【离线数仓-8-数据仓库开发DWD层设计要点-交易域相关事实表】
离线数仓-8-数据仓库开发DWD层设计要点-交易域相关事实表
- 离线数仓-8-数据仓库开发DWD层设计要点-交易域相关事实表
- 一、DWD层设计要点
- 二、交易域相关事实表
- 1.交易域加购事务事实表
- 1.加购事务事实表 前期梳理
- 2.加购事务事实表 DDL表设计分析
- 3.加购事务事实表 加载数据分析
- 1.首日全量加购的数据加载
- 2.每日增量加购的数据加载
- 2.交易域下单事务事实表
- 1.下单事务事实表 前期梳理
- 2.下单事务事实表 DDL表设计分析
- 3.下单事务事实表 加载数据分析
- 1.首日全量下单的数据加载
- 2.每日增量量下单的数据加载
- 3.交易域取消订单事务事实表
- 1.取消订单事务事实表 前期梳理
- 2.取消订单事务事实表 DDL表设计分析
- 3.取消订单事务事实表 加载数据分析
- 1.首日全量取消订单的数据加载
- 2.每日增量取消订单的数据加载
- 7.交易域购物车周期快照事实表
- 1.购物车周期快照事实表 前期梳理
- 2.购物车周期快照事实表 DDL表设计分析
- 3.购物车周期快照事实表 加载数据分析
- 4.交易域支付成功事务事实表
- 1.支付成功事务事实表 前期梳理
- 2.支付成功事务事实表 DDL表设计分析
- 3.支付成功事务事实表 加载数据分析
- 5.交易域退单事务事实表
- 1.退单事务事实表 前期梳理
- 2.退单事务事实表 DDL表设计分析
- 3.退单事务事实表 加载数据分析
- 6.交易域退款成功事务事实表
- 1.退款成功事务事实表 前期梳理
- 2.退款成功事务事实表 DDL表设计分析
- 3.退款成功事务事实表 加载数据分析
离线数仓-8-数据仓库开发DWD层设计要点-交易域相关事实表
一、DWD层设计要点
- DWD层设计要点:
- 1)DWD层的设计依据是维度建模理论,该层存储维度模型的事实表。
- 事实表维度建模理论参考之前整理资料:https://blog.csdn.net/weixin_38136584/article/details/129137583?spm=1001.2014.3001.5501
- 2)DWD层的数据存储格式为orc列式存储+snappy压缩。
- 3)DWD层表名的命名规范为dwd_数据域_表名(体现业务过程)_单分区增量全量标识(inc/full)
- 1)DWD层的设计依据是维度建模理论,该层存储维度模型的事实表。
二、交易域相关事实表
事实事务表设计流程大概分为4步:选择业务过程 --> 声明粒度 --> 确认维度–> 确认事实
1.交易域加购事务事实表
1.加购事务事实表 前期梳理
- 加购事务事实表 设计流程跟事务事实表流程一致,分为四步进行。
- 查看之前梳理的业务矩阵,基于业务矩阵来进行设计流程4步骤分析

- 1.选择业务过程:加购物车
- 2.声明粒度(业务过程确定后,需要为每个业务过程声明粒度。即精确定义每张事务型事实表的每行数据表示什么,应该尽可能选择最细粒度,以此来应各种细节程度的需求。):xx人在xx时间将xx商品加入到购物车
- 3.确认维度:寻找符合业务逻辑的并与此业务过程关联的维度,如果前期选择少了几个维度,后期可以更新表格再添加即可。
- 4.确认事实(每个业务过程的度量值):商品件数
2.加购事务事实表 DDL表设计分析
- 业务数据库对应的表格加购物车cart_info中,存在source_id字段,此字段对应的是加购物车这个操作对应的数据来源,所以需要加来源相关的信息添加到维度表中,此处做了维度弱化,直接将数据整合到加购事务事实表中了。
DROP TABLE IF EXISTS dwd_trade_cart_add_inc;
CREATE EXTERNAL TABLE dwd_trade_cart_add_inc
(`id` STRING COMMENT '编号',`user_id` STRING COMMENT '用户id',`sku_id` STRING COMMENT '商品id',`date_id` STRING COMMENT '时间id',`create_time` STRING COMMENT '加购时间',`source_id` STRING COMMENT '来源类型ID',`source_type_code` STRING COMMENT '来源类型编码',`source_type_name` STRING COMMENT '来源类型名称',`sku_num` BIGINT COMMENT '加购物车件数'
) COMMENT '交易域加购物车事务事实表'PARTITIONED BY (`dt` STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS ORCLOCATION '/warehouse/gmall/dwd/dwd_trade_cart_add_inc/'TBLPROPERTIES ('orc.compress' = 'snappy');
3.加购事务事实表 加载数据分析
- 1.加购事务事实表,来自于业务数据库中哪些表格,对应同步到ods层,事务事实表使用的是inc结尾的增量数据,full结尾的全量数据,对应到周期快照事实表使用。
cart_info - 2.加购物车这一业务过程是怎样实现的,有哪些限制条件。
- 一个用户将一个原来不存在的商品加入到购物车,insert操作
- 一个用户将原来购物车有的数据再加一件到购物车,update操作,并且数据+1
- 3.数据最终落地那个分区下面,需要明确
- 首日全量加购记录 首日默认全部加购物车,按照创建时间写入到对应时间分区里面
- 每日增量加购记录 ,过滤满足条件的数据,直接写入对应的当日时间分区。
- 4.加购事务事实表的数据流向,如下图:
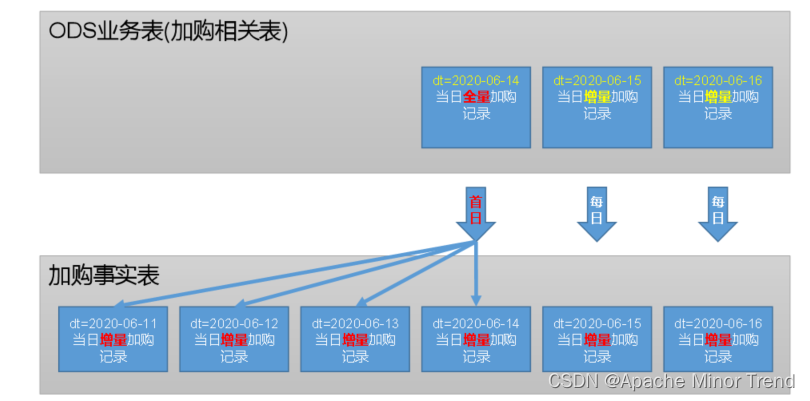
1.首日全量加购的数据加载
- 针对业务系统中,历史的数据进行处理,就是首日装载的意义。
- sql的思路:
- 1.相关表格已同步到ods层,为增量inc表格,购物车信息表和加购操作数据来源类型表
- 2.两张表格进行关联,获取到加购事务事实表所有字段,
- 3.处理数据,使用hive动态分区,将不同数据写入到不同分区
- hive中sql注意:date_format(create_time,‘yyyy-MM-dd’),跟mysql中语法不一致。
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_trade_cart_add_inc partition (dt)
selectid,user_id,sku_id,date_format(create_time,'yyyy-MM-dd') date_id,create_time,source_id,source_type,dic.dic_name,sku_num,date_format(create_time, 'yyyy-MM-dd')
from
(selectdata.id,data.user_id,data.sku_id,data.create_time,data.source_id,data.source_type,data.sku_numfrom ods_cart_info_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'
)ci
left join
(selectdic_code,dic_namefrom ods_base_dic_fullwhere dt='2020-06-14'and parent_code='24'
)dic
on ci.source_type=dic.dic_code;
2.每日增量加购的数据加载
-
sql思路:
- 一个用户将一个原来不存在的商品加入到购物车,insert操作
- 一个用户将原来购物车有的数据再加一件到购物车,update操作,并且数据变大
- 使用maxwell同步过来的json外部的ts时间作为加入购物车时间,而不使用json内部的create_time作为加购时间,这样设计比较合理。
- 对加购数量进行判断,
- 如果是insert类型,直接使用sku_num的值即可,
- 如果是update操作,需要将maxwell过来的json数据中 新值-老值得到的结果存入.
-
hive中函数的使用:
- map_keys(map集合):将此map集合中所有的key取出,作为一个数组。
- array_contains(数组,元素) :该数组中是否包含此元素 ,返回布尔类型的值
- cast(数据 as int ):将该数据强制转化为int类型
-
hive中时间戳到时间字符串的转换 ,经常用到,官网:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-DateFunctions
- 时间戳:自零时区以来,1970-01-01以来的经历的秒数(10位)或者毫秒数(13位)
- 以秒为单位的时间戳,转为时分秒
- from_unixtime(bigint unixtime[, string format]) 这个转换时间戳函数没有分区概念,所以之间转为了零时区的时间。
- from_utc_timestamp({any primitive type} ts(必选是毫秒数), string timezone) 使用:from_utc_timestamp(ts*1000, “GMT+8”)
- 使用时间格式化工具将上面处理完的数据转为想要的格式:date_format(from_utc_timestamp(ts*1000, “GMT+8”),“yyyy-MM-dd HH:mm:ss”)
-
2020-06-15的增量加购数据处理
insert overwrite table dwd_trade_cart_add_inc partition(dt='2020-06-15')
selectid,user_id,sku_id,date_id,create_time,source_id,source_type_code,source_type_name,sku_num
from
(selectdata.id,data.user_id,data.sku_id,date_format(from_utc_timestamp(ts*1000,'GMT+8'),'yyyy-MM-dd') date_id,date_format(from_utc_timestamp(ts*1000,'GMT+8'),'yyyy-MM-dd HH:mm:ss') create_time,data.source_id,data.source_type source_type_code,if(type='insert',data.sku_num,data.sku_num-old['sku_num']) sku_numfrom ods_cart_info_incwhere dt='2020-06-15'and (type='insert'or(type='update' and old['sku_num'] is not null and data.sku_num>cast(old['sku_num'] as int)))
)cart
left join
(selectdic_code,dic_name source_type_namefrom ods_base_dic_fullwhere dt='2020-06-15'and parent_code='24'
)dic
on cart.source_type_code=dic.dic_code;
- linux查看进程对应在服务器的配置
1. 首先jps,查看进程号
2. cd /proc/84912(某进程对应的进程号)
3. limits 文件里面有对应的限制信息
4. exe 是对应的启动二进制进程
5. fd 文件描述符,对应该进程所打开的文件,聚合查看一下打开多少文件即可
2.交易域下单事务事实表
设计流程大概分为4步:选择业务过程 --> 声明粒度 --> 确认维度–> 确认事实
1.下单事务事实表 前期梳理
之前梳理的业务矩阵如下,对应下单过程如下:
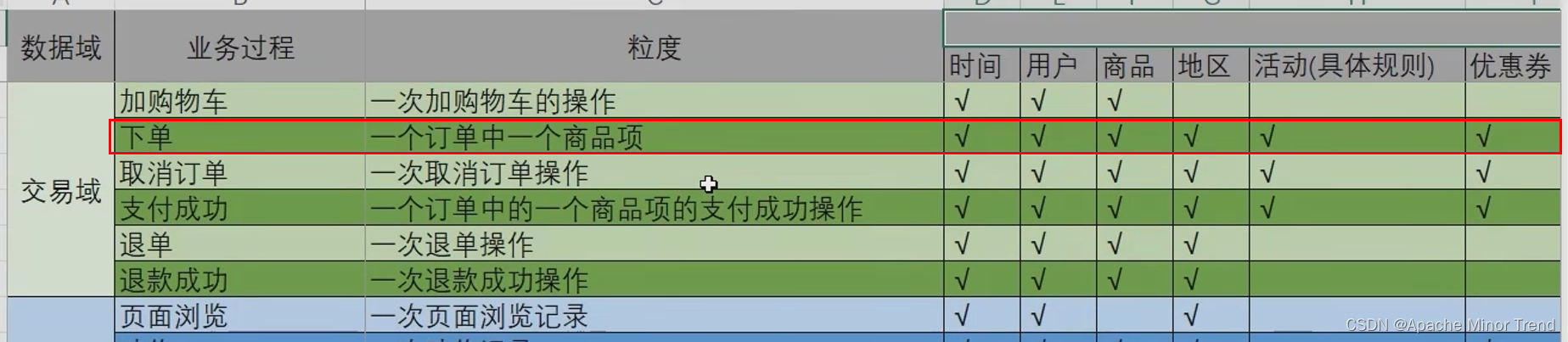
- 1.选择业务过程:下单 业务过程
- 2.声明粒度:xx订单是在xx时间,xx用户在xx地区完成下单操作,这对应的是下单事务表每行表示的含义。
- 3.确认维度:时间、用户、商品、地区、活动、优惠券等,声明维度灵活性较高,是由前面梳理的业务数据库中业务过程决定的,业务过程关联哪些表格也就是对应的环境信息,此处就添加多少维度信息。
- 4.确认事实:下单件数、下单原始金额、下单最终金额、活动优惠金额、优惠券优惠金额
2.下单事务事实表 DDL表设计分析
- 之前创建的dim层维度表以外,其他的维度都退化到对应的事实表中,没有退化的,事实表直接在本表中体现某些维度表的id即可,退化的维度直接写入对应数据即可。
DROP TABLE IF EXISTS dwd_trade_order_detail_inc;
CREATE EXTERNAL TABLE dwd_trade_order_detail_inc
(`id` STRING COMMENT '编号',`order_id` STRING COMMENT '订单id',`user_id` STRING COMMENT '用户id',`sku_id` STRING COMMENT '商品id',`province_id` STRING COMMENT '省份id',`activity_id` STRING COMMENT '参与活动规则id',`activity_rule_id` STRING COMMENT '参与活动规则id',`coupon_id` STRING COMMENT '使用优惠券id',`date_id` STRING COMMENT '下单日期id',`create_time` STRING COMMENT '下单时间',`source_id` STRING COMMENT '来源编号',`source_type_code` STRING COMMENT '来源类型编码',`source_type_name` STRING COMMENT '来源类型名称',`sku_num` BIGINT COMMENT '商品数量',`split_original_amount` DECIMAL(16, 2) COMMENT '原始价格',`split_activity_amount` DECIMAL(16, 2) COMMENT '活动优惠分摊',`split_coupon_amount` DECIMAL(16, 2) COMMENT '优惠券优惠分摊',`split_total_amount` DECIMAL(16, 2) COMMENT '最终价格分摊'
) COMMENT '交易域下单明细事务事实表'PARTITIONED BY (`dt` STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS ORCLOCATION '/warehouse/gmall/dwd/dwd_trade_order_detail_inc/'TBLPROPERTIES ('orc.compress' = 'snappy');
3.下单事务事实表 加载数据分析
- 下单会对哪些业务表格产生影响,如下图:
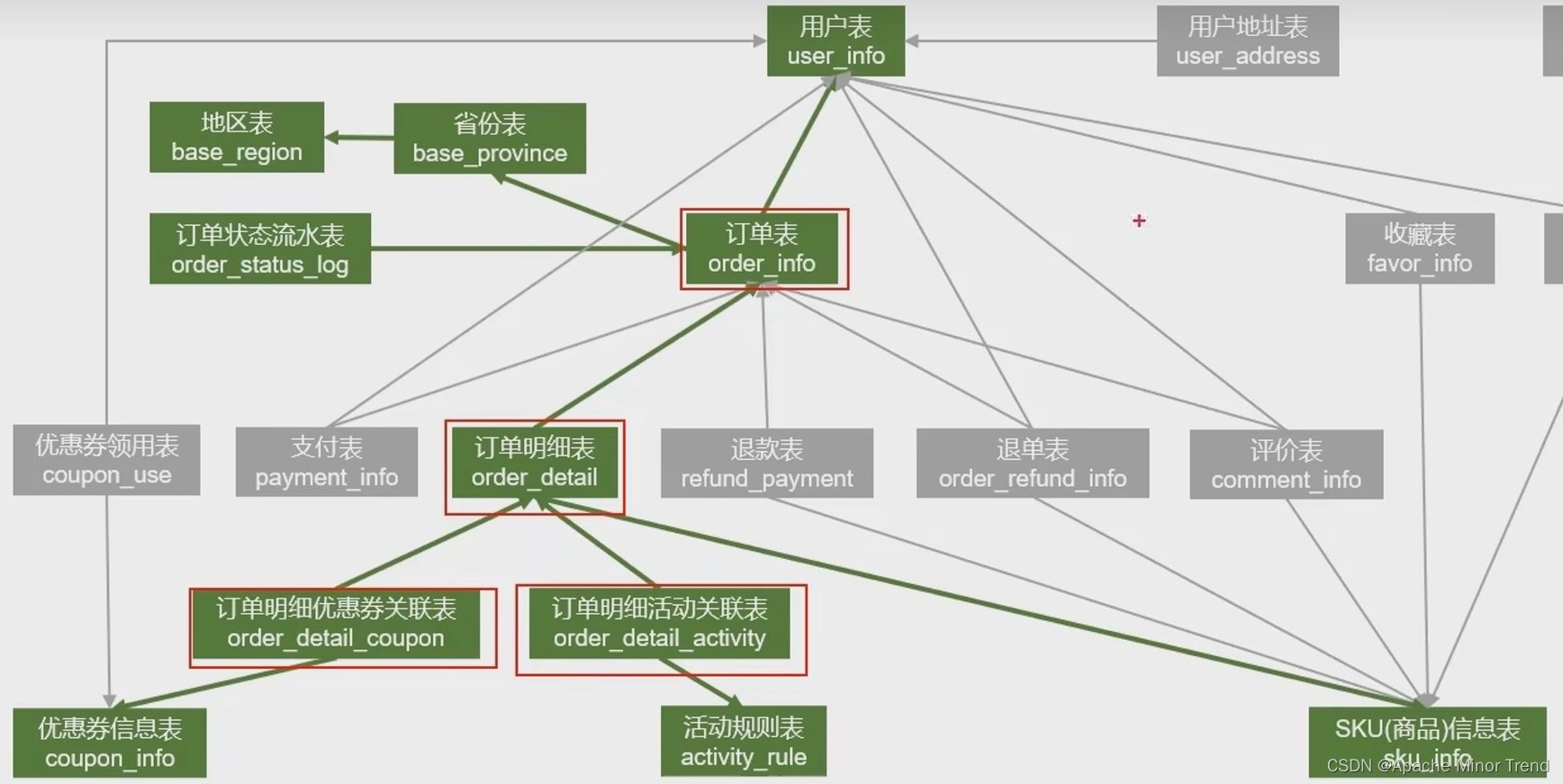
1.首日全量下单的数据加载
- 业务数据库中 下单明细表中每行数据就能代表一条下单记录,直接将数据同步到ods层然后同步到dwd层即可。
- 下单事务事实表 跟 下单明细表字段对比,观察哪些字段能获取到,哪些字段获取不到,获取不到的,直接对照数据库表格关联图,书写sql获取对应关系,如下图,没注释掉的就能获取到,注释掉的通过sql关联或者处理字段方式获取。
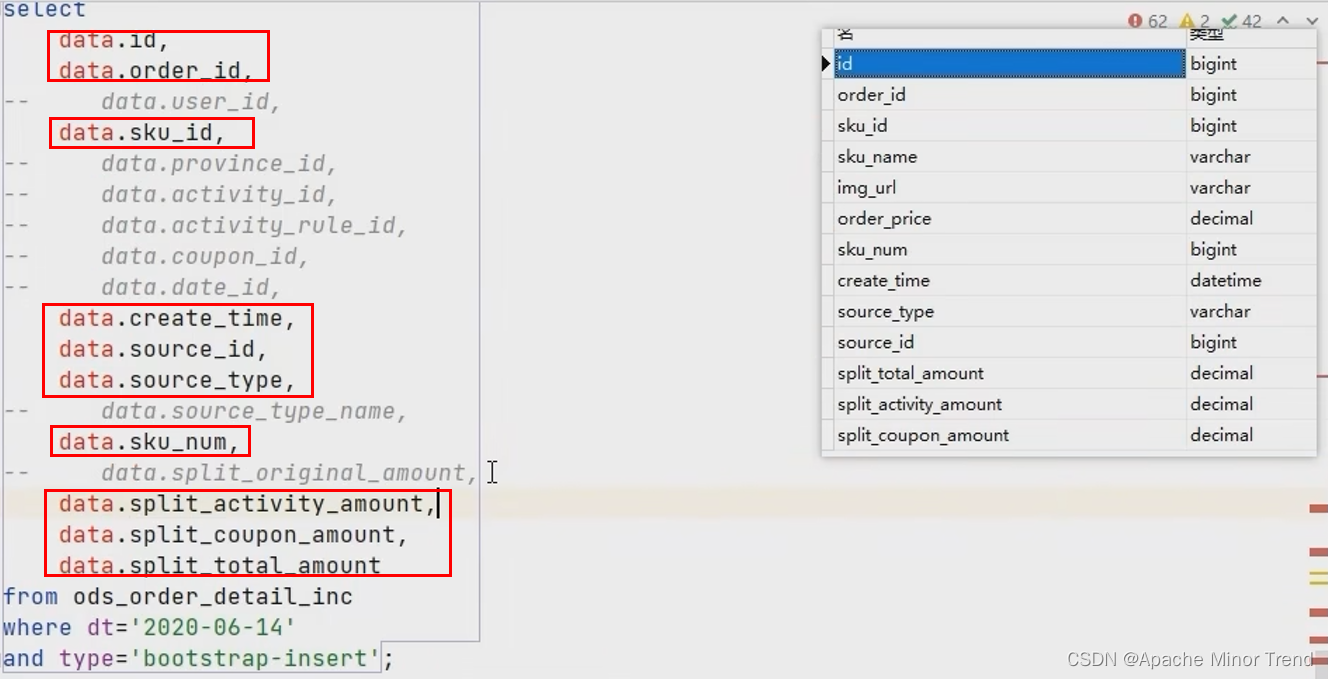
- 订单明细表不能获取到的字段,通过关联关系,进行子查询配置
- 子查询配置完成后,进行sql关联
- 关联完毕后,通过hive创建动态分区,实现收入不同时间下单数据进入到不同的分区。
- 最终整合完的sql如下:
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_trade_order_detail_inc partition (dt)
selectod.id,order_id,user_id,sku_id,province_id,activity_id,activity_rule_id,coupon_id,date_format(create_time, 'yyyy-MM-dd') date_id,create_time,source_id,source_type,dic_name,sku_num,split_original_amount,split_activity_amount,split_coupon_amount,split_total_amount,date_format(create_time,'yyyy-MM-dd')
from
(selectdata.id,data.order_id,data.sku_id,data.create_time,data.source_id,data.source_type,data.sku_num,data.sku_num * data.order_price split_original_amount,data.split_total_amount,data.split_activity_amount,data.split_coupon_amountfrom ods_order_detail_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'
) od
left join
(selectdata.id,data.user_id,data.province_idfrom ods_order_info_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'
) oi
on od.order_id = oi.id
left join
(selectdata.order_detail_id,data.activity_id,data.activity_rule_idfrom ods_order_detail_activity_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'
) act
on od.id = act.order_detail_id
left join
(selectdata.order_detail_id,data.coupon_idfrom ods_order_detail_coupon_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'
) cou
on od.id = cou.order_detail_id
left join
(selectdic_code,dic_namefrom ods_base_dic_fullwhere dt='2020-06-14'and parent_code='24'
)dic
on od.source_type=dic.dic_code;
2.每日增量量下单的数据加载
- 2020-06-15 增量下单明细数据加载-最终sql
- maxwell同步过来的数据,过滤出来insert类型数据即可。
insert overwrite table dwd_trade_order_detail_inc partition (dt='2020-06-15')
selectod.id,order_id,user_id,sku_id,province_id,activity_id,activity_rule_id,coupon_id,date_id,create_time,source_id,source_type,dic_name,sku_num,split_original_amount,split_activity_amount,split_coupon_amount,split_total_amount
from
(selectdata.id,data.order_id,data.sku_id,date_format(data.create_time, 'yyyy-MM-dd') date_id,data.create_time,data.source_id,data.source_type,data.sku_num,data.sku_num * data.order_price split_original_amount,data.split_total_amount,data.split_activity_amount,data.split_coupon_amountfrom ods_order_detail_incwhere dt = '2020-06-15'and type = 'insert'
) od
left join
(selectdata.id,data.user_id,data.province_idfrom ods_order_info_incwhere dt = '2020-06-15'and type = 'insert'
) oi
on od.order_id = oi.id
left join
(selectdata.order_detail_id,data.activity_id,data.activity_rule_idfrom ods_order_detail_activity_incwhere dt = '2020-06-15'and type = 'insert'
) act
on od.id = act.order_detail_id
left join
(selectdata.order_detail_id,data.coupon_idfrom ods_order_detail_coupon_incwhere dt = '2020-06-15'and type = 'insert'
) cou
on od.id = cou.order_detail_id
left join
(selectdic_code,dic_namefrom ods_base_dic_fullwhere dt='2020-06-15'and parent_code='24'
)dic
on od.source_type=dic.dic_code;
3.交易域取消订单事务事实表
1.取消订单事务事实表 前期梳理
之前梳理的业务矩阵如下,对应下单过程如下:

- 1.选择业务过程:取消订单 业务过程
- 2.声明粒度:xx订单是在xx时间,xx用户在xx地区完成取消订单操作,这对应的是取消订单事务表每行表示的含义。
- 3.确认维度:时间、用户、商品、地区、活动、优惠券等,声明维度灵活性较高,是由前面梳理的业务数据库中业务过程决定的,业务过程关联哪些表格也就是对应的环境信息,此处就添加多少维度信息。
- 4.确认事实:取消订单件数、取消订单原始金额、取消订单最终金额、活动优惠金额、优惠券优惠金额
2.取消订单事务事实表 DDL表设计分析
- 取消订单事务事实表中,一行代表一次用户取消订单操作。
DROP TABLE IF EXISTS dwd_trade_cancel_detail_inc;
CREATE EXTERNAL TABLE dwd_trade_cancel_detail_inc
(`id` STRING COMMENT '编号',`order_id` STRING COMMENT '订单id',`user_id` STRING COMMENT '用户id',`sku_id` STRING COMMENT '商品id',`province_id` STRING COMMENT '省份id',`activity_id` STRING COMMENT '参与活动规则id',`activity_rule_id` STRING COMMENT '参与活动规则id',`coupon_id` STRING COMMENT '使用优惠券id',`date_id` STRING COMMENT '取消订单日期id',`cancel_time` STRING COMMENT '取消订单时间',`source_id` STRING COMMENT '来源编号',`source_type_code` STRING COMMENT '来源类型编码',`source_type_name` STRING COMMENT '来源类型名称',`sku_num` BIGINT COMMENT '商品数量',`split_original_amount` DECIMAL(16, 2) COMMENT '原始价格',`split_activity_amount` DECIMAL(16, 2) COMMENT '活动优惠分摊',`split_coupon_amount` DECIMAL(16, 2) COMMENT '优惠券优惠分摊',`split_total_amount` DECIMAL(16, 2) COMMENT '最终价格分摊'
) COMMENT '交易域取消订单明细事务事实表'PARTITIONED BY (`dt` STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS ORCLOCATION '/warehouse/gmall/dwd/dwd_trade_cancel_detail_inc/'TBLPROPERTIES ('orc.compress' = 'snappy');
3.取消订单事务事实表 加载数据分析
- 数据流程
- 数据来源相关:订单表 中 取消的订单 关联 取消订单表 中 订单详情,即可获取全量字段
1.首日全量取消订单的数据加载
set hive.exec.dynamic.partition.mode=nonstrict;
insert overwrite table dwd_trade_cancel_detail_inc partition (dt)
selectod.id,order_id,user_id,sku_id,province_id,activity_id,activity_rule_id,coupon_id,date_format(canel_time,'yyyy-MM-dd') date_id,canel_time,source_id,source_type,dic_name,sku_num,split_original_amount,split_activity_amount,split_coupon_amount,split_total_amount,date_format(canel_time,'yyyy-MM-dd')
from
(selectdata.id,data.order_id,data.sku_id,data.source_id,data.source_type,data.sku_num,data.sku_num * data.order_price split_original_amount,data.split_total_amount,data.split_activity_amount,data.split_coupon_amountfrom ods_order_detail_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'
) od
join
(selectdata.id,data.user_id,data.province_id,data.operate_time canel_timefrom ods_order_info_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'and data.order_status='1003'
) oi
on od.order_id = oi.id
left join
(selectdata.order_detail_id,data.activity_id,data.activity_rule_idfrom ods_order_detail_activity_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'
) act
on od.id = act.order_detail_id
left join
(selectdata.order_detail_id,data.coupon_idfrom ods_order_detail_coupon_incwhere dt = '2020-06-14'and type = 'bootstrap-insert'
) cou
on od.id = cou.order_detail_id
left join
(selectdic_code,dic_namefrom ods_base_dic_fullwhere dt='2020-06-14'and parent_code='24'
)dic
on od.source_type=dic.dic_code;
2.每日增量取消订单的数据加载
- maxwell同步过来的数据,update过来的数据,并且order_status的状态变为了取消状态。
- 15号取消的订单,可能是之前下单的订单,所以获取订单明细数据的时候,需要关联订单明细表的前几天的数据,需要跟时间维度进行关联,获取当天或者前一天的数据。
insert overwrite table dwd_trade_cancel_detail_inc partition (dt='2020-06-15')
selectod.id,order_id,user_id,sku_id,province_id,activity_id,activity_rule_id,coupon_id,date_format(canel_time,'yyyy-MM-dd') date_id,canel_time,source_id,source_type,dic_name,sku_num,split_original_amount,split_activity_amount,split_coupon_amount,split_total_amount
from
(selectdata.id,data.order_id,data.sku_id,data.source_id,data.source_type,data.sku_num,data.sku_num * data.order_price split_original_amount,data.split_total_amount,data.split_activity_amount,data.split_coupon_amountfrom ods_order_detail_incwhere (dt='2020-06-15' or dt=date_add('2020-06-15',-1))and (type = 'insert' or type= 'bootstrap-insert')
) od
join
(selectdata.id,data.user_id,data.province_id,data.operate_time canel_timefrom ods_order_info_incwhere dt = '2020-06-15'and type = 'update'and data.order_status='1003'and array_contains(map_keys(old),'order_status')
) oi
on order_id = oi.id
left join
(selectdata.order_detail_id,data.activity_id,data.activity_rule_idfrom ods_order_detail_activity_incwhere (dt='2020-06-15' or dt=date_add('2020-06-15',-1))and (type = 'insert' or type= 'bootstrap-insert')
) act
on od.id = act.order_detail_id
left join
(selectdata.order_detail_id,data.coupon_idfrom ods_order_detail_coupon_incwhere (dt='2020-06-15' or dt=date_add('2020-06-15',-1))and (type = 'insert' or type= 'bootstrap-insert')
) cou
on od.id = cou.order_detail_id
left join
(selectdic_code,dic_namefrom ods_base_dic_fullwhere dt='2020-06-15'and parent_code='24'
)dic
on od.source_type=dic.dic_code;
7.交易域购物车周期快照事实表
1.购物车周期快照事实表 前期梳理
-
周期快照事实表,实际上类似于Hive中按天做分区,然后全量拉取mysql中数据,这样就会形成mysql的快照,每日全量快照表。
-
周期快照事实表,解决的主要问题:对于商品库存、账户余额这些存量型指标,业务系统中通常就会计算并保存最新结果,所以定期同步一份全量数据到数据仓库,构建周期型快照事实表,就能轻松应对此类统计需求,而无需再对事务型事实表中大量的历史记录进行聚合了。
-
周期快照表的创建,完全是基于需求来的,是服务于需求的,此处创建购物车周期快照事实表,是服务于需求:各分类商品购物车存量Top10
- 将购物车存量数据创建购物车周期快照事实表,直接基于此表,按照sku_id分组求和sku_num,就可简单实现上面的需求。
-
周期快照表和业务过程对照关系,没有必要进行讨论,可能对应一个业务过程,也可能对应两个业务过程。
2.购物车周期快照事实表 DDL表设计分析
DROP TABLE IF EXISTS dwd_trade_cart_full;
CREATE EXTERNAL TABLE dwd_trade_cart_full
(`id` STRING COMMENT '编号',`user_id` STRING COMMENT '用户id',`sku_id` STRING COMMENT '商品id',`sku_name` STRING COMMENT '商品名称',`sku_num` BIGINT COMMENT '加购物车件数'
) COMMENT '交易域购物车周期快照事实表'PARTITIONED BY (`dt` STRING)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'STORED AS ORCLOCATION '/warehouse/gmall/dwd/dwd_trade_cart_full/'TBLPROPERTIES ('orc.compress' = 'snappy');
3.购物车周期快照事实表 加载数据分析
insert overwrite table dwd_trade_cart_full partition(dt='2020-06-14')
selectid,user_id,sku_id,sku_name,sku_num
from ods_cart_info_full
where dt='2020-06-14'
and is_ordered='0';
4.交易域支付成功事务事实表
1.支付成功事务事实表 前期梳理
2.支付成功事务事实表 DDL表设计分析
3.支付成功事务事实表 加载数据分析
5.交易域退单事务事实表
1.退单事务事实表 前期梳理
2.退单事务事实表 DDL表设计分析
3.退单事务事实表 加载数据分析
6.交易域退款成功事务事实表
1.退款成功事务事实表 前期梳理
2.退款成功事务事实表 DDL表设计分析
3.退款成功事务事实表 加载数据分析
相关文章:
【离线数仓-8-数据仓库开发DWD层设计要点-交易域相关事实表】
离线数仓-8-数据仓库开发DWD层设计要点-交易域相关事实表离线数仓-8-数据仓库开发DWD层设计要点-交易域相关事实表一、DWD层设计要点二、交易域相关事实表1.交易域加购事务事实表1.加购事务事实表 前期梳理2.加购事务事实表 DDL表设计分析3.加购事务事实表 加载数据分析1.首日全…...
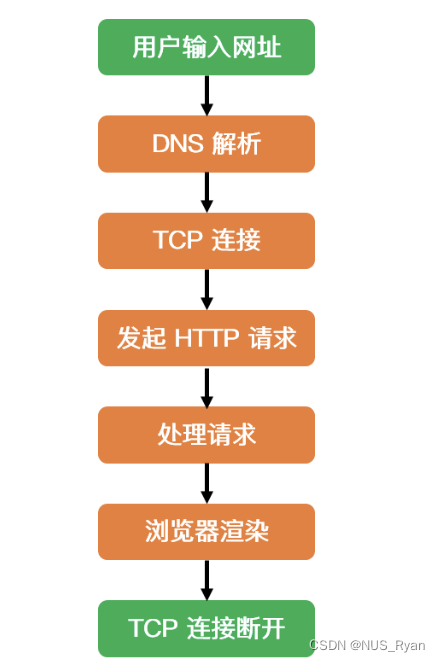
计算机网络(七):DNS协议和原理,DNS为什么用UDP,网页解析的全过程
文章目录一、什么是DNS二、DNS的作用三、DNS作用四、DNS为什么用UDP五、如果打开一个网站很慢,要如何排查六、网页解析的全过程一、什么是DNS DNS是域名系统的英文缩写,是一种组织成域层次结构的计算机和网络服务命名系统,用于TCP/IP网络。 …...
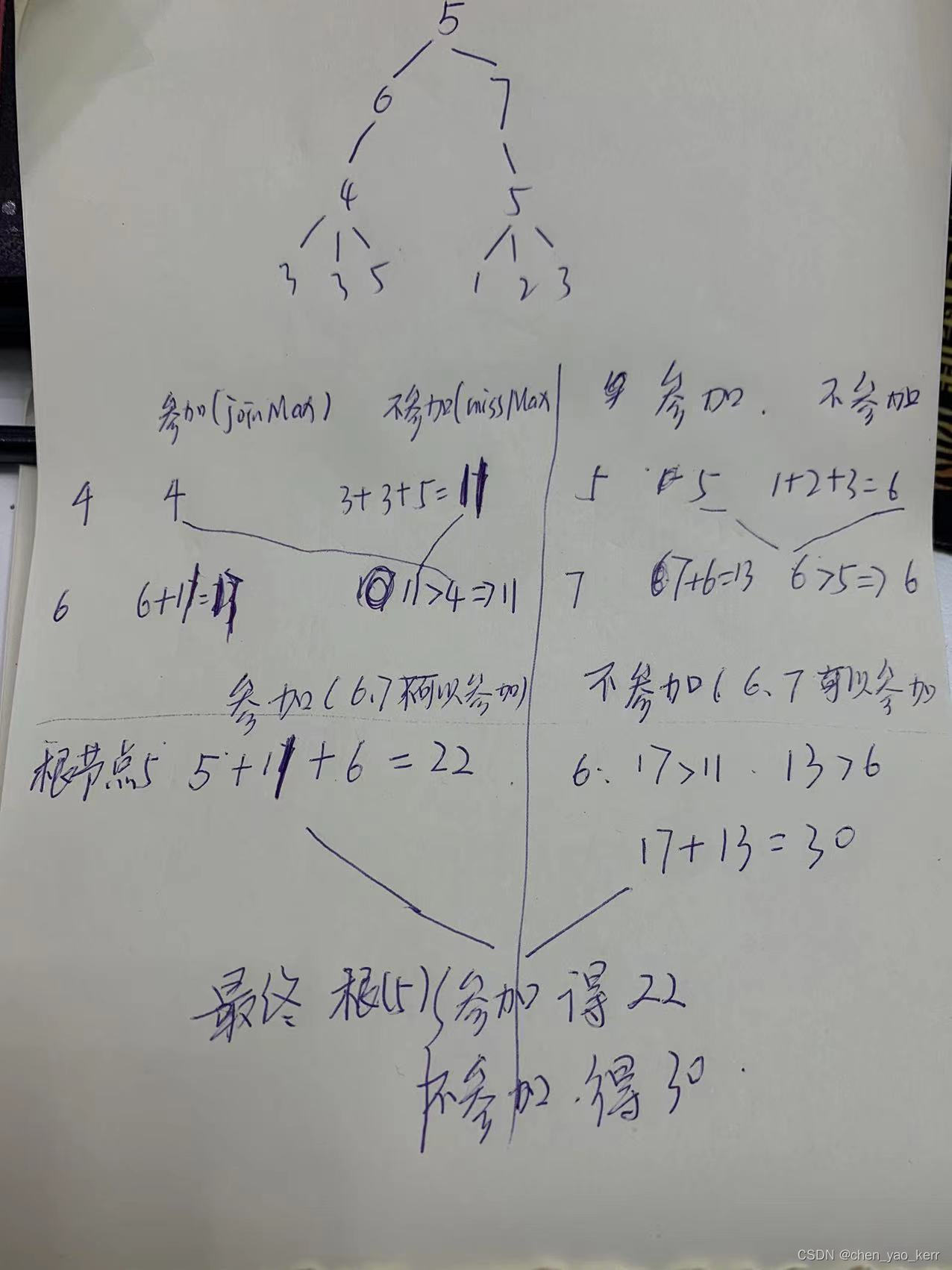
算法23:多叉树_派对的最大快乐值
公司的每个员工都符合 Employee 类的描述。整个公司的人员结构可以看作是一棵标准的、 没有环的多叉树。树的头节点是公司唯一的老板。除老板之外的每个员工都有唯一的直接上级。 叶节点是没有任何下属的基层员工(subordinates列表为空),除基层员工外,每…...

中国ETC行业市场规模及未来发展趋势
中国ETC行业市场规模及未来发展趋势编辑根据市场调研在线网发布的2023-2029年中国ETC行业发展策略分析及战略咨询研究报告分析:随着政府坚持实施绿色出行政策,ETC行业也受到了极大的支持。根据中国智能交通协会统计,2017年中国ETC行业市场规模…...
——只出现一次的数字)
每日刷题(一)——只出现一次的数字
前言 今天遇到一个位运算的题目,感觉很有意思,记录一下。 Question1 136. 只出现一次的数字 给你一个 非空 整数数组 nums ,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。 你必须设计并实…...
洛谷P5737 【深基7.例3】闰年展示 C语言/C++
【深基7.例3】闰年展示 题目描述 输入 x,yx,yx,y,输出 [x,y][x,y][x,y] 区间中闰年个数,并在下一行输出所有闰年年份数字,使用空格隔开。 输入格式 输入两个正整数 x,yx,yx,y,以空格隔开。 输出格式 第一行输出一个正整数&a…...

shell注释
注释对于任何编程语言都是不可忽视的重要组成部分,编写者通过注释来为其他人提供解释或提示,能有效提高代码的可读性。 Bash 同其他编程语言一样提供了两种类型注释的支持。 单行注释多行注释一、Bash 单行注释 在注释段落的开头使用 # ,如下…...
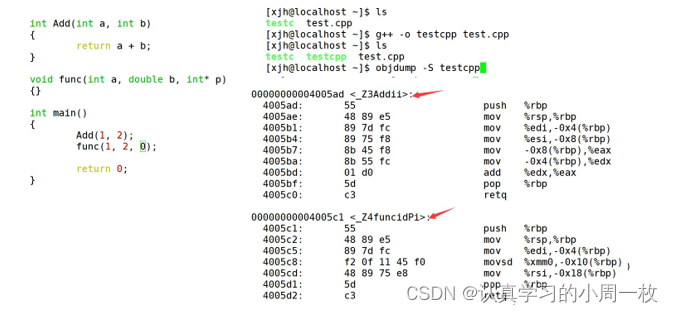
【C++入门(上篇)】C++入门学习
前言: 在之前的学习中,我们已经对初阶数据结构进行相应了学习,加上之前C语言的学习功底。今天,我们将会踏上更高一级“台阶”的学习-----即C的学习!!! 文章目录1.C 简介1.1什么是C1.2.C的发展史…...

【密码学】 一篇文章讲透数字签名
【密码学】 一篇文章讲透数字签名 数字签名介绍 数字签名(又称公钥数字签名)是只有信息的发送者才能产生的别人无法伪造的一段数字串,这段数字串同时也是对信息的发送者发送信息真实性的一个有效证明。它是一种类似写在纸上的普通的物理签名…...

POI导入导出、EasyExcel批量导入和分页导出
文件导入导出POI、EasyExcel POI:消耗内存非常大,在线上发生过堆内存溢出OOM;在导出大数据量的记录的时候也会造成堆溢出甚至宕机,如果导入导出数据量小的话还是考虑的,下面简单介绍POI怎么使用 POI导入 首先拿到文…...

手把手教你做微信公众号
手把手教你做微信公众号 微信公众号可以通过注册的方式来建立。 1.进入微信公众平台 首先,在浏览器中搜索微信公众号,网页第一个就是,如下图所示,我们点进去。 2.注册微信平台账号 进入官网之后,如下图所示&#…...
python-在macOS上安装python库 xlwings失败的解决方式
问题:python库 xlwings安装失败 今天,看到网上有wlwings库,可以用来处理excel表格,立刻想试一试。结果,安装这个python库失败了。经过排查,问题解决。 安装过程和错误提示: 我用最简单直接的…...
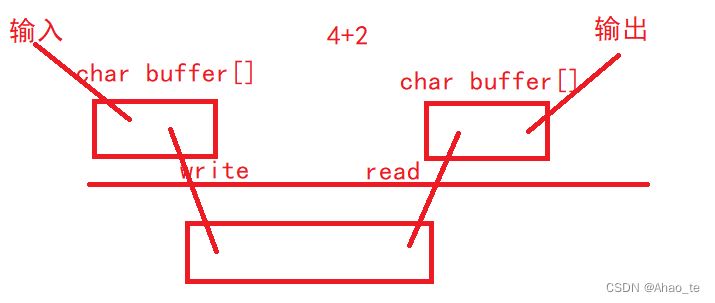
【Linux】进程间通信(匿名管道和命名管道通信、共享内存通信)
文章目录1、进程间通信1.1 进程的通信1.2 如何让进程间通信?1.3 进程间通信的本质2、管道通信2.1 匿名管道2.2 匿名管道通信2.3 命名管道2.4 命名管道的通信3、SystemV中的共享内存通信3.1 共享内存3.2 共享内存的通信3.3 共享内存的缺点以及数据保护3.4 共享内存的…...

漏洞分析: WSO2 API Manager 任意文件上传、远程代码执行漏洞
漏洞描述 某些WSO2产品允许不受限制地上传文件,从而执行远程代码。以WSO2 API Manager 为例,它是一个完全开源的 API 管理平台。它支持API设计,API发布,生命周期管理,应用程序开发,API安全性,速…...

详解Android 13种 Drawable的使用方法
前言关于自定义View,相信大家都已经很熟悉了。今天,我想分享一下关于自定义View中的一部分,就是自定义Drawable。Drawable 是可绘制对象的一个抽象类,相对比View来说,它更加的纯粹,只用来处理绘制的相关工作…...

MakeFile教程
前言 当我们需要编译一个比较大的项目时,编译命令会变得越来越复杂,需要编译的文件越来越多。其 次就是项目中并不是每一次编译都需要把所有文件都重新编译,比如没有被修改过的文件则不需要重 新编译。工程管理器就帮助我们来优化这两个问题…...
Spring使用mongoDB步骤
1. 在Linux系统使用docker安装mongoDB 1.1. 安装 在docker运行的情况下,执行下述命令。 docker run \ -itd \ --name mongoDB \ -v mongoDB_db:/data/db \ -p 27017:27017 \ mongo:4.4 \ --auth执行docker ps后,出现下列行,即表示mongoDB安…...
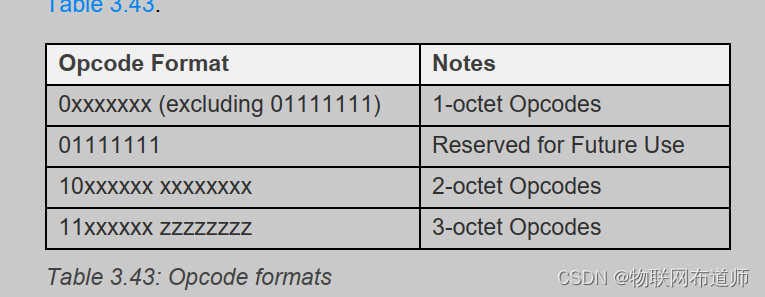
【蓝牙mesh】access层(接入层)协议介绍
【蓝牙mesh】access层(接入层)协议介绍 Access层简介 Access层定义了应用层如何使用upper协议层的接口,它不仅定义了应用层的格式,还定义了应用数据在upper层的加密和解密。当收到下层的数据包时,它会检查数据的netke…...

【一天一门编程语言】JavaScript 语言程序设计极简教程
JavaScript 语言程序设计极简教程 用 markdown 格式输出答案。 不少于3000字。细分到2级目录。 一、JavaScript 简介 1.1 什么是 JavaScript JavaScript 是一种由Netscape的LiveScript发展而来的脚本语言,是一种动态类型、弱类型、基于原型的语言,内…...

CMake调试器出炉:调试你的CMake脚本
Visual Studio 开发团队一直和 Kitware 紧密合作,致力于开发一个用于调试 CMake 脚本的调试器。 我们将继续这个工作,以便开发人员社区可以通过添加新功能和对其他 DAP 功能的支持来共同改进它。 我们很高兴地宣布,CMake 调试器的预览版现在…...

C++_核心编程_多态案例二-制作饮品
#include <iostream> #include <string> using namespace std;/*制作饮品的大致流程为:煮水 - 冲泡 - 倒入杯中 - 加入辅料 利用多态技术实现本案例,提供抽象制作饮品基类,提供子类制作咖啡和茶叶*//*基类*/ class AbstractDr…...

调用支付宝接口响应40004 SYSTEM_ERROR问题排查
在对接支付宝API的时候,遇到了一些问题,记录一下排查过程。 Body:{"datadigital_fincloud_generalsaas_face_certify_initialize_response":{"msg":"Business Failed","code":"40004","sub_msg…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

FFmpeg 低延迟同屏方案
引言 在实时互动需求激增的当下,无论是在线教育中的师生同屏演示、远程办公的屏幕共享协作,还是游戏直播的画面实时传输,低延迟同屏已成为保障用户体验的核心指标。FFmpeg 作为一款功能强大的多媒体框架,凭借其灵活的编解码、数据…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

【android bluetooth 框架分析 04】【bt-framework 层详解 1】【BluetoothProperties介绍】
1. BluetoothProperties介绍 libsysprop/srcs/android/sysprop/BluetoothProperties.sysprop BluetoothProperties.sysprop 是 Android AOSP 中的一种 系统属性定义文件(System Property Definition File),用于声明和管理 Bluetooth 模块相…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...