24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Elasticsearch示例(2)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Hive示例(6)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
24、Flink 的table api与sql之Catalogs(介绍、类型、java api和sql实现ddl、java api和sql操作catalog)-1
24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2
26、Flink 的SQL之概览与入门示例
27、Flink 的SQL之SELECT (select、where、distinct、order by、limit、集合操作和去重)介绍及详细示例(1)
27、Flink 的SQL之SELECT (SQL Hints 和 Joins)介绍及详细示例(2)
27、Flink 的SQL之SELECT (窗口函数)介绍及详细示例(3)
27、Flink 的SQL之SELECT (窗口聚合)介绍及详细示例(4)
27、Flink 的SQL之SELECT (Group Aggregation分组聚合、Over Aggregation Over聚合 和 Window Join 窗口关联)介绍及详细示例(5)
27、Flink 的SQL之SELECT (Top-N、Window Top-N 窗口 Top-N 和 Window Deduplication 窗口去重)介绍及详细示例(6)
27、Flink 的SQL之SELECT (Pattern Recognition 模式检测)介绍及详细示例(7)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(1)
29、Flink SQL之DESCRIBE、EXPLAIN、USE、SHOW、LOAD、UNLOAD、SET、RESET、JAR、JOB Statements、UPDATE、DELETE(2)
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
32、Flink table api和SQL 之用户自定义 Sources & Sinks实现及详细示例
41、Flink之Hive 方言介绍及详细示例
42、Flink 的table api与sql之Hive Catalog
43、Flink之Hive 读写及详细验证示例
44、Flink之module模块介绍及使用示例和Flink SQL使用hive内置函数及自定义函数详细示例–网上有些说法好像是错误的
文章目录
- Flink 系列文章
- 五、Catalog API
- 1、数据库操作
- 1)、jdbccatalog示例
- 2)、hivecatalog示例-查询指定数据库下的表名称
- 3)、hivecatalog示例-创建database
- 2、表操作
本文简单介绍了通过java api操作数据库、表,分别提供了具体可运行的例子。
本文依赖flink和hive、hadoop集群能正常使用。
本文分为2个部分,即数据库操作、表操作。
本文示例java api的实现是通过Flink 1.13.5版本做的示例,SQL 如果没有特别说明则是Flink 1.17版本。
五、Catalog API
1、数据库操作
下文列出了一般的数据库操作,示例是以jdbccatalog为示例,flink的版本是1.17.0。
// create database
catalog.createDatabase("mydb", new CatalogDatabaseImpl(...), false);// drop database
catalog.dropDatabase("mydb", false);// alter database
catalog.alterDatabase("mydb", new CatalogDatabaseImpl(...), false);// get databse
catalog.getDatabase("mydb");// check if a database exist
catalog.databaseExists("mydb");// list databases in a catalog
catalog.listDatabases("mycatalog");
1)、jdbccatalog示例
- pom.xml
<properties><encoding>UTF-8</encoding><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><java.version>1.8</java.version><scala.version>2.12</scala.version><flink.version>1.17.0</flink.version></properties><dependencies><dependency><groupId>jdk.tools</groupId><artifactId>jdk.tools</artifactId><version>1.8</version><scope>system</scope><systemPath>${JAVA_HOME}/lib/tools.jar</systemPath></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-scala-bridge_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>${flink.version}</version><scope>test</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.1.0-1.17</version><scope>provided</scope></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>${flink.version}</version><scope>test</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-planner-loader --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-loader</artifactId><version>${flink.version}</version><scope>provided</scope></dependency><!-- https://mvnrepository.com/artifact/org.apache.flink/flink-table-runtime --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-runtime</artifactId><version>${flink.version}</version><scope>provided</scope></dependency></dependencies>
- java
import java.util.List;import org.apache.flink.connector.jdbc.catalog.JdbcCatalog;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.Catalog;
import org.apache.flink.table.catalog.exceptions.CatalogException;
import org.apache.flink.table.catalog.exceptions.DatabaseNotExistException;/*** @author alanchan**/
public class TestJdbcCatalogDemo {/*** @param args* @throws DatabaseNotExistException* @throws CatalogException*/public static void main(String[] args) throws CatalogException, DatabaseNotExistException {// envStreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);// public JdbcCatalog(// String catalogName,// String defaultDatabase,// String username,// String pwd,// String baseUrl)// CREATE CATALOG alan_catalog WITH(// 'type' = 'jdbc',// 'default-database' = 'test?useSSL=false',// 'username' = 'root',// 'password' = 'root',// 'base-url' = 'jdbc:mysql://192.168.10.44:3306'// );Catalog catalog = new JdbcCatalog("alan_catalog", "test?useSSL=false", "root", "123456", "jdbc:mysql://192.168.10.44:3306");// Register the catalogtenv.registerCatalog("alan_catalog", catalog);List<String> tables = catalog.listTables("test");
// System.out.println("test tables:" + tablesfor (String table : tables) {System.out.println("Database:test tables:"+table);}}}
- 运行结果
Database:test tables:allowinsert
Database:test tables:author
Database:test tables:batch_job_execution
Database:test tables:batch_job_execution_context
Database:test tables:batch_job_execution_params
Database:test tables:batch_job_execution_seq
Database:test tables:batch_job_instance
Database:test tables:batch_job_seq
Database:test tables:batch_step_execution
Database:test tables:batch_step_execution_context
Database:test tables:batch_step_execution_seq
Database:test tables:book
Database:test tables:customertest
Database:test tables:datax_user
Database:test tables:dm_sales
Database:test tables:dms_attach_t
Database:test tables:dx_user
Database:test tables:dx_user_copy
Database:test tables:employee
Database:test tables:hibernate_sequence
Database:test tables:permissions
Database:test tables:person
Database:test tables:personinfo
Database:test tables:role
Database:test tables:studenttotalscore
Database:test tables:t_consume
Database:test tables:t_czmx_n
Database:test tables:t_kafka_flink_user
Database:test tables:t_merchants
Database:test tables:t_recharge
Database:test tables:t_user
Database:test tables:t_withdrawal
Database:test tables:updateonly
Database:test tables:user
2)、hivecatalog示例-查询指定数据库下的表名称
本示例需要在有hadoop和hive环境执行,本示例是打包执行jar文件。
关于flink与hive的集成请参考:42、Flink 的table api与sql之Hive Catalog
- pom.xml
<properties><encoding>UTF-8</encoding><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><java.version>1.8</java.version><scala.version>2.12</scala.version><flink.version>1.13.6</flink.version></properties><dependencies><dependency><groupId>jdk.tools</groupId><artifactId>jdk.tools</artifactId><version>1.8</version><scope>system</scope><systemPath>${JAVA_HOME}/lib/tools.jar</systemPath></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-scala_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-scala-bridge_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_2.12</artifactId><version>${flink.version}</version></dependency><!-- flink执行计划,这是1.9版本之前的 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.12</artifactId><version>${flink.version}</version></dependency><!-- blink执行计划,1.11+默认的 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version></dependency><!-- flink连接器 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-sql-connector-kafka_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-csv</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-json</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-hive_2.12</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-metastore</artifactId><version>2.1.0</version></dependency><dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>3.1.2</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-shaded-hadoop-2-uber</artifactId><version>2.7.5-10.0</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.38</version><!--<version>8.0.20</version> --></dependency><!-- 高性能异步组件:Vertx --><dependency><groupId>io.vertx</groupId><artifactId>vertx-core</artifactId><version>3.9.0</version></dependency><dependency><groupId>io.vertx</groupId><artifactId>vertx-jdbc-client</artifactId><version>3.9.0</version></dependency><dependency><groupId>io.vertx</groupId><artifactId>vertx-redis-client</artifactId><version>3.9.0</version></dependency><!-- 日志 --><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.7</version><scope>runtime</scope></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version><scope>runtime</scope></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.44</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.2</version><scope>provided</scope></dependency></dependencies><build><sourceDirectory>src/main/java</sourceDirectory><plugins><!-- 编译插件 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.5.1</version><configuration><source>1.8</source><target>1.8</target><!--<encoding>${project.build.sourceEncoding}</encoding> --></configuration></plugin><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-surefire-plugin</artifactId><version>2.18.1</version><configuration><useFile>false</useFile><disableXmlReport>true</disableXmlReport><includes><include>**/*Test.*</include><include>**/*Suite.*</include></includes></configuration></plugin><!-- 打包插件(会包含所有依赖) --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>2.3</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><filters><filter><artifact>*:*</artifact><excludes><!-- zip -d learn_spark.jar META-INF/*.RSA META-INF/*.DSA META-INF/*.SF --><exclude>META-INF/*.SF</exclude><exclude>META-INF/*.DSA</exclude><exclude>META-INF/*.RSA</exclude></excludes></filter></filters><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><!-- 设置jar包的入口类(可选) --><mainClass> org.table_sql.TestHiveCatalogDemo</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins></build>
- java
import java.util.List;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.exceptions.CatalogException;
import org.apache.flink.table.catalog.exceptions.DatabaseNotExistException;
import org.apache.flink.table.catalog.hive.HiveCatalog;/*** @author alanchan**/
public class TestHiveCatalogDemo {/*** @param args* @throws DatabaseNotExistException * @throws CatalogException */public static void main(String[] args) throws CatalogException, DatabaseNotExistException {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);String name = "alan_hive";// testhive 数据库名称String defaultDatabase = "testhive";String hiveConfDir = "/usr/local/bigdata/apache-hive-3.1.2-bin/conf";HiveCatalog hiveCatalog = new HiveCatalog(name, defaultDatabase, hiveConfDir);tenv.registerCatalog("alan_hive", hiveCatalog);// 使用注册的catalogtenv.useCatalog("alan_hive");List<String> tables = hiveCatalog.listTables(defaultDatabase); // tables should contain "test"
// System.out.println("test tables:" + tablesfor (String table : tables) {System.out.println("Database:testhive tables:" + table);}}}
- 运行结果
################hive查询结果##################
0: jdbc:hive2://server4:10000> use testhive;
No rows affected (0.021 seconds)
0: jdbc:hive2://server4:10000> show tables;
+-----------------------+
| tab_name |
+-----------------------+
| apachelog |
| col2row1 |
| col2row2 |
| cookie_info |
| dual |
| dw_zipper |
| emp |
| employee |
| employee_address |
| employee_connection |
| ods_zipper_update |
| row2col1 |
| row2col2 |
| singer |
| singer2 |
| student |
| student_dept |
| student_from_insert |
| student_hdfs |
| student_hdfs_p |
| student_info |
| student_local |
| student_partition |
| t_all_hero_part_msck |
| t_usa_covid19 |
| t_usa_covid19_p |
| tab1 |
| tb_dept01 |
| tb_dept_bucket |
| tb_emp |
| tb_emp01 |
| tb_emp_bucket |
| tb_json_test1 |
| tb_json_test2 |
| tb_login |
| tb_login_tmp |
| tb_money |
| tb_money_mtn |
| tb_url |
| the_nba_championship |
| tmp_1 |
| tmp_zipper |
| user_dept |
| user_dept_sex |
| users |
| users_bucket_sort |
| website_pv_info |
| website_url_info |
+-----------------------+
48 rows selected (0.027 seconds)################flink查询结果##################
[alanchan@server2 bin]$ flink run /usr/local/bigdata/flink-1.13.5/examples/table/table_sql-0.0.1-SNAPSHOT.jar
Database:testhive tables:student
Database:testhive tables:user_dept
Database:testhive tables:user_dept_sex
Database:testhive tables:t_all_hero_part_msck
Database:testhive tables:student_local
Database:testhive tables:student_hdfs
Database:testhive tables:student_hdfs_p
Database:testhive tables:tab1
Database:testhive tables:student_from_insert
Database:testhive tables:student_info
Database:testhive tables:student_dept
Database:testhive tables:student_partition
Database:testhive tables:emp
Database:testhive tables:t_usa_covid19
Database:testhive tables:t_usa_covid19_p
Database:testhive tables:employee
Database:testhive tables:employee_address
Database:testhive tables:employee_connection
Database:testhive tables:dual
Database:testhive tables:the_nba_championship
Database:testhive tables:tmp_1
Database:testhive tables:cookie_info
Database:testhive tables:website_pv_info
Database:testhive tables:website_url_info
Database:testhive tables:users
Database:testhive tables:users_bucket_sort
Database:testhive tables:singer
Database:testhive tables:apachelog
Database:testhive tables:singer2
Database:testhive tables:tb_url
Database:testhive tables:row2col1
Database:testhive tables:row2col2
Database:testhive tables:col2row1
Database:testhive tables:col2row2
Database:testhive tables:tb_json_test1
Database:testhive tables:tb_json_test2
Database:testhive tables:tb_login
Database:testhive tables:tb_login_tmp
Database:testhive tables:tb_money
Database:testhive tables:tb_money_mtn
Database:testhive tables:tb_emp
Database:testhive tables:dw_zipper
Database:testhive tables:ods_zipper_update
Database:testhive tables:tmp_zipper
Database:testhive tables:tb_emp01
Database:testhive tables:tb_emp_bucket
Database:testhive tables:tb_dept01
Database:testhive tables:tb_dept_bucket3)、hivecatalog示例-创建database
本示例着重在于演示如何创建database,其如何构造函数来创建database。
- pom.xml
参考示例2 - java
import java.util.HashMap;
import java.util.List;
import java.util.Map;import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
import org.apache.flink.table.catalog.CatalogDatabase;
import org.apache.flink.table.catalog.CatalogDatabaseImpl;
import org.apache.flink.table.catalog.exceptions.CatalogException;
import org.apache.flink.table.catalog.exceptions.DatabaseAlreadyExistException;
import org.apache.flink.table.catalog.exceptions.DatabaseNotExistException;
import org.apache.flink.table.catalog.hive.HiveCatalog;/*** @author alanchan**/
public class TestHiveCatalogDemo {/*** @param args* @throws DatabaseNotExistException* @throws CatalogException* @throws DatabaseAlreadyExistException*/public static void main(String[] args) throws CatalogException, DatabaseNotExistException, DatabaseAlreadyExistException {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tenv = StreamTableEnvironment.create(env);String name = "alan_hive";// testhive 数据库名称String defaultDatabase = "testhive";String hiveConfDir = "/usr/local/bigdata/apache-hive-3.1.2-bin/conf";HiveCatalog hiveCatalog = new HiveCatalog(name, defaultDatabase, hiveConfDir);tenv.registerCatalog("alan_hive", hiveCatalog);// 使用注册的catalogtenv.useCatalog("alan_hive");List<String> tables = hiveCatalog.listTables(defaultDatabase);for (String table : tables) {System.out.println("Database:testhive tables:" + table);}// public CatalogDatabaseImpl(Map<String, String> properties, @Nullable String comment) {
// this.properties = checkNotNull(properties, "properties cannot be null");
// this.comment = comment;
// }Map<String, String> properties = new HashMap();CatalogDatabase cd = new CatalogDatabaseImpl(properties, "this is new database,the name is alan_hivecatalog_hivedb");String newDatabaseName = "alan_hivecatalog_hivedb";hiveCatalog.createDatabase(newDatabaseName, cd, true);List<String> newTables = hiveCatalog.listTables(newDatabaseName);for (String table : newTables) {System.out.println("Database:alan_hivecatalog_hivedb tables:" + table);}}}
- 运行结果
################## hive查询结果 ############################
#####提交flink创建database前查询结果
0: jdbc:hive2://server4:10000> show databases;
+----------------+
| database_name |
+----------------+
| default |
| test |
| testhive |
+----------------+
3 rows selected (0.03 seconds)
#####提交flink创建database后查询结果
0: jdbc:hive2://server4:10000> show databases;
+--------------------------+
| database_name |
+--------------------------+
| alan_hivecatalog_hivedb |
| default |
| test |
| testhive |
+--------------------------+
4 rows selected (0.023 seconds)################## flink 查询结果 ############################
#### 由于只创建了database,其下是没有表的,故没有输出。至于testhive库下的表输出详见示例2,不再赘述。
2、表操作
表操作就是指hivecatalog的操作,因为jdbccatalog不能对库、表进行操作,当然查询类是可以的。故以下示例都是以hivecatalog进行说明。本处与24、Flink 的table api与sql之Catalogs(介绍、类型、java api和sql实现ddl、java api和sql操作catalog)-1的第三部分相似,具体参考其示例即可。不再赘述。
// create table
catalog.createTable(new ObjectPath("mydb", "mytable"), new CatalogTableImpl(...), false);// drop table
catalog.dropTable(new ObjectPath("mydb", "mytable"), false);// alter table
catalog.alterTable(new ObjectPath("mydb", "mytable"), new CatalogTableImpl(...), false);// rename table
catalog.renameTable(new ObjectPath("mydb", "mytable"), "my_new_table");// get table
catalog.getTable("mytable");// check if a table exist or not
catalog.tableExists("mytable");// list tables in a database
catalog.listTables("mydb");
本文简单介绍了通过java api操作数据库、表,分别提供了具体可运行的例子。
相关文章:
-2)
24、Flink 的table api与sql之Catalogs(java api操作数据库、表)-2
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

【MySQL】深入了解索引的底层逻辑结构
文章目录 主键排序一. InnoDB的索引结构1. 单个page2. 多个page 二. 为什么选择B树三. 聚簇索引和非聚簇索引结束语 主键排序 我们创建一个user表,并乱序插入数据 mysql> create table if not exists user(-> id int primary key,-> age int not null,-&…...

Android之SpannableString使用
文章目录 前言一、效果图二、实现代码总结 前言 在开发中,往往有些需求是我们不愿意遇到的,但是也不得不处理的事情,比如一段文案,需要文案中某些文字变颜色或者点击跳转,所以简单写了几句代码实现,没什么…...

【Python】Python求均值、中值和众数
Python求均值、中值和众数 我们将讨论如何使用描述性统计数据进行数据分析,包括: 均值——一组值的平均值; 中值——当所有值按顺序排列时的中间值; 众数——最常出现的值。 以上这些都是集中趋势度量,每种都会产生一个值来表示一组值中的“…...

NPM 常用命令(十二)
目录 1、npm unpublish 1.1 使用语法 1.2 描述 2、npm unstar 2.1 使用语法 3、npm update 3.1 使用语法 3.2 描述 3.3 示例 插入符号依赖 波浪号依赖 低于 1.0.0 的插入符号依赖 子依赖 更新全局安装的包 4、npm version 4.1 使用语法 5、npm view 5.1 使用语…...
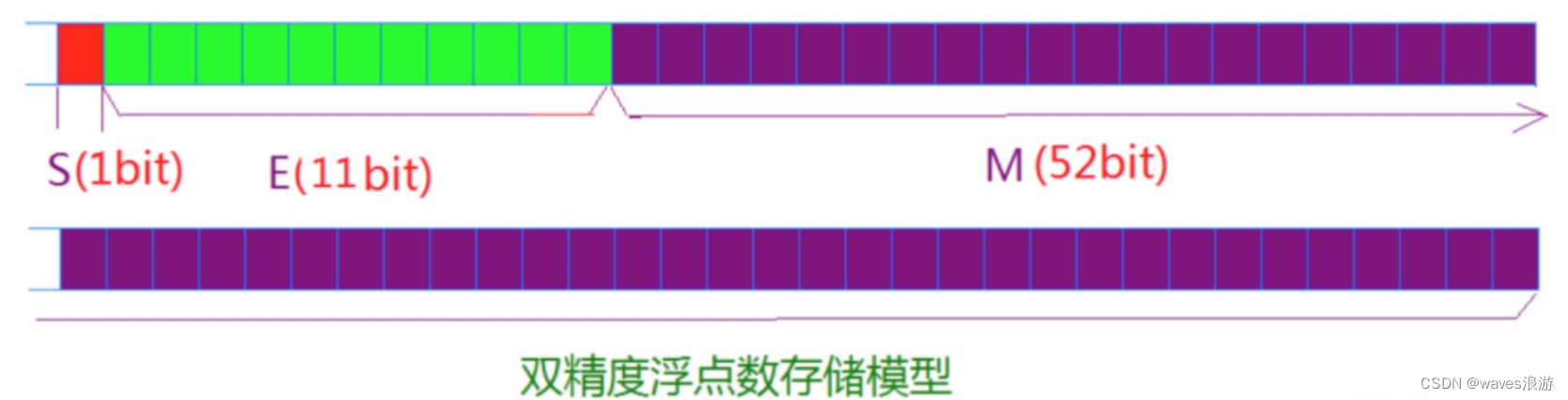
数据在内存中的存储(2)
文章目录 3. 浮点型在内存中的存储3.1 一个例子3.2 浮点数存储规则 3. 浮点型在内存中的存储 常见的浮点数: 3.14159 1E10 ------ 1.0 * 10^10 浮点数家族包括: float、double、long double 类型 浮点数表示的范围:float.h中定义 3.1 一个例…...

软件工程与计算总结(十三)详细设计中的模块化与信息隐藏
一.模块化与信息隐藏思想 1.设计质量 好的设计要着重满足以下3方面:可管理性、灵活性、可理解性好的设计需要侧重于间接性和可观察性——简洁性使得系统模块易于管理(理解和分解)、开发(修改与调试)和复用。实践者都…...

RF学习——器件的非线性失真分析
在大信号激励下的射频系统 在电路中,如果激励信号的幅度不可忽视,那么就会产生非线性失真。如二极管,晶体管等电路元件的特性在大信号激励下回变得非线性,输入和输出的形状不同,产生失真。 在功率放大器PA中,随着传输给负载的功率增大而迅速增大,传递功率的规格要始终考…...

SUB-1G SOC芯片DP4306F 32 位 ARM Cortex-M0+内核替代CMT2380F32
DP4306F是一款高性能低功耗的单片集成收发机,集成MO核MCU,工作频率可覆盖200MHiz^ 1000MHz。 支持230/408/433/470/868/915频段。该芯片集成了射频接收器、射频发射器、频率综合器、GFSK调制器、GFSK解调器等功能模块。通过SPI接口可以对输出功率、频道选…...

接收请求地址下载并输出文件流实现
代码: import httpxfrom datetime import datetime from io import BytesIO from fastapi.responses import StreamingResponse@router.get("/download", tags=["下载"]) async...
【iOS】——用单例类封装网络请求
文章目录 一、JSONModel1.JSONModel的简单介绍2.JSONModel的使用 二、单例类和Block传值 一、JSONModel 1.JSONModel的简单介绍 JSONModel一个第三方库,这个库用来将网络请求到的JSON格式的数据转化成Foundation框架下的Model类的属性,这样我们就可以直…...

再学Blazor——概述
简介 Blazor 是一种 .NET 前端 Web 框架,同时支持服务器端呈现和客户端交互性。 使用 C# 语言创建丰富的交互式 UI共享前后端应用逻辑可以生成混合桌面和移动应用受益于 .NET 的性能、可靠性和安全性需要有 HTML、CSS、JS 相关基础(开发 UI 框架的话&a…...

Ceph运维笔记
Ceph运维笔记 一、基本操作 ceph osd tree //查看所有osd情况 其中里面的weight就是CRUSH算法要使用的weight,越大代表之后PG选择该osd的概率就越大 ceph -s //查看整体ceph情况 health_ok才是正常的 ceph osd out osd.1 //将osd.1踢出集群 ceph osd i…...
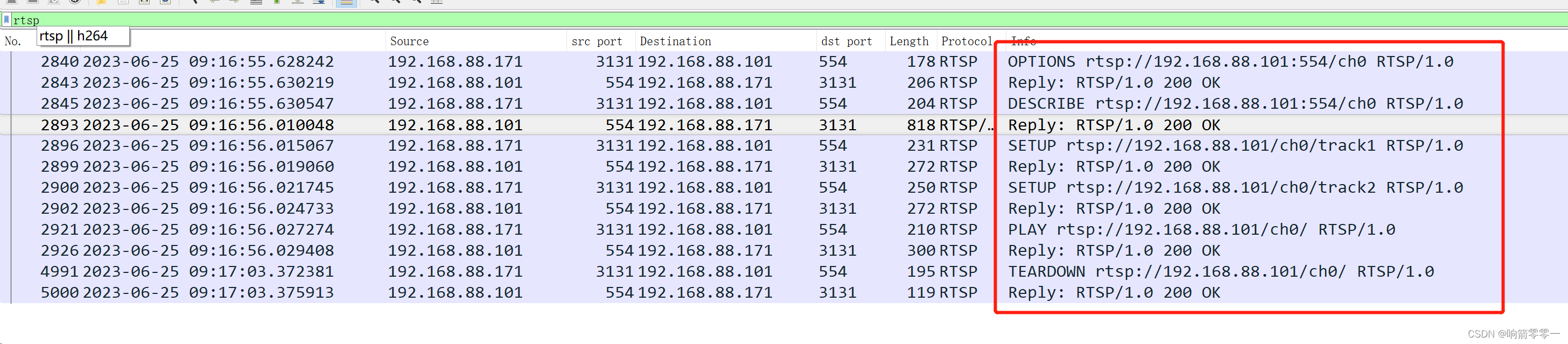
RTSP协议
1 前言 RTSP协议作为音视频实时监控一个非常重要的协议,具有非常广泛的应用。RTSP由RFC 2326规范化,它允许客户端通过请求不同的媒体资源来控制流媒体服务器。RTSP是一种应用层协议,通常基于TCP连接,用于建立和控制媒体会话。这使…...

Maven系列第6篇:生命周期和插件详解?
maven系列目标:从入门开始开始掌握一个高级开发所需要的maven技能。 这是maven系列第6篇。 整个maven系列的内容前后是有依赖的,如果之前没有接触过maven,建议从第一篇看起,本文尾部有maven完整系列的连接。 前面我们使用maven…...

【通义千问】大模型Qwen GitHub开源工程学习笔记(4)-- 模型的量化与离线部署
摘要: 量化方案基于AutoGPTQ,提供了Int4量化模型,其中包括Qwen-7B-Chat和Qwen-14B-Chat。更新承诺在模型评估效果几乎没有损失的情况下,降低存储要求并提高推理速度。量化是指将模型权重和激活的精度降低以节省存储空间并提高推理速度的过程。AutoGPTQ是一种专有量化工具。…...

2022最新版-李宏毅机器学习深度学习课程-P23 为什么用了验证集结果还是过拟合
用了验证集还有可能会过拟合 这个片段可以从理论上证明这一点 以上整个挑选模型的过程也可以想象为一种训练。 把三个模型导出的最小损失公式看成一个集合,现在要做的就是在这个集合中找到某个h(此处可以视为训练),使得在验证集…...

Spring Cloud Alibaba—Sentinel 控制台安装
1、Sentinel 控制台包含如下功能: 查看机器列表以及健康情况:收集 Sentinel 客户端发送的心跳包,用于判断机器是否在线。 监控 (单机和集群聚合):通过 Sentinel 客户端暴露的监控 API,定期拉取并且聚合应用监控信息,最…...

基于动物迁徙优化的BP神经网络(分类应用) - 附代码
基于动物迁徙优化的BP神经网络(分类应用) - 附代码 文章目录 基于动物迁徙优化的BP神经网络(分类应用) - 附代码1.鸢尾花iris数据介绍2.数据集整理3.动物迁徙优化BP神经网络3.1 BP神经网络参数设置3.2 动物迁徙算法应用 4.测试结果…...

一键搞定!黑群晖虚拟机+内网穿透实现校园公网访问攻略!
文章目录 前言本教程解决的问题是:按照本教程方法操作后,达到的效果是前排提醒: 1. 搭建群晖虚拟机1.1 下载黑群晖文件vmvare虚拟机安装包1.2 安装VMware虚拟机:1.3 解压黑群晖虚拟机文件1.4 虚拟机初始化1.5 没有搜索到黑群晖的解…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...
)
Java 语言特性(面试系列2)
一、SQL 基础 1. 复杂查询 (1)连接查询(JOIN) 内连接(INNER JOIN):返回两表匹配的记录。 SELECT e.name, d.dept_name FROM employees e INNER JOIN departments d ON e.dept_id d.dept_id; 左…...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

【OSG学习笔记】Day 16: 骨骼动画与蒙皮(osgAnimation)
骨骼动画基础 骨骼动画是 3D 计算机图形中常用的技术,它通过以下两个主要组件实现角色动画。 骨骼系统 (Skeleton):由层级结构的骨头组成,类似于人体骨骼蒙皮 (Mesh Skinning):将模型网格顶点绑定到骨骼上,使骨骼移动…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...

2025年渗透测试面试题总结-腾讯[实习]科恩实验室-安全工程师(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 腾讯[实习]科恩实验室-安全工程师 一、网络与协议 1. TCP三次握手 2. SYN扫描原理 3. HTTPS证书机制 二…...

在 Spring Boot 项目里,MYSQL中json类型字段使用
前言: 因为程序特殊需求导致,需要mysql数据库存储json类型数据,因此记录一下使用流程 1.java实体中新增字段 private List<User> users 2.增加mybatis-plus注解 TableField(typeHandler FastjsonTypeHandler.class) private Lis…...

springboot 日志类切面,接口成功记录日志,失败不记录
springboot 日志类切面,接口成功记录日志,失败不记录 自定义一个注解方法 import java.lang.annotation.ElementType; import java.lang.annotation.Retention; import java.lang.annotation.RetentionPolicy; import java.lang.annotation.Target;/***…...