【离线数仓-8-数据仓库开发DWD层-交易域相关事实表】
离线数仓-8-数据仓库开发DWD层-交易域相关事实表
- 离线数仓-8-数据仓库开发DWD层-交易域相关事实表
- 一、DWD层设计要点
- 二、交易域相关事实表
- 1.交易域加购事务事实表
- 1.加购事务事实表 前期梳理
- 2.加购事务事实表 DDL表设计分析
- 3.加购事务事实表 加载数据分析
- 1.首日全量加购的数据加载
- 2.每日增量加购的数据加载
- 2.交易域下单事务事实表
- 1.下单事务事实表 前期梳理
- 2.下单事务事实表 DDL表设计分析
- 3.下单事务事实表 加载数据分析
- 1.首日全量下单的数据加载
- 2.每日增量量下单的数据加载
- 3.交易域取消订单事务事实表
- 1.取消订单事务事实表 前期梳理
- 2.取消订单事务事实表 DDL表设计分析
- 3.取消订单事务事实表 加载数据分析
- 1.首日全量取消订单的数据加载
- 2.每日增量取消订单的数据加载
- 7.交易域购物车周期快照事实表
- 1.购物车周期快照事实表 前期梳理
- 2.购物车周期快照事实表 DDL表设计分析
- 3.购物车周期快照事实表 加载数据分析
- 4.交易域支付成功事务事实表
- 1.支付成功事务事实表 前期梳理
- 2.支付成功事务事实表 DDL表设计分析
- 3.支付成功事务事实表 加载数据分析
- 5.交易域退单事务事实表
- 1.退单事务事实表 前期梳理
- 2.退单事务事实表 DDL表设计分析
- 3.退单事务事实表 加载数据分析
- 6.交易域退款成功事务事实表
- 1.退款成功事务事实表 前期梳理
- 2.退款成功事务事实表 DDL表设计分析
- 3.退款成功事务事实表 加载数据分析
离线数仓-8-数据仓库开发DWD层-交易域相关事实表
一、DWD层设计要点
- DWD层设计要点:
- 1)DWD层的设计依据是维度建模理论,该层存储维度模型的事实表。
- 事实表维度建模理论参考之前整理资料:https://blog.csdn.net/weixin_38136584/article/details/129137583?spm=1001.2014.3001.5501
- 2)DWD层的数据存储格式为orc列式存储+snappy压缩。
- 3)DWD层表名的命名规范为dwd_数据域_表名(体现业务过程)_单分区增量全量标识(inc/full)
- 1)DWD层的设计依据是维度建模理论,该层存储维度模型的事实表。
二、交易域相关事实表
事实事务表设计流程大概分为4步:选择业务过程 --> 声明粒度 --> 确认维度–> 确认事实
1.交易域加购事务事实表
1.加购事务事实表 前期梳理
- 加购事务事实表 设计流程跟事务事实表流程一致,分为四步进行。
- 查看之前梳理的业务矩阵,基于业务矩阵来进行设计流程4步骤分析

- 1.选择业务过程:加购物车
- 2.声明粒度(业务过程确定后,需要为每个业务过程声明粒度。即精确定义每张事务型事实表的每行数据表示什么,应该尽可能选择最细粒度,以此来应各种细节程度的需求。):xx人在xx时间将xx商品加入到购物车
- 3.确认维度:寻找符合业务逻辑的并与此业务过程关联的维度,如果前期选择少了几个维度,后期可以更新表格再添加即可。
- 4.确认事实(每个业务过程的度量值):商品件数
2.加购事务事实表 DDL表设计分析
- 业务数据库对应的表格加购物车cart_info中,存在source_id字段,此字段对应的是加购物车这个操作对应的数据来源,所以需要加来源相关的信息添加到维度表中,此处做了维度弱化,直接将数据整合到加购事务事实表中了。
DROP TABLE IF EXISTS dwd_trade_cart_add_inc;
CREATE EXTERNAL TABLE dwd_trade_cart_add_inc
(`id` STRING COMMENT '编号',`user_id` STRING COMMENT '用户id',`sku_id` STRING COMMENT '商品id',`date_id` STRING COMMENT '时间id',`create_time` STRING COMMENT '加购时间',`source_id` STRING COMMENT '来源类型ID',`source_type_code` STRING COMMENT '来源类型编码',`source_type_name` STRING COMMENT '来源类型名称',`sku_num` BIGINT COMMENT '加购物车件数'
) COMMENT '交易域加购物车事务事实表'PARTITIONED BY (`dt` STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS ORCLOCATION '/warehouse/gmall/dwd/dwd_trade_cart_add_inc/'TBLPROPERTIES ('orc.compress' = 'snappy');
3.加购事务事实表 加载数据分析
- 1.加购事务事实表,来自于业务数据库中哪些表格,对应同步到ods层,事务事实表使用的是inc结尾的增量数据,full结尾的全量数据,对应到周期快照事实表使用。
cart_info - 2.加购物车这一业务过程是怎样实现的,有哪些限制条件。
- 一个用户将一个原来不存在的商品加入到购物车,insert操作
- 一个用户将原来购物车有的数据再加一件到购物车,update操作,并且数据+1
- 3.数据最终落地那个分区下面,需要明确
- 首日全量加购记录 首日默认全部加购物车,按照创建时间写入到对应时间分区里面
- 每日增量加购记录 ,过滤满足条件的数据,直接写入对应的当日时间分区。
- 4.加购事务事实表的数据流向,如下图:
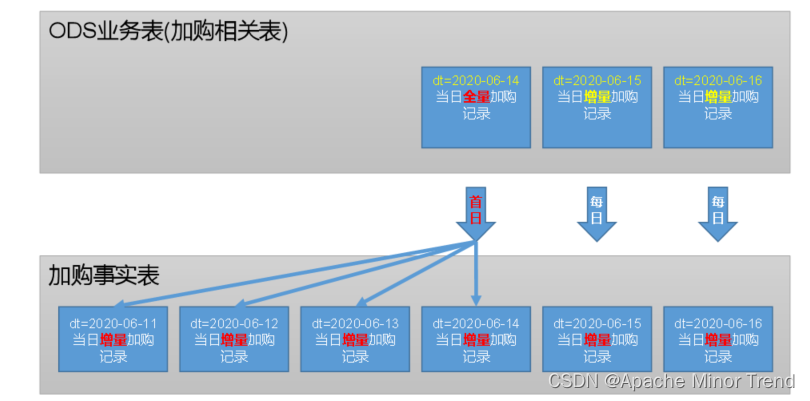
1.首日全量加购的数据加载
- 针对业务系统中,历史的数据进行处理,就是首日装载的意义。
- sql的思路:
- 1.相关表格已同步到ods层,为增量inc表格,购物车信息表和加购操作数据来源类型表
- 2.两张表格进行关联,获取到加购事务事实表所有字段,
- 3.处理数据,使用hive动态分区,将不同数据写入到不同分区
- hive中sql注意:date_format(create_time,‘yyyy-MM-dd’),跟mysql中语法不一致。
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_trade_cart_add_inc partition (dt)
selectid,user_id,sku_id,date_format(create_time,'yyyy-MM-dd') date_id,create_time,source_id,source_type,dic.dic_name,sku_num,date_format(create_time, 'yyyy-MM-dd')
from
(selectdata.id,data.user_id,data.sku_id,data.create_time,data.source_id,data.source_type,data.sku_numfrom ods_cart_info_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'
)ci
left join
(selectdic_code,dic_namefrom ods_base_dic_fullwhere dt='2020-06-14'and parent_code='24'
)dic
on ci.source_type=dic.dic_code;
2.每日增量加购的数据加载
-
sql思路:
- 一个用户将一个原来不存在的商品加入到购物车,insert操作
- 一个用户将原来购物车有的数据再加一件到购物车,update操作,并且数据变大
- 使用maxwell同步过来的json外部的ts时间作为加入购物车时间,而不使用json内部的create_time作为加购时间,这样设计比较合理。
- 对加购数量进行判断,
- 如果是insert类型,直接使用sku_num的值即可,
- 如果是update操作,需要将maxwell过来的json数据中 新值-老值得到的结果存入.
-
hive中函数的使用:
- map_keys(map集合):将此map集合中所有的key取出,作为一个数组。
- array_contains(数组,元素) :该数组中是否包含此元素 ,返回布尔类型的值
- cast(数据 as int ):将该数据强制转化为int类型
-
hive中时间戳到时间字符串的转换 ,经常用到,官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-DateFunctions
- 时间戳:自零时区以来,1970-01-01以来的经历的秒数(10位)或者毫秒数(13位)
- 以秒为单位的时间戳,转为时分秒
- from_unixtime(bigint unixtime[, string format]) 这个转换时间戳函数没有分区概念,所以之间转为了零时区的时间。
- from_utc_timestamp({any primitive type} ts(必选是毫秒数), string timezone) 使用:from_utc_timestamp(ts*1000, “GMT+8”)
- 使用时间格式化工具将上面处理完的数据转为想要的格式:date_format(from_utc_timestamp(ts*1000, “GMT+8”),“yyyy-MM-dd HH:mm:ss”)
-
2020-06-15的增量加购数据处理
insert overwrite table dwd_trade_cart_add_inc partition(dt='2020-06-15')
selectid,user_id,sku_id,date_id,create_time,source_id,source_type_code,source_type_name,sku_num
from
(selectdata.id,data.user_id,data.sku_id,date_format(from_utc_timestamp(ts*1000,'GMT+8'),'yyyy-MM-dd') date_id,date_format(from_utc_timestamp(ts*1000,'GMT+8'),'yyyy-MM-dd HH:mm:ss') create_time,data.source_id,data.source_type source_type_code,if(type='insert',data.sku_num,data.sku_num-old['sku_num']) sku_numfrom ods_cart_info_incwhere dt='2020-06-15'and (type='insert'or(type='update' and old['sku_num'] is not null and data.sku_num>cast(old['sku_num'] as int)))
)cart
left join
(selectdic_code,dic_name source_type_namefrom ods_base_dic_fullwhere dt='2020-06-15'and parent_code='24'
)dic
on cart.source_type_code=dic.dic_code;
- linux查看进程对应在服务器的配置
1. 首先jps,查看进程号
2. cd /proc/84912(某进程对应的进程号)
3. limits 文件里面有对应的限制信息
4. exe 是对应的启动二进制进程
5. fd 文件描述符,对应该进程所打开的文件,聚合查看一下打开多少文件即可
2.交易域下单事务事实表
设计流程大概分为4步:选择业务过程 --> 声明粒度 --> 确认维度–> 确认事实
1.下单事务事实表 前期梳理
之前梳理的业务矩阵如下,对应下单过程如下:
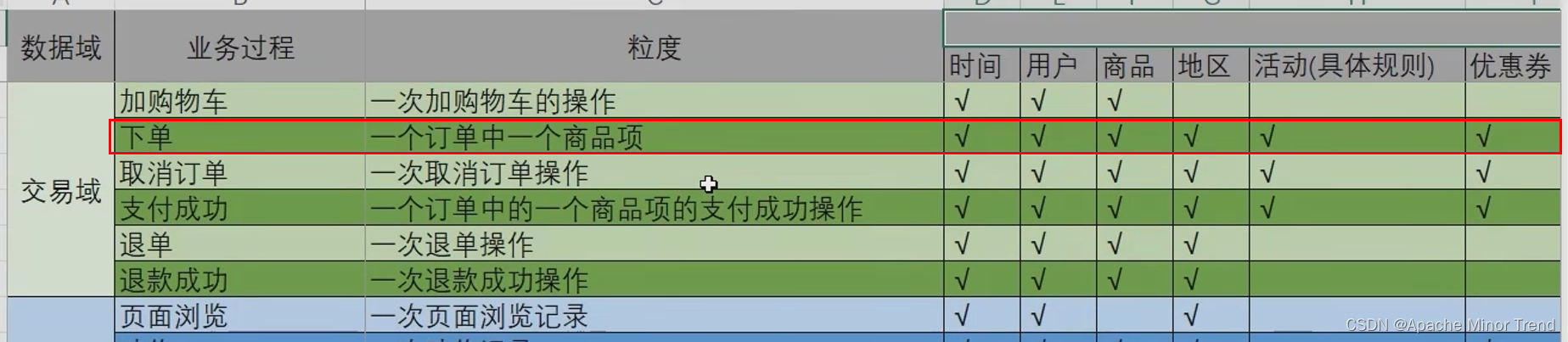
- 1.选择业务过程:下单 业务过程
- 2.声明粒度:xx订单是在xx时间,xx用户在xx地区完成下单操作,这对应的是下单事务表每行表示的含义。
- 3.确认维度:时间、用户、商品、地区、活动、优惠券等,声明维度灵活性较高,是由前面梳理的业务数据库中业务过程决定的,业务过程关联哪些表格也就是对应的环境信息,此处就添加多少维度信息。
- 4.确认事实:下单件数、下单原始金额、下单最终金额、活动优惠金额、优惠券优惠金额
2.下单事务事实表 DDL表设计分析
- 之前创建的dim层维度表以外,其他的维度都退化到对应的事实表中,没有退化的,事实表直接在本表中体现某些维度表的id即可,退化的维度直接写入对应数据即可。
DROP TABLE IF EXISTS dwd_trade_order_detail_inc;
CREATE EXTERNAL TABLE dwd_trade_order_detail_inc
(`id` STRING COMMENT '编号',`order_id` STRING COMMENT '订单id',`user_id` STRING COMMENT '用户id',`sku_id` STRING COMMENT '商品id',`province_id` STRING COMMENT '省份id',`activity_id` STRING COMMENT '参与活动规则id',`activity_rule_id` STRING COMMENT '参与活动规则id',`coupon_id` STRING COMMENT '使用优惠券id',`date_id` STRING COMMENT '下单日期id',`create_time` STRING COMMENT '下单时间',`source_id` STRING COMMENT '来源编号',`source_type_code` STRING COMMENT '来源类型编码',`source_type_name` STRING COMMENT '来源类型名称',`sku_num` BIGINT COMMENT '商品数量',`split_original_amount` DECIMAL(16, 2) COMMENT '原始价格',`split_activity_amount` DECIMAL(16, 2) COMMENT '活动优惠分摊',`split_coupon_amount` DECIMAL(16, 2) COMMENT '优惠券优惠分摊',`split_total_amount` DECIMAL(16, 2) COMMENT '最终价格分摊'
) COMMENT '交易域下单明细事务事实表'PARTITIONED BY (`dt` STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS ORCLOCATION '/warehouse/gmall/dwd/dwd_trade_order_detail_inc/'TBLPROPERTIES ('orc.compress' = 'snappy');
3.下单事务事实表 加载数据分析
- 下单会对哪些业务表格产生影响,如下图:
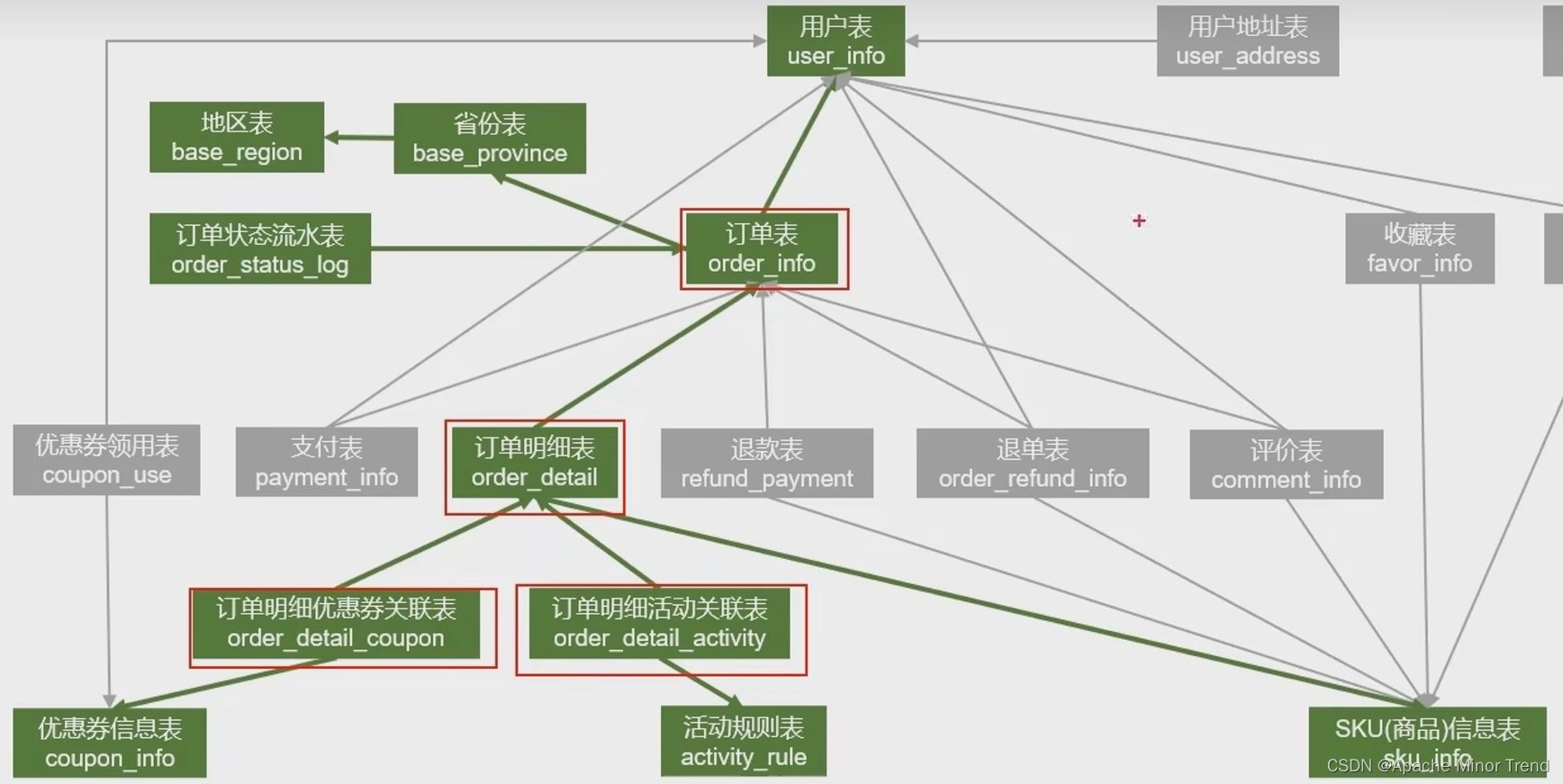
1.首日全量下单的数据加载
- 业务数据库中 下单明细表中每行数据就能代表一条下单记录,直接将数据同步到ods层然后同步到dwd层即可。
- 下单事务事实表 跟 下单明细表字段对比,观察哪些字段能获取到,哪些字段获取不到,获取不到的,直接对照数据库表格关联图,书写sql获取对应关系,如下图,没注释掉的就能获取到,注释掉的通过sql关联或者处理字段方式获取。
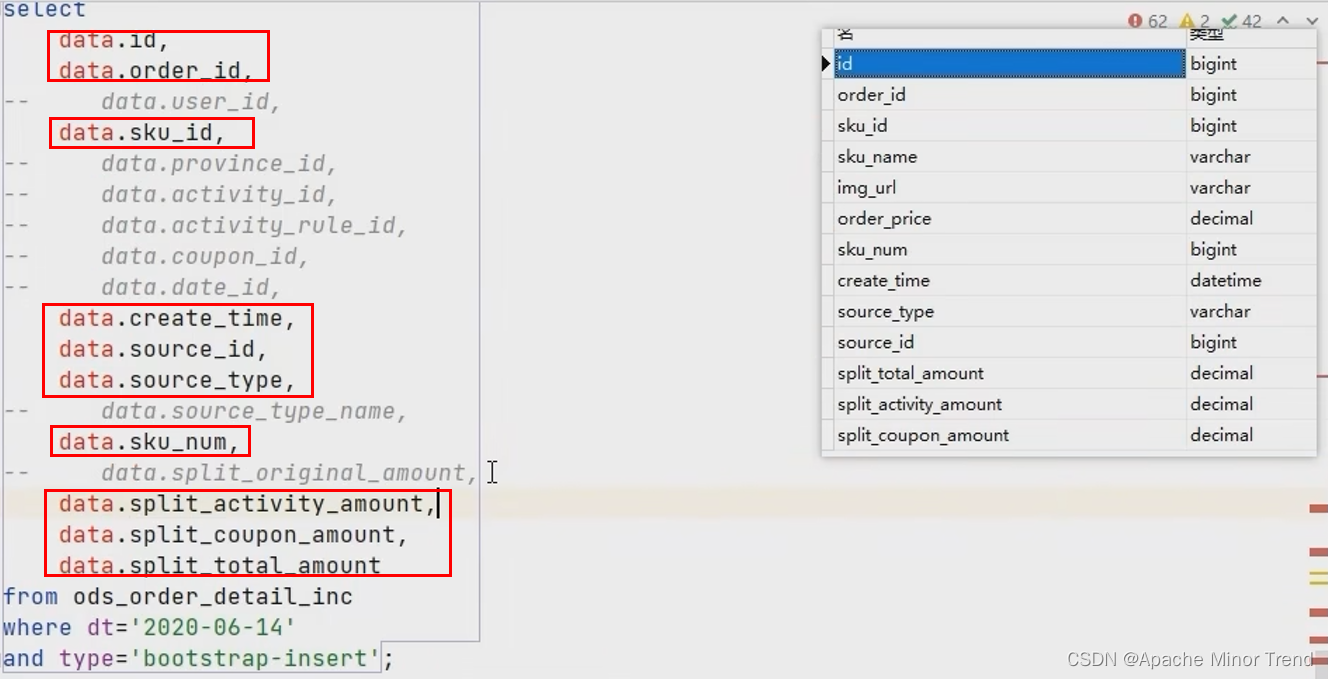
- 订单明细表不能获取到的字段,通过关联关系,进行子查询配置
- 子查询配置完成后,进行sql关联
- 关联完毕后,通过hive创建动态分区,实现收入不同时间下单数据进入到不同的分区。
- 最终整合完的sql如下:
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_trade_order_detail_inc partition (dt)
selectod.id,order_id,user_id,sku_id,province_id,activity_id,activity_rule_id,coupon_id,date_format(create_time, 'yyyy-MM-dd') date_id,create_time,source_id,source_type,dic_name,sku_num,split_original_amount,split_activity_amount,split_coupon_amount,split_total_amount,date_format(create_time,'yyyy-MM-dd')
from
(selectdata.id,data.order_id,data.sku_id,data.create_time,data.source_id,data.source_type,data.sku_num,data.sku_num * data.order_price split_original_amount,data.split_total_amount,data.split_activity_amount,data.split_coupon_amountfrom ods_order_detail_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'
) od
left join
(selectdata.id,data.user_id,data.province_idfrom ods_order_info_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'
) oi
on od.order_id = oi.id
left join
(selectdata.order_detail_id,data.activity_id,data.activity_rule_idfrom ods_order_detail_activity_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'
) act
on od.id = act.order_detail_id
left join
(selectdata.order_detail_id,data.coupon_idfrom ods_order_detail_coupon_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'
) cou
on od.id = cou.order_detail_id
left join
(selectdic_code,dic_namefrom ods_base_dic_fullwhere dt='2020-06-14'and parent_code='24'
)dic
on od.source_type=dic.dic_code;
2.每日增量量下单的数据加载
- 2020-06-15 增量下单明细数据加载-最终sql
- maxwell同步过来的数据,过滤出来insert类型数据即可。
insert overwrite table dwd_trade_order_detail_inc partition (dt='2020-06-15')
selectod.id,order_id,user_id,sku_id,province_id,activity_id,activity_rule_id,coupon_id,date_id,create_time,source_id,source_type,dic_name,sku_num,split_original_amount,split_activity_amount,split_coupon_amount,split_total_amount
from
(selectdata.id,data.order_id,data.sku_id,date_format(data.create_time, 'yyyy-MM-dd') date_id,data.create_time,data.source_id,data.source_type,data.sku_num,data.sku_num * data.order_price split_original_amount,data.split_total_amount,data.split_activity_amount,data.split_coupon_amountfrom ods_order_detail_incwhere dt = '2020-06-15'and type = 'insert'
) od
left join
(selectdata.id,data.user_id,data.province_idfrom ods_order_info_incwhere dt = '2020-06-15'and type = 'insert'
) oi
on od.order_id = oi.id
left join
(selectdata.order_detail_id,data.activity_id,data.activity_rule_idfrom ods_order_detail_activity_incwhere dt = '2020-06-15'and type = 'insert'
) act
on od.id = act.order_detail_id
left join
(selectdata.order_detail_id,data.coupon_idfrom ods_order_detail_coupon_incwhere dt = '2020-06-15'and type = 'insert'
) cou
on od.id = cou.order_detail_id
left join
(selectdic_code,dic_namefrom ods_base_dic_fullwhere dt='2020-06-15'and parent_code='24'
)dic
on od.source_type=dic.dic_code;
3.交易域取消订单事务事实表
1.取消订单事务事实表 前期梳理
之前梳理的业务矩阵如下,对应下单过程如下:

- 1.选择业务过程:取消订单 业务过程
- 2.声明粒度:xx订单是在xx时间,xx用户在xx地区完成取消订单操作,这对应的是取消订单事务表每行表示的含义。
- 3.确认维度:时间、用户、商品、地区、活动、优惠券等,声明维度灵活性较高,是由前面梳理的业务数据库中业务过程决定的,业务过程关联哪些表格也就是对应的环境信息,此处就添加多少维度信息。
- 4.确认事实:取消订单件数、取消订单原始金额、取消订单最终金额、活动优惠金额、优惠券优惠金额
2.取消订单事务事实表 DDL表设计分析
- 取消订单事务事实表中,一行代表一次用户取消订单操作。
DROP TABLE IF EXISTS dwd_trade_cancel_detail_inc;
CREATE EXTERNAL TABLE dwd_trade_cancel_detail_inc
(`id` STRING COMMENT '编号',`order_id` STRING COMMENT '订单id',`user_id` STRING COMMENT '用户id',`sku_id` STRING COMMENT '商品id',`province_id` STRING COMMENT '省份id',`activity_id` STRING COMMENT '参与活动规则id',`activity_rule_id` STRING COMMENT '参与活动规则id',`coupon_id` STRING COMMENT '使用优惠券id',`date_id` STRING COMMENT '取消订单日期id',`cancel_time` STRING COMMENT '取消订单时间',`source_id` STRING COMMENT '来源编号',`source_type_code` STRING COMMENT '来源类型编码',`source_type_name` STRING COMMENT '来源类型名称',`sku_num` BIGINT COMMENT '商品数量',`split_original_amount` DECIMAL(16, 2) COMMENT '原始价格',`split_activity_amount` DECIMAL(16, 2) COMMENT '活动优惠分摊',`split_coupon_amount` DECIMAL(16, 2) COMMENT '优惠券优惠分摊',`split_total_amount` DECIMAL(16, 2) COMMENT '最终价格分摊'
) COMMENT '交易域取消订单明细事务事实表'PARTITIONED BY (`dt` STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS ORCLOCATION '/warehouse/gmall/dwd/dwd_trade_cancel_detail_inc/'TBLPROPERTIES ('orc.compress' = 'snappy');
3.取消订单事务事实表 加载数据分析
- 数据流程
- 数据来源相关:订单表 中 取消的订单 关联 取消订单表 中 订单详情,即可获取全量字段
1.首日全量取消订单的数据加载
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_trade_cancel_detail_inc partition (dt)
selectod.id,order_id,user_id,sku_id,province_id,activity_id,activity_rule_id,coupon_id,date_format(canel_time,'yyyy-MM-dd') date_id,canel_time,source_id,source_type,dic_name,sku_num,split_original_amount,split_activity_amount,split_coupon_amount,split_total_amount,date_format(canel_time,'yyyy-MM-dd')
from
(selectdata.id,data.order_id,data.sku_id,data.source_id,data.source_type,data.sku_num,data.sku_num * data.order_price split_original_amount,data.split_total_amount,data.split_activity_amount,data.split_coupon_amountfrom ods_order_detail_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'
) od
join
(selectdata.id,data.user_id,data.province_id,data.operate_time canel_timefrom ods_order_info_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'and data.order_status='1003'
) oi
on od.order_id = oi.id
left join
(selectdata.order_detail_id,data.activity_id,data.activity_rule_idfrom ods_order_detail_activity_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'
) act
on od.id = act.order_detail_id
left join
(selectdata.order_detail_id,data.coupon_idfrom ods_order_detail_coupon_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'
) cou
on od.id = cou.order_detail_id
left join
(selectdic_code,dic_namefrom ods_base_dic_fullwhere dt='2020-06-14'and parent_code='24'
)dic
on od.source_type=dic.dic_code;
2.每日增量取消订单的数据加载
- maxwell同步过来的数据,update过来的数据,并且order_status的状态变为了取消状态。
- 15号取消的订单,可能是之前下单的订单,所以获取订单明细数据的时候,需要关联订单明细表的前几天的数据,需要跟时间维度进行关联,获取当天或者前一天的数据。
insert overwrite table dwd_trade_cancel_detail_inc partition (dt='2020-06-15')
selectod.id,order_id,user_id,sku_id,province_id,activity_id,activity_rule_id,coupon_id,date_format(canel_time,'yyyy-MM-dd') date_id,canel_time,source_id,source_type,dic_name,sku_num,split_original_amount,split_activity_amount,split_coupon_amount,split_total_amount
from
(selectdata.id,data.order_id,data.sku_id,data.source_id,data.source_type,data.sku_num,data.sku_num * data.order_price split_original_amount,data.split_total_amount,data.split_activity_amount,data.split_coupon_amountfrom ods_order_detail_incwhere (dt='2020-06-15' or dt=date_add('2020-06-15',-1))and (type = 'insert' or type= 'bootstrap-insert')
) od
join
(selectdata.id,data.user_id,data.province_id,data.operate_time canel_timefrom ods_order_info_incwhere dt = '2020-06-15'and type = 'update'and data.order_status='1003'and array_contains(map_keys(old),'order_status')
) oi
on order_id = oi.id
left join
(selectdata.order_detail_id,data.activity_id,data.activity_rule_idfrom ods_order_detail_activity_incwhere (dt='2020-06-15' or dt=date_add('2020-06-15',-1))and (type = 'insert' or type= 'bootstrap-insert')
) act
on od.id = act.order_detail_id
left join
(selectdata.order_detail_id,data.coupon_idfrom ods_order_detail_coupon_incwhere (dt='2020-06-15' or dt=date_add('2020-06-15',-1))and (type = 'insert' or type= 'bootstrap-insert')
) cou
on od.id = cou.order_detail_id
left join
(selectdic_code,dic_namefrom ods_base_dic_fullwhere dt='2020-06-15'and parent_code='24'
)dic
on od.source_type=dic.dic_code;
7.交易域购物车周期快照事实表
1.购物车周期快照事实表 前期梳理
-
周期快照事实表,实际上类似于Hive中按天做分区,然后全量拉取mysql中数据,这样就会形成mysql的快照,每日全量快照表。
-
周期快照事实表,解决的主要问题:对于商品库存、账户余额这些存量型指标,业务系统中通常就会计算并保存最新结果,所以定期同步一份全量数据到数据仓库,构建周期型快照事实表,就能轻松应对此类统计需求,而无需再对事务型事实表中大量的历史记录进行聚合了。
-
周期快照表的创建,完全是基于需求来的,是服务于需求的,此处创建购物车周期快照事实表,是服务于需求:各分类商品购物车存量Top10
- 将购物车存量数据创建购物车周期快照事实表,直接基于此表,按照sku_id分组求和sku_num,就可简单实现上面的需求。
-
周期快照表和业务过程对照关系,没有必要进行讨论,可能对应一个业务过程,也可能对应两个业务过程。
2.购物车周期快照事实表 DDL表设计分析
DROP TABLE IF EXISTS dwd_trade_cart_full;
CREATE EXTERNAL TABLE dwd_trade_cart_full
(`id` STRING COMMENT '编号',`user_id` STRING COMMENT '用户id',`sku_id` STRING COMMENT '商品id',`sku_name` STRING COMMENT '商品名称',`sku_num` BIGINT COMMENT '加购物车件数'
) COMMENT '交易域购物车周期快照事实表'PARTITIONED BY (`dt` STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS ORCLOCATION '/warehouse/gmall/dwd/dwd_trade_cart_full/'TBLPROPERTIES ('orc.compress' = 'snappy');
3.购物车周期快照事实表 加载数据分析
insert overwrite table dwd_trade_cart_full partition(dt='2020-06-14')
selectid,user_id,sku_id,sku_name,sku_num
from ods_cart_info_full
where dt='2020-06-14'
and is_ordered='0';
4.交易域支付成功事务事实表
1.支付成功事务事实表 前期梳理
2.支付成功事务事实表 DDL表设计分析
3.支付成功事务事实表 加载数据分析
5.交易域退单事务事实表
1.退单事务事实表 前期梳理
2.退单事务事实表 DDL表设计分析
3.退单事务事实表 加载数据分析
6.交易域退款成功事务事实表
1.退款成功事务事实表 前期梳理
2.退款成功事务事实表 DDL表设计分析
3.退款成功事务事实表 加载数据分析
相关文章:
【离线数仓-8-数据仓库开发DWD层-交易域相关事实表】
离线数仓-8-数据仓库开发DWD层-交易域相关事实表离线数仓-8-数据仓库开发DWD层-交易域相关事实表一、DWD层设计要点二、交易域相关事实表1.交易域加购事务事实表1.加购事务事实表 前期梳理2.加购事务事实表 DDL表设计分析3.加购事务事实表 加载数据分析1.首日全量加购的数据加载…...

你知道Java架构师学习路线该怎么走吗?你所缺少的是学习方法以及完整规划!
怎么成为一名Java架构师?都需要掌握哪些技术?Java架构师,首先要是一个高级Java攻城狮,熟练使用各种框架,并知道它们实现的原理。jvm虚拟机原理、调优,懂得jvm能让你写出性能更好的代码;池技术,什…...

华为OD机试用Python实现 -【查找树中的元素 or 查找二叉树节点】(2023-Q1 新题)
华为OD机试题 华为OD机试300题大纲查找树中的元素 or 查找二叉树节点题目描述输入描述输出描述说明示例一输入输出示例二输入输出Python 代码实现代码编写思路华为OD机试300题大纲 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。 华为 O…...
MyBatis——创建与使用
概念 当我们使用传统的jdbc进行数据库与程序的连接时,每一个操作都需要写一条sql语句,并且没法调试和修改 jdbc连接数据库流程: 创建数据库连接池DataSource获取数据库连接Connection执行带占位符的sql语句通过Connection创建操作对象Stat…...

【涨薪技术】0到1学会性能测试 —— 参数化关联
前言 上一次推文我们分享了性能测试工作原理、事务、检查点!今天给大家带来性能测试参数化,检查点知识!后续文章都会系统分享干货,带大家从0到1学会性能测试,另外还有教程等同步资料,文末免费获取~ 01、性…...
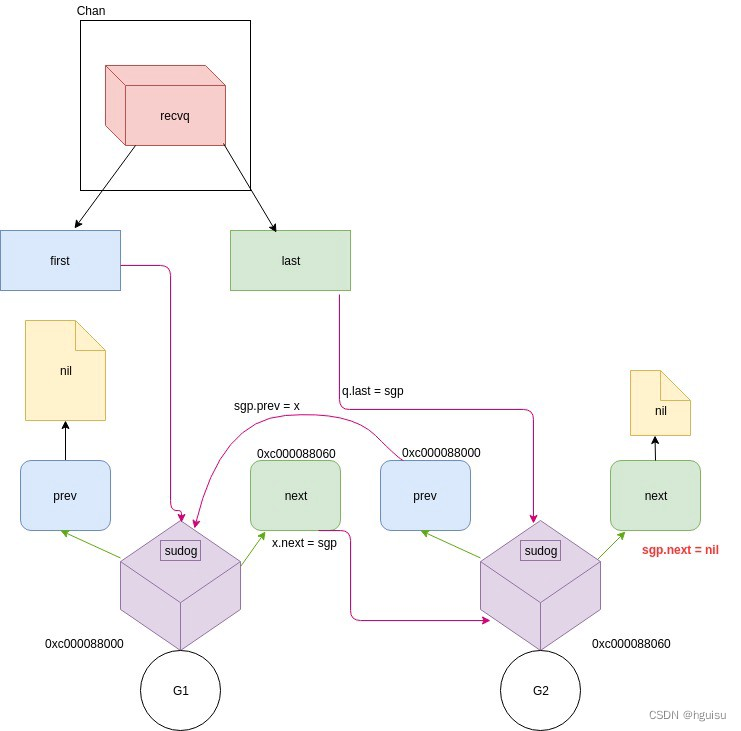
go进阶(2) -深入理解Channel实现原理
Go的并发模型已经在https://guisu.blog.csdn.net/article/details/129107148 详细说明。 1、channel使用详解 1、channel概述 Go的CSP并发模型,是通过goroutine和channel来实现的。 channel是Go语言中各个并发结构体(goroutine)之前的通信机制。 通俗的讲…...

数组(二)-- LeetCode[303][304] 区域和检索 - 数组不可变
1 区域和检索 - 数组不可变 1.1 题目描述 题目链接:https://leetcode.cn/problems/range-sum-query-immutable/ 1.2 思路分析 最朴素的想法是存储数组 nums 的值,每次调用 sumRange 时,通过循环的方法计算数组 nums 从下标 iii 到下标 jjj …...
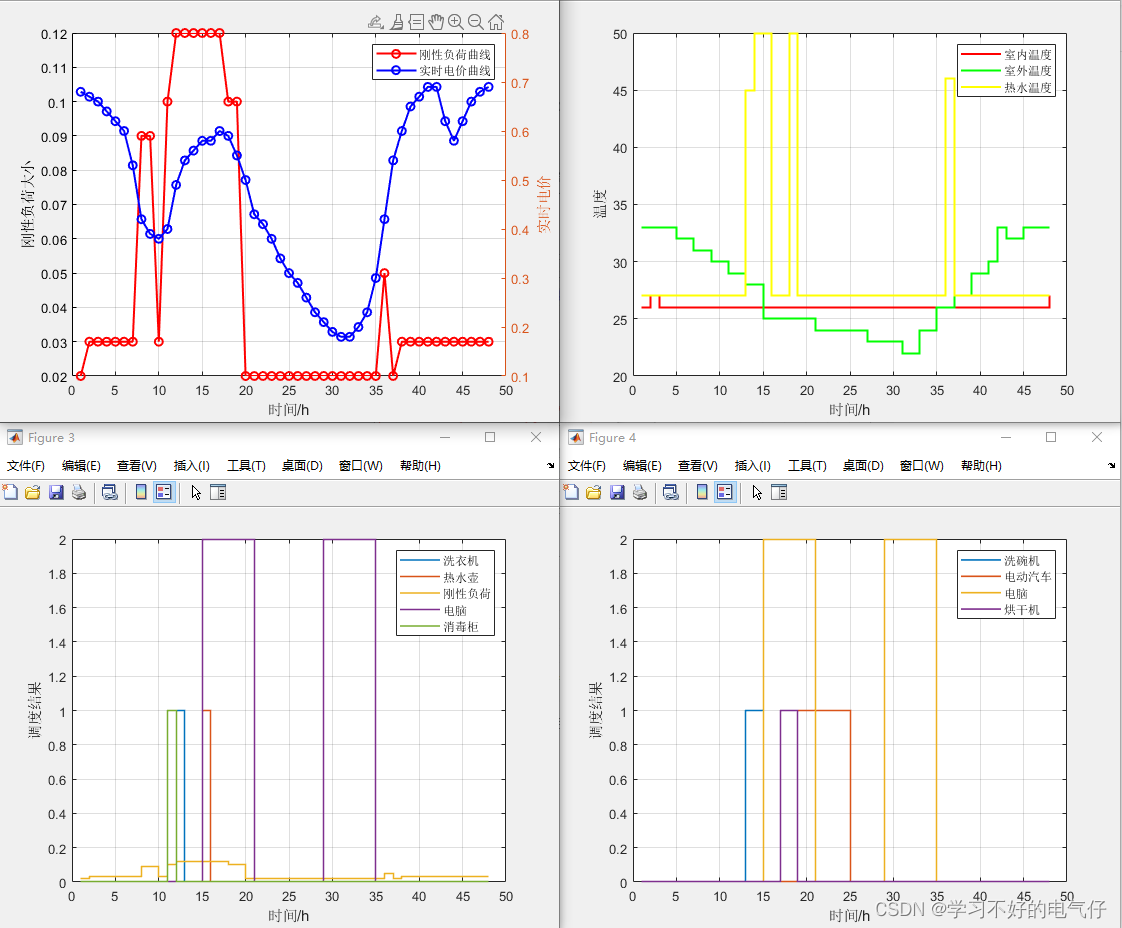
22-基于分时电价条件下家庭能量管理策略研究MATLAB程序
参考文献:《基于分时电价和蓄电池实时控制策略的家庭能量系统优化》参考部分模型《计及舒适度的家庭能量管理系统优化控制策略》参考部分模型主要内容:主要做的是家庭能量管理模型,首先构建了电动汽车、空调、热水器以及烘干机等若干家庭用户…...
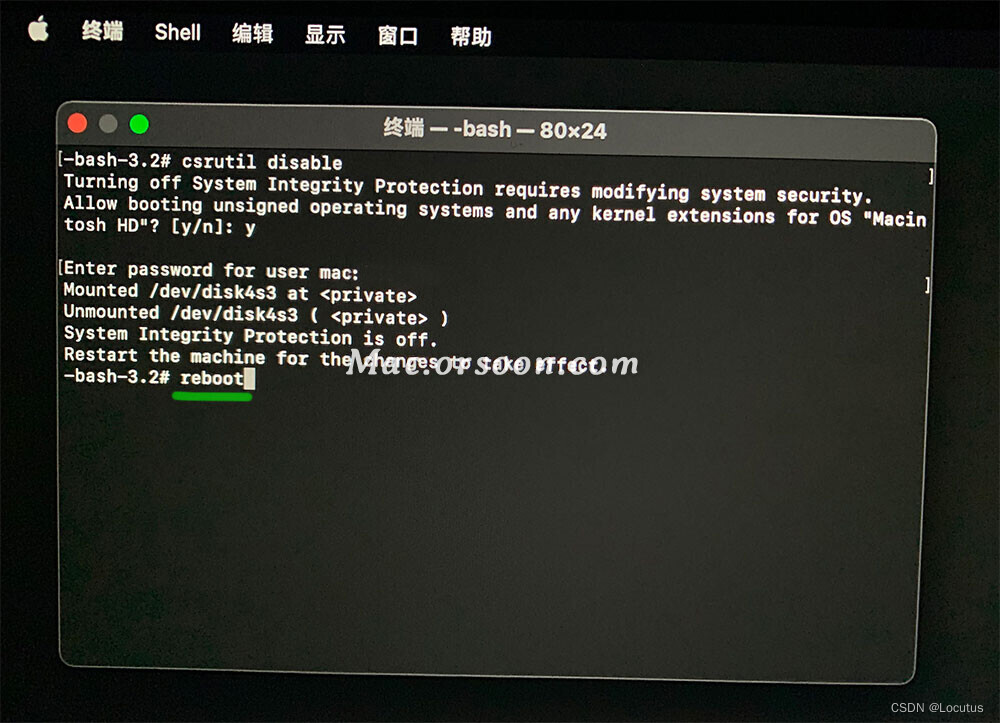
“XXX.app 已损坏,打不开。您应该将它移到废纸篓”,Mac应用程序无法打开或文件损坏的处理方法(2)
1. 检查状态 在sip系统完整性关闭前,我们先检查是否启用了SIP系统完整性保护。打开终端输入以下命令【csrutil status】并回车: 你会看到以下信息中的一个,用来指示SIP状态。已关闭 disabled: System Integrity Protection status: disabl…...

flask入门-3.Flask操作数据库
3. Flask操作数据库 1. 连接数据库 首先下载 MySQL数据库 其次下载对应的包: pip install pymysql pip install flask-sqlalchemy在 app.py 中进行连接测试 from flask import Flask, request, render_template from flask_sqlalchemy import SQLAlchemyhostname "1…...
STM32 使用microros与ROS2通信
本文主要介绍如何在STM32中使用microros与ROS2进行通信,在ROS1中标准的库是rosserial,在ROS2中则是microros,目前网上的资料也有一部分了,但是都没有提供完整可验证的demo,本文将根据提供的demo一步步给大家进行演示。1、首先如果你用的不是S…...

51单片机入门 - 测试:SDCC / Keil C51 会让没有调用的函数参与编译吗?
Small Device C Compiler(SDCC)是一款免费 C 编译器,适用于 8 位微控制器。 不想看测试过程的话可以直接划到最下面看结论:) 关于软硬件环境的信息: Windows 10STC89C52RCSDCC (构建HEX文件&…...

【计算机网络】计算机网络
目录一、概述计算机网络体系结构二、应用层DNS应用文件传输应用DHCP 应用电子邮件应用Web应用当访问一个网页的时候,都会发生什么三、传输层UDP 和 TCP 的特点UDP 首部格式TCP 首部格式TCP 的三次握手TCP 的四次挥手TCP 流量控制TCP 拥塞控制三、网络层IP 数据报格式…...
【java web篇】项目管理构建工具Maven简介以及安装配置
📋 个人简介 💖 作者简介:大家好,我是阿牛,全栈领域优质创作者。😜📝 个人主页:馆主阿牛🔥🎉 支持我:点赞👍收藏⭐️留言Ὅ…...
springboot笔记
微服务架构 微服务是一种架构风格,开发构建应用的时候把应用的业务构建成一个个的小服务(这就类似于把我们的应用程序构建成了一个个小小的盒子,它们在一个大的容器中运行,这种一个个的小盒子我们把它叫做服务)&#…...
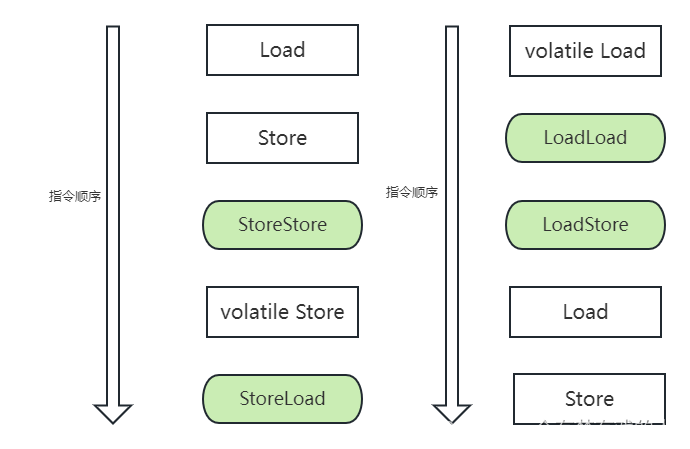
【多线程与高并发】- 浅谈volatile
浅谈volatile简介JMM概述volatile的特性1、可见性举个例子总结2、无法保证原子性举个例子分析使用volatile对原子性测试使用锁的机制总结3、禁止指令重排什么是指令重排序重排序怎么提高执行速度重排序的问题所在volatile禁止指令重排序内存屏障(Memory Barrier)作用volatile内…...
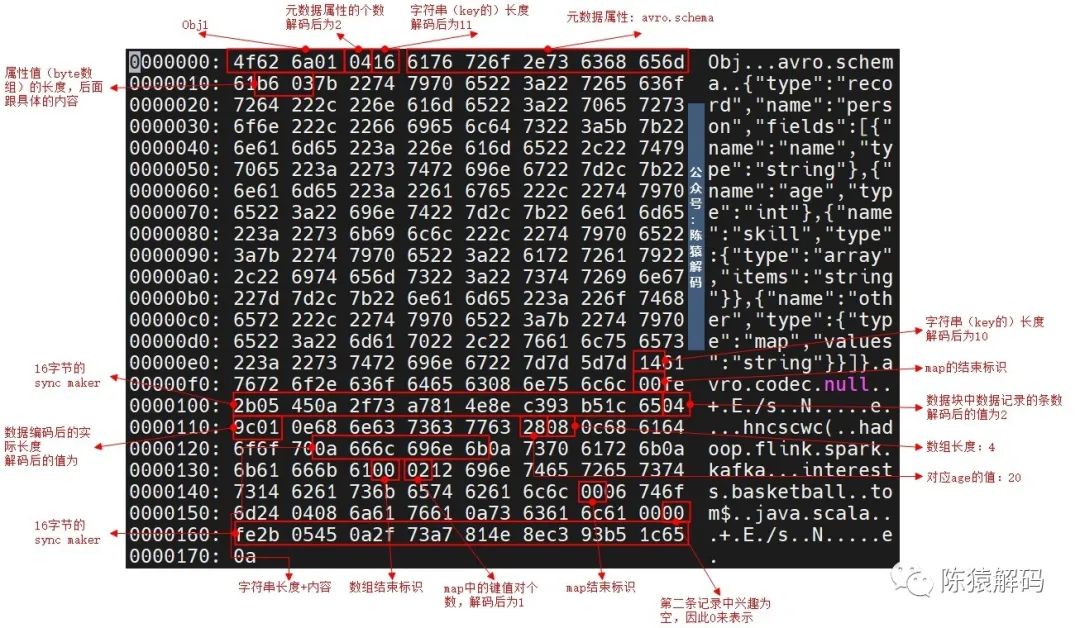
avro格式详解
【Avro介绍】Apache Avro是hadoop中的一个子项目,也是一个数据序列化系统,其数据最终以二进制格式,采用行式存储的方式进行存储。Avro提供了:丰富的数据结构可压缩、快速的二进制数据格式一个用来存储持久化数据的容器文件远程过程…...
【涨薪技术】0到1学会性能测试 —— LR录制回放事务检查点
前言 上一次推文我们分享了性能测试分类和应用领域,今天带大家学习性能测试工作原理、事务、检查点!后续文章都会系统分享干货,带大家从0到1学会性能测试,另外还有教程等同步资料,文末免费获取~ 01、LR工作原理 通常…...

卡尔曼滤波原理及代码实战
目录简介1.原理介绍场景假设(1).下一时刻的状态(2).增加系统的内部控制(3).考虑运动系统外部的影响(4).后验估计:预测结果与观测结果的融合卡尔曼增益K2.卡尔曼滤波计算过程(1).预测阶段(先验估计阶段)(2).更新阶段(后验估计阶段&…...
Jmeter使用教程
目录一,简介二,Jmeter安装1,下载2,安装三,创建测试1,创建线程组2,创建HTTP请求默认值3,创建HTTP请求4,添加HTTP请求头5,添加断言6,添加查看结果树…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

Java 8 Stream API 入门到实践详解
一、告别 for 循环! 传统痛点: Java 8 之前,集合操作离不开冗长的 for 循环和匿名类。例如,过滤列表中的偶数: List<Integer> list Arrays.asList(1, 2, 3, 4, 5); List<Integer> evens new ArrayList…...

pam_env.so模块配置解析
在PAM(Pluggable Authentication Modules)配置中, /etc/pam.d/su 文件相关配置含义如下: 配置解析 auth required pam_env.so1. 字段分解 字段值说明模块类型auth认证类模块,负责验证用户身份&am…...

VTK如何让部分单位不可见
最近遇到一个需求,需要让一个vtkDataSet中的部分单元不可见,查阅了一些资料大概有以下几种方式 1.通过颜色映射表来进行,是最正规的做法 vtkNew<vtkLookupTable> lut; //值为0不显示,主要是最后一个参数,透明度…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...
)
【服务器压力测试】本地PC电脑作为服务器运行时出现卡顿和资源紧张(Windows/Linux)
要让本地PC电脑作为服务器运行时出现卡顿和资源紧张的情况,可以通过以下几种方式模拟或触发: 1. 增加CPU负载 运行大量计算密集型任务,例如: 使用多线程循环执行复杂计算(如数学运算、加密解密等)。运行图…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...
免费数学几何作图web平台
光锐软件免费数学工具,maths,数学制图,数学作图,几何作图,几何,AR开发,AR教育,增强现实,软件公司,XR,MR,VR,虚拟仿真,虚拟现实,混合现实,教育科技产品,职业模拟培训,高保真VR场景,结构互动课件,元宇宙http://xaglare.c…...

从物理机到云原生:全面解析计算虚拟化技术的演进与应用
前言:我的虚拟化技术探索之旅 我最早接触"虚拟机"的概念是从Java开始的——JVM(Java Virtual Machine)让"一次编写,到处运行"成为可能。这个软件层面的虚拟化让我着迷,但直到后来接触VMware和Doc…...