Reactor 模式网络服务器【I/O多路复用】(C++实现)
前导:本文是 I/O 多路复用的升级和实践,如果想实现一个类似的服务器的话,需要事先学习 epoll 服务器的编写。
友情链接:
-
高级 I/O【Linux】
-
I/O 多路复用【Linux/网络】(C++实现 epoll、select 和 epoll 服务器)
1. 什么是 Reactor 模式
既然你开始了解 Reactor(反应器) 模式,说明你知道在实现服务端时,多线程只能处理少量的客户端请求,一旦数量增多,维护线程的成本会急剧上升,导致服务端性能下降。而 Reactor 模型就是为解决这个问题而诞生的。
Reactor 模式是一种基于事件驱动的设计模式,它是 I/O 多路复用在设计模式层面上的体现。Reactor 设计模式的“设计”体现在:
- 将 I/O 事件的处理分为两个阶段: 事件分发阶段(Dispatcher)和事件处理阶段(Handler)。这种分离可以将 I/O 事件的处理从阻塞 I/O 中解耦出来,从而提高系统的并发能力和吞吐量。
- 使用 I/O 多路复用技术: I/O 多路复用技术可以让一个线程或进程监听多个 I/O 事件,从而提高系统的资源利用率。
- 使用事件驱动模型: 事件驱动模型可以让系统更加灵活和可扩展。

图片来源:http://www.dre.vanderbilt.edu/~schmidt/PDF/reactor-siemens.pdf
理解这张图,需要你了解 select 服务器的写法。
这就是一个 Reactor 模型(以 select 为例),它主要包含五个组件:
| Handle(句柄) | 用于标识不同的事件,本质是文件描述符。 |
|---|---|
| Sychronous Event Demultiplexer(同步事件分离器) | 本质是系统调用,用于等待事件的发生。对于 Linux 来说,同步事件分离器指的就是 I/O 多路复用的接口,比如 select、poll、epoll 等。 |
| Event Handler(事件处理器) | 由多个回调方法构成,这些回调方法构成了与应用相关的对于某个事件的处理反馈,由用户实现。 |
| Concrete Event Handler(具体事件处理器) | 事件处理器中各个回调方法的具体实现(可以认为是 Event Handler 的函数体)。 |
| Initiation Dispatcher(初始分发器) | 初始分发器就是 Reactor 模型,它会通过同步事件分离器来等待事件的发生,当对应事件就绪时就调用事件处理器,最后调用对应的回调方法来处理这个事件。 |
2. Reactor 模型的演化
我们知道一个服务器在接收数据后,要对这个数据进行解码,反序列化,处理,有必要的话还要序列化,然后将处理后的数据返回给客户端。这些操作可以抽象为一个个模块,交给线程去做。
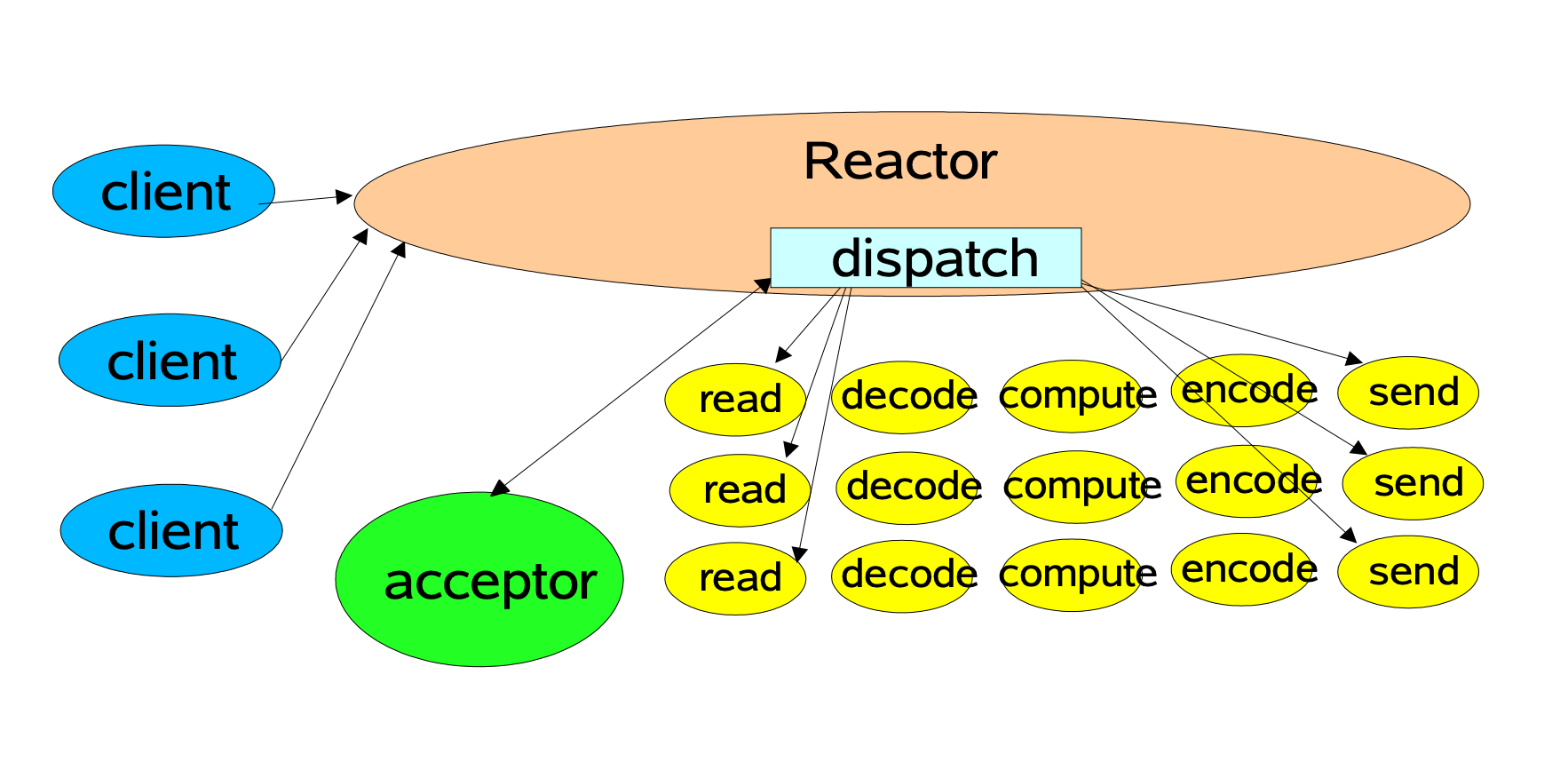
首先是单线程 Reator 模型,Reactor 模型会利用给定的 selectionKeys 进行派发操作,派发到给定的 Handler,之后当有客户端连接上来的时候,Acceptor 会调用接口 accept(),之后将接收到的连接和之前派发的 Handler 进行组合并启动。
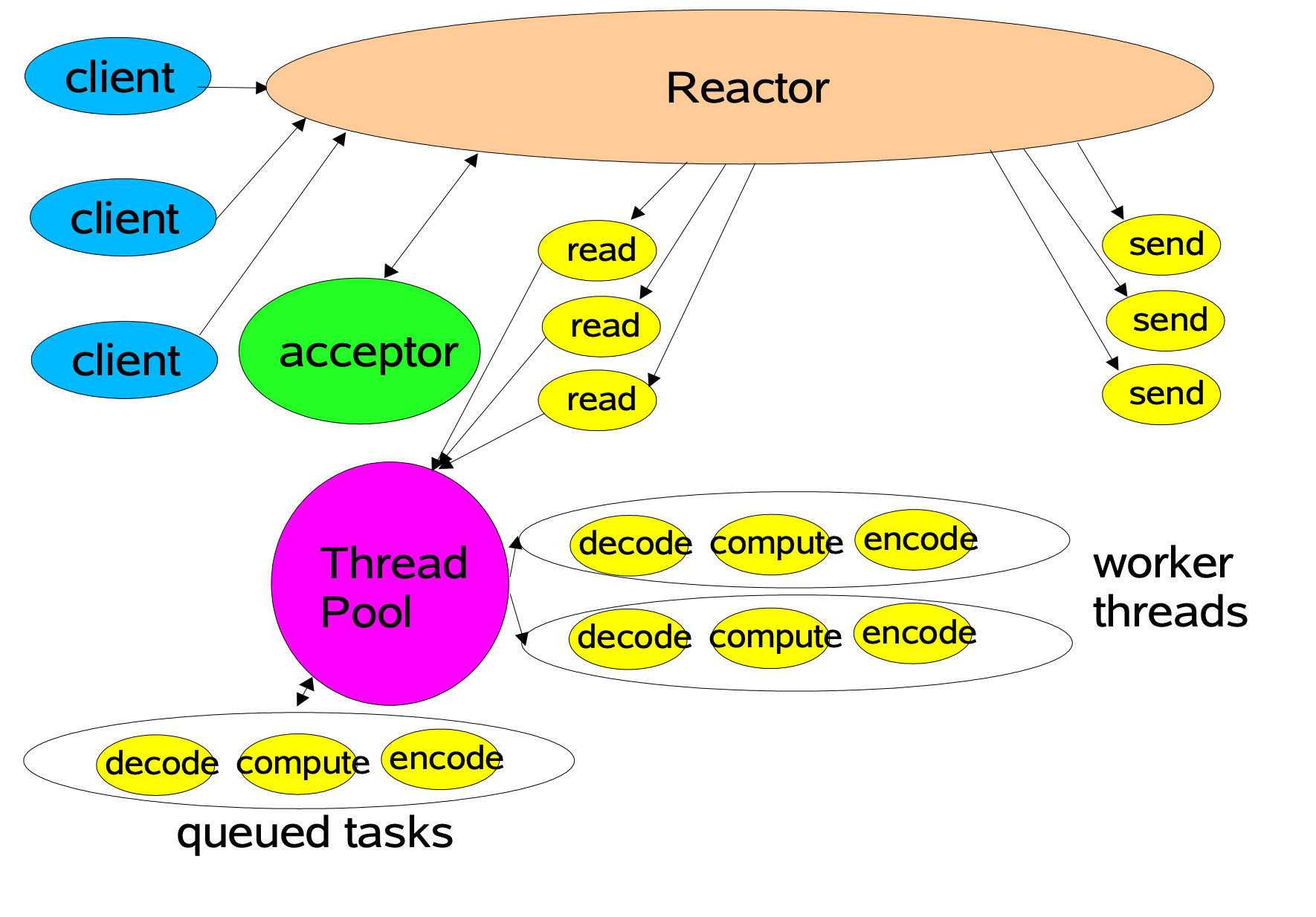
然后是接入线程池的 Reactor 模型,此模型将读操作和写操作解耦了出来,当底层有数据就绪时,将原本 Handler 的操作交给线程队列的头部线程来进行,极大地提到了整体的吞吐量和处理速度。

图片来源:https://gee.cs.oswego.edu/dl/cpjslides/nio.pdf
最后是多 Reactor 模型,此模型中,有一个主 Reactor(Main Reactor)和多个从 Reactor(Sub Reactor)。Main Reactor 负责处理客户端的连接请求,而 Sub Reactor 则负责处理已经建立的连接的读写事件。这种模型的好处就是整体职责更加明确,同时对于多核 CPU 的机器,系统资源的利用更加高一些。
3. Reactor 模式的工作流程
- Reactor 对象通过 I/O 多路复用接口监听客户端请求事件,收到事件后,通过 Dispatch 进行分发。
- 如果是建立连接请求,则 Acceptor 通过 accept() 处理连接请求,然后创建一个 Handler 对象处理完成连接后的各种事件。
- 如果不是连接请求,说明是读事件就绪,则由 Reactor 分发调用连接对应的 Handler 来处理。
- Handler 只负责相应事件,不做具体的业务处理,通过 read() 读取数据后,会分发给后面的 Worker 线程池的某个线程处理业务。
- Worker 线程池(如果有的话)会分配独立线程完成真正的业务,并将结果返回给 Handler。
- Handler 收到响应后,通过 send() 分发将结果返回给客户端。
4. Reactor 服务器
下面是一个 epoll 服务器比较完善的写法,它是 I/O 多路复用【Linux/网络】(C++实现 epoll、select 和 epoll 服务器) 中 epoll 服务器的提升版。
4.1 Connection 类
承接上一节中的 epoll 服务器:现在的问题是,来自用户的数据可能会被 TCP 协议拆分成多个报文,那么服务器怎么才能知道什么时候最后一个小报文被接收了呢?要保证完整地读取客户端发送的数据,服务器需要将这次读取到的数据保存起来,对它们进行一定的处理(报文可能会有报头,以解决粘包问题),最后将它们拼接起来,再向上层应用程序交付。
问题是 Recver 中的缓冲区 buffer 是一个局部变量,每次循环都会重置。而服务端可能会有成百上千个来自客户端建立连接后打开的文件描述符,这无法保证为每个文件描述符都保存本轮循环读取的数据。
解决办法是为套接字文件描述符建立独立的接收和发送缓冲区,因为套接字是基于连接的,所以用一个名为 Connection 的类来保存所有和连接相关的属性,例如文件描述符,收发缓冲区,以及对文件描述符的操作(包括读、写和异常操作),所以要设置三个回调函数以供后续在不同的分支调用,最后还要设置一个回指指针,它将会保存服务器对象的地址,到后面会介绍它的用处。
class TcpServer;using func_t = std::function<void(Connection*)>;// 保存所有和连接/读写相关的属性
class Connection
{
public:Connection(int sock = -1): _sock(sock), _tsvr(nullptr){}void SetCallBack(func_t recv_cb, func_t send_cb, func_t except_cb){_recv_cb = recv_cb;_send_cb = send_cb;_except_cb = except_cb;}~Connection(){}
public:int _sock; // I/O 文件描述符func_t _recv_cb; // 读事件回调函数func_t _send_cb; // 写事件回调函数func_t _except_cb; // 异常事件回调函数std::string _in_buffer; // 接收缓冲区std::string _out_buffer; // 发送缓冲区TcpServer* _tsvr; // 服务器回指指针
};
成员函数 SetCallBack 是用来设置回调函数的地址的。注意成员变量的访问权限设置为 public,这么做是测试是就不用写 Get 和 Set 方法了。
4.2 TcpServer 服务器
服务器类已经实现很多遍了,这里只是将名字从 EpollServer 换成 TcpServer,其中许多逻辑是不变的。不同的是成员变量将 epoll 的文件描述符换成了 epoll 对象,因为在服务器类中,希望直接调用函数,而不进行传参(其实不改也可以,只是换个地方传参),所以对 Epoll 类的封装改进了一下。
Epoll 类
#pragma once#include <iostream>
using namespace std;#include <sys/epoll.h>class Epoll
{const static int g_size = 256;const static int g_timeout = 5000;public:Epoll(int timeout = g_timeout) : _timeout(g_timeout){}void Create(){_epfd = epoll_create(g_size);if (_epfd < 0)exit(5);}bool Del(int sock){int n = epoll_ctl(_epfd, EPOLL_CTL_DEL, sock, nullptr);return n == 0;}bool Ctrl(int sock, uint32_t events){events |= EPOLLET;struct epoll_event ev;ev.events = events;ev.data.fd = sock;int n = epoll_ctl(_epfd, EPOLL_CTL_MOD, sock, &ev);return n == 0;}bool Add(int sock, uint32_t events){struct epoll_event ev;ev.events = events;ev.data.fd = sock;int n = epoll_ctl(_epfd, EPOLL_CTL_ADD, sock, &ev);return n == 0;}int Wait(struct epoll_event revs[], int num){return epoll_wait(_epfd, revs, num, _timeout);}void Close(){if (_epfd >= 0)close(_epfd);}~Epoll(){}public:int _epfd;int _timeout;
};
这里将成员访问限制限定为 public,这么做是方便直接访问,否则要写一些 Get 或 Set 方法。
服务器类框架
在构造函数中,除了创建 listensock 和创建 Epoll 对象等之外,要注意不仅 listensock,真正运行起来的服务器应该会存在大量的 socket,每一个 sock 都要被封装为一个 Connection 对象。那么这些 Connection 对象这么多,必须要管理它们:先描述,后组织。所以在服务器中使用哈希表组织这些 Connection 对象,key 是 sock,value 是 Connection 对象。
以后只要 sock 对应的文件描述符就绪,通过哈希表就能找到对应的 Connection 对象,这样就能立马调用它的三个回调方法,对套接字进行处理。通过这个哈希表,就将 Epoll 和应用程序解耦。Epoll 的 AddSockToEpoll 成员函数就是为维护哈希表而设计的。
class TcpServer
{const static int default_port = 8080;const static int g_num = 128;
public:TcpServer(int port = default_port): _port(port), _nrevs(g_num){// 1. 获取 listensock_listensock = Sock::Socket();Sock::Bind(_listensock, _port);Sock::Listen(_listensock);// 2. 创建 epoll 实例_poll.Create();// 3. 添加 listensock 到服务器中AddConnection(_listensock, std::bind(&TcpServer::Accepter, this, std::placeholders::_1), nullptr, nullptr);// 4. 为保存就绪事件的数组申请空间_revs = new struct epoll_event[_nrevs];}void AddConnection(int sock, func_t recv_cb, func_t send_cb, func_t except_cb){// 1. 设置 sock 为非阻塞Sock::SetNonBlock(sock);// 2. 构建 Connection 对象,封装 sockConnection *conn = new Connection(sock);conn->SetCallBack(recv_cb, send_cb, except_cb);conn->_tsvr = this;// 3. 让 epoll 对象监视_poll.Add(sock, EPOLLIN | EPOLLET);// 4. 将 Connection 对象的地址插入到哈希表_connections.insert(std::make_pair(sock, conn));}void Accepter(Connection *conn){}void Recver(Connection *conn){}void Sender(Connection *conn){}void Excepter(Connection *conn){}void LoopOnce(){int n = _poll.Wait(_revs, _nrevs);for (int i = 0; i < n; i++){int sock = _revs[i].data.fd;uint32_t revents = _revs[i].events;// 根据事件类型调用不同的回调函数// ... }}void Dispather(callback_t cb) // 原先的名字是 Start(){_cb = cb;while (true){LoopOnce();}}~TcpServer(){if (_listensock >= 0)close(_listensock);if (_poll._epfd >= 0)close(_poll._epfd);if (_revs)delete[] _revs;}private:uint16_t _port; // 端口号int _listensock; // 监听套接字文件描述符Epoll _poll; // epoll 实例struct epoll_event *_revs; // 保存从就绪队列中取出的就绪事件的文件描述符的数组int _nrevs; // 数组长度std::unordered_map<int, Connection *> _connections; // 用哈希表保存连接
};
其中,SetNonBlock 在 Sock 类中的实现:
static bool SetNonBlock(int sock)
{int fl = fcntl(sock, F_GETFL);if (fl < 0)return false;fcntl(sock, F_SETFL, fl | O_NONBLOCK);return true;
}
注意:
- 在构造函数的第三点,添加 listensock 到服务器中,实际上就是将它作为 key 值,和创建的 Connection 对象的指针绑定,插入到哈希表中。
- 用 AddConnection 函数封装这个插入的过程。不过在插入之前,首先要创建 Connection 对象,然后初始化它的成员。
- 必须设置要插入的文件描述符为非阻塞,通过调用 SetNonBlock 实现;其次,作为一个 I/O 多路复用的服务器,一般默认值打开对读事件的关心,写入事件会按需打开。除此之外,还必须设置服务器为 ET 模式。
- 注意哈希表的插入语法,以及绑定函数和参数,生成函数对象的用法。为啥要这么干呢?因为这个位置上的参数也是函数对象。
- Epoll 类型的对象取名不取为 epoll,而是取做 poll。这是因为在有些项目中,poll 这个名字更具有通用性,可以通过继承来区分不同类型。
- Excepter 函数是用来处理异常的,例如 recv 和 send 出现了错误,不管是什么错误,我们都丢到这个函数中统一处理,这样另外两个函数就能更关注它们要做的事情上。
std::bind 函数可以将一个可调用对象(如函数、函数指针或者函数对象)与其参数一起进行绑定,生成一个新的可调用对象。(其实就是把它们打包在一起)
std::bind(&TcpServer::Accepter, this, std::placeholders::_1)这行代码的含义是创建一个新的函数对象,这个对象绑定了成员函数 TcpServer::Accepter 和对象 this 指针。其中,std::placeholders::_1是一个占位符,表示这个新的函数对象的第一个参数。当这个新的函数对象被调用时,它会调用 TcpServer::Accepter 这个成员函数,同时传入的参数会替换掉占位符
std::placeholders::_1。
LoopOnce 函数
在 LoopOnce 函数中执行的是每一次循环要做的事,对于 epoll 而言,用户进程只需要用一个数组存放已经就绪的文件描述符。然后遍历它。数组的每个元素都是一个事件结构体,通过它的成员判断事件的类型,是读还是写(异常稍后再说)。
bool IsConnectionExists(int sock)
{auto iter = _connections.find(sock);if (iter == _connections.end())return false;elsereturn true;
}
void LoopOnce()
{int n = _poll.Wait(_revs, _nrevs);for (int i = 0; i < n; i++){int sock = _revs[i].data.fd;uint32_t revents = _revs[i].events;// 根据事件类型调用不同的回调函数// 先不管异常事件// 读事件就绪if (revents & EPOLLIN){if (IsConnectionExists(sock) && _connections[sock]->_recv_cb != nullptr) // 当回调函数被设置才能调用它_connections[sock]->_recv_cb(_connections[sock]);}// 写事件就绪if (revents & EPOLLOUT){if (IsConnectionExists(sock) && _connections[sock]->_send_cb != nullptr)_connections[sock]->_send_cb(_connections[sock]);}}
}
注意:只有当这个 sock 对应的 Connection 对象在哈希表中才能调用它里面的回调函数,而且要保证在调用之前回调函数是被设置过的,否则会空指针异常。
判断 Connection 对象在哈希表中,通过函数 IsConnectionExists 实现。
Accepter 回调函数
Accepter 函数要做的时和之前一样,但是和之前实现的 epoll 服务器不同的是,由于服务端要处理不止一个连接,所以要在一个死循环中执行逻辑,直到文件描述符获取失败。但这次失败不会影响到下次,因为设置的 sock 是非阻塞的。
Accept() 函数的返回值小于零,并不代表出现了很严重的错误,对于本轮循环,如果没有连接请求了,就说明底层就绪的连接被取完了,退出。EAGAIN 和 EWOULDBLOCK 是两个含义相同的错误码(因为历史版本而形式不同),它们表示数据没有就绪。
这通过一个输出型参数 accept_errno 来获取底层调用 accept() 的错误码,因此 Sock::Accept() 也有做相应修改。
当 Accept 成功,说明这个文件描述符和服务端建立了连接,所以要为这个连接创建一个 Connection 对象,以保存它的信息,不要忘了注册回调函数。这样就相当于在派发时,各自调用了回调函数。
void Accepter(Connection *conn)
{// 服务端需要处理不止一个连接while (true){std::string client_ip;uint16_t client_port;// 输出型参数,获取错误码以便判断读取情况int accept_errno = 0;int sock = Sock::Accept(conn->_sock, &client_ip, &client_port, &accept_errno);// 异常if (sock < 0){// 没有新的连接请求(取完了)if (accept_errno == EAGAIN || accept_errno == EWOULDBLOCK)break;// 被信号中断else if (accept_errno == EINTR)continue;// 失败else{logMessage(WARNING, "accept error...code[%d] : %s", accept_errno, strerror(accept_errno));break;}}// 成功// 将 sock 交给 TcpServer 监视,并注册回调函数if (sock >= 0){AddConnection(sock, std::bind(&TcpServer::Recver, this, std::placeholders::_1),std::bind(&TcpServer::Sender, this, std::placeholders::_1),std::bind(&TcpServer::Excepter, this, std::placeholders::_1));logMessage(DEBUG, "accept client[%s:%d] success, add to epoll of TcpServer success, sock: %d",client_ip.c_str(), client_port, sock);}}
}
还是那个问题,虽然 Accept 函数成功执行了,但即使建立了连接,服务端也不知道客户端何时会发送数据,但现在 sock 的性质从之前的监听套接字变成了一个普通的 I/O 套接字,那么继续交给 TcpServer 中的 epoll 实例监视。
这个将文件描述符“交付”给内核的操作,在 select 服务器的编写过程中我们通过将文件描述符添加到数组中,那么在 epoll 服务器中,我们只需要将<文件描述符,Connection 对象(三个回调函数)>这样的键值对插入到哈希表中,就实现了用户和内核之间的解耦,和数组的作用是类似的,只不过我们不用自己维护哈希表。
Recver 回调函数
由于文件描述符是非阻塞的,而且 epoll 被设置为 ET 模式,所以要不断地处理本次客户端发送的数据,因此在死循环中执行逻辑。差错处理和上面类似,不同的是当出现错误时或对端关闭连接时,调用 Excepter 函数。
当 recv() 成功时,将本轮循环读取的数据尾插到 sock 自己的接收缓冲区中。跳出循环则说明本次客户端发送的数据全部读取完毕,测试打印一下接收的数据。
void Recver(Connection *conn)
{const int num = 1024;bool err = false;while (true){char buffer[num];ssize_t n = recv(conn->_sock, buffer, sizeof(buffer) - 1, 0);if (n < 0){if (errno == EAGAIN || errno == EWOULDBLOCK)break;else if (errno == EINTR)continue;else{logMessage(ERROR, "recv error, code:[%d] : %s", errno, strerror(errno));conn->_except_cb(conn);err = true;break;}}else if (n == 0){logMessage(DEBUG, "client disconnected, sock[%d] close...", conn->_sock);conn->_except_cb(conn);err = true;break;}// 成功else{buffer[n] = '\0';// 将本轮读取的数据尾插到接收缓冲区conn->_in_buffer += buffer;}}if (!err)logMessage(DEBUG, "client[%d]>>> %s", conn->_sock, conn->_in_buffer.c_str());
}
再次强调 Recver 函数的作用是进行一次数据的接收,因为 eopll 被设置为 ET 模式,文件描述符被设置为非阻塞模式,由于缓冲区大小可能没那么大,所以要通过若干轮读取来获取客户端发送的数据。跳出循环可能是因为读取完毕了,可能是真的出错了,真正出错的情况下不应该打印,所以用一个 bool 类型的标记来限制打印的条件。
简单测试一下:
现在可以保证接收数据的逻辑基本没有问题,但是有个小细节,当客户端断开连接以后,这个文件描述符并没有关闭,这是因为没有在出错时进行差错处理,而是交给 Excepter 函数去做,只不过现在还没有实现它。
另外,由于是 Telnet 工具,所以缓冲区中拼接的内容每次都会有一个回车符,暂时不用关心这个问题(在代码中已经去除了最后的符号sizeof(buffer) - 1),因为这只是一个测试的工具,实际上客户端可能是其他软件。
在测试时,只是以字节流测试(也就是直接读取数组中的内容),但实际上客户端发送的数据可能是一个加密的报文,所以要进行协议订制,这也是解决粘包问题的手段。
服务器不应该和业务强耦合,所以应该用回调函数,回跳到上层业务设置的逻辑。什么意思呢?意思就是在服务器眼里,数据仅仅是数据,而不关心它是什么,具体要对数据做何种事,让那个运行服务器的主体去做(在这里就是 main 函数)。
实际上,可以将客户端发来请求封装为一个任务对象,然后放到任务队列中,让线程池处理,这样服务器就只用关心连接和收发数据本身,而不关心业务。发送数据只需要将序列化后的数据放到缓冲区中,让服务器帮忙转发。
using callback_t = std::function<void(Connection *, std::string &request)>;
class TcpServer
{// ...
private:// ...callback_t _cb; // 上层设置的业务处理回调函数
};
定义一个函数对象叫 callback_t,它的参数是 (Connection *, std::string &request),这其中包含连接的 sock 以及三个回调函数,还有客户端发送的请求,这个请求是上层业务需要解析的。
定制协议和解决粘包问题
关于客户端请求的处理,在 认识协议【网络基础】 有介绍,现在把其中的 Protocol.hpp 中的 Request 类和 Response 类以及 NetCal.hpp 的 calculatorHelper() 的放到这。
- Request 类和 Response 类:这两个类封装了序列化的反序列化的逻辑,用来接收客户端发送的请求(Request),处理后的数据如果有必要返回的话,那就返回应答(Response)给客户端。
- calculatorHelper():实现了简单的加减乘除,用这个简易的计算机代表上层应用程序的业务。
为了解决粘包问题,我们设置一个特殊符号X作为每个完整报文的分隔符,例如用户输入两个子请求构成一个请求:
1 + 1X2 * 2X
实际上对于业务真正有用的数据应该用 X来拆分它:
1 + 1
和
2 * 2
在 Recver 接收到客户端发送的一个完整的请求后,调用 SpliteMessage 函数将请求中的X剔除,用数组存放每一个有效子请求,然后把每个子请求交给上层业务逻辑。
void Recver(Connection *conn)
{const int num = 1024;bool err = false;while (true){char buffer[num];ssize_t n = recv(conn->_sock, buffer, sizeof(buffer) - 1, 0);// 失败// ...// 成功// ...}// 能执行到这里,就能保证缓冲区中是一个完整的请求报文if (!err){logMessage(DEBUG, "client[%d]>>> %s", conn->_sock, conn->_in_buffer.c_str());std::vector<std::string> message;// 用容器保存拆分数据中的有效请求SpliteMessage(conn->_in_buffer, &message);// 将每个有效请求交给上层业务逻辑for (auto &msg : message)_cb(conn, msg);}
}
下面是实现拆分报文以及请求和响应中的序列化和反序列化的逻辑:
// Protocol.hpp
#pragma once#include <iostream>
#include <cstring>
#include <string>
#include <vector>#define SEP "X"
#define SEP_LEN strlen(SEP)
#define SPACE " "
#define SPACE_LEN strlen(SPACE)void SpliteMessage(std::string &buffer, std::vector<std::string> *out)
{while (true){auto pos = buffer.find(SEP);if (std::string::npos == pos)break;std::string message = buffer.substr(0, pos);buffer.erase(0, pos + SEP_LEN);out->push_back(message);}
}
// 解决粘包问题
std::string Encode(std::string &s)
{return s + SEP;
}// 请求
class Request
{
public:// 序列化// 1 + 1 -> "1 + 1"// _x + _ystd::string Serialize(){std::string str;str += std::to_string(_x);str += SPACE;str += _op;str += SPACE;str += std::to_string(_y);return str;}// 反序列化// 1 + 1 <- "1 + 1"bool Deserialize(const std::string &str){std::size_t left = str.find(SPACE);if (left == std::string::npos)return false;std::size_t right = str.rfind(SPACE);if (right == std::string::npos)return false;_x = atoi(str.substr(0, left).c_str());_y = atoi(str.substr(right + SPACE_LEN).c_str());if (left + SPACE_LEN > str.size())return false;else_op = str[left + SPACE_LEN];return true;}public:Request() {}Request(int x, int y, char op): _x(x), _y(y), _op(op){}~Request() {}public:int _x;int _y;char _op;
};
// 响应
class Response
{
public:// 序列化std::string Serialize(){std::string str;str += "code:";str += std::to_string(_code);str += SPACE;str += "result:";str += std::to_string(_result);return str;}// 反序列化bool Deserialize(const std::string &str){std::size_t pos = str.find(SPACE);if (pos == std::string::npos)return false;_code = atoi(str.substr(0, pos).c_str());_result = atoi(str.substr(pos + SPACE_LEN).c_str());return true;}public:Response() {}Response(int result, int code, int x, int y, char op): _result(result), _code(code), _x(x), _y(y), _op(op){}~Response() {}public:int _result; // 结果int _code; // 错误码int _x;int _y;char _op;
};
其实就是对字符串剪切拼接的操作:
- 对于客户端发送的数据,业务逻辑应该构建 Request 对象,然后对数据进行反序列化,获取其中真正有效的数据;
- 对于服务端返回的响应,业务逻辑应该构建 Response 对象,然后对处理后的结果进行序列化,包装一下每次处理后的结果。这是因为客户端发送的报文中可能不止一个有效数据,也就是可能要进行多次处理,得到多个结果。为了保证这些结果不被混淆(即粘包问题),要进行序列化。
返回的响应中可能包含多个结果,所以也用X来区分。这部分应该是通信双方协商制定的。
注意,对于 SpliteMessage 函数而言,它的第一个参数是输入缓冲区,它是一个输入输出型参数,在函数体内剔除掉特殊字符X后,也要对输入缓冲区中的数据做同样的操作。第二个参数是一个输出型参数,这个数组用来保存取出的数据。
在服务端处理数据的粘包问题时,为什么已经获取到缓冲区中真正有效的数据以后,还要将缓冲区中的内容做修改,被处理后的缓冲区中的内容似乎没有什么作用了。
虽然内容已经被解码器拷贝出来并交给上层处理了,所以它们在缓冲区中就没有存在的意义,但是如果不删除或者移动它们,那么它们就会占用缓冲区的空间,并且可能干扰下一个数据包的读取和解析。所以解码器会将它们清理掉,以保持缓冲区的整洁和正确。
// main.cc
#include "TcpServer.hpp"
#include <memory>static Response calculatorHelper(const Request &req)
{Response resp(0, 0, req._x, req._y, req._op);switch (req._op){case '+':resp._result = req._x + req._y;break;case '-':resp._result = req._x - req._y;break;case '*':resp._result = req._x * req._y;break;case '/':if (req._y == 0)resp._code = 1;elseresp._result = req._x / req._y;break;case '%':if (req._y == 0)resp._code = 2;elseresp._result = req._x % req._y;break;default:resp._code = 3;break;}return resp;
}void calculator(Connection *conn, std::string &request)
{logMessage(DEBUG, "calculator() been called, get a request: %s", request.c_str());// 1. 构建请求Request req;// 2. 反序列化if(!req.Deserialize(request)) return;// 3. 构建应答Response resp;// 4. 业务处理resp = calculatorHelper(req);// 5. 序列化std::string sendstr = resp.Serialize();// 6. 解决粘包问题sendstr = Encode(sendstr);// 7. 将处理后的应答交给服务器conn->_out_buffer += sendstr;// 8. 让服务器的 epoll 对象设置对写事件的关心conn->_tsvr->EnableReadWrite(conn, true, true);
}
int main()
{std::unique_ptr<TcpServer> svr(new TcpServer());svr->Dispather(calculator);return 0;
}
[重点] 现在的问题是,如何让服务器将处理好的数据发送给客户端呢(我们假设 Sender 已经写完了)?在服务器的构造函数中,只关心新到来的连接的文件描述符的读事件,而不关心写事件。当一个连接到来后,按规则发送了请求,但是服务器中的 Epoll 对象并没有打开对写事件的关心,这就没办法返回响应给客户端了。
所以在要返回响应给客户端的前提是让服务器打开对写事件的关心?但是问题又来了,这里已经是服务器上层的业务逻辑了,怎么才能回到服务器中设置呢?
还记得 Connection 类中有一个 TcpServer 类型的回指指针吗?它可以帮助上层业务回到服务器中设置服务器对写事件的关心。
EnableReadWrite 函数
这个函数用来设置服务器的 epoll 对象对连接读写事件的关心与否。它接受三个参数:一个是 Connection 类型的指针,表示要设置的连接对象;两个是 bool 类型的值,表示是否允许读取或写入数据。
函数的主要逻辑是根据这两个布尔值来确定要设置的事件类型,然后调用_poll.Ctrl() 方法来修改连接的事件监听状态
void EnableReadWrite(Connection *conn, bool readable, bool writeable)
{uint32_t events = ((readable ? EPOLLIN : 0) | (writeable ? EPOLLOUT : 0));bool res = _poll.Ctrl(conn->_sock, events);if (!res){logMessage(ERROR, "EnableReadWrite() error...code:[%d]:%s", errno, strerror(errno));return;}
}
除此之外,EnableReadWrite 函数将会在 Sender 函数中也发挥作用。
Sender 函数
在 Sender 函数中,应该将上层业务处理好后的数据发送给客户端。同样地,send() 函数可能没办法一次性将发送缓冲区的数据发送给客户端,所以要在一个死循环中执行。
在本轮循环发送的数据必须从发送缓冲区中移除。在差错处理时,通过发送缓冲区为空与否,来判断数据是否全部发送给客户端。
void Sender(Connection *conn)
{while (true){ssize_t n = send(conn->_sock, conn->_out_buffer.c_str(), conn->_out_buffer.size(), 0);if (n > 0){// 发送的数据应该在缓冲区中移除conn->_out_buffer.erase(0, n);// 发送完毕,缓冲区为空,退出发送逻辑if (conn->_out_buffer.empty())break;}else{if (errno == EAGAIN || errno == EWOULDBLOCK)break;else if (errno == EINTR)continue;else{logMessage(ERROR, "send error, %d : %s", errno, strerror(errno));conn->_except_cb(conn);break;}}}// 执行到这里并不能保证数据发送完毕// a. 发送完毕,缓冲区为空,取消服务器 epoll 模型对连接写事件的关心if (conn->_out_buffer.empty())EnableReadWrite(conn, true, false);// b. 缓冲区未空,继续发送,保持服务器 epoll 模型对连接写事件的关心elseEnableReadWrite(conn, true, true);
}
[重要] 当跳出循环时,还不能保证全部数据发送完毕,这是因为出现错误时也会跳出循环,但是缓冲区中依然有数据,说明这次发送失败了。在 TCP 协议中,对端主机在进行报文的序号校验时,会发现这个错误,失败信息返回给服务端,进而发送给上层,上层会重新调用 Sender 函数来发送。不过这里并未实现重发的逻辑。
当跳出循环时,可能有以下几种情况:
- 缓冲区为空,表示用户空间的所有数据都已经拷贝到内核空间,但是还不能保证内核空间的所有数据都已经发送到对端。这时候,需要取消服务器 epoll 模型对连接写事件的关心,避免频繁触发写事件,浪费 CPU 资源。同时,需要依赖 TCP 协议的可靠性机制,确保数据最终能够到达对端。
- 缓冲区不为空,表示用户空间还有部分数据没有拷贝到内核空间,可能是因为内核空间的发送缓冲区已满或者遇到其他错误。这时候,需要继续保持服务器 epoll 模型对连接写事件的关心,等待下一次可写时再次尝试发送数据。
为什么在 epoll 实现的服务器中,服务器在发送数据之后,要关闭 epoll 对写事件的关心呢?
是因为 EPOLLOUT 事件是一个高频率触发的事件,也就是说,在大多数情况下,文件描述符都是可写的,除非缓冲区满了或者出现异常。如果不关闭 epoll 对写事件的关心,那么每次 epoll_wait 返回时,都会返回大量的 EPOLLOUT 事件,占用了服务器的 CPU 资源,并且可能干扰其他更重要的事件的处理。因此,在发送数据之后,如果数据已经发送完毕,就应该关闭 epoll 对写事件的关心,只保留对读事件或者其他事件的关心。这样可以提高服务器的性能和效率。
Excepter 函数
Excepter 函数是当内核检测到异常事件就绪时触发的回调函数。它的作用是在 Recver 函数或 Sender 函数中,当 recv() 或 send() 系统调用出现致命性错误时进行移除不需要的文件描述符以及资源回收等操作。
致命性错误指的是系统调用真的出错了,导致这个文件描述符没有再维护和监视的意义,例如在使用 revc() 来接收数据时,对端关闭了连接,那么服务端也就没有必要再监视这个文件描述符了。
在此想强调的是,要熟悉这些系统调用返回值和错误码的意义,返回值小于零,并不代表它真的出错了,还要进一步通过错误码来判断真实的错误。
例如我在调试时,我没有在初始化列表中为 timeout 参数初始化,所以当 LoopOnce() 调用 EpollWait() 函数时其中的 epoll_wait 函数执行失败了,但刚好这里面没有进行差错处理,为此花了不少时间。
我的收获是,不仅要根据返回值还要根据错误码定位错误原因。在 Recver 函数和 Sender 函数中也是这么做的。
void Excepter(Connection *conn)
{ // 0. 判断连接是否存在if (!IsConnectionExists(conn->_sock))return;// 1. 从 epoll 模型中删除bool res = _poll.Del(conn->_sock);if (!res){logMessage(ERROR, "DelFromEpoll() error...code:[%d]:%s", errno, strerror(errno));}// 2. 从服务器的哈希表中删除_connections.erase(conn->_sock);// 3. 关闭文件描述符close(conn->_sock);// 4. 释放空间;delete conn;logMessage(DEBUG, "Excepter() OK...");
}
除了 Recver 函数和 Sender 函数,LoopOnce 函数也需要差错处理,如果事件的类型是 EPOLLERR(文件描述符发生错误) 或 EPOLLHUP(对端将文件描述符关闭),那么应该调用 Excepter 函数。但是 LoopOnce 函数中应该进行的是服务器一次循环应该做的事,也就是根据就绪事件的类型,来调用 Recver 函数还是 Sender 函数。
而事件的状态是通过事件掩码保存的,那么将“出错”这个状态通过|运算设置进事件掩码中,是不影响其他状态的,因为出错后都要调用 Excepter 函数,直接让 Sender 和 Recver 函数去做就好了。
void LoopOnce(){int n = _poll.Wait(_revs, _nrevs);for (int i = 0; i < n; i++){int sock = _revs[i].data.fd;uint32_t revents = _revs[i].events;// 根据事件类型调用不同的回调函数// 错误if (revents & EPOLLERR)revents |= (EPOLLIN | EPOLLOUT); // 将读写事件添加到就绪事件中// 对端关闭连接if (revents & EPOLLHUP)revents |= (EPOLLIN | EPOLLOUT);// 读事件就绪if (revents & EPOLLIN){if (IsConnectionExists(sock) && _connections[sock]->_recv_cb != nullptr) // 当回调函数被设置才能调用它_connections[sock]->_recv_cb(_connections[sock]);}// 写事件就绪if (revents & EPOLLOUT){if (IsConnectionExists(sock) && _connections[sock]->_send_cb != nullptr)_connections[sock]->_send_cb(_connections[sock]);}}}
通过代码来看,就是当事件出错时,将它们的状态设置为可读可写,然后进入后面两个分支,这样就能通过调用 Recver 函数或 Sender 函数中的差错处理来调用 Excepter 函数。
为什么当文件描述符出错时,将它们的状态设置为可读可写,不主动调用 Excepter 函数来进行处理,而是设置出错的文件描述符状态为可读可写,然后进入 Recver 函数或 Sender 函数中的差错处理来调用 Excepter 函数呢?
这样做的目的是能够及时发现和处理各种错误情况,并且避免不必要的错误处理。什么意思呢?就是说 Excepter 函数只处理致命的错误,言外之意是文件描述符的状态无法真正表征错误的严重性。
和上面的系统调用出错时的返回值问题类似,有些错误不能仅仅通过文件描述符的状态来判断,因为一个错误状态可能对应多个问题。而且有些错误并不是立即可知的,而是需要通过 recv 或 send 函数( read 或 write 函数)来检测到。例如,如果对方正常关闭了连接,那么 read 函数会返回 0;如果对方异常关闭了连接,那么 recv 或 send 函数( read 或 write 函数)会返回 -1,并设置 errno 为 ECONNRESET 或 EPIPE。这些情况都需要通过 recv 或 send 函数( read 或 write 函数)来发现,并进行相应的处理。因此,在事件出错时,将它们的状态设置为可读可写,可以让 Recver 或 Sender 函数在尝试读或写时发现错误,并调用 Excepter 函数来处理。
同样地,有些错误并不是致命的,而是可以通过重试或忽略来解决的(注意代码中的 break 和 continue 对应着不同的错误)。如代码中写的,如果 recv 或 send 函数( read 或 write 函数)返回 -1,并设置 errno 为 EAGAIN 或 EWOULDBLOCK,那么表示缓冲区已满或者没有数据可读,只需要等待下一次可读或可写时再次尝试即可;如果 recv 或 send 函数( read 或 write 函数)返回 -1,并设置 errno 为 EINTR,那么表示被信号中断了,只需要继续尝试即可。这些情况都不需要调用 Excepter 函数来处理。因此,在事件出错时,将它们的状态设置为可读可写,可以让 Recver 或 Sender 函数在遇到这些错误时进行重试或忽略。
4.3 测试
4.4 扩展
如果有恶意节点和服务端建立大量连接,并且保持长时间不发送数据,这种无意义的连接会占用服务端大量资源,解决办法是设置一个超时时间。记录当前时间和客户端最近一次发送数据的时间,当它们的差值超过设定的超时时间,就断开连接。
class Connection
{// ...
public:// ...time_t _last_time; // 这个连接上次就绪的时间
};
class TcpServer
{// ...const static int link_timeout = 10;public:void AddConnection(int sock, func_t recv_cb, func_t send_cb, func_t except_cb){// ...// 2. 构建 Connection 对象,封装 sockconn->_last_time = time(nullptr);// ...}void Recver(Connection *conn){// 记录这个连接最近发送数据的时间conn->_last_time = time(nullptr);// ...}void ConnectAliveCheck(){for (auto &connection : _connections){time_t current_time = time(NULL);if (connection.second->_sock != connection.first) break;if (current_time - connection.second->_last_time < link_timeout)continue;else{if (connection.first != _listensock && connection.second != nullptr && (_connections.find(connection.first) != _connections.end()))Excepter(connection.second);}}}void Dispather(callback_t cb){_cb = cb;while (true){LoopOnce();ConnectAliveCheck();}}// ...
}
思路是在检查函数 ConnectAliveCheck 中遍历哈希表中的所有连接,超时且文件描述符不是监听套接字的话,则调用 Excepter 函数。
值得注意的是,当超时后调用 Excepter 函数删除超时连接在哈希表中的键值对,而哈希表的 erase 函数并不是真正的删除,而是将这个键值对设置为默认值,以表示它的空闲状态,这么做的目的是避免下次相同的键值要插入时重复计算哈希位置。
因此在 Excepter 函数中抹除了连接在哈希表中的值,但这个位置仍然是占用内存的,而且它在被再次设置之前是不能够访问它的。所以在枚举哈希表的元素时,必须判断键值对中的 key(sock)和 value(Connection)的 fd 是否相同,因为理论上它们是相同的。如果不这么做,会出现非法访问内存,即段错误,使得服务器程序崩溃。
除此之外,由于哈希表在构造函数中将监听套接字文件描述符插入到了哈希表中,这个文件描述符不应该被计时,否则会直接断开连接。
当然,这只是一个简单的计时逻辑,它很粗糙,精度很低,但可以是一个很好的引入。实际上,在多路转接(主要是 epoll)服务器中,通常使用以下几种方案实现定时器:
- 基于升序链表的定时器:这种方案是将所有的定时器按照超时时间从小到大排序,存放在一个链表中。每次调用 epoll_wait 时,将链表头部的定时器的超时时间作为超时参数,这样可以保证最先到期的定时器能够及时被处理。处理完一个定时器后,将其从链表中删除,并检查下一个定时器是否也已经超时,如果是,则继续处理,直到没有超时的定时器为止。这种方案的优点是实现简单,添加和删除定时器的时间复杂度都是 O (1),缺点是每次调用 epoll_wait 都需要遍历链表,查找最近的超时时间,时间复杂度是 O (n)。
- 基于时间轮的定时器:这种方案是将所有的定时器分配到一个环形数组中,数组的每个元素对应一个时间槽,每个时间槽可以存放多个定时器。数组有一个指针指向当前的时间槽,每隔一段固定的时间(称为槽间隔),指针就向前移动一格,并处理该槽中的所有定时器。这样可以保证定时器的精度不低于槽间隔,并且不需要每次都遍历所有的定时器。这种方案的优点是添加和删除定时器的时间复杂度都是 O (1),并且可以支持长时间的定时任务,缺点是需要额外的空间存储时间轮,并且对于短时间的定时任务,可能会有较大的误差。
- 基于最小堆的定时器:这种方案是将所有的定时器按照超时时间从小到大排序,存放在一个最小堆中。最小堆的特点是堆顶元素(根节点)是最小的元素,每次调用 epoll_wait 时,将堆顶元素的超时时间作为超时参数,这样可以保证最先到期的定时器能够及时被处理。处理完一个定时器后,将其从堆中删除,并重新调整堆结构,使其满足最小堆性质。这种方案的优点是添加和删除定时器的时间复杂度都是 O (logn),并且可以支持任意精度的定时任务,缺点是实现相对复杂,并且需要额外的空间存储最小堆。
来自网络,以后会填坑。
参考资料
- 【死磕 NIO】— Reactor 模式就一定意味着高性能吗?
- Reactor pattern–wiki
- reactor-siemens
源码:Reactor
相关文章:
Reactor 模式网络服务器【I/O多路复用】(C++实现)
前导:本文是 I/O 多路复用的升级和实践,如果想实现一个类似的服务器的话,需要事先学习 epoll 服务器的编写。 友情链接: 高级 I/O【Linux】 I/O 多路复用【Linux/网络】(C实现 epoll、select 和 epoll 服务器&#x…...
2019年[海淀区赛 第2题] 阶乘
题目描述 n的阶乘定义为n!n*(n -1)* (n - 2)* ...* 1。n的双阶乘定义为n!!n*(n -2)* (n -4)* ...* 2或n!!n(n - 2)*(n - 4)* ...* 1取决于n的奇偶性,但是阶乘的增长速度太快了,所以我们现在只想知道n!和n!!末尾的的个数 输入格式 一个正整数n ÿ…...

CMM—软件企业走向世界的通行证
正当我国计算机软件行业2000年实现产值235亿元,为自己九十年代年均30%的增长沾沾自喜的时候,从邻国印度传来捷报:1999-2000年度,印度软件产业实现产值56.5亿美元,其中出口40.5亿美元,占目前印度出口总额的1…...
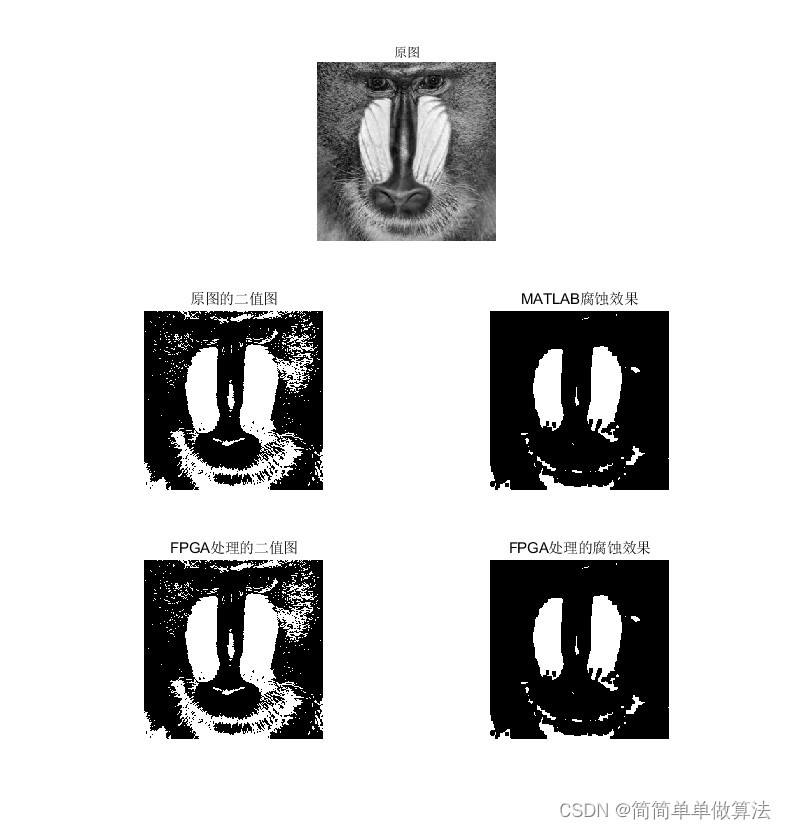
基于FPGA的图像形态学腐蚀算法实现,包括tb测试文件和MATLAB辅助验证
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 5.算法完整程序工程 1.算法运行效果图预览 将FPGA的仿真结果导入到MATLAB,结果如下所示: 2.算法运行软件版本 vivado2019.2 matlab2022a 3.部分核心程序 timescale 1ns / 1ps…...
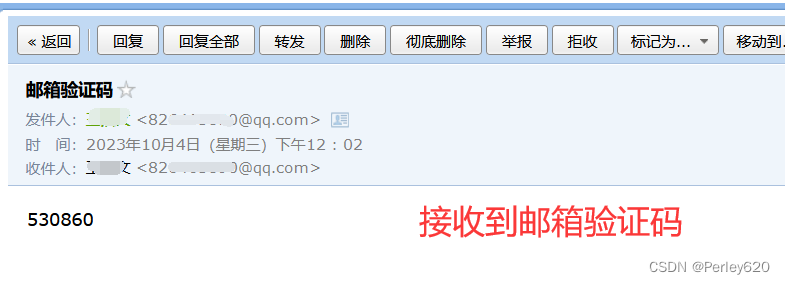
华为云云耀云服务器L实例评测|RabbitMQ的Docker版本安装 + 延迟插件安装 QQ邮箱和阿里云短信验证码的主题模式发送
前言 最近华为云云耀云服务器L实例上新,也搞了一台来玩,期间遇到各种问题,在解决问题的过程中学到不少和运维相关的知识。 本篇博客介绍RabbitMQ的Docker版本安装和配置,延迟插件的安装;结合QQ邮箱和阿里云短信验证码…...

解决Linux安装AppImage文件chrome-sandbox出错问题
问题产生 在Linux版Another Redis Desktop Manager的时候,打开无反应,使用命令行运行,出现了下面的报错信息: linux: FATAL:setuid_sandbox_host.cc(158)] The SUID sandbox helper binary was found, but is not configured co…...
Axios、SASS学习笔记
目录 前言 一、Axios基础认识 1、简介 2、相关文档 3、基本配置 4、基础快捷使用 二、Axios封装 1、公共配置文件 2、细化每个接口的配置 3、使用并发送请求 三、SASS 1、简介 2、相关文档 3、使用前奏 4、使用变量 5、嵌套规则 6、父级选择器标识 & 前言…...

开发工作中常用到的免费API分享
企业行政许可:通过公司名称/公司ID/注册号或社会统一信用代码获取企业行政许可信息,企业行政许可信息包括许可文件名称、决定许可机关、许可内容、决定日期/有效期自、截止日期/有效期至、数据来源等。企业作品著作权:通过公司名称/公司ID/注…...

外汇天眼:三大方法提高容错率——成功投资者的秘密策略!
容错率是什么? 虽然A股市场投资体验不佳,但相较于中概股市场的波动,A股投资者仍有幸福感。以中概股的代表,金龙指数ETF为例,仅一年多时间内从85.90元下跌至20.47元,跌幅高达76%。 然而,有一位…...
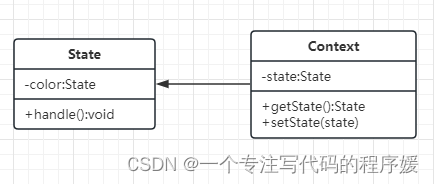
设计模式-状态模式
介绍 一个对象有状态变化每次状态变化都会触发一个逻辑不能总是用if else来控制 示例 交通信号灯不同颜色的变化 UML类图 传统UML类图 简化后的UML类图 代码演示 // 状态(红灯、绿灯、黄灯) class State {constructor(color) {this.color col…...
支持多种格式照片处理软件Lightroom Classic 2022 mac中文功能特点
Lightroom Classic 2022 mac是一款专业级数字图像处理软件,主要用于数字照片的后期处理和管理。它提供了丰富的工具和功能,可以帮助用户对照片进行调整、修饰、管理和分享。 Lightroom Classic 2022 mac软件功能和特点 RAW格式支持:Lightroo…...
UML简介
UML,全称为Unified Modeling Language(统一建模语言),是一种用于软件工程和系统设计的标准化建模语言。它提供了一套图形化的符号和标记,用于描述和表示软件系统、系统架构、流程、数据结构、行为和交互。UML的设计旨在…...
—— (AutoAnalyze)】)
【PostgreSQL内核学习(十七)—— (AutoAnalyze)】
AutoAnalyze 概述AutoAnaProcess 类AutoAnaProcess 函数AutoAnaProcess::executeSQLCommand 函数AutoAnaProcess::runAutoAnalyze 函数AutoAnaProcess::run 函数AutoAnaProcess::check_conditions 函数AutoAnaProcess::cancelAutoAnalyze 函数AutoAnaProcess::~AutoAnaProcess …...
用法说明)
C++中指向成员的指针运算符(.* 和 ->*)用法说明
目录 一 MSDN中使用说明1.1 语法1.2 备注 二 一个使用案例 一 MSDN中使用说明 1.1 语法 expression .* expression //直接成员解除引用运算符 expression –>* expression //间接成员解除引用运算符 1.2 备注 C中指向成员的指针运算符(.* 和 ->*)…...

ASUS华硕ZenBook灵耀X逍遥UXF3000E_UX363EA原装出厂预装Win11系统工厂模式安装包
下载链接:https://pan.baidu.com/s/1WLPp0e5AZErtX3bJIhTZMg?pwd2j7i 带有ASUS Recovery恢复功能、自带所有驱动、出厂主题壁纸、Office办公软件、MyASUS华硕电脑管家等预装程序 所需要工具:16G或以上的U盘(非必需) 文件格式:HDI,SWP,OFS,E…...

【数据结构】栈和队列-- OJ
目录 一 用队列实现栈 二 用栈实现队列 三 设计循环队列 四 有效的括号 一 用队列实现栈 225. 用队列实现栈 - 力扣(LeetCode) typedef int QDataType; typedef struct QueueNode {struct QueueNode* next;QDataType data; }QNode;typedef struct …...
访问Apache Tomcat的管理页面
配置访问Tomcat管理页面的用户名、密码、角色 Tomcat安装完成后,包含了一个管理应用,默认安装在 <Tomcat安装目录>/webapps/manager 例如: 要使用管理页面的功能,需要在conf/tomcat-users.xml文件中配置用户、密码及角色…...

企业组织内如何避免山头文化?
1,什么是山头文化 2,山头文化的危害 3,如何避免山头文化 01什么是山头文化 山头文化就是指某一组织中的一部分人员组成一个以共同利益为基础的集体,就如同古代占山头一样,在组织中形成一股无形的力量,其…...

【c#】线程Monitor.Wait和Monitor.Pulse使用
介绍 以一个简易版的数据库连接池的实现来说明一下 连接池的connection以队列来管理 getConnection的时候,如果队列中connection个数小于50,且暂时无可用的connection(个数为0或者peek看下头部需要先出那个元素还处于不可用状态)…...

GitLab平台安装中经典安装语句含义解析
yum -y install policycoreutils openssh-server openssh-clients postfix 这是一个Linux命令,用于使用YUM包管理器安装指定的软件包。下面是对这个命令各部分的解释: yum:这是一个Linux命令行工具,用于管理RPM(Red …...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

抖音增长新引擎:品融电商,一站式全案代运营领跑者
抖音增长新引擎:品融电商,一站式全案代运营领跑者 在抖音这个日活超7亿的流量汪洋中,品牌如何破浪前行?自建团队成本高、效果难控;碎片化运营又难成合力——这正是许多企业面临的增长困局。品融电商以「抖音全案代运营…...

现代密码学 | 椭圆曲线密码学—附py代码
Elliptic Curve Cryptography 椭圆曲线密码学(ECC)是一种基于有限域上椭圆曲线数学特性的公钥加密技术。其核心原理涉及椭圆曲线的代数性质、离散对数问题以及有限域上的运算。 椭圆曲线密码学是多种数字签名算法的基础,例如椭圆曲线数字签…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...

站群服务器的应用场景都有哪些?
站群服务器主要是为了多个网站的托管和管理所设计的,可以通过集中管理和高效资源的分配,来支持多个独立的网站同时运行,让每一个网站都可以分配到独立的IP地址,避免出现IP关联的风险,用户还可以通过控制面板进行管理功…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...