CentOS 安装 Hadoop Local (Standalone) Mode 单机模式
CentOS 安装 Hadoop Local (Standalone) Mode 单机模式
Hadoop Local (Standalone) Mode 单机模式
1. 修改yum源 并升级内核和软件
curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
yum clean all
yum makecache
yum -y update
2. 安装常用软件
yum -y install gcc gcc-c++ autoconf automake cmake make \zlib zlib-devel openssl openssl-devel pcre-devel \rsync openssh-server vim man zip unzip net-tools tcpdump lrzsz tar wget
3. 关闭防火墙
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
setenforce 0
systemctl stop firewalld
systemctl disable firewalld
4. 修改主机名和IP地址
hostnamectl set-hostname hadoop
vim /etc/sysconfig/network-scripts/ifcfg-ens32
参考如下:
TYPE="Ethernet"
PROXY_METHOD="none"
BROWSER_ONLY="no"
BOOTPROTO="none"
DEFROUTE="yes"
IPV4_FAILURE_FATAL="no"
IPV6INIT="yes"
IPV6_AUTOCONF="yes"
IPV6_DEFROUTE="yes"
IPV6_FAILURE_FATAL="no"
IPV6_ADDR_GEN_MODE="stable-privacy"
NAME="ens32"
UUID="61b382ca-cdf2-47dc-b9b4-01ea57c805d7"
DEVICE="ens32"
ONBOOT="yes"
IPADDR="192.168.171.10"
PREFIX="24"
GATEWAY="192.168.171.2"
DNS1="192.168.171.2"
IPV6_PRIVACY="no"
5. 修改hosts配置文件
vim /etc/hosts
修改内容如下:
192.168.171.10 hadoop
重启系统
reboot
6. 下载安装JDK和Hadoop并配置环境变量
创建软件目录
mkdir -p /opt/soft
进入软件目录
cd /opt/soft
下载 JDK
wget https://download.oracle.com/otn/java/jdk/8u391-b13/b291ca3e0c8548b5a51d5a5f50063037/jdk-8u391-linux-x64.tar.gz?AuthParam=1698206552_11c0bb831efdf87adfd187b0e4ccf970
下载 hadoop
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.5/hadoop-3.3.5.tar.gz
解压 JDK 修改名称
tar -zxvf jdk-8u391-linux-x64.tar.gz -C /opt/soft/
mv jdk1.8.0_391/ jdk-8
解压 hadoop 修改名称
tar -zxvf hadoop-3.3.5.tar.gz -C /opt/soft/
mv hadoop-3.3.5/ hadoop-3
配置环境变量
vim /etc/profile.d/my_env.sh
编写以下内容:
export JAVA_HOME=/opt/soft/jdk-8
export set JAVA_OPTS="--add-opens java.base/java.lang=ALL-UNNAMED"export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=rootexport YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootexport HADOOP_HOME=/opt/soft/hadoop-3export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin生成新的环境变量
source /etc/profile
7. 配置ssh免密钥登录
创建本地秘钥并将公共秘钥写入认证文件
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
ssh-copy-id root@hadoop
# 远程登录自己
ssh hadoop
# Are you sure you want to continue connecting (yes/no)? 此处输入yes
# 登录成功后exit或者logout返回
exit
8. 修改配置文件
hadoop-env.sh
core-site.xml
hdfs-site.xml
workers
mapred-site.xml
yarn-site.xml
hadoop-env.sh
hadoop-env.sh 文件末尾追加
export JAVA_HOME=/opt/soft/jdk-8
export set JAVA_OPTS="--add-opens java.base/java.lang=ALL-UNNAMED"export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_ZKFC_USER=root
export HDFS_JOURNALNODE_USER=rootexport YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootcore-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop:9000</value></property><property><name>hadoop.tmp.dir</name><value>/home/hadoop_data</value></property><property><name>hadoop.http.staticuser.user</name><value>root</value></property><property><name>dfs.permissions.enabled</name><value>false</value></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property>
</configuration>hdfs.site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.secondary.http-address</name><value>hadoop:50090</value></property>
</configuration>
workers
注意:
hadoop2.x中该文件名为slaves
hadoop3.x中该文件名为workers
hadoop
mapred-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.application.classpath</name><value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value></property>
</configuration>yarn-site.xml
<?xml version="1.0"?>
<configuration><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_HOME,PATH,LANG,TZ,HADOOP_MAPRED_HOME</value></property>
</configuration>9. 初始化集群
# 格式化文件系统
hdfs namenode -format
# 启动 NameNode SecondaryNameNode DataNode
start-dfs.sh
# 查看启动进程
jps
# 看到 DataNode SecondaryNameNode NameNode 三个进程代表启动成功
# 启动 ResourceManager daemon 和 NodeManager
start-yarn.sh
# 看到 DataNode NodeManager SecondaryNameNode NameNode ResourceManager 五个进程代表启动成功
重点提示:
# 关机之前 依关闭服务
stop-yarn.sh
stop-dfs.sh
# 开机后 依次开启服务
start-dfs.sh
start-yarn.sh
或者
# 关机之前关闭服务
stop-all.sh
# 开机后开启服务
start-all.sh
#jps 检查进程正常后开启胡哦关闭在再做其它操作
10. 修改windows下hosts文件
C:\Windows\System32\drivers\etc\hosts
追加以下内容:
192.168.171.10 hadoop
192.168.171.11 spark01
192.168.171.12 spark02
192.168.171.13 spark03
Windows11 注意 修改权限


11. 测试
浏览器访问: http://hadoop:9870

浏览器访问:http://hadoop:50090/

浏览器访问:http://hadoop:8088

11.1 测试 hdfs
本地文件系统创建 测试文件 wcdata.txt
vim wcdata.txt
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
FlinkHBase Flink
Hive StormHive Flink HadoopHBase
HiveHadoop Spark HBase StormHBase
Hadoop Hive FlinkHBase Flink Hive StormHive
Flink HadoopHBase Hive
Spark HBaseHive Flink
Storm Hadoop HBase SparkFlinkHBase
StormHBase Hadoop Hive
在 HDFS 上创建目录 /wordcount/input
hdfs dfs -mkdir -p /wordcount/input
查看 HDFS 目录结构
hdfs dfs -ls /
hdfs dfs -ls /wordcount
hdfs dfs -ls /wordcount/input
上传本地测试文件 wcdata.txt 到 HDFS 上 /wordcount/input
hdfs dfs -put wcdata.txt /wordcount/input
检查文件是否上传成功
hdfs dfs -ls /wordcount/input
hdfs dfs -cat /wordcount/input/wcdata.txt
11.2 测试 mapreduce
计算 PI 的值
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar pi 10 10
单词统计
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar wordcount /wordcount/input/wcdata.txt /wordcount/result
hdfs dfs -ls /wordcount/result
hdfs dfs -cat /wordcount/result/part-r-00000
相关文章:
CentOS 安装 Hadoop Local (Standalone) Mode 单机模式
CentOS 安装 Hadoop Local (Standalone) Mode 单机模式 Hadoop Local (Standalone) Mode 单机模式 1. 修改yum源 并升级内核和软件 curl -o /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repoyum clean allyum makecacheyum -y update2. 安…...
jenkins工具系列 —— 删除Jenkins JOB后清理workspace
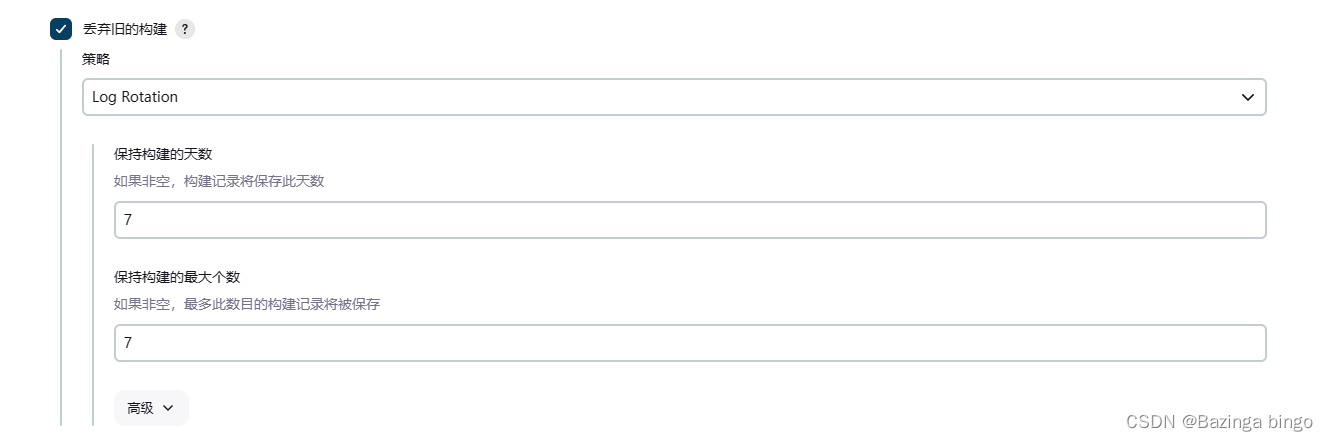
文章目录 问题现象分析解决思路脚本实现问题现象分析 Jenkins使用过程中,占用空间最大的两个位置: 1 、workspace: 工作空间,可以随便删除,删除后再次构建时间可能会比较长,因为要重新获取一些资源。 2 、job: 存放的是项目的配置、构建结果、日志等。不建议手动删除,…...

超越人眼,好用的OCR软件推荐
OCR技术(Optical Character Recognition)是一种将图像或扫描的文字转化为可编辑、搜索、存储、分享的文本的技术。OCR技术除了能够将纸质文档数字化,还可以将手写文本、印刷文本、数码照片中的文字等转化为电子文本。 以下是几个比较知名的O…...

Go语言开发网站
引言 随着互联网的迅速发展,网站已经成为人们获取各种信息和服务的主要途径。而开发一个高性能、可扩展的网站是一项挑战。Go语言作为一门现代化的编程语言,具有强大的并发能力和高效的性能,逐渐成为网站开发的首选语言之一。本文将介绍如何…...
第18章_MySQL8其它新特性
第18章_MySQL8其它新特性 讲师:尚硅谷-宋红康(江湖人称:康师傅) 官网:http://www.atguigu.com 1. MySQL8新特性概述 MySQL从5.7版本直接跳跃发布了8.0版本,可见这是一个令人兴奋的里程碑版本。MySQL 8版…...

Python爬虫实战(六)——使用代理IP批量下载高清小姐姐图片(附上完整源码)
文章目录 一、爬取目标二、实现效果三、准备工作四、代理IP4.1 代理IP是什么?4.2 代理IP的好处?4.3 获取代理IP4.4 Python获取代理IP 五、代理实战5.1 导入模块5.2 设置翻页5.3 获取图片链接5.4 下载图片5.5 调用主函数5.6 完整源码5.7 免费代理不够用怎…...
【操作系统】考研真题攻克与重点知识点剖析 - 第 1 篇:操作系统概述
前言 本文基础知识部分来自于b站:分享笔记的好人儿的思维导图与王道考研课程,感谢大佬的开源精神,习题来自老师划的重点以及考研真题。此前我尝试了完全使用Python或是结合大语言模型对考研真题进行数据清洗与可视化分析,本人技术…...
Mac删除照片快捷键ctrl加什么 Mac电脑如何批量删除照片
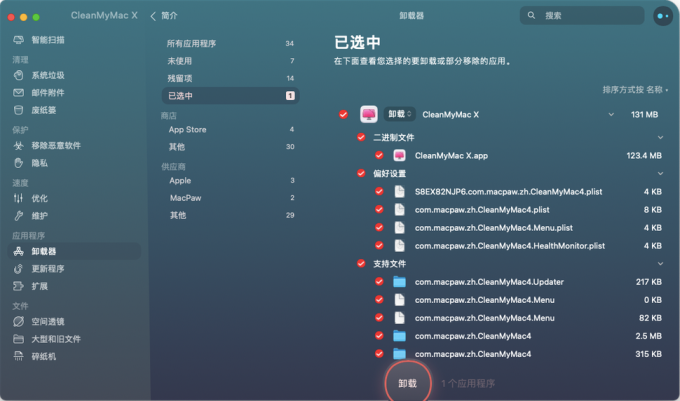
Mac电脑是很多人喜欢使用的电脑,它有着优美的设计、高效的性能和丰富的功能。如果你的Mac电脑上存储了很多不需要的照片,那么你可能会想要删除它们,以节省空间和提高速度。那么,Mac删除照片快捷键ctrl加什么呢?Mac电脑…...

数据安全认证:保护您的数据安全的关键步骤
随着信息技术的飞速发展,数据安全问题日益凸显。数据泄露、网络攻击等事件频发,给企业和个人带来极大的损失。因此,数据安全认证成为保护数据安全的重要措施。本文将探讨数据安全认证的重要性、认证流程和相关标准,以期帮助读者更…...
表白墙/留言墙 —— 初级SpringBoot项目,练手项目前后端开发(带完整源码) 全方位全步骤手把手教学
🧸欢迎来到dream_ready的博客,📜相信你对这篇博客也感兴趣o (ˉ▽ˉ;) 用户登录前后端开发(一个简单完整的小项目)——SpringBoot与session验证(带前后端源码)全方位全流程超详细教程 目录 项目前端页面展…...

【海德教育】报考建筑八大员需要满足下列条件:
1 、初级(具备以下条塌氏件之一) ( 1 )本专业或相关专业中专以上学历竖陆。 ( 2 )从事本职业工作 2 年以上。 2 、中级(具备以下条件之一) ( 1 )本专业或相关专业大专以上学历。 ( 2 )连续从事本职业工作 4 年以上。 ( 3 )取得余衫顷本职业初级证书,从事本职业工作 …...
酷开科技,让家庭更有温度!
生活中总有一些瞬间,会让我们感到无比温暖和幸福。一个拥抱、一句问候、一杯热茶,都能让我们感受到家庭的温馨和关爱。酷开科技也用自己的方式为我们带来了独属于科技的温暖,通过全新的体验将消费者带进一个充满惊喜的世界,让消费…...
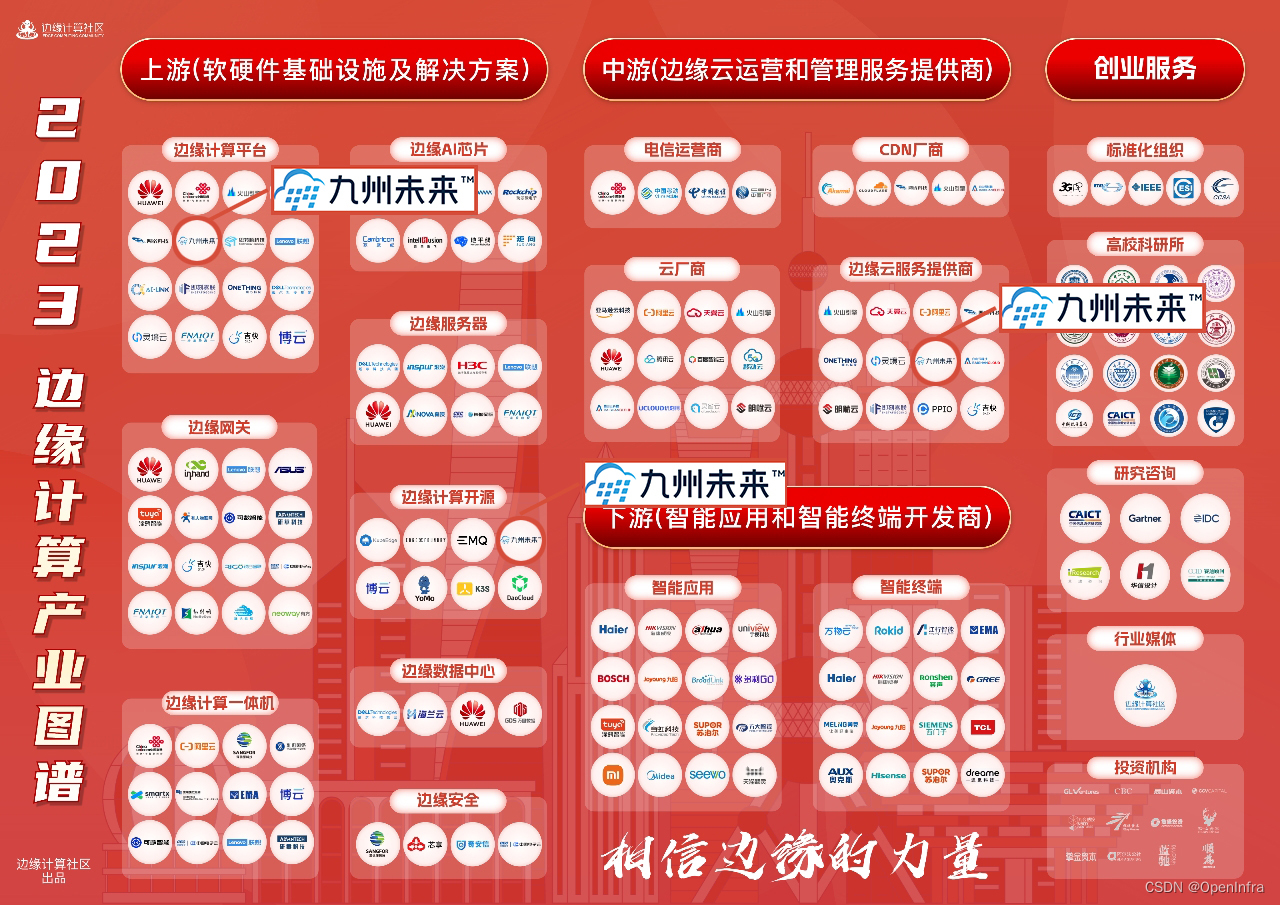
九州未来入选“2023边缘计算产业图谱”三大细分领域
10月26日,边缘计算社区正式发布《2023边缘计算产业图谱》,九州未来凭借深厚的技术积累、优秀的产品服务、完善的产品解决方案体系以及开源贡献,实力入选图谱——边缘计算平台、边缘计算开源、边缘云服务提供商三大细分领域,充分彰…...
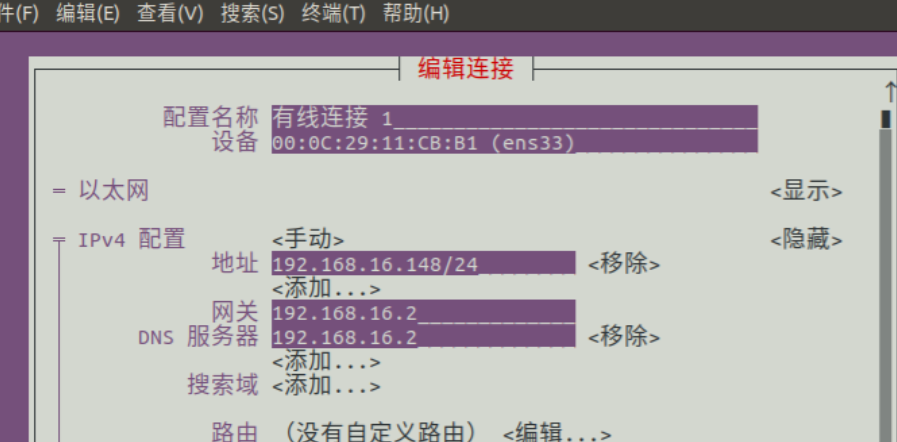
centos ubantu IP一直变化,远程连接不上问题
文章目录 一、为什么IP地址会变1.主机DHCP导致 二、解决IP地址变化1.centos2.ubantu 总结 虚拟机能连接为互联网,但下一次启动IP地址再发生变化,无法使用ssh远程连接 一、为什么IP地址会变 1.主机DHCP导致 虚拟机系统(ubantu,centos…)启动后会向本地申请IP地址租约,租聘的I…...

多线程---JUC
文章目录 什么是JUC?Callable接口ReentrantLockReentrantLock VS synchronized 原子类线程池信号量SemaphoreCountDownLatch 什么是JUC? JUC是:java.util.concurrent这个包名的缩写。它里面包含了与并发相关,即与多线程相关的很多…...

事务隔离级别
隔离级别 概念理解 事务的概念 事务是数据库管理系统中的一个基本单位,它代表了一组数据库操作。 事务是一个不可分割的工作单元,要么全部成功执行,要么全部失败回滚。 事务的目标是确保数据库的一致性、隔离性、持久性和原子性ÿ…...

centos7安装配置及Linux常用命令
目录 一.centos7的安装 1.1centos7的简介 1.2步骤 编辑 1.3登录 编辑 1.4MobaXterm使用 二.Linux常用命令&模式 1.1 常用命令 1.2 三种模式 命令模式 编辑模式 末行模式 1.3 命令使用&换源 换源 1.4 拍照备份 一.centos7的安装 1.1centos7的简…...

C语言调用lua
C语言是一种非常流行的编程语言,而Lua是一种基于C语言开发的脚本语言。相信大家都知道,Lua可以使用C语言来扩展其功能,进而实现更复杂的功能。而在Lua的各种实现中,luajit也是其中一种非常流行的实现。在本篇博客中,我…...
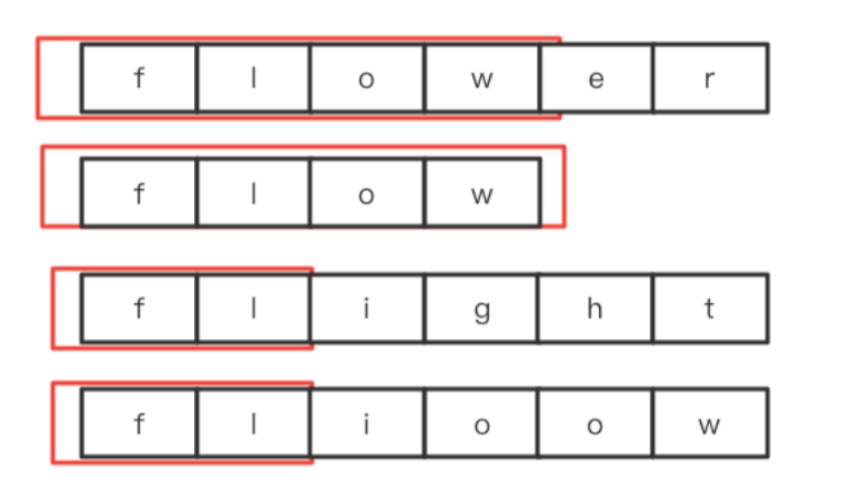
算法通关村第十二关黄金挑战——最长公共前缀问题解析
大家好,我是怒码少年小码。 最长公共前缀 LeetCode 14:编写一个函数来查找字符串数组中的最长公共前缀。 如果不存在公共前缀,返回空字符串 “”。 示例: 输入:strs [“flower”,“flow”,“flight”]输出ÿ…...
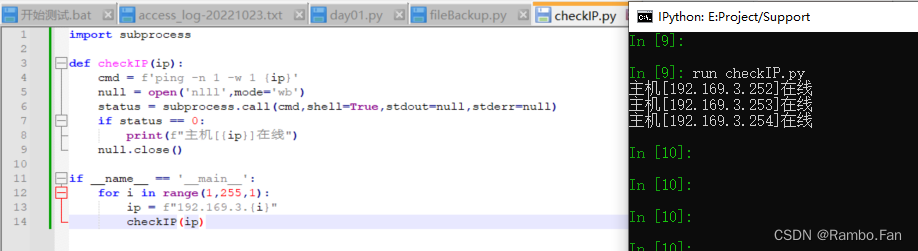
Python运维学习Day02-subprocess/threading/psutil
文章目录 1. 检测网段在线主机2. 获取系统变量的模块 psutil 1. 检测网段在线主机 import subprocessdef checkIP(ip):cmd fping -n 1 -w 1 {ip}null open(nlll,modewb)status subprocess.call(cmd,shellTrue,stdoutnull,stderrnull)if status 0:print(f"主机[{ip}]在…...

变量 varablie 声明- Rust 变量 let mut 声明与 C/C++ 变量声明对比分析
一、变量声明设计:let 与 mut 的哲学解析 Rust 采用 let 声明变量并通过 mut 显式标记可变性,这种设计体现了语言的核心哲学。以下是深度解析: 1.1 设计理念剖析 安全优先原则:默认不可变强制开发者明确声明意图 let x 5; …...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

Debian系统简介
目录 Debian系统介绍 Debian版本介绍 Debian软件源介绍 软件包管理工具dpkg dpkg核心指令详解 安装软件包 卸载软件包 查询软件包状态 验证软件包完整性 手动处理依赖关系 dpkg vs apt Debian系统介绍 Debian 和 Ubuntu 都是基于 Debian内核 的 Linux 发行版ÿ…...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

生成 Git SSH 证书
🔑 1. 生成 SSH 密钥对 在终端(Windows 使用 Git Bash,Mac/Linux 使用 Terminal)执行命令: ssh-keygen -t rsa -b 4096 -C "your_emailexample.com" 参数说明: -t rsa&#x…...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...