机器学习——代价敏感错误率与代价曲线
文章目录
- 代价敏感错误率
- 实现
- 代价曲线
- 例子
代价敏感错误率
指在分类问题中,不同类别的错误分类所造成的代价不同。在某些应用场景下,不同类别的错误分类可能会产生不同的代价。例如,在医学诊断中,将疾病患者错误地分类为健康人可能会带来严重的后果,而将健康人错误地分类为疾病患者的后果可能相对较轻。
传统的分类算法通常假设所有的错误分类代价是相同的,但在实际应用中,这种情况并不常见。代价敏感错误率的目标是通过考虑不同类别的错误分类代价,使得模型在测试阶段能够最小化总体代价。
在代价敏感错误率中,通常会引入代价矩阵(cost matrix)来描述不同类别之间的代价关系。代价矩阵是一个二维矩阵,其中的元素c(i, j)表示将真实类别为i的样本误分类为类别j的代价。通过使用代价矩阵,可以在模型训练和评估过程中更好地考虑不同类别的错误分类代价。
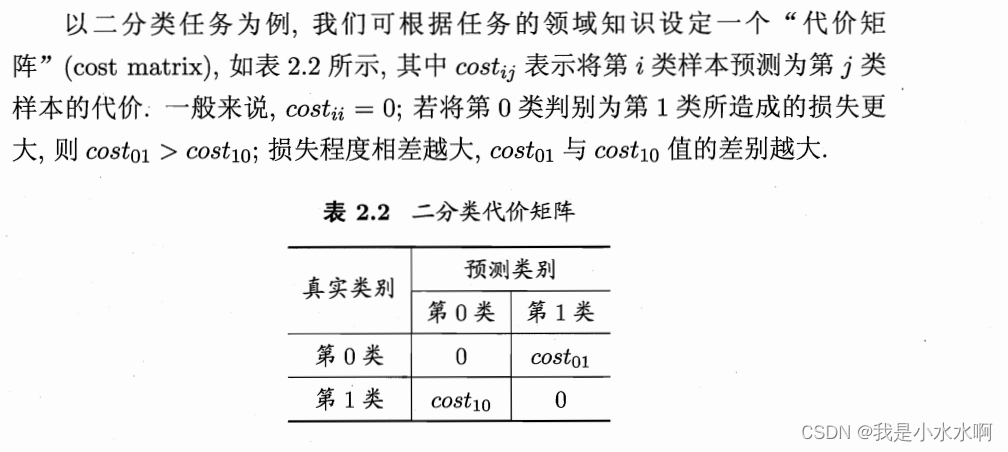
在实际应用中,代价敏感错误率通常用于处理那些不同类别错误分类代价差异较大的问题,例如欺诈检测、医学诊断等领域。在训练分类模型时,引入代价矩阵可以帮助模型更好地适应不同类别的代价,从而提高模型在实际应用中的性能。

实现
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from skmultilearn.problem_transform import ClassifierChain
from sklearn.base import BaseEstimator, ClassifierMixin
from sklearn.ensemble import RandomForestClassifier
import numpy as npclass CostSensitiveClassifier(BaseEstimator, ClassifierMixin):def __init__(self, base_estimator=None, cost_matrix=None):self.base_estimator = base_estimatorself.cost_matrix = cost_matrixdef fit(self, X, y):self.base_estimator.fit(X, y)return selfdef predict(self, X):return self.base_estimator.predict(X)def predict_proba(self, X):return self.base_estimator.predict_proba(X)# 以加载iris数据集为例
iris = load_iris()
X = iris.data
y = iris.target# 将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 定义成本矩阵
# 首先有三种分类所有这个矩阵就是3x3,可以看上面表2.2.的代价矩阵就可以理解了
cost_matrix = np.array([[0, 100, 0],[0, 0, 1000],[0, 0, 0]])# 使用RandomForestClassifier创建成本敏感分类器作为基本估计器
cost_sensitive_classifier = CostSensitiveClassifier(base_estimator=RandomForestClassifier(random_state=42), cost_matrix=cost_matrix)# Fit the model
cost_sensitive_classifier.fit(X_train, y_train)# Make predictions
predictions = cost_sensitive_classifier.predict(X_test)# Evaluate the model using confusion matrix
conf_matrix = confusion_matrix(y_test, predictions)
print("Confusion Matrix:")
print(conf_matrix)代价曲线
代价曲线(Cost Curve)是一个用于评估代价敏感学习算法性能的工具。在许多实际问题中,不同类别的错误分类可能导致不同的代价。例如,在医疗诊断中,将一个健康患者误诊为患病可能会导致不同于将一个患病患者误诊为健康的代价。代价曲线帮助我们在考虑不同错误分类代价的情况下,选择一个适当的分类阈值。
代价曲线的意义和应用包括以下几点:
-
选择最优分类阈值: 代价曲线可以帮助你选择一个最适合的分类阈值,使得在考虑不同类别错误分类代价的情况下,总代价最小化。通过观察代价曲线,你可以选择使得总代价最小的分类阈值,从而在实际应用中取得更好的性能。
-
模型选择和比较: 代价曲线可以用于比较不同模型在代价敏感情况下的性能。通过比较不同模型在代价曲线上的表现,你可以选择最适合你问题的模型。
-
业务决策支持: 在许多业务场景中,不同类型的错误可能具有不同的后果。例如,在信用卡欺诈检测中,将一个正常交易误判为欺诈交易的代价可能比将一个欺诈交易误判为正常交易的代价大得多。代价曲线可以帮助业务决策者理解模型的性能,并根据业务需求调整模型的阈值。

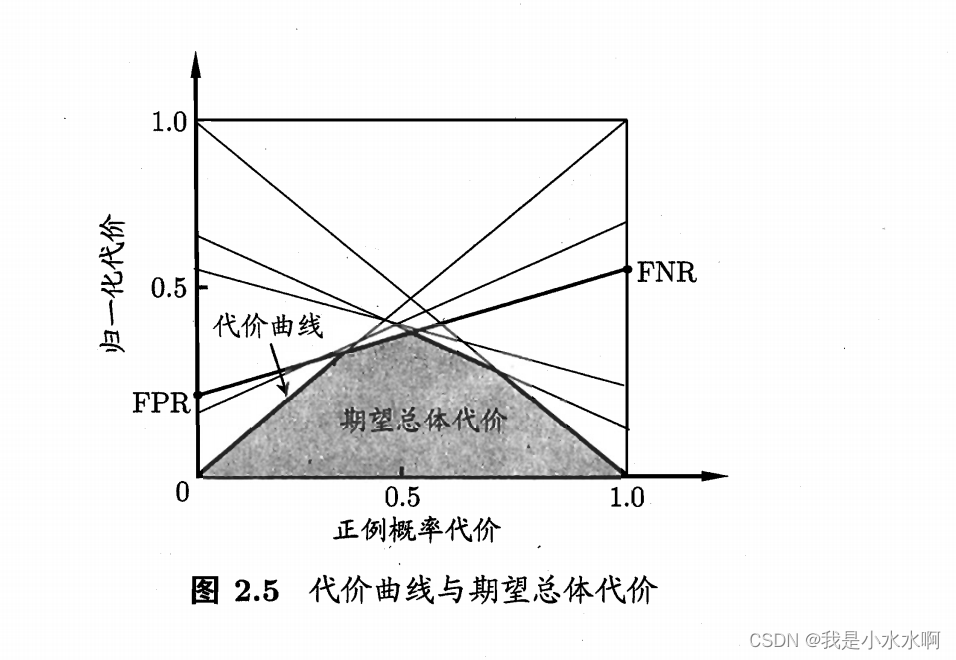
绘制代价曲线的步骤通常包括以下几个部分:
-
定义代价矩阵: 首先,你需要明确定义每种错误分类的代价。代价矩阵(cost matrix)是一个二维矩阵,其中的每个元素表示将真实类别i的样本错误地分类为类别j的代价。这个矩阵应该根据你的问题领域和需求来定义。
-
模型预测概率: 使用你的分类模型(比如随机森林、逻辑回归等)对测试数据集进行预测,并获取每个样本属于各个类别的概率。
-
计算总代价: 对于每个可能的分类阈值,使用代价矩阵和模型的预测概率计算出混淆矩阵(confusion matrix),然后根据代价矩阵计算总代价。
-
绘制代价曲线: 将不同分类阈值下的总代价绘制成图表,横轴表示阈值,纵轴表示总代价。通过观察代价曲线,你可以选择使得总代价最小的分类阈值。
以下是在Python中绘制代价曲线的基本步骤示例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix# 1. 定义代价矩阵
cost_matrix = np.array([[0, 1, 1],[10, 0, 5],[5, 5, 0]])# 2. 模型预测概率
# 这里假设你已经有了模型的预测概率,存储在变量 predicted_probs 中# 3. 计算总代价
thresholds = np.linspace(0, 1, 100)
total_costs = []for threshold in thresholds:y_pred_thresholded = np.argmax(predicted_probs, axis=1)y_pred_thresholded = np.where(predicted_probs.max(axis=1) > threshold, y_pred_thresholded, -1)conf_matrix = confusion_matrix(true_labels, y_pred_thresholded, labels=[0, 1, 2])total_cost = np.sum(conf_matrix * cost_matrix) # 计算总代价total_costs.append(total_cost)# 4. 绘制代价曲线
plt.figure(figsize=(8, 6))
plt.plot(thresholds, total_costs, marker='o', linestyle='-', color='b')
plt.xlabel('Threshold')
plt.ylabel('Total Cost')
plt.title('Cost Curve')
plt.grid(True)
plt.show()
请确保 predicted_probs 包含模型的预测概率,true_labels 包含测试数据的真实类别。这个示例代码中,total_costs 中存储了不同阈值下的总代价,将其绘制成曲线,你就得到了代价曲线。希望这个例子能帮到你理解代价曲线的绘制过程。
例子
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix# 加载数据 这个类别是有三种
iris = load_iris()
X = iris.data
y = iris.target# 假设一个代价矩阵,其中假阳性代价为1,类1的假阴性代价为10,类2的假阴性代价为5
cost_matrix = np.array([[0, 1, 1],[10, 0, 5],[5, 5, 0]])# 将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练一个随机森林分类器
rf_classifier = RandomForestClassifier(random_state=42)
rf_classifier.fit(X_train, y_train)# 作出预测
"""
三个类别(类别0、类别1、类别2),rf_classifier.predict_proba(X_test) 的输出
可能是一个形状为 (n_samples, 3) 的数组,其中 n_samples
是测试样本的数量。这个数组的每一行表示一个测试样本,每一列的值表示该样本属于对应类别的概率。
"""
y_pred_probs = rf_classifier.predict_proba(X_test)# 计算每个阈值的总成本
thresholds = np.linspace(0, 1, 100)
total_costs = []for threshold in thresholds:y_pred_thresholded = np.argmax(y_pred_probs, axis=1)y_pred_thresholded = np.where(y_pred_probs.max(axis=1) > threshold, y_pred_thresholded, -1)conf_matrix = confusion_matrix(y_test, y_pred_thresholded, labels=[0, 1, 2])total_cost = np.sum(conf_matrix * cost_matrix) # 使用给定的成本矩阵计算总成本total_costs.append(total_cost)# Plot the cost curve
plt.figure(figsize=(8, 6))
plt.plot(thresholds, total_costs, marker='o', linestyle='-', color='b')
plt.xlabel('Threshold')
plt.ylabel('Total Cost')
plt.title('Cost Curve')
plt.grid(True)
plt.show()print(y_pred_probs)
相关文章:
机器学习——代价敏感错误率与代价曲线
文章目录 代价敏感错误率实现代价曲线例子 代价敏感错误率 指在分类问题中,不同类别的错误分类所造成的代价不同。在某些应用场景下,不同类别的错误分类可能会产生不同的代价。例如,在医学诊断中,将疾病患者错误地分类为健康人可…...

如何利用 ChatGPT 提升编程技能
目录 前言代码命名与 ChatGPT设计模式与 ChatGPT代码重构与 ChatGPT代码优化与 ChatGPTChatGPT 的潜在挑战与限制成功案例分析最佳实践与注意事项结语 前言 编程是一项充满创造性和挑战的任务,但也是一个需要花费大量时间和精力的领域。在日益复杂的软件开发环境中…...
是什么意思)
ChatGPT:@EqualsAndHashCode(callSuper = false)是什么意思
ChatGPT:EqualsAndHashCode(callSuper false)是什么意思 EqualsAndHashCode(callSuper false)是什么意思? ChatGPT: EqualsAndHashCode(callSuper false) 是 Java 中的 Lombok 注解,用于自动生成 equals() 和 hashCode() 方法…...

docker部署的mariadb忘记密码
docker 里的 mariadb 数据库密码忘了,如果以前我会选择直接干掉重装,但是数据怎么办? 1 数据量小 就跳过密码登录进去备份出来 2 想办法改掉密码 我直接选择后者,跳过密码,mariadb10.4以后不能直接改密码了ÿ…...
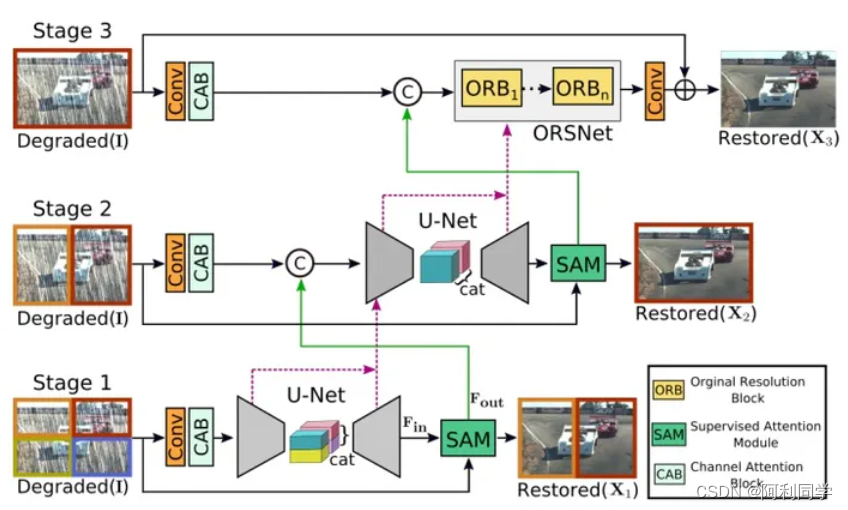
一体化模型图像去雨+图像去噪+图像去模糊(图像处理-图像复原-代码+部署运行教程)
本文主要讲述了一体化模型进行去噪、去雨、去模糊,也就是说,一个模型就可以完成上述三个任务。实现了良好的图像复原功能! 先来看一下美女复原.jpg 具体的: 在图像恢复任务中,需要在恢复图像的过程中保持空间细节…...
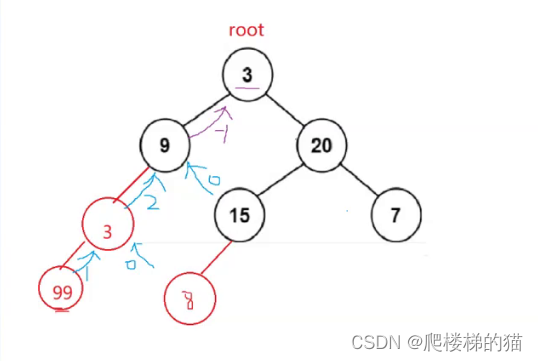
[java/力扣110]平衡二叉树——优化前后的两种方法
分析 根据平衡二叉树的定义,只需要满足:1、根节点两个子树的高度差不超过1;2、左右子树都为平衡二叉树 代码 public class BalancedBinaryTree {public class TreeNode{int val;TreeNode left;TreeNode right;TreeNode(){}TreeNode(int va…...
吉他、班卓琴和贝斯吉他降分器:Arobas Music Guitar 8.1.1
Arobas Music Guitar 是一款专业的吉他、班卓琴和贝斯吉他降分器。在熟练的手中,它不仅可以让您创作,还可以编辑、聆听和录制,以及导入和导出乐谱。如果有人感兴趣的话,录音是在八个轨道上进行的,你可以为每个轨道单独…...
cocos tilemap的setTileGIDAt方法不实时更新
需要取消勾选 Enable Culling。同时代码添加:markForUpdateRenderData函数。 floor.setTileGIDAt(102427,newP.x,newP.y,0); //中心 floor.markForUpdateRenderData(); 具体问题参考官网说明: Cocos Creator 3.2 手册 - 项目设置...

机器学习---使用 TensorFlow 构建神经网络模型预测波士顿房价和鸢尾花数据集分类
1. 预测波士顿房价 1.1 导包 from __future__ import absolute_import from __future__ import division from __future__ import print_functionimport itertoolsimport pandas as pd import tensorflow as tftf.logging.set_verbosity(tf.logging.INFO) 最后一行设置了Ten…...

铁合金电炉功率因数补偿装置设计
摘要 由于国内人民生活水平的提高,科技不断地进步,控制不断地完善,从而促使功率因数补偿装置在电力等系统领域占据主导权,也使得功率因数补偿控制系统被广泛应用。在铁合金电炉系统设计领域中,功率因数补偿控制成为目前…...

表格识别软件:科技革新引领行业先锋,颠覆性发展前景广阔
表格识别软件的兴起背景可以追溯到数字化和自动化处理的需求不断增加的时期。传统上,手动处理纸质表格是一项费时费力的工作,容易出现错误,效率低下。因此,开发出能够自动识别和提取表格数据的软件工具变得非常重要。 随着计算机…...
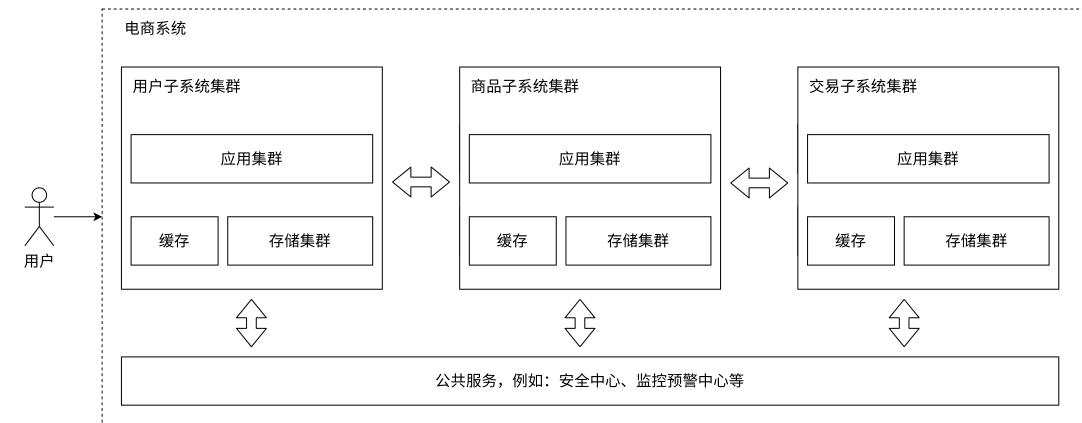
【Redis】高并发分布式结构服务器
文章目录 服务端高并发分布式结构名词基本概念评价指标1.单机架构缺点 2.应用数据分离架构应用服务集群架构读写分离/主从分离架构引入缓存-冷热分离架构分库分表(垂直分库)业务拆分⸺微服务 总结 服务端高并发分布式结构 名词基本概念 应⽤࿰…...

微信小程序拍照页面自定义demo
api文档 <template><div><imagemode"widthFix"style"width: 100%; height: 300px":src"imageSrc"v-if"imageSrc"></image><camerav-else:device-position"devicePosition":flash"flash&qu…...
单目标应用:进化场优化算法(Evolutionary Field Optimization,EFO)求解微电网优化MATLAB
一、微网系统运行优化模型 微电网优化模型介绍: 微电网多目标优化调度模型简介_IT猿手的博客-CSDN博客 二、进化场优化算法EFO 进化场优化算法(Evolutionary Field Optimization,EFO)由Baris Baykant Alagoz等人于2022年提出&…...

推荐算法面试
当然可以,请看下面的解释和回答: 一面(7.5) 问题:推荐的岗位和其他算法岗(CV,NLP)有啥区别? 解释: 面试官可能想了解你对不同算法岗位的理解,包…...

长图切图怎么切
用PS的切片工具 切片工具——基于参考线的切片——ctrl+shift+s 过长的图片怎么切 ctrl+alt+i 查看图片的长宽看图片的长宽来切成两个板块(尽量中间切成两半)用选区工具选中下半部分的区域——在选完时不…...
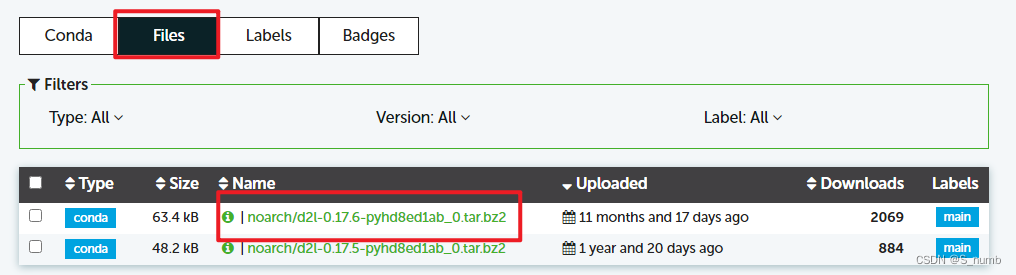
动手学深度学习 - 学习环境配置
学习环境配置 1、安装 Miniconda1.1 下载 miniconda31.2 环境变量配置1.3 安装成功测试1.4 配置文件1.5 使用conda创建、使用、删除环境1.6 conda 常用命令 2、使用 miniconda 安装 d2l2.1 下载 d2l 安装包2.2 安装 d2l 1、安装 Miniconda 参考: https://www.jb51.n…...
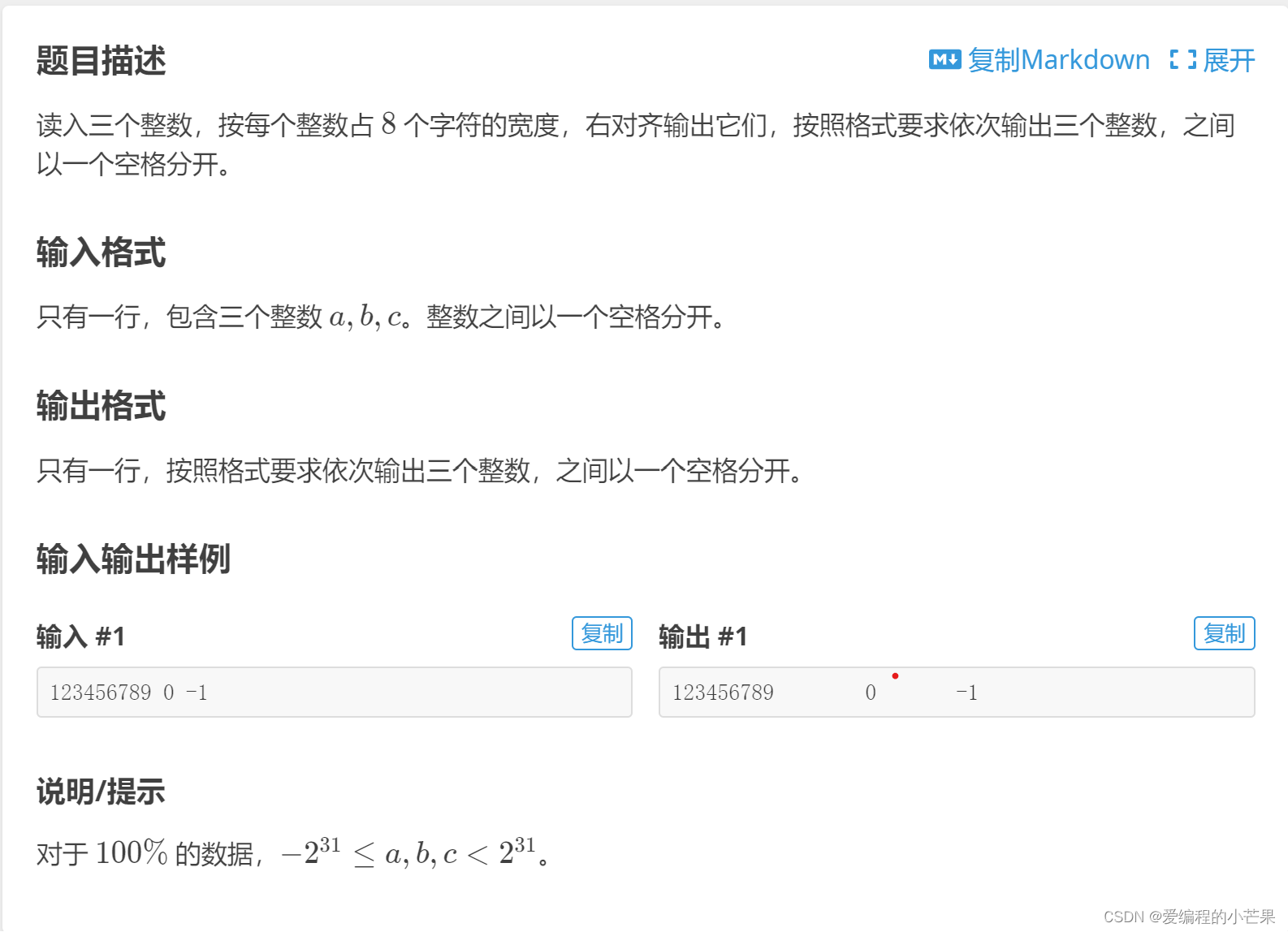
洛谷 B2004 对齐输出 C++代码
目录 推荐专栏 题目描述 AC Code 切记 推荐专栏 http://t.csdnimg.cn/Z1tCAhttp://t.csdnimg.cn/Z1tCA 题目描述 题目网址:对齐输出 - 洛谷 AC Code #include<bits/stdc.h> using namespace std; typedef long long ll; int main() { int a,b,c;cin&g…...
)
seccomp学习 (1)
文章目录 0x01. seccomp规则添加原理A. 默认规则B. 自定义规则 0x02. seccomp沙箱“指令”格式实例Task 01Task 02 0x03. 总结 今天打了ACTF-2023,惊呼已经不认识seccomp了,在被一道盲打题折磨了一整天之后,实在是不想面向题目高强度学习了。…...
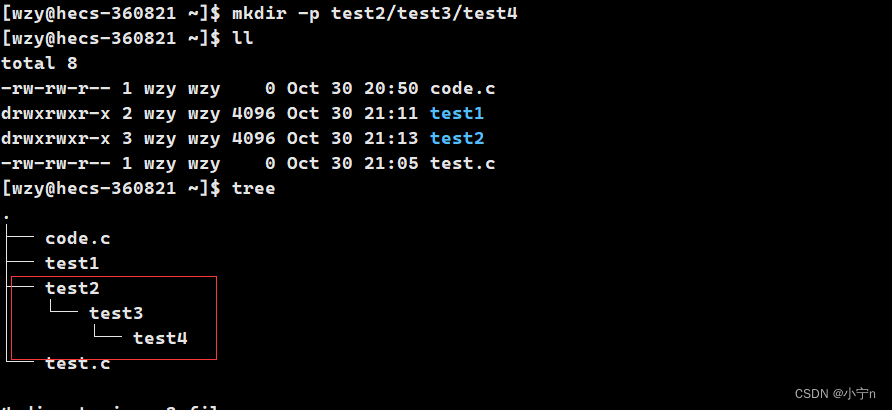
Linux指令【上】
目录 目录结构 ls cd stat touch mkdir whoami 查看当前帐号是谁 who 查看当前有哪些人在使用 pwd 当前的工作目录 目录结构 目录结构就是一颗多叉树的样子 路径 我们从 / 目录开始,定位一个叶子文件的…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

AtCoder 第409场初级竞赛 A~E题解
A Conflict 【题目链接】 原题链接:A - Conflict 【考点】 枚举 【题目大意】 找到是否有两人都想要的物品。 【解析】 遍历两端字符串,只有在同时为 o 时输出 Yes 并结束程序,否则输出 No。 【难度】 GESP三级 【代码参考】 #i…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

2025季度云服务器排行榜
在全球云服务器市场,各厂商的排名和地位并非一成不变,而是由其独特的优势、战略布局和市场适应性共同决定的。以下是根据2025年市场趋势,对主要云服务器厂商在排行榜中占据重要位置的原因和优势进行深度分析: 一、全球“三巨头”…...

「全栈技术解析」推客小程序系统开发:从架构设计到裂变增长的完整解决方案
在移动互联网营销竞争白热化的当下,推客小程序系统凭借其裂变传播、精准营销等特性,成为企业抢占市场的利器。本文将深度解析推客小程序系统开发的核心技术与实现路径,助力开发者打造具有市场竞争力的营销工具。 一、系统核心功能架构&…...
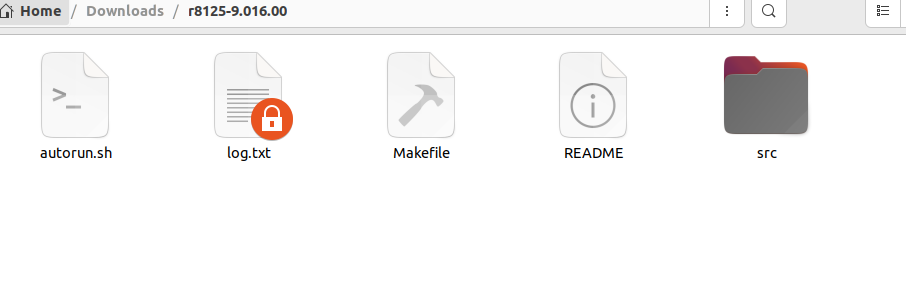
ubuntu22.04有线网络无法连接,图标也没了
今天突然无法有线网络无法连接任何设备,并且图标都没了 错误案例 往上一顿搜索,试了很多博客都不行,比如 Ubuntu22.04右上角网络图标消失 最后解决的办法 下载网卡驱动,重新安装 操作步骤 查看自己网卡的型号 lspci | gre…...
Python训练营-Day26-函数专题1:函数定义与参数
题目1:计算圆的面积 任务: 编写一个名为 calculate_circle_area 的函数,该函数接收圆的半径 radius 作为参数,并返回圆的面积。圆的面积 π * radius (可以使用 math.pi 作为 π 的值)要求:函数接收一个位置参数 radi…...