掌握 BERT:自然语言处理 (NLP) 从初级到高级的综合指南(1)

简介
BERT(来自 Transformers 的双向编码器表示)是 Google 开发的革命性自然语言处理 (NLP) 模型。它改变了语言理解任务的格局,使机器能够理解语言的上下文和细微差别。在本文[1]中,我们将带您踏上从 BERT 基础知识到高级概念的旅程,并配有解释、示例和代码片段。
BERT简介
什么是 BERT?
在不断发展的自然语言处理 (NLP) 领域,一项名为 BERT 的突破性创新已经成为游戏规则的改变者。 BERT 代表 Transformers 的双向编码器表示,它不仅仅是机器学习术语海洋中的另一个缩写词。它代表了机器理解语言方式的转变,使它们能够理解复杂的细微差别和上下文依赖性,从而使人类交流变得丰富而有意义。
为什么 BERT 很重要?
想象一句话:“她小提琴拉得很漂亮。”传统的语言模型会从左到右处理这个句子,忽略了乐器(“小提琴”)的身份影响整个句子的解释这一关键事实。然而,BERT 明白单词之间的上下文驱动关系在推导含义方面发挥着关键作用。它抓住了双向性的本质,使其能够考虑每个单词周围的完整上下文,彻底改变了语言理解的准确性和深度。
BERT 是如何工作的?
BERT 的核心由称为 Transformer 的强大神经网络架构提供支持。该架构采用了一种称为自注意力的机制,允许 BERT 根据每个单词的前后上下文来衡量其重要性。这种上下文意识使 BERT 能够生成上下文化的词嵌入,即考虑单词在句子中的含义的表示。这类似于 BERT 阅读并重新阅读句子以深入了解每个单词的作用。
考虑一下这句话:“‘主唱’将‘领导’乐队。”传统模型可能会因“领先”一词的模糊性而陷入困境。然而,BERT 毫不费力地区分出第一个“引导”是名词,而第二个“引导”是动词,展示了它在消除语言结构歧义方面的能力。
在接下来的章节中,我们将踏上揭开 BERT 神秘面纱的旅程,带您从基本概念到高级应用。您将探索如何利用 BERT 来执行各种 NLP 任务,了解其注意力机制,深入研究其训练过程,并见证其对重塑 NLP 格局的影响。
当我们深入研究 BERT 的复杂性时,您会发现它不仅仅是一个模型;它也是一个模型。这是机器理解人类语言本质的范式转变。因此,请系好安全带,让我们踏上 BERT 世界的启蒙之旅,在这里,语言理解超越平凡,实现非凡。
BERT 预处理文本
在 BERT 能够对文本发挥其魔力之前,需要以它可以理解的方式准备和结构化文本。在本章中,我们将探讨 BERT 预处理文本的关键步骤,包括标记化、输入格式和掩码语言模型 (MLM) 目标。
标记化:将文本分解为有意义的块
想象一下你正在教 BERT 读书。你不会一次性交出整本书;你会把它分成句子和段落。类似地,BERT 需要将文本分解为称为标记的更小的单元。但这里有一个不同之处:BERT 使用 WordPiece 标记化。它将单词分成更小的部分,比如把“running”变成“run”和“ning”。这有助于处理棘手的单词,并确保 BERT 不会迷失在不熟悉的单词中。
示例:原文:“ChatGPT 令人着迷。” WordPiece 标记:[“Chat”、“##G”、“##PT”、“is”、“fascinating”、“.”]
输入格式:为 BERT 提供上下文
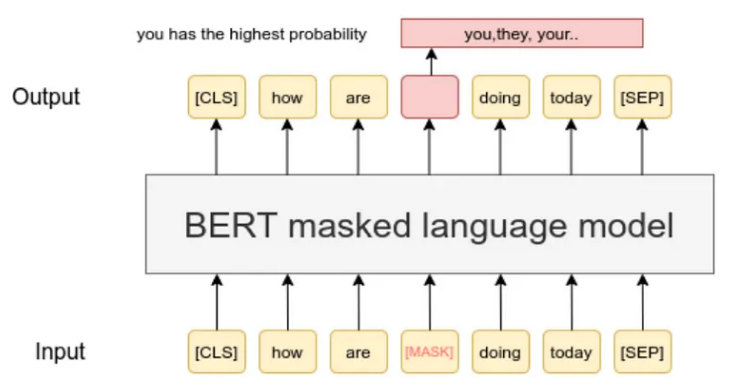
BERT 喜欢上下文,我们需要将它放在盘子里提供给他。为此,我们以 BERT 理解的方式格式化令牌。我们在开头添加特殊标记,例如 [CLS](代表分类),在句子之间添加 [SEP](代表分离)。如图(机器语言模型)所示。我们还分配分段嵌入来告诉 BERT 哪些标记属于哪个句子。
示例:原文:“ChatGPT 令人着迷。”格式化标记:[“[CLS]”、“Chat”、“##G”、“##PT”、“is”、“fascinating”、“.”、“[SEP]”]
掩码语言模型 (MLM) 目标:教授 BERT 上下文
BERT 的秘密在于它理解双向上下文的能力。在训练过程中,句子中的一些单词被屏蔽(用 [MASK] 替换),BERT 学习从上下文中预测这些单词。这有助于 BERT 掌握单词前后的相互关系。
示例:原句:“猫在垫子上。”蒙面句子:“[面具]在垫子上。”
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
text = "BERT preprocessing is essential."
tokens = tokenizer.tokenize(text)
print(tokens)
此代码使用 Hugging Face Transformers 库通过 BERT 分词器对文本进行分词。
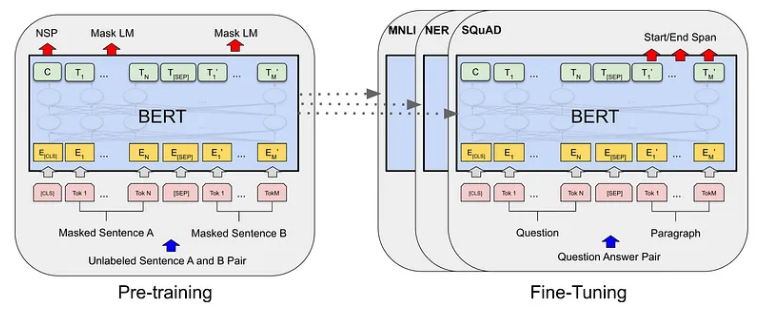
针对特定任务微调 BERT
了解 BERT 的工作原理后,是时候将其魔力付诸实际应用了。在本章中,我们将探讨如何针对特定语言任务微调 BERT。这涉及调整预训练的 BERT 模型来执行文本分类等任务。让我们深入了解一下!
BERT 的架构变化:寻找合适的方案
BERT 有不同的风格,例如 BERT-base、BERT-large 等等。这些变体具有不同的模型大小和复杂性。选择取决于您的任务要求和您拥有的资源。更大的模型可能表现更好,但它们也需要更多的计算能力。
NLP 中的迁移学习:基于预训练知识的构建
将 BERT 想象为一位已经阅读了大量文本的语言专家。我们不是从头开始教它一切,而是针对特定任务对其进行微调。这就是迁移学习的魔力——利用 BERT 预先存在的知识并针对特定任务进行定制。这就像有一位知识渊博的导师,只需要针对特定学科的一些指导。
下游任务和微调:调整 BERT 的知识
我们微调 BERT 的任务称为“下游任务”。示例包括情感分析、命名实体识别等。微调涉及使用特定于任务的数据更新 BERT 的权重。这有助于 BERT 专注于这些任务,而无需从头开始。
-
示例:使用 BERT 进行文本分类
from transformers import BertForSequenceClassification, BertTokenizer
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')
text = "This movie was amazing!"
inputs = tokenizer(text, return_tensors='pt')
outputs = model(**inputs)
predictions = torch.argmax(outputs.logits, dim=1)
print(predictions)
此代码演示了如何使用预训练的 BERT 模型通过 Hugging Face Transformer 进行文本分类。
在此代码片段中,我们加载了一个专为文本分类而设计的预训练 BERT 模型。我们对输入文本进行标记,将其传递到模型中并获得预测。针对特定任务对 BERT 进行微调,使其能够在现实应用中大放异彩。
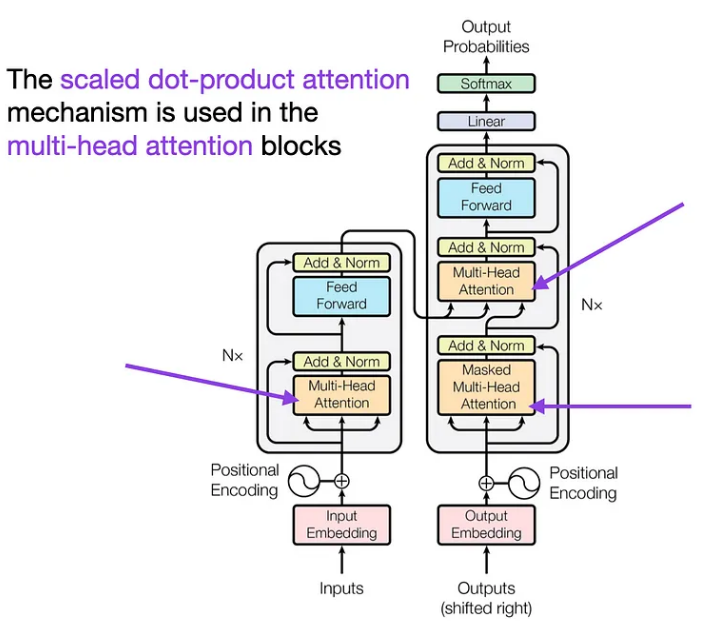
BERT的注意力机制
现在我们已经了解了如何将 BERT 应用于任务,让我们更深入地了解 BERT 如此强大的原因——它的注意力机制。在本章中,我们将探讨自注意力、多头注意力,以及 BERT 的注意力机制如何使其能够掌握语言的上下文。
Self-Attention:BERT 的超能力
想象一下阅读一本书并突出显示对您来说最重要的单词。自注意力就是这样,但是对于 BERT 来说。它会查看句子中的每个单词,并根据其他单词的重要性决定应给予多少关注。这样,BERT 就可以专注于相关单词,即使它们在句子中相距很远。
多头注意力:团队合作技巧
BERT 不仅仅依赖于一种观点;它使用多个注意力“头”。将这些负责人视为专注于句子各个方面的不同专家。这种多头方法帮助 BERT 捕获单词之间的不同关系,使其理解更丰富、更准确。
BERT 中的注意力:上下文魔法
BERT 的注意力不仅仅局限于单词之前或之后的单词。它考虑了两个方向!当 BERT 读取一个单词时,它并不孤单;它是一个单词。它知道它的邻居。通过这种方式,BERT 生成考虑单词整个上下文的嵌入。这就像理解一个笑话,不仅要通过笑点,还要通过设置。
-
代码片段:可视化注意力权重
import torch
from transformers import BertModel, BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
text = "BERT's attention mechanism is fascinating."
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True)
outputs = model(**inputs, output_attentions=True)
attention_weights = outputs.attentions
print(attention_weights)
在此代码中,我们使用 Hugging Face Transformers 可视化 BERT 的注意力权重。这些权重显示了 BERT 对句子中不同单词的关注程度。
BERT 的注意力机制就像一个聚光灯,帮助它关注句子中最重要的内容。
BERT的训练过程
了解 BERT 如何学习是欣赏其功能的关键。在本章中,我们将揭示 BERT 训练过程的复杂性,包括其预训练阶段、掩码语言模型 (MLM) 目标和下一句预测 (NSP) 目标。
预训练阶段:知识基础
BERT 的旅程从预训练开始,它从大量文本数据中学习。想象一下向 BERT 展示数百万个句子并让它预测缺失的单词。这项练习有助于 BERT 建立对语言模式和关系的扎实理解。
掩码语言模型 (MLM) 目标:填空游戏
在预训练期间,BERT 会得到一些带有掩码(隐藏)单词的句子。然后,它尝试根据周围的上下文来预测那些被屏蔽的单词。这就像填空游戏的语言版本。通过猜测缺失的单词,BERT 可以了解单词之间的相互关系,从而实现其上下文的出色表现。
下一个句子预测(NSP)目标:掌握句子流程
BERT 不仅能理解单词,还能理解单词。它掌握句子的流畅性。在 NSP 目标中,训练 BERT 来预测文本对中一个句子是否在另一个句子之后。这有助于 BERT 理解句子之间的逻辑联系,使其成为理解段落和较长文本的大师。
-
示例:预训练和传销
from transformers import BertForMaskedLM, BertTokenizer
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForMaskedLM.from_pretrained('bert-base-uncased')
text = "BERT is a powerful language model."
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True, add_special_tokens=True)
outputs = model(**inputs, labels=inputs['input_ids'])
loss = outputs.loss
print(loss)
此代码演示了 BERT 的掩码语言模型 (MLM) 的预训练。该模型在训练时预测屏蔽词,以最大限度地减少预测误差。
BERT 的训练过程就像通过填空和句对理解练习的结合来教它语言规则。在下一章中,我们将深入探讨 BERT 的嵌入以及它们如何为其语言能力做出贡献。保持学习!
BERT 嵌入

BERT 的强大之处在于它能够以捕获特定上下文中单词含义的方式表示单词。在本章中,我们将揭开 BERT 的嵌入,包括其上下文词嵌入、WordPiece 标记化和位置编码。
词嵌入与上下文词嵌入
将词嵌入视为词的代码词。 BERT 通过上下文词嵌入更进一步。 BERT 不是为每个单词只使用一个代码字,而是根据句子中的上下文为同一个单词创建不同的嵌入。这样,每个单词的表示就更加细致入微,并受到周围单词的影响。
WordPiece 标记化:处理复杂词汇
BERT 的词汇就像一个由称为子词的小块组成的拼图。它使用 WordPiece 标记化将单词分解为这些子词。这对于处理又长又复杂的单词以及处理以前从未见过的单词特别有用。
位置编码:导航句子结构
由于 BERT 以双向方式读取单词,因此它需要知道每个单词在句子中的位置。位置编码被添加到嵌入中,以赋予 BERT 空间感知能力。这样,BERT 不仅知道单词的含义,还知道它们在句子中的位置。
-
代码片段:使用拥抱面部变压器提取词嵌入
from transformers import BertTokenizer, BertModel
import torch
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
text = "BERT embeddings are fascinating."
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True, add_special_tokens=True)
outputs = model(**inputs)
word_embeddings = outputs.last_hidden_state
print(word_embeddings)
此代码展示了如何使用 Hugging Face Transformers 提取词嵌入。该模型为输入文本中的每个单词生成上下文嵌入。
BERT 的嵌入就像一个语言游乐场,单词在这里获得基于上下文的独特身份。
未完待续!
Reference
Source: https://medium.com/@shaikhrayyan123/a-comprehensive-guide-to-understanding-bert-from-beginners-to-advanced-2379699e2b51
本文由 mdnice 多平台发布
相关文章:
掌握 BERT:自然语言处理 (NLP) 从初级到高级的综合指南(1)
简介 BERT(来自 Transformers 的双向编码器表示)是 Google 开发的革命性自然语言处理 (NLP) 模型。它改变了语言理解任务的格局,使机器能够理解语言的上下文和细微差别。在本文[1]中,我们将带您踏上从 BERT 基础知识到高级概念的旅…...
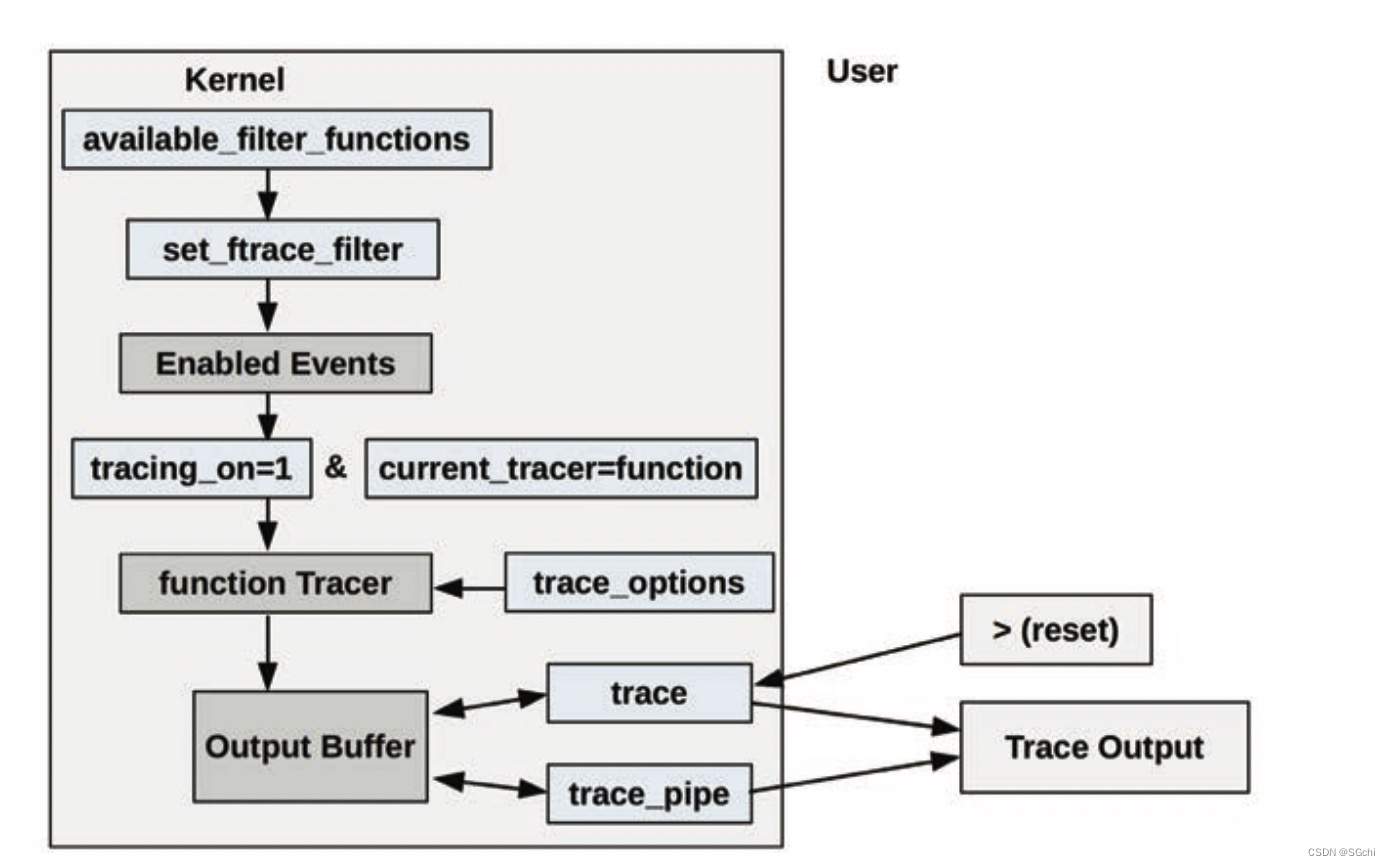
Linux Ftrace介绍
文章目录 一、简介二、内核函数调用跟踪参考链接: 一、简介 Ftrace 是 Linux 官方提供的跟踪工具,在 Linux 2.6.27 版本中引入。Ftrace 可在不引入任何前端工具的情况下使用,让其可以适合在任何系统环境中使用。 Ftrace 可用来快速排查以下相…...

Go语言进阶------>init()函数
Init()包初始化 执行优先级 Init()函数的执行优先级比main()函数的执行优先级要高,也就是说程序会优先执行Init()函数之后再执行main()函数. 代码如下 package mainimport "fmt"func init() {fmt.Println("执行了Init()函数") }func main() {fmt.Println…...

云计算:常用微服务框架
目录 一、理论 1.Java微服务框架 2.Go微服务框架 3.Python微服务框架 4.Node.js微服务框架 5..Net微服务框架 一、理论 1.Java微服务框架 Spring Cloud:最早最成熟,Java开源微服务框架方案 SpringBoot:全新框架,设计目的是…...

jmeter添加断言(详细图解)
先创建一个线程组,再创建一个http请求。 为了方便观察,我们添加两个监听器,察看结果树和断言结果。 添加断言:响应断言,响应断言也是比较常用的一个断言 设置响应断言:正常情况下响应代码是200。选择响应代…...
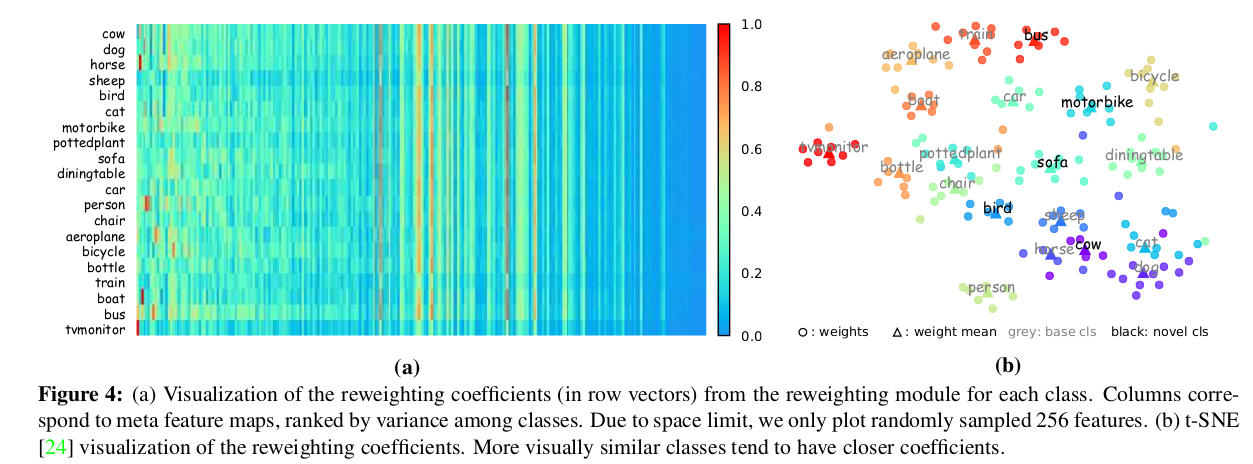
few shot object detection via feature reweight笔记
摘要部分 few shot很多用的都是faster R-CNN为基础,本文用的是one-stage 结构。 用了一个meta feature learner和reweighting模块。 和其他的few shot一样,先学习base数据集,再推广到novel数据集。 feature learner会从base数据集中提取meta…...

工会排队模式:电商新营销模式吸引消费者,提升销售!
随着电商行业的繁荣发展,私域流量已经成为了电商平台争夺消费者和促进销售的重要手段。工会排队模式正是在这种背景下应运而生的一种创新性的电商营销模式。这种模式通过奖金池的资金来为消费者和商家提供返现和排队奖励,构建了一个实现消费者和商家共赢…...
国际红外技术及设备展览会)
定档通知2024中国(北京)国际红外技术及设备展览会
时间:2024年7月14-16日 地点:北京国家会议中心 ◆展会背景background: 各有关红外企业厂商:2024年7月14~16日,2024中国国际红外技术及设…...
自助建站系统,一建建站系统api版,自动建站
安装推荐php7.2或7.2以下都行 可使用虚拟主机或者服务器进行搭建。 分站进入网站后台 域名/admin 初始账号123456qq.com密码123456 找到后台的网站设置 将主站域名及你在主站的通信secretId和通信secretKey填进去。 即可正常使用 通信secretId和通信secretKey在主站的【账号…...
算法框架-LLM-1-Prompt设计(一)
原文:算法框架-LLM-1-Prompt设计(一) - 知乎 目录 收起 1 prompt-engineering-for-developers 1.1 Prompt Engineering 1.1.1 提示原则 1. openai的环境 2. 两个基本原则 3. 示例 eg.1 eg.2 结构化输出 eg.3 模型检验 eg.4 提供示…...
一个rar压缩包如何分成三个?
一个rar压缩包体积太大了,想要将压缩包分为三个,该如何做到?其实很简单,方法就在我们经常使用的WinRAR当中。 我们先将压缩包内的文件解压出来,然后查看一下,然后打开WinRAR软件,找到文件&…...

批量获取拼多多商品详情数据,拼多多商品详情API接口
批量获取拼多多商品详情数据可以采用以下方式: 使用拼多多开放平台API接口。 拼多多开放平台提供了API接口,可以通过API接口获取拼多多平台上的商品信息,使用API接口需要进行权限申请和认证,操作较为复杂。 使用第三方工具。 市面…...

Redis Cluster Gossip Protocol: 目录
术语说明 server:当前的节点 cluster:每个节点的内存中都有一个集群信息结构,里面包含了集群中各个节点的状态信息(包括server自己) myself:当前节点在cluster中的实体 node:cluster节点字典中…...

HarmonyOS/OpenHarmony原生应用-ArkTS万能卡片组件Span
作为Text组件的子组件,用于显示行内文本的组件。无子组件 一、接口 Span(value: string | Resource) 从API version 9开始,该接口支持在ArkTS卡片中使用。 参数: 参数名 参数类型 必填 参数描述 value string | Resource 是 文本内…...

这些负载均衡都解决哪些问题?服务、网关、NGINX
这篇文章解答一下群友的一系列提问: 在微服务项目中,有服务的负载均衡、网关的负载均衡、Nginx的负载均衡,这几个负载均衡分别用来解决什么问题呢? 在微服务项目中,服务的负载均衡、网关的负载均衡和Nginx的负载均衡都…...

Lambda表达式在C++中的定义
目录 背景介绍: Lambda表达式的定义: Lambda结构介绍: 1. Lambda capture 2. Lambda parameter list 3. Lambda mutable 4. Lambda return type 5. Lambda 主体 Lambda 表达式小结: Lambda 引用参考: 背景介…...

sheng的学习笔记-【中文】【吴恩达课后测验】Course 1 - 神经网络和深度学习 - 第二周测验
课程1_第2周_测验题 目录:目录 第一题 1.神经元计算什么? A. 【 】神经元计算激活函数后,再计算线性函数(zWxb) B. 【 】神经元计算一个线性函数(zWxb),然后接一个激活函数…...

前端代码格式化规范总结
在日常开发过程中,经常会碰到代码格式化不一致的问题,还要就是 js 代码语法错误等没有及时发行改正,下面就介绍一下如何使用eslint、prettier、husky、lint-staged、commitizen来规范代码格式和提高代码质量的方法。 目录 准备工作代码检测代…...

Windows10打开应用总是会弹出提示窗口的解决方法
用户们在Windows10电脑中打开应用程序,遇到了总是会弹出提示窗口的烦人问题。这样的情况会干扰到用户的正常操作,给用户带来不好的操作体验,接下来小编给大家详细介绍关闭这个提示窗口的方法,让大家可以在Windows10电脑中舒心操作…...

易点易动固定资产管理系统: 帮助您应对2023年年终固定资产大盘点
作为一名企业的行政人员,我们都了解年终固定资产盘点对于企业来说至关重要。然而,面对众多资产、复杂的流程和繁琐的记录工作,往往会令人感到头疼不已。为了帮助您应对2023年的年终固定资产大盘点,我们推荐易点易动固定资产管理系…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

JavaSec-RCE
简介 RCE(Remote Code Execution),可以分为:命令注入(Command Injection)、代码注入(Code Injection) 代码注入 1.漏洞场景:Groovy代码注入 Groovy是一种基于JVM的动态语言,语法简洁,支持闭包、动态类型和Java互操作性,…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

Rapidio门铃消息FIFO溢出机制
关于RapidIO门铃消息FIFO的溢出机制及其与中断抖动的关系,以下是深入解析: 门铃FIFO溢出的本质 在RapidIO系统中,门铃消息FIFO是硬件控制器内部的缓冲区,用于临时存储接收到的门铃消息(Doorbell Message)。…...
详细解析)
Caliper 负载(Workload)详细解析
Caliper 负载(Workload)详细解析 负载(Workload)是 Caliper 性能测试的核心部分,它定义了测试期间要执行的具体合约调用行为和交易模式。下面我将全面深入地讲解负载的各个方面。 一、负载模块基本结构 一个典型的负载模块(如 workload.js)包含以下基本结构: use strict;/…...

在 Spring Boot 项目里,MYSQL中json类型字段使用
前言: 因为程序特殊需求导致,需要mysql数据库存储json类型数据,因此记录一下使用流程 1.java实体中新增字段 private List<User> users 2.增加mybatis-plus注解 TableField(typeHandler FastjsonTypeHandler.class) private Lis…...

Qt 事件处理中 return 的深入解析
Qt 事件处理中 return 的深入解析 在 Qt 事件处理中,return 语句的使用是另一个关键概念,它与 event->accept()/event->ignore() 密切相关但作用不同。让我们详细分析一下它们之间的关系和工作原理。 核心区别:不同层级的事件处理 方…...

【深度学习新浪潮】什么是credit assignment problem?
Credit Assignment Problem(信用分配问题) 是机器学习,尤其是强化学习(RL)中的核心挑战之一,指的是如何将最终的奖励或惩罚准确地分配给导致该结果的各个中间动作或决策。在序列决策任务中,智能体执行一系列动作后获得一个最终奖励,但每个动作对最终结果的贡献程度往往…...