python爬取boss直聘数据(selenium+xpath)
文章目录
- 一、主要目标
- 二、开发环境
- 三、selenium安装和驱动下载
- 四、主要思路
- 五、代码展示和说明
- 1、导入相关库
- 2、启动浏览器
- 3、搜索框定位
- 创建csv文件
- 招聘页面数据解析(XPATH)
- 总代码
- 效果展示
- 六、总结
一、主要目标
以boss直聘为目标网站,主要目的是爬取下图中的所有信息,并将爬取到的数据进行持久化存储。(可以存储到数据库中或进行数据可视化分析用web网页进行展示,这里我就以csv形式存在了本地)

二、开发环境
python3.8
pycharm
Firefox
三、selenium安装和驱动下载
环境安装: pip install selenium
版本对照表(火狐的)
https://firefox-source-docs.mozilla.org/testing/geckodriver/Support.html
浏览器驱动下载
https://registry.npmmirror.com/binary.html?path=geckodriver/
火狐浏览器下载
https://ftp.mozilla.org/pub/firefox/releases/
四、主要思路
- 利用selenium打开模拟浏览器,访问boss直聘首页(绕过cookie反爬)
- 定位搜索按钮输入某职位,点击搜索
- 在搜索结果页面,解析出现的职位信息,并保存
- 获取多个页面,可以定位跳转至下一页的按钮(但是这个跳转我一直没成功,于是我就将请求url写成了动态的,直接发送一个新的url来代替跳转)
五、代码展示和说明
1、导入相关库
# 用来将爬取到的数据以csv保存到本地
import csv
from time import sleep
# 使用selenium绕过cookie反爬
from selenium import webdriver
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.common.by import By
# 使用xpath进行页面数据解析
from lxml import etree2、启动浏览器
(有界面)
# 传入浏览器的驱动
ser = Service('./geckodriver.exe')
# 实例化一个浏览器对象
bro = webdriver.Firefox(service=ser)
# 设置隐式等待 超时时间设置为20s
bro.implicitly_wait(20)
# 让浏览器发起一个指定url请求
bro.get(urls[0])
(无界面)
# 1. 初始化配置无可视化界面对象
options = webdriver.FirefoxOptions()
# 2. 无界面模式
options.add_argument('-headless')
options.add_argument('--disable-gpu')# 让selenium规避被检测到的风险
options.add_argument('excludeSwitches')# 传入浏览器的驱动
ser = Service('./geckodriver.exe')# 实例化一个浏览器对象
bro = webdriver.Firefox(service=ser, options=options)# 设置隐式等待 超时时间设置为20s
bro.implicitly_wait(20)# 让浏览器发起一个指定url请求
bro.get(urls[0])
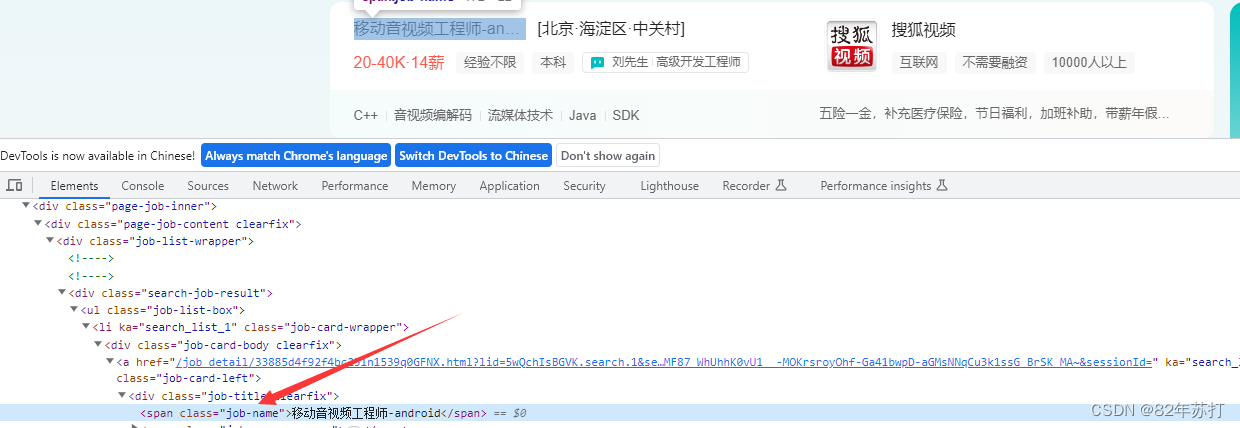
3、搜索框定位
进入浏览器,按F12进入开发者模式
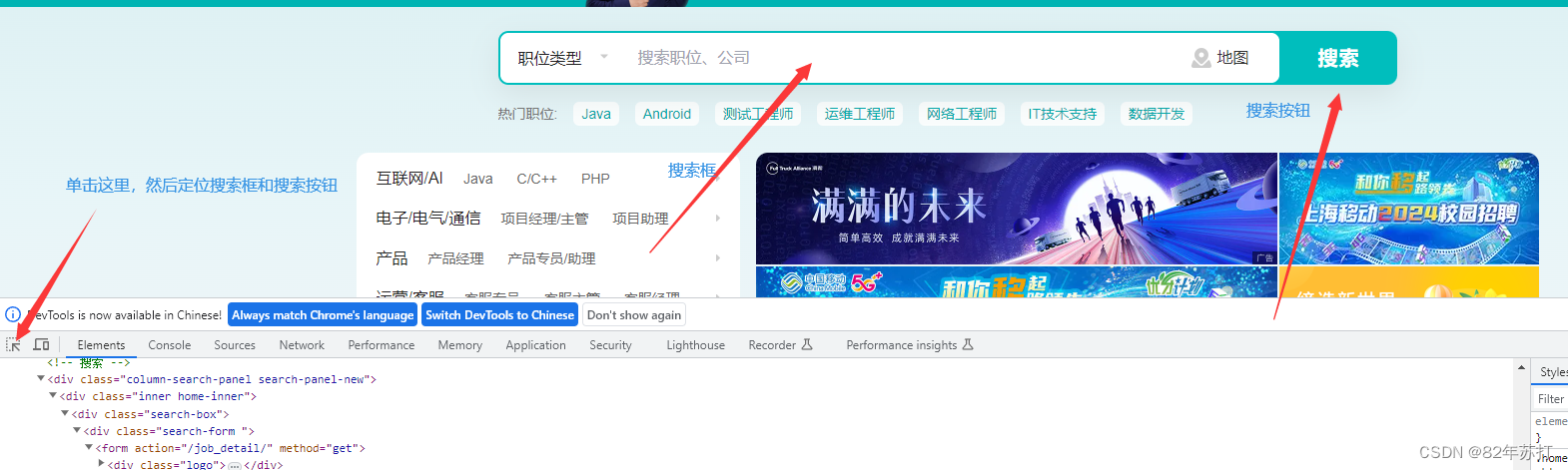
然后分析下图可知,搜索框和搜索按钮都有唯一的class值
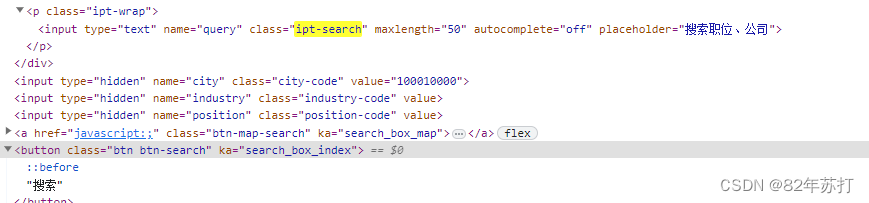
然后输入搜索内容,并跳转,代码如下
# 定位搜索框 .ipt-search
search_tag = bro.find_element(By.CSS_SELECTOR, value='.ipt-search')
# 输入搜索内容
search_tag.send_keys("")# 定位搜索按钮 .代表的是当前标签下的class
btn = bro.find_element(By.CSS_SELECTOR, value='.btn-search')
# 点击搜索按钮
btn.click()
创建csv文件
一开始编码为utf-8,但在本地打开内容是乱码,然后改成utf-8_sig就ok了
# f = open("boos直聘.csv", "w", encoding="utf-8", newline="")
f = open("boos直聘.csv", "w", encoding="utf-8_sig", newline="")
csv.writer(f).writerow(["职位", "位置", "薪资", "联系人", "经验", "公司名", "类型", "职位技能", "福利", "详情页"])招聘页面数据解析(XPATH)
通过分析可知,招聘数据全在ul标签下的li标签中
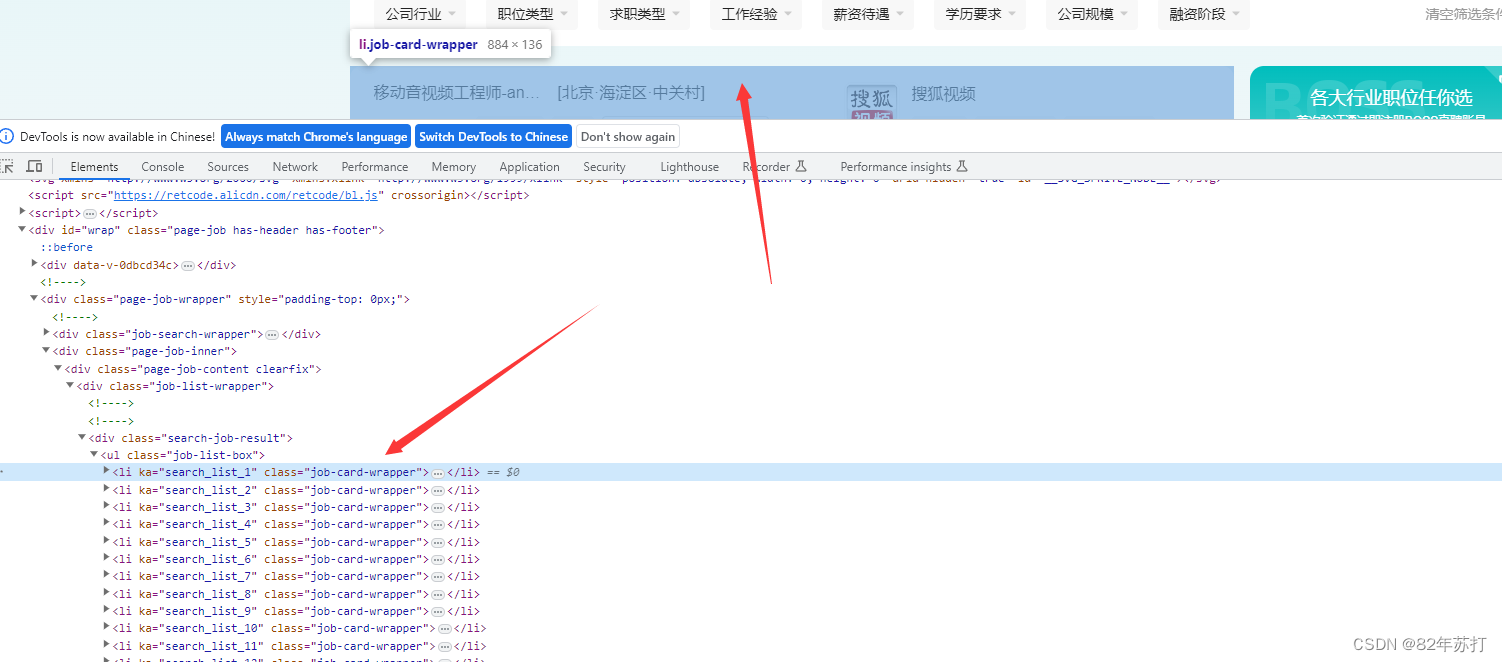
我们要获取的信息有这些,接下来就要进入li标签中,一个一个去分析
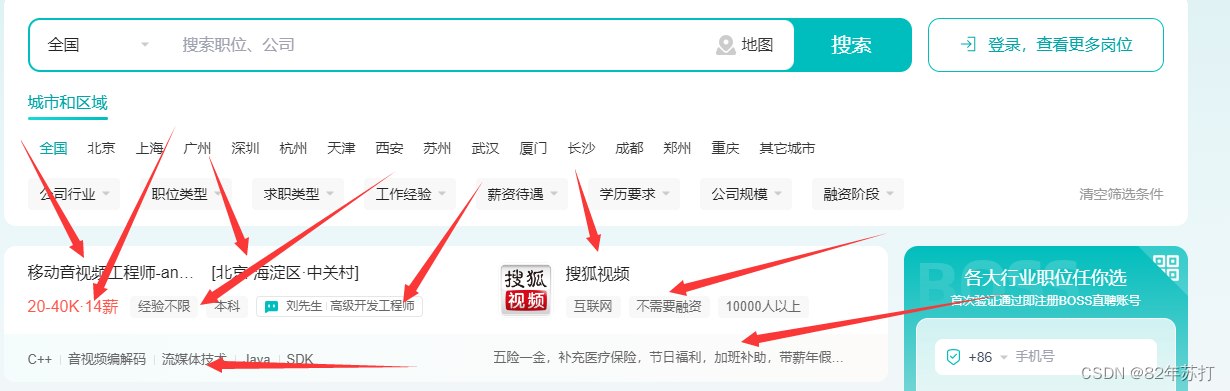
其中职位名称在span标签中,而span标签的class有唯一的值job-name
其它数据分析方式和这个相同
数据解析代码如下
def parse():# 临时存放获取到的信息jobList = []# 提取信息page_text = bro.page_source# 将从互联网上获取的源码数据加载到tree对象中tree = etree.HTML(page_text)job = tree.xpath('//div[@class="search-job-result"]/ul/li')for i in job:# 职位job_name = i.xpath(".//span[@class='job-name']/text()")[0]# 位置jobArea = i.xpath(".//span[@class='job-area']/text()")[0]# 联系人linkman_list = i.xpath(".//div[@class='info-public']//text()")linkman = "·".join(linkman_list)# 详情页urldetail_url = prefix + i.xpath(".//h3[@class='company-name']/a/@href")[0]# print(detail_url)# 薪资salary = i.xpath(".//span[@class='salary']/text()")[0]# 经验job_lable_list = i.xpath(".//ul[@class='tag-list']//text()")job_lables = " ".join(job_lable_list)# 公司名company = i.xpath(".//h3[@class='company-name']/a/text()")[0]# 公司类型和人数等companyScale_list = i.xpath(".//div[@class='company-info']/ul//text()")companyScale = " ".join(companyScale_list)# 职位技能skill_list = i.xpath("./div[2]/ul//text()")skills = " ".join(skill_list)# 福利 如有全勤奖补贴等try:job_desc = i.xpath(".//div[@class='info-desc']/text()")[0]# print(type(info_desc))except:job_desc = ""# print(type(info_desc))# print(job_name, jobArea, salary, linkman, salaryScale, name, componyScale, tags, info_desc)# 将数据写入csvcsv.writer(f).writerow([job_name, jobArea, salary, linkman, job_lables, company, companyScale, skills, job_desc, detail_url])# 将数据存入数组中jobList.append({"jobName": job_name,"jobArea": jobArea,"salary": salary,"linkman": linkman,"jobLables": job_lables,"company": company,"companyScale": companyScale,"skills": skills,"job_desc": job_desc,"detailUrl": detail_url,})return {"jobList": jobList}总代码
import csv
from time import sleep
from selenium import webdriver
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.common.by import By
from lxml import etree# 指定url
urls = ['https://www.zhipin.com/', 'https://www.zhipin.com/web/geek/job?query={}&page={}']
prefix = 'https://www.zhipin.com'# 1. 初始化配置无可视化界面对象
options = webdriver.FirefoxOptions()
# 2. 无界面模式
options.add_argument('-headless')
options.add_argument('--disable-gpu')# 让selenium规避被检测到的风险
options.add_argument('excludeSwitches')# 传入浏览器的驱动
ser = Service('./geckodriver.exe')# 实例化一个浏览器对象
bro = webdriver.Firefox(service=ser, options=options)
# bro = webdriver.Firefox(service=ser# 设置隐式等待 超时时间设置为20s
# bro.implicitly_wait(20)# 让浏览器发起一个指定url请求
bro.get(urls[0])sleep(6)# 定位搜索框 .ipt-search
search_tag = bro.find_element(By.CSS_SELECTOR, value='.ipt-search')
# 输入搜索内容
search_tag.send_keys("")# 定位搜索按钮 .代表的是当前标签下的class
btn = bro.find_element(By.CSS_SELECTOR, value='.btn-search')
# 点击搜索按钮
btn.click()
sleep(15)# f = open("boos直聘.csv", "w", encoding="utf-8", newline="")
f = open("boos直聘.csv", "w", encoding="utf-8_sig", newline="")
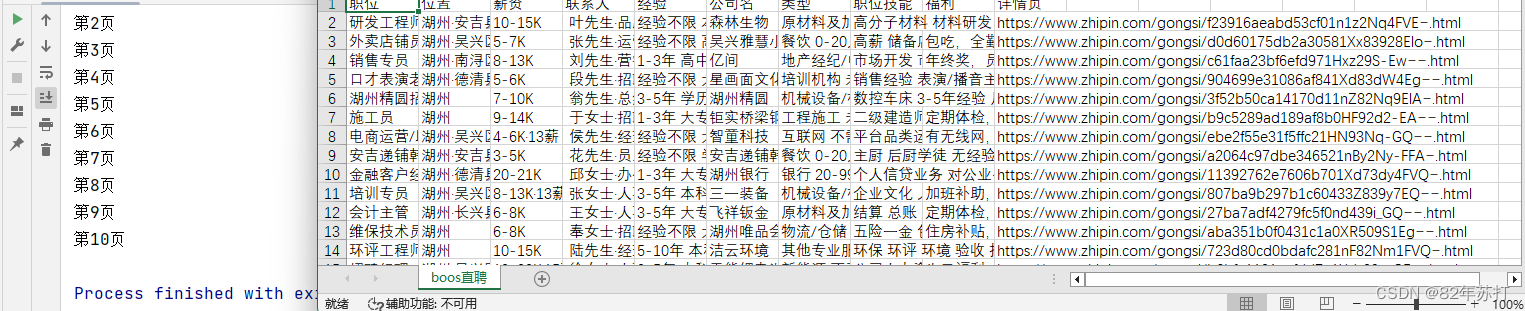
csv.writer(f).writerow(["职位", "位置", "薪资", "联系人", "经验", "公司名", "类型", "职位技能", "福利", "详情页"])def parse():# 临时存放获取到的信息jobList = []# 提取信息page_text = bro.page_source# 将从互联网上获取的源码数据加载到tree对象中tree = etree.HTML(page_text)job = tree.xpath('//div[@class="search-job-result"]/ul/li')for i in job:# 职位job_name = i.xpath(".//span[@class='job-name']/text()")[0]# 位置jobArea = i.xpath(".//span[@class='job-area']/text()")[0]# 联系人linkman_list = i.xpath(".//div[@class='info-public']//text()")linkman = "·".join(linkman_list)# 详情页urldetail_url = prefix + i.xpath(".//h3[@class='company-name']/a/@href")[0]# print(detail_url)# 薪资salary = i.xpath(".//span[@class='salary']/text()")[0]# 经验job_lable_list = i.xpath(".//ul[@class='tag-list']//text()")job_lables = " ".join(job_lable_list)# 公司名company = i.xpath(".//h3[@class='company-name']/a/text()")[0]# 公司类型和人数等companyScale_list = i.xpath(".//div[@class='company-info']/ul//text()")companyScale = " ".join(companyScale_list)# 职位技能skill_list = i.xpath("./div[2]/ul//text()")skills = " ".join(skill_list)# 福利 如有全勤奖补贴等try:job_desc = i.xpath(".//div[@class='info-desc']/text()")[0]# print(type(info_desc))except:job_desc = ""# print(type(info_desc))# print(job_name, jobArea, salary, linkman, salaryScale, name, componyScale, tags, info_desc)# 将数据写入csvcsv.writer(f).writerow([job_name, jobArea, salary, linkman, job_lables, company, companyScale, skills, job_desc, detail_url])# 将数据存入数组中jobList.append({"jobName": job_name,"jobArea": jobArea,"salary": salary,"linkman": linkman,"jobLables": job_lables,"company": company,"companyScale": companyScale,"skills": skills,"job_desc": job_desc,"detailUrl": detail_url,})return {"jobList": jobList}if __name__ == '__main__':# 访问第一页jobList = parse()query = ""# 访问剩下的九页for i in range(2, 11):print(f"第{i}页")url = urls[1].format(query, i)bro.get(url)sleep(15)jobList = parse()# 关闭浏览器bro.quit()效果展示
六、总结
不知道是boss反爬做的太好,还是我个人太菜(哭~)
我个人倾向于第二种
这个爬虫还有很多很多的不足之处,比如在页面加载的时候,boss的页面会多次加载(这里我很是不理解,我明明只访问了一次,但是他能加载好多次),这就导致是不是ip就会被封…
再比如,那个下一页的点击按钮,一直点不了,不知有没有路过的大佬指点一二(呜呜呜~)
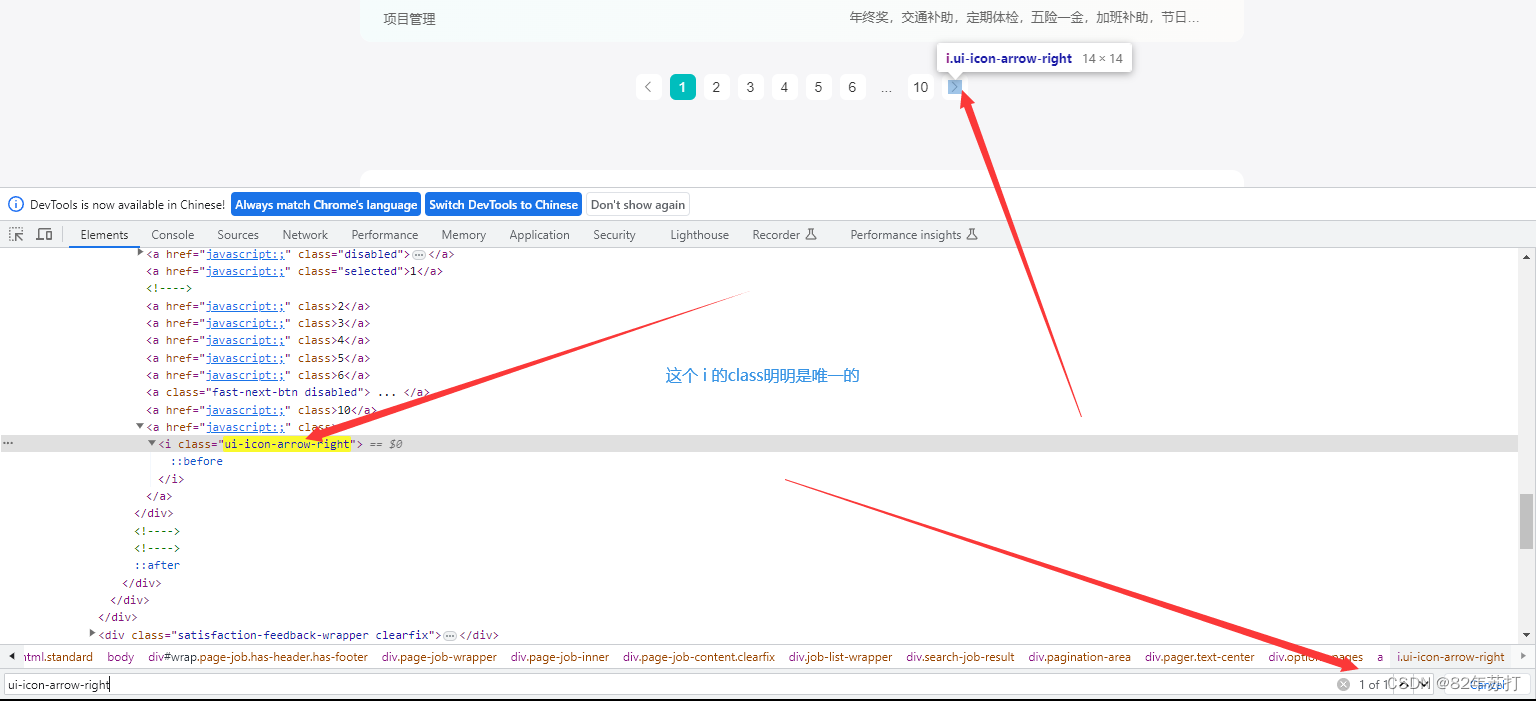
# 下一页标签定位 ui-icon-arrow-right
next_tag = bro.find_element(By.CSS_SELECTOR, value='.ui-icon-arrow-right')
# action = ActionChains(bro)
# # 点击指定的标签
# action.click(next_tag).perform()
# sleep(0.1)
# # 释放动作链
# action.release().perform()
总之boss的信息爬取,我还是无法做到完全自动化😭
相关文章:
python爬取boss直聘数据(selenium+xpath)
文章目录 一、主要目标二、开发环境三、selenium安装和驱动下载四、主要思路五、代码展示和说明1、导入相关库2、启动浏览器3、搜索框定位创建csv文件招聘页面数据解析(XPATH)总代码效果展示 六、总结 一、主要目标 以boss直聘为目标网站,主要目的是爬取下图中的所…...
GEO生信数据挖掘(六)实践案例——四分类结核病基因数据预处理分析
前面五节,我们使用阿尔兹海默症数据做了一个数据预处理案例,包括如下内容: GEO生信数据挖掘(一)数据集下载和初步观察 GEO生信数据挖掘(二)下载基因芯片平台文件及注释 GEO生信数据挖掘&…...

8.Mobilenetv2网络代码实现
代码如下: import math import os import numpy as npimport torch import torch.nn as nn import torch.utils.model_zoo as model_zoo#1.建立带有bn的卷积网络 def conv_bn(inp, oup, stride):return nn.Sequential(nn.Conv2d(inp,oup,3,stride,biasFalse),nn.Bat…...

Spring Boot Controller
刚入门小白,详细请看这篇SpringBoot各种Controller写法_springboot controller-CSDN博客 Spring Boot 提供了Controller和RestController两种注解。 Controller 返回一个string,其内容就是指向的html文件名称。 Controller public class HelloControll…...

在网络安全、爬虫和HTTP协议中的重要性和应用
1. Socks5代理:保障多协议安全传输 Socks5代理是一种功能强大的代理协议,支持多种网络协议,包括HTTP、HTTPS和FTP。相比之下,Socks5代理提供了更高的安全性和功能性,包括: 多协议支持: Socks5代…...
Web测试框架SeleniumBase
首先,SeleniumBase支持 pip安装: > pip install seleniumbase它依赖的库比较多,包括pytest、nose这些第三方单元测试框架,是为更方便的运行测试用例,因为这两个测试框架是支持unittest测试用例的执行的。 Seleniu…...

jvm打破砂锅问到底- 为什么要标记或记录跨代引用
为什么要标记或记录跨代引用. ygc时, 直接把老年代引用的新生代对象(可能是对象区域)记录下来当做根, 这其实就是依据第二假说和第三假说, 强者恒强, 跨代引用少(存在互相引用关系的两个对象,是应该倾 向于同时生存或者同时消亡的). 拿ygc老年代跨代引用对象当做根…...

小程序长期订阅
准备工作 ::: tip 管理后台配置 小程序类目:住建(硬性要求) 功能-》订阅消息-》我的模版 申请模版:1、预约进度通知 2、申请结果通知 3、业务办理进度提醒 ::: 用户订阅一次后,可长期下发多条消息。目前长期性订阅…...

Studio One6.5中文版本版下载及功能介绍
Studio One是一款专业的音乐制作软件,由美国PreSonus公司开发。该软件提供了全面的音频编辑和混音功能,包括录制、编曲、合成、采样等多种工具,可用于制作各种类型的音乐,如流行音乐、电子音乐、摇滚乐等。 Studio One的主要特点…...

07-Zookeeper分布式一致性协议ZAB源码剖析
上一篇:06-Zookeeper选举Leader源码剖析 整个Zookeeper就是一个多节点分布式一致性算法的实现,底层采用的实现协议是ZAB。 1. ZAB协议介绍 ZAB 协议全称:Zookeeper Atomic Broadcast(Zookeeper 原子广播协议)。 Zook…...

云原生安全应用场景有哪些?
当今数字化时代,数据已经成为企业最宝贵的资产之一,而云计算作为企业数字化转型的关键技术,其安全性也日益受到重视。随着云计算技术的快速发展,云原生安全应用场景也越来越广泛,下面本文将从云原生安全应用场景出发&a…...

Step 1 搭建一个简单的渲染框架
Step 1 搭建一个简单的渲染框架 万事开头难。从萌生到自己到处看源码手抄一个mini engine出来的想法,到真正敲键盘去抄,转眼过去了很久的时间。这次大概的确是抱着认真的想法,打开VS从零开始抄代码。不知道能坚持多久呢。。。 本次的主题是搭…...
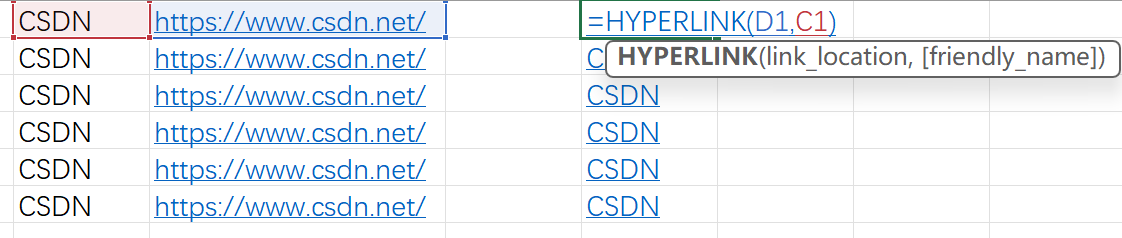
Excel 插入和提取超链接
构造超链接 HYPERLINK(D1,C1)提取超链接 Sheet页→右键→查看代码Sub link()Dim hl As HyperlinkFor Each hl In ActiveSheet.Hyperlinkshl.Range.Offset(0, 1).Value hl.AddressNext End Sub工具栏→运行→运行子过程→提取所有超链接地址参考: https://blog.cs…...

基础架构开发-操作系统、编译器、云原生、嵌入式、ic
基础架构开发-操作系统、编译器、云原生、嵌入式、ic 操作系统编译器词法分析AST语法树生成语法优化生成机器码 云原生容器开发一般遇到的岗位描述RDMA、DPDK是什么东西NFV和VNF是什么RisingWave云原生存储引擎开发实践 单片机、嵌入式雷达路线规划 ic开发 操作系统 以C和Rust…...
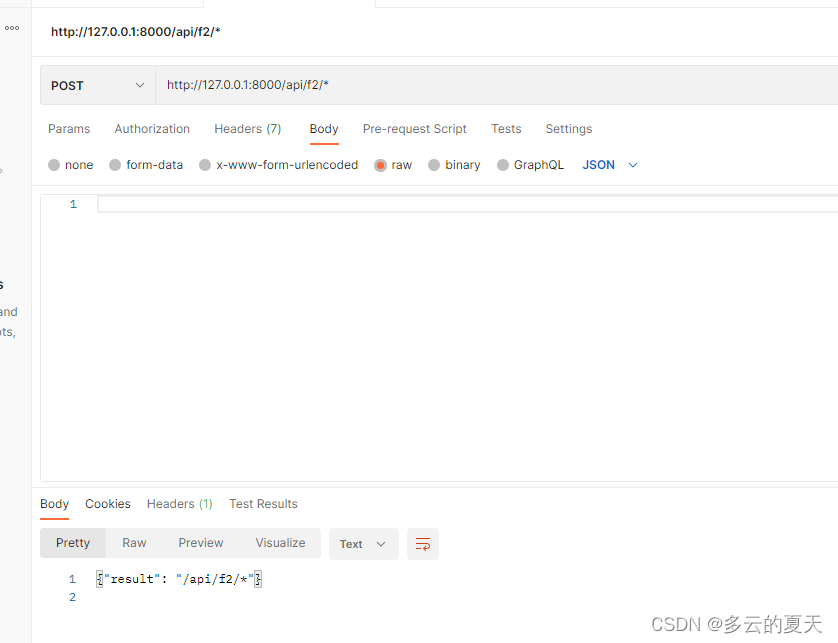
C++-Mongoose(3)-http-server-https-restful
1.url 结构 2.http和 http-restful区别在于对于mg_tls_opts的赋值 2.1 http和https 区分 a) port地址 static const char *s_http_addr "http://0.0.0.0:8000"; // HTTP port static const char *s_https_addr "https://0.0.0.0:8443"; // HTTP…...
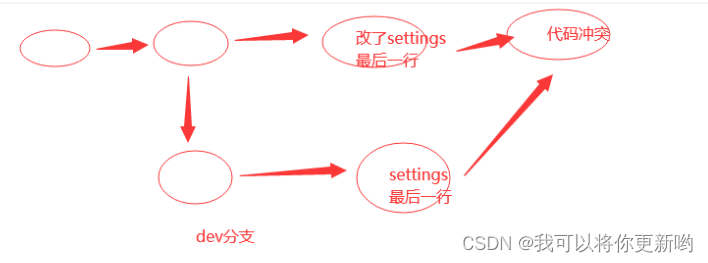
git多分支、git远程仓库、ssh方式连接远程仓库、协同开发(避免冲突)、解决协同冲突(多人在同一分支开发、 合并分支)
1 git多分支 2 git远程仓库 2.1 普通开发者,使用流程 3 ssh方式连接远程仓库 4 协同开发 4.1 避免冲突 4.2 协同开发 5 解决协同冲突 5.1 多人在同一分支开发 5.2 合并分支 1 git多分支 ## 命令操作分支-1 创建分支git branch dev-2 查看分支git branch-3 分支合…...

ChatGPT或将引发现代知识体系转变
作为当下大语言模型的典型代表,ChatGPT对人类学习方式和教育发展所产生的变革效应已然引起了广泛关注。技术的快速发展在某种程度上正在“倒逼”教育领域开启更深层次的变革。在此背景下,教育从业者势必要学会准确识变、科学应变、主动求变、以变应变&am…...
【爬虫实战】用pyhon爬百度故事会专栏
一.爬虫需求 获取对应所有专栏数据;自动实现分页;多线程爬取;批量多账号爬取;保存到mysql、csv(本案例以mysql为例);保存数据时已存在就更新,无数据就添加; 二.最终效果…...

焦炭反应性及反应后强度试验方法
声明 本文是学习GB-T 4000-2017 焦炭反应性及反应后强度试验方法. 而整理的学习笔记,分享出来希望更多人受益,如果存在侵权请及时联系我们 7— 进气口; 8— 测温热电偶。 图 A.1 单点测温加热炉体结构示意图 A.3 温度控制装置 控制精度:(11003)℃。…...
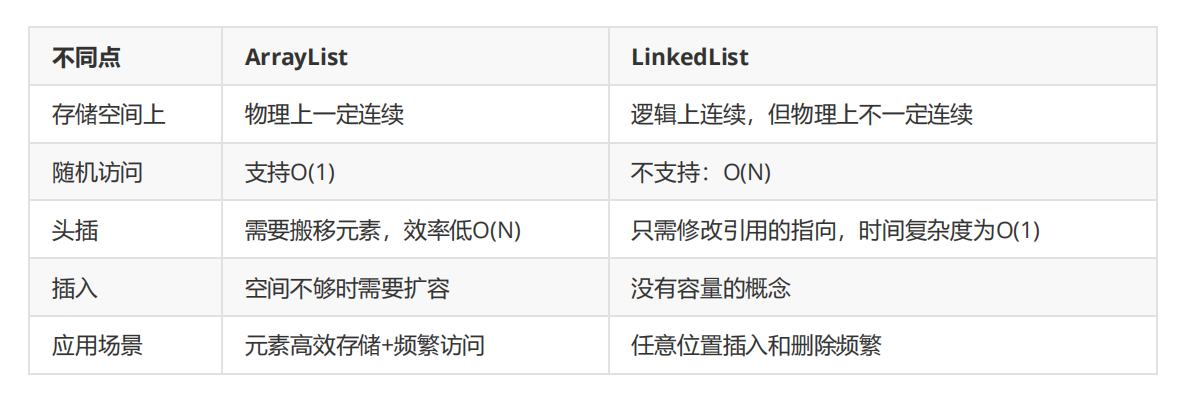
链表(3):双链表
引入 我们之前学的单向链表有什么缺点呢? 缺点:后一个节点无法看到前一个节点的内容 那我们就多设置一个格子prev用来存放前面一个节点的地址,第一个节点的prev存最后一个节点的地址(一般是null) 这样一个无头双向…...

SciencePlots——绘制论文中的图片
文章目录 安装一、风格二、1 资源 安装 # 安装最新版 pip install githttps://github.com/garrettj403/SciencePlots.git# 安装稳定版 pip install SciencePlots一、风格 简单好用的深度学习论文绘图专用工具包–Science Plot 二、 1 资源 论文绘图神器来了:一行…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

Psychopy音频的使用
Psychopy音频的使用 本文主要解决以下问题: 指定音频引擎与设备;播放音频文件 本文所使用的环境: Python3.10 numpy2.2.6 psychopy2025.1.1 psychtoolbox3.0.19.14 一、音频配置 Psychopy文档链接为Sound - for audio playback — Psy…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

管理学院权限管理系统开发总结
文章目录 🎓 管理学院权限管理系统开发总结 - 现代化Web应用实践之路📝 项目概述🏗️ 技术架构设计后端技术栈前端技术栈 💡 核心功能特性1. 用户管理模块2. 权限管理系统3. 统计报表功能4. 用户体验优化 🗄️ 数据库设…...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...

第7篇:中间件全链路监控与 SQL 性能分析实践
7.1 章节导读 在构建数据库中间件的过程中,可观测性 和 性能分析 是保障系统稳定性与可维护性的核心能力。 特别是在复杂分布式场景中,必须做到: 🔍 追踪每一条 SQL 的生命周期(从入口到数据库执行)&#…...