Transformers实战(二)快速入门文本相似度、检索式对话机器人
Transformers实战(二)快速入门文本相似度、检索式对话机器人
1、文本相似度
1.1 文本相似度简介
-
文本匹配是一个较为宽泛的概念,基本上只要涉及到两段文本之间关系的,都可以被看作是一种文本匹配的任务, -
只是在具体的场景下,不同的任务对匹配二字的定义可能是存在差异的,具体的任务场景包括文本相似度计算、问答匹配、对话匹配、文本推理等等,另外,如之前介绍的多项选择,本质上也是文本匹配
-
本次重点关注文本相似度任务,
即判断两段文本是不是表达了同样的语义 -
文本相似度本质上是一个分类任务。
| Sentence A | Sentence B | Label |
|---|---|---|
| 找一部小时候的动画片 | 求一部小时候的动画片。谢了 | 1 |
| 别急呀,我的朋友。 | 你一定要看我一下 | 0 |
| 明天多少度啊 | 明天气温多少度啊 | 1 |
| 可怕的事情终于发生 | 你到底想说什么? | 0 |
1.2 最直接的解决方案—交互策略
交互策略,就是输入句子对,对是否相似进行学习。

数据预处理方式如下:

交互策略的实现比较简单,类似于情感分析。
1.2.1 数据集预处理
数据集:https://github.com/CLUEbenchmark/SimCLUE/tree/main
预训练模型依然是哈工大开源的chinese-macbert-base
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_datasetdataset = load_dataset("json", data_files="./train_pair_1w.json", split="train")
dataset[0:2]
{'sentence1': ['找一部小时候的动画片','我不可能是一个有鉴赏能力的行家,小姐我把我的时间都花在书写上;象这样豪华的舞会,我还是头一次见到。'],'sentence2': ['求一部小时候的动画片。谢了', '蜡烛没熄就好了,夜黑得瘆人,情绪压抑。'],'label': ['1', '0']}
# 划分数据集
datasets = dataset.train_test_split(test_size=0.2)# tokenizer = AutoTokenizer.from_pretrained("hfl/chinese-macbert-base")# 离线加载
model_path = '/root/autodl-fs/models/chinese-macbert-base'
tokenizer = AutoTokenizer.from_pretrained(model_path)def process_function(examples):tokenized_examples = tokenizer(examples["sentence1"], examples["sentence2"], max_length=128, truncation=True)tokenized_examples["labels"] = [float(label) for label in examples["label"]]return tokenized_examplestokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
tokenized_datasets
DatasetDict({train: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 8000})test: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 2000})
})
print(tokenized_datasets["train"][0])
{
'input_ids': [101, 1062, 4265, 1920, 782, 8024, 1963, 3362, 2769, 1762, 6878, 1168, 2600, 1385, 808, 1184, 6878, 1168, 4640, 2370, 7363, 678, 8024, 6929, 6421, 2582, 720, 1215, 8043, 102, 800, 2697, 6230, 2533, 800, 2190, 6821, 5439, 1928, 2094, 3683, 2190, 800, 1520, 1520, 6820, 779, 8024, 4507, 754, 800, 2190, 6821, 702, 782, 772, 4495, 4638, 3946, 2658, 679, 4881, 2544, 5010, 6629, 3341, 511, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
'labels': 0.0
}
1.2.2 加载模型、创建评估函数
import evaluate# 离线加载模型
model = AutoModelForSequenceClassification.from_pretrained(model_path, num_labels=1)# 这里采用离线加载
accuracy_path = '/root/autodl-tmp/transformers-code/metrics/accuracy'
f1_path = '/root/autodl-tmp/transformers-code/metrics/f1'acc_metric = evaluate.load(accuracy_path)
f1_metirc = evaluate.load(f1_path)def eval_metric(eval_predict):predictions, labels = eval_predictpredictions = [int(p > 0.5) for p in predictions]labels = [int(l) for l in labels]acc = acc_metric.compute(predictions=predictions, references=labels)f1 = f1_metirc.compute(predictions=predictions, references=labels)acc.update(f1)return acc
1.2.3 创建TrainingArguments及Trainer
train_args = TrainingArguments(output_dir="./cross_model", # 输出文件夹per_device_train_batch_size=16, # 训练时的batch_sizeper_device_eval_batch_size=16, # 验证时的batch_sizelogging_steps=10, # log 打印的频率evaluation_strategy="epoch", # 评估策略save_strategy="epoch", # 保存策略save_total_limit=3, # 最大保存数learning_rate=2e-5, # 学习率weight_decay=0.01, # weight_decaymetric_for_best_model="f1", # 设定评估指标load_best_model_at_end=True) # 训练完成后加载最优模型
from transformers import DataCollatorWithPadding
trainer = Trainer(model=model, args=train_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["test"], data_collator=DataCollatorWithPadding(tokenizer=tokenizer),compute_metrics=eval_metric)
trainer.train()

1.2.4 模型预测
from transformers import pipelinemodel.config.id2label = {0: "不相似", 1: "相似"}
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer, device=0)result = pipe({"text": "我喜欢北京", "text_pair": "天气怎样"}, function_to_apply="none")
result["label"] = "相似" if result["score"] > 0.5 else "不相似"
result
{'label': '不相似', 'score': 0.054742373526096344}
1.3 基于向量匹配的解决方案
如果从多个文本中,找到最相似的文本,应该如何做呢?
基于交互策略,我们可以借鉴之前多项选择,用相同的处理方式(如下图)。

但是这样效率极低,因为每次都需要与全量数据进行模型推理,数据量较大时很难满足时延要求。
基于向量匹配的方案可以解决。
我们可以将候选文本经过训练好的模型进行向量化,然后存到向量数据库中(如faiss)。然后将问题也同样向量化,去向量库中进行向量匹配。(这也是检索式机器人的思路,我们将在检索机器人中,将本章节训练好的向量模型作为预训练模型,对文本进行向量化,并将向量集合存到faiss中,进行向量匹配,这里仅仅训练出向量模型。)

那么,这个向量模型该如何进行训练呢?
向量匹配训练,分别对句子进行编码,目标是让两个相似句子的相似度分数尽可能接近1。

数据预处理与多项选择类似

注意:此时没有预定义模型,需要我们自己实现模型。
模型中的损失,我们可以用pytorch提供的余弦损失函数 torch.nn.CosineEmbeddingLoss

-
余弦损失函数,常常用于评估两个向量的相似性,两个向量的余弦值越高,则相似性越高。
-
x:包括x1和x2,即需要计算相似度的prediction和GT; -
y:相当于人为给定的flag,决定按哪种方式计算得到loss的结果。 -
注意:此时label应该为正负1
-
如果需要约束使x1和x2尽可能的相似,那么就使用
y=1,prediction和GT完全一致时,loss为0
input1 = torch.randn(100, 128)
input2 = torch.randn(100, 128)
cos = nn.CosineEmbeddingLoss(reduction='mean')# # 需要初始化一个N维的1或-1
loss_flag = torch.ones([100])
output = cos(input1, input2, loss_flag)print(output) # tensor(1.0003)
1.3.1 数据预处理
数据集:https://github.com/CLUEbenchmark/SimCLUE/tree/main
预训练模型依然是哈工大开源的chinese-macbert-base
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
import torch# 离线加载数据
dataset = load_dataset("json", data_files="./train_pair_1w.json", split="train")# 数据集划分
datasets = dataset.train_test_split(test_size=0.2)# 和多项选择相似的处理方式
model_path = '/root/autodl-fs/models/chinese-macbert-base'
tokenizer = AutoTokenizer.from_pretrained(model_path)def process_function(examples):sentences = []labels = []for sen1, sen2, label in zip(examples["sentence1"], examples["sentence2"], examples["label"]):sentences.append(sen1)sentences.append(sen2)# 这里label处理为1和-1labels.append(1 if int(label) == 1 else -1)# input_ids, attention_mask, token_type_idstokenized_examples = tokenizer(sentences, max_length=128, truncation=True, padding="max_length")tokenized_examples = {k: [v[i: i + 2] for i in range(0, len(v), 2)] for k, v in tokenized_examples.items()}tokenized_examples["labels"] = labelsreturn tokenized_examplestokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
tokenized_datasets
DatasetDict({train: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 8000})test: Dataset({features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],num_rows: 2000})
})
1.3.2 自定义训练模型
from transformers import BertForSequenceClassification, BertPreTrainedModel, BertModel
from typing import Optional
from transformers.configuration_utils import PretrainedConfig
from torch.nn import CosineSimilarity, CosineEmbeddingLossclass DualModel(BertPreTrainedModel):def __init__(self, config: PretrainedConfig, *inputs, **kwargs):super().__init__(config, *inputs, **kwargs)self.bert = BertModel(config)self.post_init()def forward(self,input_ids: Optional[torch.Tensor] = None,attention_mask: Optional[torch.Tensor] = None,token_type_ids: Optional[torch.Tensor] = None,position_ids: Optional[torch.Tensor] = None,head_mask: Optional[torch.Tensor] = None,inputs_embeds: Optional[torch.Tensor] = None,labels: Optional[torch.Tensor] = None,output_attentions: Optional[bool] = None,output_hidden_states: Optional[bool] = None,return_dict: Optional[bool] = None,):return_dict = return_dict if return_dict is not None else self.config.use_return_dict# Step1 分别获取sentenceA 和 sentenceB的输入senA_input_ids, senB_input_ids = input_ids[:, 0], input_ids[:, 1]senA_attention_mask, senB_attention_mask = attention_mask[:, 0], attention_mask[:, 1]senA_token_type_ids, senB_token_type_ids = token_type_ids[:, 0], token_type_ids[:, 1]# Step2 分别获取sentenceA 和 sentenceB的向量表示senA_outputs = self.bert(senA_input_ids,attention_mask=senA_attention_mask,token_type_ids=senA_token_type_ids,position_ids=position_ids,head_mask=head_mask,inputs_embeds=inputs_embeds,output_attentions=output_attentions,output_hidden_states=output_hidden_states,return_dict=return_dict,)senA_pooled_output = senA_outputs[1] # [batch, hidden]senB_outputs = self.bert(senB_input_ids,attention_mask=senB_attention_mask,token_type_ids=senB_token_type_ids,position_ids=position_ids,head_mask=head_mask,inputs_embeds=inputs_embeds,output_attentions=output_attentions,output_hidden_states=output_hidden_states,return_dict=return_dict,)senB_pooled_output = senB_outputs[1] # [batch, hidden]# step3 计算相似度cos = CosineSimilarity()(senA_pooled_output, senB_pooled_output) # [batch, ]# step4 计算lossloss = Noneif labels is not None:loss_fct = CosineEmbeddingLoss(0.3)loss = loss_fct(senA_pooled_output, senB_pooled_output, labels)output = (cos,)return ((loss,) + output) if loss is not None else outputmodel = DualModel.from_pretrained(model_path)
1.3.3 创建评估函数
import evaluate# 这里采用离线加载
accuracy_path = '/root/autodl-tmp/transformers-code/metrics/accuracy'
f1_path = '/root/autodl-tmp/transformers-code/metrics/f1'acc_metric = evaluate.load(accuracy_path)
f1_metirc = evaluate.load(f1_path)def eval_metric(eval_predict):predictions, labels = eval_predictpredictions = [int(p > 0.7) for p in predictions]labels = [int(l > 0) for l in labels]acc = acc_metric.compute(predictions=predictions, references=labels)f1 = f1_metirc.compute(predictions=predictions, references=labels)acc.update(f1)return acc
1.3.4 创建TrainingArguments及Trainer
train_args = TrainingArguments(output_dir="./dual_model", # 输出文件夹per_device_train_batch_size=32, # 训练时的batch_sizeper_device_eval_batch_size=32, # 验证时的batch_sizelogging_steps=10, # log 打印的频率evaluation_strategy="epoch", # 评估策略save_strategy="epoch", # 保存策略save_total_limit=3, # 最大保存数learning_rate=2e-5, # 学习率weight_decay=0.01, # weight_decaymetric_for_best_model="f1", # 设定评估指标load_best_model_at_end=True) # 训练完成后加载最优模型
trainer = Trainer(model=model, args=train_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["test"], compute_metrics=eval_metric)
trainer.train()

1.3.5 自定义pipeline实现模型评估
class SentenceSimilarityPipeline:def __init__(self, model, tokenizer) -> None:self.model = model.bertself.tokenizer = tokenizerself.device = model.devicedef preprocess(self, senA, senB):return self.tokenizer([senA, senB], max_length=128, truncation=True, return_tensors="pt", padding=True)def predict(self, inputs):inputs = {k: v.to(self.device) for k, v in inputs.items()}return self.model(**inputs)[1] # [2, 768]def postprocess(self, logits):cos = CosineSimilarity()(logits[None, 0, :], logits[None,1, :]).squeeze().cpu().item()return cosdef __call__(self, senA, senB, return_vector=False):inputs = self.preprocess(senA, senB)logits = self.predict(inputs)result = self.postprocess(logits)if return_vector:return result, logitselse:return result
pipe = SentenceSimilarityPipeline(model, tokenizer)pipe("我喜欢北京", "明天不行", return_vector=True)
(0.4414671063423157,tensor([[ 0.8044, -0.7820, 0.9974, ..., -0.6317, -0.9653, -0.4989],[ 0.3756, 0.0484, 0.9767, ..., -0.9928, -0.9980, -0.5648]],device='cuda:0', grad_fn=<TanhBackward0>))
注:文本向量化更加便捷有效的工具
- sentence-transformers
https://www.sbert.net/
- text2vec
https://github.com/shibing624/text2vec
- uniem
https://github.com/wangyuxinwhy/uniem
2、检索式对话机器人
2.1 检索式对话机器人简介
-
对话机器人在本质上是一个用来模拟人类对话或聊天的计算机程序,接收人类的自然语言作为输入并给出合适的回复
-
按照任务类型划分,对话机器人简单的可以划分为闲聊机器人、问答机器人、任务型对话机器人
-
按照答案产生的逻辑划分,对话机器人可以划分为检索式对话机器人和生成式对话机器人
如何实现基于检索的问答机器人?
QQ匹配策略
可以利用QQ匹配策略,即取最优结果的Q对应的Answer作为最终结果。

-
但是使用向量匹配的模型效果并不好,很难直接取到最优结果
-
因此引入基于交互策略模型。向量匹配模块又称为召回模块,交互策略的模块又称为排序模块

2.2 向量匹配和交互策略结合实现检索对话机器人
法律知道数据集
https://github.com/SophonPlus/ChineseNlpCorpus预训练模型
1.2章节训练的交互模型
1.3章节训练的匹配模型
2.2.1 加载自己训练的向量匹配模型
import pandas as pddata = pd.read_csv("./law_faq.csv")
data.head()

# dual_model.py文件中是自定义的DualModel
from dual_model import DualModel
from transformers import AutoTokenizer# 加载自己训练好的模型
dual_model = DualModel.from_pretrained("../12-sentence_similarity/dual_model/checkpoint-500/")
dual_model = dual_model.cuda()
dual_model.eval()
print("匹配模型加载成功!")# 加载tokenzier
model_path = '/root/autodl-fs/models/chinese-macbert-base'
tokenzier = AutoTokenizer.from_pretrained(model_path)
2.2.2 将知识库中的问题编码为向量
import torch
from tqdm import tqdmquestions = data["title"].to_list()
vectors = []
with torch.inference_mode():for i in tqdm(range(0, len(questions), 32)):batch_sens = questions[i: i + 32]inputs = tokenzier(batch_sens, return_tensors="pt", padding=True, max_length=128, truncation=True)inputs = {k: v.to(dual_model.device) for k, v in inputs.items()}# 这里拿出[CLS]的向量表示vector = dual_model.bert(**inputs)[1]vectors.append(vector)
vectors = torch.concat(vectors, dim=0).cpu().numpy()
vectors.shape
(18213, 768)
2.2.3 将知识库中的问题向量存入向量库中
# pip install faiss-cpu
import faissindex = faiss.IndexFlatIP(768)
faiss.normalize_L2(vectors)
index.add(vectors)
index
2.2.4 将用户问题编码为向量
quesiton = "寻衅滋事"
with torch.inference_mode():inputs = tokenzier(quesiton, return_tensors="pt", padding=True, max_length=128, truncation=True)inputs = {k: v.to(dual_model.device) for k, v in inputs.items()}vector = dual_model.bert(**inputs)[1]q_vector = vector.cpu().numpy()
q_vector.shape
(1, 768)
2.2.5 向量匹配
faiss.normalize_L2(q_vector)
# 使用faiss进行搜索
scores, indexes = index.search(q_vector, 10)# 将匹配到的相似问题及答案召回
topk_result = data.values[indexes[0].tolist()]# 匹配到的相似问题
topk_result[:, 0]
array(['涉嫌寻衅滋事', '两个轻微伤够寻衅滋事', '敲诈勒索罪', '聚群斗殴', '飞达暴力催收', '打架斗殴','涉嫌犯罪?????', '殴打他人治安处罚', '遵守法律的措施', '十级伤残工伤'], dtype=object)
2.2.6 加载自己训练的交互模型
from transformers import BertForSequenceClassificationcorss_model = BertForSequenceClassification.from_pretrained("../12-sentence_similarity/cross_model/checkpoint-500/")
corss_model = corss_model.cuda()
corss_model.eval()
print("模型加载成功!")
2.2.7 最终的预测结果
# 候选问题集合
canidate = topk_result[:, 0].tolist()
ques = [quesiton] * len(canidate)
inputs = tokenzier(ques, canidate, return_tensors="pt", padding=True, max_length=128, truncation=True)
inputs = {k: v.to(corss_model.device) for k, v in inputs.items()}
with torch.inference_mode():logits = corss_model(**inputs).logits.squeeze()result = torch.argmax(logits, dim=-1)
result
tensor(0, device='cuda:0')
# 候选答案集合
canidate_answer = topk_result[:, 1].tolist()match_quesiton = canidate[result.item()]
final_answer = canidate_answer[result.item()]
match_quesiton, final_answer
('涉嫌寻衅滋事','说明具有寻衅滋事行为,应受到相应的处罚,行为人情形严重或行为恶劣的涉嫌了寻衅滋事罪。寻衅滋事是指行为人结伙斗殴的、追逐、拦截他人的、强拿硬要或者任意损毁、占用公私财物的、其他寻衅滋事的行为。寻衅滋事罪,是指在公共场所无事生非、起哄闹事,造成公共场所秩序严重混乱的,追逐、拦截、辱骂、恐吓他人,强拿硬要或者任意损毁、占用公私财物,破坏社会秩序,情节严重的行为。对于寻衅滋事行为的处罚:1、《中华人*共和国治安管理处罚法》第二十六条规定,有下列行为之一的,处五日以上十日以下拘留,可以并处五百元以下罚款;情节较重的,处十日以上十五日以下拘留,可以并处一千元以下罚款:(一)结伙斗殴的;(二)追逐、拦截他人的;(三)强拿硬要或者任意损毁、占用公私财物的;(四)其他寻衅滋事行为;...)
相关文章:
Transformers实战(二)快速入门文本相似度、检索式对话机器人
Transformers实战(二)快速入门文本相似度、检索式对话机器人 1、文本相似度 1.1 文本相似度简介 文本匹配是一个较为宽泛的概念,基本上只要涉及到两段文本之间关系的,都可以被看作是一种文本匹配的任务, 只是在具体…...
【错误解决方案】ModuleNotFoundError: No module named ‘PeptideBuilder‘
1. 错误提示 在python程序中,试图导入一个不存在的模块PeptideBuilder导致的错误: 错误提示:ModuleNotFoundError: No module named PeptideBuilder 2. 解决方案 解决方案是确保你已经正确安装了PeptideBuilder模块。你可以通过pip来安装它…...

汇编学习(1)
汇编、CPU架构、指令集、硬编码之间的关系 ● 汇编语言:这是一种低级语言,用于与硬件直接交互。它是由人类可读的机器码或指令组成的,这些指令告诉CPU如何执行特定的任务。每条汇编指令都有一个对应的机器码指令,CPU可以理解和执…...

C#,数值计算——分类与推理Svmlinkernel的计算方法与源程序
1 文本格式 using System; namespace Legalsoft.Truffer { public class Svmlinkernel : Svmgenkernel { public int n { get; set; } public double[] mu { get; set; } public Svmlinkernel(double[,] ddata, double[] yy) : base(yy, ddata) …...
【鸿蒙软件开发】ArkTS容器组件之Badge
文章目录 前言一、Badge组件1.1 子组件1.2 接口接口1参数 接口2参数 BadgePosition枚举说明BadgeStyle对象说明 1.3 示例代码 总结 前言 Badge组件:可以附加在单个组件上用于信息标记的容器组件。 一、Badge组件 可以附加在单个组件上用于信息标记的容器组件。 说…...
H5游戏源码分享-命悬一线
H5游戏源码分享-命悬一线 在合适的时机跳下绳子,能安全站到木桩上,就通过。 游戏源码 <!DOCTYPE html> <html> <head><meta http-equiv"Content-Type" content"text/html; charsetutf-8" /><meta name&…...

【电路笔记】-交流电阻和阻抗
交流电阻和阻抗 文章目录 交流电阻和阻抗1、概述:电阻率2、交流状态与直流状态近似性3、交流状态与直流状态的差异性3.1 趋肤效应(The Skin Effect)3.2 靠近效应(The Proximity Effect) 4、总结 电阻是一种特性,用于表征当电压差施…...
android开发使用OkHttp自带的WebSocket实现IM功能
一、背景 android app开发经常会有IM需求,很多新手不晓得如何入手,难点在于通讯不中断。其实android发展到今天,很多技术都很完善,有很多类似框架可以实现。例如有:okhttp自带的websocket框架、easysocket等等。本文主…...

前端小技巧: TS实现柯里化函数
实现 curry 函数,把其他函数柯里化 curry 返回一个函数fn执行fn, 中间状态返回函数,如 add(1), 或者 add(1)(2)最后返回执行结果,如 add(1)(2)(3) function curry(fn:Function) {const fnArgsLen fn.length // 传入函数的参数长度let args…...

【算法-数组2】有序数组的平方 和 长度最小的子数组
今天,带来数组相关算法的讲解。文中不足错漏之处望请斧正! 理论基础点这里 有序数组的平方 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。 示例 1: 输…...

H5游戏源码分享-接苹果游戏拼手速
H5游戏源码分享-接苹果游戏拼手速 看看在20秒内能接多少个苹果 <html> <head><title>我是你的小苹果</title><meta charset"utf-8"/><meta name"viewport" content"initial-scale1, user-scalableno, minimum-scale…...
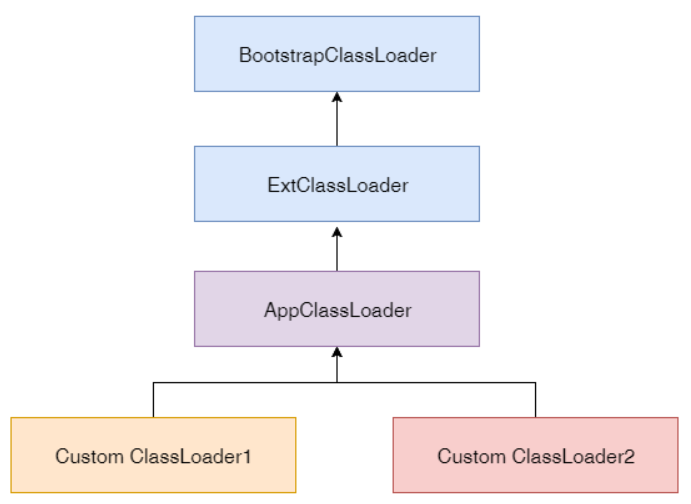
详解类生到死的来龙去脉
类生命周期和加载过程 一个类在 JVM 里的生命周期有 7 个阶段,分别是加载(Loading)、校验(Verification)、准备(Preparation)、解析(Resolution)、初始化(Ini…...
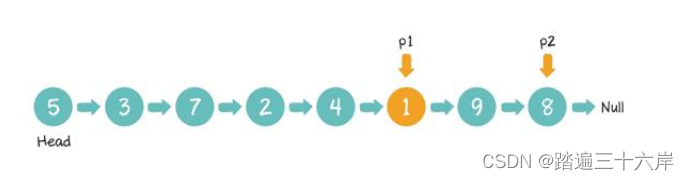
寻找倒数第K个节点
这篇文章也是凑数的 ... 寻找倒数第K个节点 描述 : 找出单向链表中倒数第 k 个节点。返回该节点的值。 题目 : LeetCode 返回倒数第K个节点 : 面试题 02.02. 返回倒数第 k 个节点 说明 : 给定的 k 保证是有效的。 分析 : 我们给出个例子 : 首先,我们创建两个…...
)
[ROS系列]ubuntu 20.04 从零配置orbslam3(无坑版)
目录 背景: 结果展示: 一、配置虚拟机 二、 同步网络时间 三、ping网络 四、 安装ros 五、下载源码 六、下载orb_slam3 error1:Pangolin error2: ./HelloPangolin: error while loading shared libraries: libpango_windowing.so: cannot open shared object file…...

网络协议--TCP的保活定时器
23.1 引言 许多TCP/IP的初学者会很惊奇地发现可以没有任何数据流通过一个空闲的TCP连接。也就是说,如果TCP连接的双方都没有向对方发送数据,则在两个TCP模块之间不交换任何信息。例如,没有可以在其他网络协议中发现的轮询。这意味着我们可以…...
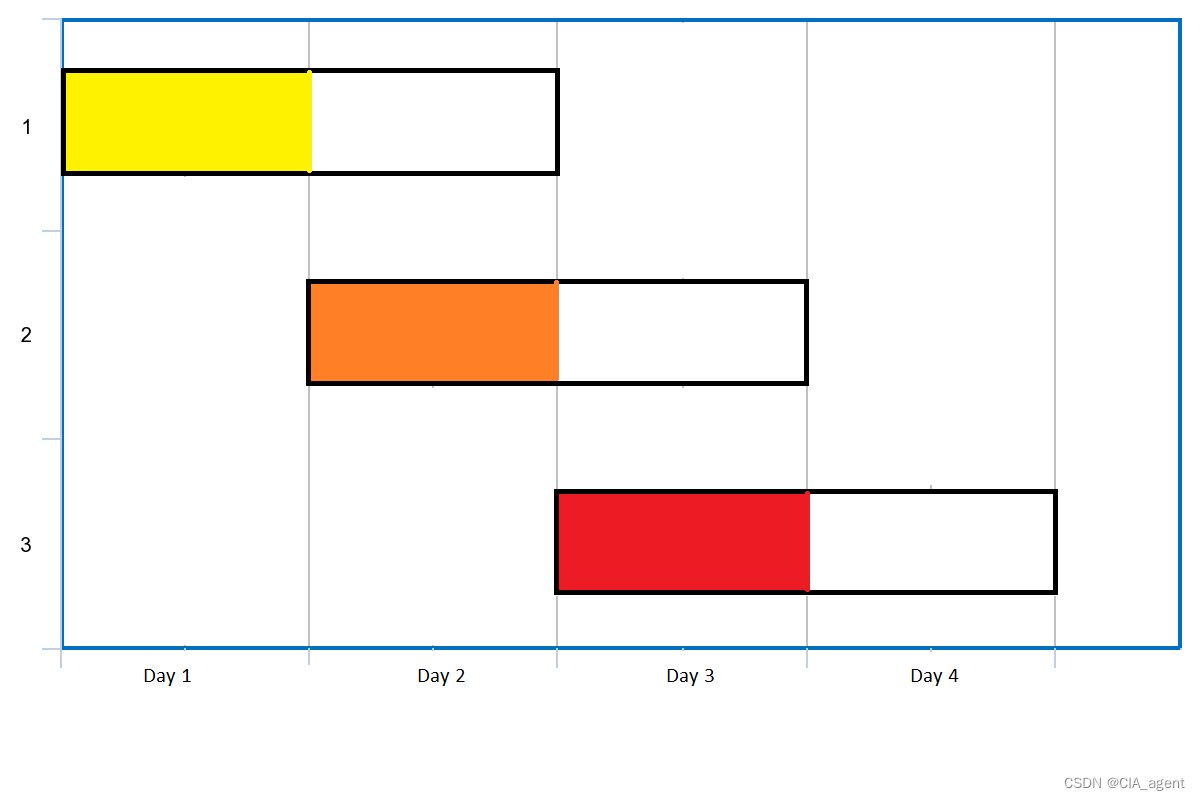
leetcode 1353. 最多可以参加的会议数目
给你一个数组 events,其中 events[i] [startDayi, endDayi] ,表示会议 i 开始于 startDayi ,结束于 endDayi 。 你可以在满足 startDayi < d < endDayi 中的任意一天 d 参加会议 i 。注意,一天只能参加一个会议。 请你返回…...
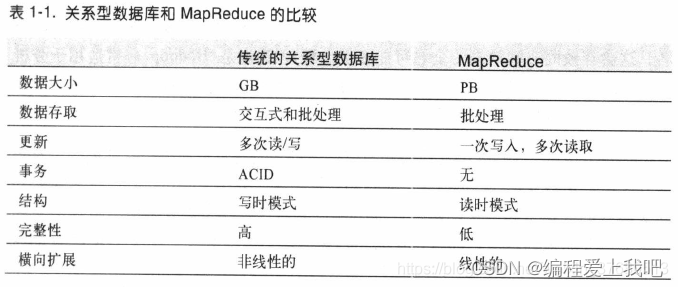
hadoop权威指南第四版
第一部分 HaDOOP基础知识 1.1 面临的问题 存储越来越大,读写跟不上。 并行读多个磁盘。 问题1 磁盘损坏 – 备份数据HDFS 问题2 读取多个磁盘用于分析,数据容易出错 --MR 编程模型 1.2 衍生品 1 在线访问的组件是hbase 。一种使用hdfs底层存储的模型。…...

LeetCode75——Day20
文章目录 一、题目二、题解 一、题目 2215. Find the Difference of Two Arrays Given two 0-indexed integer arrays nums1 and nums2, return a list answer of size 2 where: answer[0] is a list of all distinct integers in nums1 which are not present in nums2. an…...

搭建微信小程序环境及项目结构介绍
一、注册 访问微信公众平台,将鼠标的光标置于账号分类中的小程序上, 点击‘查看详情’ 点击“前往注册” 下方也可以点击注册: 小程序注册页面: 步骤a:进入小程序注册页,根据指引填写信息和提交相应的资料&#x…...
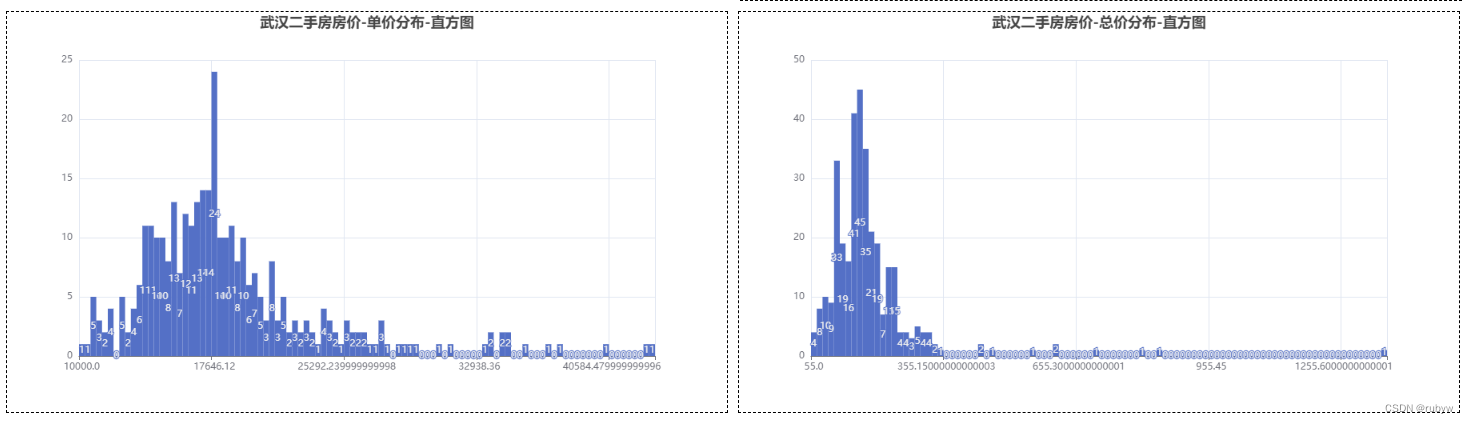
Python通过pyecharts对爬虫房地产数据进行数据可视化分析(一)
一、背景 对Python通过代理使用多线程爬取安居客二手房数据(二)中爬取的房地产数据进行数据分析与可视化展示 我们爬取到的房产数据,主要是武汉二手房的房源信息,主要包括了待售房源的户型、面积、朝向、楼层、建筑年份、小区名称…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

相机Camera日志实例分析之二:相机Camx【专业模式开启直方图拍照】单帧流程日志详解
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了: 这一篇我们开始讲: 目录 一、场景操作步骤 二、日志基础关键字分级如下 三、场景日志如下: 一、场景操作步骤 操作步…...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...

第7篇:中间件全链路监控与 SQL 性能分析实践
7.1 章节导读 在构建数据库中间件的过程中,可观测性 和 性能分析 是保障系统稳定性与可维护性的核心能力。 特别是在复杂分布式场景中,必须做到: 🔍 追踪每一条 SQL 的生命周期(从入口到数据库执行)&#…...

Proxmox Mail Gateway安装指南:从零开始配置高效邮件过滤系统
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...

OD 算法题 B卷【正整数到Excel编号之间的转换】
文章目录 正整数到Excel编号之间的转换 正整数到Excel编号之间的转换 excel的列编号是这样的:a b c … z aa ab ac… az ba bb bc…yz za zb zc …zz aaa aab aac…; 分别代表以下的编号1 2 3 … 26 27 28 29… 52 53 54 55… 676 677 678 679 … 702 703 704 705;…...