【堆】数据结构堆的实现(万字详解)
前言:
在上一期中我们讲到了树以及二叉树的基本的概念,有了之前的认识,今天我们将来具体实现一种二叉树的存储结构“堆”!!!
目录
- 1.二叉树顺序结构介绍
- 2.堆的概念及结构
- 3.调整算法
- 3.1向上调整算法
- 3.1.1算法思想
- 3.1.2算法代码
- 3.1.3算法图解分析
- 3.1.4算法复杂度分析
- 3.2向下调整算法(重点)
- 3.2.1算法思想(建小堆)
- 3.2.2算法代码
- 3.2.3算法图解分析
- 3.2.4算法复杂度分析
- 3.3算法对比
- 4.堆的实现
- 4.1 数据类型重定义
- 4.2堆结构的定义
- 4.3堆的常见操作(重点)
- 4.4接口功能实现
- 4.4.1堆的初始化
- 4.4.2堆的销毁
- 4.4.3堆元素的打印
- 4.4.4堆元素交换
- 4.4.5堆的插入
- 4.4.6堆的删除
- 4.4.7构建堆(及建堆时间复杂度)
- 4.4.8取堆顶的数据
- 4.4.9堆的数据个数
- 4.4.10堆的判空
- 5.堆的运用
- 5.1 堆排序
- 5.2TOP-K问题
- 6.选择题讲解
- 7.总结
1.二叉树顺序结构介绍
普通的二叉树是不适合用数组来存储的,因为可能会存在大量的空间浪费。而完全二叉树更适合使用顺序结构存储。现实中我们通常把堆(一种二叉树)使用顺序结构的数组来存储,需要注意的是这里的堆和操作系统虚拟进程地址空间中的堆是两回事,一个是数据结构,一个是操作系统中管理内存的一块区域分段。
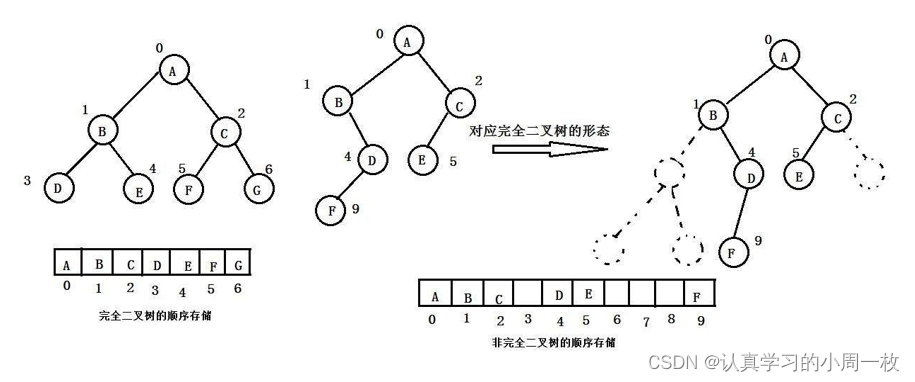
2.堆的概念及结构
如果有一个关键码的集合K = { k0, k1, k2,…,kn-1},把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中。并满足以下条件:
则称为小堆(或大堆)。
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆
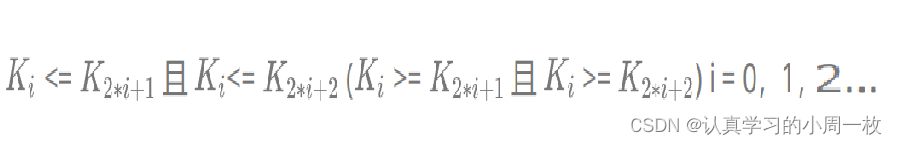
堆的性质:
1.堆中某个节点的值总是不大于或不小于其父节点的值;
2.堆总是一棵完全二叉树。
接下来对上面提到的最大堆和最小堆进行理解:
最小堆要求,对于任意一个父结点来说,其子结点的值都大于这个父节点;
同理,最大堆就是说,其子节点的值都小于这个父节点,具体如下:
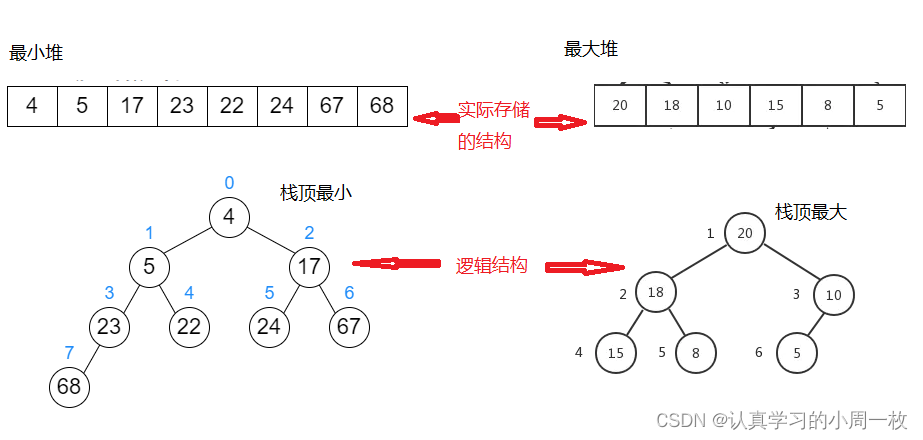
1.对于上图的树形结构,其实并不是它在内存中真正的样子,这只是我们为了更好地理解而想象出来的;它在内存中真正的样子应该是像一种数组的存储方式。
2.而且从上图我们还可以得出一个规律,就是这个堆中的各个结点之间它是存在一种关系的,在上篇博客中我们已经讲了树和二叉树的基本概念讲到了父亲结点和孩子结点。那么我们就可以用下标来表示一下父亲结点和孩子结点直接的关系,具体如下:
lchild = parent * 2 + 1 左孩子
rchild = parent * 2 + 2 右孩子
从而我们还可以得出父结点的下标表示为:
parent = (child - 1) / 2
注意:
堆的根节点中存放的是最大或者最小元素,但是其他节点的排序顺序是未知的。例如,在一个最大堆中,最大的那一个元素总是位于 index 0的位置,但是最小的元素则未必是最后一个元素。唯一能够保证的是最小的元素是一个叶节点,但是不确定是哪一个。
3.调整算法
3.1向上调整算法
3.1.1算法思想
使用向上调整算法的思路是将要插入的数据放在数组尾部,进行向上调整。
但我们需要向堆中插入数据元素,使其仍然是一个堆时,就要使用到向上调整算法进行相关的调整。因为向堆中插入数据是将数据插入到数据尾部,此时可能就会出现不满足小堆(大堆)定义的情况,因此,需要堆其进行调整,向上调整算法和向下调整算法思路类似,此处以小堆为例:在调整的过程中,我们是从数组中最后一个元素的位置开始的,不断的向上进行与父亲结点存储的值进行对比,如果出现孩子的值比父亲的值大,那么就需要交换此时的父亲和孩子的值,一直交换到child到达根节点为止,当然也可能出现比较好的情况,就是在交换的半途中就出现了满足堆的性质,那么此时就不再需要继续向上进行调整了。
3.1.2算法代码
void AdjustUp(HPDataType* a, int child)
{int parent = (child - 1) / 2;while (child > 0){if (a[child] < a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}}
}
解析:
1.首先我们需要知道传过来的孩子结点的下标;
void AdjustUp(HPDataType* a, int child)
2.当我们知道了这个孩子结点的下标之后,我们就会想着去寻找其父亲结点的下标值,因为是要和它的父亲进行相应的比较;
int parent = (child - 1) / 2;
3.紧接着我们需要对孩子结点进行一个判断的操作,向上调整孩子结点就会被赋值到它祖先的结点处,这时我们的父亲结点就会发生越界行为,因此这里的判断条件为【child > 0】;
while (child > 0)
4.孩子结点正确判断之后,就可以去进行相应的比较,这里的判断条件则是孩子比它父亲来的大,如果满足循环条件,那么就将它们俩进行一个交换即可(如果是小堆则只需改变这里的判断符号),若a[chaild]>=a[parent]则说明越界满足小堆,直接break;
if (a[child] < a[parent]){Swap(&a[child], &a[parent]);child = parent;parent = (child - 1) / 2;}else{break;}
3.1.3算法图解分析
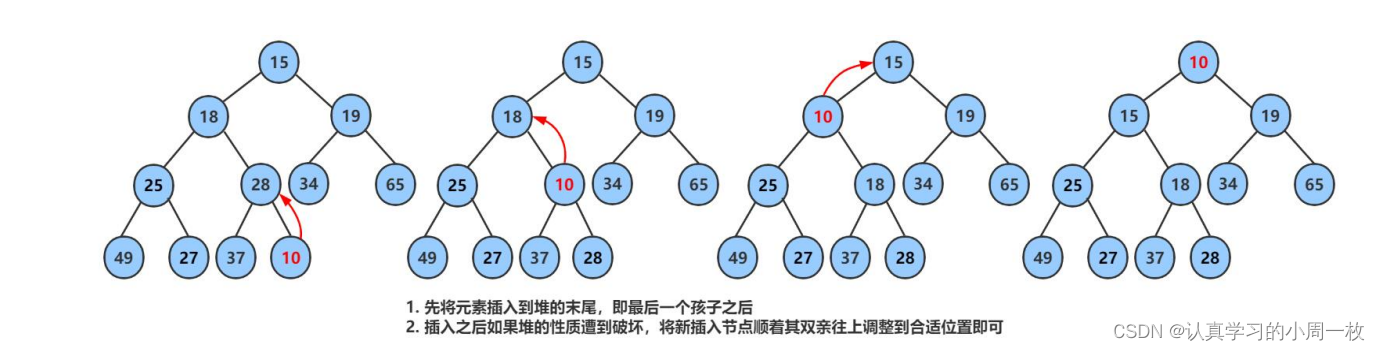
我们以下图为例,通过在尾结点插入元素10来进行相关的调整:
3.1.4算法复杂度分析
为了保证每次调整后,已经调整过的部分不被打乱,我们需要从第二层开始调整,最坏的情况就是每个节点都向上调整了
h2-1次(h2表示以该节点所在的层数),设向上调整的总次数为关于h的函数F(h),则F(h)表示如下:
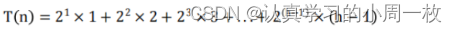

3.2向下调整算法(重点)
3.2.1算法思想(建小堆)
向下调整算法-前提:
若想将其调整为小堆,那么根结点的左右子树必须都为小堆;
若想将其调整为大堆,那么根结点的左右子树必须都为大堆。
向下调整算法的核心思想:选出左右孩子中小的哪一个,跟父亲交换,小的往上浮,大的往下沉,如果要建大堆则相反:
1.从根结点处开始,选出左右孩子中值较小的孩子。
2.让小的孩子与其父亲进行比较。若小的孩子比父亲还小,则该孩子与其父亲的位置进行交换。并将原来小的孩子的位置当成父亲继续向下进行调整,直到调整到叶子结点为止。
3.若小的孩子比父亲大,则不需处理了,调整完成,整个树已经是小堆了。
3.2.2算法代码
void AdjustDown(HPDataType* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n){// 确认child指向大的那个孩子if (child+1 < n && a[child+1] < a[child]){++child;}// 1、孩子大于父亲,交换,继续向下调整// 2、孩子小于父亲,则调整结束if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}
解析:
1.对于向下调整算法,我们开始传入的就不是孩子结点的下标了。因为调整的是堆顶数据,也就是根节点的下标,而对于根节点来说是没有父亲的,所以传入的就是父亲下标:
void AdjustDown(HPDataType* a, int n, int parent)
2.对比向上调整算法是知道孩子求父亲,这里的话就是知道父亲求孩子了,但是大家可能会有一些疑问就是,孩子结点不是分为左孩子和右孩子吗,不是有两个吗,为什么我只写了一个【child】,我们在这里就假设最大的孩子结点为左孩子,在后面在进行相关判断
int child = parent * 2 + 1;
{++child;
}
3.接下来就进行相关的判断操作,因为我们上面假设左孩子最大,在这里就判断右孩子是否合法的同时再去验证我们的假设是否成立。接下去将左右孩子的值进行一个比较,若是右孩子来的大就将【child++】,左孩子变成右孩子。
if (child+1 < n && a[child+1] < a[child])
4.紧接着和向上调整法类似的操作
// 1、孩子大于父亲,交换,继续向下调整// 2、孩子小于父亲,则调整结束if (a[child] < a[parent]){Swap(&a[child], &a[parent]);parent = child;child = parent * 2 + 1;}else{break;}
3.2.3算法图解分析
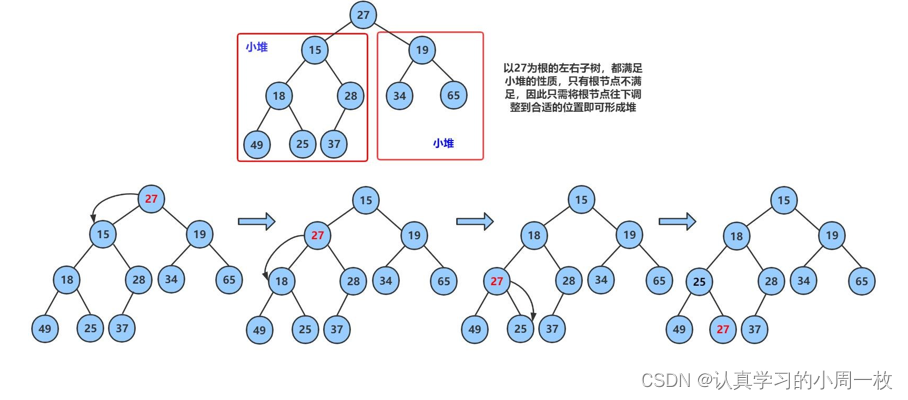
现在我们给出一个数组,逻辑上看做一颗完全二叉树。我们通过从根节点开始的向下调整算法可以把它调整成一个小堆
int array[] = {27,15,19,18,28,34,65,49,25,37};
解析:
对于向下调整算法,最主要的一个前提就是根节点的左右子树都要是大堆或者都要是小堆,就根结点不满足,才可以去进行一个向下调整,此时就需要使用到这个【向下调整算法】,我这个是小堆的调整,大堆的话刚好相反。
原理:找出当前结点的两个孩子结点中较小的那一个换上来,将这个【27】换下去,交换了之后我们发现此时还不构成小堆,因此我们还需要再根据上述方法进行调整,然后直到这个【27】的孩子结点到达【n - 1】就不作交换了,因为【n - 1】就相当于是位于数组下标的最后一个值
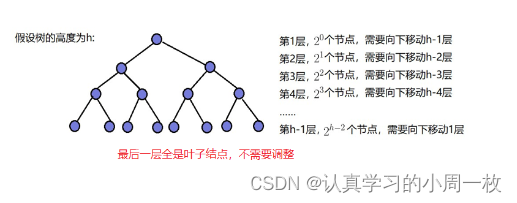
3.2.4算法复杂度分析

3.3算法对比
向下调整算法时间复杂度:O(N)
向上调整算法时间复杂度:O(N*logN)
我们发现对于向下调整算法,层数越高的结点,需调整的次数越少,而层数越高结点越多,也就是大多数结点只需要调整少次;
而向上调整算法恰恰相反,大多数结点需要调整多数次,而基于满二叉树结构的特点,我们发现最后一层节点数占总结点数的几乎一半,对于最后一层的调整次数对整体影响很大,因此我们需要让最后一层调整少次,对比我们得出,选择向下调整算法更优。
4.堆的实现
4.1 数据类型重定义
跟我们之前学习的数据结构一样,我们为了方便存储各种数据类型,我们会先对堆存储的数据类型进行重定义,具体如下:
typedef int HPDataType;
4.2堆结构的定义
通过上文的了解我们知道堆本质就是一棵完全二叉树,我们是采用顺序存储的方式来实现堆的,在前面我们已经学习过顺序表的实现,所以这里堆的实现我们可以类比顺序表的实现。我们可以考虑将堆中树的结点存储的值,按照一定的顺序存储在一个数组中,那么数组当然就是采用动态开辟的数组比较方便进行随时的扩容,其实现可以参考顺序表的实现,因此我们可以得出所需要的为:
堆的结构中需要包含一个数据域,就是动态数组;
需要一个能够随时记录堆中存储的有效数据个数的变量;
需要一个可以随时记录堆中数组的容量的变量
代码展示为:
typedef struct Heap
{HPDataType* a; // 数据域int size; // 堆中有效数据个数int capacity; // 堆的容量
}HP; //重定义
4.3堆的常见操作(重点)
堆的主要操作是插入和删除最小(最大)元素(元素值本身为优先级值,小元素享有高优先级)。在插入或者删除操作之后,我们必须保持该实现应有的性质:
- 完全二叉树
- 每个节点值都小于或等于它的子节点。
// 堆的构建
void HeapCreate(Heap* hp, HPDataType* a, int n);
// 堆的销毁
void HeapDestory(Heap* hp);
// 堆的插入
void HeapPush(Heap* hp, HPDataType x);
// 堆的删除
void HeapPop(Heap* hp);
// 取堆顶的数据
HPDataType HeapTop(Heap* hp);
// 堆的数据个数
int HeapSize(Heap* hp);
// 堆的判空
int HeapEmpty(Heap* hp);
//打印堆
void HeapPrint(HP* php);
//初始化堆
void HeapInit(HP* php);
4.4接口功能实现
4.4.1堆的初始化
第一个功能接口就是实现堆的初始化操作,这个代码比较简单,跟我们之前的顺序表的初始化思路差不多,我们直接看代码:
void HeapInit(HP* php)
{assert(php);php->a = NULL;php->size = php->capacity = 0;
}
注意:
这里初始化时空间的开辟是任我们选择的,当然你也可以在初始化这一块就把堆的数据存放空间给开出来,我们可以选择这里开空间,后面用realloc修改空间大小(realloc接收的指针为NULL时,他的作用和malloc是一样的,所以这里开不开辟空间都是可以的)
4.4.2堆的销毁
销毁函数中本质是需要对堆中向系统申请的空间进行释放,防止出现内存泄露,释放完之后最好也是需要对该指针进行置空操作。这里的销毁操作跟我们之前写的顺序表等操作大差不差,基本思想都是相同的,具体如下:
void HeapDestroy(HP* php)
{assert(php);free(php->a);php->a = NULL;php->size = php->capacity = 0;
}
4.4.3堆元素的打印
打印操作就是将堆中的各个元素打印出来,没什么可说的,具体代码如下:
void HeapPrint(HP* php)
{assert(php);for (int i = 0; i < php->size; ++i){printf("%d ", php->a[i]);}printf("\n");
}4.4.4堆元素交换
很明显就是字面意思,交换堆中数据元素的位置,在接下来的插入和删除操作中需要用到这个功能函数,具体如下:
void Swap(HPDataType* p1, HPDataType* p2)
{HPDataType tmp = *p1;*p1 = *p2;*p2 = tmp;
}
4.4.5堆的插入
1. 有了上述的操作后我们就会想到往堆中插入元素,跟我们之前的顺序表等数据结构类似。对于数组,在插入数据之前我们还是需要先检查空间是否满,如果满了,那么首先需要考虑扩容问题,扩容的基本操作和顺序表中基本保持一致。
2. 堆进行插入操作时,我们在插入数据的时候,只是将数据插入到堆中数组的最后一个位置,那么这个时候,插入数据之后,堆中的数据之间可能仍然满足堆的性质,也可能不满足堆的性质,所以,在插入数据之后我们需要对堆中的数据做进一步的调整,以保证插入数据之后,数组中的数据之间仍然可以保持堆的性质。
3. 因此进行插入操作,我们这里默认建的是大堆(因此除了有扩容之外,在底部还有一个【向上调整算法】,我们在插入新的元素后始终要保持原先的堆是一个大堆,所以要去进行一个向上调整)。首先将新插入的节点放在完全二叉树最后的位置,再和父节点比较。如果new节点比父节点小,那么交换两者。交换之后,继续和新的父节点比较……直到new节点不比父节点小,或者new节点成为根节点,到此就插入操作就结束。
void HeapPush(HP* php, HPDataType x)
{assert(php);// 扩容if (php->size == php->capacity){int newCapacity = php->capacity == 0 ? 4 : php->capacity * 2;HPDataType* tmp = (HPDataType*)realloc(php->a, sizeof(HPDataType)*newCapacity);if (tmp == NULL){perror("realloc fail");exit(-1);}php->a = tmp;php->capacity = newCapacity;}php->a[php->size] = x;php->size++;AdjustUp(php->a, php->size-1);
}
图解:
我们通过具体的例子来加深我们的理解:
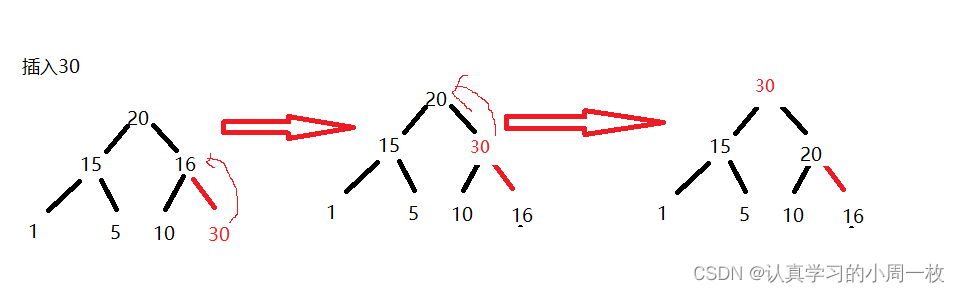
解答:
先将30插入到数组的尾结点处(即最后一个孩子之处),插入之后如果我们可以发现30比16大,则说明堆的性质不满足,我们就要进行相应的调整,即沿着双亲结点往上进行进行调整,依次类推,即可得到最后的结果。
4.4.6堆的删除
跟之前学习的数据结构类似,有插入操作就有相应的删除操作!!!
删除操作只能删除根节点,即堆顶的元素,根节点删除后,我们会有两个子树,我们需要基于它们重构堆。但是这个删除过程可并不是直接删除堆顶的数据,原因如下:
我们若是直接删除堆顶的数据,那么原堆后面数据的父子关系就全部打乱了,需要全体重新建堆,时间复杂度为O ( N ) 。若是用上述方法,那么只需要对堆进行一次向下调整即可,因为此时根结点的左右子树都是小堆,我们只需要在根结点处进行一次向下调整即可,时间复杂度为O ( log ( N ) )
思路:
首先交换数组第一个数据和最后一个数据的值,然后删除最后一个数据,这个过程中的操作就是让数组中有效数据个数减一即可。然后再进行向下调整。
void HeapPop(HP* php)
{assert(php);assert(php->size > 0);Swap(&php->a[0], &php->a[php->size - 1]);php->size--;AdjustDown(php->a, php->size, 0);
}
图解:
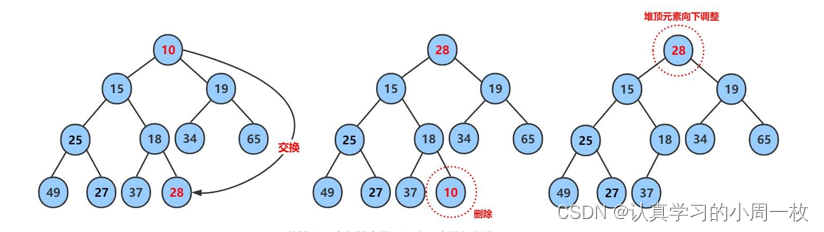
解答:
上述堆的插入我们以大堆为例,在这里我们以小堆为例(就是希望大家两种都会,我们一种举一个例子,另一种对照),具体步奏:
1.开始时我们要删除的是为【10】的元素,因此我们第一步将10堆中的最后一个元素进行交换;
2.交换之后紧接着我们删除最后一个元素;
3.当最后一个元素删除之后我们在看此时的堆是否满足条件,这里我们就不难发现此时并不满足我们小根堆的条件(即双亲结点小于孩子结点)。而这里的【28】却是大于【15】和【19】,因此我们需要向下调整达到最后满足条件即止(这里留给大家练练手看是否学会了相关方法)。
4.4.7构建堆(及建堆时间复杂度)
对于堆的构建我们有两种办法进行操作:
1.在上面我们已经写过了插入函数和初始化函数的功能实现,因此第一种方法就是利用上述两种函数进行对堆的构建,具体如下:
// 堆的构建
void HeapCreate(HP* php, HPDataType* a, int n)
{assert(php);HeapInit(php); for (int i = 0; i < n; ++i){HeapPush(php, a[i]);}
}
注意:
这种方法存在一个很明显的弊端,就是每当我们插入一个元素我们就需要进行相关的调整已达到相应的要求,这就会带来极大的不便。而我们下一种方法就会克服这个弊端!!
2.首先我们为这个堆存放数据的地方单独开辟出一块空间,然后将数组中的内容拷贝过来,当把这些数据都拿过来之后,我们整体性地做一个向下调整即可。具体如下:
void HeapCreate(HP* php, HPDataType* a, int n)
{assert(php);php->a = (HPDataType*)malloc(php->a, sizeof(HPDataType)*n);if (php->a == NULL){perror("realloc fail");exit(-1);}memcpy(php->a, a, sizeof(HPDataType)*n);php->size = php->capacity = n;// 建堆算法for (int i = (n-1-1)/2; i>=0; --i){AdjustDown(a, n, i);}
}
有了上述的两种方法之后,那么我们就会想到底该怎么构建堆呢?我将通过具体的例子来大家说明该如何构建,具体过程以下图为例:
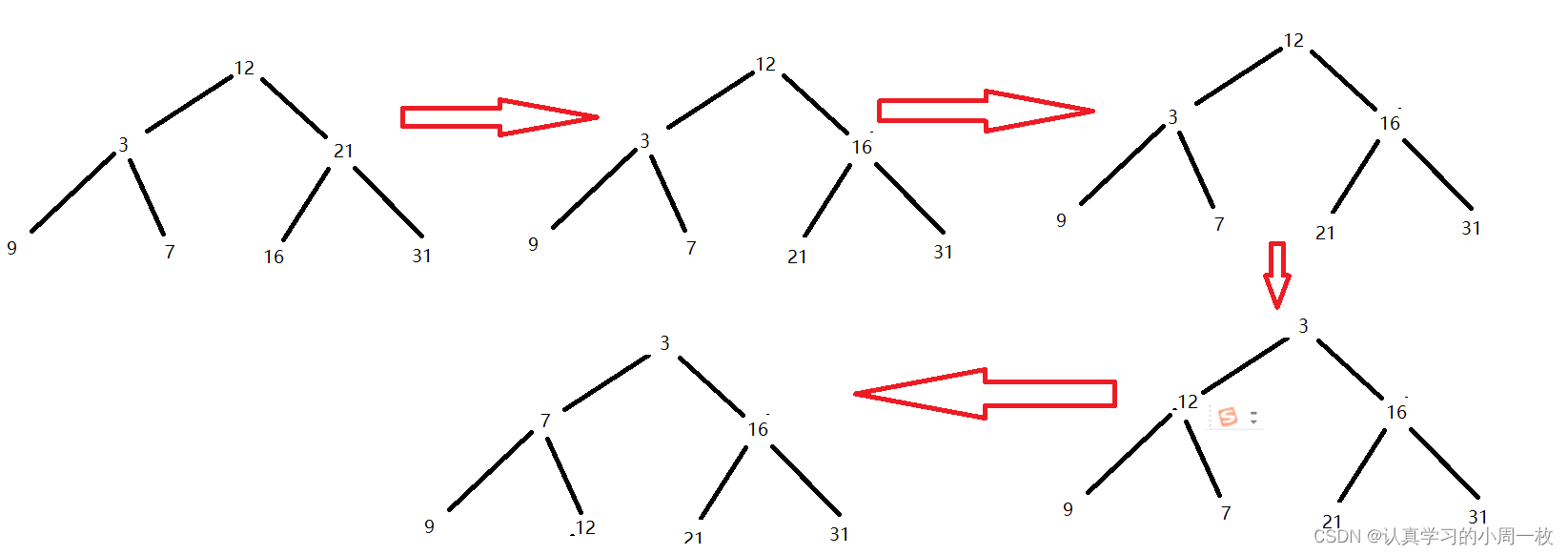
解答:
1.第一步根据我们给出的一个乱序的完全二叉树,首先找到完全二叉树中最后一个不是叶子节点中的节点,也就是图中的【21】的位置 (最后一个节点的位置 - 1) / 2.就是最后一个不为叶子节点的位置);
2.找到这个节点后向下查找(这里以小根堆为例),找到子节点中最小的节点,然后判断与自身的关系,若满足小根堆条件(parent < child),则继续,若不满足则交换节点的值,这里将【16】与 【21】交换;
3. 交换之后,若parent为叶子结点(panent->leftchild越界)则退出,否则继续向下查找,直到parent为叶子结点或子树满足小根堆.这里【21】已经是叶子节点,所以退出向下查找过程.之后找到倒数第二个不为叶子节点的节点,依上述步骤向下查找,直到将所有不为叶子结点的节点都向下查找一遍,这里继续将【3】向下查找,【3】的子树满足小根堆,退出向下查找;
4. 之后继续向前遍历,找到节点【12】向下查找,在子节点中找到【3】 和 【16】中较小的3,不满足小根堆的性质,交换【12】 和 【3】;
5. 交换完成之后【12】此处的节点依旧不是叶子结点,继续向下查找,找到叶子节点中较小的【7】,仍不满足小根堆的性质,继续交换;
6. 到最后【12】 成为叶子结点,退出向下查找,由于根节点已经向下查找完毕,所以堆的构建也就完成了.此时一个乱序的完全二叉树就已经变成了一个小根堆.
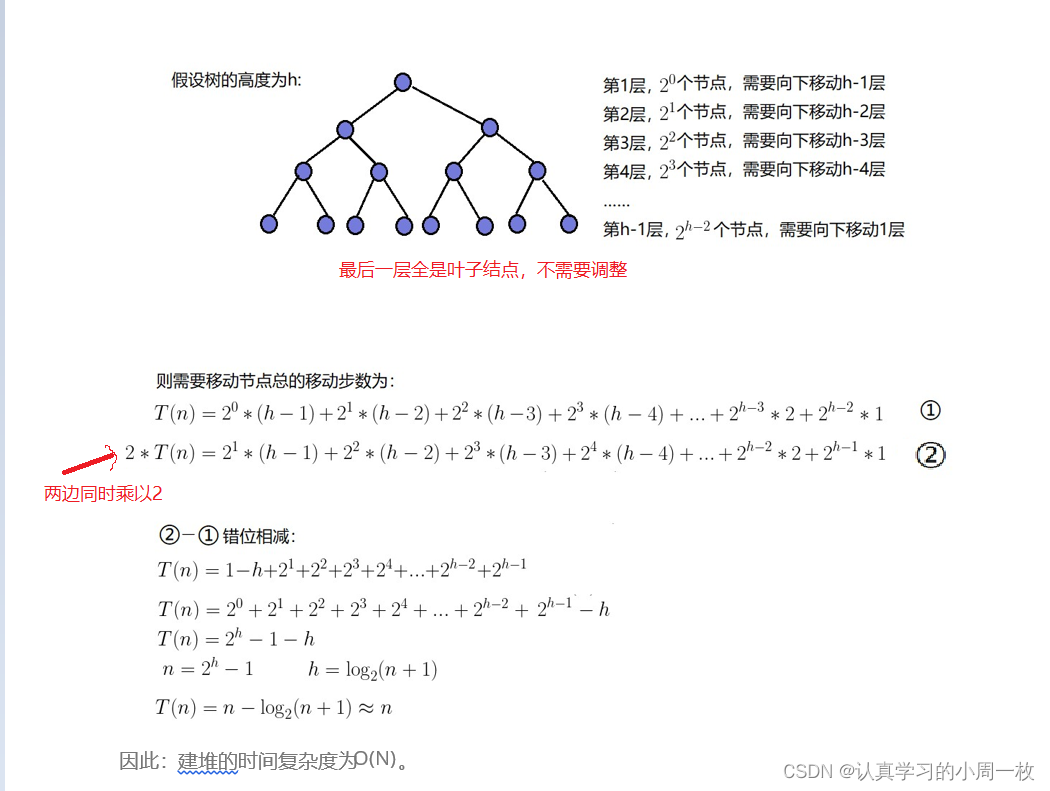
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的就是近似值,多几个节点不影响最终结果):
4.4.8取堆顶的数据
在之前我们也学过去首元素的操作,即堆顶的数据就是数组的首元素,因此直接返回堆顶的数据即可,代码如下:
HPDataType HeapTop(HP* php)
{assert(php);assert(php->size > 0);return php->a[0];
}
4.4.9堆的数据个数
学到这里大家就会发现,这里的许多操作跟我们之前写的顺序表啊等数据结构都有着类似的地方,原理都是一样的,在这里我就不多说了,直接看代码:
int HeapSize(HP* php)
{assert(php);return php->size;
}
4.4.10堆的判空
代码如下:
// 堆的判空
bool HeapEmpty(HP* php)
{assert(php);return php->size == 0;
}
5.堆的运用
5.1 堆排序
堆排序即利用堆的思想来进行排序,总共分为两个步骤:
- 建堆
升序:建大堆
降序:建小堆 - 利用堆删除思想来进行排序
建堆和堆删除中都用到了向下调整,因此掌握了向下调整,就可以完成堆排序。
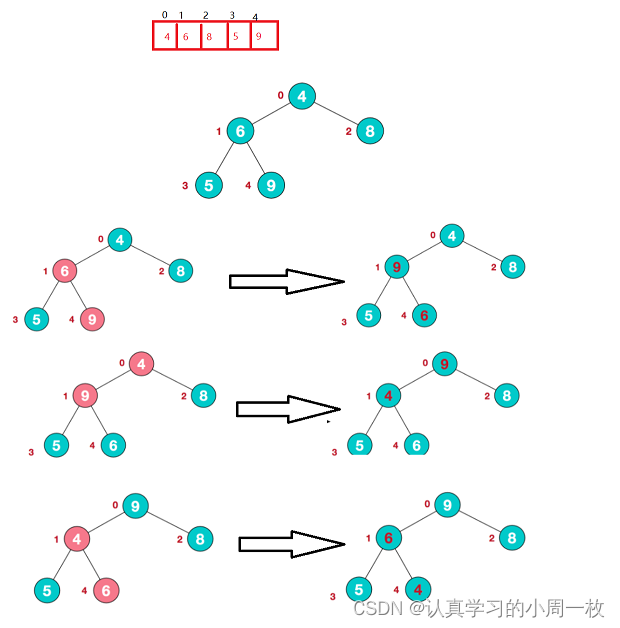
解析:
1.此时我们从最后一个非叶子结点开始(叶结点自然不用调整,第一个非叶子结点 arr.length/2-1=5/2-1=1,也就是下面的6结点),从左至右,从下至上进行调整。【9下沉之后,9变成了叶子节点,因此不会对子叶产生影响】
2.找到第二个非叶节点4 【3/2 - 1 = 0】,由于[4,9,8]中【9】元素最大,【4】和【9】交换。【4下沉之后,变动了的子树必须重新调整】
3.这时,交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换【4】和【6】
4.此时,我们就将一个无需序列构造成了一个大顶堆
最后简单总结下堆排序的基本思路:
a.将无需序列构建成一个堆,根据升序降序需求选择大堆根或小根堆;
b.将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;
c.重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。
代码实现如下:
// O(N*logN)
void HeapSort(int* a, int n)
{// 向上调整建堆 -- N*logN/*for (int i = 1; i < n; ++i){AdjustUp(a, i);}*/// 向下调整建堆 -- O(N)// 升序:建大堆for (int i = (n - 1 - 1) / 2; i >= 0; --i){AdjustDown(a, n, i);}// O(N*logN)int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);--end;}
}
总结:
堆排序是一种选择排序,整体主要由构建初始堆+交换堆顶元素和末尾元素并重建堆两部分组成。其中构建初始堆经推导复杂度为O(n),在交换并重建堆的过程中,需交换n-1次,而重建堆的过程中,根据完全二叉树的性质,[log2(n1),log2(n-2)…1]逐步递减,近似为nlogn。所以堆排序时间复杂度一般认为就是O(nlogn)。
5.2TOP-K问题
TOP-K问题:即求数据结合中前K个最大的元素或者最小的元素,一般情况下数据量都比较大。
比如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能数据都不能一下子全部加载到内存中)。最佳的方式就是用堆来解决,基本思路如下:
- 用数据集合中前K个元素来建堆
前k个最大的元素,则建小堆
前k个最小的元素,则建大堆 - 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素
将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素
代码如下:
void TestHeap5()
{// 造数据int n, k;printf("请输入n和k:>");scanf("%d%d", &n, &k);srand(time(0));FILE* fin = fopen("data.txt", "w");if (fin == NULL){perror("fopen fail");return;}int randK = k;for (size_t i = 0; i < n; ++i){int val = rand() % 100000;fprintf(fin, "%d\n", val);}fclose(fin);// 找topkFILE* fout = fopen("data.txt", "r");if (fout == NULL){perror("fopen fail");return;}int* minHeap = malloc(sizeof(int)*k);if (minHeap == NULL){perror("malloc fail");return;}for (int i = 0; i < k; ++i){fscanf(fout, "%d", &minHeap[i]);}// 建小堆for (int i = (k - 1 - 1) / 2; i >= 0; --i){AdjustDown(minHeap, k, i);}int val = 0;while (fscanf(fout, "%d", &val) != EOF){if (val > minHeap[0]){minHeap[0] = val;AdjustDown(minHeap, k, 0);}}for (int i = 0; i < k; ++i){printf("%d ", minHeap[i]);}printf("\n");fclose(fout);
}
复杂度分析:
首先需要对K个元素进行建堆,时间复杂度为O(k),然后要遍历数组,最坏的情况是,每个元素都与堆顶比较并排序,需要堆化n次
所以是O(nlog(k)),因此总复杂度是O(k+nlog(k));
6.选择题讲解
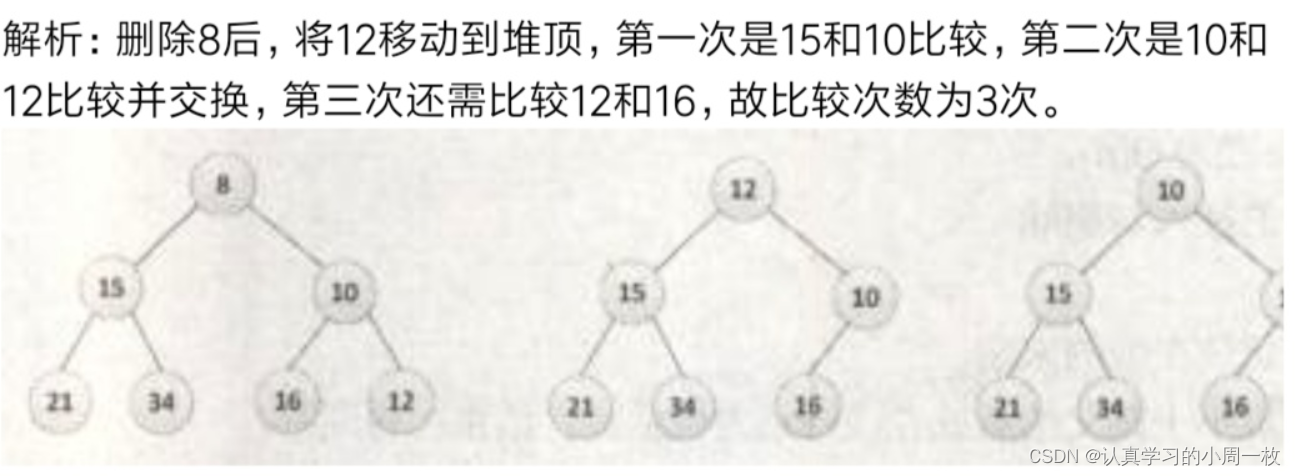
1.已知小根堆为8,15,10,21,34,16,12,删除关键字 8 之后需重建堆,在此过程中,关键字之间的比较次数是()。
A.1 B.2 C.3 D.4
解答:
2.最小堆[0,3,2,5,7,4,6,8],在删除堆顶元素0之后,其结果是()
A[3,2,5,7,4,6,8]
B[2,3,5,7,4,6,8]
C[2,3,4,5,7,8,6]
D[2,3,4,5,6,7,8]
解答:
根据堆的删除规则,删除操作只能在堆顶进行,也就是删除0元素。
然后让最后一个节点放在堆顶,做向下调整工作,让剩下的数组依然满足最小堆。
删除0后用8填充0的位置,为[8,3,2,5,7,4,6]
然后8和其子节点3,2比较,结果2最小,将2和8交换,为:[2,3,8,5,7,4,6]
然后8的下标为2,其两个孩子节点下标分别为22+1=5,22+2=6
也就是4和6两个元素,经比较,4最小,将8与4交换,为[2,3,4,5,7,8,6]
这时候8已经没有孩子节点了,调整完成。
7.总结
本文开始时对二叉树的顺序存储进行了相关的介绍,紧接着就引出了“堆”的概念,把堆的基本概念讲解完之后我们就对两种基本的算法进行展开详解,学习完算法之后,我们就根据一定的算法去实现堆的基本功能以及堆的运用,最后通过简单的练习题加深我们对“堆”的了解!!!
以上就是全文的基本内容了,希望对大家有所帮助,觉得写的不错的话记得三连哟。
相关文章:
【堆】数据结构堆的实现(万字详解)
前言: 在上一期中我们讲到了树以及二叉树的基本的概念,有了之前的认识,今天我们将来具体实现一种二叉树的存储结构“堆”!!! 目录1.二叉树顺序结构介绍2.堆的概念及结构3.调整算法3.1向上调整算法3.1.1算法…...
Docker进阶 - 9. docker network 之自定义网络
1. 运行两个tomcat实例,并进入容器内部 docker run -d -p 8081:8080 --name tomcat81 billygoo/tomcat8-jdk8 docker exec -it tomcat81 bashdocker run -d -p 8082:8080 --name tomcat82 billygoo/tomcat8-idk8 docker exec -it tomcat82 bash2. ping一下各自的ip…...
springcloud-工程创建(IDEA)
文章目录介绍springcloud 常用组件1.创建父工程2.删除父工程的src目录3.修改父工程的pom文件4 springcloud 版本依赖5.创建子模块6 子项目下创建启动类介绍 Spring Cloud 是一个基于 Spring Boot 实现的云应用开发工具,它为开发中的配置管理、服务发现、断路器、智…...
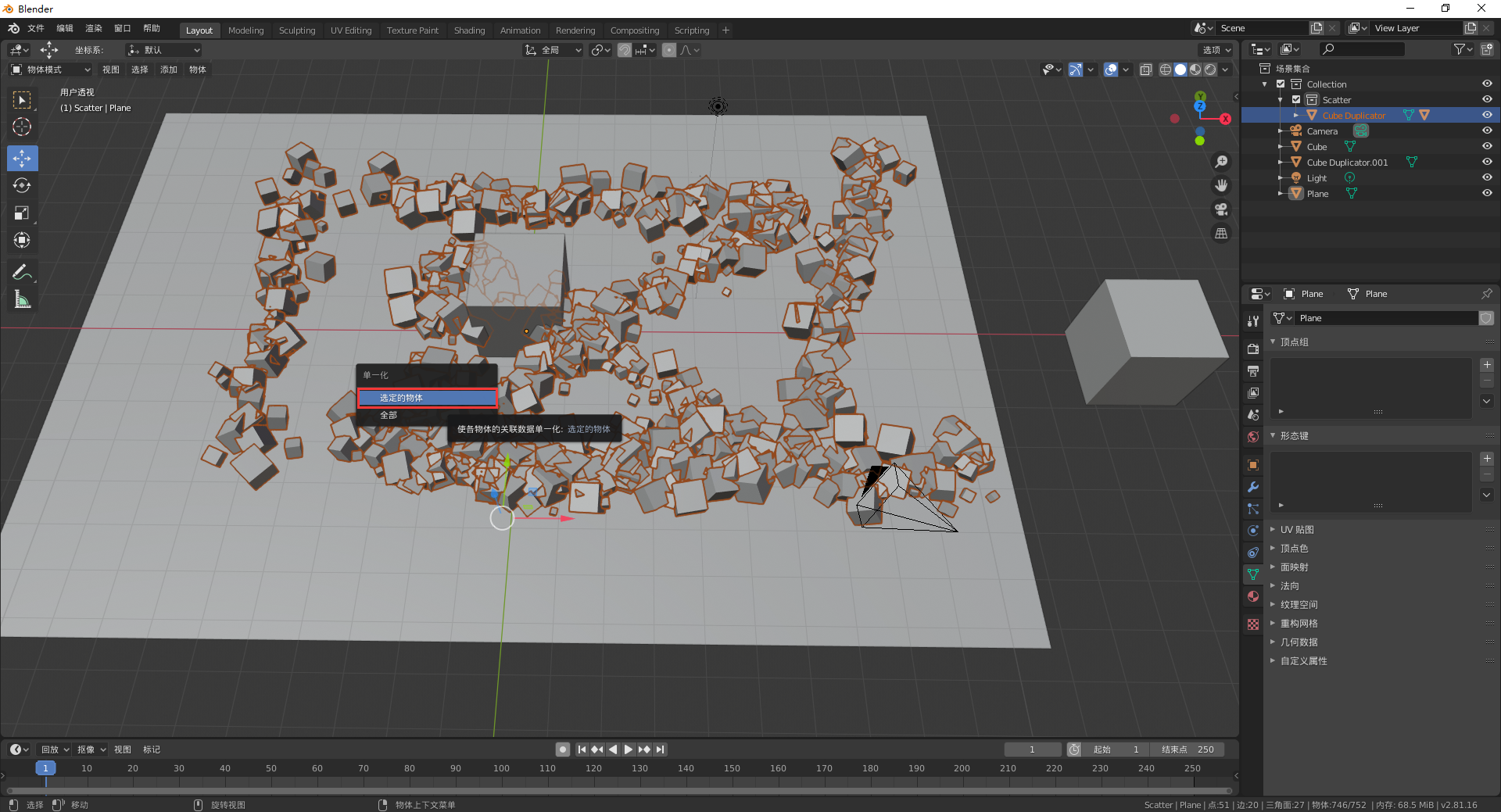
Blender——物体的随机分布
问题描述将正方体随机分布在平面上。问题解决点击编辑-->偏好设置。在【插件】中的【物体】类型中勾选【Object: Scatter Objects】。右下的活动工具与工作区设置中就会出现【物体散列】的模块,可以调节各参数。选中正方体,按着Shift,选中…...
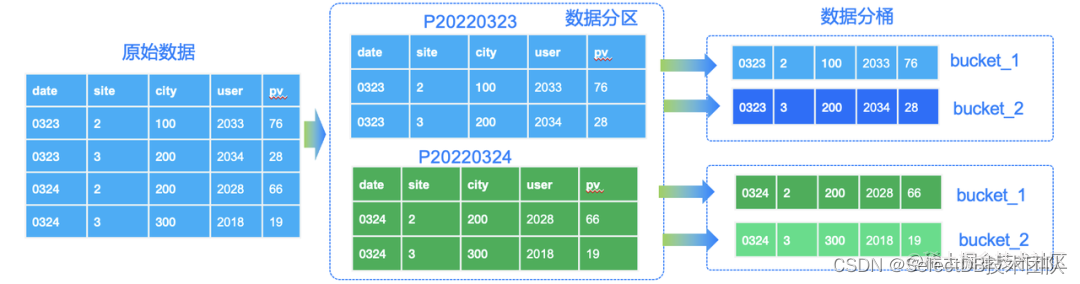
一文教你玩转 Apache Doris 分区分桶新功能
数据分片(Sharding)是分布式数据库分而治之 (Divide And Conquer) 这一设计思想的体现。过去的单机数据库在大数据量下往往面临存储和 IO 的限制,而分布式数据库则通过数据划分的规则,将数据打散分布至不同的机器或节点上…...

Spring JdbcTemplate 和 事务
JdbcTemplate概述 JdbcTemplate是spring框架中提供的一个对象,是对原始繁琐的Jdbc API对象的简单封装。spring框架为我们提供了很多的操作模板类。例如:操作关系型数据的JdbcTemplate和,操作nosql数据库的RedisTemplate,操作消息…...
C/C++:程序环境和预处理/宏
程序的翻译环境和执行环境 在ANSI C的任何一种实现中,存在两个不同的环境。第1种是翻译环境,在这个环境中源代码被转换为可执行的机器指令。第2种是执行环境,它用于实际执行代码。 编译和链接 一份源代码(比如test.c)需要通过编译…...

什么是死锁?死锁产生的四个必要条件是啥?如何避免和预防死锁的产生?
点个关注,必回关 文章目录什么是死锁死锁产生的原因:1、系统资源的竞争2、进程运行推进顺序不当引起死锁产生死锁的四个必要条件:死锁的避免与预防什么是死锁 死锁是指两个或两个以上的线程在执行过程中,由于竞争资源或者由于彼此…...

工程管理系统源码-物料管理-工程项目管理系统-建筑施工管理软件
如今建筑行业竞争激烈,内卷严重,发展趋势呈现两极分化,中小微企业的生存空间被逐步压缩,利润逐年减少。事实证明,工地上粗放式的人管人管理模式已经落于时代,劳动力纠纷和物料浪费现象尤其普遍,…...
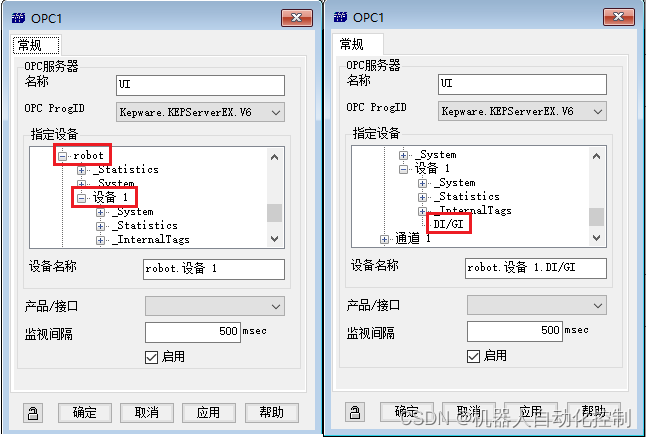
Roboguide与TIA V16通讯
软件需求:1. roboguide;2. TIA V16;3. KEPServer; 在之前的文章中介绍过KEPServer与TIA V16的通讯,此处不再介绍。接下来,介绍roboguide与KEPServer的仿真通讯。 创建一个roboguide项目。选择【外部设备】➡【添加外部设备】 选择【OPC Server】➡【OK】 OPC服务器名称命…...

利用PyTorch深度学习框架进行多元回归
目录前言数据加载数据转换模型定义模型训练模型评估模型保存与加载完整代码讨论参考文献前言 大多数数据科学家以往经常常是利用传统的机器学习框架sklearn搭建多元回归模型,随着深度学习和强化学习越来越普及,很多数据科学家尝试使用深度学习框架来进行…...

EBS常用接口开发
整理了一些工作中常用的Oracle EBS接口和API,最早是看着大神黄建华文档起来的,格式内容参考他的文档,加上一些自己开发的程序和经历而已。 PO PO接收、检验、入库、退货-InterfaceAPI_刘文钊1的博客-CSDN博客 基础数据 EBS物料、bom、工艺导入…...

【完整】UR机械臂逆运动学求解过程及c++代码实现
有任何问题请在评论区留言,我尽可能的回复大家 一. 逆运动学的求解需要以下数学运算 利用DH参数得到每个关节的变换矩阵;利用变换矩阵求出机械臂整个链的变换矩阵;求出末端位姿;利用已知末端位姿和整个链的变换矩阵,…...

68. Python的相对路径
68. Python的相对路径 文章目录68. Python的相对路径1. 知识回顾2. 什么是相对路径3. 相对路径的语法4. 查看相对路径的方法5. 写出所有txt文件的相对路径5.1 同目录5.2 上级目录6. 用相对路径读取txt文件6.1 读取旅游.txt6.2 读取旅游经费.txt6.3 读取笔记.txt和new.txt6.4 读…...
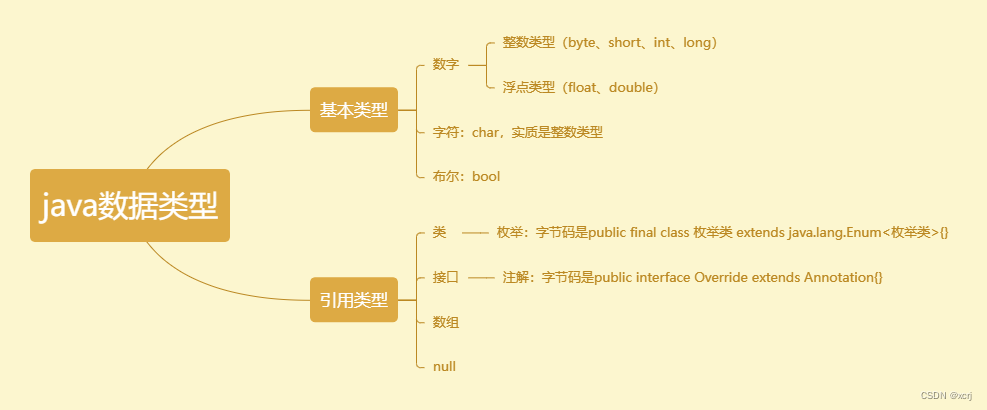
java数据类型
数据类型 类型分类,存储范围,字面量,默认值,类型转换 类型分类 存储范围 数据类型字节数表示范围byte1-128~127short2-32768~32767,正负3万左右int4-2147483648~2147483647,正负21亿左右long8-922337203…...

Kotlin 替换非空断言的几种方式
Kotlin 出现断言的两种情形 IDE java 与 kotlin 自动转换时,自动添加非空断言的代码Smart Cast 失效 代码展示: class JavaConvertExample {private var name: String? nullfun init() {name ""}fun foo() {name null;}fun test() {if (…...
2023年了,来试试前端格式化工具
在大前端时代,前端的各种工具链穷出不断,有eslint, prettier, husky, commitlint 等, 东西太多有的时候也是trouble😂😂😂,怎么正确的使用这个是每一个前端开发者都需要掌握的内容,请上车🚗&…...

spring cloud 企业工程项目管理系统源码+项目模块功能清单
工程项目各模块及其功能点清单 一、系统管理 1、数据字典:实现对数据字典标签的增删改查操作 2、编码管理:实现对系统编码的增删改查操作 3、用户管理:管理和查看用户角色 4、菜单管理:实现对系统菜单的增删改查操…...

TCP分片解析
本文目录什么是IP分片为什么会产生IP分片为什么要避免IP分片如何避免IP分片什么是IP分片 IP协议栈将TCP/UDP传输层要求它发送的,但长度大于发送端口MTU的一个数据包,分割成多个IP报文后分多次发送。这些分成多次发送的多个IP报文就是IP分片。 为什么会…...
开发了一款基于 Flask 框架的在线电影网站系统(附 Python 源码)
文章目录前言项目介绍源码获取运行环境安装依赖库项目截图首页展示图视频展示页视频播放页后台管理页整体架构设计图项目目录结构图前台功能模块图后台功能模块图本地运行图前言 今天我给大家分享的是基于 Python 的 Flask 框架开发的在线电影网站系统,大家平时需要…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

Opencv中的addweighted函数
一.addweighted函数作用 addweighted()是OpenCV库中用于图像处理的函数,主要功能是将两个输入图像(尺寸和类型相同)按照指定的权重进行加权叠加(图像融合),并添加一个标量值&#x…...

【python异步多线程】异步多线程爬虫代码示例
claude生成的python多线程、异步代码示例,模拟20个网页的爬取,每个网页假设要0.5-2秒完成。 代码 Python多线程爬虫教程 核心概念 多线程:允许程序同时执行多个任务,提高IO密集型任务(如网络请求)的效率…...

python爬虫——气象数据爬取
一、导入库与全局配置 python 运行 import json import datetime import time import requests from sqlalchemy import create_engine import csv import pandas as pd作用: 引入数据解析、网络请求、时间处理、数据库操作等所需库。requests:发送 …...

前端调试HTTP状态码
1xx(信息类状态码) 这类状态码表示临时响应,需要客户端继续处理请求。 100 Continue 服务器已收到请求的初始部分,客户端应继续发送剩余部分。 2xx(成功类状态码) 表示请求已成功被服务器接收、理解并处…...
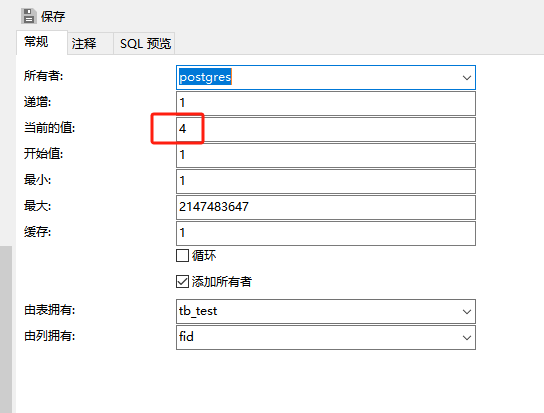
pgsql:还原数据库后出现重复序列导致“more than one owned sequence found“报错问题的解决
问题: pgsql数据库通过备份数据库文件进行还原时,如果表中有自增序列,还原后可能会出现重复的序列,此时若向表中插入新行时会出现“more than one owned sequence found”的报错提示。 点击菜单“其它”-》“序列”,…...
leetcode73-矩阵置零
leetcode 73 思路 记录 0 元素的位置:遍历整个矩阵,找出所有值为 0 的元素,并将它们的坐标记录在数组zeroPosition中置零操作:遍历记录的所有 0 元素位置,将每个位置对应的行和列的所有元素置为 0 具体步骤 初始化…...

Python爬虫实战:研究Restkit库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的有价值数据。如何高效地采集这些数据并将其应用于实际业务中,成为了许多企业和开发者关注的焦点。网络爬虫技术作为一种自动化的数据采集工具,可以帮助我们从网页中提取所需的信息。而 RESTful API …...