SnowFlake 雪花算法和原理(分布式 id 生成算法)
一、概述
SnowFlake 算法:是 Twitter 开源的分布式 id 生成算法。
核心思想:使用一个 64 bit 的 long 型的数字作为全局唯一 id。
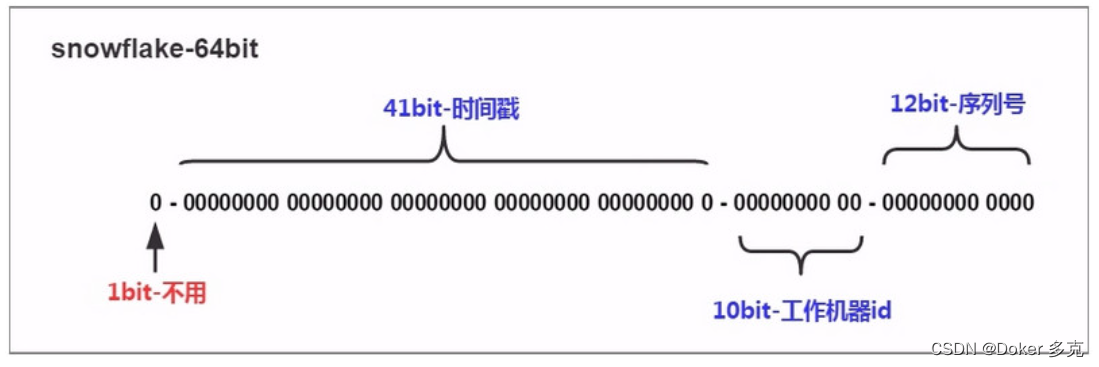
算法原理
最高位是符号位,始终为0,不可用。
41位的时间序列,精确到毫秒级,41位的长度可以使用69年。时间位还有一个很重要的作用是可以根据时间进行排序。
10位的机器标识,10位的长度最多支持部署1024个节点
12位的计数序列号,序列号即一系列的自增id,可以支持同一节点同一毫秒生成多个ID序号,12位的计数序列号支持每个节点每毫秒产生4096个ID序号
算法优缺点
优点
高并发分布式环境下生成不重复 id,每秒可生成百万个不重复 id。
基于时间戳,以及同一时间戳下序列号自增,基本保证 id 有序递增。
不依赖第三方库或者中间件。
算法简单,在内存中进行,效率高。
缺点
依赖服务器时间,服务器时钟回拨时可能会生成重复 id。算法中可通过记录最后一个生成 id 时的时间戳来解决,每次生成 id 之前比较当前服务器时钟是否被回拨,避免生成重复 id。
二、算法实现
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.11</version>
</dependency>public class IdWorker {//下面两个每个5位,加起来就是10位的工作机器idprivate long workerId; //工作idprivate long datacenterId; //数据id//12位的序列号private long sequence;public IdWorker(long workerId, long datacenterId, long sequence) {// sanity check for workerIdif (workerId > maxWorkerId || workerId < 0) {throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));}if (datacenterId > maxDatacenterId || datacenterId < 0) {throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));}System.out.printf("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId);this.workerId = workerId;this.datacenterId = datacenterId;this.sequence = sequence;}//初始时间戳private long twepoch = 1288834974657L;//长度为5位private long workerIdBits = 5L;private long datacenterIdBits = 5L;//最大值private long maxWorkerId = -1L ^ (-1L << workerIdBits);private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);//序列号id长度private long sequenceBits = 12L;//序列号最大值private long sequenceMask = -1L ^ (-1L << sequenceBits);//工作id需要左移的位数,12位private long workerIdShift = sequenceBits;//数据id需要左移位数 12+5=17位private long datacenterIdShift = sequenceBits + workerIdBits;//时间戳需要左移位数 12+5+5=22位private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;//上次时间戳,初始值为负数private long lastTimestamp = -1L;public long getWorkerId() {return workerId;}public long getDatacenterId() {return datacenterId;}public long getTimestamp() {return System.currentTimeMillis();}//下一个ID生成算法public synchronized long nextId() {long timestamp = timeGen();//获取当前时间戳如果小于上次时间戳,则表示时间戳获取出现异常if (timestamp < lastTimestamp) {System.err.printf("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds",lastTimestamp - timestamp));}//获取当前时间戳如果等于上次时间戳(同一毫秒内),则在序列号加一;否则序列号赋值为0,从0开始。if (lastTimestamp == timestamp) {sequence = (sequence + 1) & sequenceMask;if (sequence == 0) {timestamp = tilNextMillis(lastTimestamp);}} else {sequence = 0;}//将上次时间戳值刷新lastTimestamp = timestamp;/*** 返回结果:* (timestamp - twepoch) << timestampLeftShift) 表示将时间戳减去初始时间戳,再左移相应位数* (datacenterId << datacenterIdShift) 表示将数据id左移相应位数* (workerId << workerIdShift) 表示将工作id左移相应位数* | 是按位或运算符,例如:x | y,只有当x,y都为0的时候结果才为0,其它情况结果都为1。* 因为个部分只有相应位上的值有意义,其它位上都是0,所以将各部分的值进行 | 运算就能得到最终拼接好的id*/return ((timestamp - twepoch) << timestampLeftShift) |(datacenterId << datacenterIdShift) |(workerId << workerIdShift) |sequence;}//获取时间戳,并与上次时间戳比较private long tilNextMillis(long lastTimestamp) {long timestamp = timeGen();while (timestamp <= lastTimestamp) {timestamp = timeGen();}return timestamp;}//获取系统时间戳private long timeGen() {return System.currentTimeMillis();}//---------------测试---------------public static void main(String[] args) {IdWorker worker = new IdWorker(1, 1, 1);for (int i = 0; i < 30; i++) {System.out.println(worker.nextId());}}}解决时间回拨问题
原生的 Snowflake 算法是完全依赖于时间的,如果有时钟回拨的情况发生,会生成重复的 ID,市场上的解决方案也是不少。简单粗暴的办法有:
最简单的方案,就是关闭生成唯一 ID 机器的时间同步。
使用阿里云的的时间服务器进行同步,2017 年 1 月 1 日的闰秒调整,阿里云服务器 NTP 系统 24 小时“消化”闰秒,完美解决了问题。
如果发现有时钟回拨,时间很短比如 5 毫秒,就等待,然后再生成。或者就直接报错,交给业务层去处理。也可以采用 SonyFlake 的方案,精确到 10 毫秒,以 10 毫秒为分配单元。
twitter的雪花算法:https://github.com/twitter-archive/snowflake
其它全局唯一的分布式ID的方式:如百度的uid-generator、美团的Leaf、滴滴的TinyId等
相关文章:
SnowFlake 雪花算法和原理(分布式 id 生成算法)
一、概述 SnowFlake 算法:是 Twitter 开源的分布式 id 生成算法。核心思想:使用一个 64 bit 的 long 型的数字作为全局唯一 id。算法原理最高位是符号位,始终为0,不可用。41位的时间序列,精确到毫秒级,41位…...
【死磕数据库专栏】MySQL对数据库增删改查的基本操作
前言 本文是专栏【死磕数据库专栏】的第二篇文章,主要讲解MySQL语句最常用的增删改查操作。我一直觉得这个世界就是个程序,每天都在执行增删改查。 MySQL 中我们最常用的增删改查,对应SQL语句就是 insert 、delete、update、select…...
阿里软件测试二面:adb 连接 Android 手机的两种方式,看完你就懂了
前言 随着现在移动端技术的突飞猛进,导致现在市场上,APP 应用数不胜数,那对于测试工程师而言,对于 APP 的测试,那基本就是一个必修课了。 今天,我就来给大家介绍一下,adb 连接 Android 手机的两…...
Docker安装YApi
目录0、Docker 环境准备1、数据库准备 MongoDB2、启动 YAPI3、官网教程0、Docker 环境准备 Docker 容器之间网络互通需要使用 docker network create yapi 创建一个自定义网络 docker network create yapi1、数据库准备 MongoDB YAPI 的数据库是 MongoDB,准备镜像…...

springboot自定义参数解析器
为什么要自定义参数解析器呢? 因为很多项目每次获取用户信息,需要重复从请求头中获取token,用token再去redis或是sql中去拿到存储的计本对象,再将获取到的Json数据,转化为我们需要的对象等代码,作为一名程…...

Python Unittest ddt数据驱动
1、数据驱动介绍: ddt.ddt(类装饰器,申明当前类使用ddt框架)ddt.data(函数装饰器,用于给测试用例传递数据),支持传python所有数据类型:数字(int,…...

Vue自定义组件遇到分页传输数据不正确解决办法
测试环境 Vue3 Element Plus 遇到问题 <el-table:data"tableData">...其他el-table-column<template #default"scope">// 自定义组件<my-button name"编辑" :id"scope.row.id"/ ></template></el-table&…...

ABAP 辨析CO|CN|CA|NA|CS|NS|CP|NP
1、文档说明 本篇文档将通过举例,解析字符的比较运算符之间的用法和区别,涉及到的操作符:CO|CN|CA|NA|CS|NS|CP|NP 2、用法和区别 用法总览 以下举例,几乎都使用一个字符变量和一个硬编码字符进行对比的方式,忽略尾…...
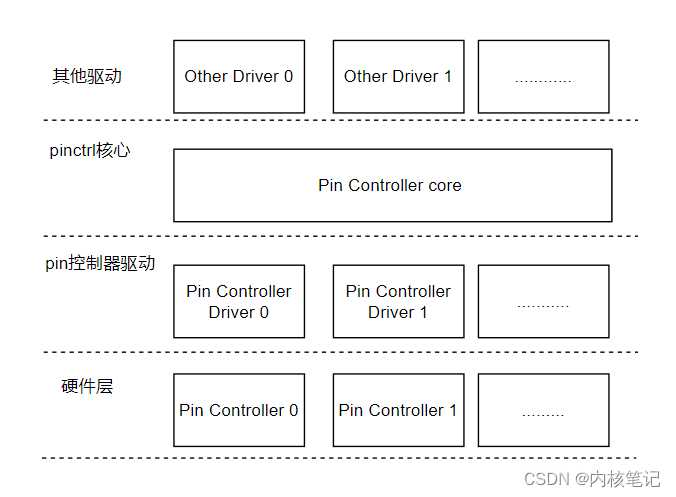
RK3568平台开发系列讲解(设备驱动篇)Pinctrl子系统详解
🚀返回专栏总目录 文章目录 一、pinctrl子系统结构描述二、重要的概念三、主要的数据结构和接口沉淀、分享、成长,让自己和他人都能有所收获!😄 📢我们知道在许多soc内部包含有多个pin控制器,通过pin控制器的寄存器,我们可以配置一个或者一组引脚的功能和特性。Linux…...

ROS小车研究笔记:二维SLAM建图简介与源码分析
ROS提供了现成的各类建图算法实现。如果只是应用的话不需要了解详细算法原理,只需要了解其需要的输入输出即可。 1 Gmapping Gmapping使用粒子滤波算法进行建图,在小场景下准确度高,但是在大场地中会导致较大计算量和内存需求 Gmapping需要…...
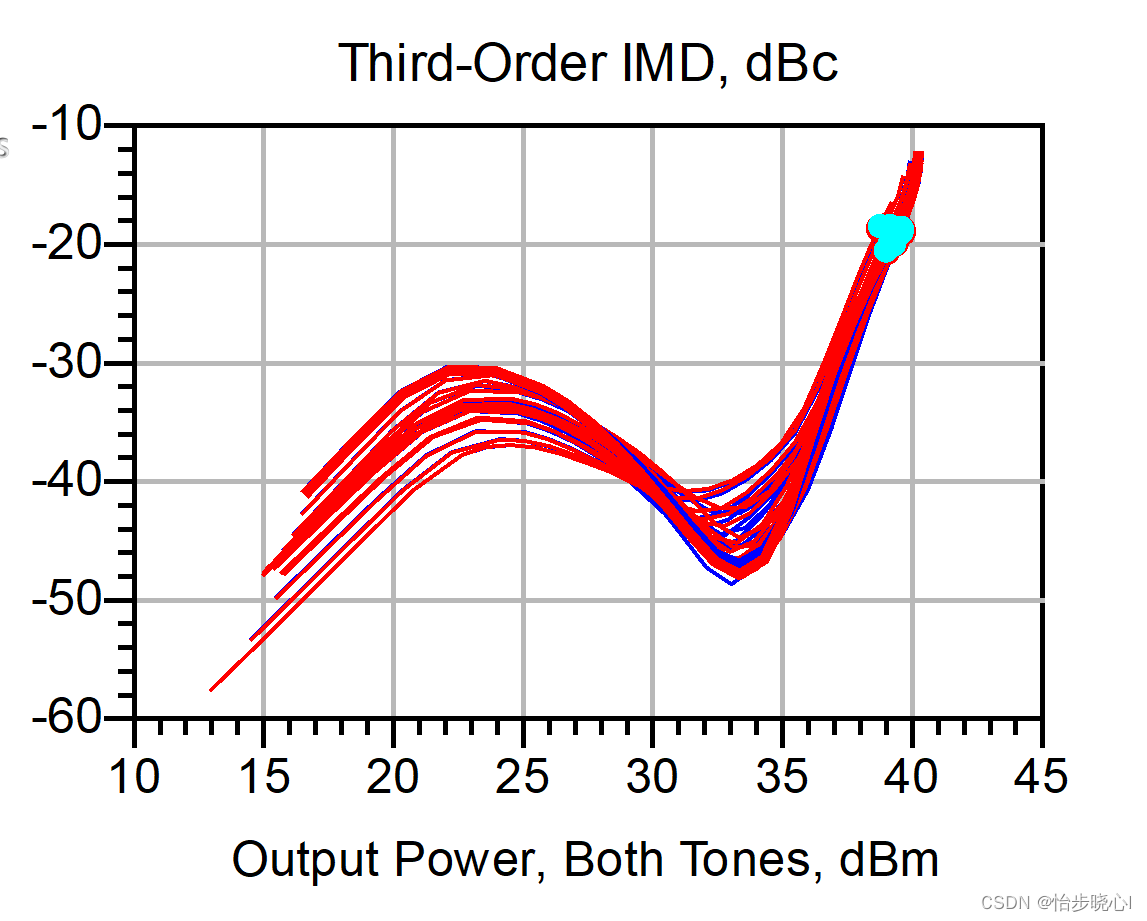
番外9:使用ADS对射频功率放大器进行非线性测试1(以IMD3测试为例)
番外9:使用ADS对射频功率放大器进行非线性测试1(以IMD3测试为例) 一般可以有多种方式对射频功率放大器的非线性性能进行测试,包括IMD3、ACPR、ACLR等等,其中IMD3的实际测试较为简单方便不需要太多的仪器。那么在ADS中…...
)
车载软件背景(留坑)
目前,车载软件已经成为汽车电子系统中不可或缺的一部分。随着汽车制造商不断增加车载软件的功能和性能,车载软件的市场规模也在不断扩大。据市场研究公司 Grand View Research 预测,到2025年,全球车载软件市场规模将达到190亿美元…...

Hadoop-MapReduce
Hadoop-MapReduce 文章目录Hadoop-MapReduce1 MapRedcue的介绍1.1 MapReduce定义1.2 MapReduce的思想1.3MapReduce优点1.4MapReduce的缺点1.5 MapReduce进程1.6 MapReduce-WordCount1.6.1 job的讲解2 Hadoop序列化2.1 序列化的定义2.2 hadoop序列化和java序列化的区别3 MapRedu…...

ChatGPT来了,软件测试工程师距离失业还远吗?
小伙伴们前一段是不是都看到过ChatGPT的相关视频,那它到底是什么?对软件测试行业会有什么影响? 今天汇智妹就用一篇文章来给大家讲清楚。 一、ChatGPT是什么? 简单来说,ChatGPT是一款人工智能聊天机器人,…...

【项目实战】Linux服务管理 之 开启/关闭防火墙
一、service命令是什么? service命令用于对系统服务进行管理,比如 启动(start)停止(stop)重启(restart)查看状态(status) service命令本身是一个shell脚本…...
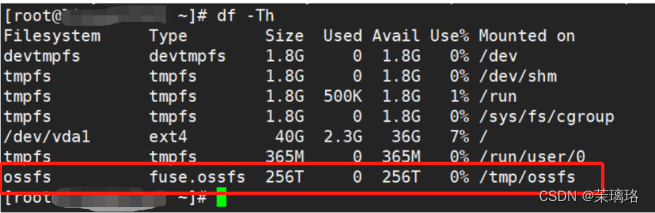
OSS存储使用之centOS系统ossfs挂载
以CentOS7系统为例 下载CentOS系统支持的ossfs工具的版本,以下载CentOS 7.0 (x64)版本为例,可以通过wget命令进行安装包的下载 wget http://gosspublic.alicdn.com/ossfs/ossfs_1.80.6_centos7.0_x86_64.rpm 也可以通过yum命令来进行安装包的下载 sud…...
配置)
【项目实战】SpringBoot多环境(dev、test、prod)配置
一、三套环境介绍 1.1 开发环境(dev) 开发环境是程序猿们专门用于开发的服务器,配置可以比较随意 为了开发调试方便,一般打开全部错误报告。 1.2 测试环境(test) 一般是克隆一份生产环境的配置 一个程序在测试环境工作不正常,那么肯定不能把它发布到生产机上。 有些…...
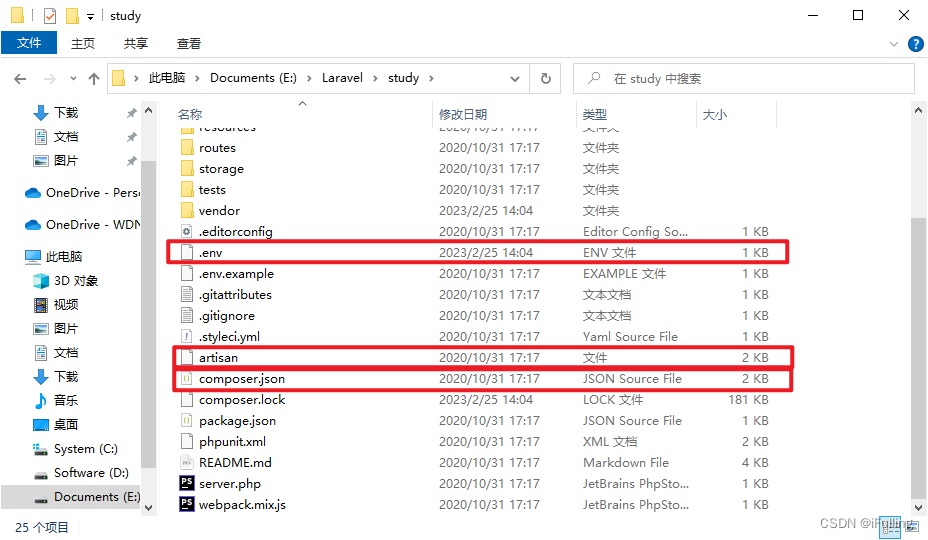
Laravel框架01:composer和Laravel简介
Laravel框架01:composer和Laravel简介一、Composer介绍二、创建Laravel项目三、Laravel目录结构四、Laravel启动方式一、Composer介绍 composer 是PHP中用来管理依赖关系的工具。类似于Javascript的NPM。composer官网:https://getcomposer.org/安装结束…...

【bug】Transformer输出张量的值全部相同?!
【bug】Transformer输出张量的值全部相同?!现象原因解决现象 输入经过TransformerEncoderLayer之后,基本所有输出都相同了。 核心代码如下, from torch.nn import TransformerEncoderLayer self.trans TransformerEncoderLayer…...
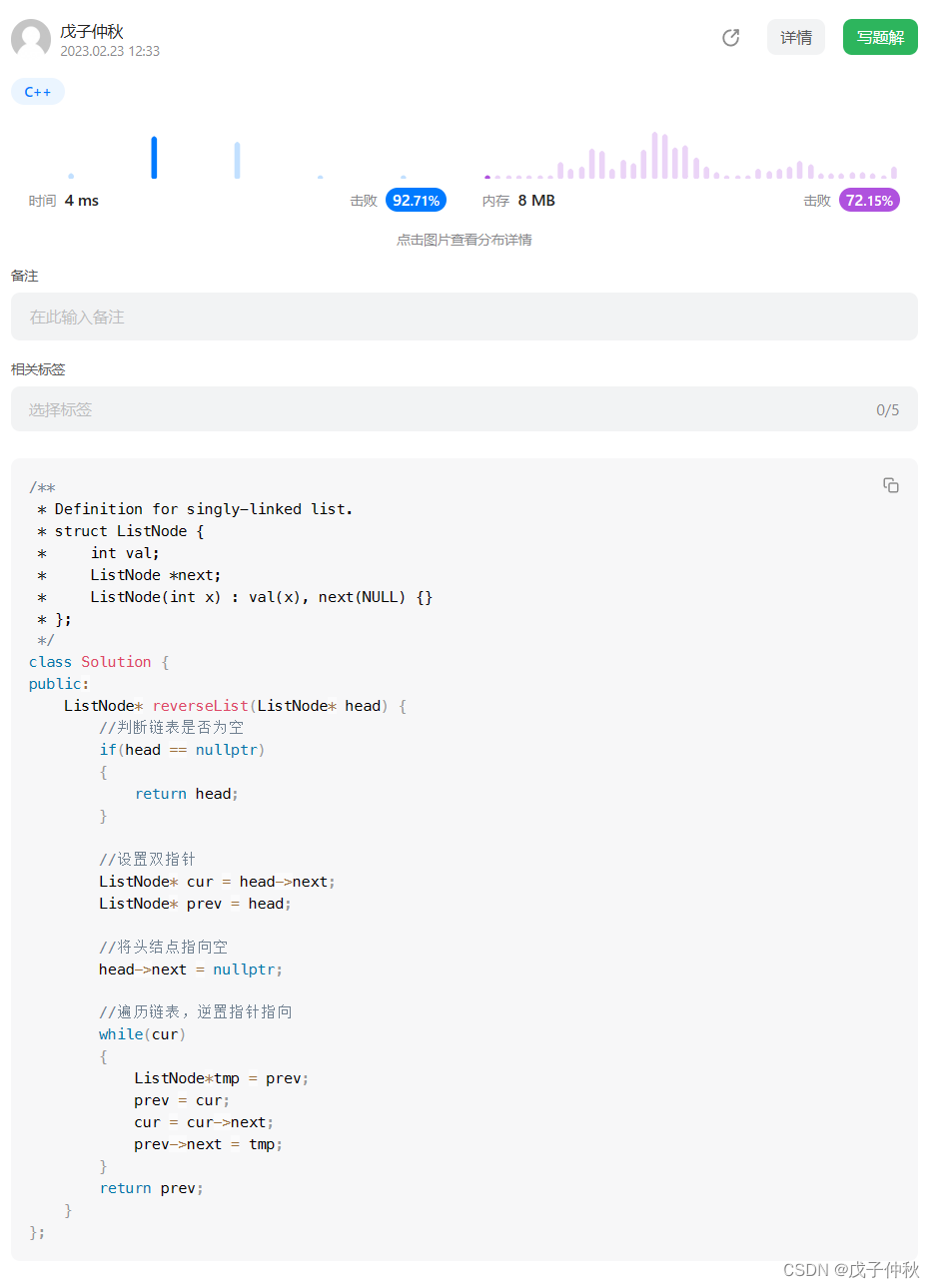
【LeetCode】剑指 Offer(8)
目录 题目:剑指 Offer 21. 调整数组顺序使奇数位于偶数前面 - 力扣(Leetcode) 题目的接口: 解题思路: 代码: 过啦!!! 题目:剑指 Offer 24. 反转链表 - …...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

C++:std::is_convertible
C++标志库中提供is_convertible,可以测试一种类型是否可以转换为另一只类型: template <class From, class To> struct is_convertible; 使用举例: #include <iostream> #include <string>using namespace std;struct A { }; struct B : A { };int main…...

【Oracle APEX开发小技巧12】
有如下需求: 有一个问题反馈页面,要实现在apex页面展示能直观看到反馈时间超过7天未处理的数据,方便管理员及时处理反馈。 我的方法:直接将逻辑写在SQL中,这样可以直接在页面展示 完整代码: SELECTSF.FE…...

【JavaEE】-- HTTP
1. HTTP是什么? HTTP(全称为"超文本传输协议")是一种应用非常广泛的应用层协议,HTTP是基于TCP协议的一种应用层协议。 应用层协议:是计算机网络协议栈中最高层的协议,它定义了运行在不同主机上…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...