redis数据结构的底层实现
文章目录
- 一.引言
- 二.redis的特点
- 三.Redis的数据结构
- a.字符串
- b.hash
- c.list
- d.set
- e.zset(有序集合)
一.引言
redis是一个开源的使用C语言编写、支持网络、可基于内存亦可持久化的日志型、key-value的NoSQL数据库。
通常使用redis作为缓存中间件来降低数据库的压力,除此之外,redis还有很多使用场景,比如分布式锁、计数、队列等等。
二.redis的特点
- 读写速度快。每秒10w次左右。原因
- 数据存储在内存中,访问速度快
- 采用单线程的架构,避免上下文的切换和多线程带来的竞争,不存在加锁和释放锁的操作,减少了CPU的消耗
- 采用了非阻塞IO多路复用机制
- 数据结构丰富。redis不仅仅支持简单的key-value类型的数据,同时还提供list、set、zset、hash等数据结构
- 支持持久化。RDB和AOF两种持久化策略
- 支持高可用。可以使用主从复制,并且提供哨兵机制,保证服务器的高可用
- 客户端语言多。涵盖了所有主流编程语言
三.Redis的数据结构
常见的五种数据类型:string、list、set、zset、hash
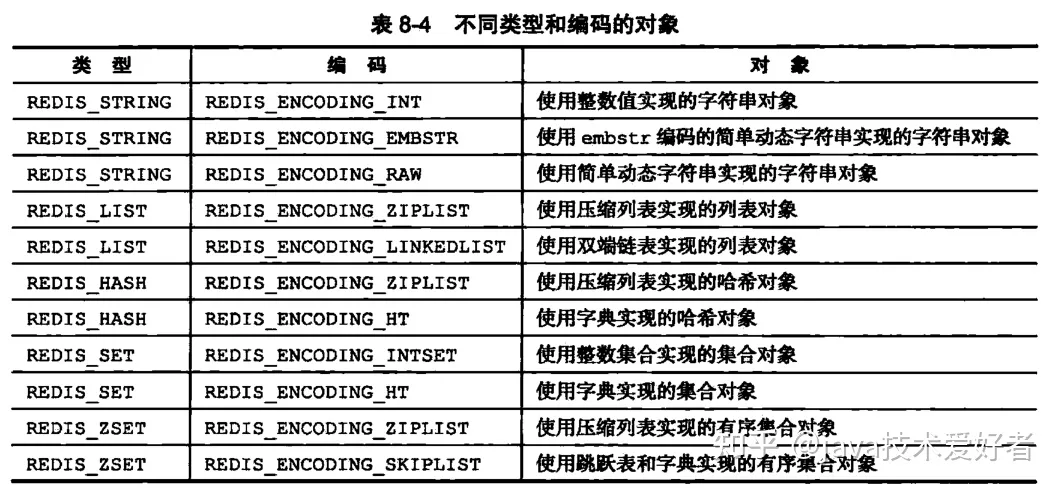
redis的这些数据结构,在底层都是使用redisObject来进行表示的。redisObject有三个重要的属性,分别是type、encoding、ptr。
type代表保存的value的类型。通常有以下五种:
- 字符串REDIS_STRING
- 列表 REDIS_LIST
- 集合 REDIS_SET
- 有序集合 REDIS_ZSET
- 字典 REDIS_HASH
encoding表示保存的value的编码,通常有以下几种:
- 字符串:REDIS_ENCODING_RAW
- 整数:REDIS_ENCODING_INT
- 哈希表:REDIS_ENCODING_HT
- zipmap:REDIS_ENCODING_ZIPMAP
- 双端链表:REDIS_ENCODING_LINKEDLIST
- 压缩列表:REDIS_ENCODING_ZIPLIST
- 整数集合:REDIS_ENCODING_INTSET
- 跳跃表:REDIS_ENCODING_SKIPLIST
ptr是一个指针,指向实际保存的value的数据结构
数据类型和编码方式是有一定关系的,所以数据类型和编码方式是可以确定底层采用什么数据结构的。
a.字符串
字符串对象的encoding有三种,分别是:int、raw、embstr
常用命令有:set、get、decr、incr、mget
底层不是使用c语言的字符串动态类型,而是自己开发了一种数据类型SDS(Simple Dynamic String:动态字符串)进行存储:
struct sdshdr{int len;/*字符串长度*/int free;/*未使用的字节长度*/char buf[];/*保存字符串的字节数组*/
}
SDS与C语言的字符串有什么区别?
- C语言获取字符串长度是从头到尾遍历,时间复杂度是O(n),而SDS有len属性记录字符串长度,时间复杂度尾O(1)
- 避免缓冲区溢出。SDS在需要修改时,会先检查空间是否满足大小,如果不满足,则先拓展至所需大小再进行修改操作。
- 空间预分配。当SDS需要进行扩展时,redis会为SDS分配好内存,并且根据特定的算法分配多余的free空间,避免连续执行字符串带来的内存分配的消耗
- 惰性释放。如果需要缩短字符串,不会立即回收多余的内存空间,而是用free近路剩余的空间,以便下次扩展时使用,避免了再次分配内存的操作
- 二进制安全。c语言存储字符串是采用N+1的字符串数据,末尾使用‘\0’标识字符串的结束,如过我们存储的字符串中出现‘\0’,那么就会出现识别出错,而SDS因为记录了字符串的长度len,则没有这个问题。
redis规定了字符串的长度不得超过512M
b.hash
哈希对象的编码方式有两种:ziplist和hashtable
当哈希对象保存的键值对数量小于512,并且所有键值对的长度都小于64自己饿时,使用ziplist存储;否则使用hashtable存储。
redis中的hashtable跟java中的hashMap类似,都是通过数组+链表的实现方式解决部分的哈希冲突。
typedf struct dict{dictType *type;//类型特定函数,包括一些自定义函数,这些函数使得key和value能够存储void *private;//私有数据dictht ht[2];//两张hash表 int rehashidx;//rehash索引,字典没有进行rehash时,此值为-1unsigned long iterators; //正在迭代的迭代器数量
}dict;typedef struct dictht{//哈希表数组dictEntry **table;//哈希表大小unsigned long size;//哈希表大小掩码,用于计算索引值//总是等于 size-1unsigned long sizemask;//该哈希表已有节点的数量unsigned long used;
}dictht;typedf struct dictEntry{void *key;//键union{void val;unit64_t u64;int64_t s64;double d;}v;//值struct dictEntry *next;//指向下一个节点的指针
}dictEntry;
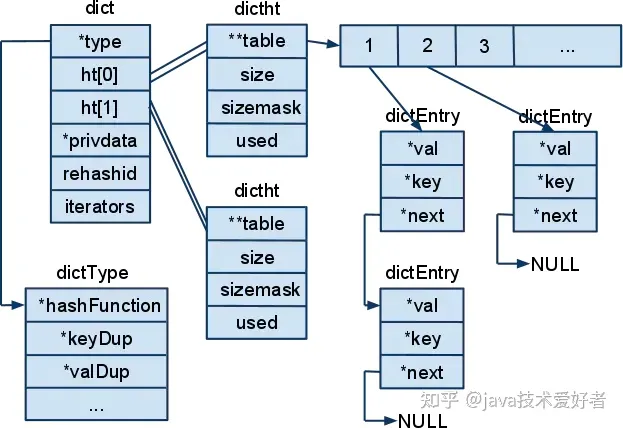
扩容和收缩的过程:
- 如果执行扩展操作,会基于哈希表创建一个大小等于ht[0].used*2n的哈希表(每次都是根据原哈希表已使用的空间扩大一倍创建另一个哈希表)。相反如果执行的是收缩操作,每次收缩是根据已使用精简缩小一倍创建一个新的哈希表。
- 重新利用hash算法,计算索引值,然后将键值对放到新的哈希表位置上。
- 所有键值对都迁徙完毕后,释放原哈希表的内存空间。
在redis执行扩容和收缩的规则是:
- 服务器目前没有执行bgsave或bgrewrite命令,并且负载因子大于等于1
- 服务器目前没有执行bgsave或bgrewrite命令,并且负载因子大于等于5
负载因子=哈希表已保存节点数量/哈希表大小
渐进式rehash
扩容和收缩不是一次性集中式完成,而是通过多次逐渐地完成的。为什么要采用这种方式呢?在键值对数量达到几十万,几百万的键值对要一次性进行rehash,势必会导致redis性能严重下降,自然而然地redis开发者就想到采用渐进式rehash,过程如下:
- 使用rehashindex字段保存迁移的进度,从0开始
- 在迁移过程中ht[0]和ht[1]同时保存数据,ht[0]指向旧哈希表,ht[1]指向新hash表,每次对字典进行添加、删除、查找或更新操作是,程序除了执行指定的操作外,还会顺带将ht[0]的元素迁移到ht[1]中
- 迁移完成后,rehashindex设置为-1
- rehash完成后,ht[0]指向的旧表会被释放,之后会将新表的持有权交给ht[0],再重置ht[1]指向NULL
渐进式rehash的优缺点
优点:
- rehash操作分散到每一个字典操作和定时函数上,避免了一次性集中式rehash带来的服务器压力
缺点:
- rehash期间需要使用两个hash表,内存占用稍大
常用命令
hget、hset、hgetall
c.list
列表对象的编码有两种,分别是:ziplist、linkedlist。当列表的长度小于512,并且所有元素的长度都小于64字节时,使用ziplist存储;否则使用linkedlist存储
redis中的linkedlist类似于java的linkedlist,是一个双向链表,插入和删除操作效率比较快,时间复杂度是O(1)
typedef struct listNode {struct listNode *prev;struct listNode *next;void *value;
} listNode;typedef struct listIter {listNode *next;int direction;
} listIter;typedef struct list {listNode *head;listNode *tail;void *(*dup)(void *ptr);void (*free)(void *ptr);int (*match)(void *ptr, void *key);unsigned long len;
} list;
常用命令:
lpush、rpush、lpop、rpop、lrange
d.set
特点:无序、不重复,跟java的hashset类似。它的编码有两种,分别是intset和hashtable。如果value可以转换成整数值,并且长度不超过512的话就使用intset存储,否则采用hashtable
typedef struct intset{uint32_t encoding;//编码方式uint32_t length;//集合包含的元素数量int8_t contents[];//保存元素的数组
}intset;
encoding的值有三种,分别是INTSET_ENC_INT16、INTSET_ENC_INT32、INTSET_ENC_INT64,代表着整数的取值范围。redis会根据添加进来的元素的大小,选择不同的类型进行存储。尽可能地节省内存空间。
INTSET_ENC_INT16–>INTSET_ENC_INT32–>INTSET_ENC_INT64的升级过程:
- 根据新元素的类型扩展数组contents的空间
- 从尾部将数据插入
- 根据新编码格式重置之前的值,因为这是的contents存在着两种编码的值。从插入的数据的位置,也就是尾部,从后到前将之前的数据按照新的编码格式进行移动和设置。从后往前是为了防止数据被覆盖
优点:节省内存;缺点:升级会消耗系统资源。而且升级是不可逆的,一旦升级,编码就会一直保存升级后的状态
set常见的命令有:
sadd、spop、smembers、sunion
redis为set类型提供了求交集、并集、差集的操作,可以非常方便地实现比如共同关注、共同爱好、共同好友等功能
e.zset(有序集合)
zset和set一样是不可重复的,区别在于多了score值,用来代表排序的权重。也就是当你需要一个有序的,不可重复的集合列表时,就可以考虑使用这种数据类型。
zset的编码方式有两种,分别是:ziplist、skiplist。当zset的长度小于128,并且所有元素的长度都小于64字节时,使用ziplist存储,否则使用skiplist存储。

跳远表的数据结构设计如上,设计的好处是什么呢?
查询的时候可以减少时间复杂度,如果是链表,我们要插入并且保持有序的话,那就要从头节点开始遍历,遍历到合适的位置,然后插入,如果这样性能肯定是不理想的。
而使用跳表可以像二分查找一样定位到插入的点,查找过程:
- L4,查询87,查询一次
- L3,查询到在24、87之间,需要查询2次
- L2,查询到48,查询1次
- L1,查询到37、48,查询两次,确定插入点在37、48之间
相关文章:
redis数据结构的底层实现
文章目录一.引言二.redis的特点三.Redis的数据结构a.字符串b.hashc.listd.sete.zset(有序集合)一.引言 redis是一个开源的使用C语言编写、支持网络、可基于内存亦可持久化的日志型、key-value的NoSQL数据库。 通常使用redis作为缓存中间件来降低数据库的压力,除此…...
【JavaSE】复习(进阶)
文章目录1.final关键字2.常量3.抽象类3.1概括3.2 抽象方法4. 接口4.1 接口在开发中的作用4.2类型和类型之间的关系4.3抽象类和接口的区别5.包机制和import5.1 包机制5.2 import6.访问控制权限7.Object7.1 toString()7.2 equals()7.3 String类重写了toString和equals8.内部类8.1…...

Java 主流日志工具库
日志系统 java.util.logging (JUL) JDK1.4 开始,通过 java.util.logging 提供日志功能。虽然是官方自带的log lib,JUL的使用确不广泛。 JUL从JDK1.4 才开始加入(2002年),当时各种第三方log lib已经被广泛使用了JUL早期存在性能问题&#x…...

产品经理有必要考个 PMP吗?(含PMP资料)
现在基本上做产品的都有一个PMP证件,从结果导向来说,不对口不会有这么大范围的人来考,但是需要因地制宜,在公司内部里,标准程序并不流畅,产品和项目并不规范,关系错综复杂。 而产品经理的职能又…...
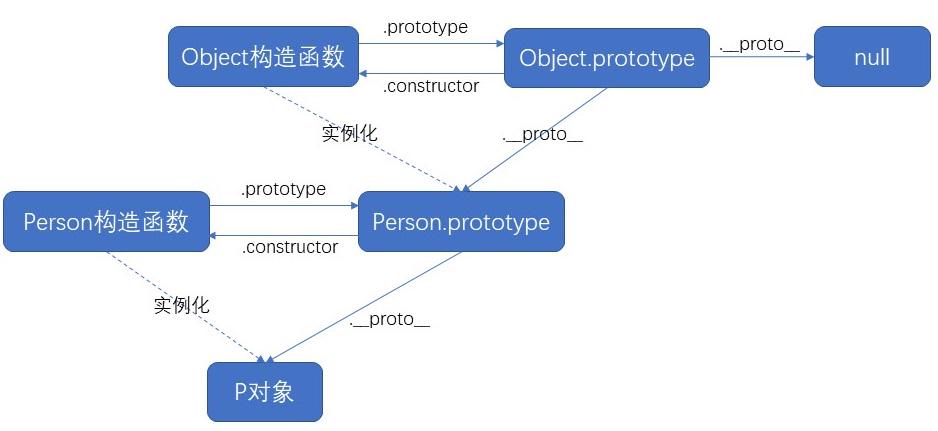
什么是原型、原型链?原型和原型链的作用
1、ES6之前,继承都用构造函数来实现;对象的继承,先申明一个对象,里面添加实例成员<!DOCTYPE html> <html><head><meta charset"utf-8" /><title></title></head><body><script…...

条件期望4
条件期望例题----快排算法的分析 快速排序算法的递归定义如下: 有n个数(n≥2n\geq 2n≥2), 一开始随机选取一个数xix_ixi, 并将xix_ixi和其他n-1个数进行比较, 记SiS_iSi为比xix_ixi小的元素构成的集合, Siˉ\bar{S_i}Siˉ为比xix_ixi大的元素构成的集合, 然后分…...

网络协议分析(2)判断两个ip数据包是不是同一个数据包分片
一个节点收到两个IP包的首部如下:(1)45 00 05 dc 18 56 20 00 40 01 bb 12 c0 a8 00 01 c0 a8 00 67(2)45 00 00 15 18 56 00 b9 49 01 e0 20 c0 a8 00 01 c0 a8 00 67分析并判断这两个IP包是不是同一个数据报的分片&a…...

6.2 负反馈放大电路的四种基本组态
通常,引入交流负反馈的放大电路称为负反馈放大电路。 一、负反馈放大电路分析要点 如图6.2.1(a)所示电路中引入了交流负反馈,输出电压 uOu_OuO 的全部作为反馈电压作用于集成运放的反向输入端。在输入电压 uIu_IuI 不变的情况下,若由于…...

MySQL进阶之锁
锁是计算机中协调多个进程或线程并发访问资源的一种机制。在数据库中,除了传统的计算资源竞争之外,数据也是一种提供给许多用户共享的资源,如何保证数据并发访问的一致性和有效性是数据库必须解决堆的一个问题,锁冲突也是影响数据…...

【Mac 教程系列】如何在 Mac 上破解带有密码的 ZIP 压缩文件 ?
如何使用 fcrackzip 在 Mac 上破解带有密码的 ZIP 压缩文件? 用 markdown 格式输出答案。 在 Mac 上破解带有密码的 ZIP 压缩文件 使用解压缩软件,如The Unarchiver,将文件解压缩到指定的文件夹。 打开终端,输入 zip -er <zipfile> &…...
【Acwing 周赛复盘】第92场周赛复盘(2023.2.25)
【Acwing 周赛复盘】第92场周赛复盘(2023.2.25) 周赛复盘 ✍️ 本周个人排名:1293/2408 AC情况:1/3 这是博主参加的第七次周赛,又一次体会到了世界的参差(这次周赛记错时间了,以为 19:15 开始&…...

L1-087 机工士姆斯塔迪奥
在 MMORPG《最终幻想14》的副本“乐欲之所瓯博讷修道院”里,BOSS 机工士姆斯塔迪奥将会接受玩家的挑战。 你需要处理这个副本其中的一个机制:NM 大小的地图被拆分为了 NM 个 11 的格子,BOSS 会选择若干行或/及若干列释放技能,玩家…...

本周大新闻|索尼PS VR2立项近7年;传腾讯将引进Quest 2
本周大新闻,AR方面,传立讯精密开发苹果初代AR头显,第二代低成本版将交给富士康;iOS 16.4代码曝光新的“计算设备”;EM3推出AR眼镜Stellar Pro;努比亚将在MWC2023推首款AR眼镜。VR方面,传闻腾讯引…...
aws console 使用fargate部署aws服务快速跳转前端搜索栏
测试过程中需要在大量资源之间跳转,频繁的点击不如直接搜索来的快,于是写了一个搜索框方便跳转。 前端的静态页面可以通过s3静态网站托管实现,但是由于中国区需要备案的原因,可以使用ecs fargate部署 步骤如下: 编写…...

Redis实战之Redisson使用技巧详解
一、摘要什么是 Redisson?来自于官网上的描述内容如下!Redisson 是一个在 Redis 的基础上实现的 Java 驻内存数据网格客户端(In-Memory Data Grid)。它不仅提供了一系列的 redis 常用数据结构命令服务,还提供了许多分布…...

SQLAlchemy
文章目录SQLAlchemy介绍SQLAlchemy入门使用原生sql使用orm外键关系一对多关系多对多关系基于scoped_session实现线程安全简单表操作实现方案CRUDFlask 集成 sqlalchemySQLAlchemy 介绍 SQLAlchemy是一个基于Python实现的ORM框架。该框架建立在 DB API之上,使用关系…...
【Linux学习笔记】8.Linux yum 命令和apt 命令
前言 本章介绍Linux的yum命令和apt命令。 Linux yum 命令 yum( Yellow dog Updater, Modified)是一个在 Fedora 和 RedHat 以及 SUSE 中的 Shell 前端软件包管理器。 基于 RPM 包管理,能够从指定的服务器自动下载 RPM 包并且安装…...
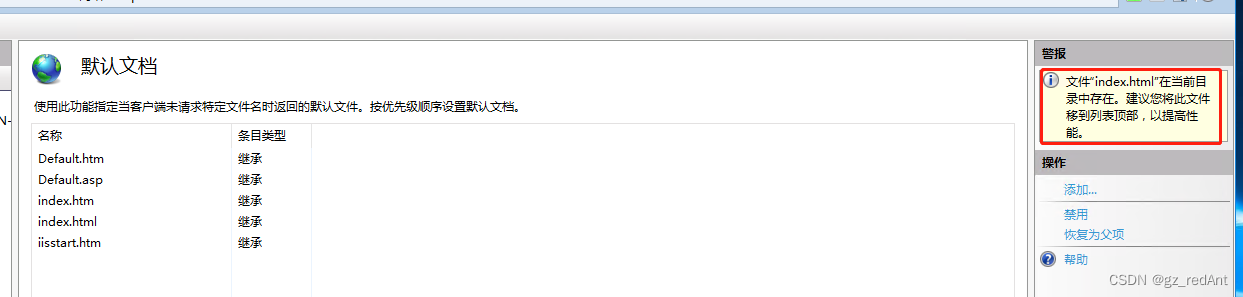
windows服务器实用(4)——使用IIS部署网站
windows服务器实用——IIS部署网站 如果把windows服务器作为web服务器使用,那么在这个服务器上部署网站是必须要做的事。在windows服务器上,我们一般使用IIS部署。 假设此时前端给你一个已经完成的网站让你部署在服务器上,别人可以在浏览器…...
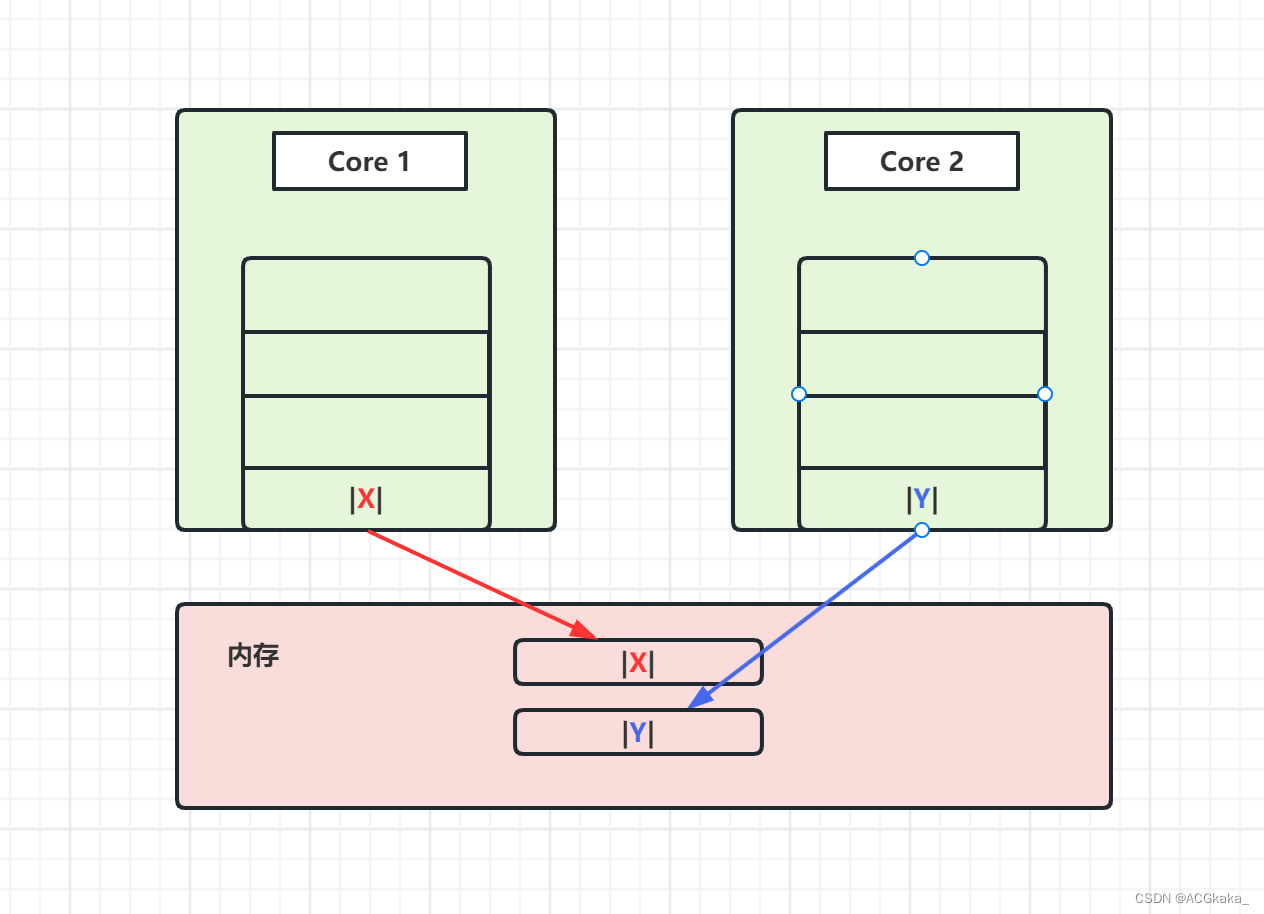
Random(二)什么是伪共享?@sun.misc.Contended注解
目录1.背景简介2.伪共享问题3.问题解决4.JDK使用示例1.背景简介 我们知道,CPU 是不能直接访问内存的,数据都是从高速缓存中加载到寄存器的,高速缓存又有 L1,L2,L3 等层级。在这里,我们先简化这些复杂的层级…...

Linux解压压缩
打包tar首先我们得提一下专门用于打包文件的命令——tartar用于备份文件,打包多个文件或者目录,也可以用于还原被打包的文件假设打包目录test下的文件 tar -cvf test.tar ./test 假设打包目录test下的文件,并用gzip命令将包压缩 tar -zcvf test.tar ./te…...

《Qt C++ 与 OpenCV:解锁视频播放程序设计的奥秘》
引言:探索视频播放程序设计之旅 在当今数字化时代,多媒体应用已渗透到我们生活的方方面面,从日常的视频娱乐到专业的视频监控、视频会议系统,视频播放程序作为多媒体应用的核心组成部分,扮演着至关重要的角色。无论是在个人电脑、移动设备还是智能电视等平台上,用户都期望…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...

推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材)
推荐 github 项目:GeminiImageApp(图片生成方向,可以做一定的素材) 这个项目能干嘛? 使用 gemini 2.0 的 api 和 google 其他的 api 来做衍生处理 简化和优化了文生图和图生图的行为(我的最主要) 并且有一些目标检测和切割(我用不到) 视频和 imagefx 因为没 a…...

MySQL 索引底层结构揭秘:B-Tree 与 B+Tree 的区别与应用
文章目录 一、背景知识:什么是 B-Tree 和 BTree? B-Tree(平衡多路查找树) BTree(B-Tree 的变种) 二、结构对比:一张图看懂 三、为什么 MySQL InnoDB 选择 BTree? 1. 范围查询更快 2…...
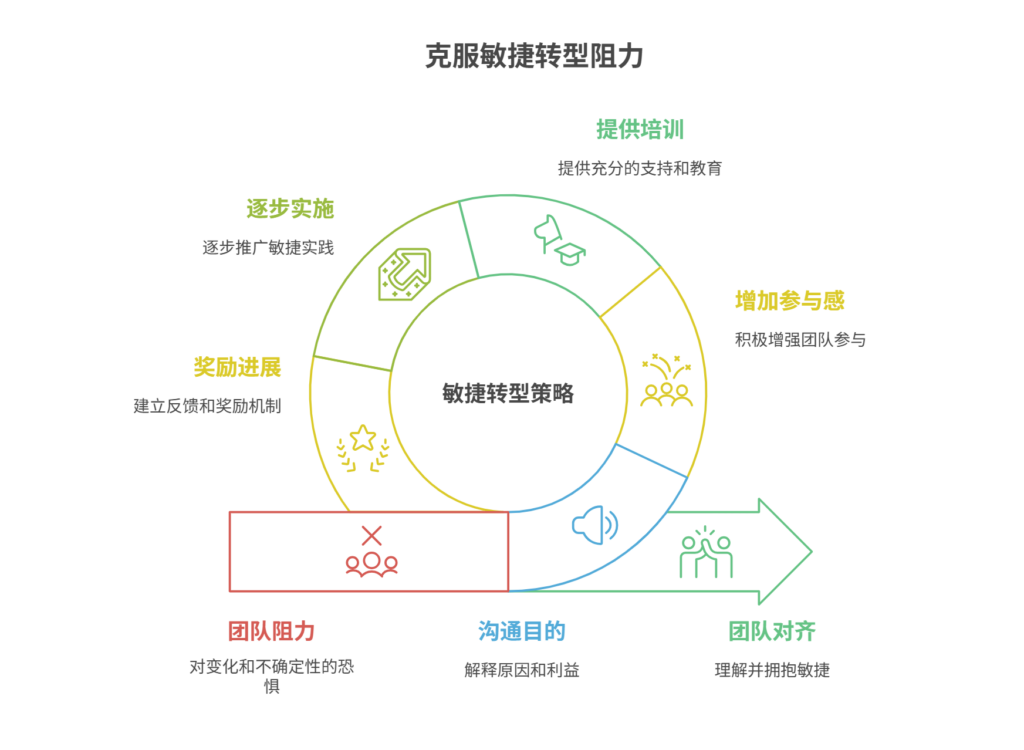
如何应对敏捷转型中的团队阻力
应对敏捷转型中的团队阻力需要明确沟通敏捷转型目的、提升团队参与感、提供充分的培训与支持、逐步推进敏捷实践、建立清晰的奖励和反馈机制。其中,明确沟通敏捷转型目的尤为关键,团队成员只有清晰理解转型背后的原因和利益,才能降低对变化的…...