C语言数据结构(二)—— 受限线性表 【栈(Stack)、队列(Queue)】
在数据结构逻辑层次上细分,线性表可分为一般线性表和受限线性表。一般线性表也就是我们通常所说的“线性表”,可以自由的删除或添加结点。受限线性表主要包括栈和队列,受限表示对结点的操作受限制。
一般线性表详解,请参考文章:C语言数据结构(一)—— 数据结构理论、线性表【动态数组、链表(企业版单向链表)】
1栈(Stack)
1.1栈的基本概念
概念:
首先它是一个线性表,也就是说,栈元素具有线性关系,即前驱后继关系。只不过它是一种特殊的线性表而已。定义中说是在线性表的表尾进行插入和删除操作,这里表尾是指栈顶,而不是栈底。
特性
它的特殊之处在于限制了这个线性表的插入和删除的位置,它始终只在栈顶进行。这也就使得:栈底是固定的,最先进栈的只能在栈底。符合先进后出的数据结构。
操作
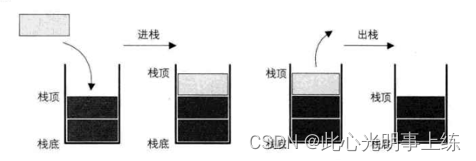
栈的插入操作,叫做进栈,也成压栈。类似子弹入弹夹(如下图所示)
栈的删除操作,叫做出栈,也有的叫做弾栈,退栈。如同弹夹中的子弹出夹(如下图所示)
遍历:不重复不遗漏查看每个元素,并且执行过后不会更改元素
遍历算法属于非质变算法
栈能否遍历?不能
1.2栈的顺序存储
基本概念
栈的顺序存储结构简称顺序栈,它是运算受限制的顺序表。顺序栈的存储结构是:利用一组地址连续的的存储单元依次存放自栈底到栈顶的数据元素,同时附设指针top只是栈顶元素在顺序表中的位置。
设计与实现
因为栈是一种特殊的线性表,所以栈的顺序存储可以通过顺序线性表来实现。数组首地址端做栈底,尾地址端做栈顶,方便数据插入和删除。
对外接口设计:
初始化
入栈
出栈
返回栈顶
返回元素个数
判断是否为空
销毁栈
#define _CRT_SECURE_NO_WARNINGS
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
#define MAX 1024struct SStack {//栈中的数组void * data[MAX];//栈的大小int m_Size;
};typedef void * SeqStack;//初始化栈
SeqStack init_SeqStack() {struct SStack * myStack = malloc(sizeof(struct SStack));if (myStack == NULL) {return NULL;}memset(myStack->data, 0, sizeof(void *) * MAX);myStack->m_Size = 0;return myStack;
}//入栈
void push_SeqStack(SeqStack stack, void * data) {//本质 数组的尾插if (stack == NULL) {return;}if (data == NULL) {return;}//还原栈结构体struct SStack * myStack = stack;//判断栈是否满if (myStack->m_Size == MAX) {return;}//数组进行尾插myStack->data[myStack->m_Size] = data;//更新栈大小myStack->m_Size++;
}//出栈
void pop_SeqStack(SeqStack stack) {//本质 数组的尾删除if (stack == NULL) {return;}//还原栈结构体struct SStack * myStack = stack;if (myStack->m_Size == 0) {return;}myStack->data[myStack->m_Size - 1] = NULL;myStack->m_Size--;
}//返回栈顶
void * top_SeqStack(SeqStack stack) {//本质 返回数组的最后一个元素if (stack == NULL) {return NULL;}//还原栈结构体struct SStack * myStack = stack;if (myStack->m_Size == 0) {return NULL;}return myStack->data[myStack->m_Size - 1];
}//返回栈大小
int size_SeqStack(SeqStack stack) {if (stack == NULL) {return -1;}//还原栈结构体struct SStack * myStack = stack;return myStack->m_Size;
}//判断栈是否为空
int isEmpty_SeqStack(SeqStack stack) {if (stack == NULL) {return -1; //传入空指针 返回真 栈也是空}//还原栈结构体struct SStack * myStack = stack;if (myStack->m_Size == 0) {return 1; //1 代表真 栈确实为空}return 0;// 0假 不为空
}//销毁
void destroy_SeqStack(SeqStack stack) {if (stack == NULL) {return;}free(stack);stack = NULL;
}struct Person {char name[64];int age;
};void test() {//创建栈SeqStack myStack = init_SeqStack();//创建数据struct Person p1 = { "赵云", 18 };struct Person p2 = { "张飞", 19 };struct Person p3 = { "关羽", 20 };struct Person p4 = { "刘备", 19 };struct Person p5 = { "诸葛亮", 12 };struct Person p6 = { "黄忠", 17 };//入栈push_SeqStack(myStack, &p1);push_SeqStack(myStack, &p2);push_SeqStack(myStack, &p3);push_SeqStack(myStack, &p4);push_SeqStack(myStack, &p5);push_SeqStack(myStack, &p6);printf("栈的大小为:%d\n", size_SeqStack(myStack));//栈不为空 开始查看栈顶 并出栈while (isEmpty_SeqStack(myStack) == 0) {struct Person * pTop = top_SeqStack(myStack);printf("栈顶元素-姓名:%s 年龄:%d \n", pTop->name, pTop->age);//出栈pop_SeqStack(myStack);}printf("栈的大小为:%d\n", size_SeqStack(myStack));}//程序入口
int main() {test();system("pause"); // 按任意键暂停 阻塞功能return EXIT_SUCCESS; //返回 正常退出值 0}1.3栈的链式存储
基本概念
栈的链式存储结构简称链栈。
思考如下问题:
栈只是栈顶来做插入和删除操作,栈顶放在链表的头部还是尾部呢?
由于单链表有头指针,而栈顶指针也是必须的,那干嘛不让他俩合二为一呢,所以比较好的办法就是把栈顶放在单链表的头部。另外都已经有了栈顶在头部了,单链表中比较常用的头结点也就失去了意义,通常对于链栈来说,是不需要头结点的。
设计与实现
链栈是一种特殊的线性表,链栈可以通过链式线性表来实现。头节点端做栈顶比较方便。
对外接口设计:
初始化
入栈
出栈
返回栈顶
返回元素个数
判断是否为空
销毁栈
#define _CRT_SECURE_NO_WARNINGS
#include<stdlib.h>
#include<stdio.h>
#include<string.h>//节点结构体
struct LinkNode{//只维护指针域struct LinkNode * next;
};//链表结构体
struct LStack {struct LinkNode pHeader;//头节点int m_Size;//栈大小
};typedef void * LinkStack;//初始化
LinkStack init_LinkStack() {struct LStack * mystack = malloc(sizeof(struct LStack));if (mystack == NULL) {return NULL;}mystack->pHeader.next = NULL;mystack->m_Size = 0;return mystack;
}//入栈
void push_LinkStack(LinkStack stack, void * data) {//本质 头插if (stack == NULL) {return;}if (data == NULL) {return;}struct LStack * mystack = stack;//取出用户的前4个字节struct LinkNode * myNode = data;//建立节点之间的关系myNode->next = mystack->pHeader.next;mystack->pHeader.next = myNode;//更新栈的大小mystack->m_Size++;
}//出栈
void pop_LinkStack(LinkStack stack) {//本质 头删if (stack == NULL) {return;}struct LStack * mystack = stack;if (mystack->m_Size == 0) {return;}//记录指向第一个节点的指针struct LinkNode * pFirst = mystack->pHeader.next;//更新节点指向mystack->pHeader.next = pFirst->next;//更新栈大小mystack->m_Size--;
}//返回栈顶
void * top_LinkStack(LinkStack stack) {if (stack == NULL) {return NULL;}struct LStack * mystack = stack;if (mystack->m_Size == 0) {return NULL;}return mystack->pHeader.next;
}//返回元素个数
int size_LinkStack(LinkStack stack) {if (stack == NULL) {return -1;}struct LStack * mystack = stack;return mystack->m_Size;
}//判断是否为空
int isEmpty_LinkStack(LinkStack stack) {if (stack == NULL) {return -1;}struct LStack * mystack = stack;if (mystack->m_Size == 0) {return 1; //为空 返回真}return 0;
}//销毁栈
void destroy_LinkStack(LinkStack stack) {if (stack == NULL) {return;}free(stack);stack = NULL;
}struct Person {struct LinkNode node;char name[64];int age;
};void test() {//创建栈LinkStack myStack = init_LinkStack();//创建数据struct Person p1 = { NULL,"赵云", 18 };struct Person p2 = { NULL,"张飞", 19 };struct Person p3 = { NULL,"关羽", 20 };struct Person p4 = { NULL,"刘备", 19 };struct Person p5 = { NULL,"诸葛亮", 12 };struct Person p6 = { NULL,"黄忠", 17 };//入栈push_LinkStack(myStack, &p1);push_LinkStack(myStack, &p2);push_LinkStack(myStack, &p3);push_LinkStack(myStack, &p4);push_LinkStack(myStack, &p5);push_LinkStack(myStack, &p6);printf("栈的大小为:%d\n", size_LinkStack(myStack));//栈不为空 开始查看栈顶 并出栈while (isEmpty_LinkStack(myStack) == 0) {struct Person * pTop = top_LinkStack(myStack);printf("栈顶元素-姓名:%s 年龄:%d \n", pTop->name, pTop->age);//出栈pop_LinkStack(myStack);}printf("栈的大小为:%d\n", size_LinkStack(myStack));
}//程序入口
int main() {test();system("pause"); // 按任意键暂停 阻塞功能return EXIT_SUCCESS; //返回 正常退出值 0}1.4 栈的应用(案例)
1.4.1 就近匹配
几乎所有的编译器都具有检测括号是否匹配的能力,那么如何实现编译器中的符号成对检测?如下字符串:
5+5*(6)+9/3*1)-(1+3(
算法思路
从第一个字符开始扫描
当遇见普通字符时忽略,
当遇见左括号时压入栈中
当遇见右括号时从栈中弹出栈顶符号,并进行匹配
匹配成功:继续读入下一个字符
匹配失败:立即停止,并报错
结束:
成功: 所有字符扫描完毕,且栈为空
失败:匹配失败或所有字符扫描完毕但栈非空
总结
当需要检测成对出现但又互不相邻的事物时可以使用栈“后进先出”的特性;
栈非常适合于需要“就近匹配”的场合;
1.4.2 中缀表达式和后缀表达式
后缀表达式(由波兰科学家在20世纪50年代提出)
将运算符放在数字后面 ===》 符合计算机运算
我们习惯的数学表达式叫做中缀表达式===》符合人类思考习惯
实例
5 +4 => 5 4 +
1 +2 * 3 => 1 2 3 * +
8 +(3 – 1 ) * 5 => 8 3 1 – 5 * +
中缀转后缀算法:
遍历中缀表达式中的数字和符号:
对于数字:直接输出
对于符号:
左括号:进栈
运算符号:与栈顶符号进行优先级比较
若栈顶符号优先级低:此符号进栈
(默认栈顶若是左括号,左括号优先级最低)
若栈顶符号优先级不低:将栈顶符号弹出并输出,之后进栈
右括号:将栈顶符号弹出并输出,直到匹配左括号,将左括号和右括号同时舍弃
遍历结束:将栈中的所有符号弹出并输出
动手练习
将我们喜欢的读的中缀表达式转换成计算机喜欢的后缀表达式
中缀表达式: 8 + ( 3 – 1 ) * 5
后缀表达式: 8 3 1 – 5 * +
1.4.3 基于后缀表达式计算
思考
计算机是如何基于后缀表达式计算的?
例如:8 3 1 –5 * +
计算规则
遍历后缀表达式中的数字和符号
对于数字:进栈
对于符号:
从栈中弹出右操作数
从栈中弹出左操作数
根据符号进行运算
将运算结果压入栈中
遍历结束:栈中的唯一数字为计算结果
2队列(Queue)
2.1队列基本概念
队列是一种特殊的受限制的线性表。
队列(queue)是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
队列是一种先进先出的t(First In First Out)的线性表,简称FIFO。允许插入的一端为队尾,允许删除的一端为队头。队列不允许在中间部位进行操作!假设队列是q=(a1,a2,……,an),那么a1就是队头元素,而an是队尾元素。这样我们就可以删除时,总是从a1开始,而插入时,总是在队列最后。这也比较符合我们通常生活中的习惯,排在第一个的优先出列,最后来的当然排在队伍最后。如下图:

2.3队列的顺序存储
基本概念
队列也是一种特殊的线性表;可以用线性表顺序存储来模拟队列。
对外接口设计:
初始化队列 init
入队 push
出队 pop
返回队头 front
返回队尾 back
返回队列大小 size
判断是否为空 isEmpty
销毁队列 destroy
头文件 dynamicArray.h:
#pragma once
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string.h>
#include<stdlib.h>//动态数据结构体
struct dynamicArray
{void ** pAddr; // 维护开辟到堆区真实数组的指针int m_Capacity; //数组容量int m_Size; //数组大小
};//初始化数组 参数代表 初始化的容量
struct dynamicArray * init_dynamicArray(int capacity);//插入元素
void insert_dynamicArray(struct dynamicArray * arr, int pos, void * data);//遍历数组
void foreach_dynamicArray(struct dynamicArray * arr, void(*myPrint)(void *));//删除数组
void removeByPos_dynamicArray(struct dynamicArray * arr, int pos);//按照值 来删除数组中数据
void removeByValue_dynamicArray(struct dynamicArray * arr, void * data, int(*myCompare)(void *, void *));//销毁数组
void destroy_dynamicArray(struct dynamicArray * arr);
头文件dynamicArray.h :
#pragma once
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include "dynamicArray.h"#define MAX 1024typedef void * seqQueue;//初始化队列
seqQueue init_SeqQueue();
//入队
void push_SeqQueue( seqQueue queue , void * data);
//出队
void pop_SeqQueue(seqQueue queue);
//返回队头元素
void * front_SeqQueue(seqQueue queue);//返回队尾元素
void * back_SeqQueue(seqQueue queue);//队列大小
int size_SeqQueue(seqQueue queue);//判断是否为空
int isEmpty_SeqQueue(seqQueue queue);//销毁队列
void destroy_SeqQueue(seqQueue queue);源文件 dynamicArray.c :
#include "dynamicArray.h"//初始化数组 参数代表 初始化的容量
struct dynamicArray * init_dynamicArray(int capacity)
{struct dynamicArray * array = malloc(sizeof(struct dynamicArray));if (array == NULL){return NULL;}//给数组属性初始化array->m_Capacity = capacity;array->m_Size = 0;array->pAddr = malloc(sizeof(void *)* capacity);if (array->pAddr == NULL){return NULL;}return array;
}//插入元素
void insert_dynamicArray(struct dynamicArray * arr, int pos, void * data)
{if (arr == NULL){return;}if (data == NULL){return;}if (pos < 0 || pos > arr->m_Size){//无效的位置 进行尾插pos = arr->m_Size;}//判断是否有空间进行插入,如果没有空间了,那么动态扩展if (arr->m_Size >= arr->m_Capacity){//1、计算申请空间大小int newCapacity = arr->m_Capacity * 2;//2、创建新空间void ** newSpace = malloc(sizeof (void *)* newCapacity);//3、 将原有数据拷贝到新空间下memcpy(newSpace, arr->pAddr, sizeof(void*)* arr->m_Capacity);//4、 释放原有空间free(arr->pAddr);//5、 更新指针的指向arr->pAddr = newSpace;//6、更新新数组容量arr->m_Capacity = newCapacity;}//插入数据for (int i = arr->m_Size - 1; i >= pos; i--){//数据后移arr->pAddr[i + 1] = arr->pAddr[i];}//将新数据放入到指定位置中arr->pAddr[pos] = data;//更新数组大小arr->m_Size++;
}//遍历数组
void foreach_dynamicArray(struct dynamicArray * arr, void(*myPrint)(void *))
{if (arr == NULL){return;}if (myPrint == NULL){return;}for (int i = 0; i < arr->m_Size; i++){myPrint(arr->pAddr[i]);}
}//删除数组
void removeByPos_dynamicArray(struct dynamicArray * arr, int pos)
{if (arr == NULL){return;}//无效位置 就直接returnif (pos < 0 || pos >arr->m_Size - 1){return;}//移动数据for (int i = pos; i < arr->m_Size - 1; i++){arr->pAddr[i] = arr->pAddr[i + 1];}//更新大小arr->m_Size--;}//按照值 来删除数组中数据
void removeByValue_dynamicArray(struct dynamicArray * arr, void * data, int(*myCompare)(void *, void *))
{if (arr == NULL){return;}if (data == NULL){return;}for (int i = 0; i < arr->m_Size; i++){if (myCompare(arr->pAddr[i], data)){//如果对比成功了,那么要删除i下标的元素removeByPos_dynamicArray(arr, i);break;}}}//销毁数组
void destroy_dynamicArray(struct dynamicArray * arr)
{if (arr == NULL){return;}if (arr->pAddr != NULL){free(arr->pAddr);arr->pAddr = NULL;}free(arr);arr = NULL;}源文件 seqQueue.c :
#include "seqQueue.h"//初始化队列
seqQueue init_SeqQueue()
{struct dynamicArray * array = init_dynamicArray(MAX);return array;
}
//入队
void push_SeqQueue(seqQueue queue, void * data)
{//等价于 尾插if (queue == NULL){return;}if (data == NULL){return;}struct dynamicArray * array = queue;if (array->m_Size >= MAX){return;}insert_dynamicArray(array, array->m_Size, data);
}
//出队
void pop_SeqQueue(seqQueue queue)
{//等价于 头删除if (queue == NULL){return;}struct dynamicArray * array = queue;if (array->m_Size <= 0){return;}removeByPos_dynamicArray(array, 0);
}
//返回队头元素
void * front_SeqQueue(seqQueue queue)
{if (queue == NULL){return NULL;}struct dynamicArray * array = queue;return array->pAddr[0];}//返回队尾元素
void * back_SeqQueue(seqQueue queue)
{if (queue == NULL){return NULL;}struct dynamicArray * array = queue;return array->pAddr[array->m_Size - 1];}//队列大小
int size_SeqQueue(seqQueue queue)
{if (queue == NULL){return -1;}struct dynamicArray * array = queue;return array->m_Size;}//判断是否为空
int isEmpty_SeqQueue(seqQueue queue)
{if (queue == NULL){return -1;}struct dynamicArray * array = queue;if (array->m_Size == 0){return 1;}return 0;
}//销毁队列
void destroy_SeqQueue(seqQueue queue)
{if (queue == NULL){return ;}destroy_dynamicArray(queue);queue = NULL;
}源文件test.c :
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include "seqQueue.h"struct Person
{char name[64];int age;
};void test01()
{//初始化队列seqQueue myQueue = init_SeqQueue();//准备数据struct Person p1 = { "aaa", 10 };struct Person p2 = { "bbb", 20 };struct Person p3 = { "ccc", 30 };struct Person p4 = { "ddd", 40 };struct Person p5 = { "eee", 50 };//入队push_SeqQueue(myQueue, &p1);push_SeqQueue(myQueue, &p2);push_SeqQueue(myQueue, &p3);push_SeqQueue(myQueue, &p4);push_SeqQueue(myQueue, &p5);printf("队列大小为:%d\n", size_SeqQueue(myQueue));while (isEmpty_SeqQueue(myQueue) == 0) {//队头元素struct Person * pFront = front_SeqQueue(myQueue);printf("队头元素姓名:%s 年龄:%d \n", pFront->name, pFront->age);//队尾元素struct Person * pBack = back_SeqQueue(myQueue);printf("队尾元素姓名:%s 年龄:%d \n", pBack->name, pBack->age);//出队pop_SeqQueue(myQueue);}printf("队列大小为:%d\n", size_SeqQueue(myQueue));//销毁队列destroy_SeqQueue(myQueue);myQueue = NULL;
}int main(){test01();system("pause");return EXIT_SUCCESS;
}2.4队列的链式存储
基本概念
队列也是一种特殊的线性表;可以用线性表链式存储来模拟队列的链式存储。
头文件 linkQueue.h :
#pragma once
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string.h>
#include<stdlib.h>//节点结构体
struct QueueNode
{struct QueueNode * next;};//链表的结构体 --- 队列
struct LQueue
{struct QueueNode pHeader; //头节点int m_Size; //队列的大小struct QueueNode * pTail; //记录尾节点的指针
};typedef void * LinkQueue;//初始化队列
LinkQueue init_LinkQueue();
//入队
void push_LinkQueue(LinkQueue queue, void * data);
//出队
void pop_LinkQueue(LinkQueue queue);
//返回队头
void * front_LinkQueue(LinkQueue queue);
//返回队尾
void * back_LinkQueue(LinkQueue queue);
//返回队列大小
int size_LinkQueue(LinkQueue queue);
//判断队列是否为空
int isEmpty_LinkQueue(LinkQueue queue);
//销毁队列
void destroy_LinkQueue(LinkQueue queue);源文件 linkQueue.c :
#include "linkQueue.h"//初始化队列
LinkQueue init_LinkQueue()
{struct LQueue * myQueue = malloc(sizeof(struct LQueue));if (myQueue == NULL){return NULL;}myQueue->m_Size = 0;myQueue->pHeader.next = NULL;myQueue->pTail = &myQueue->pHeader; //尾节点开始指向的就是头节点return myQueue;
}
//入队
void push_LinkQueue(LinkQueue queue, void * data)
{//等价于 尾插if (queue == NULL){return;}if (data == NULL){return;}struct LQueue * myQueue = queue;struct QueueNode * myNode = data; //更改指针指向myQueue->pTail->next = myNode;myNode->next = NULL;//更新尾节点myQueue->pTail = myNode;//更新队列大小myQueue->m_Size++;}
//出队
void pop_LinkQueue(LinkQueue queue)
{//等价于 头删 if (queue == NULL){return;}struct LQueue * myQueue = queue;if (myQueue->m_Size == 0){return;}if (myQueue->m_Size == 1){myQueue->pHeader.next = NULL;myQueue->pTail = &myQueue->pHeader; //维护尾节点指针myQueue->m_Size = 0;return;}//记录第一个节点struct QueueNode * pFirst = myQueue->pHeader.next;myQueue->pHeader.next = pFirst->next;//更新队列大小myQueue->m_Size--;}
//返回队头
void * front_LinkQueue(LinkQueue queue)
{if (queue == NULL){return NULL;}struct LQueue * myQueue = queue;return myQueue->pHeader.next;}
//返回队尾
void * back_LinkQueue(LinkQueue queue)
{if (queue == NULL){return NULL;}struct LQueue * myQueue = queue;return myQueue->pTail;}
//返回队列大小
int size_LinkQueue(LinkQueue queue)
{if (queue == NULL){return -1;}struct LQueue * myQueue = queue;return myQueue->m_Size;}
//判断队列是否为空
int isEmpty_LinkQueue(LinkQueue queue)
{if (queue == NULL){return -1;}struct LQueue * myQueue = queue;if (myQueue->m_Size == 0){return 1;}return 0;}
//销毁队列
void destroy_LinkQueue(LinkQueue queue)
{if (queue == NULL){return;}free(queue);queue = NULL;
}源文件 test.c :
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
#include<string.h>
#include<stdlib.h>
#include "linkQueue.h"struct Person
{void * node;char name[64];int age;
};void test01()
{//初始化队列LinkQueue myQueue = init_LinkQueue();//准备数据struct Person p1 = { NULL, "aaa", 10 };struct Person p2 = { NULL, "bbb", 20 };struct Person p3 = { NULL, "ccc", 30 };struct Person p4 = { NULL, "ddd", 40 };struct Person p5 = { NULL, "eee", 50 };//入队push_LinkQueue(myQueue, &p1);push_LinkQueue(myQueue, &p2);push_LinkQueue(myQueue, &p3);push_LinkQueue(myQueue, &p4);push_LinkQueue(myQueue, &p5);printf("队列大小为:%d\n", size_LinkQueue(myQueue));while (isEmpty_LinkQueue(myQueue) == 0){//队头元素struct Person * pFront = front_LinkQueue(myQueue);printf("链式存储 队头元素姓名:%s 年龄:%d \n", pFront->name, pFront->age);//队尾元素struct Person * pBack = back_LinkQueue(myQueue);printf("链式存储 队尾元素姓名:%s 年龄:%d \n", pBack->name, pBack->age);//出队pop_LinkQueue(myQueue);}printf("队列大小为:%d\n", size_LinkQueue(myQueue));//销毁队列destroy_LinkQueue(myQueue);myQueue = NULL;
}int main(){test01();system("pause");return EXIT_SUCCESS;
}一般线性表详解,请参考文章:C语言数据结构(一)—— 数据结构理论、线性表【动态数组、链表(企业版单向链表)】
相关文章:
C语言数据结构(二)—— 受限线性表 【栈(Stack)、队列(Queue)】
在数据结构逻辑层次上细分,线性表可分为一般线性表和受限线性表。一般线性表也就是我们通常所说的“线性表”,可以自由的删除或添加结点。受限线性表主要包括栈和队列,受限表示对结点的操作受限制。一般线性表详解,请参考文章&…...
线程安全之synchronized和volatile
目录 1.线程不安全的原因 2.synchronized和volatile 2.1 synchronized 2.1.1 synchornized的特性 2.1.2 synchronized使用示例 2.2 volatile 我们先来看一段代码: 分析以上代码,t1和t2这两个线程的任务都是分别将count这个变量自增5000次ÿ…...

量子计算对网络安全的影响
量子计算的快速发展,例如 IBM 的 Quantum Condor 处理器具有 1000 个量子比特的容量,促使专家们宣称第四次工业革命即将实现“量子飞跃”。 量子计算机的指数处理能力已经受到政府和企业的欢迎。 由于从学术和物理原理到商业可用解决方案的不断转变&am…...
MyBatis——增删改查操作的实现
开启mybatis sql日志打印 可以在日志中看到sql中执行的语句 在配置文件中加上下面这几条语句 mybatis.configuration.log-implorg.apache.ibatis.logging.stdout.StdOutImpl logging.level.com.example.demodebug查询操作 根据用户id查询用户 UserMapper: User…...
【7】linux命令每日分享——cat查看文件内容
大家好,这里是sdust-vrlab,Linux是一种免费使用和自由传播的类UNIX操作系统,Linux的基本思想有两点:一切都是文件;每个文件都有确定的用途;linux涉及到IT行业的方方面面,在我们日常的学习中&…...

新氧2023年财务业绩预测:退市风险大幅降低,收入增长将放缓
来源:猛兽财经 作者:猛兽财经 公司进展 与新氧(SY)有关的两个重要积极进展值得一提。 第一个积极进展是新氧的退市风险已在很大程度上降低。 2023年1月6日,新氧披露,它已经“重新符合纳斯达克规定的股价每…...

C++使用shared_ptr与weak_ptr轻松管理内存
智能指针之shared_ptr与weak_ptr前言智能指针实例分析前言 C与其他语言的不同点之一就是可以直接操作内存,这是一把双刃剑,直接操作内存可以提高开发的灵活度,开发人员在合适的时机申请内存,在合适的时机释放内存,减少…...

Buuctf reverse [FlareOn4]IgniteMe 题解
一. 查壳 无壳32位程序 二. ida打开 GetStdHandle函数根据微软官方文档可以得知是获取标准输入/输出/错误的句柄 参数里的 0xFFFFFFF6转换一下是4294967286, 对应(DWORD) -10 所以这里的WriteFile函数实际上是实现了printf的功能 sub_4010F0()函数 其功能是通过ReadFile函数读取…...

ChatGPT懂SAP吗?跟ChatGPT聊完后,我暂时不担心会失业
我弄了个ChatGPT账号。随便问了一下他SAP的问题。贴出来跟大家分享一下。 问题1:我是 SAP 开发工程师,你有什么可以帮到我。 作为一个语言模型,我可以为您提供关于SAP开发的一般性建议,以及关于如何使用SAP软件的一些技巧。以下是…...

Communications link failure 解决方法 !!!
Communications link failure 解决方法 最近在使用mybatis逆向生成的时候遇到了link failure的问题, 这里记录解决方法 文章目录Communications link failure 解决方法generatorConfig 里的数据库链接或数据库或密码或账户填写错误mysql响应时间设置太短, 还没等链接上就关闭连…...

pytorch入门2--数据预处理、线性代数的矩阵实现、求导
数据预处理是指将原始数据读取进来使得能用机器学习的方法进行处理。 首先介绍csv文件: CSV 代表逗号分隔值(comma-separated values),CSV 文件就是使用逗号分隔数据的文本文件。 一个 CSV 文件包含一行或多行数据,每一…...

15.消息队列RabbitMQ
一、基本概念 RabbitMQ 是一个开源的AMQP实现,服务器端用Erlang语言编写,支持多种客户端,如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等,支持AJAX。用于在分布式系统中存储转发消息…...

并发编程之死锁问题介绍
一、本文概览 死锁问题在并发编程中是一个非常致命的问题,问题一旦产生,只能通过重启机器、修改代码来修复问题,下面我们通过一小段文章内容介绍下死锁以及如何死锁的预防 二、什么是死锁? 在介绍死锁之前,先来明确下什…...
【python学习笔记】:SQL常用脚本(一)
1、行转列的用法PIVOT CREATE table test (id int,name nvarchar(20),quarter int,number int) insert into test values(1,N苹果,1,1000) insert into test values(1,N苹果,2,2000) insert into test values(1,N苹果,3,4000) insert into test values(1,N苹果,4,5000) insert…...
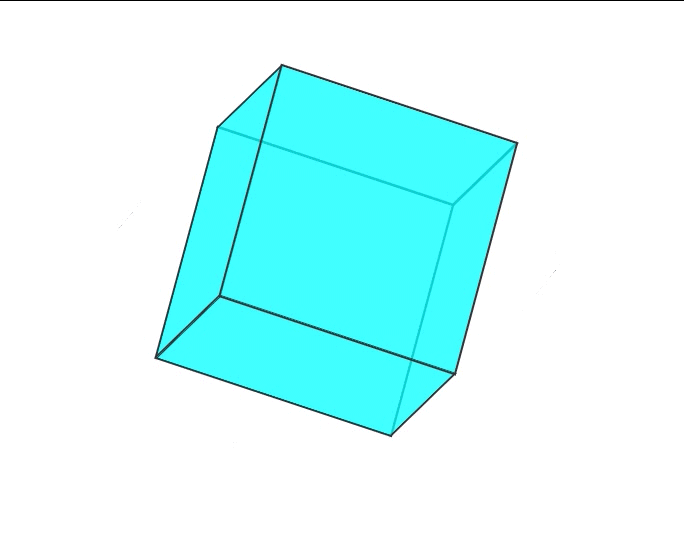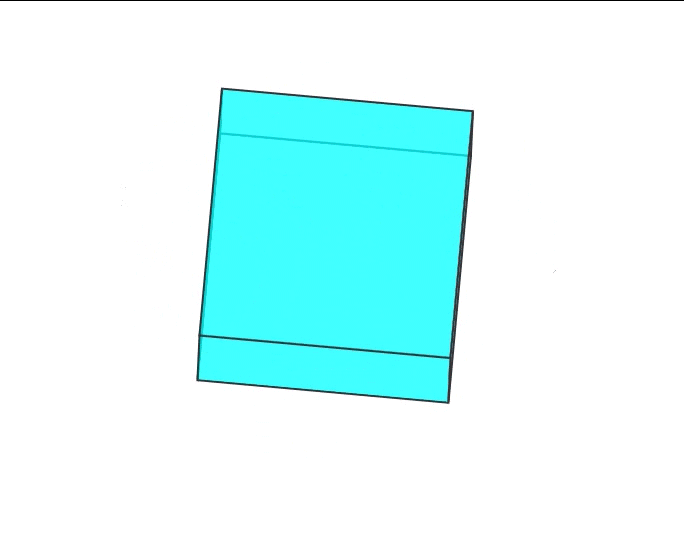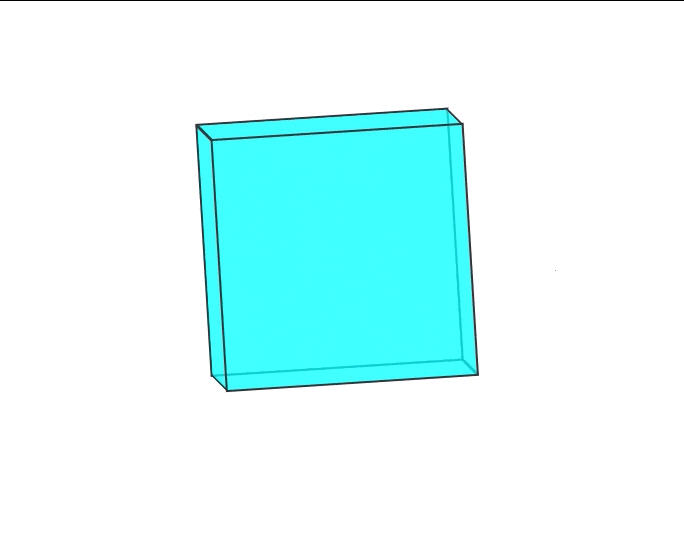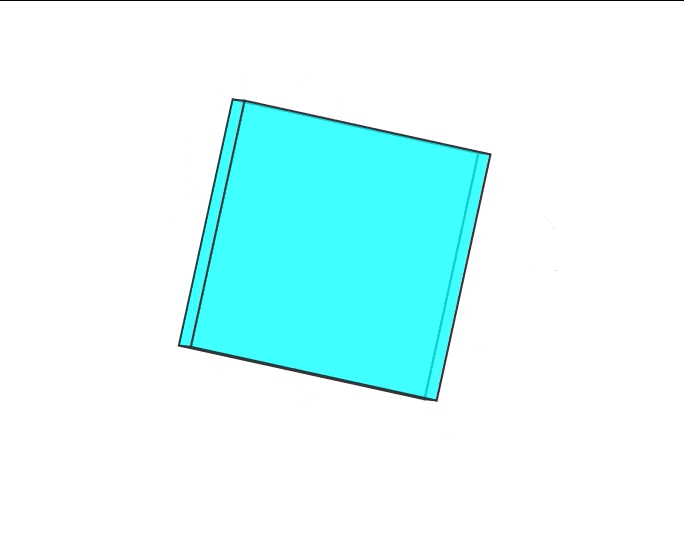
Spring是怎么解决循环依赖的
1.什么是循环依赖: 这里给大家举个简单的例子,相信看了上一篇文章大家都知道了解了spring的生命周期创建流程。那么在Spring在生命周期的哪一步会出现循环依赖呢? 第一阶段:实例化阶段 Instantiation 第二阶段:属性赋…...
HTML创意动画代码
目录1、动态气泡背景2、创意文字3、旋转立方体1、动态气泡背景 <!DOCTYPE html> <html> <head><title>Bubble Background</title><style>body {margin: 0;padding: 0;height: 100vh;background: #222;display: flex;flex-direction: colum…...

软工第一次个人作业——阅读和提问
软工第一次个人作业——阅读和提问 项目内容这个作业属于哪个课程2023北航敏捷软件工程这个作业的要求在哪里个人作业-阅读和提问我在这个课程的目标是体验敏捷开发过程,掌握一些开发技能,为进一步发展作铺垫这个作业在哪个具体方面帮助我实现目标对本课…...

urho3d的自定义文件格式
Urho3D尽可能使用现有文件格式,仅在绝对必要时才定义自定义文件格式。当前使用的自定义文件格式有: 二进制模型格式(.mdl) Model geometry and vertex morph data byte[4] Identifier "UMDL" or "UMD2" …...
spark第一章:环境安装
系列文章目录 spark第一章:环境安装 文章目录系列文章目录前言一、文件准备1.文件上传2.文件解压3.修改配置4.启动环境二、历史服务器1.修改配置2.启动历史服务器总结前言 spark在大数据环境的重要程度就不必细说了,直接开始吧。 一、文件准备 1.文件…...

MySQL---存储过程与存储函数的相关概念
MySQL—存储过程与存储函数的相关概念 存储函数和存储过程的主要区别: 存储函数一定会有返回值的存储过程不一定有返回值 存储过程和函数能后将复杂的SQL逻辑封装在一起,应用程序无需关注存储过程和函数内部复杂的SQL逻辑,而只需要简单地调…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

Java多线程实现之Thread类深度解析
Java多线程实现之Thread类深度解析 一、多线程基础概念1.1 什么是线程1.2 多线程的优势1.3 Java多线程模型 二、Thread类的基本结构与构造函数2.1 Thread类的继承关系2.2 构造函数 三、创建和启动线程3.1 继承Thread类创建线程3.2 实现Runnable接口创建线程 四、Thread类的核心…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

【Linux】Linux 系统默认的目录及作用说明
博主介绍:✌全网粉丝23W,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物…...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...

jmeter聚合报告中参数详解
sample、average、min、max、90%line、95%line,99%line、Error错误率、吞吐量Thoughput、KB/sec每秒传输的数据量 sample(样本数) 表示测试中发送的请求数量,即测试执行了多少次请求。 单位,以个或者次数表示。 示例:…...

深入理解Optional:处理空指针异常
1. 使用Optional处理可能为空的集合 在Java开发中,集合判空是一个常见但容易出错的场景。传统方式虽然可行,但存在一些潜在问题: // 传统判空方式 if (!CollectionUtils.isEmpty(userInfoList)) {for (UserInfo userInfo : userInfoList) {…...

elementUI点击浏览table所选行数据查看文档
项目场景: table按照要求特定的数据变成按钮可以点击 解决方案: <el-table-columnprop"mlname"label"名称"align"center"width"180"><template slot-scope"scope"><el-buttonv-if&qu…...

CVPR2025重磅突破:AnomalyAny框架实现单样本生成逼真异常数据,破解视觉检测瓶颈!
本文介绍了一种名为AnomalyAny的创新框架,该方法利用Stable Diffusion的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真且多样化的异常样本,有效解决了视觉异常检测中异常样本稀缺的难题,为工业质检、医疗影像…...
协议转换利器,profinet转ethercat网关的两大派系,各有千秋
随着工业以太网的发展,其高效、便捷、协议开放、易于冗余等诸多优点,被越来越多的工业现场所采用。西门子SIMATIC S7-1200/1500系列PLC集成有Profinet接口,具有实时性、开放性,使用TCP/IP和IT标准,符合基于工业以太网的…...