x = m(x) # runy.append(x if m.i in self.save else None) # save outputif visualize:feature_visualization(x, m.type, m.i, save_dir=visualize)return xdef _descale_pred(self, p, flips, scale, img_size):# de-scale predictions following augmented inference (inverse operation)if self.inplace:p[..., :4] /= scale # de-scaleif flips == 2:p[..., 1] = img_size[0] - p[..., 1] # de-flip udelif flips == 3:p[..., 0] = img_size[1] - p[..., 0] # de-flip lrelse:x, y, wh = p[..., 0:1] / scale, p[..., 1:2] / scale, p[..., 2:4] / scale # de-scaleif flips == 2:y = img_size[0] - y # de-flip udelif flips == 3:x = img_size[1] - x # de-flip lrp = torch.cat((x, y, wh, p[..., 4:]), -1)return pdef _clip_augmented(self, y):# Clip YOLOv5 augmented inference tailsnl = self.model[-1].nl # number of detection layers (P3-P5)g = sum(4 ** x for x in range(nl)) # grid pointse = 1 # exclude layer counti = (y[0].shape[1] // g) * sum(4 ** x for x in range(e)) # indicesy[0] = y[0][:, :-i] # largei = (y[-1].shape[1] // g) * sum(4 ** (nl - 1 - x) for x in range(e)) # indicesy[-1] = y[-1][:, i:] # smallreturn ydef _profile_one_layer(self, m, x, dt):c = isinstance(m, Detect) # is final layer, copy input as inplace fixo = thop.profile(m, inputs=(x.copy() if c else x,), verbose=False)[0] / 1E9 * 2 if thop else 0 # FLOPst = time_sync()for _ in range(10):m(x.copy() if c else x)dt.append((time_sync() - t) * 100)if m == self.model[0]:LOGGER.info(f"{'time (ms)':>10s} {'GFLOPs':>10s} {'params':>10s} {'module'}")LOGGER.info(f'{dt[-1]:10.2f} {o:10.2f} {m.np:10.0f} {m.type}')if c:LOGGER.info(f"{sum(dt):10.2f} {'-':>10s} {'-':>10s} Total")def _initialize_biases(self, cf=None): # initialize biases into Detect(), cf is class frequency# https://arxiv.org/abs/1708.02002 section 3.3# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1.m = self.model[-1] # Detect() modulefor mi, s in zip(m.m, m.stride): # fromb = mi.bias.view(m.na, -1) # conv.bias(255) to (3,85)b.data[:, 4] += math.log(8 / (640 / s) ** 2) # obj (8 objects per 640 image)b.data[:, 5:] += math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # clsmi.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)def _print_biases(self):m = self.model[-1] # Detect() modulefor mi in m.m: # fromb = mi.bias.detach().view(m.na, -1).T # conv.bias(255) to (3,85)LOGGER.info(('%6g Conv2d.bias:' + '%10.3g' * 6) % (mi.weight.shape[1], *b[:5].mean(1).tolist(), b[5:].mean()))# def _print_weights(self):# for m in self.model.modules():# if type(m) is Bottleneck:# LOGGER.info('%10.3g' % (m.w.detach().sigmoid() * 2)) # shortcut weightsdef fuse(self): # fuse model Conv2d() + BatchNorm2d() layersLOGGER.info('Fusing layers... ')for m in self.model.modules():if isinstance(m, (Conv, DWConv)) and hasattr(m, 'bn'):m.conv = fuse_conv_and_bn(m.conv, m.bn) # update convdelattr(m, 'bn') # remove batchnormm.forward = m.forward_fuse # update forwardself.info()return selfdef autoshape(self): # add AutoShape moduleLOGGER.info('Adding AutoShape... ')m = AutoShape(self) # wrap modelcopy_attr(m, self, include=('yaml', 'nc', 'hyp', 'names', 'stride'), exclude=()) # copy attributesreturn mdef info(self, verbose=False, img_size=640): # print model informationmodel_info(self, verbose, img_size)def _apply(self, fn):# Apply to(), cpu(), cuda(), half() to model tensors that are not parameters or registered buffersself = super()._apply(fn)m = self.model[-1] # Detect()if isinstance(m, Detect):m.stride = fn(m.stride)m.grid = list(map(fn, m.grid))if isinstance(m.anchor_grid, list):m.anchor_grid = list(map(fn, m.anchor_grid))return selfdef parse_model(d, ch): # model_dict, input_channels(3)LOGGER.info(f"\n{'':>3}{'from':>18}{'n':>3}{'params':>10} {'module':<40}{'arguments':<30}")anchors, nc, gd, gw = d['anchors'], d['nc'], d['depth_multiple'], d['width_multiple']na = (len(anchors[0]) // 2) if isinstance(anchors, list) else anchors # number of anchorsno = na * (nc + 5) # number of outputs = anchors * (classes + 5)layers, save, c2 = [], [], ch[-1] # layers, savelist, ch outfor i, (f, n, m, args) in enumerate(d['backbone'] + d['head']): # from, number, module, argsm = eval(m) if isinstance(m, str) else m # eval stringsfor j, a in enumerate(args):try:args[j] = eval(a) if isinstance(a, str) else a # eval stringsexcept NameError:passn = n_ = max(round(n * gd), 1) if n > 1 else n # depth gainif m in [Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, MixConv2d, Focus, CrossConv,BottleneckCSP, C3, C3TR, C3SPP, C3Ghost]:c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, 8)args = [c1, c2, *args[1:]]if m in [BottleneckCSP, C3, C3TR, C3Ghost]:args.insert(2, n) # number of repeatsn = 1elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum(ch[x] for x in f)elif m is Detect:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)elif m is Contract:c2 = ch[f] * args[0] ** 2elif m is Expand:c2 = ch[f] // args[0] ** 2else:c2 = ch[f]m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # modulet = str(m)[8:-2].replace('__main__.', '') # module typenp = sum(x.numel() for x in m_.parameters()) # number paramsm_.i, m_.f, m_.type, m_.np = i, f, t, np # attach index, 'from' index, type, number paramsLOGGER.info(f'{i:>3}{str(f):>18}{n_:>3}{np:10.0f} {t:<40}{str(args):<30}') # printsave.extend(x % i for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelistlayers.append(m_)if i == 0:ch = []ch.append(c2)return nn.Sequential(*layers), sorted(save)3 数据集处理
中国交通标志检测数据集CCTSDB,由长沙理工大学提供,包括上万张有标注的图片
推荐只使用前4000张照片,因为后面有很多张图片没有标注,需要一张一张的删除,太过于麻烦,所以尽量用前4000张图
3.1 VOC格式介绍
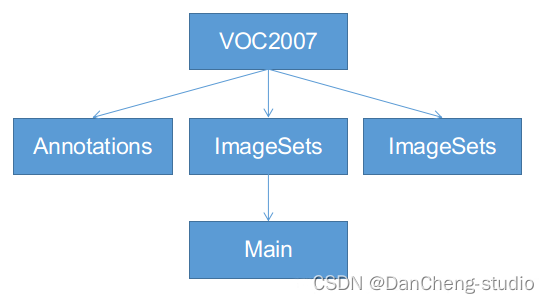
VOC格式主要包含三个文件夹Annotations,ImageSets,JPEGImages,主要适用于faster-
rcnn等模型的训练,ImageSets下面有一个Main的文件夹,如下图,一定按照这个名字和格式建好文件夹:
-
Annotations:这里是存放你对所有数据图片做的标注,每张照片的标注信息必须是xml格式。
-
JPEGImages:用来保存你的数据图片,一定要对图片进行编号,一般按照voc数据集格式,采用六位数字编码,如000001.jpg、000002.jpg等。
-
ImageSets:该文件下有一个main文件,main文件下有四个txt文件,分别是train.txt、test.txt、trainval.txt、val.txt,里面都是存放的图片号码。
3.2 将中国交通标志检测数据集CCTSDB数据转换成VOC数据格式
将标注的数据提取出来并且排序,并将里面每一行分割成一个文件

3.3 手动标注数据集
如果为了更深入的学习也可自己标注,但过程相对比较繁琐,麻烦。
以下简单介绍数据标注的相关方法,数据标注这里推荐的软件是labelimg,通过pip指令即可安装,相关教程可网上搜索
pip install labelimg
4 模型训练
修改train.py中的weights、cfg、data、epochs、batch_size、imgsz、device、workers等参数
训练代码成功执行之后会在命令行中输出下列信息,接下来就是安心等待模型训练结束即可。

5 实现效果
5.1 视频效果
6 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
竞赛选题 深度学习 opencv python 实现中国交通标志识别
文章目录 0 前言1 yolov5实现中国交通标志检测2.算法原理2.1 算法简介2.2网络架构2.3 关键代码 3 数据集处理3.1 VOC格式介绍3.2 将中国交通标志检测数据集CCTSDB数据转换成VOC数据格式3.3 手动标注数据集 4 模型训练5 实现效果5.1 视频效果 6 最后 0 前言 🔥 优质…...
-- fskv - kv数据库,掉电不丢数据)
LuatOS-SOC接口文档(air780E)-- fskv - kv数据库,掉电不丢数据
示例 -- 本库的目标是替代fdb库 -- 1. 兼容fdb的函数 -- 2. 使用fdb的flash空间,启用时也会替代fdb库 -- 3. 功能上与EEPROM是类似的 fskv.init() fskv.set("wendal", 1234) log.info("fskv", "wendal", fskv.get("wendal"))--[[ fs…...

一篇文章教你Pytest快速入门和基础讲解,一定要看!
前言 目前有两种纯测试的测试框架,pytest和unittestunittest应该是广为人知,而且也是老框架了,很多人都用来做自动化,无论是UI还是接口pytest是基于unittest开发的另一款更高级更好用的单元测试框架出去面试也好,跟别…...
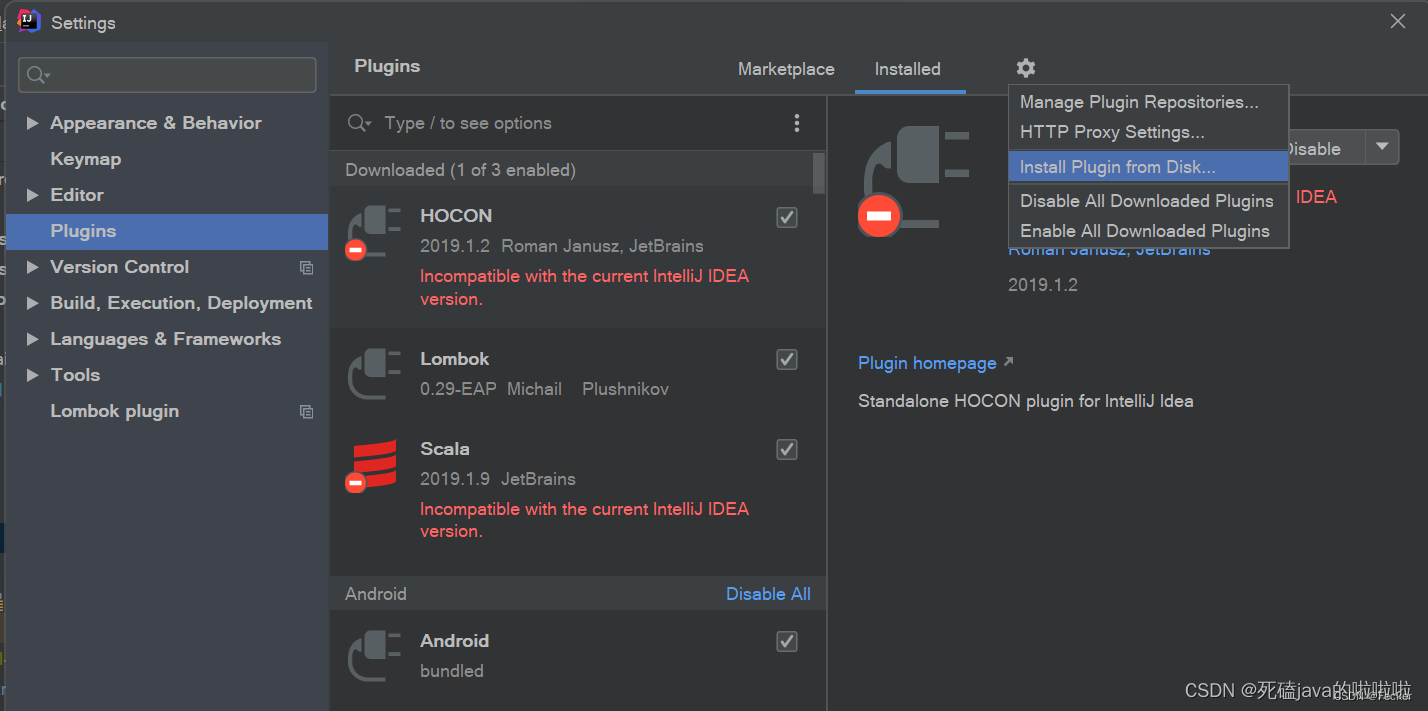
SpringBoot项目:Cannot find declaration to go to
SpringBoot项目get,set方法总报Cannot find declaration to go to 搜了很多答案,没解决 后来仔细一想,原来是我的idea软件重装了,lombok插件没重新安装导致。 安装步骤: 1、下载地址:https://plugins.jetbrains.com…...

【高并发】多线程和高并发提纲
文章目录 三大源头两个主要问题三大解决方案 最近正在面试,对多线程和高并发相关问题整理了一个简单的提纲。 个人感觉这三大部分由底向上,足够引出对并发编程中大部分问题的讨论~ 三大源头 线程切换带来的原子性问题。 原子操作:利用CPU提…...

vue.js处理数组对象中某个字段是否变为两个字段
一、场景: 产品要求做一个时间步骤条,使用目前后端已返回的数据进行操作实现。时间步骤条要求日期和时间分开显示且相同日期只显示第一个日期。 图左边为实现效果,右边为后台返回的接口。接口中current字段表示当前到达第几步,从…...
)
从零开始的C++(补充三的内容)
auto:在编译阶段根据数据的类型确认auto所代表的类型,并将auto换成对应的类型。 特点: 1、auto所能代表的类型必须是在编译阶段就能确认的。 2、auto修饰的变量必须初始化,否则编译器无法判断auto的实际类型。 3、auto会根据第一个数据来…...
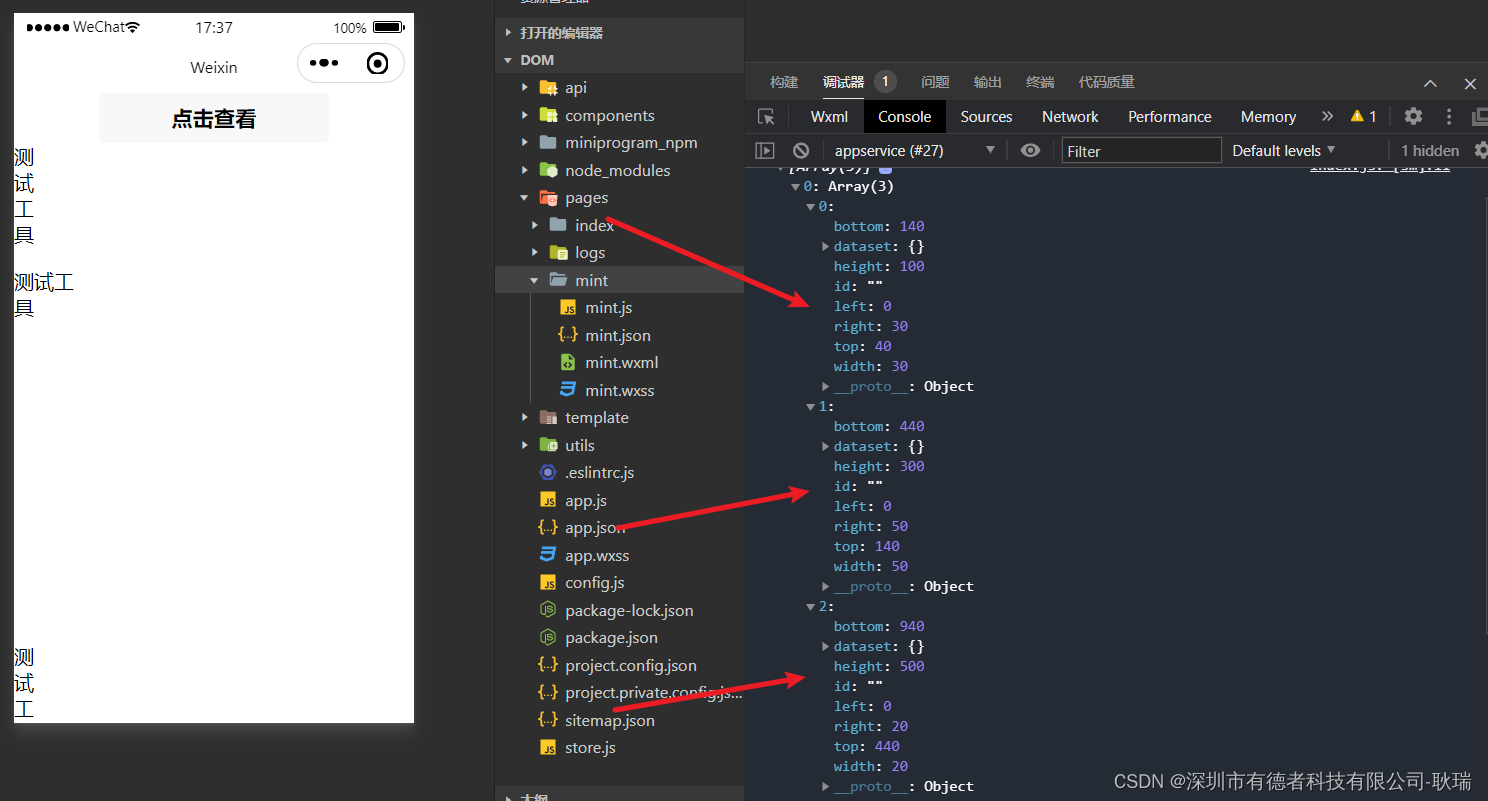
微信小程序通过createSelectorQuery获取元素 高度,宽度与界面距离
小程序官方有提供给我们一个 const query wx.createSelectorQuery() 函数 我们可以先编写这样一段代码 wxml <view><button bindtap"getDom">点击查看</button><view class "textIn" style "height: 100px;width: 30px;&quo…...

MySQL-事务
MySQL-事务 1.什么是事务 举例:想象炒菜的过程。 洗菜切菜炒菜装盘 我相信缺少任何任何一个步骤,都不完美!!!可以将炒菜的过程理解为一个事务,是一组操作的集合,而MySQL中的事务也是如此。但…...

自动定时删除磁盘文件的脚本(从文件日期最早的开始删)
#!/bin/bash# 指定的挂载点 MOUNTPOINT"/media/vm/MyDisk512GB"# 设置磁盘大小的限制 (例如:800G) LIMIT$((800 * 1024 * 1024)) # 单位是KB# 获取挂载点的已使用空间 USED_SPACE$(df -kP "$MOUNTPOINT" | tail -1 | awk {print $3})echo &quo…...

拆解CPU的基本结构和运行原理
CPU的基本结构 CPU是一个计算系统的核心 南北桥芯片将CPU与外设连接起来 CPU执行流程 CPU的电路基础 组合电路基本原理 时序电路基本原理 多核成为主流 汇编语言和寄存器 中断的基本原理 中断的产生 中断服务程序 CPU 做为计算机的总司令官,它管理着计算…...
Docker安装——Ubuntu (Jammy 22.04)
一、为什么要用 Ubuntu?(centos和ubuntu有什么区别) 使用lsb_release命令:lsb_release -a ,即可查看ubantu的版本,但是为什么要使用ubantu 呢? 区别:1、centos基于EHEL开发,而ubunt…...
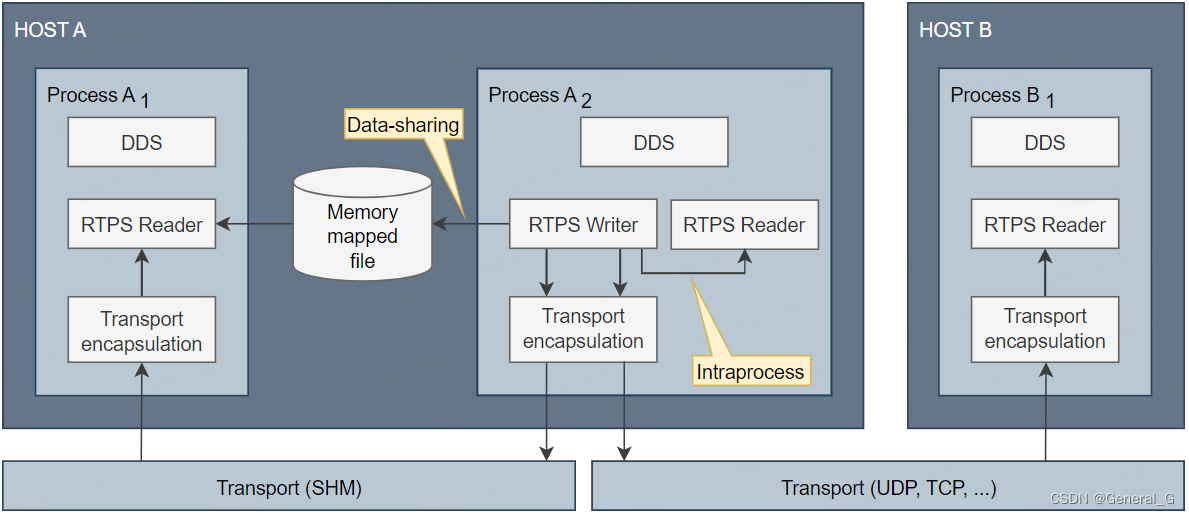
Fast DDS之Transport
目录 transport层负责为DDS用户数据收发和服务发现提供通信。包含UDP,TCP,SHM。...

爱普生L125X_L325X系列打印机Wi-Fi配置方法(Smart Panel)
准备工作: 手机需要下载“Epson Smart Panel”APP; 配置无线(Wi-Fi)方法 说明:SSID名称(Wi-Fi名)不能包含中文字符,路由器需要选择2.4GHz频段; 1. 打开“Epson Smart Panel”软件࿰…...
【回顾一下Docker的基本用法】
文章目录 回顾一下Docker的基本用法1.初识Docker1.1.什么是Docker1.1.1.应用部署的环境问题1.1.2.Docker解决依赖兼容问题1.1.3.Docker解决操作系统环境差异1.1.4.小结 1.2.Docker和虚拟机的区别1.3.Docker架构1.3.1.镜像和容器1.3.2.DockerHub1.3.3.Docker架构1.3.4.小结 1.4.…...

【Python】Python基础知识
【Python】Python基础知识 关键字 查看Python关键字: >python >>>import keyword >>>keyword.kwlist 注释 注释有两方面作用: (1)提高程序的可读性(最重要的作用);…...

【计算机视觉 05】YOLO论文讲解:V1-V7
https://ai.deepshare.net/live_pc/l_63243a65e4b050af23b79338 Part1.目标检测与YOLO系列 1. 目标检测任务及发展脉络 2. YOLO的发展史 Anchors Base原理: Part2.YOLOV1-V3 3. YOLO V1的网络结构 4. YOLO V3的网络结构与实验结果 Part3.YOLO的进化 5. YOLO V4的网络…...

git全局与单仓库的密码管理
概要 在使用git时,有默认的全局配置,每个仓库也有自己的配置,在使用时常常傻傻分不清楚,现在进行一个简单的整理记录。 一般情况下全局配置中的git账号和邮箱通常设置成自己的,其他仓库再根据项目需要进行单独配置&a…...
IDEA的使用(一) (IntelliJ IDEA 2022.1.3版本)
目录 1. IDEA项目结构 2. 模块的导入操作 2.1 正规操作 2.2 取巧操作 2.3 出现乱码 2.4 模块改名 3. 代码模板的使用 后缀补全(Postfix Completion)、实时模板(Live Templates)菜单里面什么介绍都有,可以自学&a…...
javaee SpringMVC文件上传 项目结构
引入依赖 <?xml version"1.0" encoding"UTF-8"?><project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0…...

系统设计 --- MongoDB亿级数据查询优化策略
系统设计 --- MongoDB亿级数据查询分表策略 背景Solution --- 分表 背景 使用audit log实现Audi Trail功能 Audit Trail范围: 六个月数据量: 每秒5-7条audi log,共计7千万 – 1亿条数据需要实现全文检索按照时间倒序因为license问题,不能使用ELK只能使用…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...
【C++特殊工具与技术】优化内存分配(一):C++中的内存分配
目录 一、C 内存的基本概念 1.1 内存的物理与逻辑结构 1.2 C 程序的内存区域划分 二、栈内存分配 2.1 栈内存的特点 2.2 栈内存分配示例 三、堆内存分配 3.1 new和delete操作符 4.2 内存泄漏与悬空指针问题 4.3 new和delete的重载 四、智能指针…...

c++第七天 继承与派生2
这一篇文章主要内容是 派生类构造函数与析构函数 在派生类中重写基类成员 以及多继承 第一部分:派生类构造函数与析构函数 当创建一个派生类对象时,基类成员是如何初始化的? 1.当派生类对象创建的时候,基类成员的初始化顺序 …...

git: early EOF
macOS报错: Initialized empty Git repository in /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/.git/ remote: Enumerating objects: 2691797, done. remote: Counting objects: 100% (1760/1760), done. remote: Compressing objects: 100% (636/636…...

离线语音识别方案分析
随着人工智能技术的不断发展,语音识别技术也得到了广泛的应用,从智能家居到车载系统,语音识别正在改变我们与设备的交互方式。尤其是离线语音识别,由于其在没有网络连接的情况下仍然能提供稳定、准确的语音处理能力,广…...
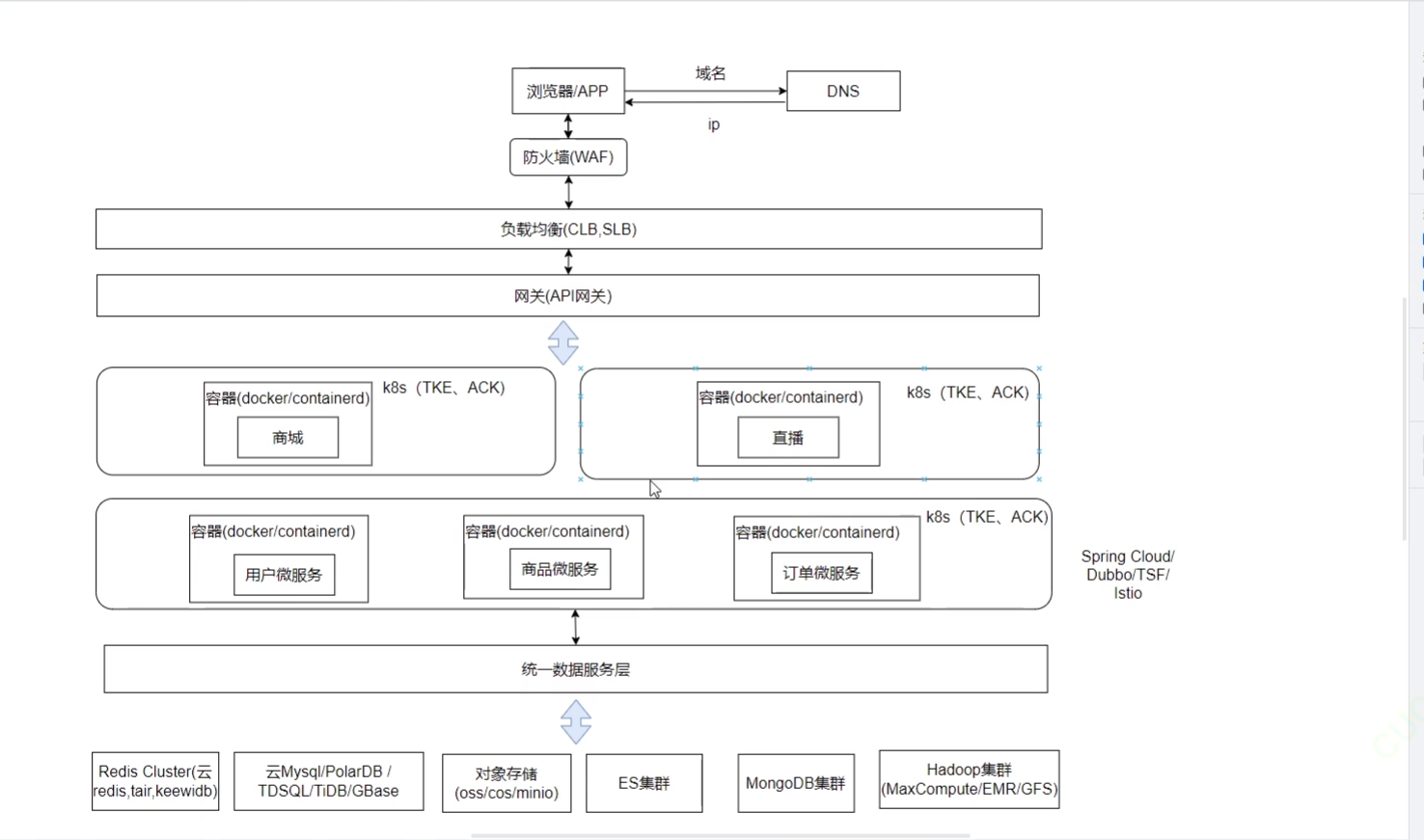
《Docker》架构
文章目录 架构模式单机架构应用数据分离架构应用服务器集群架构读写分离/主从分离架构冷热分离架构垂直分库架构微服务架构容器编排架构什么是容器,docker,镜像,k8s 架构模式 单机架构 单机架构其实就是应用服务器和单机服务器都部署在同一…...
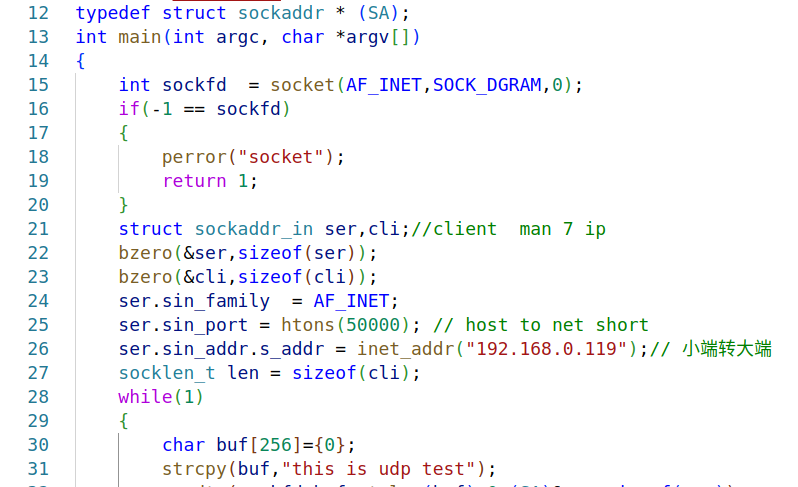
嵌入式学习之系统编程(九)OSI模型、TCP/IP模型、UDP协议网络相关编程(6.3)
目录 一、网络编程--OSI模型 二、网络编程--TCP/IP模型 三、网络接口 四、UDP网络相关编程及主要函数 编辑编辑 UDP的特征 socke函数 bind函数 recvfrom函数(接收函数) sendto函数(发送函数) 五、网络编程之 UDP 用…...
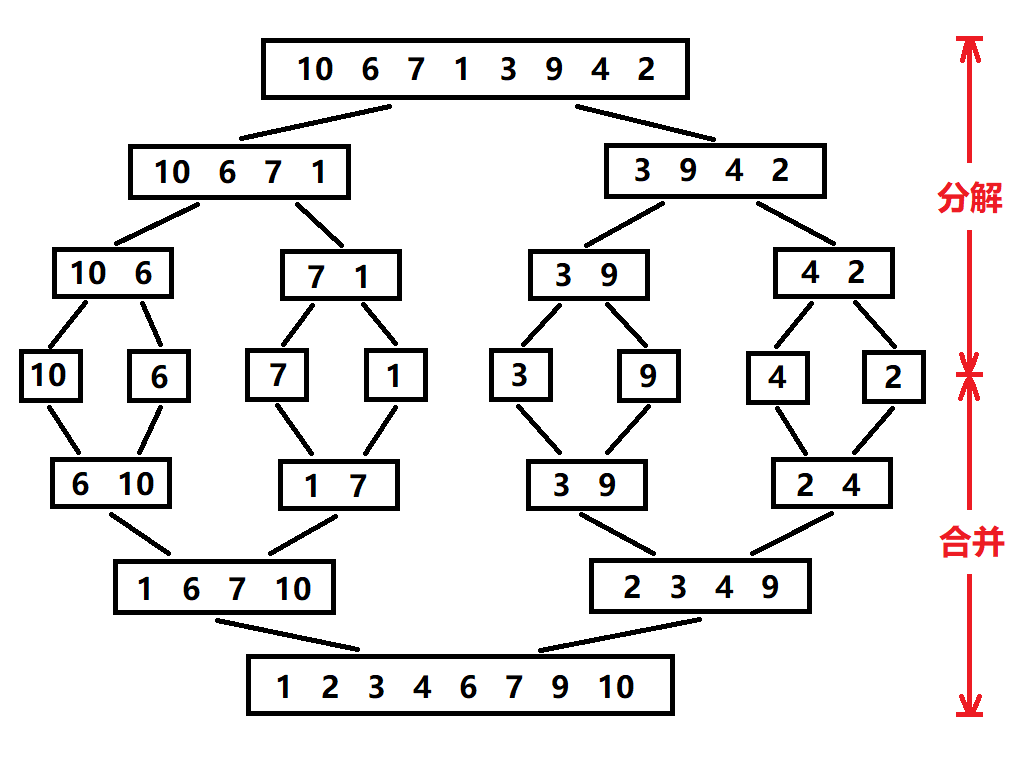
归并排序:分治思想的高效排序
目录 基本原理 流程图解 实现方法 递归实现 非递归实现 演示过程 时间复杂度 基本原理 归并排序(Merge Sort)是一种基于分治思想的排序算法,由约翰冯诺伊曼在1945年提出。其核心思想包括: 分割(Divide):将待排序数组递归地分成两个子…...