每个人都应该知道的5个NLP代码库

在本文中,将详细介绍目前常用的Python NLP库。
内容译自网络。
这些软件包可处理多种NLP任务,例如词性(POS)标注,依存分析,文档分类,主题建模等等。
NLP库的基本目标是简化文本预处理。
目前有许多工具和库用于解决NLP问题……但是只要掌握了其中的一些基本知识,就可以掌握相关基本知识。这就是为什么只介绍其中最常用的五个Python NLP库的原因。
但是在此之前,应该掌握有关NLP的各个组成领域和主题的一些基础知识。
扎实基础
对于学习自然语言处理的理论基础,网络上有丰富的资源可以学习:
· 斯坦福课程 — 深度学习中的自然语言处理(http://web.stanford.edu/class/cs224n/)
· Deeplearning.ai专业化 - 自然语言处理专业(https://www.coursera.org/specializations/natural-language-processing)
· 适用于基础知识的最佳书籍(又名NLP圣经) — 自然语言处理,语音识别和计算语言学导论(https://web.stanford.edu/~jurafsky/slp3/)
· 另一本不错的参考书 - 统计自然语言处理的基础(https://nlp.stanford.edu/fsnlp/)
1. Spacy
spaCy 是Python中比较出名,专门用于自然语言处理的库。它有助于实现最先进的效率和敏捷性,并拥有活跃的开源组织积极贡献代码。
加分项:
· 与所有主要的深度学习框架很好地结合,并预装了一些出色且有用的语言模型
· 由于Cython支持,速度相对较快
使用spaCy最适合做的事情
1. 词性(POS)标注:这是给单词标记制定语法属性(例如名词,动词,形容词,副词等)过程。
2. 实体识别:将文本中发现的命名实体标记到预定义实体类型。
3. 依存分析:分配语法依存标签,描述各个标记(例如主题或客体)之间的关系。
4. 文本分类:为整个文档或文档的一部分分配类别或标签。
5. 句子边界检测(SBD):查找和分割单个句子。
相关资源
免费官方课程的链接:基于spaCy的高级NLP(https://course.spacy.io/en/)

官方课程
更多资源
· 一篇不错的博客文章,包括安装过程和其他Spacy用法(入门博客):使用Python中的spaCy进行自然语言处理(https://realpython.com/natural-language-processing-spacy-python/)
· Python Spacy简介(视频)— 视频讲座和教程(https://realpython.com/natural-language-processing-spacy-python/)
2. NLTK
NLTK是目前可用的最优秀的NLP模型训练库之一。该库是NLP入门python库。它是NLP的初学者常用的库。它具有许多预先训练的模型和语料库,可帮助我们非常快速地分析事物。
加分项:内置支持数十种语料库和训练完备的模型
使用NLTK可以实现一下需求:
1. 推荐:可以基于相似性来推荐内容。
2. 情感分析:通过自然语言处理来衡量人们的观点倾向
3. Wordnet [1]支持:我们可以使用Synset 在WordNet中查找单词。因此可以访问许多单词的同音异义词,上位词,同义词,定义,词族等
4. 机器翻译:用于将源语言翻译成目标语言
其他资源
· 学习NLTK的最佳资源是官方的教材:《使用自然语言工具包分析文本》(https://www.nltk.org/book/)
· 相关文章整理:Python的NLTK(自然语言工具包)教程(https://www.guru99.com/nltk-tutorial.html)
· Wordnet文档— WordNet 3.0参考手册(https://wordnet.princeton.edu/documentation)
与spaCy专注于提供用于生产用途的软件不同,NLTK被广泛用于教学和研究— Wikipedia
3.Transformers
来自Transformers GitHub Repo
该Transformers库是开源,基于社区的信息库,使用和共享模型基于Transformer结构[2]如Bert[3],Roberta[4],GPT2 [5],XLNet [6],等等
该库提供自然语言理解(NLU)和自然语言生成(NLG)任务预训练模型下载。
加分项:超过32种采用100种以上语言的训练的预训练模型,以及TensorFlow 2.0和PyTorch之间的深度互操作性。最适合深度学习。
Transformers可以做到一下事情
1. 摘要生成:摘要是将文本/文章摘要为较短文本的任务。
2. 翻译:将文本从一种语言翻译成另一种语言的任务。
3. 文本生成:基于上下文,生成连贯的下文。
4. 抽取式问答:从给定问题的文本中提取答案的任务。
相关资源:
· 官方文档-HuggingfaceTransformers(https://huggingface.co/transformers/)
· 使用BERT,HuggingFace和AWS Lambda构建问题解答API – 使用HuggingFace和AWS Lambda的无服务器BERT(https://towardsdatascience.com/serverless-bert-with-huggingface-and-aws-lambda-625193c6cc04)
· 了解如何微调BERT以进行情感分析— 使用BERT和Transformers进行情感分析(https://www.curiousily.com/posts/sentiment-analysis-with-bert-and-hugging-face-using-pytorch-and-python/)
4. Gensim
Gensim是一个Python库,专门用于通过向量空间建模和主题建模工具包来识别两个文档之间的语义相似性
顺便说一下,它是“ Generate Similar”(Gensim)的缩写:)
优点:高水平的处理速度和可以处理大量文本。
Gensim适合处理的需求:
1. 分布式计算:它可以在计算机集群上运行隐语义分析和隐Dirichlet分配。(可以处理大量数据的原因)
2. 文档索引:将信息与文件或特定标签相关联的过程,以便以后可以轻松检索
3. 主题建模:自动聚类单词group和定义一组文档的相似表达式。
4. 相似性检索:处理文档存储库中相似信息的组织,存储,检索和评估(此处为文本信息)
资源
· 官方API文档-API参考(https://radimrehurek.com/gensim/apiref.html)
· 官方教程- 核心教程(https://radimrehurek.com/gensim/auto_examples/)
· 使用Gensim LDA进行分层文档聚类— 使用Python进行文档聚类(http://brandonrose.org/clustering#Latent-Dirichlet-Allocation)
· 安装,处理等入门教程— 适用于NLP的Python:使用Gensim库(https://stackabuse.com/python-for-nlp-working-with-the-gensim-library-part-1/)
5. Stanza
Stanza将许多准确而有效自然语言处理工具收集在一起,组成工具包。从原始文本到句法分析和实体识别,Stanza将最新的NLP模型引入语言处理中。
该工具包建立在PyTorch库的之上,并支持使用GPU和预训练的神经模型。
此外,Stanza包括一个CoreNLP Java包的Python接口,并从那里继承了附加功能。
优点:快速,准确,并且能够支持几种主要语言。适用于生产部署环境。
资源:CoreNLP的Python包装器列表(http://stanfordnlp.github.io/CoreNLP/other-languages.html#python)
Stanza适合处理的需求:
1. 形态特征标记:对于句子中的每个单词,Stanza都会评估其普遍的形态特征(例如,单身/复数,第一/第二/第三人称等)。
2. 多词令牌扩展:将句子扩展成句法词,作为下游处理的基础。
这五个库的固有特性使其成为依赖于机器对人类表达的理解的所有项目的首选。
参考文献
1. WordNet简介:在线词汇数据库 — George A. Miller等。1993年(https://wordnetcode.princeton.edu/5papers.pdf)
2. Attention Is All You Need — Vaswani等人,2017。(https://arxiv.org/abs/1706.03762)
3. BERT:用于语言理解的深度双向Transformers的预训练 — Devlin等人,2018年。(https://arxiv.org/abs/1810.04805)
4. RoBERTa:一种经过严格优化的BERT预训练方法 — Liu等,2019年。(https://arxiv.org/abs/1907.11692)
5. 语言模型是无监督的多任务学习者(GPT2) — Radford等人,2019年。(https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf)
6. XLNet:用于语言理解的广义自回归预训练 — Yang等人,2019年。(https://arxiv.org/abs/1906.08237)
7. Stanza:适用于多种人类语言的Python自然语言处理工具包 — Peng等人,2020年。(https://arxiv.org/abs/2003.07082)
往期精品内容推荐
观点问题如何练就“火眼金睛”?百度人工智能开源大赛开启报名
20年校招DL/NLP/推荐系统/ML/算法基础面试必看300问及答案
2020年新书-《神经网络新手入门必备数学基础》免费pdf分享
免费好书-《机器学习入门-第二版》最新pdf分享
GPT-3语言模型原理详细解读
机器学习基础-《统计学习-SLT》教材分享
DeepMind 2020年新课-《强化学习进阶课程》视频分享
中文自然语言处理医疗、法律等公开数据集整理分享
自然语言领域中图神经网络模型(GNN)应用现状(论文)
深度学习基础:正向模型、可微损失函数与优化
新书分享-嵌入式深度学习:持续性神经网路算法、结构和电路设计
深度神经网络压缩和加速相关最全资源分享
相关文章:
每个人都应该知道的5个NLP代码库
在本文中,将详细介绍目前常用的Python NLP库。内容译自网络。这些软件包可处理多种NLP任务,例如词性(POS)标注,依存分析,文档分类,主题建模等等。NLP库的基本目标是简化文本预处理。目前有许多工…...
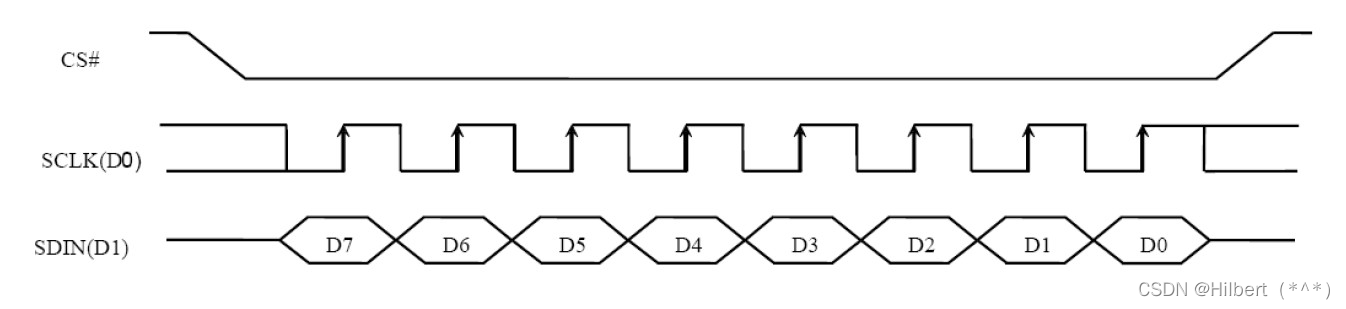
SPI协议介绍
SPI协议介绍 文章目录SPI协议介绍一、 SPI硬件知识1.1 硬件连线1.2 SPI控制器内部结构二、 SPI协议2.1 传输示例2.2 SPI模式致谢一、 SPI硬件知识 1.1 硬件连线 引脚含义如下: 引脚含义DO(MOSI)Master Output, Slave Input,SPI主控用来发出数据&#x…...

MySQL数据库中索引的优点及缺点
一、索引的优点 1)创建索引可以大幅提高系统性能,帮助用户提高查询的速度; 2)通过索引的唯一性,可以保证数据库表中的每一行数据的唯一性; 3)可以加速表与表之间的链接; 4&#…...
sort函数总结(基础篇))
(q)sort函数总结(基础篇)
1.sort函数 介绍:这是一个C的函数,包含于algorithm头文件中。 基本格式: sort(起始地址(常为变量名),排序终止的地址(变量名加上排序长度),自定义的比较函数) 重点&a…...

【数据库】MongoDB数据库详解
目录 一,数据库管理系统 1, 什么是数据库 2,什么是数据库管理系统 二, NoSQL 是什么 1,NoSQL 简介 2,NoSQL数据库 3,NoSQL 与 RDBMS 对比 三,MongoDB简介 1, MongoDB 是什…...

【linux】进程间通信——system V
system V一、system V介绍二 、共享内存2.1 共享内存的原理2.2 共享内存接口2.2.1 创建共享内存shmget2.2.2 查看IPC资源2.2.3 共享内存的控制shmctl2.2.4 共享内存的关联shmat2.2.5 共享内存的去关联shmdt2.3 进程间通信2.4 共享内存的特性2.5 共享内存的大小三、消息队列3.1 …...

计算机网络的基本组成
计算机网络是由多个计算机、服务器、网络设备(如路由器、交换机、集线器等)通过各种通信线路(如有线、无线、光纤等)和协议(如TCP/IP、HTTP、FTP等)互相连接组成的复杂系统,它们能够在物理层、数…...
【数据结构趣味多】Map和Set
1.概念及场景 Map和set是一种专门用来进行搜索的容器或者数据结构,其搜索的效率与其具体的实例化子类有关。 在此之前,我还接触过直接查询O(N)和二分查询O(logN),这两个查询有很多不足之出,直接查询的速率太低,而二分查…...

Redis 之企业级解决方案
文章目录一、缓存预热二、缓存雪崩三、缓存击穿四、缓存穿透五、性能指标监控5.1 监控指标5.2 监控方式🍌benchmark🍌monitor🍌slowlog提示:以下是本篇文章正文内容,Redis系列学习将会持续更新 一、缓存预热 1.1 现象…...
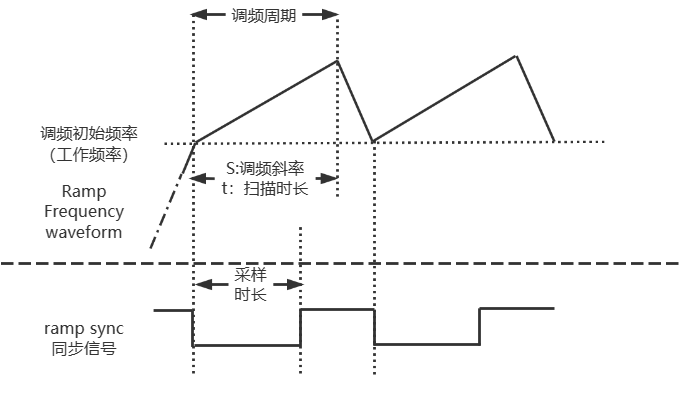
雷达实战之射频前端配置说明
在无线通信领域,射频系统主要分为射频前端,以及基带。从发射通路来看,基带完成语音等原始信息通过AD转化等手段转化成基带信号,然后经过调制生成包含跟多有效信息,且适合信道传输的信号,最后通过射频前端将信号发射出去…...

Android SDK删除内置的触宝输入法
问题 Android 8.1.0, 展锐平台。 过CTA认证,内置的触宝输入法会连接网络,且默认就获取到访问网络的权限,没有弹请求窗口访问用户,会导致过不了认证。 预置应用触宝输入法Go版连网未明示(开启后࿰…...

[202002][Spring 实战][第5版][张卫滨][译]
[202002][Spring 实战][第5版][张卫滨][译] habuma/spring-in-action-5-samples: Home for example code from Spring in Action 5. https://github.com/habuma/spring-in-action-5-samples 第 1 部分 Spring 基础 第 1 章 Spring 起步 1.1 什么是 Spring 1.2 初始化 Spr…...

H5视频上传与播放
背景 需求场景: 后台管理系统: (1)配置中支持上传视频、上传成功后封面缩略图展示,点击后自动播放视频; (2)配置中支持上传多个文件; 前台系统: &#…...
通过OpenAI来做机械智能故障诊断-测试(1)
通过OpenAI来做机械智能故障诊断 1. 注册使用2. 使用案例1-介绍故障诊断流程2.1 对话内容2.2 对话小结3. 使用案例2-写一段轴承故障诊断的代码3.1 对话内容3.2 对话小结4. 对话加载Paderborn轴承故障数据集并划分4.1 加载轴承故障数据集并划分第一次测试4.2 第二次加载数据集自…...

ASE40N50SH-ASEMI高压MOS管ASE40N50SH
编辑-Z ASE40N50SH在TO-247封装里的静态漏极源导通电阻(RDS(ON))为100mΩ,是一款N沟道高压MOS管。ASE40N50SH的最大脉冲正向电流ISM为160A,零栅极电压漏极电流(IDSS)为1uA,其工作时耐温度范围为-55~150摄氏度。ASE40N…...

MySQL基础命令大全——新手必看
Mysql 是一个流行的开源关系型数据库管理系统,广泛用于各种 Web 应用程序和服务器环境中。Mysql 有很多命令可以使用,以下是 Mysql 基础命令: 1、连接到Mysql服务器: mysql -h hostname -u username -p 其中,"ho…...
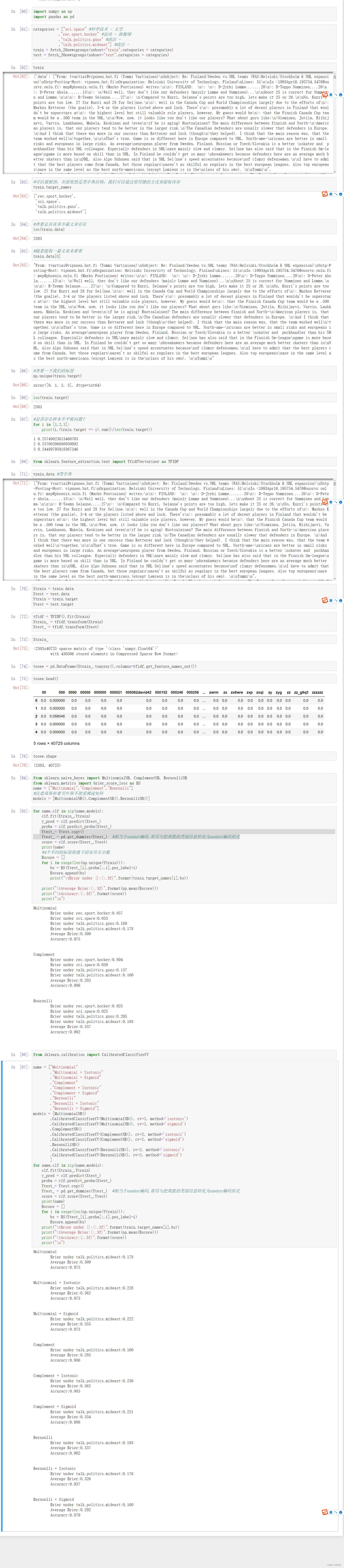
sklearn学习-朴素贝叶斯(二)
文章目录一、概率类模型的评估指标1、布里尔分数Brier Score对数似然函数Log Loss二、calibration_curve:校准可靠性曲线三、多项式朴素贝叶斯以及其变化四、伯努利朴素贝叶斯五、改进多项式朴素贝叶斯:补集朴素贝叶斯ComplementNB六、文本分类案例TF-ID…...

MySQL_主从复制读写分离
主从复制 概述 主从复制是指将主数据库的DDL和DML操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。 MySQL支持一台主库同时向多台从库进行复制,从…...
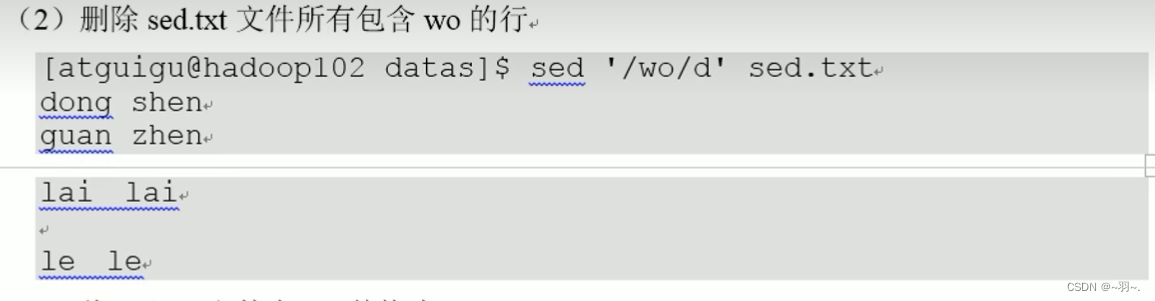
shell基础学习
文章目录查看shell解释器写hello world多命令处理执行变量常用系统变量自定义变量撤销变量静态变量变量提升为全局环境变量特殊变量$n$#$* $$?运算符:条件判断比较流程控制语句ifcasefor 循环while 循环read读取控制台输入基本语法:函数系统函数basenamedirname自定义函数shel…...
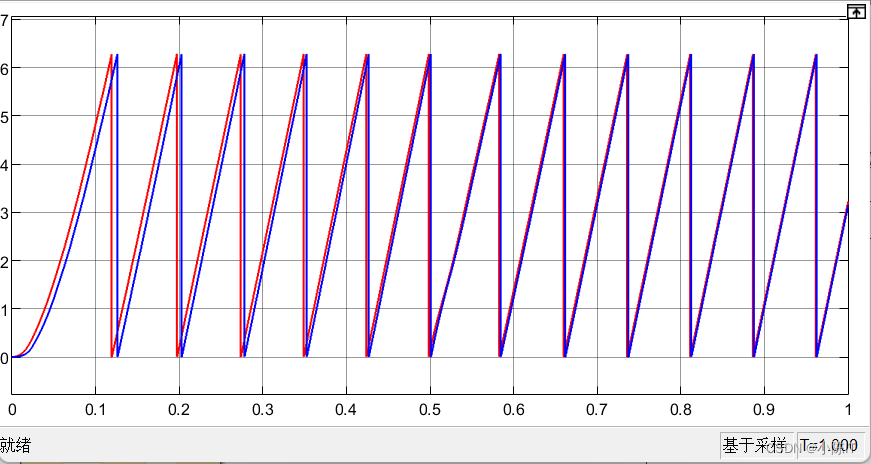
考虑交叉耦合因素的IPMSM无传感器改进线性自抗扰控制策略
考虑交叉耦合因素的IPMSM无传感器改进线性自抗扰控制策略一级目录二级目录三级目录控制原理ELADRC信号提取龙格贝尔观测器方波注入simulink仿真给定转速:转速环:电流环:一级目录 二级目录 三级目录 首先声明一下,本篇博客是复现…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

Linux简单的操作
ls ls 查看当前目录 ll 查看详细内容 ls -a 查看所有的内容 ls --help 查看方法文档 pwd pwd 查看当前路径 cd cd 转路径 cd .. 转上一级路径 cd 名 转换路径 …...

STM32F4基本定时器使用和原理详解
STM32F4基本定时器使用和原理详解 前言如何确定定时器挂载在哪条时钟线上配置及使用方法参数配置PrescalerCounter ModeCounter Periodauto-reload preloadTrigger Event Selection 中断配置生成的代码及使用方法初始化代码基本定时器触发DCA或者ADC的代码讲解中断代码定时启动…...

将对透视变换后的图像使用Otsu进行阈值化,来分离黑色和白色像素。这句话中的Otsu是什么意思?
Otsu 是一种自动阈值化方法,用于将图像分割为前景和背景。它通过最小化图像的类内方差或等价地最大化类间方差来选择最佳阈值。这种方法特别适用于图像的二值化处理,能够自动确定一个阈值,将图像中的像素分为黑色和白色两类。 Otsu 方法的原…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

基于数字孪生的水厂可视化平台建设:架构与实践
分享大纲: 1、数字孪生水厂可视化平台建设背景 2、数字孪生水厂可视化平台建设架构 3、数字孪生水厂可视化平台建设成效 近几年,数字孪生水厂的建设开展的如火如荼。作为提升水厂管理效率、优化资源的调度手段,基于数字孪生的水厂可视化平台的…...

React19源码系列之 事件插件系统
事件类别 事件类型 定义 文档 Event Event 接口表示在 EventTarget 上出现的事件。 Event - Web API | MDN UIEvent UIEvent 接口表示简单的用户界面事件。 UIEvent - Web API | MDN KeyboardEvent KeyboardEvent 对象描述了用户与键盘的交互。 KeyboardEvent - Web…...

使用van-uploader 的UI组件,结合vue2如何实现图片上传组件的封装
以下是基于 vant-ui(适配 Vue2 版本 )实现截图中照片上传预览、删除功能,并封装成可复用组件的完整代码,包含样式和逻辑实现,可直接在 Vue2 项目中使用: 1. 封装的图片上传组件 ImageUploader.vue <te…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...