【图像配准】多图配准/不同特征提取算法/匹配器比较测试
前言
本文首先完成之前专栏前置博文未完成的多图配准拼接任务,其次对不同特征提取器/匹配器效率进行进一步实验探究。
各类算法原理简述
看到有博文[1]指出,在速度方面SIFT<SURF<BRISK<FREAK<ORB,在对有较大模糊的图像配准时,BRISK算法在其中表现最为出色,后面考虑选取其中SIFT、BRISK、ORB三种算法进行验证。
在此之前,先对后续算法的原理做一些初步了解。
SIFT算法
在前文【图像配准】SIFT算法原理及二图配准拼接已经对此做过分析,这里不作赘述。
BRISK算法
BRISK算法是2011年ICCV上《BRISK:Binary Robust Invariant Scalable Keypoints》文章中,提出来的一种特征提取算法。
BRISK算法通过利用简单的像素灰度值比较,进而得到一个级联的二进制比特串来描述每个特征点,之后采用了邻域采样模式,即以特征点为圆心,构建多个不同半径的离散化Bresenham同心圆,然后再每一个同心圆上获得具有相同间距的N个采样点。

更详细的内容可参考文献[3]对论文的解读。
ORB算法
ORB(Oriented FAST and rotated BRIEF)是OpenCV实验室开发的一种特征检测与特征描述算法,将 FAST 特征检测与 BRIEF 特征描述结合并进行了改进,具有尺度不变性和旋转不变性,对噪声有较强的抗干扰能力[4]。
ORB算法在图像金字塔中使用FAST算法检测关键点,通过一阶矩计算关键点的方向,使用方向校正的BRIEF生成特征描述符。
更详细的内容可参考文献[4]。
AKAZE算法
Alcantarilla等人提出了AKAZE(Accelerated-KAZE)算法,即加速KAZE算法,加速了非线性尺度空间的构造,效率较KAZE有所提升,以各向异性的非线性滤波来构造尺度空间,将整个尺度空间进行分割,利用局部自适应分级获得细节和噪声,保留较多的边缘细节信息,但该算法关键点检测能力不足,且鲁棒性不强[5]。
多图配准
无论何种算法,图像配准无非是这样几个步骤->图像灰度化->提取特征->构建匹配器->计算变换矩阵->图像合并。
那么多图配准,实际上可以分解为多个双图配准。
以下代码主要参考了这个仓库:https://github.com/799034552/concat_pic
下面按处理顺序对各部分内容进行分块拆解:
图像读取
首先是读取图像再进行灰度化转换。
这里进行了一个判断,判断传入的是否是图像的文本路径,这一步主要是为了后面多图拼接的便利性,因为后面多图拼接会把拼接好的部分图像直接放在内存中,这里若不是路径,就直接赋值给变量,相当于用整张大图去和另外一张小图去做拼接。
# 读取图像-转换灰度图用于检测
# 这里做一个文本判断是为了后面多图拼接处理
if isinstance(path2, str):imageA = cv2.imread(path2)
else:imageA = path2
if isinstance(path1, str):imageB = cv2.imread(path1)
else:imageB = path1
imageA_gray = cv2.cvtColor(imageA, cv2.COLOR_BGR2GRAY)
imageB_gray = cv2.cvtColor(imageB, cv2.COLOR_BGR2GRAY)
构建特征提取器
OpenCV对各种算法都进行了较好的封装,这里主要对比测试了sift,brisk,orb,akaze这几种算法,所用opencv-python版本为4.7.0,值得注意的是,OpenCV4以后的版本,cv2.SURF_create()无法使用,只能用老版本的cv2.xfeatures2d.SURF_create()来实现SURF,因此这里没有对SURF算法进行比较测试。
# 选择特征提取器函数
def detectAndDescribe(image, method=None):if method == 'sift':descriptor = cv2.SIFT_create()elif method == 'surf':descriptor = cv2.xfeatures2d.SURF_create() # OpenCV4以上不可用elif method == 'brisk':descriptor = cv2.BRISK_create()elif method == 'orb':descriptor = cv2.ORB_create()elif method == 'akaze':descriptor = cv2.AKAZE_create()(kps, features) = descriptor.detectAndCompute(image, None)return kps, features
提取特征/特征匹配
# 提取两张图片的特征
kpsA, featuresA = detectAndDescribe(imageA_gray, method=feature_extractor)
kpsB, featuresB = detectAndDescribe(imageB_gray, method=feature_extractor)
# 进行特征匹配
if feature_matching == 'bf':matches = matchKeyPointsBF(featuresA, featuresB, method=feature_extractor)
elif feature_matching == 'knn':matches = matchKeyPointsKNN(featuresA, featuresB, ratio=0.75, method=feature_extractor)if len(matches) < 10:return None, None
这里比较了两种匹配器,一种是暴力匹配器(BFMatcher),函数接口为cv2.BFMatcher,主要有下面两个参数可以设置:
- normType:距离类型,可选项,默认为欧式距离NORM_L2。
- NORM_L1:L1范数,曼哈顿距离。
- NORM_L2:L2范数,欧式距离。
- NORM_HAMMING:汉明距离。
- NORM_HAMMING2:汉明距离2,对每2个比特相加处理。
- crossCheck:交叉匹配选项,可选项,默认为False,若为True,即两张图像中的特征点必须互相都是唯一选择
注:对于SIFT、SURF描述符,推荐选择欧氏距离L1和L2范数;对于ORB、BRISK、BRIEF描述符,推荐选择汉明距离NORM_HAMMING;对于ORB描述符,当WTA_K=3或4时,推荐使用汉明距离NORM_HAMMING2。
对于该函数更详细的内容,可参考博文[6]。
另一个是FLANN匹配器,Flann-based matcher 使用快速近似最近邻搜索算法寻找,FlannBasedMatcher接受两个参数:index_params和search_params:
- index_params:可用不同的数值表示不同的算法,有下表这些可选项(表中数据来源文章[7])

- search_params(int checks=32, float eps=0, bool sorted=true)
checks为int类型,是遍历次数,一般只改变这个参数
# 创建匹配器
def createMatcher(method, crossCheck):"""不同的方法创建不同的匹配器参数,参数释义BFMatcher:暴力匹配器NORM_L2-欧式距离NORM_HAMMING-汉明距离crossCheck-若为True,即两张图像中的特征点必须互相都是唯一选择"""if method == 'sift' or method == 'surf':bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=crossCheck)elif method == 'orb' or method == 'brisk' or method == 'akaze':# 创建BF匹配器# bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=crossCheck)index_params = dict(algorithm=1, trees=5)search_params = dict(checks=50)# 创建Flann匹配器bf = cv2.FlannBasedMatcher(index_params, search_params)return bf
二者的区别在于BFMatcher总是尝试所有可能的匹配,从而使得它总能够找到最佳匹配,这也是Brute Force(暴力法)的原始含义。
而FlannBasedMatcher中FLANN的含义是Fast Library forApproximate Nearest Neighbors,从字面意思可知它是一种近似法,算法更快但是找到的是最近邻近似匹配,所以当我们需要找到一个相对好的匹配但是不需要最佳匹配的时候往往使用FlannBasedMatcher。当然也可以通过调整FlannBasedMatcher的参数来提高匹配的精度或者提高算法速度,但是相应地算法速度或者算法精度会受到影响[8]。
特征匹配也有两种方式,可以直接进行暴力检测,也可以采用KNN进行检测,不同检测方式的代码如下:
# 暴力检测函数
def matchKeyPointsBF(featuresA, featuresB, method):start_time = time.time()bf = createMatcher(method, crossCheck=True)best_matches = bf.match(featuresA, featuresB)rawMatches = sorted(best_matches, key=lambda x: x.distance)print("Raw matches (Brute force):", len(rawMatches))end_time = time.time()print("暴力检测共耗时" + str(end_time - start_time))return rawMatches# 使用knn检测函数
def matchKeyPointsKNN(featuresA, featuresB, ratio, method):start_time = time.time()bf = createMatcher(method, crossCheck=False)# rawMatches = bf.knnMatch(featuresA, featuresB, k=2)# 上面这行在用Flann时会报错rawMatches = bf.knnMatch(np.asarray(featuresA, np.float32), np.asarray(featuresB, np.float32), k=2)matches = []for m, n in rawMatches:if m.distance < n.distance * ratio:matches.append(m)print(f"knn匹配的特征点数量:{len(matches)}")end_time = time.time()print("KNN检测共耗时" + str(end_time - start_time))return matches
计算视角变换矩阵/透视变换
匹配完关键点后,就可以计算视角变换矩阵,然后一幅图不动,另一幅图进行透视变换,这里的具体方式和前文较为类似。
# 计算视角变换矩阵
def getHomography(kpsA, kpsB, matches, reprojThresh):start_time = time.time()# 将各关键点保存为ArraykpsA = np.float32([kp.pt for kp in kpsA])kpsB = np.float32([kp.pt for kp in kpsB])# 如果匹配点大于四个点,再进行计算if len(matches) > 4:# 构建出匹配的特征点ArrayptsA = np.float32([kpsA[m.queryIdx] for m in matches])ptsB = np.float32([kpsB[m.trainIdx] for m in matches])# 计算视角变换矩阵(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)end_time = time.time()print("透视关系计算共耗时" + str(end_time - start_time))return matches, H, statuselse:return NoneM = getHomography(kpsA, kpsB, matches, reprojThresh=4)if M is None:print("Error!")(matches, H, status) = M# 将图片A进行透视变换result = cv2.warpPerspective(imageA, H, ((imageA.shape[1] + imageB.shape[1]) * 2, (imageA.shape[0] + imageB.shape[0]) * 2))resultAfterCut = cutBlack(result)
图片黑边裁剪
在做透视变换时,往往会采取一个比较大的背景,以确保图片能够不遗漏的拼接上去,比如这里图片的尺寸设定为(imageA.shape[1] + imageB.shape[1]) * 2, (imageA.shape[0] + imageB.shape[0]) * 2),这样会产生一些背景黑边,需要进行裁切。
之前的文章提到过一种通过膨胀方式来找到最大内接矩形,这里的代码处理方式更为巧妙,直接采用像素点搜索的方式,找到图像的最大外接矩形。
# 去除图像黑边
def cutBlack(pic):rows, cols = np.where(pic[:, :, 0] != 0)min_row, max_row = min(rows), max(rows) + 1min_col, max_col = min(cols), max(cols) + 1return pic[min_row:max_row, min_col:max_col, :]
图片位置检查
由于无法提前知道两张图片的位置关系,对于透视变换,可能图片会映射到整个选取区域的左边,这样的话,无法正常显示图片,因此,要对透视变换后的图片进行面积检查,如果比原来的图片面积小太多,就用另一张图片来进行透视变换[9]。
if np.size(resultAfterCut) < np.size(imageA) * 0.95:print("图片位置不对,将自动调换")# 调换图片kpsA, kpsB = swap(kpsA, kpsB)imageA, imageB = swap(imageA, imageB)if feature_matching == 'bf':matches = matchKeyPointsBF(featuresB, featuresA, method=feature_extractor)elif feature_matching == 'knn':matches = matchKeyPointsKNN(featuresB, featuresA, ratio=0.75, method=feature_extractor)if len(matches) < 10:return None, NonematchCount = len(matches)M = getHomography(kpsA, kpsB, matches, reprojThresh=4)if M is None:print("Error!")(matches, H, status) = Mresult = cv2.warpPerspective(imageA, H,((imageA.shape[1] + imageB.shape[1]) * 2, (imageA.shape[0] + imageB.shape[0]) * 2))
图像融合
图像融合这里处理得也比较巧妙,对图片接壤部分选取最大值,这样确保了色调的统一性。
# 合并图片-相同的区域选取最大值,从而实现融合result[0:imageB.shape[0], 0:imageB.shape[1]] = np.maximum(imageB, result[0:imageB.shape[0], 0:imageB.shape[1]])result = cutBlack(result) # 结果去除黑边
多图拼接
最后是拼接多幅图像,反复调用拼接双图即可。
# 合并多张图
def handleMulti(*args):l = len(args)assert (l > 1)# isHandle用于标记图片是否参与合并isHandle = [0 for i in range(l - 1)]nowPic = args[0]args = args[1:]for j in range(l - 1):isHas = False # 在一轮中是否找到matchCountList = []resultList = []indexList = []for i in range(l - 1):if isHandle[i] == 1:continueresult, matchCount = handle(nowPic, args[i])if not result is None:matchCountList.append(matchCount) # matchCountList存储两图匹配的特征点resultList.append(result)indexList.append(i)isHas = Trueif not isHas: # 一轮找完都没有可以合并的return Noneelse:index = matchCountList.index(max(matchCountList))nowPic = resultList[index]isHandle[indexList[index]] = 1print(f"合并第{indexList[index] + 2}个")return nowPic
完整代码
utils.py
import cv2
import numpy as np
import time# 选择特征提取器函数
def detectAndDescribe(image, method=None):if method == 'sift':descriptor = cv2.SIFT_create()elif method == 'surf':descriptor = cv2.xfeatures2d.SURF_create() # OpenCV4以上不可用elif method == 'brisk':descriptor = cv2.BRISK_create()elif method == 'orb':descriptor = cv2.ORB_create()elif method == 'akaze':descriptor = cv2.AKAZE_create()(kps, features) = descriptor.detectAndCompute(image, None)return kps, features# 创建匹配器
def createMatcher(method, crossCheck):"""不同的方法创建不同的匹配器参数,参数释义BFMatcher:暴力匹配器NORM_L2-欧式距离NORM_HAMMING-汉明距离crossCheck-若为True,即两张图像中的特征点必须互相都是唯一选择"""if method == 'sift' or method == 'surf':bf = cv2.BFMatcher(cv2.NORM_L2, crossCheck=crossCheck)elif method == 'orb' or method == 'brisk' or method == 'akaze':# 创建BF匹配器# bf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=crossCheck)index_params = dict(algorithm=1, trees=5)search_params = dict(checks=50)# 创建Flann匹配器bf = cv2.FlannBasedMatcher(index_params, search_params)return bf# 暴力检测函数
def matchKeyPointsBF(featuresA, featuresB, method):start_time = time.time()bf = createMatcher(method, crossCheck=True)best_matches = bf.match(featuresA, featuresB)rawMatches = sorted(best_matches, key=lambda x: x.distance)print("Raw matches (Brute force):", len(rawMatches))end_time = time.time()print("暴力检测共耗时" + str(end_time - start_time))return rawMatches# 使用knn检测函数
def matchKeyPointsKNN(featuresA, featuresB, ratio, method):start_time = time.time()bf = createMatcher(method, crossCheck=False)# rawMatches = bf.knnMatch(featuresA, featuresB, k=2)# 上面这行在用Flann时会报错rawMatches = bf.knnMatch(np.asarray(featuresA, np.float32), np.asarray(featuresB, np.float32), k=2)matches = []for m, n in rawMatches:if m.distance < n.distance * ratio:matches.append(m)print(f"knn匹配的特征点数量:{len(matches)}")end_time = time.time()print("KNN检测共耗时" + str(end_time - start_time))return matches# 计算视角变换矩阵
def getHomography(kpsA, kpsB, matches, reprojThresh):start_time = time.time()# 将各关键点保存为ArraykpsA = np.float32([kp.pt for kp in kpsA])kpsB = np.float32([kp.pt for kp in kpsB])# 如果匹配点大于四个点,再进行计算if len(matches) > 4:# 构建出匹配的特征点ArrayptsA = np.float32([kpsA[m.queryIdx] for m in matches])ptsB = np.float32([kpsB[m.trainIdx] for m in matches])# 计算视角变换矩阵(H, status) = cv2.findHomography(ptsA, ptsB, cv2.RANSAC, reprojThresh)end_time = time.time()print("透视关系计算共耗时" + str(end_time - start_time))return matches, H, statuselse:return None# 去除图像黑边
def cutBlack(pic):rows, cols = np.where(pic[:, :, 0] != 0)min_row, max_row = min(rows), max(rows) + 1min_col, max_col = min(cols), max(cols) + 1return pic[min_row:max_row, min_col:max_col, :]# 交换
def swap(a, b):return b, a
main.py
from utils import *# 合并两张图(合并多张图基于此函数)
def handle(path1, path2):# 超参数-选择具体算法feature_extractor = 'brisk'feature_matching = 'knn'# 读取图像-转换灰度图用于检测# 这里做一个文本判断是为了后面多图拼接处理if isinstance(path2, str):imageA = cv2.imread(path2)else:imageA = path2if isinstance(path1, str):imageB = cv2.imread(path1)else:imageB = path1imageA_gray = cv2.cvtColor(imageA, cv2.COLOR_BGR2GRAY)imageB_gray = cv2.cvtColor(imageB, cv2.COLOR_BGR2GRAY)# 提取两张图片的特征kpsA, featuresA = detectAndDescribe(imageA_gray, method=feature_extractor)kpsB, featuresB = detectAndDescribe(imageB_gray, method=feature_extractor)# 进行特征匹配if feature_matching == 'bf':matches = matchKeyPointsBF(featuresA, featuresB, method=feature_extractor)elif feature_matching == 'knn':matches = matchKeyPointsKNN(featuresA, featuresB, ratio=0.75, method=feature_extractor)if len(matches) < 10:return None, None# 计算视角变换矩阵matchCount = len(matches)M = getHomography(kpsA, kpsB, matches, reprojThresh=4)if M is None:print("Error!")(matches, H, status) = M# 将图片A进行透视变换result = cv2.warpPerspective(imageA, H, ((imageA.shape[1] + imageB.shape[1]) * 2, (imageA.shape[0] + imageB.shape[0]) * 2))resultAfterCut = cutBlack(result)# 查看裁剪完黑边后的图片# cv2.imshow("resultAfterCut", resultAfterCut)# cv2.waitKey(0)if np.size(resultAfterCut) < np.size(imageA) * 0.95:print("图片位置不对,将自动调换")# 调换图片kpsA, kpsB = swap(kpsA, kpsB)imageA, imageB = swap(imageA, imageB)if feature_matching == 'bf':matches = matchKeyPointsBF(featuresB, featuresA, method=feature_extractor)elif feature_matching == 'knn':matches = matchKeyPointsKNN(featuresB, featuresA, ratio=0.75, method=feature_extractor)if len(matches) < 10:return None, NonematchCount = len(matches)M = getHomography(kpsA, kpsB, matches, reprojThresh=4)if M is None:print("Error!")(matches, H, status) = Mresult = cv2.warpPerspective(imageA, H,((imageA.shape[1] + imageB.shape[1]) * 2, (imageA.shape[0] + imageB.shape[0]) * 2))# 合并图片-相同的区域选取最大值,从而实现融合result[0:imageB.shape[0], 0:imageB.shape[1]] = np.maximum(imageB, result[0:imageB.shape[0], 0:imageB.shape[1]])result = cutBlack(result) # 结果去除黑边return result, matchCount# 合并多张图
def handleMulti(*args):l = len(args)assert (l > 1)# isHandle用于标记图片是否参与合并isHandle = [0 for i in range(l - 1)]nowPic = args[0]args = args[1:]for j in range(l - 1):isHas = False # 在一轮中是否找到matchCountList = []resultList = []indexList = []for i in range(l - 1):if isHandle[i] == 1:continueresult, matchCount = handle(nowPic, args[i])if not result is None:matchCountList.append(matchCount) # matchCountList存储两图匹配的特征点resultList.append(result)indexList.append(i)isHas = Trueif not isHas: # 一轮找完都没有可以合并的return Noneelse:index = matchCountList.index(max(matchCountList))nowPic = resultList[index]isHandle[indexList[index]] = 1print(f"合并第{indexList[index] + 2}个")return nowPicif __name__ == "__main__":start_time_all = time.time()# 传入图片路径列表,既可以处理两张,也可以处理多张result = handleMulti("./input/foto2B.jpg", "./input/foto2A.jpg")if not result is None:cv2.imwrite("output.tif", result[:, :, [0, 1, 2]])else:print("没有找到对应特征点,无法合并")end_time_all = time.time()print("共耗时" + str(end_time_all - start_time_all))
实验结果
拿原仓库中的两张无人机图片进行了测试,拼接效果如下:
两张原图:

拼接后的图像:

此外,我选取了更大分辨率(4k x 7k)的图像进行拼接测试,比较不同算法的所用时间,结果如下表所示:
| 特征提取算法 | 匹配器 | 特征点个数 | 时间(s) |
|---|---|---|---|
| sift | bf | 14438 | 463 |
| brisk | bf | 9648 | 31.83 |
| orb | bf | 109 | 20.57 |
| akaze | bf | 4872 | 26.58 |
| brisk | flann | 5000 | 24.71 |
| orb | flann | 50 | 22.02 |
结论
经过此番实验,可以发现:
- 从速度上来说orb算法是最快的,比sift这种古老的算法快了一个数量级。但是通过观察生成的图像质量会发现,orb的图像会比较模糊,拼接质量不如其它算法高,增加速度的同时会牺牲部分质量。
- akaze算法速度和质量和brisk相差不大
- flann匹配器比bf匹配器通常情况下速度更快
因此,后续实验可以首选brisk算法+flann匹配器的组合方式。
另外说明,上面这些实验参数并没有针对性的进行调参,基本使用默认参数;若进行调优,可能会结果会发生一定变化。
Todo
- 此示例中,默认图像位置是未知的,而在遥感图像中,可以通过gps坐标来确定图像的大致方位,后续考虑引进gps坐标,构建图像排布坐标系,从而加快配准速度。
- 此示例中,多图拼接是直接用大图和小图去做配准,效率并不是太高。后续可能可以结合gps信息,从大图中挖出一部分小图来做配准。
参考文献
[1] BRISK特征点描述算法详解 https://blog.csdn.net/weixin_41063476/article/details/90407916
[2] 基于视觉的特征匹配算法(持续更新)https://zhuanlan.zhihu.com/p/147325381?ivk_sa=1024320u
[3] BRISK算法学习笔记 https://blog.csdn.net/weixin_40196271/article/details/84143545
[4] 【OpenCV 例程 300篇】246. 特征检测之ORB算法 https://blog.csdn.net/youcans/article/details/128033070
[5] 一种无人机滑坡遥感影像的快速匹配算法 https://mp.weixin.qq.com/s?__biz=MzIxOTY4NDQ1MA==&mid=2247493784&idx=1&sn=65676fc368e6b4fa62c965a996f956ef
[6]【OpenCV 例程 300篇】251. 特征匹配之暴力匹配 https://blog.csdn.net/youcans/article/details/128253435
[7] 以图搜图–基于FLANN特征匹配 https://zhuanlan.zhihu.com/p/520575652
[8] [opencv] BF匹配器和Flann匹配器 https://blog.csdn.net/simonyucsdy/article/details/112682566
[9] 基于opencv的图像拼接 https://blog.csdn.net/qq_30111427/article/details/121127233
相关文章:
【图像配准】多图配准/不同特征提取算法/匹配器比较测试
前言 本文首先完成之前专栏前置博文未完成的多图配准拼接任务,其次对不同特征提取器/匹配器效率进行进一步实验探究。 各类算法原理简述 看到有博文[1]指出,在速度方面SIFT<SURF<BRISK<FREAK<ORB,在对有较大模糊的图像配准时&…...
2023金三银四季跳槽季,啃完这软件测试面试题,跳槽不就稳稳的了
前言 2023年也到来了,接近我们所说的“金三银四”也正在执行了,时间晃眼就过去了,有的人为了2023跳槽早早做足了准备,有的人在临阵磨刀,想必屏幕前的你也想在2023年涨薪吧,那么问题来了,怎么才…...
【C++详解】——vector类
📖 前言:本期介绍vector类。 目录🕒 1. vector的介绍🕒 2. vector的使用🕘 2.1 定义🕘 2.2 iterator🕘 2.3 空间增长🕘 2.4 增删查改🕒 2. vector的模拟实现🕘…...
uniapp 离线本地打包
uniapp打包教程地址 https://nativesupport.dcloud.net.cn/AppDocs/usesdk/android.html点击查看 需要的环境: java (1.8)离线SDK(上面的连接下载即可)Android Studio(同上) 配置环境变量 依次点击“计算机”-“属性”&#…...
)
初识马尔科夫模型(Markov Model)
初识马尔科夫模型(Markov Model)一、概念二、性质三、学习步骤一、概念 马尔科夫模型(Markov Model)是一种概率模型,用于描述随机系统中随时间变化的概率分布。马尔科夫模型基于马尔科夫假设,即当前状态只…...
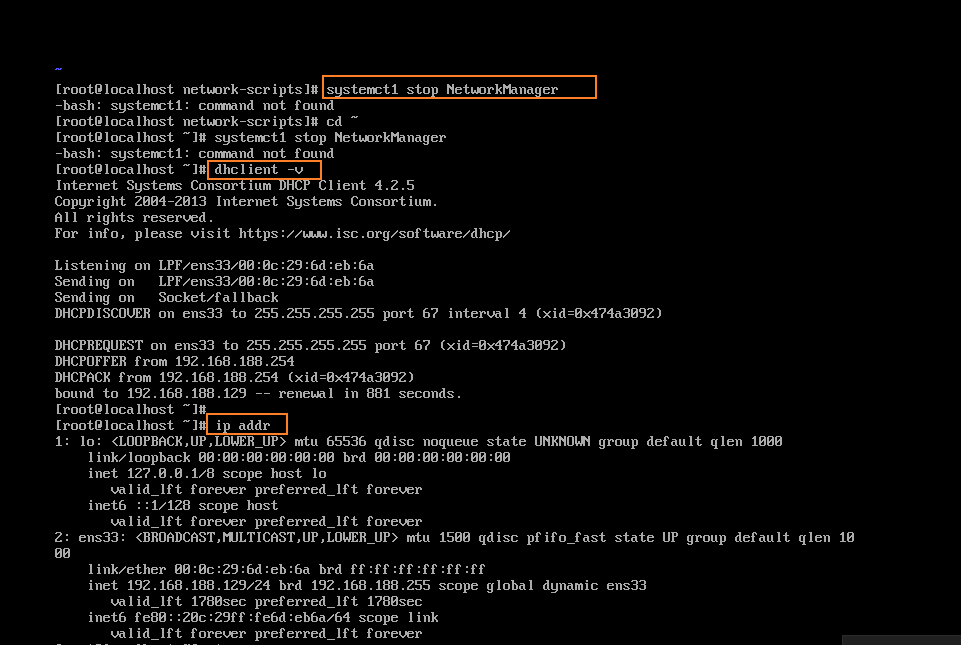
CentOS7 ifconfig(或 ip addr)命令不显示IP地址
问题(因为当时没有存图 所以这个图上是网上找的 )解决办法第一:可能是本地服务没有开启,检查本地服务。如图所示,检查这两个服务是否开启。注:如何快速找到服务 可以把光标放在其中一个上面 然后按下VM就可…...

2023/2/10总结
拓扑排序 拓扑排序是在一个有向无环图(DAG)所有顶点的线性排序。 拓扑排序核心思想非常简单,就是先找一个入度为0的顶点输出,再从图中删除该顶点和以它为起点的有向边。继续上面的操作知道所有的顶点访问完为止。 入度…...

2023最新版!宝塔面板Docker自建Bitwarden密码管理
Powered by:NEFU AB-IN 请一定要结合B站视频食用!!!!,下面的博客总体来说只是起到提纲作用 B站视频链接!!! 文章目录2023最新版!宝塔面板Docker自建Bitwarden密码管理前…...

【Hello Linux】 Linux基础命令
作者:小萌新 专栏:Linux 作者简介:大二学生 希望能和大家一起进步! 本篇博客简介:介绍Linux的基础命令 Linux基础命令ls指令lsls -als -dls -ils -sls -lls -nls -Fls -rls -tls -Rls -1总结思维导图pwd指令whoami指令…...
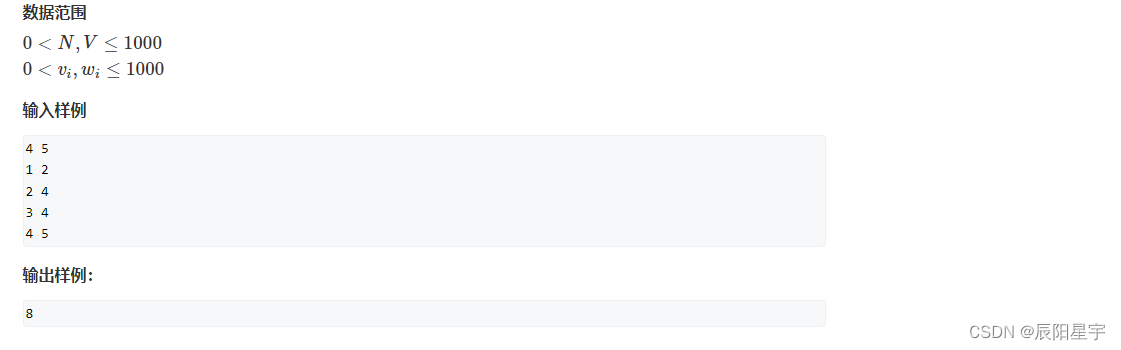
151、【动态规划】leetcode ——2. 01背包问题:二维数组+一维数组(C++版本)
题目描述 原题链接:2. 01背包问题 解题思路 (1)二维dp数组 动态规划五步曲: (1)dp[i][j]的含义: 容量为j时,从物品1-物品i中取物品,可达到的最大价值 (2…...

2023-02-09 - 3 Elasticsearch基础操作
本章主要介绍ES的基础操作,具体包括索引、映射和文档的相关操作。其中,在文档操作中将分别介绍单条操作和批量操作。在生产实践中经常会通过程序对文档进行操作,因此在介绍文档操作时会分别介绍DSL请求形式和Java的高级REST编码形式。 1 索引…...
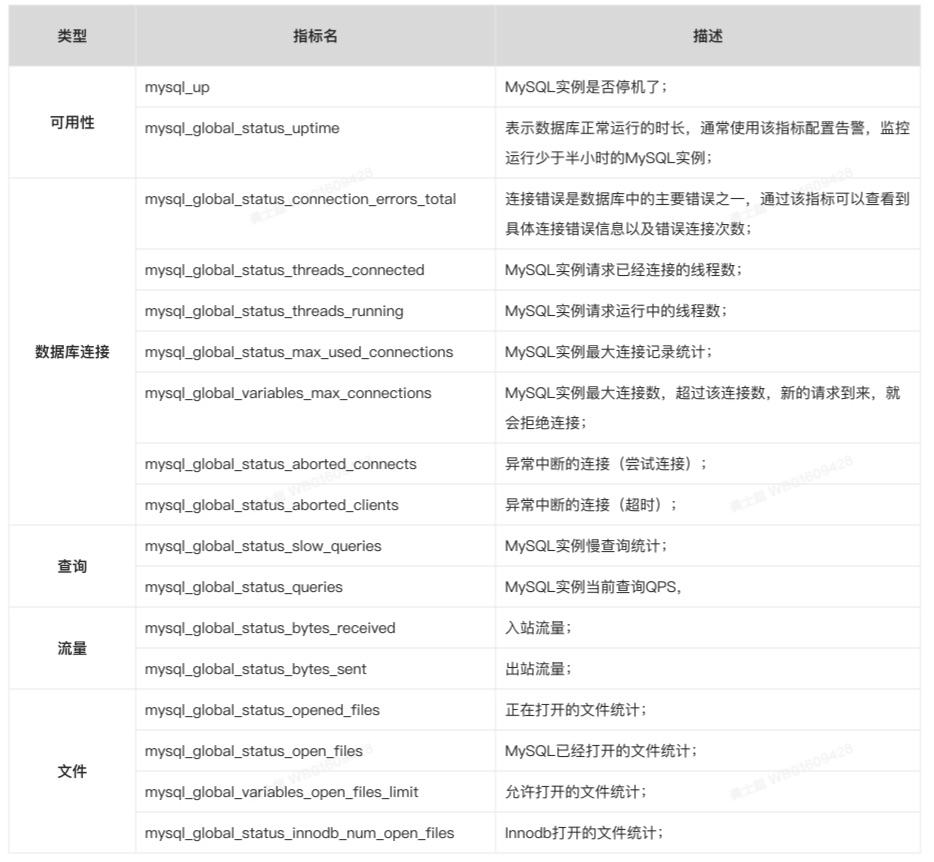
云原生系列之使用 prometheus监控MySQL实战
文章目录前言一. 实验环境二. 安装MySQL5.72.1 配置yum源2.2 安装MySQL之前的环境检查2.3 开始使用yum安装2.4 启动MySQL并测试三. 安装MySQL_exporter3.1 MySQL_exporter的介绍3.2 mysql_exporter的安装3.3 设置MySQL账户,用于数据收集3.4 启动mysql_exporter3.5 配…...
电脑分盘怎么分?分盘详细教程来了,图文教学
电脑作为小伙伴日常生活使用的工具,很多事情都需要使用电脑来进行处理。虽然小伙伴使用电脑比较多,但是还是有不少的小伙伴不知道电脑分盘怎么分?其实电脑分盘很简单,下面小编就以图文教学的方式,详细的向小伙伴介绍电…...
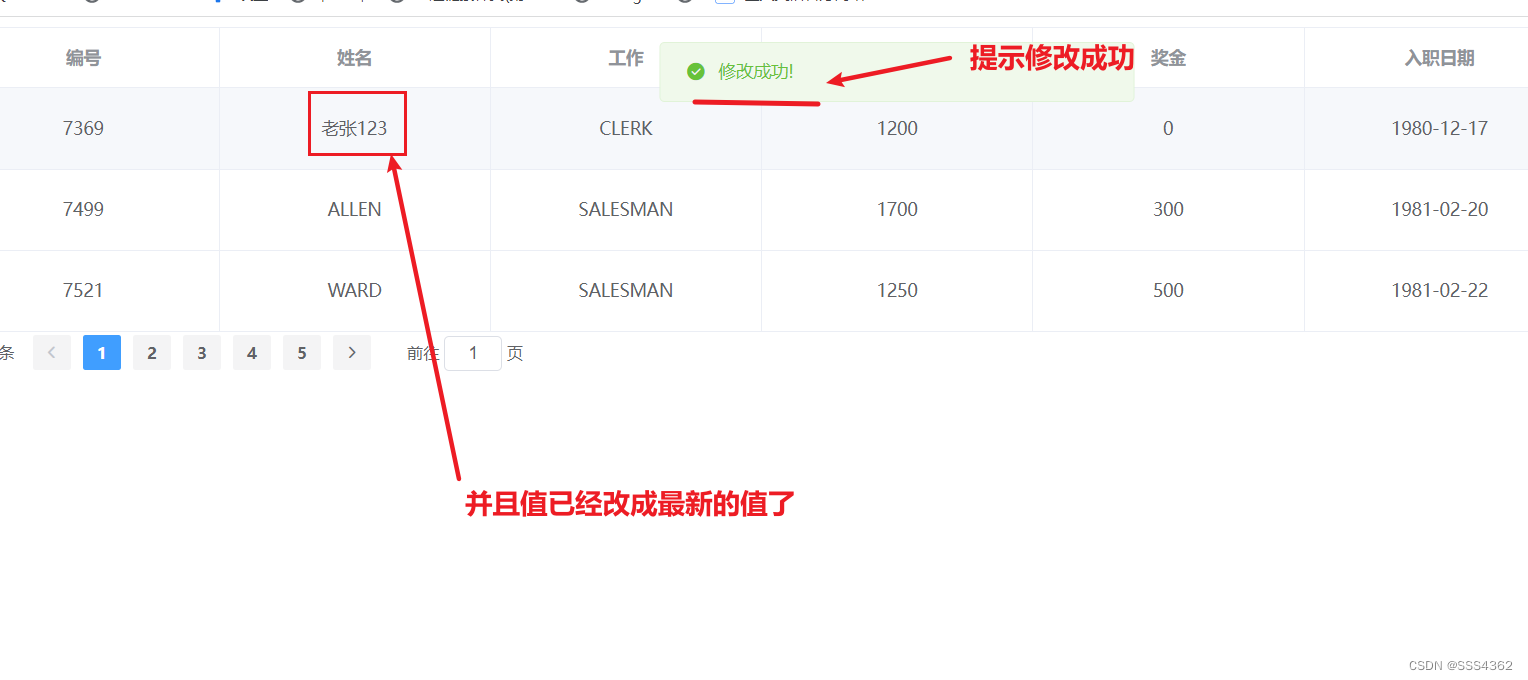
Element UI框架学习篇(四)
Element UI框架学习篇(四) 1 准备工作 1.0 创建Emp表并插入相应数据的sql语句 /*MySQL数据库*/SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS 0;-- ---------------------------- -- Table structure for emp -- ---------------------------- DROP TABLE IF EXISTS emp; CRE…...
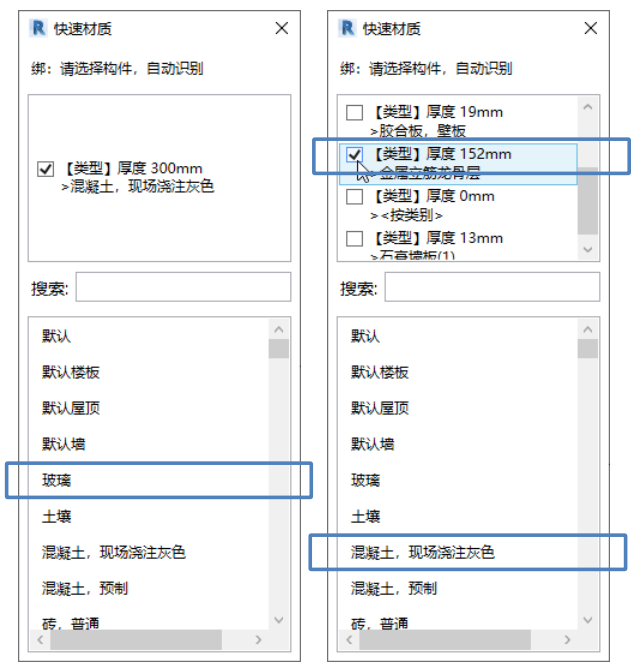
Revit快速材质切换:同一墙面赋予不同材质的方法
一、Revit中对同一墙面赋予不同材质的方法 方法1:零件法 重点:通过工作平面面板上的设置工作平面命令选取正确的面取消勾选通过原始分类的材质,如图1所示 方法2:拆分构造层绘制一道墙体,选择创建的墙体,单击…...
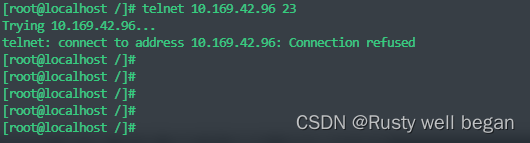
【Linux operation 56】Linux 系统验证端口连通性
linux 系统验证端口连通性 1、前提 Linux系统有时候需要测试某个端口的连通性,然而ping命令只能测试某个IP通不通,不能测试某端口的连通性。 因为ping命令是基于ICMP协议,是计算机网络中的网络层的协议,但是想要测试某个的连通…...
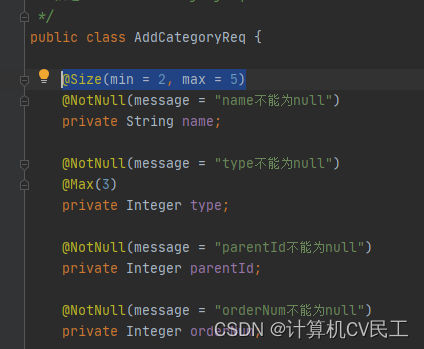
@Valid注解配合属性校验注解完成参数校验并且优化异常处理
Valid注解配合属性校验注解完成参数校验并且优化参数校验异常处理1 Valid注解配合属性校验注解完成参数校验2 优化参数校验异常处理1 Valid注解配合属性校验注解完成参数校验 向数据库商品分类表中新增商品分类字段,并校验传入的参数 不使用注解的传统方法…...

每天一道大厂SQL题【Day08】
每天一道大厂SQL题【Day08】 大家好,我是Maynor。相信大家和我一样,都有一个大厂梦,作为一名资深大数据选手,深知SQL重要性,接下来我准备用100天时间,基于大数据岗面试中的经典SQL题,以每日1题…...

朗润国际期货:2023/2/10今日期市热点及未来焦点
2023/2/10今日期市热点及未来焦点 1月份人 民币贷款增加4.9万亿元 创历史新高 中国央行: 1月份人民币贷款增加4.9万亿元,同比多增9227亿元。分部门看,住户贷款增加2572亿元,其中,短期贷款增加341亿元,中长期贷款增加…...
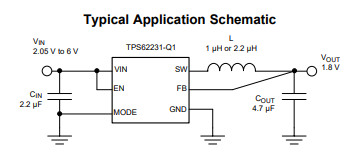
TLV73312PQDRVRQ1稳压器TPS622314TDRYRQ1应用原理图
一、TLV73312PQDRVRQ1低压差稳压器 1.2V 300MATLV733 300mA 低压差稳压器是有 300mA 拉电流能力的超小型、低静态电流 LDO,具有良好的线路和负载瞬态性能。这些器件具有 1% 的典型精度。TLV733 系列设计具有先进的无电容器结构,确保无需输入或输出电容器…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

基于服务器使用 apt 安装、配置 Nginx
🧾 一、查看可安装的 Nginx 版本 首先,你可以运行以下命令查看可用版本: apt-cache madison nginx-core输出示例: nginx-core | 1.18.0-6ubuntu14.6 | http://archive.ubuntu.com/ubuntu focal-updates/main amd64 Packages ng…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...
-HIve数据分析)
大数据学习(132)-HIve数据分析
🍋🍋大数据学习🍋🍋 🔥系列专栏: 👑哲学语录: 用力所能及,改变世界。 💖如果觉得博主的文章还不错的话,请点赞👍收藏⭐️留言Ǵ…...

在QWebEngineView上实现鼠标、触摸等事件捕获的解决方案
这个问题我看其他博主也写了,要么要会员、要么写的乱七八糟。这里我整理一下,把问题说清楚并且给出代码,拿去用就行,照着葫芦画瓢。 问题 在继承QWebEngineView后,重写mousePressEvent或event函数无法捕获鼠标按下事…...

DingDing机器人群消息推送
文章目录 1 新建机器人2 API文档说明3 代码编写 1 新建机器人 点击群设置 下滑到群管理的机器人,点击进入 添加机器人 选择自定义Webhook服务 点击添加 设置安全设置,详见说明文档 成功后,记录Webhook 2 API文档说明 点击设置说明 查看自…...