[C++]:1.初识C++和C语言缺陷补充。
初识C++和C语言缺陷补充
- 一.主要内容:
- 二.具体内容:
- 一: 作用域
- 1.命名空间:
- 2.函数声明和定义:
- 3.不存在命名冲突的情况:
- 二.输入输出:
- 1.基本输入输出:
- 2.关于std的展开:
- 三.函数:
- 1.缺省参数(部分):
- 2.全缺省:
- 3.缺省参数的定义和参数的传递
- 4.函数重载:
- >1.参数个数:
- >2.类型:
- >3.类型顺序:
- >4.总结:如果存在一种情况:
- 5.为什么出现函数重载?(编译链接的原理):
- 1.预编译(预处理)
- 2.编译
- 3.汇编
- 4.链接:
- 6.引用:
- 1.基本概念:
- 1-1:关于函数的引用:
- 1-2:引用用的特殊:
- 1-3:常引用:
- 2.常规用法:
- 1.作为函数参数:
- 2.作为函数返回值:
- 3.特殊用法:
- 1.解决方法一:二级指针:
- 2.解决方法二:引用:
- 4.总结:
- 7.内联函数:
- 1.概念:
- 2.inline的优缺点:
一.主要内容:
1.对于C++ 来说是在C语言的基础之上刚开始进行对C语言的缺陷进行了优化解决,加入面向对象的编程思想,加入了非常多有用的库,和一些编程范式。对于C语言比较属性那么对于C++的学习是有帮助的。
2.那么C++对于C语言的一些些缺陷是在那一些方面呢?包括有作用域,IO方面,函数方面,指针,宏方面进行了修改。
二.具体内容:
一: 作用域
1.命名空间:
1.在C语言中存在这样的一个情况我们使用一个全局变量的时候有可能在命名变量名称的时候和C语言标准库中的内容产生冲突(1.我们的标准库在全局展开会和自己的变量名称冲突 2.在我们做一个项目的时候我们定义的变量名函数名和其他人会有冲突)。
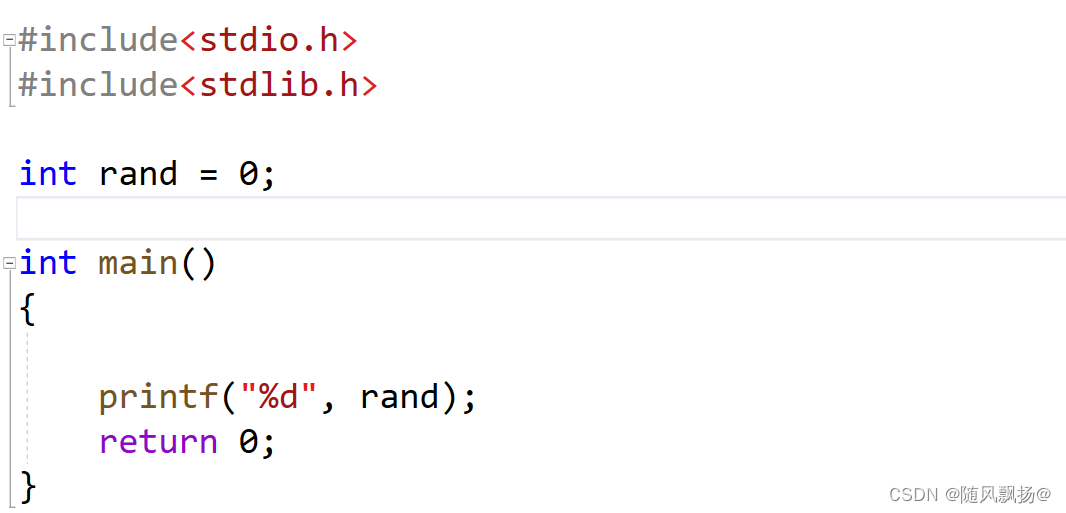


2.解决方法:使用命名空间这一个C++提供的语法:namespace关键字,它可以把我们本地定义的内容进行包裹,在正常开始访问变量的时候默认只访问全局。下面这个代码没有进入命名空间在全局只有一个rand函数所以打印出来了一个随机值。
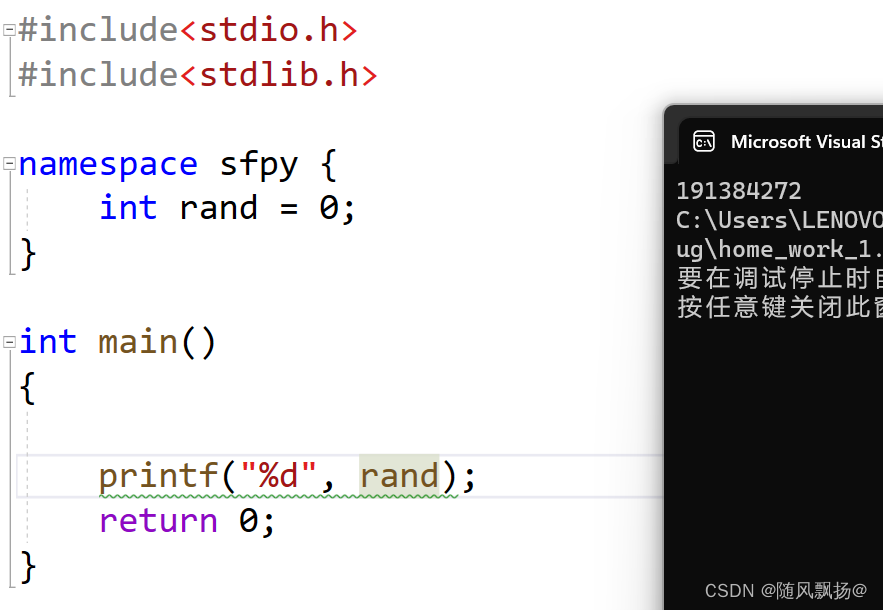
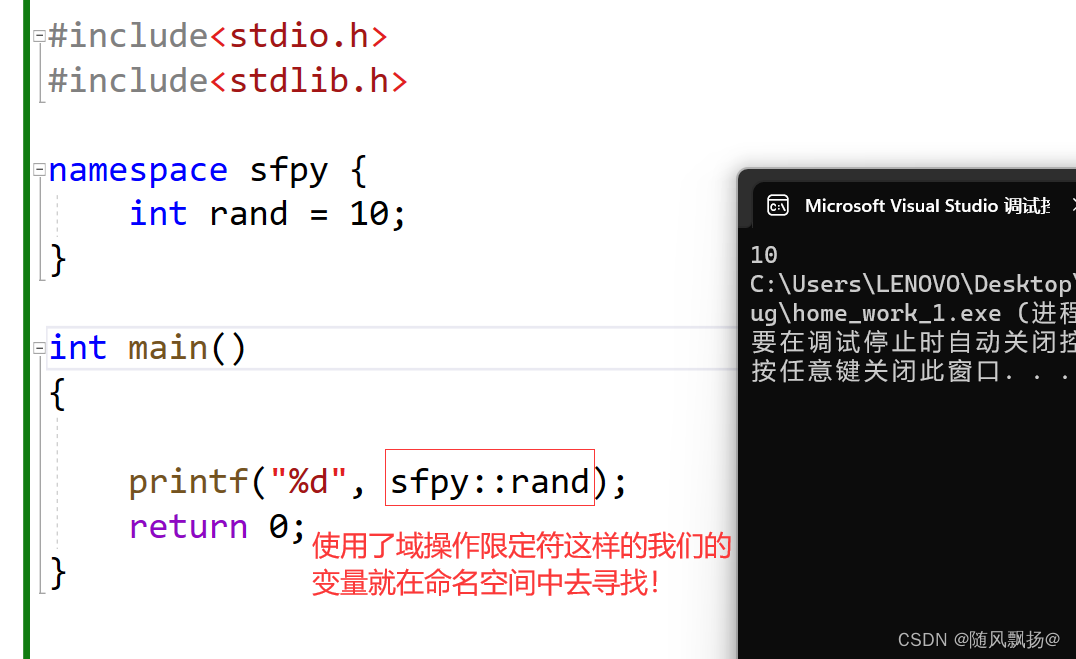
3.如何使用自己的命名空间呢?
:: 域作用限定符 命名空间名称+域作用限定符去访问这个命名空间。
命名空间中可以放什么东西呢?
变量名,函数声明,函数定义,结构体,联合体,枚举,等等。
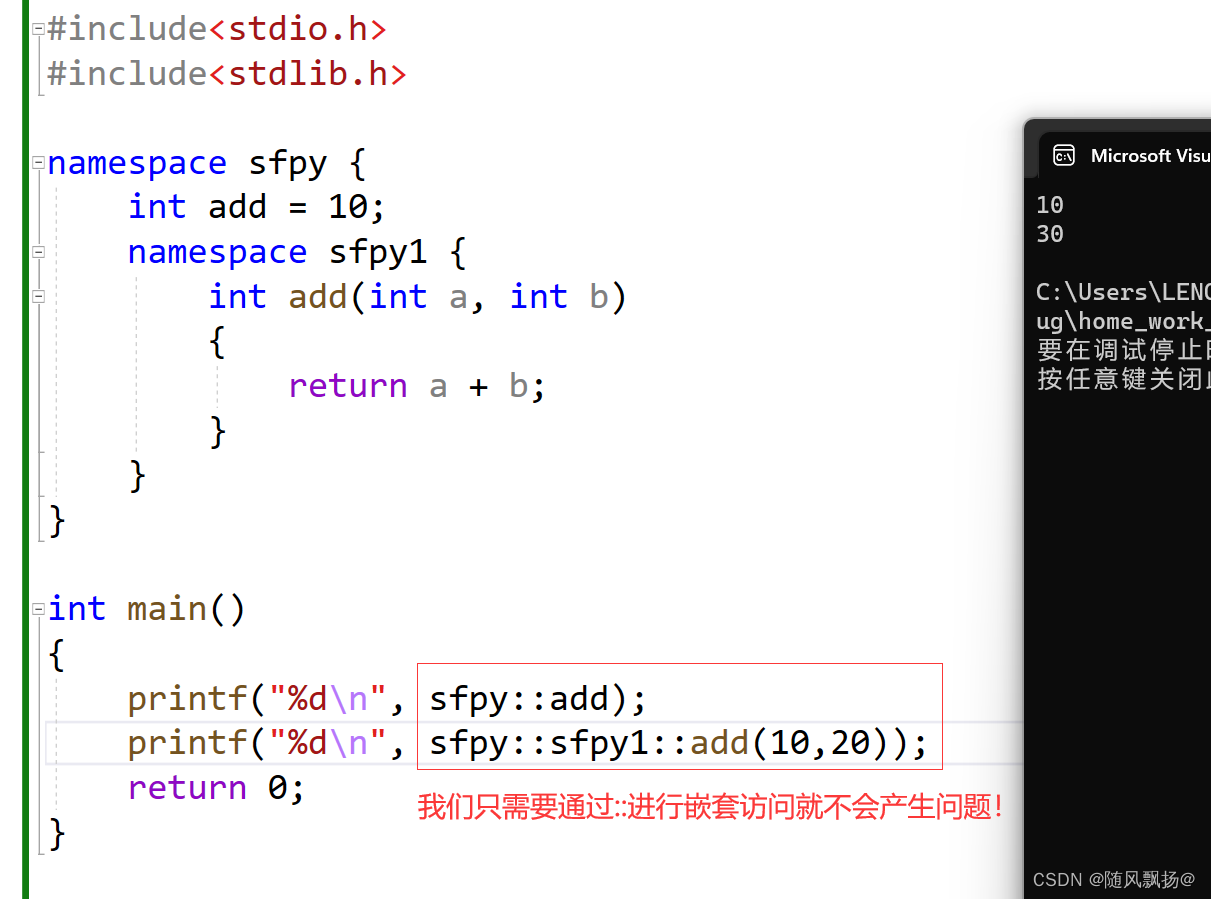
4.如果出现了在一个命名空间中有两个这个同名称的变量或者函数等等。非常容易解决这个问题因为我们C++是支持命名空间的嵌套的:
2.函数声明和定义:
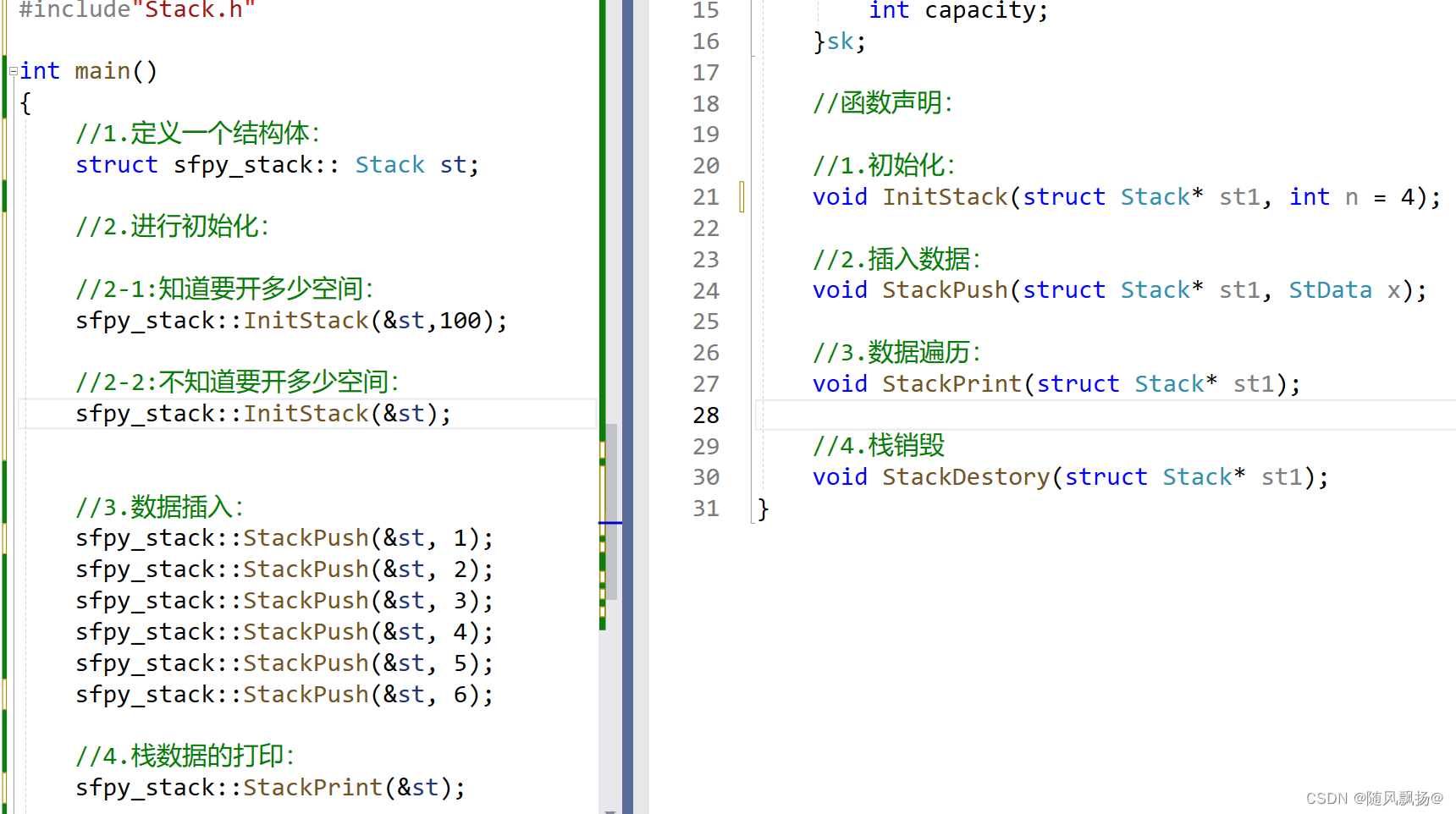
1自己的函数声明放在自己的命名空间中自己的定义放在自己的命名空间中在我们进行定义和声明分离的时候我们要把定义和声明放在同一个空间中:
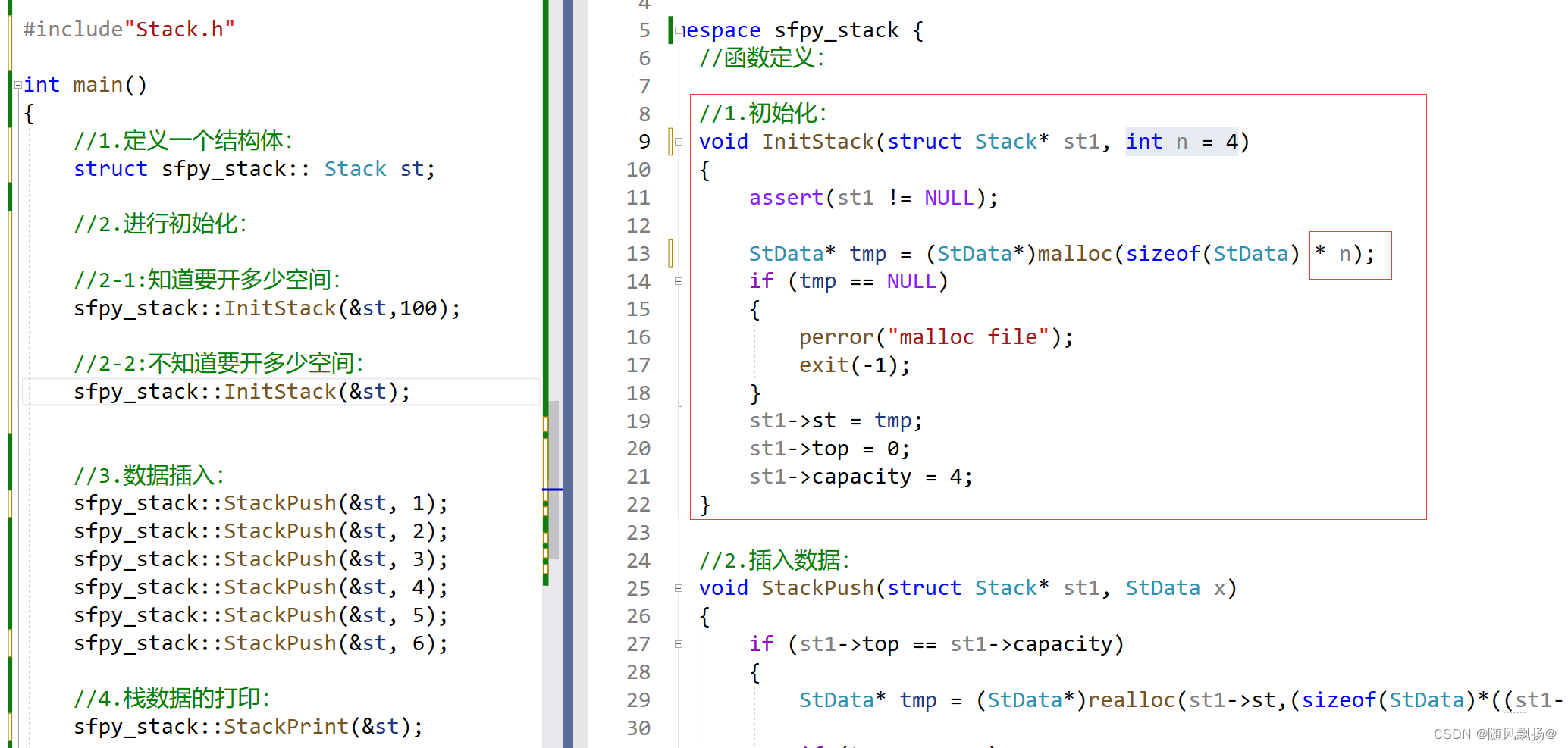
#include"Stack.h"namespace sfpy_stack {//函数定义://1.初始化:void InitStack(struct Stack* st1){assert(st1 != NULL);StData* tmp = (StData*)malloc(sizeof(StData) * 4);if (tmp == NULL){perror("malloc file");exit(-1);}st1->st = tmp;st1->top = 0;st1->capacity = 4;}//2.插入数据:void StackPush(struct Stack* st1, StData x){if (st1->top == st1->capacity){StData* tmp = (StData*)realloc(st1->st,(sizeof(StData)*((st1->capacity)*2)));if (tmp == NULL){perror("malloc file");exit(-1);}st1->st = tmp;st1->capacity = (st1->capacity) * 2;}st1->st[st1->top] = x;st1->top++;}//3.数据遍历:void StackPrint(struct Stack* st1){assert(st1 != NULL);for (int i = 0; i < st1->top; i++){printf("%d ", st1->st[i]);}}//4.栈销毁void StackDestory(struct Stack* st1){free(st1->st);st1->st = NULL;}
}??????????????????????????????????????????#include<stdio.h>
#include<stdlib.h>
#include<assert.h>namespace sfpy_stack {typedef int StData;typedef struct Stack{StData* st;int top;int capacity;}sk;//函数声明://1.初始化:void InitStack(struct Stack* st1);//2.插入数据:void StackPush(struct Stack* st1, StData x);//3.数据遍历:void StackPrint(struct Stack* st1);//4.栈销毁void StackDestory(struct Stack* st1);
}#include"Stack.h"int main()
{//1.定义一个结构体:struct sfpy_stack::Stack st;//1-1:在有struct的情况下//我们定义结构体变量使用上面这个方法//sfpy_stack::struct Stack st2;//1-2:重命名之后就可以使用下面这个方法://sfpy_stack::sk st2;//2.进行初始化:sfpy_stack::InitStack(&st);//3.数据插入:sfpy_stack::StackPush(&st, 1);sfpy_stack::StackPush(&st, 2);sfpy_stack::StackPush(&st, 3);sfpy_stack::StackPush(&st, 4);sfpy_stack::StackPush(&st, 5);sfpy_stack::StackPush(&st, 6);//4.栈数据的打印:sfpy_stack::StackPrint(&st);//4.进行销毁:sfpy_stack::StackDestory(&st);return 0;
}
3.不存在命名冲突的情况:
1.如何打开命名空间:使用using namespace spfy_stack;
2.打开命名空间就可以不使用域限定操作符直接使用变量函数等。
3.在我们的个人作业不存在命名冲突的情况使用using namespace spfy_stack ,可以在你去使用命名空间内容就可以不使用域限定操作符:

二.输入输出:
1.基本输入输出:
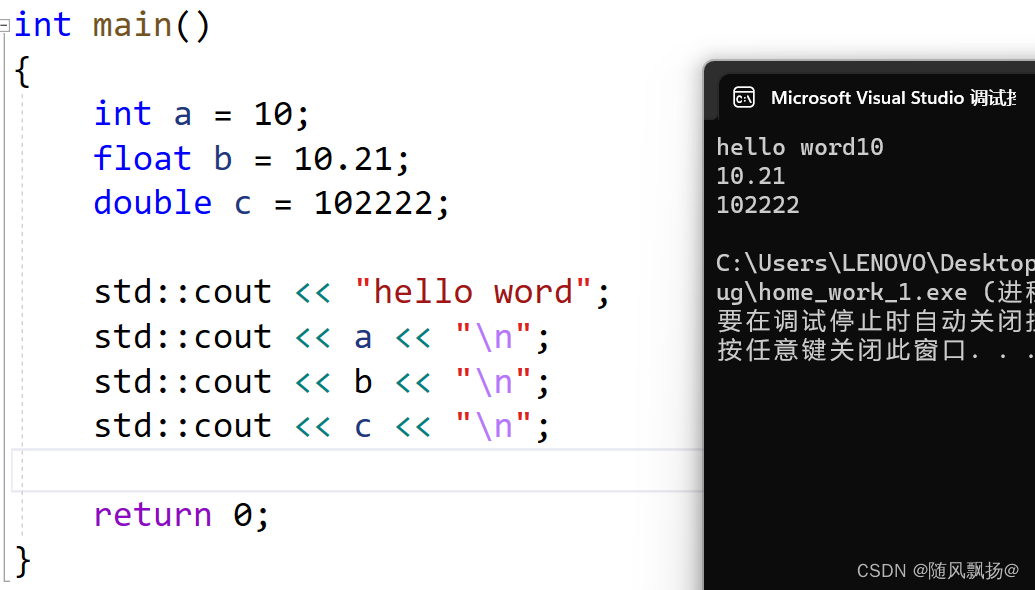
1.C++ 官方标准库iostream。
2.我们的std空间名称是C++的官方定义的输入输出相关的命名空间。
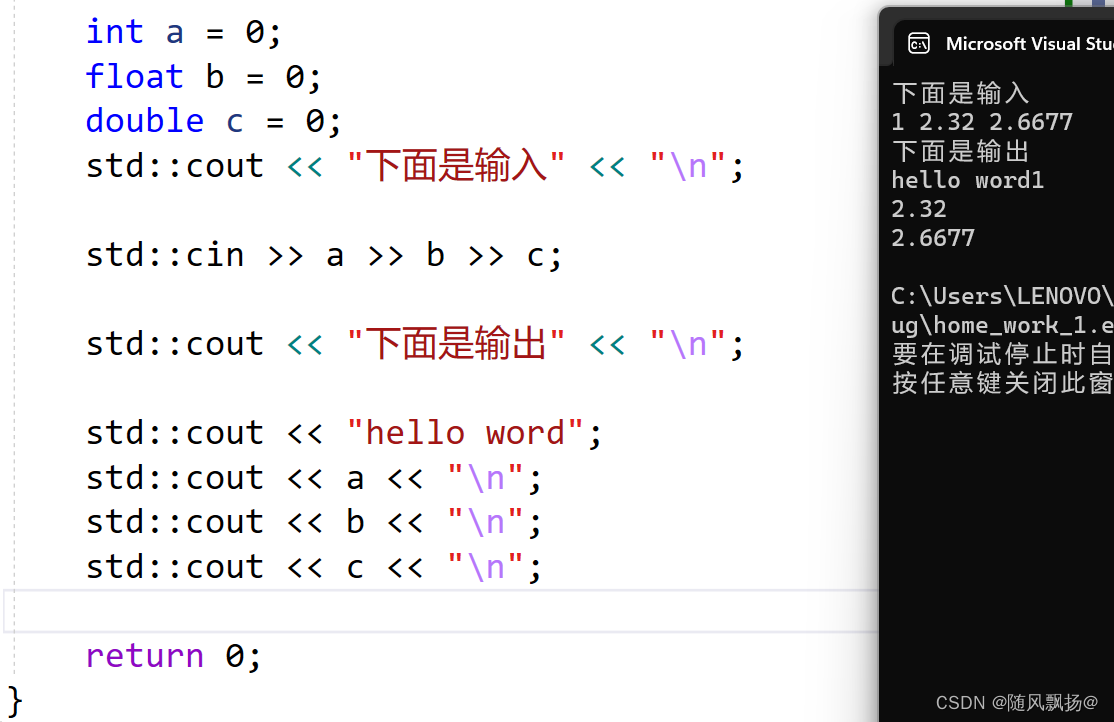
- 使用cout标准输出对象(控制台)和cin标准输入对象(键盘)时,必须包含< iostream >头文件以及按命名空间使用方法使用std。
- cout和cin是全局的流对象,endl是特殊的C++符号,表示换行输出,他们都包含在包含< iostream >头文件中。
- <<是流插入运算符,>>是流提取运算符。
- 使用C++输入输出更方便,不需要像printf/scanf输入输出时那样,需要手动控制格式。C++的输入输出可以自动识别变量类型。
- 实际上cout和cin分别是ostream和istream类型的对象,>>和<<也涉及运算符重载等知识。

2.关于std的展开:
1.std是C++ 标准库中的一个命名空间他的展开是需要考虑情况的因为对于一个由多个人完成的项目来说这个空间是不可以展开的。
2。在自己的练习上面去使用using namespace std;打开标准库的这一个命名空间,这样可以不需要去使用标准库名称和域限定操作符。
3-1:换行的多种方法:
3-1:1.在字符串中结尾使用\n. 2.在输出到控制台的单词后面加一个“\n”.3.使用endl结尾这个是std这个命名空间中的一个用来换行的根第2个是同样的效果。
endl==end line
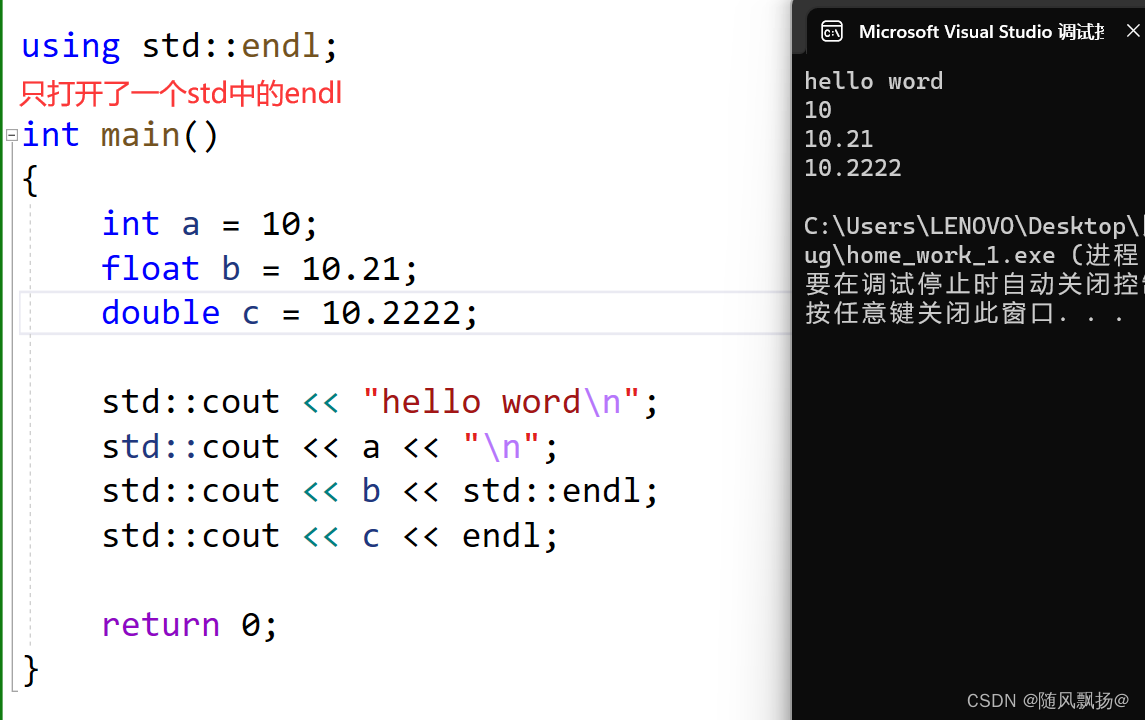
4:如果存在一种情况需要换行多次但是其他的std中的有冲突(不允许完全打开命名空间)我们可以只打开命名空间中的一个操作符。
三.函数:
1.缺省参数(部分):
如果我们给这个函数的这个变量进行了传参我们就使用我们的传参,如果我们没有去进行传参就使用默认的缺省参数。
2.作用:我们开辟栈空间知道要看多少空间和不知道需要开多少空间:
2-1:不知道要开多少空间我们就使用默认开辟空间的值后面动态增长:
2-2:知道要开多少空间我们就使用传参的值一下开辟好空间不需要多次判断扩容:
2-3:函数相同在存在一个缺省值的情况下完成了多个功能。
注意:如果生命与定义位置同时出现,恰巧两个位置提供的值不同,那编译器就无法确定到底该用那个缺省值。
2.全缺省:
1.函数的参数全部都具有缺省值这样我们对于一个函数就有n+1种调用方式:为什么可以使用相同的函数名称呢?我们接下来再说!
3.缺省参数的定义和参数的传递
1`.缺省参数值只能从右往左给。
2.函数传实参只能从左往右。
3.如果我们给了全部缺省我们不能跳跃的进行实参传递。
4.函数的声明和定义中不要同时出现缺省参数我们一般在函数的声明中给缺省值,如果函数的定义和声明中都有缺省值我们的编译器不知道使用哪一个缺省值。

4.函数重载:
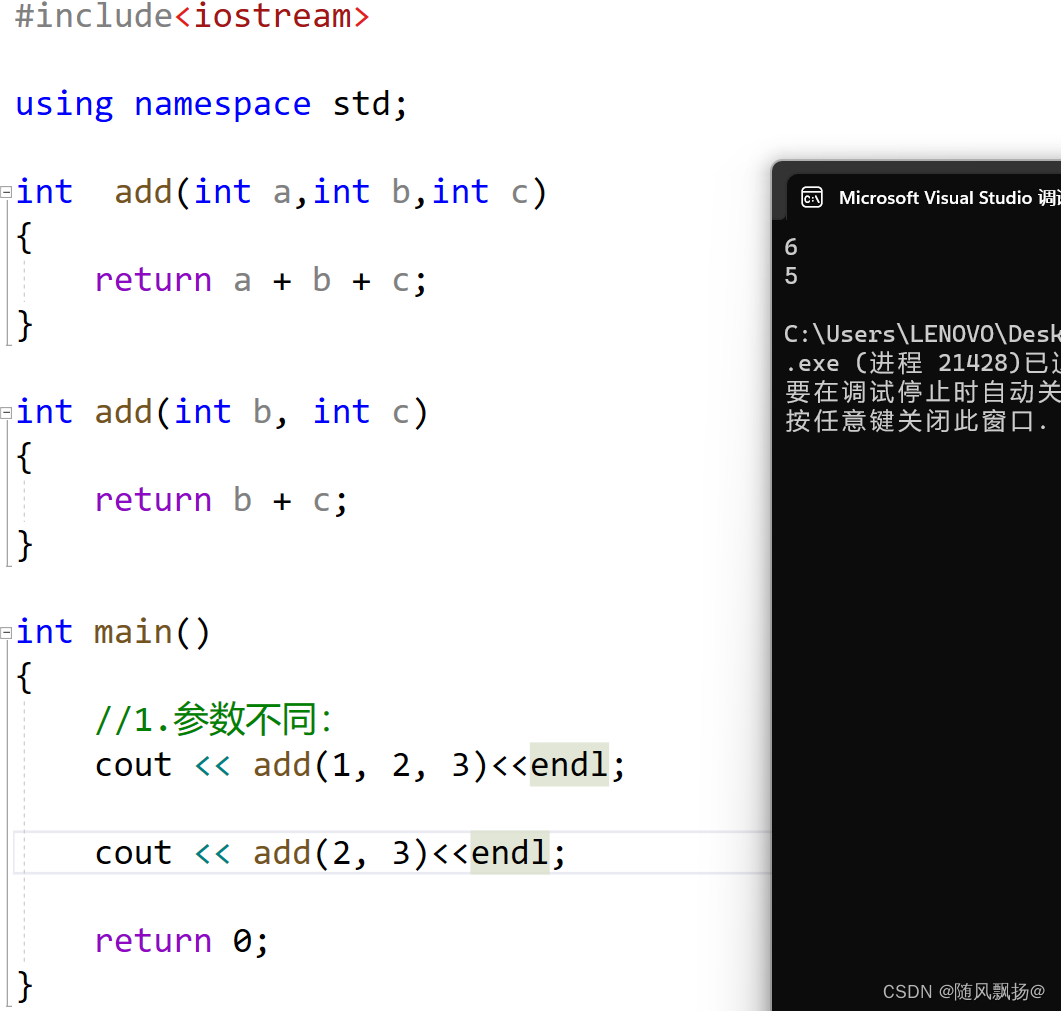
1.函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表==(参数个数 或 类型 或 类型顺序)==不同,常用来处理实现功能类似数据类型不同的问题。
>1.参数个数:
>2.类型:

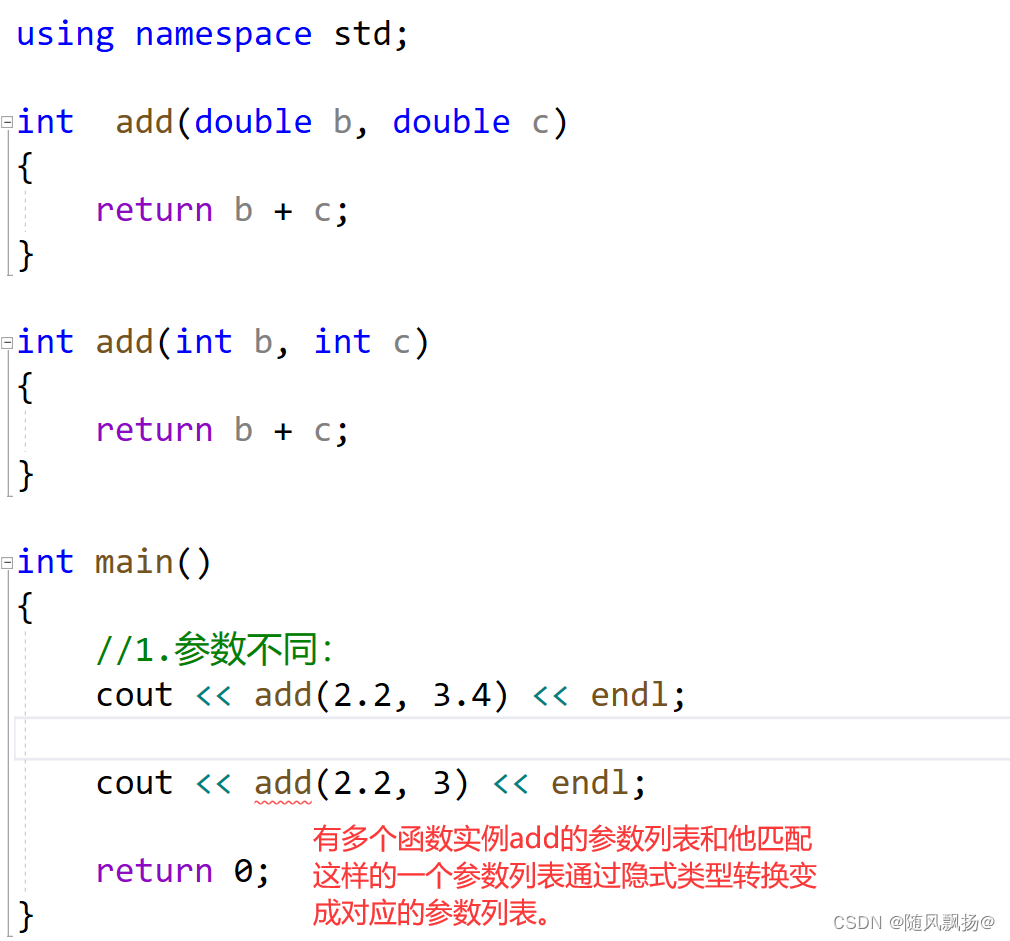
>3.类型顺序:
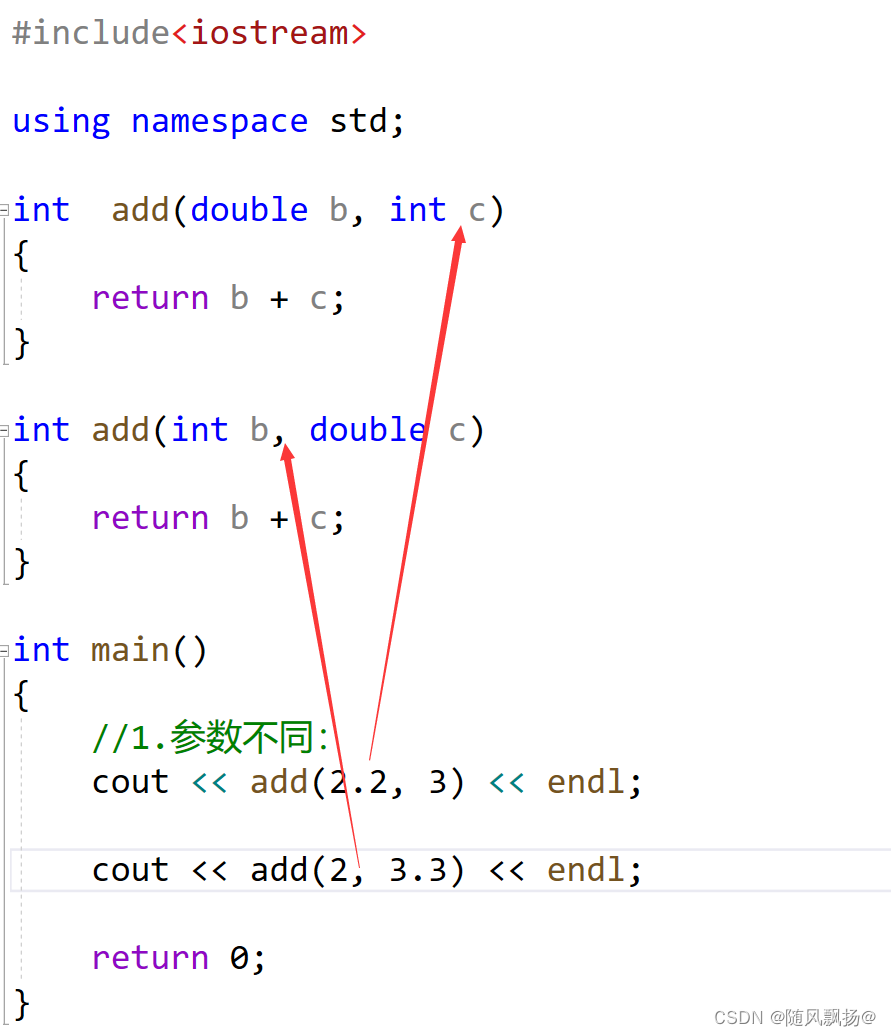
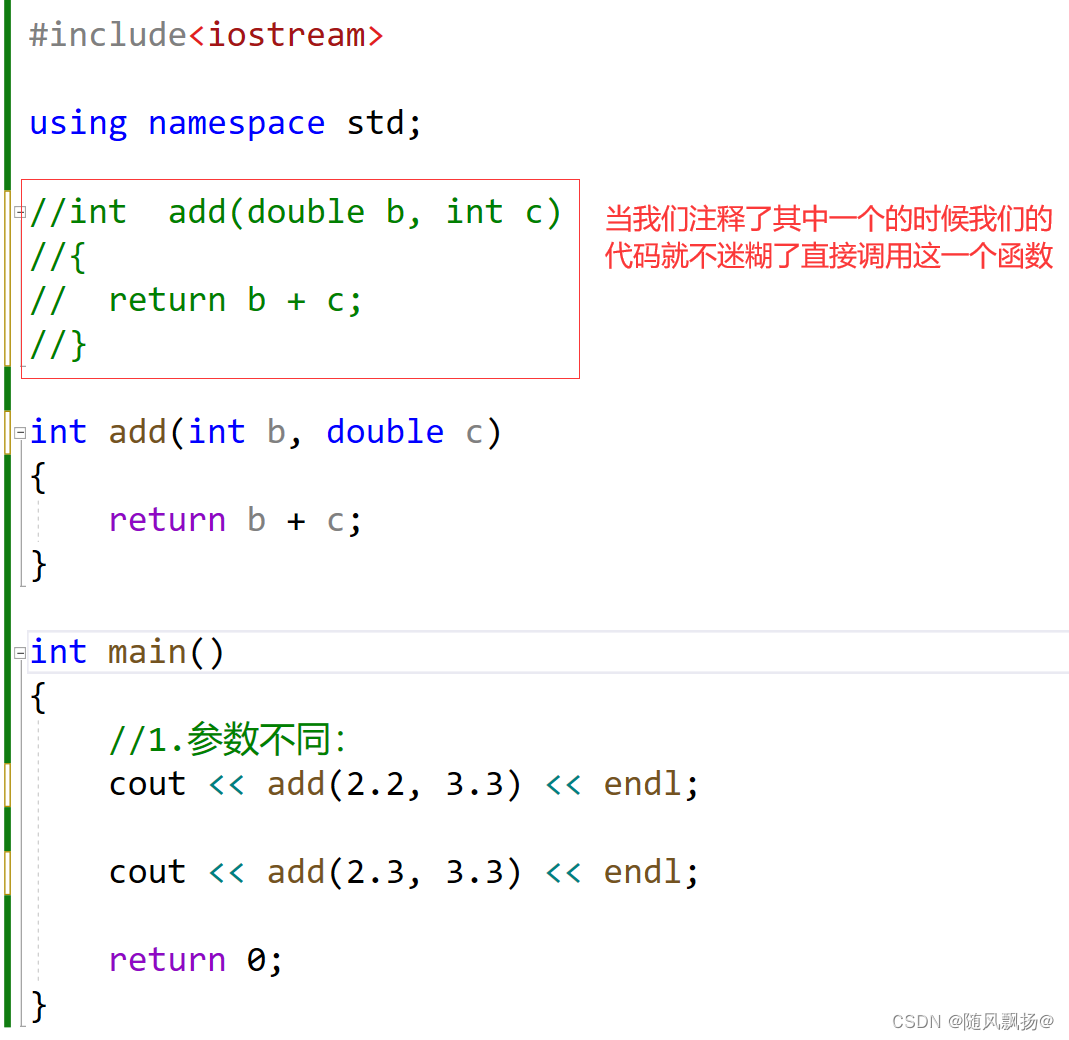
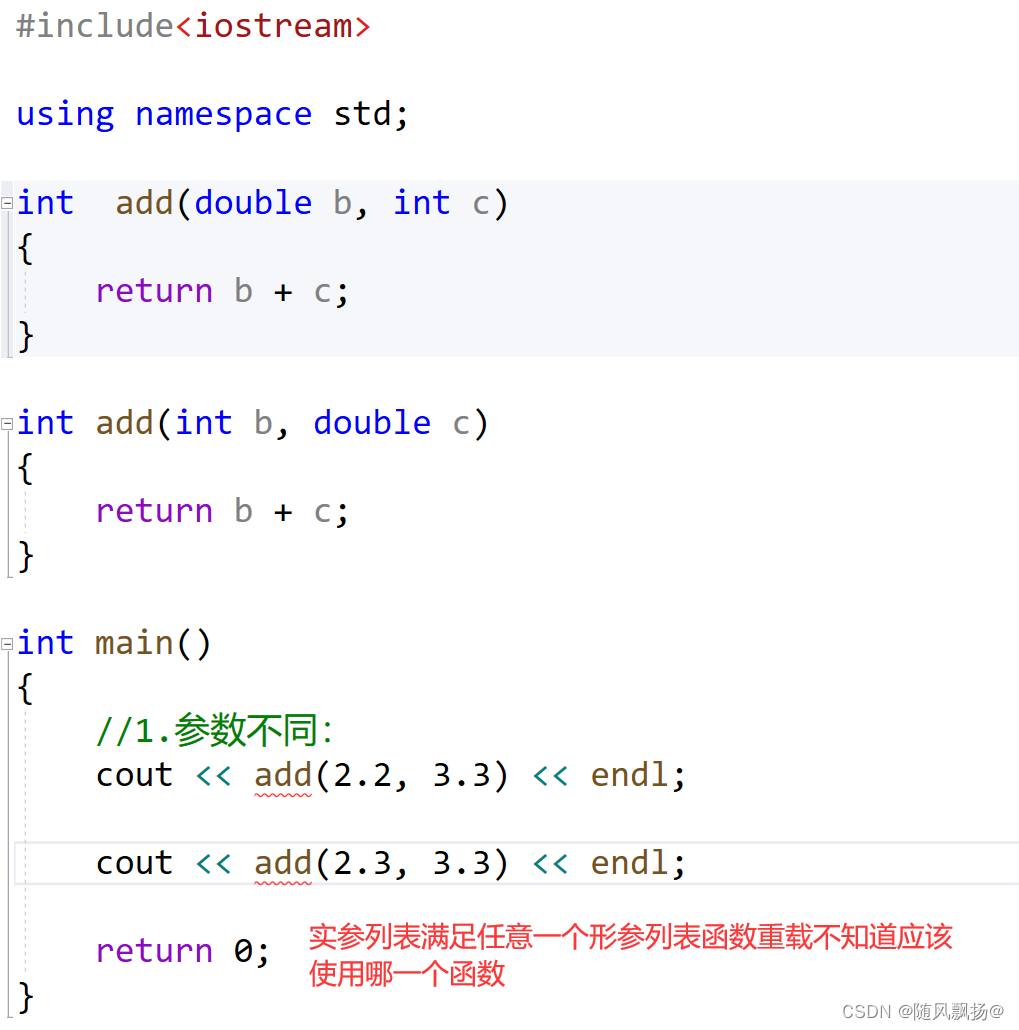
>4.总结:如果存在一种情况:
事情A单独出现必须去做。
事情B单独出现必须去做。
事情A和B同时出现怎么办?编译器面对这样的情况不知道怎么办的那就报错:
A:妈妈掉水里了 B:爸爸掉水里了
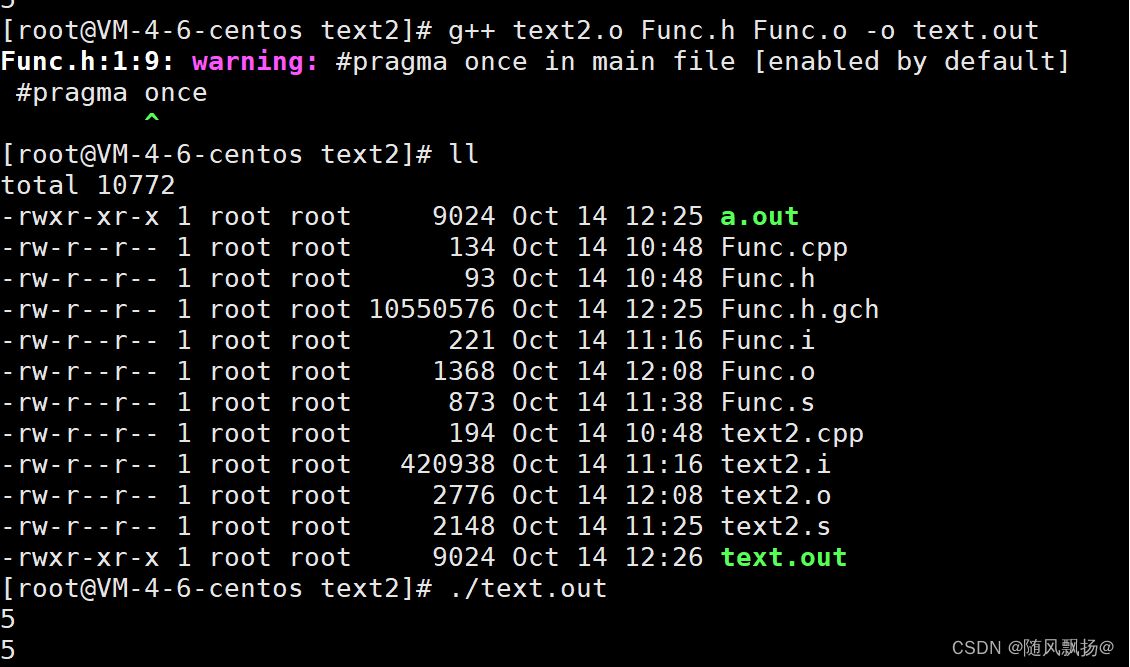
5.为什么出现函数重载?(编译链接的原理):
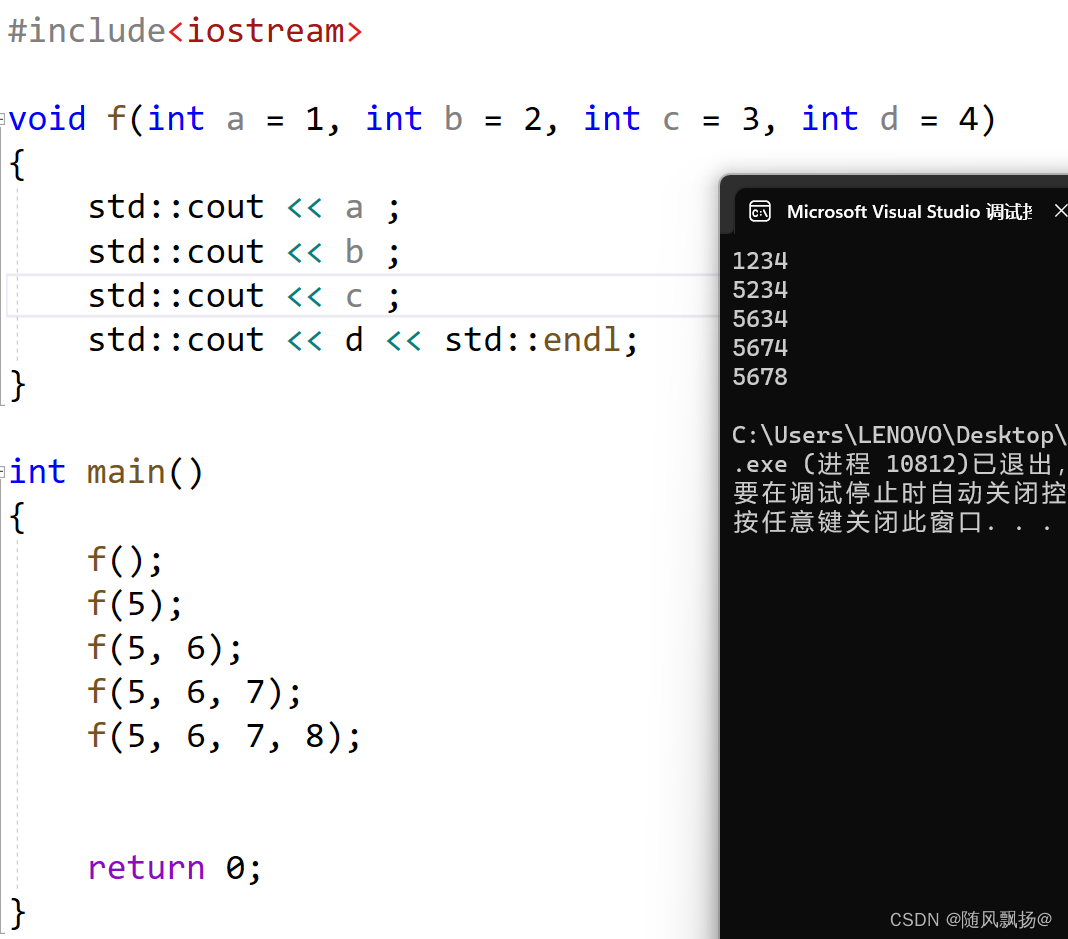
为什么C++支持函数重载但是C语言不支持函数重载呢?
定义:Func.cpp
声明:Func.h
主函数:text2.cpp
//Func.cpp
int add(double b, int c)
{return b + c;
}int add(int b, double c)
{return b + c;
}
//Func.h
#include<iostream>int add(double b, int c);int add(int b, double c);//text2
#include"Func.h"using namespace std;int main()
{//1.参数不同:cout << add(2.2, 3) << endl;cout << add(2, 3.3) << endl;return 0;
}
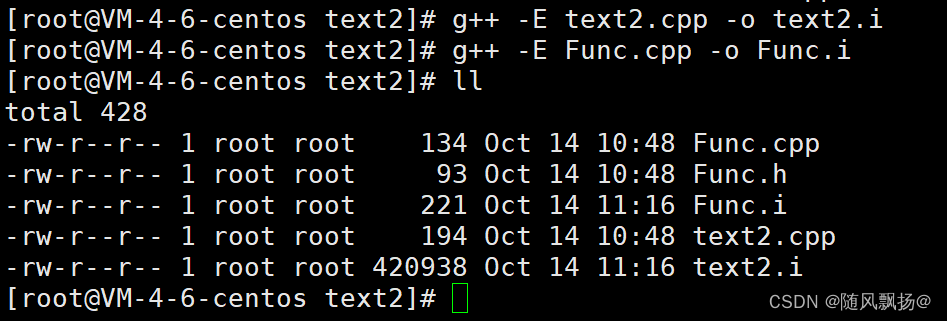
这里我们通过linux进行预编译,编译,汇编,链接整个过程:
1.预编译(预处理)
1.头文件的展开,宏替换,条件编译,去掉注释。
生成:通过预编译生成==func.i test2.i文件
2.编译
2.编译进行:语法分析,词法分析,语意分析,符号汇总。
生成:通过编译生成汇编代码:Func.s text2.s
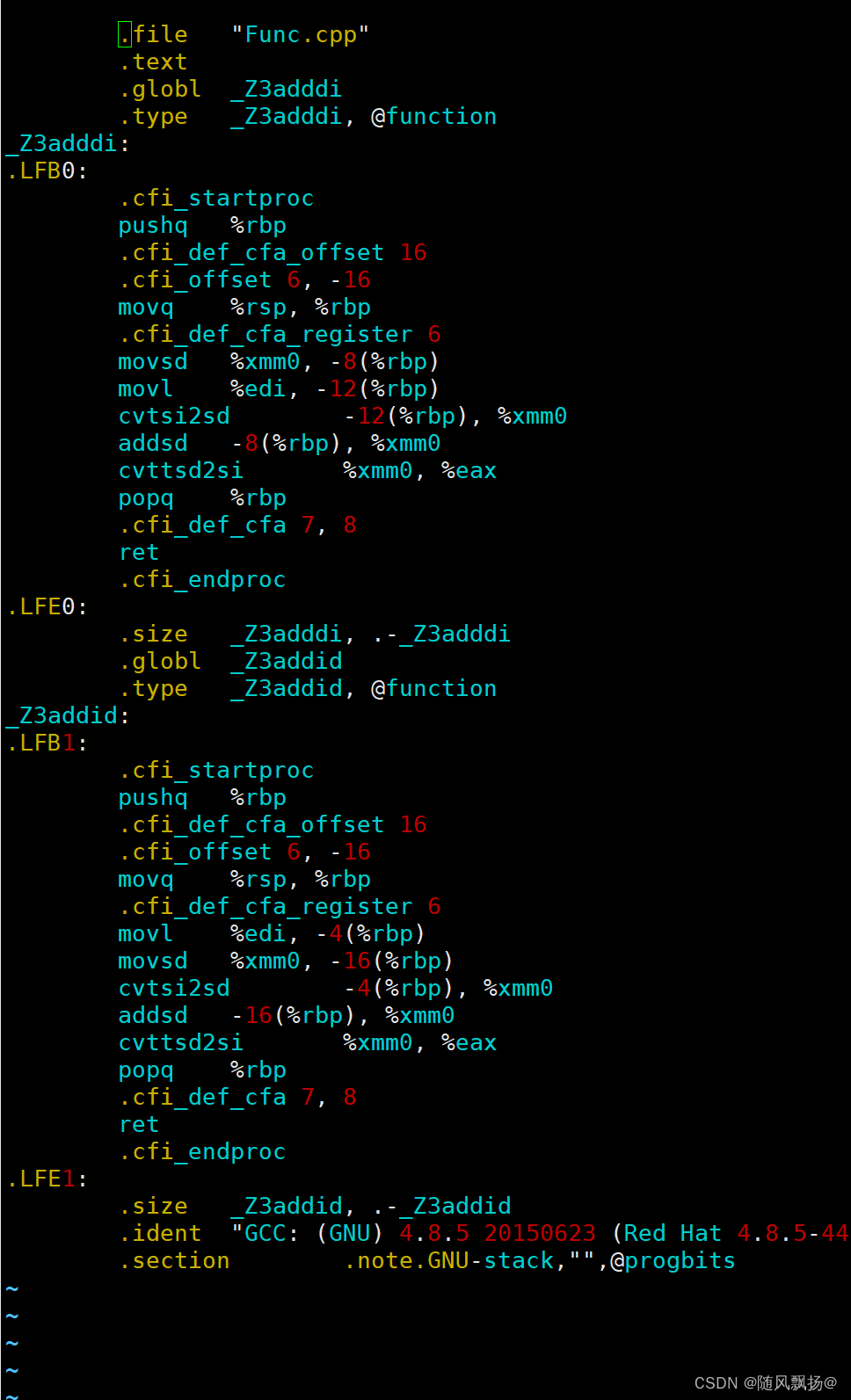
通过vim观察一下汇编代码我们看一看两个函数的地址名称:
关于linux下的函数定义的汇编代码通过什么方法命名的呢?
_Z + (函数名字符个数) +(函数名称)+参数类型的首字母:
通过观察下面两个函数名称我们就可以看出来!!!
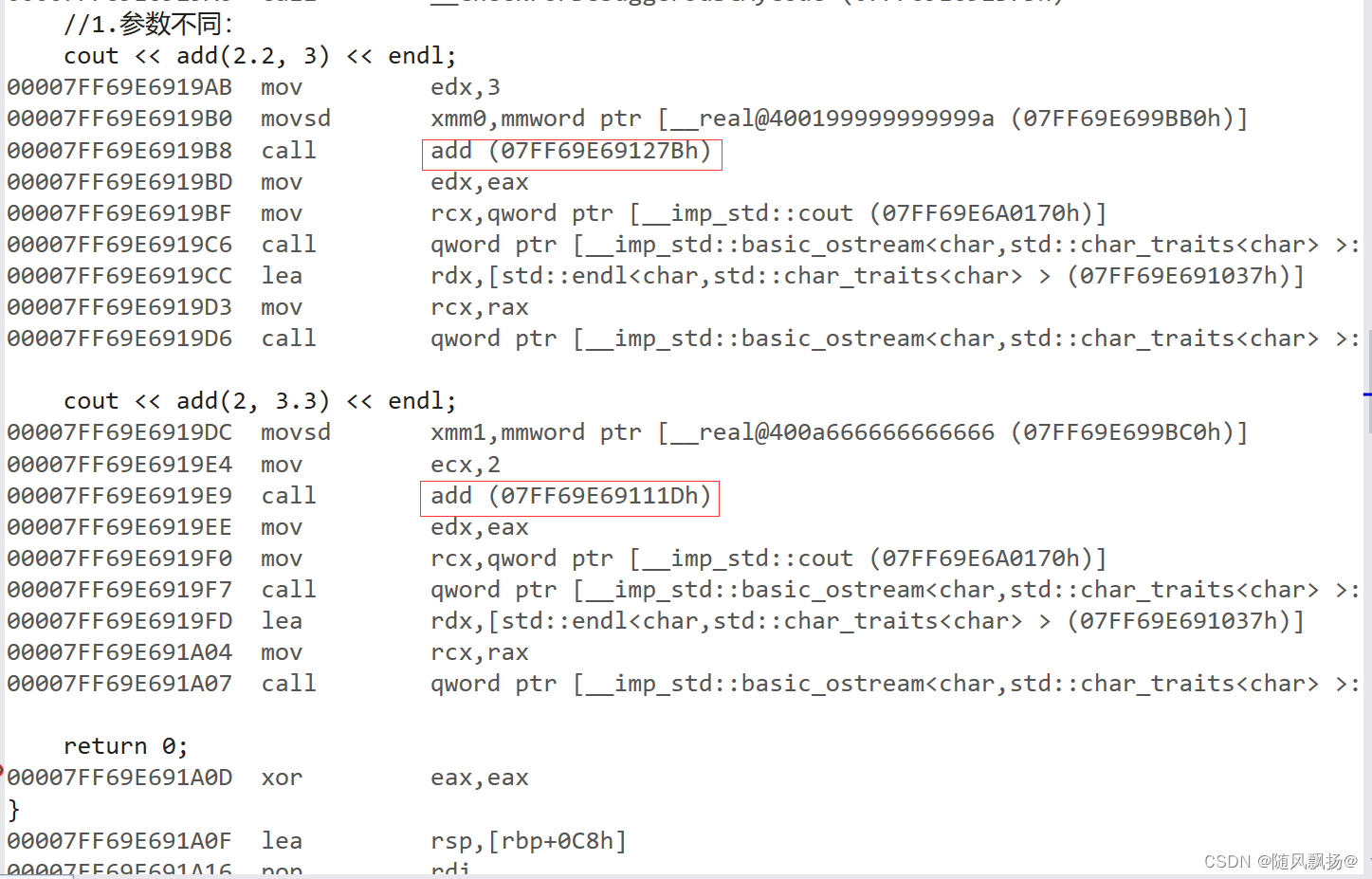
通过vs上的反汇编我们可以观察到两个函数定义call的地址是不相同的!
在vs下定义相同函数名称的函数重载的方法比较linux下的是,windows下是通过特殊符号(对应一个类型)进行的函数名称的汇编定义!!
3.汇编
在linux下汇编后生成的二进制文件是是以.o结尾的文件,在linux下生成的是以.obj
为后缀的二进制文件。
4.链接:
链接机器会把各种.o文件和并对文件需要的库进行链接生成可执行的二进制文件 .out
如果我们的函数没有定义在func.cpp中那么到链接的时候会显示链接错误说明链接错误是发生在链接的过程中!!!!。这个时候我们的代码已经生成了二进制的机器码了。但是在链接的过程中找不到函数的定义了!!!
6.引用:
1.基本概念:
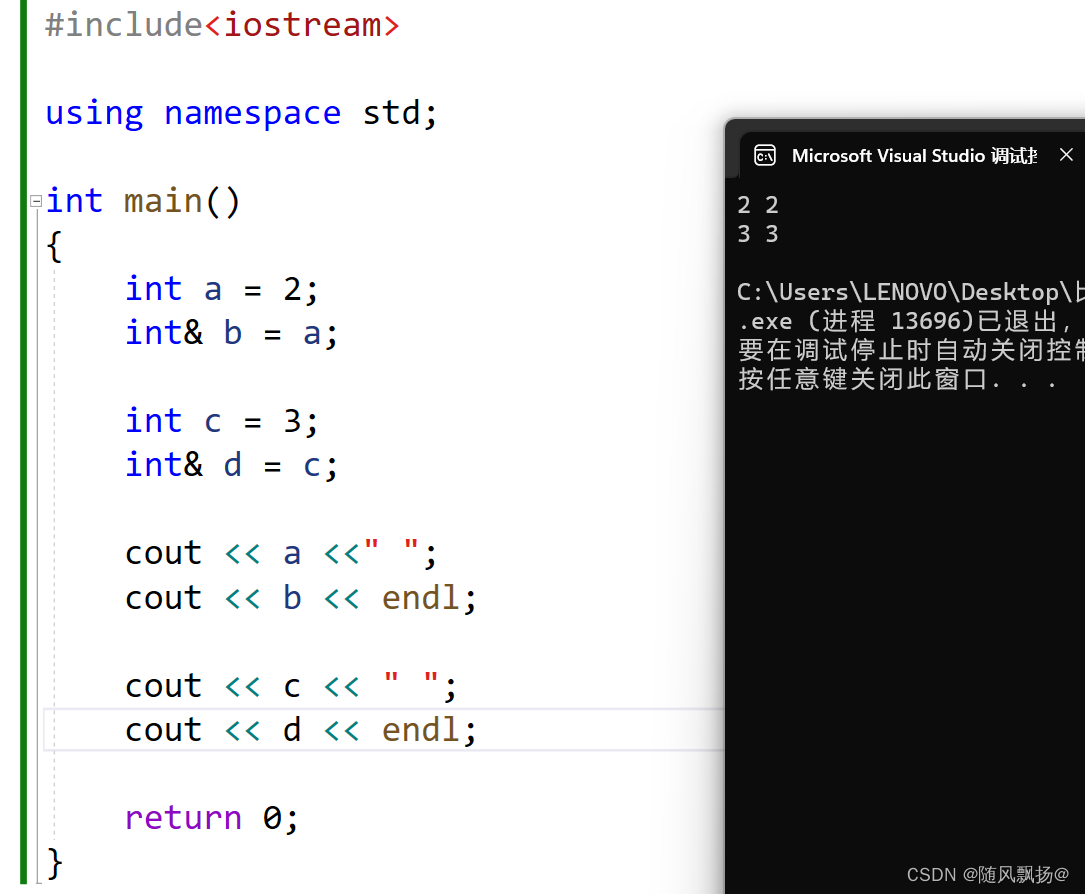
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
1-1:关于函数的引用:
1-2:引用用的特殊:
1.引用必须要初始化:
2.一个变量可以被多次引用:
3.一个引用只能被初始化一次之后如果a=b(a已经引用初始化过了b对a是赋值操作)
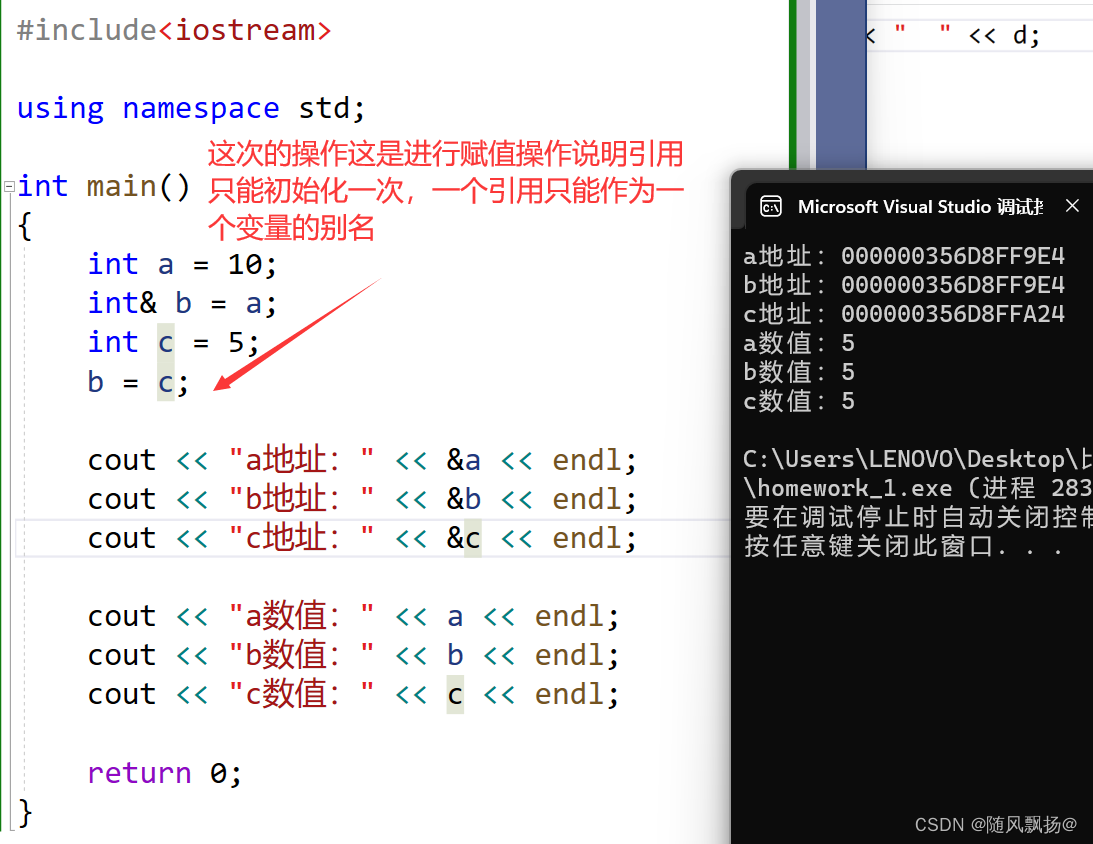
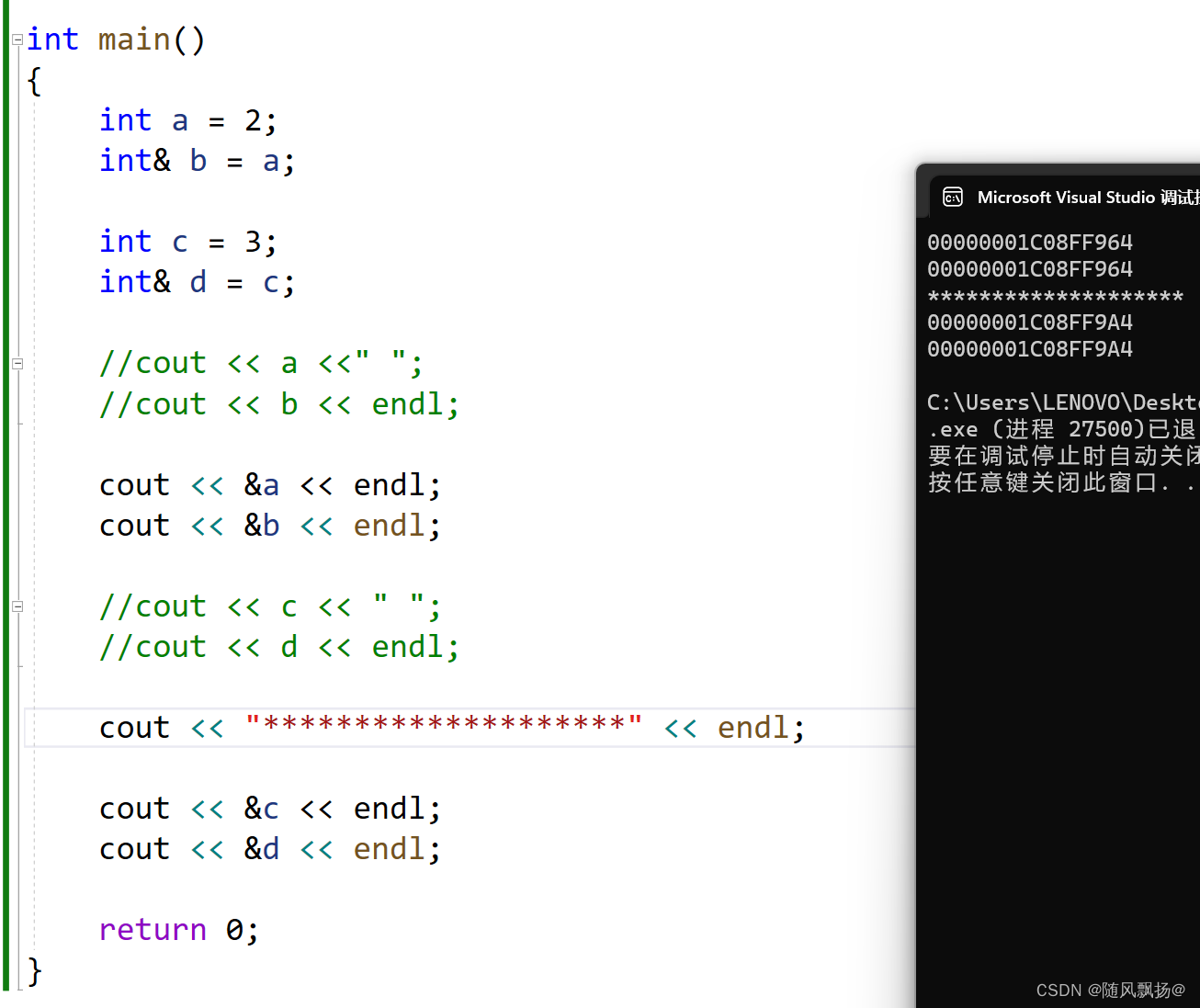
1-3:常引用:
1.常引用:常表示的是常变量。
2.给一个常量取别名:
2-1:访问打印 或者 进行改变(常量是不可以改变的)
图1

从图1到图2是一种权限的缩小,原来的引用可以干两个事情
1.通过引用改变–引用的变量的值。2。获取引用变量的值进行打印:
3.图二中的引用只能做(获取引用变量的值进行打印)
图2:

图三:

图四:

图五:

图6
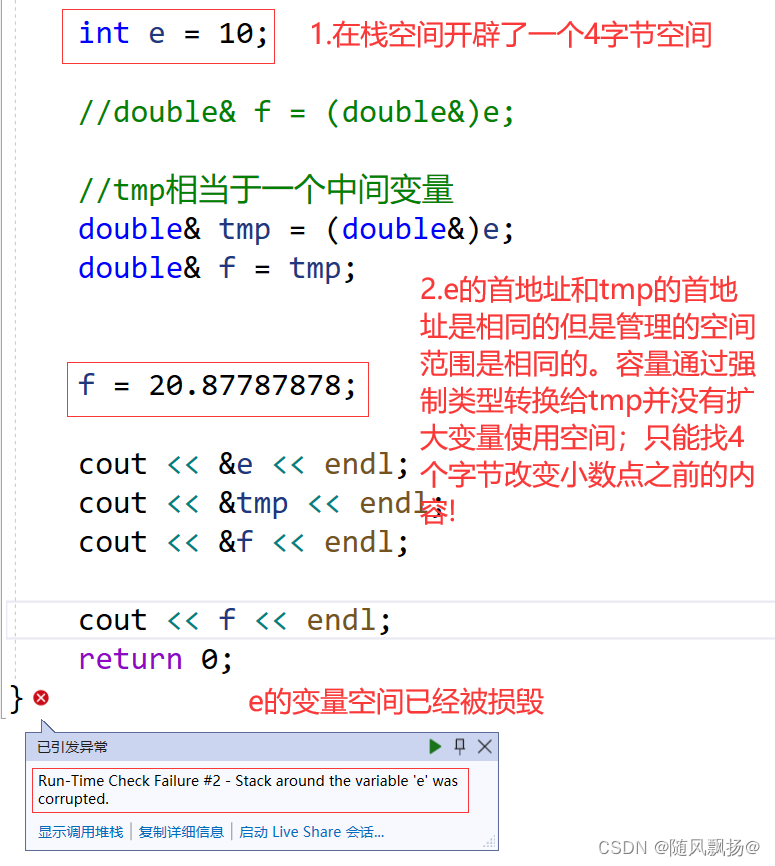
图7:
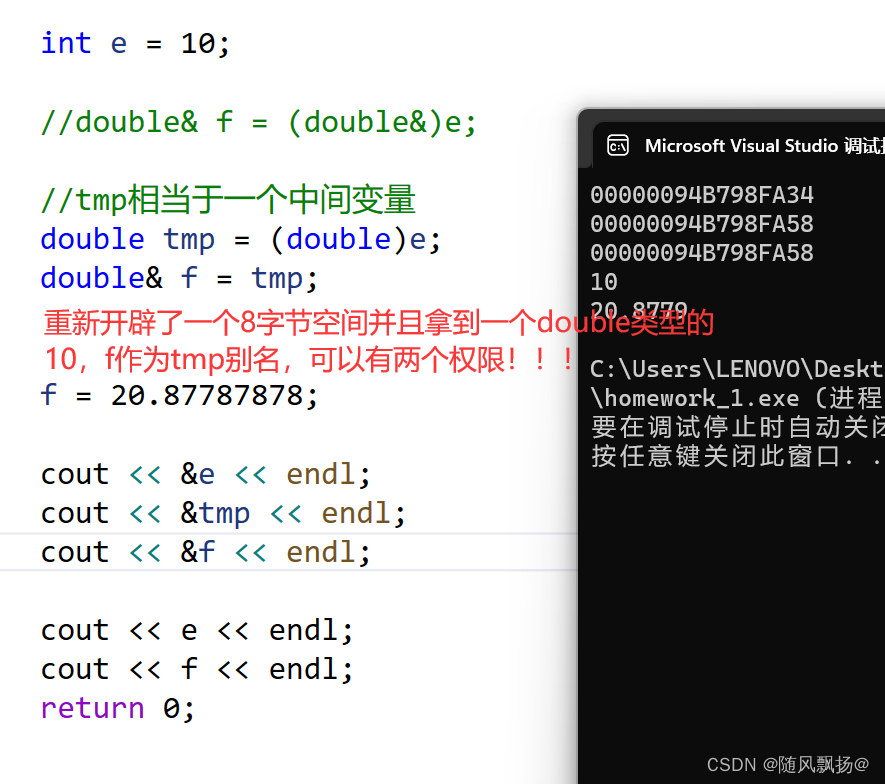
图8:


总结我们观察上面的两个图片我们会发现引用和指针在汇编实现的时候是相同的但是题目有不同的作用:
1.在语法上r是ch的别名改变r就是改变ch
2.但是在底层r是开辟了一个4字节空间用来保存地址:
2.常规用法:
1.作为函数参数:
swap函数用来交换数值:
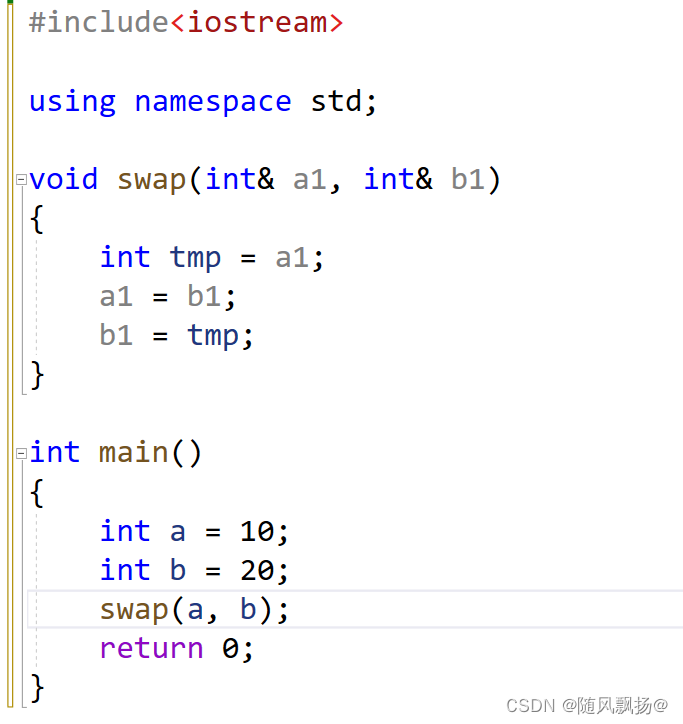
2.作为函数返回值:
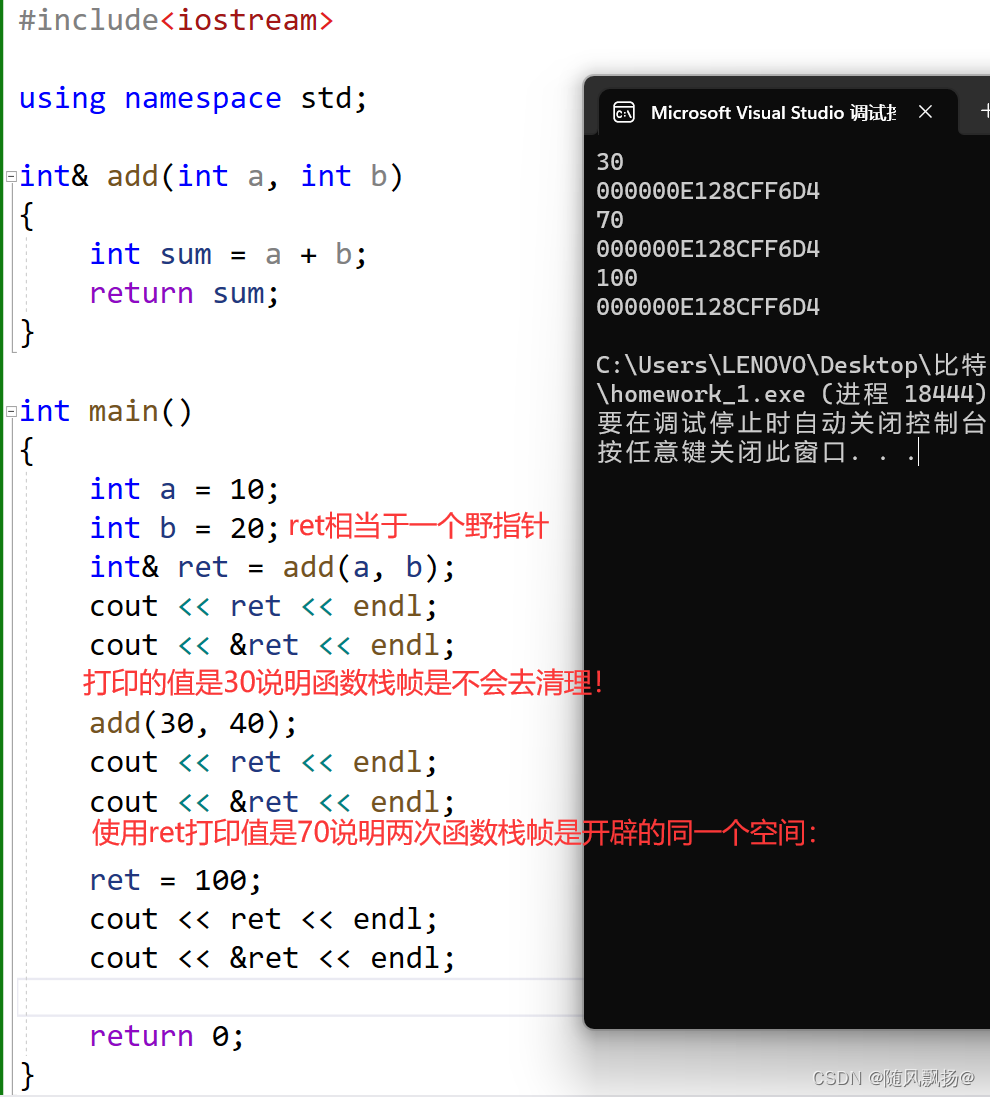
如何保存函数返回值:
1.函数返回值比较小的时候就用一个寄存器去保存函数返回值:
2.函数返回值比较大的时候在main和函数栈帧空间中开辟一个位置保存这个返回值。
3ret的值取绝于函数栈帧销毁之后是否清理空,清理的化就是随机值不清理就是上面的情况但是范围一个不属于当前代码的空间是比较危险。

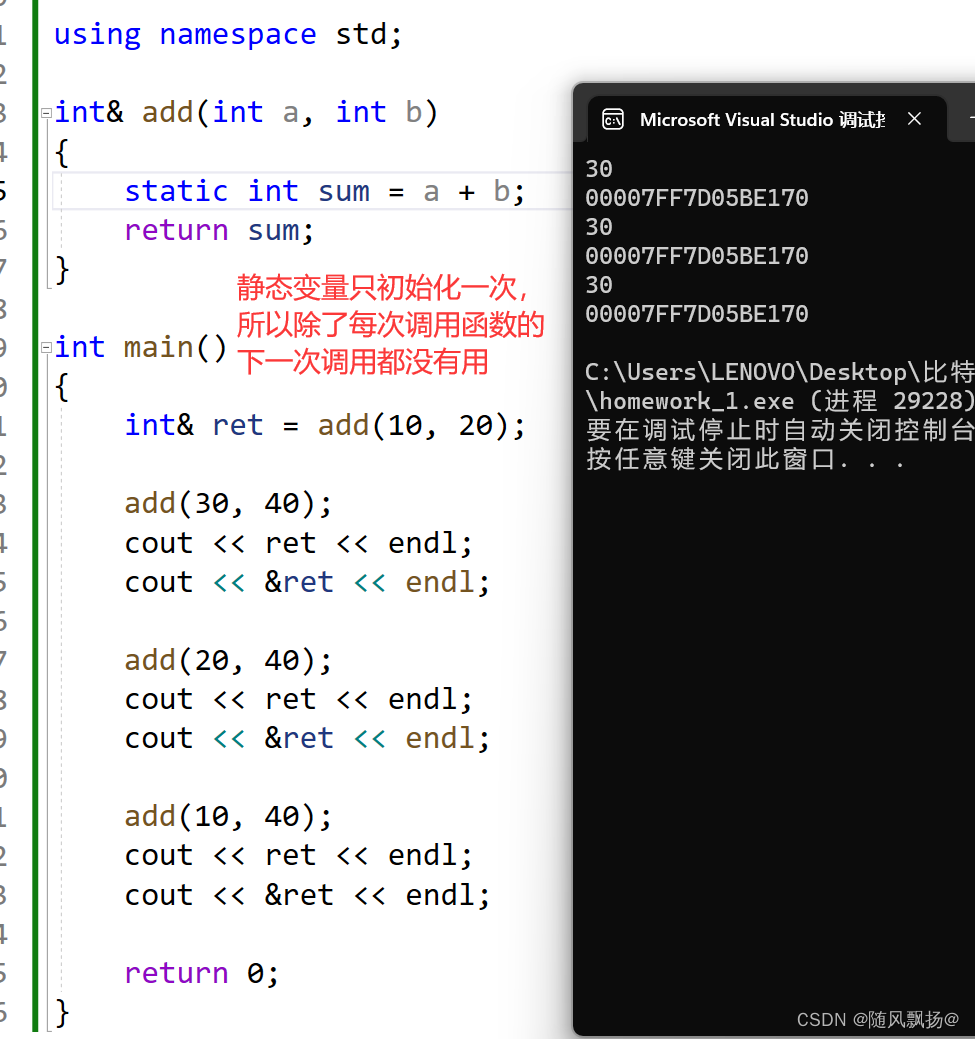
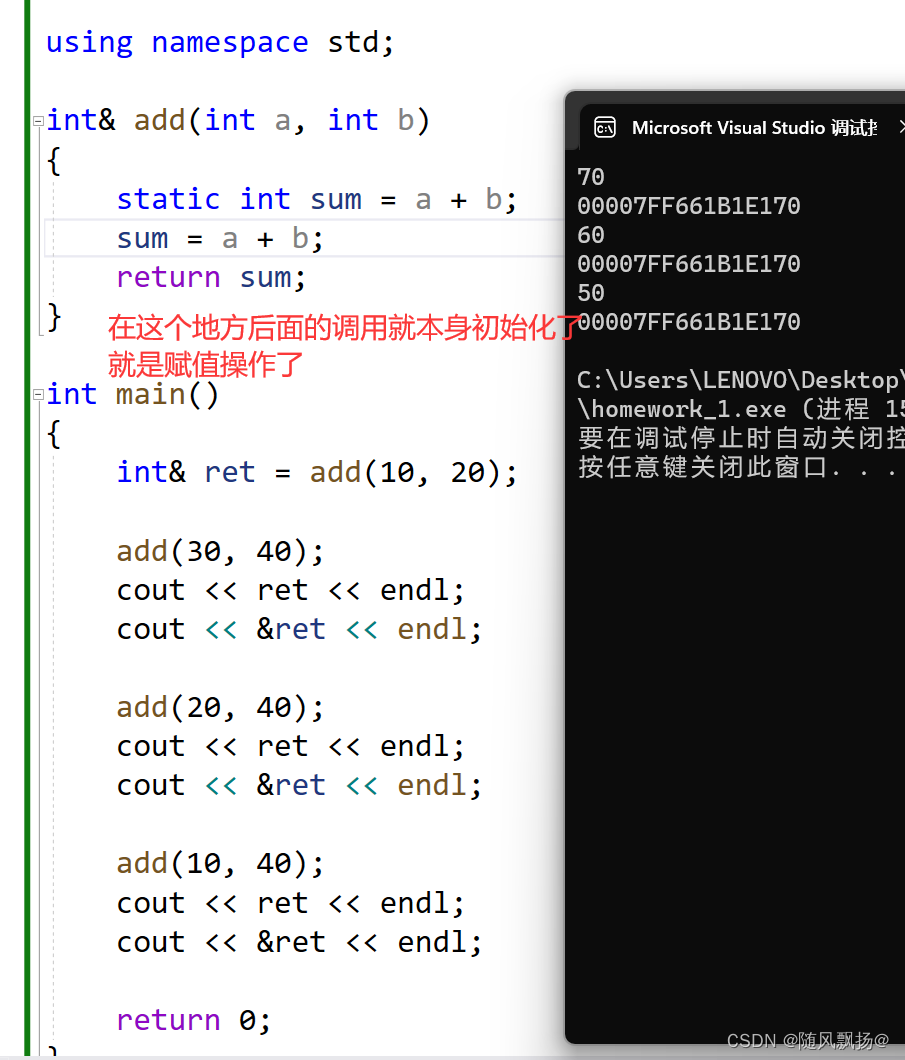
怎么样引用才可以作为函数返回值呢:
1.这个变量在函数栈帧销毁的时候它不会被销毁:
1-1:static静态变量(存放在静态区)
1-2:开辟在堆区的变量(存放在堆区)
3.特殊用法:
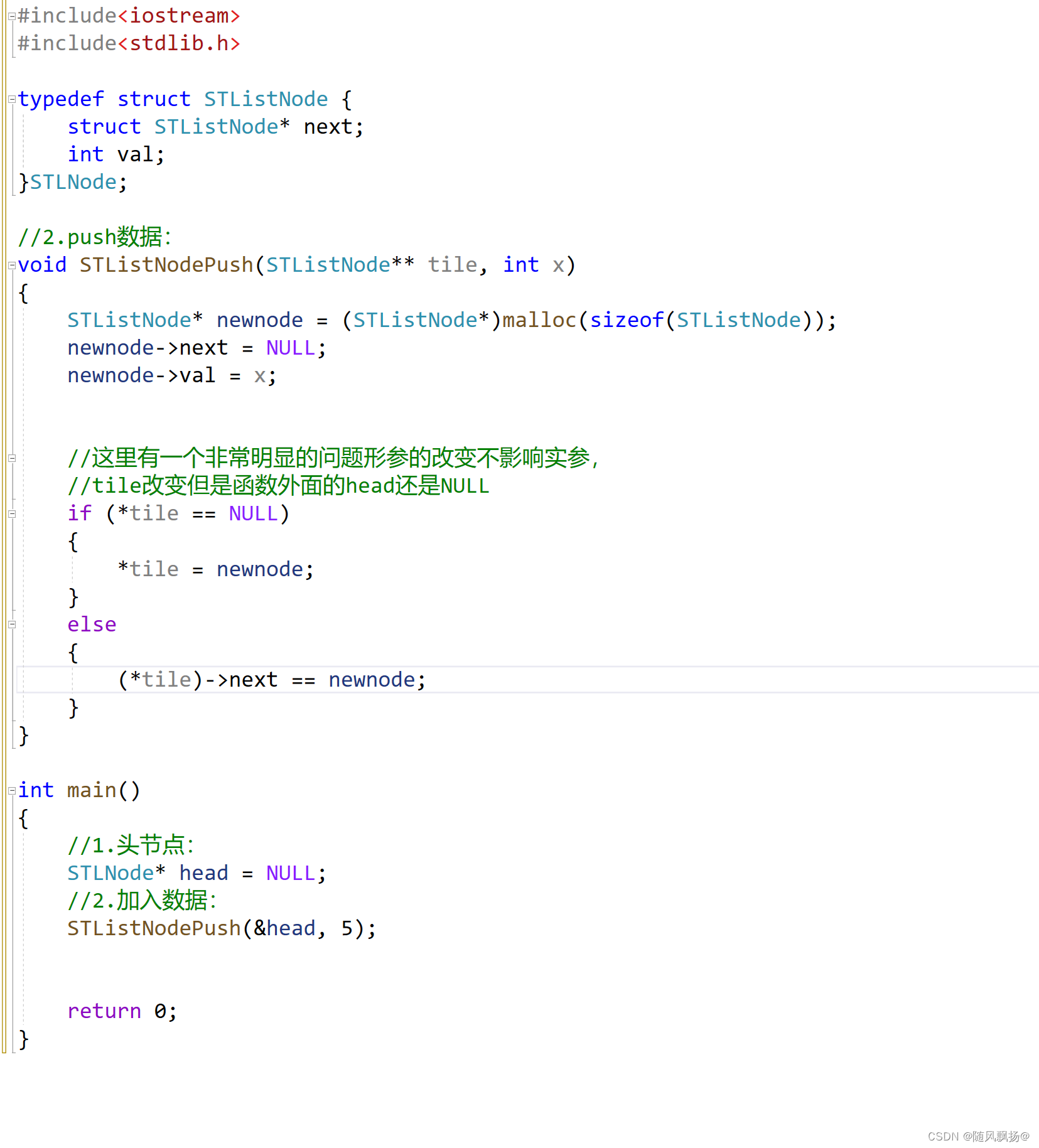
1.我们在模拟实现单链表的时候因为进行开始的头节点的改变和头插都需要改变头节点而传了一个二级指针的操作:
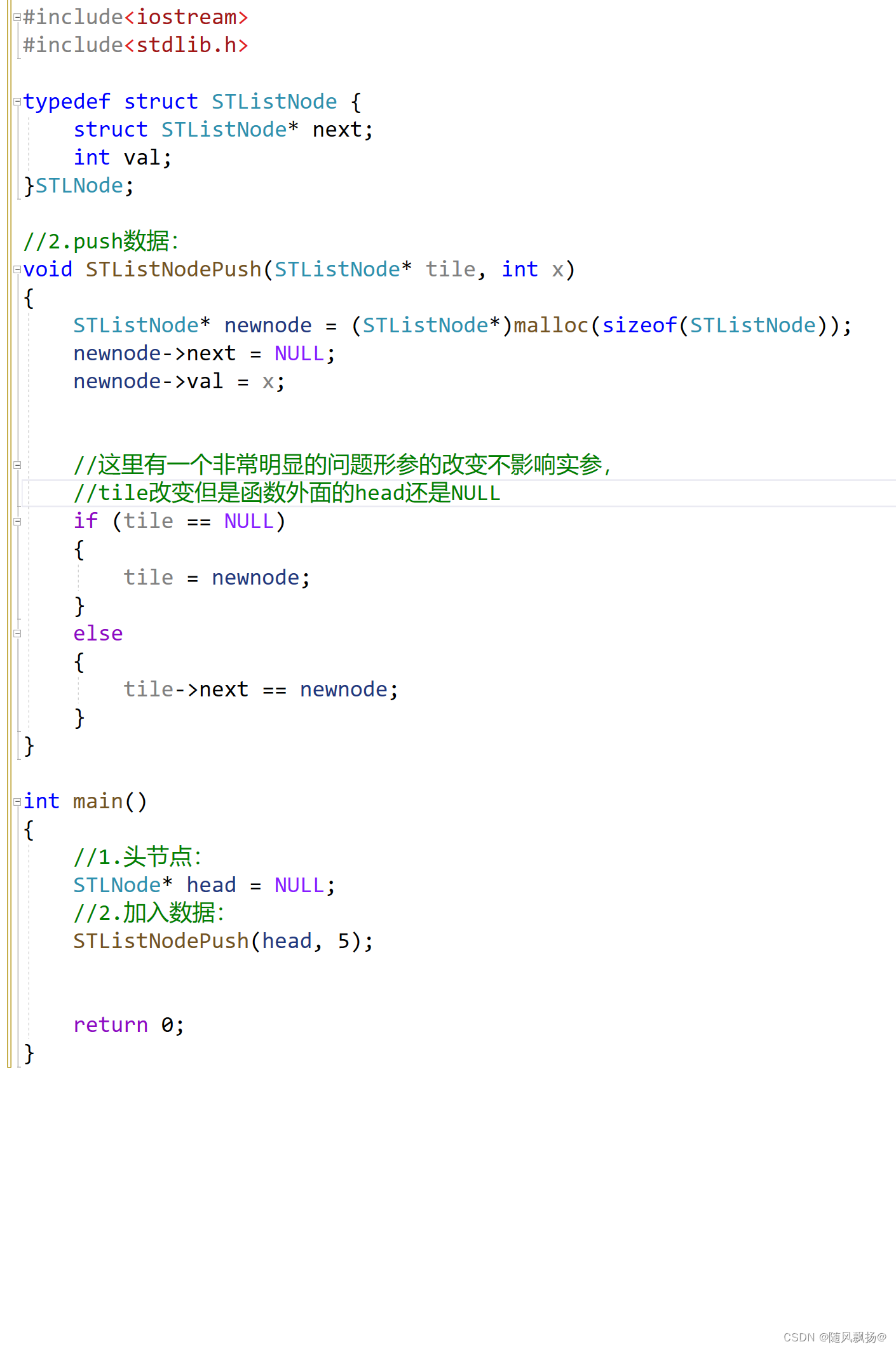
1.解决方法一:二级指针:
我们通过二级指针的方法就可以直接改变我们头节点的地址:
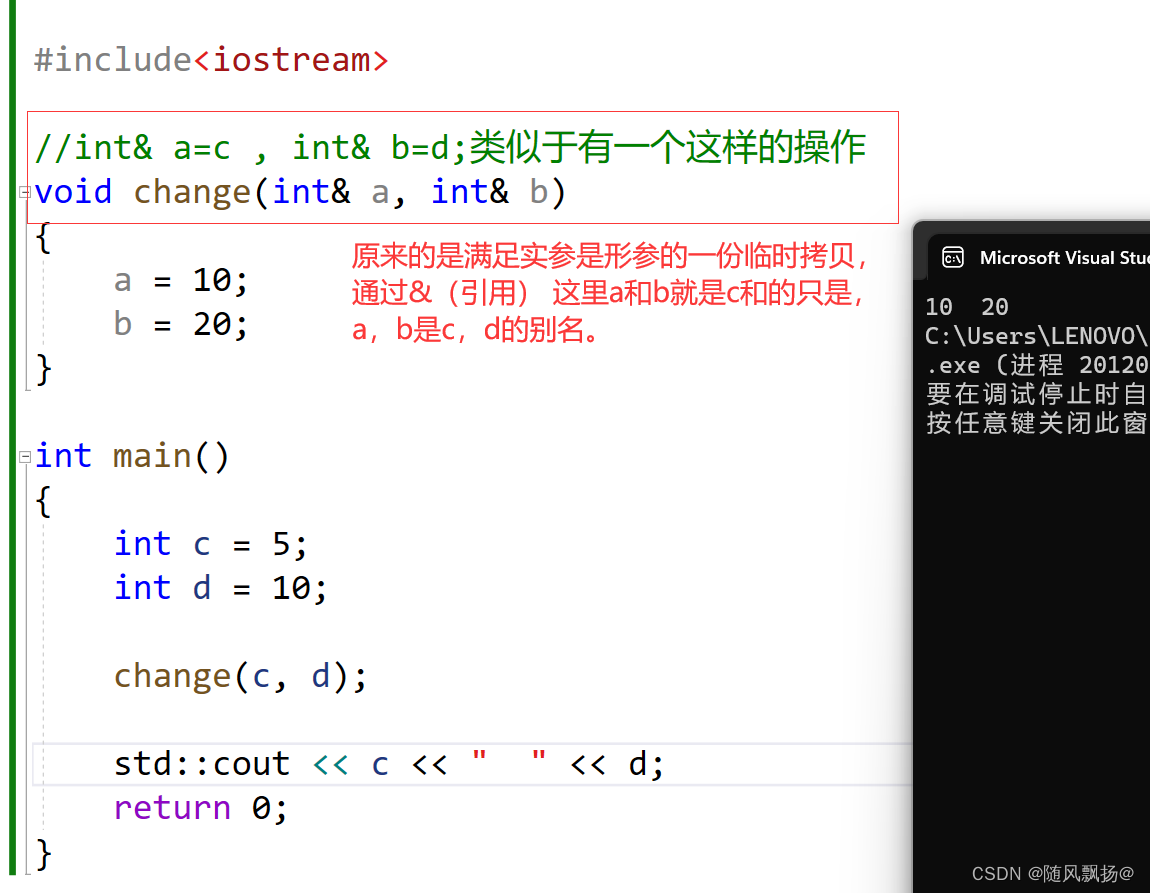
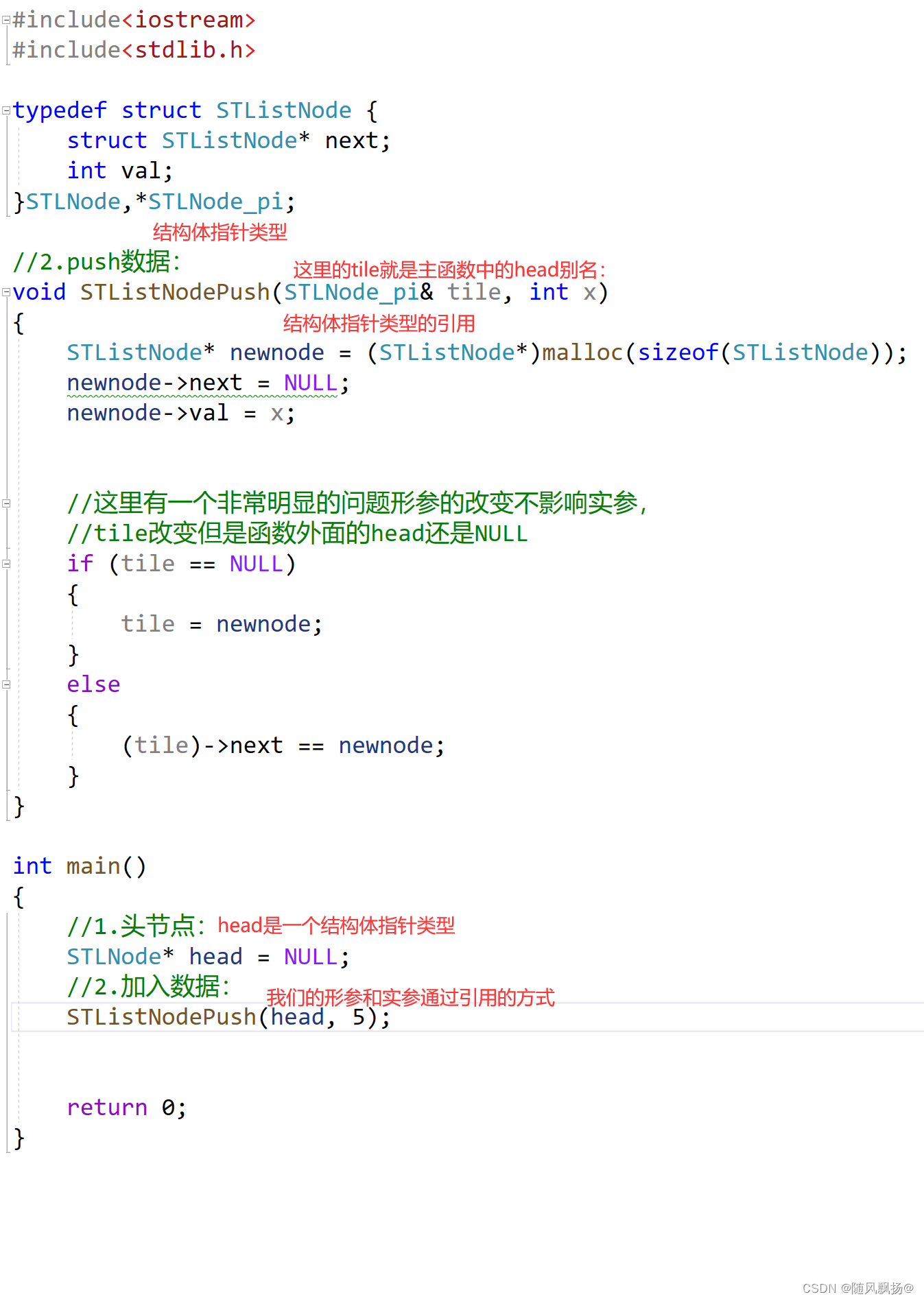
2.解决方法二:引用:
通过上面的知识我们知道int是可以有别名的int*有别人名的。当然结构体类型有别名的。结构体指针类型有别名。
4.总结:
1.引用在语法上就是另一个变量的别名,指针是存储了另一个变量的地址。
2.引用必须初始化,指针无所谓初始化。
3.引用初始化是一种传址,后面的赋值都是一种改变变量数值的操作。
4.引用初始化一个变量之后就不可以在引用其他变量,然鹅指针可以在任何时候指向另一个同类型的实体:
5.sizeof 中的含义不同因为我引用是你的别名应该有你的所有属性所以sizeof大小应该满足引用类型的字节大小,指针类型是地址地址在32为平台下就是4字节:
6.引用++ 就是引用的实际个体数值++,指针++就是向后移动应该类型的字节大小。
7.有多级指针但是没有多级引用。
8.访问实体的方式不同,指针靠解引用,引用靠编译器自己处理。
9.引用比指针使用起来更加安全,这个安全是相对的内容。
7.内联函数:
关于宏:
优点:
1.不需要开辟函数栈帧,节省空间。
2.宏的效率会快一些。
缺点:
1.容易出现优先级的问题。
2.不可以调试
3.宏的内容过多会产生空间的浪费。
4.宏是没有类型检查的。
1.概念:
一个inline加在一个函数的前面就让这个函数获得了宏的所有优点但是并没有宏的一些缺陷(优先级,函数调试,类型检查),内联提高了函数的运行效率:
1.因为inline是一个对代码的优化,默认不会打开这个代码优化。
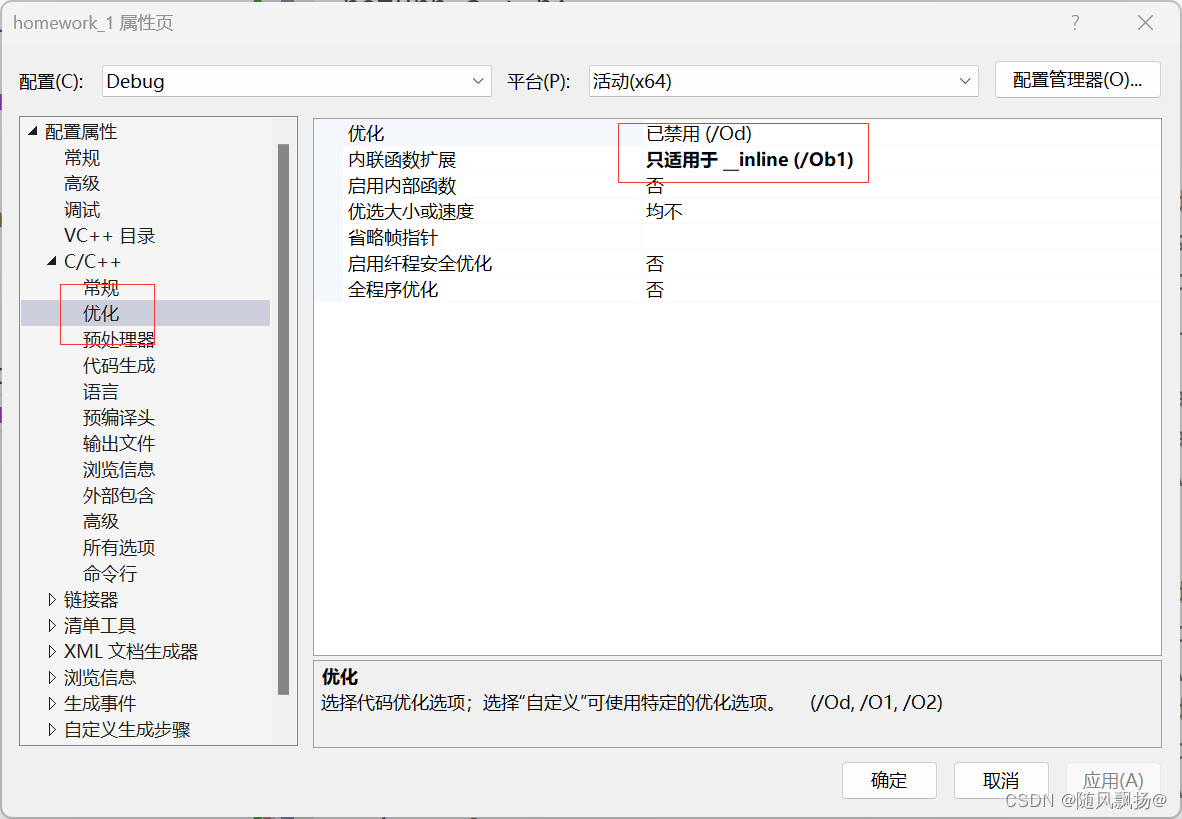
打开之后的结果:
2.inline的优缺点:
1.inline是具有不错的优点但是inline不是一个非常好的处理方法。
2.inline本质上是一个用空间换时间的做法,如果编译器把函数当作内联函数处理。那么在代码进行预编译的时候我们就进行替换,好处:节省了调用函数栈帧的时间消耗,缺点:导致目标文件变大。
3.inline对于编译器只是一个建议,不同的的编译器对于inline的实现的机制可能不同,一般函数比较小,不是递归并且频繁调用的函数可以去用inline修饰。
4.inline不建议定义和声明分开会导致连接错误因为inline函数需要展开但是如果定义和声明分离展开是没有内容的(找不到函数地址链接找不到的)。5.优点:
1.有宏的所有优点,没有宏的缺点
2.频繁调用一个小函数效率是比较高的:
6.缺点:
1.内联函数比较大,就会大大使用了目标空间。
2.使用一个较大函数我们内联就都会去编译函数代码,对于正常的函数调用只会编译一条函数代码。
相关文章:

[C++]:1.初识C++和C语言缺陷补充。
初识C和C语言缺陷补充 一.主要内容:二.具体内容:一: 作用域1.命名空间:2.函数声明和定义:3.不存在命名冲突的情况: 二.输入输出:1.基本输入输出:2.关于std的展开: 三.函数…...
BUUCTF学习(三): PHP 代码审计
1、介绍 2、解题 (1)查看网页源代码 (2)返回链接 (3)代码审计...

推荐《Blue prison》
电视动画片《蓝色监狱》改编自金城宗幸原作、野村优介作画的同名漫画作品,于2021年7月31日宣布电视动画化的消息 [1]。该片由8Bit负责动画制作,于2022年10月9日起播出 [2],全24集。 该作评为Anime Corner 2022年年度体育动画 [24]࿰…...
goland安装教程
安装版本: goland-2023.2.3.exe...

java中okhttp和httpclient那个效率高
在比较OkHttp和HttpClient的效率时,需要考虑多个因素,包括性能、吞吐量、资源消耗等。这些因素往往取决于具体的使用场景和需求。 OkHttp是一个由Square开发的现代化HTTP客户端库,它在Android平台上广泛使用,并且也可以在Java应用…...
内存占用问题
虚拟内存介绍 虚拟内存就是将部分磁盘变成内存的拓展,用上去就好像是将内存变大了一样。 比如同样是16G的物理内存,有人能比你多开几个应用,你开两三个就要黑屏,然后浏览器说你内存不够。 打开任务管理器,内存也没有…...

代码随想录二刷 Day 34
455.分发饼干 这个题差不多是两个for循环遍历,然后用双指针法化简,自己可以大概写出来,漏了一个边界条件 class Solution { public:int findContentChildren(vector<int>& g, vector<int>& s) {sort(g.begin(), g.end(…...

软件开源快速开发框架:降本增效,助力流程化办公!
随着时代的进步和社会的发展,应用软件开源快速开发框架的优势特点,可以让不少客户朋友顺利实现流程化办公,朝着数字化方向迈进。流辰信息是专业研发低代码技术平台的服务商,一直在低代码平台领域深耕细作,努力钻研&…...

Flink on k8s容器日志生成原理及与Yarn部署时的日志生成模式对比
Flink on k8s部署日志详解及与Yarn部署时的日志生成模式对比 最近需要将flink由原先部署到Yarn集群切换到kubernetes集群,在切换之后需要熟悉flink on k8s的运行模式。在使用过程中针对日志模块发现,在k8s的容器中,flink的系统日志只有jobma…...

AD20绘制电路板的外形
今天学习了绘制电路板外形的方法,记录一下,回头忘了还能在看看,便能很快的回忆起来了,比看视频啥的要高效的多。毕竟是自己写的,印象要深刻的多。 首先新建一个PCBDoc文件,方法如下图: 在新建的…...

linux 设置开机启动
1、Fedora 20系列操作系统 touch /etc/rc.d/rc.local chmod x /etc/rc.d/rc.local vi /etc/rc.d/rc.local 按“i”进入编辑模式,在文件末尾补充如下内容: 可以根据需要添加你要开机自启动的脚本命令(下面是举例): …...
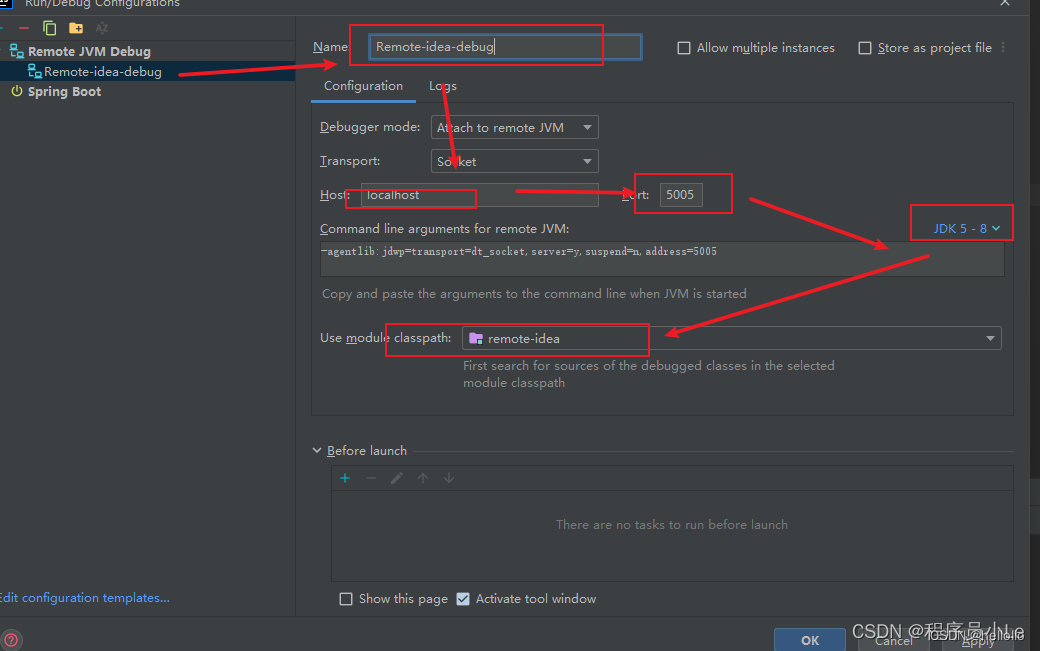
IDEA实现远程Debug调试
一、 前提 需要准备JDK1.8环境,安装IDEA(版本不限) 二、 IDEA中如何实现远程Debug模式 (1)、创建demo项目 1.File一>New一>project… 2.Maven Archetype一>填写Name一>选择jdk1.8一>选择Web一>创建 (2)、配置Idea 找到Remote Jvm Debug java…...
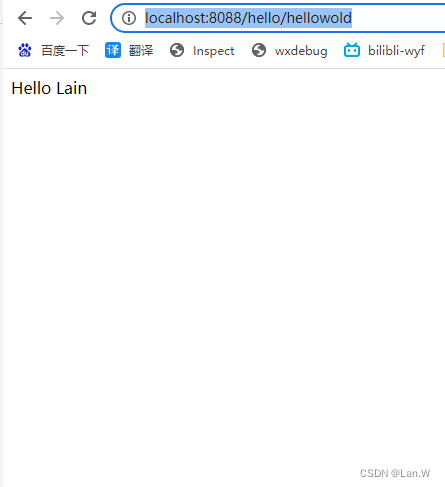
SpringBoot项目入门: IDEA 创建SpringBoot项目
方式1:在线创建项目 https://start.spring.io/ 环境准备 (1)JDK 环境必须是 1.8 及以上,传送门:jdk1.8.191 下载(2)后面要使用到 Maven 管理工具 3.2.5 及以上版本(3)开发工具建议…...

Vue2+SpringBoot实现数据导出到csv文件并下载
前言 该功能用于导出数据到csv文件,并且前端进行下载操作。涉及到java后端以及前端。后端获取数据并处理,前端获取返回流并进行下载操作。csv与excel文件不大相同。如果对导出的数据操作没有很高要求的话,csv文件就够了。具体差异自行百度。我…...
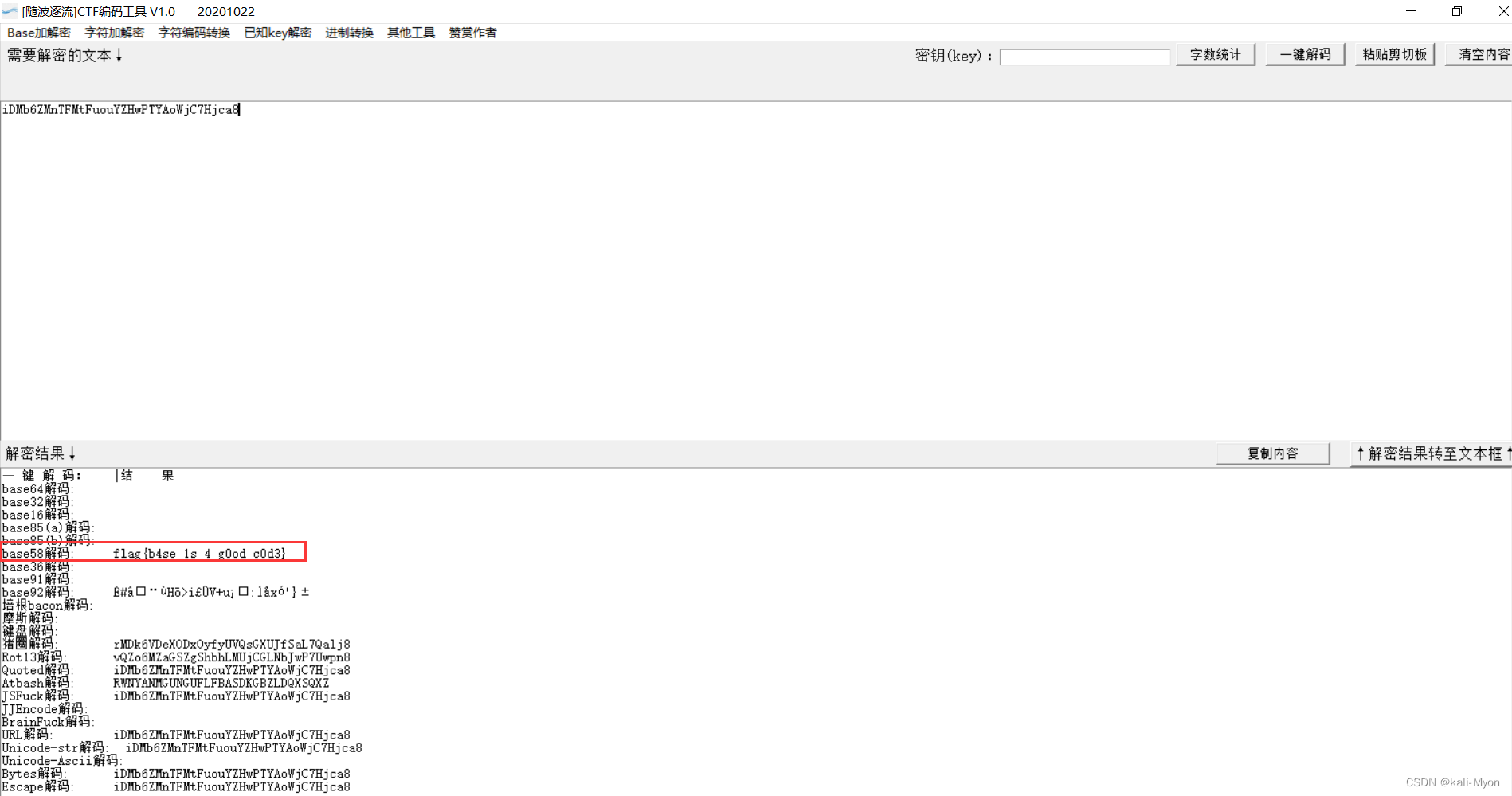
NewStarCTF2023week2-base!(base低位隐写)
附件内容是很多的base64编码的字符串 常见的Base64隐写一般会给一个txt文本文档,内含多个经过base64编码的字符串。解码规则是将所有被修改过的base64字符串结尾的二进制值提取出来组成一个二进制串,以8位分割并转为十进制值,最终十进制对应的…...

众和策略:国际油价走高,石油板块强势拉升,通源石油、和顺石油等涨停
石油板块16日盘中大幅拉升,到发稿,通源石油、和顺石油、贝肯动力、中曼石油、泰山石油、仁智股份等涨停,潜能恒信、博迈科涨约8%。 燃气板块亦上扬,到发稿,洪通燃气、美能动力涨约5%,新疆火炬、九丰动力涨…...

C++笔记之获取线程ID以及线程ID的用处
C笔记之获取线程ID以及线程ID的用处 code review! 文章目录 C笔记之获取线程ID以及线程ID的用处一.获取ID二.线程ID的用处2.1.线程池管理2.2.动态资源分配2.3.使用线程同步机制实现互斥访问共享资源2.4.使用线程 ID 辅助线程同步2.5.任务分发:线程ID可以用于将任务…...

机器人硬件在环仿真:解决实体开发与测试挑战,提升效率与安全性
工业机器人具备出色的灵活性和运动能力,广泛应用于工业制造领域。它们可以完成装配、焊接、喷涂、搬运、加工、品质检测等任务,提高了生产效率,保证了产品质量。此外,在医疗领域也有辅助手术等特殊应用,展现了其在多个…...
)
stream()
stream().map,stream().filter,stream().peek 1、stream().map:该方法用于将一个流中的元素通过指定的函数进行映射,最终生成一个新的流。例如,如果我们有一个存储了字符串的列表,可以使用 map 方法将列表…...
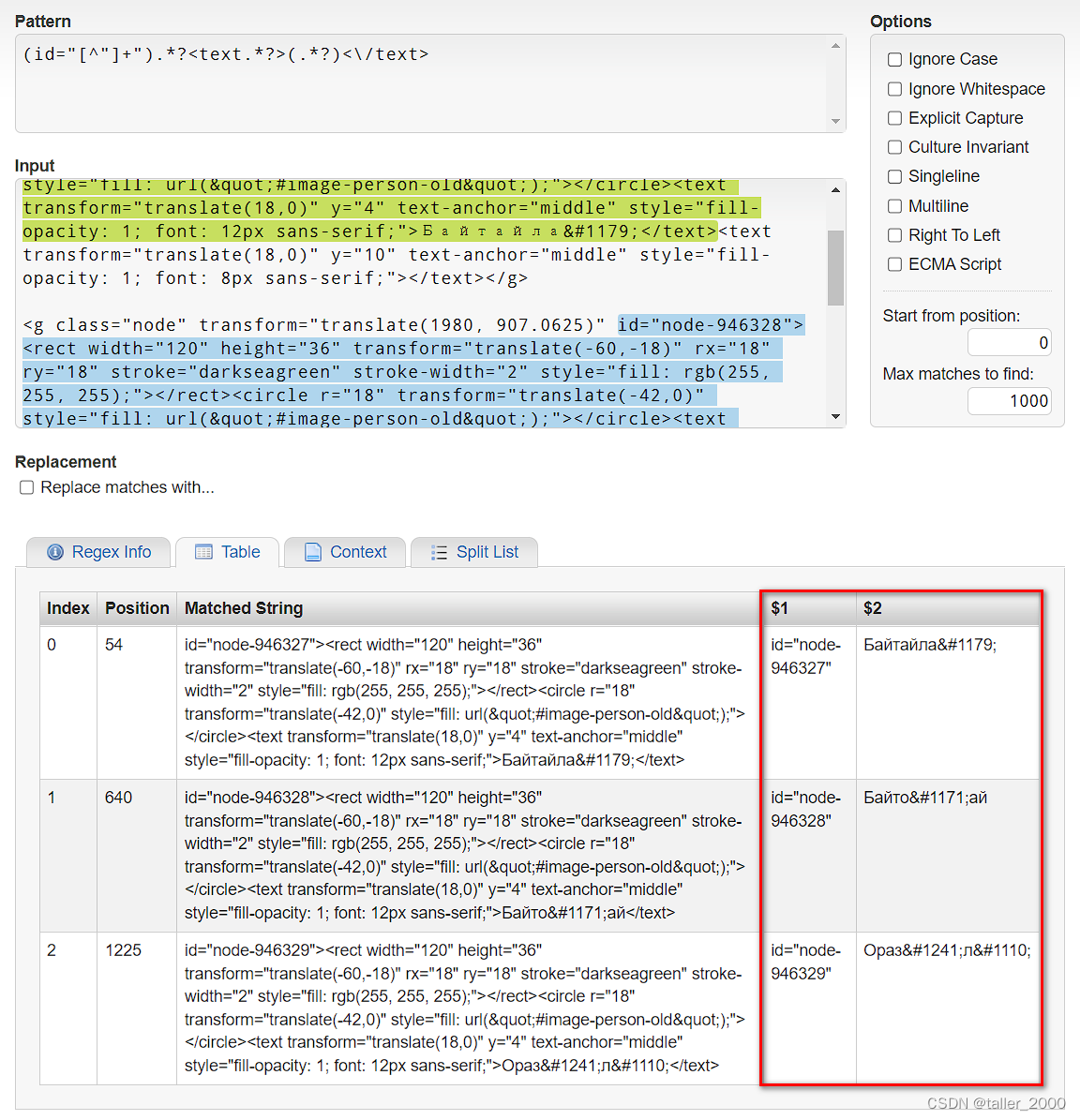
VBA之正则表达式(43)-- 从网页中提取指定数据
实例需求:由网页中提取下图中颜色标记部分内容,网页中其他部分与此三行格式相同。 方法1 Sub Demo()Dim objRegex As ObjectDim inputString As StringDim objMatches As ObjectDim objMatch As ObjectSet objRegex CreateObject("VBScript.RegEx…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

Java数值运算常见陷阱与规避方法
整数除法中的舍入问题 问题现象 当开发者预期进行浮点除法却误用整数除法时,会出现小数部分被截断的情况。典型错误模式如下: void process(int value) {double half = value / 2; // 整数除法导致截断// 使用half变量 }此时...

R 语言科研绘图第 55 期 --- 网络图-聚类
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

TSN交换机正在重构工业网络,PROFINET和EtherCAT会被取代吗?
在工业自动化持续演进的今天,通信网络的角色正变得愈发关键。 2025年6月6日,为期三天的华南国际工业博览会在深圳国际会展中心(宝安)圆满落幕。作为国内工业通信领域的技术型企业,光路科技(Fiberroad&…...
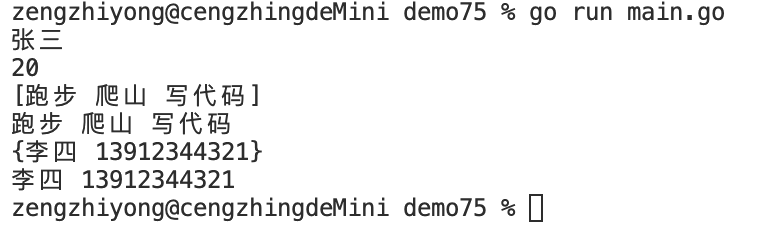
Golang——7、包与接口详解
包与接口详解 1、Golang包详解1.1、Golang中包的定义和介绍1.2、Golang包管理工具go mod1.3、Golang中自定义包1.4、Golang中使用第三包1.5、init函数 2、接口详解2.1、接口的定义2.2、空接口2.3、类型断言2.4、结构体值接收者和指针接收者实现接口的区别2.5、一个结构体实现多…...

Python异步编程:深入理解协程的原理与实践指南
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 持续学习,不断…...
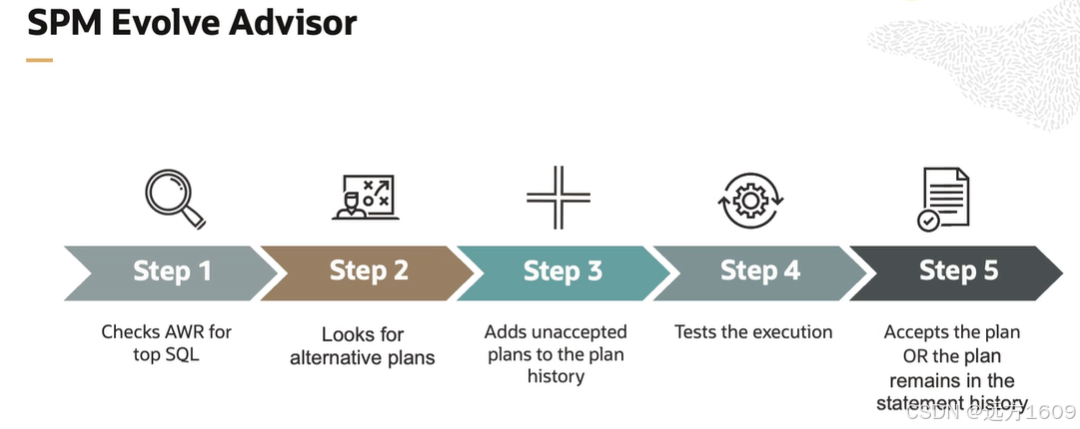
21-Oracle 23 ai-Automatic SQL Plan Management(SPM)
小伙伴们,有没有迁移数据库完毕后或是突然某一天在同一个实例上同样的SQL, 性能不一样了、业务反馈卡顿、业务超时等各种匪夷所思的现状。 于是SPM定位开始,OCM考试中SPM必考。 其他的AWR、ASH、SQLHC、SQLT、SQL profile等换作下一个话题…...