Flink学习笔记(一):Flink重要概念和原理
文章目录
- 1、Flink 介绍
- 2、Flink 概述
- 3、Flink 组件介绍
- 3.1、Deploy 物理部署层
- 3.2、Runtime 核心层
- 3.3、API&Libraries 层
- 3.4、扩展库
- 4、Flink 四大基石
- 4.1、Checkpoint
- 4.2、State
- 4.3、Time
- 4.4、Window
- 5、Flink 的应用场景
- 5.1、Event-driven Applications【事件驱动】
- 5.2、Data Analytics Applications【数据分析】
- 5.3、Data Pipeline Applications【数据管道】
- 6、Flink 的优势
- 6.1、主要优势
- 6.2、其他优势
- 7、Flink 编程模型
- 7.1、抽象的层级
- 7.2、程序和数据流
- 7.3、并行的数据流
- 7.4、窗口(Windows)
- 7.5、时间(Time)
- 7.6、有状态的数据操作(Stateful Operations)
- 7.7、容错的 Checkpoint
- 7.8、流上的批处理
- 8、Flink 分布式执行环境
- 8.1、任务和运算(算子)链(Tasks and Operator Chains)
- 8.2、Job Managers,Task Managers,Clients
- 8.3、Task Slots 和资源
- 8.4、状态后端
- 8.5、保存点(Savepoints)
1、Flink 介绍
Apache Flink是一个框架和分布式处理引擎,用于对无限制和有限制的数据流进行有状态的计算。Flink被设计为可以在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
官网:https://flink.apache.org/
官网中文:https://flink.apache.org/zh/
Flink 开发文档:https://nightlies.apache.org/flink/flink-docs-release-1.12/zh/
本示例以 1.12 版本进行介绍,当前版本更新至 1.17 。
2、Flink 概述
Apache Flink 是一个面向数据流处理和批量数据处理的可分布式的开源计算框架,它基于同一个 Flink 流式执行模型(streaming execution model),能够支持流处理和批处理两种应用类型。由于流处理和批处理所提供的SLA(服务等级协议)是完全不相同, 流处理一般需要支持低延迟、Exactly-once 保证,而批处理需要支持高吞吐、高效处理,所以在实现的时候通常是分别给出两套实现方法,或者通过一个独立的开源框架来实现其中每一种处理方案。比较典型的有:实现批处理的开源方案有 MapReduce、Spark;实现流处理的开源方案有 Storm;Spark的Streaming 其实本质上也是微批处理。
Flink 在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来:Flink 是完全支持流处理,也就是说作为流处理看待时输入数据流是无界的;批处理被作为一种特殊的流处理,只是它的输入数据流被定义为有界的。
Flink 官方提供了Java、Scala、Python 语言接口用以开发 Flink 应用程序,但是 Flink 的源码是使用 Java 语言进行开发的,且 Flink 被阿里收购后(2019 年1 月 8 日),未来的主要编程语言可能主要会是 Java,且 GitHub 上关于 Flink 的项目,大多数是使用 Java 语言编写的。
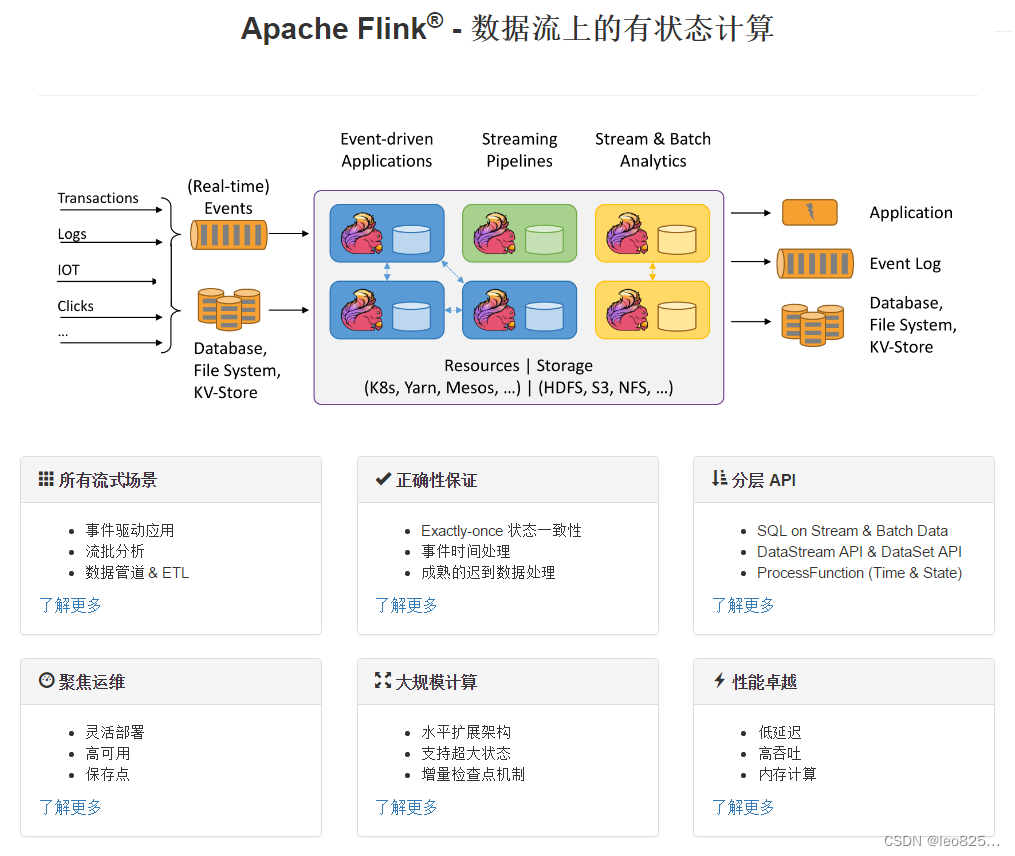
3、Flink 组件介绍
3.1、Deploy 物理部署层
Flink 支持本地运行、能在独立集群或者在被 YARN 管理的集群上运行, 也能部署在云上,该层主要涉及 Flink 的部署模式,目前 Flink 支持多种部署模式:本地、集群(Standalone、YARN)、云(GCE/EC2)、Kubenetes。Flink 能够通过该层能够支持不同平台的部署,用户可以根据需要选择使用对应的部署模式。
3.2、Runtime 核心层
Runtime 层提供了支持 Flink 计算的全部核心实现,为上层 API 层提供基础服务,该层主要负责对上层不同接口提供基础服务,也是 Flink 分布式计算框架的核心实现层,支持分布式 Stream 作业的执行、JobGraph 到 ExecutionGraph 的映射转换、任务调度等。将 DataSteam 和 DataSet 转成统一的可执行的 Task Operator,达到在流式引擎下同时处理批量计算和流式计算的目的。
3.3、API&Libraries 层
Flink 首先支持了 Scala 和 Java 的 API、Python 。DataStream、DataSet、Table、SQL API,作为分布式数据处理框架,Flink 同时提供了支撑计算和批计算的接口,两者都提供给用户丰富的数据处理高级 API ,例如 Map、FlatMap 操作等,也提供比较低级的 Process Function API,用户可以直接操作状态和时间等底层数据。
3.4、扩展库
Flink 还包括用于复杂事件处理的CEP,机器学习库 FlinkML,图处理库 Gelly 等。Table 是一种接口化的 SQL 支持,也就是 API 支持(DSL),而不是文本化的 SQL 解析和执行。
4、Flink 四大基石
Flink 之所以能这么流行,离不开它最重要的四个基石:Checkpoint、State、Time、Window。

4.1、Checkpoint
这是 Flink 最重要的一个特性。
Flink基于 Chandy-Lamport 算法实现了一个分布式的一致性的快照,从而提供了一致性的语义。
Chandy-Lamport算法实际上在1985年的时候已经被提出来,但并没有被很广泛的应用,而 Flink 则把这个算法发扬光大了。
Spark 最近在实现 Continue streaming,Continue streaming 的目的是为了降低处理的延时,其也需要提供这种一致性的语义,最终也采用了 Chandy-Lamport 这个算法,说明Chandy-Lamport 算法在业界得到了一定的肯定。(https://zhuanlan.zhihu.com/p/53482103)
4.2、State
提供了一致性的语义之后,Flink 为了让用户在编程时能够更轻松、更容易地去管理状态,还提供了一套非常简单明了的 State API,包括里面的有 ValueState、ListState 、MapState ,近期添加了 BroadcastState ,使用 State API 能够自动享受到这种一致性的语义。
4.3、Time
除此之外,Flink 还实现了 Watermark 的机制,能够支持基于事件的时间的处理,能够容忍迟到/乱序的数据。
4.4、Window
另外流计算中一般在对流数据进行操作之前都会先进行开窗,即基于一个什么样的窗口上做这个计算。Flink 提供了开箱即用的各种窗口,比如滑动窗口、滚动窗口、会话窗口以及非常灵活的自定义的窗口。
5、Flink 的应用场景
Flink 功能强大,支持开发和运行多种不同种类的应用程序。它的主要特性包括:批流一体化、精密的状态管理、事件时间支持以及精确一次的状态一致性保障等。Flink 不仅可以运行在包括 YARN、 Mesos、Kubernetes 在内的多种资源管理框架上,还支持在裸机集群上独立部署。在启用高可用选项的情况下,它不存在单点失效问题。事实证明,Flink 已经可以扩展到数千核心,其状态可以达到 TB 级别,且仍能保持高吞吐、低延迟的特性。世界各地有很多要求严苛的流处理应用都运行在 Flink 之上。
https://flink.apache.org/zh/use-cases/
5.1、Event-driven Applications【事件驱动】
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。
事件驱动型应用是在计算存储分离的传统应用基础上进化而来。在传统架构中,应用需要读写远程事务型数据库。相反,事件驱动型应用是基于状态化流处理来完成。在该设计中,数据和计算不会分离,应用只需访问本地(内存或磁盘)即可获取数据。
系统容错性的实现依赖于定期向远程持久化存储写入 checkpoint。下图描述了传统应用和事件驱动型应用架构的区别。
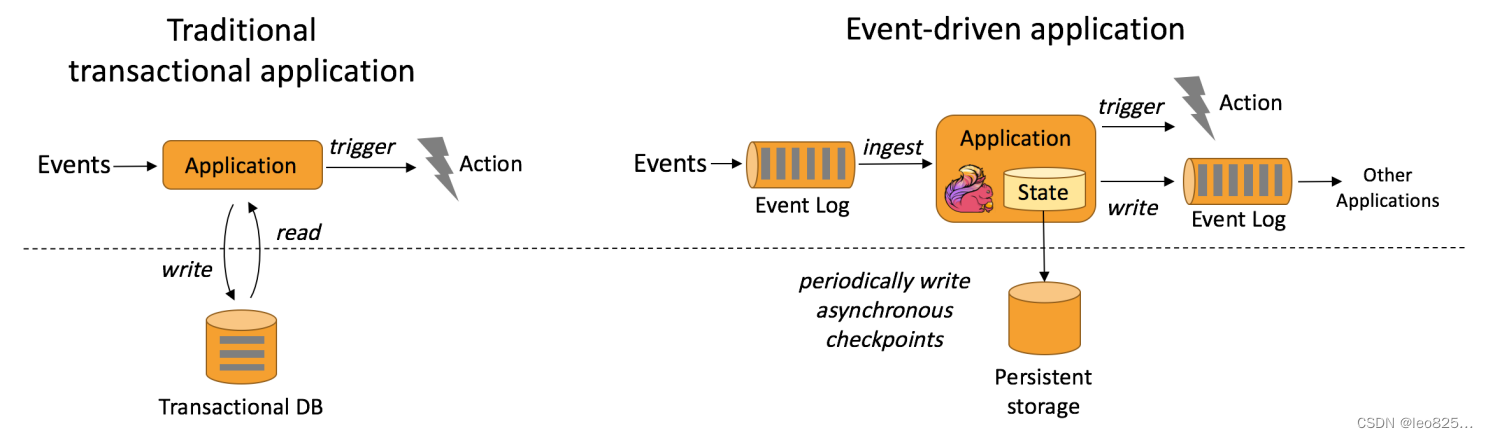
从某种程度上来说,所有的实时的数据处理或者是流式数据处理都应该是属于Data Driven ,流计算本质上是 Data Driven 计算。应用较多的如风控系统,当风控系统需要处理各种各样复杂的规则时,Data Driven 就会把处理的规则和逻辑写入到Datastream 的API 或者是 ProcessFunction 的API 中,然后将逻辑抽象到整个 Flink 引擎,当外面的数据流或者是事件进入就会触发相应的规则,这就是 Data Driven 的原理。在触发某些规则后,Data Driven 会进行处理或者是进行预警,这些预警会发到下游产生业务通知,这是Data Driven 的应用场景,Data Driven 在应用上更多应用于复杂事件的处理。
典型实例:
- 欺诈检测(Fraud detection)
- 异常检测(Anomaly detection)
- 基于规则的告警(Rule-based alerting)
- 业务流程监控(Business process monitoring)
- Web应用程序(社交网络)
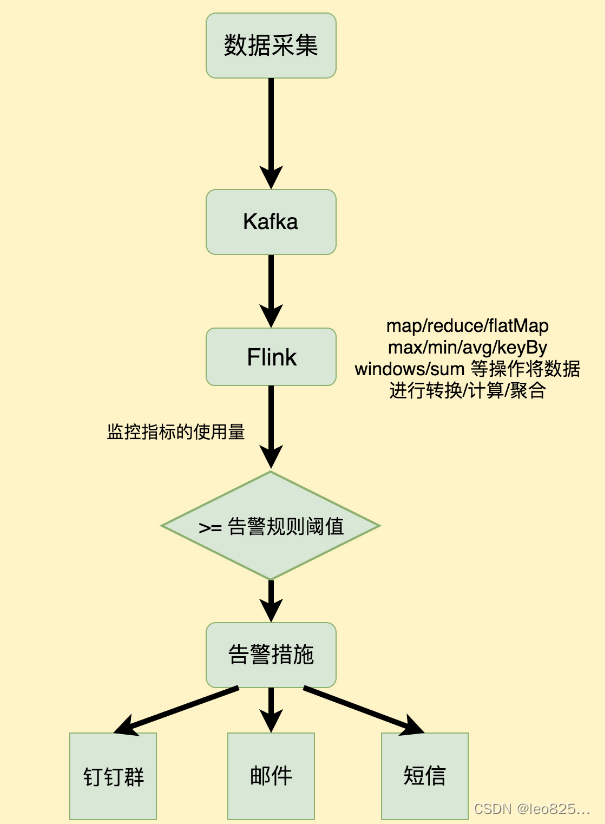
5.2、Data Analytics Applications【数据分析】
数据分析任务需要从原始数据中提取有价值的信息和指标。如下图所示,Flink 同时支持流式及批量分析应用。
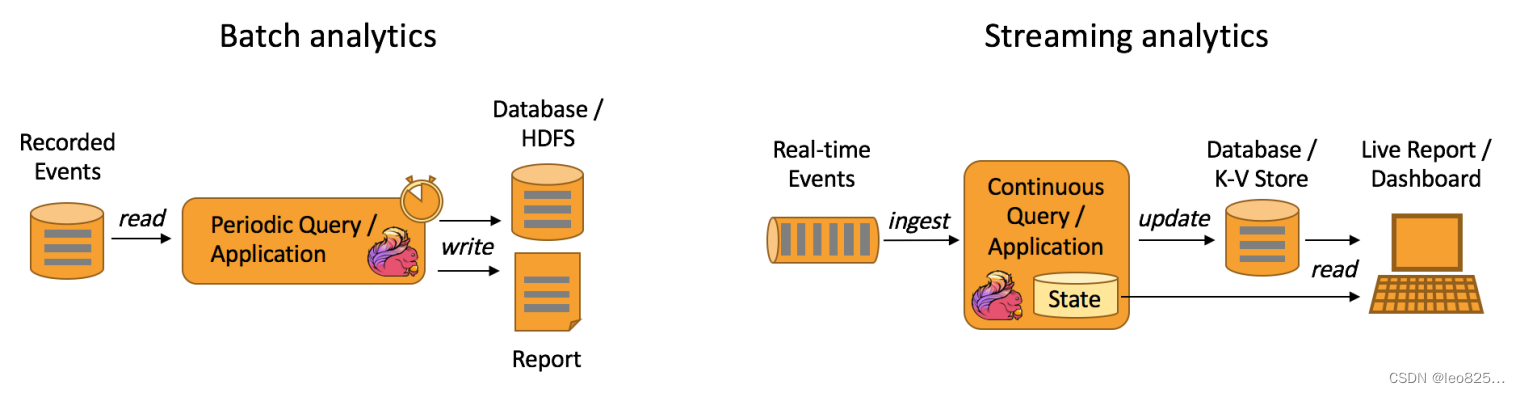
Data Analytics Applications:包含 Batch analytics (批处理分析)和 Streaming analytics (流处理分析)
Batch analytics:可以理解为周期性查询:Batch Analytics 就是传统意义上使用类似于 Map Reduce、Hive、Spark Batch 等,对作业进行分析、处理、生成离线报表。比如Flink应用凌晨从 Recorded Events 中读取昨天的数据,然后做周期查询运算,最后将数据写入 Database 或者 HDFS ,或者直接将数据生成报表供公司上层领导决策使用。
Streaming analytics:可以理解为连续性查询:比如实时展示双十一天猫销售 GMV(Gross Merchandise Volume 成交总额),用户下单数据需要实时写入消息队列,Flink 应用源源不断读取数据做实时计算,然后不断的将数据更新至 Database 或者 K-VStore ,最后做大屏实时展示。
典型实例:
- 电信网络质量监控
- 移动应用中的产品更新及实验评估分析
- 消费者技术中的实时数据即席分析
- 大规模图分析
5.3、Data Pipeline Applications【数据管道】
什么是数据管道?
提取-转换-加载(ETL)是一种在存储系统之间进行数据转换和迁移的常用方法。ETL 作业通常会周期性地触发,将数据从事务型数据库拷贝到分析型数据库或数据仓库。数据管道和 ETL 作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。但数据管道是以持续流模式运行,而非周期性触发。因此数据管道支持从一个不断生成数据的源头读取记录,并将它们以低延迟移动到终点。
例如:数据管道可以用来监控文件系统目录中的新文件,并将其数据写入事件日志;另一个应用可能会将事件流物化到数据库或增量构建和优化查询索引。和周期性 ETL 作业相比,持续数据管道可以明显降低将数据移动到目的端的延迟。此外,由于它能够持续消费和发送数据,因此用途更广,支持用例更多。下图描述了周期性 ETL 作业和持续数据管道的差异。
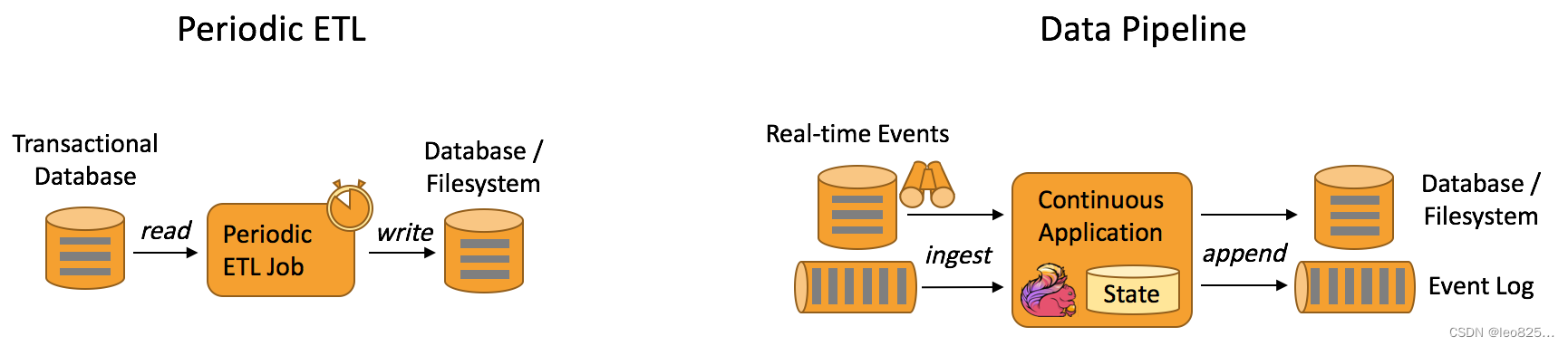
Periodic ETL:比如每天凌晨周期性的启动一个 Flink ETL Job,读取传统数据库中的数据,然后做ETL,最后写入数据库和文件系统。
Data Pipeline:比如启动一个 Flink 实时应用,数据源(比如数据库、Kafka )中的数据不断的通过 Flink Data Pipeline 流入或者追加到数据仓库(数据库或者文件系统),或者 Kafka 消息队列。Data Pipeline 的核心场景类似于数据搬运并在搬运的过程中进行部分数据清洗或者处理,而整个业务架构图的左边是 Periodic ETL,它提供了流式 ETL 或者实时 ETL,能够订阅消息队列的消息并进行处理,清洗完成后实时写入到下游的 Database 或 File system 中。
典型实例:
- 电子商务中的持续 ETL(实时数仓)
当下游要构建实时数仓时,上游则可能需要实时的 Stream ETL。这个过程会进行实时清洗或扩展数据,清洗完成后写入到下游的实时数仓的整个链路中,可保证数据查询的时效性,形成实时数据采集、实时数据处理以及下游的实时 Query。 - 电子商务中的实时查询索引构建(搜索引擎推荐)
搜索引擎这块以淘宝为例,当卖家上线新商品时,后台会实时产生消息流,该消息流经过Flink 系统时会进行数据的处理、扩展。然后将处理及扩展后的数据生成实时索引,写入到搜索引擎中。这样当淘宝卖家上线新商品时,能在秒级或者分钟级实现搜索引擎的搜索。
6、Flink 的优势

6.1、主要优势
- Flink 具备统一的框架处理有界和无界两种数据流的能力
- 部署灵活,Flink 底层支持多种资源调度器,包括Yarn、Kubernetes 等。Flink 自身带的Standalone 的调度器,在部署上也十分灵活。
- 极高的可伸缩性,可伸缩性对于分布式系统十分重要,阿里巴巴双 11 大屏采用 Flink 处理海量数据,使用过程中测得 Flink 峰值可达17 亿条/秒。
- 极致的流式处理性能。Flink 相对于 Storm 最大的特点是将状态语义完全抽象到框架中,支持本地状态读取,避免了大量网络 IO,可以极大提升状态存取的性能。
6.2、其他优势
-
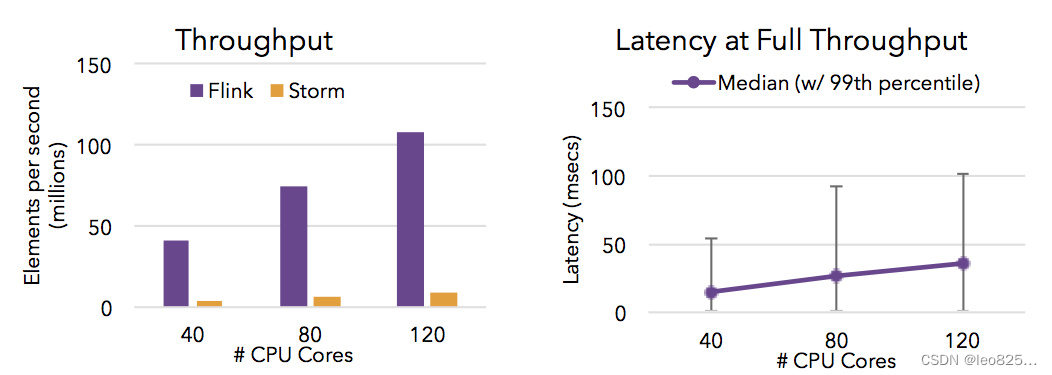
同时支持高吞吐、低延迟、高性能
Flink 是目前开源社区中唯一一套集高吞吐、低延迟、高性能三者于一身的分布式流式数据处理框架。Spark 只能兼顾高吞吐和高性能特性,无法做到低延迟保障,因为Spark是用批处理来做流处理; Storm 只能支持低延时和高性能特性,无法满足高吞吐的要求。下图显示了 Apache Flink 与 Apache Storm 在完成流数据清洗的分布式任务的性能对比。
-
支持事件时间(Event Time)概念
在流式计算领域中,窗口计算的地位举足轻重,但目前大多数框架窗口计算采用的都是系统时间(Process Time),也就是事件传输到计算框架处理时,系统主机的当前时间。Flink 能够支持基于事件时间(Event Time)语义进行窗口计算,这种基于事件驱动的机制使得事件即使乱序到达甚至延迟到达,流系统也能够计算出精确的结果,保持了事件原本产生时的时序性,尽可能避免网络传输或硬件系统的影响。

-
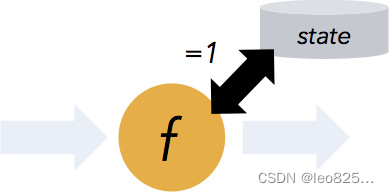
支持有状态计算
Flink1.4开始支持有状态计算,所谓状态就是在流式计算过程中将算子的中间结果保存在内存或者文件系统中,等下一个事件进入算子后可以从之前的状态中获取中间结果,计算当前的结果,从而无须每次都基于全部的原始数据来统计结果,极大的提升了系统性能,状态化意味着应用可以维护随着时间推移已经产生的数据聚合。
-
支持高度灵活的窗口(Window)操作
Flink 将窗口划分为基于 Time 、Count 、Session、以及 Data-Driven 等类型的窗口操作,窗口可以用灵活的触发条件定制化来达到对复杂的流传输模式的支持,用户可以定义不同的窗口触发机制来满足不同的需求。 -
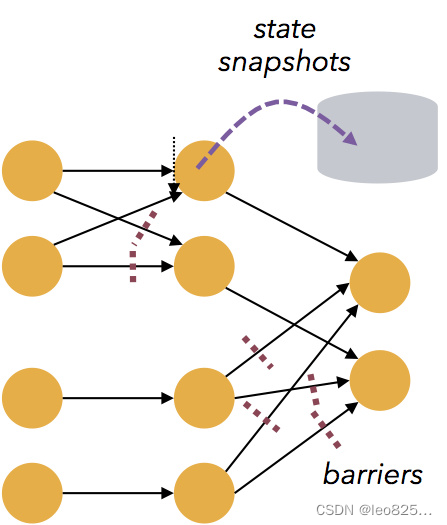
基于轻量级分布式快照(Snapshot/Checkpoints)的容错机制
Flink 能够分布运行在上千个节点上,通过基于分布式快照技术的 Checkpoints ,将执行过程中的状态信息进行持久化存储,一旦任务出现异常停止,Flink 能够从 Checkpoints 中进行任务的自动恢复,以确保数据处理过程中的一致性,Flink 的容错能力是轻量级的,允许系统保持高并发,同时在相同时间内提供强一致性保证。
-
基于 JVM 实现的独立的内存管理
Flink 实现了自身管理内存的机制,通过使用散列,索引,缓存和排序有效地进行内存管理,通过序列化/反序列化机制将所有的数据对象转换成二进制在内存中存储,降低数据存储大小的同时,更加有效的利用空间。使其独立于 Java 的默认垃圾收集器,尽可能减少 JVM GC 对系统的影响。 -
基于 JVM 实现的独立的内存管理
Flink 实现了自身管理内存的机制,通过使用散列,索引,缓存和排序有效地进行内存管理,通过序列化/反序列化机制将所有的数据对象转换成二进制在内存中存储,降低数据存储大小的同时,更加有效的利用空间。使其独立于 Java 的默认垃圾收集器,尽可能减少 JVM GC 对系统的影响。 -
SavePoints 保存点
对于 7 * 24 小时运行的流式应用,数据源源不断的流入,在一段时间内应用的终止有可能导致数据的丢失或者计算结果的不准确。比如集群版本的升级,停机运维操作等。值得一提的是,Flink 通过 SavePoints 技术将任务执行的快照保存在存储介质上,当任务重启的时候,可以从事先保存的 SavePoints 恢复原有的计算状态,使得任务继续按照停机之前的状态运行。Flink 保存点提供了一个状态化的版本机制,使得能以无丢失状态和最短停机时间的方式更新应用或者回退历史数据。
-
灵活的部署方式,支持大规模集群
Flink 被设计成能用上千个点在大规模集群上运行。除了支持独立集群部署外,Flink 还支持 YARN 和 Mesos 方式部署。 -
Flink 的程序内在是并行和分布式的
数据流可以被分区成 stream partitions,operators 被划分为 operator subtasks;这些 subtasks 在不同的机器或容器中分不同的线程独立运行;operator subtasks 的数量就是operator的并行计算数,不同的 operator 阶段可能有不同的并行数;如下图所示,source operator 的并行数为 2,但最后的 sink operator 为1;
-
丰富的库
Flink 拥有丰富的库来进行机器学习,图形处理,关系数据处理等。
7、Flink 编程模型
7.1、抽象的层级
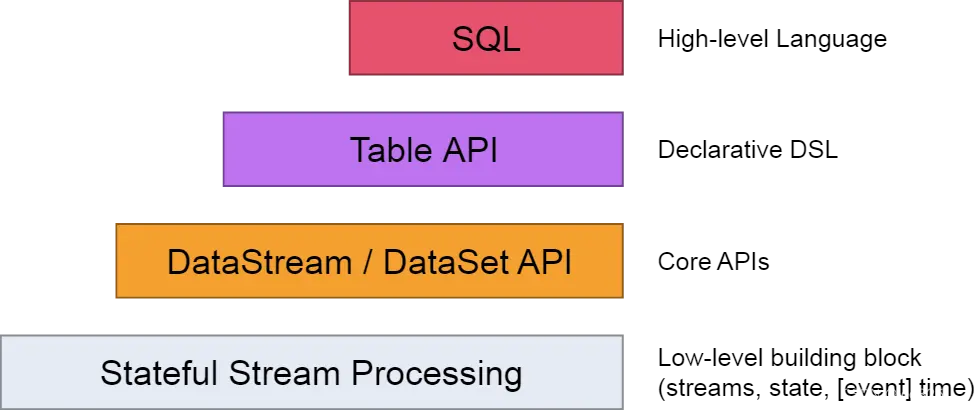
- 有状态的数据流处理层
最底层的抽象仅仅提供有状态的数据流,它通过处理函数(Process Function)嵌入到数据流api(DataStream API). 用户可以通过它自由的处理单流或者多流,并保持一致性和容错。同时用户可以注册事件时间和处理时间的回调处理,以实现复杂的计算逻辑。 - 核心API层
它提供了数据处理的基础模块,像各种transformation, join,aggregations,windows,stat 以及数据类型等等 - Table API层
定了围绕关系表的DSL(领域描述语言)。Table API遵循了关系模型的标准:Table类型关系型数据库中的表,API也提供了相应的操作,像select,project,join,group-by,aggregate等。Table API声明式的定义了逻辑上的操作(logical operation)不是code for the operation;Flink会对Table API逻辑在执行前进行优化。同时代码上,Flink允许混合使用Table API和DataStram/DataSet API - SQL层
它很类似Table API的语法和表达,也是定义与Table API层次之上的,但是提供的是纯SQL的查询表达式。
7.2、程序和数据流
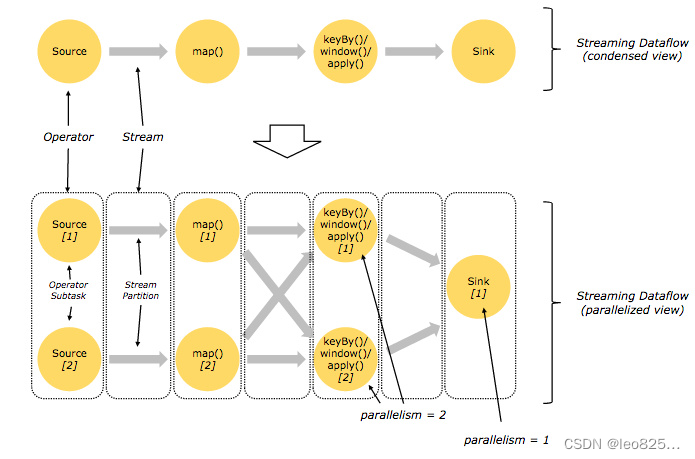
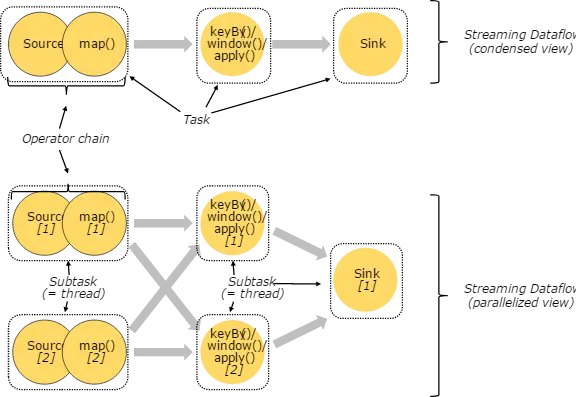
用户实现的 Flink 程序是由 Stream 和 Transformation 这两个基本构建块组成,其中 Stream 是一个中间结果数据,而 Transformation 是一个操作,它对一个或多个输入 Stream 进行计算处理,输出一个或多个结果 Stream 。当一个Flink程序被执行的时候,它会被映射为 Streaming Dataflow 。一个 Streaming Dataflow 是由一组 Stream 和 Transformation Operator 组成,它类似于一个 DAG 图,在启动的时候从一个或多个 Source Operator 开始,结束于一个或多个 Sink Operator。
下面是一个由 Flink 程序映射为 Streaming Dataflow 的示意图,如下所示:
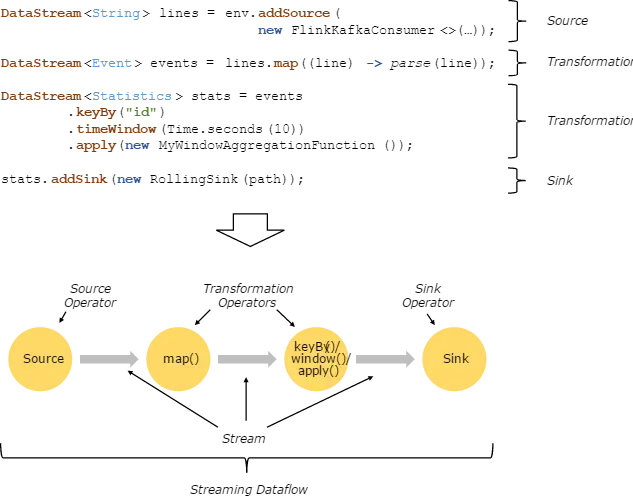
上图中,FlinkKafkaConsumer 是一个 Source Operator,map、keyBy、timeWindow、apply是Transformation Operator,RollingSink 是一个 Sink Operator。
7.3、并行的数据流
在 Flink 中,程序天生是并行和分布式的:一个 Stream 可以被分成多个 Stream 分区(Stream Partitions),一个 Operator 可以被分成多个 Operator Subtask ,每一个 Operator Subtask 是在不同的线程中独立执行的。一个 Operator 的并行度,等于 Operator Subtask 的个数,一个 Stream 的并行度总是等于生成它的 Operator 的并行度。有关 Parallel Dataflow 的实例,如下图所示:
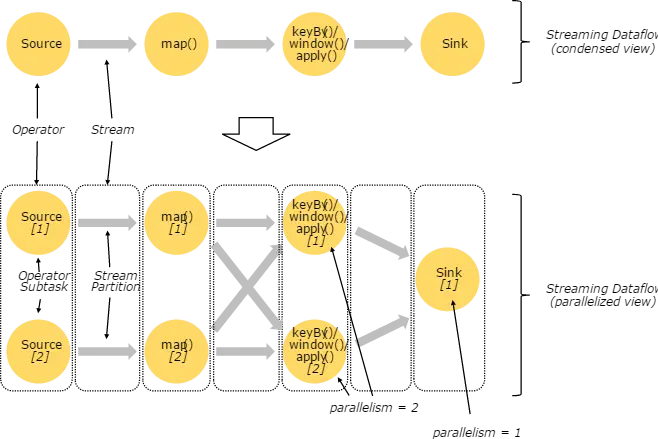
上图 Streaming Dataflow 的并行视图中,展现了在两个 Operator 之间的 Stream 的两种模式:
- One-to-one 模式:比如从 Source[1] 到 map()[1] ,它保持了 Source 的分区特性(Partitioning)和分区内元素处理的有序性,也就是说 map()[1] 的 Subtask 看到数据流中记录的顺序,与 Source[1] 中看到的记录顺序是一致的。
- Redistribution 模式:这种模式改变了输入数据流的分区,比如从 map()[1] 、map()[2] 到keyBy()/window()/apply()[1]、keyBy()/window()/apply()[2],上游的 Subtask 向下游的多个不同的 Subtask 发送数据,改变了数据流的分区,这与实际应用所选择的 Operator 有关系。
7.4、窗口(Windows)
流处理中的聚合操作(counts,sums等等)不同于批处理,因为数据流是无限,无法在其上应用聚合,所以通过限定窗口(window)的范围,来进行流的聚合操作。例如:5分钟的数据计数,或者计算100个元素的总和等等。
窗口可以由时间驱动 (every 30 seconds) 或者数据驱动(every 100 elements)。如:滚动窗口tumbling windows(无叠加),滑动窗口sliding windows(有叠加),以及会话窗口session windows(被无事件活动的间隔隔开)。

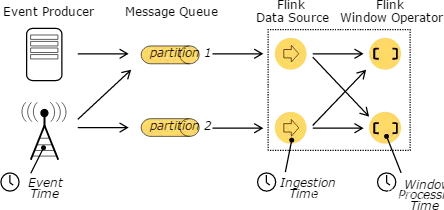
7.5、时间(Time)
三种不同的时间概念:
- 事件时间 Event Time:事件的创建时间,通常通过时间中的一个时间戳来描述
- 摄入时间 Ingestion time: 事件进入Flink 数据流的source的时间
- 处理时间 Processing Time:Processing Time表示某个Operator对事件进行处理时的本地系统时间(是在TaskManager节点上)
7.6、有状态的数据操作(Stateful Operations)
在流处理中,有些操作仅仅在某一时间针对单一事件(如事件转换map),有些操作需要记住多个事件的信息并进行处理(window operators),后者的这些操作称为有状态的操作。有状态的操作一般被维护在内置的 key/value 存储中。这些状态信息会跟数据流一起分区并且分布存储,并且可以通过有状态的数据操作来访问。因此这些 key/value 的状态信息仅在带 key 的数据流(通过 keyBy() 函数处理过)中才能访问到。数据流按照 key 排列能保证所有的状态更新都是本地操作,保证一致性且无事务问题。同时这种排列方式使 Flink 能够透明的再分发状态信息和调整数据流分区。
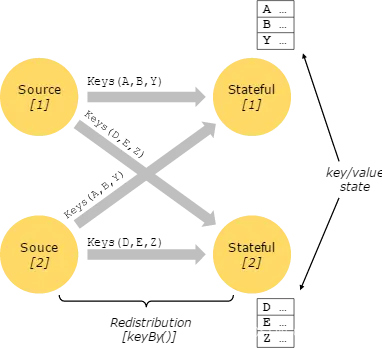
7.7、容错的 Checkpoint
Flink 通过流回放和设置检查点的方式实现容错。一个checkpoint关联了输入流中的某个记录和相应状态和操作。数据流可以从checkpoint中进行恢复,并保证一致性(exactly-once 的处理语义)。 Checkpoint的间隔关系到执行是的容错性和恢复时间。
7.8、流上的批处理
Flink 把批处理作为特殊的流处理程序来执行,许多概念也都可以应用的批处理中,除了一些小的不同:
- 批处理的API(DataSet API )不使用 checkpoints ,恢复通过完整的流回放来实现;
- DataSet API 的有状态操作使用简单的内存和堆外内存 的数据结构,而不是key/value 的索引;
- DataSet API 引入一种同步的迭代操作,这个仅应用于有界数据流。
8、Flink 分布式执行环境
Flink 部署方式:
- Local — 本地单机模式,学习测试时使用;
- Standalone — 独立集群模式,Flink 自带集群,开发测试环境使用;
- StandaloneHA — 独立集群高可用模式,Flink 自带集群,开发测试环境使用;
- On Yarn — 计算资源统一由 Hadoop YARN 管理,生产环境使用。部署前提,最新版本1.17要求 java 11 以上版本,1.12 还可以使用 java 8 版本。
8.1、任务和运算(算子)链(Tasks and Operator Chains)
在 Flink 分布式执行环境中,会将多个运算子任务 Operator Subtask 串起来组成一个 Operator Chain ,实际上就是一个运算链。每个运算会在 TaskManager 上一个独立的线程中执行。将算子串连到任务中是一种很好的优化:它能减少线程间的数据交接和缓存,并且提高整体的吞吐,降低处理的时延。这种串联的操作,可以通过 API 来进行配置。如下图的数据流就有 5 个子任务,通过 5 个并行的线程来执行,所示:
Source Operator 对应 2 个 Subtask,所以并行度为 2 ,而 Sink Operator 的 Subtask 只有1个,故而并行度为 1 。这个 Flink 作业的任务有 2 + 2 + 1 = 5 个,则会有 5 个不同的线程执行。
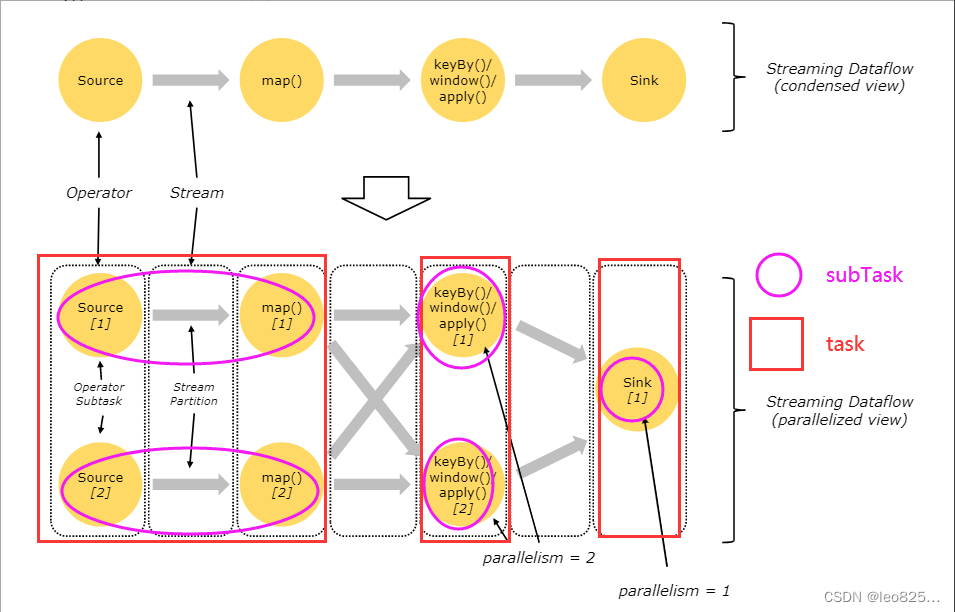
什么情况下算子可以组合为算子链?
-
上下游的并行度一致
-
上游算子将所有数据前向传播到下游算子上,数据不进行任何交换,那么这两个算子可以被链接到一起。比如,先进行 filter(),再进行map() 这两个算子可以被链接到一起。(Flink 源码 org.apache.flink.streaming.api.graph.StreamingJob-
raphGenerator中的 isChainable() 方法定义了何种情况可以进行链接) -
下游节点的入并行度为 1 (也就是说下游算子节点没有来自其他算子节点的输入)
-
上下游节点都在同一个 slot group 中
- 为了防止同一个 Slot 包含太多的 task,Flink 提供了资源组(group)的概念。group 就是对 operator (算子)进行分组,同一 group 的不同operator task 可以共享同一个 Slot。默认所有 operator 属于同一个组 “default”,也就是所有 operator task 可以共享一个 Slot。我们可以通过 slotSharingGroup() 为不同的operator设置不同的group。
dataStream.filter(e->e.getId()!=0).slotSharingGroup("groupName"); -
下游节点的 chain 策略为 ALWAYS(可以与上下游算子链接,map、flatmap、filter 等默认是 ALWAYS )
-
上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source 默认是 HEAD )
-
两个节点间数据分区方式是 forward
-
用户没有禁用 chain
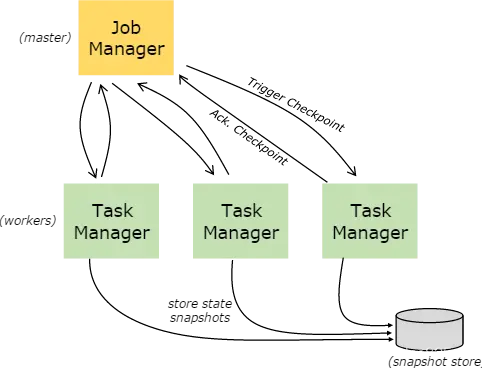
8.2、Job Managers,Task Managers,Clients
Flink的运行时,由两种类型的进程组成:
- JobManagers: 也就是 masters ,协调分布式任务的执行 。用来调度任务,协调 checkpoints ,协调错误恢复等等。至少需要一个 JobManager ,高可用的系统会有多个,一个 leader ,其他是 standby;
- TaskManagers: 也就是 workers ,用来执行数据流任务或者子任务,缓存和交互数据流。至少需要一个 TaskManager;
- Client: Client 不是运行是和程序执行的一部分,它是用来准备和提交数据流到JobManagers。之后,可以断开连接或者保持连接以获取任务的状态信息。
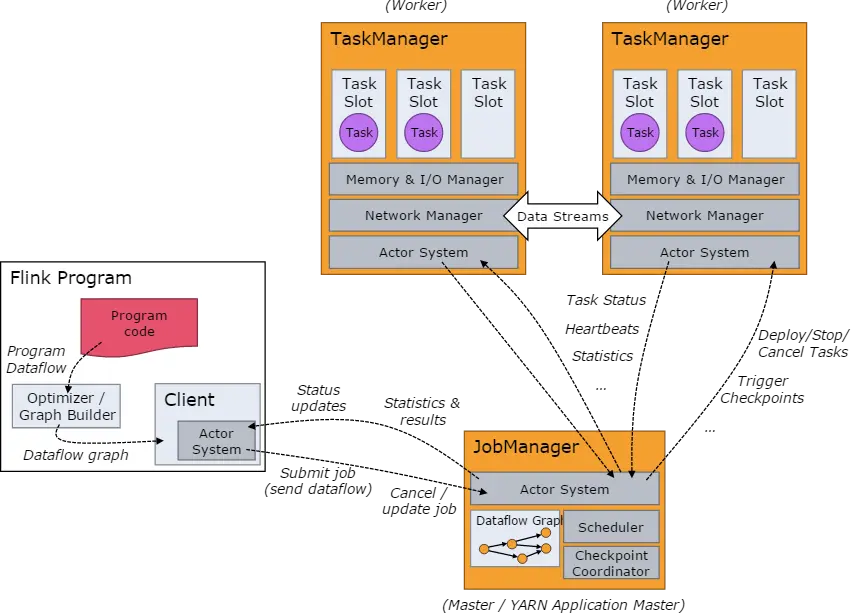
- 客户端不是运行时和程序执行的一部分,但它用于准备并发送dataflow(JobGraph)给Master(JobManager),然后,客户端断开连接或者维持连接以等待接收计算结果。而Job Manager会产生一个执行图(Dataflow Graph)
- 当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
- Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程(Streaming的任务),也可以不结束并等待结果返回。
- JobManager 主要负责调度 Job 并协调 Task 做 checkpoint,职责上很像 Storm 的 Nimbus。从 Client 处接收到 Job 和 JAR 包等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
- TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,Task 为线程。从 JobManager 处接收需要部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
注:如果一个 Slot 中启动多个线程,那么这几个线程类似 CPU 调度一样共用同一个 Slot。JobManagers 与 TaskManagers
之间的任务管理,Checkpoints 的触发,任务状态,心跳等等消息处理都是通过 ActorSystem。
8.3、Task Slots 和资源
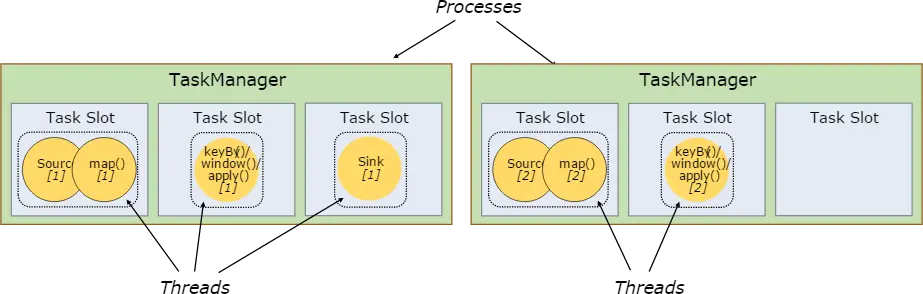
- 考虑 Slot 分组,实际运行 Job 时所需的 Slot 总数 = 每个 Slot 组中的最大并行度;
- Flink 中 每个 TaskManager 都是一个 JVM 进程,它可能会在独立的线程上执行一个或多个 subtask;
- TaskManager 抽象出多个 Task Slot(至少一个),每个 Task Slot 代表固定的资源子集。
- 可通过算子的 slotSharingGroup(“组名”)指定算子所在的 Slot 组名,默认每一个算子的 SlotGroup 和上一个算子相同,而默认的 SlotGroup 就是 “default”。同一个 SlotGroup 的算子能共享同一个 slot ,不同组则必须另外分配独立的 Slot。
上边这幅图呢,表示了 source/map 算子链 与 keyby/window/apply 算子链的两个 subtask 都进入了不同的 Task Slot ,sink 单独进入了一个 Task Slot,由于 TaskManger 会根据 Task Slot 数量 对每个 Task Slot 平分系统资源,但是呢,我们发现,上述情况,有一个 Task Slot 为空闲状态并未使用,因为白白浪费了系统资源…
为什么会出现这种情况呢?因为并行度设置不合理导致的…由于上方 2+2+1 并行度,总共才会有2个subtask,就算每个subtask都进入了不同的Task Slot,仍会有TaskSlot为空闲状态 (因为上图 Task Slot有6个…)
这个时候呢,为了能充分利用slot资源,我们需要对我们的Flink作业并行度进行优化设置。
比如,我们设置 source/map、keyby/window/apply 的算子链并行度为6(并行度为6,表示算子(Task)的并行数为6,即同时可有6个subTask执行),sink 并行度保持为1
每一个 sourec/map keyBy/window/apply 算子链进入到不同TaskSlot 如下图所示:
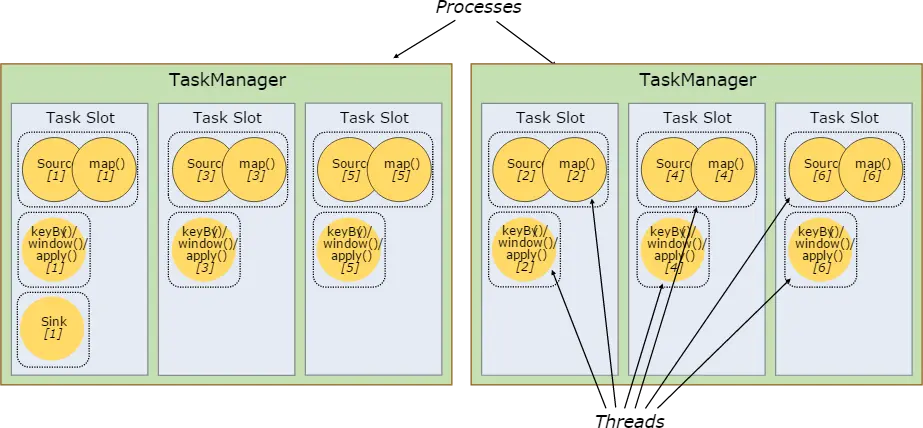
那么,此时,我们的 Task Slot都被利用到了,就能充分利用 Slot 资源,同时保证每个 TaskManager 能平均分配到重的 subtasks,比如keyby/window/apply 操作就会均分到申请的所有 Slot 里,也保证了 Slot 的负载均衡。默认情况下,Flink 允许子任务共享 Slot ,即便它们是不同任务的子任务,只要属于同一个 job。这样的结果就是一个 Slot 会负责一个 job 的整个 pipeline。
-
不同任务共享同一个 Slot 的前提
这几个任务前后顺序不同,如上图中 Source 和 keyBy 是两个不同步骤顺序的任务,所以可以在同一个 Slot 执行。 -
一个 Slot 可以保存作业的整个管道的好处
- 如果有某个 Slot 执行完了整个任务流程,那么其他任务就可以不用继续了,这样也省去了跨 Slot 、跨 TaskManager 的通信损耗(降低了并行度)
- 同时 Slot 能够保存整个管道,使得整个任务执行健壮性更高,因为某些 Slot 执行出异常也能有其他 Slot 补上。
- 有些 Slot 分配到的子任务非 CPU 密集型,有些则 CPU 密集型,如果每个 Slot 只完成自己的子任务,将出现某些 Slot 太闲,某些 Slot 过忙的现象。
-
更实现更好的资源利用
假设拆分的多个Source子任务放到同一个Slot,那么任务不能并行执行了=>因为多个相同步骤的子任务需要抢占的具体资源相同,比如抢占某个锁,这样就不能并行。 使用共享的 Slot 的将充分的利用分槽的资源,使代价较大的 subtask 能够均匀的分布在 TaskManager 上。如图中的共享 Slot 的执行模式中可以并行运行 6 个 pipeline 而上图的只可以运行 2 个 pipeline。同时 APIs 也提供了资源组的机制,可以实现不想进行资源隔离的情况。实践中,比较好的每个 TaskManager 的 Task Slot 的默认数量最好是 CPU 的核数。 -
Task Slot 是静态概念
Task Slot是静态的概念,是指 TaskManager 具有的并发执行能力,可以通过参数 taskmanager.numberOfTaskSlots 进行配置。而并行度 parallelism 是动态概念,即 TaskManager 运行程序时实际使用的并发能力,可以通过参数 parallelism.default 进行配置。
例如一个 TaskManager 有 3 个 Slots,每个 Slot 能管理对这个 Worker 分配的资源的三分之一的内存。对资源分槽,意味着 Subtask 不会同其他 Subtasks 竞争内存,同时可以预留一定的可用内存。目前 Task Slot 没有对 CPU 进行隔离,仅是针对内存。通过动态的调整 Task Slot 的个数,用户可以定义哪些子任务可以相互隔离。只有一个 Slot 的 TaskManager 意味着每个任务组运行在一个单独 JVM 中。 在拥有多个 Slot 的 TaskManager 上, subtask 共用 JVM ,可以共用 TCP 连接和心跳消息,同时可以共用一些数据集和数据结构,从而减小任务的开销。
8.4、状态后端
数据的 KV 索引信息存储在设定的状态后端的存储中。一种是内存中的 Hash map,另一种是存在 Rocksdb(KV存储)中。另外,状态后端还是实现了在时间点上对 KV 状态的快照,并作为 Checkpoint 的一部分存储起来。
8.5、保存点(Savepoints)
通过 Data Stream API 编写的程序可以从一个保存点重新开始执行。即便你更新了你的程序和Flink集群都不会有状态数据丢失。
保存点是手动触发的,触发时会将它写入状态后端。 Savepoints 的实现也是依赖 Checkpoint 的机制。Flink 程序在执行中会周期性的在worker 节点上进行快照并生成Checkpoint。因为任务恢复的时候只需要最后一个完成的 Checkpoint 的,所以旧有的 Checkpoint 会在新的 Checkpoint 完成时被丢弃。
Savepoints 和周期性的 Checkpoint 非常的类似,只是有两个重要的不同。一个是由用户触发,而且不会随着新的 Checkpoint 生成而被丢弃。
相关文章:
Flink学习笔记(一):Flink重要概念和原理
文章目录 1、Flink 介绍2、Flink 概述3、Flink 组件介绍3.1、Deploy 物理部署层3.2、Runtime 核心层3.3、API&Libraries 层3.4、扩展库 4、Flink 四大基石4.1、Checkpoint4.2、State4.3、Time4.4、Window 5、Flink 的应用场景5.1、Event-driven Applications【事件驱动】5.…...

网络中的一些基本概念
数据共享本质是网络数据传输 ,即计算机之间通过网络来传输数据,也称为 网络通信 。 根据网络互连的规模不同,可以划分为局域网和广域网。 局域网 LAN 局域网,即 Local Area Network ,简称 LAN 。 Local 即标识了局…...

mysql中varchar长度为多少
一. varchar存储规则: 4.0版本以下,varchar(20),指的是20字节,如果存放UTF8汉字时,只能存6个(每个汉字3字节) 5.0版本以上,varchar(20),指的是20字符,无论存…...
python+selenium实现UI自动化(入门篇)
一、基础准备。 python环境安装,参考:CSDN pycharm安装,参考:CSDN 谷歌浏览器驱动配置,参考:CSDN二、新建pycharm项目 截图中,上面是项目地址(可以提前在指定位置创建文件夹…...

深度学习基础知识 nn.Sequential | nn.ModuleList | nn.ModuleDict
深度学习基础知识 nn.Sequential | nn.ModuleList | nn.ModuleDict 1、nn.Sequential 、 nn.ModuleList 、 nn.ModuleDict 类都继承自 Module 类。2、nn.Sequential、nn.ModuleList 和 nn.ModuleDict语法3、Sequential 、ModuleDict、 ModuleList 的区别…...

【DevOps】搭建你的第一个 Docker 应用栈
搭建你的第一个 Docker 应用栈 1.Docker 集群部署2.第一个 Hello World2.1 获取应用栈各节点所需镜像2.2 应用栈容器节点互联2.3 应用栈容器节点启动2.4 应用栈容器节点的配置2.4.1 Redis Master 主数据库容器节点的配置2.4.2 Redis Slave 从数据库容器节点的配置2.4.3 Redis 数…...
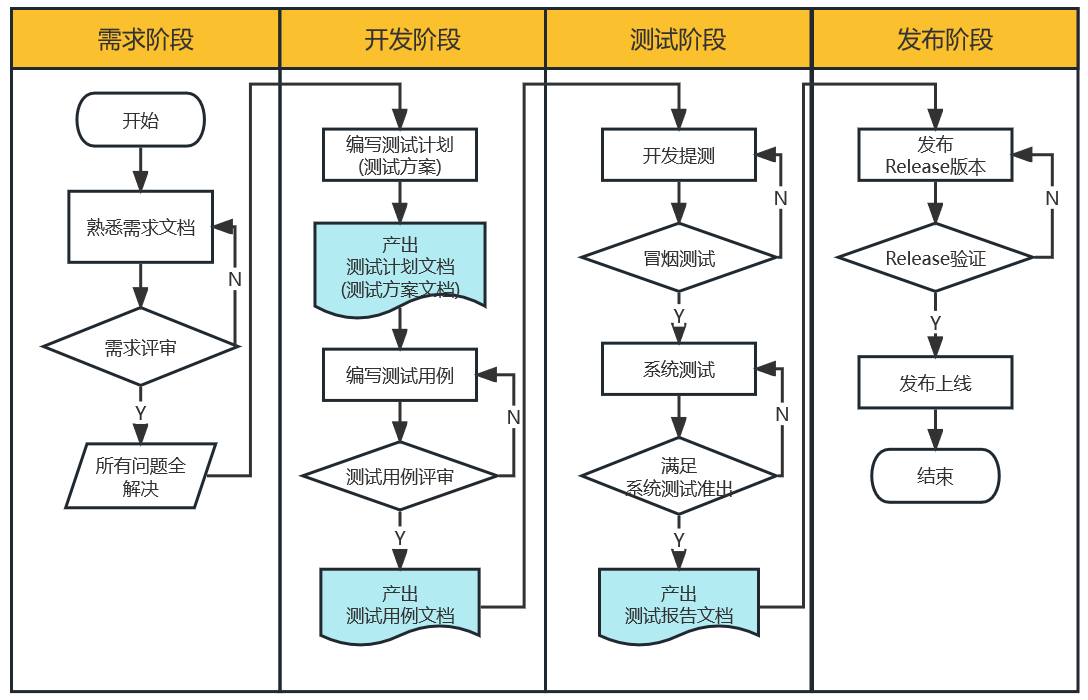
软件测试职业生涯需要编写的全套文档模板,收藏这一篇就够了 ~
作为一名测试工程师,在整个的职业生涯中,会涉及到各种不同类型的文档编写,大体包括如下: 对应文档模板及文档编写视频如下: 一、测试岗位必备的文档 在一个常规的软件测试流程中,会涉及到测试计划、测试方…...

【Kubernetes】Pod——k8s中最重要的对象之一
Pod是什么?如何使用Pod?资源共享和通信Pod 中的存储Pod 联网:跨 Pod 通信 静态 Pod感谢 💖 Pod是什么? Pod是k8s中创建和管理的、最小的可部署的计算单元。它包含一个或多个容器。就像豌豆荚里面包含了多个豌豆一样。…...

vue-cli-service: command not found问题解决
解决方案:重新安装一下: npm install -g vue/cli...

每日一练 | 华为认证真题练习Day117
1、缺省情况下,广播网络上OSPF协议Deadtime是? A. 20s B. 40s C. 10s D. 30s 2、当两台OSPF路由器形成TWO-WAY邻居关系时,LSDB已完成同步,但是SPF算法尚未运行。 A. 对 B. 错 3、以下哪种协议不属于文件传输协? …...
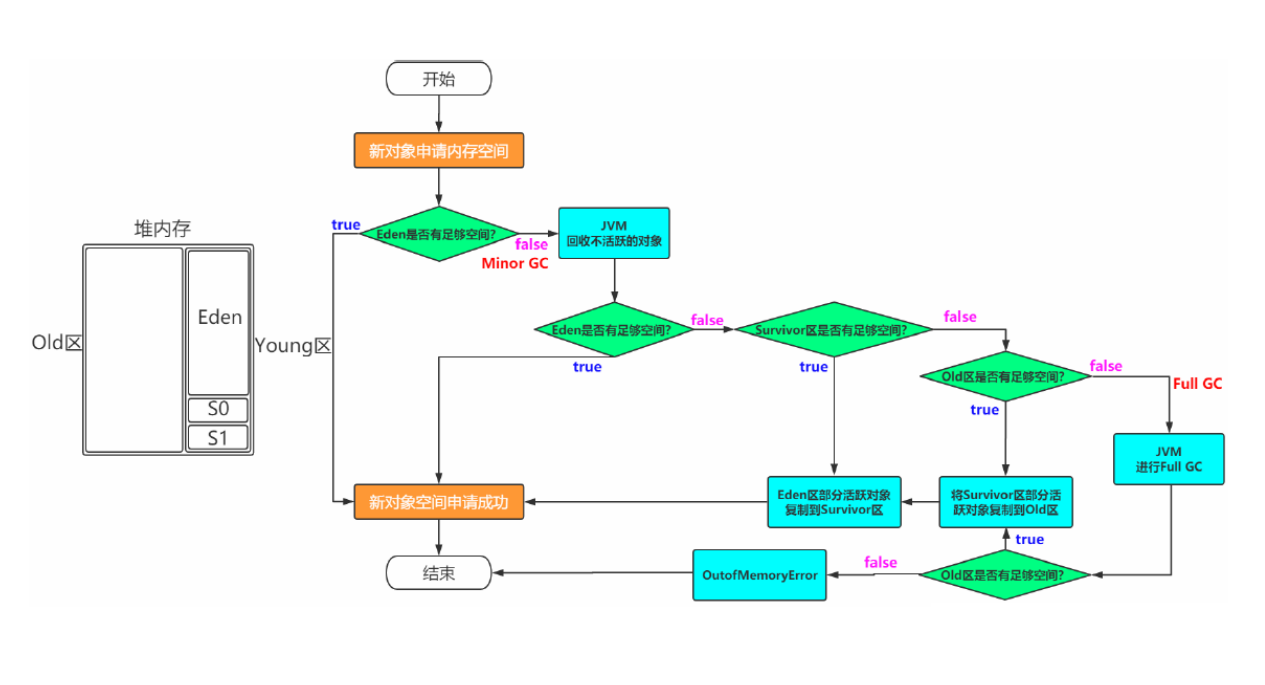
【JVM】垃圾回收(GC)详解
垃圾回收(GC)详解 一. 死亡对象的判断算法1. 引用计数算法2. 可达性分析算法 二. 垃圾回收算法1. 标记-清除算法2. 复制算法3. 标记-整理算法4. 分代算法 三. STW1. 为什么要 STW2. 什么情况下 STW 四. 垃圾收集器1. CMS收集器(老年代收集器&…...

阿里云服务器公网带宽多少钱1M?
阿里云服务器公网带宽计费模式按固定带宽”计费多少钱1M?地域不同带宽价格不同,北京、杭州、深圳等大陆地域价格是23元/Mbps每月,中国香港1M带宽价格是30元一个月,美国硅谷是30元一个月,日本东京1M带宽是25元一个月&am…...

应用DeepSORT实现目标跟踪
在ByteTrack被提出之前,可以说DeepSORT是最好的目标跟踪算法之一。本文,我们就来应用这个算法实现目标跟踪。 DeepSORT的官方网址是https://github.com/nwojke/deep_sort。但在这里,我们不使用官方的代码,而使用第三方代码&#…...

Beyond Compare 4 30天评估到期 解决方法
Beyond Compare 4 用习惯了,突然提示评估到期了,糟心😄 该方法将通过修改注册表,使BeyondCompare 版本4可以恢复到未评估状态,使其可以持续使用30天评估😄。 修改注册表 第一步:打开注册表。 在…...
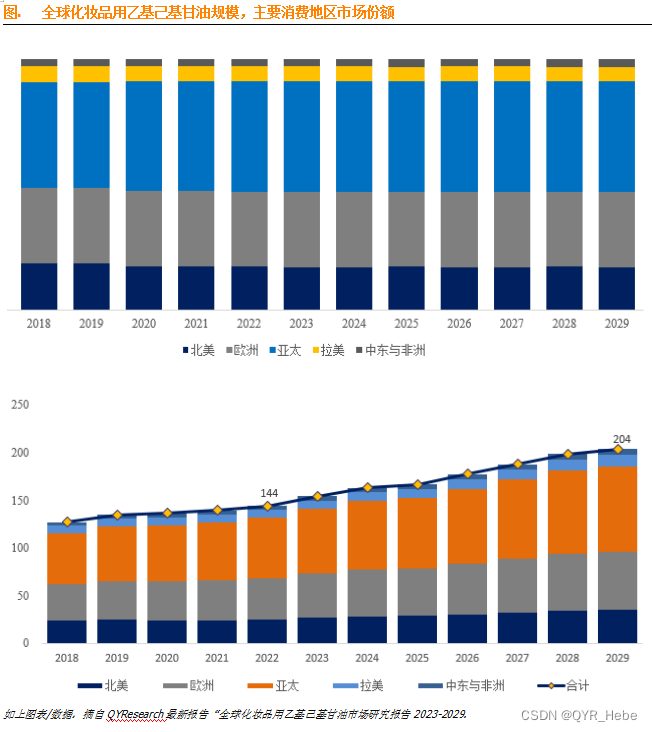
化妆品用乙基己基甘油全球市场总体规模2023-2029
乙基己基甘油又名辛氧基甘油,分子式 C11H24O3,分子量 204.306,沸点 325℃,密度 0.962,无色液体,涂抹性能适中的润肤剂、保湿剂及润湿剂。它能够在提高配方滋润效果的同时又具有柔滑的肤感。加入在某些膏霜体…...
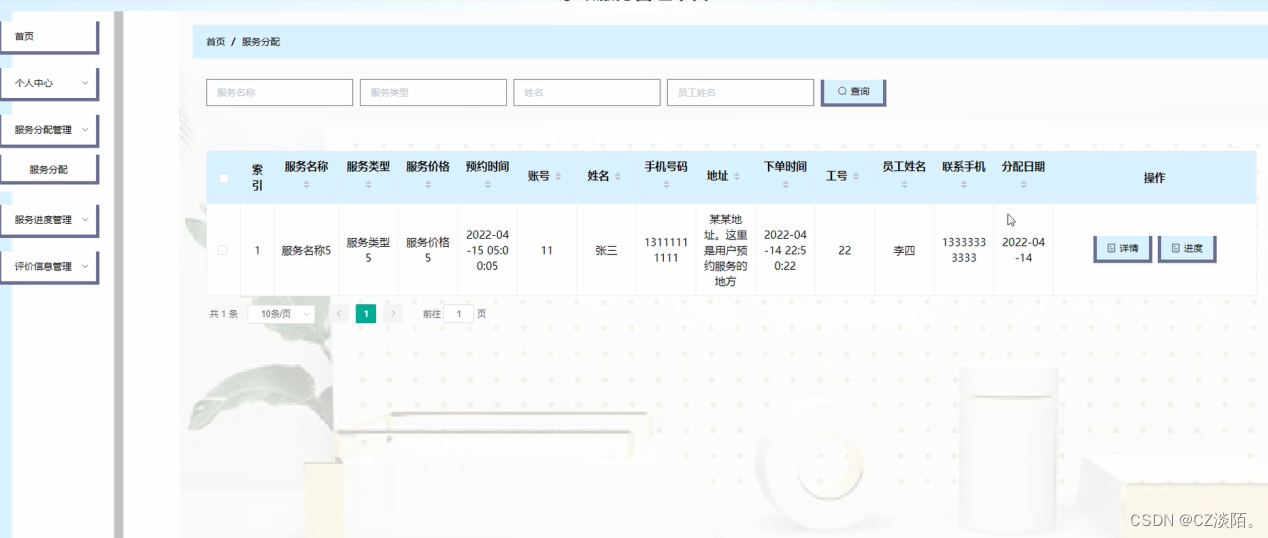
springboot家政服务管理平台springboot29
大家好✌!我是CZ淡陌。一名专注以理论为基础实战为主的技术博主,将再这里为大家分享优质的实战项目,本人在Java毕业设计领域有多年的经验,陆续会更新更多优质的Java实战项目,希望你能有所收获,少走一些弯路…...

【网络安全】如何保护IP地址?
使用防火墙是保护IP地址的一个重要手段。防火墙可以监控和过滤网络流量,并阻止未经授权的访问。一家网络安全公司的研究显示,超过80%的企业已经部署了防火墙来保护他们的网络和IP地址。 除了防火墙,定期更新操作系统和应用程序也是保护IP地址…...
2023年失业了,想学一门技术可以学什么?
有一个朋友,大厂毕业了,原本月薪估计有5w吧,年终奖也不错,所以早早的就买了房生了娃,一直是人生赢家的姿态。 但是今年突然就被毕业了,比起房货还有个几百万没还来说,他最想不通的是自己的价值…...

MySQL-MVCC(Multi-Version Concurrency Control)
MySQL-MVCC(Multi-Version Concurrency Control) MVCC(多版本并发控制):为了解决数据库并发读写和数据一致性的问题,是一种思想,可以有多种实现方式。 核心思想:写入时创建行的新版…...
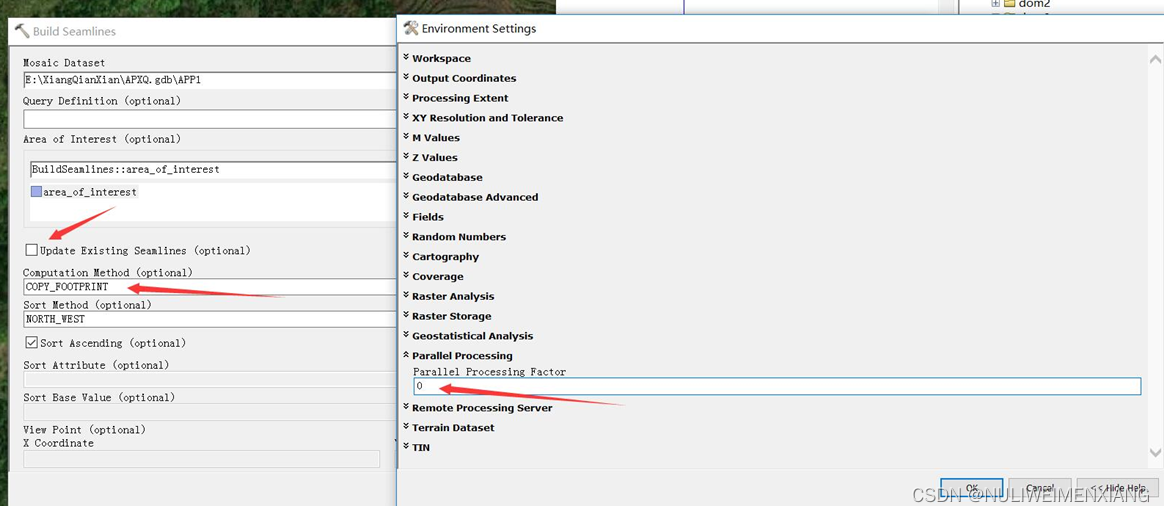
ArcGIS中的镶嵌数据集与接缝线
此处介绍一种简单方法,根据生成的轮廓线来做镶嵌数据集的拼接。 一、注意修改相邻影像的上下重叠。注意修改ZOrder和每幅影像的范围。 二、修改新的镶嵌线并且导出影像文件。 三、还有其他方法和注意事项。...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

spring:实例工厂方法获取bean
spring处理使用静态工厂方法获取bean实例,也可以通过实例工厂方法获取bean实例。 实例工厂方法步骤如下: 定义实例工厂类(Java代码),定义实例工厂(xml),定义调用实例工厂ÿ…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

聊一聊接口测试的意义有哪些?
目录 一、隔离性 & 早期测试 二、保障系统集成质量 三、验证业务逻辑的核心层 四、提升测试效率与覆盖度 五、系统稳定性的守护者 六、驱动团队协作与契约管理 七、性能与扩展性的前置评估 八、持续交付的核心支撑 接口测试的意义可以从四个维度展开,首…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

Fabric V2.5 通用溯源系统——增加图片上传与下载功能
fabric-trace项目在发布一年后,部署量已突破1000次,为支持更多场景,现新增支持图片信息上链,本文对图片上传、下载功能代码进行梳理,包含智能合约、后端、前端部分。 一、智能合约修改 为了增加图片信息上链溯源,需要对底层数据结构进行修改,在此对智能合约中的农产品数…...

安全突围:重塑内生安全体系:齐向东在2025年BCS大会的演讲
文章目录 前言第一部分:体系力量是突围之钥第一重困境是体系思想落地不畅。第二重困境是大小体系融合瓶颈。第三重困境是“小体系”运营梗阻。 第二部分:体系矛盾是突围之障一是数据孤岛的障碍。二是投入不足的障碍。三是新旧兼容难的障碍。 第三部分&am…...
)
GitHub 趋势日报 (2025年06月06日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 590 cognee 551 onlook 399 project-based-learning 348 build-your-own-x 320 ne…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...
《Docker》架构
文章目录 架构模式单机架构应用数据分离架构应用服务器集群架构读写分离/主从分离架构冷热分离架构垂直分库架构微服务架构容器编排架构什么是容器,docker,镜像,k8s 架构模式 单机架构 单机架构其实就是应用服务器和单机服务器都部署在同一…...