PointRend: 将图像分割视为渲染——PointRend:Image Segmentation as Rendering
0.摘要
我们提出了一种新的方法,用于高效、高质量的对象和场景图像分割。通过将经典的计算机图形学方法与像素标记任务中面临的过采样和欠采样挑战进行类比,我们开发了一种将图像分割视为渲染问题的独特视角。基于这个视角,我们提出了PointRend(基于点的渲染)神经网络模块:一个在自适应选择的位置上执行基于点的分割预测的模块,该位置是基于迭代细分算法选择的。PointRend可以灵活地应用于实例分割和语义分割任务,通过构建在现有的最先进模型之上。虽然许多具体实现都是可能的,但我们表明,一个简单的设计已经可以实现出色的结果。在质量上,PointRend在先前方法平滑过度的区域输出清晰的物体边界。在数量上,PointRend在COCO和Cityscapes上为实例分割和语义分割带来了显著的收益。PointRend的效率使得输出分辨率比现有方法在存储器或计算方面都更加实用。代码已经在https://github.com/facebookresearch/detectron2/tree/master/projects/PointRend上开放。
1.引言
图像分割任务涉及将在规则网格上采样的像素映射到相同网格上的标签地图或一组标签地图。在语义分割的情况下,标签地图指示每个像素的预测类别。在实例分割的情况下,预测每个检测到的对象的二进制前景与背景地图。这些任务的现代工具是建立在卷积神经网络(CNN)[24、23]上的。用于图像分割的CNN通常在规则网格上运行:输入图像是像素的规则网格,它们的隐藏表示是规则网格上的特征向量,它们的输出是规则网格上的标签地图。规则网格很方便,但不一定是适合图像分割的计算理想。这些网络预测的标签地图应该是大部分光滑的,即相邻的像素通常取相同的标签,因为高频区域被限制在对象之间稀疏的边界上。规则网格将不必要地过采样光滑区域,同时欠采样对象边界。结果是在光滑区域中进行过度计算和模糊的轮廓(图1,左上角)。图像分割方法通常在低分辨率规则网格上预测标签,例如,在语义分割中输入的1/8 [30]或在实例分割中的28×28 [17],以在欠采样和过采样之间进行折衷。
类似的采样问题在计算机图形学中已经研究了几十年。例如,渲染器将一个模型(例如,一个三维网格)映射到光栅化图像,即像素的规则网格。虽然输出是在规则网格上的,但计算并不均匀地分配在网格上。相反,一个常见的图形策略是在图像平面上计算自适应选择的点的不规则子集的像素值。例如,[43]的经典细分技术产生了一种类似四叉树的采样模式,可以有效地渲染高分辨率的抗锯齿图像。本文的核心思想是将图像分割视为渲染问题,并从计算机图形学中借鉴经典思想,以高效地“渲染”高质量的标签地图(见图1,左下角)。我们将这个计算思想封装在一个新的神经网络模块中,称为PointRend,它使用细分策略来自适应地选择计算标签的非均匀点集。PointRend可以集成到流行的元架构中,用于实例分割(例如,Mask R-CNN [17])和语义分割(例如,FCN [30])。它的细分策略使用比直接密集计算少一个数量级的浮点运算来高效地计算高分辨率的分割地图。
PointRend是一个通用模块,可以有许多可能的实现方式。抽象地看,一个PointRend模块接受一个或多个在规则网格上定义的典型CNN特征图f(xi,yi),并在更细的网格上输出高分辨率的预测p(x′i,yi′)。PointRend不会在输出网格上过度预测所有点,而是仅在精心选择的点上进行预测。为了进行这些预测,它通过插值f提取所选点的逐点特征表示,并使用一个小的点头子网络从逐点特征中预测输出标签。我们将提供一个简单而有效的PointRend实现。我们使用COCO [26]和Cityscapes [8]基准测试来评估PointRend在实例分割和语义分割任务中的性能。在质量方面,PointRend能够高效地计算对象之间的锐利边界,如图2和图8所示。我们还观察到定量的改进,尽管这些任务的标准交集联合比度量(mask AP和mIoU)偏向于对象内部像素,并且相对于边界改进比较不敏感。PointRend显著地改进了强大的Mask R CNN和DeepLabV3 [4]模型。

图2:使用带有标准掩膜头的Mask R-CNN [17](左图)与使用PointRend(右图)的示例结果对比,使用ResNet-50 [18]和FPN [25]。请注意,PointRend在物体边界周围预测具有更细致的细节的掩膜。
2.相关工作
计算机图形学中的渲染算法输出像素的规则网格。然而,它们通常在非均匀的点集上计算这些像素值。像细分[43]和自适应采样[33,37]这样的高效程序可以在像素值方差较大的区域中细化粗略的光栅化。射线追踪渲染器通常使用超采样[45],这是一种比输出网格更密集地采样某些点的技术,以避免走样效应。在这里,我们将经典的细分应用于图像分割。非均匀网格表示。在二维图像分析中,基于规则网格的计算是主导范式,但对于其他视觉任务来说并非如此。在三维形状识别中,由于立方体缩放,大型三维网格是不可行的。大多数基于CNN的方法不超过64×64×64的粗略网格[11,7]。相反,最近的作品考虑更高效的非均匀表示,例如网格[42,13]、符号距离函数[32]和oc树[41]。与符号距离函数类似,PointRend可以在任何点计算分割值。最近,Marin等人[31]提出了一种基于输入图像非均匀子采样的高效语义分割网络,然后再使用标准语义分割网络进行处理。相比之下,PointRend专注于输出时的非均匀采样。可能可以将这两种方法结合起来,但是[31]目前尚未证明适用于实例分割。
基于Mask R-CNN元架构[17]的实例分割方法在最近的挑战中占据了前几名[29,2]。这些基于区域的架构通常在一个28×28的网格上预测掩膜,而不考虑物体的大小。这对于小物体已经足够,但对于大物体,它会产生不良的“blobby”输出,过度平滑大物体的细节(见图1,左上角)。另一方面,自底向上的方法将像素分组形成对象掩膜[28,1,22]。这些方法可以产生更详细的输出,但在大多数实例分割基准测试[26,8,35]中落后于基于区域的方法。TensorMask [6]是一种替代的滑动窗口方法,使用复杂的网络设计来预测大物体的清晰高分辨率掩模,但它的准确性也略低。在本文中,我们展示了一个配备PointRend的基于区域的分割模型可以产生具有细节层次的掩膜,同时提高了基于区域的方法的准确性。
语义分割。全卷积网络(FCNs)[30]是现代语义分割方法的基础。它们通常预测输出比输入网格具有更低的分辨率,并使用双线性上采样来恢复其余的8-16×分辨率。可以通过用一些下采样层替换膨胀/空洞卷积[3,4]来改进结果,但代价是更多的内存和计算。替代方法包括编码器-解码器架构[5,21,39,40],其中编码器对网格表示进行下采样,然后在解码器中进行上采样,使用跳连接[39]来恢复过滤的细节。当前的方法将膨胀卷积与编码器解码器结构相结合[5,27],在应用双线性插值之前,将输出产生在比输入网格稀疏4×的网格上。在我们的工作中,我们提出了一种方法,可以在与输入网格一样密集的网格上高效地预测细节层次。
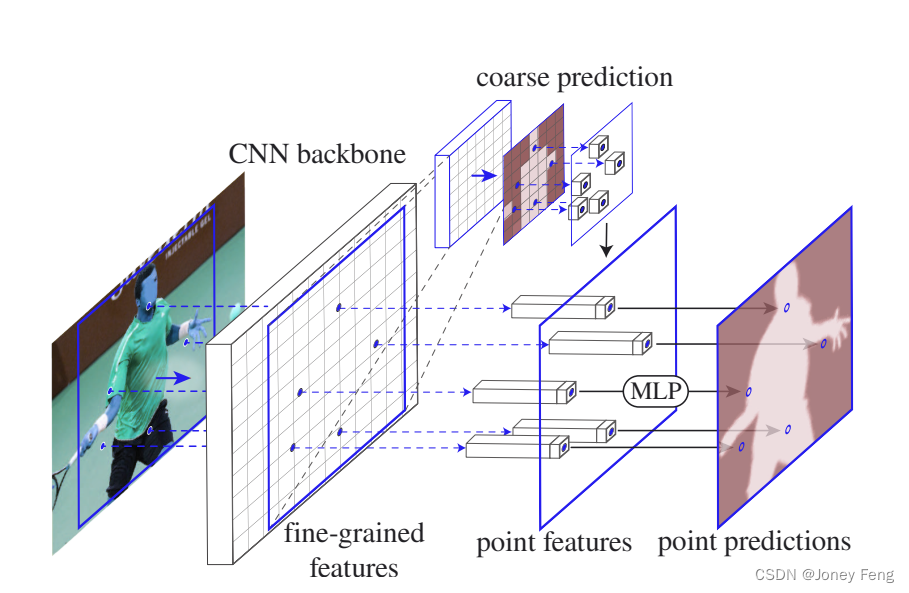
图3: PointRend应用于实例分割。标准的实例分割网络(实线红箭头)接受输入图像,并使用轻量级分割头为每个检测到的对象(红框)产生粗略(例如7×7)的掩膜预测。为了细化粗糙的掩膜,PointRend选择一组点(红色点),并使用小型MLP独立地对每个点进行预测。MLP使用从(1)主干CNN的细粒度特征映射和(2)粗略预测掩膜计算的这些点的插值特征(虚线红箭头)。粗略掩膜特征使MLP能够在包含两个或多个框的单个点上进行不同的预测。所提出的细分掩膜渲染算法(见图4和§3.1)迭代地应用这个过程,以细化预测掩膜的不确定区域。
3.方法
我们将计算机视觉中的图像分割(对象和/或场景)类比于计算机图形学中的图像渲染。渲染是关于将模型(例如,3D网格)显示为像素的常规网格,即图像。虽然输出表示是一个常规网格,但底层的物理实体(例如,3D模型)是连续的,其物理占用和其他属性可以使用物理和几何推理(如射线跟踪)在图像平面上的任何实值点进行查询。类比地,在计算机视觉中,我们可以将图像分割看作是底层连续实体的占用地图,并且从中“渲染”分割输出,该输出是预测标签的常规网格。该实体被编码在网络的特征图中,并且可以通过插值在任何点访问。一个参数化函数,该函数通过这些插值点特征表示来训练预测占用的,是物理和几何推理的对应项。
基于这个类比,我们提出了PointRend(基于点的渲染)作为使用点表示的图像分割方法。一个PointRend模块接受一个或多个C通道的典型CNN特征图f∈RC×H×W,每个特征图都在一个常规网格上定义(通常比图像网格粗略4到16倍),并输出在不同(可能更高)分辨率的常规网格上的K类标签p∈RK×H′×W′的预测。PointRend模块由三个主要组成部分组成:(i)点选择策略选择少量实值点进行预测,避免高分辨率输出网格中所有像素的过度计算。(ii)对于每个选择的点,提取点特征表示。实值点的特征是通过对f进行双线性插值计算得出的,使用f的正常网格上的点的4个最近邻居。因此,它能够利用编码在f的通道维度中的亚像素信息来预测具有比f更高分辨率的分割。(iii)点头:一个小型神经网络,训练预测每个点的标签。PointRend架构可以应用于实例分割(例如,Mask R-CNN [17])和语义分割(例如,FCN [30])任务。对于实例分割,PointRend被应用于每个区域。它通过在一组选定的点上进行预测以粗到细的方式计算掩膜(见图3)。对于语义分割,整个图像可以被视为单个区域,因此在不失一般性的情况下,我们将在实例分割的上下文中描述PointRend。接下来,我们将详细讨论三个主要组成部分。
3.1.推理和训练的点选择
我们方法的核心思想是灵活和自适应地选择图像平面上预测分割标签的点。直观地,这些点应该位于高频区域附近更密集的位置,例如物体边界,类似于射线追踪中的抗锯齿问题。我们针对推断和训练开发了这个想法。推断。我们的推断选择策略受计算机图形学中自适应细分[43]的启发。该技术用于通过仅在可能值与其邻居显著不同的位置计算高分辨率图像(例如,通过射线追踪),对于所有其他位置,值是通过插值已经计算的输出值获得的(从粗网格开始)。
对于每个区域,我们以粗到细的方式迭代地“渲染”输出掩膜。最粗糙的级别预测是在常规网格上的点上进行的(例如,通过使用标准的粗糙分割预测头)。在每次迭代中,PointRend使用双线性插值上采样其先前预测的分割,然后在这个更密集的网格上选择N个最不确定的点(例如,对于二进制掩膜,概率最接近0.5的点)。然后,PointRend计算每个这些N个点的点特征表示(稍后在§3.2中描述),并预测它们的标签。该过程重复进行,直到分割被上采样到所需的分辨率。该过程的一步在图4的玩具示例中说明。对于所需的输出分辨率为M×M像素和起始分辨率为M0×M0,PointRend所需的点预测不超过N log2 MM0。这比M×M小得多,使PointRend能够更有效地进行高分辨率预测。例如,如果M0为7,所需分辨率为M=224,则需要5个细分步骤。如果在每个步骤中选择N=282个点,PointRend仅对282·4.25个点进行预测,这比2242小15倍。请注意,总体选择的点数少于N log2 MM0,因为在第一次细分步骤中,只有142个点可用。
在训练期间,PointRend还需要选择点来构建用于训练点头的点特征。原则上,点选择策略可以类似于推断中使用的细分策略。然而,细分引入了顺序步骤,不利于使用反向传播训练神经网络。相反,在训练中,我们使用基于随机采样的非迭代策略。采样策略在特征图上选择N个点进行训练。它旨在偏向于不确定区域的选择,同时保持一定程度的均匀覆盖,使用三个原则。(i)过度生成:我们通过从均匀分布中随机采样kN个点(k>1)来过度生成候选点。(ii)重要性采样:我们通过在所有kN个点上插值粗糙预测值并计算特定任务的不确定性估计(在§4和§5中定义)来关注具有不确定粗略预测的点。从kN个候选点中选择最不确定的βN个点(β∈[0,1])。(iii)覆盖:剩余的(1−β)N个点从均匀分布中采样。我们在图5中使用不同的设置说明了这个过程,并将其与常规网格选择进行了比较。在训练时,预测和损失函数仅在N个采样点(除了粗糙分割)上计算,这比通过细分步骤反向传播更简单和更有效。这个设计类似于在Faster R-CNN系统[12]中并行训练RPN + Fast R-CNN,其推断是顺序的。
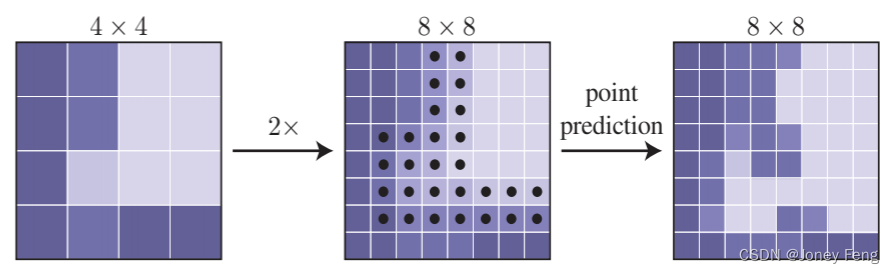
图4:一个自适应细分步骤的示例。对4×4网格的预测使用双线性插值上采样2×。然后,PointRend对N个最模糊的点(黑点)进行预测,以恢复更细网格上的细节。这个过程重复进行,直到达到所需的网格分辨率。
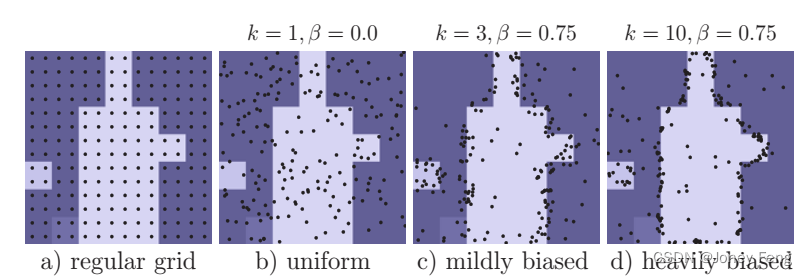 图5:训练过程中的点采样。我们展示了使用不同策略采样的N=142个点,对应于相同的基础粗略预测。为了实现高性能,每个区域只采样少量点,采用轻微偏置的采样策略,使系统在训练过程中更加高效。
图5:训练过程中的点采样。我们展示了使用不同策略采样的N=142个点,对应于相同的基础粗略预测。为了实现高性能,每个区域只采样少量点,采用轻微偏置的采样策略,使系统在训练过程中更加高效。
3.2.点表示和点头
PointRend通过组合(例如,连接)两种特征类型,即细粒度和粗略预测特征,在所选点上构建点特征,下面进行描述。细粒度特征:为了允许PointRend呈现细分割细节,我们从CNN特征图中在每个采样点提取一个特征向量。因为一个点是一个实值2D坐标,我们对特征图执行双线性插值来计算特征向量,遵循标准实践[19,17,9]。特征可以从单个特征图(例如ResNet中的res2)中提取;它们也可以从多个特征图(例如res2到res5或它们的特征金字塔[25]对应项)中提取并连接,遵循Hypercolumn方法[15]。粗略预测特征:细粒度特征使得分辨细节变得可行,但在两个方面也存在缺陷。首先,它们不包含区域特定的信息,因此,两个实例的边界框重叠的同一点将具有相同的细粒度特征。然而,该点只能在一个实例的前景中。因此,对于实例分割任务,不同区域可能会为同一点预测不同的标签,需要其他区域特定的信息。
其次,根据用于细粒度特征的特征图,特征可能仅包含相对较低级别的信息(例如,我们将使用DeepLabV3中的res2)。在这种情况下,具有更多上下文和语义信息的特征源可能会有所帮助。这个问题影响实例和语义分割。基于这些考虑,第二个特征类型是来自网络的粗略分割预测,即表示K类预测的每个区域(框)中每个点的K维向量。通过设计,粗略分辨率提供了更全局的上下文,而通道传达语义类别。这些粗略预测类似于现有架构产生的输出,并以与现有模型相同的方式在训练期间进行监督。对于实例分割,粗略预测可以是例如Mask R-CNN中轻量级7×7分辨率掩模头的输出。对于语义分割,它可以是例如来自步幅16特征图的预测。点头。给定每个选择点的点级特征表示,PointRend使用简单的多层感知器(MLP)进行点级分割预测。这个MLP在所有点(和所有区域)之间共享权重,类似于图卷积[20]或PointNet[38]。由于MLP为每个点预测分割标签,因此可以通过标准的特定任务分割损失(在§4和§5中描述)进行训练。
4.实验:实例分割
数据集。我们使用两个标准的实例分割数据集:COCO [26]和Cityscapes [8]。我们使用中位数报告COCO的3次运行和Cityscapes的5次运行的标准掩码AP度量[26](其方差较高)。COCO具有80个具有实例级注释的类别。我们在train2017(约118k张图像)上进行训练,并在val2017(5k张图像)上报告结果。正如[14]中所述,COCO的真实情况通常很粗糙,数据集的AP可能无法完全反映掩码质量的改进。因此,我们使用LVIS [14]的80个COCO类别子集进行AP补充,表示为AP!。LVIS的注释质量显著更高。请注意,对于AP!,我们使用在COCO上训练的相同模型,并使用LVIS评估API重新评估其预测,以针对更高质量的LVIS注释进行评估。Cityscapes是一个自我中心的街景数据集,具有8个类别,2975个训练图像和500个验证图像。与COCO相比,这些图像具有更高的分辨率(1024×2048像素),并且具有更精细,更像素准确的地面实例分割注释。
架构。我们的实验证明使用ResNet-50 [18] + FPN [25]骨干网络的Mask R-CNN。Mask R-CNN中的默认蒙版头是区域级FCN,我们将其表示为“4×conv”。2我们使用这个作为比较的基线。对于PointRend,我们对这个基线进行适当的修改,下面描述了这些修改。轻量级、粗略的掩码预测头。为了计算粗略的预测,我们使用一个更轻量级的设计来替换4×conv掩码头,类似于Mask R-CNN的框头,并产生一个7×7的掩码预测。具体来说,对于每个边界框,我们使用双线性插值从FPN的P2级别中提取一个14×14的特征图。特征在边界框内的正则网格上计算(这个操作可以看作是RoIAlign的简单版本)。接下来,我们使用一个步长为2的2×2卷积层,具有256个输出通道,后跟ReLU [34],将空间大小减小到7×7。最后,类似于Mask R-CNN的框头,应用一个具有两个1024宽隐藏层的MLP,以产生每个K类的7×7掩码预测。在MLP的隐藏层中使用ReLU,并将sigmoid激活函数应用于其输出。PointRend。在每个选择点处,使用双线性插值从粗略预测头的输出中提取一个K维特征向量。PointRend还使用双线性插值从FPN的P2级提取一个256维的特征向量。这个级别相对于输入图像具有4个步长。这些粗糙预测和细粒度特征向量被连接起来。我们使用具有256个通道的3个隐藏层的MLP在选择点处进行K类预测。在MLP的每个层中,我们使用K个粗略预测特征来补充256个输出通道,以使输入向量用于下一层。我们在MLP内部使用ReLU,并将sigmoid应用于其输出。
训练。我们默认使用Detectron2 [44]的标准1×训练计划和数据增强(完整的细节在附录中)。对于PointRend,我们使用k = 3和β = 0.75的偏置采样策略随机采样142个点。我们使用从粗糙预测中插值出的与地面实例分割类别概率的0.5之间的距离作为点级不确定度度量。对于具有地面实例分割类别c的预测框,我们对142个点上c-th MLP输出的二元交叉熵损失进行求和。轻量级粗略预测头使用平均交叉熵损失来预测类别c的掩码,即与基线4×conv头相同的损失。我们将所有损失相加,没有任何重新加权。在训练期间,Mask R-CNN并行应用框和掩码头,而在推理期间,它们作为级联运行。我们发现级联训练不会改善基线Mask R-CNN,但PointRend可以从中受益,因为它在更准确的框内采样点,略微改善了整体性能(约0.2%AP,绝对)。推理。对于预测类别c的框,在没有特殊说明的情况下,我们使用自适应细分技术将类别c的粗略7×7预测优化到224×224,需要5步。在每一步中,我们基于预测值与0.5之间的绝对差异选择并更新(最多)N = 282个最不确定的点。
4.1.主要结果
我们在表1中将PointRend与Mask R-CNN中的默认4×conv头进行了比较。PointRend在两个数据集上都优于默认头。当使用LVIS注释评估COCO类别时(AP!),以及在Cityscapes上,差距更大,我们将其归因于这些数据集中的优越注释质量。即使具有相同的输出分辨率,PointRend也优于基线。28×28和224×224之间的差异相对较小,因为AP使用交并比[10],因此严重偏向于对象内部像素,对边界质量不太敏感。然而,在视觉上,边界质量的差异是显而易见的,见图6。
Subdivision推理允许PointRend使用超过30倍的计算(FLOPs)和内存来产生高分辨率224×224预测,而默认的4×conv头需要输出相同分辨率(基于采用112×112 RoIAlign输入),见表2。PointRend通过忽略物体的粗略预测足够的区域(例如,远离物体边界的区域)使高分辨率输出成为Mask R-CNN框架中的可行方案。就墙钟运行时间而言,我们的未优化实现以∼13 fps输出224×224掩码,这与修改为输出56×56掩码(通过加倍默认的RoIAlign大小)的4×conv头具有大致相同的帧速率,实际上,这种设计与28×28的4×conv头相比,COCO AP更低(34.5%vs.35.2%)。表3显示了在每个细分步骤中选择不同输出分辨率和点数的PointRend细分推理。在更高的分辨率上预测掩码可以改善结果。尽管AP饱和,但在从较低(例如56×56)到更高(例如224×224)分辨率输出时,视觉改进仍然显而易见,见图7。由于点是首先在最模糊的区域中选择的,因此随着每个细分步骤中采样的点数量增加,AP也会饱和。额外的点可能会在已经足够粗略预测的区域中进行预测。然而,对于具有复杂边界的物体,使用更多的点可能是有益的。
表1:PointRend与Mask R-CNN [17]默认的4×卷积掩码头部的比较。报告了Mask AP。AP!是对更高质量的LVIS注释[14]进行的COCO掩码AP评估(详见文本)。COCO和Cityscapes模型均使用ResNet-50-FPN骨干网络。PointRend在数量和质量上都优于标准的4×卷积掩码头,更高的输出分辨率导致更详细的预测,见图2和图6。


图6:PointRend使用不同输出分辨率的推理。高分辨率掩码与物体边界对齐更好。
表2:224×224输出分辨率掩码的FLOPs(乘加)和激活计数。PointRend的高效子细分使224×224输出成为可能,而标准的4×卷积掩码头则修改为使用112×112的RoIAlign大小。

表3:细分推理参数。更高的输出分辨率可以提高AP。尽管每个细分步骤采样的点数在下划线值下很快饱和,但对于复杂对象,质量结果可能会继续改善。AP!是对更高质量的LVIS注释[14]进行的COCO掩码AP评估(详见文本)。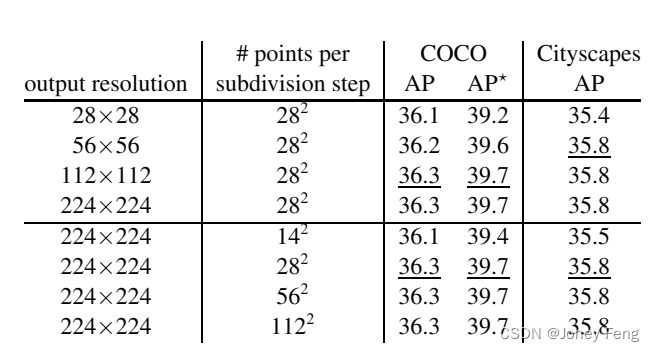
 图7:PointRend的抗锯齿。精确的对象勾 delin需要输出掩码分辨率与对象占据的输入图像区域的分辨率相匹配或超过。
图7:PointRend的抗锯齿。精确的对象勾 delin需要输出掩码分辨率与对象占据的输入图像区域的分辨率相匹配或超过。
表4:使用每个盒子142个点的训练时间点选择策略。轻微偏向于不确定区域的采样效果最好。重度偏向的采样甚至比均匀或常规网格采样效果更差,表明覆盖率的重要性。AP!是对更高质量的LVIS注释[14]进行的COCO掩码AP评估(详见文本)。
表5:更大的模型和更长的3×调度[16]。PointRend受益于更先进的模型和更长的训练时间。PointRend与Mask R-CNN中的默认掩码头之间的差距保持不变。AP!是对更高质量的LVIS注释[14]进行的COCO掩码AP评估(详见文本)。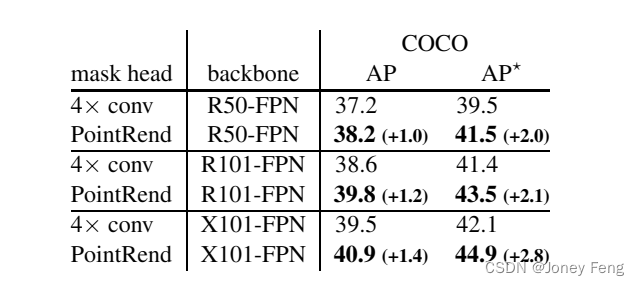
4.2.消融实验
我们进行了许多分析来分析PointRend。总体而言,我们注意到它对点头MLP的确切设计是稳健的。在我们的实验中,其深度或宽度的变化没有显示出任何显着差异。训练期间的点选择。在训练期间,我们按照偏倚的采样策略(§3.1)选择每个对象的142个点。仅采样142个点使训练具有计算和内存效率,我们发现使用更多的点并不会改善结果。令人惊讶的是,每个框仅采样49个点仍然保持AP,尽管我们观察到AP的增加方差。表4显示了不同选择策略下PointRend的性能。在训练期间,正则网格选择实现了类似于均匀采样的结果。而偏向于模糊区域的偏倚采样可以提高AP。然而,过于偏向于粗略预测的边界的采样策略(k>10且β接近1.0)会降低AP。总体而言,我们发现广泛的参数2<k<5和0.75<β<1.0可以提供类似的结果。更大的模型,更长的训练。使用1×调度在COCO上训练ResNet-50 + FPN(表示为R50-FPN)会导致欠拟合。在表5中,我们展示了PointRend相对于基线的改进在更长的训练计划和更大的模型上仍然有效(详情请见附录)。
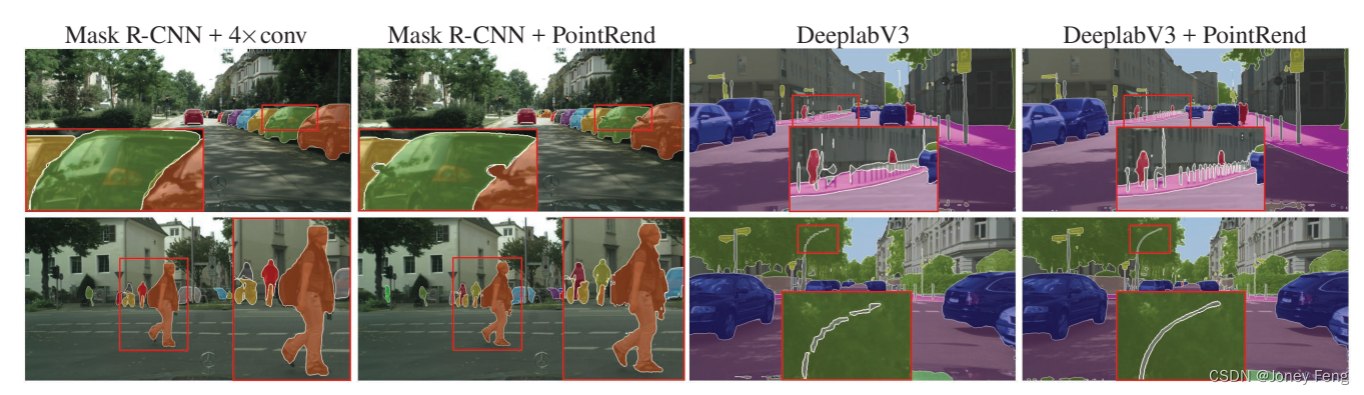 图8:实例分割和语义分割的Cityscapes示例结果。在实例分割中,更大的对象从PointRend产生高分辨率输出中受益更多。而对于语义分割,PointRend可以恢复小对象和细节。
图8:实例分割和语义分割的Cityscapes示例结果。在实例分割中,更大的对象从PointRend产生高分辨率输出中受益更多。而对于语义分割,PointRend可以恢复小对象和细节。
5.实验:语义分割
PointRend不仅限于实例分割,还可以扩展到其他像素级别的识别任务。在这里,我们展示了PointRend如何受益于两个语义分割模型:使用扩张卷积在更密集的网格上进行预测的DeeplabV3 [4]和简单的编码器-解码器结构SemanticFPN [21]。数据集。我们使用包含19个类别、2975张训练图像和500张验证图像的Cityscapes [8]语义分割集。我们报告了5次试验的中位数mIoU。实现细节。我们重新实现了DeeplabV3和SemanticFPN,遵循它们各自的论文。SemanticFPN使用标准的ResNet-101 [18],而DeeplabV3使用[4]中提出的ResNet-103。我们遵循原始论文的训练计划和数据增强(详细信息请见附录)。我们使用与实例分割相同的PointRend架构。粗略预测特征来自语义分割模型的(已经粗略的)输出。细粒度特征从res2插值得到DeeplabV3,从P2插值得到SemanticFPN。在训练期间,我们采样与输入的stride 16特征图上的点数相同的点(deeplabV3为2304,SemanticFPN为2048)。我们使用相同的k=3,β=0.75点选择策略。在推理期间,细分使用N=8096(即1024×2048图像的stride 16映射中的点数),直到达到输入图像分辨率。为了衡量预测的不确定性,我们在训练和推理期间使用相同的策略:最自信和次自信类别概率之间的差异。
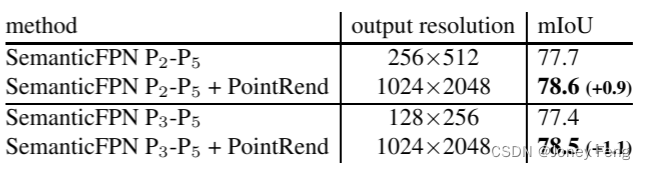
在DeeplabV3中,表6比较了DeepLabV3和带有PointRend的DeeplabV3。输出分辨率也可以通过在res4阶段使用扩张卷积将其增加2倍,在[4]中进行了描述。与两者相比,PointRend具有更高的mIoU。定性的改进也很明显,见图8。通过自适应地采样点,PointRend通过仅对32k个点进行预测就可以达到1024×2048分辨率(即2M个点),见图9。SemanticFPN。表7显示,带有PointRend的SemanticFPN比没有PointRend的8×和4×输出步幅变体都有所改进。
表6:使用PointRend的DeepLabV3进行Cityscapes语义分割,优于基准DeepLabV3。在推理期间扩大res4阶段会产生更大、更准确的预测,但计算和存储成本要高得多;仍然不如使用PointRend。

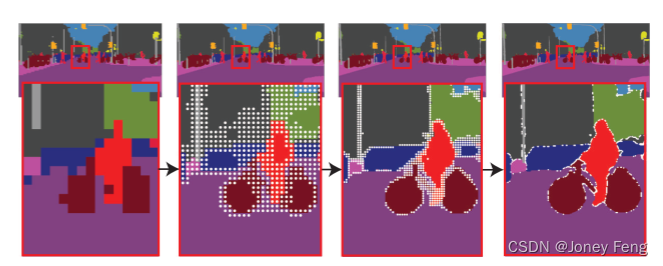
图9:用于语义分割的PointRend推理。PointRend为粗略预测不足的区域细化预测得分。为了可视化每个步骤的分数,我们在给定分辨率下采用arg max而没有双线性插值。
表7:使用PointRend的SemanticFPN进行Cityscapes语义分割优于基准SemanticFPN。
相关文章:
PointRend: 将图像分割视为渲染——PointRend:Image Segmentation as Rendering
0.摘要 我们提出了一种新的方法,用于高效、高质量的对象和场景图像分割。通过将经典的计算机图形学方法与像素标记任务中面临的过采样和欠采样挑战进行类比,我们开发了一种将图像分割视为渲染问题的独特视角。基于这个视角,我们提出了PointRe…...
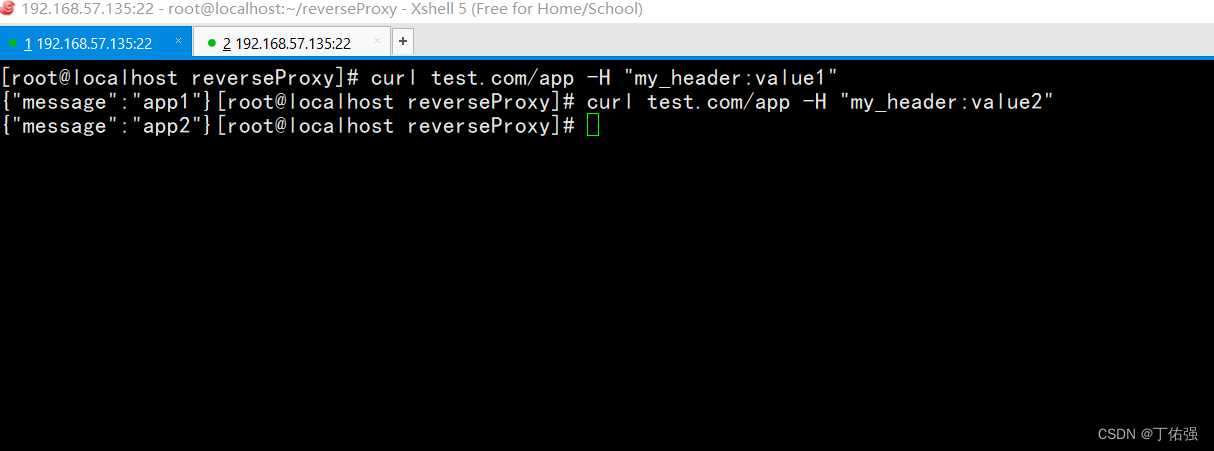
【k8s】ingress-nginx通过header路由到不同后端
K8S中ingress-nginx通过header路由到不同后端 背景 公司使用ingress-nginx作为网关的项目,需要在相同域名、uri,根据header将请求转发到不同的后端中在稳定发布的情况下,ingress-nginx是没有语法直接支持根据header做转发的。但是这个可以利…...
-- httpsrv - http服务端)
LuatOS-SOC接口文档(air780E)-- httpsrv - http服务端
httpsrv.start(port, func)# 启动并监听一个http端口 参数 传入值类型 解释 int 端口号 function 回调函数 返回值 返回值类型 解释 bool 成功返回true, 否则返回false 例子 -- 监听80端口 httpsrv.start(80, function(client, method, uri, headers, body)-- m…...
Android Studio: unrecognized Attribute name MODULE
错误完整代码: ������ (1.8.0_291) �г����쳣������ÿ…...
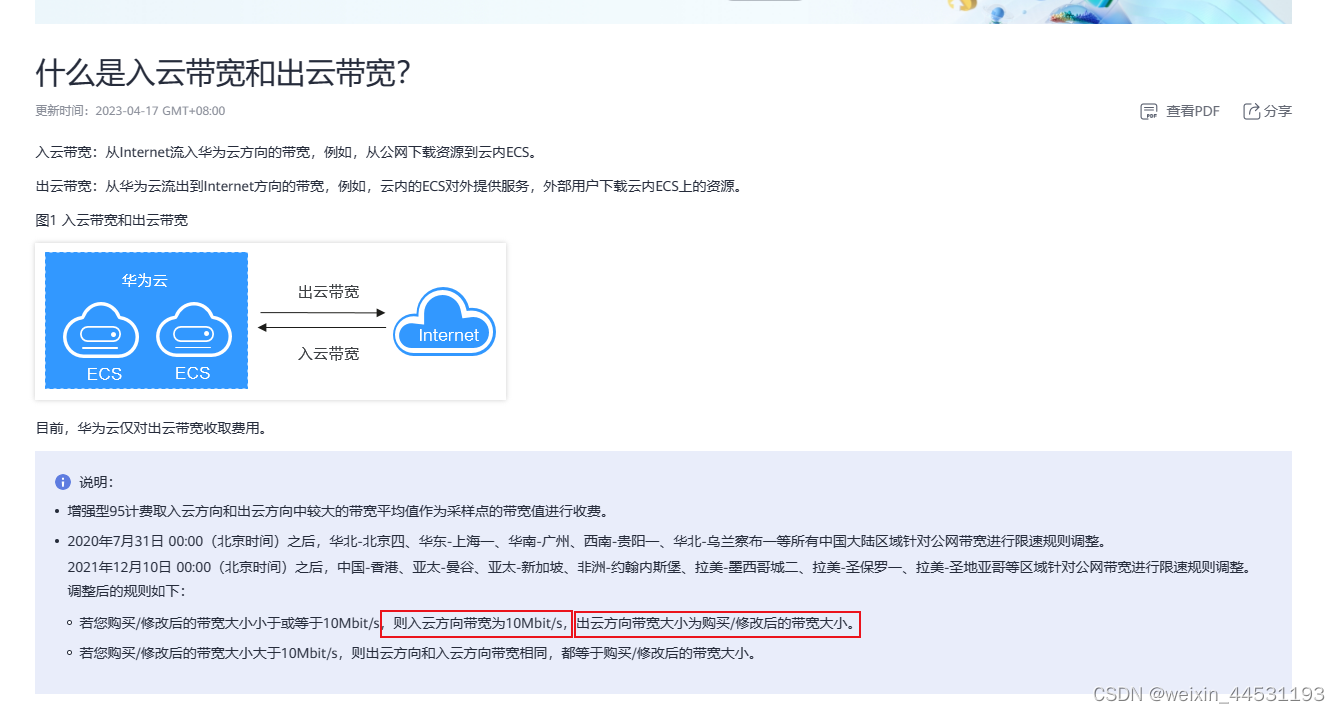
云服务器带宽对上传下载速度的影响
简单来说就是 云服务器收到数据代表入,带宽大小 < 10时,入带宽大小10 带宽大小 > 10时,出入带宽上限 等于实际购买时候的大小...
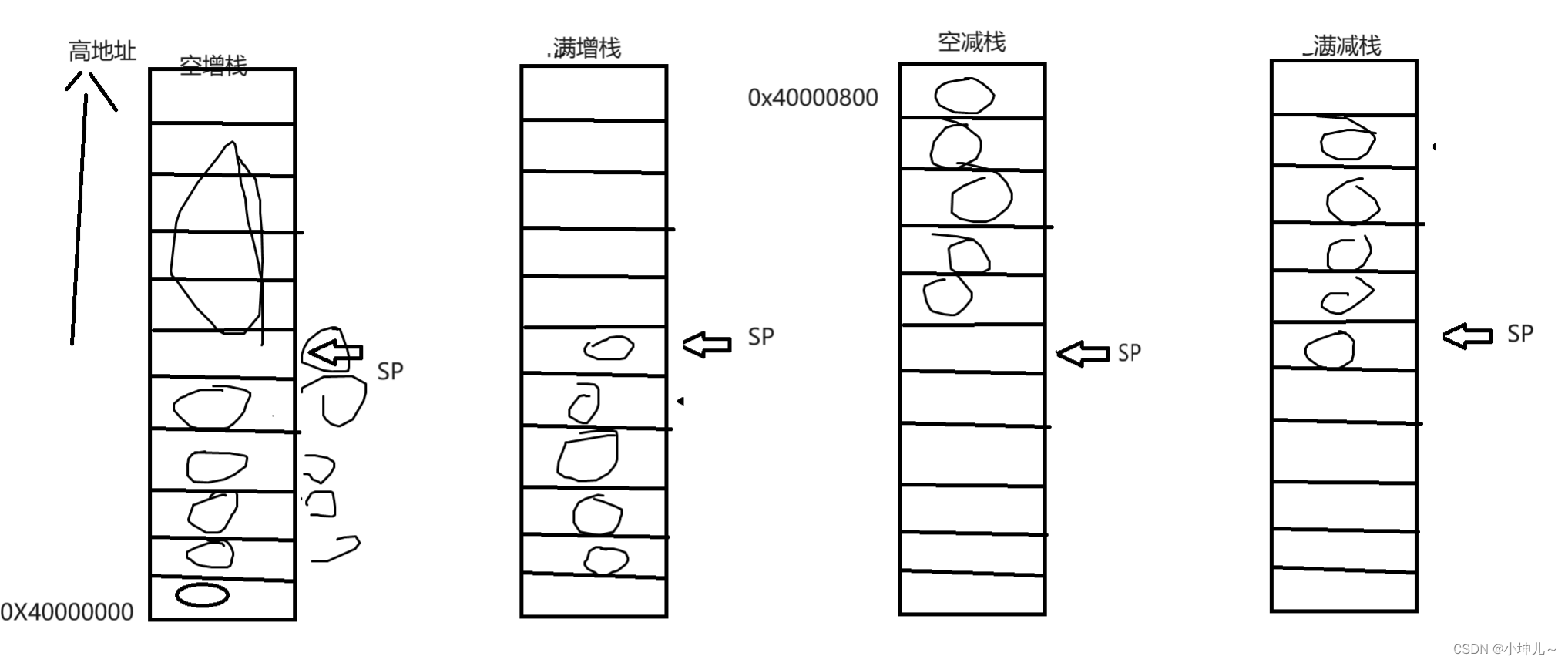
2023/9/28 -- ARM
【内存读写指令】 int *p0X12345678 *p100;//向内存中写入数据 int a *p;//从内存读取 1.单寄存器内存读写指令 1.1 指令码以及功能 向内存中写: str:向内存中写一个字(4字节)的数据 strh:向内存写半个字(2字节)的数据 strb:向内存写一个字…...

vue原生实现element上传多张图片浏览删除
vue原生实现element上传多张图片浏览删除 <div class"updata-component" style"width:100%;"><div class"demo-upload-box clearfix"><div class"demo-upload-image-box" v-if"imageUrlArr && imageUrlAr…...

黑群晖video station评级问题
黑群晖video station评级问题 环境 群晖Version: 6.2.3-25423video station 2.4.10方法1,py文件 登录ssh,获取sudo权限 cd /var/packages/VideoStation/target/plugins/syno_themoviedbsudo vim search.py替换movie_data[vote_average] 替换为 round(movie_data[vote_avera…...

Godot快速精通-从看懂英文文档开始-翻译插件
视频教程地址:https://www.bilibili.com/video/BV1t8411q7hw/ 大家好,我今天要和大家分享的是如何快速精通Godot,众所周知,一般一个开源项目都会有一个文档,对于有一定基础或者是理解能力强的同学,看文档比…...

vue项目的学习周报03
学习周报 日期范围:2023年9月25日~2023年10月1日 学习目标:本周的学习目标是学习vue的基础知识 学习成果:在本周我完成以下任务和学习活动: 1.我完成了对vue.js的基础认识; 2.学习了通过index.js导入新的组件&#…...

ES中个别字段属性说明
DEFAULT_NO_CFS_RATIO DEFAULT_NO_CFS_RATIO这个用于判断生成新段的时候,是否使用复合文件, 复合文件(Compound File)是将多个索引文件合并为一个单一的文件组合,以减少文件数量和提高性能。 在 Lucene 中&…...

Web前端-Vue2+Vue3基础入门到实战项目-Day3(生命周期, 案例-小黑记账清单, 工程化开发入门)
Web前端-Vue2Vue3基础入门到实战项目-Day3 生命周期生命周期 & 生命周期四个阶段生命周期钩子生命周期案例created应用mounted应用 案例 - 小黑记账清单工程化开发入门工程化开发和脚手架项目运行流程index.htmlmain.js 组件化组件注册局部注册全局注册 来源 生命周期 生命…...
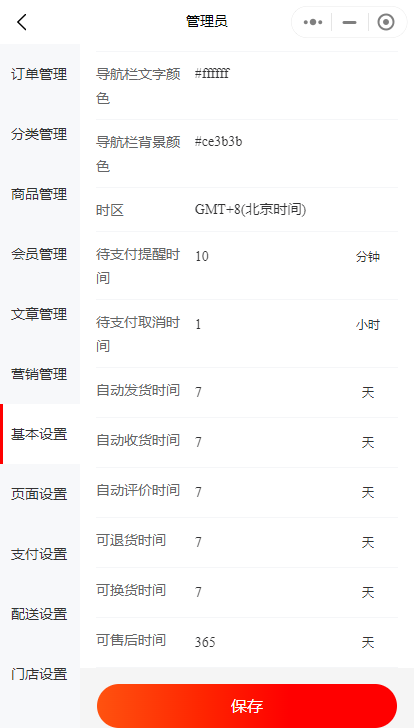
如何在小程序首页设置标题栏文字
小程序的首页标题栏是用户进入小程序时首先看到的部分,因此设置一个适合文字对于树立品牌非常有作用。以下是一些简单的步骤,教你如何在小程序的首页设置标题栏文字(如下图,白色的“商城”文字)。 1. 在小程序管理员后…...
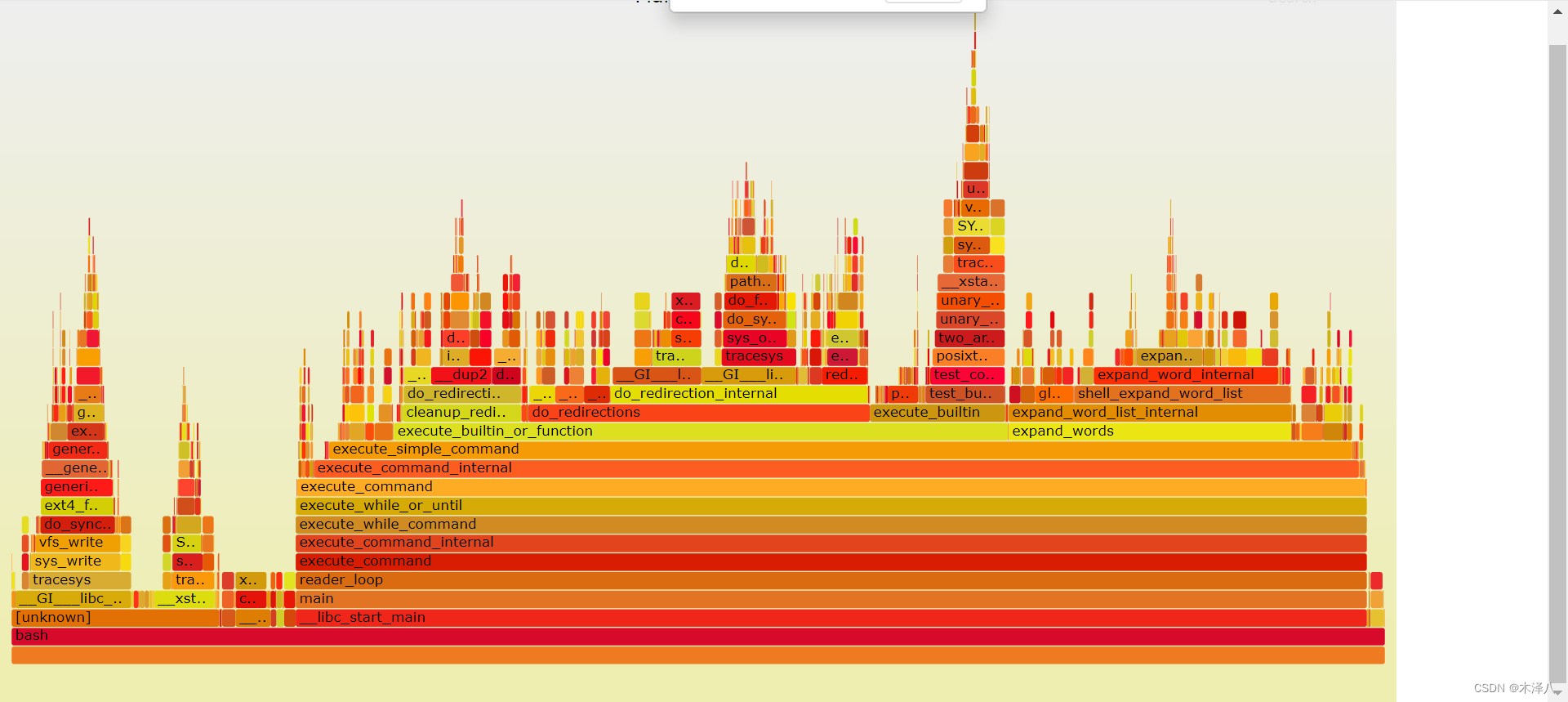
CPU性能分析--火焰图使用
记录工具使用说明,火焰图原理网上分析很多。主要用来分析函数调用栈占用的cpu利用率,分析函数性能。 perf安装: sudo apt-get install linux-tools-common sudo apt-get install linux-tools-"(uname -r)" sudo apt-get install …...

微服务10-Sentinel中的隔离和降级
文章目录 降级和隔离1.Feign整合Sentinel来完成降级1.2总结 2.线程隔离两种实现方式的区别3.线程隔离中的舱壁模式3.2总结 4.熔断降级5.熔断策略(根据异常比例或者异常数) 回顾 我们的限流——>目的:在并发请求的情况下服务出现故障&…...
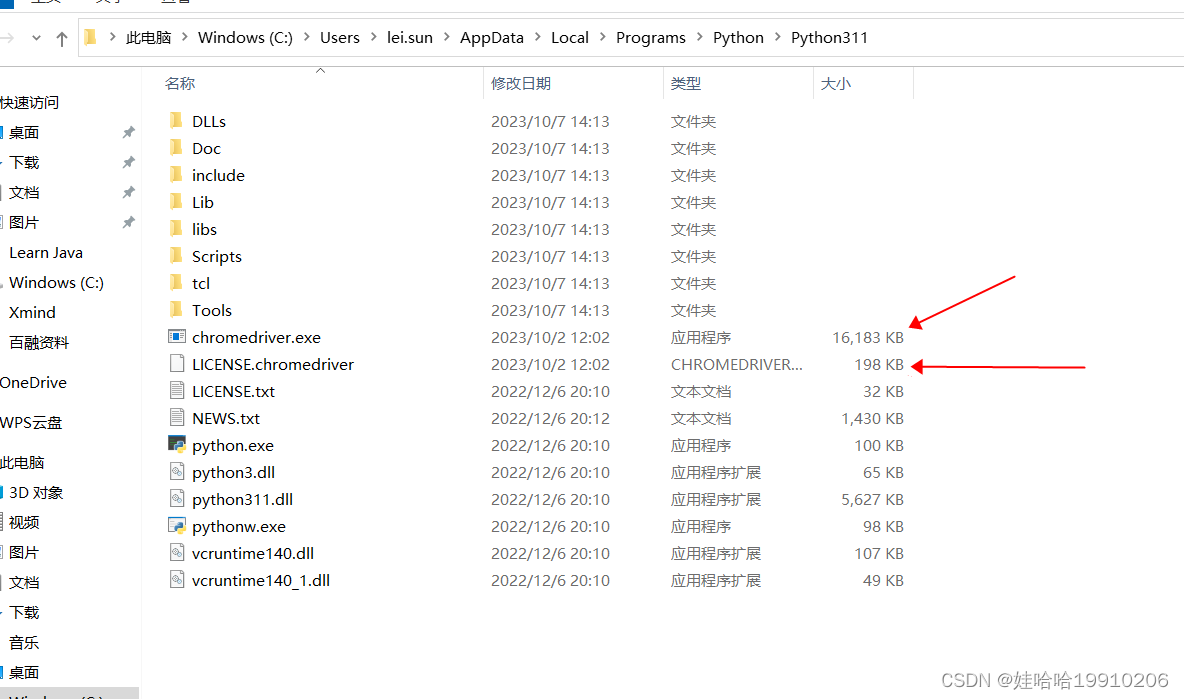
python实现UI自动化配置谷歌浏览器驱动
web端UI自动化执行在哪个浏览器,需要对应哪个浏览器的驱动。以谷歌浏览器为例,进行配置。一、查看谷歌浏览器版本 如下截图:我的谷歌浏览器版本是: 117.0.5938.150 二、下载对应版本谷歌浏览器驱动 首先可以从其他版本驱动地址中…...

AI如何帮助Salesforce从业者找工作?
在当今竞争激烈的就业市场中,找到满意的工作是一项艰巨的任务。成千上万的候选人竞争一个岗位,你需要利用一切优势从求职大军中脱颖而出。 这就是AI的用武之地,特别是像ChatGPT这样的人工智能工具,可以成为你的秘密武器。本篇文章…...
【Vue面试题十七】、你知道vue中key的原理吗?说说你对它的理解
文章底部有个人公众号:热爱技术的小郑。主要分享开发知识、学习资料、毕业设计指导等。有兴趣的可以关注一下。为何分享? 踩过的坑没必要让别人在再踩,自己复盘也能加深记忆。利己利人、所谓双赢。 面试官:你知道vue中key的原理吗…...
【数据结构】二叉树--堆排序
目录 一 降序(建小堆) 二 升序 (建大堆) 三 优化(以升序为例) 四 TOP-K问题 一 降序(建小堆) void Swap(int* x, int* y) {int tmp *x;*x *y;*y tmp; }//降序 建小堆 void AdjustUp(int* a, int child) {int parent (child - 1) / 2;while (child > 0){if (a[chil…...

项目log日志mysql记录,熟悉python的orm框架
直接在项目里面创建一个class,这个类对应着mysql里面的表 我们运行项目,可以自动建立表 在.env中找到mysql的配置信息,这个是在NB服务器上运行的mysql,localhost需要变成NB服务器的ipv4地址 使用Mysql工具连接查看,连…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

AI-调查研究-01-正念冥想有用吗?对健康的影响及科学指南
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...
。】2022-5-15)
【根据当天日期输出明天的日期(需对闰年做判定)。】2022-5-15
缘由根据当天日期输出明天的日期(需对闰年做判定)。日期类型结构体如下: struct data{ int year; int month; int day;};-编程语言-CSDN问答 struct mdata{ int year; int month; int day; }mdata; int 天数(int year, int month) {switch (month){case 1: case 3:…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

代理篇12|深入理解 Vite中的Proxy接口代理配置
在前端开发中,常常会遇到 跨域请求接口 的情况。为了解决这个问题,Vite 和 Webpack 都提供了 proxy 代理功能,用于将本地开发请求转发到后端服务器。 什么是代理(proxy)? 代理是在开发过程中,前端项目通过开发服务器,将指定的请求“转发”到真实的后端服务器,从而绕…...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...