Android数据对象序列化原理与应用

序列化与反序列化
序列化是将对象转换为可以存储或传输的格式的过程。在计算机科学中,对象通常是指内存中的数据结构,如数组、列表、字典等。通过序列化,可以将这些对象转换为字节流或文本格式,以便在不同的系统之间进行传输或存储。序列化后的数据可以被传输到远程系统,或者存储在磁盘上,以便在需要时进行读取和恢复。序列化的逆过程称为反序列化,即将序列化后的数据重新转换为原始对象的过程。
反序列化是将序列化后的数据恢复为原始对象的过程。在编程中,我们经常需要将对象序列化为字节流或者其他形式的数据,以便在网络传输或者持久化存储中使用。而反序列化则是将这些序列化后的数据重新转换为原始对象。
在不同的编程语言中,反序列化的实现方式可能会有所不同。一般来说,反序列化的过程包括以下几个步骤:
- 读取序列化后的数据:从文件、网络传输等地方读取序列化后的数据。
- 解析数据:根据序列化的格式,解析数据并还原为原始的对象结构。
- 创建对象:根据解析得到的数据,创建对应的对象实例。
- 恢复对象状态:将解析得到的数据赋值给对象的属性,恢复对象的状态。
反序列化的过程可以用以下伪代码表示:
data = 读取序列化后的数据
object = 解析数据(data)
在实际应用中,反序列化的方式和具体实现会根据编程语言和序列化库的不同而有所差异。不同的序列化格式有不同的特点和适用场景,开发者可以根据具体需求选择合适的序列化方式。
Android数据对象序列化的用途
Android数据对象序列化的主要用途是将对象转换为字节流的形式,以便在网络传输、持久化存储或进程间通信中使用。具体的用途包括:
-
网络传输:在Android开发中,我们经常需要将对象通过网络传输给其他设备或服务器。通过序列化,我们可以将对象转换为字节流,然后通过网络发送给目标设备或服务器,目标设备或服务器再将字节流反序列化为对象进行处理。
-
持久化存储:Android应用程序通常需要将数据保存在本地存储中,以便在应用程序关闭后仍然可以访问。通过序列化,我们可以将对象转换为字节流,并将其保存在本地文件或数据库中。当应用程序再次启动时,我们可以将字节流反序列化为对象,以便恢复之前保存的数据。
-
进程间通信:在Android中,不同的组件(如Activity、Service、BroadcastReceiver等)可能运行在不同的进程中。通过序列化,我们可以将对象转换为字节流,并通过进程间通信机制(如Binder)将字节流传递给其他进程,其他进程再将字节流反序列化为对象进行处理。
序列化提供了一种方便的方式来在不同的场景中传输和存储对象数据。它在网络传输、持久化存储和进程间通信等方面都有广泛的应用。
Android实现对象序列化的方式
在Android中,常用的实现对象序列化有以下几种方式:
- 实现Serializable接口:在需要序列化的类中实现Serializable接口,该接口没有任何方法,只是作为一个标记接口。然后使用ObjectOutputStream将对象写入输出流,使用ObjectInputStream从输入流中读取对象。示例代码如下:
public class MyClass implements Serializable {// 类的成员变量和方法public static void main(String[] args) {// 序列化对象MyClass obj = new MyClass();try {FileOutputStream fileOut = new FileOutputStream("object.ser");ObjectOutputStream out = new ObjectOutputStream(fileOut);out.writeObject(obj);out.close();fileOut.close();System.out.println("对象已序列化");} catch (IOException e) {e.printStackTrace();}// 反序列化对象MyClass newObj = null;try {FileInputStream fileIn = new FileInputStream("object.ser");ObjectInputStream in = new ObjectInputStream(fileIn);newObj = (MyClass) in.readObject();in.close();fileIn.close();System.out.println("对象已反序列化");} catch (IOException | ClassNotFoundException e) {e.printStackTrace();}}
}
- 实现Parcelable接口:Parcelable接口是Android特有的接口,相比Serializable接口,它更高效。在需要序列化的类中实现Parcelable接口,并实现相关方法。然后使用Parcel对象将对象写入Parcel,使用Parcel对象从Parcel中读取对象。示例代码如下:
public class MyClass implements Parcelable {// 类的成员变量和方法protected MyClass(Parcel in) {// 从Parcel中读取数据并赋值给成员变量}public static final Creator<MyClass> CREATOR = new Creator<MyClass>() {@Overridepublic MyClass createFromParcel(Parcel in) {return new MyClass(in);}@Overridepublic MyClass[] newArray(int size) {return new MyClass[size];}};@Overridepublic int describeContents() {return 0;}@Overridepublic void writeToParcel(Parcel dest, int flags) {// 将成员变量写入Parcel}
}
- 使用Gson库:Gson是Google提供的一个用于在Java对象和JSON数据之间进行序列化和反序列化的库。可以使用Gson将对象转换为JSON字符串,然后再将JSON字符串转换为对象。示例代码如下:
public class MyClass {// 类的成员变量和方法public static void main(String[] args) {// 序列化对象MyClass obj = new MyClass();Gson gson = new Gson();String json = gson.toJson(obj);System.out.println("对象已序列化为JSON字符串:" + json);// 反序列化对象MyClass newObj = gson.fromJson(json, MyClass.class);System.out.println("JSON字符串已反序列化为对象");}
}
序列化原理
Serializable是Java中的一个接口,用于实现对象的序列化和反序列化。序列化是指将对象转换为字节流的过程,而反序列化则是将字节流转换为对象的过程。
Serializable接口没有任何方法,它只是一个标记接口,用于告诉Java虚拟机,该类可以被序列化。要实现序列化,只需要让类实现Serializable接口即可。
在序列化过程中,Java虚拟机会将对象的状态转换为字节序列,然后可以将字节序列保存到文件、数据库或通过网络传输。反序列化过程则是将字节序列重新转换为对象的状态。
在序列化过程中,Java虚拟机会对对象的各个字段进行序列化。对于基本类型和引用类型,Java虚拟机会自动进行序列化。对于自定义类型,需要实现Serializable接口,并且保证该类型的所有成员变量也是可序列化的。
在反序列化过程中,Java虚拟机会根据字节序列重新创建对象,并将字节序列中的数据赋值给对象的各个字段。
需要注意的是,序列化和反序列化的过程中,对象的构造函数不会被调用。因此,在反序列化过程中,如果需要进行一些初始化操作,可以使用特殊的方法readObject()来实现。
总结起来,Serializable接口提供了一种简单的方式来实现对象的序列化和反序列化。通过实现Serializable接口,可以将对象转换为字节序列,以便在不同的环境中进行传输和存储。
Parcelable是Android中用于实现对象序列化的接口。它的原理是将对象的数据按照一定的格式进行打包和解包,以便在不同的组件之间传输或存储。
具体实现步骤如下:
-
实现Parcelable接口:在需要序列化的类中实现Parcelable接口,并实现其中的方法,包括
describeContents()和writeToParcel(Parcel dest, int flags)。 -
describeContents()方法:该方法返回一个标志位,用于描述Parcelable对象特殊对象的类型。一般情况下,返回0即可。 -
writeToParcel(Parcel dest, int flags)方法:该方法将对象的数据写入Parcel对象中。在该方法中,需要将对象的各个字段按照一定的顺序写入Parcel对象中,以便在解包时按照相同的顺序读取。 -
实现Parcelable.Creator接口:在需要序列化的类中实现Parcelable.Creator接口,并实现其中的方法,包括
createFromParcel(Parcel source)和newArray(int size)。 -
createFromParcel(Parcel source)方法:该方法从Parcel对象中读取数据,并创建出Parcelable对象。在该方法中,需要按照写入Parcel对象时的顺序读取数据,并将其赋值给相应的字段。 -
newArray(int size)方法:该方法返回一个指定大小的Parcelable数组。
通过实现Parcelable接口,可以将对象的数据打包成一个Parcel对象,然后可以通过Intent传递给其他组件,或者通过Bundle存储到本地。在接收端,可以通过读取Parcel对象的数据,重新构建出原始的对象。
总结起来,Parcelable的原理就是将对象的数据按照一定的格式进行打包和解包,以实现对象的序列化和反序列化。这种方式相对于Java中的Serializable接口,更加高效和灵活。
Serializable/Parcelable对比
Serializable和Parcelable都是用于实现对象的序列化和反序列化的接口,但在实现方式和性能方面有所不同。
- Serializable:
- Serializable是Java提供的默认序列化机制,通过实现Serializable接口,可以将对象转换为字节流,以便在网络传输或保存到文件中。
- Serializable使用反射机制,将对象的状态保存到字节流中,然后再从字节流中恢复对象的状态。这种方式相对简单,但效率较低。
- Serializable的缺点是序列化和反序列化的过程需要大量的I/O操作,对性能要求较高的场景下可能会影响程序的执行效率。
- Parcelable:
- Parcelable是Android提供的专门用于Android平台的序列化机制,通过实现Parcelable接口,可以将对象转换为字节流,以便在Activity之间传递。
- Parcelable使用了更加高效的序列化方式,将对象的状态拆分为多个字段,分别写入和读取字节流。这种方式相对复杂,但效率较高。
- Parcelable的优点是序列化和反序列化的过程更加高效,对性能要求较高的场景下可以提升程序的执行效率。
Serializable适用于简单的序列化场景,而Parcelable适用于对性能要求较高的Android平台。在选择使用Serializable还是Parcelable时,需要根据具体的需求和性能要求进行权衡。
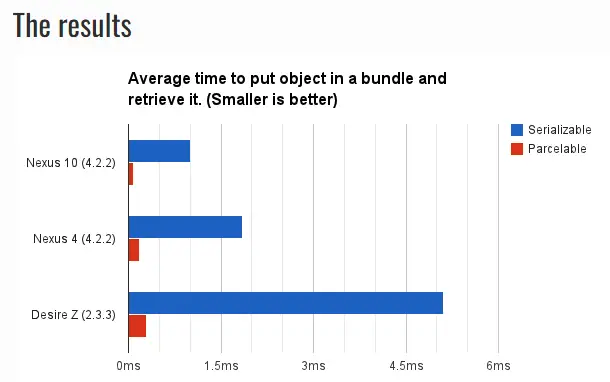
数据来自parcelable-vs-serializable,实验结果对比Parcelable的效率比Serializable快10倍以上。
总结
| 对比 | Serializable | Parcelable |
|---|---|---|
| 所属API | Java API | Android SDK API |
| 特点 | 序列化和反序列化会经过大量的I/O操作,产生大量的临时变量引起GC,且反序列化时需要反射 | 基于内存拷贝实现的封装和解封(marshalled& unmarshalled),序列化基于Native层实现 |
| 开销 | 相对高 | 相对低 |
| 效率 | 相对低 | 相对高 |
| 适用场景 | 简单序列化 | Android |
在使用Serializable进行对象的序列化时,有一些注意点需要注意:
-
类的定义:被序列化的类需要实现
Serializable接口,这是Java提供的一个标记接口,用于表示该类可以被序列化。如果一个类没有实现Serializable接口,那么在进行序列化时会抛出NotSerializableException异常。 -
成员变量的序列化:被序列化的类的所有成员变量都会被序列化,包括私有成员变量。但是,如果某个成员变量不希望被序列化,可以使用
transient关键字进行修饰,被修饰的成员变量在序列化过程中会被忽略。 -
对象引用的序列化:如果一个类中包含其他对象的引用,那么在序列化时,被引用的对象也会被序列化。但是,如果被引用的对象没有实现
Serializable接口,那么在序列化时会抛出NotSerializableException异常。为了解决这个问题,可以将被引用的对象设置为transient,或者让被引用的对象也实现Serializable接口。 -
序列化版本号:在进行对象的序列化时,会为每个被序列化的类自动生成一个序列化版本号。这个版本号用于在反序列化时判断序列化的类和反序列化的类是否兼容。如果序列化的类和反序列化的类的版本号不一致,会抛出
InvalidClassException异常。为了避免这个问题,可以显式地为类指定一个固定的序列化版本号,可以使用serialVersionUID关键字进行指定。 -
序列化的安全性:在进行对象的序列化时,需要注意序列化的安全性。因为序列化的数据可以被反序列化成对象,如果序列化的数据被篡改,可能会导致安全漏洞。为了增强序列化的安全性,可以使用加密算法对序列化的数据进行加密,或者对序列化的类进行签名验证。
在使用Parcelable进行序列化时,有几个注意点需要注意:
-
实现Parcelable接口:要使一个类可序列化,需要让该类实现Parcelable接口,并实现其中的方法。这些方法包括
writeToParcel()和createFromParcel()等。 -
内部类的序列化:如果要序列化的类中包含内部类,需要确保内部类也实现了Parcelable接口,并在外部类的
writeToParcel()和createFromParcel()方法中对内部类进行序列化和反序列化。 -
序列化顺序:在
writeToParcel()方法中,需要按照成员变量的顺序将数据写入Parcel对象。在createFromParcel()方法中,需要按照写入的顺序读取数据。 -
序列化和反序列化的一致性:在序列化和反序列化过程中,需要确保写入和读取的数据类型一致。例如,如果在
writeToParcel()方法中写入了一个整数,那么在createFromParcel()方法中读取时也需要使用相同的方法读取整数。 -
版本控制:如果在序列化的类中进行了修改,需要注意版本控制。可以通过给类添加一个版本号来实现版本控制,以便在反序列化时能够正确处理不同版本的数据。
使用Parcelable进行序列化时,需要确保实现了Parcelable接口,并注意序列化顺序、内部类的序列化、数据类型的一致性和版本控制等问题。
相关文章:
Android数据对象序列化原理与应用
序列化与反序列化 序列化是将对象转换为可以存储或传输的格式的过程。在计算机科学中,对象通常是指内存中的数据结构,如数组、列表、字典等。通过序列化,可以将这些对象转换为字节流或文本格式,以便在不同的系统之间进行传输或存…...

Linux cp命令:复制文件和目录
cp 命令,主要用来复制文件和目录,同时借助某些选项,还可以实现复制整个目录,以及比对两文件的新旧而予以升级等功能。 cp 命令的基本格式如下: [rootlocalhost ~]# cp [选项] 源文件 目标文件 选项: -a&…...

SpringBoot 接收不到 post 请求数据与接收 post 请求数据
文章归档:https://www.yuque.com/u27599042/coding_star/xwrknb7qyhqgdt10 SpringBoot 接收不到 post 请求数据 接收 post 请求数据,控制器方法参数需要使用 RequestParam 注解修饰 public BaseResponseResult<Object> getMailCode(RequestParam…...
vue3学习(十四)--- vue3中css新特性
文章目录 样式穿透:deep()scoped的原理 插槽选择器:slotted()全局选择器:global()动态绑定CSScss module 样式穿透:deep() 主要是用于修改很多vue常用的组件库(element, vant, AntDesigin),虽然配好了样式但是还是需要更改其他的样式就需要用…...

Python爬虫基础之Requests详解
目录 1. 简介2. 安装3. 发送请求4. 处理响应5. IP代理6. Cookie登录参考文献 原文地址:https://program-park.top/2023/10/27/reptile_4/ 本文章中所有内容仅供学习交流使用,不用于其他任何目的,严禁用于商业用途和非法用途,否则由…...

C++求根节点到叶子节点数字之和
文章目录 题目链接题目描述解题思路代码复杂度分析 题目链接 LCR 049. 求根节点到叶节点数字之和 - 力扣(LeetCode) 题目描述 给定一个二叉树的根节点 root ,树中每个节点都存放有一个 0 到 9 之间的数字。 每条从根节点到叶节点的路径都代表…...
C++搜索二叉树
本章主要是二叉树的进阶部分,学习搜索二叉树可以更好理解后面的map和set的特性。 1.二叉搜索树概念 二叉搜索树的递归定义为:非空左子树所有元素都小于根节点的值,非空右子树所有元素都大于根节点的值,而左右子树也是二叉搜索树…...
软件工程17-18期末试卷
2.敏捷开发提倡一个迭代80%以上的时间都在编程,几乎没有设计阶段。敏捷方法可以说是一种无计划性和纪律性的方法。错 敏捷开发是一种软件开发方法论,它强调快速响应变化、持续交付有价值的软件、紧密合作和适应性。虽然敏捷方法鼓励迭代开发和灵活性&…...
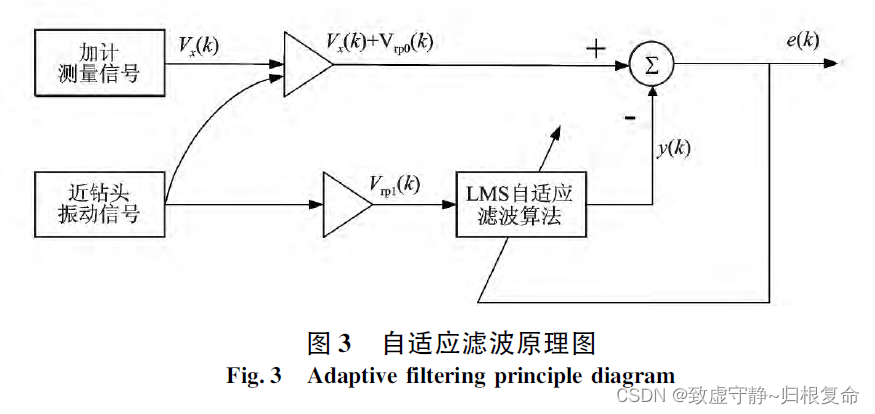
课题学习(九)----阅读《导向钻井工具姿态动态测量的自适应滤波方法》论文笔记
一、 引言 引言直接从原论文复制,大概看一下论文的关键点: 垂直导向钻井工具在近钻头振动和工具旋转的钻井工作状态下,工具姿态参数的动态测量精度不高。为此,通过理论分析和数值仿真,提出了转速补偿的算法以消除工具旋…...

阿里云服务器—ECS快速入门
这里对标阿里云的课程,一步步学习,链接在下面,学习完考试及格即可获取阿里云开发认证和领取证书,大家可以看看这个,这里我当作笔记,记一下提升印象! 内容很长,请耐心看完࿰…...

Hive简介及核心概念
本专栏案例数据集链接: https://download.csdn.net/download/shangjg03/88478038 1.简介 Hive 是一个构建在 Hadoop 之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类 SQL 查询功能,用于查询的 SQL 语句会被转化为 MapReduce 作业,然后提交到 Hadoop 上运行。 …...

CrossOver 23.6.0 虚拟机新功能介绍
CrossOver 23.6.0 Mac 此应用程序允许您运行为 Microsoft Windows 编写的程序,而无需实际安装操作系统。 CrossOver 23.6.0 Mac 包括一个 Windows 程序库,用于它可以运行的 Windows 程序。 您会发现非常流行的应用程序,例如 Microsoft Word…...
(免费领源码)Java#Springboot#mysql农产品销售管理系统47627-计算机毕业设计项目选题推荐
摘 要 随着互联网趋势的到来,各行各业都在考虑利用互联网将自己推广出去,最好方式就是建立自己的互联网系统,并对其进行维护和管理。在现实运用中,应用软件的工作规则和开发步骤,采用Java技术建设农产品销售管理系统。…...

centos更改yum源
1、更改yum源 阿里云/etc/yum.repos.d/CentOS-Base.repo 金山云/etc/yum.repos.d/cloud.repo vi /etc/yum.repos.d/cloud.repo 替换为 [base] nameCentOS-$releasever - Base mirrorlisthttp://mirrorlist.centos.org/?release$releasever&arch$basearch&repoos&…...
React-快速搭建开发环境
1.安装 说明:react-excise-01是创建的文件名 npx create-react-app react-excise-01 2. 打开文件 说明:we suggest that you begin by typing:下面即是步骤。 cd react-excise-01 npm start 3.显示...

算法随想录算法训练营第四十六天| 583. 两个字符串的删除操作 72. 编辑距离
583. 两个字符串的删除操作 题目:给定两个单词 word1 和 word2 ,返回使得 word1 和 word2 相同所需的最小步数。 每步 可以删除任意一个字符串中的一个字符。 思路:这题思路主要是求出 word1 字符串和 word2 字符串中的最长相同的子字符串&…...
vue源码分析(五)——vue render 函数的使用
文章目录 前言一、render函数1、render函数是什么? 二、render 源码分析1.执行initRender方法2.vm._c 和 vm.$createElement 调用 createElement 方法详解(1)区别(2)代码 3、原型上的_render方法(1…...

Maven第三章:IDEA集成与常见问题
Maven第三章:IDEA集成与常见问题 前言 本章内容重点:了解如何将Maven集成到IDE(如IntelliJ IDEA或Eclipse)中,以及使用过程中遇到的常见的问题、如何解决,如何避免等,可以大大提高开发效率。 IEAD导入Maven项目 File ->Open 选择上一章创建的Maven项目 my-app查看po…...

数据结构—线性实习题目(二)5迷宫问题(栈)
迷宫问题(栈) #include <iostream> #include <assert.h> using namespace std;int qi1, qi2; int n; int m1, p1; int** Maze NULL; int** mark NULL;struct items {int x, y, dir; };struct offsets {int a, b;char* dir; };const int…...
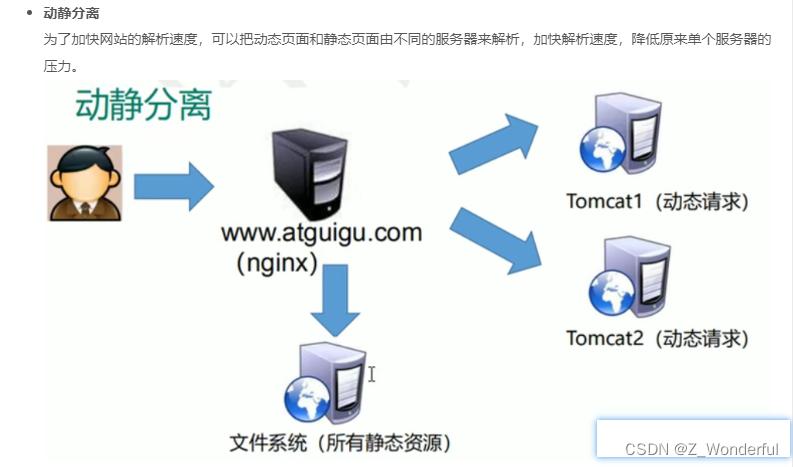
Nginx 的配置文件(负载均衡,反向代理)
Nginx可以配置代理多台服务器,当一台服务器宕机之后,仍能保持系统可用。 cmd查找端口是否使用:netstat -ano Nginx出现403 forbidden #解决办法:修改web目录的读写权限,或者是把nginx的启动用户改成目录的所属用户&…...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

关键领域软件测试的突围之路:如何破解安全与效率的平衡难题
在数字化浪潮席卷全球的今天,软件系统已成为国家关键领域的核心战斗力。不同于普通商业软件,这些承载着国家安全使命的软件系统面临着前所未有的质量挑战——如何在确保绝对安全的前提下,实现高效测试与快速迭代?这一命题正考验着…...
)
Angular微前端架构:Module Federation + ngx-build-plus (Webpack)
以下是一个完整的 Angular 微前端示例,其中使用的是 Module Federation 和 npx-build-plus 实现了主应用(Shell)与子应用(Remote)的集成。 🛠️ 项目结构 angular-mf/ ├── shell-app/ # 主应用&…...

【VLNs篇】07:NavRL—在动态环境中学习安全飞行
项目内容论文标题NavRL: 在动态环境中学习安全飞行 (NavRL: Learning Safe Flight in Dynamic Environments)核心问题解决无人机在包含静态和动态障碍物的复杂环境中进行安全、高效自主导航的挑战,克服传统方法和现有强化学习方法的局限性。核心算法基于近端策略优化…...

Git 3天2K星标:Datawhale 的 Happy-LLM 项目介绍(附教程)
引言 在人工智能飞速发展的今天,大语言模型(Large Language Models, LLMs)已成为技术领域的焦点。从智能写作到代码生成,LLM 的应用场景不断扩展,深刻改变了我们的工作和生活方式。然而,理解这些模型的内部…...
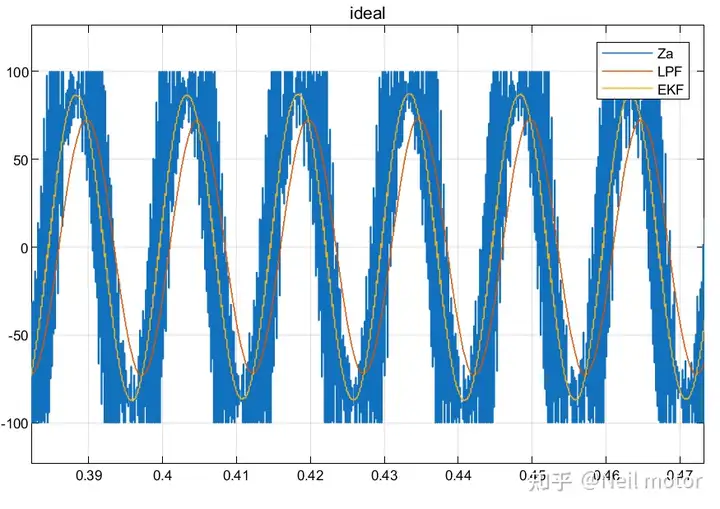
永磁同步电机无速度算法--基于卡尔曼滤波器的滑模观测器
一、原理介绍 传统滑模观测器采用如下结构: 传统SMO中LPF会带来相位延迟和幅值衰减,并且需要额外的相位补偿。 采用扩展卡尔曼滤波器代替常用低通滤波器(LPF),可以去除高次谐波,并且不用相位补偿就可以获得一个误差较小的转子位…...
HybridVLA——让单一LLM同时具备扩散和自回归动作预测能力:训练时既扩散也回归,但推理时则扩散
前言 如上一篇文章《dexcap升级版之DexWild》中的前言部分所说,在叠衣服的过程中,我会带着团队对比各种模型、方法、策略,毕竟针对各个场景始终寻找更优的解决方案,是我个人和我司「七月在线」的职责之一 且个人认为,…...
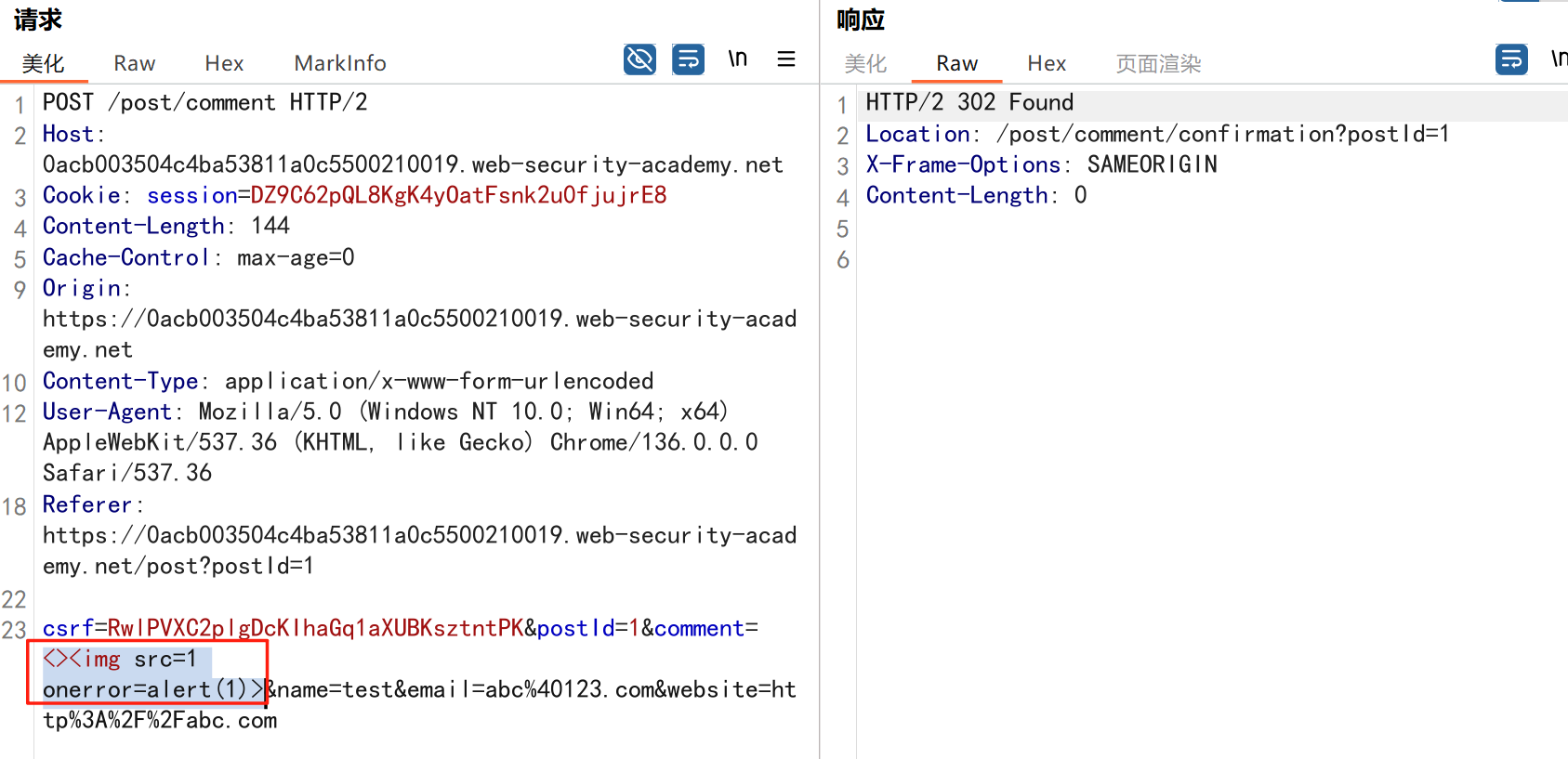
渗透实战PortSwigger靶场:lab13存储型DOM XSS详解
进来是需要留言的,先用做简单的 html 标签测试 发现面的</h1>不见了 数据包中找到了一个loadCommentsWithVulnerableEscapeHtml.js 他是把用户输入的<>进行 html 编码,输入的<>当成字符串处理回显到页面中,看来只是把用户输…...