pyflink学习笔记(二):table_apisql
Joins
Inner Join
官网说明:和 SQL 的 JOIN 子句类似。关联两张表。两张表必须有不同的字段名,并且必须通过 join 算子或者使用 where 或 filter 算子定义至少一个 join 等式连接谓词。
先创建2个表,两个表的字段是相同的,我想验证下,是不是必须两个表列名得不同
orders1 = table_env.from_elements([(1,'Jack', 'FRANCE', 10, datetime.now()+timedelta(hours=1)),(2,'Bob', 'USA', 20, datetime.now()+timedelta(hours=2))],DataTypes.ROW([DataTypes.FIELD("id", DataTypes.INT()), DataTypes.FIELD("name", DataTypes.STRING()), DataTypes.FIELD("country", DataTypes.STRING()),DataTypes.FIELD("revenue", DataTypes.INT()),DataTypes.FIELD("r_time", DataTypes.TIMESTAMP(3))]))orders2 = table_env.from_elements([(1,'Jack12', 'FRANCE12', 30, datetime.now()+timedelta(hours=1)),(2,'Bob12', 'USA12', 30, datetime.now()+timedelta(hours=2))],DataTypes.ROW([DataTypes.FIELD("id", DataTypes.INT()), DataTypes.FIELD("name", DataTypes.STRING()), DataTypes.FIELD("country", DataTypes.STRING()),DataTypes.FIELD("revenue", DataTypes.INT()),DataTypes.FIELD("r_time", DataTypes.TIMESTAMP(3))]))试着运行
left = orders1.select(col('id'), col('name'), col('country'))
right = orders2.select(col('id'), col('name'), col('country'))result = left.join(right).where(col('id') == col('id')).select(col('id'), col('name'), col('country'))
result .execute().print()报错:说是无法区分开country, name, id 这三个字段,所以看样子真不行
org.apache.flink.table.api.ValidationException: join relations with ambiguous names: [country, name, id]所以在生成left/right集合的时候alias下字段名:
left = orders1.select(col('id'), col('name'), col('country'))
right = orders2.select(col('id').alias('id1'), col('name').alias('name1'), col('country').alias('country1'))
result = left.join(right).where(col('id') == col('id1')).select(col('id'), col('name1'), col('country'))
result .execute().print()
这样就能将两个列相同的表进行Inner Join 但是这种方式不太靠谱,等以后有别的方式在补充。
+----+-------------+--------------------------------+--------------------------------+
| op | id | name1 | country |
+----+-------------+--------------------------------+--------------------------------+
| +I | 1 | Jack12 | FRANCE |
| +I | 2 | Bob12 | USA |
+----+-------------+--------------------------------+--------------------------------+Outer Join
和 SQL LEFT/RIGHT/FULL OUTER JOIN 子句类似。 关联两张表。 两张表必须有不同的字段名,并且必须定义至少一个等式连接谓词。与innter join 差不多
left = orders1.select(col('id'), col('name'), col('country'))
right = orders2.select(col('id').alias('id1'), col('name').alias('name1'), col('country').alias('country1'))
#左
left_outer_result = left.left_outer_join(right, col('id') == col('id1')).select(col('id'), col('name1'), col('country'))
#右
right_outer_result = left.right_outer_join(right, col('id') == col('id1')).select(col('id'), col('name1'), col('country'))
#全
full_outer_result = left.full_outer_join(right, col('id') == col('id1')).select(col('id'), col('name1'), col('country'))
result.execute().print()Interval Join
Interval join 是可以通过流模式处理的常规 join 的子集。
Interval join 至少需要一个 equi-join 谓词和一个限制双方时间界限的 join 条件。这种条件可以由两个合适的范围谓词(<、<=、>=、>)或一个比较两个输入表相同时间属性(即处理时间或事件时间)的等值谓词来定义。
from pyflink.table.expressions import colleft = orders1.select(col('id'), col('name'), col('country'),col('r_time'))
right = orders2.select(col('id').alias('id1'), col('name').alias('name1'), col('country').alias('country1'),col('r_time').alias('r_time1'))joined_table = left.join(right).where((col('id') == col('id1')) & (col('r_time') >= col('r_time1') - lit(1).hours) & (col('r_time') <= col('r_time1') + lit(2).seconds))
result = joined_table.select(col('id'), col('name1'), col('country'), col('r_time1'))
result.execute().print()+----+-------------+--------------------------------+--------------------------------+-------------------------+
| op | id | name1 | country | r_time1 |
+----+-------------+--------------------------------+--------------------------------+-------------------------+
| +I | 1 | Jack12 | FRANCE | 2023-02-23 15:51:17.793 |
| +I | 2 | Bob12 | USA | 2023-02-23 16:51:17.793 |
+----+-------------+--------------------------------+--------------------------------+-------------------------+Inner Join with Table Function (UDTF)
join 表和表函数的结果。左(外部)表的每一行都会 join 表函数相应调用产生的所有行。 如果表函数调用返回空结果,则删除左侧(外部)表的一行。
通过调用UDTF函数来实现一些数据处理。
from pyflink.table.udf import udtf
from pyflink.common import Row
split_res = table_env.from_elements([("1,2",),("3,4",) ],["a"])
# 注册 User-Defined Table Function
# result_type 参数,声明 split function 的结果类型;
@udtf(result_types=[DataTypes.STRING(), DataTypes.STRING()])
def split(s):splits = s.split(",")yield splits[0], splits[1]# join
joined_table = split_res.join_lateral(split(col('a')).alias("s", "t"))
result = joined_table.select(col('a'), col('s'), col('t'))
result.execute().print()+----+--------------------------------+--------------------------------+--------------------------------+
| op | a | s | t |
+----+--------------------------------+--------------------------------+--------------------------------+
| +I | 1,2 | 1 | 2 |
| +I | 3,4 | 3 | 4 |
这样运行结果是出来了,也没问题但是会报错了,暂时没找到解决办法,后期有机会查查,可能大概是有界流数据运行超时的问题
Py4JJavaError: An error occurred while calling o2665.print.
: java.lang.RuntimeException: Failed to fetch next resultat org.apache.flink.streaming.api.operators.collect.CollectResultIterator.nextResultFromFetcher(CollectResultIterator.java:109)at org.apache.flink.streaming.api.operators.collect.CollectResultIterator.hasNext(CollectResultIterator.java:80)at org.apache.flink.table.planner.connectors.CollectDynamicSink$CloseableRowIteratorWrapper.hasNext(CollectDynamicSink.java:222)at org.apache.flink.table.utils.print.TableauStyle.print(TableauStyle.java:147)at org.apache.flink.table.api.internal.TableResultImpl.print(TableResultImpl.java:153)at sun.reflect.GeneratedMethodAccessor112.invoke(Unknown Source)at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)at java.lang.reflect.Method.invoke(Method.java:498)at org.apache.flink.api.python.shaded.py4j.reflection.MethodInvoker.invoke(MethodInvoker.java:244)at org.apache.flink.api.python.shaded.py4j.reflection.ReflectionEngine.invoke(ReflectionEngine.java:357)at org.apache.flink.api.python.shaded.py4j.Gateway.invoke(Gateway.java:282)at org.apache.flink.api.python.shaded.py4j.commands.AbstractCommand.invokeMethod(AbstractCommand.java:132)at org.apache.flink.api.python.shaded.py4j.commands.CallCommand.execute(CallCommand.java:79)at org.apache.flink.api.python.shaded.py4j.GatewayConnection.run(GatewayConnection.java:238)at java.lang.Thread.run(Thread.java:748)Union
和 SQL UNION 子句类似。Union 两张表会删除重复记录。两张表必须具有相同的字段类型。 并集操作。
#生成2张表,table_env一定是有界的,无界表不支持Union
table1 = table_env.from_elements([("hello|word", 1), ("abc|def", 2)], ['a', 'b'])
table2 = table_env.from_elements([("hello|word", 3), ("abc|def", 4)], ['a', 'b'])
result= table1.union(table2)
result.execute().print()+--------------------------------+----------------------+
| a | b |
+--------------------------------+----------------------+
| abc|def | 4 |
| abc|def | 2 |
| hello|word | 3 |
| hello|word | 1 |
+--------------------------------+----------------------+UnionAll
和 SQL UNION ALL 子句类似。Union 两张表。 两张表必须具有相同的字段类型。
UNION ALL 包含重复数据
#生成2张表 支持无界
table1 = table_env.from_elements([("hello|word", 1), ("abc|def", 2)], ['a', 'b'])
table2 = table_env.from_elements([("hello|word", 3), ("abc|def", 4)], ['a', 'b'])
result= table1.union_all(table2)
result.execute().print()Intersect
和 SQL INTERSECT 子句类似。Intersect 返回两个表中都存在的记录。如果一条记录在一张或两张表中存在多次,则只返回一条记录,也就是说,结果表中不存在重复的记录。两张表必须具有相同的字段类型。
交集操作
#生成2张表 只支持batch
table1 = table_env.from_elements([("hello|word", 1), ("abc|def", 2)], ['a', 'b'])
table2 = table_env.from_elements([("hello|word", 3), ("abc|def", 4)], ['a', 'b'])
result= table1.intersect(table2)
result.execute().print()IntersectAll
和 SQL INTERSECT ALL 子句类似。IntersectAll 返回两个表中都存在的记录。如果一条记录在两张表中出现多次,那么该记录返回的次数同该记录在两个表中都出现的次数一致,也就是说,结果表可能存在重复记录。两张表必须具有相同的字段类型。
#生成2张表 只支持batch
table1 = table_env.from_elements([("hello|word", 1), ("abc|def", 2)], ['a', 'b'])
table2 = table_env.from_elements([("hello|word", 3), ("abc|def", 4)], ['a', 'b'])
result= table1.intersect_all(table2)
result.execute().print()Minus
和 SQL EXCEPT 子句类似。Minus 返回左表中存在且右表中不存在的记录。左表中的重复记录只返回一次,换句话说,结果表中没有重复记录。两张表必须具有相同的字段类型。
#生成2张表 只支持batch
table1 = table_env.from_elements([("hello|word", 1), ("abc|def", 2)], ['a', 'b'])
table2 = table_env.from_elements([("hello|word", 3), ("abc|def", 4)], ['a', 'b'])
result= table1.minus(table2)
result.execute().print()MinusAll
和 SQL EXCEPT ALL 子句类似。MinusAll 返回右表中不存在的记录。在左表中出现 n 次且在右表中出现 m 次的记录,在结果表中出现 (n - m) 次,例如,也就是说结果中删掉了在右表中存在重复记录的条数的记录。两张表必须具有相同的字段类型。
#生成2张表 只支持batch
table1 = table_env.from_elements([("hello|word", 1), ("abc|def", 2)], ['a', 'b'])
table2 = table_env.from_elements([("hello|word", 3), ("abc|def", 4)], ['a', 'b'])
result= table1.minus_all(table2)
result.execute().print()In
和 SQL IN 子句类似。如果表达式的值存在于给定表的子查询中,那么 In 子句返回 true。子查询表必须由一列组成。这个列必须与表达式具有相同的数据类型。
#生成2张表 都支持
left = orders1.select(col('id'), col('name'), col('country'))
right = orders2.select(col('id'))
result = left.select(col('id'), col('name'), col('country')).where(col('id').in_(right))
result.execute().print()----+-------------+--------------------------------+--------------------------------+
| op | id | name | country |
+----+-------------+--------------------------------+--------------------------------+
| +I | 1 | Jack | FRANCE |
| +I | 2 | Bob | USA |
+----+-------------+--------------------------------+--------------------------------+OrderBy
和 SQL ORDER BY 子句类似。返回跨所有并行分区的全局有序记录。对于无界表,该操作需要对时间属性进行排序或进行后续的 fetch 操作。
如果是无界表只能直接对时间属性排序,如果其他属性需要后续的fetch操作
orders = table_env.from_elements([('Jack', 'FRANCE', 10, datetime.now()+timedelta(hours=2)),('Rose', 'ENGLAND', 30, datetime.now()+timedelta(hours=12)),('Jack', 'FRANCE', 20, datetime.now()+timedelta(hours=22)),('Bob', 'CH', 40, datetime.now()+timedelta(hours=32)),('Bob', 'CH', 50, datetime.now()+timedelta(hours=32)),('YU', 'CH', 100, datetime.now()+timedelta(hours=5))],DataTypes.ROW([DataTypes.FIELD("name", DataTypes.STRING()), DataTypes.FIELD("country", DataTypes.STRING()),DataTypes.FIELD("revenue", DataTypes.INT()),DataTypes.FIELD("r_time", DataTypes.TIMESTAMP(3))]))
#时间排序
result=orders.order_by(col('r_time').asc)
result.execute().print()+--------------------------------+--------------------------------+-------------+-------------------------+
| name | country | revenue | r_time |
+--------------------------------+--------------------------------+-------------+-------------------------+
| Jack | FRANCE | 10 | 2023-02-23 19:42:48.538 |
| YU | CH | 100 | 2023-02-23 22:42:48.538 |
| Rose | ENGLAND | 30 | 2023-02-24 05:42:48.538 |
| Jack | FRANCE | 20 | 2023-02-24 15:42:48.538 |
| Bob | CH | 40 | 2023-02-25 01:42:48.538 |
| Bob | CH | 50 | 2023-02-25 01:42:48.538 |
+--------------------------------+--------------------------------+-------------+-------------------------+Offset & Fetch
和 SQL 的 OFFSET 和 FETCH 子句类似。Offset 操作根据偏移位置来限定(可能是已排序的)结果集。Fetch 操作将(可能已排序的)结果集限制为前 n 行。通常,这两个操作前面都有一个排序操作。对于无界表,offset 操作需要 fetch 操作。
# 从已排序的结果集中返回前2条记录
result1 = orders.order_by(col('r_time').asc).fetch(2)# 从已排序的结果集中返回跳过1条记录之后的所有记录
result2 = orders.order_by(col('r_time').asc).offset(1)# 从已排序的结果集中返回跳过2条记录之后的前5条记录
result3 = orders.order_by(col('r_time').asc).offset(2).fetch(5)Insert
和 SQL 查询中的 INSERT INTO 子句类似,该方法执行对已注册的输出表的插入操作。 insertInto() 方法会将 INSERT INTO 转换为一个 TablePipeline。 该数据流可以用 TablePipeline.explain() 来解释,用 TablePipeline.execute() 来执行。
输出表必须已注册在 TableEnvironment(详见表连接器)中。此外,已注册表的 schema 必须与查询中的 schema 相匹配。
#myskintable 必须是已存在的结果表
#简单的例子,仅供参考,就是orders这个表经过一系列的操作后,将结果写入另外一张已存在并且scheam对应的skin_table表中
revenue = orders \.select(col("name"), col("country"), col("revenue")) \.where(col("country") == 'FRANCE') \.group_by(col("name")) \.select(col("name"), orders.revenue.sum.alias('rev_sum')).execute_insert("myskintable")相关文章:
:table_apisql)
pyflink学习笔记(二):table_apisql
Joins Inner Join 官网说明:和 SQL 的 JOIN 子句类似。关联两张表。两张表必须有不同的字段名,并且必须通过 join 算子或者使用 where 或 filter 算子定义至少一个 join 等式连接谓词。先创建2个表,两个表的字段是相同的,我想验证…...
嵌入式 STM32 实现STemwin移植+修改其配置文件,驱动LCD显示文本 (含源码,建议收藏)
目录 一、STemwin 简介 二、源码下载 1、在移植STemwin源码之前,需要一个已经具备LCD读写,填充指定颜色等函数功能的一个工程; 2、STemwin 3、源码下载 三、STemwin移植 1、解压源码路径 2、STemwin文件介绍 四、修改配置文件&…...
[计算机网络(第八版)]第一章 概述(学习笔记)
1.1 计算机网络在信息时代中的作用 21世纪是以网络为核心的信息时代,21世纪的重要重要特征:数字化、网络化与信息化。 三大类网络 电信网络:向用户提供电话、电报、传真等服务;有线电视网络:向用户传送各种电视节目&am…...

AI绘图:常用镜头和视角
镜头 Establishing Shot 通过宽广或超宽广的视角交待故事发生的大地理环境 Master Shot 众多人物都能完整地出现在镜头里。 Wide Shot 广角镜头。又称“长镜头” Long Shot。人物全身展现,但在画面中所占比例相对较少 Ultrawide Shot 超广角镜头 Low Angle Sho…...
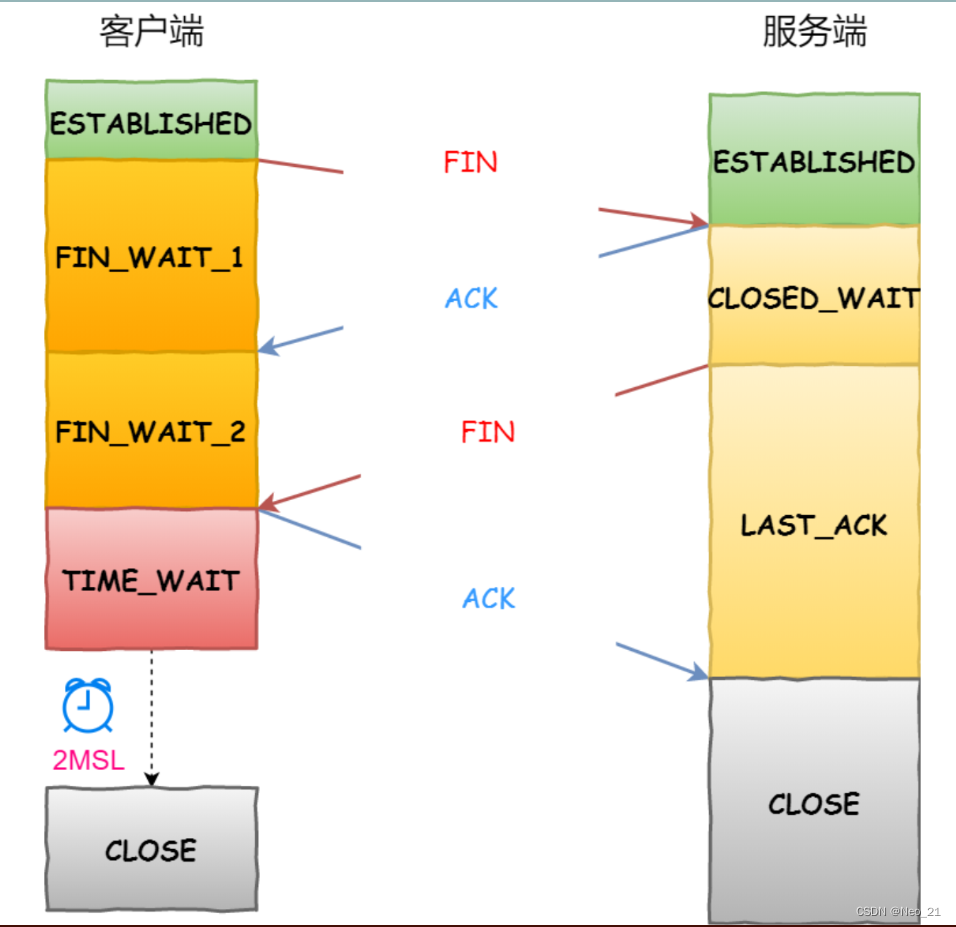
TCP四次挥手
TCP 四次挥手过程是怎样的? TCP 断开连接是通过四次挥手方式。 双方都可以主动断开连接,断开连接后主机中的「资源」将被释放,四次挥手的过程如下图: 客户端打算关闭连接,此时会发送一个 TCP 首部 FIN 标志位被置为 1…...

Tomcat源码分析-类加载器
类加载器 在分析 tomcat 类加载之前,我们简单的回顾下 java 体系的类加载器 启动类加载器(Bootstrap ClassLoader):加载对象是java的核心类库,把一些的 java 类加载到 jvm 中,它并不是我们熟悉的 ClassLoader&#x…...

MySQL进阶篇之视图/存储过程/触发器
今天我们主要来快速学习视图,存储过程,触发器四个方面的内容,一起加油学习吧,还有半年就有秋招了,要加快速度了,迫在眉睫,冲吧,兄弟们。 目录 1、视图 2、存储过程 3、存储函数 4、…...
【一看就会】实现仿京东移动端页面滚动条布局
简单粗暴直接上代码: <!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8"> <meta http-equiv"X-UA-Compatible" content"IEedge"> <meta name"viewport" content&q…...

网易的“草长莺飞二月天”:增长稳健,加码研发,逐浪AI
2月23日,网易发布了2022年第四季度财报。 这是网易与暴雪分道扬镳后的首份财报,加上近期AIGC热度扩散至游戏、教育等各个领域,网易第四季度业绩及其对于GPT等热门技术的探索受到市场关注。 根据财报,第四季度,网易营…...
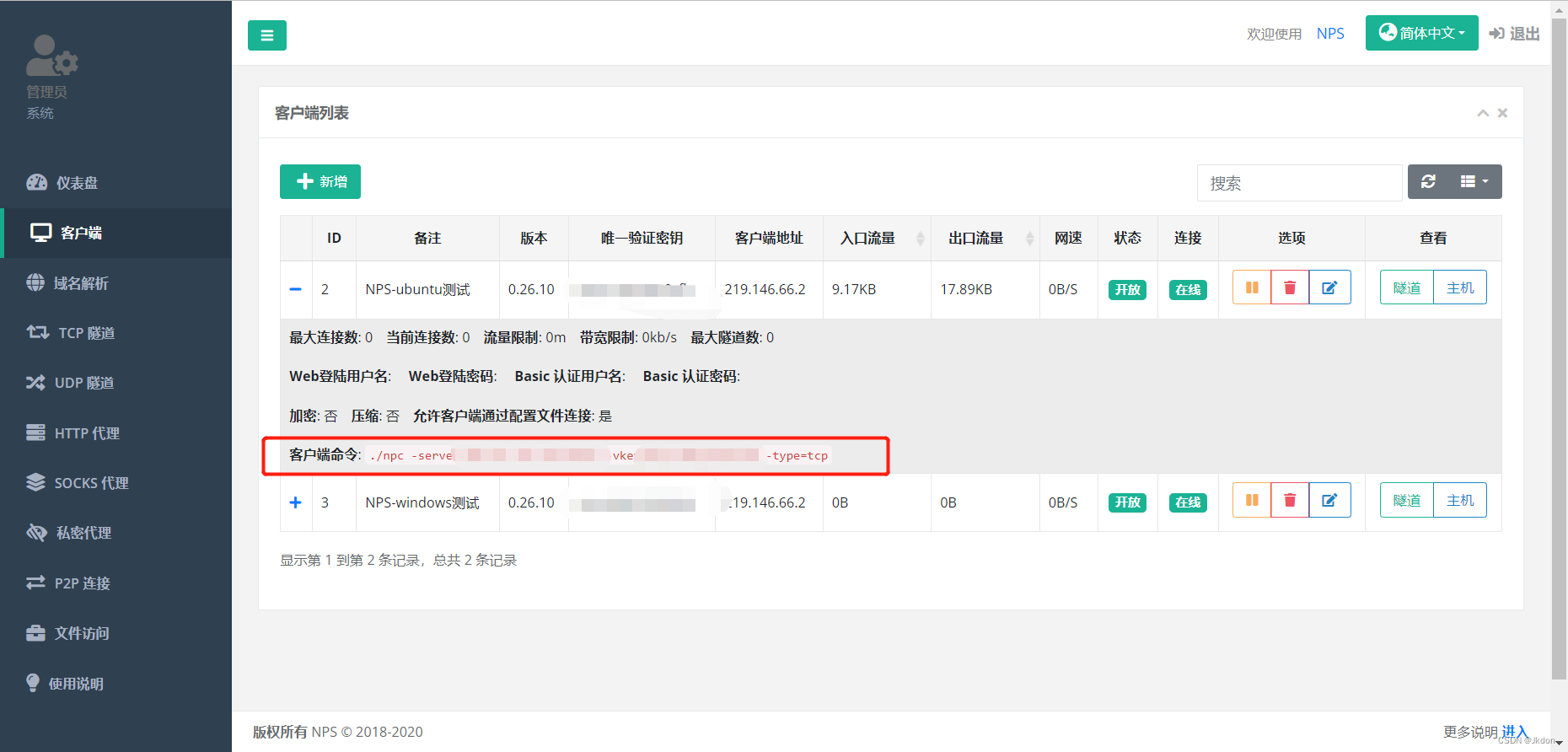
NPC内网穿透教程-入门
安装 安装包安装 releases下载 下载对应的系统版本即可,服务端和客户端是单独的 源码安装 安装源码 go get -u ehang.io/nps 编译 服务端go build cmd/nps/nps.go 客户端go build cmd/npc/npc.go docker安装 server安装说明 client安装说明 启动 服务端 下…...
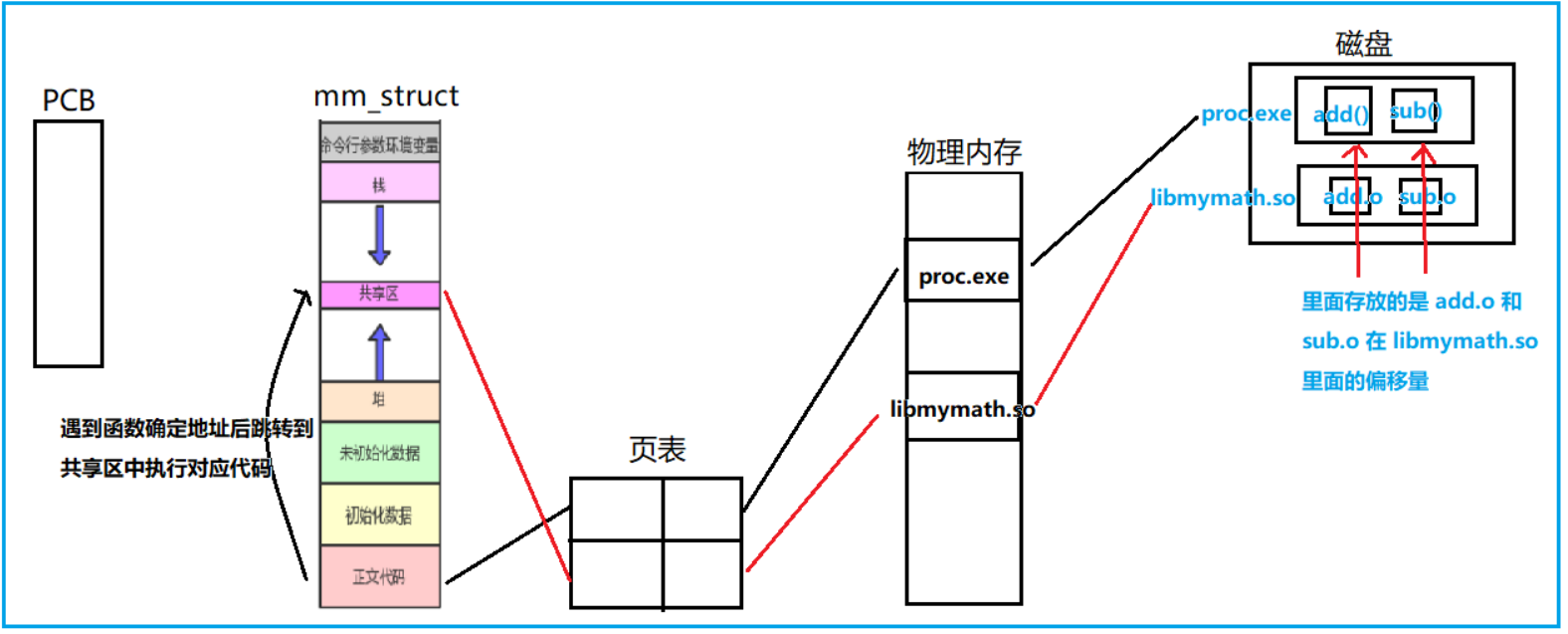
【Linux修炼】14.磁盘结构/文件系统/软硬链接/动静态库
每一个不曾起舞的日子,都是对生命的辜负。 磁盘结构/文件系统/软硬链接/动静态库前言一.磁盘结构1.1 磁盘的物理结构1.2 磁盘的存储结构1.3 磁盘的逻辑结构二.理解文件系统2.1 对IO单位的优化2.2 磁盘分区与分组2.3 分组的管理方法2.4 文件操作三.软硬链接3.1理解硬…...
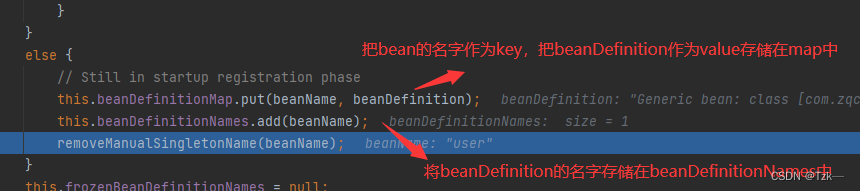
Spring源码分析:创建 BeanDefinition 流程
一、前期准备1.1 环境依赖<dependencies><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.1.7.RELEASE</version></dependency><dependency><groupId&…...
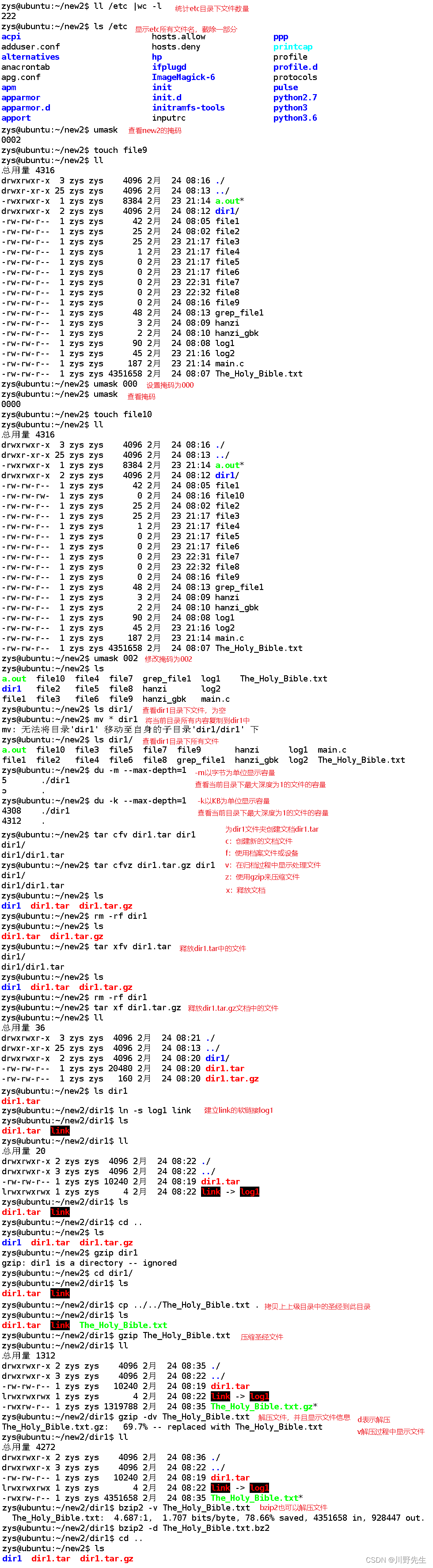
Linux 练习一(思维导图 + 练习过程)
文章目录一、Linux 用户管理及文件操作第一段练习记录:主要对用户进行删除添加设置密码等操作第二段练习记录:主要包括权限设置和查找命令第三段练习记录:关于文件的命令练习第四段练习记录:查找命令及查看内存命令的使用二、Linu…...
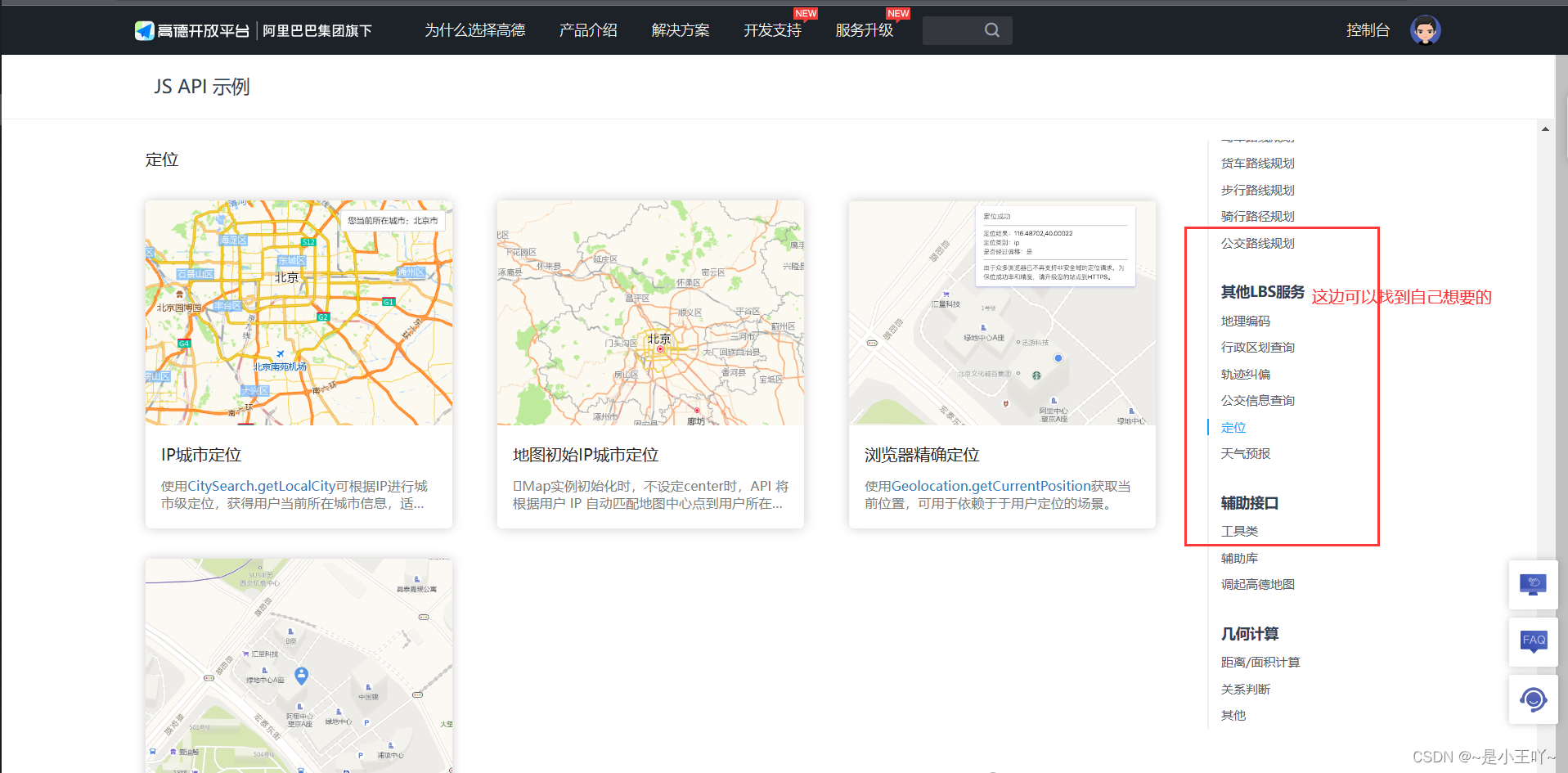
高德地图基础教程超详细版
在当前社会,对于地图的使用是很必须的,所以对于程序员来说也是需要掌握的技能,目前主流的又百度地图和高德地图,但是我建议使用高德地图,因为百度地图的API着实不好用吖,不好理解,对于开发人员来…...

基于A7核开发板的串口实现控制LED亮灭
1.通过操作Cortex-A7核,串口输入相应的命令,控制LED灯进行工作 1>例如在串口输入led1on,开饭led1灯点亮 2>例如在串口输入led1off,开饭led1灯熄灭 3>例如在串口输入led2on,开饭led2灯点亮 4>例如在串口输入led2off,开饭led2灯熄灭 5>例如…...
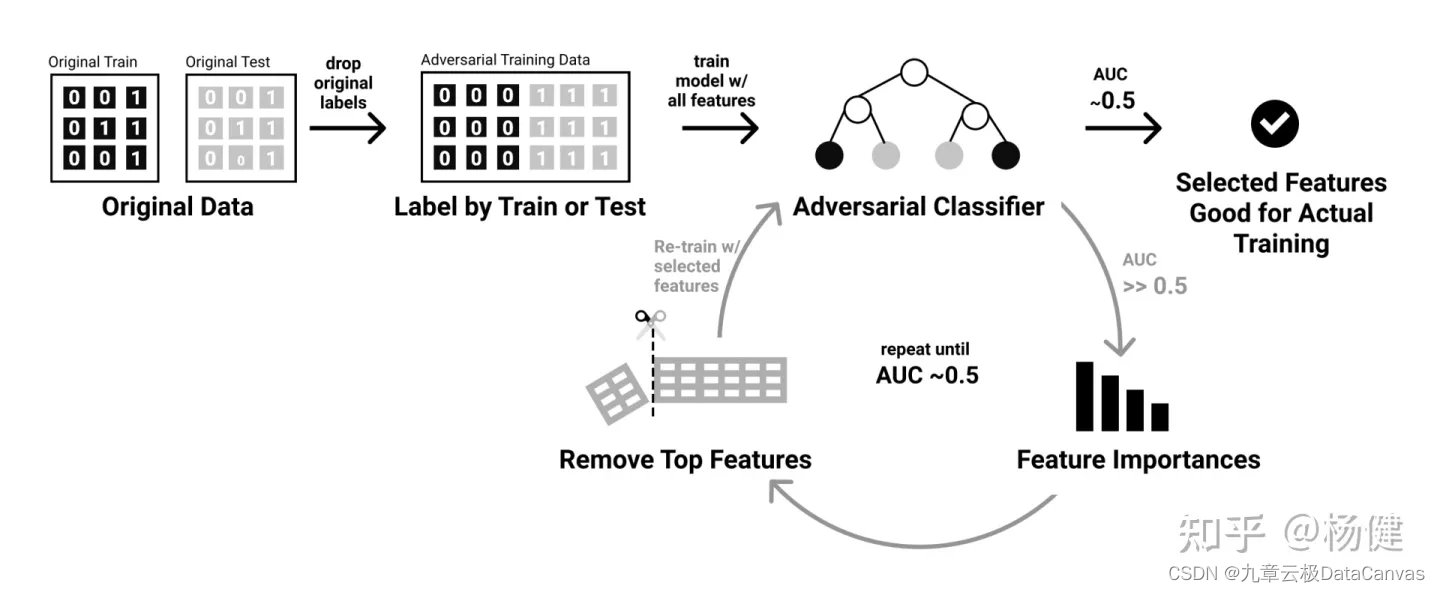
HyperGBM用Adversarial Validation解决数据漂移问题
本文作者:杨健,九章云极 DataCanvas 主任架构师 数据漂移问题近年在机器学习领域来越来越得到关注,成为机器学习模型在实际投产中面对的一个主要挑战。当数据的分布随着时间推移逐渐发生变化,需要预测的数据和用于训练的数据分布…...

关基系统三月重保安全监测怎么做?ScanV提供纯干货!
三月重保当前,以政府、大型国企央企、能源、金融等重要行业和领域为代表的关键信息基础设施运营单位都将迎来“网络安全大考”。 对重要关基系统进行安全风险监测并收敛暴露面,响应监管要求进行安全加固,重保期间实时安全监测与数据汇报等具体…...
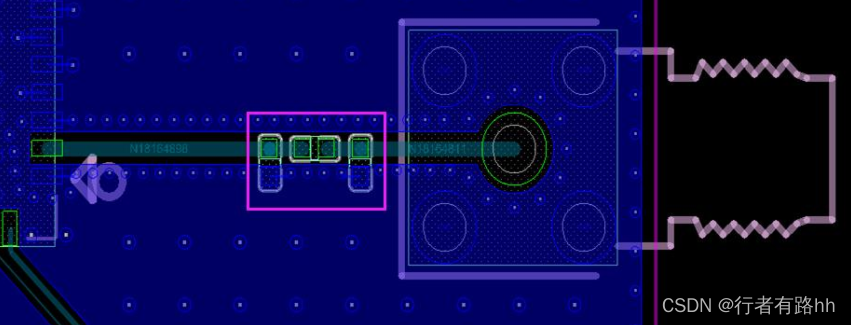
RK3588关键电路 PCB Layout设计指南
1、音频接口电路 PCB 设计(1)所有 CLK 信号建议串接 22ohm 电阻,并靠近 RK3588 放置,提高信号质量;(2)所有 CLK 信号走线不得挨在一起,避免串扰;需要独立包地,…...

二分边界详细总结
一、查找精确值 从一个有序数组中找到一个符合要求的精确值(如猜数游戏)。如查找值为Key的元素下标,不存在返回-1。 //这里是left<right。 //考虑这种情况:如果最后剩下A[i]和A[i1](这也是最容易导致导致死循环的…...
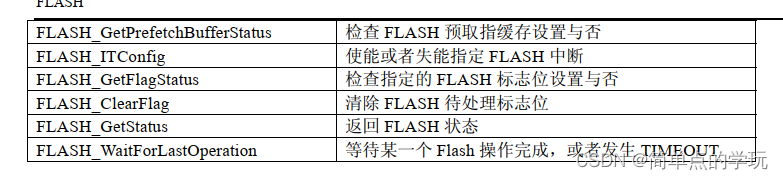
STM32---备份寄存器BKP和 FLASH学习使用
BKP库函数 学习BKP,首先就是知道BKP每一个函数的作用然后如何使用即可 使用备份域的作用只需要操作上面的两个函数即可,其余的都是它的其他功能 BKP简介 备份寄存器是42个16位的寄存器,可用来存储84个字节的用户应用程序数据。他们处在备份…...

XCTF-web-easyupload
试了试php,php7,pht,phtml等,都没有用 尝试.user.ini 抓包修改将.user.ini修改为jpg图片 在上传一个123.jpg 用蚁剑连接,得到flag...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

Mac软件卸载指南,简单易懂!
刚和Adobe分手,它却总在Library里给你写"回忆录"?卸载的Final Cut Pro像电子幽灵般阴魂不散?总是会有残留文件,别慌!这份Mac软件卸载指南,将用最硬核的方式教你"数字分手术"࿰…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习)
Aspose.PDF 限制绕过方案:Java 字节码技术实战分享(仅供学习) 一、Aspose.PDF 简介二、说明(⚠️仅供学习与研究使用)三、技术流程总览四、准备工作1. 下载 Jar 包2. Maven 项目依赖配置 五、字节码修改实现代码&#…...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...

Chromium 136 编译指南 Windows篇:depot_tools 配置与源码获取(二)
引言 工欲善其事,必先利其器。在完成了 Visual Studio 2022 和 Windows SDK 的安装后,我们即将接触到 Chromium 开发生态中最核心的工具——depot_tools。这个由 Google 精心打造的工具集,就像是连接开发者与 Chromium 庞大代码库的智能桥梁…...

华为OD机试-最短木板长度-二分法(A卷,100分)
此题是一个最大化最小值的典型例题, 因为搜索范围是有界的,上界最大木板长度补充的全部木料长度,下界最小木板长度; 即left0,right10^6; 我们可以设置一个候选值x(mid),将木板的长度全部都补充到x,如果成功…...

Vue 模板语句的数据来源
🧩 Vue 模板语句的数据来源:全方位解析 Vue 模板(<template> 部分)中的表达式、指令绑定(如 v-bind, v-on)和插值({{ }})都在一个特定的作用域内求值。这个作用域由当前 组件…...

WEB3全栈开发——面试专业技能点P4数据库
一、mysql2 原生驱动及其连接机制 概念介绍 mysql2 是 Node.js 环境中广泛使用的 MySQL 客户端库,基于 mysql 库改进而来,具有更好的性能、Promise 支持、流式查询、二进制数据处理能力等。 主要特点: 支持 Promise / async-await…...