异步使用langchain
文章目录
- 一.先利用langchain官方文档的AI功能问问
- 二.langchain async api
- 三.串行,异步速度比较
一.先利用langchain官方文档的AI功能问问

- 然后看他给的 Verified Sources
- 这个页面里面虽然有些函数是异步函数,但是并非专门讲解异步的
二.langchain async api
还不如直接谷歌搜😂 一下搜到, 上面那个AI文档问答没给出这个链接
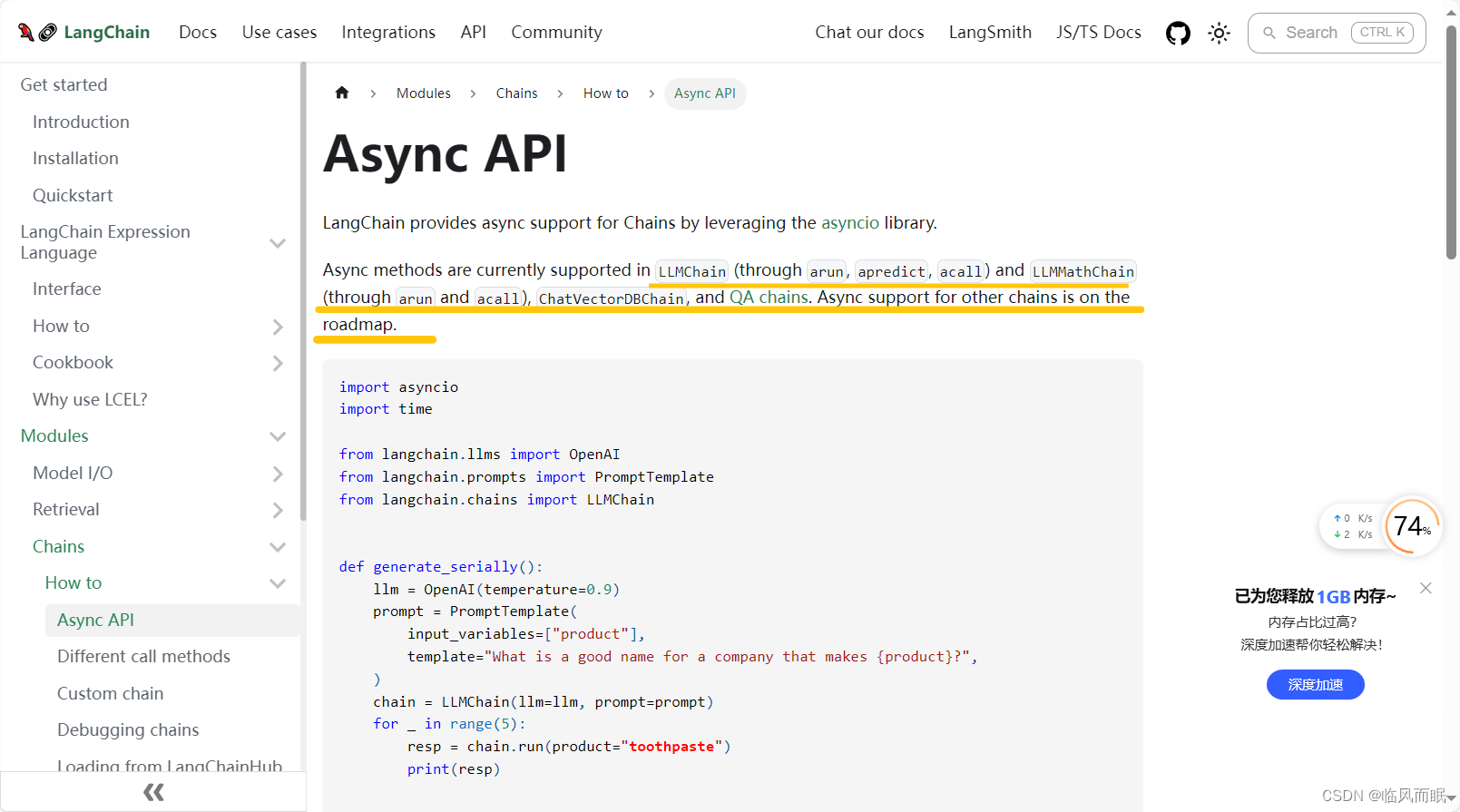
-
官方示例
import asyncio import timefrom langchain.llms import OpenAI from langchain.prompts import PromptTemplate from langchain.chains import LLMChaindef generate_serially():llm = OpenAI(temperature=0.9)prompt = PromptTemplate(input_variables=["product"],template="What is a good name for a company that makes {product}?",)chain = LLMChain(llm=llm, prompt=prompt)for _ in range(5):resp = chain.run(product="toothpaste")print(resp)async def async_generate(chain):resp = await chain.arun(product="toothpaste")print(resp)async def generate_concurrently():llm = OpenAI(temperature=0.9)prompt = PromptTemplate(input_variables=["product"],template="What is a good name for a company that makes {product}?",)chain = LLMChain(llm=llm, prompt=prompt)tasks = [async_generate(chain) for _ in range(5)]await asyncio.gather(*tasks)s = time.perf_counter() # If running this outside of Jupyter, use asyncio.run(generate_concurrently()) await generate_concurrently() elapsed = time.perf_counter() - s print("\033[1m" + f"Concurrent executed in {elapsed:0.2f} seconds." + "\033[0m")s = time.perf_counter() generate_serially() elapsed = time.perf_counter() - s print("\033[1m" + f"Serial executed in {elapsed:0.2f} seconds." + "\033[0m") -
不过官方代码报错了

-
我让copilot修改一下,能跑了
import time import asyncio from langchain.llms import OpenAI from langchain.prompts import PromptTemplate from langchain.chains import LLMChaindef generate_serially():llm = OpenAI(temperature=0.9)prompt = PromptTemplate(input_variables=["product"],template="What is a good name for a company that makes {product}?",)chain = LLMChain(llm=llm, prompt=prompt)for _ in range(5):resp = chain.run(product="toothpaste")print(resp)async def async_generate(chain):resp = await chain.arun(product="toothpaste")print(resp)async def generate_concurrently():llm = OpenAI(temperature=0.9)prompt = PromptTemplate(input_variables=["product"],template="What is a good name for a company that makes {product}?",)chain = LLMChain(llm=llm, prompt=prompt)tasks = [async_generate(chain) for _ in range(5)]await asyncio.gather(*tasks)async def main():s = time.perf_counter()await generate_concurrently()elapsed = time.perf_counter() - sprint("\033[1m" + f"Concurrent executed in {elapsed:0.2f} seconds." + "\033[0m")s = time.perf_counter()generate_serially()elapsed = time.perf_counter() - sprint("\033[1m" + f"Serial executed in {elapsed:0.2f} seconds." + "\033[0m")asyncio.run(main())
-
这还有一篇官方blog

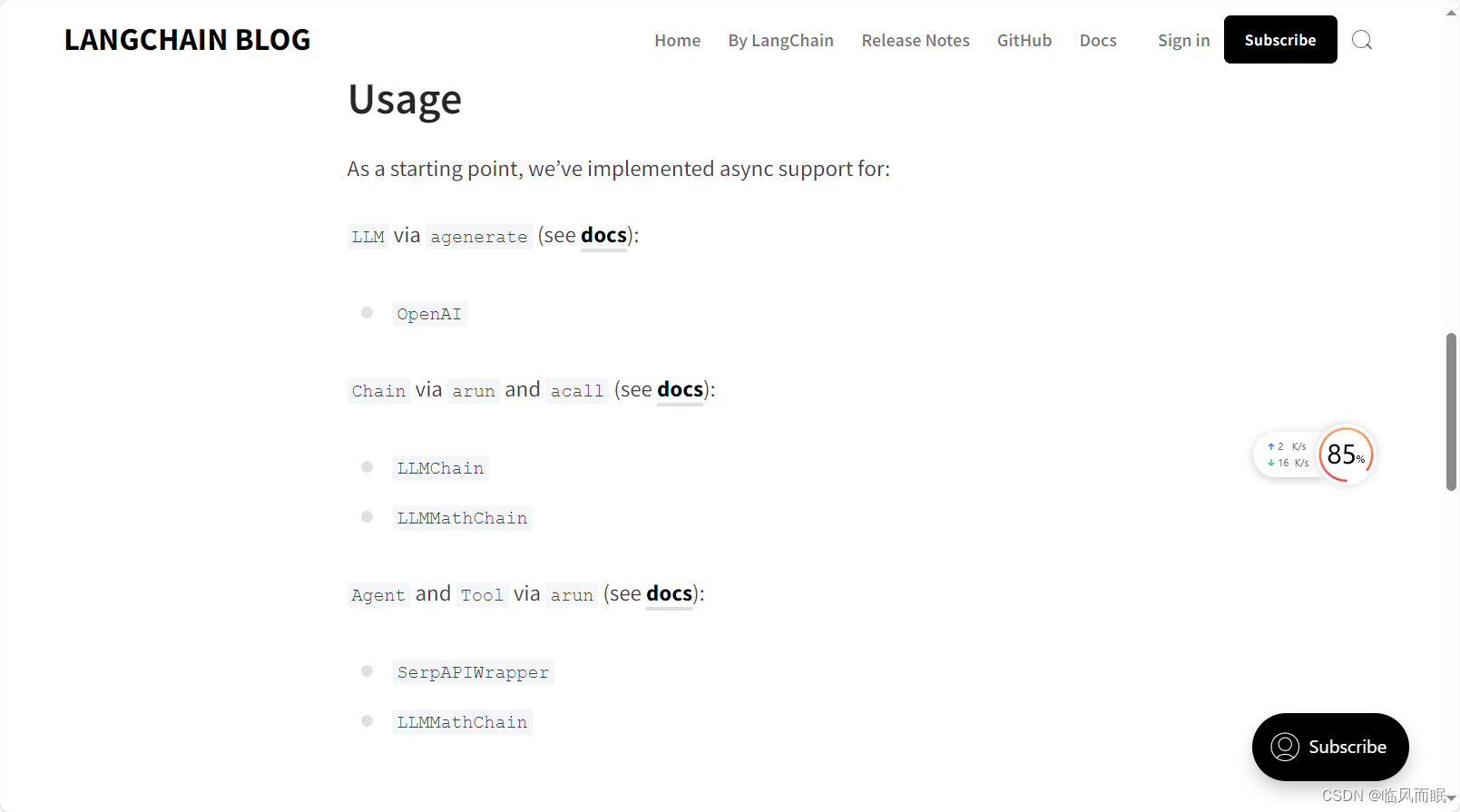
三.串行,异步速度比较
- 先学习一下掘金上看到的一篇:https://juejin.cn/post/7231907374688436284
- 为了更方便的看到异步效果,我在原博主的基础上,print里面加了一个提示


# 引入time和asyncio模块
import time
import asyncio
# 引入OpenAI类
from langchain.llms import OpenAI# 定义异步函数async_generate,该函数接收一个llm参数和一个name参数
async def async_generate(llm, name):# 调用OpenAI类的agenerate方法,传入字符串列表["Hello, how are you?"]并等待响应resp = await llm.agenerate(["Hello, how are you?"])# 打印响应结果的生成文本和函数名print(f"{name}: {resp.generations[0][0].text}")# 定义异步函数generate_concurrently
async def generate_concurrently():# 创建OpenAI实例,并设置temperature参数为0.9llm = OpenAI(temperature=0.9)# 创建包含10个async_generate任务的列表tasks = [async_generate(llm, f"Function {i}") for i in range(10)]# 并发执行任务await asyncio.gather(*tasks)# 主函数
# 如果在Jupyter Notebook环境运行该代码,则无需手动调用await generate_concurrently(),直接在下方执行单元格即可执行该函数
# 如果在命令行或其他环境下运行该代码,则需要手动调用asyncio.run(generate_concurrently())来执行该函数
asyncio.run(generate_concurrently())
免费用户一分钟只能3次,实在是有点难蚌
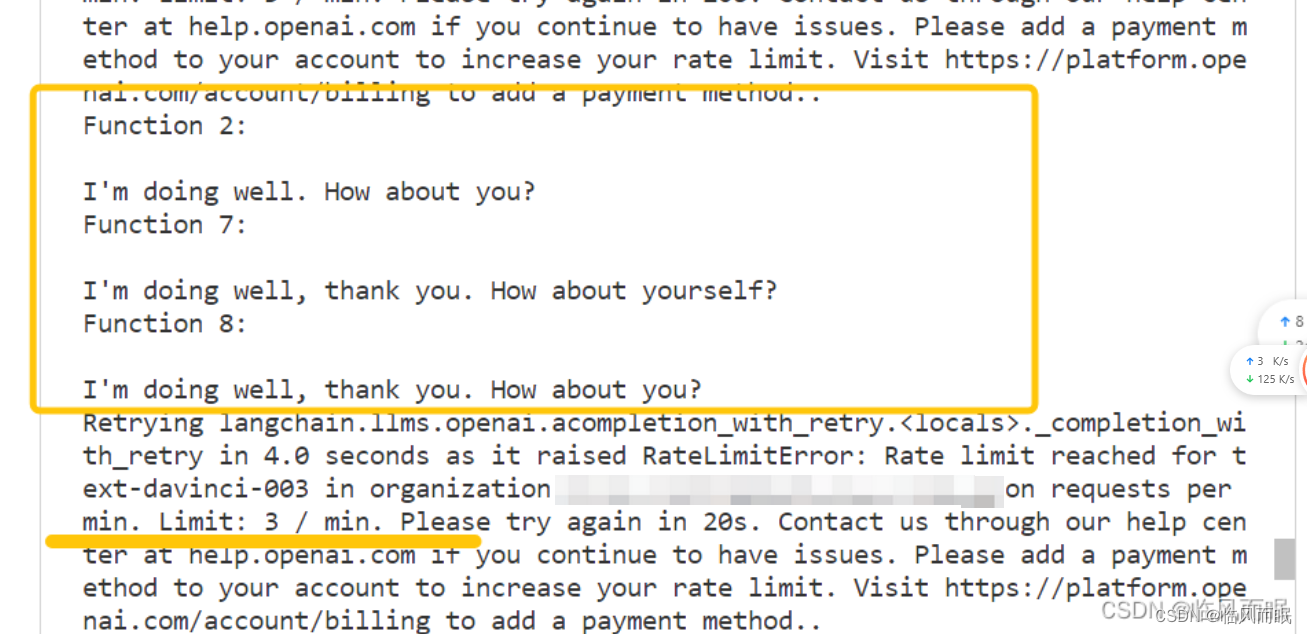
-
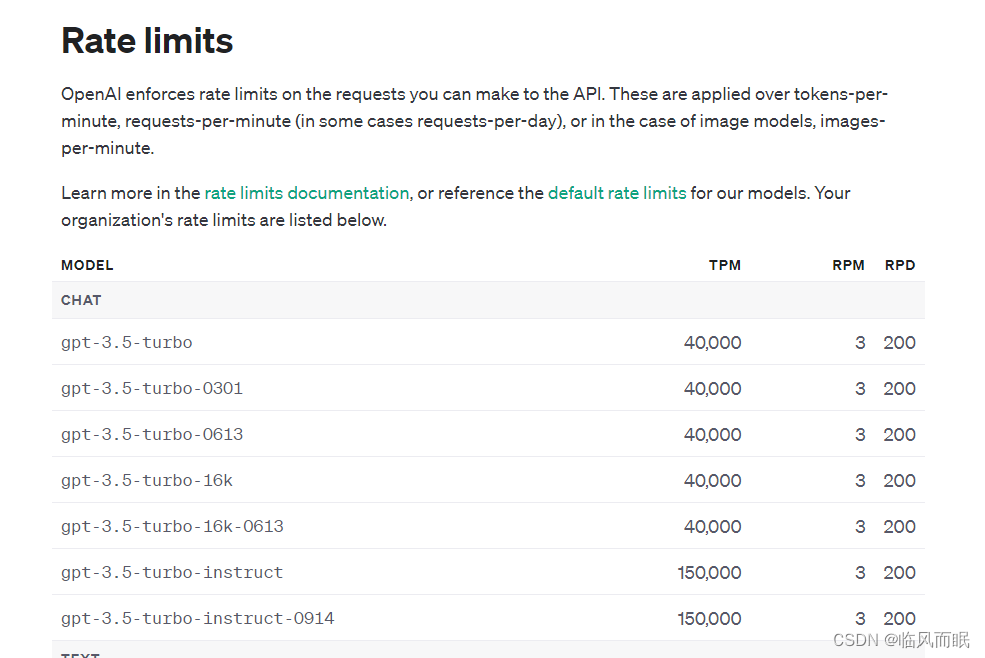
整合一下博主的代码,对两个速度进行比较,但是这个调用限制真的很搞人啊啊啊
import time import asyncio from langchain.llms import OpenAIasync def async_generate(llm, name):resp = await llm.agenerate(["Hello, how are you?"])# print(f"{name}: {resp.generations[0][0].text}")async def generate_concurrently():llm = OpenAI(temperature=0.9)tasks = [async_generate(llm, f"Function {i}") for i in range(3)]await asyncio.gather(*tasks)def generate_serially():llm = OpenAI(temperature=0.9)for _ in range(3):resp = llm.generate(["Hello, how are you?"])# print(resp.generations[0][0].text)async def main():s = time.perf_counter()await generate_concurrently()elapsed = time.perf_counter() - sprint("\033[1m" + f"Concurrent executed in {elapsed:0.2f} seconds." + "\033[0m")s = time.perf_counter()generate_serially()elapsed = time.perf_counter() - sprint("\033[1m" + f"Serial executed in {elapsed:0.2f} seconds." + "\033[0m")asyncio.run(main())

- 再看一篇blog
- 作者将代码开源在这里了:https://github.com/gabrielcassimiro17/async-langchain
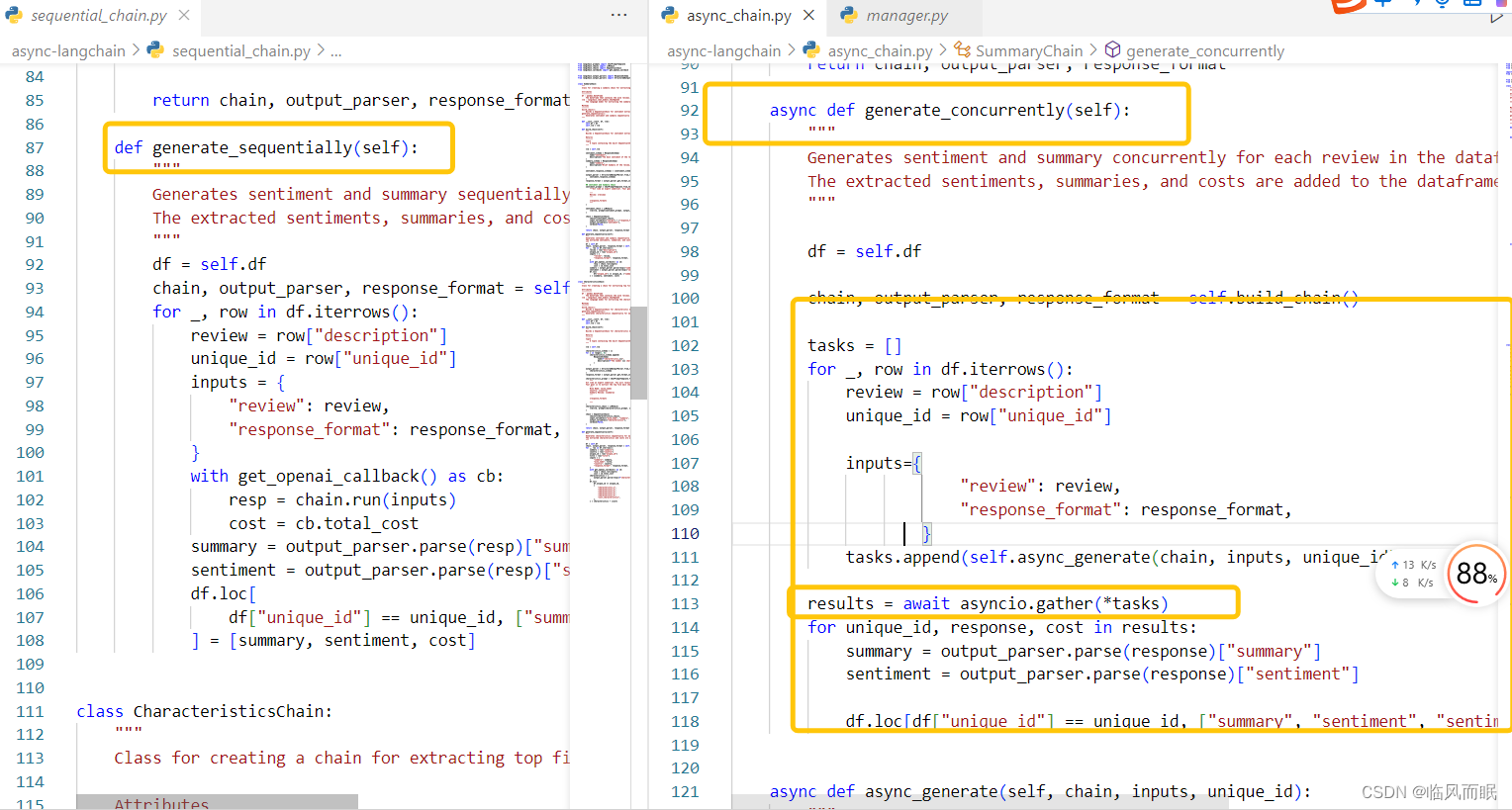
- 测试一下它的async_chain.py文件
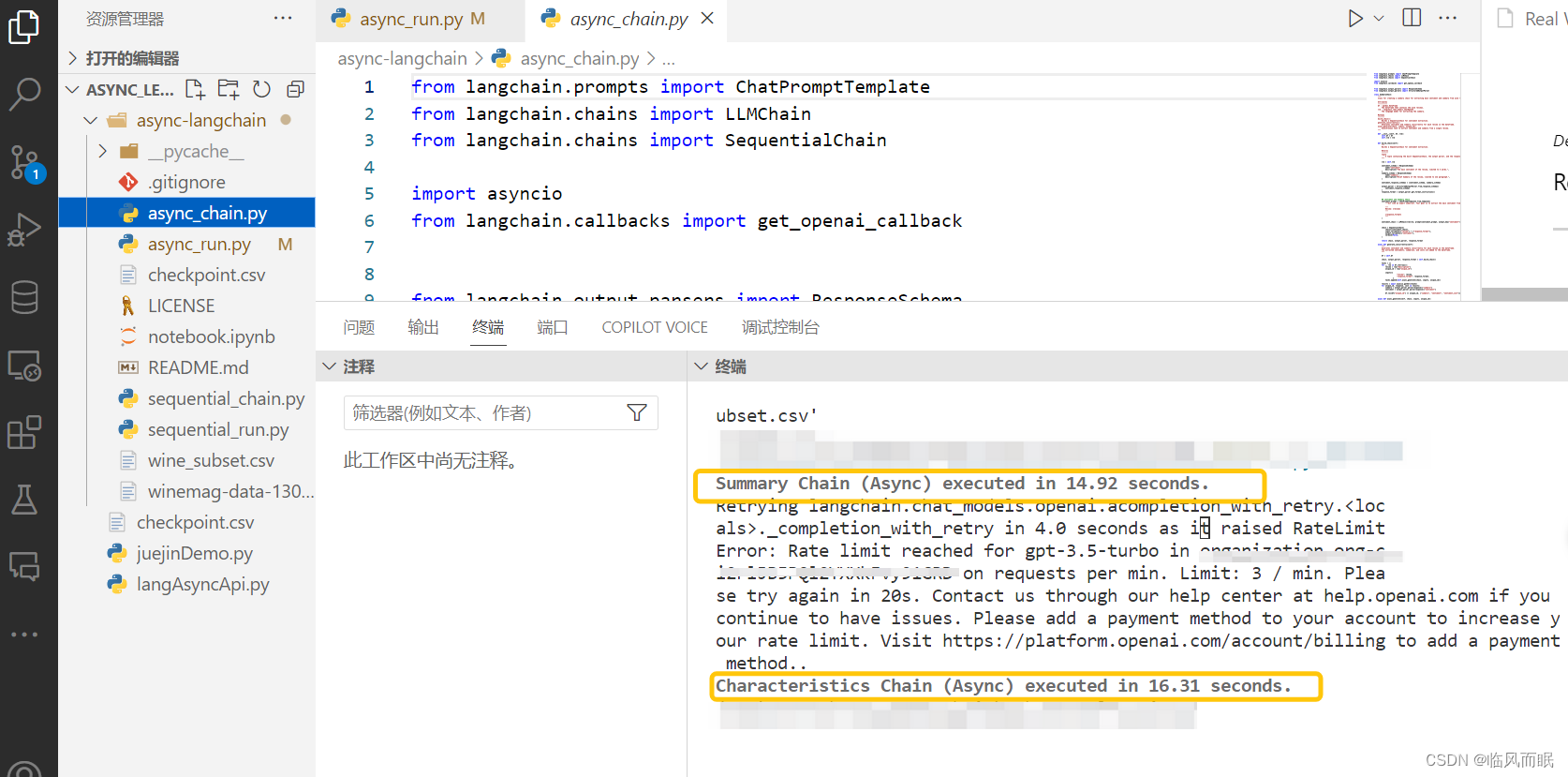
- 读取csv的时候路径一直报错,还好不久前总结了一篇blog:Python中如何获取各种目录路径
-
直接获取当前脚本路径了
import os import pandas as pd# Get the directory where the script is located script_directory = os.path.dirname(os.path.abspath(__file__))# Construct the path to the CSV file csv_path = os.path.join(script_directory, 'wine_subset.csv')# Read the CSV file df = pd.read_csv(csv_path)- sequential_run.py 就不跑了… 一天200次调用都快没了
-
- 主要是看看两者区别
相关文章:
异步使用langchain
文章目录 一.先利用langchain官方文档的AI功能问问二.langchain async api三.串行,异步速度比较 一.先利用langchain官方文档的AI功能问问 然后看他给的 Verified Sources 这个页面里面虽然有些函数是异步函数,但是并非专门讲解异步的 二.langchain asy…...

抖音开放平台第三方代小程序开发,授权事件、消息与事件通知总结
大家好,我是小悟 关于抖音开放平台第三方代小程序开发的两个事件接收推送通知,是开放平台代小程序实现业务的重要功能。 授权事件推送和消息与事件推送类型都以Event的值判断。 授权事件推送通知 授权事件推送包括:推送票据、授权成功、授…...
华为9.20笔试 复现
第一题 丢失报文的位置 思路:从数组最小索引开始遍历 #include <iostream> #include <vector> using namespace std; // 求最小索引值 int getMinIdx(vector<int> &arr) {int minidx 0;for (int i 0; i < arr.size(); i){if (arr[i] …...
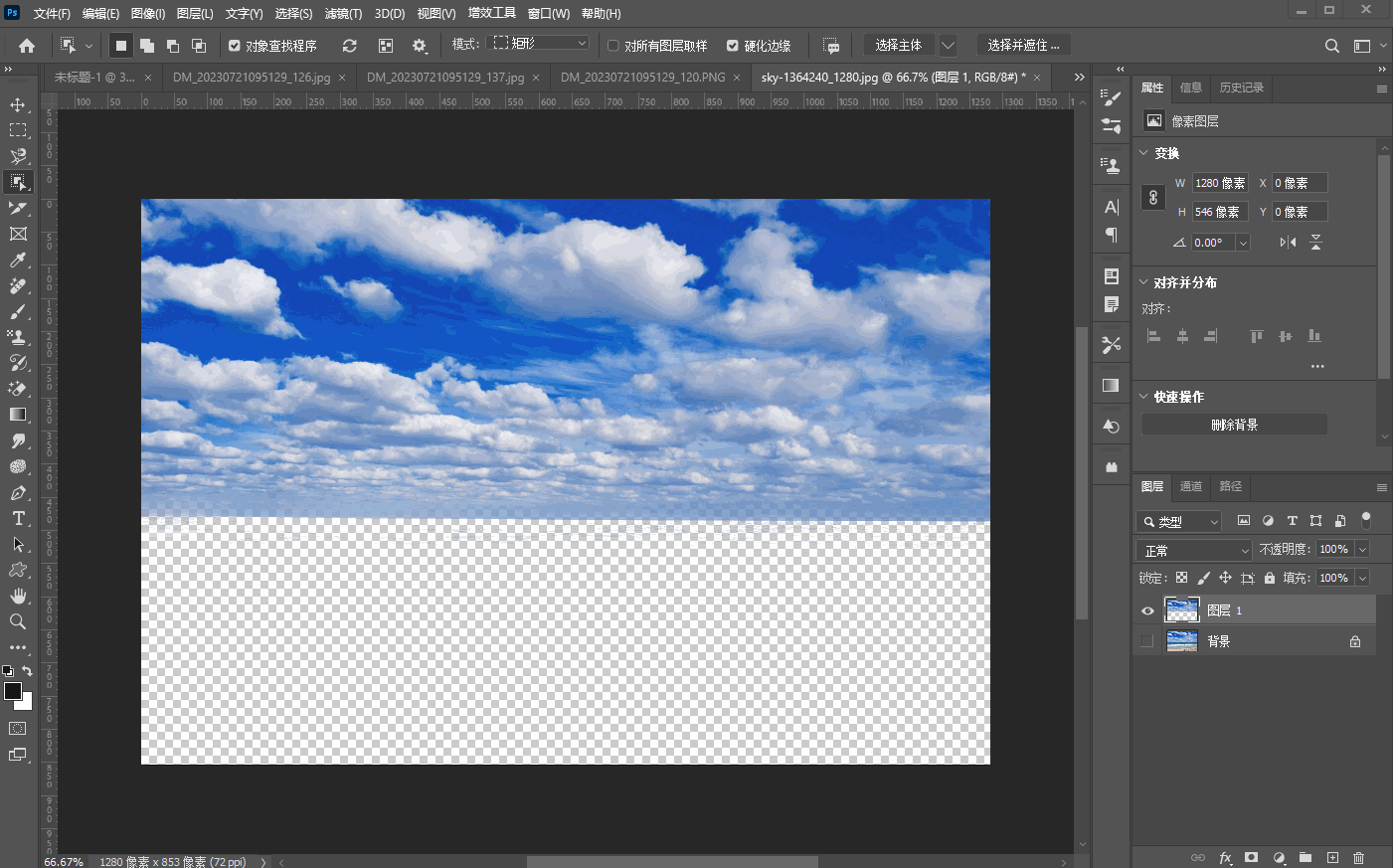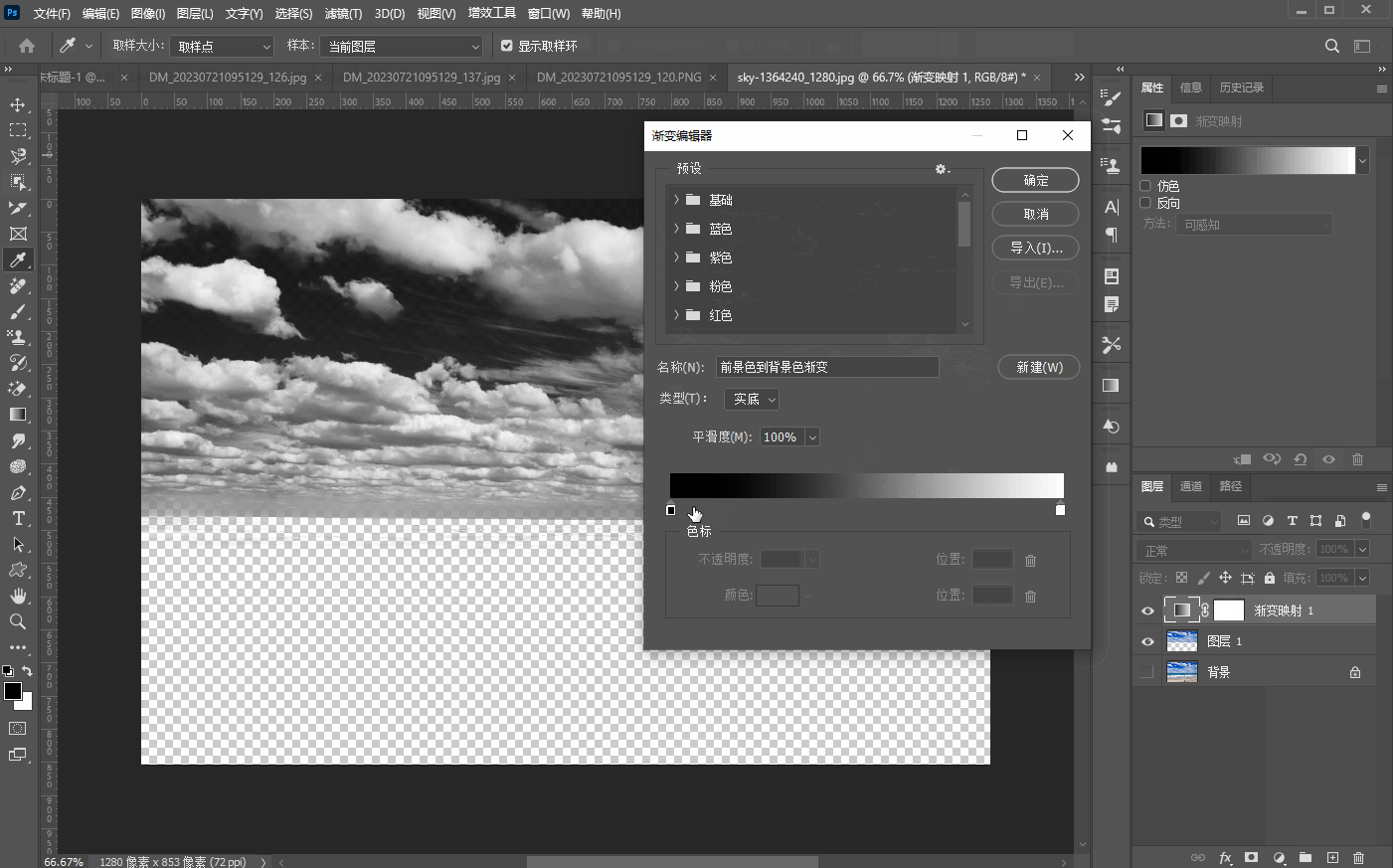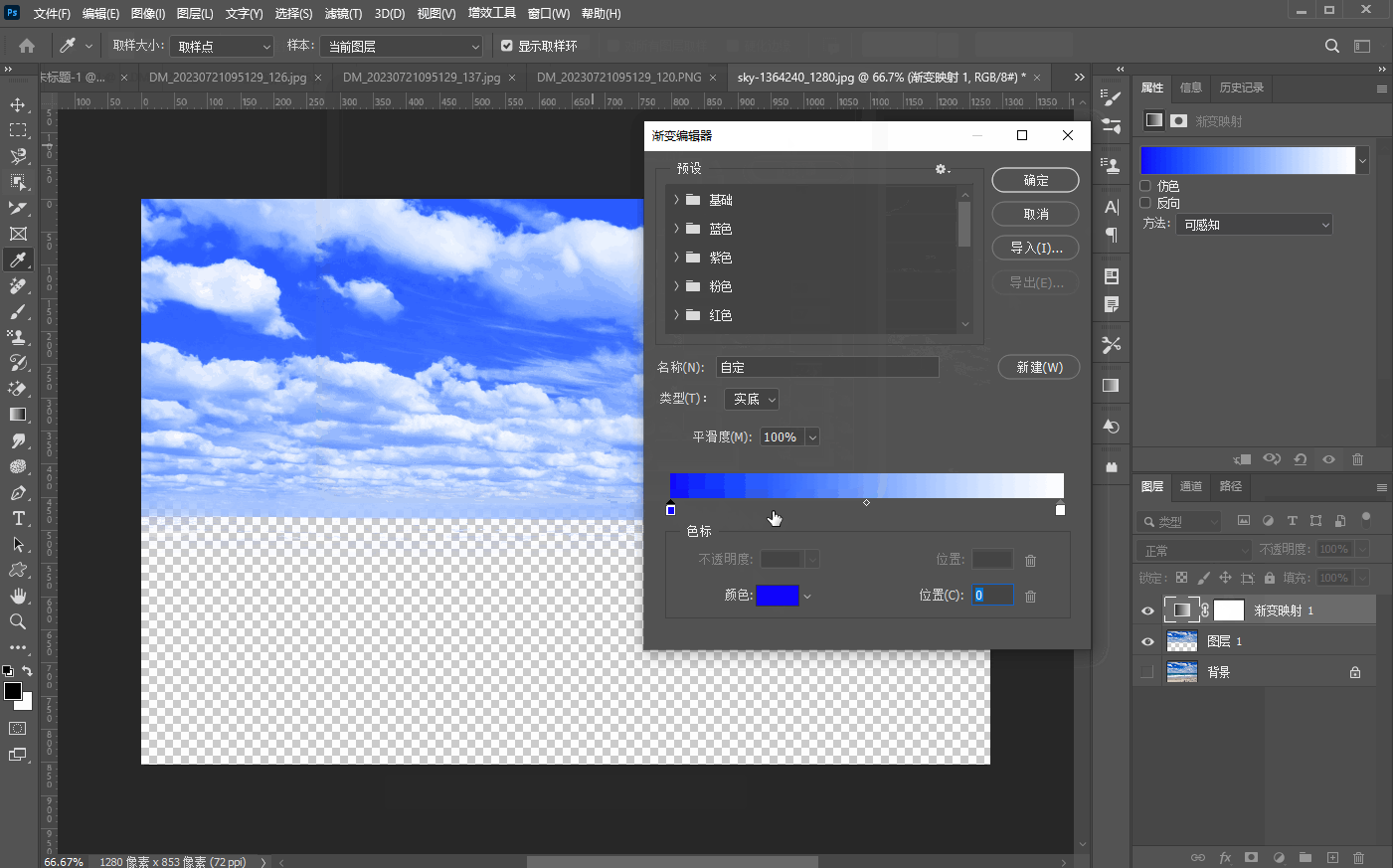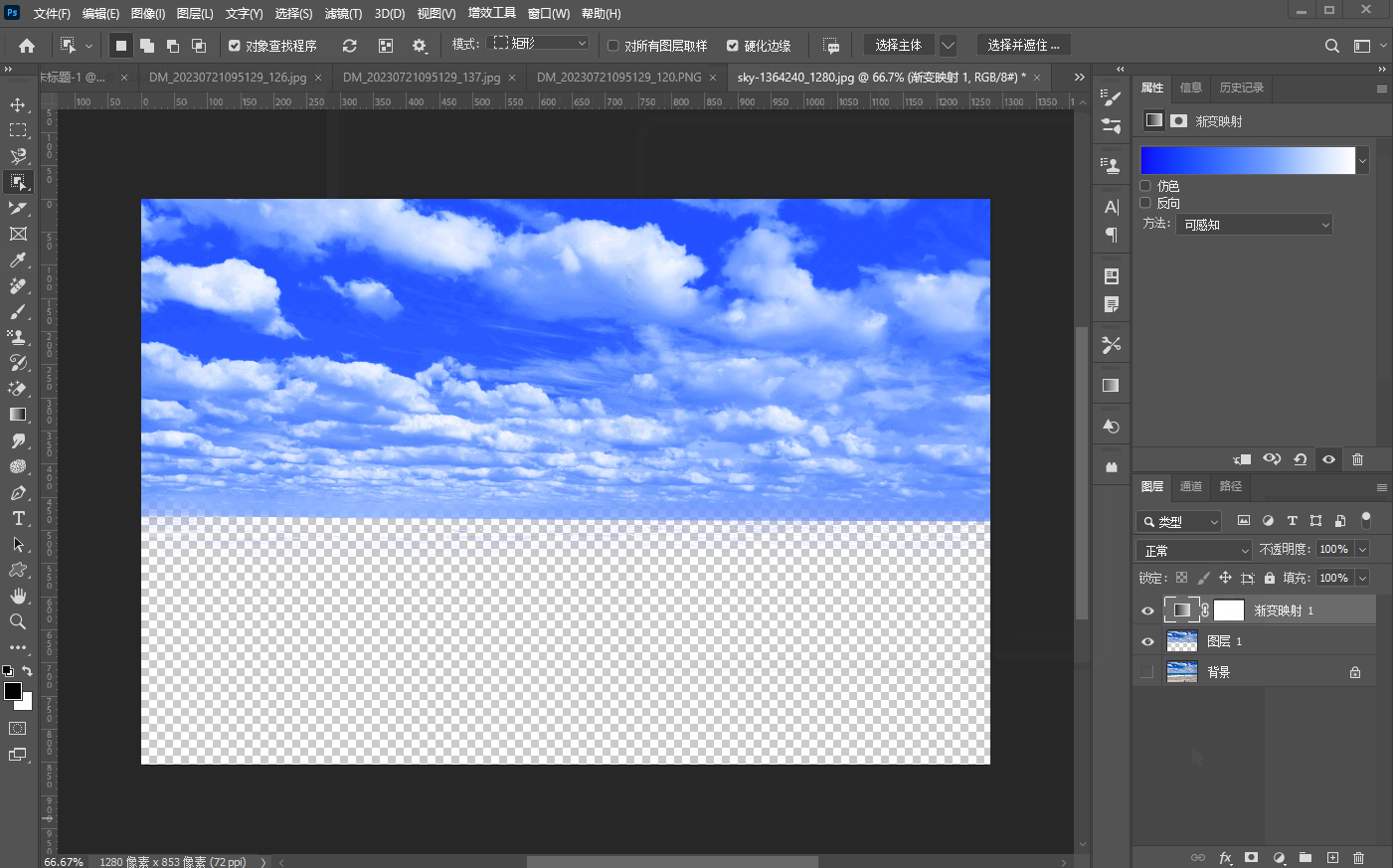
二十五、【色调调整基础】
文章目录 1、亮度/对比度a、亮度b、对比度 2、曝光度3、阈值4、色阶5、反相6、黑白7、渐变映射 1、亮度/对比度 a、亮度 亮度是指画面的明亮程度 b、对比度 对比度指的是一幅图像中,明暗区域最亮和最暗之间不同亮度层级的测量,如下图所示࿰…...
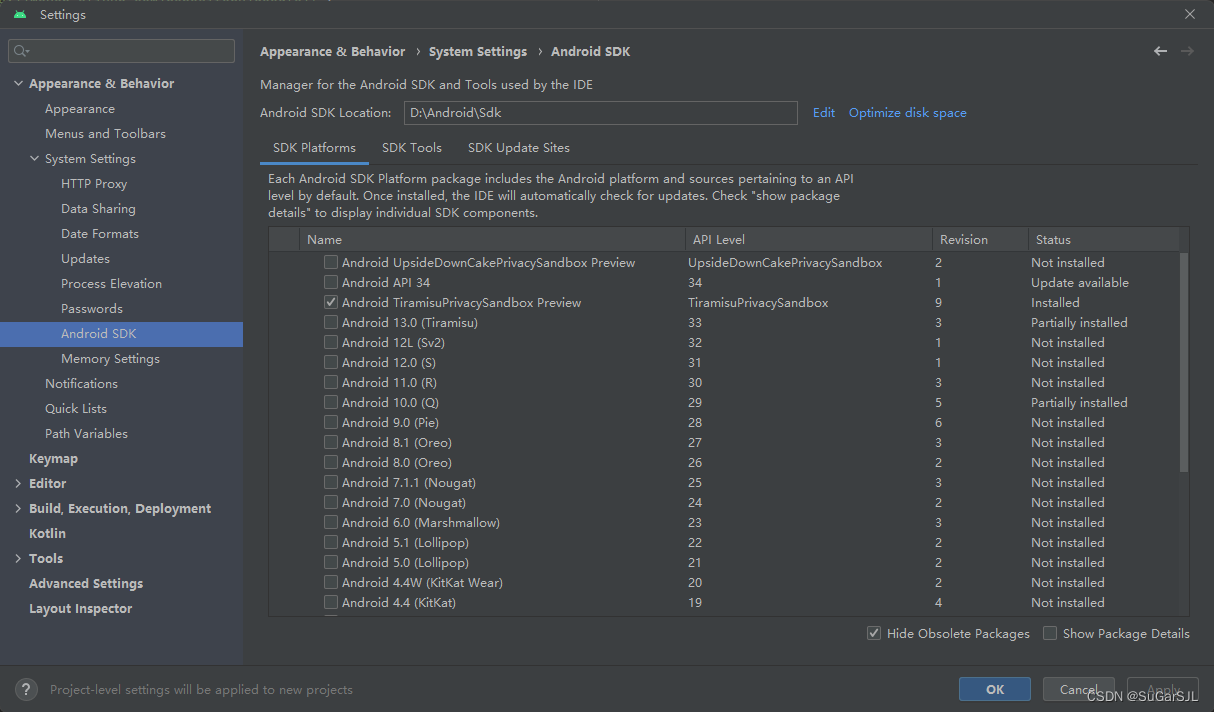
Android Studio SDK manager加载packages不全
打开Android Studio里的SDK manager,发现除了已安装的,其他的都不显示。 解决方法: 设置代理: 方便复制> http://mirrors.neusoft.edu.cn/ 重启Android Studio...

[esp32-wroom]基础开发
1、点亮LED灯 int led_pin2; void setup() {// put your setup code here, to run once:pinMode(led_pin,OUTPUT);}void loop() {// put your main code here, to run repeatedly:digitalWrite(led_pin,HIGH);delay(1000);digitalWrite(led_pin,LOW);delay(1000); } 2、LED流…...

利用Docker 实现 MiniOB环境搭建
官方文档有,但是感觉写的跟shift一样(或者是我的阅读理解跟shift一样 下面是自己的理解 一.下载docker 这个去官网下载安装,没什么说的 Docker: Accelerated Container Application Development 二.用docker下载MiniOB环境 1.打开powershell ( win r ,然后输入powershell…...

【DB2】—— 数据库表查询一直查不出来数据
问题描述 近日,数据库的测试环境中有一个打印日志表,一共有将近50w的数据,Java程序在查询的时候一直超时。 在DBvisualizer中查询数据无论是使用select * 还是 select count(*)查询的时候都是一直在执行,就是查询不到结果。 排查…...
【教程】使用vuepress构建静态文档网站,并部署到github上
官网 快速上手 | VuePress (vuejs.org) 构建项目 我们跟着官网的教程先构建一个demo 这里我把 vuepress-starter 这个项目名称换成了 howtolive 创建并进入一个新目录 mkdir howtolive && cd howtolive使用你喜欢的包管理器进行初始化 yarn init 这里的问题可以一…...

python 机器视觉 车牌识别 - opencv 深度学习 机器学习 计算机竞赛
1 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 基于python 机器视觉 的车牌识别系统 🥇学长这里给一个题目综合评分(每项满分5分) 难度系数:3分工作量:3分创新点:3分 🧿 更多资…...
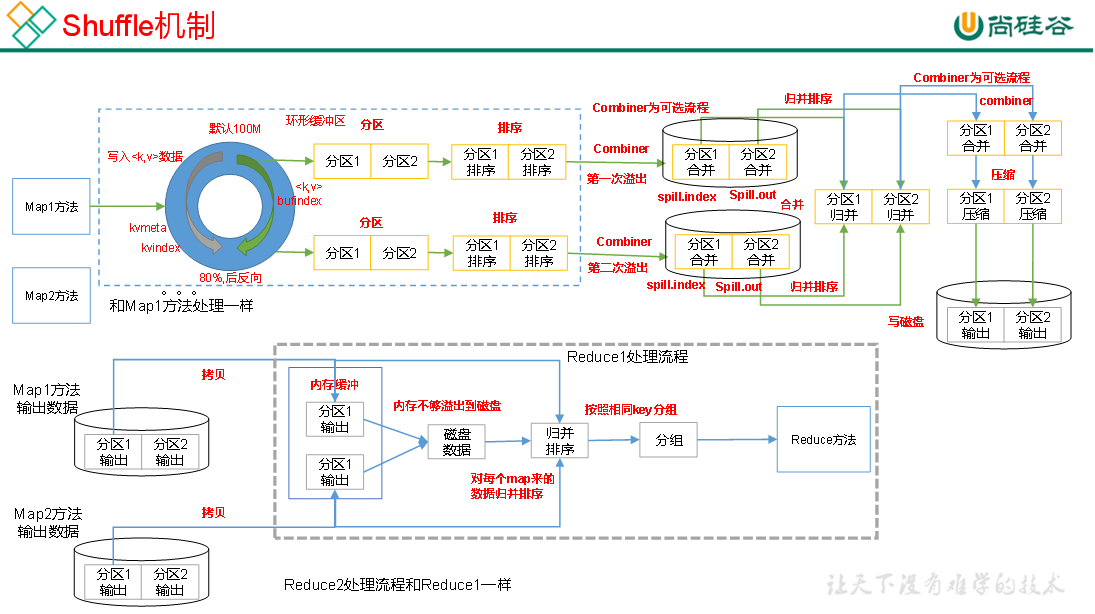
Hadoop3教程(十二):MapReduce中Shuffle机制的概述
文章目录 (95) Shuffle机制什么是shuffle?Map阶段Reduce阶段 参考文献 (95) Shuffle机制 面试的重点 什么是shuffle? Map方法之后,Reduce方法之前的这段数据处理过程,就叫做shuff…...

MySQL为什么用b+树
索引是一种数据结构,用于帮助我们在大量数据中快速定位到我们想要查找的数据。 索引最形象的比喻就是图书的目录了。注意这里的大量,数据量大了索引才显得有意义,如果我想要在[1,2,3,4]中找到4这个数据,直接对全数据检索也很快&am…...

浅谈机器学习中的概率模型
浅谈机器学习中的概率模型 其实,当牵扯到概率的时候,一切问题都会变的及其复杂,比如我们监督学习任务中,对于一个分类任务,我们经常是在解决这样一个问题,比如对于一个n维的样本 X [ x 1 , x 2 , . . . .…...

MySQL 函数 索引 事务 管理
目录 一. 字符串相关的函数 二.数学相关函数 编辑 三.时间日期相关函数 date.sql 四.流程控制函数 centrol.sql 分页查询 使用分组函数和分组字句 group by 数据分组的总结 多表查询 自连接 子查询 subquery.sql 五.表的复制 六.合并查询 七.表的外连接 …...

Flink如何基于事件时间消费分区数比算子并行度大的kafka主题
背景 使用flink消费kafka的主题的情况我们经常遇到,通常我们都是不需要感知数据源算子的并行度和kafka主题的并行度之间的关系的,但是其实在kafka的主题分区数大于数据源算子的并行度时,是有一些注意事项的,本文就来讲解下这些注…...
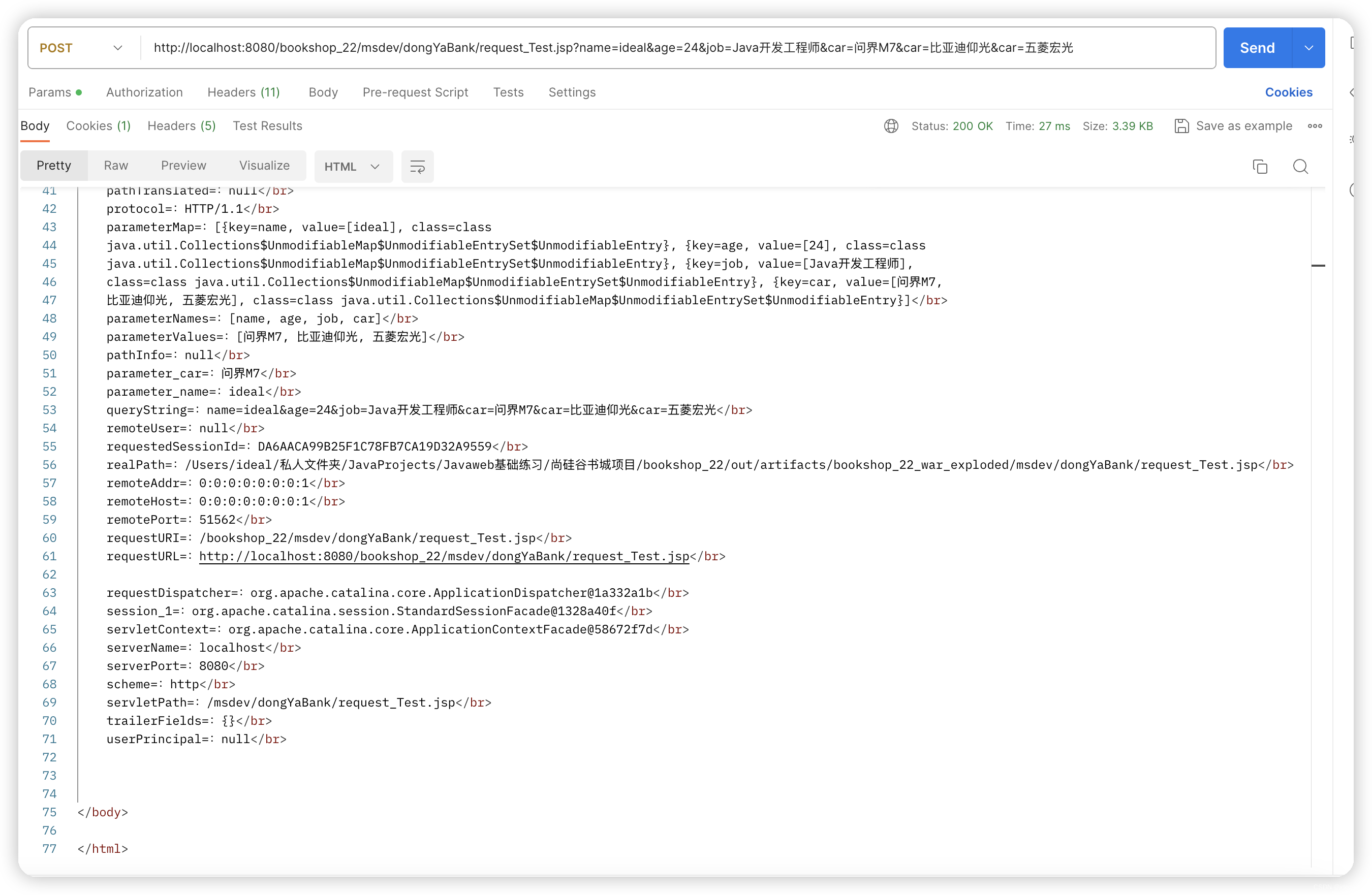
总结:JavaEE的Servlet中HttpServletRequest请求对象调用各种API方法结果示例
总结:JavaEE的Servlet中HttpServletRequest请求对象调用各种API方法结果示例 一方法调用顺序是按照英文字母顺序从A-Z二该示例可以用作servlet中request的API参考,从而知道该如何获取哪些路径参数等等三Servlet的API版本5.0.0、JSP的API版本:…...
ChatGPT AIGC 完成Excel跨多表查找操作vlookup+indirect
VLOOKUP和INDIRECT的组合在Excel中用于跨表查询,其中VLOOKUP函数用于在另一张表中查找数据,INDIRECT函数则用于根据文本字符串引用不同的工作表。具体操作如下: 1.假设在工作表1中,A列有你要查找的值,B列是你希望查询的工作表名称。 2.在工作表1的C列输入以下公式:=VLO…...

Linux系统conda虚拟环境离线迁移移植
本人创建的conda虚拟环境名为yys(每个人的虚拟环境名不一样,替换下就行) 以下为迁移步骤: 1.安装打包工具将虚拟环境打包: conda install conda-pack conda pack -n yys -o yys.tar.gz 2.将yys.tar.gz上传到服务器&…...

Vue16 绑定css样式 style样式
绑定样式: 1. class样式写法:class"xxx" xxx可以是字符串、对象、数组。字符串写法适用于:类名不确定,要动态获取。对象写法适用于:要绑定多个样式,个数不确定,名字也不确定。数组写法适用于&…...
[Spring] SpringMVC 简介(三)
目录 九、SpringMVC 中的 AJAX 请求 1、简单示例 2、RequestBody(重点关注“赋值形式”) 3、ResponseBody(经常用) 4、为什么不用手动接收 JSON 字符串、转换 JSON 字符串 5、RestController 十、文件上传与下载 1、Respo…...

Python爬虫实战:研究MechanicalSoup库相关技术
一、MechanicalSoup 库概述 1.1 库简介 MechanicalSoup 是一个 Python 库,专为自动化交互网站而设计。它结合了 requests 的 HTTP 请求能力和 BeautifulSoup 的 HTML 解析能力,提供了直观的 API,让我们可以像人类用户一样浏览网页、填写表单和提交请求。 1.2 主要功能特点…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

相机从app启动流程
一、流程框架图 二、具体流程分析 1、得到cameralist和对应的静态信息 目录如下: 重点代码分析: 启动相机前,先要通过getCameraIdList获取camera的个数以及id,然后可以通过getCameraCharacteristics获取对应id camera的capabilities(静态信息)进行一些openCamera前的…...

Mysql8 忘记密码重置,以及问题解决
1.使用免密登录 找到配置MySQL文件,我的文件路径是/etc/mysql/my.cnf,有的人的是/etc/mysql/mysql.cnf 在里最后加入 skip-grant-tables重启MySQL服务 service mysql restartShutting down MySQL… SUCCESS! Starting MySQL… SUCCESS! 重启成功 2.登…...

DingDing机器人群消息推送
文章目录 1 新建机器人2 API文档说明3 代码编写 1 新建机器人 点击群设置 下滑到群管理的机器人,点击进入 添加机器人 选择自定义Webhook服务 点击添加 设置安全设置,详见说明文档 成功后,记录Webhook 2 API文档说明 点击设置说明 查看自…...

WPF八大法则:告别模态窗口卡顿
⚙️ 核心问题:阻塞式模态窗口的缺陷 原始代码中ShowDialog()会阻塞UI线程,导致后续逻辑无法执行: var result modalWindow.ShowDialog(); // 线程阻塞 ProcessResult(result); // 必须等待窗口关闭根本问题:…...
协议转换利器,profinet转ethercat网关的两大派系,各有千秋
随着工业以太网的发展,其高效、便捷、协议开放、易于冗余等诸多优点,被越来越多的工业现场所采用。西门子SIMATIC S7-1200/1500系列PLC集成有Profinet接口,具有实时性、开放性,使用TCP/IP和IT标准,符合基于工业以太网的…...
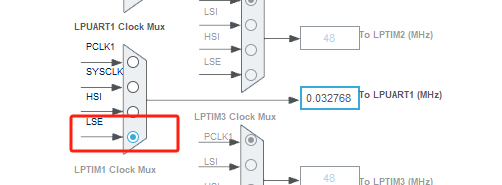
stm32wle5 lpuart DMA数据不接收
配置波特率9600时,需要使用外部低速晶振...

[USACO23FEB] Bakery S
题目描述 Bessie 开了一家面包店! 在她的面包店里,Bessie 有一个烤箱,可以在 t C t_C tC 的时间内生产一块饼干或在 t M t_M tM 单位时间内生产一块松糕。 ( 1 ≤ t C , t M ≤ 10 9 ) (1 \le t_C,t_M \le 10^9) (1≤tC,tM≤109)。由于空间…...

大数据治理的常见方式
大数据治理的常见方式 大数据治理是确保数据质量、安全性和可用性的系统性方法,以下是几种常见的治理方式: 1. 数据质量管理 核心方法: 数据校验:建立数据校验规则(格式、范围、一致性等)数据清洗&…...