数据库:Hive转Presto(五)
此篇将所有代码都补充完了,之前发现有的代码写错了,以这篇为准,以下为完整代码,如果发现我有什么考虑不周的地方,可以评论提建议,感谢。代码是想哪写哪,可能比较繁琐,还需要优化。
import re
import os
import tkinter.filedialog
from tkinter import *class Hive2Presto:def __int__(self):self.t_funcs = ['substr', 'nvl', 'substring', 'unix_timestamp'] + \['to_date', 'concat', 'sum', 'avg', 'abs', 'year', 'month', 'ceiling', 'floor']self.time_funcs = ['date_add', 'datediff', 'add_months', 'date_sub']self.funcs = self.t_funcs + self.time_funcsself.current_path = os.path.abspath(__file__)self.dir = os.path.dirname(self.current_path)self.result = []self.error = []self.filename = ''def main(self):self.root = Tk()self.root.config(bg='#ff741d') # 背景颜色设置为公司主题色^_^self.root.title('Hive转Presto')self.win_width = 550self.win_height = 500self.screen_width = self.root.winfo_screenwidth()self.screen_height = self.root.winfo_screenheight()self.x = (self.screen_width - self.win_width) // 2self.y = (self.screen_height - self.win_height) // 2self.root.geometry(f'{self.win_width}x{self.win_height}+{self.x}+{self.y}')font = ('楷体', 11)self.button = Button(self.root, text='转换', command=self.trans, bg='#ffcc8c', font=font, anchor='e')self.button.grid(row=0, column=0, padx=100, pady=10, sticky=W)self.file_button = Button(self.root, text='选择文件', command=self.choose_file, bg='#ffcc8c', font=font,anchor='e')self.file_button.grid(row=0, column=1, padx=0, pady=10, sticky=W)self.entry = Entry(self.root, width=65, font=font)self.entry.insert(0, '输入Hive代码')self.entry.grid(row=1, column=0, padx=10, pady=10, columnspan=2)self.entry.bind('<Button-1>', self.delete_text)self.text = Text(self.root, width=75, height=20)self.text.grid(row=2, column=0, padx=10, pady=10, columnspan=2)self.des_label = Label(self.root, text='可以复制结果,也有生成的文件,与选取的文件同文件夹', bg='#ffcc8c',font=('楷体', 10))self.des_label.grid(row=3, column=0, padx=10, pady=10, columnspan=2)s = ''for i in range(0, (n := len(self.funcs)), 4):if i + 4 <= n:s += ','.join(self.funcs[i:i + 4]) + '\n'else:s += ','.join(self.funcs[i:]) + '\n's = s[:-1]self.des_label1 = Label(self.root, text=s, bg='#ffcc8c',font=('楷体', 10))self.des_label1.grid(row=4, column=0, padx=10, pady=10, columnspan=2)self.root.columnconfigure(0, minsize=10)self.root.columnconfigure(1, minsize=10)self.root.columnconfigure(0, pad=5)self.root.mainloop()def replace_func(self, s, res):"""把搜索到函数整体取出来,处理括号中的参数:param s::param res::return:"""for f in res:f1 = f.replace('\n', '').strip()f1 = re.sub(r'(\(s*)', '(', f1)# 搜索括号里的字符串if re.findall(r'(\w+)\(', f1):func_name = re.findall(r'(\w+)\(', f1)[0].strip()else:continuetry:if 'date_add' == func_name.lower():date, date_num = self.extact_func(f1, func_name)s_n = f"date_add('day',{date_num},cast(substr(cast{date} as varchar,1,10) as date))"s = s.replace(f, s_n)elif 'datediff' == func_name.lower():date1, date2 = self.extact_func(f1, func_name)s_n = f"date_add('day',{date2},cast(substr(cast{date1} as varchar,1,10) as date),cast(substr(cast{date1} as varchar),1,10) as date))"s = s.replace(f, s_n)elif 'nvl' == func_name.lower():s1, s2 = self.extact_func(f1, func_name)s_n = f"coalesce({s1},{s2})"s = s.replace(f, s_n)elif 'substr' == func_name.lower():date, start, end = self.extact_func(f1, func_name)s_n = f"substr(cast({date} as varchar),{start},{end}"s = s.replace(f, s_n)elif 'substring' == func_name.lower():date, start, end = self.extact_func(f1, func_name)s_n = f"substring(cast({date} as varchar),{start},{end}"s = s.replace(f, s_n)elif 'unit_timestamp' == func_name.lower():date = self.extact_func(f1, func_name)[0]s_n = f"to_unixtime(cast({date} as timestanp))"s = s.replace(f, s_n)elif 'to_date' == func_name.lower():date = self.extact_func(f1, func_name)[0]s_n = f"cast({date} as date)"s = s.replace(f, s_n)elif 'concat' == func_name.lower():res = self.extact_func(f1, func_name)[0]s_n = f'concat('for r in res:r = r.strip().replace('\n', '')s_n += f"cast({r} as varchar),"s_n = s_n[:-1] + ')'s = s.replace(f, s_n)elif 'sum' == func_name.lower():if 'unix_timestamp' in f1 or 'to_unixtime' in f1:continuess = self.extact_func(f1, func_name)[0]if 'if(' in ss.replace(' ', ''):continues = self.func_trans(f, f1, func_name, ss, s)elif 'avg' == func_name.lower():if 'unix_timestamp' in f1 or 'to_unixtime' in f1:continuess = self.extact_func(f1, func_name)[0]if 'if(' in ss.replace(' ', ''):continues = self.func_trans(f, f1, func_name, ss, s)elif 'abs' == func_name.lower():if 'unix_timestamp' in f1 or 'to_unixtime' in f1:continuess = self.extact_func(f1, func_name)[0]if 'if(' in ss.replace(' ', ''):continues = self.func_trans(f, f1, func_name, ss, s)elif 'ceiling' == func_name.lower():if 'unix_timestamp' in f1 or 'to_unixtime' in f1:continuess = self.extact_func(f1, func_name)[0]if 'if(' in ss.replace(' ', ''):continues = self.func_trans(f, f1, func_name, ss, s)elif 'floor' == func_name.lower():if 'unix_timestamp' in f1 or 'to_unixtime' in f1:continuess = self.extact_func(f1, func_name)[0]if 'if(' in ss.replace(' ', ''):continues = self.func_trans(f, f1, func_name, ss, s)elif 'year' == func_name.lower():date = self.extact_func(f1, func_name)[0]s_n = f"year(cast(substr(cast({date} as varchar,1,10) as date))"s = s.replace(f, s_n)elif 'month' == func_name.lower():date = self.extact_func(f1, func_name)[0]s_n = f"month(cast(substr(cast({date} as varchar,1,10) as date))"s = s.replace(f, s_n)elif 'date_sub' == func_name.lower():date, date_num = self.extact_func(f1, func_name)s_n = f"date_add('day',-{date_num},cast(substr(cast{date} as varchar,1,10) as date))"s = s.replace(f, s_n)except:self.error.append(f"源代码中{func_name}函数参数输入可能有错误,具体为:{f1}")continueif self.error:self.entry.delete(0, END)self.text.delete("1.0", END)self.text.insert("end", f"{s}")self.error.insert(0, '转换失败,有部分没有转成功\n')root_ex = Tk()root_ex.title('错误')win_width = 600win_height = 200screen_width = root_ex.winfo_screenwidth()screen_height = root_ex.winfo_screenheight()x = (screen_width - win_width) // 2y = (screen_height - win_height) // 2root_ex.geometry(f'{win_width}x{win_height}+{x}+{y}')label_ex = Label(root_ex, text="\n".join(self.error), font=("楷体", 10))label_ex.pack()root_ex.mainloop()return sdef func_trans(self, f, f1, func_name, ss, s):if not ('+' in ss or '-' in ss or '*' in ss or '/' in ss):date = self.extact_func(f1, func_name)[0]s_n = f'{func_name}(cast{date} as double))'s = s.replace(f, s_n)else:res1 = self.mysplit(f1)s_n = fn = len(s_n)for item in res1:if any(c.isalpha() for c in item.replace(' ', '')):idxs = s_n.find(item)idxs = [idxs] if type(idxs) != list else idxsfor idx in idxs:if idx + len(item) + 3 <= n:if not 'as' in s_n[idx:idx + len(item) + 4]:s_n = re.sub(rf'\b{item}\b', f'cast({item} as double)', s_n)else:s_n = re.sub(rf'\b{item}\b', f'cast({item} as double)', s_n)s = s.replace(f, s_n)return sdef choose_file(self):"""如果代码太多,从text中输入会很卡,直接选择代码文件输入会很快:return:"""self.filename = tkinter.filedialog.askopenfilename()if '/' in self.filename:self.filename = self.filename.replace('/', '\\')self.entry.delete(0, END)self.entry.insert(0, self.filename)def findvar(self, ss):"""搜索与计算有关的字段:param ss::return:"""global r1b = ['+', '-', '*', '/', '=', '!=', '>', '<', '<=', '>=', '<>']result1 = []result2 = []result1_n = []result2_n = []res_ops = []res1_ops = []res_adj = []res1_adj = []for op in b:s_temp1 = ss.replace('\n', ' ')s_temp2 = ss.replace('\n', ' ')s_temp3 = ss.replace('\n', ' ')if op == '/' or op == '=':op = opelif op == '+' or op == '-' or op == '*' or op == '>' or op == '<':op = f'\\{op[0]}'else:op = f'\\{op[0]}\\{op[1]}'parttern = f'\s*-*\d+\s*{op}\s*\w+|' + f'\s*-*\d+\.\s*{op}\s*\w+\.\s*\w+|' \+ f'\s*\w+\.\s*\w+\s*{op}\s*\w+\.\s*\w+|' + f'\s*\w+\s*{op}\s*\w+\.\s*\w+|' \+ f'\s*\w+\.\s*\w+\s*{op}\s*\w+|' + f'\s*\w+\s*{op}\s*\w+'parttern1 = f'\s*\)+\s*{op}\s*\w+|' + f'\s*\)+\s*{op}\s*\w+\.\s*\w+|' \+ f'\s*\w+\s*{op}\s*\(+|' + f'f\s*\w+\.\s*{op}\s*\(+'parttern2 = f'\s*\w+\s*{op}\s*\w+|' + f'\s*\w+\s*{op}\s*\w+\.\s*\w+|' \+ f'\s*\w+\s*{op}\s*\w+|' + f'f\s*\w+\.\s*{op}\s*\w+'while True:res = re.findall(parttern, s_temp1)if not res:breakresult2.extend(res)for r in res:r1 = r.replace(' ', '').split(f'op')result1.append(r1)res_ops.append(f'{op}')res_adj.append(False)s_temp1 = s_temp1.replace(f'{r1[0]}', '')# 搜索带括号的计算if op == '+' or op == '-' or op == '*' or op == '/':while True:res = re.findall(parttern1, s_temp2)if not res:breakresult2.extend(res)for r in res:r1 = r.replace(' ', '').split(f'{op}')result1.append(r1)res_ops.append(f'{op}')res_adj.append(False)tem = r1[0] if r1[0].strip() not in ['(', ')'] else r1[1]s_temp2 = s_temp2.replace(f'{tem}', '')else:res = re.findall(parttern2, s_temp3)result2.extend(res)for r in res:r1 = r.replace(' ', '').split(f'{op}')result1.append(r1)res_ops.append(f'{op}')res_adj.append(True)str_ = re.findall(r'\'([^\']*)\'', ss)str_ = list(set(str_))str_ = [v.rstrip(' \n') for v in str_]for i, fun in enumerate(result1):flag = 0for item in fun:if any(item.strip() in v for v in str_) or any(item.strip() == v for v in self.t_funcs):breakflag += 1if flag == 2 and result1[i] not in result1_n:result1_n.append(result1[i])result2_n.append(result2[i])res1_ops.append(res_ops[i])adj = result1[i][0] in self.time_funcs or result1[i][0] in self.time_funcsres1_adj.append(adj)if result1_n:z = zip(result1_n, result2_n, res1_ops, res1_adj)z1 = sorted(z, key=lambda x: len(x[1].replace(' ', '')), reverse=True)result1_n, result2_n, res1_ops, res1_adj = zip(*z1)return result1_n, result2_n, res1_ops, res1_adjdef mysplit(self, s):"""分割字段:param s::return:"""s = s.strip().replace(')', '').replace('(', '')b = ['+', '-', '*', '/']res = [s]result = []for op in b:n_res = []for item in res:n_res.extend(item.split(op))res = n_resfor item in res:if ' as ' not in item:result.append(re.findall(r'^[\w+_*]+$', item.replace(' ', ''))[0])result = list(set(res))return resultdef extact_func(self, s, func_name):res = []s = s[:-1].replace(f'{func_name}(', '', 1)com_idx = [i for i, v in enumerate(s) if v == ',']jd_com_idx = []for i in com_idx:s1 = s[0:i]if s1.count('(') == s1.count(')'):jd_com_idx.append(i)jd_com_idx.append(len(s))jd_com_idx.insert(0, -1)for i in range(1, len(jd_com_idx)):res.append(s[jd_com_idx[i - 1] + 1:jd_com_idx[i]])return resdef sort_funcs(self, li):li = sorted(li, key=lambda x: x.count('('), reverse=True)li_n = []for l in li:li_n.append(l)return li_ndef delete_text(self, event):self.entry.delete(0, END)self.filename = ''def trans(self):if self.filename:data = open(self.filename, 'r', encoding='utf-8').readlines()self.folder_path = os.path.dirname(self.filename)file_res = self.folder_path + r'\hive转presto_res.sql'os.startfile(f'{self.folder_path}')else:data = self.entry.get().split('\n')file_res = self.dir + r'\hive转presto_res.sql'data_n = []for s in data:if not s.rstrip(' \n'):continueif '”' in s:s = s.replace('“', '')if ',' in s:s = s.replace(',', ',')if '(' in s:s = s.replace('(', '(')if ')' in s:s = s.replace(')', ')')if (idx := s.find('--')) == -1:data_n.append(s + '\n')else:data_n.append(s[:idx] + '\n')data = ''.join(data_n)res1, res2, ops, adj = self.findvar(data)for i, ss in enumerate(res1):s_n = res2[i]s_n1 = res2[i]s_n2 = res2[i]s_t = res2[i]flag = 0for elem in ss:elem1 = elem.replace(' ', '')if any(c.isalpha() for c in elem1):if ops[i] in ['=', '!=', '>', '<', '<=', '>=', '<>']:if adj[i]:if elem1 not in self.time_funcs:s_n = re.sub(rf'\b{elem}\b', f'cast(substr({elem1},1,10) as date', s_n)continueelse:continueif any(op in s_t for op in ['+', '-', '*', '/']):s_n = re.sub(rf'\b{elem}\b', f'cast({elem1} as double)', s_n)else:s_n = re.sub(rf'\b{elem}\b', f'cast({elem1} as varchar)', s_n)else:if elem.strip() not in ['(', ')']:s_n = re.sub(rf'\b{elem}\b', f'cast({elem1} as double)', s_n)flag += 1data = data.replace(res2[i].strip(), s_n)if flag == 2:if any(op in s_t for op in ['+', '-', '*', '/']):s_n1 = re.sub(rf'\b{ss[0]}\b', f'cast({ss[0]} as double)', s_n)s_n2 = re.sub(rf'\b{ss[1]}\b', f'cast({ss[1]} as double)', s_n)else:s_n1 = re.sub(rf'\b{ss[0]}\b', f'cast({ss[0]} as varchar)', s_n)s_n2 = re.sub(rf'\b{ss[1]}\b', f'cast({ss[1]} as varchar)', s_n)data = data.replace(s_n1, s_n)data = data.replace(s_n2, s_n)self.error = []self.result = []for func_name in self.funcs:r = [m.start() for m in re.finditer(func_name, data.lower())]for idx in r:n = 1while True:s = data[idx:idx + n]if (s.count(')') == s.count('(') and s.count(')') != 0) and idx + n > len(data):breakn += 1if s not in self.result and s.rstrip(' \n')[len(func_name)] == '(':self.result.append(s)self.result = self.sort_funcs(self.result)res = self.replace_func(data, self.result)res_new = []for r in res.split('\n'):if r.rstrip(' \n'):res_new.append(r)res_new = '\n'.join(res_new)self.text.delete("1.0", END)self.text.insert("end", f'{res_new}')with open(file_res, 'w', encoding='utf-8') as f:f.write(res_new)if __name__ == '__main__':pro = Hive2Presto()pro.__int__()pro.main()
效果如下所示:

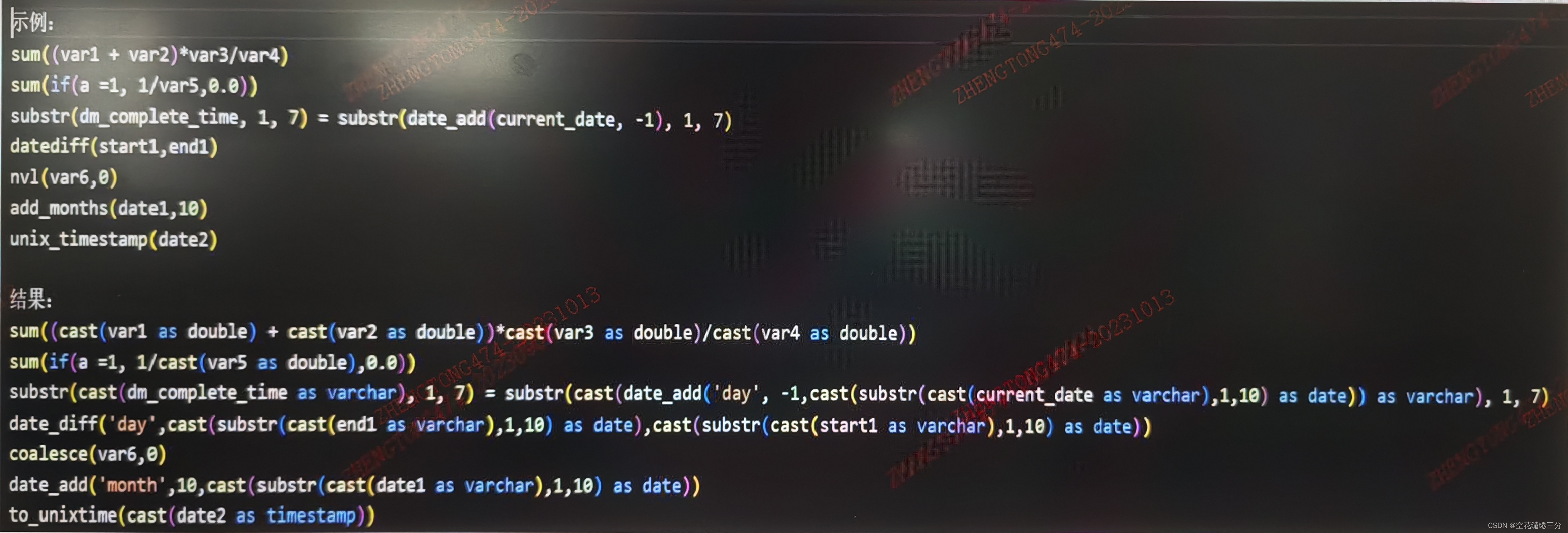
相关文章:
数据库:Hive转Presto(五)
此篇将所有代码都补充完了,之前发现有的代码写错了,以这篇为准,以下为完整代码,如果发现我有什么考虑不周的地方,可以评论提建议,感谢。代码是想哪写哪,可能比较繁琐,还需要优化。 …...
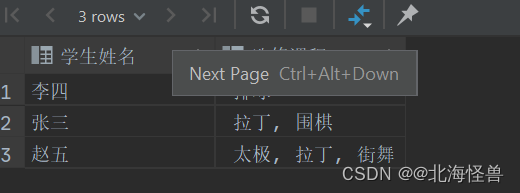
SQL中for xml path 的用法
1. 用法 是一种将查询结果转换为 XML 格式的方法。它可以将查询结果中的每一行转换为一个 XML 元素,并且可以指定元素的名称和属性。 2. 应用示例 有一张学生选修课程的表,如下图所示 希望整合成下图所示效果 --建表 if object_id(StudentInfo,u) is…...

【TensorFlow2 之014】在 TF 2.0 中实现 LeNet-5
一、说明 在这篇文章中,我们将展示如何在 TensorFlow 中实现像 \(LeNet-5\) 这样的基础卷积神经网络。LeNet-5 架构由 Yann LeCun 于 1998 年发明,是第一个卷积神经网络。 数据黑客变种rs 深度学习 机器学习 TensorFlow 2020 年 2 月 29 日 | 0 …...

【2023】redis-stream配合spring的data-redis详细使用(包括广播和组接收)
目录 一、简介1、介绍2、对比 二、整合spring的data-redis实现1、使用依赖2、配置类2.1、配置RedisTemplate bean2.2、异常类 3、实体类3.1、User3.2、Book 4、发送消息4.1、RedisStreamUtil工具类4.2、通过延时队列线程池模拟发送消息4.3、通过http主动发送消息 5、dz…...
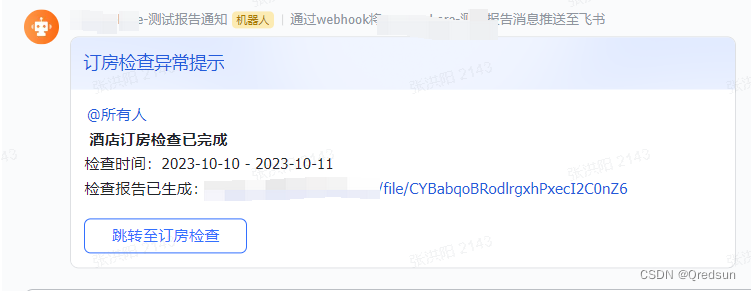
飞书应用机器人文件上传
背景: 接上一篇 flask_apscheduler实现定时推送飞书消息,当检查出的异常结果比较多的时候,群里会有很多推送消息,一条条检查工作量会比较大,且容易出现遗漏。 现在需要将定时任务执行的结果记录到文件,…...

高版本Mac系统如何打开低版本的Xcode
这里写目录标题 前言解决方案 前言 大家偶尔也碰见过更新Mac系统后经常发现低版本的Xcode用不了的情况吧.基本每年大版本更新之后都可以在各个开发群里碰见问这个问题的. 解决方案 打开访达->应用程序->选中打不开的那个版本的Xcode并且右键显示包内容->Contents-…...

测试H5需要注意的交互测试用例点
H5(HTML5)是一种用于构建网页的标准,可以实现丰富的交互和功能。测试H5交互通常涉及到验证网页在各种情况下的行为,包括用户输入、按钮点击、页面加载等等。以下是一些可能的H5交互测试用例: 页面加载: 验…...

1014蓝桥算法双周赛,学习算法技巧,助力蓝桥杯
家人们,我来免费给大家送福利了!!! 【1014蓝桥算法双周赛 】 背景 蓝桥杯全国软件和信息技术专业人才大赛是由工业和信息化部人才交流中心举办的全国性IT学科赛事。参赛高校超过1200余所,累计参赛人数超过40万人。该…...
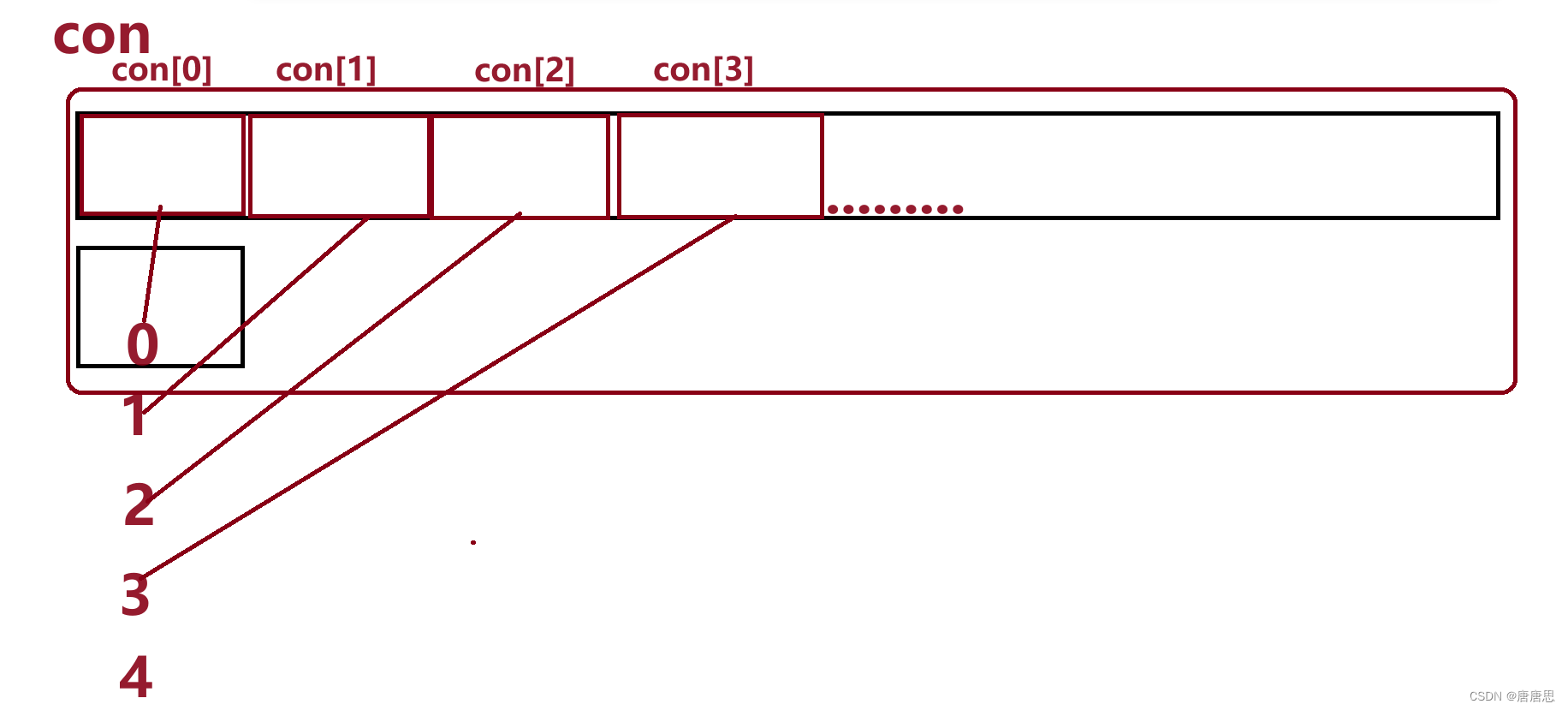
C语言之通讯录的实现篇
目录 test.c 主菜单menu 创建通讯录con 初始化通讯录InitContact 增加个人信息AddContact 展示个人信息ShowContact 删除个人信息DelContact 查找个人信息SearchContact 修改个人信息ModifyContact test.c总代码 contact.h 头文件包含 PeoInfo_个人信息的设置声…...
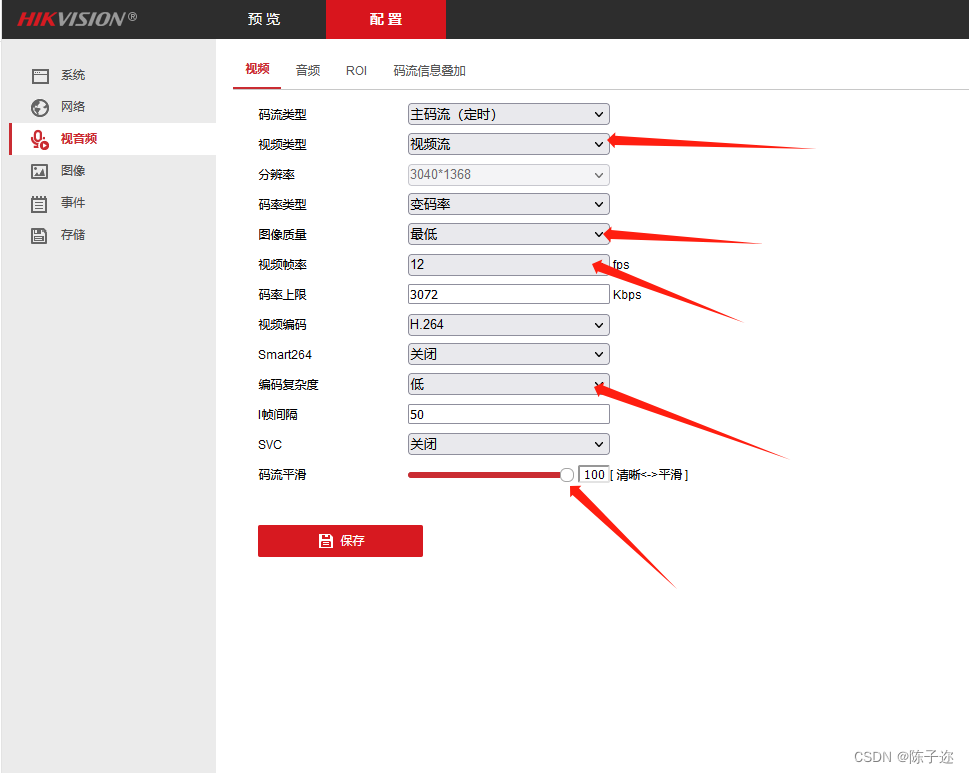
如何降低海康、大华等网络摄像头调用的高延迟问题(二)
目录 1.RTSP介绍 2.解决办法1 3.解决办法2 1.RTSP介绍 RTSP(Real-time Streaming Protocol)是一种用于实时流媒体传输的网络协议。它被设计用于在服务器和客户端之间传输音频、视频以及其他流媒体数据。 RTSP协议允许客户端通过与服务器建立RTSP会话…...

centos清理日志和缓存
今天使用redmine修改密码,修改报错,再去试试创建用户,创建用户的页面直接报错显示不出来。然后看了一下服务器,发现服务器磁盘空间全部占满了。 CentOS系统也会在使用很长一段时间后出现硬盘空间开始不够的情况,而这并…...

排序算法的稳定性
什么是排序算法的稳定性? 排序算法的稳定性: 假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i] r[j],且 r[i…...

kafka属性说明
kafka中关于一些字段说明 groupId :标识消费者分组id,如果多个消费者id相同,就表示这几个消费者是一组,当一组多个消费者消费同一个topic时,一组中只会有一个成功消费 代码如下 这时只会有一条消息被消费...

STM32F4使用ucosii时操作浮点数卡死的问题
STM32F4使用ucosii时操作浮点数卡死的问题_stm32 fpu float 程序跑不起来_shou撕代码的博客-CSDN博客...

python练习:赋值运算 => 输入身高,体重,求BMI = 体重(kg)/身高(m)的平方。
赋值运算 > 输入身高,体重,求BMI 体重(kg)/身高(m)的平方。 代码: height float(input(‘请输入您的身高(m):’)) weight float(input(‘请输入您的体重(kg):’))…...
)
PCL ICP精配准(点到点)
文章目录 一、简介二、实现过程三、实现效果参考资料一、简介 迭代最近点(ICP)算法作为是目前最常用的刚性点集配准方法,它有着简单、计算复杂度低等优点,该算法的具体计算过程如下: (1)在目标点云P中取点集 p i ∈ P p_i∈P p...
)
Redis数据缓存(Redis的缓存击穿和穿透的区别)
Redis是一个高性能的内存中数据存储系统,可以使用它作为数据缓存。使用Redis作为数据缓存可以提高应用程序的性能和可伸缩性,因为Redis运行在内存中,读写速度非常快。 Redis支持许多数据结构,如字符串、哈希表、列表、集合和有序…...

八大排序算法(含时间复杂度、空间复杂度、算法稳定性)
文章目录 八大排序算法(含时间复杂度、空间复杂度、算法稳定性)1、(直接)插入排序1.1、算法思想1.2、排序过程图解1.3、排序代码 2、希尔排序3、冒泡排序3.1、算法思想3.2、排序过程图解3.3、排序代码 4、(简单)选择排序4.1、算法…...
【C++】:引用的概念/引用的特性/常引用/引用的使用场景/传值与传引用的效率比较/引用和指针的区别/内联函数的概念/内联函数的特性
引用的概念 引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间 比如:李逵,在家称为"铁牛",江湖上人称"黑旋风&…...
点云地面点提取——基于格网算法)
Python点云处理(十七)点云地面点提取——基于格网算法
目录 0 简述1 算法流程2 优缺点3 实现4 效果5 结语0 简述 提取地面点是点云数据分析和处理中的重要任务,而点云格网法是一种常用的地面点提取方法。点云格网法(Grid-based Method),通过将点云数据划分为网格单元,根据高程值分析来实现地面点的提取。 1 算法流程 步骤1:…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

MySQL账号权限管理指南:安全创建账户与精细授权技巧
在MySQL数据库管理中,合理创建用户账号并分配精确权限是保障数据安全的核心环节。直接使用root账号进行所有操作不仅危险且难以审计操作行为。今天我们来全面解析MySQL账号创建与权限分配的专业方法。 一、为何需要创建独立账号? 最小权限原则…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

在Ubuntu24上采用Wine打开SourceInsight
1. 安装wine sudo apt install wine 2. 安装32位库支持,SourceInsight是32位程序 sudo dpkg --add-architecture i386 sudo apt update sudo apt install wine32:i386 3. 验证安装 wine --version 4. 安装必要的字体和库(解决显示问题) sudo apt install fonts-wqy…...

Go 语言并发编程基础:无缓冲与有缓冲通道
在上一章节中,我们了解了 Channel 的基本用法。本章将重点分析 Go 中通道的两种类型 —— 无缓冲通道与有缓冲通道,它们在并发编程中各具特点和应用场景。 一、通道的基本分类 类型定义形式特点无缓冲通道make(chan T)发送和接收都必须准备好࿰…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...
混合(Blending))
C++.OpenGL (20/64)混合(Blending)
混合(Blending) 透明效果核心原理 #mermaid-svg-SWG0UzVfJms7Sm3e {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-icon{fill:#552222;}#mermaid-svg-SWG0UzVfJms7Sm3e .error-text{fill…...

CVPR2025重磅突破:AnomalyAny框架实现单样本生成逼真异常数据,破解视觉检测瓶颈!
本文介绍了一种名为AnomalyAny的创新框架,该方法利用Stable Diffusion的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真且多样化的异常样本,有效解决了视觉异常检测中异常样本稀缺的难题,为工业质检、医疗影像…...

消防一体化安全管控平台:构建消防“一张图”和APP统一管理
在城市的某个角落,一场突如其来的火灾打破了平静。熊熊烈火迅速蔓延,滚滚浓烟弥漫开来,周围群众的生命财产安全受到严重威胁。就在这千钧一发之际,消防救援队伍迅速行动,而豪越科技消防一体化安全管控平台构建的消防“…...