Redis微服务架构
Redis微服务架构
缓存设计
缓存穿透
缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,通常出于容错的考虑,如果从存储层查不到数据则不写入缓层。
缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去了缓存保护后端存储的意义。造成缓存穿透的基本原因有两个:
第一,自身业务代码或者数据出现问题。
第二,一些恶意攻击、爬虫等造成大量空命中。
缓存穿透问题解决方案:
1、缓存空对象
string get( String key ) {
//从缓存中获取数据
string cacheValue = cache.get ( key ) ;//缓存为空if ( Stringutils.isBlank)( cachevalue)) {//从存储中获取(数据库)string storageValue = storage.get( key ) ;cache. set( key, storageValue) ;//如果存储数据为空,需要设置一个过期时间(300秒)if ( storageValue == null) { cache.expire( key, 60* 5);)return storagevalue;} else {//缓存非空return cacheValue;}
}
2、布隆过滤器
对于恶意攻击,向服务器请求大量不存在的数据造成的缓存穿透,还可以用布隆过滤器先做一次过滤,对于不存在的数据布隆过滤器一般都能够过滤掉,不让请求再往后端发送。当布隆过滤器说某个值存在时,这个值可能不存在;当它说不存在时,那就肯定不存在。
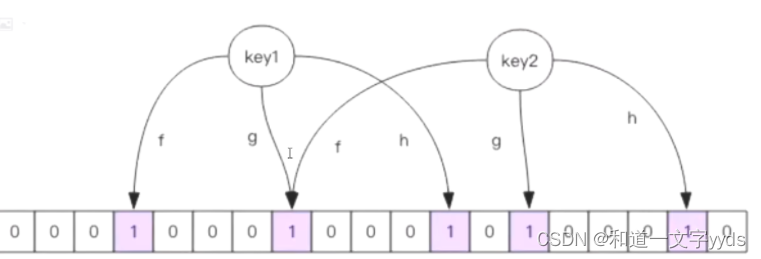
布隆过滤器就是一个大型的位数组和几个不一样的无偏 hash 函数。所谓无偏就是能够把元素的 hash值算得比较均匀。
向布隆过滤器中添加key时,会使用多个hash函数对key进行hash算得一个整数索引值然后对位数组长度进行取模运算得到一个位置,每个hash 函数都会算得一个不同的位置。再把位数组的这几个位置都置为1就完成了add操作。
向布隆过滤器询问key是否存在时,跟add一样,也会把 hash的几个位置都算出来,看看位数组中这几个位置是否都为1,只要有一个位为0,那么说明布隆过滤器中这个key 不存在。如果都是1,这并不能说明这个key就一定存在,只是极有可能存在,因为这些位被置为1可能是因为其它的key存在所致。如果这个位数组比较稀疏,这个概率就会很大,如果这个位数组比较拥挤,这个概率就会降低。
这种方法适用于数据命中不高、数据相对固定、实时性低(通常是数据集较大)的应用场景,代码维护较为复杂,但是缓存空间占用很少。
可以用redisson实现布隆过滤器,引入依赖:
<dependency><groupId>org.redisson</ groupId><artifactId>redisson <artifactId><verSion>3.6.5</version>
</dependency>
public static void main ( string[ ] args) {Config config = new Config( ) ;config.useSingleServer().setAddress ( "redis : // localhost:6379" );//构造RedissonRedissonclient redisson = Redisson.create( config ) ;RBloomFilter<String> bloomFilter = redisson.getBloomFilter ( "nameList" ) ;//初始化布隆过滤器:预计元素为100000000L,误差率为3%,根据这两个参数会计算出底层的bit数组大小bloomFilter .tryInit( 108eaaeecL, 0.83 ) ;//料zhuge插入到布隆过滤器中bloomFilter.add( "zhuge" ) ;//判断下面号码是否在布隆过滤器中system.out.printin( bloomFilter.contains ( "guojia" ) ) ; //falsesystem.out.println( bloomFilter.contains ( "baiqi" ) ) ; //falsesystem.out.printin( bloomFilter.contains ( "zhuge" ) ) ; //true
}
缓存失效(击穿)
由于大批量缓存在同一时间失效可能导致大量请求同时穿透缓存直达数据库,可能会造成数据库瞬间压力过大甚至挂掉,对于这种情况我们在批量增加缓存时最好将这一批数据的缓存过期时间设置为一个时间段内的不同时间。
伪代码示例:
string get(String key) {//从缓存中获取数据string cacheValue = cache.get( key ) ;//缓存为空if ( stringutils.isBlank ( cacheValue)) {//从存储中获取string storageValue = storage.get ( key );cache.set(key, storagevalue) ;//设置一个过期时间(300到680之间的一个随机数)int expireTime = new Random().nextInt(300)+300;if (storageValue == null{cache.expire( key expireTime); }return storageValue;} else {//缓存非空return cacheValue; }
}
缓存雪崩
缓存雪崩指的是缓存层支撑不住或宕掉后,流量会像奔逃的野牛一样,打向后端存储层。
由于缓存层承载着大量请求,有效地保护了存储层,但是如果缓存层由于某些原因不能提供服务(比如超大并发过来,缓存层支撑不住,或者由于缓存设计不好,类似大量请求访问bigkey,导致缓存能支撑的并发急剧下降),于是大量请求都会打到存储层,存储层的调用量会暴增,造成存储层也会级联宕机的情况。
预防和解决缓存雪崩问题,可以从以下三个方面进行着手。
- 保证缓存层服务高可用性,比如使用Redis Sentinel或Redis Cluster。
- 依赖隔离组件为后端限流熔断并降级。比如使用Sentinel或Hystrix限流降级组件。
比如服务降级,我们可以针对不同的数据采取不同的处理方式。当业务应用访问的是非核心数据(例如电商商品属性,用户信息等)时,暂时停止从缓存中查询这些数据,而是直接返回预定义的默认降级信息、空值或是错误提示信息;当业务应用访问的是核心数据(例如电商商品库存)时,仍然允许查询缓存,如果缓存缺失,也可以继续通过数据库读取。 - 提前演练。在项目上线前,演练缓存层宕掉后,应用以及后端的负载情况以及可能出现的问题,在此基础上做一些预案设定。(缓存备份)
热点缓存key重建优化
开发人员使用"缓存+过期时间的策略既可以加速数据读写,又保证数据的定期更新,这种模式基本能够满足绝大部分需求。但是有两个问题如果同时出现,可能就会对应用造成致命的危害:
- 当前key是一个热点key(例如一个热门的娱乐新闻),并发量非常大。
- 重建缓存不能在短时间完成,可能是一个复杂计算,例如复杂的SQL、多次I0、多个依赖等.
在缓存失效的瞬间,有大量线程来重建缓存,造成后端负载加大,甚至可能会让应用崩溃。要解决这个问题主要就是要避免大量线程同时重建缓存。
我们可以利用互斥锁来解决,此方法只允许一个线程重建缓存,其他线程等待重建缓存的线程执行完,重新从缓存获取数据即可。
示例伪代码:
String get(string key) { //从Redis中获取数据string value = redis.get( key ) ;//如果value为空,则开始重构缓存if (value == null) {//只允许一个线程重建缓存,使用nx,并设置过期时间exstring mutexKey = "mutext: key : " + key ;if ( redis.set(mutexKey,"1", "ex 180", "nx" )) {//从数据源获取数据value = db.get( key) ;//回写Redis,并设置过期时间redis.setex(key , timeout, value) ;//删除key_mutexredis.delete( mutexKey ) ;}//其他线程休息50毫秒后重试else { Thread .sleep( 50) ;get( key) ;}}return value
}
缓存与数据库双写不一致
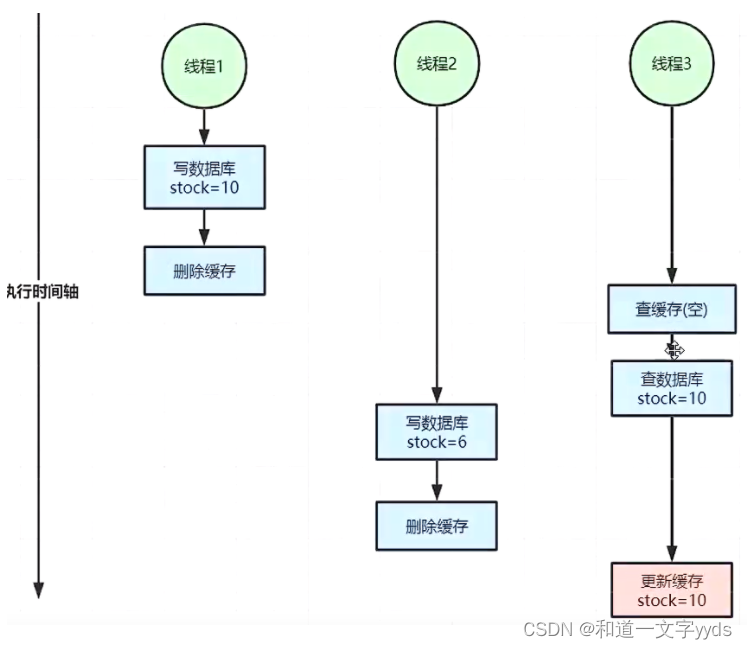
在大并发下,同时操作数据库与缓存会存在数据不一致性问题
1、双写不一致情况

2、读写并发不一致
解决方案:
1、对于并发几率很小的数据(如个人维度的订单数据、用户数据等),这种几乎不用考虑这个问题,很少会发生缓存不一致,可以给缓存数据加上过期时间,每隔一段时间触发读的主动更新即可。
2、就算并发很高,如果业务上能容忍短时间的缓存数据不一致(如商品名称,商品分类菜单等),缓存加上过期时间依然可以解决大部分业务对于缓存的要求。
3、如果不能容忍缓存数据不一致,可以通过加读写锁保证并发读写或写写的时候按顺序排好队,读读的时候相当于无锁。
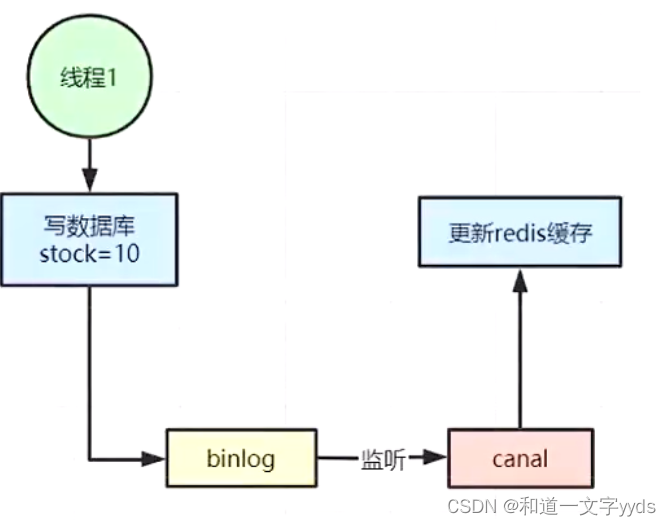
4、也可以用阿里开源的canali通过监听数据库的binlog日志及时的去修改缓存,但是引入了新的中间件,增加了系统的复杂度。
总结
以上我们针对的都是读多写少的情况加入缓存提高性能,如果写多读多的情况又不能容忍缓存数据不一致那就没必要加缓存了,可以直接操作数据库。放入缓存的数据应该是对实时性、一致性要求不是很高的数据。切记不要为了用缓存,同时又要保证绝对的一致性做大量的过度设计和控制,增加系统复杂性!
键值设计
key名设计
(1)【建议】∶可读性和可管理性
以业务名(或数据库名)为前缀(防止key冲突),用冒号分隔,比如业务名:表名:id
trade : order : 1
(2)【建议】︰简洁性
保证语义的前提下,控制key的长度,当key较多时,内存占用也不容忽视,例如:
user: {uid} :friends : messages : {mid} 简化为 u:{uid} : fr:m: {mid}
(3)【强制】:不要包含特殊字符
反例:包含空格、换行、单双引号以及其他转义字符
value设计
- (1)【强制】︰拒绝bigkey(防止网卡流量、慢查询)
在Redis中,一个字符串最大512MB,一个二级数据结构(例如hash、list、set、zset)可以存储大约40亿个(2^32-1)个元素,但实际中如果下面两种情况,我就会认为它是bigkey。
1.字符串类型:它的big体现在单个value值很大,一般认为超过10KB就是bigkey。
2.非字符串类型:哈希、列表、集合、有序集合,它们的big体现在元素个数太多。
一般来说,string类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000。反例:一个包含200万个元素的list。非字符串的bigkey,不要使用del删除,使用hscan、sscan、zscan方式渐进式删除,同时要注意防止bigkey过期时间自动删除问题(例如一个200万的zset设置1小时过期,会触发del操作,造成阻塞)
bigkey的危害
1.导致redis阻塞
⒉网络拥塞
bigkey也就意味着每次获取要产生的网络流量较大,假设一个bigkey为1MB,客户端每秒访问量为1000,那么每秒产生1000MB的流量,对于普通的千兆网卡(按照字节算是128MB/s)的服务器来说简直是灭顶之灾而且一般服务器会采用单机多实例的方式来部署,也就是说一个bigkey可能会对其他实例也造成影响,其后果不堪设想。
3.过期删除
有个bigkey,它安分守己(只执行简单的命令,例如hget、lpop、zscore 等),但它设置了过期时间,当它过期后,会被删除,如果没有使用Redis 4.0的过期异步删除(lazyfree-lazy-expire yes),就会存在阻塞Redis的可能性。
bigkey的产生
一般来说, bigkey的产生都是由于程序设计不当,或者对于数据规模预料不清楚造成的,来看几个例子:
(1)社交类:粉丝列表,如果某些明星或者大v不精心设计下,必是bigkey。
(2)统计类:例如按天存储某项功能或者网站的用户集合,除非没几个人用,否则必是bigkey.
(3)缓存类:将数据从数据库load出来序列化放到Redis里,这个方式非常常用,但有两个地方需要注意,第一,是不是有必要把所有字段都缓存;第二,有没有相关关联的数据,有的同学为了图方便把相关数据都存一个key下,产生bigkey。
如何优化bigkey
1.拆
big list: list1、list2、…listN
big hash:可以讲数据分段存储,比如一个大的key,假设存了1百万的用户数据,可以拆分成200个key,每个key下面存放5000个用户数据
2.如果bigkey不可避免,也要思考一下要不要每次把所有元素都取出来(例如有时候仅仅需要hmget,而不是hgetall),删除也是一样,尽量使用优雅的方式来处理。
- (2)【推荐】︰选择适合的数据类型。
例如:实体类型(要合理控制和使用数据结构,但也要注意节省内存和性能之间的平衡)反例:
1 set user : 1 : name tom
2 set user : 1 :age 19
3 set user : 1 :favor football
正例:
1 hmset user : 1 name tom age 19 favor football
3.【推荐】︰控制key的生命周期,redis不是垃圾桶。
建议使用expire设置过期时间(条件允许可以打散过期时间,防止集中过期)。
命令使用
1.【推荐】o(N)命令关注N的数量
例如hgetall、lrange、smembers、zrange、sinter等并非不能使用,但是需要明确N的值。有遍历的需求可以使用hscan、sscan、zscan代替。
2.【推荐】∶禁用命令
禁止线上使用key、flushall、flushdb等,通过redis的rename机制禁掉命令,或者使用scan的方式渐进式处理。
3.【推荐】合理使用select
redis的多数据库较弱,使用数字进行区分,很多客户端支持较差,同时多业务用多数据库实际还是单线程处理,会有干扰。
4.【推荐】使用批量操作提高效率
1原生命令:例如mget、mset。
2非原生命令:可以使用pipeline提高效率。
但要注意控制一次批量操作的元素个数(例如500以内,实际也和元素字节数有关)。注意两者不同:
1 1.原生命令是原子操作,pipeline是非原子操作。
2 2. pipeline可以打包不同的命令,原生命令做不到
3 3. pipeline需要客户端和服务端同时支持。
5.【建议】Redis事务功能较弱,不建议过多使用,可以用lua替代
客户端使用
1.【推荐】
避免多个应用使用一个Redis实例
正例:不相干的业务拆分,公共数据做服务化。
2.【推荐】
使用带有连接池的数据库,可以有效控制连接,同时提高效率,标准使用方式:
优化建议
-
maxTotal:最大连接数,早期的版本maxActive实际上这个是一个很难回答的问题,考虑的因素比较多:
- 业务希望Redis并发量
- 客户端执行命令时间
- Redis资源:例如nodes(例如应用个数)*maxTotal是不能超过redis的最大连接数maxclients。
- 资源开销:例如虽然希望控制空闲连接(连接池此刻可马上使用的连接),但是不希望因为连接池的频繁释放创建连接造成不必靠开销。
以一个例子说明,假设:
- 一次命令时间(borrowlreturn resource + Jedis执行命令(含网络))的平均耗时约为1ms,一个连接的QPS大约是1000
- 业务期望的QPS是50000
那么理论上需要的资源池大小是50000 /1000=50个。但事实上这是个理论值,还要考虑到要比理论值预留一些资源,通常来讲maxTotal可以比理论值大一些。
但这个值不是越大越好,一方面连接太多占用客户端和服务端资源,另一方面对于Redis这种高QPS的服务器,一个大命令的阻寒即使设置再大资源池仍然会无济于事。 -
maxldle和minldle
maxldle实际上才是业务需要的最大连接数,maxTotal是为了给出余量,所以maxldle不要设置过小,否则会有newJedis(新连接)开销。
连接池的最佳性能是maxTotal = maxldle,这样就避免连接池伸缩带来的性能干扰。但是如果并发量不大或者
maxTotal设置过高,会导致不必要的连接资源浪费。一般推荐maxldle可以设置为按上面的业务期望QPS计算出来的理论连接数,maxTotal可以再放大一倍。
minldle(最小空闲连接数),与其说是最小空闲连接数,不如说是"至少需要保持的空闲连接数",在使用连接的过程中,如果连接数超过了minldle,那么继续建立连接,如果超过了maxldle,当超过的连接执行完业务后会慢慢被移出连接池释放掉。
如果系统启动完马上就会有很多的请求过来,那么可以给redis连接池做预热,比如快速的创建一些redis连接,执行简单命令,类似ping(),快速的将连接池里的空闲连接提升到minldle的数量。
List<Jedis> minIdleJedisList = new ArrayList<Jedis>(jedisPoolConfig.getMinIdle());
for (int i = 0; i < jedisPoolconfig.getMinIdle( ); i++) {Jedis jedis = null;try {jedis = pool.getResource( ) ;minIdleJedisList.add(jedis);jedis.ping();}catch (Exception e) {logger.error(e.getMessage(), e);} finally {//注意,这里不能马上close将连接还回连接池,否则最后连接池里只会建立1个连接//jedis.close( );}
} //统一将预热的连接还回连接池
for (int i = e; i < jedisPoolConfig.getMinIdle(); i++) {Jedis jedis = null;try {jedis = minIdleJedisList.get(i);//将连接归还回连接池jedis.close( ) ;} catch (Exception e) {logger.error(e.getMessage(), e);} finally {}
}
总之,要根据实际系统的QPS和调用redis客户端的规模整体评估每个节点所使用的连接池大小。
3.【建议】
高并发下建议客户端添加熔断功能(例如sentinel、hystrix)
4.【推荐】
设置合理的密码,如有必要可以使用SSL加密访问
5.【建议】
Redis对于过期键有三种清除策略:
1.被动删除:当读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key
2.主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期主动淘汰一批已过期的key
3.当前已用内存超过maxmemory限定时,触发主动清理策略
主动清理策略在Redis 4.0之前一共实现了6种内存淘汰策略,在4.0之后,又增加了2种策略,总共8种:
a)针对设置了过期时间的key做处理:
- volatile-tt:在筛选时,会针对设置了过期时间的键值对,根据过期时间的先后进行删除,越早过期的越先被删除。
- volatile-random:就像它的名称一样,在设置了过期时间的键值对中,进行随机删除。
- volatile-lru:会使用LRU 算法筛选设置了过期时间的键值对删除。
- volatile-lfu:会使用LFU算法筛选设置了过期时间的键值对删除。
b)针对所有的key做处理:
5. allkeys-random:从所有键值对中随机选择并删除数据。
6. allkeys-lru:使用LRU算法在所有数据中进行筛选删除。
7. allkeys-lfu:使用LFU算法在所有数据中进行筛选删除。
c)不处理:
- noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息"(error) OOM command not allowedwhen used memory",此时Redis只响应读操作。
LRU算法(Least Recently Used,最近最少使用)淘汰很久没被访问过的数据,以最近一次访问时间作为参考。
LFU算法(Least Frequently Used,最不经常使用)淘汰最近一段时间被访问次数最少的数据,以次数作为参考。
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。这时使用LFU可能更好点。
用LRU算法在所有数据中进行筛选删除。
7. allkeys-lfu:使用LFU算法在所有数据中进行筛选删除。
c)不处理:
- noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息"(error) OOM command not allowedwhen used memory",此时Redis只响应读操作。
LRU算法(Least Recently Used,最近最少使用)淘汰很久没被访问过的数据,以最近一次访问时间作为参考。
LFU算法(Least Frequently Used,最不经常使用)淘汰最近一段时间被访问次数最少的数据,以次数作为参考。
当存在热点数据时,LRU的效率很好,但偶发性的、周期性的批量操作会导致LRU命中率急剧下降,缓存污染情况比较严重。这时使用LFU可能更好点。
根据自身业务类型,配置好maxmemory-policy(默认是noeviction),推荐使用volatile-lru。如果不设置最大内存,当Redis 内存超出物理内存限制时,内存的数据会开始和磁盘产生频繁的交换(swap),会让Redis的性能急剧下降。当Redis运行在主从模式时,只有主结点才会执行过期删除策略,然后把删除操作"del key"同步到从结点删除数据。
相关文章:
Redis微服务架构
Redis微服务架构 缓存设计 缓存穿透 缓存穿透是指查询一个根本不存在的数据,缓存层和存储层都不会命中,通常出于容错的考虑,如果从存储层查不到数据则不写入缓层。 缓存穿透将导致不存在的数据每次请求都要到存储层去查询,失去…...

【C++】 局部对象,引用返回
1、new 关键字 会在堆内申请空间,如果仅仅是普通调用构造函数,不会在堆内开辟空间。 2、函数调用会形成栈帧,进行压栈操作,函数调用结束,会进行弹栈。 函数内的局部对象,会随着弹栈,而被销毁(…...

线性代数中涉及到的matlab命令-第二章:矩阵及其运算
目录 1,矩阵定义 2,矩阵的运算 3,方阵的行列式和伴随矩阵 4,矩阵的逆 5,克莱默法则 6,矩阵分块 1,矩阵定义 矩阵与行列式的区别: (1)形式上行列式…...

计算机毕业设计选什么题目好?springboot 美食推荐系统
✍✍计算机编程指导师 ⭐⭐个人介绍:自己非常喜欢研究技术问题!专业做Java、Python、微信小程序、安卓、大数据、爬虫、Golang、大屏等实战项目。 ⛽⛽实战项目:有源码或者技术上的问题欢迎在评论区一起讨论交流! ⚡⚡ Java实战 |…...
爆肝整理,Jmeter接口性能测试-跨线程调用变量实操(超详细)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 1、Jmeter中线程运…...
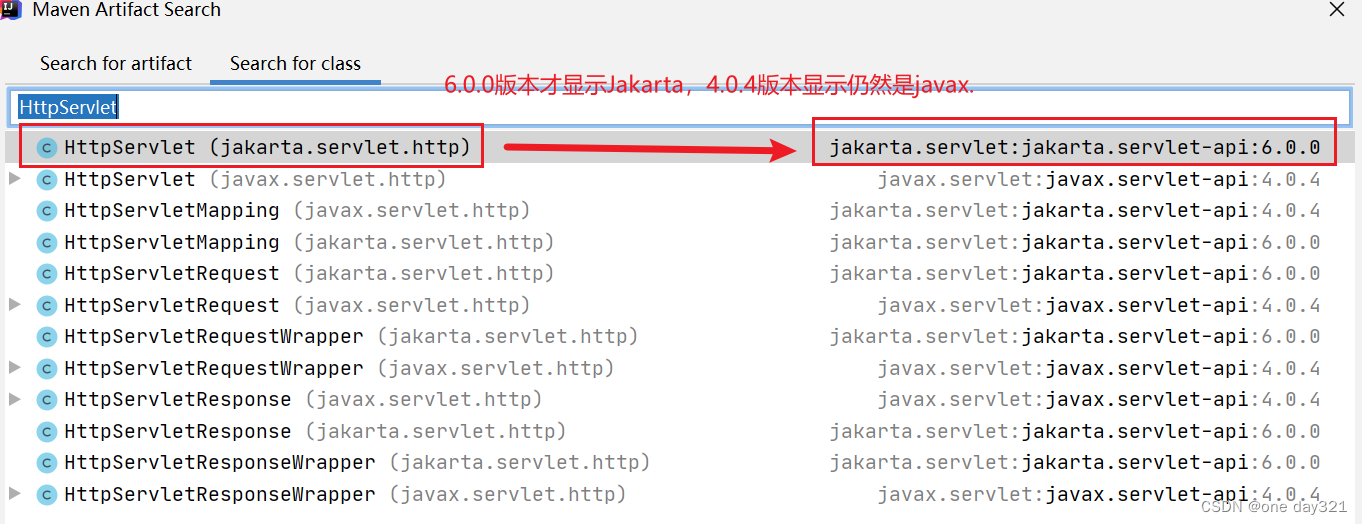
Maven导入程序包jakarta.servlet,但显示不存在
使用前提:(Tomcat10版本)已知tomcat10版本之后,使用jakart.servlet。而tomcat9以及之前使用javax.servlet。 问题描述:在maven仓库有导入了Jakarta程序包,但是界面仍然显示是javax。(下图&…...
es6(二)——常用es6说明
ES6的系列文章目录 es6(一)——var和let和const的区别 文章目录 ES6的系列文章目录一、变量的结构赋值1.数组的结构赋值2.对象的结构赋值 二、模板字符串三、扩展运算符1.字符串的使用2.数组的使用 四、箭头函数1.普通函数的定义2.箭头函数的定义3.箭头…...
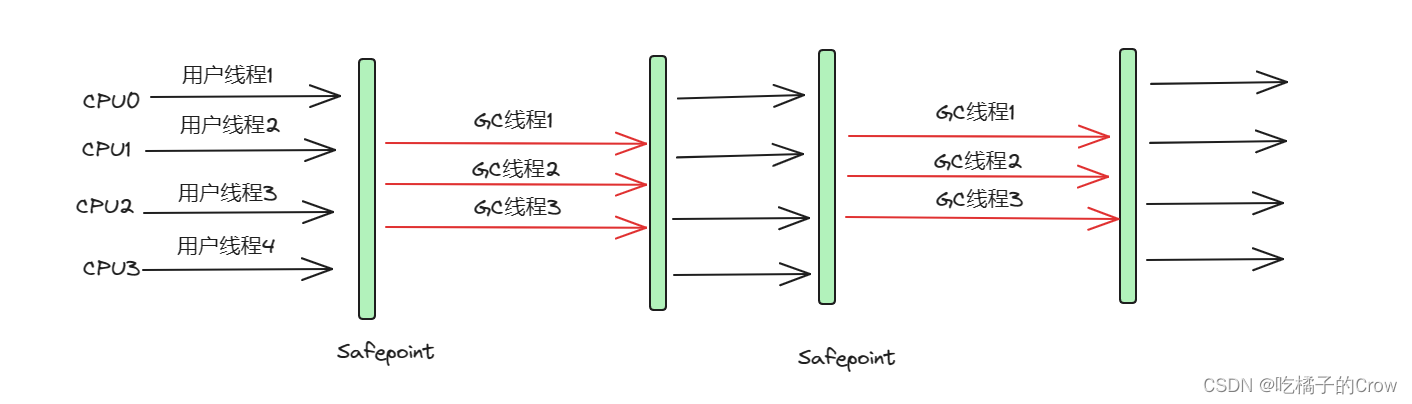
经典垃圾回收器
1.各垃圾回收器之间的配合使用关系 2.垃圾回收器的种类 2.1 Serial收集器(默认新生代收集器) Serial收集器是历史最悠久的收集器,曾经是新生代收集器的唯一选择,它是一个单线程工作的收集器,其“单线程”的意义不仅仅…...

台达DOP-B07S410触摸屏出现HMI no response无法上传的解决办法
台达DOP-B07S410触摸屏出现HMI no response无法上传的解决办法 台达触摸屏(B07S410)在上载程序时(显示No response from HMI)我以前的电脑是WIN7的,从来没出现过这样的问题,现在换成win10的,怎么都不行,(USB显示是一个大容量存储)换一台电脑(win10)有些行,有些不行…...

[资源推荐] 复旦大学张奇老师科研分享
刷B站的时候首页给我推了这个:【直播回放】复旦大学张奇教授亲授:人工智能领域顶会论文的发表指南先前也散漫地读了些许论文,但没有在一些宏观的方法论下去训练,读的时候能感觉出一些科研的套路,论文写作的套路&#x…...

C++数位动态规划算法:统计整数数目
题目 给你两个数字字符串 num1 和 num2 ,以及两个整数 max_sum 和 min_sum 。如果一个整数 x 满足以下条件,我们称它是一个好整数: num1 < x < num2 min_sum < digit_sum(x) < max_sum. 请你返回好整数的数目。答案可能很大&…...

ip 网段设置 --chatGPT
问:host all all 127.0.0.1/32 scram-sha-256 里的 127.0.0.1/32 是什么含义 ,要指定某个呢 gpt: 在 PostgreSQL 的 pg_hba.conf 文件中,127.0.0.1/32 是一个用于定义访问控制规则的CIDR(无类域间路由)标记࿰…...

使用JMeter进行接口测试教程
安装 使用JMeter的前提需要安装JDK,需要JDK1.7以上版本目前在用的是JMeter5.2版本,大家可自行下载解压使用 运行 进入解压路径如E: \apache-jmeter-5.2\bin,双击jmeter.bat启动运行 启动后默认为英文版本,可通过Options – Cho…...

文本生成解码策略
解码策略 1. sample实现了怎样的功能 不是直接选择概率最大的token,而是根据多项式分布进行采样获得下一个token 这里的概率通过设置一些策略,进行处理。例如,解码最小长度(当长度小于该值的时候,eos的采样概率为0&am…...
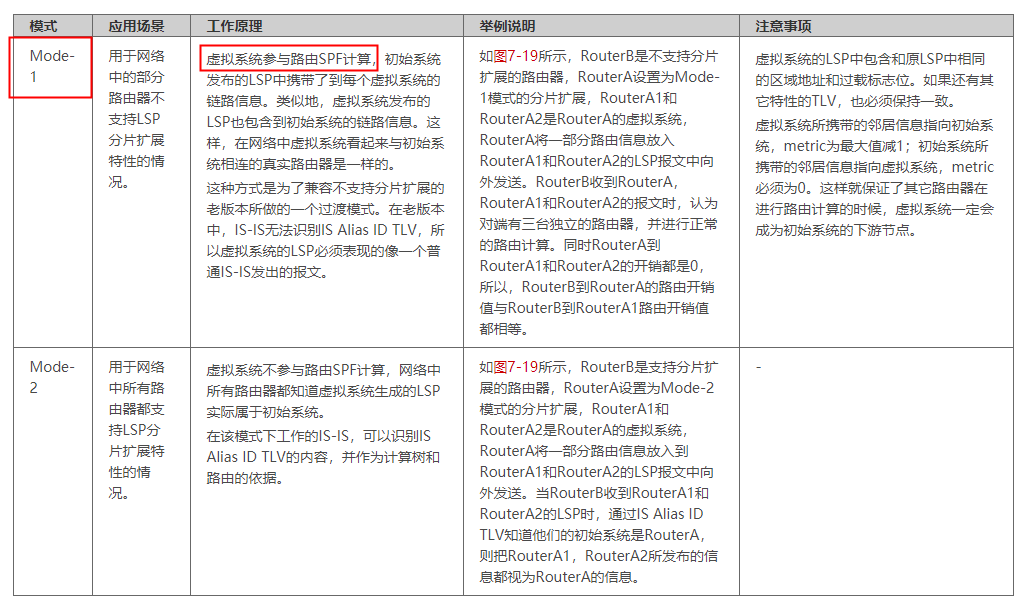
华为数通方向HCIP-DataCom H12-831题库(单选题:221-240)
第221题 以下关于IS-IS的LSP分片功能的描述,正确的是哪一项? A、IS-IS的分片扩展功能的Mode-1模式,虚拟系统是需要参与路由SPF计算的 B、IS-IS的LSP分片功能,是用于让收到LSP分片报文的设备老化相关路由信息 C、IS-IS的分片扩展功能,是通过LSP报文中的LSPID实现的 D、IS-…...

AttributeError: module ‘hanlp.utils.rules‘ has no attribute ‘tokenize_english‘
附原文链接:http://t.csdnimg.cn/wVLib import hanlp tokenizer hanlp.utils.rules.tokenize_english tokenizer(Mr. Hankcs bought hankcs.com for 1.5 thousand dollars.) 改为: from hanlp.utils.lang.en.english_tokenizer import tokenize_eng…...

苍穹外卖(四) AOP切面公共字段自动填充及文件上传
一.AOP切面公共字段填充 问题分析 如果都按照上述的操作方式来处理这些公共字段, 需要在每一个业务方法中进行操作, 编码相对冗余、繁琐,那能不能对于这些公共字段在某个地方统一处理,来简化开发呢? 答案是可以的,我们使用AOP切…...

vue-cli + vue3 项目 ios 苹果手机白屏问题
目录 问题描述原因分析解决方案遇到的坑1,架构问题2,项目引入其他依赖的问题 参考 问题描述 vue-cli vue3 的项目,在苹果手机上打开白屏,安卓手机正常显示。 原因分析 1,借助 vconsole 发现并没有打印报错信息&…...

Spring Boot中的JdbcTemplate是什么,如何使用
Spring Boot中的JdbcTemplate是什么,如何使用 Spring Boot是一个流行的Java应用程序开发框架,它简化了Java应用程序的开发过程,并提供了丰富的功能和工具。在Spring Boot中,JdbcTemplate是一个强大的数据库访问工具,它…...

Python测网络连通性、能否访问某个网络或者端口号<网络检测、ping主机、测试端口>
一、ping命令及其使用 ping命令是在计算机网络领域中用来测试目标主机是否可达以及其延迟时间的命令。对于Python来说,我们可以通过subprocess模块来实现执行命令。下面是示例代码: import subprocessdef ping(host):result subprocess.run([ping, -c…...

接口测试中缓存处理策略
在接口测试中,缓存处理策略是一个关键环节,直接影响测试结果的准确性和可靠性。合理的缓存处理策略能够确保测试环境的一致性,避免因缓存数据导致的测试偏差。以下是接口测试中常见的缓存处理策略及其详细说明: 一、缓存处理的核…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...

在鸿蒙HarmonyOS 5中实现抖音风格的点赞功能
下面我将详细介绍如何使用HarmonyOS SDK在HarmonyOS 5中实现类似抖音的点赞功能,包括动画效果、数据同步和交互优化。 1. 基础点赞功能实现 1.1 创建数据模型 // VideoModel.ets export class VideoModel {id: string "";title: string ""…...

DBAPI如何优雅的获取单条数据
API如何优雅的获取单条数据 案例一 对于查询类API,查询的是单条数据,比如根据主键ID查询用户信息,sql如下: select id, name, age from user where id #{id}API默认返回的数据格式是多条的,如下: {&qu…...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...

pycharm 设置环境出错
pycharm 设置环境出错 pycharm 新建项目,设置虚拟环境,出错 pycharm 出错 Cannot open Local Failed to start [powershell.exe, -NoExit, -ExecutionPolicy, Bypass, -File, C:\Program Files\JetBrains\PyCharm 2024.1.3\plugins\terminal\shell-int…...

Cursor AI 账号纯净度维护与高效注册指南
Cursor AI 账号纯净度维护与高效注册指南:解决限制问题的实战方案 风车无限免费邮箱系统网页端使用说明|快速获取邮箱|cursor|windsurf|augment 问题背景 在成功解决 Cursor 环境配置问题后,许多开发者仍面临账号纯净度不足导致的限制问题。无论使用 16…...