注意力机制详解系列(二):通道注意力机制

👨💻作者简介: 大数据专业硕士在读,CSDN人工智能领域博客专家,阿里云专家博主,专注大数据与人工智能知识分享。
🎉专栏推荐: 目前在写CV方向专栏,更新不限于目标检测、OCR、图像分类、图像分割等方向,目前活动仅19.9,虽然付费但会长期更新,感兴趣的小伙伴可以关注下➡️专栏地址
🎉学习者福利: 强烈推荐一个优秀AI学习网站,包括机器学习、深度学习等理论与实战教程,非常适合AI学习者。➡️网站链接。
🎉技术控福利:程序员兼职社区招募!靠谱覆盖技术范围广,CV、NLP均可,Pyhton、matlab各类编程语言, 有意向者➡️访问。
📝导读:本篇为注意力机制系列第二篇,主要介绍注意力机制中的通道注意力机制,对通道注意力机制方法进行详细讲解,会对重点论文会进行标注 * ,并配上论文地址和对应代码。
🆙 注意力机制详解系列目录:1️⃣注意力机制详解系列(一):注意力机制概述
2️⃣注意力机制详解系列(二):通道注意力机制
3️⃣注意力机制详解系列(三):空间注意力机制(待更新)
4️⃣注意力机制详解系列(四):混合与时域注意力机制(待更新)
5️⃣注意力机制详解系列(五):注意力机制总结(待更新)
1.通道注意力机制
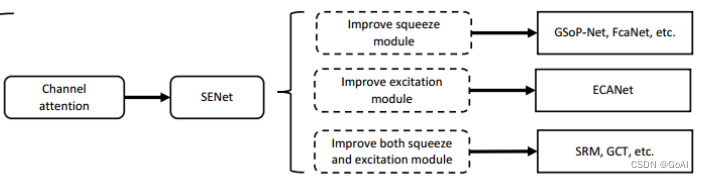
通道注意力机制模型总结
通道注意力机制在计算机视觉中,更关注特征图中channel之间的关系,而普通的卷积会对通道做通道融合,这个开山鼻祖是SENet,后面有GSoP-Net,FcaNet 对SENet中的squeeze部分改进,EACNet对SENet中的excitation部分改进,SRM,GCT等对SENet中的scale部分改进。
通道注意力机制模型对比:
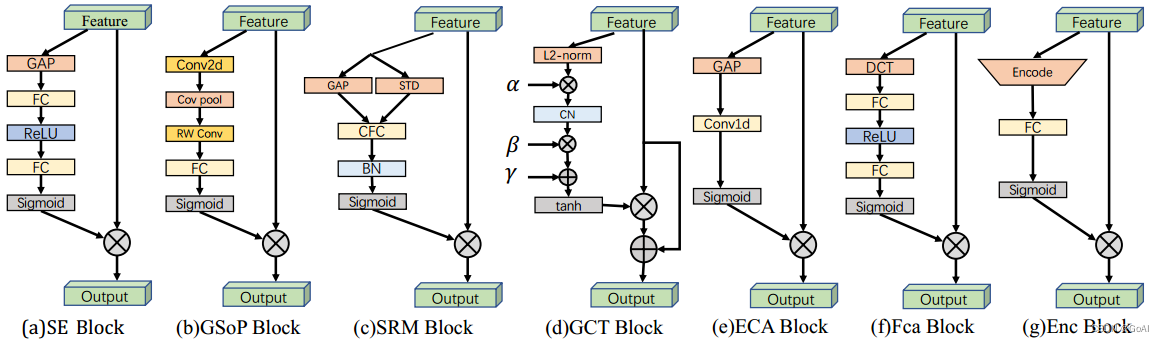
对应论文链接:
| 论文缩写 | 论文名称 | 链接 | 权重范围 | 论文投稿 |
|---|---|---|---|
| SE Block | Squeeze-and-Excitation Networks | (0,1) | CVPR2018 |
| GSoP Block | Global Second-order Pooling Convolutional Networks | (0,1) | CVPR2019 |
| SRM Block | SRM : A Style-based Recalibration Module for Convolutional Neural Networks | (0,1) | ICCV2019 |
| GCT Block | Gated Channel Transformation for Visual Recognition | (0,1) | CVPR2020 |
| ECA Block | ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks | (0,1) | CVPR2020 |
| Fca Block | FcaNet: Frequency Channel Attention Networks | (0,1) | ICCV2021 |
| Enc Block | Context Encoding for Semantic Segmentation | (-1,1) | CVPR2018 |
1.SENet
论文:https://arxiv.org/abs/1709.01507
Github:https://github.com/hujie-frank/SENet
https://github.com/moskomule/senet.pytorch
SENet是CVPR17年的一篇文章提出。在卷积神经网络中,卷积操作更多的是关注感受野,在通道上默认为是所有通道的融合(深度可分离卷积不对通道进行融合,但是没有学习通道之间的关系,其主要目的是为了减少计算量),SENet提出SE模块,通过学习的方式自动获取每个特征通道的重要程度,学习到不同通道之间的权重,并且利用得到的重要程度来提升特征并抑制对当前任务不重要的特征。
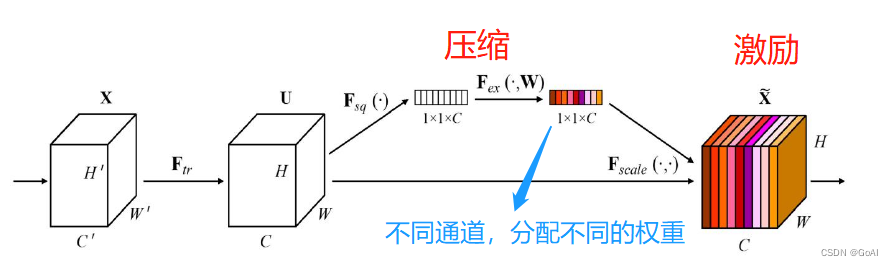
SE模块主要由三部分组成:squeeze、excitation和scale。实现步骤如下:
总体概述:
(1)Squeeze:通过全局平均池化,将每个通道的二维特征(H*W)压缩为1个实数,将特征图从 [h, w, c] ==> [1,1,c]
(2)excitation:给每个特征通道生成一个权重值,论文中通过两个全连接层构建通道间的相关性,输出的权重值数目和输入特征图的通道数相同。[1,1,c] ==> [1,1,c]
(3)Scale:将前面得到的归一化权重加权到每个通道的特征上。论文中使用的是乘法,逐通道乘以权重系数。[h,w,c]*[1,1,c] ==> [h,w,c]
在这种方式下,每一个样本,都会有自己独立的一组权重。换言之,任意的两个样本,它们的权重,都是不一样的。在SENet中,获得权重的具体路径是,“全局池化→全连接层→ReLU函数→全连接层→Sigmoid函数”。
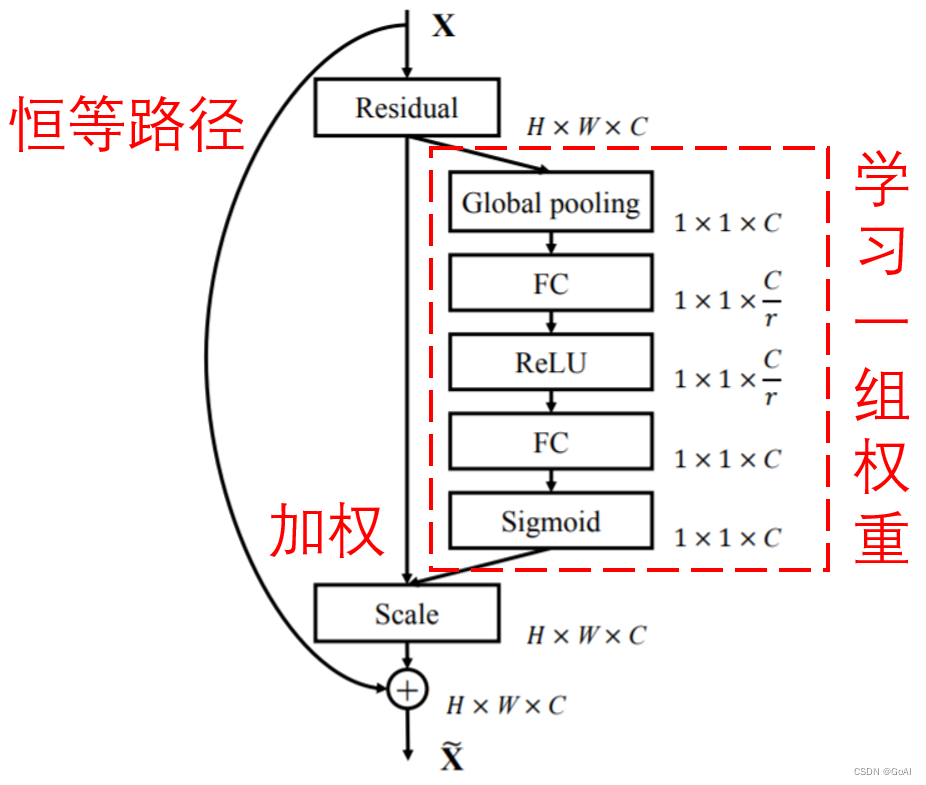
详细解释:
第一步首先对h* w* c大小的feature map 做squeeze操作将其变成1 * 1 * c大小,这一步原文中使用简单粗暴的GAP(全局平均池化);
第二步excitation操作,对1 * 1 * c的特征图经过两次全连接,特征图大小1 * 1 * c→1 * 1 * 3→1* 1 * c,再对1 * 1* c的特征图做sigmoid将值限制到[0,1]范围内;
第三步scale,将1 * 1 * c的特征权重图与输入的h * w * c的feature map在通道上相乘;完成SE模块的通道注意力机制。
值得注意的是,在squeeze部分,作者使用的是最简单的全局平均池化的方式,主要原因是作者基于通道的整体信息,关注通道之间的相关性,而不是空间分布的相关性,也尽可能的屏蔽掉空间分布信息;在excitation部分,作者通过两个全连接实现1 * 1 * c2→1 * 1 * c3→1 * 1 * c2,第一个全连接层将c2压缩到c3,用于计算量减少,在原文中作者做实验后发现c3=c2/16时,能实现性能和计算量的平衡。
SE模型同Inception,可以即插即用,理论上可以安插在任意一个卷积后面,简单方便,只会增加一点参数量和计算量。
SENet的实现代码如下:
class SELayer(nn.Module):def __init__(self, channel, reduction=1):super(SELayer, self).__init__()self.avg_pool = nn.AdaptiveAvgPool2d(1)self.fc1 = nn.Sequential(nn.Linear(channel, channel / reduction),nn.ReLU(inplace=True),nn.Linear(channel / reduction, channel),nn.Sigmoid())self.fc2 = nn.Sequential(nn.Conv2d(channel , channel / reduction, 1, bias=False)nn.ReLU(inplace=True),nn.Conv2d(channel / reduction, channel, 1, bias=False)nn.Sigmoid())def forward(self, x):b, c, _, _ = x.size()y = self.avg_pool(x).view(b, c)y = self.fc1(y).view(b, c, 1, 1)return x * y
SE模块插入Resnet代码:
class SEBottleneck(nn.Module):expansion = 4def __init__(self, inplanes, planes, stride=1, downsample=None, reduction=16):super(SEBottleneck, self).__init__()self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)self.bn1 = nn.BatchNorm2d(planes)self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,padding=1, bias=False)self.bn2 = nn.BatchNorm2d(planes)self.conv3 = nn.Conv2d(planes, planes * 4, kernel_size=1, bias=False)self.bn3 = nn.BatchNorm2d(planes * 4)self.relu = nn.ReLU(inplace=True)self.se = SELayer(planes * 4, reduction)self.downsample = downsampleself.stride = stridedef forward(self, x):residual = xout = self.conv1(x)out = self.bn1(out)out = self.relu(out)out = self.conv2(out)out = self.bn2(out)out = self.relu(out)out = self.conv3(out)out = self.bn3(out)out = self.se(out)if self.downsample is not None:residual = self.downsample(x)out += residualout = self.relu(out)return out
GSoP-Net
论文:https://arxiv.org/abs/1811.12006
github:https://github.com/ZilinGao/Global-Second-order-Pooling-Convolutional-Networks

SE模块中squeeze部分用的是全局平均池化,GSoP-Net的主要创新点是将一阶全局平均池化替换成二阶池化,主要操作为对输入为hwc‘的特征图先通过卷积降维到hwc,然后通道之间两两计算相关性,得到cc的协方差矩阵,第i行元素表明第i i个通道和其他通道的统计层面的依赖。由于二次运算涉及到改变数据的顺序,因此对协方差矩阵执行逐行归一化,保留固有的结构信息。然后通过激励模块对协方差特征图做非线性逐行卷积得到11*4c的特征信息,后面同SENet。相对于SNet,增加了全局的统计建模。
FcaNet
论文:http://arxiv.org/abs/2012.11879
github: https://github.com/cfzd/FcaNet

FCANet主要也是更新SE模块中squeeze部分,作者设计了一种新的高效多谱通道注意力框架。该框架在GAP是DCT的一种特殊形式的基础上,在频域上推广了GAP通道注意力机制,提出使用有限制的多个频率分量代替只有最低频的GAP。通过集成更多频率分量,不同的信息被提取从而形成一个多谱描述。此外,为了更好进行分量选择,作者设计了一种二阶段特征选择准则,在该准则的帮助下,提出的多谱通道注意力框架达到了SOTA效果。
ECA-Net
论文: https://arxiv.org/pdf/1910.03151
代码: https://github.com/BangguWu/ECANet
ECANet介绍:
ECANet主要对SENet模块进行了一些改进,提出了一种不降维的局部跨信道交互策略(ECA模块)和自适应选择一维卷积核大小的方法,使得通道数较大的层可以更多地进行跨通道交互,从而实现了性能上的提优。
ECANet主要对SENet中的excitation部分改进,SENet采用的降维操作会对通道注意力的预测产生负面影响,且获取依赖关系效率低且不必要,因此提出了一种针对CNN的高效通道注意力(ECA)模块,避免了降维,有效地实现了跨通道交互。
ECANet通过大小为 k 的快速一维卷积实现,其中核大小k表示局部跨通道交互的覆盖范围,即有多少领域参与了一个通道的注意预测 ;同时为了避免通过交叉验证手动调整 k,开发了一种自适应方法确定 k,其中跨通道交互的覆盖范围 (即核大小k) 与通道维度成比例 。
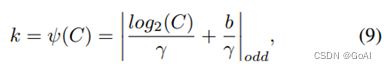
这里 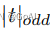 表示最近的奇数t。本文中将γ设置为2,b设置为1。
表示最近的奇数t。本文中将γ设置为2,b设置为1。

ECANet实现流程:
(1)将输入特征图经过全局平均池化,特征图从 [h,w,c] 的矩阵变成 [1,1,c] 的向量
(2)根据特征图的通道数计算得到自适应的一维卷积核大小 kernel_size
(3)将 kernel_size 用于一维卷积中,得到对于特征图的每个通道的权重
(4)将归一化权重和原输入特征图逐通道相乘,生成加权后的特征图
核心:ECA 注意力机制模块直接在全局平均池化层之后使用1x1卷积层,去除了全连接层。该模块避免了维度缩减,并有效捕获了跨通道交互。并且ECANet 只涉及少数参数就能达到很好的效果。
ECANet实战代码:
#ECANet使用1D卷积代替SE注意力机制中的全连接层
import torch
from torch import nn
import math
from torchstat import stat # 查看网络参数# 定义ECANet的类
class eca_block(nn.Module):# 初始化, in_channel代表特征图的输入通道数, b和gama代表公式中的两个系数def __init__(self, in_channel, b=1, gama=2):# 继承父类初始化super(eca_block, self).__init__()# 根据输入通道数自适应调整卷积核大小kernel_size = int(abs((math.log(in_channel, 2)+b)/gama))# 如果卷积核大小是奇数,就使用它if kernel_size % 2:kernel_size = kernel_size# 如果卷积核大小是偶数,就把它变成奇数else:kernel_size = kernel_size# 卷积时,为例保证卷积前后的size不变,需要0填充的数量padding = kernel_size // 2# 全局平均池化,输出的特征图的宽高=1self.avg_pool = nn.AdaptiveAvgPool2d(output_size=1)# 1D卷积,输入和输出通道数都=1,卷积核大小是自适应的self.conv = nn.Conv1d(in_channels=1, out_channels=1, kernel_size=kernel_size,bias=False, padding=padding)# sigmoid激活函数,权值归一化self.sigmoid = nn.Sigmoid()# 前向传播def forward(self, inputs):# 获得输入图像的shapeb, c, h, w = inputs.shape# 全局平均池化 [b,c,h,w]==>[b,c,1,1]x = self.avg_pool(inputs)# 维度调整,变成序列形式 [b,c,1,1]==>[b,1,c]x = x.view([b,1,c])# 1D卷积 [b,1,c]==>[b,1,c]x = self.conv(x)# 权值归一化x = self.sigmoid(x)# 维度调整 [b,1,c]==>[b,c,1,1]x = x.view([b,c,1,1])# 将输入特征图和通道权重相乘[b,c,h,w]*[b,c,1,1]==>[b,c,h,w]outputs = x * inputsreturn outputs
SRM
论文: https://arxiv.org/pdf/1903.10829
代码:https://github.com/hyunjaelee410/style-based-recalibration-module
SRM受风格迁移的启发,对SENet中的squeeze和excitation部分进行更新:

提出了一种基于style的重新校准模块(SRM),可以通过利用其style自适应地重新校准中间特征图。SRM首先通过样式池从特征图的每个通道中提取样式信息,然后通过与通道无关的style集成来估计每个通道的重新校准权重。

给定一个输入特征特征图大小为C × H × W ,SRM首先通过结合全局平均池和全局标准差池化的风格式池化收集全局信息。然后使用通道全连接层(即每个通道全连接)、批量归一化BN和sigmoid函数σ来提供注意力向量。最后,与SE块一样,输入特征乘以注意力向量。它利用输入特征的均值和标准差来提高捕获全局信息的能力。为了降低计算层(CFC)的完全连接要求,在全连接的地方也采用了CFC。通过将各个style的相对重要性纳入特征图,SRM有效地增强了CNN的表示能力。重点是轻量级,引入的参数非常少,同时效果还优于SENet.。
GCT
论文: GCT
代码: https://github.com/z-x-yang/GCT

GCT是由百度提出,一种通用且轻量型变化单元,结合了归一化和注意力机制,分析通道之间的相互关系(竞争or协作),对SENet中的squeeze、excitation和scale部分进行更新:在squeeze部分中使用L2 norm进行了global context embeding,同时在excitation中,仍然使用L2 norm 对通道归一化,在scale中通过设置权重γ和偏置β来控制通道特征是否激活。当一个通道的特征权重γc被正激活,GCT将促进这个通道的特征和其它通道的特征“竞争”。当一个通道的特征 γc 被负激活,GCT将促进这个通道的特征和其它通道的特征“合作”。
参考论文
- [1] Squeeze-and-Excitation Networks
- [2] Global Second-order Pooling Convolutional Networks
- [3] FcaNet: Frequency Channel Attention Networks
- [4] ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
- [5] SRM : A Style-based Recalibration Module for Convolutional Neural Networks
- [6] Gated Channel Transformation for Visual Recognition
- [7] Recurrent Models of Visual Attention
具体链接见对应介绍!
总结:
本篇主要介绍注意力机制中的通道注意力机制,对通道注意力机制方法进行详细讲解,通道注意力机制在计算机视觉中,更关注特征图中channel之间的关系,重点对SENet、ECANe进行重点讲解,下篇将对空间注意力机制展开详细介绍.
相关文章:
注意力机制详解系列(二):通道注意力机制
👨💻作者简介: 大数据专业硕士在读,CSDN人工智能领域博客专家,阿里云专家博主,专注大数据与人工智能知识分享。 🎉专栏推荐: 目前在写CV方向专栏,更新不限于目标检测、…...

动态规划-规划兼职工作
动态规划-规划兼职工作 一、问题描述 你打算利用空闲时间来做兼职工作赚些零花钱。这里有 n 份兼职工作,每份工作预计从 startTime 开始到 endTime 结束,报酬为 profit。给你一份兼职工作表,包含开始时间 startTime,结束时间 en…...

Redis学习笔记(二)Redis基础(基于5.0.5版本)
一、Redis定位与特性 Redis是一个速度非常快的非关系数据库(non-relational database),用 Key-Value 的形式来存储数据。数据主要存储在内存中,所以Redis的速度非常快,另外Redis也可以将内存中的数据持久化到硬盘上。…...

Ancaonda常用cmd命令总结
1) 查看以创建的虚拟环境: conda info --envs / conda env list 2) 激活创建的环境:conda activate xxx(虚拟环境名称) 3) 退出激活的环境:conda deactivate 4) 删除一个已有虚拟环境:conda remove --name(已创建虚拟…...

yolov5_reid【附代码,行人重识别,可做跨视频人员检测】
该项目利用yolov5reid实现的行人重识别功能,可做跨视频人员检测。 应用场景: 可根据行人的穿着、体貌等特征在视频中进行检索,可以把这个人在各个不同摄像头出现时检测出来。可应用于犯罪嫌疑人检索、寻找走失儿童等。 支持功能:…...
多模态预训练模型综述
经典预训练模型还未完成后续补上预训练模型在NLP和CV上取得巨大成功,学术届借鉴预训练模型>下游任务finetune>prompt训练>人机指令alignment这套模式,利用多模态数据集训练一个大的多模态预训练模型(跨模态信息表示)来解…...

华为OD机试题,用 Java 解【玩牌高手】问题
最近更新的博客 华为OD机试 - 猴子爬山 | 机试题算法思路 【2023】华为OD机试 - 分糖果(Java) | 机试题算法思路 【2023】华为OD机试 - 非严格递增连续数字序列 | 机试题算法思路 【2023】华为OD机试 - 消消乐游戏(Java) | 机试题算法思路 【2023】华为OD机试 - 组成最大数…...
数学建模 latex 图片以及表格排版整理(overleaf)
无论是什么比赛,图片和表格的格式都非常重要,这边的重要不只是指规范性,还有抓住评委眼球的能力。 那么怎样抓住评委的眼球? 最重要的一点就是善用图片和表格(当然撰写论文最重要的是逻辑,这个是需要长期…...
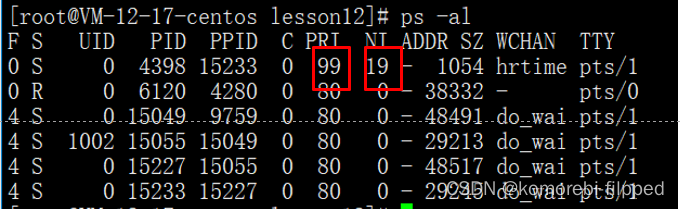
进程优先级(Linux)
目录 优先级VS权限 基本概念 查看系统进程 几个重要信息 PRI and NI PRI vs NI top命令 上限: 详细步骤 下限: 其他概念 优先级VS权限 权限:能or不能 优先级:已经能,但是谁先谁后的问题(CPU资源有…...
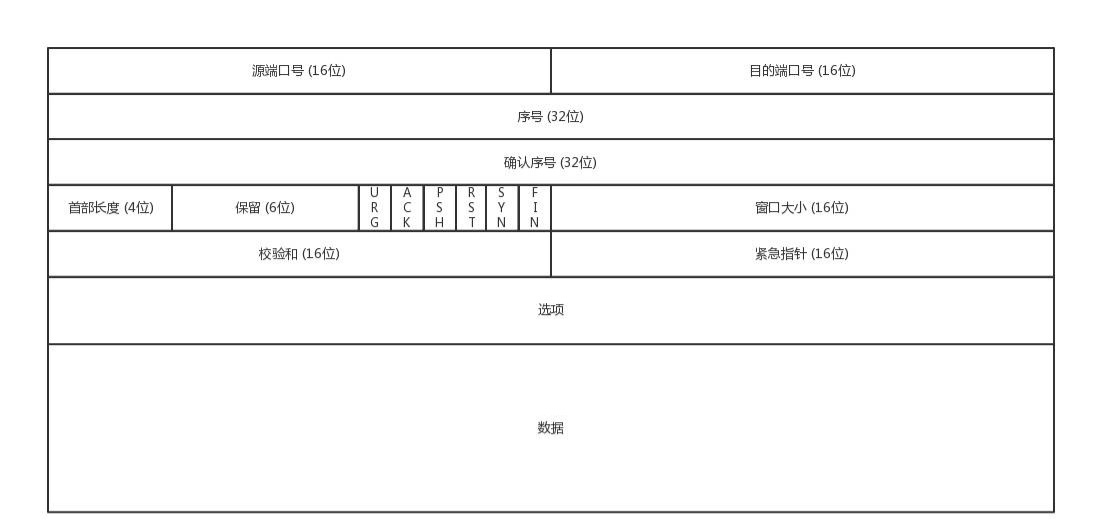
[面试直通版]网络协议面试核心之IP,TCP,UDP-TCP与UDP协议的区别
点击->计算机网络复习的文章集<-点击 目录 前言 UDP TCP 区别小总结 前言 TCP和UDP都是在传输层,在程序之间传输数据传输层OSI模型:第四层TCP/IP模型:第三层关键协议:TCP协议、UDP协议传输层属于主机间不同进程的通信传…...
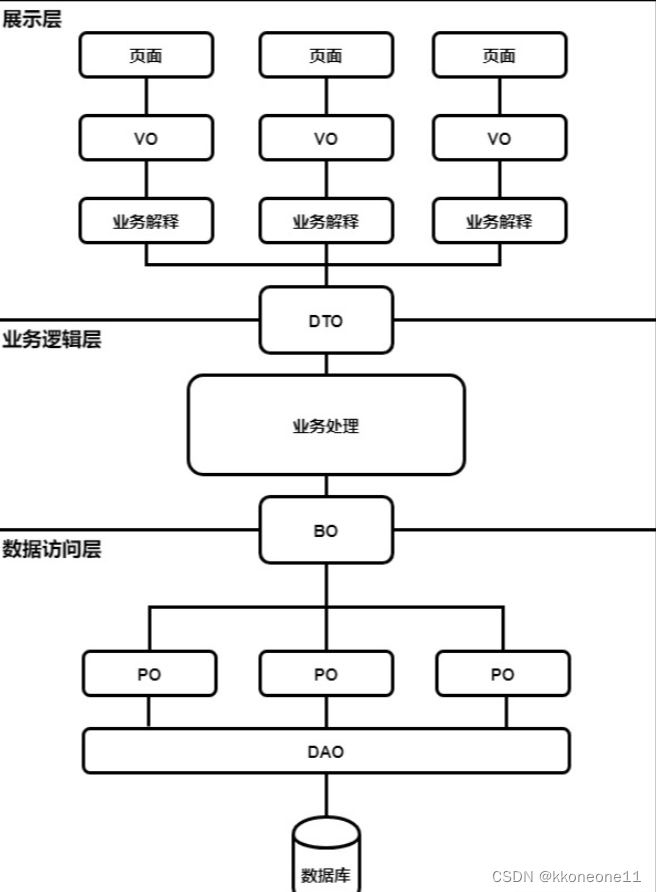
VO,BO,PO,DO,DTO,AO的区别
DTO(Data Transfer Object)数据传输对象 这个传输通常指的前后端之间的传输 1.在前端的时候: 存在形式通常是js里面的对象(也可以简单理解成json),也就是通过ajax请求的那个数据体 2.在后端的时候&…...

JavaSE学习笔记day15
零、 复习昨日 HashSet 不允许重复元素,无序 HashSet去重原理: 先比较hashcode,如果hashcode不一致,直接存储如果hashcode值一样,再比较equals如果equals值为true,则认为完全一样,不存储即去重否则存储 如果使用的是空参构造创建出的TreeSet集合,那么它底层使用的就是自然排序,…...
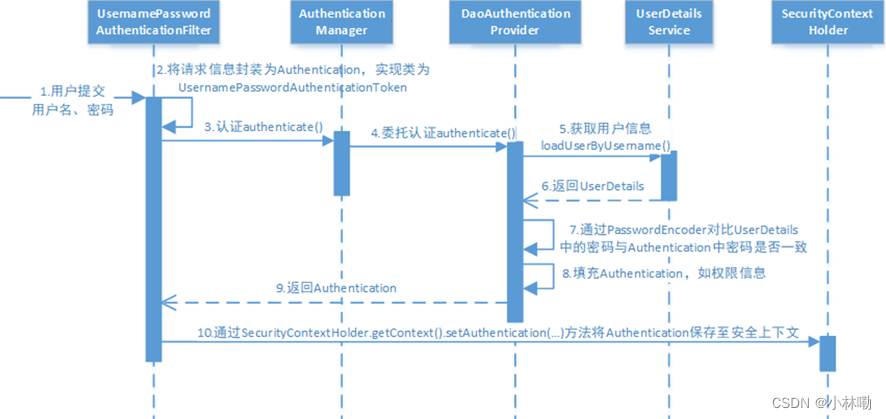
Spring Security认证研究
1.项目中认证的三种方式: 1.统一认证 认证通过由认证服务向给用户颁发令牌,相当于访问系统的通行证,用户拿着令牌去访问系统的资源。 2.单点登录,对于微服务项目,因为包含多个模块,所以单点登录就是使得用户…...

BigKey、布隆过滤器、分布式锁、红锁
文章目录 BigKey发现 BigKey如何删除BigKeyunlinkdelBigKey配置优化布隆过滤器布隆过滤器构建、使用、减少误判布隆过滤器二进制数组,如何处理删除?实现白名单 whitelistCustomer解决缓存穿透分布式锁依赖Redis 分布式锁代码使用红锁POM依赖yaml使用其他redis分布式锁容错率公…...
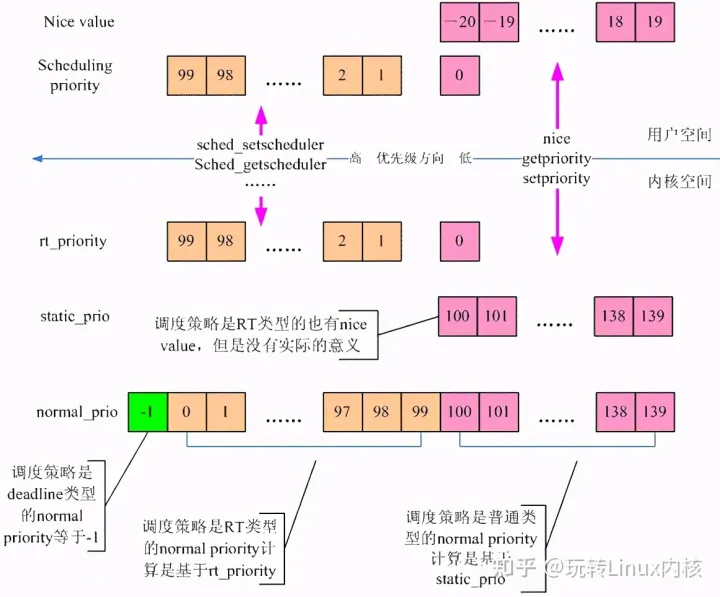
一文让你彻底理解Linux内核调度器进程优先级
一、前言 本文主要描述的是进程优先级这个概念。从用户空间来看,进程优先级就是nice value和scheduling priority,对应到内核,有静态优先级、realtime优先级、归一化优先级和动态优先级等概念。我们希望能在第二章将这些相关的概念描述清楚。…...

Java 抽象类和接口
文章目录一、抽象类1. 抽象类定义2. 抽象类成员特点二、接口1. 接口概述2. 接口成员特点3. 类和接口的关系4. 抽象类和接口的区别5. 接口案例三、形参和返回值一、抽象类 1. 抽象类定义 在 Java 中,一个没有方法体的方法应该定义为抽象方法,而类中如果…...
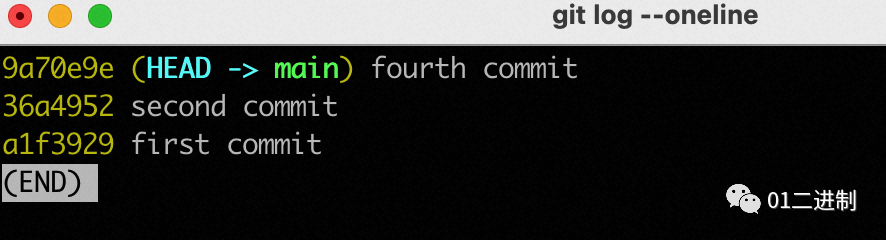
三行代码让你的git记录保持整洁
前言笔者最近在主导一个项目的架构迁移工作,由于迁移项目的历史包袱较重,人员合作较多,在迁移过程中免不了进行多分支、多次commit的情况,时间一长,git的提交记录便混乱不堪,随便截一个图形化的git提交历史…...

阿里巴巴内网 Java 面试 2000 题解析(2023 最新版)
前言 这份面试清单是今年 1 月份之后开始收集的,一方面是给公司招聘用,另一方面是想用它来挖掘在 Java 技术栈中,还有一些知识点是我还在探索的,我想找到这些技术盲点,然后修复它,以此来提高自己的技术水平…...
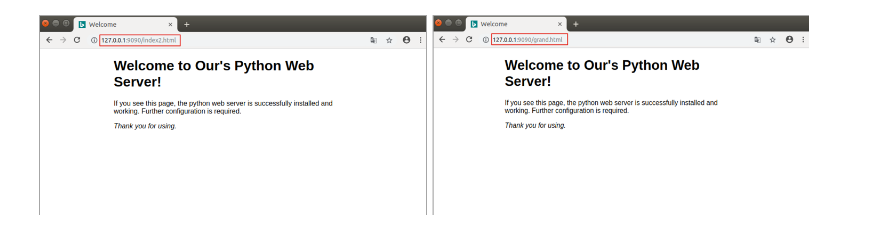
网络应用之静态Web服务器
静态Web服务器-返回固定页面数据学习目标能够写出组装固定页面数据的响应报文1. 开发自己的静态Web服务器实现步骤:编写一个TCP服务端程序获取浏览器发送的http请求报文数据读取固定页面数据,把页面数据组装成HTTP响应报文数据发送给浏览器。HTTP响应报文数据发送完…...

IndexDB 浏览器服务器
IndexDB 浏览器服务器 文章部分内容引用: https://www.ruanyifeng.com/blog/2018/07/indexeddb.html https://juejin.cn/post/7026900352968425486#heading-15 基本概念 数据库:IDBDatabase 对象对象仓库:IDBObjectStore 对象索引࿱…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...
:爬虫完整流程)
Python爬虫(二):爬虫完整流程
爬虫完整流程详解(7大核心步骤实战技巧) 一、爬虫完整工作流程 以下是爬虫开发的完整流程,我将结合具体技术点和实战经验展开说明: 1. 目标分析与前期准备 网站技术分析: 使用浏览器开发者工具(F12&…...

微服务商城-商品微服务
数据表 CREATE TABLE product (id bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 商品id,cateid smallint(6) UNSIGNED NOT NULL DEFAULT 0 COMMENT 类别Id,name varchar(100) NOT NULL DEFAULT COMMENT 商品名称,subtitle varchar(200) NOT NULL DEFAULT COMMENT 商…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...

Android Bitmap治理全解析:从加载优化到泄漏防控的全生命周期管理
引言 Bitmap(位图)是Android应用内存占用的“头号杀手”。一张1080P(1920x1080)的图片以ARGB_8888格式加载时,内存占用高达8MB(192010804字节)。据统计,超过60%的应用OOM崩溃与Bitm…...

基于IDIG-GAN的小样本电机轴承故障诊断
目录 🔍 核心问题 一、IDIG-GAN模型原理 1. 整体架构 2. 核心创新点 (1) 梯度归一化(Gradient Normalization) (2) 判别器梯度间隙正则化(Discriminator Gradient Gap Regularization) (3) 自注意力机制(Self-Attention) 3. 完整损失函数 二…...