大模型技术实践(五)|支持千亿参数模型训练的分布式并行框架
在上一期的大模型技术实践中,我们介绍了增加式方法、选择式方法和重新参数化式方法三种主流的参数高效微调技术(PEFT)。微调模型可以让模型更适合于我们当前的下游任务,但当模型过大或数据集规模很大时,单个加速器(比如GPU)负载和不同加速器之间的通信是值得关注的问题,这就需要关注并行技术。
并行化是大规模训练中训练大型模型的关键策略,本期内容UCloud将为大家带来“加速并行框架”的技术科普和实践。在学习Accelerate、DeepSpeed、Megatron加速并行框架之前,我们先来了解一下数据并行和模型并行。
01
数据并行与模型并行
1.1 数据并行
数据并行可分为DP(Data Parallelism,数据并行)、DDP(Distributed Data Parallelism,分布式数据并行)、ZeRO(Zero Redundancy Optimizer,零冗余优化器)3种方式。
其中,DP的做法是在每个设备上复制1份模型参数,在每个训练步骤中,一个小批量数据均匀地分配给所有数据并行的进程,以便每个进程在不同子集的数据样本上执行前向和反向传播,并使用跨进程的平均梯度来局部更新模型。
DP通常用参数服务器(Parameters Server)来实现,其中用作计算的GPU称为Worker,用作梯度聚合的GPU称为Server,Server要和每个Worker传输梯度,那么通信的瓶颈就在Server上。受限于通信开销大和通信负载不均的因素,DP通常用于单机多卡场景。
DDP为了克服Server的带宽制约计算效率,采用Ring-AllReduce的通信方式。在Ring-AllReduce中,所有的GPU形成1个环形通信拓扑,在1轮环形传递后,所有GPU都获得了数据的聚合结果,带宽利用率高。在Ring-AllReduce的每1轮通信中,各个GPU都与相邻GPU通信,而不依赖于单个GPU作为聚合中心,有效解决了通信负载不均的问题。DDP同时适用于单机和多机场景。
ZeRO采用的是数据并行结合张量并行的方式,后面将详细展开讲解。
1.2 模型并行
模型并行(MP,Model Parallelism)可分为流水线并行(PP,Pipeline Parallelism)和张量并行(TP,Tensor Parallesim),都是解决当GPU放不下一个模型时,而将模型拆分到不同的GPU上的方法。
流水线并行
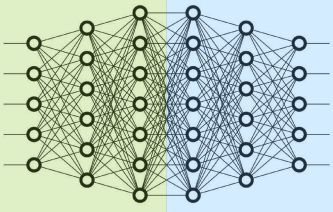
如上图所示,PP将模型在Layer层面上进行水平切分,不同切分部分在不同GPU上运行,并使用微批处理(Micro-Batching,在1个Batch上再划分得到Micro-Batch)和隐藏流水线泡沫(Pipeline Bubble,GPU空转的部分)。由于水平分割和微批处理,模型功能(如权重共享和批量归一化)的实现都很困难。
张量并行
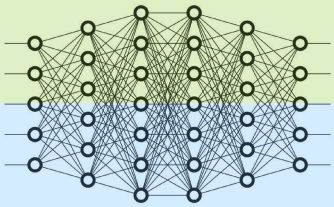
如上图所示,TP在模型的Layer内部进行切分,所有GPU计算所有层的不同部分在单个节点之外无法高效扩展,这是由于细粒度计算和昂贵的通信所致。
02
分布式框架
2.1 Megatron
2019年英伟达发布的Megatron是一个基于PyTorch的分布式训练框架,实现了一种简单高效的层内模型并行方法(TP,是切分矩阵的形式实现的),可以训练具有数十亿参数的Transformer模型。Megatron不需要新的编译器或库更改,可以通过在PyTorch中插入几个通信操作来完全实现。当然Megatron目前支持TP、PP、SP(Sequence Parallelism)和Selective Activation Recomputation,此处对TP进行讲解。
切分矩阵的方式
切分矩阵的方式可按行或者按列,其目的是为了当1个模型无法完整放入1个GPU时,让这个模型能塞到多个GPU中[1]。
1.对于MLP层的切分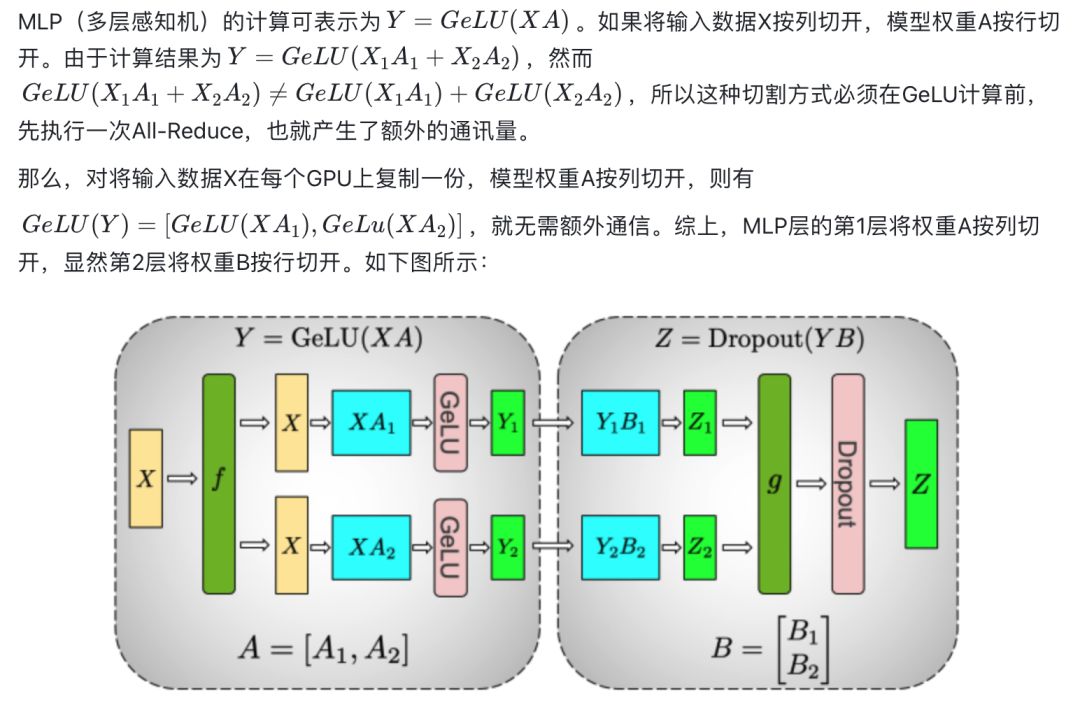
上图中的f和g分别表示2个算子,每个算子都包含一组Forward + Backward操作,也就是前向传播和后向传播操作。具体[2]可表示为: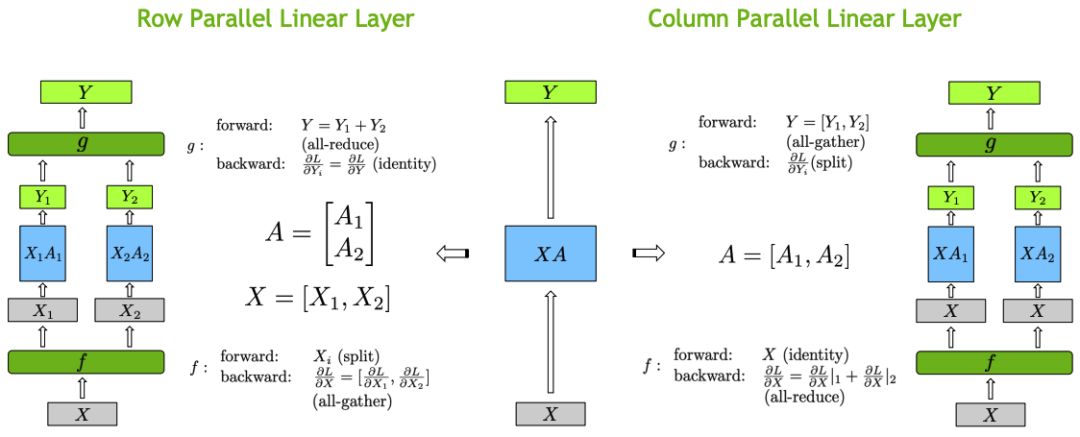
左侧为输入数据X按列切开,将权重矩阵A按行切开。右侧为将输入数据X复制到2个GPU上,将权重矩阵A按列切开。当然,这里是2个GPU的例,同理可类推到多个GPU的情况。
2.对于Multi-Head Attention层的切分Multi-Head Attention,也就是多头注意力,其结构如下图所示: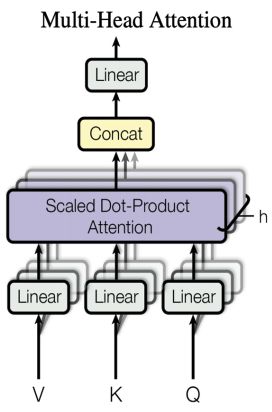
其每个Head本身就是独立计算,再将结果Concat起来,就可以把每个Head的权重放到1个GPU上。当然,1个GPU上可以有多个Head。
如上图所示,先把输入数据X复制到多个GPU上,此时每个Head分别在1个GPU上。对每个Head的参数矩阵Q、K、V按列切开,切分原理、算子f、算子g与MLP层切分章节中的描述一致。之后,各个GPU按照Self-Attention的计算方式得到结果,再经过权重B按行切开的线性层计算。
MLP层和Multi-Head Attention层的通信量
1.MLP层的通信量由上述章节可知,MLP层进行Forward和Backward操作都有一次All-Reduce操作。All-Reduce操作包括Reduce-Scatter操作和All-Gather操作,每个操作的通讯量都相等,假设这2个操作的通讯量都为φ,则进行一次All-Reduce的通讯量为2φ,MLP层的总通讯量为4φ。
2.Multi-head Attention层的通信量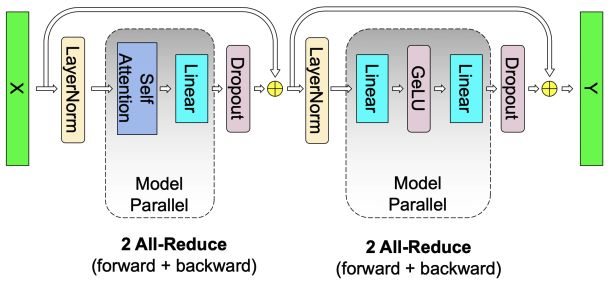
由上图可知,Self-Attention层在Forward和Backward中都要做一次All-Reduce,总通讯量也是。
张量并行与数据并行的结合
1.MP+DP混合的结构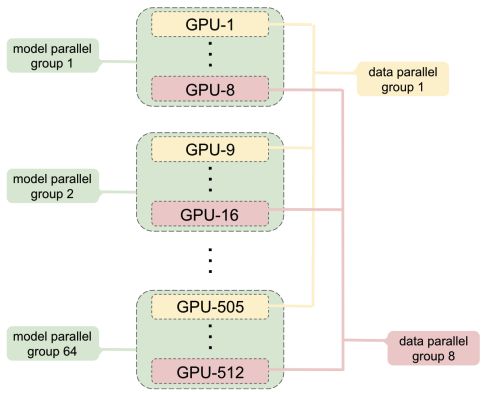
由上图可知,中间每个虚线框表示一台机器,每台机器有8个GPU,合计512个GPU。同一个机器内的1个或多个GPU构成1个模型并行组,不同机器上同一个位置的GPU构成1个数据并行组,图中有8路模型并行组和64路数据并行组。
2.MP与MP+DP的通信量对比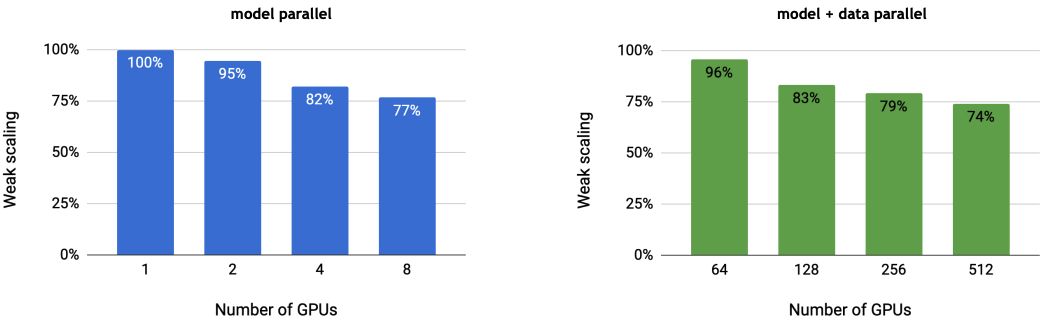
左图是MP模式,可以看到单个GPU的计算效率为100%。随着GPU个数的增加,通信量增大,GPU的计算效率有一定的下降。右图是MP+DP模式,64个GPU(可理解为64台机器,1台机器1个GPU,此时相当于DP模式)的计算效率有96%之高,是由于DP在计算梯度时,可一边继续往下做Backward,一边把梯度发送出去和DP组内其他GPU做All-Reduce。同理,当GPU个数增多,GPU的计算效率也会下降。
2.2 DeepSpeed
2020年微软发布了分布式训练框DeepSpeed和一种新型内存优化技术ZeRO-1,极大地推进了大模型训练的进程。后续,微软又陆续推出ZeRO-2、ZeRO-3技术等,ZeRO这3个阶段称为ZeRO-DP(ZeRO-Powered Data Parallelism)。另外,DeepSpeed还支持自定义混合精度训练处理,一系列基于快速CUDA扩展的优化器,ZeRO-Offload到CPU和磁盘/NVMe。DeepSpeed支持PP、DP、TP这3种范式,支持万亿参数模型的训练。
其中,ZeRO-DP用来克服数据并行性和模型并行性的限制,通过将模型状态(参数、梯度和优化器状态)在数据并行进程之间进行分片,使用动态通信调度实现在分布式设备之间共享必要的状态。ZeRO-R技术可减少剩余的显存消耗。在模型训练过程中产生的激活值(Activations)、存储中间结果的临时缓冲区、显存碎片,我们称之为剩余状态。
ZeRO-DP
1.ZeRO-DP的3个阶段
ZeRO-DP[3]的3个阶段,可在参数zero_optimization中设置。比如:{
"zero_optimization": {
"stage": stage_number,
}
}
其中,stage_number可写1、2、3,当然也可以写0。ZeRO-1只对优化器状态进行分片,ZeRO-2在ZeRO-1的基础上还对梯度分片,ZeRO-3在ZeRO-2的基础上还对模型参数分片。当stage_number为0时,不做任何分片处理,此时相当于DDP。
在ZeRO-DP优化的3个阶段下,1个模型状态在各个GPU上内存消耗情况,如下图所示: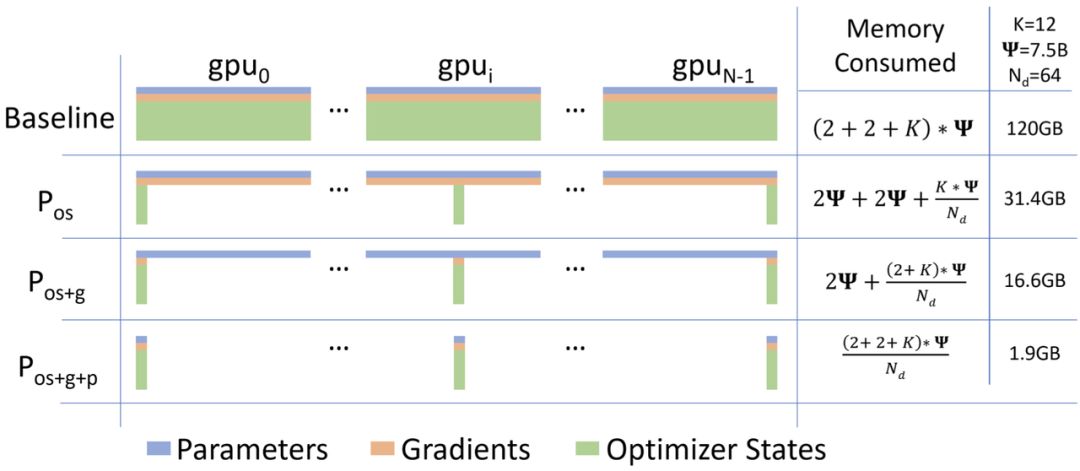
其中Ψ表示模型大小(参数数量),K表示优化器状态的内存倍增器。Nd表示数据并行度,也就是GPU的个数。1. Pos对应优化器状态分片,也就是ZeRO-1,内存减少4倍。2. Pos+g对应添加梯度分片,也就是ZeRO-2, 内存减少8倍。3. Pos+g+p对应模型参数分片,内存减少与数据并行性程度Nd线性相关。
论文中提到,使用64个GPU(Nd = 64)将导致内存减少64倍、通信量略有增加约50%。
2.ZeRO-DP的通信量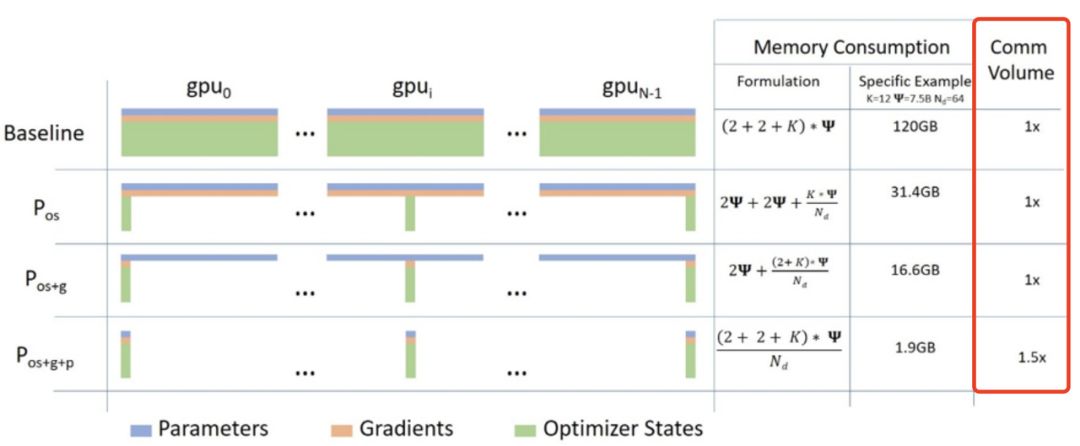
由上图可知,ZeRO-DP在使用Pos和Pg时不会增加额外的通信,同时可以实现高达8倍的内存减少。使用PP,除了Pos和Pg之外,ZeRO-DP最多会引入1.5倍的通信开销,同时进一步降低内存占用Nd倍。
ZeRO-R
1.ZeRO-R的思路将Activations Checkpoints分片到各个GPU上,并使用All-Gather操作按需重构它们,消除了模型并行中的内存冗余。对于非常大的模型,甚至可以选择将激活分区移动到CPU内存。
2.ZeRO-R的通信量分片Activations Checkpoints(记为Pa)的通信量权衡取决于模型大小、Checkpoints策略和模型并行策略。对于模型并行来说,Pa的总通信开销不到原始通信量的10%。
当模型并行与数据并行结合使用时,Pa可以用来将数据并行的通信量降低一个数量级,代价是模型并行的通信量增加了10%,并在数据并行通信成为性能瓶颈时显著提高效率。
2.3 Accelerate
Accelerate[4]由Huggingface于2021年发布,是一个适用于Pytorch用户的简单封装的库,其简化了分布式训练和混合精度训练的过程。Accelerate基于torch_xla和torch.distributed,只需要添加几行代码,使得相同的PyTorch代码可以在任何分布式配置下运行!简而言之,它使得大规模训练和推理变得简单、高效和适应性强。Accelerate 可与DeepSpeed、Megatron-LM 和FSDP(PyTorch Fully Sharded Data Parallel)等扩展一起使用。
2.4 小结
Accelerate更加稳定和易于使用,适合中小规模的训练任务。DeepSpeed和Megatron支持更大规模的模型。通过Accelerate库,可轻松在单个设备或多个设备上结合Megatron、DeepSpeed进行分布式训练。当然,Megatron、Deepspeed 也可以结合使用,比如Megatron-DeepSpeed,这是NVIDIA的Megatron-LM的DeepSpeed版本。
03
在UCloud云平台选择A800
进行Baichuan2大模型的微调实验
首先参照UCloud文档中心(https://docs.ucloud.cn),登录UCloud控制台(https://console.ucloud.cn/uhost/uhost/create)。
在UCloud云平台上创建云主机,选择显卡为A800,配置如下:
实验项目代码获取:https://github.com/hiyouga/LLaMA-Efficient-Tuning
模型下载方式:Git Clone https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat
数据集来源于:1.https://huggingface.co/datasets/neuclir/csl/viewer/default/csl 包含多篇论文摘要、标题、关键词、学科, 可用来做标题总结,关键词提取,学科分类。2.https://huggingface.co/datasets/hugcyp/LCSTS/viewer/default/train?p=24002微博新闻缩写成标题。3.https://huggingface.co/datasets/csebuetnlp/xlsum 中文/英文 BBC新闻、摘要和标题。
本实验的微调任务是从一段文字中提取出概括性的标题。选8万条数据去训练,1000条数据作为测试集,数据样例为:[
{
"instruction": "为以下内容生成一个概括性的标题:\n",
"input": "随着IT巨头们将触角逐渐伸向移动中的汽车产品,鲶鱼效应推动了“车联网”的迅速发展,领军人物苹果与谷歌率先在这场跨界之争中形成了针锋相对的格局,继手机屏幕、电视屏幕等领域之后,又展开了新一轮的“入口”抢滩战。",
"output": "汽车联网苹果已获进展谷歌紧随其后开发",
"source": "LCSTS"
},
{
"instruction": "为以下内容生成一个概括性的标题:\n",
"input": "调查显示,近半数俄罗斯人一年内未读过一本书。曾在苏联时期受到极度喜爱的书籍为何在今天遭遇几乎无人问津的尴尬境地,实体书店又将如何应对危机?《透视俄罗斯》记者带您一探究竟。",
"output": "阅读形式多元化俄罗斯或将告别纸质图书时代",
"source": "LCSTS"
}
]
根据以下配置去执行训练(此处并未做参数调优):deepspeed --num_gpus 8 --master_port=9901 src/train_bash.py \--deepspeed ds_config.json \--stage sft \--model_name_or_path /data/text-generation-webui/models/Baichuan2-13B-Chat \--do_train True \--overwrite_cache False \--finetuning_type lora \--template baichuan2 \--dataset_dir data \--dataset summary_instruction_train \--cutoff_len 1024 \--learning_rate 1e-05 \--num_train_epochs 5.0 \--max_samples 100000 \--per_device_train_batch_size 8 \--gradient_accumulation_steps 4 \--lr_scheduler_type cosine \--max_grad_norm 1.0 \--logging_steps 5 \--save_steps 800 \--warmup_steps 0 \--flash_attn False \--lora_rank 8 \--lora_dropout 0.1 \--lora_target W_pack \--resume_lora_training True \--output_dir saves/Baichuan2-13B-Chat/lora/2023-10-08-18-20-07 \--fp16 True \--plot_loss True
再进行测试,测试结果为:{ "predict_bleu-4": 15.863159399999999,
"predict_rouge-1": 29.348522,"predict_rouge-2": 10.655794799999999,"predict_rouge-l": 26.600239000000002,"predict_runtime": 120.571,"predict_samples_per_second": 8.294,"predict_steps_per_second": 1.037 }
上述结果中:BLEU-4是一种用于评估机器翻译结果的指标;ROUGE-1、ROUGE-2和ROUGE-L是ROUGE系统中的三个常用变体,一组用于评估文本摘要和生成任务的自动评估指标;predict_runtime是模型进行预测所花费的总运行时间,单位为秒;predict_samples_per_second是模型每秒钟处理的样本数量;predict_steps_per_second是模型每秒钟执行的步骤数量。
【参考文献】[1]《Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism》
[2] Megatron-LM:https://developer.download.nvidia.com/video/gputechconf/gtc/2020/presentations/s21496-megatron-lm-training-multi-billion-parameter-language-models-using-model-parallelism.pdf[3]《ZeRO: Memory Optimizations Toward Training Trillion Parameter Models》[4] accelerate Hugging Face:https://huggingface.co/docs/accelerate/index
相关文章:
大模型技术实践(五)|支持千亿参数模型训练的分布式并行框架
在上一期的大模型技术实践中,我们介绍了增加式方法、选择式方法和重新参数化式方法三种主流的参数高效微调技术(PEFT)。微调模型可以让模型更适合于我们当前的下游任务,但当模型过大或数据集规模很大时,单个加速器&…...
[正式学习java②]——数组的基本使用,java内存图与内存分配
一、数组的两种初始化方式 1.完整格式(静态初始化) 数据类型[] 数组名 new 数据类型[]{元素1,元素2…}; //范例 int[] arr new int[]{1,2,3,4}; 简化书写 一般我们会省略后面的 new 数据类型[] int[] arr {1,2,3,4}; 2.动态初始化 当不知道数组里面的初始值的时候…...

ESP32网络开发实例-TCP服务器数据传输
TCP服务器数据传输 文章目录 TCP服务器数据传输1、IP/TCP简单介绍2、软件准备3、硬件准备4、TCP服务器实现本文将详细介绍在Arduino开发环境中,实现一个ESP32 TCP服务器,从而达到与TCP客户端数据交换的目标。 1、IP/TCP简单介绍 Internet 协议(IP)是 Internet 的地址系统,…...

四川天蝶电子商务有限公司抖音电商服务引领行业标杆
随着电子商务的飞速发展,四川天蝶电子商务有限公司作为一家领先的抖音电商服务提供商,已经脱颖而出。本文将详细解析四川天蝶电子商务有限公司的抖音电商服务,让您一探究竟。 一、卓越的服务理念 四川天蝶电子商务有限公司始终坚持以客户为中…...

复制活动工作表和计数未保存工作簿进行
我给VBA下的定义:VBA是个人小型自动化处理的有效工具。可以大大提高自己的劳动效率,而且可以提高数据的准确性。我这里专注VBA,将我多年的经验汇集在VBA系列九套教程中。 作为我的学员要利用我的积木编程思想,积木编程最重要的是积木如何搭建…...

ORA-12541:TNS:no listener 无监听程序
问题截图 解决方法 1、删除Listener 新建一个新的 2、主机为服务器ip 3、设置数据库环境 只需要设置实例名不需要设置路径 4、服务命名 一样设置为ip 服务名与监听名一直 eg:orcl...

UE 多线程
详细参考:《Exploring in UE4》多线程机制详解[原理分析] - 知乎 (zhihu.com) UE4 C基础 - 多线程 - 知乎 (zhihu.com) 多线程的好处 通过为每种事件类型的处理分配单独的线程,能够简化处理异步事件的代码。每个线程在进行事件处理时可以采用同步编程…...

BootStrap5基础入门
BootStrap5 项目搭建 1、引入依赖 从官网 getbootstrap.com 下载 Bootstrap 5。 或者Bootstrap 5 CDN <!-- 新 Bootstrap5 核心 CSS 文件 --> <link rel"stylesheet" href"https://cdn.staticfile.org/twitter-bootstrap/5.1.1/css/bootstrap.min.c…...

企业文件防泄密软件!好用的文件加密系统推荐
由于众多企业内部都有大量的机密数据以电子文档的形式存储着,且传播手段多样,很容易造成文件泄密的问题发生。若是员工通过网络泄密重要文件,或是有黑客入侵窃取机密数据等,造成重要文件被非法查看盗取,都会给企业业务…...
【LLM微调范式1】Prefix-Tuning: Optimizing Continuous Prompts for Generation
论文标题:Prefix-Tuning: Optimizing Continuous Prompts for Generation 论文作者:Xiang Lisa Li, Percy Liang 论文原文:https://arxiv.org/abs/2101.00190 论文出处:ACL 2021 论文被引:1588(2023/10/14&…...
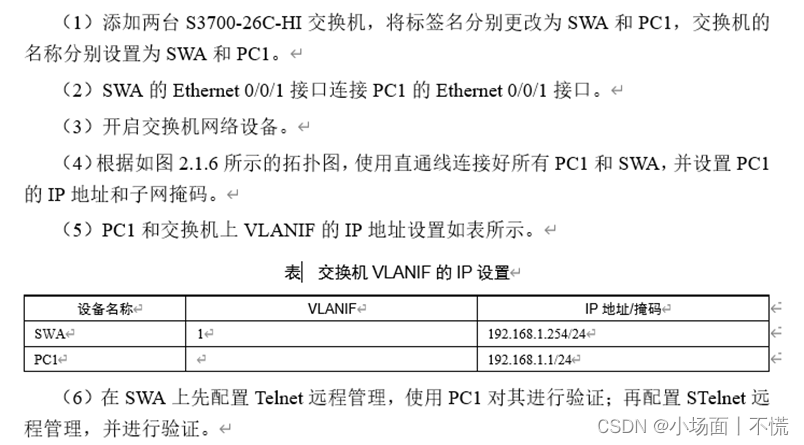
实验2.1.3 交换机的远程配置
实验2.1.3 交换机的远程配置 一、任务描述二、任务分析三、实验拓扑四、具体要求五、任务实施(一) password认证1. 进入系统视图重命名交换机的名称为SWA2. 关闭干扰信息3. 设置vty为0-44. 设置认证方式为password5. 设置登录密码为:huawei6.…...
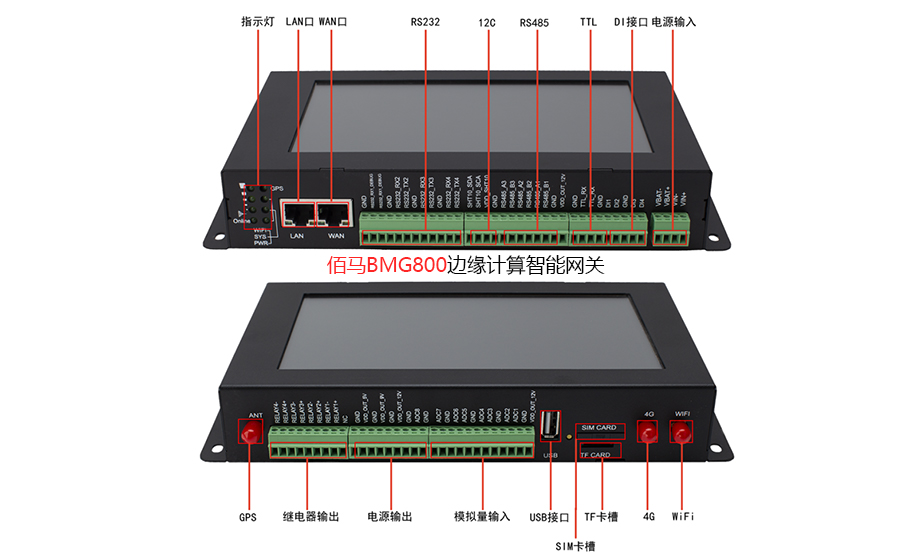
基于边缘网关构建水污染监测治理方案
绿水青山就是金山银山,生态环境才是人类最宝贵的财富。但是在日常生活生产中,总是免不了各种污水的生产、排放。针对生产生活与环境保护的均衡,可以借助边缘网关打造环境污水监测治理体系,保障生活与环境的可持续性均衡发展。 水污…...

Spring事件ApplicationEvent源码浅读
文章目录 demo应用实现基于注解事件过滤异步事件监听 源码解读总结 ApplicationContext 中的事件处理是通过 ApplicationEvent 类和 ApplicationListener 接口提供的。如果将实现了 ApplicationListener 接口的 bean 部署到容器中,则每次将 ApplicationEvent 发布到…...

51单片机点阵
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、点阵是什么?1.点阵的原理2. 3*3 点阵显示原理3. 8*8点阵实物图4. 8*8点阵内部原理图5. 16*16点阵实物图,显示原理 二、使用步骤1.先…...
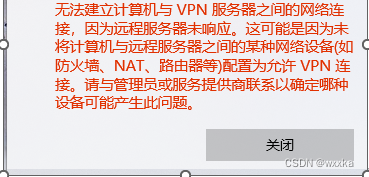
远程VPN登录,IPsec,VPN,win10
windows10 完美解决L2TP无法连接问题 windows10 完美解决L2TP无法连接问题 - 哔哩哔哩...
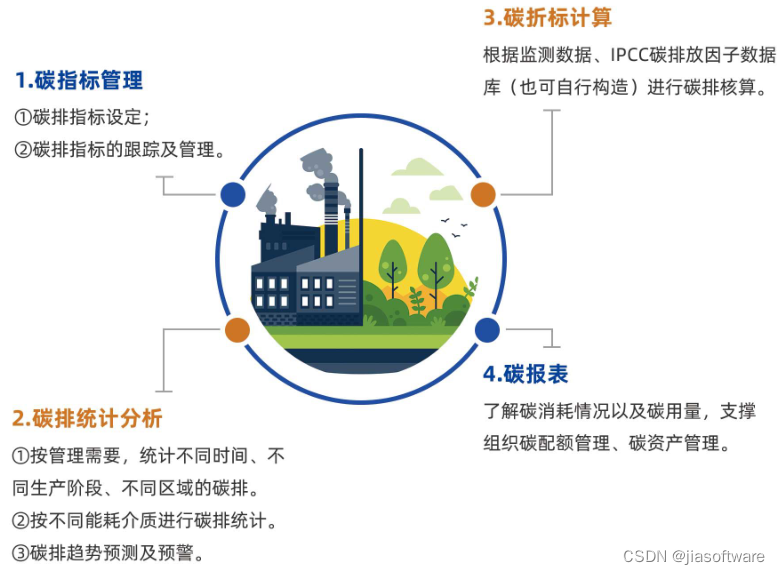
“零代码”能源管理平台:智能管理能源数据
随着能源的快速增长,有效管理和监控能源数据变得越来越重要。为了帮助企业更好的管理能源以及降低能源成本,越来越多的能源管理平台出现在市面上。 “零代码”形式的能源管理平台,采用IT与OT深度融合为理念,可进行可视化、拖拽、…...
】06 - SA8295P XBL Loader 阶段 sbl1_main_ctl 函数代码分析)
【SA8295P 源码分析 (一)】06 - SA8295P XBL Loader 阶段 sbl1_main_ctl 函数代码分析
【SA8295P 源码分析】06 - SA8295P XBL Loader 阶段 sbl1_main_ctl 函数代码分析 一、XBL Loader 汇编源码分析1.1 解析 boot\QcomPkg\XBLLoader\XBLLoader.inf1.2 boot\QcomPkg\XBLDevPrg\ModuleEntryPoint.S:跳转 sbl1_entry 函数1.3 XBLLoaderLib\sbl1_Aarch64.s:跳转 sbl…...
Java版本spring cloud + spring boot企业电子招投标系统源代码
项目说明 随着公司的快速发展,企业人员和经营规模不断壮大,公司对内部招采管理的提升提出了更高的要求。在企业里建立一个公平、公开、公正的采购环境,最大限度控制采购成本至关重要。符合国家电子招投标法律法规及相关规范,以及审…...

软考高级信息系统项目管理师系列论文一:论信息系统项目的整体管理
软考高级信息系统项目管理师系列论文一:论信息系统项目的整体管理 一、项目整体管理相关知识点二、摘要三、正文四、总结一、项目整体管理相关知识点 软考高级信息系统项目管理师系列之:项目整体管理...
【前端】JS - WebAPI
目 录 一.WebAPI 背景知识什么是 WebAPI什么是 APIAPI 参考文档 二.DOM 基本概念什么是 DOMDOM 树 三.获取元素querySelectorquerySelectorAll 四.事件初识基本概念事件三要素 五.操作元素获取/修改元素内容(innerHTML)获取/修改元素属性获取/修改样式属…...

2.2.2.3 Spark实战:词频统计
本次实战涵盖了Spark词频统计(WordCount)的两种主流实现方式。首先,利用Scala在spark-shell中完成从读取文件、flatMap分词、map映射到reduceByKey聚合的完整流程,并实现结果的降序排序。其次,针对Spark 3.3.2版本的需…...

AI学习路线及建议
1.python快速入门(边用边学,建议3天) 2.人工智能必备数学的基础(边用边学,建议3天) 3.机器学习(找工作面试考点,临面试前晚一点刷) 数据分析:短期找工作 ML/D…...
)
SiameseAOE中文-base高性能部署:WebUI响应<800ms,吞吐达12QPS(RTX4090)
SiameseAOE中文-base高性能部署:WebUI响应<800ms,吞吐达12QPS(RTX4090) 今天要跟大家聊一个非常实用的工具——SiameseAOE通用属性观点抽取模型。你可能听说过信息抽取,但面对海量文本,如何快速、准确地…...

开源吐槽大会:技术圈的幽默自省
开源项目吐槽大会技术文章大纲主题与目的开源项目吐槽大会旨在通过幽默、犀利的视角,揭示开源生态中的常见问题,促进开发者反思与改进。文章将从技术、社区、维护等角度展开,兼顾娱乐性与建设性。核心内容结构技术层面的经典槽点 依赖地狱&am…...

485总线硬件设计必看:电平匹配、TVS防护,还有exmodbus库快速上手
RS485是工业物联网的标配通信接口。合宙Air780EHV系列Cat.1模组凭借强大外设扩展能力(LCD、摄像头、以太网、CAN等)和LuatOS高效开发环境,支持TCP/MQTT/HTTP/Modbus等主流协议,是工业场景的高性价比之选。 本文聚焦RS485实战&…...

开发笔记:VSCode + Qt + clangd 明明能正常运行却满屏红波浪线
目录 开发笔记:VSCode Qt clangd 明明能正常运行却满屏红波浪线 前言 一、问题现象 二、根本原因:两套工具互不沟通 三、完整解决方案 方案 1:配置 .clangd(最推荐、最根治) 方案 2:自动生成 comp…...

2026年知网AIGC检测卡在20%降不下去怎么办?这3招解决
直接说方案,不绕弯子。知网AIGC检测不通过、降AIGC率、降AI这个问题,核心是找准降不下去的原因,再用对工具。 我花了一个月测出来的结论:用嘎嘎降AI(www.aigcleaner.com) 全文上传,基本能解决大…...

Linux下CMake多版本共存实战:不卸载旧版也能用上新功能
Linux下CMake多版本共存实战:不卸载旧版也能用上新功能 在软件开发的世界里,版本管理就像一场永不停歇的舞蹈。想象一下这样的场景:你正在维护一个历史悠久的C项目,突然客户要求你同时开发一个全新的模块,而这个模块需…...

10分钟掌握Deep-Live-Cam:从零搭建实时AI换脸系统的完整指南
10分钟掌握Deep-Live-Cam:从零搭建实时AI换脸系统的完整指南 【免费下载链接】Deep-Live-Cam real time face swap and one-click video deepfake with only a single image 项目地址: https://gitcode.com/GitHub_Trending/de/Deep-Live-Cam Deep-Live-Cam是…...

软件测试之压力测试总结
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一、什么是压力测试软件测试中:压力测试(Stress Test),也称为强度测试、负载测试。压力测试是模拟实际应用的软硬件…...