本地部署多语言代码生成模型CodeGeeX2
🏠 Homepage|💻 GitHub|🛠 Tools VS Code, Jetbrains|🤗 HF Repo|📄 Paper
👋 Join our Discord, Slack, Telegram, WeChat
BF16/FP16版本|BF16/FP16 version codegeex2-6b
CodeGeeX2: 更强大的多语言代码生成模型
A More Powerful Multilingual Code Generation Model
一、CodeGeeX2模型简介
CodeGeeX2 是多语言代码生成模型 CodeGeeX (KDD’23) 的第二代模型。CodeGeeX2 基于 ChatGLM2 架构加入代码预训练实现,得益于 ChatGLM2 的更优性能,CodeGeeX2 在多项指标上取得性能提升(+107% > CodeGeeX;仅60亿参数即超过150亿参数的 StarCoder-15B 近10%),更多特性包括:
- 更强大的代码能力:基于 ChatGLM2-6B 基座语言模型,CodeGeeX2-6B 进一步经过了 600B 代码数据预训练,相比一代模型,在代码能力上全面提升,HumanEval-X 评测集的六种编程语言均大幅提升 (Python +57%, C++ +71%, Java +54%, JavaScript +83%, Go +56%, Rust +321%),在Python上达到 35.9% 的 Pass@1 一次通过率,超越规模更大的 StarCoder-15B。
- 更优秀的模型特性:继承 ChatGLM2-6B 模型特性,CodeGeeX2-6B 更好支持中英文输入,支持最大 8192 序列长度,推理速度较一代 CodeGeeX-13B 大幅提升,量化后仅需6GB显存即可运行,支持轻量级本地化部署。
- 更全面的AI编程助手:CodeGeeX插件(VS Code, Jetbrains)后端升级,支持超过100种编程语言,新增上下文补全、跨文件补全等实用功能。结合 Ask CodeGeeX 交互式AI编程助手,支持中英文对话解决各种编程问题,包括且不限于代码解释、代码翻译、代码纠错、文档生成等,帮助程序员更高效开发。
- 更开放的协议:CodeGeeX2-6B 权重对学术研究完全开放,填写登记表申请商业使用。
下载地址:
CodeGeeX2-6B-int4 · 模型库 (modelscope.cn)
二、软件依赖 | Dependency
pip install protobuf cpm_kernels torch>=2.0 gradio mdtex2html sentencepiece accelerate三、模型部署使用
3.1 python生成冒泡排序算法
from modelscope import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("E:\Data\CodeGeeX2-6B-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("E:\Data\CodeGeeX2-6B-int4", trust_remote_code=True, device='cuda')
model = model.eval()# remember adding a language tag for better performance
prompt = "# language: Python\n# 用python写一个冒泡排序算法,并用中文逐行注释\n"
# inputs = tokenizer.encode(prompt, return_tensors="pt").to(model.device)
inputs = tokenizer.encode(prompt, return_tensors="pt", padding=True, truncation=True).to(model.device)
# outputs = model.generate(inputs, max_length=256, top_k=1)
outputs = model.generate(inputs, max_length=256)
response = tokenizer.decode(outputs[0])print(response)反馈结果
# language: Python
# 用python写一个冒泡排序算法,并用中文逐行注释def bubble_sort(list):"""冒泡排序算法:param list: 要排序的列表:return: 排序后的列表"""for i in range(len(list) - 1):for j in range(len(list) - i - 1):if list[j] > list[j + 1]:list[j], list[j + 1] = list[j + 1], list[j]return listif __name__ == "__main__":list = [1, 3, 2, 4, 5, 6, 7, 9, 8]print(bubble_sort(list))3.2 python实现Bert+对抗训练+对比学习的文本分类任务
from modelscope import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("E:\Data\CodeGeeX2-6B-int4", trust_remote_code=True)
model = AutoModel.from_pretrained("E:\Data\CodeGeeX2-6B-int4", trust_remote_code=True, device='cuda')
model = model.eval()# remember adding a language tag for better performance
prompt = "# language: Python\n# 用python写一个用Bert结合对抗训练和对比学习实现SST-2数据集文本分类的代码,并用中文逐行注释\n"
# inputs = tokenizer.encode(prompt, return_tensors="pt").to(model.device)
inputs = tokenizer.encode(prompt, return_tensors="pt", padding=True, truncation=True).to(model.device)
# outputs = model.generate(inputs, max_length=256, top_k=1)
outputs = model.generate(inputs, max_length=20000)
response = tokenizer.decode(outputs[0])print(response)反馈结果
import torch
import torch.nn as nn
import torch.nn.functional as F
from pytorch_pretrained_bert import BertModel, BertTokenizer
from torch.utils.data import TensorDataset, DataLoader, RandomSampler
from torch.utils.tensorboard import SummaryWriter
from tqdm import tqdm, trange
import os
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import f1_score, accuracy_score
from pprint import pprint
import logging
import argparselogging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s: %(message)s")class SST2Dataset:def __init__(self, data_dir, tokenizer, max_seq_len, train_mode):self.data_dir = data_dirself.tokenizer = tokenizerself.max_seq_len = max_seq_lenself.train_mode = train_modeself.data_df = self.load_data()self.train_df, self.valid_df = self.split_data()self.train_inputs, self.train_masks = self.tokenize_data(self.train_df)self.valid_inputs, self.valid_masks = self.tokenize_data(self.valid_df)self.train_labels = self.train_df["label"].tolist()self.valid_labels = self.valid_df["label"].tolist()def load_data(self):data_df = pd.read_csv(os.path.join(self.data_dir, "train.tsv"), sep="\t")return data_dfdef split_data(self):data_df = self.data_dftrain_df, valid_df = train_test_split(data_df, test_size=0.2, random_state=42)return train_df, valid_dfdef tokenize_data(self, data_df):inputs_1 = list(data_df["sentence1"])inputs_2 = list(data_df["sentence2"])inputs = inputs_1 + inputs_2masks = [1] * len(inputs_1) + [0] * len(inputs_2)inputs = [self.tokenizer.tokenize(sent)[:self.max_seq_len] for sent in inputs]inputs = [self.tokenizer.convert_tokens_to_ids(["[CLS]"] + input) for input in inputs]inputs = [input[0 : self.max_seq_len] + [0] * (self.max_seq_len - len(input)) for input in inputs]inputs = torch.tensor(inputs)masks = torch.tensor(masks)return inputs, masksdef get_data(self, data_type):if data_type == "train":inputs, masks, labels = self.train_inputs, self.train_masks, self.train_labelselif data_df == "valid":inputs, masks, labels = self.valid_inputs, self.valid_masks, self.valid_labelsreturn inputs, masks, labelsclass BertClassifier(nn.Module):def __init__(self, bert_model, out_dim):super(BertClassifier, self).__init__()self.bert_model = bert_modelself.out = nn.Linear(768, out_dim)def forward(self, inputs, masks):_, _, _ = self.bert_model(inputs, masks)pooled = outputs[:, 0]out = self.out(pooled)return outdef train_epoch(train_data, optimizer, scheduler, writer, epoch, args):# 训练模型bert_model.train()train_loss = 0num_train_data = 0for batch_idx, train_batch in enumerate(train_data):train_batch_inputs, train_batch_masks, train_batch_labels = train_batchtrain_batch_inputs, train_batch_masks, train_batch_labels = (train_batch_inputs.to(args.device),train_batch_masks.to(args.device),train_batch_labels.to(args.device),)optimizer.zero_grad()bert_out = bert_model(train_batch_inputs, train_batch_masks)loss = F.cross_entropy(bert_out, train_batch_labels)train_loss += loss.item()num_train_data += len(train_batch_labels)loss.backward()optimizer.step()if scheduler is not None:scheduler.step()writer.add_scalar("loss", loss.item(), global_step=num_train_data)writer.add_scalar("learning_rate", optimizer.param_groups[0]["lr"], global_step=num_train_data)writer.add_scalar("train_loss", train_loss / (batch_idx + 1), global_step=num_train_data)writer.add_scalar("train_acc", accuracy_score(train_batch_labels, np.argmax(bert_out.detach().cpu().numpy(), axis=-1)), global_step=num_train_data)def eval_epoch(valid_data, writer, epoch, args):# 验证模型bert_model.eval()valid_loss = 0num_valid_data = 0valid_preds = []valid_labels = []with torch.no_grad():for batch_idx, valid_batch in enumerate(valid_data):valid_batch_inputs, valid_batch_masks, valid_batch_labels = valid_batchvalid_batch_inputs, valid_batch_masks, valid_batch_labels = (valid_batch_inputs.to(args.device),valid_batch_masks.to(args.device),valid_batch_labels.to(args.device),)bert_out = bert_model(valid_batch_inputs, valid_batch_masks)loss = F.cross_entropy(bert_out, valid_batch_labels)valid_loss += loss.item()num_valid_data += len(valid_batch_labels)valid_preds.append(bert_out.detach().cpu().numpy())valid_labels.append(valid_batch_labels.detach().cpu().numpy())valid_preds = np.concatenate(valid_preds, axis=0)valid_labels = np.concatenate(valid_labels, axis=0)valid_acc = accuracy_score(valid_labels, np.argmax(valid_preds, axis=-1))valid_loss = valid_loss / (batch_idx + 1)writer.add_scalar("valid_loss", valid_loss, global_step=epoch + 1)writer.add_scalar("valid_acc", valid_acc, global_step=epoch + 1)writer.add_scalar("valid_f1", f1_score(valid_labels, np.argmax(valid_preds, axis=-1)), global_step=epoch + 1)def train(args):# 训练模型writer = SummaryWriter(log_dir=os.path.join(args.log_dir, "train"))for epoch in trange(args.num_epochs, desc="Epoch"):train_epoch(train_data=train_data,optimizer=optimizer,scheduler=scheduler,writer=writer,epoch=epoch,args=args,)eval_epoch(valid_data=valid_data, writer=writer, epoch=epoch, args=args)bert_model.save_pretrained(os.path.join(args.log_dir, "bert_model"))writer.close()def test_epoch(test_data, writer, epoch, args):# 测试模型bert_model.eval()test_loss = 0num_test_data = 0test_preds = []test_labels = []with torch.no_grad():for batch_idx, test_batch in enumerate(test_data):test_batch_inputs, test_batch_masks, test_batch_labels = test_batchtest_batch_inputs, test_batch_masks, test_batch_labels = (test_batch_inputs.to(args.device),test_batch_masks.to(args.device),test_batch_labels.to(args.device),)bert_out = bert_model(test_batch_inputs, test_batch_masks)loss = F.cross_entropy(bert_out, test_batch_labels)test_loss += loss.item()num_test_data += len(test_batch_labels)test_preds.append(bert_out.detach().cpu().numpy())test_labels.append(test_batch_labels.detach().cpu().numpy())test_preds = np.concatenate(test_preds, axis=0)test_labels = np.concatenate(test_labels, axis=0)test_acc = accuracy_score(test_labels, np.argmax(test_preds, axis=-1))test_loss = test_loss / (batch_idx + 1)writer.add_scalar("test_loss", test_loss, global_step=epoch + 1)writer.add_scalar("test_acc", test_acc, global_step=epoch + 1)writer.add_scalar("test_f1", f1_score(test_labels, np.argmax(test_preds, axis=-1)), global_step=epoch + 1)def test(args):writer = SummaryWriter(log_dir=os.path.join(args.log_dir, "test"))for epoch in trange(args.num_epochs, desc="Epoch"):test_epoch(test_data=test_data, writer=writer, epoch=epoch, args=args)writer.close()if __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument("--data_dir", type=str, default="./data")parser.add_argument("--log_dir", type=str, default="./logs")parser.add_argument("--num_epochs", type=int, default=10)parser.add_argument("--train_mode", type=str, default="train")parser.add_argument("--max_seq_len", type=int, default=128)parser.add_argument("--batch_size", type=int, default=32)parser.add_argument("--lr", type=float, default=2e-5)parser.add_argument("--num_workers", type=int, default=0)parser.add_argument("--seed", type=int, default=42)parser.add_argument("--device", type=str, default="cuda")args = parser.parse_args()pprint(vars(args))bert_tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")bert_model = BertModel.from_pretrained("bert-base-uncased")bert_model.to(args.device)if args.train_mode == "train":train_data = SST2Dataset(data_dir=args.data_dir,tokenizer=bert_tokenizer,max_seq_len=args.max_seq_len,train_mode=args.train_mode,).get_data(data_type="train")train_data = TensorDataset(*train_data)train_data = DataLoader(train_data,batch_size=args.batch_size,shuffle=True,num_workers=args.num_workers,)valid_data = SST2Dataset(data_dir=args.data_dir,tokenizer=bert_tokenizer,max_seq_len=args.max_seq_len,train_mode=args.train_mode,).get_data(data_type="valid")valid_data = TensorDataset(*valid_data)valid_data = DataLoader(valid_data,batch_size=args.batch_size,shuffle=False,num_workers=args.num_workers,)test_data = SST2Dataset(data_dir=args.data_dir,tokenizer=bert_tokenizer,max_seq_len=args.max_seq_len,train_mode=args.train_mode,).get_data(data_type="test")test_data = TensorDataset(*test_data)test_data = DataLoader(test_data,batch_size=args.batch_size,shuffle=False,num_workers=args.num_workers,)optimizer = torch.optim.Adam(bert_model.parameters(), lr=args.lr)scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer=optimizer, mode="min", factor=0.5, patience=2, verbose=True)train(args)test(args)elif args.train_mode == "test":test_data = SST2Dataset(data_dir=args.data_dir,tokenizer=bert_tokenizer,max_seq_len=args.max_seq_len,train_mode=args.train_mode,).get_data(data_type="test")test_data = TensorDataset(*test_data)test_data = DataLoader(test_data,batch_size=args.batch_size,shuffle=False,num_workers=args.num_workers,)test(args)
四、结果分析
4.1 提问内容
prompt = "# language: Python\n# 帮忙写一个冒泡排序\n"prompt中中文文字部分为需要实现的问题。
4.2 反馈内容长度设置
outputs = model.generate(inputs, max_length=256)max_length 为设置反馈的长度,可以根据自己实际情况进行调整。
相关文章:

本地部署多语言代码生成模型CodeGeeX2
🏠 Homepage|💻 GitHub|🛠 Tools VS Code, Jetbrains|🤗 HF Repo|📄 Paper 👋 Join our Discord, Slack, Telegram, WeChat BF16/FP16版本|BF16…...

C语言刷题练习(Day2)
✅作者简介:大家好我是:侠客er,是一名普通电子信息工程专业的大学学生,希望一起努力,一起进步! 📃个人主页:侠客er 🔥系列专栏:C语言刷题练习 🏷️…...
docker- harbor私有仓库部署与管理
什么是 harbor harbor是一个开源的云原生镜像仓库,它允许用户存储、签名、和分发docker镜像。可以将 harbor 看作是私有的docker hub ,它提供了更新安全性和控制性,让组织能够安全的存储和管理镜像 harbor RBAC(基于角色访问控制…...

自动化测试的优缺点
自动化测试的优势 能够极大地提升测试的效率,测试人员可以迅速地在指定平台部署测试脚本且对相应功能进行测试。 “弱化”了软件测试人员个体差异对测试结果的影响。 提高整个测试团队的技能水平。 自动化测试的缺陷 自动化测试的缺陷在于:总是按照…...
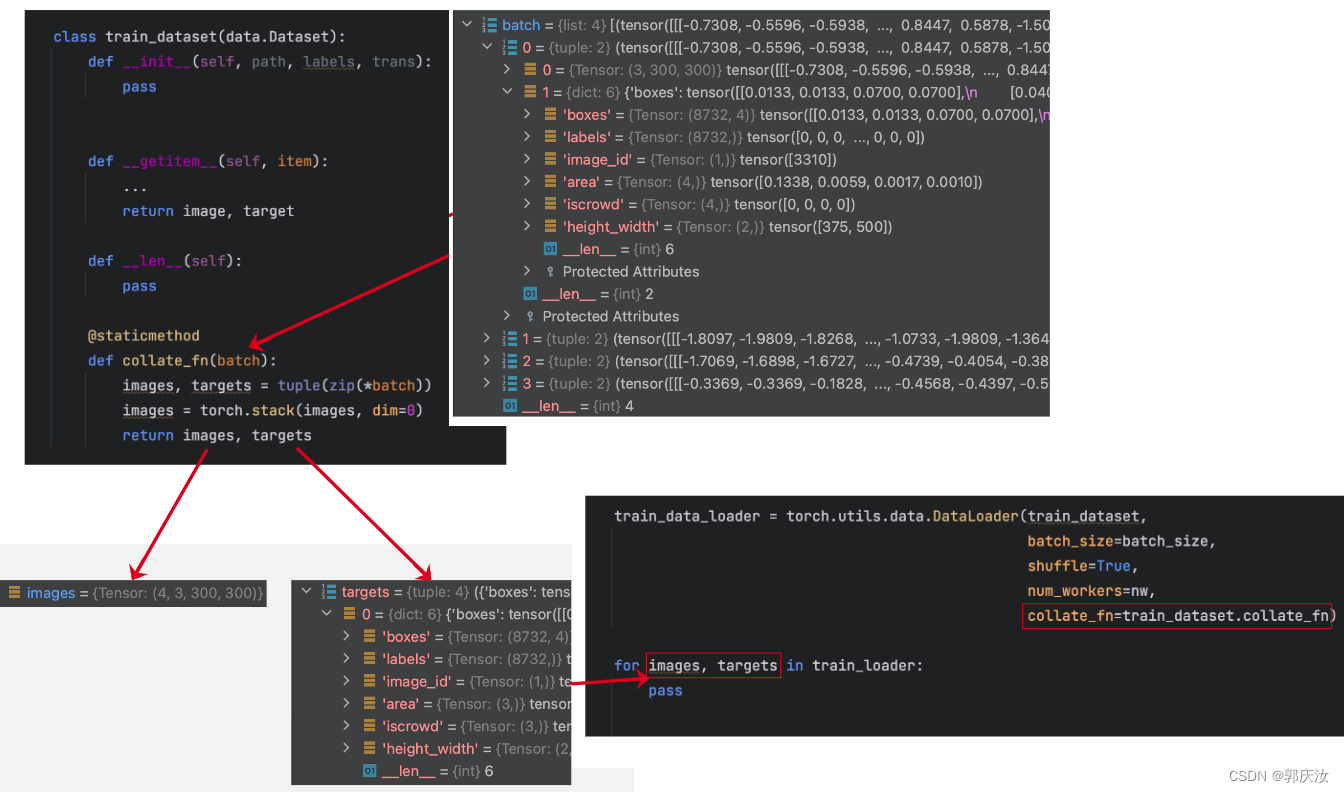
深度学习基础知识 Dataset 与 DataLoade的用法解析
深度学习基础知识 Dataset 与 DataLoade的用法解析 1、Dataset2、DataLoader参数设置:1、pin_memory2、num_workers3、collate_fn分类任务目标检测任务 1、Dataset 代码: import torch from torch.utils import dataclass MyDataset(torch.utils.data.D…...
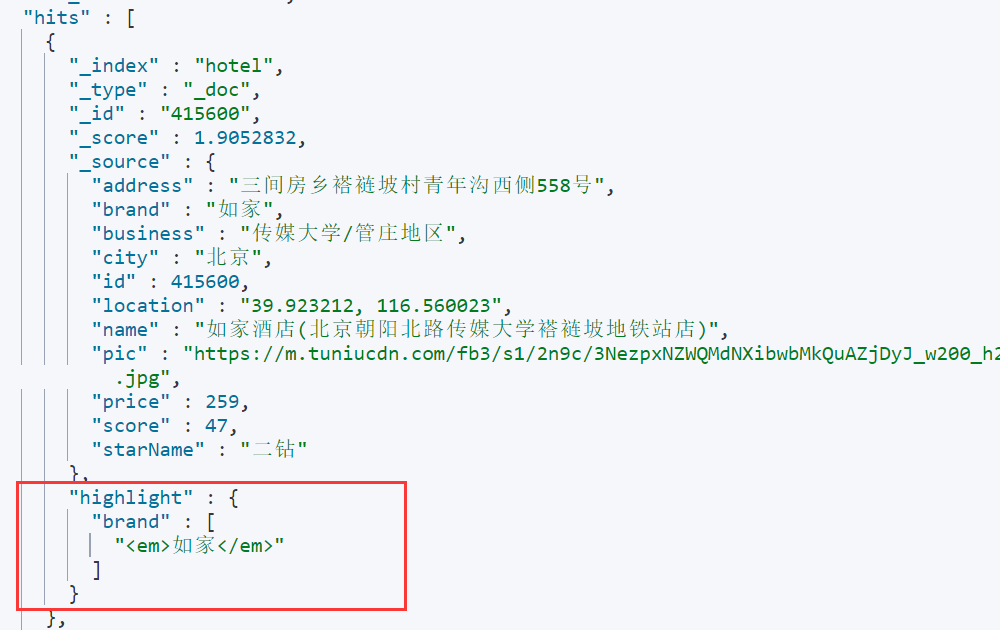
【ElasticSearch】深入探索 DSL 查询语法,实现对文档不同程度的检索,以及对搜索结果的排序、分页和高亮操作
文章目录 前言一、Elasticsearch DSL Query 的分类二、全文检索查询2.1 match 查询2.2 multi_match 查询 三、精确查询3.1 term 查询3.2 range 查询 四、地理坐标查询4.1 geo_bounding_box 查询4.2 geo_distance 查询 五、复合查询5.1 function score 查询5.2 boolean 查询 六、…...
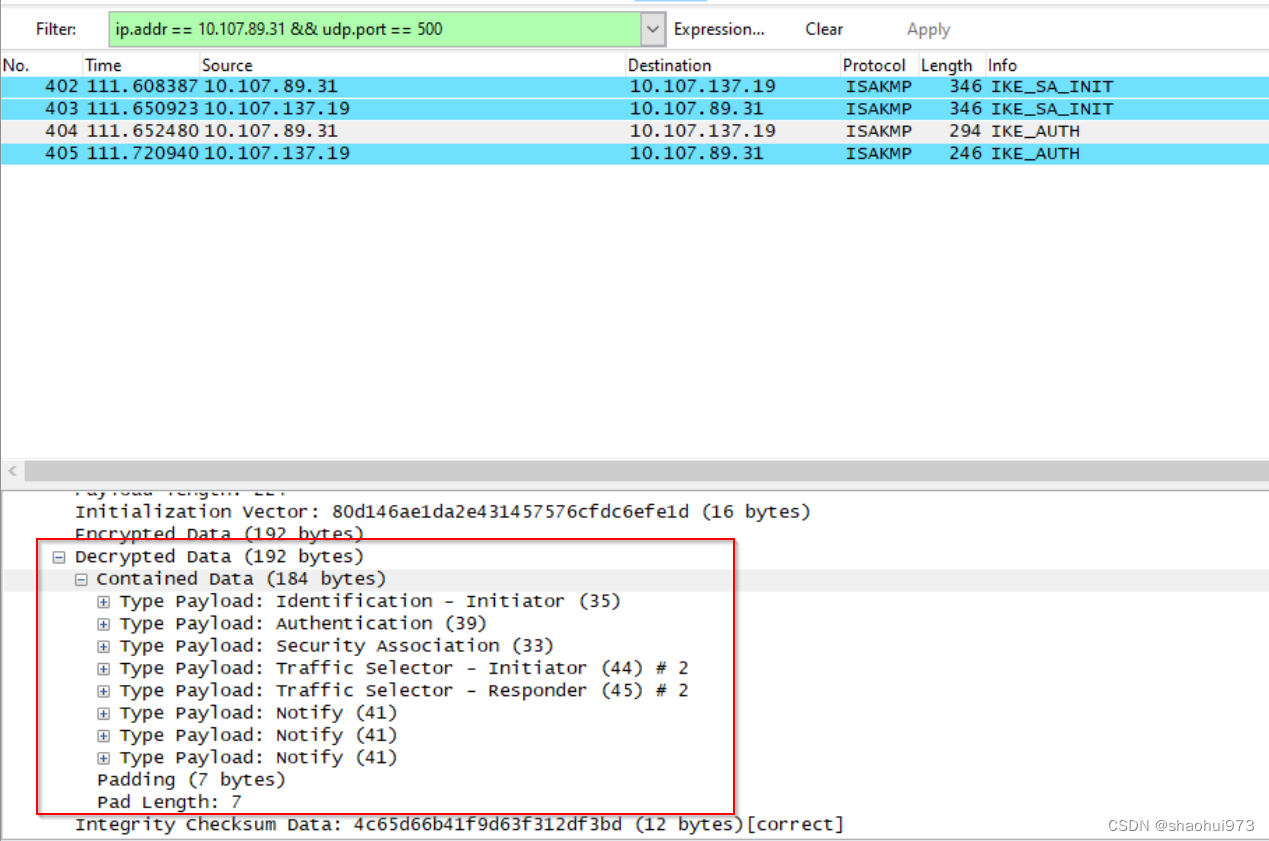
使用wireshark解密ipsec ISAKMP包
Ipsec首先要通过ikev2协议来协商自己后续协商所用的加解密key以及用户数据的esp包用的加解密包。 ISAKMP就是加密过的ike-v2的加密包,有时候我们需要解密这个包来查看协商数据。如何来解密这样的包? 首先导出strongswan协商生成的各种key. 要能导出这些key&#…...

算法进阶-搜索
算法进阶-搜索 题目描述:给定一张N个点M条边的有向无环图,分别统计从每个点除法能够到达的点的数量 **数据规模:**1 < n < 3e4 **分析:**这里我们可以使用拓扑排序根据入边对所有点进行排序,排序后我们按照逆序&…...
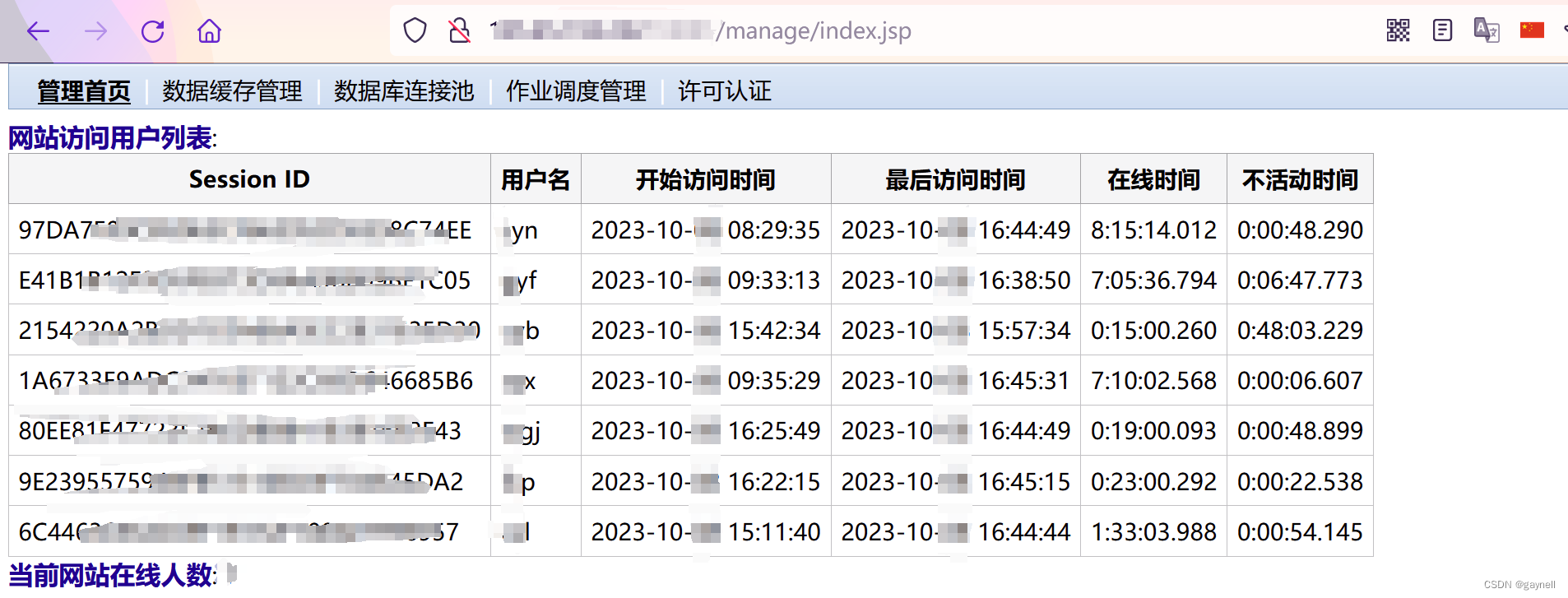
时空智友企业流程化管控系统 sessionid泄露漏洞 复现
文章目录 时空智友企业流程化管控系统 sessionid泄露漏洞 复现0x01 前言0x02 漏洞描述0x03 影响平台0x04 漏洞环境0x05 漏洞复现1.访问漏洞环境2.构造POC3.复现 时空智友企业流程化管控系统 sessionid泄露漏洞 复现 0x01 前言 免责声明:请勿利用文章内的相关技术从…...

QT编程,QMainWindow、事件
目录 1、QMainWindow 2、事件 1、QMainWindow QMenuBar:菜单栏 QMenu: 菜单 QAction: 动作 QToolBar: 工具栏 QStatusBar: 状态栏 setWindowTitle("主窗口"); //: 前缀 文件名 setWindowIcon(QIcon(":/mw_images/10.png")); resize(640, 4…...
人工智能在教育上的应用2-基于大模型的未来数学教育的情况与实际应用
大家好,我是微学AI ,今天给大家介绍一下人工智能在教育上的应用2-基于大模型的未来数学教育的情况与实际应用,随着人工智能(AI)和深度学习技术的发展,大模型已经开始渗透到各个领域,包括数学教育。本文将详细介绍基于大模型在数学…...
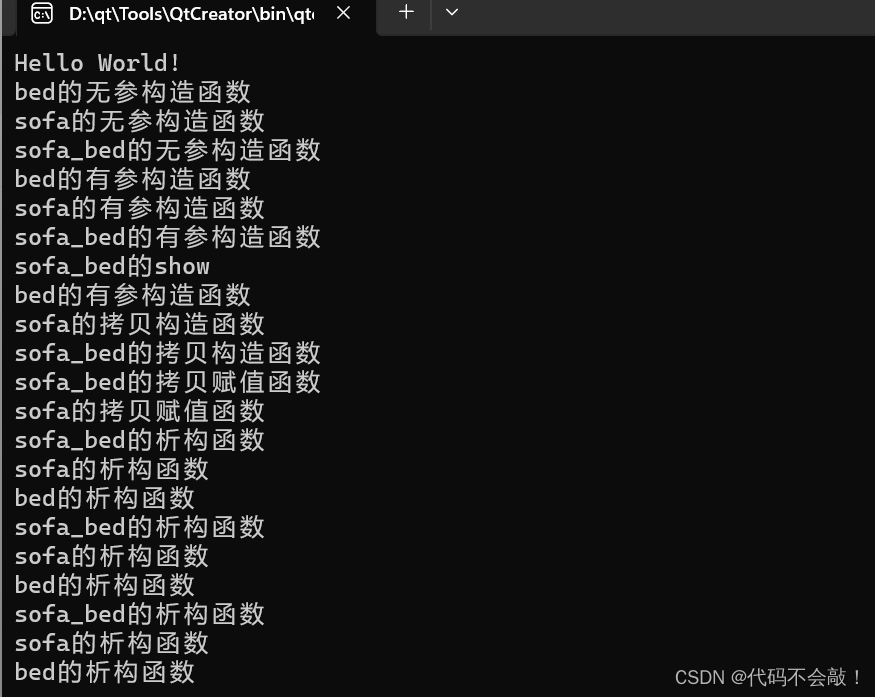
C++学习day5
目录 作业: 1> 思维导图 2> 多继承代码实现沙发床 1>思维导图 2> 多继承代码实现沙发床 #include <iostream>using namespace std; //创建沙发类 class sofa { private:string sitting; public:sofa(){cout << "sofa的无参构造函数…...

1.软件开发-HTML结构-元素剖析
元素的嵌套 代码注释 ctrl/ URL url 统一资源定位符 一个给定的独特资源在web上的地址 URI...
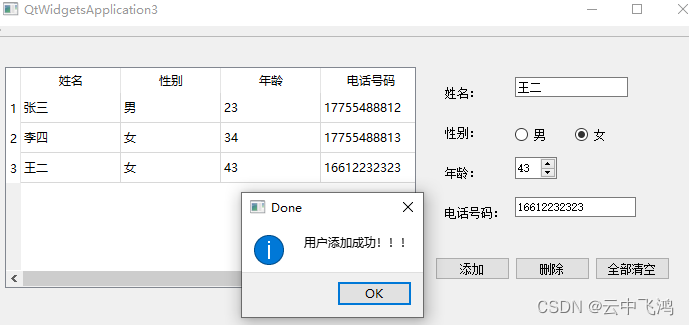
QTableWidget 表格增删数据
QTableWidgetQTableWidgetQTableWidget部分使用方法,如在表格中插入或删除一行数据以及清空表格数据等。在添加数据时,设置了条件判断如正则表达式,若用户输入的数据不合法,则添加失败并提示用户错误的地方,便于用户修…...
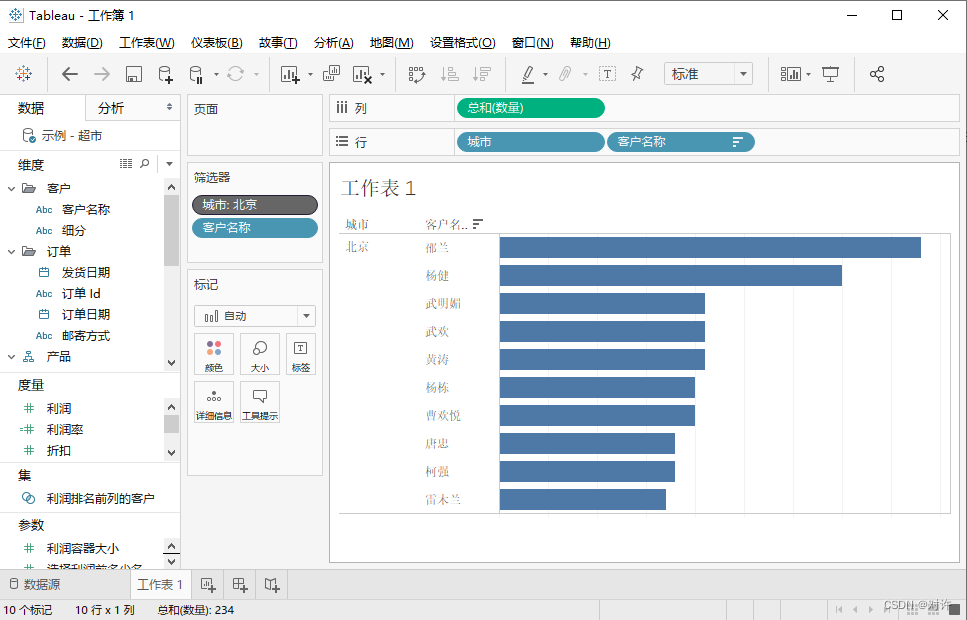
Tableau:商业智能(BI)工具
Tableau入门 1、Tableau概述2、Tableau Desktop2.1、初识Tableau Desktop2.2、Tableau工作区2.3、数据窗格与分析窗格2.4、功能区和标记卡2.4.1、列和行功能区2.4.2、标记卡2.4.3、筛选器功能区2.4.4、页面功能区2.4.5、附加功能区、图例、控件 3、Tableau视图4、Tableau工作簿…...

【gmail注册教程】手把手教你注册Google邮箱账号
手把手教你注册Google邮箱账号 写在前面: 要注意,注册Google邮箱必须要确保自己能够 科学上网,如果暂时做不到,请先进行相关学习。使用的手机号是大陆(86)的。 在保证自己能够科学上网后,在浏…...

docker版jxTMS使用指南:数据采集系统的高可用性
本文讲解4.6版jxTMS中数据采集系统的高可用性,整个系列的文章请查看:4.6版升级内容 docker版本的使用,请查看:docker版jxTMS使用指南 4.0版jxTMS的说明,请查看:4.0版升级内容 4.2版jxTMS的说明ÿ…...

vue如何禁止通过页面输入路径跳转页面
要禁止通过页面输入路径跳转页面,你可以使用Vue Router的导航守卫(navigation guards)来拦截导航并阻止不希望的跳转。 下面是一种常见的方法,你可以在全局导航守卫(global navigation guards)中实现这个功…...

mac,linux环境的基础工具安装【jdk,tomcat】
安装 一 linux环境一)、JDK安装卸载: 二)、 tomcat 安装1、[下载](https://mirrors.bfsu.edu.cn/apache/tomcat/tomcat-8/v8.5.63/bin/apache-tomcat-8.5.63.tar.gz)后,在目录 /usr/local/tomcat下,解压缩2、配置tomca…...
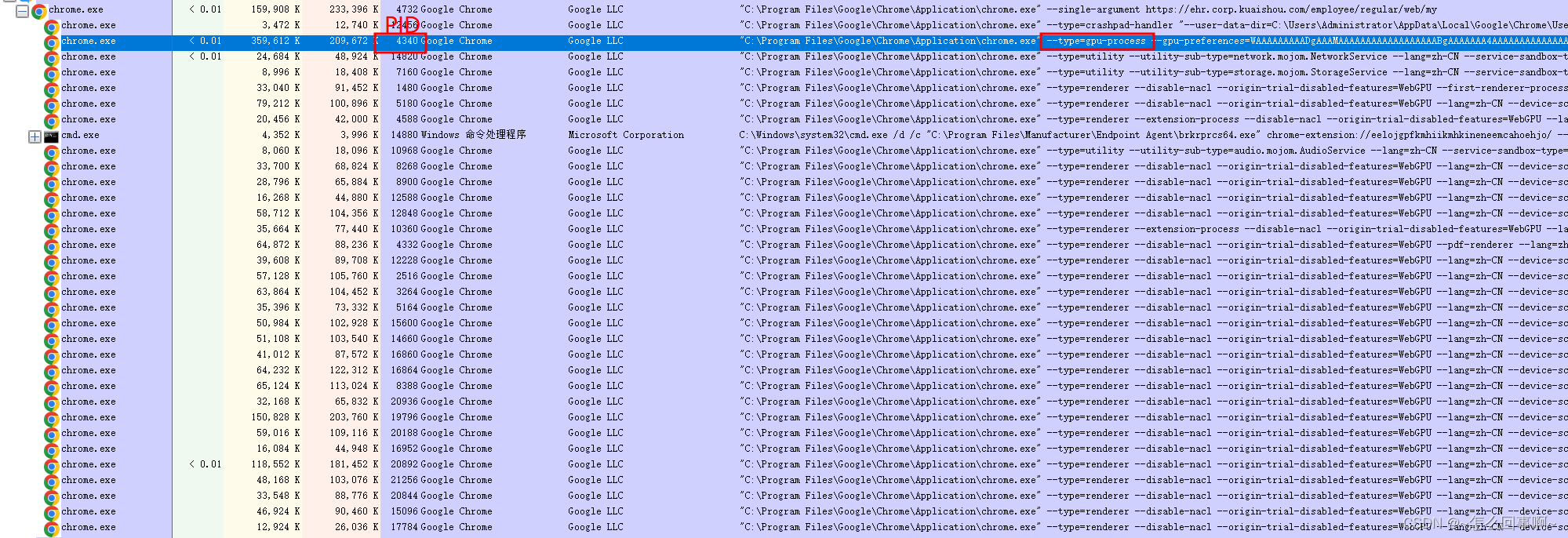
chrome窗口
chrome 窗口的层次: 父窗口类名:Chrome_WidgetWin_1 有两个子窗口: Chrome_RenderWidgetHostHWNDIntermediate D3D Window // 用于匹配 Chrome 窗口的窗口类的前缀。 onst wchar_t kChromeWindowClassPrefix[] L"Chrome_WidgetWin_…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

CTF show Web 红包题第六弹
提示 1.不是SQL注入 2.需要找关键源码 思路 进入页面发现是一个登录框,很难让人不联想到SQL注入,但提示都说了不是SQL注入,所以就不往这方面想了 先查看一下网页源码,发现一段JavaScript代码,有一个关键类ctfs…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

Xen Server服务器释放磁盘空间
disk.sh #!/bin/bashcd /run/sr-mount/e54f0646-ae11-0457-b64f-eba4673b824c # 全部虚拟机物理磁盘文件存储 a$(ls -l | awk {print $NF} | cut -d. -f1) # 使用中的虚拟机物理磁盘文件 b$(xe vm-disk-list --multiple | grep uuid | awk {print $NF})printf "%s\n"…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...

【JVM面试篇】高频八股汇总——类加载和类加载器
目录 1. 讲一下类加载过程? 2. Java创建对象的过程? 3. 对象的生命周期? 4. 类加载器有哪些? 5. 双亲委派模型的作用(好处)? 6. 讲一下类的加载和双亲委派原则? 7. 双亲委派模…...

如何更改默认 Crontab 编辑器 ?
在 Linux 领域中,crontab 是您可能经常遇到的一个术语。这个实用程序在类 unix 操作系统上可用,用于调度在预定义时间和间隔自动执行的任务。这对管理员和高级用户非常有益,允许他们自动执行各种系统任务。 编辑 Crontab 文件通常使用文本编…...