Flink on k8s容器日志生成原理及与Yarn部署时的日志生成模式对比
Flink on k8s部署日志详解及与Yarn部署时的日志生成模式对比
最近需要将flink由原先部署到Yarn集群切换到kubernetes集群,在切换之后需要熟悉flink on k8s的运行模式。在使用过程中针对日志模块发现,在k8s的容器中,flink的系统日志只有jobmanager.log/taskmanager.log 两个,而当时在使用Yarn集群部署时,flink的日志会有多个,比如:jobmanager.log、jobmanager.err和jobmanager.out,TaskManager同理。
因此,有同事就提出为什么在k8s中部署时,只有.log一个文件,能不能类似Yarn部署时那样对日志文件进行区分。只是从容器日志来看的话,在一开始不够了解k8s的情况下,会觉得日志收集的不够准确。
因此针对上面的这个问题,就归我进行研究和解决了。网上的相关资料也比较少,因此,在本次对上面这个问题整体了解分析之后,进行一次学习记录。有遇到相关类似问题的,也可以参考这个思路。
一、认为需要修改log4j配置即可
拿到这个问题的第一步首先想到的是,既然要对日志的类别进行区分,则可以修改log4j的配置,将INFO类别和ERROR类别分别写入不同的日志文件即可。于是,先对flink路径下的conf/log4j-console.properties进行修改(flink on k8s部署时,使用的log4j配置文件是flink-console.properties文件,而不是log4j.properties)。
这里我们留下一个小疑问:为什么部署到k8s中时,使用的是log4j-console.properties,而不是部署到Yarn时的log4j.properties?有什么区别?
修改后的log4j-console.properties示例如下所示:
################################################################################
# Licensed to the Apache Software Foundation (ASF) under one
# or more contributor license agreements. See the NOTICE file
# distributed with this work for additional information
# regarding copyright ownership. The ASF licenses this file
# to you under the Apache License, Version 2.0 (the
# "License"); you may not use this file except in compliance
# with the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
################################################################################# Allows this configuration to be modified at runtime. The file will be checked every 30 seconds.
monitorInterval=30# This affects logging for both user code and Flink
rootLogger.level = INFO
rootLogger.appenderRef.console.ref = ConsoleAppender
rootLogger.appenderRef.rolling.ref = RollingFileAppender
rootLogger.appenderRef.errorLogFile.ref = errorLogFile# Uncomment this if you want to _only_ change Flink's logging
#logger.flink.name = org.apache.flink
#logger.flink.level = INFO# The following lines keep the log level of common libraries/connectors on
# log level INFO. The root logger does not override this. You have to manually
# change the log levels here.
logger.akka.name = akka
logger.akka.level = INFO
logger.kafka.name= org.apache.kafka
logger.kafka.level = INFO
logger.hadoop.name = org.apache.hadoop
logger.hadoop.level = INFO
logger.zookeeper.name = org.apache.zookeeper
logger.zookeeper.level = INFO# Log all infos to the console
appender.console.name = ConsoleAppender
appender.console.type = CONSOLE
appender.console.layout.type = PatternLayout
appender.console.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n# Log all infos in the given rolling file
appender.rolling.name = RollingFileAppender
appender.rolling.type = RollingFile
appender.rolling.append = true
appender.rolling.fileName = ${sys:log.file}
appender.rolling.filePattern = ${sys:log.file}.%i
appender.rolling.layout.type = PatternLayout
appender.rolling.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.rolling.policies.type = Policies
appender.rolling.policies.size.type = SizeBasedTriggeringPolicy
appender.rolling.policies.size.size=100MB
appender.rolling.policies.startup.type = OnStartupTriggeringPolicy
appender.rolling.strategy.type = DefaultRolloverStrategy
appender.rolling.strategy.max = ${env:MAX_LOG_FILE_NUMBER:-10}
appender.rolling.filter.threshold.type = LevelMatchFilter
appender.rolling.filter.threshold.level = INFO
appender.rolling.filter.threshold.onMatch = ACCEPT
appender.rolling.filter.threshold.onMisMatch = DENYappender.errorFile.name = errorLogFile
appender.errorFile.type = RollingFile
appender.errorFile.append = true
appender.errorFile.fileName = ${sys:log.file}.err
appender.errorFile.filePattern = ${sys:log.file}.err.%i
appender.errorFile.layout.type = PatternLayout
appender.errorFile.layout.pattern = %d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
appender.errorFile.policies.type = Policies
appender.errorFile.policies.size.type = SizeBasedTriggeringPolicy
appender.errorFile.policies.size.size = 100MB
appender.errorFile.policies.startup.type = OnStartupTriggeringPolicy
appender.errorFile.strategy.type = DefaultRolloverStrategy
appender.errorFile.strategy.max = ${env:MAX_LOG_FILE_NUMBER:-10}
appender.errorFile.filter.threshold.type = ThresholdFilter
appender.errorFile.filter.threshold.level = ERROR
appender.errorFile.filter.threshold.onMatch = ACCEPT
appender.errorFile.filter.threshold.onMisMatch = DENY# Suppress the irrelevant (wrong) warnings from the Netty channel handler
logger.netty.name = org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline
logger.netty.level = OFF
这里相比原始文件的修改,主要集中在以下两个方面:
- 增加RollingFileAppender的threshold参数。因为我最初希望.log日志就只显示INFO日志,而不显示其他类型日志。但是在log4j官网中介绍的threshold.level参数,其过滤的是低于设置类型的日志。比如当threshold.level=INFO时,过滤的是低于INFO类型的日志,比如DEBUG,而高于的比如ERROR类型的日志还是会保留。在查找一番资料后,发现了threshold.type = LevelMatchFilter的配置,这种配置可以使得当前appender只保留所设置的日志类型的日志,从而实现了只保留INFO日志的需求。
- 增加了errorLogFile的appender。配置同上,使得当前appender只保留ERROR类型的日志数据。
观察上面的log4j-console.properties配置可以发现,在设置文件名时,使用了一个系统变量${sys:log.file},这个系统变量使用过flink配置的应该都比较熟悉,指定本地flink日志的默认路径,比如/opt/log/jobmanager.log。
经过测试后,使用上面的log4j配置能够实现我最初的想法,即将INFO日志和ERROR日志区分开,写入不同的文件。但是经过与Yarn部署时的文件对比发现,实际上并不能满足原始需求。
因为在Yarn中,.log日志中也会存在ERROR日志类型的数据,似乎并不是利用log4j配置进行分开。而且我查看log4j.properties配置,也没有发现类似这种区分日志类型的配置。同时在Yarn中,.err日志输出的是任务异常信息,比如e.printStackTrace(),.out日志输出的是类似System.out.println中的数据。而log4j的配置实际上单纯的只是针对flink执行时的系统日志进行配置处理,似乎跟上面的场景还不是一样的。
因此,就要去寻找新的思路,在摸索之后,决定从根据这个log.file的系统变量,从flink的源码入手
二、Flink源码分析-Yarn
在本地git clone好flink的源码后,切换到flink1.12版本分支,进行全局搜索"log.file",在flink-runtime模块下发现了BootstrapTools类,在该类下,有一个getTaskManagerShellCommand的方法,在方法中,有一处代码非常有用,如下所示:
startCommandValues.put("redirects","1> "+ logDirectory+ "/taskmanager.out "+ "2> "+ logDirectory+ "/taskmanager.err");
可以看到,这里不就是我们最初想要生成的.out和.err文件吗!!。那么这里的redirects表示什么意思呢?
观察后源码知道,flink设置了一个启动命令行的template模块,有一个redirects的占位符,因此上面实际上就是后续将重定向命令替换redirects占位符。
接下来看一下这个方法在哪里被调用了,发现除了在BootstrarpToolsTest测试类中被调用外,只在flink-yarn项目下src/main/java/org/apache/flink/yarn/Utils.java类中被使用,如下所示:
String launchCommand =BootstrapTools.getTaskManagerShellCommand(flinkConfig,tmParams,".",ApplicationConstants.LOG_DIR_EXPANSION_VAR,hasLogback,hasLog4j,hasKrb5,taskManagerMainClass,taskManagerDynamicProperties);if (log.isDebugEnabled()) {log.debug("Starting TaskManagers with command: " + launchCommand);} else {log.info("Starting TaskManagers");}
因此,当部署到Yarn集群上上时,在构建TaskManager的启动命令时,会使用上述的方法。同时,上面的代码发现,当满足log.isDebugEnabled()条件时,可以打印出这个启动命令。如何能满足这个条件呢?实际上,log.isDebugEnabled()就是表示当前log4j的配置是允许打印DEBUG类型日志的,因此,我们去到flink的conf/log4j.properties下,修改rootLogger.level = INFO => rootLogger.level = DEBUG,然后再重新运行任务,即可在日志中看到这个启动命令:

可以看到,在启动命令的最后位置,有上面代码中的重定向命令,这个重定向命令将标准输出和标准错误分别重定向到了.out和.err文件。
至此,我们就成功定位了在Yarn中为什么能够生成.err和.out日志的原因了。实际上就是由于这样的一条重定向语句,将flink任务执行时的标准输出和标准错误分别重定向到了.out和.err文件。这也解释了为什么在Yarn部署时,.err日志里显示的是异常信息,比如e.printStackTrace(),.out文件输出的是包括System.out的日志数据
弄明白了Yarn的日志生成机制后,我们接下来去看一下k8s是怎么实现的?
三、Flink源码分析-Kubernetes
那么在k8s部署时,是否也有这样的重定向语句呢?为了一探究竟,仍然是分析flink 1.12版本的源码。在flink-kubernetes项目下,有一个src/main/java/org/apache/flink/kubernetes/utils/KubernetesUtils.java类,在该类下,存在一个getCommonStartCommand方法,该方法类似于上面getTaskManagerShellCommand方法,也是用来构造启动命令参数的,但是在该方法下,我发现就不存在这样的一条重定向语句:
startCommandValues.put("logging",getLogging(logDirectory + "/" + logFileName + ".log",configDirectory,hasLogback,hasLog4j));
只有这样的一个写入.log文件的启动命令配置。同时遗憾的是,在k8s部署时,也没有类似上面Yarn那样可以在DEBUG日志类型下,打印出启动命令的语句。但是,我们仍然能做出一个初步的结论:
flink部署在k8s上时,没有.out和.err文件,就是由于源码中在启动TaskManager/JobManager的启动命令参数中,没有将标准输出和标准错误进行重定向到指定的.out和.err文件导致的。而生成的.log文件,就是在log4j-console.properties中配置的RollingFile滚动的系统日志。
同时我发现,在flink1.11版本时,上面的方法中还保留着跟Yarn一样的重定向语句,只是从1.12版本之后,就去掉了该重定向语句,是什么原因呢?
至此,我们找出了flink部署到k8s中时,只有一个.log文件的根源。接下来,为了解决最初的原始问题,需要向方案去解决。
四、设计解决方案
首先想到的解决方案,肯定就是将Yarn那里的重定向源码复制一份到上面的k8s代码中,然后重新打包Flink再进行部署。但这种方案尝试之后发现,在用maven打包flink时会出现很多异常,比如包找不到。而且flink有180多个pom要打包,时间应该会花费非常长,在本次需求对flink源码改动要求不是很大的情况下,感觉这种调试会花费太多不必要的时间。遂舍弃改方案。
另一个方案,就是想办法在外层,能不能在将flink打包成镜像的时候,在它原先源码中定义的启动命令参数后,再手动添加上重定向命令。为此,观察pod的yaml可以发现,容器启动的参数有args下,启动命令时执行/docker-entrypoint.sh脚本

有了这些信息后,就找到docker-entrypoint.sh的启动脚本,打开后进行分析,通过日志可以知道,脚本执行的过程中,会进入到下面的这个分支下:

其中args参数就是上面容器中的args参数,可以看到原先这个分支的最后一行是去执行exec $(drop_privs_cmd) bash -c "${args[@]}"。因此,我们就可以在这里,手动添加上标准输出和标准错误的重定向到指定文件,也相当于实现了在启动参数中加入重定向语句。
这里我们还需要借助args参数中的-Dlog.file中显示的是jobmanager还是taskmanager来决定重定向写入的文件名是jobmanager.err还是taskmanager.err。为此使用sed命令,先获取到args中的-Dlog.file内容(即上面的参数logFilePath),然后从logFilePath中,获取到jobmanager/taskmanager的文件名(即logFileName参数)。
然后,我们添加上重定向命令:
exec $(drop_privs_cmd) bash -c "${args[@]} 1> /opt/flink/log/${logFileName}.out 2> /opt/flink/log/${logFileName}.err
至此,我们就成功在外层flink打包成镜像时,手动在启动命令参数后添加了重定向命令,模拟了Yarn执行时的命令,来生成.err和.out文件。接下来,就是打包成镜像,然后在k8s中进行测试了。经过测试,我们发现,在/opt/log/路径下,真的生成了.out、.err和.log三个文件!!!

同时经过测试可以发现,.err、.out和.log文件分别对应了标准错误、标准输出和系统文件三部分内容。实现了跟部署在Yarn上时一样的场景,解决了我们文章最初提出的问题!!!
然而。。却出现了问题。
五、问题以及对k8s日志的理解
在完成上述测试之后,当我再次点击pod,或者使用kubectl logs命令来查看日志时发现,日志里竟然只有启动脚本的一些日志,而flink执行的系统日志都没有了!!
没办法,只能再去分析原因了。在kubernetes的官网中,在日志架构章节中,赫然写着如下一段话:
容器运行时对写入到容器化应用程序的
stdout和stderr流的所有输出进行处理和转发。 不同的容器运行时以不同的方式实现这一点;不过它们与 kubelet 的集成都被标准化为 CRI 日志格式。默认情况下,如果容器重新启动,kubelet 会保留一个终止的容器及其日志。 如果一个 Pod 被逐出节点,所对应的所有容器及其日志也会被逐出。
kubelet 通过 Kubernetes API 的特殊功能将日志提供给客户端访问。 访问这个日志的常用方法是运行
kubectl logs。
虽然我现在对k8s的理解也不够,但看上面这段话让我意识到,容器的日志收集或许也是通过监听stdout和stderr来生成的。。。 而由于我上面使用重定向命令,将标准输出和标准错误都重定向到了指定的文件中,导致stdout和stderr无法监听到日志数据,所以容器内的日志就获取不到了。
或者说,利用上面将标准输出和标准错误重定向写入指定指定文件的方式,是相当于将原先容器里的日志,分别根据日志类型映射到了.err、.out和.log日志文件下来展示。
那这样分析下来,我发现,flink之所以在1.12版本之后将重定向命令从源码中去掉,可能为的就是利用k8s的日志聚合,将stdout和stderr都写入容器日志中,方便后续对容器日志的监控和分析等操作。
嗯。。此时,感觉上面最开始的分析都白费了,因为本身容器的日志实际上就已经包含了所有日志数据了,根本不用再做.out和.err的区分了
这里插一句,还记得文章在第一部分提出的问题吗?这里,大家再思考另一个问题,就是讲到这里,我们知道容器会对stdout和stderr流进行处理和转发。stderr包含flink任务执行时的异常信息,stdout包含任务执行时的标准输出信息,那么flink执行时的系统日志比如INFO、ERROR日志数据,容器时从哪里获取到的呢?log4j中配置的RollingFile类型的appender可不属于标准输出。
那么这个问题的答案,也就是flink提交到k8s部署时,为什么使用的是log4j-console.properties配置的原因了。
因为在log4j-console.properties中,会有一个ConsoleAppender的配置,将flink的系统日志打印到CONSOLE(System.out),所以相当于将系统日志打印到了标准输出,然后容器再通过监听stdout从而获取到系统日志。
而部署到Yarn时,使用的log4j.properties的配置中,就可以看到并没有ConsoleAppender的配置,所以它的系统日志全部打印到了.log文件中。
解决了这个问题,再说回之前的分析。我们上面添加的重定向操作,相当于是模仿着Yarn上部署的方式,将原先容器里的日志,分别根据日志类型映射到了.err、.out和.log日志文件下来展示。但是此时容器中的日志却丢失了,可能会对后续我们最容器上的日志采集和分析有影响。
那有没有什么解决方案呢?
双写。尝试在将标准输出和标准错误重定向到指定文件时,同时重定向到stdout和stderr。为此,我们进行了测试,也就是docker-entrypoint.sh中的下面这行代码:
exec $(drop_privs_cmd) bash -c "${args[@]} 1> >(tee /opt/flink/log/${logFileName}.out >/dev/stdout) 2> >(tee /opt/flink/log/${logFileName}.err >/dev/stderr)"
命令中的1> >(tee /opt/flink/log/${logFileName}.out >/dev/stdout)表示将标准输出重定向到一个匿名的管道中,并将管道中的内容通过tee命令同时输出到文件/opt/flink/log/${logFileName}.out和标准输出设备中。
经过测试,可以实现上面的功能,即既有.out和.err文件,同时,容器日志也恢复最初的状态。
但是需要说明一点的是,由于log4j-console.properties配置把系统日志也作为标准输出的一部分,因此生成的.out文件中实际上包含了任务中System.out的输出和系统文件两部分内容。而.err文件则只包含了标准错误的日志内容。
至此,实现的日志效果是:
- 容器日志:包含系统日志、标准输出、标准错误
- .out日志:包含系统日志、标准输出
- .err日志:包含标准错误
以上就是本次,针对最初提出的k8s日志问题,进行的一次深入探究和思考。在研究过程中,对log4j的日志配置也有了更深入的理解,由于一开始对容器和k8s技术的不了解,导致最后似乎实现的结果不理想,但技术不就是不断探究的过程吗!
关于上面的问题,如果有遇到类似的也欢迎找我探讨,感谢阅读!
相关文章:
Flink on k8s容器日志生成原理及与Yarn部署时的日志生成模式对比
Flink on k8s部署日志详解及与Yarn部署时的日志生成模式对比 最近需要将flink由原先部署到Yarn集群切换到kubernetes集群,在切换之后需要熟悉flink on k8s的运行模式。在使用过程中针对日志模块发现,在k8s的容器中,flink的系统日志只有jobma…...

AD20绘制电路板的外形
今天学习了绘制电路板外形的方法,记录一下,回头忘了还能在看看,便能很快的回忆起来了,比看视频啥的要高效的多。毕竟是自己写的,印象要深刻的多。 首先新建一个PCBDoc文件,方法如下图: 在新建的…...

linux 设置开机启动
1、Fedora 20系列操作系统 touch /etc/rc.d/rc.local chmod x /etc/rc.d/rc.local vi /etc/rc.d/rc.local 按“i”进入编辑模式,在文件末尾补充如下内容: 可以根据需要添加你要开机自启动的脚本命令(下面是举例): …...
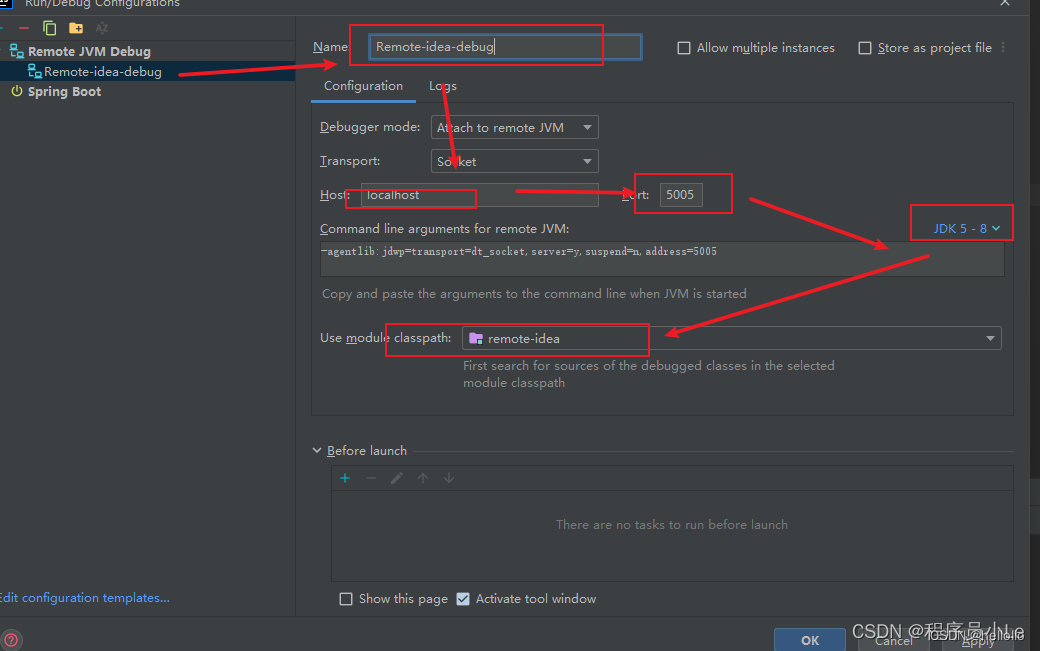
IDEA实现远程Debug调试
一、 前提 需要准备JDK1.8环境,安装IDEA(版本不限) 二、 IDEA中如何实现远程Debug模式 (1)、创建demo项目 1.File一>New一>project… 2.Maven Archetype一>填写Name一>选择jdk1.8一>选择Web一>创建 (2)、配置Idea 找到Remote Jvm Debug java…...
SpringBoot项目入门: IDEA 创建SpringBoot项目
方式1:在线创建项目 https://start.spring.io/ 环境准备 (1)JDK 环境必须是 1.8 及以上,传送门:jdk1.8.191 下载(2)后面要使用到 Maven 管理工具 3.2.5 及以上版本(3)开发工具建议…...

Vue2+SpringBoot实现数据导出到csv文件并下载
前言 该功能用于导出数据到csv文件,并且前端进行下载操作。涉及到java后端以及前端。后端获取数据并处理,前端获取返回流并进行下载操作。csv与excel文件不大相同。如果对导出的数据操作没有很高要求的话,csv文件就够了。具体差异自行百度。我…...
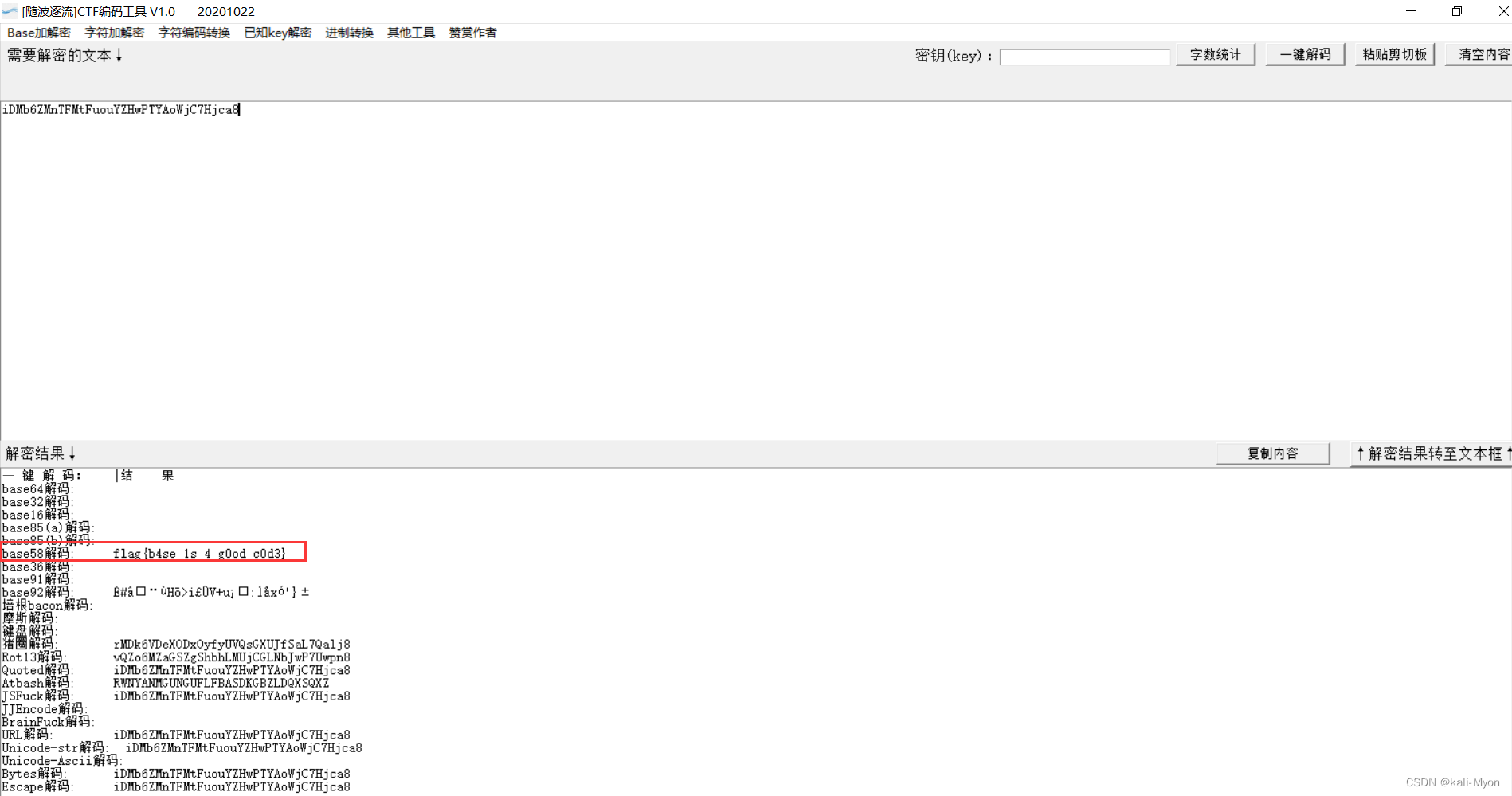
NewStarCTF2023week2-base!(base低位隐写)
附件内容是很多的base64编码的字符串 常见的Base64隐写一般会给一个txt文本文档,内含多个经过base64编码的字符串。解码规则是将所有被修改过的base64字符串结尾的二进制值提取出来组成一个二进制串,以8位分割并转为十进制值,最终十进制对应的…...

众和策略:国际油价走高,石油板块强势拉升,通源石油、和顺石油等涨停
石油板块16日盘中大幅拉升,到发稿,通源石油、和顺石油、贝肯动力、中曼石油、泰山石油、仁智股份等涨停,潜能恒信、博迈科涨约8%。 燃气板块亦上扬,到发稿,洪通燃气、美能动力涨约5%,新疆火炬、九丰动力涨…...

C++笔记之获取线程ID以及线程ID的用处
C笔记之获取线程ID以及线程ID的用处 code review! 文章目录 C笔记之获取线程ID以及线程ID的用处一.获取ID二.线程ID的用处2.1.线程池管理2.2.动态资源分配2.3.使用线程同步机制实现互斥访问共享资源2.4.使用线程 ID 辅助线程同步2.5.任务分发:线程ID可以用于将任务…...

机器人硬件在环仿真:解决实体开发与测试挑战,提升效率与安全性
工业机器人具备出色的灵活性和运动能力,广泛应用于工业制造领域。它们可以完成装配、焊接、喷涂、搬运、加工、品质检测等任务,提高了生产效率,保证了产品质量。此外,在医疗领域也有辅助手术等特殊应用,展现了其在多个…...
)
stream()
stream().map,stream().filter,stream().peek 1、stream().map:该方法用于将一个流中的元素通过指定的函数进行映射,最终生成一个新的流。例如,如果我们有一个存储了字符串的列表,可以使用 map 方法将列表…...
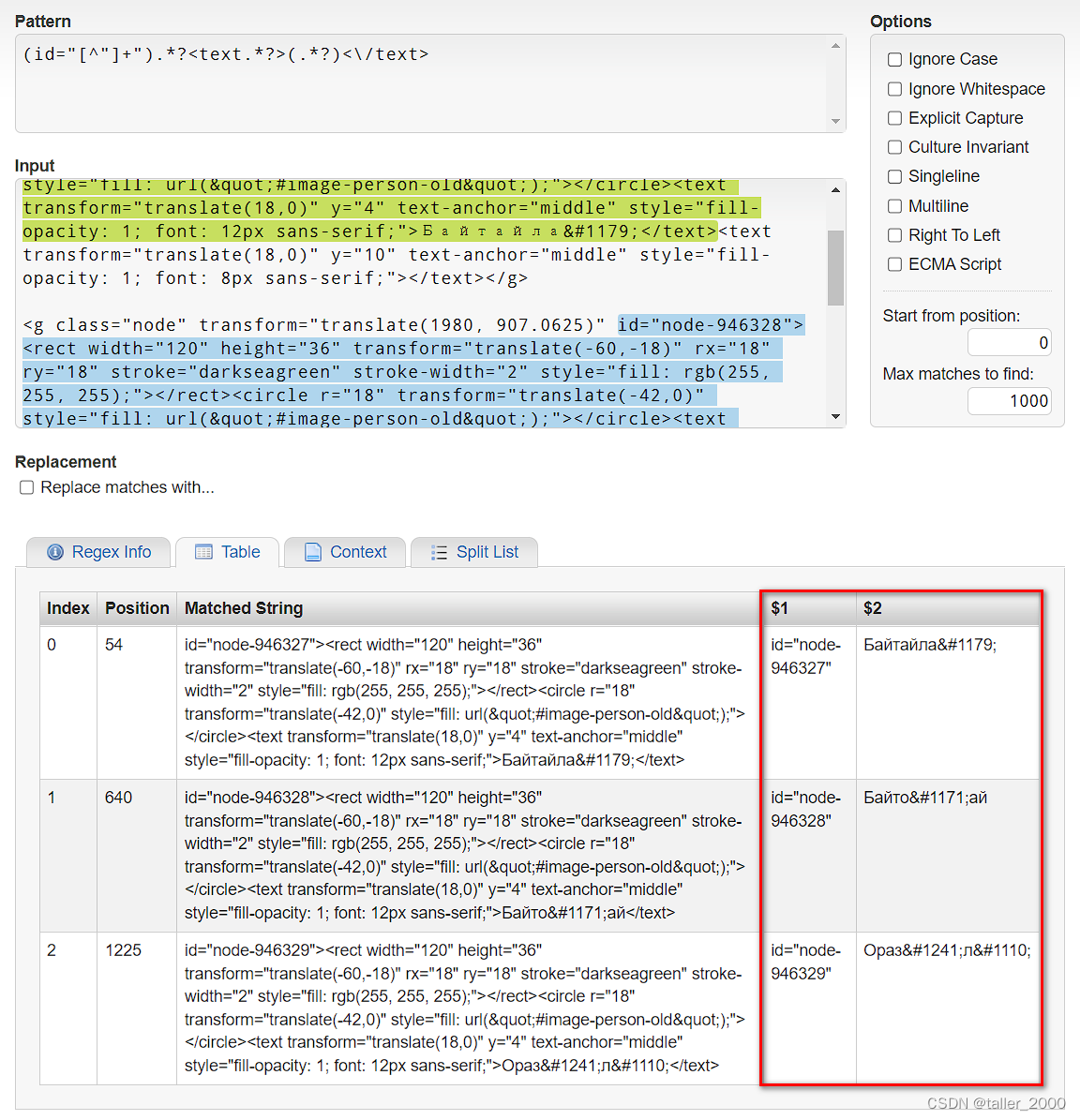
VBA之正则表达式(43)-- 从网页中提取指定数据
实例需求:由网页中提取下图中颜色标记部分内容,网页中其他部分与此三行格式相同。 方法1 Sub Demo()Dim objRegex As ObjectDim inputString As StringDim objMatches As ObjectDim objMatch As ObjectSet objRegex CreateObject("VBScript.RegEx…...

Elucidating the Design Space of Diffusion-Based Generative Models 阅读笔记
文章使用模块化(modular)的思想,分别从采样、训练、score network设计三个方面分析和改进diffusion-based models。 之前的工作1已经把diffusion-based models统一到SDE或者ODE框架下了,这篇文章的作者同样也从SDE和ODE的角度出发…...
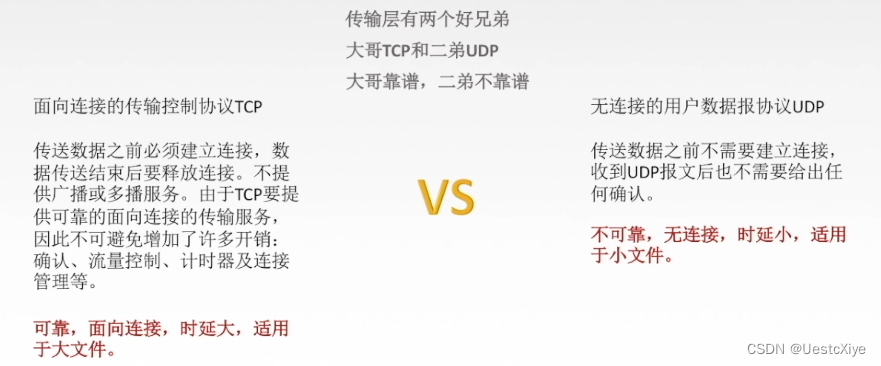
计算机网络 | 传输层
计算机网络 | 传输层 计算机网络 | 传输层功能概述 参考视频:王道计算机考研 计算机网络 参考书:《2022年计算机网络考研复习指导》 计算机网络 | 传输层 功能概述 传输层是主机才有的层次。 复用:发送方的不同应用进程都可以使用同一个传…...

Android 13 隐私权限和安全变更之通知
介绍 根据官网https://developer.android.com/about/versions/13/summary?hlzh-cn展示的Android 13 功能和变更列表中提及的,Android 13(API 级别 33)引入了新的权限POST_NOTIFICATIONS。 使用 在Android 13及以上版本,如需向…...
)
docker-compose安装和使用(自启、redis、mysql、rabbitmq、activemq、es、nginx、java应用)
1.在线安装docker-compose: 参考官网:https://docs.docker.com/compose/install/other/ docker-compose安装及简单入门 [Docker] docker-compose使用教程 Docker系列教程22-docker-compose.yml常用命令 # 安装(加速下载https://ghproxy.…...

dll文件缺失,ps,pr无法打开,游戏运行不了如何解决
最近重装了系统,然后打开原来的软件发现都会报错,说***.dll文件缺失 于是找了很多解决办法 方案一 说是下载一个dll文件恢复助手,一键恢复 不要信 统统不管用,不是收费高就是没作用 方案二 下载对应dll文件去c盘对应软件位置…...
前后端数据导入导出Excel
一:导入 Excel有读取也便有写出,Hutool针对将数据写出到Excel做了封装。 原理 Hutool将Excel写出封装为ExcelWriter,原理为包装了Workbook对象,每次调用merge(合并单元格)或者write(写出数据&…...

RackNerd 圣何塞 VPS 测评
发布于 2023-07-06 on https://chenhaotian.top/vps/racknerd-ca/ RackNerd 圣何塞 VPS 测评 官网链接:https://my.racknerd.com/index.php?rp/store/kvm-vps 这款是2022年双十一特别款,现在已经买不到了 网络是G口,4T流量 稳定性不错&…...
php74 安装sodium
下载编译安装libsodium wget https://download.libsodium.org/libsodium/releases/libsodium-1.0.18-stable.tar.gz tar -zxf libsodium-1.0.18-stable.tar.gz cd libsodium-stable ./configure --without-libsodium make && make check sudo make install下载编译安装…...
)
Fluent-Rocky耦合插件实战排障指南(2025R1版)
1. Fluent-Rocky耦合插件快速入门 刚接触Fluent-Rocky耦合插件的朋友可能会觉得有点懵,其实它的核心功能很简单:让Fluent和Rocky这对好兄弟能够顺畅地"聊天"。具体来说,它主要负责把Fluent计算出的流场数据(比如速度、压…...

如何用Maestro提升移动应用UI自动化测试效率:5个实战技巧
如何用Maestro提升移动应用UI自动化测试效率:5个实战技巧 【免费下载链接】maestro Painless Mobile UI Automation 项目地址: https://gitcode.com/GitHub_Trending/ma/maestro 在移动应用开发中,你是否遇到过UI测试跨平台适配难、脚本维护成本高…...

【技术解析】MaskFormer:超越逐像素分类的语义分割新范式
1. 从像素到掩码:语义分割的范式革命 第一次看到MaskFormer论文时,我正被一个医疗影像分割项目折磨得焦头烂额。传统方法在细胞边界处总是产生模糊的预测,直到尝试了这个将Transformer与掩码分类结合的新范式,准确率突然提升了8个…...

快速上手Stable Diffusion v1.5 Archive:镜像免配置,一键生成创意图像
快速上手Stable Diffusion v1.5 Archive:镜像免配置,一键生成创意图像 1. 为什么选择这个镜像? 如果你曾经尝试手动部署Stable Diffusion,一定经历过这些痛苦:安装Python环境、配置CUDA、下载几十GB的模型文件、解决…...

NaViL-9B科研效率提升:文献图表理解+相关工作对比表格自动生成
NaViL-9B科研效率提升:文献图表理解相关工作对比表格自动生成 1. 平台介绍 NaViL-9B是由专业研究机构开发的原生多模态大语言模型,能够同时处理文本和图像信息。这个模型特别适合科研场景,可以帮助研究人员快速理解文献中的图表内容&#x…...

告别手动测试:基于Playwright的智能自动化测试方案
告别手动测试:基于Playwright的智能自动化测试方案 【免费下载链接】awesome-claude-skills A curated list of awesome Claude Skills, resources, and tools for customizing Claude AI workflows 项目地址: https://gitcode.com/GitHub_Trending/aw/awesome-cl…...

突破硬字幕提取困境:Video-Subtitle-Extractor如何实现本地化AI精准识别
突破硬字幕提取困境:Video-Subtitle-Extractor如何实现本地化AI精准识别 【免费下载链接】video-subtitle-extractor 视频硬字幕提取,生成srt文件。无需申请第三方API,本地实现文本识别。基于深度学习的视频字幕提取框架,包含字幕…...

Z-Image-Distilled V3:5步极速AI绘图新突破
Z-Image-Distilled V3:5步极速AI绘图新突破 【免费下载链接】Z-Image-Distilled 项目地址: https://ai.gitcode.com/hf_mirrors/GuangyuanSD/Z-Image-Distilled 导语:AI图像生成领域再迎效率革命——Z-Image-Distilled V3模型实现5步即可生成高质…...

K8s 蓝绿发布与金丝雀发布生产级实战:从流量切换到可观测、自动化与高并发治理
K8s 蓝绿发布与金丝雀发布生产级实战:从流量切换到可观测、自动化与高并发治理 摘要:很多文章把 Kubernetes 蓝绿发布和金丝雀发布讲成了“改一下 Service selector”或“写几个 Ingress 注解”就结束了,但真正到了生产环境,问题往往不在 YAML 是否能跑通,而在于流量是否可…...

如何快速安装EmuDeck:Steam Deck模拟器配置完全教程
如何快速安装EmuDeck:Steam Deck模拟器配置完全教程 【免费下载链接】EmuDeck Emulator configurator for Steam Deck 项目地址: https://gitcode.com/gh_mirrors/em/EmuDeck EmuDeck是一款专为Steam Deck设计的模拟器配置工具,能够帮助玩家轻松搭…...