极简的MapReduce实现
目录
1. MapReduce概述
2. 极简MapReduce内存版
3. 复杂MapReduce磁盘版
4. MapReduce思想的总结
1. MapReduce概述
以前写过一篇 MapReduce思想 ,这次再深入一点,简单实现一把单机内存的。MapReduce就是把它理解成高阶函数,需要传入map和reduce所需的函数,即可对一个集合的键值对进行按需变换。
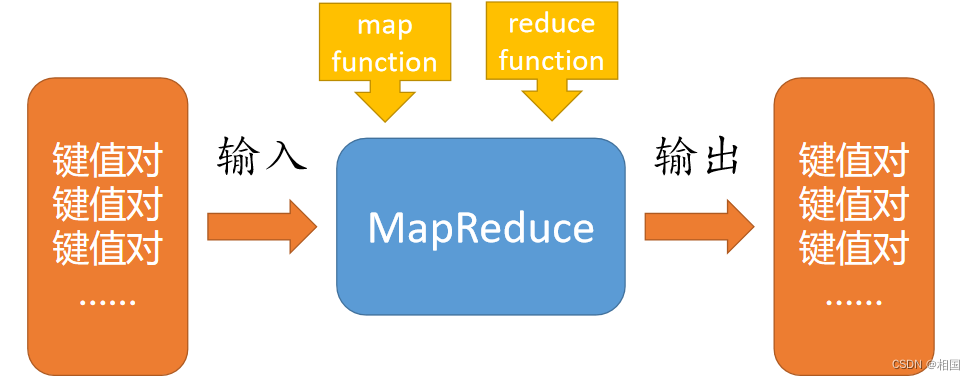
我们按Python的map和reduce逻辑,接收这两个高阶函数所需的函数形态,而不是像Java那样写一个Mapper/Reducer,当然如果需要复杂一点map功能,可以通过闭包来实现。
2. 极简MapReduce内存版
如果是效仿Python,很容易想到实现MapReduce 就是map + 分组 + reduce。一头一尾的map和reduce都可以直接用py的内置函数,中间分组也容易用sort+groupby实现。因此首先约定map和reduce的自定义函数写法就是直接按内置函数要求来写,只不过map输出是键值对,要求用长度是2的tuple/list 来装key和value;reduce时候只对一组的values做自定义聚合,不能操作key。到这里很容易实现严格的MapReduce,你用起来大概就和Spark提供的mapreduce一样了。如果想直接做wordcount好像不太容易,因为一行文本得输出一个词表数组,因此可以宽松一点,实现类似flatMap的效果,也就是即使map只输出一个,也要放进列表里,由框架去展开。
def wc_map(line):return [(x,1) for x in line.strip().split()]reduce就是严格的两个参数和一个返回值形式(其中y表示上一轮迭代的结果,x表示遍历数组每次拿到的值,这种严格的reduce函数完成特定功能并容易设计)
def wc_reduce(y, x):return y+x剩下要做的事就是把map出来的数据做 拉平和排序分组,最后对每一组做reduce。
from itertools import groupby
from functools import reduce
def map_reduce(f_map, f_reduce, seq):map_result = map(f_map, seq)flattened = sum(map_result, []) #拉平shuffled = sorted(flattened, key= lambda x:x[0]) #排序mr_result = [(key, reduce(f_reduce, (x[1] for x in data))) for key, data in groupby( shuffled, key=lambda x:x[0])] #groupby分组return mr_result3. 复杂MapReduce磁盘版
如果内存不够,就必须不断把数据写到磁盘上,也就是过去大数据面试题最喜欢考察的点。那些题若是有单机版MapReduce,基本都可以直接做出来。大体结构如下图:
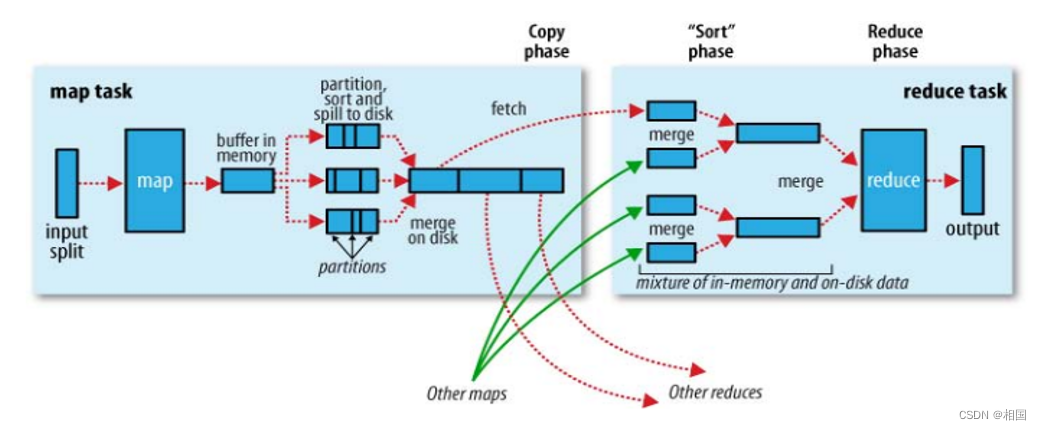
其中partition只有一个,就不用单独设计了。过程也简化很多,也就是每当buffer满了,就排序写出到成一个数据块,最后将所有的数据块merge起来。merge过程写起来不是很容易,需要维持所有数据块的句柄数组有序:每次读取所有句柄中最小的那一条,随后数组需要重新按最小值排序,直到所有数据块读取完。
另外就是因为中间数据需要落地,所以这一版的MapReduce框架直接从文件到文件。那么让写map和reduce函数直接对着文件输出,类似Java那样提供一个context的参数呢?我选择允许用yield来输出内容,这样相当于也宽松了输出多个键值对的要求。
def wc_map(line):for t in line.strip().split():yield (t, 1)最后同样宽松reduce的写法,不用写那么复杂的两参数一返回,而是像Java那样,拿到一组key和可迭代的values,甚至可以这一组key输出多个结果。
def reduce_func(key , kv_pairs):s = 0for k,v in kv_pairs : s += vyield (key, s)很显然我们要补充很多东西,要读取文件、要设计缓存、要做merge,因此设计了一个类,过程就不解释了
import os
import itertools
import sys
class MapReduce:class Buffer:def __init__(self, buffer_size = 80000):self.buffer_size = buffer_sizeself.buffer = []self.current_size = 0def add_data(self, kv) -> bool :self.current_size += len(str(kv))self.buffer.append(kv)return True if self.current_size > self.buffer_size else False def spill(self, file_path):if self.buffer:self.buffer.sort(key = lambda x:x[0]) with open(file_path, mode='w') as f:for kv in self.buffer:f.write(str(kv) + '\n')self.buffer = []self.current_size = 0def __init__(self, buffer_size,temp_dir):self.buffer = self.Buffer(buffer_size)self.temp_dir = temp_dirself.block_id = 0def __fetch_kvs_from_map(self, map_f, infile):with open(infile, mode='r', encoding='utf-8') as f:for line in f:for k,v in map_f(line):yield (k,v)def __run_map(self, map_f, infile):block_files = [x for x in os.listdir(self.temp_dir) if x.startswith('block.') and x.split('.',1)[1].isdigit() ]for block in block_files:os.remove(f'{self.temp_dir}/{block}')for kv in self.__fetch_kvs_from_map(map_f, infile):if self.buffer.add_data(kv):self.buffer.spill(f'{self.temp_dir}/block.{self.block_id}')self.block_id += 1self.buffer.spill(f'{self.temp_dir}/block.{self.block_id}')def __merge_sort_from_files(self):block_files = [x for x in os.listdir(self.temp_dir) if x.startswith('block.') and x.split('.',1)[1].isdigit() ]block_files.sort(key = lambda filename: int(filename.split('.',1)[1]))ffs = [open(f'{self.temp_dir}/{block}', 'r') for block in block_files]first_kvs = [ eval(f.readline()) for f in ffs ]shuffled_files = [[fk, ff] for fk, ff in zip(first_kvs, ffs)]shuffled_files.sort(key = lambda x:x[0][0], reverse=True) with open(f'{self.temp_dir}/final_one.dat', mode='w') as fw:while len(shuffled_files ) > 1:first_keys = [x[0][0] for x in shuffled_files]min_key = first_keys[-1]min_idx_bound = first_keys.index(min_key)sffs = shuffled_files[min_idx_bound:]for sff in sffs:fw.write(str(sff[0]) + '\n')n = sff[1].readline()if n :sff[0] = eval(n)else:sff[0] = ''sff[1].close()shuffled_files = sorted(filter(lambda x:x[0], shuffled_files), key = lambda x:x[0][0], reverse=True)if shuffled_files:fw.write(str(shuffled_files[0][0]) + '\n') #already existfor line in shuffled_files[0][1]:fw.write(line)shuffled_files[0][1].close()def __run_reduce(self, reduce_f, outfile):def read_mapper_output(file):for line in file:yield eval(line.rstrip())with open(f'{self.temp_dir}/final_one.dat', encoding='utf-8') as f , \open(f'{self.temp_dir}/{outfile}', encoding='utf-8',mode='w') as fw:stdin_generator=read_mapper_output(f)for key, kv_pairs in itertools.groupby(stdin_generator, lambda x:x[0] ):for key,result in reduce_f(key, kv_pairs):fw.write(f"{key}\t{result}\n")def run_mrjob(self, map_f, reduce_f, infile, outfile):#====mapself.__run_map(map_f, infile)#====shuffle===self.__merge_sort_from_files()#====reduceself.__run_reduce(reduce_f, outfile)def map_func(x):for t in x.strip().split():yield (t, 1)def reduce_func(key , kv_pairs):s = 0for k,v in kv_pairs : s += vyield (key, s)if __name__ == "__main__":mr = MapReduce(30, "./")mr.run_mrjob(map_func, reduce_func, "words.txt", "result.txt")代码明显复杂了很多,其中reduce读取有序文件依次分key的组,还借鉴了Hadoop streaming 中Python代码的处理方式。
4. MapReduce思想的总结
这个系列到这算完结了,为了讲解MapReduce我都是先讲解高阶函数map和reduce,深入思考以后发现这些个东西确实还有一些值得补充的地方。但应该不止于此,对于没有完全学过函数式编程的我来说就纯个人观点一下:
写map有什么用?在你写了很多独立地循环处理逻辑以后, 你发现你可以把循环与处理分离了。反过来更多使用map会习惯这种分离的思维,甚至提升这种分离。 这种分离意味着一种共性的抽象。
reduce被设计出来的意义何在? 不使用全局变量,而是部分变量传递,以完成全局功能的设计。全局功能线性拆分成N个独立的有部分依赖的功能总和。其本质也是一种分离或拆分思想。反过来使用reduce实现功能,习惯这种等价的整体拆分成部分的思维,强化这种拆分,意味着进行带依赖的共性的提炼。
最后概括一下MapReduce的学习意义:证明了对任务的工序拆分能有效实现并行加速。即对任务抽象拆分出同质(独立或依赖)的步骤,这些同质工作能并行/自动化。而工序拆分,靠的是前面高阶函数训练出来的思维。
相关文章:
极简的MapReduce实现
目录 1. MapReduce概述 2. 极简MapReduce内存版 3. 复杂MapReduce磁盘版 4. MapReduce思想的总结 1. MapReduce概述 以前写过一篇 MapReduce思想 ,这次再深入一点,简单实现一把单机内存的。MapReduce就是把它理解成高阶函数,需要传入map和…...
)
更新暑假做过的项目(医学数据多标签分类与多标签分割,医学数据二分类)
写在前面 暑假参与了两个项目,收获颇多。搭建网络有许多走过的弯路与经验,调参也是一个必要的技能,在这里想一并分享给大家我在项目中积累的经验和一些小技巧。 PS:结合个人经验与网上经验,大家斟酌自取。 下面的几个…...

谷歌浏览器访问127.0.0.1时报错 Failed to read the ‘sessionStorage‘ property from ‘Window‘
谷歌浏览器访问 127.0.0.1 时报错如下: Uncaught DOMException: Failed to read the ‘sessionStorage’ property from ‘Window’: Access is denied for this document. 原因: 谷歌浏览器设置中禁止了 127.0.0.1 存储数据到浏览器设备上 解决方法…...
云技术分享 | 快速构建 CodeWhisperer 代码生成服务,让 AI 辅助编程
前言 Amazon CodeWhisperer 是 2023 年 4 月份发布的一款通用的、机器学习驱动的代码生成器服务,CodeWhisperer 经过数十亿行 Amazon 和公开可用代码的训练,可以理解用自然语言(英语)编写的评论,可在集成式开发环境 (…...

开发万岳互联网医院APP:技术要点和关键挑战
随着移动技术和互联网的飞速发展,互联网医院APP成为医疗领域的一项重要创新。这些应用程序为患者和医生提供了更多便利和互动性,但开发互联网医院APP也伴随着一系列的技术要点和关键挑战。本文将探讨互联网医院APP的技术要点以及在开发过程中需要面对的挑…...
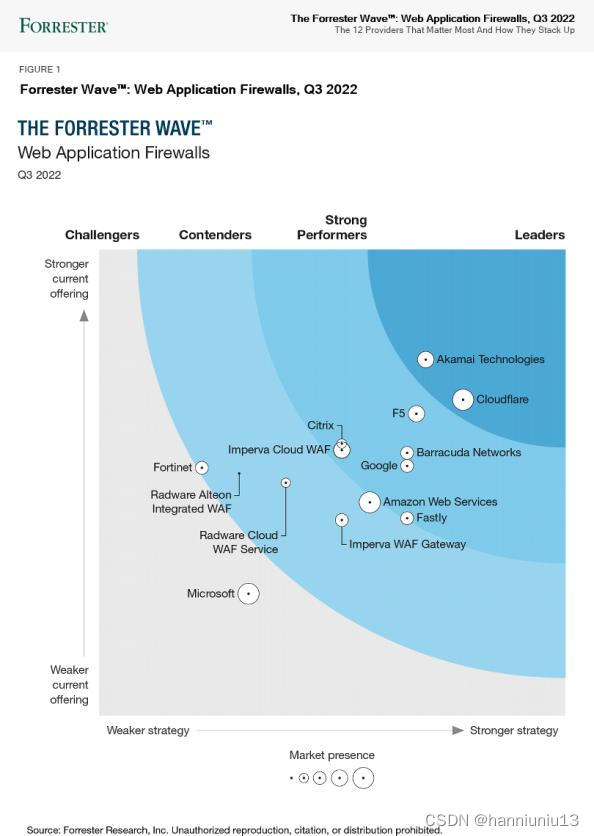
漫谈下一代防火墙与Web应用防火墙的区别
如今,Web应用程序变得越来越复杂,更是黑客非常感兴趣的目标。在谈到网络安全的话题时,我们总会讨论下一代防火墙与Web应用防火墙的区别。当已经拥有下一代防火墙(NGFW)时,为什么需要Web应用程序防火墙&…...

基于马尔可夫随机场的图像去噪算法matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1、马尔可夫随机场的基本原理 4.2、基于马尔可夫随机场的图像去噪算法 5.算法完整程序工程 1.算法运行效果图预览 原图: 加入噪声的图像: 滤波后的图像 迭代过程…...

【综合类型第 39 篇】HTTP 状态码详解
这是【综合类型第 39 篇】,如果觉得有用的话,欢迎关注专栏。 注: 本篇博客只是在「阿里云开发者社区版 HTTP 状态码详解」中按自己的写作风格做了断句,归纳整理,方便查看和阅读。 尊重原创,原文链接&…...

win10 hosts文件修改不生效
解决办法可以参考:修改hosts 不生效? 三种方法解决...
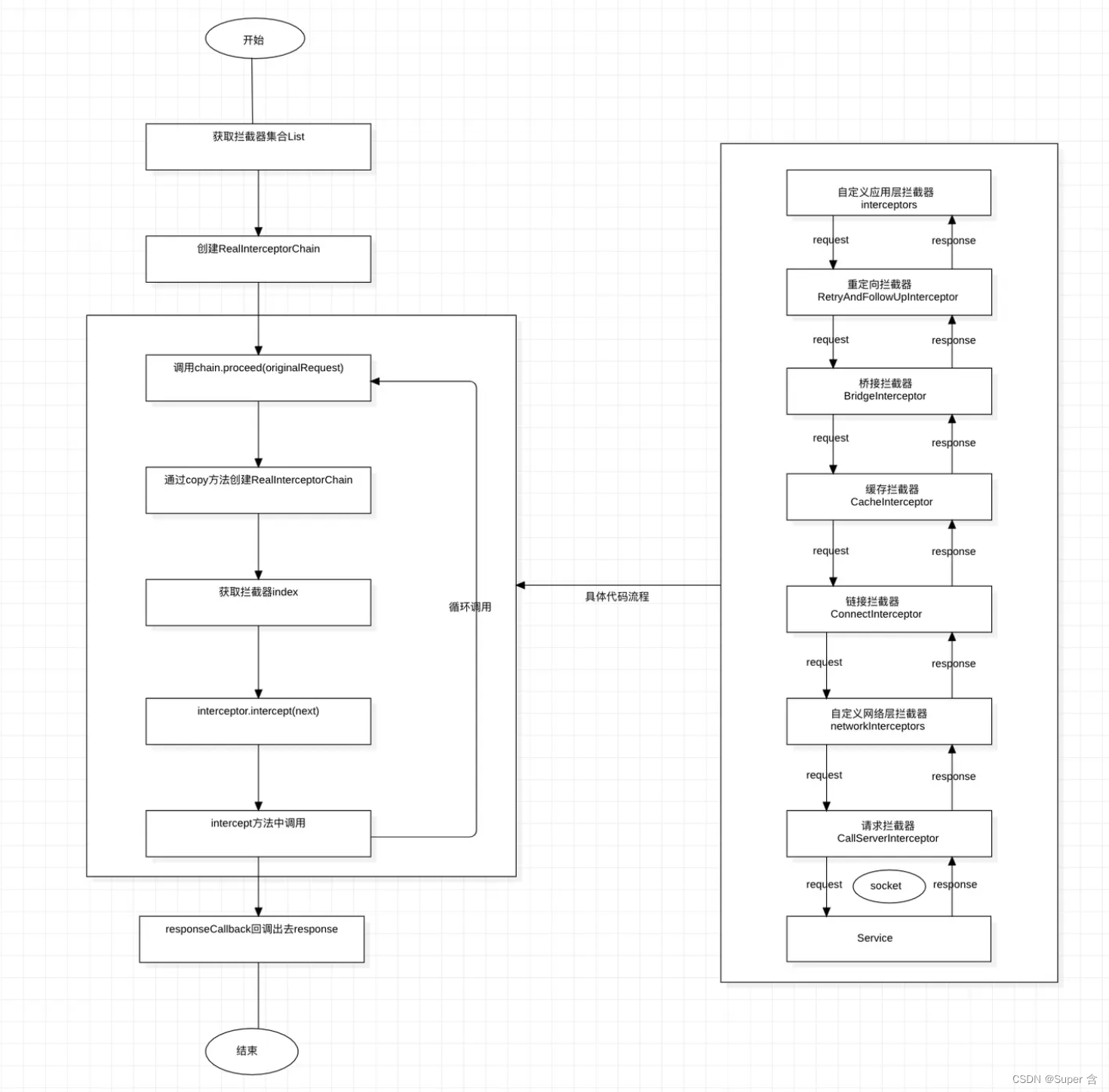
网络库OKHttp(1)流程+拦截器
序、慢慢来才是最快的方法。 背景 OkHttp 是一套处理 HTTP 网络请求的依赖库,由 Square 公司设计研发并开源,目前可以在 Java 和 Kotlin 中使用。对于 Android App 来说,OkHttp 现在几乎已经占据了所有的网络请求操作。 OKHttp源码官网 版…...
关于 Invalid bound statement (not found): 错误的解决
关于 Invalid bound statement not found: 错误的解决 前言错误原因解决方法1. 检查SQL映射文件2. 检查MyBatis配置3. 检查SQL语句4. 检查命名约定5. 清除缓存6. 启用日志记录 重点注意 结语 我是将军我一直都在,。! 前言 当开发Java Spring Boot应用程…...
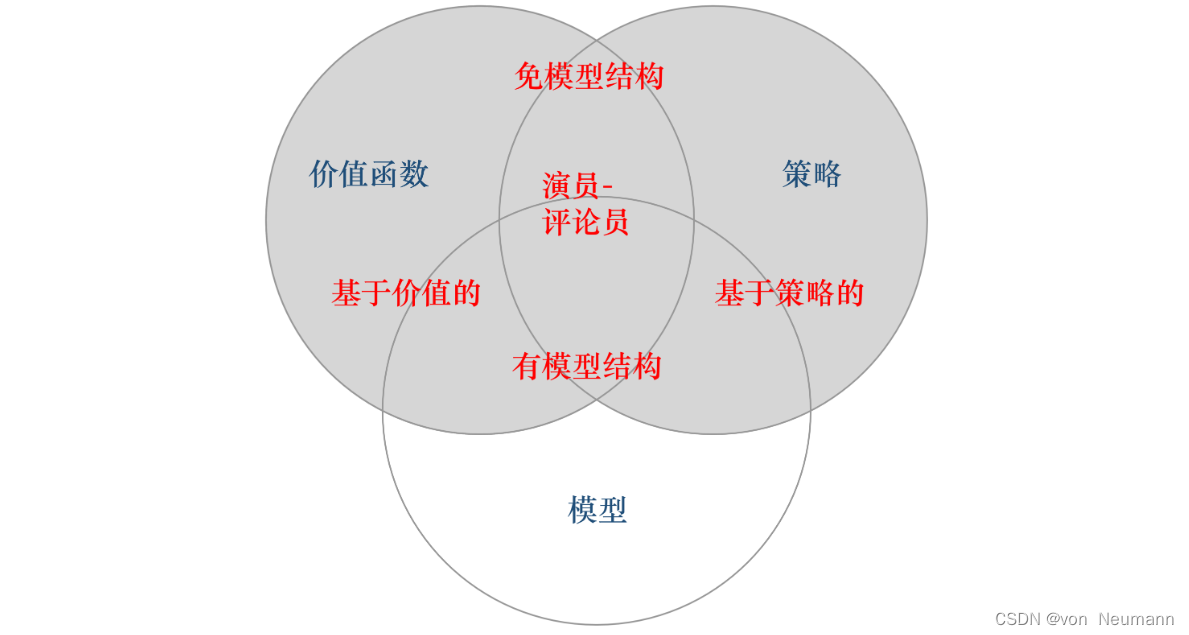
深入理解强化学习——智能体的类型:有模型强化学习智能体与免模型强化学习智能体
分类目录:《深入理解强化学习》总目录 根据智能体学习的事物不同,我们可以把智能体进行归类。基于价值的智能体(Value-based agent)显式地学习价值函数,隐式地学习它的策略。策略是其从学到的价值函数里面推算出来的。…...
vue项目获得开源代码之后跳过登录界面
readme运行 进入到账号和密码 找到main.js 比如说,以上这段代码 剩下next()就成功进入了...
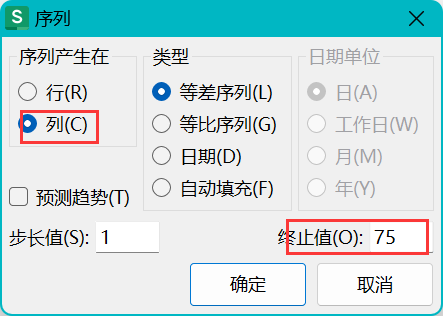
WPS、Excel表格增加一列,序列1到任意大小 / 填充某个范围的数字到列
Excel添加一列递增的数字方法有如下: 一、最常用的,使用鼠标放到右下角下拉增加 1、选中起始框的右下角,直到显示黑色实心十字 2、一直向下拖动 3、成功 这种填充方式是最常用的,100以内都可以轻松瞬间完成 1~100填充 但是如果…...
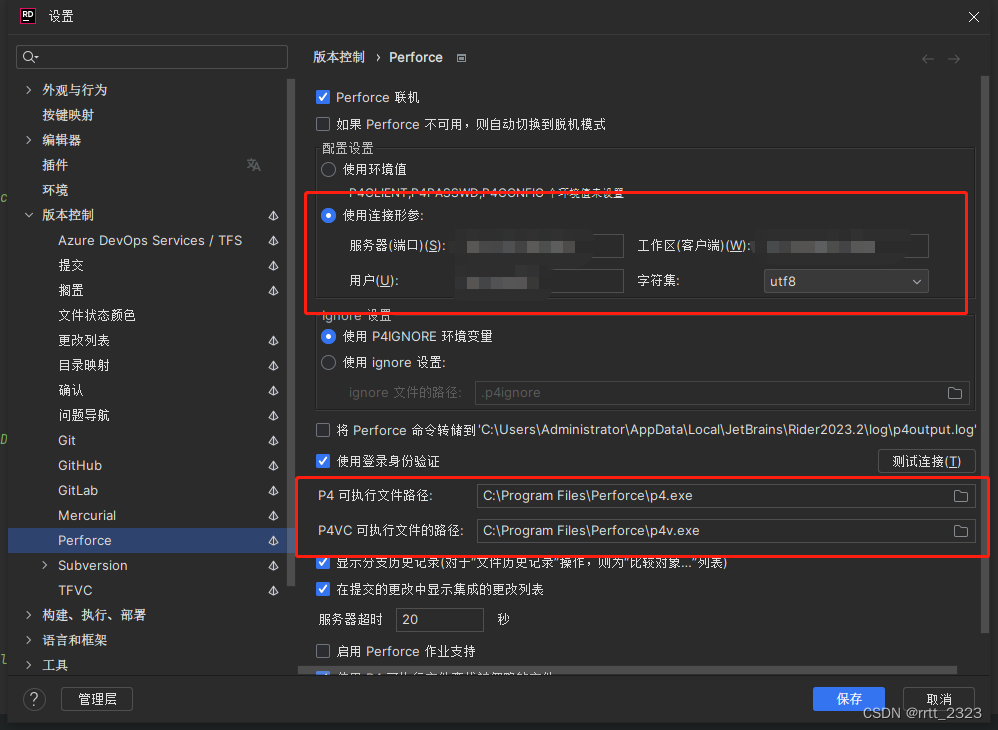
在 rider 里用配置 Perforce(P4)的注意事项
整个配置界面里,关键就配2处位置,但是都有些误导性。 1是连接形参的4个参数都得填,字符集看你项目的要求,这里工作区其实指的是你的工作空间,还不如显示英文的 Workspace 呢,搞得我一开始没填,…...
)
在Spring中,标签管理的Bean中,为什么使用@Autowired自动装配修饰引用类(前提条件该引用类也是标签管理的Bean)
Autowired是Spring框架的一个注解,它可以用来完成自动装配。 自动装配是Spring框架的一个特性,它可以避免手动去注入依赖,而是由框架自动注入。这样可以减少代码的重复性和提高开发效率。 在使用Autowired注解时,Spring会自动搜…...

俄罗斯YandexGPT 2在国家考试中获得高分;OpenAI API开发者快速入门指南
🦉 AI新闻 🚀 俄罗斯YandexGPT 2聊天机器人成功在国家考试中获得高分 摘要:俄罗斯YandexGPT 2聊天机器人通过国家统一考试文学科目,以55分的加权分数成功进入大学。Yandex团队强调他们在开发过程中确保数据库不包含任何关于统考…...

Nginx 同一端口下部署多个 Vue3 项目
前言 前端多项目部署到 Nginx 的同一监听端口下的解决方案,项目由一个主项目和多个子项目组成,主项目和子项目都是单独打包。 主子项目之间是使用的腾讯开源的无界(WebComponent 容器 iframe 沙箱)前端框架,能够完善…...
计算机毕业设计 无人智慧超市管理系统的设计与实现 Javaweb项目 Java实战项目 前后端分离 文档报告 代码讲解 安装调试
🍊作者:计算机编程-吉哥 🍊简介:专业从事JavaWeb程序开发,微信小程序开发,定制化项目、 源码、代码讲解、文档撰写、ppt制作。做自己喜欢的事,生活就是快乐的。 🍊心愿:点…...

js构造函数和原型链
以下是一个简单的JS原型链代码示例: function Person(name, age) {this.name name;this.age age; }Person.prototype.sayHello function() {console.log(Hello, Im ${this.name} and Im ${this.age} years old.); }let person1 new Person(Alice, 20);person1.…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

【HTTP三个基础问题】
面试官您好!HTTP是超文本传输协议,是互联网上客户端和服务器之间传输超文本数据(比如文字、图片、音频、视频等)的核心协议,当前互联网应用最广泛的版本是HTTP1.1,它基于经典的C/S模型,也就是客…...

[Java恶补day16] 238.除自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O(n) 时间复杂度…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...