Kubernetes 集群部署 Prometheus 和 Grafana
Kubernetes 集群部署 Prometheus 和 Grafana
文章目录
- Kubernetes 集群部署 Prometheus 和 Grafana
- 一.部署 node-exporter
- 1.node-exporter 安装
- 2.部署 node-exporter
- 二.部署Prometheus
- 1.Prometheus 安装和配置
- (1)创建 sa 账号,对 sa 做 rbac 授权
- (2)创建一个 configmap 存储卷,用来存放 prometheus 配置信息
- (3)通过 deployment 部署 prometheus
- (4)给 prometheus pod 创建一个 service
- 2.Prometheus 配置热加载
- 三.Grafana 安装
- 1.安装Grafana
- 2.Grafana 配置
- (1)浏览器访问,登陆
- (2)配置 grafana 的 web 界面
- (3)导入监控模板
- (4)监控 node 状态
- (5)监控 容器 状态
- 四.k8s 部署 kube-state-metrics 组件
- 1.安装 kube-state-metrics 组件
- 2.Grafana 配置
- 五.kubernetes 配置 alertmanager 发送报警到邮箱
- 1.Prometheus报警处理流程
- 2.Prometheus 及 Alertmanager 配置
- (1)创建 alertmanager 配置文件
- (2)创建 prometheus 和告警规则配置文件
- (3)安装 prometheus 和 alertmanager
- (4)部署 alertmanager 的 service,方便在浏览器访问
- 3.处理 kube-proxy 监控告警
实验环境
| 节点 | 地址 | |
|---|---|---|
| 控制节点/master01 | 192.168.198.11 | |
| 工作节点/node01 | 192.168.198.12 | |
| 工作节点/node02 | 192.168.198.13 |
一.部署 node-exporter
1.node-exporter 安装
#创建监控 namespace
kubectl create ns monitor-sa
2.部署 node-exporter
#部署 node-exporter
mkdir /opt/prometheus
cd /opt/prometheus/
vim node-export.yaml
---
apiVersion: apps/v1
kind: DaemonSet #可以保证 k8s 集群的每个节点都运行完全一样的 pod
metadata:name: node-exporternamespace: monitor-salabels:name: node-exporter
spec:selector:matchLabels:name: node-exportertemplate:metadata:labels:name: node-exporterspec:hostPID: truehostIPC: truehostNetwork: truecontainers:- name: node-exporterimage: prom/node-exporter:v0.16.0ports:- containerPort: 9100resources:requests:cpu: 0.15 #这个容器运行至少需要0.15核cpusecurityContext:privileged: true #开启特权模式args:- --path.procfs- /host/proc- --path.sysfs- /host/sys- --collector.filesystem.ignored-mount-points- '"^/(sys|proc|dev|host|etc)($|/)"'volumeMounts:- name: devmountPath: /host/dev- name: procmountPath: /host/proc- name: sysmountPath: /host/sys- name: rootfsmountPath: /rootfstolerations:- key: "node-role.kubernetes.io/master"operator: "Exists"effect: "NoSchedule"volumes:- name: prochostPath:path: /proc- name: devhostPath:path: /dev- name: syshostPath:path: /sys- name: rootfshostPath:path: /#hostNetwork、hostIPC、hostPID都为True时,表示这个Pod里的所有容器,会直接使用宿主机的网络,直接与宿主机进行IPC(进程间通信)通信,可以看到宿主机里正在运行的所有进程。加入了hostNetwork:true会直接将我们的宿主机的9100端口映射出来,从而不需要创建service在我们的宿主机上就会有一个9100的端口。
kubectl apply -f node-export.yaml
kubectl get pods -n monitor-sa -o wide
netstat -antp | grep 9100

#通过 node-exporter 采集数据
node-exporter 默认的监听端口是 9100,可以执行
curl http://192.168.198.11:9100/metrics 获取到主机的所有监控数据
curl -Ls http://192.168.198.11:9100/metrics | grep node_cpu_seconds
# HELP node_cpu_seconds_total Seconds the cpus spent in each mode. #Help 用于解释当前指标的含义
# TYPE node_cpu_seconds_total counter #Type 用于说明数据的类型,这是一个 counter(计数器)类型的数据
node_cpu_seconds_total{cpu="0",mode="idle"} 27815.89 #接下来就是具体的指标的值
node_cpu_seconds_total{cpu="0",mode="iowait"} 43.2
node_cpu_seconds_total{cpu="0",mode="irq"} 0
node_cpu_seconds_total{cpu="0",mode="nice"} 0.09
node_cpu_seconds_total{cpu="0",mode="softirq"} 55.58
node_cpu_seconds_total{cpu="0",mode="steal"} 0
node_cpu_seconds_total{cpu="0",mode="system"} 334.41
node_cpu_seconds_total{cpu="0",mode="user"} 315.43
node_cpu_seconds_total{cpu="1",mode="idle"} 27759.06
node_cpu_seconds_total{cpu="1",mode="iowait"} 44.4
node_cpu_seconds_total{cpu="1",mode="irq"} 0
node_cpu_seconds_total{cpu="1",mode="nice"} 0.09
node_cpu_seconds_total{cpu="1",mode="softirq"} 55.21
node_cpu_seconds_total{cpu="1",mode="steal"} 0
node_cpu_seconds_total{cpu="1",mode="system"} 355.37
node_cpu_seconds_total{cpu="1",mode="user"} 319.74
node_cpu_seconds_total{cpu="2",mode="idle"} 27828.94
node_cpu_seconds_total{cpu="2",mode="iowait"} 43.26
node_cpu_seconds_total{cpu="2",mode="irq"} 0
node_cpu_seconds_total{cpu="2",mode="nice"} 0.04
node_cpu_seconds_total{cpu="2",mode="softirq"} 45.4
node_cpu_seconds_total{cpu="2",mode="steal"} 0
node_cpu_seconds_total{cpu="2",mode="system"} 331.04
node_cpu_seconds_total{cpu="2",mode="user"} 317.42
node_cpu_seconds_total{cpu="3",mode="idle"} 27785.67
node_cpu_seconds_total{cpu="3",mode="iowait"} 53.06
node_cpu_seconds_total{cpu="3",mode="irq"} 0
node_cpu_seconds_total{cpu="3",mode="nice"} 0.05
node_cpu_seconds_total{cpu="3",mode="softirq"} 42.76
node_cpu_seconds_total{cpu="3",mode="steal"} 0
node_cpu_seconds_total{cpu="3",mode="system"} 338.82
node_cpu_seconds_total{cpu="3",mode="user"} 336.5
curl -Ls http://192.168.198.11:9100/metrics | grep node_load
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 0.09
# HELP node_load15 15m load average.
# TYPE node_load15 gauge
node_load15 0.56
# HELP node_load5 5m load average.
# TYPE node_load5 gauge
node_load5 0.5
二.部署Prometheus
1.Prometheus 安装和配置
(1)创建 sa 账号,对 sa 做 rbac 授权
#创建一个 sa 账号 monitor
kubectl create serviceaccount monitor -n monitor-sa#把 sa 账号 monitor 通过 clusterrolebing 绑定到 clusterrole 上
kubectl create clusterrolebinding monitor-clusterrolebinding -n monitor-sa --clusterrole=cluster-admin --serviceaccount=monitor-sa:monitor
(2)创建一个 configmap 存储卷,用来存放 prometheus 配置信息
vim prometheus-cfg.yaml
---
kind: ConfigMap
apiVersion: v1
metadata:labels:app: prometheusname: prometheus-confignamespace: monitor-sa
data:prometheus.yml: |global: #指定prometheus的全局配置,比如采集间隔,抓取超时时间等scrape_interval: 15s #采集目标主机监控数据的时间间隔,默认为1mscrape_timeout: 10s #数据采集超时时间,默认10sevaluation_interval: 1m #触发告警生成alert的时间间隔,默认是1mscrape_configs: #配置数据源,称为target,每个target用job_name命名。又分为静态配置和服务发现- job_name: 'kubernetes-node'kubernetes_sd_configs: # *_sd_configs 指定的是k8s的服务发现- role: node #使用node角色,它使用默认的kubelet提供的http端口来发现集群中每个node节点relabel_configs: #重新标记- source_labels: [__address__] #配置的原始标签,匹配地址regex: '(.*):10250' #匹配带有10250端口的urlreplacement: '${1}:9100' #把匹配到的ip:10250的ip保留target_label: __address__ #新生成的url是${1}获取到的ip:9100action: replace #动作替换- action: labelmapregex: __meta_kubernetes_node_label_(.+) #匹配到下面正则表达式的标签会被保留,如果不做regex正则的话,默认只是会显示instance标签- job_name: 'kubernetes-node-cadvisor' #抓取cAdvisor数据,是获取kubelet上/metrics/cadvisor接口数据来获取容器的资源使用情况kubernetes_sd_configs:- role: nodescheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- action: labelmap #把匹配到的标签保留regex: __meta_kubernetes_node_label_(.+) #保留匹配到的具有__meta_kubernetes_node_label的标签- target_label: __address__ #获取到的地址:__address__="192.168.192.11:10250"replacement: kubernetes.default.svc:443 #把获取到的地址替换成新的地址kubernetes.default.svc:443- source_labels: [__meta_kubernetes_node_name]regex: (.+) #把原始标签中__meta_kubernetes_node_name值匹配到target_label: __metrics_path__ #获取__metrics_path__对应的值replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor #把metrics替换成新的值api/v1/nodes/k8s-master1/proxy/metrics/cadvisor#${1}是__meta_kubernetes_node_name获取到的值#新的url就是https://kubernetes.default.svc:443/api/v1/nodes/k8s-master1/proxy/metrics/cadvisor- job_name: 'kubernetes-apiserver'kubernetes_sd_configs:- role: endpoints #使用k8s中的endpoint服务发现,采集apiserver 6443端口获取到的数据scheme: httpstls_config:ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crtbearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/tokenrelabel_configs:- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] #[endpoint这个对象的名称空间,endpoint对象的服务名,exnpoint的端口名称]action: keep #采集满足条件的实例,其他实例不采集regex: default;kubernetes;https #正则匹配到的默认空间下的service名字是kubernetes,协议是https的endpoint类型保留下来- job_name: 'kubernetes-service-endpoints'kubernetes_sd_configs:- role: endpointsrelabel_configs:- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape]action: keepregex: true#重新打标仅抓取到的具有"prometheus.io/scrape: true"的annotation的端点, 意思是说如果某个service具有prometheus.io/scrape = true的annotation声明则抓取,annotation本身也是键值结构, 所以这里的源标签设置为键,而regex设置值true,当值匹配到regex设定的内容时则执行keep动作也就是保留,其余则丢弃。- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme]action: replacetarget_label: __scheme__regex: (https?)#重新设置scheme,匹配源标签__meta_kubernetes_service_annotation_prometheus_io_scheme也就是prometheus.io/scheme annotation,如果源标签的值匹配到regex,则把值替换为__scheme__对应的值。- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path]action: replacetarget_label: __metrics_path__regex: (.+)#应用中自定义暴露的指标,也许你暴露的API接口不是/metrics这个路径,那么你可以在这个POD对应的service中做一个 "prometheus.io/path = /mymetrics" 声明,上面的意思就是把你声明的这个路径赋值给__metrics_path__, 其实就是让prometheus来获取自定义应用暴露的metrices的具体路径, 不过这里写的要和service中做好约定,如果service中这样写 prometheus.io/app-metrics-path: '/metrics' 那么你这里就要__meta_kubernetes_service_annotation_prometheus_io_app_metrics_path这样写。- source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port]action: replacetarget_label: __address__regex: ([^:]+)(?::\d+)?;(\d+)replacement: $1:$2#暴露自定义的应用的端口,就是把地址和你在service中定义的 "prometheus.io/port = <port>" 声明做一个拼接, 然后赋值给__address__,这样prometheus就能获取自定义应用的端口,然后通过这个端口再结合__metrics_path__来获取指标,如果__metrics_path__值不是默认的/metrics那么就要使用上面的标签替换来获取真正暴露的具体路径。- action: labelmap #保留下面匹配到的标签regex: __meta_kubernetes_service_label_(.+)- source_labels: [__meta_kubernetes_namespace]action: replace #替换__meta_kubernetes_namespace变成kubernetes_namespacetarget_label: kubernetes_namespace- source_labels: [__meta_kubernetes_service_name]action: replacetarget_label: kubernetes_name
kubectl apply -f prometheus-cfg.yaml
(3)通过 deployment 部署 prometheus
node1 节点操作
#将 prometheus 调度到 node1 节点,在 node1 节点创建 prometheus 数据存储目录
mkdir /data && chmod 777 /data
master节点操作
#通过 deployment 部署 prometheus
vim prometheus-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:name: prometheus-servernamespace: monitor-salabels:app: prometheus
spec:replicas: 1selector:matchLabels:app: prometheuscomponent: server#matchExpressions:#- {key: app, operator: In, values: [prometheus]}#- {key: component, operator: In, values: [server]}template:metadata:labels:app: prometheuscomponent: serverannotations:prometheus.io/scrape: 'false'spec:nodeName: node01 #指定pod调度到哪个节点上 serviceAccountName: monitorcontainers:- name: prometheusimage: prom/prometheus:v2.2.1imagePullPolicy: IfNotPresentcommand:- prometheus- --config.file=/etc/prometheus/prometheus.yml- --storage.tsdb.path=/prometheus #数据存储目录- --storage.tsdb.retention=720h #数据保存时长- --web.enable-lifecycle #开启热加载ports:- containerPort: 9090protocol: TCPvolumeMounts:- mountPath: /etc/prometheus/prometheus.ymlname: prometheus-configsubPath: prometheus.yml- mountPath: /prometheus/name: prometheus-storage-volumevolumes:- name: prometheus-configconfigMap:name: prometheus-configitems:- key: prometheus.ymlpath: prometheus.ymlmode: 0644- name: prometheus-storage-volumehostPath:path: /datatype: Directory
kubectl apply -f prometheus-deploy.yamlkubectl get pods -o wide -n monitor-sa

(4)给 prometheus pod 创建一个 service
vim prometheus-svc.yaml
---
apiVersion: v1
kind: Service
metadata:name: prometheusnamespace: monitor-salabels:app: prometheus
spec:type: NodePortports:- port: 9090targetPort: 9090protocol: TCPnodePort: 31000selector:app: prometheuscomponent: server
kubectl apply -f prometheus-svc.yamlkubectl get svc -n monitor-sa

#通过上面可以看到 service 在 node 节点上映射的端口是 31000,这样我们访问 k8s 集群的 node 节点的 ip:31000,就可以访问到 prometheus 的 web ui 界面了。
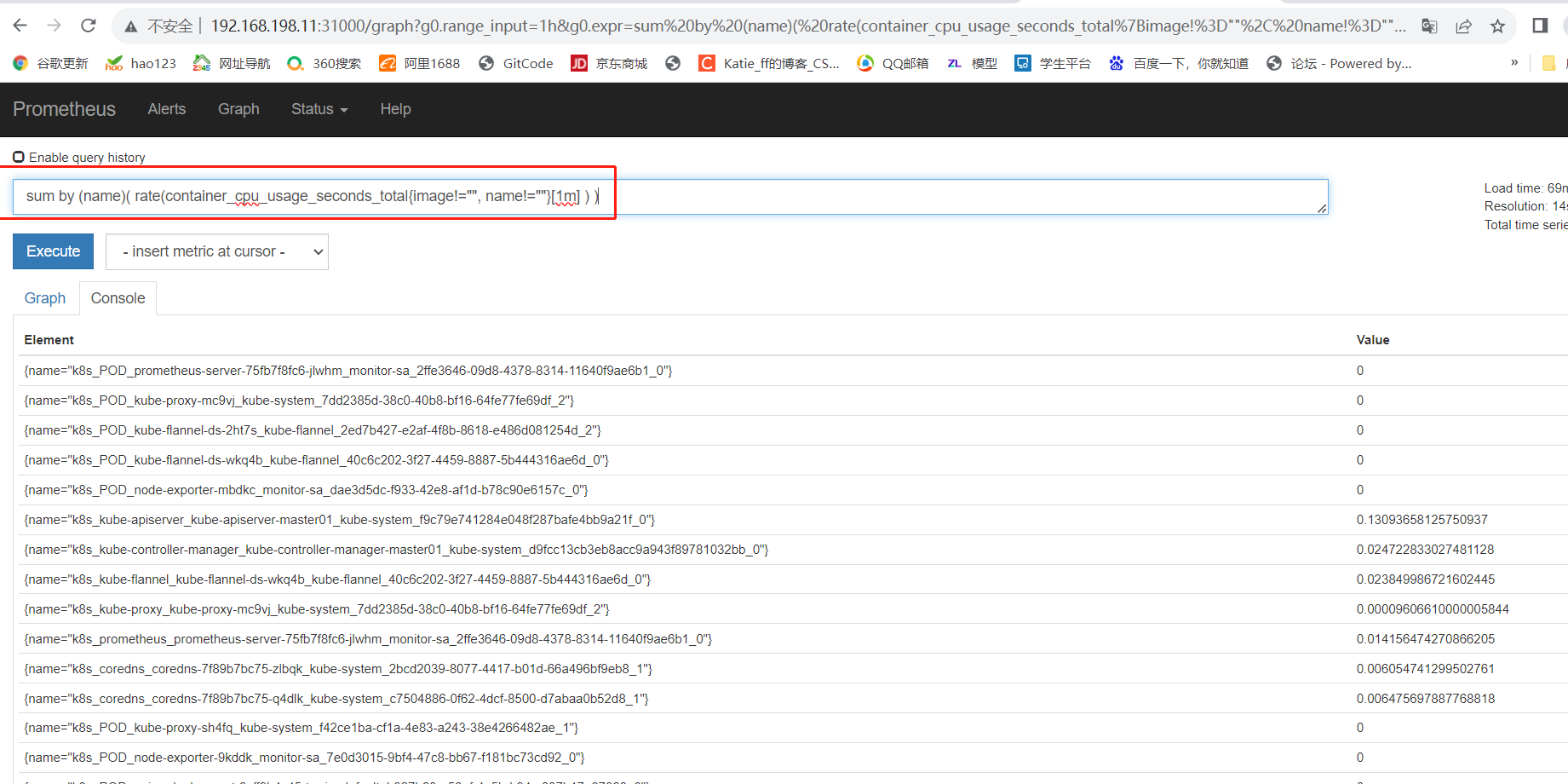
浏览器访问 http://192.168.198.11:31000
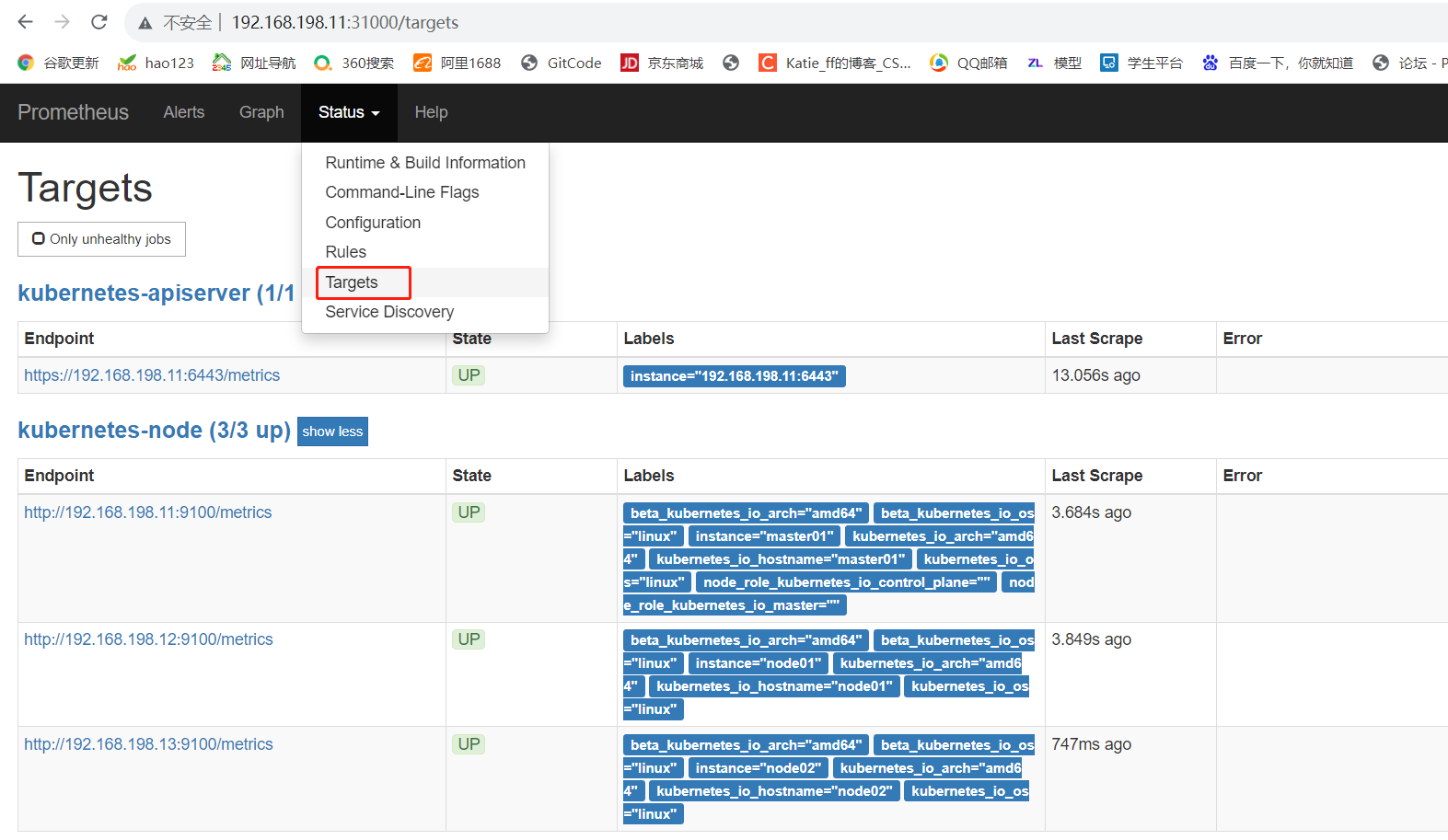
#点击页面的Status->Targets,如看到所有 Target 状态都为 UP,说明我们配置的服务发现可以正常采集数据
#查询 K8S 集群中一分钟之内每个 Pod 的 CPU 使用率
sum by (name)( rate(container_cpu_usage_seconds_total{image!="", name!=""}[1m] ) )
2.Prometheus 配置热加载
###为了每次修改配置文件可以热加载prometheus,也就是不停止prometheus,就可以使配置生效,想要使配置生效可用如下热加载命令:
kubectl get pods -n monitor-sa -o wide -l app=prometheusNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
prometheus-server-75fb7f8fc6-jlwhm 1/1 Running 0 7m35s 10.244.2.9 node01 <none> <none>

#想要使配置生效可用如下命令热加载
curl -X POST -Ls http://10.244.2.9:9090/-/reload
#查看 log
kubectl logs -n monitor-sa prometheus-server-75fb7f8fc6-jlwhm | grep "Loading configuration file"

###一般热加载速度比较慢,可以暴力重启prometheus,如修改上面的 prometheus-cfg.yaml 文件之后,可用如下命令:
#可执行先强制删除,然后再通过 apply 更新
kubectl delete -f prometheus-cfg.yaml
kubectl delete -f prometheus-deploy.yaml
kubectl apply -f prometheus-cfg.yaml
kubectl apply -f prometheus-deploy.yaml
注意:线上环境最好使用热加载,暴力删除可能造成监控数据的丢失
三.Grafana 安装
1.安装Grafana
vim grafana.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:name: monitoring-grafananamespace: kube-system
spec:replicas: 1selector:matchLabels:task: monitoringk8s-app: grafanatemplate:metadata:labels:task: monitoringk8s-app: grafanaspec:containers:- name: grafanaimage: grafana/grafana:5.0.4ports:- containerPort: 3000protocol: TCPvolumeMounts:- mountPath: /etc/ssl/certsname: ca-certificatesreadOnly: true- mountPath: /varname: grafana-storageenv:- name: INFLUXDB_HOSTvalue: monitoring-influxdb- name: GF_SERVER_HTTP_PORTvalue: "3000"# The following env variables are required to make Grafana accessible via# the kubernetes api-server proxy. On production clusters, we recommend# removing these env variables, setup auth for grafana, and expose the grafana# service using a LoadBalancer or a public IP.- name: GF_AUTH_BASIC_ENABLEDvalue: "false"- name: GF_AUTH_ANONYMOUS_ENABLEDvalue: "true"- name: GF_AUTH_ANONYMOUS_ORG_ROLEvalue: Admin- name: GF_SERVER_ROOT_URL# If you're only using the API Server proxy, set this value instead:# value: /api/v1/namespaces/kube-system/services/monitoring-grafana/proxyvalue: /volumes:- name: ca-certificateshostPath:path: /etc/ssl/certs- name: grafana-storageemptyDir: {}
---
apiVersion: v1
kind: Service
metadata:labels:# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)# If you are NOT using this as an addon, you should comment out this line.kubernetes.io/cluster-service: 'true'kubernetes.io/name: monitoring-grafananame: monitoring-grafananamespace: kube-system
spec:# In a production setup, we recommend accessing Grafana through an external Loadbalancer# or through a public IP.# type: LoadBalancer# You could also use NodePort to expose the service at a randomly-generated port# type: NodePortports:- port: 80targetPort: 3000selector:k8s-app: grafanatype: NodePort
kubectl apply -f grafana.yaml
kubectl get pods -n kube-system -l task=monitoring -o wide
kubectl get svc -n kube-system | grep grafana monitoring-grafana NodePort 10.96.13.243 <none> 80:32605/TCP 87s

2.Grafana 配置
(1)浏览器访问,登陆
浏览器访问http://192.168.198.11:32605 ,登陆 grafana
(2)配置 grafana 的 web 界面
开始配置 grafana 的 web 界面:选择 Add data source
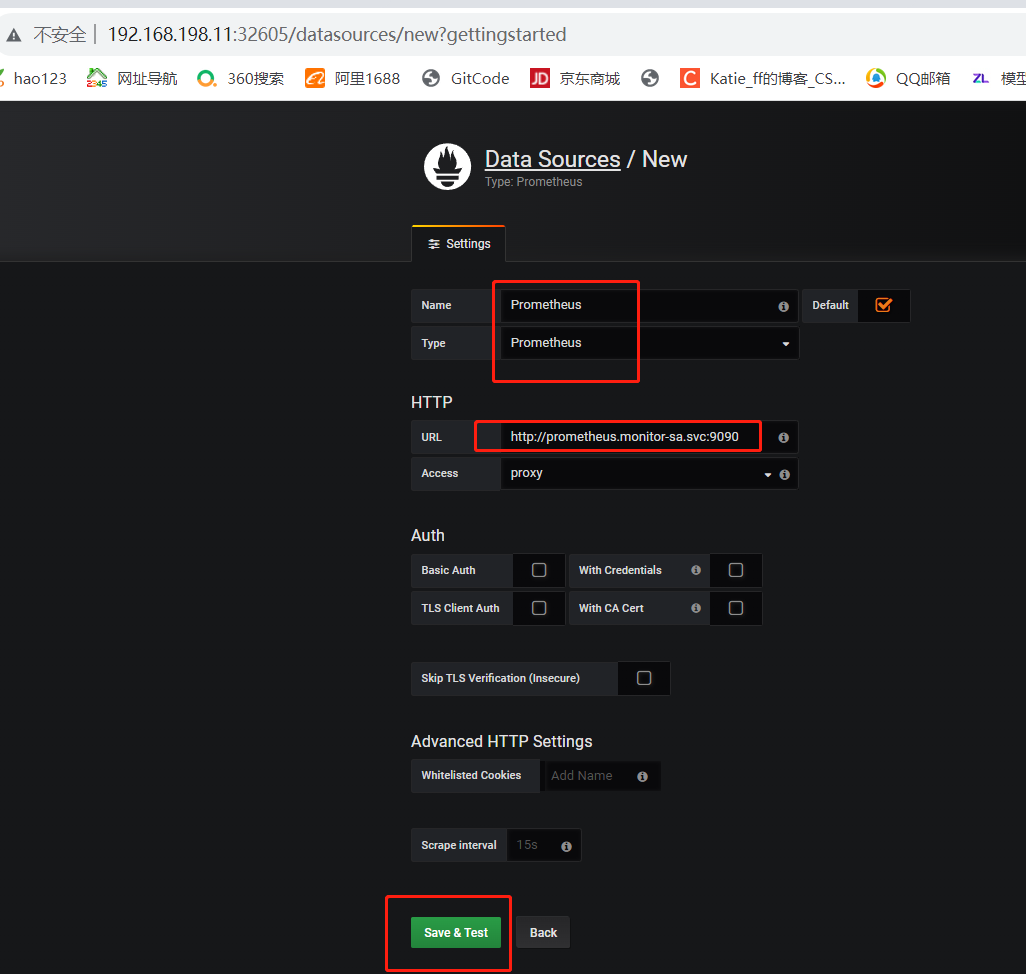
【Name】设置成 Prometheus
【Type】选择 Prometheus
【URL】设置成 http://prometheus.monitor-sa.svc:9090 #使用service的集群内部端口配置服务端地址
点击 【Save & Test】
(3)导入监控模板
官方链接搜索:https://grafana.com/dashboards?dataSource=prometheus&search=kubernetes
搜索随便点击下载一个模板
(4)监控 node 状态
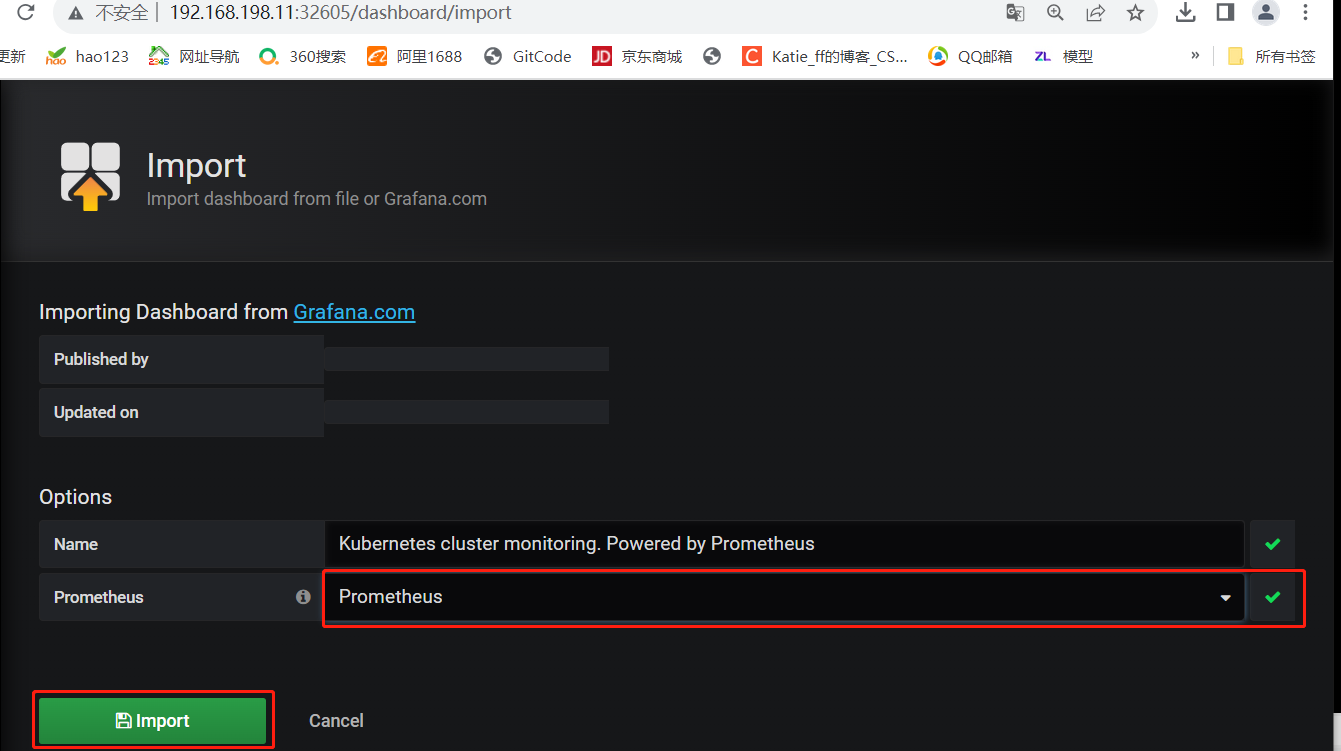
点击左侧+号选择【Import】
点击【Upload .json File】导入 node_exporter.json 模板
【Prometheus】选择 Prometheus
点击【Import】
(5)监控 容器 状态
提前下载docker模板
点击左侧+号选择【Import】
点击【Upload .json File】导入 docker_rev1.json 模板
【Prometheus】选择 Prometheus
点击【Import】
四.k8s 部署 kube-state-metrics 组件
1.安装 kube-state-metrics 组件
#创建 sa,并对 sa 授权
vim kube-state-metrics-rbac.yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:name: kube-state-metricsnamespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:name: kube-state-metrics
rules:
- apiGroups: [""]resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"]verbs: ["list", "watch"]
- apiGroups: ["extensions"]resources: ["daemonsets", "deployments", "replicasets"]verbs: ["list", "watch"]
- apiGroups: ["apps"]resources: ["statefulsets"]verbs: ["list", "watch"]
- apiGroups: ["batch"]resources: ["cronjobs", "jobs"]verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]resources: ["horizontalpodautoscalers"]verbs: ["list", "watch"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:name: kube-state-metrics
roleRef:apiGroup: rbac.authorization.k8s.iokind: ClusterRolename: kube-state-metrics
subjects:
- kind: ServiceAccountname: kube-state-metricsnamespace: kube-system
kubectl apply -f kube-state-metrics-rbac.yaml
#安装 kube-state-metrics 组件和 service
vim kube-state-metrics-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:name: kube-state-metricsnamespace: kube-system
spec:replicas: 1selector:matchLabels:app: kube-state-metricstemplate:metadata:labels:app: kube-state-metricsspec:serviceAccountName: kube-state-metricscontainers:- name: kube-state-metricsimage: quay.io/coreos/kube-state-metrics:v1.9.0ports:- containerPort: 8080
---
apiVersion: v1
kind: Service
metadata:annotations:prometheus.io/scrape: 'true'name: kube-state-metricsnamespace: kube-systemlabels:app: kube-state-metrics
spec:ports:- name: kube-state-metricsport: 8080protocol: TCPselector:app: kube-state-metrics
kubectl apply -f kube-state-metrics-deploy.yaml
kubectl get pods,svc -n kube-system -l app=kube-state-metricsNAME READY STATUS RESTARTS AGE
pod/kube-state-metrics-58d4957bc5-jshg6 1/1 Running 0 72sNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-state-metrics ClusterIP 10.96.14.114 <none> 8080/TCP 72s

2.Grafana 配置
#监控 k8s 群集状态
点击左侧+号选择【Import】
点击【Upload .json File】导入 kubernetes-cluster-prometheus_rev4.json 模板
【Prometheus】选择 Prometheus
点击【Import】

#监控 k8s 群集性能状态
点击左侧+号选择【Import】
点击【Upload .json File】导入 kubernetes-cluster-monitoring-via-prometheus_rev3.json 模板
【Prometheus】选择 Prometheus
点击【Import】
五.kubernetes 配置 alertmanager 发送报警到邮箱
1.Prometheus报警处理流程
1)Prometheus Server 监控目标主机上暴露的 http接口(假设接口A),通过Promethes配置的’scrape_interval’ 定义的时间间隔, 定期采集目标主机上监控数据。
2)当接口A不可用的时候,Server 端会持续的尝试从接口中取数据,直到 “scrape_timeout” 时间后停止尝试。 这时候把接口的状态变为 “DOWN”。
3)Prometheus 同时根据配置的 evaluation_interval 的时间间隔,定期(默认1min)的对 Alert Rule 进行评估; 当到达评估周期的时候,发现接口A为 DOWN,即 UP=0 为真,激活 Alert,进入 PENDING 状态,并记录当前 active 的时间;
4)当下一个 alert rule 的评估周期到来的时候,发现 UP=0 继续为真,然后判断警报 Active 的时间是否已经超出 rule 里的 for 持续时间,如果未超出,则进入下一个评估周期;如果时间超出,则 alert 的状态变为 FIRING;同时调用 Alertmanager 接口, 发送相关报警数据。
5)AlertManager 收到报警数据后,会将警报信息进行分组,然后根据 alertmanager 配置的 group_wait 时间先进行等待。等 wait 时间过后再发送报警信息。
6)属于同一个 Alert Group的警报,在等待的过程中可能进入新的 alert,如果之前的报警已经成功发出,那么间隔 group_interval 的时间间隔后再重新发送报警信息。比如配置的是邮件报警,那么同属一个 group 的报警信息会汇总在一个邮件里进行发送。
7)如果 Alert Group里的警报一直没发生变化并且已经成功发送,等待 repeat_interval 时间间隔之后再重复发送相同的报警邮件; 如果之前的警报没有成功发送,则相当于触发第6条条件,则需要等待 group_interval 时间间隔后重复发送。
8)同时最后至于警报信息具体发给谁,满足什么样的条件下指定警报接收人,设置不同报警发送频率,这里使用 alertmanager 的 route 路由规则进行配置。
2.Prometheus 及 Alertmanager 配置
(1)创建 alertmanager 配置文件
vim alertmanager-cm.yaml
---
kind: ConfigMap
apiVersion: v1
metadata:name: alertmanagernamespace: monitor-sa
data:alertmanager.yml: |-global: #设置发件人邮箱信息resolve_timeout: 1msmtp_smarthost: 'smtp.qq.com:25'smtp_from: '2841168113@qq.com'smtp_auth_username: '2841168113@qq.com'smtp_auth_password: 'zekytapfkalvdcce' #此处为授权码,登录QQ邮箱【设置】->【账户】中的【生成授权码】获取smtp_require_tls: falseroute: #用于设置告警的分发策略group_by: [alertname] #采用哪个标签来作为分组依据group_wait: 10s #组告警等待时间。也就是告警产生后等待10s,如果有同组告警一起发出group_interval: 10s #上下两组发送告警的间隔时间repeat_interval: 10m #重复发送告警的时间,减少相同邮件的发送频率,默认是1hreceiver: default-receiver #定义谁来收告警receivers: #设置收件人邮箱信息- name: 'default-receiver'email_configs:- to: '1479219114@qq.com' #设置收件人邮箱地址send_resolved: true
kubectl apply -f alertmanager-cm.yaml
(2)创建 prometheus 和告警规则配置文件
#上传 prometheus-alertmanager-cfg.yaml 文件
#删除之前的配置,更新配置
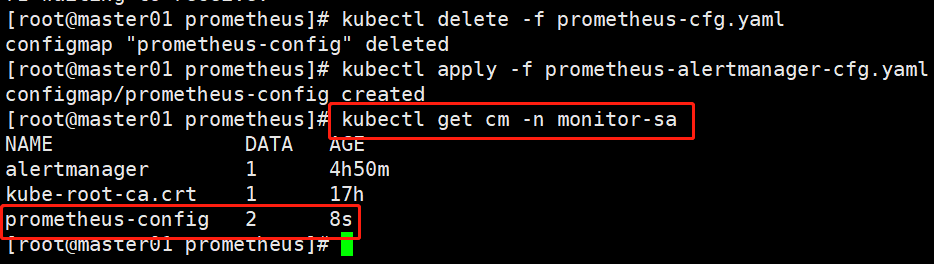
kubectl delete -f prometheus-cfg.yaml
kubectl apply -f prometheus-alertmanager-cfg.yaml
kubectl get cm -n monitor-sa NAME DATA AGE
alertmanager 1 4h50m
kube-root-ca.crt 1 17h
prometheus-config 2 8s
(3)安装 prometheus 和 alertmanager
#生成一个 secret 资源 etcd-certs,这个在部署 prometheus 需要,用于监控 etcd 相关资源
kubectl -n monitor-sa create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt
#更新资源清单 yaml 文件,安装 prometheus 和 alertmanager
vim prometheus-alertmanager-deploy.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:name: prometheus-servernamespace: monitor-salabels:app: prometheus
spec:replicas: 1selector:matchLabels:app: prometheuscomponent: server#matchExpressions:#- {key: app, operator: In, values: [prometheus]}#- {key: component, operator: In, values: [server]}template:metadata:labels:app: prometheuscomponent: serverannotations:prometheus.io/scrape: 'false'spec:nodeName: node01serviceAccountName: monitorcontainers:- name: prometheusimage: prom/prometheus:v2.2.1imagePullPolicy: IfNotPresentcommand:- "/bin/prometheus"args:- "--config.file=/etc/prometheus/prometheus.yml"- "--storage.tsdb.path=/prometheus"- "--storage.tsdb.retention=24h"- "--web.enable-lifecycle"ports:- containerPort: 9090protocol: TCPvolumeMounts:- mountPath: /etc/prometheusname: prometheus-config- mountPath: /prometheus/name: prometheus-storage-volume- name: k8s-certsmountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/- name: localtimemountPath: /etc/localtime- name: alertmanagerimage: prom/alertmanager:v0.14.0imagePullPolicy: IfNotPresentargs:- "--config.file=/etc/alertmanager/alertmanager.yml"- "--log.level=debug"ports:- containerPort: 9093protocol: TCPname: alertmanagervolumeMounts:- name: alertmanager-configmountPath: /etc/alertmanager- name: alertmanager-storagemountPath: /alertmanager- name: localtimemountPath: /etc/localtimevolumes:- name: prometheus-configconfigMap:name: prometheus-config- name: prometheus-storage-volumehostPath:path: /datatype: Directory- name: k8s-certssecret:secretName: etcd-certs- name: alertmanager-configconfigMap:name: alertmanager- name: alertmanager-storagehostPath:path: /data/alertmanagertype: DirectoryOrCreate- name: localtimehostPath:path: /usr/share/zoneinfo/Asia/Shanghai
kubectl delete -f prometheus-deploy.yaml
kubectl apply -f prometheus-alertmanager-deploy.yaml
kubectl get pods -n monitor-sa | grep prometheus

(4)部署 alertmanager 的 service,方便在浏览器访问
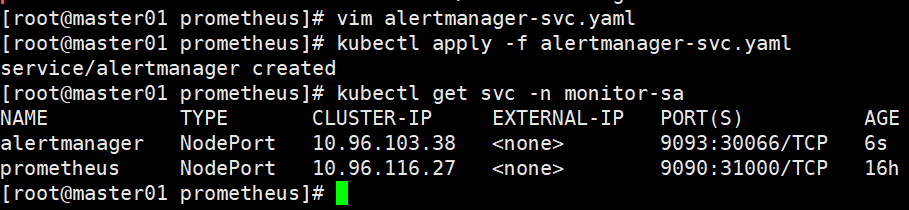
vim alertmanager-svc.yaml
---
apiVersion: v1
kind: Service
metadata:labels:name: prometheuskubernetes.io/cluster-service: 'true'name: alertmanagernamespace: monitor-sa
spec:ports:- name: alertmanagernodePort: 30066port: 9093protocol: TCPtargetPort: 9093selector:app: prometheussessionAffinity: Nonetype: NodePort
kubectl apply -f alertmanager-svc.yaml
#查看 service 在物理机映射的端口
kubectl get svc -n monitor-sa
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager NodePort 10.96.103.38 <none> 9093:30066/TCP 6s
prometheus NodePort 10.96.116.27 <none> 9090:31000/TCP 16h#此时可以看到 prometheus 的 service 在物理机映射的端口是 31000,alertmanager 的 service 在物理机映射的端口是 30066
浏览器访问 http://192.168.198.11:30066/#/alerts ,登陆 alertmanager
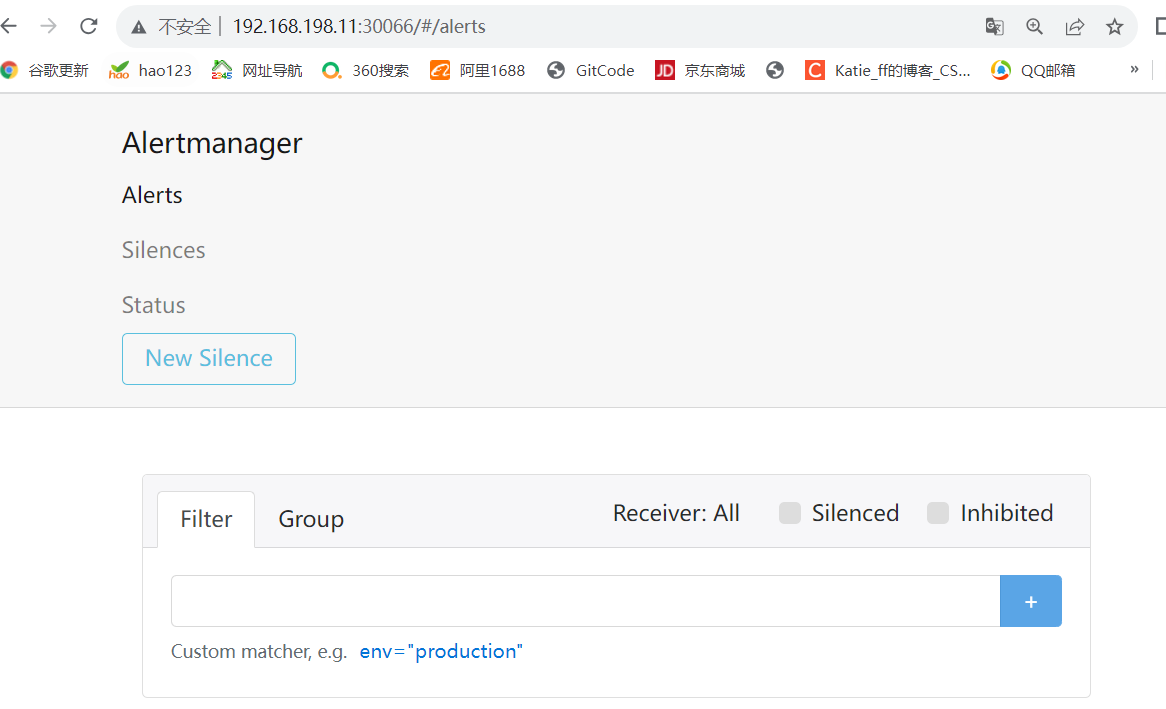
查看接收到的邮件报警,可以发现与 alertmanager 显示的告警一致
浏览器访问 http://192.168.198.11:31000 ,点击页面的 Status->Targets,查看 prometheus 的 targets
3.处理 kube-proxy 监控告警
kubectl edit configmap kube-proxy -n kube-system
......
metricsBindAddress: "0.0.0.0:10249"
#因为 kube-proxy 默认端口10249是监听在 127.0.0.1 上的,需要改成监听到物理节点上
#重新启动 kube-proxy
kubectl get pods -n kube-system | grep kube-proxy |awk '{print $1}' | xargs
kubectl delete pods -n kube-system
ss -antulp |grep :10249
tcp LISTEN 0 128 127.0.0.1:10249 *:* users:(("kube-proxy",pid=6844,fd=13))#alert 查看
点击 prometheus 页面的 Alerts,点开一个告警项,FIRING 表示 prometheus 已经将告警发给 alertmanager,在 Alertmanager 中可以看到有一个 alert。登录到 浏览器访问 http://192.168.198.11:30066/#/alerts ,登陆 alertmanager 即可看到。
相关文章:
Kubernetes 集群部署 Prometheus 和 Grafana
Kubernetes 集群部署 Prometheus 和 Grafana 文章目录 Kubernetes 集群部署 Prometheus 和 Grafana一.部署 node-exporter1.node-exporter 安装2.部署 node-exporter 二.部署Prometheus1.Prometheus 安装和配置(1)创建 sa 账号,对 sa 做 rbac…...

【算法-动态规划】零钱兑换 II-力扣 518
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kuan 的首页,持续学…...
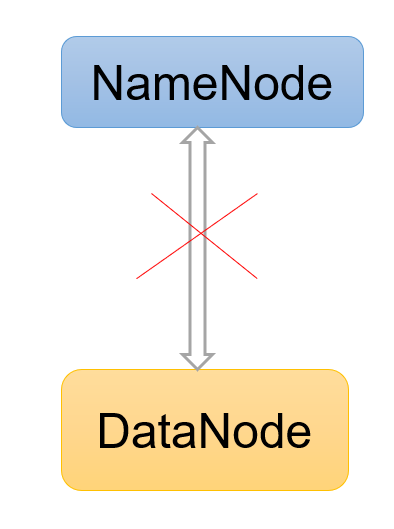
Hadoop3教程(六):HDFS中的DataNode
文章目录 (63)DataNode工作机制(64)数据完整性(65)掉线时限参数设置参考文献 (63)DataNode工作机制 DataNode内部存储了一个又一个Block,每个block由数据和数据元数据组…...
Macos音乐制作:Ableton Live 11 Suite for Mac中文版
Ableton Live 11是一款数字音频工作站软件,用于音乐制作、录音、混音和现场演出。它由Ableton公司开发,是一款极其流行的音乐制作软件之一。 以下是Ableton Live 11的一些主要特点和功能: Comping功能:Live 11增加了Comping功能…...
ThinkPHP5小语种学习平台
有需要请加文章底部Q哦 可远程调试 ThinkPHP5小语种学习平台 一 介绍 此小语种学习平台基于ThinkPHP5框架开发,数据库mysql,前端bootstrap。平台角色分为学生,教师和管理员三种。学生注册登录后可观看学习视频,收藏视频…...

升级包版本之后Reflections反射包在springboot jar环境下扫描不到class排查过程记录
📢📢📢📣📣📣 哈喽!大家好,我是「奇点」,江湖人称 singularity。刚工作几年,想和大家一同进步🤝🤝 一位上进心十足的【Java ToB端大厂…...
Excel 函数大全应用,包含各类常用函数
Excel 函数大全应用,各类函数应用与案例实操。 AIGC ChatGPT 职场案例 AI 绘画 与 短视频制作, Power BI 商业智能 68集, 数据库Mysql8.0 54集 数据库Oracle21C 142集, Office 2021实战, Python 数据分析࿰…...
深入浅出的介绍一下虚拟机VMware Workstation——part3(VMware快照)
虚拟机VMware使用 前言快照的原理快照的使用 前言 可以先查看之前的2篇博文,学习基础的虚拟机使用 深入浅出的介绍一下虚拟机VMware Workstation——part1 深入浅出的介绍一下虚拟机VMware Workstation——part2(详细安装与使用) 由于我们使用虚拟机的初衷就是用来…...

《Python基础教程》专栏总结篇
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。…...

JavaScript 事件
HTML 事件是发生在 HTML 元素上的事情。 当在 HTML 页面中使用 JavaScript 时, JavaScript 可以触发这些事件。 HTML 事件 HTML 事件可以是浏览器行为,也可以是用户行为。 以下是 HTML 事件的实例: HTML 页面完成加载HTML input 字段改变…...
轻松学会这招,给大量视频批量添加滚动字幕不求人
想要给大量视频批量添加滚动字幕不求人吗?下面就教你一个简单的方法。首先你需要下载并安装一款名为“固乔剪辑助手”的软件,这是一款非常专业的视频剪辑软件,它可以帮助你快速地给大量视频添加滚动字幕。 打开固乔剪辑助手软件后,…...
哪个文字转语音配音软件最好用?
现在TTS技术不断发展,文字转语音技术已经越来越成熟,声音听着拟人度非常高,现在好用的软件也不在少数。很多手机里面都有自带的朗读功能,如果觉得声音不够,也可以自己下载软件使用。给大家分享一下我一直使用的一款文字…...

多关键词高亮显示
引入关键词文件,符合有条件的背景色高亮显示,也可取消。 <div id"testHtml"><p>写入的文本</p><p>关键词</p></div> var str 多个关键词,关键词文件,关键词 var strL str.replac…...

浅谈 33 台 iPad 发展史;OpenAI“悄悄”修改了企业核心价值观丨 RTE 开发者日报 Vol.67
开发者朋友们大家好: 这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE (Real Time Engagement) 领域内「有话题的 新闻 」、「有态度的 **观点 **」、「有意思的 数据 」、「有思考…...
)
Mysql之备份(Mysqldump)
本篇文章旨在介绍Mysql的备份,借助mysqldump命令。 1.准备数据 准备一个数据库d1,表t1 表结构如下: mysql> desc t1; ------------------------------------------------------- | Field | Type | Null | Key | Default | Extra …...
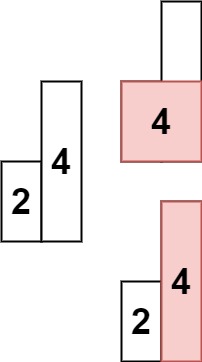
算法leetcode|84. 柱状图中最大的矩形(rust重拳出击)
文章目录 84. 柱状图中最大的矩形:样例 1:样例 2:提示: 分析:题解:rust:go:c:python:java: 84. 柱状图中最大的矩形: 给定 n 个非负整…...

Java中通过List中的stream流去匹配相同的字段去赋值,避免for循环去查询数据库进行赋值操作
List<EquipmentDeviceMessage> equipmentDeviceMessageInfo greenThinkTanksInfoPlanMapper.getEquipmentDeviceMessageInfo(phone, startDate, endDate); List<BladeUserVo> userList bladexsqlMapper.getUserList();Q:上面两个列表怎么使用流&#…...
开源酒店预订订房小程序源码系统+多元商户 前端+后端完整搭建教程 可二次开发
大家好啊,罗峰今天来给大家分享一款酒店预订订房小程序源码系统,这款系统进行了全新的升级,从原来的单门店升级成了多门店,可以自由切换账号,统一管理。功能强大。以下是部分代码截图: 酒店预订订房小程序源…...

Leetcode 2906. Construct Product Matrix
Leetcode 2906. Construct Product Matrix 1. 解题思路2. 代码实现 题目链接:2906. Construct Product Matrix 1. 解题思路 这道题其实算是一道数论题。 本来其实python的pow内置函数已经帮我们基本处理了所有的问题了,但是这里稍微做了一点复杂化操…...

【Leetcode Sheet】Weekly Practice 11
Leetcode Test 2731 移动机器人(10.10) 有一些机器人分布在一条无限长的数轴上,他们初始坐标用一个下标从 0 开始的整数数组 nums 表示。当你给机器人下达命令时,它们以每秒钟一单位的速度开始移动。 给你一个字符串 s ,每个字符按顺序分别…...

AI Agent在智能风控中的实战:多智能体欺诈检测与预警
AI Agent在智能风控中的实战:多智能体欺诈检测与预警 你有没有过明明是正常交易却被银行冻结账户的糟糕体验?或是听说过某电商平台上线新活动首日就被黑产团伙薅走数千万补贴的新闻?随着黑产欺诈向团伙化、专业化、动态化演进,传统依赖规则引擎、单模型机器学习的风控体系已…...

Shiro RememberMe反序列化漏洞深度解析与实战利用
1. 这个漏洞不是“老古董”,而是理解Java安全边界的活教材很多人看到CVE-2016-4437,第一反应是“Shiro都淘汰了,还讲这个干啥?”——我去年在给一家做政企内部系统的客户做渗透复测时,就遇到过一个上线三年的审批平台&…...

用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程
用Python和MNE库玩转BCI Competition IV 2a脑电数据集:从数据加载到可视化全流程当你第一次接触脑电信号处理时,面对原始数据文件可能会感到无从下手。BCI Competition IV 2a数据集作为脑机接口领域的经典基准数据,包含了9名受试者四种运动想…...

App Inventor蓝牙调试避坑指南:从连接失败到数据乱码,一次讲清所有常见问题
App Inventor蓝牙调试避坑指南:从连接失败到数据乱码的实战解决方案在移动应用开发领域,蓝牙通信一直是实现设备间短距离数据交换的核心技术之一。对于使用App Inventor的开发者而言,蓝牙模块提供了无需复杂编码即可实现无线通信的便捷途径。…...

番茄小说下载器终极指南:三步构建你的离线阅读自由王国
番茄小说下载器终极指南:三步构建你的离线阅读自由王国 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 你是否曾在地铁里读到精彩章节时突然断网?是否在…...

自制BLE112串口编程器:基于Bootloader的免调试器烧录方案
1. 项目概述:为BLE112模块打造一款免调试器的RS232编程器在嵌入式开发,特别是早期的蓝牙低功耗(BLE)模块应用中,我们常常会遇到一个棘手的问题:官方开发工具链的依赖和限制。以Silicon Labs(当时…...

Python合并Excel文档
有若干个Excel文档,每个文档格式一致,及第一行为文件标题,第二行为表格表头(表头不完全一致)。现需要将他们合并。合并规则为:去掉每个文档的第一行,以第二行为表头,将每个文档的第三…...

终极鼠标连点器使用指南:3分钟掌握高效自动化技巧
终极鼠标连点器使用指南:3分钟掌握高效自动化技巧 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,操作…...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...

基于ATtiny84的智能冰箱监控器:低功耗温度与门状态监测方案
1. 项目概述:一个装在树莓派盒子里的智能冰箱管家如果你家里有台老冰箱,或者对食物储存温度特别在意,总担心冰箱门没关严或者突然断电导致内部升温,那么这个自己动手做的“冰箱看门狗”项目就太适合你了。它本质上是一个高度定制化…...