Linux内核中的软中断、tasklet和工作队列
软中断、tasklet和工作队列并不是Linux内核中一直存在的机制,而是由更早版本的内核中的“下半部”(bottom half)演变而来。下半部的机制实际上包括五种,但2.6版本的内核中,下半部和任务队列的函数都消失了,只剩下了前三者。 介绍这三种下半部实现之前,有必要说一下上半部与下半部的区别。 上半部指的是中断处理程序,下半部则指的是一些虽然与中断有相关性但是可以延后执行的任务。举个例子:在网络传输中,网卡接收到数据包这个事件不一定需要马上被处理,适合用下半部去实现;但是用户敲击键盘这样的事件就必须马上被响应,应该用中断实现。 两者的主要区别在于:中断不能被相同类型的中断打断,而下半部依然可以被中断打断;中断对于时间非常敏感,而下半部基本上都是一些可以延迟的工作。由于二者的这种区别,所以对于一个工作是放在上半部还是放在下半部去执行,可以参考下面4条:
- 如果一个任务对时间非常敏感,将其放在中断处理程序中执行。
- 如果一个任务和硬件相关,将其放在中断处理程序中执行。
- 如果一个任务要保证不被其他中断(特别是相同的中断)打断,将其放在中断处理程序中执行。
- 其他所有任务,考虑放在下半部去执行。 有写内核任务需要延后执行,因此才有的下半部,进而实现了三种实现下半部的方法。这就是本文要讨论的软中断、tasklet和工作队列。
下表可以更直观的看到它们之间的关系:

软中断
软中断作为下半部机制的代表,是随着SMP(share memory processor)的出现应运而生的,它也是tasklet实现的基础(tasklet实际上只是在软中断的基础上添加了一定的机制)。软中断一般是“可延迟函数”的总称,有时候也包括了tasklet(请读者在遇到的时候根据上下文推断是否包含tasklet)。它的出现就是因为要满足上面所提出的上半部和下半部的区别,使得对时间不敏感的任务延后执行,而且可以在多个CPU上并行执行,使得总的系统效率可以更高。它的特性包括:
- 产生后并不是马上可以执行,必须要等待内核的调度才能执行。软中断不能被自己打断(即单个cpu上软中断不能嵌套执行),只能被硬件中断打断(上半部)。
- 可以并发运行在多个CPU上(即使同一类型的也可以)。所以软中断必须设计为可重入的函数(允许多个CPU同时操作),因此也需要使用自旋锁来保其数据结构。
相关数据结构
- 软中断描述符 struct softirq_action{ void (*action)(struct softirq_action *);}; 描述每一种类型的软中断,其中void(*action)是软中断触发时的执行函数。
- 软中断全局数据和类型
static struct softirq_action softirq_vec[NR_SOFTIRQS]
__cacheline_aligned_in_smp;
enum {
HI_SOFTIRQ=0, /*用于高优先级的tasklet*/
TIMER_SOFTIRQ, /*用于定时器的下半部*/
NET_TX_SOFTIRQ, /*用于网络层发包*/
NET_RX_SOFTIRQ, /*用于网络层收报*/
BLOCK_SOFTIRQ,
BLOCK_IOPOLL_SOFTIRQ,
TASKLET_SOFTIRQ, /*用于低优先级的tasklet*/
SCHED_SOFTIRQ,
HRTIMER_SOFTIRQ,
RCU_SOFTIRQ, /* Preferable RCU should always be the last softirq */
NR_SOFTIRQS };
相关API
- 注册软中断
void open_softirq(int nr, void (*action)(struct softirq_action *))即注册对应类型的处理函数到全局数组softirq_vec中。例如网络发包对应类型为NET_TX_SOFTIRQ的处理函数net_tx_action.
- 触发软中断
void raise_softirq(unsigned int nr)实际上即以软中断类型nr作为偏移量置位每cpu变量irq_stat[cpu_id]的成员变量__softirq_pending,这也是同一类型软中断可以在多个cpu上并行运行的根本原因。
- 软中断执行函数
do_softirq-->__do_softirq
执行软中断处理函数__do_softirq前首先要满足两个条件: (1)不在中断中(硬中断、软中断和NMI) 。1 (2)有软中断处于pending状态。 系统这么设计是为了避免软件中断在中断嵌套中被调用,并且达到在单个CPU上软件中断不能被重入的目的。对于ARM架构的CPU不存在中断嵌套中调用软件中断的问题,因为ARM架构的CPU在处理硬件中断的过程中是关闭掉中断的。只有在进入了软中断处理过程中之后才会开启硬件中断,如果在软件中断处理过程中有硬件中断嵌套,也不会再次调用软中断,because硬件中断是软件中断处理过程中再次进入的,此时preempt_count已经记录了软件中断!对于其它架构的CPU,有可能在触发调用软件中断前,也就是还在处理硬件中断的时候,就已经开启了硬件中断,可能会发生中断嵌套,在中断嵌套中是不允许调用软件中断处理的。Why?我的理解是,在发生中断嵌套的时候,表明这个时候是系统突发繁忙的时候,内核第一要务就是赶紧把中断中的事情处理完成,退出中断嵌套。避免多次嵌套,哪里有时间处理软件中断,所以把软件中断推迟到了所有中断处理完成的时候才能触发软件中断。
实现原理和实例
软中断的调度时机:
- do_irq完成I/O中断时调用irq_exit。
- 系统使用I/O APIC,在处理完本地时钟中断时。
- local_bh_enable,即开启本地软中断时。
- SMP系统中,cpu处理完被CALL_FUNCTION_VECTOR处理器间中断所触发的函数时。
- ksoftirqd/n线程被唤醒时。 下面以从中断处理返回函数irq_exit中调用软中断为例详细说明。 触发和初始化的的流程如图所示:

软中断处理流程
asmlinkage void __do_softirq(void) {
struct softirq_action *h; __u32 pending;
int max_restart = MAX_SOFTIRQ_RESTART;
int cpu;
pending = local_softirq_pending();
account_system_vtime(current);
__local_bh_disable((unsigned long)__builtin_return_address(0));
lockdep_softirq_enter();
cpu = smp_processor_id();
restart: /* Reset the pending bitmask before enabling irqs */
set_softirq_pending(0);
local_irq_enable();
h = softirq_vec; do {
if (pending & 1) {
int prev_count = preempt_count(); kstat_incr_softirqs_this_cpu(h - softirq_vec);
trace_softirq_entry(h, softirq_vec);
h->action(h);
trace_softirq_exit(h, softirq_vec);
if (unlikely(prev_count != preempt_count())) {
printk(KERN_ERR "huh, entered softirq %td %s %p" "
with preempt_count %08x," " exited with %08x?\n", h - softirq_vec,
softirq_to_name[h - softirq_vec],
h->action, prev_count, preempt_count());
preempt_count() = prev_count; }
rcu_bh_qs(cpu); }
h++;
pending >>= 1; } while (pending);
local_irq_disable();
pending = local_softirq_pending();
if (pending && --max_restart)
goto restart;
if (pending) wakeup_softirqd(); lockdep_softirq_exit();
account_system_vtime(current);
_local_bh_enable(); }- 首先调用local_softirq_pending函数取得目前有哪些位存在软件中断。
- 调用__local_bh_disable关闭软中断,其实就是设置正在处理软件中断标记,在同一个CPU上使得不能重入__do_softirq函数。
- 重新设置软中断标记为0,set_softirq_pending重新设置软中断标记为0,这样在之后重新开启中断之后硬件中断中又可以设置软件中断位。
- 调用local_irq_enable,开启硬件中断。
- 之后在一个循环中,遍历pending标志的每一位,如果这一位设置就会调用软件中断的处理函数。在这个过程中硬件中断是开启的,随时可以打断软件中断。这样保证硬件中断不会丢失。
- 之后关闭硬件中断(local_irq_disable),查看是否又有软件中断处于pending状态,如果是,并且在本次调用__do_softirq函数过程中没有累计重复进入软件中断处理的次数超过max_restart=10次,就可以重新调用软件中断处理。如果超过了10次,就调用wakeup_softirqd()唤醒内核的一个进程来处理软件中断。设立10次的限制,也是为了避免影响系统响应时间。
- 调用_local_bh_enable开启软中断。
软中断内核线程
之前我们分析的触发软件中断的位置其实是中断上下文中,而在软中断的内核线程中实际已经是进程的上下文。 这里说的软中断上下文指的就是系统为每个CPU建立的ksoftirqd进程。 软中断的内核进程中主要有两个大循环,外层的循环处理有软件中断就处理,没有软件中断就休眠。内层的循环处理软件中断,每循环一次都试探一次是否过长时间占据了CPU,需要调度就释放CPU给其它进程。具体的操作在注释中做了解释。
set_current_state(
TASK_INTERRUPTIBLE); //外层大循环。
while (!kthread_should_stop()) {
preempt_disable();//禁止内核抢占,自己掌握cpu
if (!local_softirq_pending()) {
preempt_enable_no_resched(); //如果没有软中断在pending中就让出cpu
schedule(); //调度之后重新掌握cpu preempt_disable(); } __set_current_state(TASK_RUNNING);
while (local_softirq_pending()) { /* Preempt disable stops cpu going offline.
If already offline, we'll be on wrong CPU:
don't process */ if (cpu_is_offline((long)__bind_cpu))
goto wait_to_die; //有软中断则开始软中断调度
do_softirq(); //查看是否需要调度,避免一直占用cpu
preempt_enable_no_resched();
cond_resched();
preempt_disable();
rcu_sched_qs((long)__bind_cpu);
} preempt_enable();
set_current_state(TASK_INTERRUPTIBLE);
} __set_current_state(TASK_RUNNING);
return 0; wait_to_die: preempt_enable(); /* Wait for kthread_stop */
set_current_state(TASK_INTERRUPTIBLE);
while (!kthread_should_stop()) {
schedule();
set_current_state(TASK_INTERRUPTIBLE);
} __set_current_state(TASK_RUNNING);
return 0;
由于软中断必须使用可重入函数,这就导致设计上的复杂度变高,作为设备驱动程序的开发者来说,增加了负担。而如果某种应用并不需要在多个CPU上并行执行,那么软中断其实是没有必要的。因此诞生了弥补以上两个要求的tasklet。它具有以下特性: a)一种特定类型的tasklet只能运行在一个CPU上,不能并行,只能串行执行。 b)多个不同类型的tasklet可以并行在多个CPU上。 c)软中断是静态分配的,在内核编译好之后,就不能改变。但tasklet就灵活许多,可以在运行时改变(比如添加模块时)。 tasklet是在两种软中断类型的基础上实现的,因此如果不需要软中断的并行特性,tasklet就是最好的选择。也就是说tasklet是软中断的一种特殊用法,即延迟情况下的串行执行。
相关数据结构
- tasklet描述符
struct tasklet_struct {
struct tasklet_struct *next;//将多个tasklet链接成单向循环链表
unsigned long state;//TASKLET_STATE_SCHED(Tasklet is scheduled for execution)
TASKLET_STATE_RUN(Tasklet is running (SMP only))
atomic_t count;//0:激活tasklet 非0:禁用tasklet
void (*func)(unsigned long); //用户自定义函数
unsigned long data; //函数入参 };
- tasklet链表
static DEFINE_PER_CPU(struct tasklet_head, tasklet_vec);//低优先级
static DEFINE_PER_CPU(struct tasklet_head, tasklet_hi_vec);//高优先级
- 定义tasklet
#define DECLARE_TASKLET(
name, func, data) \ struct tasklet_struct name = {NULL, 0, ATOMIC_INIT(0), func, data
} //定义名字为name的非激活tasklet #define DECLARE_TASKLET_DISABLED(
name, func, data) \ struct tasklet_struct name = {
NULL, 0, ATOMIC_INIT(1), func, data } //定义名字为name的激活tasklet void tasklet_init(
struct tasklet_struct *t,void (*func)(unsigned long), unsigned long data) //动态初始化tasklet
- tasklet操作
static inline void tasklet_disable(struct tasklet_struct *t) //函数暂时禁止给定的tasklet被tasklet_schedule调度,直到这个tasklet被再次被enable;若这个tasklet当前在运行, 这个函数忙等待直到这个tasklet退出 static inline void tasklet_enable(struct tasklet_struct *t) //使能一个之前被disable的tasklet;若这个tasklet已经被调度, 它会很快运行。tasklet_enable和tasklet_disable必须匹配调用, 因为内核跟踪每个tasklet的"禁止次数" static inline void tasklet_schedule(struct tasklet_struct *t) //调度 tasklet 执行,如果tasklet在运行中被调度, 它在完成后会再次运行; 这保证了在其他事件被处理当中发生的事件受到应有的注意. 这个做法也允许一个 tasklet 重新调度它自己 tasklet_hi_schedule(struct tasklet_struct *t) //和tasklet_schedule类似,只是在更高优先级执行。当软中断处理运行时, 它处理高优先级 tasklet 在其他软中断之前,只有具有低响应周期要求的驱动才应使用这个函数, 可避免其他软件中断处理引入的附加周期. tasklet_kill(struct tasklet_struct *t) //确保了 tasklet 不会被再次调度来运行,通常当一个设备正被关闭或者模块卸载时被调用。如果 tasklet 正在运行, 这个函数等待直到它执行完毕。若 tasklet 重新调度它自己,则必须阻止在调用 tasklet_kill 前它重新调度它自己,如同使用 del_timer_sync
实现原理
- 调度原理
static inline void tasklet_schedule(
struct tasklet_struct *t) {
if (!test_and_set_bit(TASKLET_STATE_SCHED, &t->state))
__tasklet_schedule(t);} void __tasklet_schedule(struct tasklet_struct *t) {
unsigned long flags; local_irq_save(flags);
t->next = NULL;
*__get_cpu_var(tasklet_vec).tail = t;
__get_cpu_var(tasklet_vec).tail = &(t->next);//加入低优先级列表
raise_softirq_irqoff(TASKLET_SOFTIRQ);//触发软中断
local_irq_restore(flags); }- tasklet执行过程 TASKLET_SOFTIRQ对应执行函数为tasklet_action,HI_SOFTIRQ为tasklet_hi_action,以tasklet_action为例说明,tasklet_hi_action大同小异。
static void tasklet_action(
struct softirq_action *a) {
struct tasklet_struct *list;
local_irq_disable();
list = __get_cpu_var(tasklet_vec).head; __get_cpu_var(tasklet_vec).head = NULL;
__get_cpu_var(tasklet_vec).tail = &__get_cpu_var(tasklet_vec).head;//取得tasklet链表
local_irq_enable(); while (list) {
struct tasklet_struct *t = list;
list = list->next;
if (tasklet_trylock(t)) { if (!atomic_read(&t->count)) { //执行tasklet
if (!test_and_clear_bit(TASKLET_STATE_SCHED, &t->state))
BUG();
t->func(t->data);
tasklet_unlock(t);
continue; }
tasklet_unlock(t);
} //如果t->count的值不等于0,说明这个tasklet在调度之后,被disable掉了,所以会将tasklet结构体重新放回到tasklet_vec链表,并重新调度TASKLET_SOFTIRQ软中断,在之后enable这个tasklet之后重新再执行它 local_irq_disable(); t->next = NULL;
*__get_cpu_var(tasklet_vec).tail = t;
__get_cpu_var(tasklet_vec).tail = &(t->next);
__raise_softirq_irqoff(TASKLET_SOFTIRQ); local_irq_enable(); } }
工作队列
从上面的介绍看以看出,软中断运行在中断上下文中,因此不能阻塞和睡眠,而tasklet使用软中断实现,当然也不能阻塞和睡眠。但如果某延迟处理函数需要睡眠或者阻塞呢?没关系工作队列就可以如您所愿了。 把推后执行的任务叫做工作(work),描述它的数据结构为work_struct ,这些工作以队列结构组织成工作队列(workqueue),其数据结构为workqueue_struct ,而工作线程就是负责执行工作队列中的工作。系统默认的工作者线程为events。 工作队列(work queue)是另外一种将工作推后执行的形式。工作队列可以把工作推后,交由一个内核线程去执行—这个下半部分总是会在进程上下文执行,但由于是内核线程,其不能访问用户空间。最重要特点的就是工作队列允许重新调度甚至是睡眠。 通常,在工作队列和软中断/tasklet中作出选择非常容易。可使用以下规则: - 如果推后执行的任务需要睡眠,那么只能选择工作队列。 - 如果推后执行的任务需要延时指定的时间再触发,那么使用工作队列,因为其可以利用timer延时(内核定时器实现)。 - 如果推后执行的任务需要在一个tick之内处理,则使用软中断或tasklet,因为其可以抢占普通进程和内核线程,同时不可睡眠。 - 如果推后执行的任务对延迟的时间没有任何要求,则使用工作队列,此时通常为无关紧要的任务。 实际上,工作队列的本质就是将工作交给内核线程处理,因此其可以用内核线程替换。但是内核线程的创建和销毁对编程者的要求较高,而工作队列实现了内核线程的封装,不易出错,所以我们也推荐使用工作队列。
相关数据结构
- 正常工作结构体
struct work_struct {
atomic_long_t data; //传递给工作函数的参数
#define WORK_STRUCT_PENDING 0 /* T if work item pending execution */
#define WORK_STRUCT_FLAG_MASK (3UL)
#define WORK_STRUCT_WQ_DATA_MASK (~WORK_STRUCT_FLAG_MASK)struct list_head entry; //链表结构,链接同一工作队列上的工作。
work_func_t func; //工作函数,用户自定义实现
#ifdef CONFIG_LOCKDEP struct lockdep_map lockdep_map; #endif }; //工作队列执行函数的原型:void (*work_func_t)(struct work_struct *work); //该函数会由一个工作者线程执行,因此其在进程上下文中,可以睡眠也可以中断。但只能在内核中运行,无法访问用户空间。
- 延迟工作结构体(延迟的实现是在调度时延迟插入相应的工作队列)
struct delayed_work { struct work_struct work; struct timer_list timer; //定时器,用于实现延迟处理 };
- 工作队列结构体
struct workqueue_struct { struct cpu_workqueue_struct *cpu_wq; //指针数组,其每个元素为per-cpu的工作队列 struct list_head list; const char *name; int singlethread; //标记是否只创建一个工作者线程 int freezeable; /* Freeze threads during suspend */ int rt; #ifdef CONFIG_LOCKDEP struct lockdep_map lockdep_map; #endif };
资料直通车:最新Linux内核源码资料文档+视频资料
内核学习地址:Linux内核源码/内存调优/文件系统/进程管理/设备驱动/网络协议栈
- 每cpu工作队列(每cpu都对应一个工作者线程worker_thread)
struct cpu_workqueue_struct {
spinlock_t lock;
struct list_head worklist;
wait_queue_head_t more_work;
struct work_struct *current_work;
struct workqueue_struct *wq;
struct task_struct *thread;
} ____cacheline_aligned;
- 缺省工作队列
静态创建 DECLARE_WORK(name,function); //定义正常执行的工作项 DECLARE_DELAYED_WORK(name,function);//定义延后执行的工作项 动态创建 INIT_WORK(_work, _func) //创建正常执行的工作项 INIT_DELAYED_WORK(_work, _func)//创建延后执行的工作项 调度默认工作队列 int schedule_work(struct work_struct *work) //对正常执行的工作进行调度,即把给定工作的处理函数提交给缺省的工作队列和工作者线程。工作者线程本质上是一个普通的内核线程,在默认情况下,每个CPU均有一个类型为“events”的工作者线程,当调用schedule_work时,这个工作者线程会被唤醒去执行工作链表上的所有工作。 系统默认的工作队列名称是:keventd_wq,默认的工作者线程叫:events/n,这里的n是处理器的编号,每个处理器对应一个线程。比如,单处理器的系统只有events/0这样一个线程。而双处理器的系统就会多一个events/1线程。 默认的工作队列和工作者线程由内核初始化时创建: start_kernel()-->rest_init-->do_basic_setup-->init_workqueues 调度延迟工作 int schedule_delayed_work(struct delayed_work *dwork,unsigned long delay) 刷新缺省工作队列 void flush_scheduled_work(void) //此函数会一直等待,直到队列中的所有工作都被执行。 取消延迟工作 static inline int cancel_delayed_work(struct delayed_work *work) //flush_scheduled_work并不取消任何延迟执行的工作,因此,如果要取消延迟工作,应该调用cancel_delayed_work。
以上均是采用缺省工作者线程来实现工作队列,其优点是简单易用,缺点是如果缺省工作队列负载太重,执行效率会很低,这就需要我们创建自己的工作者线程和工作队列。
- 自定义工作队列
create_workqueue(name) //宏定义 返回值为工作队列,name为工作线程名称。
创建新的工作队列和相应的工作者线程,name用于该内核线程的命名。
int queue_work(
struct workqueue_struct *wq,
struct work_struct *work) //类似于schedule_work,区别在于queue_work把给定工作提交给创建的工作队列wq而不是缺省队列。
int queue_delayed_work(struct workqueue_struct *wq,
struct delayed_work *dwork, unsigned long delay) //调度延迟工作。
void flush_workqueue(struct workqueue_struct *wq) //刷新指定工作队列。
void destroy_workqueue(struct workqueue_struct *wq) //释放创建的工作队列。
实现原理
- 工作队列的组织结构 即workqueue_struct、cpu_workqueue_struct与work_struct的关系。 一个工作队列对应一个work_queue_struct,工作队列中每cpu的工作队列由cpu_workqueue_struct表示,而work_struct为其上的具体工作。 关系如下图所示:

2.工作队列的工作过程

- 应用实例 linux各个接口的状态(up/down)的消息需要通知netdev_chain上感兴趣的模块同时上报用户空间消息。这里使用的就是工作队列。 具体流程图如下所示:
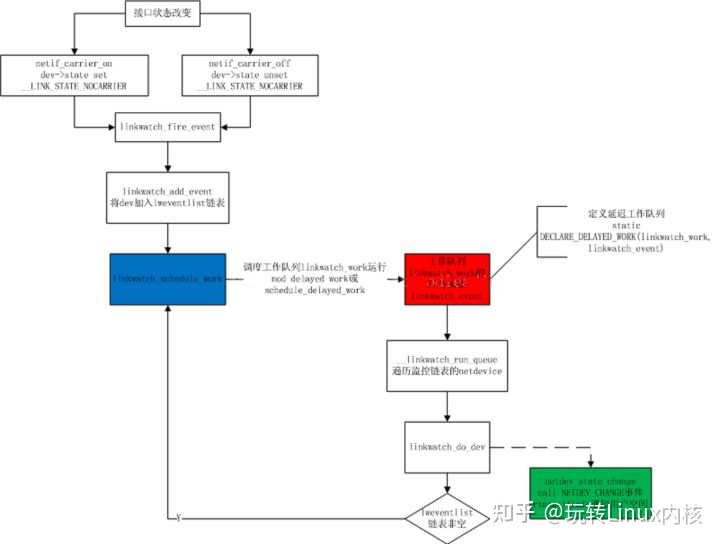
- 是否处于中断中在Linux中是通过preempt_count来判断的,具体如下: 在linux系统的进程数据结构里,有这么一个数据结构: #define preempt_count() (current_thread_info()->preempt_count) 利用preempt_count可以表示是否处于中断处理或者软件中断处理过程中,如下所示: # define hardirq_count() (preempt_count() & HARDIRQ_MASK) #define softirq_count() (preempt_count() & SOFTIRQ_MASK) #define irq_count() (preempt_count() & (HARDIRQ_MASK | SOFTIRQ_MASK | NMI_MASK)) #define in_irq() (hardirq_count()) #define in_softirq() (softirq_count()) #define in_interrupt() (irq_count())

preempt_count的8~23位记录中断处理和软件中断处理过程的计数。如果有计数,表示系统在硬件中断或者软件中断处理过程中。
相关文章:
Linux内核中的软中断、tasklet和工作队列
软中断、tasklet和工作队列并不是Linux内核中一直存在的机制,而是由更早版本的内核中的“下半部”(bottom half)演变而来。下半部的机制实际上包括五种,但2.6版本的内核中,下半部和任务队列的函数都消失了,…...
【Java】Spring Boot 2 集成 nacos
官方文档:https://nacos.io/zh-cn/docs/quick-start-spring-boot.html pom 本次Springboot版本 2.2.6.RELEASE,nacos-config 版本 0.2.7,nacos-discovery版本 0.2.7 parent <parent><groupId>org.springframework.boot</gr…...
JavaSE学习笔记day14
二、Set Set集合是Collection集合的子接口,该集合中不能有重复元素!! Set集合提供的方法签名,与父接口Collection的方法完全一致!! 即没有关于下标操作的方法 Set接口,它有两个常用的子实现类HashSet,TreeSet 三、HashSet HashSet实现了Set接口,底层是hash表(实际上底层是HashM…...
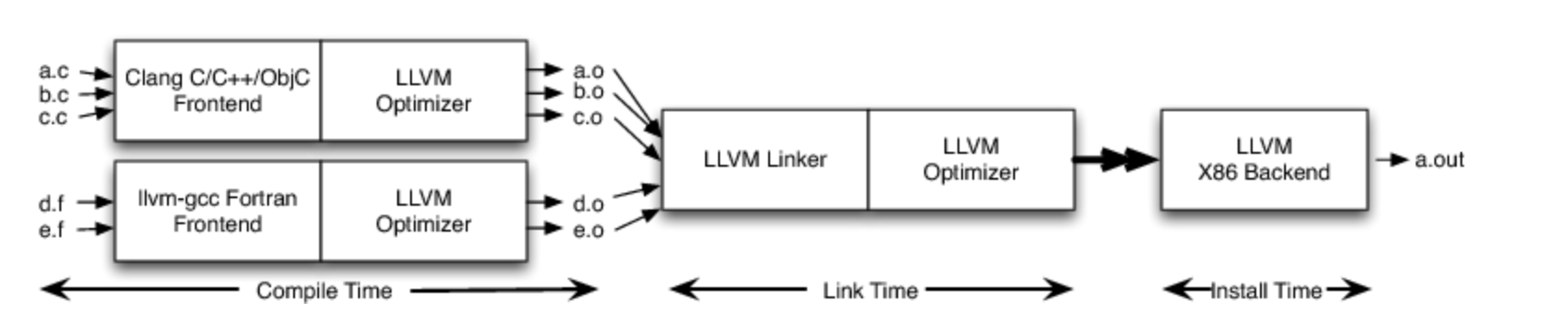
LLVM高级架构介绍
LLVM 为什么要开一个LLVM的新坑呢? 我从智能穿戴转行到芯片软件行业,从事编译器开发,不过是AI编译器。不过基本的传统编译器还是绕不过去啊,所以开始学习LLVM,后面开始学习TVM,MLIR。 LLVM GitHub地址 L…...

全网最经典函数题型【详解】——C语言
文章目录1. 写一个函数可以判断一个数是不是素数。2. 写一个函数判断一年是不是闰年。3. 写一个函数,实现一个整形有序数组的二分查找。4. 写一个函数,每调用一次这个函数,就会将 num 的值增加1。5. 写一个函数,打印乘法口诀表。6…...
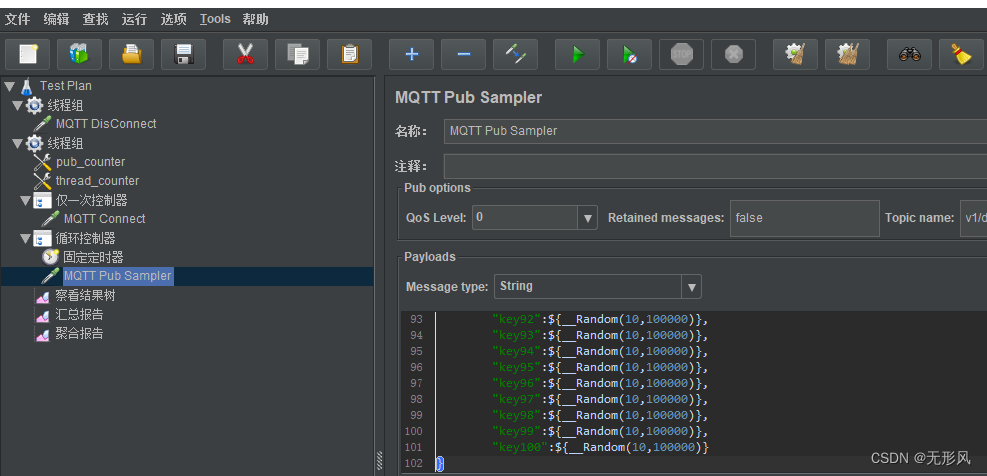
emqx桥接配置+常见问题解决+jmeter压测emqx
一,桥接资源配置及规则配置 Emqx桥接配置流程 1,配置资源并测试连接通过 规则引擎——>资源——>新建——>选择MQTT Bridge——>填写参数测试连接 参数描述详见3.1资源配置 2,配置规则 2.1根据实际业务选择合适sql 规则引擎…...
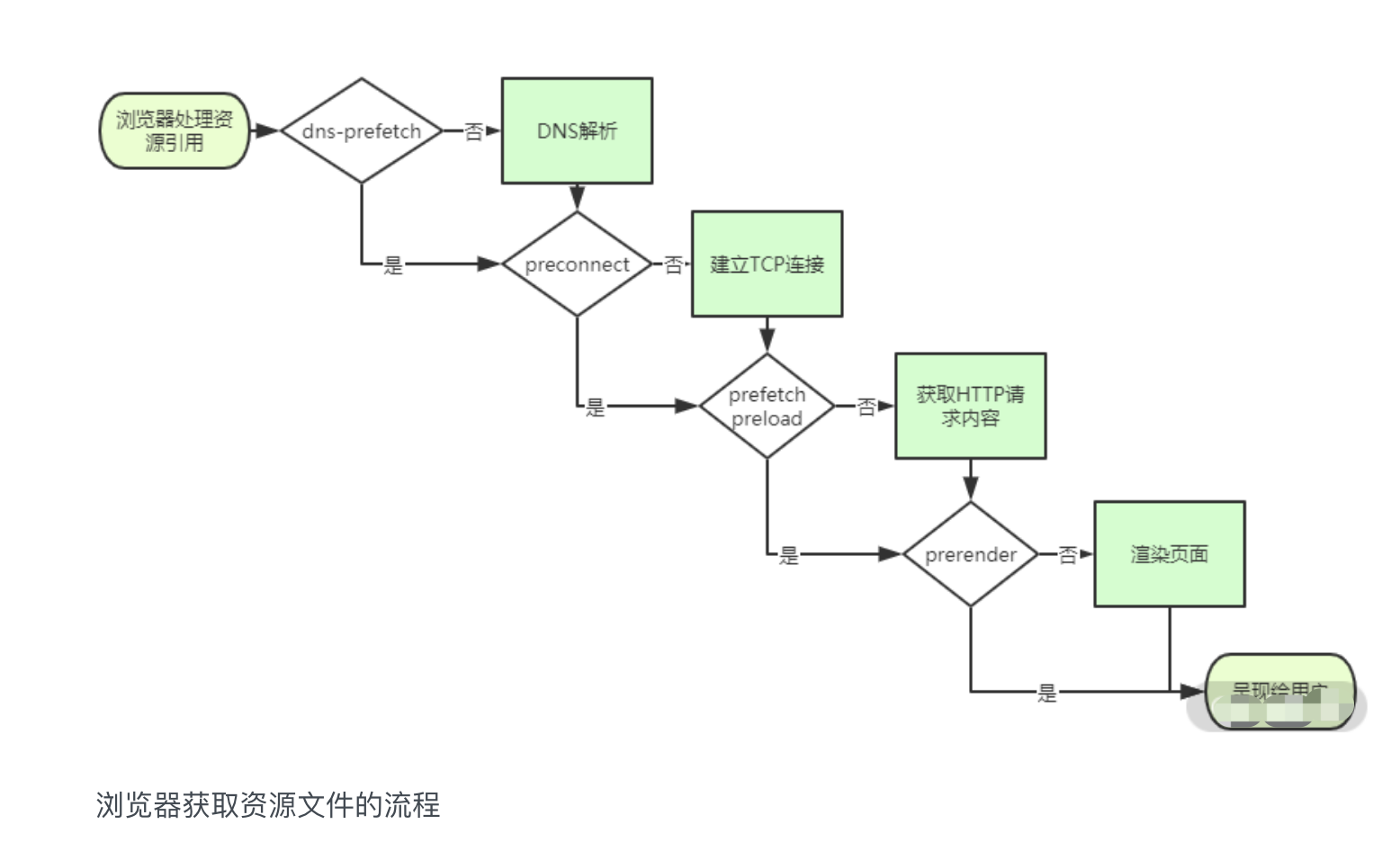
improve-1
类型及检测方式 1. JS内置类型 JavaScript 的数据类型有下图所示 其中,前 7 种类型为基础类型,最后 1 种(Object)为引用类型,也是你需要重点关注的,因为它在日常工作中是使用得最频繁,也是需要…...

华为OD机试用Python实现 -【云短信平台优惠活动】(2023-Q1 新题)
华为OD机试题 华为OD机试300题大纲云短信平台优惠活动题目描述输入描述输出描述示例一输入输出说明示例二输入输出说明Python 代码实现代码编写思路华为OD机试300题大纲 参加华为od机试,一定要注意不要完全背诵代码,需要理解之后模仿写出,通过率才会高。 华为 OD 清单查看…...

Facebook广告投放运营中的关键成功因素是什么?
在当今数字化的时代,广告投放已经成为了各种企业获取市场份额和增加品牌曝光的重要手段之一。Facebook作为全球最大的社交媒体平台之一,其广告投放运营的成功,将直接影响企业的品牌推广和市场营销效果。本文将探讨Facebook广告投放运营中的关…...
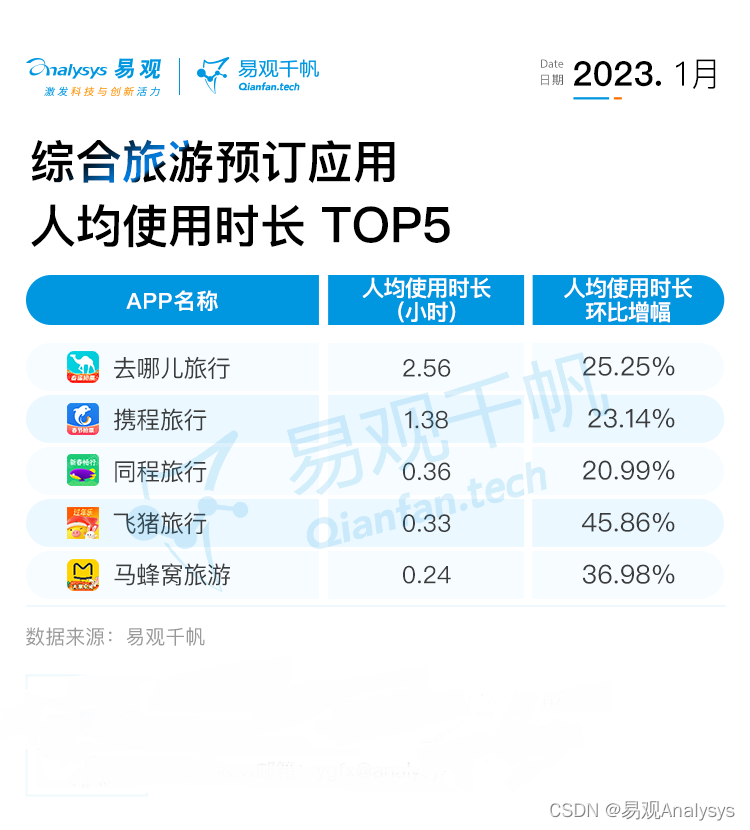
2023年1月综合预订类APP用户洞察——旅游市场复苏明显,三年需求春节集中释放
2023年1月,随着国家对新型冠状病毒感染实施“乙类乙管”,不再对入境人员和货物等采取检疫传染病管理措施,并且取消入境后全员核酸检测和集中隔离,横亘在旅游者与旅游目的地之间的隔阂从此彻底消失。2023年1月恰逢春节假期…...

基于stm32计算器设计
这里写目录标题 完整de代码可q我获取1 系统功能设计2 系统硬件系统分析设计2.1 STM32单片机核心电路设计2.2 LCD1602液晶显示模块电路设计2.3 4X4矩阵键盘模块设计3 STM32单片机系统软件设计3.1 编程语言选择3.2 Keil程序开发环境3.3 FlyMcu程序烧录软件介绍3.4 CH340串口程序烧…...
)
基于SpringCloud的可靠消息最终一致性02:项目骨架代码(上)
在上一节中咱们已经把分布式事务问题交代了一遍,包括两大定理、五大解决方案和一个成熟的开源框架,而咱们最终的目标是用Spring Cloud实现一个实际创业项目的可靠消息最终一致性的分布式事务方案。 先交代一下项目背景。 前几年,社会上慢慢兴起一种称为C2C同城快递的业务,也…...

RockerMQ集群部署
目录一、Broker集群模式1、单Master:2、多Master多Slave模式异步复制3、多Master多Slave模式同步双写二、集群搭建实践1、集群架构2、克隆生成rocketmqos13、修改rocketmqos1配置文件4、克隆生成rocketmqOS25、修改rocketmqOS2配置文件6、启动服务器7、测试一、Brok…...

unicloud的aggregate聚合查询时间戳转日期
我特么不知道看了这个帖子几百遍才看明白到-----》unicloud数据库中,聚合操作如何操作时间戳? - DCloud问答 自己淋过雨老想着为别人撑伞,可怜我这35岁的老人家,给我去点关注!!!!&a…...

Vue2.0开发之——使用ref引用组件实例(41)
一 概述 在本组件内部修改count的值在父组件内修改子组件的count值 二 在本组件内部修改count的值 2.1 Left.vue 布局代码 <template><div class"left-container"><h3 >Left 组件---{{count}}</h3><button click"count 1"&…...

极狐GitLab仓库瘦身
参考文章: [分享] 极狐GitLab仓库瘦身 - 官方技术分享 - 极狐GitLab 论坛 一、瘦身概述 Git仓库随着时间推移会变得越来越大,比如很多比较大的文件加入Git仓库时,可能引起以下问题: 下载仓库越来越慢,因为每个人都…...

2288hv5超融合服务器 数码管报888
【问题现象】 2288hv5超融合服务器,前面板数码管报888,电源灯黄灯闪烁,开不了机,ibmc网络是通的,但是web网页打不开 【问题原因】 iBMC的版本过低,iBMC在智能诊断数据库保护机制存在异常,导…...

【Zabbix实战之部署篇】Zabbix监控windows系统配置方法
【Zabbix实战之部署篇】Zabbix监控windows系统配置方法 一、检查Zabbix监控平台状态1.检查Zabbix各组件状态2.检查Zabbix的首页二、下载windows代理1.访问Zabbix官网下载界面2.查看下载安装包三、安装windows agent2代理1.安装windows agent2代理2.代理基本配置信息3.开始进行安…...

在Windows上编译Nginx
《在Windows上编译Nginx》视频教程官方编译说明 Building nginx on the Win32 platform with Visual C 环境准备 1. Microsoft Visual Studio(Microsoft Visual C 编译器),下载地址:https://visualstudio.microsoft.com/zh-hans/。 2. Git(备用)&…...

语音识别与Python编程实践
博主简介 博主是一名大二学生,主攻人工智能研究。感谢让我们在CSDN相遇,博主致力于在这里分享关于人工智能,c,Python,爬虫等方面知识的分享。 如果有需要的小伙伴可以关注博主,博主会继续更新的,…...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

Linux 文件类型,目录与路径,文件与目录管理
文件类型 后面的字符表示文件类型标志 普通文件:-(纯文本文件,二进制文件,数据格式文件) 如文本文件、图片、程序文件等。 目录文件:d(directory) 用来存放其他文件或子目录。 设备…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

Spring数据访问模块设计
前面我们已经完成了IoC和web模块的设计,聪明的码友立马就知道了,该到数据访问模块了,要不就这俩玩个6啊,查库势在必行,至此,它来了。 一、核心设计理念 1、痛点在哪 应用离不开数据(数据库、No…...

Linux 内存管理实战精讲:核心原理与面试常考点全解析
Linux 内存管理实战精讲:核心原理与面试常考点全解析 Linux 内核内存管理是系统设计中最复杂但也最核心的模块之一。它不仅支撑着虚拟内存机制、物理内存分配、进程隔离与资源复用,还直接决定系统运行的性能与稳定性。无论你是嵌入式开发者、内核调试工…...

Netty从入门到进阶(二)
二、Netty入门 1. 概述 1.1 Netty是什么 Netty is an asynchronous event-driven network application framework for rapid development of maintainable high performance protocol servers & clients. Netty是一个异步的、基于事件驱动的网络应用框架,用于…...