h2database BTree 设计实现与查询优化思考
h2database 是使用Java 编写的开源数据库,兼容ANSI-SQL89。
即实现了常规基于 BTree 的存储引擎,又支持日志结构存储引擎。功能非常丰富(死锁检测机制、事务特性、MVCC、运维工具等),数据库学习非常好的案例。
本文理论结合实践,通过BTree 索引的设计和实现,更好的理解数据库索引相关的知识点以及优化原理。
BTree 实现类
h2database 默认使用的 MVStore 存储引擎,如果要使用 基于 BTree 的存储引擎,需要特别指定(如下示例代码 jdbcUrl)。
以下是常规存储引擎(BTree 结构) 相关的关键类。
-
org.h2.table.RegularTable
-
org.h2.index.PageBtreeIndex (SQL Index 本体实现)
-
org.h2.store.PageStore (存储层,对接逻辑层和文件系统)
BTree 的数据结构可以从网上查到详细的描述和讲解,不做过多赘述。
需要特别说明的是:PageStore。我们数据查询和优化关键的缓存、磁盘读取、undo log都是由 PageStore 完成。可以看到详细的文档和完整的实现。
BTree add index entry 调用链
提供索引数据新增的调用链。同样的,索引的删除和查询都会涉及到,方便 debug 参考。
-
org.h2.command.dml.Insert#insertRows (Insert SQL 触发数据和索引新增)
-
org.h2.mvstore.db.RegularTable#addRow (处理完的数据Row, 执行新增)
-
org.h2.index.PageBtreeIndex#add (逻辑层增加索引数据)
-
org.h2.index.PageDataIndex#addTry (存储层增加索引数据)
-
org.h2.index.PageDataLeaf#addRowTry (存储层新增实现)
// 示例代码
// CREATE TABLE city (id INT(10) NOT NULL AUTO_INCREMENT, code VARCHAR(40) NOT NULL, name VARCHAR(40) NOT NULL);
public static void main(String[] args) throws SQLException {// 注意:MV_STORE=false,MVStore is used as default storageConnection conn = DriverManager.getConnection("jdbc:h2:~/test;MV_STORE=false", "sa", "");Statement statement = conn.createStatement();// CREATE INDEX IDX_NAME ON city(code); 添加数据触发 BTree 索引新增// -- SQL 实例化为:IDX_NAME:16:org.h2.index.PageBtreeIndexstatement.executeUpdate("INSERT INTO city(code,name) values('cch','长春')");statement.close();conn.close();
}
Code Insight
结合上述的示例代码,从索引新增的流程实现来了解BTree 索引的特性以及使用的注意事项。从底层实现分析索引的运行,对 SQL 索引使用和优化有进一步认识。
表添加数据
public void addRow(Session session, Row row) {// MVCC 控制机制,记录和比对当前事务的 idlastModificationId = database.getNextModificationDataId();if (database.isMultiVersion()) {row.setSessionId(session.getId());}int i = 0;try {// 根据设计规范,indexes 肯定会有一个聚集索引(h2 称之为scan index)。①for (int size = indexes.size(); i < size; i++) {Index index = indexes.get(i);index.add(session, row);checkRowCount(session, index, 1);}// 记录当前 table 的数据行数,事务回滚后会相应递减。rowCount++;} catch (Throwable e) {try {while (--i >= 0) {Index index = indexes.get(i);// 对应的,如果发生任何异常,会移除对应的索引数据。index.remove(session, row);}}throw de;}
}
① 同Mysql InnoDB 数据存储一样, RegularTable 必有,且只有一个聚集索引。以主键(或者隐含自增id)为key, 存储完整的数据。
聚集索引添加数据
-
索引中的 key 是查询要搜索的内容,而其值可以是以下两种情况之一:它可以是实际的行(文档,顶点),也可以是对存储在别处的行的引用。在后一种情况下,行被存储的地方被称为 堆文件(heap file),并且存储的数据没有特定的顺序(根据索引相关的)。
-
从索引到堆文件的额外跳跃对读取来说性能损失太大,因此可能希望将被索引的行直接存储在索引中。这被称为聚集索引(clustered index)。
-
基于主键扫描即可唯一确定、并且获取到数据,聚集索引性能比非主键索引少一次扫描
public void add(Session session, Row row) {// 索引key 生成 ②if (mainIndexColumn != -1) {// 如果主键非 long, 使用 org.h2.value.Value#convertTo 尝试把主键转为 longrow.setKey(row.getValue(mainIndexColumn).getLong());} else {if (row.getKey() == 0) {row.setKey((int) ++lastKey);retry = true;}}// 添加行数据到聚集索引 ③while (true) {try {addTry(session, row);break;} catch (DbException e) {if (!retry) {throw getNewDuplicateKeyException();}}}
}
② 对于有主键的情况,会获取当前 row 主键的值,转为long value。对于没有指定主键的情况,从当前聚集索引属性 lastKey 自增得到唯一 key。
只有指定主键的情况,才会校验数据重复(也就是索引key 重复,自增 lastKey 是不会有重复值的问题)。
③ 聚集索引 PageDataIndex 按照BTree 结构查找对应的key 位置,按照主键/key 的顺序,将 Row 存储到page 中。非聚集索引 PageBtreeIndex 也是这样的处理流程。
这其中涉及到三个问题:
-
如何查找 key 的位置,也就是 BTree 位置的计算?
-
如何计算 Row (实际数据)存储 Page 中的 offsets?
-
Row 是怎样写入到磁盘中的,何时写入的?
索引数据存取实现
-
B 树将数据库分解成固定大小的 块(block) 或 分页(page),传统上大小为 4KB(有时会更大),并且一次只能读取或写入一个页面。
-
每个页面都可以使用地址或位置来标识,这允许一个页面引用另一个页面 —— 类似于指针,但在硬盘而不是在内存中。(对应h2 database PageBtreeLeaf 和 PageBtreeNode)
-
不同于 PageDataIndex ,PageBtreeIndex 按照 column.value 顺序来存储。添加的过程就是比对查找 column.value,确定在块(block)中offsets 的下标 x。剩下就是计算数据的offset 并存入下标 x 中。
/*** Find an entry. 二分查找 compare 所在的位置。这个位置存储 compare 的offset。* org.h2.index.PageBtree#find(org.h2.result.SearchRow, boolean, boolean, boolean)* @param compare 查找的row, 对应上述示例 compare.value = 'cch'* @return the index of the found row*/
int find(SearchRow compare, boolean bigger, boolean add, boolean compareKeys) {// 目前 page 持有的数据量 ④int l = 0, r = entryCount;int comp = 1;while (l < r) {int i = (l + r) >>> 1;// 根据 offsets[i],读取对应的 row 数据 ⑤SearchRow row = getRow(i);// 比大小 ⑥comp = index.compareRows(row, compare);if (comp == 0) {// 唯一索引校验 ⑦if (add && index.indexType.isUnique()) {if (!index.containsNullAndAllowMultipleNull(compare)) {throw index.getDuplicateKeyException(compare.toString());}}}if (comp > 0 || (!bigger && comp == 0)) {r = i;} else {l = i + 1;}}return l;
}
④ 每个块(page)entryCount ,两个方法初始化。根据块分配和实例创建初始化,或者 PageStore 读取块文件,从Page Data 解析得到。
⑤ 反序列化过程,从page 文件字节码(4k的字节数组),根据协议读取数据并实例化为 row 对象。参考: org.h2.index.PageBtreeIndex#readRow(org.h2.store.Data, int, boolean, boolean) 。
⑥ 全类型支持大小比对,具体的规则参考:org.h2.index.BaseIndex#compareRows
⑦ 如果数据中存在重复的键值,则不能创建唯一索引、UNIQUE 约束或 PRIMARY KEY 约束。h2database 兼容多种数据库模式,MySQL NULL 非唯一,MSSQLServer NULL 唯一,仅允许出现一次。
private int addRow(SearchRow row, boolean tryOnly) {// 计算数据所占字节的长度int rowLength = index.getRowSize(data, row, onlyPosition);// 块大小,默认 4kint pageSize = index.getPageStore().getPageSize();// 块文件可用的 offset 获取int last = entryCount == 0 ? pageSize : offsets[entryCount - 1];if (last - rowLength < start + OFFSET_LENGTH) {// 校验和尝试分配计算,这其中就涉及到分割页面生长 B 树的过程 ⑧}// undo log 让B树更可靠 ⑨index.getPageStore().logUndo(this, data);if (!optimizeUpdate) {readAllRows();}int x = find(row, false, true, true);// 新索引数据的offset 插入到 offsets 数组中。使用 System.arraycopy(x + 1) 来挪动数据。offsets = insert(offsets, entryCount, x, offset);// 重新计算 offsets,写磁盘就按照 offsets 来写入数据。add(offsets, x + 1, entryCount + 1, -rowLength);// 追加实际数据 rowrows = insert(rows, entryCount, x, row);entryCount++;// 标识 page.setChanged(true);index.getPageStore().update(this);return -1;
}
⑧如果你想添加一个新的键,你需要找到其范围能包含新键的页面,并将其添加到该页面。如果页面中没有足够的可用空间容纳新键,则将其分成两个半满页面,并更新父页面以反映新的键范围分区
⑨为了使数据库能处理异常崩溃的场景,B 树实现通常会带有一个额外的硬盘数据结构:预写式日志(WAL,即 write-ahead log,也称为 重做日志,即 redo log)。这是一个仅追加的文件,每个 B 树的修改在其能被应用到树本身的页面之前都必须先写入到该文件。当数据库在崩溃后恢复时,这个日志将被用来使 B 树恢复到一致的状态。
实践总结
-
查询优化实质上就是访问数据量的优化,磁盘IO 的优化。
-
如果数据全部缓存到内存中,实际上就是计算量的优化,CPU 使用的优化。
-
索引是有序的,实际上就是指块文件内的 offsets 是以数组形式体现的。 特殊的是,在h2database 中,offsets数组元素也是有序的(例如:[4090, 4084, 4078, 4072, 4066, 4060, 4054, 4048, 4042]),应该是方便磁盘顺序读,防止磁盘碎片化。
-
理论上,聚集索引扫描 IO 比 BTree 索引要多,因为同样的块文件内,BTree 索引 存储的数据量更大,所占的块文件更少。如果一个table 列足够少,聚集索引扫描效率更高。
建表需要谨慎,每个列的字段长度尽可能的短,来节省页面空间。
-
合理使用覆盖索引查询,避免回表查询。 如述示例,
select id from city where code = 'cch',扫描一次 BTree 索引即可得到结果。如果select name from city where code = 'cch', 需要扫描一次 BTree 索引得到索引key (主键),再遍历扫描聚集索引,根据 key 得到结果。 -
合理的使用缓存,让磁盘IO 的影响降到最低。 比如合理配置缓存大小,冷热数据区分查询等。
其他知识点
- 分支因子为 500 的 4KB 页面的四层树可以存储多达 256TB 的数据)。(在 B 树的一个页面中对子页面的引用的数量称为 分支因子(branching factor)。
参考
ddia/ch3.md B树
相关文章:

h2database BTree 设计实现与查询优化思考
h2database 是使用Java 编写的开源数据库,兼容ANSI-SQL89。 即实现了常规基于 BTree 的存储引擎,又支持日志结构存储引擎。功能非常丰富(死锁检测机制、事务特性、MVCC、运维工具等),数据库学习非常好的案例。 本文理论…...
之sz)
Linux命令(100)之sz
linux命令之sz 1.sz介绍 linux命令sz是用来把文件从Linux平台下载到Windows上 2.sz用法 sz [参数] file sz参数 参数说明-b使用binary的方式下载,不解释字符为ascii-y相同文件名,覆盖-E相同文件名,不会将其覆盖,而是会在所上传…...

Insight h2database SQL like 查询
我们认为的 SQL like 查询和优化技巧,设计的初衷和真正的实现原理是什么。 在 h2database SQL like 查询实现类中(CompareLike),可以看到 SQL 语言到具体执行的实现、也可以看到数据库尝试优化语句的过程,以及查询优化…...

wpf中listview内容居中显示
在WPF中使用ListView经常会用到GridView作为视图,但是却碰到GridViewColumn不能居中对齐的问题, 实现方法 给ListViewItem设置Style,让ListViewItem在水平方向拉伸填充: <Setter Property"HorizontalContentAlignment" Value&…...

第二章 C++的输出
系列文章目录 第一章 C的输入 文章目录 系列文章目录前言一、个人名片二、cout三、printf总结 前言 今天来学C的输出吧! 一、个人名片 二、cout cout 三、printf printf 总结 最近懒得写博客怎么办?...
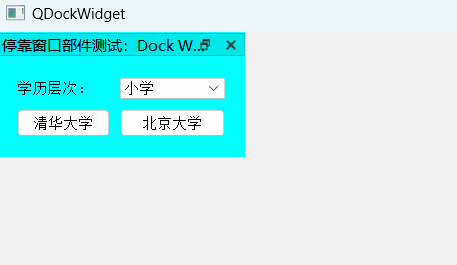
Qt中常用容器组控件介绍和实操
目录 常用容器组控件(Containers): 1.Group Box 2.Scroll Area 3.Tab Widget 4.Frame 5.Dock Widget 常用容器组控件(Containers): 控件名称依次解释如下(常用的用红色标出): Group Box: 组合框: 提供带有标题的组合框框架Scroll Area…...
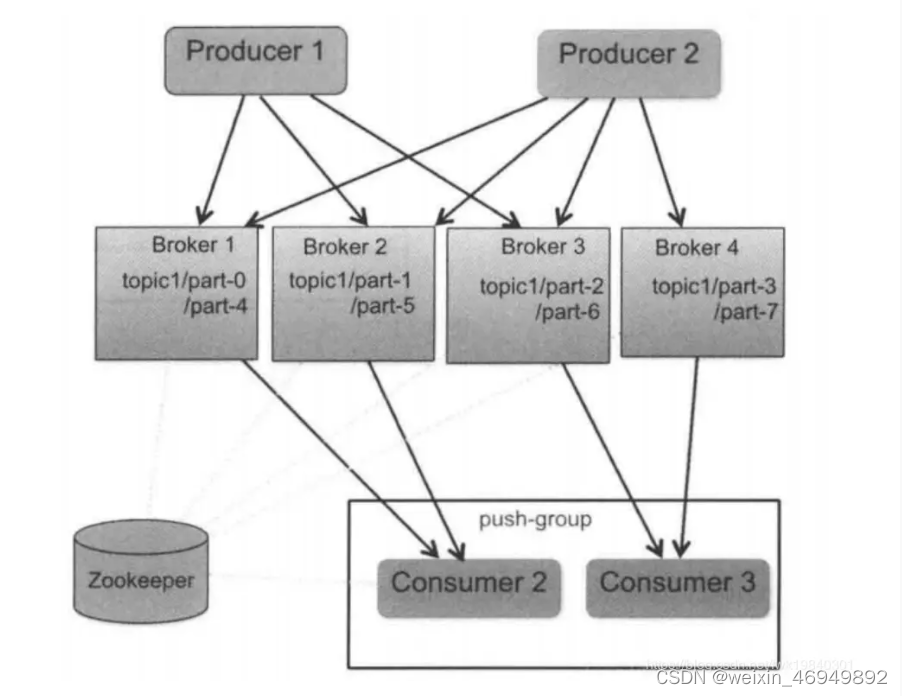
kafka、rabbitmq 、rocketmq的区别
一、语言不同 RabbitMQ是由内在高并发的erlanng语言开发,用在实时的对可靠性要求比较高的消息传递上。 kafka是采用Scala语言开发,它主要用于处理活跃的流式数据,大数据量的数据处理上 RocketMQ是采用java语言开发的 二、吞吐量 kafka吞吐量更高&…...

java的amazonaws接口出现无法执行http请求:管道中断
java使用amazonaws的接口上传文件到minio出现以下异常: com.amazonaws.SdkClientException: Unable to execute HTTP request: Broken pipe (Write failed) at com.amazonaws.http.AmazonHttpClient R e q u e s t E x e c u t o r . h a n d l e R e t r y a b l e…...

cmake 多线程编译 指定 Visual Studio 编译器 命令行
当使用CMake来配置和构建一个Visual Studio 项目时,以下命令是关键的。 第一行是用于配置项目,而第二行用于构建项目。 Visual Studio 15 2017 Visual Studio 16 2019 Visual Studio 17 2022 在CMake中,DCMAKE_BUILD_TYPE是用于指定项目的构建…...
将 mysql 数据迁移到 clickhouse (最新版)
一、前驱知识 已经在mysql中插入了海量的数据了,这个时候mysql 承载不了这么大的数据,并且数据只需要查询,修改和删除非常少,并且不需要支持事务,这个时候需要换一个底层存储,这里选用的是 clickhouse 来进…...

LeetCode 69.x的平方
LeetCode 69.x的平方 思路: 二分查找。从1到x进行二分查找,每次判断mid的平方是否<x, 如果是,则更新ansmid,并缩小区间; 如果不是,则缩小区间; 最后则找到最接近的ans࿰…...

【小白入门】ASP.NET Core 创建 Web API
ASP.NET Core 支持使用 C# 创建 RESTful 服务,也称为 Web API。 若要处理请求,Web API 使用控制器。 Web API 中的 控制器 是派生自 ControllerBase 的类。 本文介绍了如何使用控制器处理 Web API 请求。 Web API 包含一个或多个派生自 ControllerBase …...
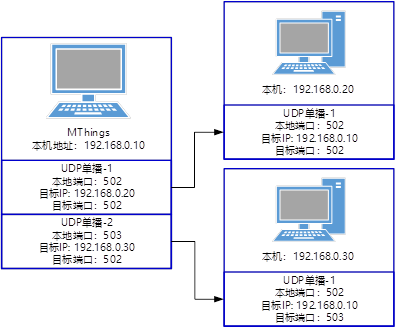
如何使用摩尔信使MThings连接网络设备
帽子: 摩尔信使MThings支持Modbus-TCP、Modbus-RTU Over TCP、Modbus-TCP Over UDP、Modbus-RTU Over UDP。 TCP链接中,摩尔信使MThings支持灵活的连接方式,主机可作为客户端也可以作为服务端,同时支持模拟从机以客户端方式向远…...

2023自动驾驶 车道线检测数据集
目录 2023自动驾驶 车道线检测关键数据集 下载链接 labelme标注制作数据: 车道线分割项目记录-tusimple数据集处理 2023自动驾驶 车道线检测关键数据集 下载链接 2023自动驾驶 车道线检测关键数据集 下载链接_Xiaobai_Zhao的博客-CSDN博客 labelme标注制作数据:...
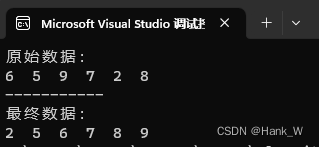
排序算法-冒泡排序法(BubbleSort)
排序算法-冒泡排序法(BubbleSort) 1、说明 冒泡排序法又称为交换排序法,是从观察水中的气泡变化构思而成的,原理是从第一个元素开始,比较相邻元素的大小,若大小顺序有误,则对调后再进行下一个…...
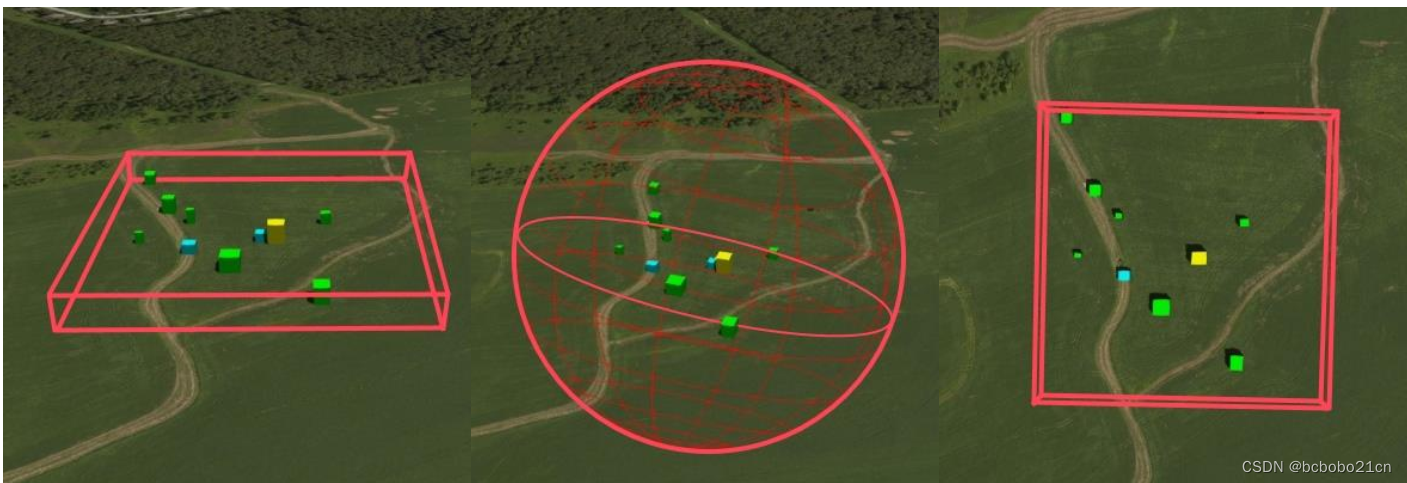
3d tiles规范boundingVolume属性学习
3d tiles的瓦片(Tiles)包含一些属性,其中第一项是boundingVolume;下面学习boundingVolume; boundingVolume,这个翻译为边界范围框,如果直译为边界体积可能有问题,其实就是包围盒的意…...

【开题报告】如何借助chatgpt完成毕业论文开题报告
步骤 1:确定论文主题和研究问题 首先,你需要确定你的论文主题和研究问题。这可以是与软件开发、算法、人工智能等相关的任何主题。确保主题具有一定的研究性和可行性。 步骤 2:收集相关文献和资料 在开始撰写开题报告之前,收集相…...
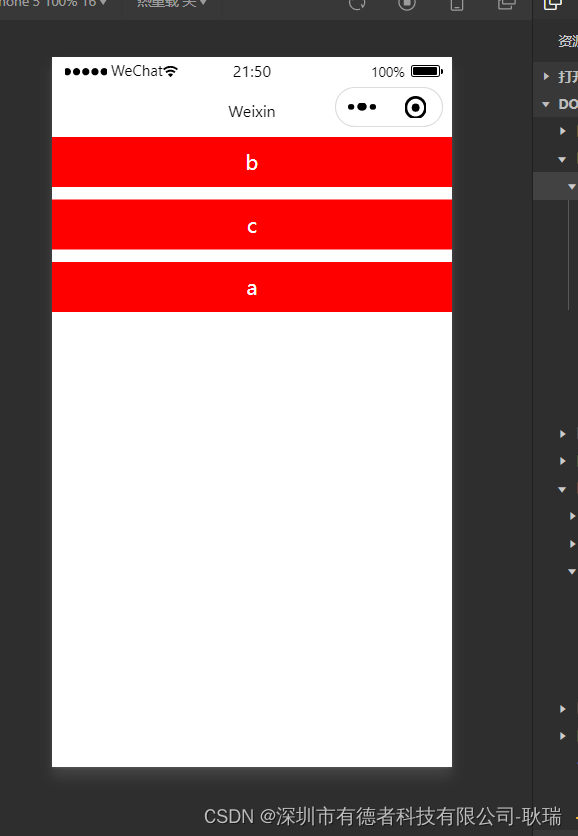
微信小程序通过 movable-area 做一个与vuedraggable相似的上下拖动排序控件
因为只是做个小案例 我就直接代码写page页面里了 其实很简单 组件稍微改一下就好了 wxss /* 设置movable-area的宽度 */ .area{width: 100%; }/* a b c 每条元素的样式 */ movable-view {width: 100%;background-color: red;height: 40px;line-height: 40px;color: #FFFFFF;tex…...

Ceph入门到精通-Nginx超时参数分析设置
nginx中有些超时设置,本文汇总了nginx中几个超时设置 Nginx 中的超时设置包括: “client_body_timeout”:设置客户端向服务器发送请求体的超时时间,单位为秒。 “client_header_timeout”:设置客户端向服务器发送请…...

TCP/IP(十)TCP的连接管理(七)CLOSE_WAIT和TCP保活机制
一 CLOSE_WAIT探究 CLOSE_WAIT 状态出现在被动关闭方,当收到对端FIN以后回复ACK,但是自身没有发送FIN包之前 ① 服务器出现大量 CLOSE_WAIT 状态的原因有哪些? 1、通常来讲,CLOSE_WAIT状态的持续时间应该很短,正如SYN_RCVD状态2、但是在一些特殊情况下,就会出现大量连接长…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

06 Deep learning神经网络编程基础 激活函数 --吴恩达
深度学习激活函数详解 一、核心作用 引入非线性:使神经网络可学习复杂模式控制输出范围:如Sigmoid将输出限制在(0,1)梯度传递:影响反向传播的稳定性二、常见类型及数学表达 Sigmoid σ ( x ) = 1 1 +...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...

day36-多路IO复用
一、基本概念 (服务器多客户端模型) 定义:单线程或单进程同时监测若干个文件描述符是否可以执行IO操作的能力 作用:应用程序通常需要处理来自多条事件流中的事件,比如我现在用的电脑,需要同时处理键盘鼠标…...

什么是VR全景技术
VR全景技术,全称为虚拟现实全景技术,是通过计算机图像模拟生成三维空间中的虚拟世界,使用户能够在该虚拟世界中进行全方位、无死角的观察和交互的技术。VR全景技术模拟人在真实空间中的视觉体验,结合图文、3D、音视频等多媒体元素…...