【机器学习笔记】Python基础笔记
目录
- 基础语法
- 加载数据:pd.read_csv
- 查看数据大小:shape
- 浏览数据行字段:columns
- 浏览少量数据:head()
- 浏览数据概要:describe()
- 基础功能语法
- 缺省值
- 去除缺失值:dropna
- 按行删除:存在空值,即删除该行
- 按行删除:所有数据都为空值,即删除该行
- 按列删除:该列非空元素小于10个的,即去除该列
- 设置子集:去除多列都为空的行
- 分割后删除缺省列:.drop
- 插补:SimpleImputer()
- 插补的扩展
- 选择数据集里的目标
- 单一目标
- 多个目标
- 输出:to_csv
- 分类变量
- 删除分类列:select_dtypes()
- 顺序编码:OrdinalEncoder()
- One-Hot 编码:OneHotEncoder()
- 计算唯一值:unique()和nunique()
- 建模方法
- 基本流程
- 决策树模型:DecisionTreeRegressor
- 定义
- 加载数据
- 分割数据:train_test_split(X, y, random_state = 0)
- 拟合:.fit(train_X, train_y)
- 预测:.predict(val_X)
- 评估:mean_absolute_error(val_y, val_predictions)
- 范例
- 随机森林模型:DecisionTreeRegressor
- 定义
- 拟合:.fit(train_X, train_y)
- 预测:predict(val_X)
- 评估:mean_absolute_error(val_y, melb_preds)
- 范例1
- 范例2
- 简单函数
- 通用的MAE计算
- 随机森林计算MAE
- 复杂函数
- 决策树叶子节点的选择
- 管道:Pipeline
- 介绍
- 使用步骤
- 计算
- 计算数据平局值:round
- 计算日期:datetime
基础语法
加载数据:pd.read_csv
- 加载csv格式的数据,并以pd格式存储
import pandas as pd
# 查看文件相关路径
iowa_file_path = '../input/home-data-for-ml-course/train.csv'
# 读取数据并保存为 DataFrame 格式 ,以train.csv数据为例
home_data = pd.read_csv(iowa_file_path)
查看数据大小:shape
home_data.shape
结果:
(1460, 81)
浏览数据行字段:columns
home_data.columns
结果:
Index(['MSSubClass', 'MSZoning', 'LotFrontage', 'LotArea', 'Street', 'Alley','LotShape', 'LandContour', 'Utilities', 'LotConfig', 'LandSlope','Neighborhood', 'Condition1', 'Condition2', 'BldgType', 'HouseStyle','OverallQual', 'OverallCond', 'YearBuilt', 'YearRemodAdd', 'RoofStyle','RoofMatl', 'Exterior1st', 'Exterior2nd', 'MasVnrType', 'MasVnrArea','ExterQual', 'ExterCond', 'Foundation', 'BsmtQual', 'BsmtCond','BsmtExposure', 'BsmtFinType1', 'BsmtFinSF1', 'BsmtFinType2','BsmtFinSF2', 'BsmtUnfSF', 'TotalBsmtSF', 'Heating', 'HeatingQC','CentralAir', 'Electrical', '1stFlrSF', '2ndFlrSF', 'LowQualFinSF','GrLivArea', 'BsmtFullBath', 'BsmtHalfBath', 'FullBath', 'HalfBath','BedroomAbvGr', 'KitchenAbvGr', 'KitchenQual', 'TotRmsAbvGrd','Functional', 'Fireplaces', 'FireplaceQu', 'GarageType', 'GarageYrBlt','GarageFinish', 'GarageCars', 'GarageArea', 'GarageQual', 'GarageCond','PavedDrive', 'WoodDeckSF', 'OpenPorchSF', 'EnclosedPorch', '3SsnPorch','ScreenPorch', 'PoolArea', 'PoolQC', 'Fence', 'MiscFeature', 'MiscVal','MoSold', 'YrSold', 'SaleType', 'SaleCondition'],dtype='object')
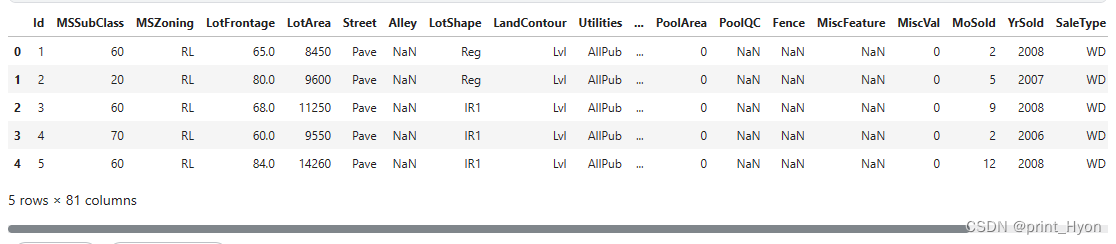
浏览少量数据:head()
- 查看前五行数据
home_data.head()
结果:
浏览数据概要:describe()
- 打印pd格式存储的数据
# 打印 home_data 的数据集
home_data.describe()
- 结果:
Rooms Price Distance Postcode Bedroom2 \
count 13580.000000 1.358000e+04 13580.000000 13580.000000 13580.000000
mean 2.937997 1.075684e+06 10.137776 3105.301915 2.914728
std 0.955748 6.393107e+05 5.868725 90.676964 0.965921
min 1.000000 8.500000e+04 0.000000 3000.000000 0.000000
25% 2.000000 6.500000e+05 6.100000 3044.000000 2.000000
50% 3.000000 9.030000e+05 9.200000 3084.000000 3.000000
75% 3.000000 1.330000e+06 13.000000 3148.000000 3.000000
max 10.000000 9.000000e+06 48.100000 3977.000000 20.000000 Bathroom Car Landsize BuildingArea YearBuilt \
count 13580.000000 13518.000000 13580.000000 7130.000000 8205.000000
mean 1.534242 1.610075 558.416127 151.967650 1964.684217
std 0.691712 0.962634 3990.669241 541.014538 37.273762
min 0.000000 0.000000 0.000000 0.000000 1196.000000
25% 1.000000 1.000000 177.000000 93.000000 1940.000000
50% 1.000000 2.000000 440.000000 126.000000 1970.000000
75% 2.000000 2.000000 651.000000 174.000000 1999.000000
max 8.000000 10.000000 433014.000000 44515.000000 2018.000000 Lattitude Longtitude Propertycount
count 13580.000000 13580.000000 13580.000000
mean -37.809203 144.995216 7454.417378
std 0.079260 0.103916 4378.581772
min -38.182550 144.431810 249.000000
25% -37.856822 144.929600 4380.000000
50% -37.802355 145.000100 6555.000000
75% -37.756400 145.058305 10331.000000
max -37.408530 145.526350 21650.000000 - 结果解释:
- 这部分为数据的概要,描述每个字段的基本情况,最顶行是数据集里的每一个字段,左侧第一列是每个字段的基本情况,每个字段有8个数字。
- 第一个数字count,显示了有多少行没有缺失值。
- 缺失值的原因有很多。例如,在调查一套一居室的房子时,不会收集第二居室(Bedroom2)的大小。这套房子的第二居室的count值就不会计算该套房子。
- 第二个值是mean,它是平均值。在这种情况下,std是标准偏差,用于测量数值在数值上的分布情况。
- min、25%、50%、75%和max:请想象将每列从最低值到最高值进行排序。第一个值就是最小值min,最后一个值就是最大值max。如果你在列表中遍历四分之一个,它就是25%的值(比如10000个数据,第2500个数据就是25%值),第50%和第75%值的定义类似。
基础功能语法
缺省值
去除缺失值:dropna
去除结束最好借助home_data.shape检查一下去掉了多少
按行删除:存在空值,即删除该行
- 如果有一项数值不存在,则判定为缺失值,进行删除。
- 去除前需要确定不要有某一列数据全部缺失
home_data = home_data.dropna(axis=0)
按行删除:所有数据都为空值,即删除该行
- 如果有一项数值不存在,则判定为缺失值,进行删除。
- 去除前需要确定不要有某一列数据全部缺失
home_data = home_data.dropna(axis=0)
或
home_data = home_data.dropna(axis=0,how='any')
按列删除:该列非空元素小于10个的,即去除该列
home_data = home_data.dropna(axis='columns', thresh=10)
设置子集:去除多列都为空的行
- 将列Alley和FireplaceQu为空的行去除
home_data = home_data.dropna(axis='index', how='all', subset=['Alley','FireplaceQu'])
分割后删除缺省列:.drop
- 当我们分割好了训练集和验证集,已经进行了一系列操作,这时我们想知道同一训练集和验证集,删除缺省列比不删除缺省列的MAE值是否会更优秀,我们可以通过下述语句来检验。
# 获取缺少值的列的名称
cols_with_missing = [col for col in X_train.columnsif X_train[col].isnull().any()]# 删除训练和验证数据中的列
reduced_X_train = X_train.drop(cols_with_missing, axis=1)
reduced_X_valid = X_valid.drop(cols_with_missing, axis=1)
print("删除缺省列后的MAE值:")
print(score_dataset(reduced_X_train, reduced_X_valid, y_train, y_valid))
插补:SimpleImputer()
- 将缺少的值替换为每列的平均值。
- SimpleImputer可以携带的参数
- missing_values:int, float, str, (默认)np.nan或是None, 即缺失值是什么。
- strategy:默认为mean,还有median、most_frequent、constant
- mean表示该列的缺失值由该列的均值填充
- median为中位数
- most_frequent为众数
- constant表示将空值填充为自定义的值,但这个自定义的值要通过fill_value来定义。
- fill_value:str或数值,默认为Zone。当strategy == “constant"时,fill_value被用来替换所有出现的缺失值(missing_values)。fill_value为Zone,当处理的是数值数据时,缺失值(missing_values)会替换为0,对于字符串或对象数据类型则替换为"missing_value” 这一字符串。
- verbose:int,(默认)0,控制imputer的冗长。
- copy:boolean,(默认)True,表示对数据的副本进行处理,False对数据原地修改。
- add_indicator:boolean,(默认)False,True则会在数据后面加入n列由0和1构成的同样大小的数据,0表示所在位置非缺失值,1表示所在位置为缺失值
from sklearn.impute import SimpleImputer# 插补,生成新的训练特征和验证特征,暂时没有列名
my_imputer = SimpleImputer()
imputed_X_train = pd.DataFrame(my_imputer.fit_transform(X_train))
imputed_X_valid = pd.DataFrame(my_imputer.transform(X_valid))# 对新的训练特征和验证特征赋予真实的列名
imputed_X_train.columns = X_train.columns
imputed_X_valid.columns = X_valid.columnsprint("插补后的MAE值:")
print(score_dataset(imputed_X_train, imputed_X_valid, y_train, y_valid))插补的扩展
- 我们像以前一样对缺失的值进行插补,之后,对于原始数据集中缺少条目的每一列,我们添加一个新列,显示该条目是否为缺失后进行插补的值。
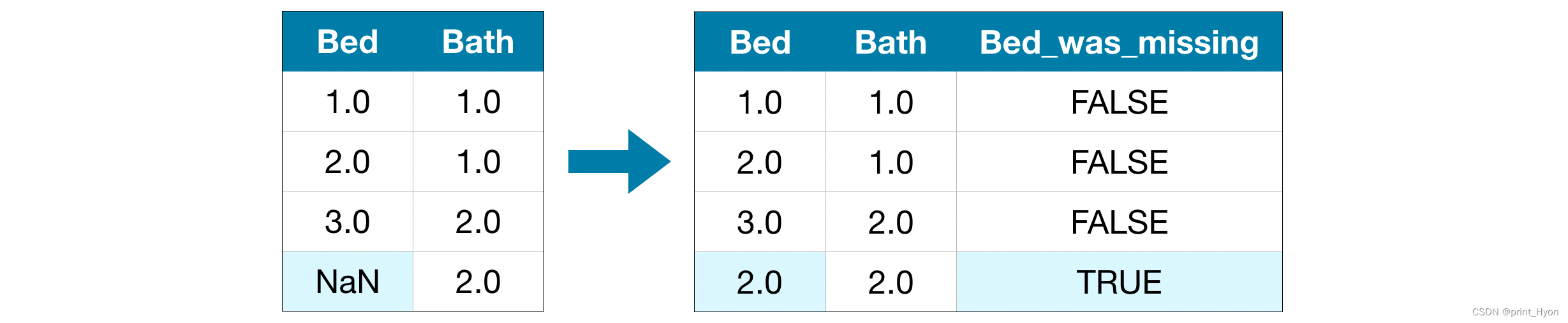
# 制作副本以避免更改原始数据(输入时)
X_train_plus = X_train.copy()
X_valid_plus = X_valid.copy()# 制作新的栏目,标明因缺省需要新增的列
for col in cols_with_missing:X_train_plus[col + '_was_missing'] = X_train_plus[col].isnull()X_valid_plus[col + '_was_missing'] = X_valid_plus[col].isnull()# 插补,生成新的训练特征和验证特征,暂时没有列名
my_imputer = SimpleImputer()
imputed_X_train_plus = pd.DataFrame(my_imputer.fit_transform(X_train_plus))
imputed_X_valid_plus = pd.DataFrame(my_imputer.transform(X_valid_plus))# 对新的训练特征和验证特征赋予真实的列名
imputed_X_train_plus.columns = X_train_plus.columns
imputed_X_valid_plus.columns = X_valid_plus.columnsprint("插补扩展后的MAE值:")
print(score_dataset(imputed_X_train_plus, imputed_X_valid_plus, y_train, y_valid))选择数据集里的目标
单一目标
- 直接用
.取出目标值- 该方法适仅用于英文
y = home_data.Price
- 用中括号加引号
- 该方法适用于中文和英文
y = home_data.['Price']
结果:
- Price为特征,数据集里全部的Price称为目标,结果为列表
1 181500
2 223500
3 140000
4 250000
6 307000...
1451 287090
1454 185000
1455 175000
1456 210000
1457 266500
通常预测结果我们定义为:y
多个目标
- 定义特征,选择目标
- 变量X具有包含’LotArea’, 'LotConfig’两个特征的数据集
home_data_features = ['LotArea', 'LotConfig']
X = home_data[home_data_features]
结果:
LotArea LotConfig
1 9600 FR2
2 11250 Inside
3 9550 Corner
4 14260 FR2
6 10084 Inside
... ... ...
1451 9262 Inside
1454 7500 Inside
1455 7917 Inside
1456 13175 Inside
1457 9042 Inside
通常已知数据集我们定义为:X
输出:to_csv
- 生成一个CSV文件submission.csv,包含Id和SalePrice
output = pd.DataFrame({'Id': test_data.Id,'SalePrice': test_preds})
output.to_csv('submission.csv', index=False)
分类变量
- 如果数据不是数值,则需要进行特殊处理
- 一般来说,one-hot编码的性能通常最好,删除分类列的性能通常最差,但具体情况会有所不同。
删除分类列:select_dtypes()
- 删除非数值
drop_X_train = X_train.select_dtypes(exclude=['object'])
drop_X_valid = X_valid.select_dtypes(exclude=['object'])print("MAE值:")
print(score_dataset(drop_X_train, drop_X_valid, y_train, y_valid))
顺序编码:OrdinalEncoder()
from sklearn.preprocessing import OrdinalEncoder# 制作副本以避免更改原始数据
label_X_train = X_train.copy()
label_X_valid = X_valid.copy()# 对包含分类数据的每一列应用顺序编码器
ordinal_encoder = OrdinalEncoder()
label_X_train[object_cols] = ordinal_encoder.fit_transform(X_train[object_cols])
label_X_valid[object_cols] = ordinal_encoder.transform(X_valid[object_cols])print("MAE值:")
print(score_dataset(label_X_train, label_X_valid, y_train, y_valid))One-Hot 编码:OneHotEncoder()
- 设置handle_unknown='ignore’以避免验证数据包含训练数据中未表示的类时出错
- 设置sparse=False可确保编码的列作为numpy数组(而不是稀疏矩阵)返回。
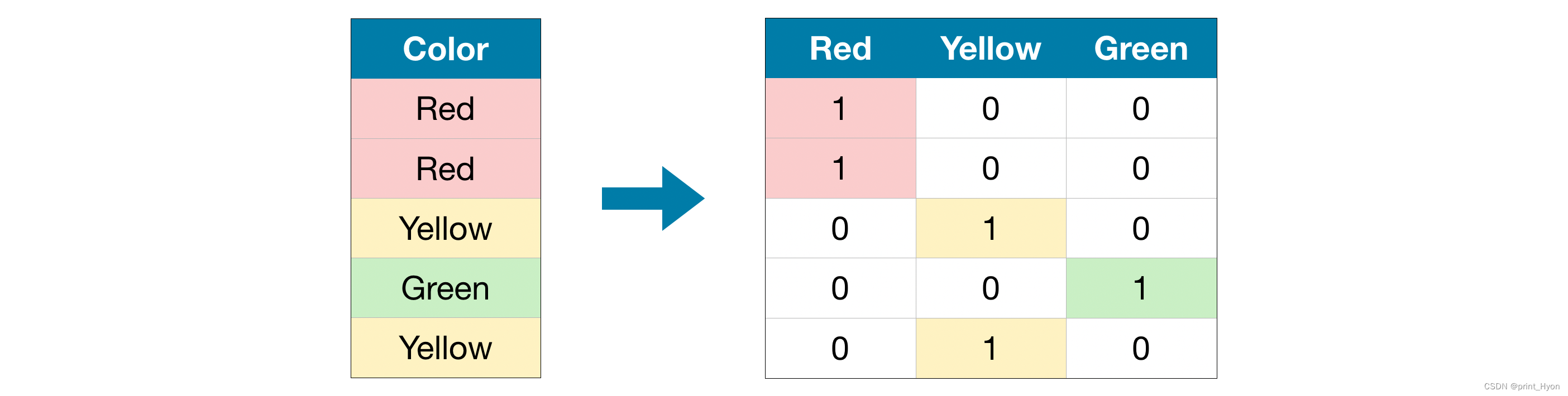
from sklearn.preprocessing import OneHotEncoder# 对包含分类数据的每一列生成one-hot编码列
OH_encoder = OneHotEncoder(handle_unknown='ignore', sparse=False)
OH_cols_train = pd.DataFrame(OH_encoder.fit_transform(X_train[object_cols]))
OH_cols_valid = pd.DataFrame(OH_encoder.transform(X_valid[object_cols]))# One-hot编码索引重置
OH_cols_train.index = X_train.index
OH_cols_valid.index = X_valid.index# 删除原始分类列,比如Color列
num_X_train = X_train.drop(object_cols, axis=1)
num_X_valid = X_valid.drop(object_cols, axis=1)# 将one-hot编码列加入其中,比如Red\Yellow\Green
OH_X_train = pd.concat([num_X_train, OH_cols_train], axis=1)
OH_X_valid = pd.concat([num_X_valid, OH_cols_valid], axis=1)print("MAE值:")
print(score_dataset(OH_X_train, OH_X_valid, y_train, y_valid))计算唯一值:unique()和nunique()
- unique()方法返回的是去重之后的不同值
- nunique()方法则直接返回不同值的个数
- dropna为True时不包含空值,为False时包含空值
import pandas as pd
import numpy as np
s1 = pd.Series(['A', 7, 6, 3, 4, 1, 2, 3, 5, 4, 1, 1])
print('s1中不同值s1.unique():', s1.unique())
print('s1中不同值的个数len(s1.unique()):', len(s1.unique()))
print('s1中不同值的个数s1.nunique():', s1.nunique())# 当存在Nan、None时
print('='*30)
s2 = pd.Series(['A', 7, 6, 3, np.NAN, np.NaN,4, 1, 2, 3, 5, 4, 1, 1, pd.NaT, None])
print('s2中不同值s2.unique():', s2.unique())
print('s2中不同值的个数len(s2.unique()):', len(s2.unique()))
print('s2中不同值的个数s2.nunique():', s2.nunique())
print('s2中不同值的个数(包含空值)s2.nunique(dropna=False):', s2.nunique(dropna=False))
print('s2中不同值的个数(不包含空值)s2.nunique(dropna=True):', s2.nunique(dropna=True))
结果:
s1中不同值s1.unique(): ['A' 7 6 3 4 1 2 5]
s1中不同值的个数len(s1.unique()): 8
s1中不同值的个数s1.nunique(): 8
==============================
s2中不同值s2.unique(): ['A' 7 6 3 nan 4 1 2 5 NaT None]
s2中不同值的个数len(s2.unique()): 11
s2中不同值的个数s2.nunique(): 8
s2中不同值的个数(包含空值)s2.nunique(dropna=False): 11
s2中不同值的个数(不包含空值)s2.nunique(dropna=True): 8
建模方法
基本流程
- 定义:它将是什么类型的模型?决策树、随机森林等模型,以及定义模型的一些基本参数。
- 拟合:从提供的数据集中捕获模式。
- 预测:预测想要的数值。
- 评估:确定模型预测的准确性。
决策树模型:DecisionTreeRegressor
- 拟合过程不能处理非数值字段,数据集中若有字母、符号、中文等,需要进行特殊处理
定义
- 决策树是一种非参数的有监督学习方法,它能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题。决策树中每个内部节点表示一个属性上的判断,每个分支代表一个判断结果的输出,最后每个叶节点代表一种分类结果。
加载数据
from sklearn.tree import DecisionTreeRegressor# 定义模型为random_state指定一个数字,以确保每次运行的结果相同
iowa_model= DecisionTreeRegressor(random_state=1)# 预测目标:价格
y = home_data.SalePrice# 模型特征
feature_names = ["LotArea", "YearBuilt", "1stFlrSF", "2ndFlrSF","FullBath", "BedroomAbvGr", "TotRmsAbvGrd"]
# 定义特征集
X=home_data[feature_names]分割数据:train_test_split(X, y, random_state = 0)
- X:特征集
- y:目标集
- train_X:训练特征集
- val_X:验证特征集
- train_y:训练目标集
- val_y :验证目标集
- random_state:参数值保证每次得到相同的分割的数据
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 0)
其他参数介绍:
- train_size:训练集占比,训练集占数据集的比重,如果是整数的话就是训练的数量
- test_size:验证集占比,验证集占数据集的比重,如果是整数的话就是验证的数量
拟合:.fit(train_X, train_y)
iowa_model.fit(train_X, train_y)
预测:.predict(val_X)
- 在验证数据上获得预测值
val_predictions = iowa_model.predict(val_X)
评估:mean_absolute_error(val_y, val_predictions)
- 计算验证数据中的平均绝对误差
val_mae = mean_absolute_error(val_y, val_predictions)
范例
https://www.kaggle.com/code/hyon666666/exercise-underfitting-and-overfitting?scriptVersionId=119421539
# Code you have previously used to load data
import pandas as pd
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor# Path of the file to read
iowa_file_path = '../input/home-data-for-ml-course/train.csv'home_data = pd.read_csv(iowa_file_path)
# Create target object and call it y
y = home_data.SalePrice
# Create X
features = ['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd']
X = home_data[features]# Split into validation and training data
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1)# Specify Model
iowa_model = DecisionTreeRegressor(random_state=1)
# Fit Model
iowa_model.fit(train_X, train_y)# Make validation predictions and calculate mean absolute error
val_predictions = iowa_model.predict(val_X)
val_mae = mean_absolute_error(val_predictions, val_y)
print("Validation MAE: {:,.0f}".format(val_mae))# Set up code checking
from learntools.core import binder
binder.bind(globals())
from learntools.machine_learning.ex5 import *
print("\nSetup complete")def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)model.fit(train_X, train_y)preds_val = model.predict(val_X)mae = mean_absolute_error(val_y, preds_val)return(mae)candidate_max_leaf_nodes = [5, 25, 50, 100, 250, 500]
# Write loop to find the ideal tree size from candidate_max_leaf_nodes
scores = {leaf_size: get_mae(leaf_size, train_X,val_X, train_y, val_y) for leaf_size in candidate_max_leaf_nodes}# Store the best value of max_leaf_nodes (it will be either 5, 25, 50, 100, 250 or 500)
best_tree_size = min(scores, key=scores.get)# Fill in argument to make optimal size and uncomment
final_model =DecisionTreeRegressor(max_leaf_nodes=best_tree_size, random_state=1)# fit the final model and uncomment the next two lines
final_model.fit(X, y)
随机森林模型:DecisionTreeRegressor
定义
import pandas as pd# 获取数据
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# 筛选缺少值的行
melbourne_data = melbourne_data.dropna(axis=0)
# 选择模板及特征
y = melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea', 'YearBuilt', 'Lattitude', 'Longtitude']
X = melbourne_data[melbourne_features]from sklearn.model_selection import train_test_split# 拆分数据为训练集和验证集
train_X, val_X, train_y, val_y = train_test_split(X, y,random_state = 0)
拟合:.fit(train_X, train_y)
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_errorforest_model = RandomForestRegressor(random_state=1)
forest_model.fit(train_X, train_y)
预测:predict(val_X)
melb_preds = forest_model.predict(val_X)
print(mean_absolute_error(val_y, melb_preds))
评估:mean_absolute_error(val_y, melb_preds)
- 计算验证数据中的平均绝对误差
val_mae = mean_absolute_error(val_y, melb_preds)
范例1
# Set up code checking
from learntools.core import binder
binder.bind(globals())
from learntools.machine_learning.ex7 import *# Set up filepaths
import os
if not os.path.exists("../input/train.csv"):os.symlink("../input/home-data-for-ml-course/train.csv", "../input/train.csv") os.symlink("../input/home-data-for-ml-course/test.csv", "../input/test.csv") # Import helpful libraries
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error
from sklearn.model_selection import train_test_split# Load the data, and separate the target
iowa_file_path = '../input/train.csv'
home_data = pd.read_csv(iowa_file_path)
y = home_data.SalePrice# Create X (After completing the exercise, you can return to modify this line!)
features = ['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd']# Select columns corresponding to features, and preview the data
X = home_data[features]
X.head()# Split into validation and training data
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state=1)# Define a random forest model
rf_model = RandomForestRegressor(random_state=1)
rf_model.fit(train_X, train_y)
rf_val_predictions = rf_model.predict(val_X)
rf_val_mae = mean_absolute_error(rf_val_predictions, val_y)print("Validation MAE for Random Forest Model: {:,.0f}".format(rf_val_mae))范例2
- 获取数据
# Set up code checking
import os
if not os.path.exists("../input/train.csv"):os.symlink("../input/home-data-for-ml-course/train.csv", "../input/train.csv") os.symlink("../input/home-data-for-ml-course/test.csv", "../input/test.csv")
from learntools.core import binder
binder.bind(globals())
from learntools.ml_intermediate.ex1 import *
print("Setup Complete")- 分割数据
import pandas as pd
from sklearn.model_selection import train_test_split# Read the data
X_full = pd.read_csv('../input/train.csv', index_col='Id')
X_test_full = pd.read_csv('../input/test.csv', index_col='Id')# Obtain target and predictors
y = X_full.SalePrice
features = ['LotArea', 'YearBuilt', '1stFlrSF', '2ndFlrSF', 'FullBath', 'BedroomAbvGr', 'TotRmsAbvGrd']
X = X_full[features].copy()
X_test = X_test_full[features].copy()# Break off validation set from training data
X_train, X_valid, y_train, y_valid = train_test_split(X, y, train_size=0.8, test_size=0.2,random_state=0)
- 查看部分数据
X_train.head()
'''
LotArea YearBuilt 1stFlrSF 2ndFlrSF FullBath BedroomAbvGr TotRmsAbvGrd
Id
619 11694 2007 1828 0 2 3 9
871 6600 1962 894 0 1 2 5
93 13360 1921 964 0 1 2 5
818 13265 2002 1689 0 2 3 7
303 13704 2001 1541 0 2 3 6
'''
- 定义了五种不同的随机森林模型
from sklearn.ensemble import RandomForestRegressor# Define the models
model_1 = RandomForestRegressor(n_estimators=50, random_state=0)
model_2 = RandomForestRegressor(n_estimators=100, random_state=0)
model_3 = RandomForestRegressor(n_estimators=100, criterion='mae', random_state=0)
model_4 = RandomForestRegressor(n_estimators=200, min_samples_split=20, random_state=0)
model_5 = RandomForestRegressor(n_estimators=100, max_depth=7, random_state=0)models = [model_1, model_2, model_3, model_4, model_5]
- 定义一个MAE计算函数
from sklearn.metrics import mean_absolute_error# Function for comparing different models
def score_model(model, X_t=X_train, X_v=X_valid, y_t=y_train, y_v=y_valid):model.fit(X_t, y_t)preds = model.predict(X_v)return mean_absolute_error(y_v, preds)
- 计算每一个随机森林的MAE
for i in range(0, len(models)):mae = score_model(models[i])print("Model %d MAE: %d" % (i+1, mae))
简单函数
通用的MAE计算
- model:模型
- X_t:函数内部变量,代表验证特征
- X_train:函数外部变量,代表训练特征
- X_t=X_train:调用此函数时,无需输入该变量,会自动获取上文中的X_train,赋值给X_t,其他用法同理
- y_t:函数内部变量,代表验证集
- y_valid:函数外部变量,代表训练集
- 函数使用方法:mae = score_model(model)
from sklearn.metrics import mean_absolute_error# Function for comparing different models
def score_model(model, X_t=X_train, X_v=X_valid, y_t=y_train, y_v=y_valid):model.fit(X_t, y_t)preds = model.predict(X_v)return mean_absolute_error(y_v, preds)
随机森林计算MAE
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error# Function for comparing different approaches
def score_dataset(X_train, X_valid, y_train, y_valid):model = RandomForestRegressor(n_estimators=10, random_state=0)model.fit(X_train, y_train)preds = model.predict(X_valid)return mean_absolute_error(y_valid, preds)
复杂函数
决策树叶子节点的选择
- 决策树叶子节点选择过大或过小,会导致出现过拟合或欠拟合问题
- 过拟合:捕捉未来不会再次出现的虚假模式,导致预测不太准确
- 欠拟合:未能捕捉相关模式,再次导致预测不准确。
- 使用工具函数来帮助比较max_leaf_nodes不同值的MAE分数
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressordef get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)model.fit(train_X, train_y)preds_val = model.predict(val_X)mae = mean_absolute_error(val_y, preds_val)return(mae)
- 使用for循环来比较用max_leaf_nodes的不同值构建的模型的精度。
# 不同的max_leaf_nodes对应不同的 MAE
for max_leaf_nodes in [5, 50, 500, 5000]:my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))
- 结果
Max leaf nodes: 5 Mean Absolute Error: 347380
Max leaf nodes: 50 Mean Absolute Error: 258171
Max leaf nodes: 500 Mean Absolute Error: 243495
Max leaf nodes: 5000 Mean Absolute Error: 254983
由此可以得出,500是一个比较合适的叶子节点
- 更精简的使用方法
# 叶子节点集合
candidate_max_leaf_nodes = [5, 25, 50, 100, 250, 500]
# 一行代码计算叶子节点对应的MAE
scores = {leaf_size: get_mae(leaf_size, train_X,val_X, train_y, val_y) for leaf_size in candidate_max_leaf_nodes}
# 选择最合适的叶子节点
best_tree_size = min(scores, key=scores.get)
管道:Pipeline
介绍
管道是保持数据预处理和建模代码井然有序的一种简单方法。具体来说,管道将预处理和建模步骤捆绑在一起,这样您就可以像使用单个步骤一样使用整个包。
使用步骤
- 加载数据
import pandas as pd
from sklearn.model_selection import train_test_split# 读取训练集
X_full = pd.read_csv('../input/train.csv', index_col='Id')
# 读取测试集
X_test_full = pd.read_csv('../input/test.csv', index_col='Id')# 将'SalePrice'列数值为空的行删除
X_full.dropna(axis=0, subset=['SalePrice'], inplace=True)# 将'SalePrice'列数值放到y上
y = X_full.SalePrice# 将'SalePrice'列在X_full上删除
X_full.drop(['SalePrice'], axis=1, inplace=True)# 从训练数据中分离出验证集
X_train_full, X_valid_full, y_train, y_valid = train_test_split(X_full, y, train_size=0.8, test_size=0.2,random_state=0)
- 选择数值列和字符列
# 选择重复值小于10且为object类型的列(一般都是字符串,重复数小于10为了便于分类变量)
categorical_cols = [cname for cname in X_train_full.columns ifX_train_full[cname].nunique() < 10 and X_train_full[cname].dtype == "object"]#选择'int64'和'float64'类型的列
numerical_cols = [cname for cname in X_train_full.columns if X_train_full[cname].dtype in ['int64', 'float64']]
- 创建新的训练集、验证集、测试集
# 创建新的训练集、验证集、测试集,只保留选定的列数据
my_cols = categorical_cols + numerical_cols
X_train = X_train_full[my_cols].copy()
X_valid = X_valid_full[my_cols].copy()
X_test = X_test_full[my_cols].copy()
- 搭建管道
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import OneHotEncoder
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_absolute_error# 数字数据预处理,采用插补的constant策略
numerical_transformer = SimpleImputer(strategy='constant')# 分类数据的预处理,采用插补的most_frequent策略和OneHot编码方法
categorical_transformer = Pipeline(steps=[('imputer', SimpleImputer(strategy='most_frequent')),('onehot', OneHotEncoder(handle_unknown='ignore'))
])# 数值和分类数据的束预处理
# 这里的numerical_cols和categorical_cols是刚才获取到的变量,表示数值类型的列和object类型的列
preprocessor = ColumnTransformer(transformers=[('num', numerical_transformer, numerical_cols),('cat', categorical_transformer, categorical_cols)])# 定义随机森林模型
model = RandomForestRegressor(n_estimators=100, random_state=0)# 在管道中将预处理和建模的代码进行捆绑
clf = Pipeline(steps=[('preprocessor', preprocessor),('model', model)])# 拟合模型
clf.fit(X_train, y_train)# 预测数值
preds = clf.predict(X_valid)# 验证模型
print('MAE:', mean_absolute_error(y_valid, preds))
计算
计算数据平局值:round
- 计算某一列数据的平局值,保留到整数
- home_data为pd:处理过的数据集
- LotArea:数据集的某一字段
avg_lot_size = round(home_data['LotArea'].mean())
计算日期:datetime
- 计算到今天为止,最新的房子最悠久的历史(今年 - 它的建造日期)
- home_data为pd:处理过的数据集
- datetime.datetime.now().year:当前时间
- YearBuilt:在数据集中表示房子建造市场
import datetime
newest_home_age = datetime.datetime.now().year-home_data['YearBuilt'].max()
相关文章:
【机器学习笔记】Python基础笔记
目录基础语法加载数据:pd.read_csv查看数据大小:shape浏览数据行字段:columns浏览少量数据:head()浏览数据概要:describe()基础功能语法缺省值去除缺失值:dropna按行删除:存在空值,即…...

js-DOM03-DOM对CSS的操作
DOM对CSS的操作 - 读取和修改内联样式 - 使用style属性来操作元素的内联样式 - 读取内联样式: 语法:元素.style.样式名 - 例子: 元素.style.width 元素.style.…...

tun驱动之tun_init
tun驱动的初始化方法是tun_init。 static int __init tun_init(void) {int ret 0;pr_info("%s, %s\n", DRV_DESCRIPTION, DRV_VERSION);ret rtnl_link_register(&tun_link_ops);if (ret) {pr_err("Cant register link_ops\n");goto err_linkops;}re…...

模拟退火算法优化bp
%% 基于模拟退火遗传算法优化BP神经网络的钢带厚度预测 clear clc close all format short %% 加载训练数据 Xtrxlsread(train_data.xlsx); DDsize(Xtr,2); input_trainXtr(:,1:DD-1);% output_trainXtr(:,DD);% %% 加载测试数据 Xtexlsread(test_data.xlsx); input_testXte(…...
【NFC音乐相册】简易制作
欢迎来到 Claffic 的博客 💞💞💞 前言: NFC音乐相册在前段时间火了一把,想必大家都听过了,最近我刷到了这个东西,闲来无事就弄了几个,这篇博客就记录下制作工序。 注:我所…...

每日一题——L1-085 试试手气(15)
L1-085 试试手气 我们知道一个骰子有 6 个面,分别刻了 1 到 6 个点。下面给你 6 个骰子的初始状态,即它们朝上一面的点数,让你一把抓起摇出另一套结果。假设你摇骰子的手段特别精妙,每次摇出的结果都满足以下两个条件:…...
FreeRTOS信号量
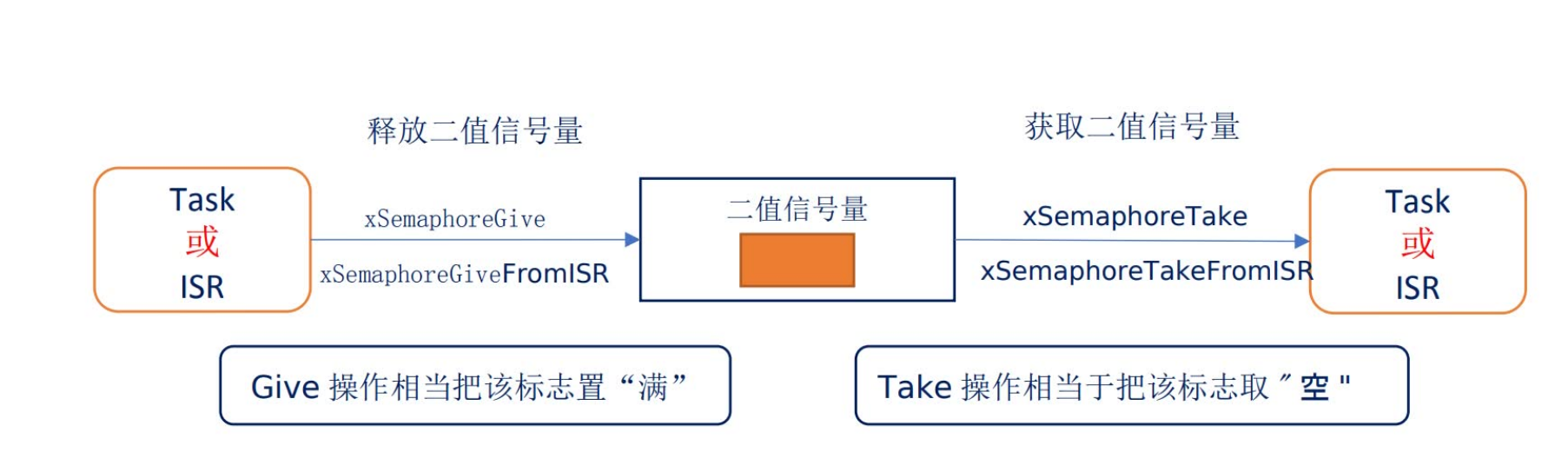
前面介绍过,队列(queue)可以用于传输数据:在任务之间,任务和中断之间。消息队列用于传输多个数据,但是有时候我们只需要传递一个状态,这个状态值需要用一个数值表示,比如:…...
Leetcode.2385 感染二叉树需要的总时间
题目链接 Leetcode.2385 感染二叉树需要的总时间 Rating : 1711 题目描述 给你一棵二叉树的根节点 root,二叉树中节点的值 互不相同 。另给你一个整数 start。在第 0分钟,感染 将会从值为 start的节点开始爆发。 每分钟,如果节点…...

[蓝桥杯 2022 国 B] 卡牌(贪心/二分)
题目传送门 该题第一思路是想去模拟题目中所描述的过程 这里我选择从大到小遍历可能凑出的牌套数,计算凑出它需要补的牌数以及判断是否会超出能补的牌数 #include<iostream> #include<climits> #include<vector> #include<algorithm> #def…...
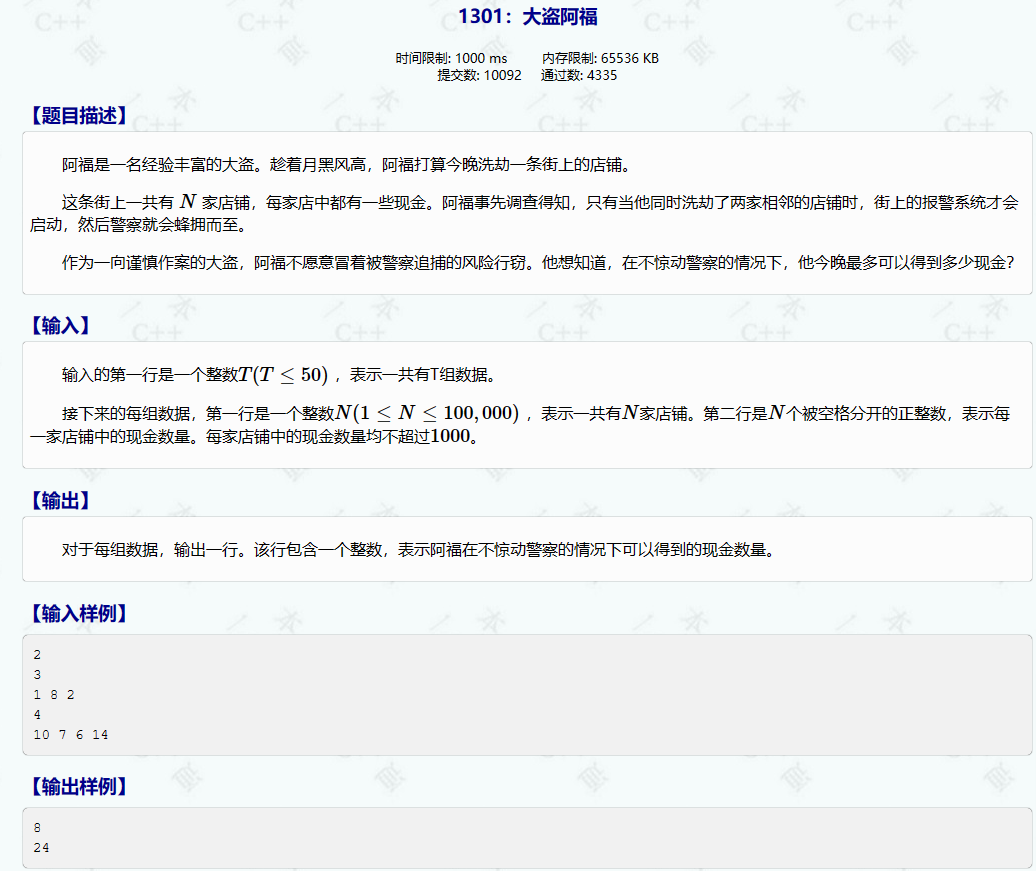
1301:大盗阿福
经典的dp打家劫舍问题状态设计dp[i][0]:在前i个店铺中选,且不选第i家的最大和dp[i][1]:在前i个店铺中选,且选第i家的最大和状态转移dp[i][0] max(dp[i-1][1], dp[i-1][0];第i家店不选,那么我们可以选第i-1个店 也可以…...
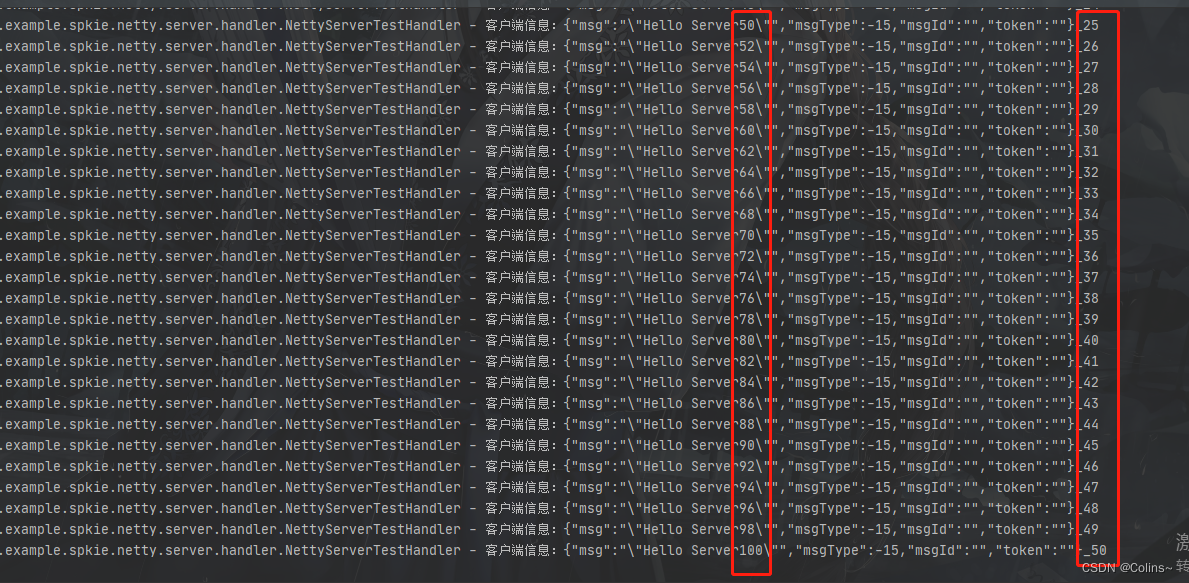
Netty——序列化的作用及自定义协议
序列化的作用及自定义协议序列化的重要性大小对比效率对比自定义协议序列化数据结构自定义编码器自定义解码器安全性验证NettyClientNettyServerNettyClientTestHandlerNettyServerTestHandler结果上一章已经说了怎么解决沾包和拆包的问题,但是这样离一个成熟的通信…...
)
一起Talk Android吧(第五百零五回:如何调整组件在约束布局中的大小)
文章目录 背景介绍调整方法各位看官们大家好,上一回中咱们说的例子是"如何调整组件在约束布局中的位置",这一回中咱们说的例子是" 如何调整组件在约束布局中的大小"。闲话休提,言归正转, 让我们一起Talk Android吧! 背景介绍 在使用约束(constraintl…...

【数据库】数据库的完整性
第五章 数据库完整性 数据库完整性 数据库的完整性是指数据的正确性和相容性 数据的正确性是指数据是符合现实世界语义,反映当前实际状况的数据的相容性是指数据库的同一对象在不同的关系中的数据是符合逻辑的 关系模型中有三类完整性约束:实体完整性…...

基因净化车间装修设计方案SICOLAB
基因净化车间的设计方案应该根据实际需求进行定制,以下是一些规划建设要点和洁净设计要注意的事项:一、净化车间规划建设要点:(1)基因车间的面积应该根据实验项目的规模进行规划,包括充足的操作区域和足够的…...
java 内部类的四种“写法”
基本介绍语法格式分类成员内部类静态内部类局部内部类匿名内部类(🐂🖊)一、基本介绍 : 1.概述当一个类的内部又完整地嵌套了另一个类时,被嵌套于内部的“内核”我们称之为“内部类”(inner class);而包含该…...

【python】main方法教程
嗨害大家好鸭! 我是小熊猫~ 首先 if name "main": 可以看成是python程序的入口, 就像java中的main()方法, 但不完全正确。 事实上python程序是从上而下逐行运行的, 在.py文件中, 除…...

公司对不同职级能力抽象要求的具体化
要先把当前级别要求的能力提升到精通,然后尝试做下一级别的事情。 但可能不确定高一级的能力要求究竟怎样,不同Title,如“工程师”“高级工程师”和“资深工程师”等。但这样 Title 对我们理解不同级别的能力要求,完全无用。“高…...

Java之MinIO存储桶和对象API使用
环境搭建 创建一个 maven项目,引入依赖: <!-- minio依赖--><dependency><groupId>io.minio</groupId><artifactId>minio</artifactId><version>8.3.3</version></dependency><!-- 官方 minio…...

如何用java实现同时进行多个请求,可以将它们并行执行,从而减少总共的请求时间。
1.使用线程池 通过使用Java提供的线程池,可以将多个请求分配到不同的线程中并行执行。可以通过创建固定数量的线程池,然后将请求分配给线程池来实现。线程池会自动管理线程的数量和复用,从而减少了线程创建和销毁的开销,提高了程序…...
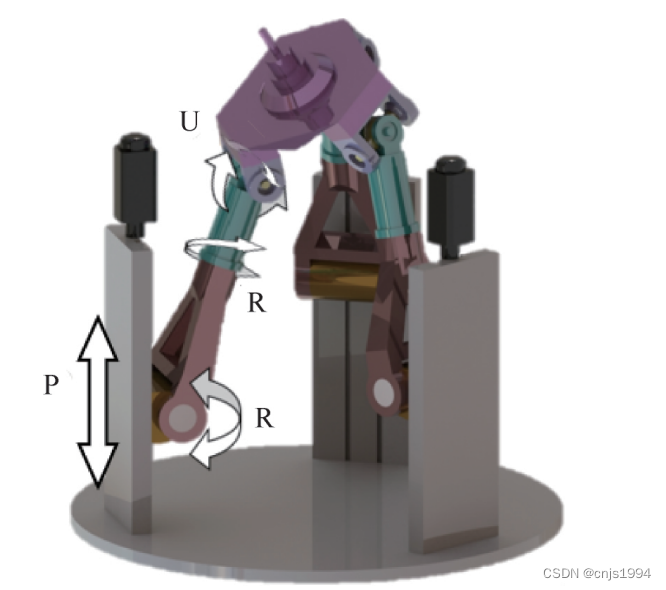
高端装备的AC主轴头结构
加工机器人的AC主轴头和位置相关动力学特性1. 位置依赖动态特性及其复杂性2. AC主轴头2.1 常见主轴头摆角结构2.2 摆动机构3. 加装AC主轴头的作用和局限性4. 切削机器人的减速器类型5. 其他并联结构形式参考文献资料1. 位置依赖动态特性及其复杂性 However, FRF measurements …...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...

【C++进阶篇】智能指针
C内存管理终极指南:智能指针从入门到源码剖析 一. 智能指针1.1 auto_ptr1.2 unique_ptr1.3 shared_ptr1.4 make_shared 二. 原理三. shared_ptr循环引用问题三. 线程安全问题四. 内存泄漏4.1 什么是内存泄漏4.2 危害4.3 避免内存泄漏 五. 最后 一. 智能指针 智能指…...

基于Java+VUE+MariaDB实现(Web)仿小米商城
仿小米商城 环境安装 nodejs maven JDK11 运行 mvn clean install -DskipTestscd adminmvn spring-boot:runcd ../webmvn spring-boot:runcd ../xiaomi-store-admin-vuenpm installnpm run servecd ../xiaomi-store-vuenpm installnpm run serve 注意:运行前…...

毫米波雷达基础理论(3D+4D)
3D、4D毫米波雷达基础知识及厂商选型 PreView : https://mp.weixin.qq.com/s/bQkju4r6med7I3TBGJI_bQ 1. FMCW毫米波雷达基础知识 主要参考博文: 一文入门汽车毫米波雷达基本原理 :https://mp.weixin.qq.com/s/_EN7A5lKcz2Eh8dLnjE19w 毫米波雷达基础…...