SQLAlchemy
文章目录
- SQLAlchemy
- 介绍
- SQLAlchemy入门
- 使用原生sql
- 使用orm
- 外键关系
- 一对多关系
- 多对多关系
- 基于scoped_session实现线程安全
- 简单表操作
- 实现方案
- CRUD
- Flask 集成 sqlalchemy
SQLAlchemy
介绍
SQLAlchemy是一个基于Python实现的ORM框架。该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之便是:将类和对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
pip3 install sqlalchemy
组成部分:
Engine,框架的引擎
Connection Pooling ,数据库连接池
Dialect,选择连接数据库的DB API种类
Schema/Types,架构和类型
SQL Exprression Language,SQL表达式语言
SQLAlchemy本身无法操作数据库,其必须以来pymsql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
MySQL-Pythonmysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>pymysqlmysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]MySQL-Connectormysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>cx_Oracleoracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]更多:http://docs.sqlalchemy.org/en/latest/dialects/index.html
扩充:
orm 框架,除django内置的 和 sqlalchemy 外,还有 peewee 轻量级框架,这些都是同步 orm 框架
搭配异步web 框架 fastapi sanic 的异步orm框架有 peewee-async
虽然异步框架搭配 同步 orm 框架也能用,不过局限性比较大。一般来讲,一旦用了异步,后续所有都需要用异步
SQLAlchemy入门
使用原生sql
from sqlalchemy import create_engine
from sqlalchemy.engine.base import Engine
from urllib import parse
import threadinguser = "root"
password = "xxx@000"
pwd = parse.quote_plus(password) # 解决密码中含@符导致报错
host = "127.0.0.1:"
# 第一步: 创建engine
engine = create_engine(f"mysql+pymysql://{user}:{pwd}@{host}3306/test1?charset=utf8",max_overflow=0, # 超过连接池大小外最多创建的连接pool_size=5, # 连接池大小pool_timeout=30, # 池中没有线程最多等待的时间,否则报错pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)# 第二步:使用
def task():conn = engine.raw_connection() # 从连接池中取一个连接cursor = conn.cursor()sql = "select * from signer"cursor.execute(sql)print(cursor.fetchall())if __name__ == '__main__':for i in range(20):t = threading.Thread(target=task)t.start()
使用orm
import datetime
from sqlalchemy.ext.declarative import declarative_base
from model import engine # 用的简单使用里面的engine
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, IndexBase = declarative_base() # 基类# 表模型
class Users(Base):__tablename__ = 'users' # 数据库表名称, 必须写id = Column(Integer, primary_key=True) # id 主键name = Column(String(32), index=True, nullable=False) # name列,索引,不可为空email = Column(String(32), unique=True)# datetime.datetime.now不能加括号,加了括号,以后永远是当前时间ctime = Column(DateTime, default=datetime.datetime.now)extra = Column(Text, nullable=True)__table_args__ = ( # 可选UniqueConstraint('id', 'name', name='uix_id_name'), # 联合唯一Index('ix_id_name', 'name', 'email'), # 索引)def init_db():"""根据类创建数据库表:return:"""Base.metadata.create_all(engine)def drop_db():"""根据类删除数据库表:return:"""Base.metadata.drop_all(engine)if __name__ == '__main__':init_db() # 创建表# drop_db() # 删除表
总结:
- 生成一个基类,所有表模型都要继承这个基类(base)
- 继承父类写表模型,写字段
- 迁移通过表模型生成表
注意:
- 不管是 sqlalchemy 还是 django 的orm 都不支持对数据库的操作,只能对表进行操作
- sqlalchemy 只支持 创建和删除表,不支持修改表(django orm支持)。sqlalchemy 需要借助第三方实现
外键关系
外键关系,实际上就是一个 ForeignKey ,指定 一对一,一对多,多对多三种关系
一对多关系
class Hobby(Base):__tablename__ = 'hobby'id = Column(Integer, primary_key=True)caption = Column(String(50), default='篮球')class Person(Base):__tablename__ = 'person'nid = Column(Integer, primary_key=True)name = Column(String(32), index=True, nullable=True)# hobby指的是tablename而不是类名hobby_id = Column(Integer, ForeignKey("hobby.id"))# 跟数据库无关,不会新增字段,只用于快速链表操作# 类名,backref用于反向查询 参数 uselist=False , 设置就变成了一对一,其他和一对多一样hobby=relationship('Hobby',backref='pers')# hobby=relationship('Hobby',backref='pers', uselist=False) # 一对一关系
多对多关系
class Boy2Girl(Base):__tablename__ = 'boy2girl'id = Column(Integer, primary_key=True, autoincrement=True)girl_id = Column(Integer, ForeignKey('girl.id'))boy_id = Column(Integer, ForeignKey('boy.id'))class Girl(Base):__tablename__ = 'girl'id = Column(Integer, primary_key=True)name = Column(String(64), unique=True, nullable=False)class Boy(Base):__tablename__ = 'boy'id = Column(Integer, primary_key=True, autoincrement=True)hostname = Column(String(64), unique=True, nullable=False)# 与生成表结构无关,仅用于查询方便,放在哪个单表中都可以servers = relationship('Girl', secondary='boy2girl', backref='boys')'''
girl_id = Column(Integer, ForeignKey("hobby.id", ondelete='SET NULL')) # 一般用SET NULL
外键约束1. RESTRICT:若子表中有父表对应的关联数据,删除父表对应数据,会阻止删除。默认项2. NO ACTION:在MySQL中,同RESTRICT。3. CASCADE:级联删除。4. SET NULL:父表对应数据被删除,子表对应数据项会设置为NULL。
'''
扩充
在 django 中,外键管理有个参数 db_contraint=False 用来在逻辑上关联表,但实体不建立约束。同样在SQLAlchemy 中也可以通过配值 relationship 参数来实现同样的效果
class Boy2Girl(Base):__tablename__ = 'boy2girl'id = Column(Integer, primary_key=True, autoincrement=True)girl_id = Column(Integer) # 不用ForeignKeyboy_id = Column(Integer)gitl = db.relationship("Girl",# uselist=False, # 一对一设置backref=backref("to_course", uselist=False), # backref用于反向查询 uselist 作用同上lazy="subquery", # 懒加载 用来指定sqlalchemy 什么时候加载数据primaryjoin="Girl.id==Boy2Girl.girl_id", # 指定对应关系foreign_keys="Boy2Girl.girl_id" # 指定表的外键字段)
'''
lazy 可选值select:就是访问到属性的时候,就会全部加载该属性的数据 默认值joined:对关联的两个表使用联接subquery:与joined类似,但使用子子查询dynamic:不加载记录,但提供加载记录的查询,也就是生成query对象
'''
基于scoped_session实现线程安全
简单表操作
基于sqlalchemy orm 来简单实现一条数据的添加
from sqlalchemy.orm import sessionmakerfrom model import engine
from db_model import Users# 定义一个 session, 以后操作数据都用 session 来执行
Session = sessionmaker(bind=engine)
session = Session()
# 创建User对象
usr = Users(name="yxh", email="152@11.com", extra="xxx")
# 通过 user对象 添加到session中
session.add(usr)
# 提交,才会刷新到数据库中,不提交不会执行
session.commit()
从上面demo中,可以发现一点,session 如果是一个全局对象。那么在多线程的情况下,并发使用同一个变量 session 是不安全的,解决方案如下:
- 将session定义在局部,每一个view函数都定义一个session。 代码冗余,不推荐
- 基于scoped_session 实现线程安全。原理同 request对象,g对象一致。也是基于local,给每一个线程创造一个session
实现方案
from sqlalchemy.orm import sessionmaker, scoped_session
from model import engine
from db_model import Users# 定义一个 session
Session = sessionmaker(bind=engine)
# session = Session()
session = scoped_session(Session) # 后续使用这个session就是线程安全的
# 创建User对象
usr = Users(name="yxh", email="152@11.com", extra="xxx")
# 通过 user对象 添加到session中
session.add(usr)
# 提交,才会刷新到数据库中,不提交不会执行
session.commit()
CRUD
基础
from sqlalchemy.orm import sessionmaker, scoped_session
from sqlalchemy.sql import text
from model import engine
from db_model import Users# 定义一个 session
Session = sessionmaker(bind=engine)
# session = Session()
session = scoped_session(Session) # 后续使用这个session就是线程安全的# 1 增加操作
obj1 = Users(name="yxh003")
session.add(obj1)
# 增加多个,不同对象
session.add_all([Users(name="yxh009"),Users(name="yxh008"),
])
session.commit()# 2 删除操作---》查出来再删---》
session.query(Users).filter(Users.id > 2).delete()
session.commit()# 3 修改操作--》查出来改 传字典
session.query(Users).filter(Users.id > 0).update({"name": "yxh"})
# 类似于django的F查询
# 字符串加
session.query(Users).filter(Users.id > 0).update({Users.name: Users.name + "099"}, synchronize_session=False)
# 数字加
session.query(Users).filter(Users.id > 0).update({"age": Users.age + 1}, synchronize_session="evaluate")
session.commit()# 4 查询操作----》
r1 = session.query(Users).all() # 查询所有
# 只取age列,把name重命名为xx
# select name as xx,age from user;
r2 = session.query(Users.name.label('xx'), Users.email).all()# filter传的是表达式,filter_by传的是参数
r3 = session.query(Users).filter(Users.name == "yxh").all()
r3 = session.query(Users).filter(Users.id >= 1).all()
r4 = session.query(Users).filter_by(name='yxh').all()
r5 = session.query(Users).filter_by(name='yxh').first()
# :value 和:name 相当于占位符,用params传参数
r6 = session.query(Users).filter(text("id<:value and name=:name")).params(value=224, name='yxh').order_by(Users.id).all()
# 自定义查询sql
r7 = session.query(Users).from_statement(text("SELECT * FROM users where name=:name")).params(name='yxh').all()# 执行原生sql
# 查询
cursor = session.execute("select * from users")
result = cursor.fetchall()
# 添加
cursor = session.execute('insert into users(name) values(:value)', params={"value": 'yxh'})
session.commit()
print(cursor.lastrowid)
进阶
from sqlalchemy.orm import sessionmaker, scoped_session
from sqlalchemy.sql import text, func
from sqlalchemy import and_, or_
from model import engine
from db_model import Users, Person, Favor# 定义一个 session
Session = sessionmaker(bind=engine)
# session = Session()
session = scoped_session(Session) # 后续使用这个session就是线程安全的# 条件
# select * form user where name =lqz
ret = session.query(Users).filter_by(name='lqz').all()# 表达式,and条件连接
# select * from user where id >1 and name = lqz
ret = session.query(Users).filter(Users.id > 1, Users.name == 'lqz').all()# select * from user where id between 1,3 and name = lqz
ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == 'lqz').all()# # 注意下划线
# select * from user where id in (1,3,4)
ret = session.query(Users).filter(Users.id.in_([1, 3, 4])).all()
# # ~非,除。。外# select * from user where id not in (1,3,4)
ret = session.query(Users).filter(~Users.id.in_([1, 3, 4])).all()# # 二次筛选
ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='lqz'))).all()# # or_包裹的都是or条件,and_包裹的都是and条件
ret = session.query(Users).filter(and_(Users.id > 3, Users.name == 'eric')).all()
ret = session.query(Users).filter(or_(Users.id < 2, Users.name == 'eric')).all()
ret = session.query(Users).filter(or_(Users.id < 2,and_(Users.name == 'eric', Users.id > 3),Users.extra != "")).all()# 通配符,以e开头,不以e开头
ret = session.query(Users).filter(Users.name.like('e%')).all()
ret = session.query(Users).filter(~Users.name.like('e%')).all()# # 限制,用于分页,区间
ret = session.query(Users)[1:2]# # 排序,根据name降序排列(从大到小)
ret = session.query(Users).order_by(Users.id.desc()).all()
# # 第一个条件重复后,再按第二个条件升序排
ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all()# 分组
# select * from user group by user.extra;
ret = session.query(Users).group_by(Users.extra).all()
# # 分组之后取最大id,id之和,最小id
# select max(id),sum(id),min(id) from user group by name ;
ret = session.query(func.max(Users.id),func.sum(Users.id),func.min(Users.id)).group_by(Users.name).all()# haviing筛选
# select max(id),sum(id),min(id) from user group by name having min(id)>2;
ret = session.query(func.max(Users.id),func.sum(Users.id),func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) > 2).all()# select max(id),sum(id),min(id) from user where id >=1 group by name having min(id)>2;
ret = session.query(func.max(Users.id),func.sum(Users.id),func.min(Users.id)).filter(Users.id >= 1).group_by(Users.name).having(func.min(Users.id) > 2).all()# 连表(默认用orm中forinkey关联)# select * from user,favor where user.id=favor.id
ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all()# join表,默认是inner join
# select * from Person inner join favor on person.favor=favor.id;
ret = session.query(Person).join(Favor).all()
# isouter=True 外连,表示Person left join Favor,没有右连接,反过来即可
ret = session.query(Person).join(Favor, isouter=True).all()
ret = session.query(Favor).join(Person, isouter=True).all()# 打印原生sql
aa = session.query(Person).join(Favor, isouter=True)
# print(aa)# 自己指定on条件(连表条件),第二个参数,支持on多个条件,用and_,同上
# select * from person left join favor on person.id=favor.id;
ret = session.query(Person).join(Favor, Person.id == Favor.id, isouter=True).all()# 组合 UNION 操作符用于合并两个或多个 SELECT 语句的结果集 多用于分表后 上下连表
# union和union all union 去重, union all 不去重
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union(q2).all()q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union_all(q2).all()
Flask 集成 sqlalchemy
flask 中集成 sqlalchemy 可以选择直接配置第三方库,来的更方便 比如:
-
flask_sqlalchemy 用来操作数据库
-
flask_migrate 用来实现表迁移(类似django)
'''
flask_migrate 中使用了flask_sqlalchemy 下载时,会自动帮你下载flask_sqlalchemy
flask_migrate 3.0之前和之后使用方法有区别。这里以2.x 做演示
'''
# flask_migrate使用步骤
from flask_sqlalchemy import SQLAlchemy
# Flask_SQLAlchemy给你包装了基类,和session,以后拿到db
db = SQLAlchemy() # 全局SQLAlchemy,就是线程安全的,内部就是上述那么实现的
app = Flask(__name__)
# SQLAlchemy 连接数据库配置是在 config 配置字典中获取的,所以需要我们将配置添加进去
app.config.from_object('DevelopmentConfig')
'''
基本写这些就够了
"SQLALCHEMY_DATABASE_URI"
"SQLALCHEMY_POOL_SIZE"
"SQLALCHEMY_POOL_TIME"
"SQLALCHEMY_POOL_RECYCLE"
"SQLALCHEMY_TRACK_MODIFICATIONS"
"SQLALCHEMY_ENGINE_OPTIONS"
'''
# 将db注册到app中,加载配置文件,flask-session,用一个类包裹一下app
db.init_app(app)
# 下面三句会创建出两个命令:runserver db 命令(flask_migrate)
manager=Manager(app)
Migrate(app, db)
manager.add_command('db', MigrateCommand ) # 添加一个db命令使用命令:1. python xxx.py db init # 初始化,刚开始干,生成一个migrate文件夹2. python xxx.py db migrate # 同django makemigartions3. python xxx.py db upgrade # 同django migrate
补充:
如果使用flask_sqlalchemy, 那么建表orm 的继承 db.Model 即可(和django越来越像了)
相关文章:

SQLAlchemy
文章目录SQLAlchemy介绍SQLAlchemy入门使用原生sql使用orm外键关系一对多关系多对多关系基于scoped_session实现线程安全简单表操作实现方案CRUDFlask 集成 sqlalchemySQLAlchemy 介绍 SQLAlchemy是一个基于Python实现的ORM框架。该框架建立在 DB API之上,使用关系…...
【Linux学习笔记】8.Linux yum 命令和apt 命令
前言 本章介绍Linux的yum命令和apt命令。 Linux yum 命令 yum( Yellow dog Updater, Modified)是一个在 Fedora 和 RedHat 以及 SUSE 中的 Shell 前端软件包管理器。 基于 RPM 包管理,能够从指定的服务器自动下载 RPM 包并且安装…...
windows服务器实用(4)——使用IIS部署网站
windows服务器实用——IIS部署网站 如果把windows服务器作为web服务器使用,那么在这个服务器上部署网站是必须要做的事。在windows服务器上,我们一般使用IIS部署。 假设此时前端给你一个已经完成的网站让你部署在服务器上,别人可以在浏览器…...
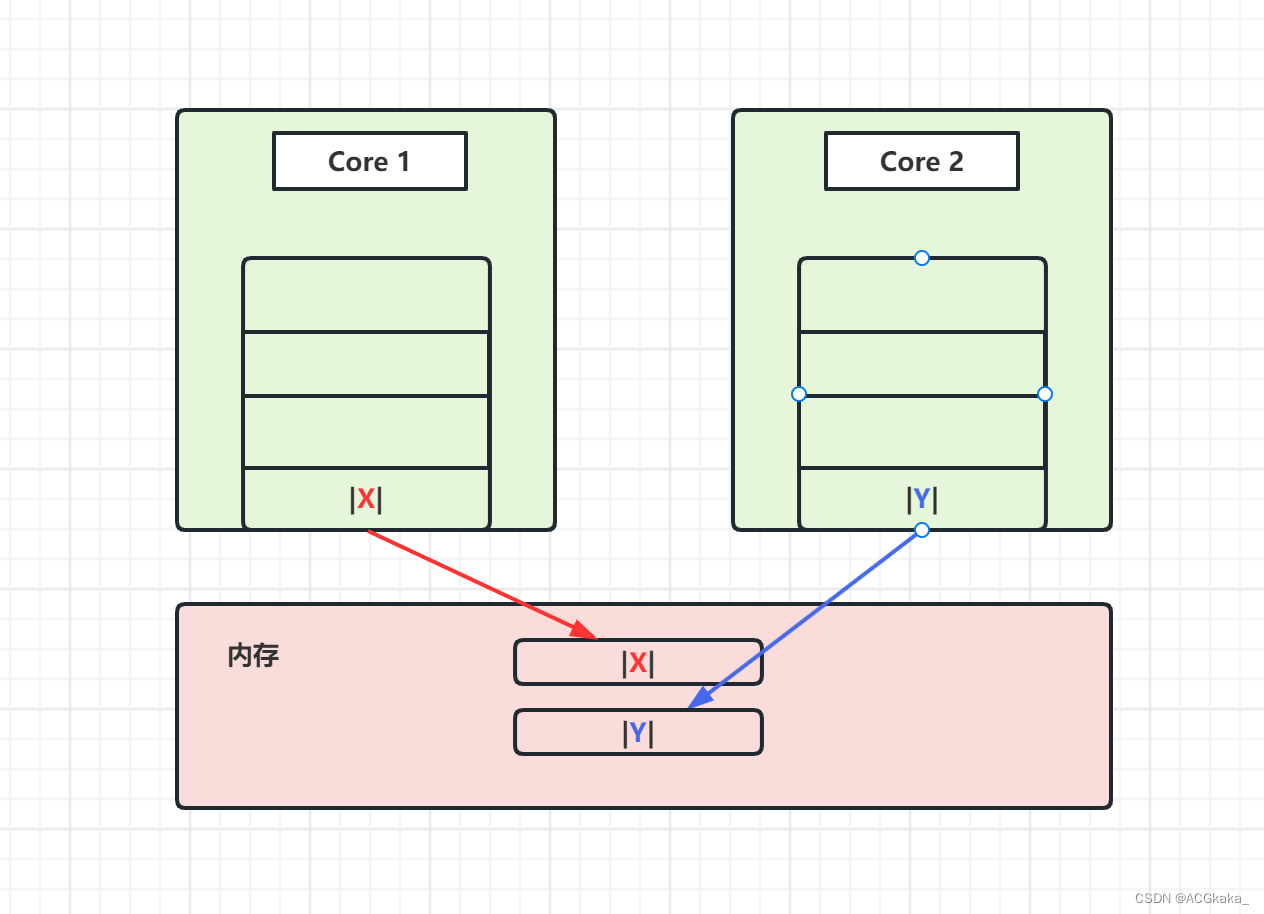
Random(二)什么是伪共享?@sun.misc.Contended注解
目录1.背景简介2.伪共享问题3.问题解决4.JDK使用示例1.背景简介 我们知道,CPU 是不能直接访问内存的,数据都是从高速缓存中加载到寄存器的,高速缓存又有 L1,L2,L3 等层级。在这里,我们先简化这些复杂的层级…...

Linux解压压缩
打包tar首先我们得提一下专门用于打包文件的命令——tartar用于备份文件,打包多个文件或者目录,也可以用于还原被打包的文件假设打包目录test下的文件 tar -cvf test.tar ./test 假设打包目录test下的文件,并用gzip命令将包压缩 tar -zcvf test.tar ./te…...

JavaSe第3次笔记
1.String str "hello";字符串类型。 2.两个字符串类型相加意思是拼接,类似于c语言里面的strcat函数。 3.整型变成字符串类型: int a 10; String str String. valueOf(a); 4.当字符串和其他类型进行相加的时候,结果就是字符串。(不完全…...

非人工智能专业怎样从零开始学人工智能?
人工智能(Artificial Intelligence,AI)是指让机器具有类似人类智能的能力,包括感知、理解、推理、学习、规划、决策、创造等多个方面。人工智能研究涉及到计算机科学、数学、物理学、心理学、哲学等多个领域,旨在模拟和…...

MyBatis之增、删、查、改
目录 前言 一、配置MyBatis开发环境 1.1 创建数据库和表 1.2 添加框架支持 1.3 创建目录结构 1.4 配置数据库连接 1.5 配置MyBatis中的XML文件路径 二、添加业务代码 2.1 查询数据库操作 2.1.1 添加实体类 2.1.2 添加mapper接口 2.1.3 在xml中实现mapper接口 2.1.…...
死磕Spring,什么是SPI机制,对SpringBoot自动装配有什么帮助
文章目录如果没时间看的话,在这里直接看总结一、Java SPI的概念和术语二、看看Java SPI是如何诞生的三、Java SPI应该如何应用四、从0开始,手撸一个SPI的应用实例五、SpringBoot自动装配六、Spring SPI机制与Spring Factories机制做对比七、这里是给我自…...
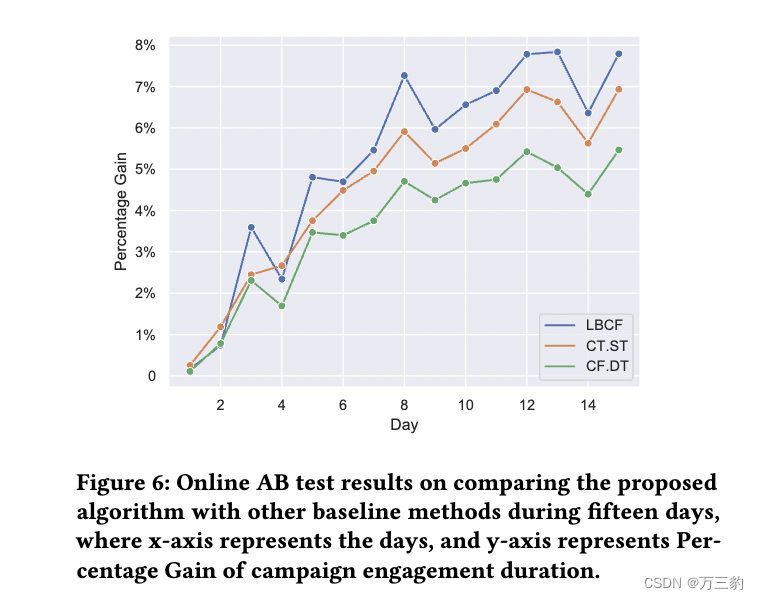
因果推断10--一种大规模预算约束因果森林算法(LBCF)
论文:A large Budget-Constrained Causal Forest Algorithm 论文:http://export.arxiv.org/pdf/2201.12585v2.pdf 目录 0 摘要 1 介绍 2 问题的制定 3策略评价 4 方法 4.1现有方法的局限性。 4.2提出的LBCF算法 5验证 5.1合成数据 5.2离线生…...

Linux基础命令-df显示磁盘的使用情况
文章目录 文章目录 df 命令介绍 语法格式 基本参数 参考实例 1)以人类可读形式显示磁盘空间的使用情况 2)显示磁盘的inode信息 3)显示磁盘和文件系统类型 4)指定显示文件系统 5)显示所有磁盘空间中的内容 …...
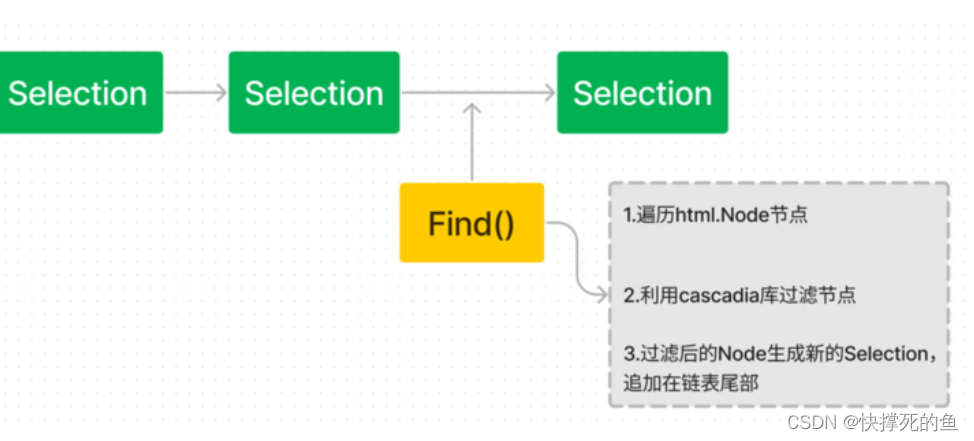
如何使用goquery进行HTML解析以及它的源码分析和实现原理
目录 goquery 是什么 goquery 能用来干什么 goquery quick start 玩转goquery.Find() 查找多个标签 Id 选择器 Class 选择器 属性选择器 子节点选择器 内容过滤器 goquery 源码分析 图解源码 总结 goquery 简介 goquery是一款基于Go语言的HTML解析库,…...

【Java 数组和集合 区别及使用案例】
Java中数组和集合都是用来存储一组数据的容器,但是在实际使用中,它们有一些区别和不同的使用场景。 数组 vs 集合:存储方式 数组是一个固定长度的容器,它的长度一旦被初始化之后,就无法再改变了。而集合是一个动态长…...
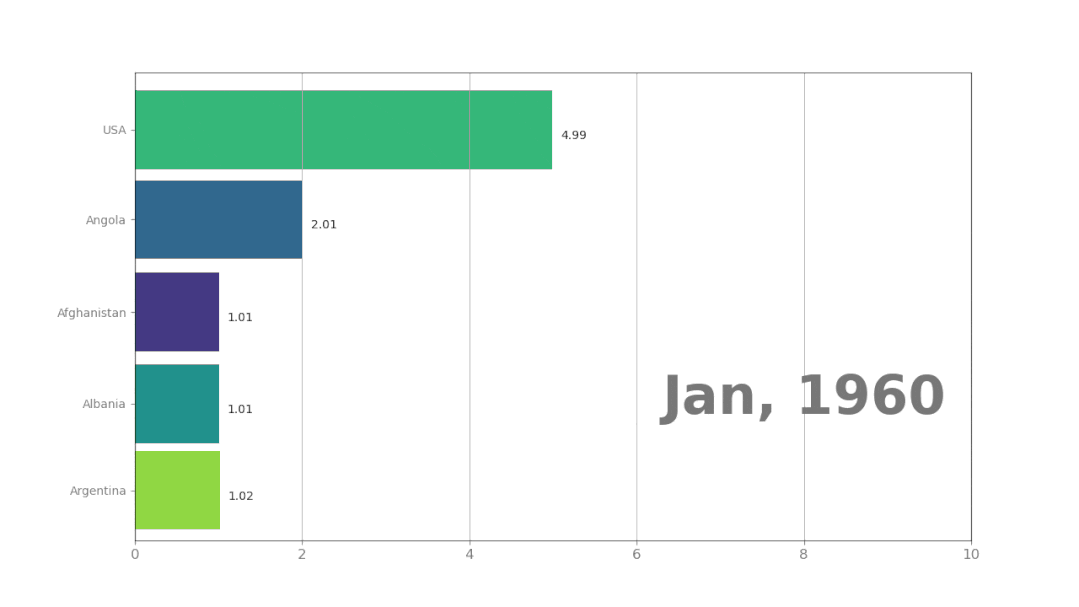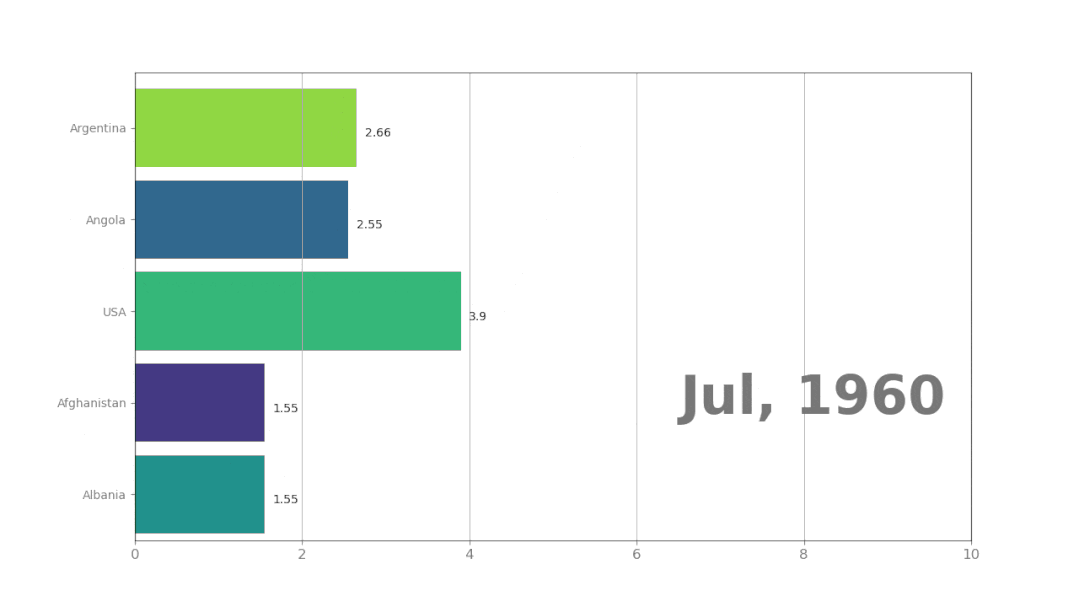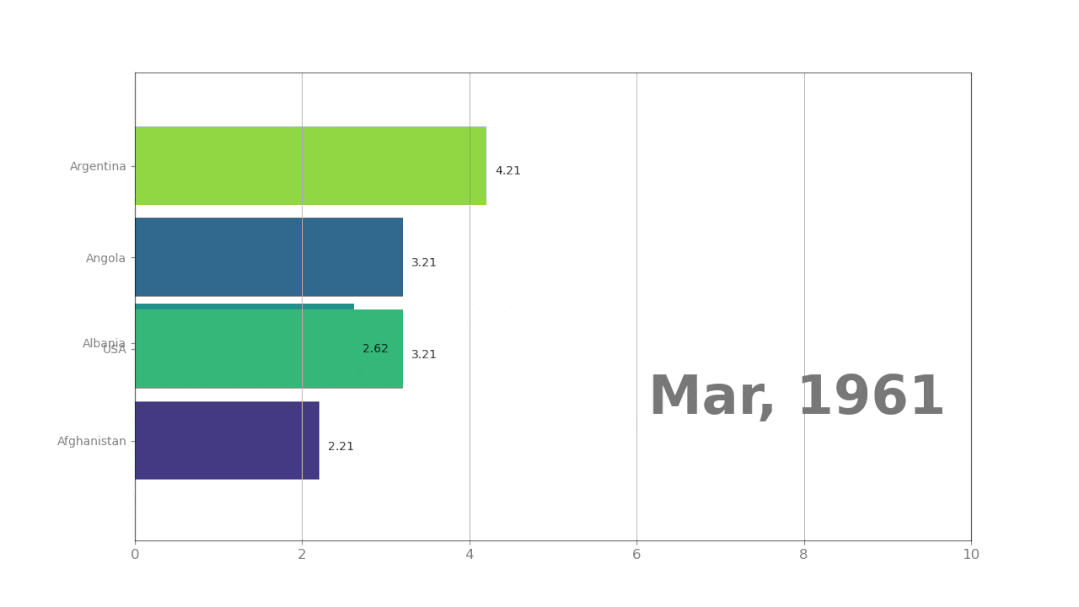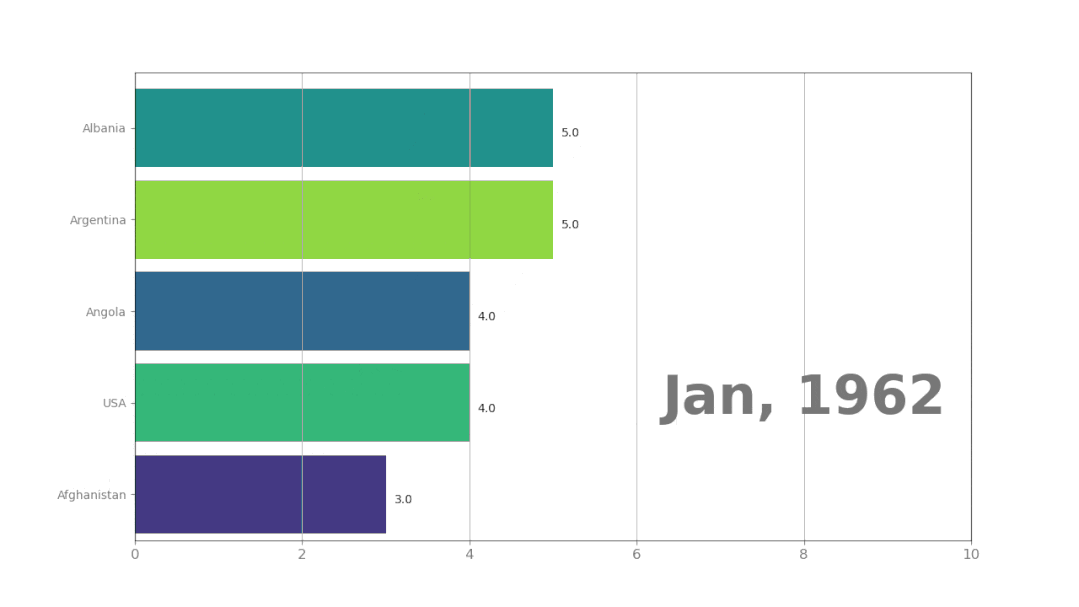
使用pynimate制作动态排序图
大家好,数据可视化动画使用Python包就可以完成,效果如下:想要使用Pynimate,直接import一下就行:import pynimate as nim输入数据后,Pynimate将使用函数Barplot()来创建条形数据动画。…...
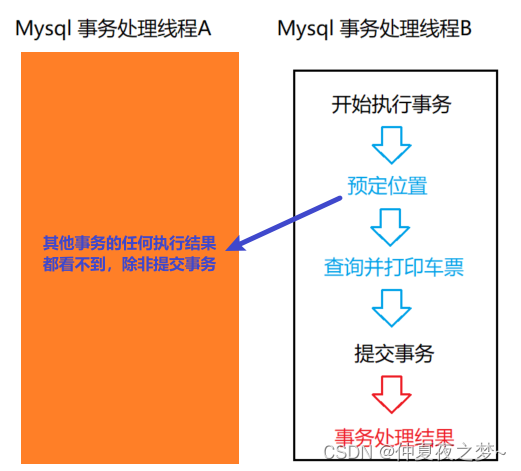
Mysql 事务的隔离性(隔离级别)
Mysql 中的事务分为手动提交和自动提交,默认是自动提交,所以我们在Mysql每输入一条语句,其实就会被封装成一个事务提交给Mysql服务端。 手动提交需要先输入begin,表示要开始处理事务,然后就是常见的sql语句操作了&…...

2023年网络安全竞赛——Python渗透测试PortScan.py
端口扫描Python渗透测试:需求环境可私信博主获取 任务环境说明: 服务器场景:PYsystem0041服务器场景操作系统:未知服务器场景FTP用户名:anonymous 密码:空1. 从靶机服务器的FTP上下载PortScan.py,编辑Python程序PortScan.py,实现...

【数据结构】栈的接口实现(附图解和源码)
栈的接口实现(附图解和源码) 文章目录栈的接口实现(附图解和源码)前言一、定义结构体二、接口实现(附图解源码)1.初始化栈2.销毁栈3.入栈4.判断栈是否为空5.出栈6.获取栈顶元素7.获取栈中元素个数三、源代码…...
)
LC-1255. 得分最高的单词集合(回溯)
1255. 得分最高的单词集合 难度困难60 你将会得到一份单词表 words,一个字母表 letters (可能会有重复字母),以及每个字母对应的得分情况表 score。 请你帮忙计算玩家在单词拼写游戏中所能获得的「最高得分」:能够由…...

从中国文化看面试挑人标准
文章目录标准一、面相1. 1 四白眼1.2 浓眉二、讲话2.1 言多与气虚总结本文结合中国面相,是个概率性问题,对于个体无效。 标准 正直,三观正,沟通好,技术。从概率上讲: 正直且三观正的人----有恒心&#x…...

谦卑对象设计模式
谦卑设计模式介绍 “谦卑”在这里是拟人化的,指难以测试的对象清晰地认识到自己的局限性,只发挥自己的桥梁和通信作用,并不从中干预信息的传输。 谦卑对象模式‘最初的设计目的是帮助单元测试的编写者区分容易测试的行为与难以测试的行为,并将它们隔离。其设计思路…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

JVM虚拟机:内存结构、垃圾回收、性能优化
1、JVM虚拟机的简介 Java 虚拟机(Java Virtual Machine 简称:JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,实现了 Java 程序的跨平台特性。JVM 屏蔽了与具体操作系统平台相关的信息,使得 Java 程序只需生成在 JVM 上运行的目标代码(字节码),就可以…...

Git 3天2K星标:Datawhale 的 Happy-LLM 项目介绍(附教程)
引言 在人工智能飞速发展的今天,大语言模型(Large Language Models, LLMs)已成为技术领域的焦点。从智能写作到代码生成,LLM 的应用场景不断扩展,深刻改变了我们的工作和生活方式。然而,理解这些模型的内部…...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...

智能职业发展系统:AI驱动的职业规划平台技术解析
智能职业发展系统:AI驱动的职业规划平台技术解析 引言:数字时代的职业革命 在当今瞬息万变的就业市场中,传统的职业规划方法已无法满足个人和企业的需求。据统计,全球每年有超过2亿人面临职业转型困境,而企业也因此遭…...

VASP软件在第一性原理计算中的应用-测试GO
VASP软件在第一性原理计算中的应用 VASP是由维也纳大学Hafner小组开发的一款功能强大的第一性原理计算软件,广泛应用于材料科学、凝聚态物理、化学和纳米技术等领域。 VASP的核心功能与应用 1. 电子结构计算 VASP最突出的功能是进行高精度的电子结构计算ÿ…...

在ubuntu等linux系统上申请https证书
使用 Certbot 自动申请 安装 Certbot Certbot 是 Let’s Encrypt 官方推荐的自动化工具,支持多种操作系统和服务器环境。 在 Ubuntu/Debian 上: sudo apt update sudo apt install certbot申请证书 纯手动方式(不自动配置)&…...

软件工程教学评价
王海林老师您好。 您的《软件工程》课程成功地将宏观的理论与具体的实践相结合。上半学期的理论教学中,您通过丰富的实例,将“高内聚低耦合”、SOLID原则等抽象概念解释得十分透彻,让这些理论不再是停留在纸面的名词,而是可以指导…...