自然语言处理(NLP)之求近义词和类比词<MXNet中GloVe和FastText的模型使用>
这节主要就是熟悉MXNet框架中的两种模型:GloVe和FastText的模型(词嵌入名称),每个模型下面有很多不同的词向量,这些基本都来自wiki维基百科和twitter推特这些子集预训练得到的。
我们只需要导入mxnet.contrib中的text模块即可,这里面提供了很多关于自然语言处理相关的函数和类。
from mxnet import nd
from mxnet.contrib import text
print(text.embedding.get_pretrained_file_names().keys())
#dict_keys(['glove', 'fasttext'])
print(text.embedding.get_pretrained_file_names('glove'))
'''
['glove.42B.300d.txt', 'glove.6B.50d.txt', 'glove.6B.100d.txt', 'glove.6B.200d.txt',
'glove.6B.300d.txt', 'glove.840B.300d.txt', 'glove.twitter.27B.25d.txt', 'glove.twitter.27B.50d.txt',
'glove.twitter.27B.100d.txt', 'glove.twitter.27B.200d.txt']
'''这些模型的命名大概是"模型名.(数据集.)数据集词数.词向量维度.txt",比如最后这个'glove.twitter.27B.200d.txt'表示glove模型,基于twitter的数据,200个维度的词向量,这个有1.4G,我们选择一个小点的'glove.6B.50d.txt'来测试,822M,可以自己手动也可以让程序自动下载。这里下载下来之后里面包括了50维、100维、200维、300维的文档,下载的目录,本人的是C:\Users\Tony\AppData\Roaming\mxnet\embeddings\glove\glove.6B.zip 解压之后分别是glove.6B.50d.txt、glove.6B.100d.txt、glove.6B.200d.txt、glove.6B.300d.txt这四个文本文档,对于不愿意下载这么大文件的伙伴可以只下载glove.6B.50d.txt,只有163M,下载地址:https://download.csdn.net/download/weixin_41896770/87464231
我们用Notepad++打开看下这个50维的词向量的内容。如下图:
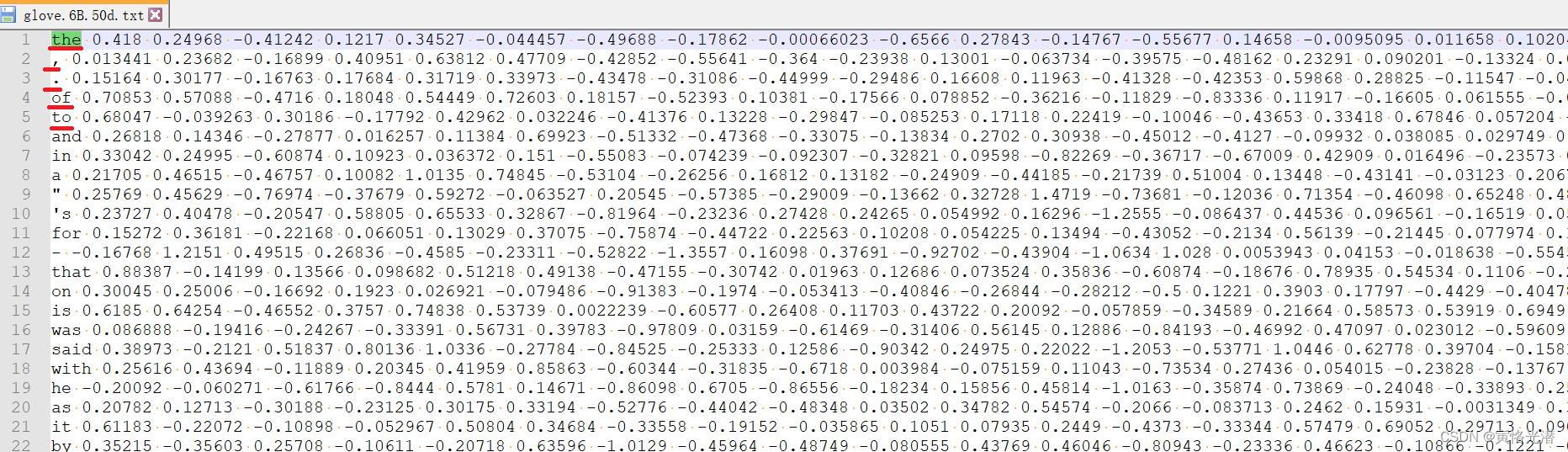
可以看到每行第一个词对应后面的数字有50个,也就是说是50维的意思,这个50个可以使用一个统计函数来快速验证下:
>>> import collections
>>> collections.Counter('of 0.70853 0.57088 -0.4716 0.18048 0.54449 0.72603 0.18157 -0.52393 0.10381 -0.17566 0.078852 -0.36216 -0.11829 -0.83336 0.11917 -0.16605 0.061555 -0.012719 -0.56623 0.013616 0.22851 -0.14396 -0.067549 -0.38157 -0.23698 -1.7037 -0.86692 -0.26704 -0.2589 0.1767 3.8676 -0.1613 -0.13273 -0.68881 0.18444 0.0052464 -0.33874 -0.078956 0.24185 0.36576 -0.34727 0.28483 0.075693 -0.062178 -0.38988 0.22902 -0.21617 -0.22562 -0.093918 -0.80375')
Counter({'0': 69, ' ': 50, '.': 50, '1': 34, '6': 33, '8': 32, '-': 29, '3': 28, '7': 27, '2': 26, '5': 23, '4': 17, '9': 16, 'o': 1, 'f': 1})其中点'.'是50,说明有50个数字,就是说每个词都映射成50维的数字来表示。
GloVe模型
创建词向量实例:
glove_6b50d=text.embedding.create('glove',pretrained_file_name='glove.6B.50d.txt')
print(len(glove_6b50d))#400001这个词典有40万个词和一个特殊的未知词符号。我们可以通过词来获取它在词典中的索引或者通过索引获取词。
print(glove_6b50d.token_to_idx['of'],glove_6b50d.idx_to_token[4])#4 of上面图片中我们看到的of是第四个,索引应该是3,为什么是4呢?我们打印索引为0的词就明白了,是未知词<unk>
我们通过上面的操作应该了解了这个预训练的词向量。接下来我们就以GloVe模型为例,展示这个预训练词向量的应用。
近义词
我们通过余弦相似度来搜索近义词,在后面求类比词也将用到k近邻(k-nearest neighbor,knn)的逻辑,所以这里写一个knn的方法
def knn(W, x, k):# 1e-9为了数值稳定性cos = nd.dot(W, x.reshape((-1,))) / ((nd.sum(W**2, axis=1) + 1e-9).sqrt() * nd.sum(x**2).sqrt())#topk选取最大值的索引,k表示取前几个最大topk = nd.topk(cos, k=k, ret_typ="indices").asnumpy().astype("int32")return topk, [cos[i].asscalar() for i in topk]然后通过词向量实例来搜索近义词
我们再次来了解下这个词向量,在上面我们知道第一个是未知词,打开文档没有看到,所以我们这里通过输出来看下
print(glove_6b50d.idx_to_vec)
'''
[[ 0. 0. 0. ... 0. 0. 0. ][ 0.418 0.24968 -0.41242 ... -0.18411 -0.11514 -0.78581 ][ 0.013441 0.23682 -0.16899 ... -0.56657 0.044691 0.30392 ]...[-0.51181 0.058706 1.0913 ... -0.25003 -1.125 1.5863 ][-0.75898 -0.47426 0.4737 ... 0.78954 -0.014116 0.6448 ][ 0.072617 -0.51393 0.4728 ... -0.18907 -0.59021 0.55559 ]]
<NDArray 400001x50 @cpu(0)>
'''可以看到第一行都是0,这个是<unk>的词向量,其余400000个词都对应着50维的数值。
还可以指定词来查询对应的向量:
print(glove_6b50d.get_vecs_by_tokens(["the", "of"]))
'''
[[ 4.1800e-01 2.4968e-01 -4.1242e-01 1.2170e-01 3.4527e-01 -4.4457e-02-4.9688e-01 -1.7862e-01 -6.6023e-04 -6.5660e-01 2.7843e-01 -1.4767e-01-5.5677e-01 1.4658e-01 -9.5095e-03 1.1658e-02 1.0204e-01 -1.2792e-01-8.4430e-01 -1.2181e-01 -1.6801e-02 -3.3279e-01 -1.5520e-01 -2.3131e-01-1.9181e-01 -1.8823e+00 -7.6746e-01 9.9051e-02 -4.2125e-01 -1.9526e-014.0071e+00 -1.8594e-01 -5.2287e-01 -3.1681e-01 5.9213e-04 7.4449e-031.7778e-01 -1.5897e-01 1.2041e-02 -5.4223e-02 -2.9871e-01 -1.5749e-01-3.4758e-01 -4.5637e-02 -4.4251e-01 1.8785e-01 2.7849e-03 -1.8411e-01-1.1514e-01 -7.8581e-01][ 7.0853e-01 5.7088e-01 -4.7160e-01 1.8048e-01 5.4449e-01 7.2603e-011.8157e-01 -5.2393e-01 1.0381e-01 -1.7566e-01 7.8852e-02 -3.6216e-01-1.1829e-01 -8.3336e-01 1.1917e-01 -1.6605e-01 6.1555e-02 -1.2719e-02-5.6623e-01 1.3616e-02 2.2851e-01 -1.4396e-01 -6.7549e-02 -3.8157e-01-2.3698e-01 -1.7037e+00 -8.6692e-01 -2.6704e-01 -2.5890e-01 1.7670e-013.8676e+00 -1.6130e-01 -1.3273e-01 -6.8881e-01 1.8444e-01 5.2464e-03-3.3874e-01 -7.8956e-02 2.4185e-01 3.6576e-01 -3.4727e-01 2.8483e-017.5693e-02 -6.2178e-02 -3.8988e-01 2.2902e-01 -2.1617e-01 -2.2562e-01-9.3918e-02 -8.0375e-01]]
<NDArray 2x50 @cpu(0)>
'''这个可以跟上面的图片比对下,是不是一样。
然后通过上面的knn,我们来做个示例:
def get_similar_tokens(query_token, k, embed):topk, cos = knn(embed.idx_to_vec, embed.get_vecs_by_tokens([query_token]), k + 1)for i, c in zip(topk[1:], cos[1:]):print("余弦相似度:%.3f:%s" % (c, embed.idx_to_token[i]))get_similar_tokens("chip", 3, glove_6b50d)
'''
余弦相似度:0.856:chips
余弦相似度:0.749:intel
余弦相似度:0.749:electronics
'''get_similar_tokens("beautiful", 3, glove_6b50d)
'''
余弦相似度:0.921:lovely
余弦相似度:0.893:gorgeous
余弦相似度:0.830:wonderful
'''当然这里的近义词,跟我们传统上的近义词还是有点区别,比如上面的芯片和英特尔不是近义词,这里相似度很高,是因为英特尔主营芯片。
类比词
类比词跟近义词不一样,它类似于一种对照出来的词,例如:"man"类比"woman"那么"son"类比是"daughter",那么如何求类比词,这里就是需要三个词求第四个词,对于a:b::c:d,给定a、b、c求出d。假设词w的词向量为vec(w),求类比词的思路是,搜索与vec(b)+vec(c)-vec(a)的结果向量最相似的词向量。
def get_analogy(a, b, c, embed):vecs = embed.get_vecs_by_tokens([a, b, c])x = vecs[1] + vecs[2] - vecs[0]topk, cos = knn(embed.idx_to_vec, x, 1)return embed.idx_to_token[topk[0]], cosprint(get_analogy("man", "woman", "son", glove_6b50d))
'''
('daughter', [0.9658343])
'''
print(get_analogy("beijing", "china", "tokyo", glove_6b50d))
'''
('japan', [0.9054066])
'''
print(get_analogy("bad", "worst", "big", glove_6b50d))
'''
('biggest', [0.8059626])
'''
print(get_analogy("do", "did", "go", glove_6b50d))
'''
('went', [0.9242296])
'''FastText模型
上面介绍了全局词向量模型GloVe,接下来看下FastText模型,我们回到最开始,先来看下它下面有哪些词向量模型:
print(text.embedding.get_pretrained_file_names('fasttext'))
'''
['crawl-300d-2M.vec', 'wiki.aa.vec', 'wiki.ab.vec', 'wiki.ace.vec', 'wiki.ady.vec', 'wiki.af.vec', 'wiki.ak.vec', 'wiki.als.vec', 'wiki.am.vec', 'wiki.ang.vec', 'wiki.an.vec', 'wiki.arc.vec', 'wiki.ar.vec', 'wiki.arz.vec', 'wiki.ast.vec', 'wiki.as.vec', 'wiki.av.vec', 'wiki.ay.vec', 'wiki.azb.vec', 'wiki.az.vec', 'wiki.bar.vec', 'wiki.bat_smg.vec', 'wiki.ba.vec', 'wiki.bcl.vec', 'wiki.be.vec', 'wiki.bg.vec', 'wiki.bh.vec', 'wiki.bi.vec', 'wiki.bjn.vec', 'wiki.bm.vec', 'wiki.bn.vec', 'wiki.bo.vec', 'wiki.bpy.vec', 'wiki.br.vec', 'wiki.bs.vec', 'wiki.bug.vec', 'wiki.bxr.vec', 'wiki.ca.vec', 'wiki.cbk_zam.vec', 'wiki.cdo.vec', 'wiki.ceb.vec', 'wiki.ce.vec', 'wiki.cho.vec', 'wiki.chr.vec', 'wiki.ch.vec', 'wiki.chy.vec', 'wiki.ckb.vec', 'wiki.co.vec', 'wiki.crh.vec', 'wiki.cr.vec', 'wiki.csb.vec', 'wiki.cs.vec', 'wiki.cu.vec', 'wiki.cv.vec', 'wiki.cy.vec', 'wiki.da.vec', 'wiki.de.vec', 'wiki.diq.vec', 'wiki.dsb.vec', 'wiki.dv.vec', 'wiki.dz.vec', 'wiki.ee.vec', 'wiki.el.vec', 'wiki.eml.vec', 'wiki.en.vec', 'wiki.eo.vec', 'wiki.es.vec', 'wiki.et.vec', 'wiki.eu.vec', 'wiki.ext.vec', 'wiki.fa.vec', 'wiki.ff.vec', 'wiki.fiu_vro.vec', 'wiki.fi.vec', 'wiki.fj.vec', 'wiki.fo.vec', 'wiki.frp.vec', 'wiki.frr.vec', 'wiki.fr.vec', 'wiki.fur.vec', 'wiki.fy.vec', 'wiki.gag.vec', 'wiki.gan.vec', 'wiki.ga.vec', 'wiki.gd.vec', 'wiki.glk.vec', 'wiki.gl.vec', 'wiki.gn.vec', 'wiki.gom.vec', 'wiki.got.vec', 'wiki.gu.vec', 'wiki.gv.vec', 'wiki.hak.vec', 'wiki.ha.vec', 'wiki.haw.vec', 'wiki.he.vec', 'wiki.hif.vec', 'wiki.hi.vec', 'wiki.ho.vec', 'wiki.hr.vec', 'wiki.hsb.vec', 'wiki.ht.vec', 'wiki.hu.vec', 'wiki.hy.vec', 'wiki.hz.vec', 'wiki.ia.vec', 'wiki.id.vec', 'wiki.ie.vec', 'wiki.ig.vec', 'wiki.ii.vec', 'wiki.ik.vec', 'wiki.ilo.vec', 'wiki.io.vec', 'wiki.is.vec', 'wiki.it.vec', 'wiki.iu.vec', 'wiki.jam.vec', 'wiki.ja.vec', 'wiki.jbo.vec', 'wiki.jv.vec', 'wiki.kaa.vec', 'wiki.kab.vec', 'wiki.ka.vec', 'wiki.kbd.vec', 'wiki.kg.vec', 'wiki.ki.vec', 'wiki.kj.vec', 'wiki.kk.vec', 'wiki.kl.vec', 'wiki.km.vec', 'wiki.kn.vec', 'wiki.koi.vec', 'wiki.ko.vec', 'wiki.krc.vec', 'wiki.kr.vec', 'wiki.ksh.vec', 'wiki.ks.vec', 'wiki.ku.vec', 'wiki.kv.vec', 'wiki.kw.vec', 'wiki.ky.vec', 'wiki.lad.vec', 'wiki.la.vec', 'wiki.lbe.vec', 'wiki.lb.vec', 'wiki.lez.vec', 'wiki.lg.vec', 'wiki.lij.vec', 'wiki.li.vec', 'wiki.lmo.vec', 'wiki.ln.vec', 'wiki.lo.vec', 'wiki.lrc.vec', 'wiki.ltg.vec', 'wiki.lt.vec', 'wiki.lv.vec', 'wiki.mai.vec', 'wiki.map_bms.vec', 'wiki.mdf.vec', 'wiki.mg.vec', 'wiki.mhr.vec', 'wiki.mh.vec', 'wiki.min.vec', 'wiki.mi.vec', 'wiki.mk.vec', 'wiki.ml.vec', 'wiki.mn.vec', 'wiki.mo.vec', 'wiki.mrj.vec', 'wiki.mr.vec', 'wiki.ms.vec', 'wiki.mt.vec', 'wiki.multi.ar.vec', 'wiki.multi.bg.vec', 'wiki.multi.ca.vec', 'wiki.multi.cs.vec', 'wiki.multi.da.vec', 'wiki.multi.de.vec', 'wiki.multi.el.vec', 'wiki.multi.en.vec', 'wiki.multi.es.vec', 'wiki.multi.et.vec', 'wiki.multi.fi.vec', 'wiki.multi.fr.vec', 'wiki.multi.he.vec', 'wiki.multi.hr.vec', 'wiki.multi.hu.vec', 'wiki.multi.id.vec', 'wiki.multi.it.vec', 'wiki.multi.mk.vec', 'wiki.multi.nl.vec', 'wiki.multi.no.vec', 'wiki.multi.pl.vec', 'wiki.multi.pt.vec', 'wiki.multi.ro.vec', 'wiki.multi.ru.vec', 'wiki.multi.sk.vec', 'wiki.multi.sl.vec', 'wiki.multi.sv.vec', 'wiki.multi.tr.vec', 'wiki.multi.uk.vec', 'wiki.multi.vi.vec', 'wiki.mus.vec', 'wiki.mwl.vec', 'wiki.my.vec', 'wiki.myv.vec', 'wiki.mzn.vec', 'wiki.nah.vec', 'wiki.nap.vec', 'wiki.na.vec', 'wiki.nds_nl.vec', 'wiki.nds.vec', 'wiki.ne.vec', 'wiki-news-300d-1M-subword.vec', 'wiki-news-300d-1M.vec', 'wiki.new.vec', 'wiki.ng.vec', 'wiki.nl.vec', 'wiki.nn.vec', 'wiki.no.vec', 'wiki.nov.vec', 'wiki.nrm.vec', 'wiki.nso.vec', 'wiki.nv.vec', 'wiki.ny.vec', 'wiki.oc.vec', 'wiki.olo.vec', 'wiki.om.vec', 'wiki.or.vec', 'wiki.os.vec', 'wiki.pag.vec', 'wiki.pam.vec', 'wiki.pap.vec', 'wiki.pa.vec', 'wiki.pcd.vec', 'wiki.pdc.vec', 'wiki.pfl.vec', 'wiki.pih.vec', 'wiki.pi.vec', 'wiki.pl.vec', 'wiki.pms.vec', 'wiki.pnb.vec', 'wiki.pnt.vec', 'wiki.ps.vec', 'wiki.pt.vec', 'wiki.qu.vec', 'wiki.rm.vec', 'wiki.rmy.vec', 'wiki.rn.vec', 'wiki.roa_rup.vec', 'wiki.roa_tara.vec', 'wiki.ro.vec', 'wiki.rue.vec', 'wiki.ru.vec', 'wiki.rw.vec', 'wiki.sah.vec', 'wiki.sa.vec', 'wiki.scn.vec', 'wiki.sco.vec', 'wiki.sc.vec', 'wiki.sd.vec', 'wiki.se.vec', 'wiki.sg.vec', 'wiki.sh.vec', 'wiki.simple.vec', 'wiki.si.vec', 'wiki.sk.vec', 'wiki.sl.vec', 'wiki.sm.vec', 'wiki.sn.vec', 'wiki.so.vec', 'wiki.sq.vec', 'wiki.srn.vec', 'wiki.sr.vec', 'wiki.ss.vec', 'wiki.stq.vec', 'wiki.st.vec', 'wiki.su.vec', 'wiki.sv.vec', 'wiki.sw.vec', 'wiki.szl.vec', 'wiki.ta.vec', 'wiki.tcy.vec', 'wiki.tet.vec', 'wiki.te.vec', 'wiki.tg.vec', 'wiki.th.vec', 'wiki.ti.vec', 'wiki.tk.vec', 'wiki.tl.vec', 'wiki.tn.vec', 'wiki.to.vec', 'wiki.tpi.vec', 'wiki.tr.vec', 'wiki.ts.vec', 'wiki.tt.vec', 'wiki.tum.vec', 'wiki.tw.vec', 'wiki.ty.vec', 'wiki.tyv.vec', 'wiki.udm.vec', 'wiki.ug.vec', 'wiki.uk.vec', 'wiki.ur.vec', 'wiki.uz.vec', 'wiki.vec.vec', 'wiki.vep.vec', 'wiki.ve.vec', 'wiki.vi.vec', 'wiki.vls.vec', 'wiki.vo.vec', 'wiki.war.vec', 'wiki.wa.vec', 'wiki.wo.vec', 'wiki.wuu.vec', 'wiki.xal.vec', 'wiki.xh.vec', 'wiki.xmf.vec', 'wiki.yi.vec', 'wiki.yo.vec', 'wiki.za.vec', 'wiki.zea.vec', 'wiki.zh_classical.vec', 'wiki.zh_min_nan.vec', 'wiki.zh.vec', 'wiki.zh_yue.vec', 'wiki.zu.vec']
'''可以看到基本都是维基百科的子集,还是挺多的(327个),有各种语言,还有粤语,我们来使用其中一个包含中文的['wiki.zh.vec']来看看效果是怎么样的。
同样可以自动下载或手动下载,https://apache-mxnet.s3-accelerate.dualstack.amazonaws.com/gluon/embeddings/fasttext/wiki.zh.zip
本人下载之后的地址为C:\Users\Tony\AppData\Roaming\mxnet\embeddings\fasttext
然后自动解压之后的wiki.zh.vec有821M,这么大的文件使用Notepad++打不开。
同样的创建词向量,这里使用预处理文件是:'wiki.zh.vec'
fasttext_zh = text.embedding.create("fasttext", pretrained_file_name="wiki.zh.vec")这里我这里出现了一个警告:
UserWarning: At line 1 of the pre-trained text embedding file: token 332647 with 1-dimensional vector [300.0] is likely a header and is skipped.
'skipped.' % (line_num, token, elems))
也就是说这里的第一行应该是头,然后就忽略掉了,这里我们不管它。
另外从警告中的信息我们侧面知道了这个词典大小有332648个词包括一个未知词<unk>,词向量是300维度。当然这里我们也可以验证下是不是这样的:
print(fasttext_zh.idx_to_vec)
'''
[[ 0. 0. 0. ... 0. 0. 0. ][ 2.6678 5.4073 -0.057711 ... -1.8354 0.36975 2.8985 ][-0.11755 1.1515 -0.63657 ... 0.1388 1.0023 0.31335 ]...[-0.36881 -0.21542 -0.20998 ... -0.12527 0.36239 0.56859 ][-0.1583 -0.47584 -0.22553 ... 0.27256 0.033567 0.34423 ][-0.17572 0.31794 -0.40152 ... 0.22954 0.48944 -0.0054855]]
<NDArray 332648x300 @cpu(0)>
'''没有问题,跟警告信息是相符合的。
接下来我们看下在中文中的近义词和类比词:
get_similar_tokens("县长", 3, fasttext_zh)
'''
余弦相似度:0.950:县政
余弦相似度:0.950:省长
余弦相似度:0.949:县外
'''恩,基本上还是比较接近
但是在类比词的时候,就不对了
print(get_analogy("爸爸", "妈妈", "儿子", fasttext_zh))
'''
('儿子', [0.95196044])
'''英文能够很好的识别出来,为什么这里的中文就不可以了?正常来说中英文是没有区别的,都使用了词向量来代替原本的中英文。
然后我将那个get_analogy函数修改如下,多返回几个值看下什么情况:
def get_analogy(a, b, c, embed):vecs = embed.get_vecs_by_tokens([a, b, c])x = vecs[1] + vecs[2] - vecs[0]topk, cos = knn(embed.idx_to_vec, x, 4)return (embed.idx_to_token[topk[0]],embed.idx_to_token[topk[1]],embed.idx_to_token[topk[2]],embed.idx_to_token[topk[3]],cos,)print(get_analogy("湖南", "长沙", "贵州", fasttext_zh))
print(get_analogy("爸爸", "妈妈", "儿子", fasttext_zh))
'''
('贵州', '长沙', '贵阳', '遵义', [0.9504416, 0.9466409, 0.9465305, 0.94506186])
('儿子', '女儿', '母亲', '妈妈', [0.95196044, 0.940535, 0.9378925, 0.9308049])
'''候选的答案有正确的,只不过不是第一个,也不固定是第二个。这是什么情况,从占位来看,中文的处理跟英文还是存在区别,这里的具体原因是什么不是很清楚,有大神知道的,请指正!
相关文章:
自然语言处理(NLP)之求近义词和类比词<MXNet中GloVe和FastText的模型使用>
这节主要就是熟悉MXNet框架中的两种模型:GloVe和FastText的模型(词嵌入名称),每个模型下面有很多不同的词向量,这些基本都来自wiki维基百科和twitter推特这些子集预训练得到的。我们只需要导入mxnet.contrib中的text模块即可,这里…...
)
2023年CDGA考试-第13章-数据质量(含答案)
2023年CDGA考试-第13章-数据质量(含答案) 单选题 1.在导致数据质量问题的常见原因中关于数据输入问题以下描述正确的是: A.数据采集端缺乏数据质量管控 B.相同字段重复设计导致数据不一致 C.缺乏数据采集规范的制定 D.所有描述都正确 答案 D 2.数据质量计划应将其范围限…...
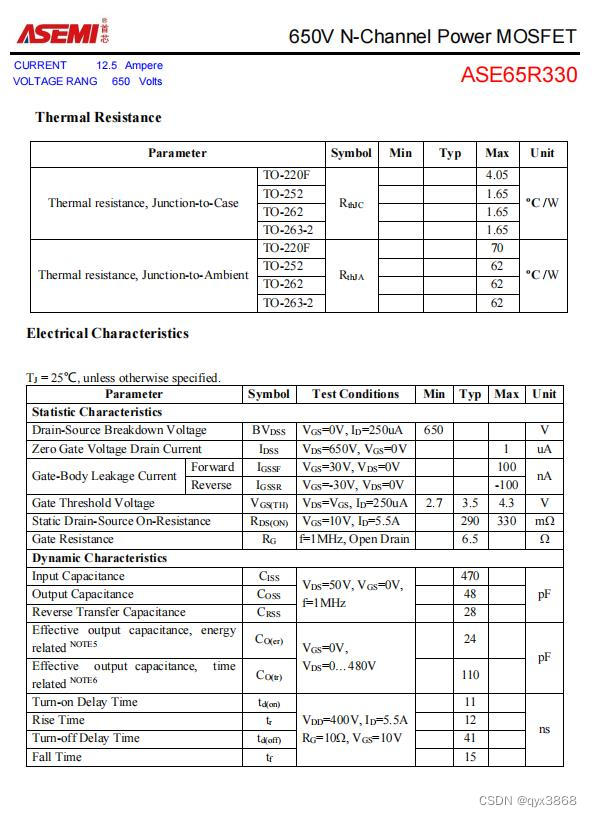
ASEMI高压MOS管ASE65R330参数,ASE65R330图片
编辑-Z ASEMI高压MOS管ASE65R330参数: 型号:ASE65R330 漏极-源极电压(VDS):650V 栅源电压(VGS):20V 漏极电流(ID):12.5A 功耗(P…...
:子序列、子数组问题)
LeetCode动态规划经典题目(九):子序列、子数组问题
目录 31. LeetCode674. 最长连续递增序列 32. LeetCode18. 最长重复子数组 33. LeetCode1143. 最长公共子序列 34. LeetCode1035. 不相交的线 35. LeetCode53. 最大子数组和 36. LeetCode392.判断子序列 37. LeetCode115. 不同的子序列 38. LeetCode583. 两个字符串的删…...

如何利用有限的数据发表更多的SCI论文?——利用ArcGIS探究环境和生态因子对水体、土壤和大气污染物的影响
SCI的写作和发表是科研人提升自身实力和实现自己价值的必要途径。“如何利用有限的数据发表更多的SCI论文?”是我们需要解决的关键问题。软件应用只是过程和手段,理解事件之间的内在逻辑和寻找事物之间的内在规律才是目的。如何利用有限的数据发表更多的…...
六【 SpringMVC框架】
一 SpringMVC框架 目录一 SpringMVC框架1.什么是MVC2.SpringMVC概述3.SpringMVC常见开发方式4.SpringMVC执行流程5.SpringMVC核心组件介绍6.快速构建Spring MVC程序✅作者简介:Java-小白后端开发者 🥭公认外号:球场上的黑曼巴 🍎个…...
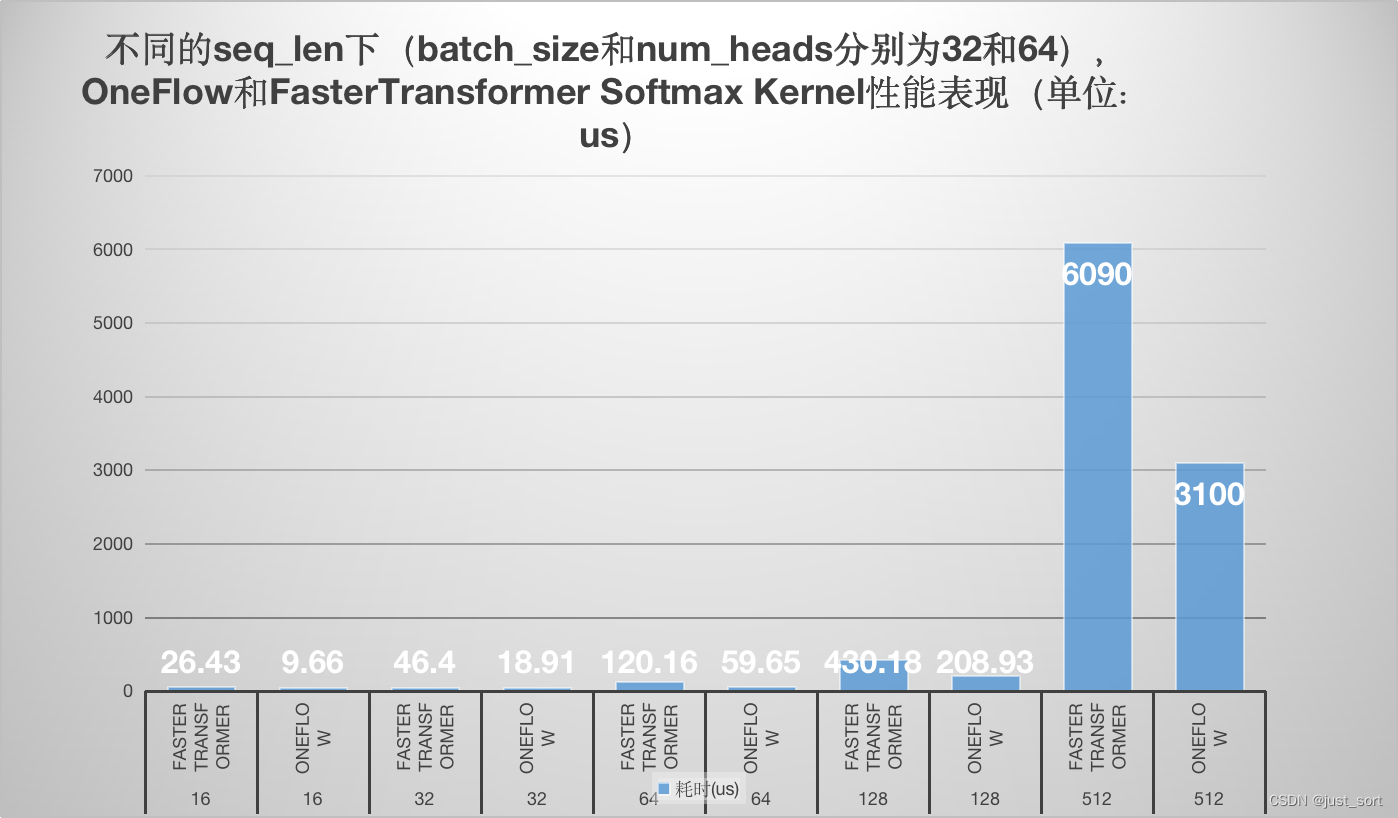
【BBuf的CUDA笔记】八,对比学习OneFlow 和 FasterTransformer 的 Softmax Cuda实现
0x1. OneFlow/FasterTransformer SoftMax CUDA Kernel 实现学习 这篇文章主要学习了oneflow的softmax kernel实现以及Faster Transformer softmax kernel的实现,并以个人的角度分别解析了原理和代码实现,最后对性能做一个对比方便大家直观的感受到onefl…...

python 类对象的析构释放代码演示
文章目录一、类的构造函数与析构函数二、代码演示1. 引用的更迭2. 只在函数内部的类对象三、函数内部返回的类对象1. 使用全局变量 引用 函数内部的类对象一、类的构造函数与析构函数 init 函数是python 类的构造函数,在创建一个类对象的时候,就会自动调…...
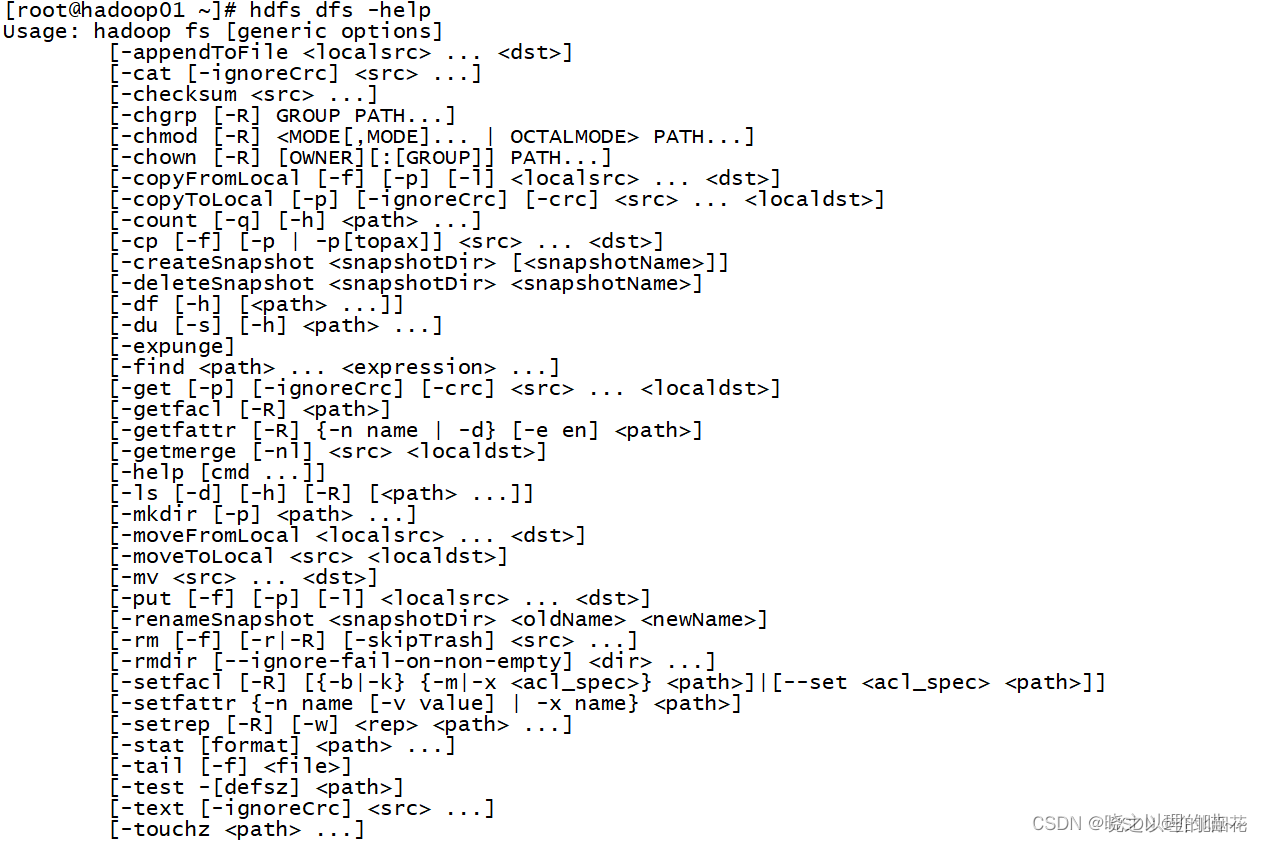
Hadoop Shell常用命令
Hadoop Shell命令在管理HDFS的时候还是比较常用的,Hadoop Shell命令与shell命令极为相似,但是方便查询,在这里总结分享,大家enjoy~~ 1,cat 语法格式:hadoop fs -cat URI [URI …] 含义:将路径…...

Android中级——色彩处理和图像处理
色彩处理 通过色彩矩阵处理 色彩矩阵介绍 图像的RGBA可拆分为一个4行5列的矩阵和5行1列矩阵相乘 其中4行5列矩阵即为ColorMatrix,可通过调整ColorMatrix间接调整RGBA 第一行 abcde 决定新的 R第二行 fghij 决定新的 G第三行 klmno 决定新的 G第四行 pqrst 决定新…...
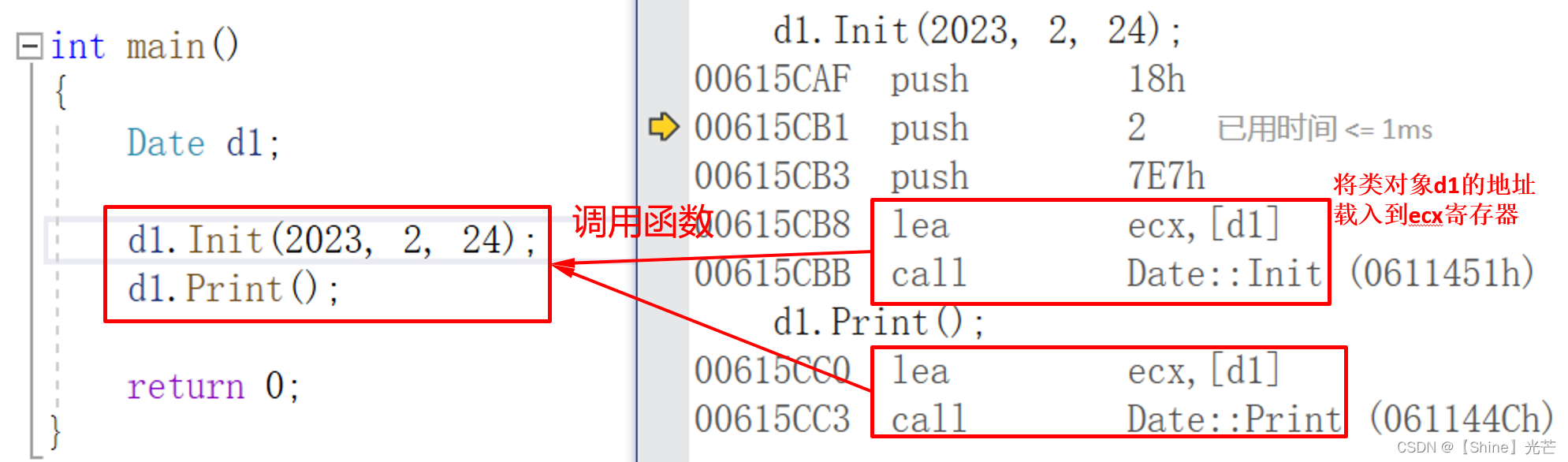
C++类和对象:类的定义、类对象的存储、this指针
目录 一. 对于面向过程和面向对象的认识 二. 类 2.1 struct关键字定义类 2.1.1 C语言中的struct关键字 2.1.2 C中的struct关键字 2.2 class关键字 2.1 使用class关键字定义类 三. 类的访问限定及封装 3.1 类的访问权限及访问限定符 3.1.1 访问权限 3.1.2 访问限定…...
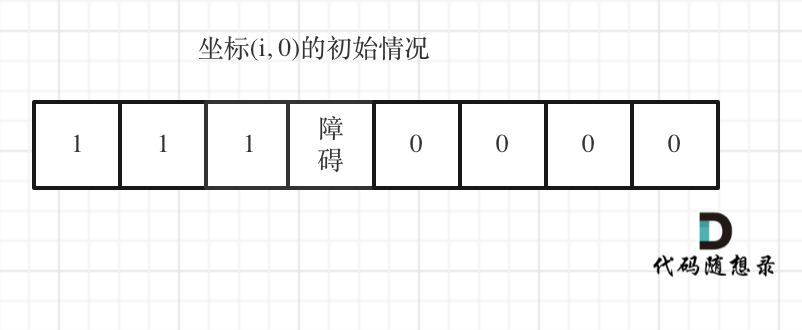
代码随想录算法训练营第三十九天 | 62.不同路径,63. 不同路径 II
一、参考资料不同路径https://programmercarl.com/0062.%E4%B8%8D%E5%90%8C%E8%B7%AF%E5%BE%84.html 视频讲解:https://www.bilibili.com/video/BV1ve4y1x7Eu不同路径 IIhttps://programmercarl.com/0063.%E4%B8%8D%E5%90%8C%E8%B7%AF%E5%BE%84II.htmlhttps://progr…...

数据库复习3
一. 简答题(共1题,100分) 1. (简答题) 存在数据库test,数据库中有如下表: 1.学生表 Student(Sno,Sname,Sage,Ssex) --Sno 学号,Sname 学生姓名,Sage 出生年月,Ssex 学生性别 主键Sno 2.教师表 Teacher(Tno,Tname) --T…...

顺序表的增删查改
数据结构 是数据存储的方式,对于不同的数据我们要采用不同的数据结构。就像交通运输,选用什么交通工具取决于你要运输的是人还是货物,以及它们的数量。 顺序存储结构 包括顺序表、链表、栈和队列等。 例如腾讯QQ中的好友列表,…...

jupyter matplotlib中文乱码解决
中文乱码可能有两种情况 1. matplotlib里面有中文字体 2. 没有中文字体 查看是否有中文字体: # 查询当前系统所有字体 from matplotlib.font_manager import FontManager import subprocessmpl_fonts = set(f.name for f in FontManager().ttflist)print(all font list get f…...
Smtplib之发邮件模块
目录 创建Smtp对象 Smtp类中的方法 MIME MIMEBase MIMEBase MIMEMultipart MIMEApplication MIMEAudio MIMEImage MIMEText 实例 texthtml格式 发送带图片附件的邮件 发送带附件的邮件 含多种格式 SMTP模块 SMTP 简单传输协议,它是一组用于由源…...

Android 适配手机和平板
一、屏幕适配限定符Android 系统加载应用资源时 , 会根据当前运行应用的设备的相关属性 , 如 : 屏幕尺寸 / 屏幕像素密度 / 宽高比 / 屏幕方向 等属性 , 加载不同的屏幕适配限定符目录下的资源 ;如 : 横竖屏切换时 , res/layout-land 目录中 , 存放的是横屏布局 , res/layout-p…...

时序预测 | MATLAB实现LSTM-SVR(长短期记忆神经网络-支持向量机)时间序列预测
时序预测 | MATLAB实现LSTM-SVR(长短期记忆神经网络-支持向量机)时间序列预测 目录时序预测 | MATLAB实现LSTM-SVR(长短期记忆神经网络-支持向量机)时间序列预测效果一览基本介绍模型介绍LSTM模型SVR模型LSTM-SVR模型程序设计参考资料致谢效果一览 基本介绍 本次运行测试环境MA…...
分阶段构建golang运行环境Dockerfile镜像
在开始这项工作之前大家可以先去看一下docker官方给出关于空镜像scratch的说明,采用官方简单的一句话就是:scratch是一个明确的空图像,特别是对于“从头开始”构建图像。分阶段构建镜像就会用到scratch这个空镜像,这样的好处是可以…...
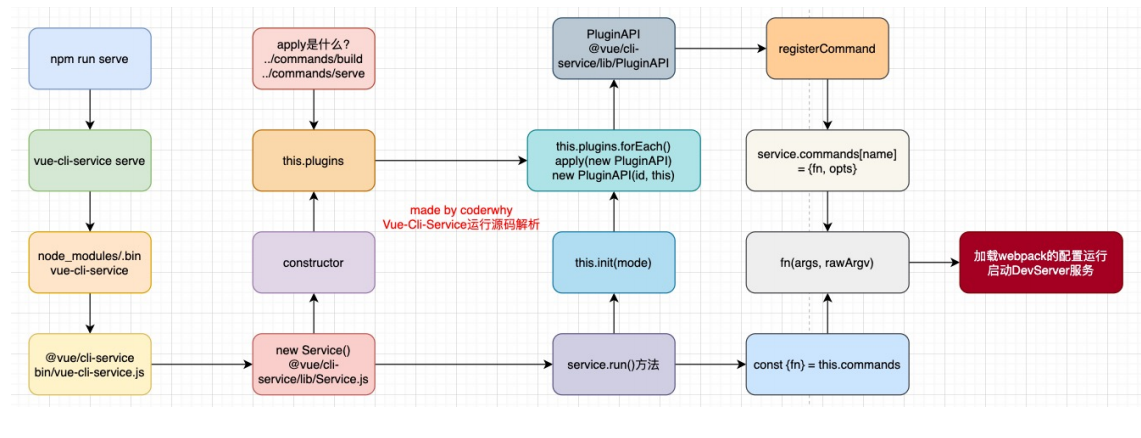
Vue-cli脚手架在做些什么(源码角度分析)
什么是Vue脚手架?在学习初期,我们的项目往往需要借助webpack、vite等打包工具配置Vue的开发环境,但是在真实开发中我们不可能每个项目从头来完成所有的webpack配置,这样显得开发的效率会大大的降低;所有的真实开发中&a…...

【网络】每天掌握一个Linux命令 - iftop
在Linux系统中,iftop是网络管理的得力助手,能实时监控网络流量、连接情况等,帮助排查网络异常。接下来从多方面详细介绍它。 目录 【网络】每天掌握一个Linux命令 - iftop工具概述安装方式核心功能基础用法进阶操作实战案例面试题场景生产场景…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...

零基础设计模式——行为型模式 - 责任链模式
第四部分:行为型模式 - 责任链模式 (Chain of Responsibility Pattern) 欢迎来到行为型模式的学习!行为型模式关注对象之间的职责分配、算法封装和对象间的交互。我们将学习的第一个行为型模式是责任链模式。 核心思想:使多个对象都有机会处…...

Springboot社区养老保险系统小程序
一、前言 随着我国经济迅速发展,人们对手机的需求越来越大,各种手机软件也都在被广泛应用,但是对于手机进行数据信息管理,对于手机的各种软件也是备受用户的喜爱,社区养老保险系统小程序被用户普遍使用,为方…...

深度剖析 DeepSeek 开源模型部署与应用:策略、权衡与未来走向
在人工智能技术呈指数级发展的当下,大模型已然成为推动各行业变革的核心驱动力。DeepSeek 开源模型以其卓越的性能和灵活的开源特性,吸引了众多企业与开发者的目光。如何高效且合理地部署与运用 DeepSeek 模型,成为释放其巨大潜力的关键所在&…...
算法打卡第18天
从中序与后序遍历序列构造二叉树 (力扣106题) 给定两个整数数组 inorder 和 postorder ,其中 inorder 是二叉树的中序遍历, postorder 是同一棵树的后序遍历,请你构造并返回这颗 二叉树 。 示例 1: 输入:inorder [9,3,15,20,7…...