YOLOV7量化第二步: 模型标定
2.模型标定
当然可以,模型量化中的标定(calibration)是一个关键过程,它主要确保在降低计算精度以减少模型大小和提高推理速度的同时,不会显著损害模型的准确性。现在,我将根据您提供的步骤解释这一过程。
1. 收集网络层的输入/输出信息
首先,我们需要通过运行模型(使用标定数据集,而不是训练数据或测试数据)来收集关于每层的输入和输出的信息。这个数据集应该是多样化的,以便涵盖到可能的各种情况。
在这一步中,模型是在推理模式下运行的,所有层的输出都被记录下来。这通常是通过修改模型的代码来实现的,以便在每个层之后捕获并存储激活的分布。这些数据将用于下一步中的统计分析。
具体实施时,这一步可能涉及编写一个循环,该循环遍历标定数据集的每个样本,并逐一通过模型。在每一层,您需要捕获并可能临时存储输入和输出数据(通常是张量的形式)。
def collect_stats(model, data_loader, device, num_batch=200):model.eval() # 将模型设置为评估(推理)模式。这在PyTorch中很重要,因为某些层(如Dropout和BatchNorm)在训练和评估时有不同的行为。# 开启校准器for name, module in model.named_modules(): # 遍历模型中的所有模块。`named_modules()`方法提供了一个迭代器,按层次结构列出模型的所有模块及其名称。if isinstance(module, quant_nn.TensorQuantizer): # 检查当前模块是否为TensorQuantizer类型,即我们想要量化的特定类型的层。if module._calibrator is not None: # 如果此层配备了校准器。module.disable_quant() # 禁用量化。这意味着层将正常(未量化)运行,使校准器能够收集必要的统计数据。module.enable_calib() # 启用校准。这使得校准器开始在此层的操作期间收集数据。else:module.disable() # 如果没有校准器,简单地禁用量化功能,但不进行数据收集。# 在此阶段,模型准备好接收数据,并通过处理未量化的数据来进行校准。# testwith torch.no_grad(): # 关闭自动求导系统。这在进行推理时是有用的,因为它减少了内存使用量,加速了计算,而且我们不需要进行反向传播。for i, datas in enumerate(data_loader): # 遍历数据加载器。数据加载器将提供批量的数据,通常用于训练或评估。imgs = datas[0].to(device, non_blocking=True).float()/255.0 # 获取图像数据,转换为适当的设备(例如GPU),并将其类型转换为float。除以255是常见的归一化技术,用于将像素值缩放到0到1的范围。model(imgs) # 用当前批次的图像数据执行模型推理。if i >= num_batch: # 如果我们已经处理了指定数量的批次,则停止迭代。break# 关闭校准器for name, module in model.named_modules(): # 再次遍历所有模块,就像我们之前做的那样。if isinstance(module, quant_nn.TensorQuantizer): # 对于TensorQuantizer类型的模块。if module._calibrator is not None: # 如果有校准器。module.enable_quant() # 重新启用量化。现在,校准器已经收集了足够的统计数据,我们可以再次量化层的操作。module.disable_calib() # 禁用校准。数据收集已经完成,因此我们关闭校准器。else:module.enable() # 如果没有校准器,我们只需重新启用量化功能。# 在此阶段,校准过程完成,模型已经准备好以量化的状态进行更高效的运行。
2. 计算动态范围和比例因子
一旦我们收集了各层的激活数据,接下来的步骤是分析这些数据来确定量化参数,即动态范围(也称为量化范围)和比例因子(scale)。
- 动态范围是指在量化过程中,张量数据可以扩展到的范围。它是原始数据的最大值和最小值之间的差值。这个范围很重要,因为我们希望我们的量化表示能够覆盖可能的所有值,从而避免饱和和信息丢失。
这个过程中,method: A string. One of [‘entropy’, ‘mse’, ‘percentile’] 我们有三种办法,这个实际上要在做实验的时候看哪一个精度更高,这个就是看map值计算的区别
def compute_amax(model, device, **kwargs):# 遍历模型中的所有模块,`model.named_modules()`方法提供了一个迭代器,包含模型中所有模块的名称和模块本身。for name, module in model.named_modules():# 检查当前模块是否为TensorQuantizer的实例,这是处理量化的部分。if isinstance(module, quant_nn.TensorQuantizer):# (这里的print语句已被注释掉,如果取消注释,它将打印当前处理的模块的名称。)# print(name)# 检查当前的量化模块是否具有校准器。if module._calibrator is not None:# 如果该模块的校准器是MaxCalibrator的实例(一种特定类型的校准器)...if isinstance(module._calibrator, calib.MaxCalibrator):# ...则调用load_calib_amax()方法,该方法计算并加载适当的'amax'值,它是量化过程中用于缩放的最大激活值。module.load_calib_amax()else:# ...如果校准器不是MaxCalibrator,我们仍然调用load_calib_amax方法,但是可以传递额外的关键字参数。# 这些参数可能会影响'amax'值的计算。module.load_calib_amax(**kwargs) # ['entropy', 'mse', 'percentile'] 这里有三个计算方法,实际过程中要看哪一个比较准,再考虑用哪一个# 将计算出的'amax'值(现在存储在模块的'_amax'属性中)转移到指定的设备上。# 这确保了与模型数据在同一设备上的'amax'值,这对于后续的计算步骤(如训练或推理)至关重要。module._amax = module._amax.to(device)
Scanning '/app/dataset/coco2017/val2017.cache' images and labels... 4952 found, 48 missing, 0 empty, 0 corrupted: 100%|███████████████████████| 5000/5000 [00:00<?, ?it/s]
Origin pth_Model map: Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|█████████████████████████████████████| 625/625 [00:49<00:00, 12.61it/s]all 5000 36781 0.717 0.626 0.675 0.454
Fusing layers...
RepConv.fuse_repvgg_block
RepConv.fuse_repvgg_block
RepConv.fuse_repvgg_block
IDetect.fuse
QDQ auto init map: Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|█████████████████████████████████████| 625/625 [00:39<00:00, 15.78it/s]all 5000 36781 0.718 0.627 0.676 0.455
Calibrate Model map: Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|█████████████████████████████████████| 625/625 [01:42<00:00, 6.09it/s]all 5000 36781 0.73 0.618 0.674 0.454
2.3 完整代码
import torch
from pytorch_quantization import quant_modules
from models.yolo import Model
from pytorch_quantization.nn.modules import _utils as quant_nn_utils
from pytorch_quantization import calib
import sys
import re
import yaml
import os
os.chdir("/app/bob/yolov7_QAT/yolov7")def load_yolov7_model(weight, device="cpu"):ckpt = torch.load(weight, map_location=device) # 加载模型,模型参数在哪个设备上model = Model("cfg/training/yolov7.yaml", ch=3, nc=80).to(device) # 跟yolov7的结构,这里没有包含参数state_dict = ckpt["model"].float().state_dict() # 从加载的权重中提取模型的状态字典(state_dict), 包含了模型全部的参数,包括卷积权重等model.load_state_dict(state_dict, strict=False) # 把提取出来的参数放到yolov7的结构中return model # 返回正确权重和参数的模型import collections
from utils.datasets import create_dataloader
def prepare_dataset(cocodir, batch_size=8): dataloader = create_dataloader( # 这里的参数是跟官网的是一样的f"{cocodir}/val2017.txt",imgsz=640,batch_size=batch_size,opt=collections.namedtuple("Opt", "single_cls")(False), # collections.namedtuple("Opt", "single_cls")(False)augment=False, hyp=None, rect=True, cache=False, stride=32, pad=0.5, image_weights=False,)[0]return dataloaderimport test as test
from pathlib import Path
import os
def evaluate_coco(model, loader, save_dir='.', conf_thres=0.001, iou_thres=0.65):if save_dir and os.path.dirname(save_dir) != "":os.makedirs(os.path.dirname(save_dir), exist_ok=True)return test.test("./data/coco.yaml",save_dir=Path(save_dir),conf_thres=conf_thres,iou_thres=iou_thres,model=model,dataloader=loader,is_coco=True,plots=False,half_precision=True,save_json=False)[0][3] from pytorch_quantization import nn as quant_nn
from pytorch_quantization.tensor_quant import QuantDescriptor
from absl import logging as quant_logging
# intput QuantDescriptor: Max ==> Histogram
def initialize():quant_desc_input = QuantDescriptor(calib_method="histogram") # "max" quant_nn.QuantConv2d.set_default_quant_desc_input(quant_desc_input)quant_nn.QuantMaxPool2d.set_default_quant_desc_input(quant_desc_input)quant_nn.QuantLinear.set_default_quant_desc_input(quant_desc_input)quant_logging.set_verbosity(quant_logging.ERROR) def prepare_model(weight, device):# quant_modules.initialize() # 自动加载qdq节点initialize() # intput QuantDescriptor: Max ==> Histogrammodel = load_yolov7_model(weight, device)model.float()model.eval()with torch.no_grad():model.fuse() # conv bn 进行层的合并, 加速return model# 执行量化替换
def transfer_torch_to_quantization(nn_instance, quant_mudule):quant_instance = quant_mudule.__new__(quant_mudule)for k, val in vars(nn_instance).items():setattr(quant_instance, k, val)def __init__(self):# 返回两个QuantDescriptor的实例 self.__class__是quant_instance的类, EX: QuantConv2dquant_desc_input, quant_desc_weight = quant_nn_utils.pop_quant_desc_in_kwargs(self.__class__)if isinstance(self, quant_nn_utils.QuantInputMixin):self.init_quantizer(quant_desc_input)if isinstance(self._input_quantizer._calibrator, calib.HistogramCalibrator):self._input_quantizer._calibrator._torch_hist = Trueelse:self.init_quantizer(quant_desc_input, quant_desc_weight)if isinstance(self._input_quantizer._calibrator, calib.HistogramCalibrator):self._input_quantizer._calibrator._torch_hist = Trueself._weight_quantizer._calibrator._torch_hist = True__init__(quant_instance)return quant_instancedef quantization_ignore_match(ignore_layer, path):if ignore_layer is None:return Falseif isinstance(ignore_layer, str) or isinstance(ignore_layer, list):if isinstance(ignore_layer, str):ignore_layer = [ignore_layer]if path in ignore_layer:return Truefor item in ignore_layer:if re.match(item, path): return True return False# 递归函数
def torch_module_find_quant_module(module, module_dict, ignore_layer, prefix=''):for name in module._modules:submodule = module._modules[name]path = name if prefix == '' else prefix + '.' + nametorch_module_find_quant_module(submodule, module_dict, ignore_layer, prefix=path)submodule_id = id(type(submodule))if submodule_id in module_dict:ignored = quantization_ignore_match(ignore_layer, path)if ignored:print(f"Quantization : {path} has ignored.")continue# 转换module._modules[name] = transfer_torch_to_quantization(submodule, module_dict[submodule_id])# 用量化模型替换
def replace_to_quantization_model(model, ignore_layer=None):"""这里构建的module_dict里面的元素是一个映射的关系, 例如torch.nn -> quant_nn.QuantConv2d, 一共是15个, 跟DEFAULT_QUANT_MAP对齐"""module_dict = {}for entry in quant_modules._DEFAULT_QUANT_MAP: # 构建module_dict, 把DEFAULT_QUANT_MAP填充module = getattr(entry.orig_mod, entry.mod_name) # 提取的原始的模块,从torch.nn中获取conv2d这个字符串module_dict[id(module)] = entry.replace_mod # 使用替换的模块torch_module_find_quant_module(model, module_dict, ignore_layer)def collect_stats(model, data_loader, device, num_batch=200):model.eval() # 将模型设置为评估(推理)模式。这在PyTorch中很重要,因为某些层(如Dropout和BatchNorm)在训练和评估时有不同的行为。# 开启校准器for name, module in model.named_modules(): # 遍历模型中的所有模块。`named_modules()`方法提供了一个迭代器,按层次结构列出模型的所有模块及其名称。if isinstance(module, quant_nn.TensorQuantizer): # 检查当前模块是否为TensorQuantizer类型,即我们想要量化的特定类型的层。if module._calibrator is not None: # 如果此层配备了校准器。module.disable_quant() # 禁用量化。这意味着层将正常(未量化)运行,使校准器能够收集必要的统计数据。module.enable_calib() # 启用校准。这使得校准器开始在此层的操作期间收集数据。else:module.disable() # 如果没有校准器,简单地禁用量化功能,但不进行数据收集。# 在此阶段,模型准备好接收数据,并通过处理未量化的数据来进行校准。# testwith torch.no_grad(): # 关闭自动求导系统。这在进行推理时是有用的,因为它减少了内存使用量,加速了计算,而且我们不需要进行反向传播。for i, datas in enumerate(data_loader): # 遍历数据加载器。数据加载器将提供批量的数据,通常用于训练或评估。imgs = datas[0].to(device, non_blocking=True).float()/255.0 # 获取图像数据,转换为适当的设备(例如GPU),并将其类型转换为float。除以255是常见的归一化技术,用于将像素值缩放到0到1的范围。model(imgs) # 用当前批次的图像数据执行模型推理。if i >= num_batch: # 如果我们已经处理了指定数量的批次,则停止迭代。break# 关闭校准器for name, module in model.named_modules(): # 再次遍历所有模块,就像我们之前做的那样。if isinstance(module, quant_nn.TensorQuantizer): # 对于TensorQuantizer类型的模块。if module._calibrator is not None: # 如果有校准器。module.enable_quant() # 重新启用量化。现在,校准器已经收集了足够的统计数据,我们可以再次量化层的操作。module.disable_calib() # 禁用校准。数据收集已经完成,因此我们关闭校准器。else:module.enable() # 如果没有校准器,我们只需重新启用量化功能。# 在此阶段,校准过程完成,模型已经准备好以量化的状态进行更高效的运行。def compute_amax(model, device, **kwargs):# 遍历模型中的所有模块,`model.named_modules()`方法提供了一个迭代器,包含模型中所有模块的名称和模块本身。for name, module in model.named_modules():# 检查当前模块是否为TensorQuantizer的实例,这是处理量化的部分。if isinstance(module, quant_nn.TensorQuantizer):# (这里的print语句已被注释掉,如果取消注释,它将打印当前处理的模块的名称。)# print(name)# 检查当前的量化模块是否具有校准器。if module._calibrator is not None:# 如果该模块的校准器是MaxCalibrator的实例(一种特定类型的校准器)...if isinstance(module._calibrator, calib.MaxCalibrator):# ...则调用load_calib_amax()方法,该方法计算并加载适当的'amax'值,它是量化过程中用于缩放的最大激活值。module.load_calib_amax()else:# ...如果校准器不是MaxCalibrator,我们仍然调用load_calib_amax方法,但是可以传递额外的关键字参数。# 这些参数可能会影响'amax'值的计算。module.load_calib_amax(**kwargs) # ['entropy', 'mse', 'percentile'] 这里有三个计算方法,实际过程中要看哪一个比较准,再考虑用哪一个# 将计算出的'amax'值(现在存储在模块的'_amax'属性中)转移到指定的设备上。# 这确保了与模型数据在同一设备上的'amax'值,这对于后续的计算步骤(如训练或推理)至关重要。module._amax = module._amax.to(device)def calibrate_model(model, dataloader, device):# 收集信息collect_stats(model, dataloader, device)# 获取动态范围,计算amax值,scale值compute_amax(model, device, method='mse')if __name__ == "__main__":weight = "./yolov7.pt"cocodir = "/app/dataset/coco2017" #../dataset/coco2017device = torch.device("cuda:2" if torch.cuda.is_available() else "cpu")# load最初版本的模型pth_model = load_yolov7_model(weight=weight, device=device)# print(pth_model)dataloader = prepare_dataset(cocodir=cocodir, )print("Origin pth_Model map: ")ap = evaluate_coco(pth_model, dataloader)# 加载自动插入QDQ节点的模型# print("Before prepare_model")model = prepare_model(weight=weight, device=device)# print("After prepare_model")print("QDQ auto init map: ")qdq_auto_ap = evaluate_coco(model, dataloader)# print("Before replace_to_quantization_model")replace_to_quantization_model(model)# print("After replace_to_quantization_model")# print("Before calibrate_model")calibrate_model(model, dataloader, device)# print("After calibrate_model")print("Calibrate Model map: ")cali_ap = evaluate_coco(model, dataloader)
相关文章:

YOLOV7量化第二步: 模型标定
2.模型标定 当然可以,模型量化中的标定(calibration)是一个关键过程,它主要确保在降低计算精度以减少模型大小和提高推理速度的同时,不会显著损害模型的准确性。现在,我将根据您提供的步骤解释这一过程。 …...
前端-uniapp-开发指南
美团外卖微信小程序开发 uniapp-美团外卖微信小程序开发P1 成果展示P2外卖小程序后端,学习给小程序写http接口P3 主界面配置P4 首页组件拆分P13 外卖列表布局筛选组件商家 布局测试数据创建样式 请求商家外卖数据封装请求并发请求 uni-app框架调用https接口 开发小程…...
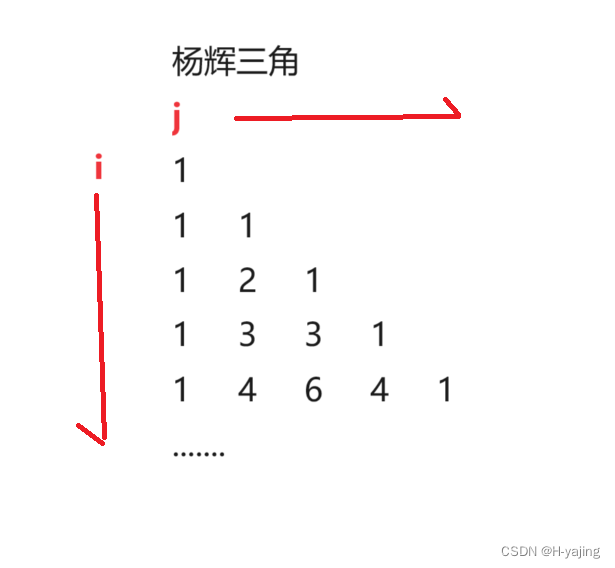
Java集合类ArrayList的应用-杨辉三角的前n行
目录 一、题目 杨辉三角 二、题解 三、代码 四、总结 一、题目 题目链接:https://leetcode.cn/problems/pascals-triangle/description/ 杨辉三角 题目描述:给定一个非负整数 numRows,生成「杨辉三角」的前 numRows 行。 在「杨…...
C语言-函数
函数是一组一起执行一个任务的语句。每个 C 程序都至少有一个函数,即主函数 main() 。 主函数可以调用其他函数,其他函数也可以相互调用,用户也可以那个自定义函数。 函数声明告诉编译器函数的名称、返回类型和参数。函数定义提供了函数的实…...
蓝桥杯 枚举算法 (c++)
枚举就是根据提出的问题,——列出该问题的所有可能的解,并在逐一列出的过程中,检验每个可能解是否是问题的真正解, 如果是就采纳这个解,如果不是就继续判断下一个。 枚举法一般比较直观,容易理解࿰…...
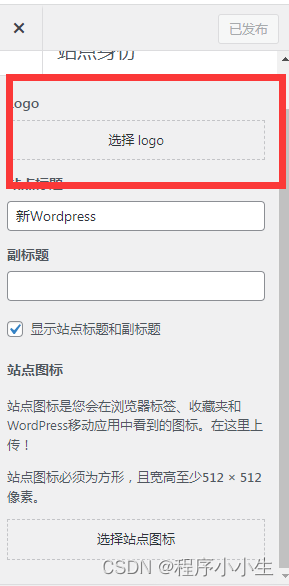
Wordpress自定义小工具logo调用设置(可视化)
在主题开发中,需要调用网站的logo,最简单的办法就是用wp自带的函数,那就是the_custom_logo(),使用它还可以通过后台-自定义-logo,边修改边预览,还是很香的。 自定义徽标支持应首先使用add_theme_support()添…...
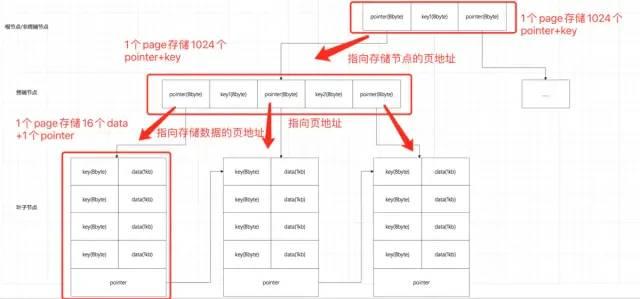
面试常考数据结构:红黑树、B树、B+树各自适用的场景
1. 磁盘基础知识 分页: 现代操作系统都使用虚拟内存来印射到物理内存,内存大小有限且价格昂贵,所以数据的持久化是在磁盘上。虚拟内存、物理内存、磁盘都使用页作为内存读取的最小单位。一般一页为4KB(8个扇区,每个扇…...
Paddle GPU版本需要安装CUDA、CUDNN
完整的教程 深度学习环境配置:linuxwindows系统下的显卡驱动、Anaconda、Pytorch&Paddle、cuda&cudnn的安装与说明 - 知乎这篇文档的内容是尽量将深度学习环境配置(使用GPU)所需要的内容做一些说明,由于笔者只在windows和linux下操作过…...

MYSQL length函数
mysql length函数计算结果的单位是啥,和varchar字段类型的单位是相同的吗? 做了一下实验,结果如下: 1.mysql length 函数计算的是有多少个字符,比如字段值是 permission 则length函数计算结果为10。 2.如果字段类型是…...

uniapp 在android手机上运行tab栏页面跳转问题
【问题描述】: 使用uniapp写的项目,在tab页面,无论使用哪种方式的跳转,只要是在url后面拼接参数,在打包成apk文件后,在手机上面安装使用,都是获取不到susIndex参数的,而在浏览器上面…...

css3 hover效果
CSS3中的:hover伪类用于创建鼠标悬停时的样式效果。当用户将鼠标悬停在页面元素上时,你可以为这些元素定义不同的样式规则,以实现交互效果 /* 一般样式规则 */ element {/* 正常状态下的样式 */ }/* 悬停样式规则 */ element:hover {/* 鼠标悬停时的样式…...
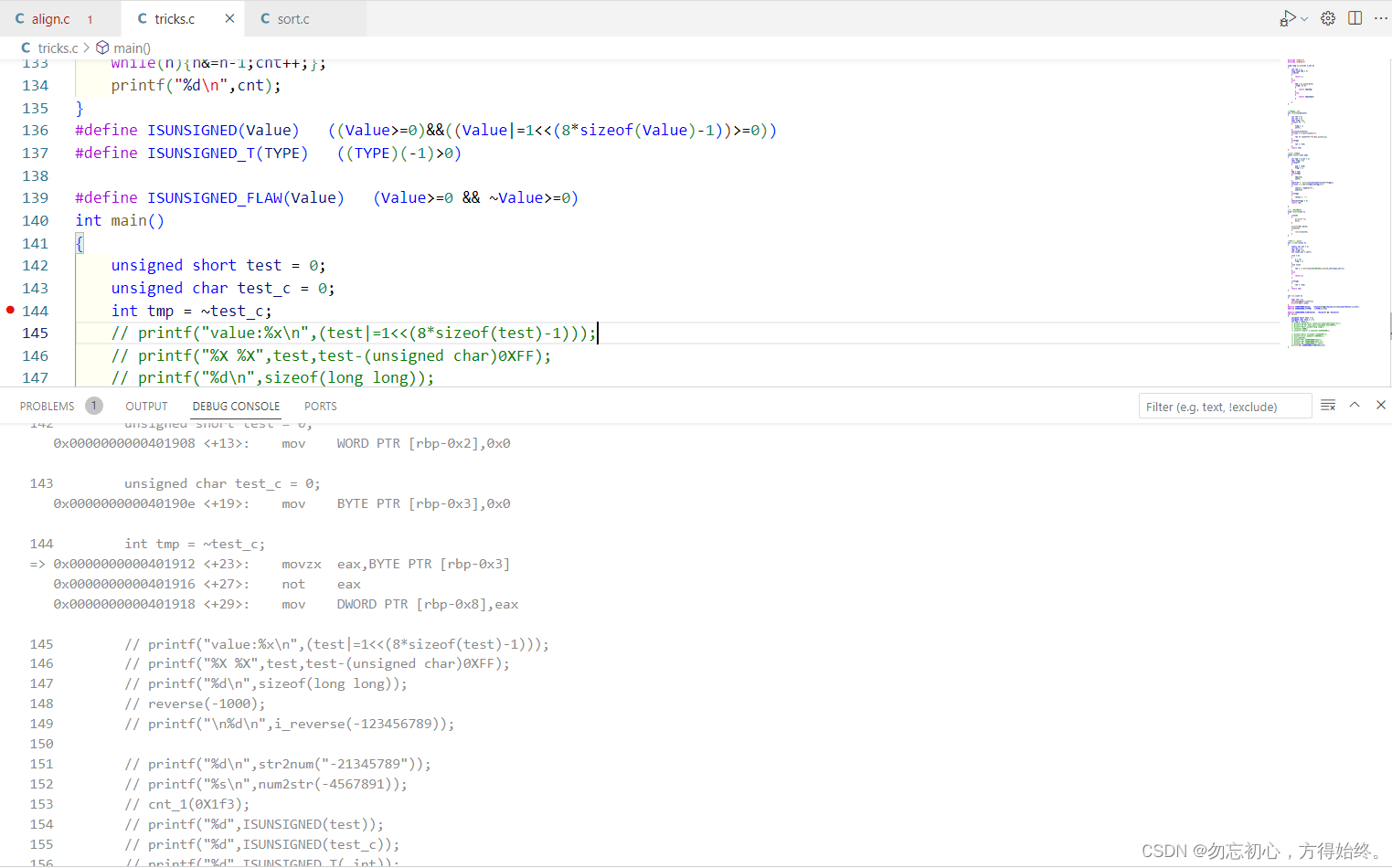
C语言char与short取反以及符号判断问题
这个问题主要是在从对一个变量进行符号判断引出,有一种判断方法是#define ISUNSIGNED(Value) (Value >0 && ~Value >0) 主要是通过将符号位取反然后将变量与0进行比较。传入int与unsigned int结果正确,但是当传入unsigned char 与unsign…...

Gpt-4多模态功能强势上线,景联文科技多模态数据采集标注服务等您来体验!
就在上个月,OpenAI 宣布对ChatGPT 进行重大更新,该模型不仅能够通过文字输入进行识别和分析,还能够通过语音、图像甚至视频等多种模态的输入来获取、识别、分析和输出信息。这一重要技术突破,将促进多模态自然语言处理的发展&…...

【idea】 java: 找不到符号
idea 启动时提示 java: 找不到符号 java: 找不到符号 符号: 方法 getCompanyDisputeCount() 位置: 类型为com.yang.entity.AreaAnalyse的变量 areaAnalyse 在setting ——> Compiler ——>Shared build process VM options: 添加: -Djps.track.ap.dep…...

Flink测试利器之DataGen初探 | 京东云技术团队
什么是 Flinksql Flink SQL 是基于 Apache Calcite 的 SQL 解析器和优化器构建的,支持ANSI SQL 标准,允许使用标准的 SQL 语句来处理流式和批处理数据。通过 Flink SQL,可以以声明式的方式描述数据处理逻辑,而无需编写显式的代码…...
)
linux更换常用软件的默认缓存路径(.conda, .huggingface等)
在使用linux的过程中,我们往往会使用软件安装很多packages,其中的大多数软件(例如conda)会把当前安装的packages缓存起来,以加速之后的相同package的安装。 而很多软件的默认缓存路径是user自己的home路径。下面罗列几…...
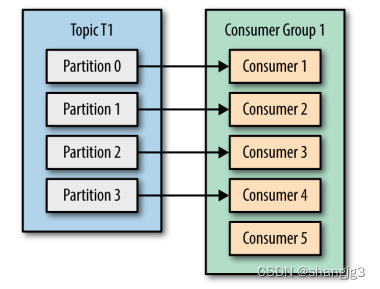
Kafka消费者使用案例
本文代码链接:https://download.csdn.net/download/shangjg03/88422633 1.消费者和消费者群组 在 Kafka 中,消费者通常是消费者群组的一部分,多个消费者群组共同读取同一个主题时,彼此之间互不影响。Kafka 之所以要引入消费者群组…...
SpringMVC全注解开发
在学习过程中,框架给我们最大的作用,就是想让开发人员尽可能地只将精力放在具体业务功能的实现之上,而对于各种映射关系的配置,统统由框架来进行完成,由此,注解就很好的将映射功能进行实现,并且…...

解决 android Cannot access ‘<init>‘: it is private in
最近要在2个非直接依赖module使用单例,有一种注入依赖的方式可以,但是报了如下错误: Cannot access <init>: it is private in 经过查阅资料,原来是依赖的单例类的构造函数不能使用private,这里做个记录&#…...
不容易解的题10.15
395.至少有K个重复字符的最长字串 395. 至少有 K 个重复字符的最长子串 - 力扣(LeetCode)https://leetcode.cn/problems/longest-substring-with-at-least-k-repeating-characters/description/?envTypelist&envIdZCa7r67M自认为是不好做的题。尤其…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...

服务器--宝塔命令
一、宝塔面板安装命令 ⚠️ 必须使用 root 用户 或 sudo 权限执行! sudo su - 1. CentOS 系统: yum install -y wget && wget -O install.sh http://download.bt.cn/install/install_6.0.sh && sh install.sh2. Ubuntu / Debian 系统…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...

push [特殊字符] present
push 🆚 present 前言present和dismiss特点代码演示 push和pop特点代码演示 前言 在 iOS 开发中,push 和 present 是两种不同的视图控制器切换方式,它们有着显著的区别。 present和dismiss 特点 在当前控制器上方新建视图层级需要手动调用…...
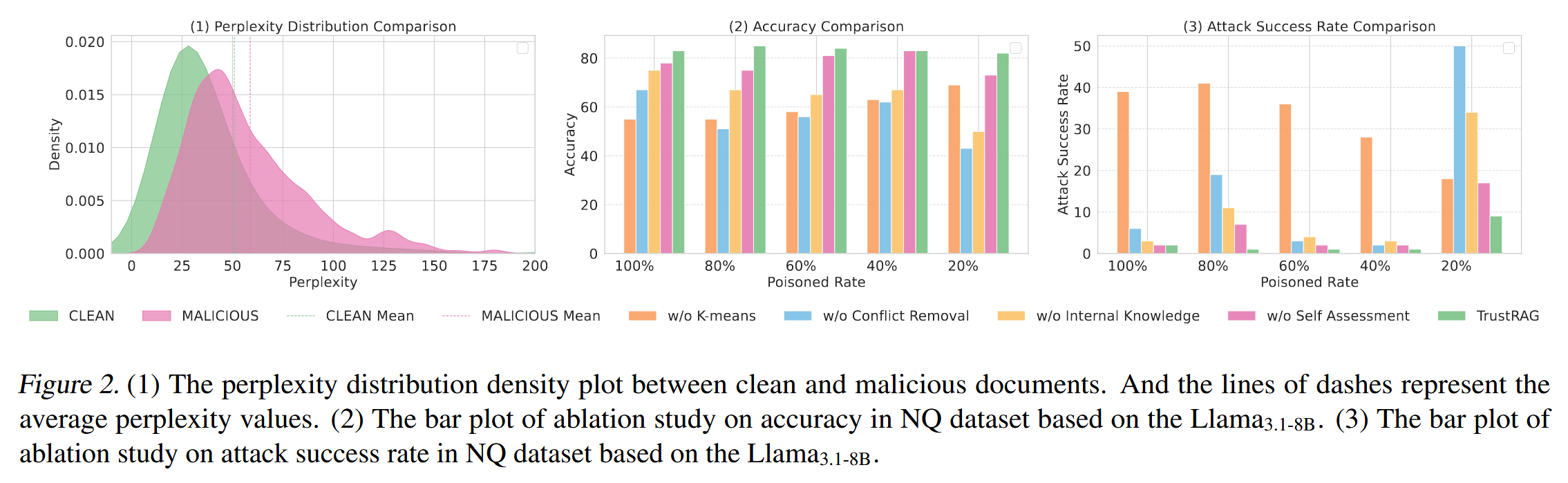
[论文阅读]TrustRAG: Enhancing Robustness and Trustworthiness in RAG
TrustRAG: Enhancing Robustness and Trustworthiness in RAG [2501.00879] TrustRAG: Enhancing Robustness and Trustworthiness in Retrieval-Augmented Generation 代码:HuichiZhou/TrustRAG: Code for "TrustRAG: Enhancing Robustness and Trustworthin…...
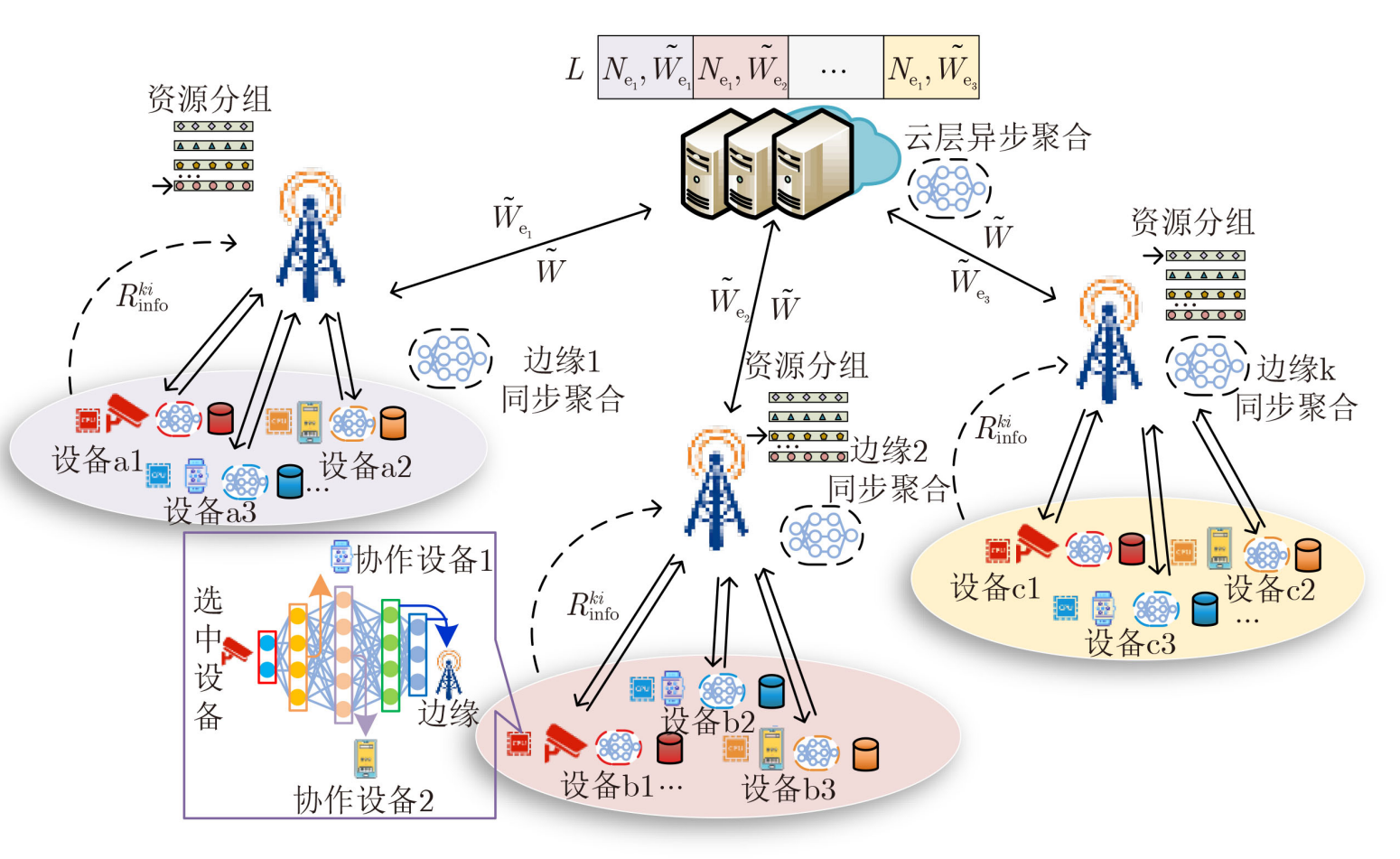
联邦学习带宽资源分配
带宽资源分配是指在网络中如何合理分配有限的带宽资源,以满足各个通信任务和用户的需求,尤其是在多用户共享带宽的情况下,如何确保各个设备或用户的通信需求得到高效且公平的满足。带宽是网络中的一个重要资源,通常指的是单位时间…...