【PostgreSQL内核学习(十七)—— (AutoAnalyze)】
AutoAnalyze
- 概述
- AutoAnaProcess 类
- AutoAnaProcess 函数
- AutoAnaProcess::executeSQLCommand 函数
- AutoAnaProcess::runAutoAnalyze 函数
- AutoAnaProcess::run 函数
- AutoAnaProcess::check_conditions 函数
- AutoAnaProcess::cancelAutoAnalyze 函数
- AutoAnaProcess::~AutoAnaProcess 函数
声明:本文的部分内容参考了他人的文章。在编写过程中,我们尊重他人的知识产权和学术成果,力求遵循合理使用原则,并在适用的情况下注明引用来源。
本文主要参考了《PostgresSQL数据库内核分析》一书,OpenGauss1.1.0 的开源代码和《OpenGauss数据库源码解析》一书以及OpenGauss社区学习文档
概述
AutoAnalyze 是一种自动统计信息收集和优化功能,用于数据库管理系统中。其主要目的是在数据库中定期收集表的统计信息,以便查询优化器能够生成更有效的执行计划。以下是有关 AutoAnalyze 的详细信息:
- 自动统计信息收集: AutoAnalyze 会自动定期检查数据库中的表,并确定哪些表需要更新统计信息。这些统计信息包括行数、唯一值数量、最小值、最大值等,这些信息对于查询优化非常重要。
- 查询优化: 收集的统计信息可帮助查询优化器更好地估算查询成本,从而选择更优的执行计划。这可以提高查询性能,减少查询的执行时间。
- 避免过度分析: AutoAnalyze 会智能地选择哪些表需要进行统计信息收集,以避免不必要的分析。它通常会关注哪些表的数据发生了变化,以及哪些表的统计信息可能已经过时。
- 自动化: 一旦启用,AutoAnalyze 会自动在后台执行,无需手动干预。这使得数据库管理员的工作更加轻松,不需要手动分析每个表。
此外,我们先前学习过 ANALYZE, 该命令是一个手动命令,它允许数据库管理员明确指示系统去收集特定表的统计信息。相比之下,AutoAnalyze 是自动执行的 ,系统会自动选择需要分析的表,并在后台进行统计信息收集。
AutoAnalyze 通常用于处理大量表,以确保它们的统计信息保持最新。而 ANALYZE 通常用于手动分析那些特殊需要或数据分布变化较大的表。本文,我们则来学习 AutoAnalyze 的相关源码实现。
AutoAnaProcess 类
AutoAnaProcess 类用于支持自动分析(Auto-Analyze)功能,该功能用于执行表的自动统计信息收集和优化。该类用于管理和执行自动分析操作,它包含了与数据库连接、SQL 查询命令的执行以及资源管理相关的方法和属性。
AutoAnaProcess 类函数源码如下:(路径:src/include/optimizer/autoanalyzer.h)
/* Auto-Analyze */
// 自动分析进程类,用于处理自动分析操作
class AutoAnaProcess : public BaseObject {
public:// 构造函数,接收一个关系对象作为参数AutoAnaProcess(Relation rel);// 析构函数~AutoAnaProcess();// 静态方法,用于执行自动分析操作,接收一个关系对象作为参数static bool runAutoAnalyze(Relation rel);// 静态方法,用于取消自动分析操作static void cancelAutoAnalyze();protected:// PostgreSQL数据库连接对象PGconn* m_pgconn;// PostgreSQL查询结果对象PGresult* m_res;// 存储SQL查询命令的列表List* m_query;private:// 静态方法,用于检查自动分析的条件,接收一个关系对象作为参数static bool check_conditions(Relation rel);// 执行自动分析操作的私有方法bool run();// 执行SQL查询命令的私有方法,接收一个SQL命令字符串作为参数bool executeSQLCommand(char* cmd);// 清理资源的静态方法static void tear_down();
};
在这个类中,包含了类的构造函数、析构函数、runAutoAnalyze 静态方法、cancelAutoAnalyze 静态方法以及一些需要用到的属性和方法。接下来我们分别来看一看该类中这些相关函数的实现吧。
AutoAnaProcess 函数
AutoAnaProcess 是AutoAnaProcess 类的构造函数,主要用于初始化自动分析处理对象的属性和设置需要执行的自动分析相关的 SQL 命令。该函数的执行过程如下所示:
- AutoAnaProcess::AutoAnaProcess(Relation rel) : m_pgconn(NULL), m_res(NULL):
- 这是构造函数的定义,接受一个名为Relation rel的参数,表示要执行自动分析的数据库表。
- m_pgconn 和 m_res 是 AutoAnaProcess 类的私有属性,用于管理与数据库连接和查询结果相关的信息。在构造函数中,它们都被初始化为 NULL。
- m_query = NIL;:
- m_query 是一个列表,用于存储将要执行的 SQL 查询命令。在构造函数中,它被初始化为空列表。
- StringInfoData str_lockwait_timeout;:
- str_lockwait_timeout 是一个 StringInfoData 结构,用于存储关于锁等待超时的配置信息。
- initStringInfo(&str_lockwait_timeout);:
- initStringInfo 是一个宏,用于初始化 str_lockwait_timeout,使其可以存储字符串信息。
- appendStringInfo(&str_lockwait_timeout, “set lockwait_timeout=%d ;”, AUTOANALYZE_LOCKWAIT_TIMEOUT);:
- appendStringInfo 用于将字符串 “set lockwait_timeout=某个值 ;” 添加到 str_lockwait_timeout 中,该值由常量 AUTOANALYZE_LOCKWAIT_TIMEOUT 决定。这个 SQL 命令用于设置锁等待超时时间。
- m_query = lappend(m_query, str_lockwait_timeout.data);:
- 这一行代码将 str_lockwait_timeout 中的 SQL 命令添加到 m_query 列表中。
- 类似的过程重复了两次,用于设置另外两个配置参数:
- str_allow_concurrent_tuple_update 用于设置是否允许并发元组更新。
- str_max_query_retry_times 用于设置最大查询重试次数。
- 最后,通过以下代码设置了执行自动分析的 SQL 命令:
StringInfoData str_analyze_command; initStringInfo(&str_analyze_command); appendStringInfo(&str_analyze_command,"analyze %s.%s ;",quote_identifier(get_namespace_name(rel->rd_rel->relnamespace)),quote_identifier(NameStr(rel->rd_rel->relname))); m_query = lappend(m_query, str_analyze_command.data);
- 这部分代码构建了一个 analyze 命令,该命令用于执行自动分析操作。它包括了要分析的表的模式名和表名,通过调用 quote_identifier 函数来确保这些标识符的正确引用。
- 最后,这个 SQL 命令被添加到 m_query 列表中,以便后续执行。
函数源码如下所示:(路径:src/gausskernel/optimizer/util/autoanalyzer.cpp)
/* Constructor */
// 构造函数
AutoAnaProcess::AutoAnaProcess(Relation rel) : m_pgconn(NULL), m_res(NULL)
{m_query = NIL; // 初始化查询命令列表为一个空列表StringInfoData str_lockwait_timeout; // 创建一个用于存储锁等待超时配置的字符串信息结构initStringInfo(&str_lockwait_timeout); // 初始化字符串信息结构// 向字符串信息结构中追加锁等待超时的设置命令,AUTOANALYZE_LOCKWAIT_TIMEOUT是一个常量,表示锁等待超时的时间appendStringInfo(&str_lockwait_timeout, "set lockwait_timeout=%d ;", AUTOANALYZE_LOCKWAIT_TIMEOUT);m_query = lappend(m_query, str_lockwait_timeout.data); // 将设置命令添加到查询命令列表中StringInfoData str_allow_concurrent_tuple_update; // 创建一个用于存储是否允许并发元组更新的字符串信息结构initStringInfo(&str_allow_concurrent_tuple_update); // 初始化字符串信息结构// 向字符串信息结构中追加允许并发元组更新的设置命令appendStringInfo(&str_allow_concurrent_tuple_update, "set allow_concurrent_tuple_update='off';");m_query = lappend(m_query, str_allow_concurrent_tuple_update.data); // 将设置命令添加到查询命令列表中StringInfoData str_max_query_retry_times; // 创建一个用于存储最大查询重试次数的字符串信息结构initStringInfo(&str_max_query_retry_times); // 初始化字符串信息结构// 向字符串信息结构中追加最大查询重试次数的设置命令appendStringInfo(&str_max_query_retry_times, "set max_query_retry_times=0;");m_query = lappend(m_query, str_max_query_retry_times.data); // 将设置命令添加到查询命令列表中StringInfoData str_analyze_command; // 创建一个用于存储执行自动分析的SQL命令的字符串信息结构initStringInfo(&str_analyze_command); // 初始化字符串信息结构// 构建执行自动分析的SQL命令,包括要分析的表的模式名和表名,通过quote_identifier函数确保标识符的正确引用appendStringInfo(&str_analyze_command,"analyze %s.%s ;",quote_identifier(get_namespace_name(rel->rd_rel->relnamespace)),quote_identifier(NameStr(rel->rd_rel->relname)));m_query = lappend(m_query, str_analyze_command.data); // 将执行命令添加到查询命令列表中
}
AutoAnaProcess::executeSQLCommand 函数
executeSQLCommand 函数的主要作用是执行传入的 SQL 命令字符串,并返回执行结果的布尔值。它还会记录执行成功或失败的信息,并在执行期间允许取消或终止请求的处理。
函数首先保存当前线程的中断状态,以允许在等待期间处理取消或终止请求,然后执行 SQL 查询,检查执行结果的状态,如果成功则记录成功信息,如果失败则记录错误信息,并最后返回执行结果的布尔值。这个函数通常用于执行数据库操作,如自动分析(Auto-Analyze)等。
函数源码如下:(路径:src/gausskernel/optimizer/util/autoanalyzer.cpp)
bool AutoAnaProcess::executeSQLCommand(char* queryString)
{// 初始化执行结果标志为falsebool result = false;// 保存原始的ImmediateInterruptOK标志,用于在等待期间处理取消或终止请求bool ImmediateInterruptOK_Old = t_thrd.int_cxt.ImmediateInterruptOK;/* 允许在等待期间处理取消或终止请求 */t_thrd.int_cxt.ImmediateInterruptOK = true;// 检查是否有中断请求CHECK_FOR_INTERRUPTS();// 执行 SQL 查询并将结果存储在m_res中m_res = PQexec(m_pgconn, queryString);// 恢复原始的ImmediateInterruptOK标志t_thrd.int_cxt.ImmediateInterruptOK = ImmediateInterruptOK_Old;// 检查执行结果的状态if (PQresultStatus(m_res) != PGRES_COMMAND_OK) {// 如果执行失败,记录失败信息和错误信息elog(DEBUG2, "[AUTO-ANALYZE] autoanalyze failed: %s, error: %s", queryString, PQerrorMessage(m_pgconn));} else {// 如果执行成功,设置执行结果标志为true,并记录成功信息result = true;elog(DEBUG2, "[AUTO-ANALYZE] autoanalyze success: %s", queryString);}// 清理执行结果对象PQclear(m_res);m_res = NULL;// 返回执行结果的布尔值return result;
}
以下是 ExecutorRun 函数的执行过程的解释:
- 首先,函数接收一个字符串参数 queryString,该参数包含要执行的 SQL 命令。
- 函数开始时,初始化一个布尔型变量 result,用于表示 SQL 命令的执行结果,默认值为 false。
- 接着,函数保存当前线程的 ImmediateInterruptOK 标志的原始值,并将其设置为 true。这允许在等待期间处理取消或终止请求。
- 然后,函数调用 CHECK_FOR_INTERRUPTS() 检查是否有中断请求,以确保可以响应取消请求。
- 接下来,函数使用 PQexec 函数执行传入的 queryString,并将执行结果存储在成员变量 m_res 中。这个结果可能是执行成功的命令返回的信息,或者执行失败的错误信息。
- 函数恢复原始的 ImmediateInterruptOK 标志值,以确保不再处理取消或终止请求。
- 接着,函数检查执行结果的状态。如果执行失败,函数记录失败信息和错误信息到日志中。
- 如果执行成功,函数将 result 设置为 true,表示执行成功,并记录成功信息到日志中。
- 最后,函数清理执行结果对象 m_res,将其置为 NULL。
- 最终,函数返回 result,表示 SQL 命令的执行结果,如果执行成功,则为 true;如果执行失败,则为 false。
AutoAnaProcess::runAutoAnalyze 函数
runAutoAnalyze 函数的主要作用是触发自动分析(Auto-Analyze)过程,用于更新数据库中表的统计信息以优化查询性能。它检查是否满足自动分析的条件,获取可用的自动分析进程,执行自动分析,并记录自动分析的执行时间。函数的功能包括条件检查、进程管理、自动分析的执行,以及记录自动分析时间信息。
runAutoAnalyze 函数非常重要,因为它实现了数据库自动分析(Auto-Analyze)的关键逻辑。自动分析是数据库优化的一部分,它负责监测表的数据变化并定期进行统计信息的收集,以便查询优化器可以更好地选择执行计划。通过这个函数,数据库能够自动化地维护和更新这些统计信息,从而保持查询性能的稳定性和高效性。因此,该函数的正确执行对于数据库的性能和稳定性至关重要。
runAutoAnalyze 函数源码如下所示:(路径:src/gausskernel/optimizer/util/autoanalyzer.cpp)
bool AutoAnaProcess::runAutoAnalyze(Relation rel)
{// 获取自动分析进程是否可用的标志bool getProcess = false;// 记录自动分析的执行结果bool result = false;// 记录自动分析开始的时间TimestampTz start_time = 0;// 如果需要在 EXPLAIN ANALYZE 中显示自动分析的执行时间if (u_sess->analyze_cxt.autoanalyze_timeinfo) {// 获取当前时间作为自动分析的开始时间start_time = GetCurrentTimestamp();}// 第一步:检查是否满足自动分析的条件if (!check_conditions(rel)) {// 如果不满足条件,记录日志并返回执行结果为失败elog(DEBUG2, "[AUTO-ANALYZE] 检查自动分析条件失败: 表 \"%s\"", NameStr(rel->rd_rel->relname));return result;}// 第二步:获取可用的自动分析进程(void)LWLockAcquire(AutoanalyzeLock, LW_EXCLUSIVE);if (autoAnalyzeFreeProcess > 0) {// 如果存在可用进程,设置标志为可获取进程并减少可用进程数getProcess = true;autoAnalyzeFreeProcess--;}(void)LWLockRelease(AutoanalyzeLock);// 如果没有可用进程,记录日志并返回执行结果为失败if (!getProcess) {elog(DEBUG2, "[AUTO-ANALYZE] 没有可用的自动分析进程");return result;}// 第三步:执行自动分析Assert(u_sess->analyze_cxt.autoanalyze_process == NULL);// 创建自动分析进程u_sess->analyze_cxt.autoanalyze_process = New(CurrentMemoryContext) AutoAnaProcess(rel);// 执行自动分析,并记录执行结果result = u_sess->analyze_cxt.autoanalyze_process->run();// 清理自动分析进程资源tear_down();// 第四步:释放可用自动分析进程LWLockAcquire(AutoanalyzeLock, LW_EXCLUSIVE);autoAnalyzeFreeProcess++;LWLockRelease(AutoanalyzeLock);// 第五步:如果需要,在 EXPLAIN ANALYZE 中记录自动分析的执行时间if (u_sess->analyze_cxt.autoanalyze_timeinfo && result) {// 计算自动分析的执行时间long secs;long msecs;int usecs;TimestampDifference(start_time, GetCurrentTimestamp(), &secs, &usecs);msecs = usecs / 1000L;msecs = secs * 1000 + msecs;usecs = usecs % 1000;// 将自动分析的执行时间信息添加到相应的字符串中MemoryContext oldcontext = MemoryContextSwitchTo(u_sess->temp_mem_cxt);appendStringInfo(u_sess->analyze_cxt.autoanalyze_timeinfo,"\"%s.%s\" %ld.%03dms ",get_namespace_name(rel->rd_rel->relnamespace),NameStr(rel->rd_rel->relname),msecs,usecs);(void)MemoryContextSwitchTo(oldcontext);}// 返回自动分析的执行结果return result;
}
以下是函数的执行过程简述:
- 首先,函数接收一个参数 rel,表示一个关系(表)。
- 函数初始化了一些局部变量,包括 getProcess(用于表示是否获取到了可用的 Auto-Analyze 进程)、result(用于表示 Auto-Analyze 的执行结果是否成功)、start_time(用于记录 Auto-Analyze 开始时间)。
- 如果当前会话的上下文(
u_sess->analyze_cxt.autoanalyze_timeinfo)允许记录自动分析时间信息,函数记录 Auto-Analyze 的开始时间。- 接着,函数调用 check_conditions(rel) 检查是否满足执行自动分析的条件,如果不满足条件,则函数返回执行结果 result 为 false。
- 如果条件满足,函数尝试获取一个可用的 Auto-Analyze 进程。它首先获取了自动分析锁(AutoanalyzeLock),并检查是否还有可用的 Auto-Analyze 进程。如果有可用的进程,则将 getProcess 设为 true,并减少可用进程的数量。
- 如果没有可用的 Auto-Analyze 进程,函数返回执行结果 result 为 false,并记录日志,表示没有可用的进程。
- 如果成功获取到 Auto-Analyze 进程,函数进入执行 Auto-Analyze 的步骤。首先,它确保当前会话的 autoanalyze_process 为空,然后创建一个新的 AutoAnaProcess 实例,传入 rel,并执行 Auto-Analyze。
- 执行完 Auto-Analyze 后,函数执行 tear_down(),清理资源。
- 最后,函数释放 AutoanalyzeLock,增加可用 Auto-Analyze 进程的数量,并在成功执行 Auto-Analyze 且允许记录自动分析时间信息的情况下,记录 Auto-Analyze 的耗时信息到
u_sess->analyze_cxt.autoanalyze_timeinfo。- 函数返回执行结果 result,表示 Auto-Analyze 的执行结果,如果执行成功,则为 true;如果执行失败或没有可用进程,则为 false。
AutoAnaProcess::run 函数
AutoAnaProcess::run 函数的作用是执行自动分析操作,其功能包括建立数据库连接、执行一系列自动分析操作的查询命令、记录执行结果,并最终返回操作是否成功的结果。其函数源码如下:(路径:src/gausskernel/optimizer/util/autoanalyzer.cpp)
bool AutoAnaProcess::run()
{char conninfo[CHAR_BUF_SIZE]; // 存储数据库连接信息的字符数组int ret; // 保存函数返回值bool result = false; // 用于表示自动分析是否成功ListCell* lc = NULL; // 用于遍历查询命令列表// 遍历自动分析操作的查询命令列表foreach (lc, m_query) {char* cmd = (char*)lfirst(lc); // 获取当前查询命令字符串// 记录自动分析操作的开始elog(DEBUG2, "[AUTO-ANALYZE] autoanalyze start: %s", cmd);}// 构建数据库连接信息字符串ret = snprintf_s(conninfo,sizeof(conninfo),sizeof(conninfo) - 1,"dbname=%s port=%d application_name='auto_analyze' enable_ce=1 ",get_and_check_db_name(u_sess->proc_cxt.MyDatabaseId, true), // 获取当前数据库名g_instance.attr.attr_network.PostPortNumber); // 获取数据库端口号securec_check_ss_c(ret, "\0", "\0"); // 安全检查// 连接数据库m_pgconn = PQconnectdb(conninfo);// 检查数据库连接是否成功if (PQstatus(m_pgconn) == CONNECTION_OK) {foreach (lc, m_query) {char* cmd = (char*)lfirst(lc); // 获取当前查询命令字符串// 执行自动分析操作的查询命令result = executeSQLCommand(cmd);if (!result) {break;}}} else {// 记录连接数据库失败的信息elog(DEBUG2, "[AUTO-ANALYZE] connection to database failed: %s", PQerrorMessage(m_pgconn));}// 清理资源PQclear(m_res); // 清理查询结果PQfinish(m_pgconn); // 关闭数据库连接m_res = NULL;m_pgconn = NULL;return result; // 返回自动分析操作是否成功的结果
}
这个函数的作用是执行自动分析操作,其执行过程如下:
- 函数开始时,遍历存储在 m_query 列表中的查询命令,将每个命令打印到日志中,以便跟踪执行进度。
- 然后,构建数据库连接信息字符串 conninfo,该字符串包括数据库名、端口号、应用程序名称以及其他参数。
- 使用 PQconnectdb 函数基于构建好的连接信息建立与数据库的连接(m_pgconn)。
- 检查与数据库的连接状态是否正常(
PQstatus(m_pgconn) == CONNECTION_OK)。- 如果连接成功,继续遍历 m_query 列表中的每个查询命令,依次执行这些命令,同时记录执行结果。
- 如果某个查询命令执行失败(executeSQLCommand 返回 false),则中断执行,并将 result 设置为 false。
- 如果与数据库的连接失败,将错误信息打印到日志中。
- 最后,清理资源,包括释放查询结果对象(PQclear(m_res))、关闭与数据库的连接(PQfinish(m_pgconn)),并将 m_res 和 m_pgconn 置为 NULL。
- 返回执行的结果,如果所有查询都成功执行,则 result 为 true,否则为 false。
AutoAnaProcess::check_conditions 函数
在 AutoAnaProcess::runAutoAnalyze 函数中采用 AutoAnaProcess::check_conditions 函数检查是否满足自动分析的条件。该函数主要用于确保执行自动分析的用户有足够的权限,并且不分析临时表以及在只读模式下的表。如果满足这些条件,函数返回 true,允许执行自动分析操作。否则,返回 false,不执行自动分析。
AutoAnaProcess::runAutoAnalyze 函数源码如下:(路径:src/gausskernel/optimizer/util/autoanalyzer.cpp)
/** check_conditions* 检查执行自动分析的用户权限以及表是否为临时表*/
bool AutoAnaProcess::check_conditions(Relation rel)
{/* 如果传入的关系(表)是无效的,直接返回false */if (!rel)return false;/* 如果传入的关系是临时表,直接返回false */if (RelationIsLocalTemp(rel))return false;/** 如果关系处于只读模式(非数据重分布的情况),我们跳过对该关系的分析。*/if (!u_sess->attr.attr_sql.enable_cluster_resize && RelationInClusterResizingReadOnly(rel))return false;// 使用ACL检查当前用户是否有执行VACUUM操作的权限AclResult aclresult = pg_class_aclcheck(RelationGetRelid(rel), GetUserId(), ACL_VACUUM);if (aclresult != ACLCHECK_OK && !(pg_class_ownercheck(RelationGetRelid(rel), GetUserId()) ||(pg_database_ownercheck(u_sess->proc_cxt.MyDatabaseId, GetUserId()) && !rel->rd_rel->relisshared))) {return false;}return true; // 如果所有条件都满足,返回true表示可以执行自动分析
}
以下是函数的执行过程简述:
- 首先,函数接收一个名为 rel 的参数,这个参数是一个数据库表(关系)的指针,用于表示要进行自动分析的表。
- 函数开始执行时,首先检查传入的表是否为无效表,如果是无效表(即空指针),则直接返回 false,表示不满足执行自动分析的条件。
- 接下来,函数检查传入的表是否为临时表,如果是临时表,则同样返回 false,因为临时表通常不需要进行自动分析。
- 如果传入的表不是临时表,函数会继续检查是否处于只读模式。如果表处于只读模式,通常意味着它是分布式数据库中的只读副本,不需要进行自动分析。如果在只读模式下,函数也会返回 false。
- 最后,函数会进行访问控制列表(ACL)检查,以确保当前用户具有执行 VACUUM 操作的权限。如果用户没有这个权限,并且用户不是表的所有者,也不是数据库的所有者(只有在表不是共享表的情况下),则函数返回 false。
- 如果所有条件都满足,即表有效、不是临时表、不处于只读模式,且用户有足够的权限,函数将返回 true,表示可以执行自动分析操作。
AutoAnaProcess::cancelAutoAnalyze 函数
AutoAnaProcess::cancelAutoAnalyze 函数的作用是取消正在执行的自动分析过程。它通过释放相关资源、增加可用的自动分析进程数量,以及清除执行计划信息来中止自动分析,从而管理和控制自动分析的执行。
cancelAutoAnalyze 函数源码如下:(路径:src/gausskernel/optimizer/util/autoanalyzer.cpp)
void AutoAnaProcess::cancelAutoAnalyze()
{/* 如果当前存在正在执行的自动分析进程 */if (u_sess->analyze_cxt.autoanalyze_process != NULL) {/* 执行资源清理操作 */tear_down();/* 释放自动分析进程资源,增加可用的自动分析进程数量 */(void)LWLockAcquire(AutoanalyzeLock, LW_EXCLUSIVE);autoAnalyzeFreeProcess++;LWLockRelease(AutoanalyzeLock);}/* 清除自动分析的执行计划信息,如果存在的话 */if (u_sess->analyze_cxt.autoanalyze_timeinfo != NULL) {/* 释放执行计划信息的内存 */pfree_ext(u_sess->analyze_cxt.autoanalyze_timeinfo->data);pfree_ext(u_sess->analyze_cxt.autoanalyze_timeinfo);u_sess->analyze_cxt.autoanalyze_timeinfo = NULL;}
}
该函数用于取消正在执行的自动分析过程,其执行过程如下:
- 首先检查是否存在正在执行的自动分析进程(
u_sess->analyze_cxt.autoanalyze_process不为空)。- 如果存在正在执行的自动分析进程,执行资源清理操作(tear_down 函数),包括关闭与数据库的连接等。
- 释放自动分析进程资源,并增加可用的自动分析进程数量(通过获取和释放锁 AutoanalyzeLock 来实现并发安全性)。
- 接着,检查是否存在自动分析的执行计划信息(
u_sess->analyze_cxt.autoanalyze_timeinfo不为空)。- 如果存在执行计划信息,释放执行计划信息的内存,将其清空。
AutoAnaProcess::~AutoAnaProcess 函数
~AutoAnaProcess为析构函数,用于释放AutoAnaProcess 对象所占用的资源,包括关闭数据库连接、清理查询结果、释放查询命令列表的资源,并将相关指针和列表重置为空或 NULL,以确保资源的正确释放和避免内存泄漏。函数源码如下:(路径:src/gausskernel/optimizer/util/autoanalyzer.cpp)
AutoAnaProcess::~AutoAnaProcess()
{if (t_thrd.utils_cxt.CurrentResourceOwner == NULL) {m_res = NULL;}PQclear(m_res); // 清理查询结果PQfinish(m_pgconn); // 关闭数据库连接if (m_query != NIL) {list_free_deep(m_query); // 递归释放查询命令列表的资源}m_pgconn = NULL; // 重置数据库连接指针m_res = NULL; // 重置查询结果指针m_query = NIL; // 重置查询命令列表
}
相关文章:
—— (AutoAnalyze)】)
【PostgreSQL内核学习(十七)—— (AutoAnalyze)】
AutoAnalyze 概述AutoAnaProcess 类AutoAnaProcess 函数AutoAnaProcess::executeSQLCommand 函数AutoAnaProcess::runAutoAnalyze 函数AutoAnaProcess::run 函数AutoAnaProcess::check_conditions 函数AutoAnaProcess::cancelAutoAnalyze 函数AutoAnaProcess::~AutoAnaProcess …...
用法说明)
C++中指向成员的指针运算符(.* 和 ->*)用法说明
目录 一 MSDN中使用说明1.1 语法1.2 备注 二 一个使用案例 一 MSDN中使用说明 1.1 语法 expression .* expression //直接成员解除引用运算符 expression –>* expression //间接成员解除引用运算符 1.2 备注 C中指向成员的指针运算符(.* 和 ->*)…...

ASUS华硕ZenBook灵耀X逍遥UXF3000E_UX363EA原装出厂预装Win11系统工厂模式安装包
下载链接:https://pan.baidu.com/s/1WLPp0e5AZErtX3bJIhTZMg?pwd2j7i 带有ASUS Recovery恢复功能、自带所有驱动、出厂主题壁纸、Office办公软件、MyASUS华硕电脑管家等预装程序 所需要工具:16G或以上的U盘(非必需) 文件格式:HDI,SWP,OFS,E…...

【数据结构】栈和队列-- OJ
目录 一 用队列实现栈 二 用栈实现队列 三 设计循环队列 四 有效的括号 一 用队列实现栈 225. 用队列实现栈 - 力扣(LeetCode) typedef int QDataType; typedef struct QueueNode {struct QueueNode* next;QDataType data; }QNode;typedef struct …...
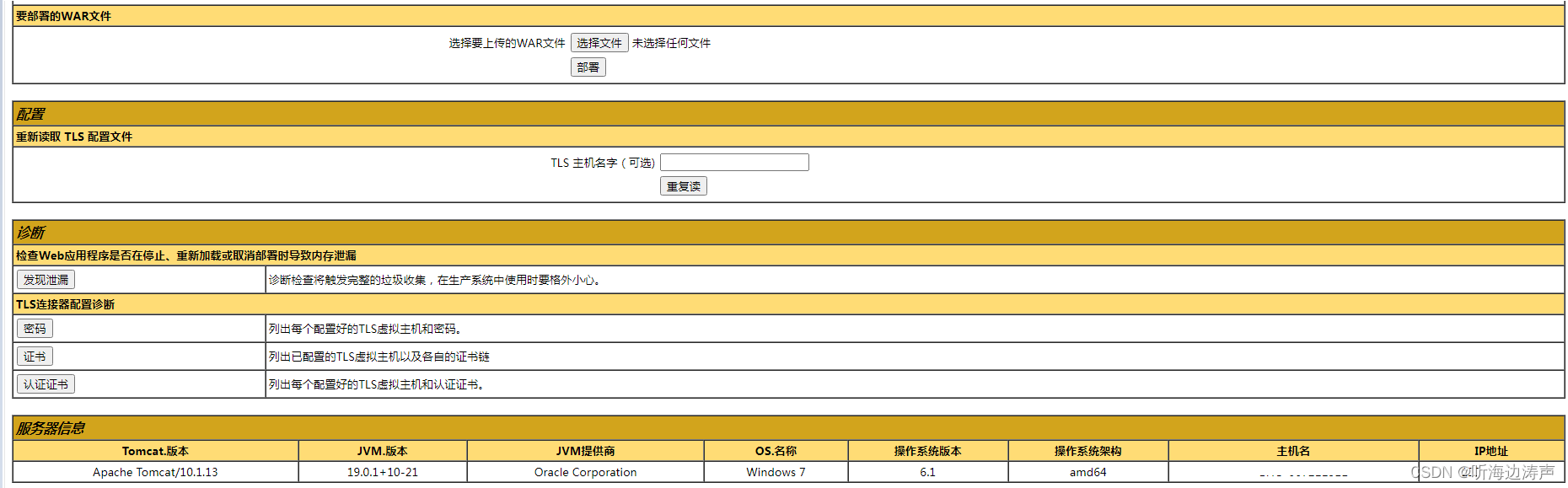
访问Apache Tomcat的管理页面
配置访问Tomcat管理页面的用户名、密码、角色 Tomcat安装完成后,包含了一个管理应用,默认安装在 <Tomcat安装目录>/webapps/manager 例如: 要使用管理页面的功能,需要在conf/tomcat-users.xml文件中配置用户、密码及角色…...

企业组织内如何避免山头文化?
1,什么是山头文化 2,山头文化的危害 3,如何避免山头文化 01什么是山头文化 山头文化就是指某一组织中的一部分人员组成一个以共同利益为基础的集体,就如同古代占山头一样,在组织中形成一股无形的力量,其…...

【c#】线程Monitor.Wait和Monitor.Pulse使用
介绍 以一个简易版的数据库连接池的实现来说明一下 连接池的connection以队列来管理 getConnection的时候,如果队列中connection个数小于50,且暂时无可用的connection(个数为0或者peek看下头部需要先出那个元素还处于不可用状态)…...

GitLab平台安装中经典安装语句含义解析
yum -y install policycoreutils openssh-server openssh-clients postfix 这是一个Linux命令,用于使用YUM包管理器安装指定的软件包。下面是对这个命令各部分的解释: yum:这是一个Linux命令行工具,用于管理RPM(Red …...

湘潭大学 2023年下学期《C语言》作业0x03-循环1 XTU OJ 1094,1095,1096,1112,1113
第一题 #include<stdio.h>int main() {int t;int count1;scanf("%d",&t);while(t--){int a,b,c;scanf("%d%d",&a,&b);cab;printf("Case %d: %d\n",count,c);count;}return 0; } 记住多样例输入的模板,熟悉计数器…...

【Linux系统满足产品实时性需求】
一、背景: 应用实时性:应用程序1以固定周期执行实时算法; 应用程序2以固定周期,执行串口收发; 驱动实时性:驱动sdio接口,实现与FPGA数据交互,实现串口数据收发。 二、实时性保证&…...
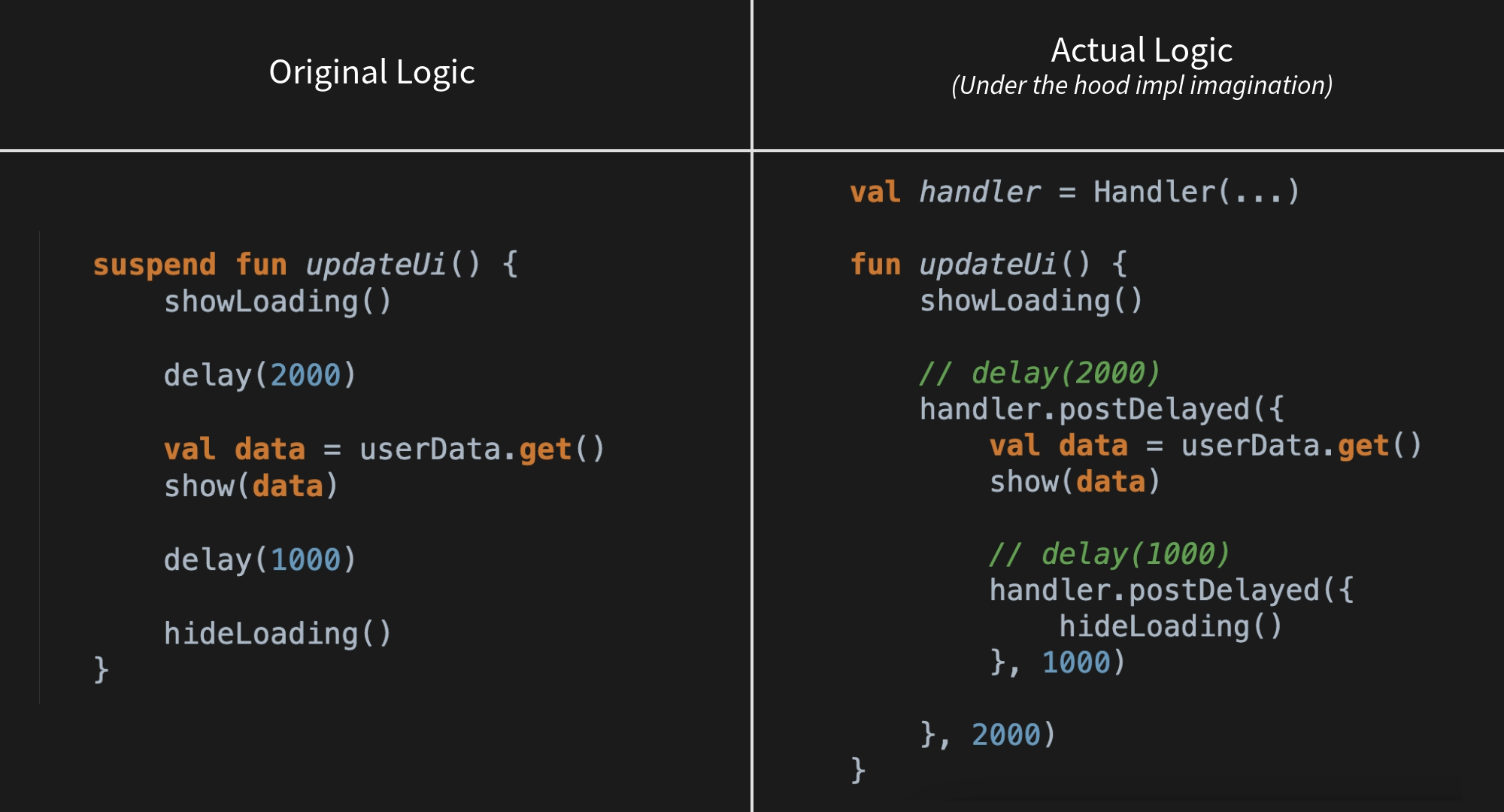
不用休眠的 Kotlin 并发:深入对比 delay() 和 sleep()
本文翻译自: https://blog.shreyaspatil.dev/sleepless-concurrency-delay-vs-threadsleep 毫无疑问,Kotlin 语言中的协程 Coroutine 极大地帮助了开发者更加容易地处理异步编程。该特性中封装的诸多高效 API,可以确保开发者花费更小的精力去…...

在Ubuntu中批量创建用户
一、背景知识 在Linux操作系统中创建新用户可以使用useradd或adduser命令。 使用useradd命令创建用户时,不会在/home目录下创建用户文件夹,需要用户自己指定主目录和bash目录的位置。同时,创建的用户没有设置密码,无法进行登录&a…...
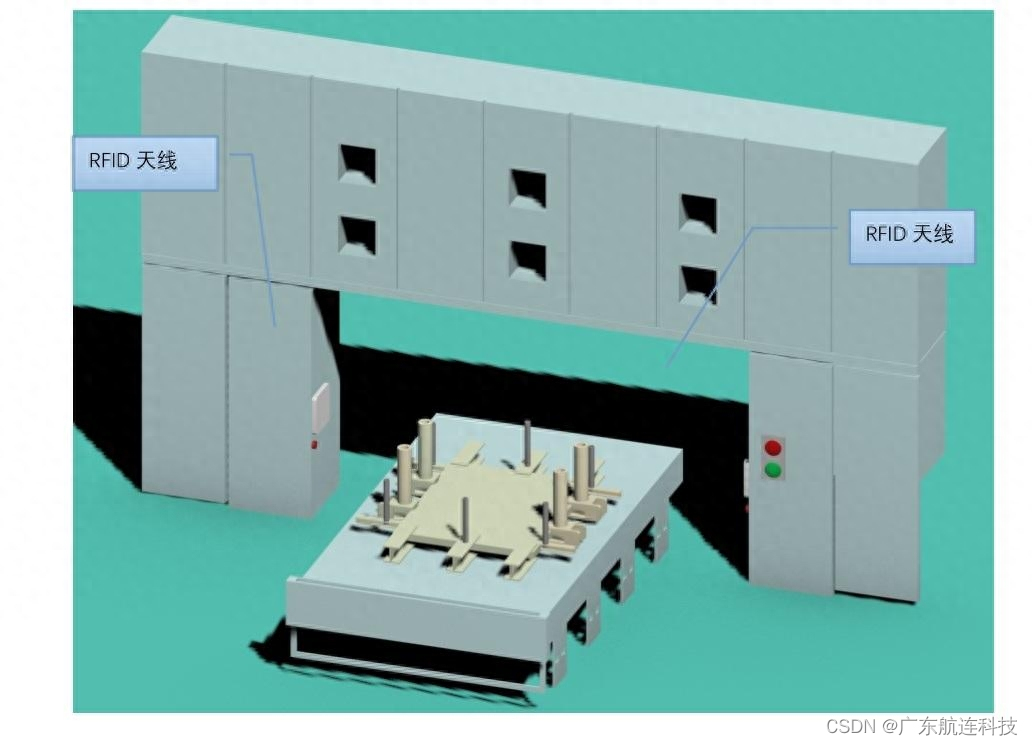
汽车冲压车间的RFID技术设计解决方案
一、RFID技术的基本原理 RFID技术是一种利用非接触式自动识别的技术,通过将RFID标签放置在被识别物品上,并使用RFID读写器对标签进行扫描和识别,实现对物品的自动识别和追踪。RFID标签分为被动式和主动式两种。被动式标签无内置电源…...
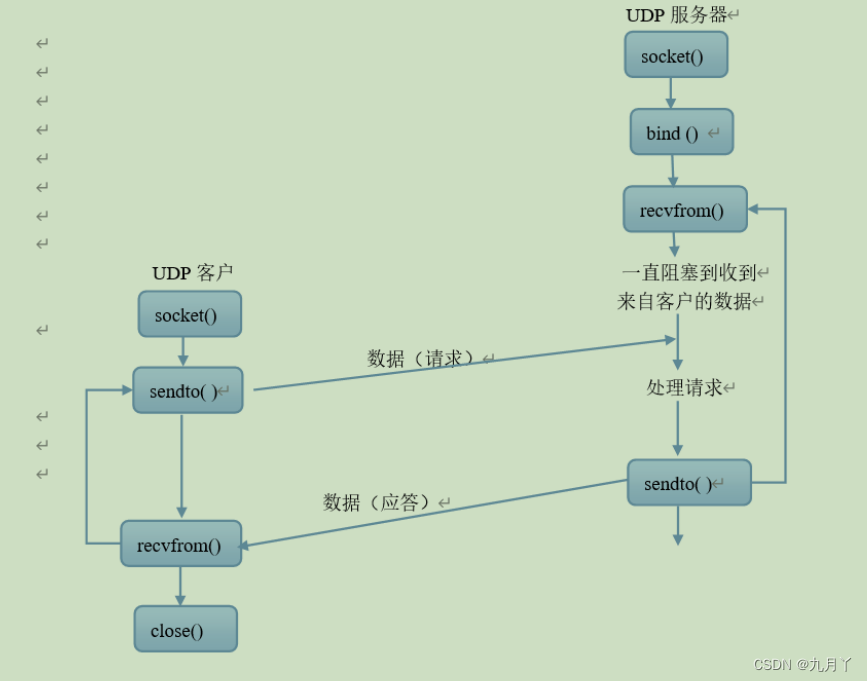
TCP 和UDP通信流程
TCP 通信流程 根据上图可以看到,TCP 服务器和客户端通信分为 TCP 服务端和客户端,需要先建立服务 端然后再建立客户端与之连接进行数据交互。 服务端编程步骤: 1.使用 socket 创建流式套接字 2.使用 bind 绑定将服务器绑定到 IP 3.listen…...
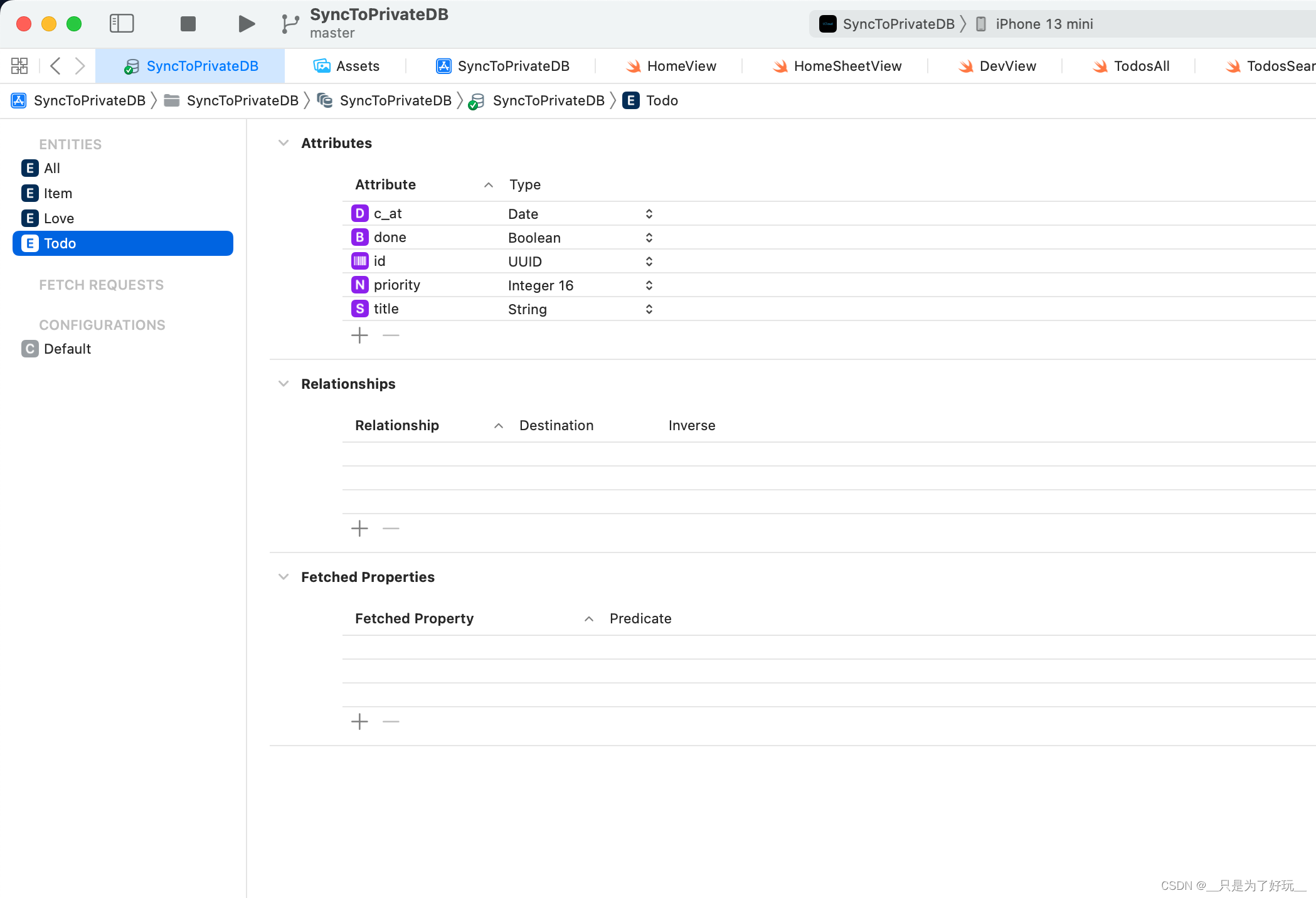
Swift SwiftUI CoreData 过滤数据 1
Xcode: Version 14.3.1 (14E300c) iOS: 16 预览: Code: import SwiftUI import CoreDatastruct TodosSearch: View {State private var search_title "测试"FetchRequest var todos_search: FetchedResults<Todo>init() {let request: NSFetchReq…...
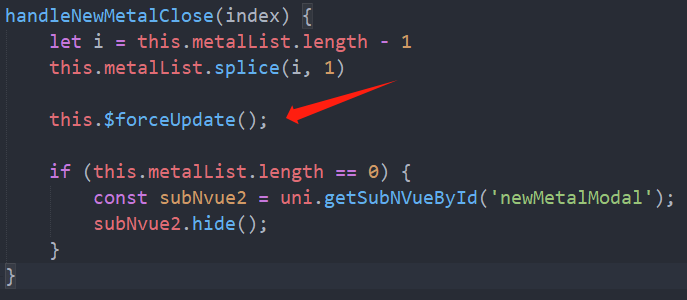
【uniapp】subnvue组件数据更新视图未更新问题
背景 : 页面中的弹窗使用了subnvue来写, 根据数据依次展示一个一个的弹窗, 点击"关闭"按钮关闭当前弹窗, 显示下一个弹窗 问题 : 当点击关闭时( 使用的splice() ), 数据更新了 , 而视图没有更新, 实际上splice() 是不仅更新数据, 也可以更新视图的 解决 : this.$fo…...

Unity编辑器拓展-Odin
1.相比于原生Unity的优势 Unity不支持泛型类型序列化,例如字典原生Unity不支持序列化,而Odin可以继承序列化的Mono实现功能强大且使用简单,原生Unity想实现一些常见的功能需要额外自己编写Unity扩展的编码,实现功能只需要加一个特…...

小红书婴童产业探索,解析消费者需求!
在消费升级、市场引导的背景下,众多产业都在悄然发生着变化,其中“婴童产业”就是非常有代表性的一个。今天就来深入分析小红书婴童产业探索,解析消费者需求! 一、何为婴童产业 事实上,婴童产业,并不仅仅局…...

离线安装mysql客户端
下载路径 oracle网站总是在不断更新,所以下载位置随时可能变动但万变不离其宗,学习也要学会一通百通。 首先直接搜索,就能找找到mysql官网 打开网站,并点击 DOWNLOADS 往下滚动,找到社区版下载按钮。…...
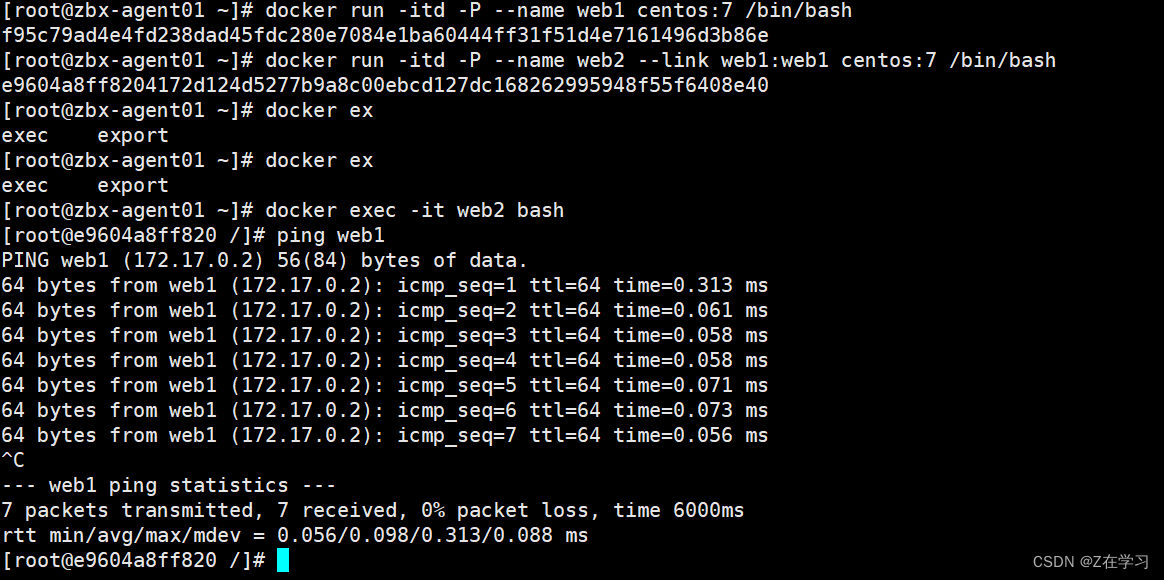
Docker 数据管理
管理 Docker 容器中数据主要有两种方式: 数据卷(Data Volumes) 数据卷容器(DataVolumes Containers)。 数据卷 数据卷是一个供容器使用的特殊目录,位于容器中。可将宿主机的目录挂载到数据卷上…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

渲染学进阶内容——模型
最近在写模组的时候发现渲染器里面离不开模型的定义,在渲染的第二篇文章中简单的讲解了一下关于模型部分的内容,其实不管是方块还是方块实体,都离不开模型的内容 🧱 一、CubeListBuilder 功能解析 CubeListBuilder 是 Minecraft Java 版模型系统的核心构建器,用于动态创…...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

深入浅出深度学习基础:从感知机到全连接神经网络的核心原理与应用
文章目录 前言一、感知机 (Perceptron)1.1 基础介绍1.1.1 感知机是什么?1.1.2 感知机的工作原理 1.2 感知机的简单应用:基本逻辑门1.2.1 逻辑与 (Logic AND)1.2.2 逻辑或 (Logic OR)1.2.3 逻辑与非 (Logic NAND) 1.3 感知机的实现1.3.1 简单实现 (基于阈…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...

关于uniapp展示PDF的解决方案
在 UniApp 的 H5 环境中使用 pdf-vue3 组件可以实现完整的 PDF 预览功能。以下是详细实现步骤和注意事项: 一、安装依赖 安装 pdf-vue3 和 PDF.js 核心库: npm install pdf-vue3 pdfjs-dist二、基本使用示例 <template><view class"con…...

redis和redission的区别
Redis 和 Redisson 是两个密切相关但又本质不同的技术,它们扮演着完全不同的角色: Redis: 内存数据库/数据结构存储 本质: 它是一个开源的、高性能的、基于内存的 键值存储数据库。它也可以将数据持久化到磁盘。 核心功能: 提供丰…...

TCP/IP 网络编程 | 服务端 客户端的封装
设计模式 文章目录 设计模式一、socket.h 接口(interface)二、socket.cpp 实现(implementation)三、server.cpp 使用封装(main 函数)四、client.cpp 使用封装(main 函数)五、退出方法…...