Pandas数据导入和导出:CSV、Excel、MySQL、JSON
导入MySQL查询结果:read_sql
import pandascon = "mysql+pymysql://user:pass@127.0.0.1/test"
sql = "SELECT * FROM `student` WHERE id = 2"# sql查询
df1 = pandas.read_sql(sql=sql, con=con)
print(df1)
导入MySQL整张表:read_sql_table
# 整张表
df2 = pandas.read_sql_table(table_name="student", con=con)
print(df2)遍历数据:items、itertuples
# 按列遍历
for key, value in df2.items():print("Key:", key) # 列名print("Value:", value) # 列数据# 按行遍历
for row in df2.itertuples():print(row) # 命名元组类型print(row[0], row[1], row[2])print(row.age)
导出到CSV:to_csv
# 导出到csv
df2.to_csv(path_or_buf="sql_table.csv", columns=['id', 'name'])
函数参数:
path_or_buf: 字符串、路径对象、file-like对象、None,默认值None。
字符串、路径对象,或实现了write()函数的file-like对象,如果为None,则结果以字符串形式返回。
sep: 字符串,默认值’,‘。分隔符,to_csv()默认分隔符为’,‘。
na_rep: 字符串,默认值’'(空字符)。缺失值表示方式。
float_format: 字符串,可调用对象,默认值None。
设置字符串格式化输出时浮点数的小数位数。如果给出一个可调用对象,他优先于其他数字格式参数。
columns: 序列,可选。要写入的列。
header: 布尔值或字符串组成的列表,默认值True。
写入列名称。如果传入一个字符串列表,则设置为列的别名。
index: 布尔值,默认值True。写入数据时会将行名称(索引)写入。
index_label: 字符串、序列、False,默认值None。
索引列的列标签(如果需要)。如果设置为None,并且header和index参数为True,则使用索引的names。如果使用MultiIndex,则应传入一个序列。如果设置为False,则不会打印索引名称的字段,使用index_label=False可在R中更方便地导入。
mode: 字符串,默认值’w’。Python写入模式,可用的写入模式与open()相同。
encoding: 字符串,可选。
表示要在输出文件中使用的编码的字符串,默认值为’utf-8’。如果path_or_buf是非二进制文件对象,则不支持encoding。
compression: 字符串或字典,默认值’infer’。用于在线压缩输出数据。
如果使用’infer’,且如果path_or_buf参数是path-like对象,则从以下扩展名中检测压缩:‘.gz’, ‘.bz2’, ‘.zip’, ‘.xz’, ‘.zst’, ‘.tar’, ‘.tar.gz’, ‘.tar.xz’或‘.tar.bz2’(否则不会进行压缩)。设置为None,表示不进行压缩。
quoting: 来自csv模块的可选常量。
默认为csv.QUOTE_MINIMAL。如果设置了float_format格式,则将float转换为字符串,csv.QUOTE_NONNUMERIC将其视为非数字格式。
quotechar: 字符串,默认值单边双引号"。长度为1的字符串,用于引用字段的字符。
lineterminator: 字符串,可选。
在输出文件中使用的换行字符或字符序列。默认为os.linesep,这取决于调用此方法的操作系统(linux为’\n’,Windows为‘\r\n’)。
chunksize: 整数或Noen。一次写入chunksize行。
date_format: 字符串,默认值None。日期时间对象的格式字符串。
doublequote: 布尔值,默认值True。控制同一个quotechar参数引用的范围内的quoting参数。
escapechar: 字符串,默认值None。长度为1的字符串,用于避开sep参数和quotechar参数的字符。
decimal: 字符串,默认值’.‘。识别为十进制分隔符的字符串。例如,对欧洲数据使用’,'。
errors: 字符串,默认值’strict’。
指定如何处理编码和解码错误。完整的选项列表,可以参考open()的错误参数,有strict, ignore, replace, surrogateescape, xmlcharrefreplace, backslashreplace, namereplace。
storage_options: 字典,可选。
对特定存储连接(例如主机、端口、用户名、密码等)有意义的额外选项。
导出到Excel:to_excel
# 导出到Excel
df2.to_excel(excel_writer="1.xlsx", sheet_name='Sheet_name_1')
函数参数:
excel_writer: path-like、file-like、ExcelWriter对象。
文件路径或已有的ExcelWriter对象。
sheet_name: 字符串,默认值’Sheet1’。
即将写入DataFrame数据的sheet页名称。
na_rep: 字符串,默认值’'(空字符)。缺失值表示方式。
float_format: 字符串,可选。
设置字符串格式化输出时浮点数的小数位数。如float_format=‘%.2f’。
columns: 字符串序列或字符串列表,可选。要写入的列。
header: 布尔值或字符串列表,默认值True。
写入列名称。如果传入一个字符串列表,则设置为列的列名。
index: 布尔值,默认值True。
写入数据时会将行名称(索引)写入。
index_label: 字符串或序列,可选。
索引列的列标签(如果需要)。如果没有设置,并且header和index参数为True,则使用索引的names。如果使用MultiIndex,则应传入一个序列。
startrow: 整数,默认值0。存储DataFrame时,设置左上方单元格的行。
startcol: 整数,默认值0。存储DataFrame时,设置左上方单元格的列。
engine: 字符串,可选。
写入时使用的引擎,openpyxl或xlsxwriter,可以通过io.excel.xlsx.writer, io.excel.xls.writer和io.excel.xlsm.write设置。
1.2.0版本后已弃用。
merge_cells: 布尔值,默认值True。
将MultiIndex和分层行写为合并单元格。
encoding: 字符串,可选。
设置写入excel文件的编码。仅xlsxwriter有必要设置此参数,其他writer本身就支持unicode。
1.5.0版本后已弃用。
inf_rep: 字符串,默认值’inf’。
无穷大的表示方式(在Excel中没有无穷大的原始表示)。
verbose: 布尔值,默认值True。
在错误日志中显示更多信息。
1.5.0版本后已弃用。
freeze_panes: 整数组成的元组,长度为2,可选。
指定要冻结单元格的最下方行和最右侧列。
storage_options: 字典,可选。
对特定存储连接(例如主机、端口、用户名、密码等)有意义的额外选项。
导出到Mysql:to_sql
# 导入Mysql另一张表
from sqlalchemy import create_engineengine = create_engine(con, echo=False)
df2.to_sql(name="student1", con=engine, if_exists="append", index=False)
导入CSV:read_csv
import pandas as pd
df = pd.read_csv('myc1.csv')
dfimport pandas as pd
df = pd.read_csv('myc1.csv',header=1)
dfimport pandas as pd
df = pd.read_csv('myc1.csv',header=3,names=['a','b','c','d','e'])
dfimport pandas as pd
df = pd.read_csv('myc1.csv',index_col='单价')
dfimport pandas as pd
df = pd.read_csv('myc1.csv',usecols=['水果名','单价'])
df函数参数:
filepath_or_buffer: 字符串、路径对象、file-like对象,必填。
任何有效的字符串路径都可以接受,字符串可以是一个URL。有效的URL格式包括http、ftp、s3和file,对于文件URL,最好有个主机地址,例如一个本地文件可以是file://localhost/path/to/table.csv这样的格式。
如果传递路径对象,则pandas接受所有os.Pathlike对象。
通过file-like对象,可以引用具有read()方法的对象,例如文件处理(如内置函数open()函数)或StringIO。
sep: 字符串,默认值’,‘。分隔符,read_csv()默认分隔符为’,'。
delimiter: 字符串,默认值None。sep的替代参数。
delim_whitespace: 布尔值,默认值False。
指定是否将空格(如’ ‘或‘\t’)当作delimiter,等价于设置sep=’\s+'。如果这个选项被设置为True,就不要给delimiter传参了。
header: 整数或整数组成的列表、None,默认值’infer’。
将某一行或几行设置成列名,默认’infer’,自动推导。当设置为默认值或header=0时,将首行设为列名。
如果列名(names参数)传入指定值时要设置header=0或默认值。当header=0时,传入的列名会覆盖header=0取到的列名。
header可以用整数构成的列表指定多行,这样结果的列名就是多重索引MultiIndex,例如[1, 2, 3]。
如果指定的多个行中间跳过了某些行,则读取数据时跳过的行不会读取出来。如[0, 1, 3]跳过了索引2的行,读取的数据中也没有索引2这行的数据。
注意,如果skip_blank_lines=True,此参数将忽略空行和注释行,header=0表示第一行数据而非文件的第一行。
names: array-like,可选。
指定列名的列表,如果数据文件中不包含列名,通过names指定列名,那么应该设置header=None。列名列表中不允许有重复值。
index_col: 整数、字符串、整数/字符串组成的列表,False,默认值None,可选。
设置DataFrame的行索引,可以是数字或字符串(通过列名选一列作为行索引),默认None(行索引为整数索引,False也一样)。
如果传入一个字符串列表/整数列表,则组合为MultiIndex。
usecols: list-like或可调用对象,可选。
返回指定列的数据,用list-like的方式传入,即使只取一列数据也用列表,默认None,返回所有列的数据。
列表中可以是列名或列索引(但不能两者混合),列名的列表构成所有列的一个子集,列表中的元素顺序可以忽略,usecols=[0, 1]等价于usecols=[1, 0]。
如果想实例化一个自定义列顺序的DataFrame,可以使用pd.read_csv(data, usecols=[‘foo’, ‘bar’])[[‘foo’, ‘bar’]],这样列的顺序为[‘foo’, ‘bar’]。
usecols也可以传入函数,函数将根据列名计算,返回计算结果为True的列名,如usecols=lambda x: x.upper() in [‘AAA’, ‘BBB’, ‘DDD’]。
使用usecols可以加快解析时间并降低内存使用率。
squeeze: 布尔值,默认值False。
如果解析的数据仅包含一个列,那么结果将以Series的形式返回,默认False。
1.4.0版本后已弃用。
prefix: 字符串,可选。
当没有header时,可通过该参数为数字列名添加前缀,默认None。
1.4.0版本后已弃用。
mangle_dupe_cols: 布尔值,默认值True。
当列名有重复时,将列名解析为‘X’, ‘X.1’, …’X.N’。如果该参数为False,那么当列名中有重复时,前列会被后列覆盖。
1.5.0版本后已弃用。
dtype: 类型名,或列名和类型名组成的字典,默认值None。
指定部分列或整体数据的数据类型,如{‘a’: np.float64, ‘b’: np.int32}。
1.5.0版本新增。
engine: {‘c’, ‘python’, ‘pyarrow’},可选。
使用的解析引擎。C引擎的速度更快,python引擎的功能更完备。多线程目前仅支持pyarrow引擎。
1.4.0版本新增。
converters: 字典,可选。
列和转换函数构成的字典,keys可以是列索引或列名,values是接收一个参数并返回已转换内容的函数。
true_values: 列表,可选。考虑为True的值。
false_values: 列表,可选。考虑为False的值。
skipinitialspace: 布尔值,默认值False。在分隔符之后跳过空格。
skiprows: list-like、整数、可调用对象,可选。
要跳过的行索引列表或文件开头要跳过的行数(int)。
可以传入可调用函数,函数将行索引作为参数传入,跳过返回计算结果为True的行,如skiprows=lambda x: x in [0, 2]。
skipfooter: 整数,默认值0。设置文件底部要忽略的行数。
nrows: 整数,默认值None。每次读取的行数,适用于读取大文件的片段。
low_memory: 布尔值,默认值True。
在处理数据时,解析时内存利用率降低,可能是混合类型推理。如果确认没有混合类型,请设置为False,或使用dtype参数指定类型。
注意,无论数据大小或迭代器参数是多少,整个文件都会被读取到单个DataFrame中。(仅C引擎有效)
memory_map: 布尔值,默认值False。
如果用filepath_or_buffer指定文件路径,可以将文件对象直接映射到内存并直接从内存访问数据。
使用此选项可以提高性能,因为不再有任何I/O开销。
na_values: 标量、字符串、list-like、字典,可选。
识别为NaN的其他字符串,指定某些值为空值。
默认情况下,以下值被解析为空值:‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IND’, ‘1.#QNAN’, ‘’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘n/a’, ‘nan’, ‘null’。
keep_default_na: 布尔值,默认值True。
在解析数据时是否包括默认的空值。根据是否传入na_values,分为如下四种情况:
如果keep_default_na为True,并且指定na_values,则会将na_values指定的值和默认的NaN值解析为空值。
如果keep_default_na为True,并且未指定na_values,则只将默认的NaN值解析为空值。
如果keep_default_na为False,并且指定na_values,则只将na_values指定的值解析为空值。
如果keep_default_na为False,并且未指定na_values,则不会将任何字符串解析为空值。
注意,如果na_filter传入为False,则keep_default_na和na_values参数将被忽略。
na_filter: 布尔值,默认值True。
检测缺失值(默认的NaN和na_values指定的值)。在没有NaN的数据中,设置na_filter=False可以提高读取大文件的性能。
verbose: 布尔值,默认值False。指定放在非数字列中的NaN值的数量。
skip_blank_lines: 布尔值,默认值True。
如果为True,则跳过空白行,而不是将其解析为NaN值。
parse_dates: 布尔值、数字列表、列名列表、嵌套列表、字典,默认值False。
布尔值如果为True,尝试将索引当成日期解析。
整数或列名的列表,例如[1, 2, 3]尝试将1,2,3列分别作为单独的日期列进行解析。
嵌套列表,例如[[1, 3]]将第一列和第三列合并解析为一个日期列。
字典,例如{‘foo’: [1, 3]},将第一列和第三列解析为日期,并且合并成一列将列名重命名为foo。
如果列或索引包含不可解析的日期,则整个列或索引将作为对象数据类型返回,不会被更改。
infer_datetime_format: 布尔值,默认值False。
如果设置为True且有列启用了parse_dates,尝试推断日期格式以加快处理。
keep_date_col: 布尔值,默认值False。
如果设置为True且parse_dates指定组合多列,则保留原始列。
date_parser: 函数,可选。
用于将字符串列转换为datetime实例的函数,默认使用dateutil.parser.parser进行转换。
pandas将尝试以三种不同的方式调用date_parser,如果发生异常则前进到下一种方式:
-
将一个或多个数组(由date_parser定义)作为参数传递。
-
将date_parser定义的列中的字符串值(按行)连接起来存到一个数组中,并传递该数组。
-
使用一个或多个字符串(对应于date_parser定义的列)作为参数为每行调用一次date_parser。
dayfirst: 布尔值,默认值False。DD/MM格式日期,国际和欧洲格式。
cache_dates: 布尔值,默认值True。
如果为True,请使用已转换的唯一日期的缓存来应用日期时间转换。在分析重复日期字符串时,可能会产生显著的提速,尤其是具有失去偏移量的字符串。
iterator: 布尔值,默认值False。为get_chunk()迭代或获取数据块返回TextFileReader对象。
chunksize: 整数,默认值None。返回用于迭代的TextFileReader对象,每次读取chunksize行。
compression: 字符串或字典,默认值’infer’。
用于磁盘数据的实时解压缩。可选值:{‘infer’, ‘zip’, ‘gzip’, ‘bz2’, ‘zstd’, ‘tar’}。
如果使用’infer’,且如果filepath_or_buffer是以‘.gz’, ‘.bz2’, ‘.zip’, ‘.xz’结尾的字符串,则使用gzip、bz2、zip或xz,否则不进行解压缩。如果使用‘.zip’,则ZIP文件必须只包含一个要读取的数据文件。设置为None,表示不解压。
thousands: 字符串,可选。千分隔符。
decimal: 字符串,默认’.'。识别为小数点的字符。
float_precision: 字符串,可选。
指定C引擎浮点值使用哪个转换器。
None: 普通转换器。
high: 高精度转换器。
round_trip: 往返转换器。
lineterminator: 字符串(长度为1),可选。设置文件分行的字符,仅对C引擎有效。
quotechar: 字符串(长度为1),可选。用于表示引用项的开始和结束的字符,引用的项可以包括分隔符,他将被忽略。
quoting: 整数或csv.QUOTE_*实例,默认值0。
控制每个csv.QUOTE_*常量的字段引用行为。使用QUOTE_MINIMAL(0), QUOTE_ALL(1), QUOTE_NONNUMERIC(2)或QUOTE_NONE(3)中的一个。
doublequote: 布尔值,默认值True。
当指定quotechar并且quoting不是QUOTE_NONE时,指示是否将字段内的两个连续quotechar元素解释为单个quotechar元素。
escapechar: 字符串(长度为1),默认值None。
当quoting为QUOTE_NONE时,用于转义分隔符的一个字符串。
comment: 字符串,可选。
设置注释符号,注释掉行的其余内容。如果在一行开头匹配到该字符,则该行将被完全忽略,此参数必须为单个字符。
与空行(只要skip_blank_lines=True)一样,完全注释的行被参数header忽略,而不是被参数skiprows忽略。
例如,如果comment=‘#’,解析’#empty\na,b,c\n1,2,3’且header=0,结果将’a,b,c’视为header。也就是第一行被comment注释了,header=0取到第二行。
encoding: 字符串,可选。读/写时使用UTF的编码(如’utf-8’)。
encoding_errors: 字符串,可选,默认值’strict’。如何处理编码错误。
1.3.0版本新增。
dialect: 字符串或csv.Dialect实例,可选。
如果提供,则此参数将覆盖以下参数的值: delimiter, doublequote, escapechar, skipinitialspace, quotechar和quoting。
error_bad_lines: 布尔值,可选,默认值True。
字段过多(例如,带有过多逗号的csv行)的行默认会引发异常,不会返回DataFrame。如果设置为False,则这些“坏行”将从返回的DataFrame中删除。
1.3.0版本已弃用。
warn_bad_lines: 布尔值,可选,默认值True。
如果error_bad_lines为False,并且warn_bad_lines为True,则会为每个“坏行”输出一条警告。
1.3.0版本已弃用。
on_bad_lines: {‘error’, ‘warn’, ‘skip’}中的一个、可调用对象,默认值’error’。
当遇到坏行(字段太多的行)时要执行的操作。
error: 遇到坏行时抛出异常。
warn: 遇到坏行时发出警告并跳过该行。
skip:遇到坏行时跳过他们,不抛出异常和警告。
1.3.0版本新增。
storage_options: 字典,可选。
对特定存储连接(例如主机、端口、用户名、密码等)有意义的额外选项。
导入Excel:read_excel
import pandasdf = pandas.read_excel("1.xlsx", index_col=0, header=0)
print(df)
函数参数:
io: 字符串、字节、ExcelFile、xlrd.Book、路径对象或file-like对象。
任何有效的字符串路径都可以接受,字符串可以是一个URL,有效的URL格式包括http、ftp、s3和file,对于文件URL,最好有个主机地址,例如一个本地文件可以是file://localhost/path/to/table.xlsx这样的格式。
如果传递的是路径对象,则Pandas接受所有os.Pathlike对象。
通过file-like对象,可以引用具有read()方法的对象,例如文件处理(如内置函数open()函数)或StringIO。
sheet_name: 字符串、整数、列表、None,默认值0。
字符串用表格(sheet页)名称。整数用从0开始的表格索引(图表chart sheet不计算)。字符串/整数的列表用于获取多张表格。设置为None可获取所有表格(sheet页)。
示例:
0(默认): 将第一个sheet页读为一个DataFrame。
1: 将第二个sheet页读为一个DataFrame。
‘Sheet1’: 将名称为Sheet1的sheet页读为一个DataFrame。
None: 将所有sheet页读为一个DataFrame组成的字典。
header: 整数或整数组成的列表,默认值0。
用作DataFrame的列名的行(通过0开始的行索引选一行),如果用整数列表指定多个行,则组合为MultiIndex。如果没有header,则设置为None。
names: array-like,默认值None。
指定列名的列表,如果数据文件中不包含列名,通过names指定列名,同时应该设置header=None。names中不允许有重复值。
indexl_col: 整数或整数组成的列表,默认值None。
设置DataFrame的行索引(通过0开始的列索引选一列),如果用整数列表指定多个列,则组合为MultiIndex。如果没有用作行索引的列,则设置为None。如果使用usecols选择了数据的子集,则indexl_col将基于这个子集。
usecols: 字符串、list-like、可调用对象,默认值None。
None: 解析所有列。
字符串:解析以逗号分隔的Excel列字母和列范围。例如“A:E”或“A,C,E:F”,E:F这种范围包括两端的列。
整数列表:解析列表中索引编号的列。
字符串列表:解析列表中指定列名的列。
可调用对象:根据可调用对象(如函数)判断每个列名,如果返回True,则解析该列。
使用usecols可以大大加快解析时间并降低内存使用率。
squeeze: 布尔值,默认值False。
如果解析的数据仅包含一个列,那么结果将以Series的形式返回。
1.4.0版本后已弃用。
dtype: 类型名,或列名和类型名组成的字典,默认值None。
指定部分列或整体数据的数据类型,如{‘a’: np.float64, ‘b’: np.int32}。
engine: 字符串,默认值None。
支持的引擎:xlrd, openpyxl, odf, pyxlsb。
xlrd: 支持旧式Excel文件(.xls扩展名)。
openpyxl: 支持最新的Excel文件格式(.xlsx)。
odf: 支持OpenDocument文件格式(.odf, .ods, .odt)。
pyxlsb: 支持二进制excel文件。
converters: 字典,默认值None。
列和转换函数构成的字典,keys可以是列索引或列名,values是接收一个参数(Excel单元格内容)并返回已转换内容的函数。
true_values: 列表,默认值None。考虑为True的值。
false_values: 列表,默认值None。考虑为False的值。
skiprows: list-like、整数、可调用对象,可选。
要跳过的行索引列表或文件开头要跳过的行数(int)。
可以传入可调用函数,函数将行索引作为参数传入,跳过返回计算结果为True的行,如skiprows=lambda x: x in [0, 2]。
nrows: 整数,默认值None。每次读取的行数,适用于读取大文件的片段。
na_values: 标量、字符串、list-like、字典,默认值None。
识别为NaN的其他字符串,指定某些值为空值。
默认情况下,以下值被解析为空值:‘’, ‘#N/A’, ‘#N/A N/A’, ‘#NA’, ‘-1.#IND’, ‘-1.#QNAN’, ‘-NaN’, ‘-nan’, ‘1.#IND’, ‘1.#QNAN’, ‘’, ‘N/A’, ‘NA’, ‘NULL’, ‘NaN’, ‘n/a’, ‘nan’, ‘null’。
keep_default_na: 布尔值,默认值True。
在解析数据时是否包括默认的空值。根据是否传入na_values,分为如下四种情况:
如果keep_default_na为True,并且指定na_values,则会将na_values指定的值和默认的NaN值解析为空值。
如果keep_default_na为True,并且未指定na_values,则只将默认的NaN值解析为空值。
如果keep_default_na为False,并且指定na_values,则只将na_values指定的值解析为空值。
如果keep_default_na为False,并且未指定na_values,则不会将任何字符串解析为空值。
注意,如果na_filter传入为False,则keep_default_na和na_values参数将被忽略。
na_filter: 布尔值,默认值True。
检测缺失值(默认的NaN和na_values指定的值)。在没有NaN的数据中,设置na_filter=False可以提高读取大文件的性能。
verbose: 布尔值,默认值False。指定放在非数字列中的NaN值的数量。
parse_dates: 布尔值、list-like、字典,默认值False。
布尔值如果为True,尝试将索引当成日期解析。
整数或列名的列表,例如[1, 2, 3]尝试将1,2,3列分别作为单独的日期列进行解析。
嵌套列表,例如[[1, 3]]将第一列和第三列合并解析为一个日期列。
字典,例如{‘foo’: [1, 3]},将第一列和第三列解析为日期,并且合并成一列将列名重命名为foo。
如果列或索引包含不可解析的日期,则整个列或索引将作为对象数据类型返回,不会被更改。
如果不希望将某些单元格解析为日期,只需将它们在Excel中的类型修改为“文本”。
对于非标准的datetime解析,在pd.read_excel之后使用pd.to_datetime。
date_parser: 函数,可选。
用于将字符串列转换为datetime实例的函数,默认使用dateutil.parser.parser进行转换。
pandas将尝试以三种不同的方式调用date_parser,如果发生异常则前进到下一种方式:
-
将一个或多个数组(由date_parser定义)作为参数传递。
-
将date_parser定义的列中的字符串值(按行)连接起来存到一个数组中,并传递该数组。
-
使用一个或多个字符串(对应于date_parser定义的列)作为参数为每行调用一次date_parser。
thousands: 字符串,默认值None。
千分位符。注意,此参数仅对Excel中存储为TEXT的列必须,其他任何数值列都会自动解析,无论显示格式如何。
decimal: 字符串,默认’.'。
识别为小数点的字符。注意,此参数仅对Excel中存储为TEXT的列必须,其他任何数值列都会自动解析,无论显示格式如何。
comment: 字符串,默认值None。
设置注释符号,注释掉行的其余内容。将一个或多个字符串传递给此参数以在输入文件中指示注释。注释字符串与当前行结尾之间的任何数据都将被忽略。
skipfooter: 整数,默认值0。设置文件底部要忽略的行数。
convert_float: 布尔值,默认值True。
将浮点整数转换为整数(如1.0 -> 1)。如果为False,则所有数字数据将被读取为浮点数,Excel将所有数字存储为内部浮点数。
1.3.0版本后已弃用。
mangle_dupe_cols: 布尔值,默认值True。
当列名有重复时,将列名解析为‘X’, ‘X.1’, …’X.N’。如果该参数为False,那么当列名中有重复时,前列会被后列覆盖。
1.5.0版本后已弃用。
storage_options: 字典,可选。
对特定存储连接(例如主机、端口、用户名、密码等)有意义的额外选项。
导入JSON:read_json
read_json()
函数参数:
path_or_buf: 一个有效的JSON字符串、路径对象、file-like对象。
任何有效的字符串路径都可以接受,字符串可以是一个URL。有效的URL格式包括http、ftp、s3和file,对于文件URL,最好有个主机地址,例如一个本地文件可以是file://localhost/path/to/table.json这样的格式。
如果传递路径对象,则pandas接受所有os.Pathlike对象。
通过file-like对象,可以引用具有read()方法的对象,例如文件处理(如内置函数open()函数)或StringIO。
typ: {‘frame’, ‘series’},默认值frame。要恢复的对象类型。
orient: 期望的JSON字符串格式。兼容的JSON字符串可以由to_json()生成。并具有相应的orient值。
split: 类似于{index -> [index], columns -> [columns], data -> [values]}的字典。
records: 类似于[{column -> value}, … , {column -> value}]的列表。
index: 类似于{index -> {column -> value}}的字典。
columns: 类似于{column -> {index -> value}}的字典。
values: 仅为值的数组。
table: 类似于{‘schema’: {schema}, ‘data’: {data}}的字典。
typ == ‘series’: 默认为index,允许的值为{‘split’,‘records’,‘index’},Series的索引在orient为index时必须是唯一的。
typ == ‘frame’: 默认为columns,允许的值为{‘split’,‘records’,‘index’, ‘columns’,‘values’, ‘table’},DataFrame的索引在orient为index和columns时必须是唯一的,DataFrame的列名在orient为index、columns和records时必须是唯一的。
dtype: 布尔值、字典,默认值None。
如果为True,推断dtypes,如果为列和dtype组成的字典,则使用字典中的dtype。如果为False,则不推断dtypes,仅适用于数据。
对于除table之外的所有orient参数,默认值为True。
convert_axes: 布尔值,默认值None。
尝试将列转换为正确的dtypes。对于除table之外的所有orient参数,默认值为True。
convert_dates: 布尔值或字符串列表,默认值True。
如果为True,则可以转换默认日期格式的列(取决于keep_default_dates参数),如果为False,则不会转换日期。
如果是一个列名组成的列表,则将转换这些列,并且也可以转换默认日期格式的列(取决于keep_default_dates参数)。
keep_default_dates: 布尔值,默认值True。
如果解析日期(convert_dates不是False),则尝试解析默认的日期格式列。列标签属于日期格式的列为:以’_at’结尾、以’_time’结尾、以’timestamp’开头、列名为’modified’或’date’。
numpy: 布尔值,默认值False。
直接解析为numpy数组。虽然column和index标签可能是非数字的,但仅支持数字数据。
注意,如果numpy=True,则每个组的JSON顺序必须相同。
1.0.0版本后已弃用。
precise_float: 布尔值,默认值False。
当解码字符串为双精度类型值时,设置为能使用更高精度(strtod)函数。默认(False)使用快速但不精确的内置功能。
date_unit: 字符串,默认值None。
用于检测转换日期的时间戳单位。默认情况下,尝试并检测正确的精度,如果不满足期望,则传递‘s’, ‘ms’, ‘us’或‘ns’中的一个,以强制设置时间戳精度分别为秒、毫秒、微秒或纳秒。
encoding: 字符串,默认值’utf-8’。用于解码python3字节的编码。
encoding_errors: 字符串,默认值’strict’。
指定如何处理编码错误。完整的选项列表,可以参考open()的错误参数,有strict, ignore, replace, surrogateescape, xmlcharrefreplace, backslashreplace, namereplace。
1.3.0版本新增。
lines: 布尔值,默认值False。读取文件每行作为一个JSON对象。
chunksize: 整数,可选。
与lines=True结合使用,返回一个JSON读取器(JsonReader),每次迭代读取chunksize行。如果为None,则文件将一次性全部读入内存。
compression: 字符串或字典,默认值’infer’。
用于磁盘数据的实时解压缩。如果使用’infer’,且如果path_or_buf参数是path-like对象,则从以下扩展名中检测压缩:‘.gz’, ‘.bz2’, ‘.zip’, ‘.xz’, ‘.zst’, ‘.tar’, ‘.tar.gz’, ‘.tar.xz’或‘.tar.bz2’(否则不会进行压缩)。如果使用’zip’或‘tar’,则ZIP文件必须只包含一个要读取的数据文件。设置为None,表示不进行压缩。
nrows: 整数,可选。
每次从jsonfile中读取的行数。仅当lines参数为True时才能生效。如果为None,则返回所有行。
storage_options: 字典,可选。
对特定存储连接(例如主机、端口、用户名、密码等)有意义的额外选项。
导出JSON:to_json
DataFrame.to_json()
函数参数:
path_or_buf: 字符串、路径对象、file-like对象、None,默认值None。
字符串、路径对象,或实现了write()函数的file-like对象,如果为None,则结果返回一个JSON字符串。
orient: 字符串。期望的JSON字符串格式。
Series: 默认为index,允许的值为{‘split’, ‘records’, ‘index’, ‘table’}。
DataFrame: 默认为columns,允许的值为{‘split’, ‘records’, ‘index’, ‘columns’, ‘values’, ‘table’}。
split: 类似于{index -> [index], columns -> [columns], data -> [values]}的字典。
records: 类似于[{column -> value}, … , {column -> value}]的列表。
index: 类似于{index -> {column -> value}}的字典。
columns: 类似于{column -> {index -> value}}的字典。
values: 仅为值的数组。
table: 类似于{‘schema’: {schema}, ‘data’: {data}}的字典。
date_format: 字符串,{None, ‘epoch’, ‘iso’}。
日期类型的转换。epoch是时间戳,iso是ISO8601标准。
默认值取决于orient参数,对于orient=‘table’,默认值为iso,对于其他的orient值,默认值为epoch。
double_precision: 整数,默认值10。对浮点值进行编码时使用的小数位数。
force_ascii: 布尔值,默认值True。强制设置编码字符串为ASCI。
date_unit: 字符串,默认值’ms’(milliseconds,毫秒)。
编码的时间单位,管理时间戳和ISO8601的精度,可选‘s’, ‘ms’, ‘us’, ‘ns’中的一个,分布表示秒、毫秒、微秒和纳秒。
default_handler: 可调用对象,默认值None。
如果一个对象没有转换成一个恰当的JSON格式,处理程序就会被调用。采用单个参数(即要转换的对象),并返回一个序列化的对象。
lines: 布尔值,默认值False。
如果orient参数为records,则将每行写入记录为json,orient参数是其他格式,将抛出ValueError异常,因为其他格式不是list-like。
compression: 字符串或字典,默认值’infer’。用于在线压缩输出数据。
如果使用’infer’,且如果path_or_buf参数是path-like对象,则从以下扩展名中检测压缩:‘.gz’, ‘.bz2’, ‘.zip’, ‘.xz’, ‘.zst’, ‘.tar’, ‘.tar.gz’, ‘.tar.xz’或‘.tar.bz2’(否则不会进行压缩)。设置为None,表示不进行压缩。
index: 布尔值,默认值True。
是否在JSON字符串中包含索引值。仅当orient为split或table时,才支持不包含索引(index=False)。
indent: 整数,可选。用于缩进每条记录的空格长度。
storage_options: 字典,可选。
对特定存储连接(例如主机、端口、用户名、密码等)有意义的额外选项。
参考
https://pandas.pydata.org/docs/reference/io.html
相关文章:

Pandas数据导入和导出:CSV、Excel、MySQL、JSON
导入MySQL查询结果:read_sql import pandascon "mysqlpymysql://user:pass127.0.0.1/test" sql "SELECT * FROM student WHERE id 2"# sql查询 df1 pandas.read_sql(sqlsql, concon) print(df1)导入MySQL整张表:read_sql_table…...

第16期 | GPTSecurity周报
GPTSecurity是一个涵盖了前沿学术研究和实践经验分享的社区,集成了生成预训练 Transformer(GPT)、人工智能生成内容(AIGC)以及大型语言模型(LLM)等安全领域应用的知识。在这里,您可以…...
省钱兄短剧短视频视频滑动播放模块源码支持微信小程序h5安卓IOS
# 开源说明 开源省钱兄短剧系统的播放视频模块(写了测试弄了好久才弄出来、最核心的模块、已经实战了),使用uniapp技术,提供学习使用,支持IOSAndroidH5微信小程序,使用Hbuilder导入即可运行 #注意ÿ…...
SDRAM学习笔记(MT48LC16M16A2,w9812g6kh)
一、基本知识 SDRAM : 即同步动态随机存储器(Synchronous Dynamic Random Access Memory), 同步是指其时钟频率与对应控制器(CPU/FPGA)的系统时钟频率相同,并且内部命令 的发送与数据传输都是以该时钟为基准ÿ…...
ARM 学习笔记3 STM32G4 定时器相关资料整理
官方文档 AN4539 HRTIM cookbookAN4539_HRTIM使用指南 中文版的文档,注意文档的版本号滞后于英文原版ST MCU中文文档 中文文档汇总 博客文章 STM32-定时器详解【STM32H7教程】第63章 STM32H7的高分辨率定时器HRTIM基础知识和HAL库APIstm32f334 HRTIM触发ADC注入中…...

LeetCode 917 仅仅反转字母 简单
题目 - 点击直达 1. XXXXX1. 917 仅仅反转字母 简单1. 原题链接2. 题目要求3. 基础框架 2. 解题思路1. 思路分析2. 时间复杂度3. 代码实现 1. XXXXX 1. 917 仅仅反转字母 简单 给你一个字符串 s ,根据下述规则反转字符串: 所有非英文字母保留在原有位置…...
JAVA深化篇_25—— IO流章节全网最全总结(附详细思维导图)
IO流章节全网最全总结(附详细思维导图) 本篇开始,先奉上思维导图:(下载下来为超高清图,不愁小伙伴看不清!) 按流的方向分类: 输入流:数据源到程序(InputStr…...

易基因:ChIP-seq等揭示BRWD3调控KDM5活性以维持H3K4甲基化水平的表观机制|PNAS
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。 组蛋白修饰对调控染色质结构和基因表达至关重要,组蛋白修饰失调可能导致疾病状态和癌症。染色质结合蛋白BRWD3(Bromodomain and WD repeat-containing protein 3&…...

C++深度优先(DFS)算法的应用:收集所有金币可获得的最大积分
涉及知识点 深度优化(DFS) 记忆化 题目 节点 0 处现有一棵由 n 个节点组成的无向树,节点编号从 0 到 n - 1 。给你一个长度为 n - 1 的二维 整数 数组 edges ,其中 edges[i] [ai, bi] 表示在树上的节点 ai 和 bi 之间存在一条边。另给你一个下标从 0…...

uniapp中APP端使用echarts用formatter设置y轴保留2位小数点不生效
uniapp使用echarts,在内置浏览器中,设置保留2位小数能正常显示(代码如下),但是在APP端这个设置不起作用。 yAxis: {type: value,axisLabel: {formatter: function (val) {return val.toFixed(2); //y轴始终保留小数点…...

无糖茶饮三十年,从无人问津到人手一瓶
【潮汐商业评论/原创】 Joan又在外卖上点了一堆瓶装茶饮,东方树叶、燃茶、三得利乌龙茶……买了四五种纯茶,用她的话说,和美式咖啡相比,这些无糖茶更适合他这个中国体质。 事实上,越来越多的消费者开始像Joan一样&am…...

面向Three.js开发者的3D自动纹理化开发包
DreamTexture.js 是面向 three.js 开发者的 3D 模型纹理自动生成与设置开发包,可以为 webGL 应用增加 3D 模型的快速自动纹理化能力。 图一为原始模型, 图二图三为贴图后的模型。提示词: city, Realistic , cinematic , Front view ,Game scene graph 1、…...

数字孪生技术与VR:创造数字未来
在当今数字化浪潮中,数字孪生和虚拟现实(VR)技术是两大亮点,它们以独特的方式相互结合,为各个领域带来了创新和无限可能。本篇文章将探讨数字孪生与VR之间的关系,以及它们如何共同开辟未来的新前景。 数字…...

系统架构设计师-第15章-面向服务架构设计理论与实践-软考学习笔记
面向服务的体系结构(Service-Oriented Architecture, SOA) 面向服务的体系结构(Service-Oriented Architecture, SOA)是一种软件架构模式,它将应用程序的不同功能组织为一组可重用的、松耦合的、自治的服务,这些服务通…...
为什么我觉得Rust比C++复杂得多?
为什么我觉得Rust比C复杂得多? Rust自学确实有一定门槛,很多具体问题解决起来搜索引擎也不太帮的上忙,会出现卡住的情况,卡的时间长了就放弃了。最近很多小伙伴找我,说想要一些c语言资料,然后我根据自己从…...
- 03 增删改查)
python sqlalchemy(ORM)- 03 增删改查
文章目录 ORM更新数据ORM查询ORM删除操作处理关系对象多表的关联查询 本节所有案例基于(第一节 python sqlalchemy(ORM)- 01 ORM简单使用)中的User、Address两个模型类 ORM更新数据 查询到模型类对象,直接修改其属性…...

Flutter笔记:完全基于Flutter绘图技术绘制一个精美的Dash图标(上)
Flutter笔记 完全基于Flutter绘图技术绘制一个精美的Dart语言吉祥物Dash(上) 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址:https://…...

学习gorm:彻底弄懂Find、Take、First和Last函数的区别
在gorm中,要想从数据库中查找数据有多种方法,可以通过Find、Take和First来查找。但它们之间又有一些不同。本文就详细介绍下他们之间的不同。 一、准备工作 首先我们有一个m_tests表,其中id字段是自增的主键,同时该表里有3条数据…...
796. 子矩阵的和(二维前缀和)
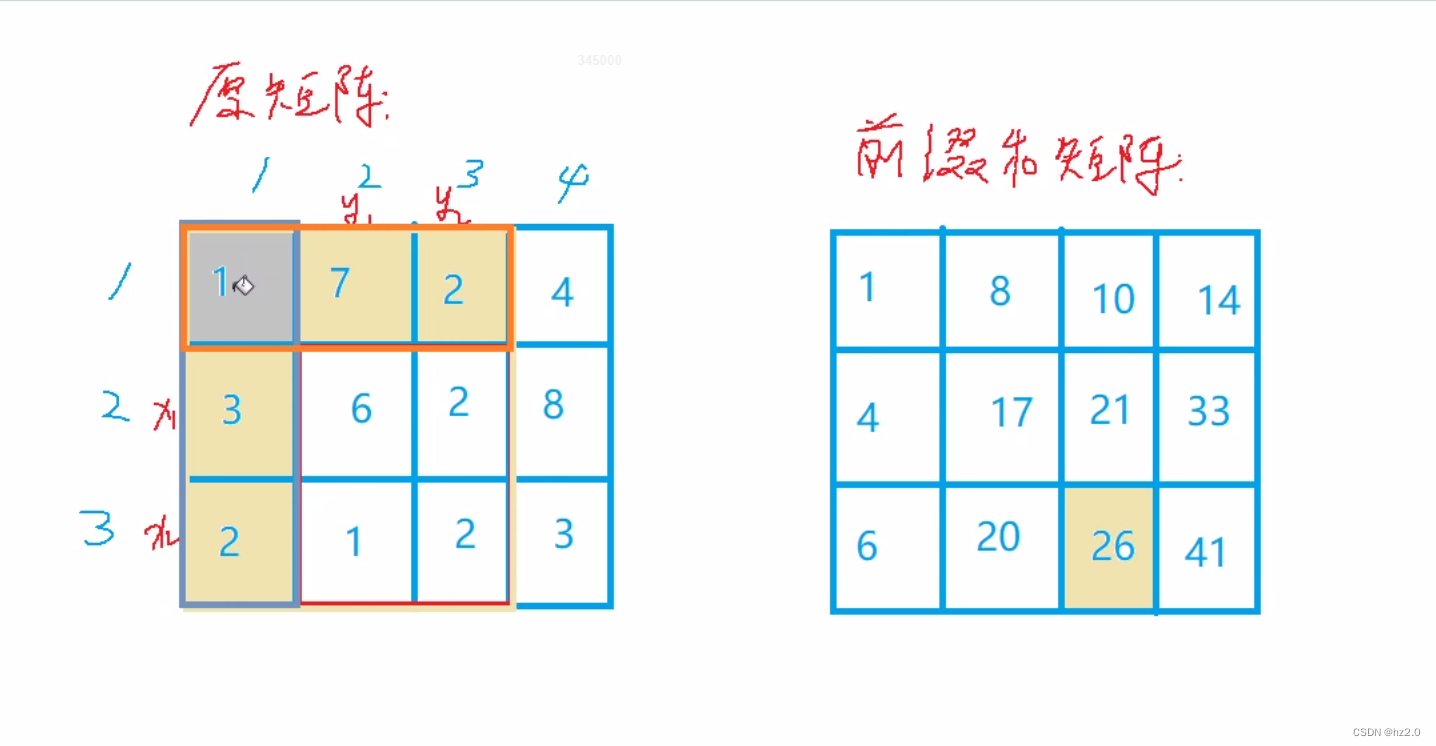
题目: 796. 子矩阵的和 - AcWing题库 思路: 1.暴力搜索(搜索时间复杂度为O(n2),很多时候会超时) 2. 前缀和(左上角(二维)前缀和):本题特殊在不是直接求前…...
利用ChatGPT进行股票走势分析
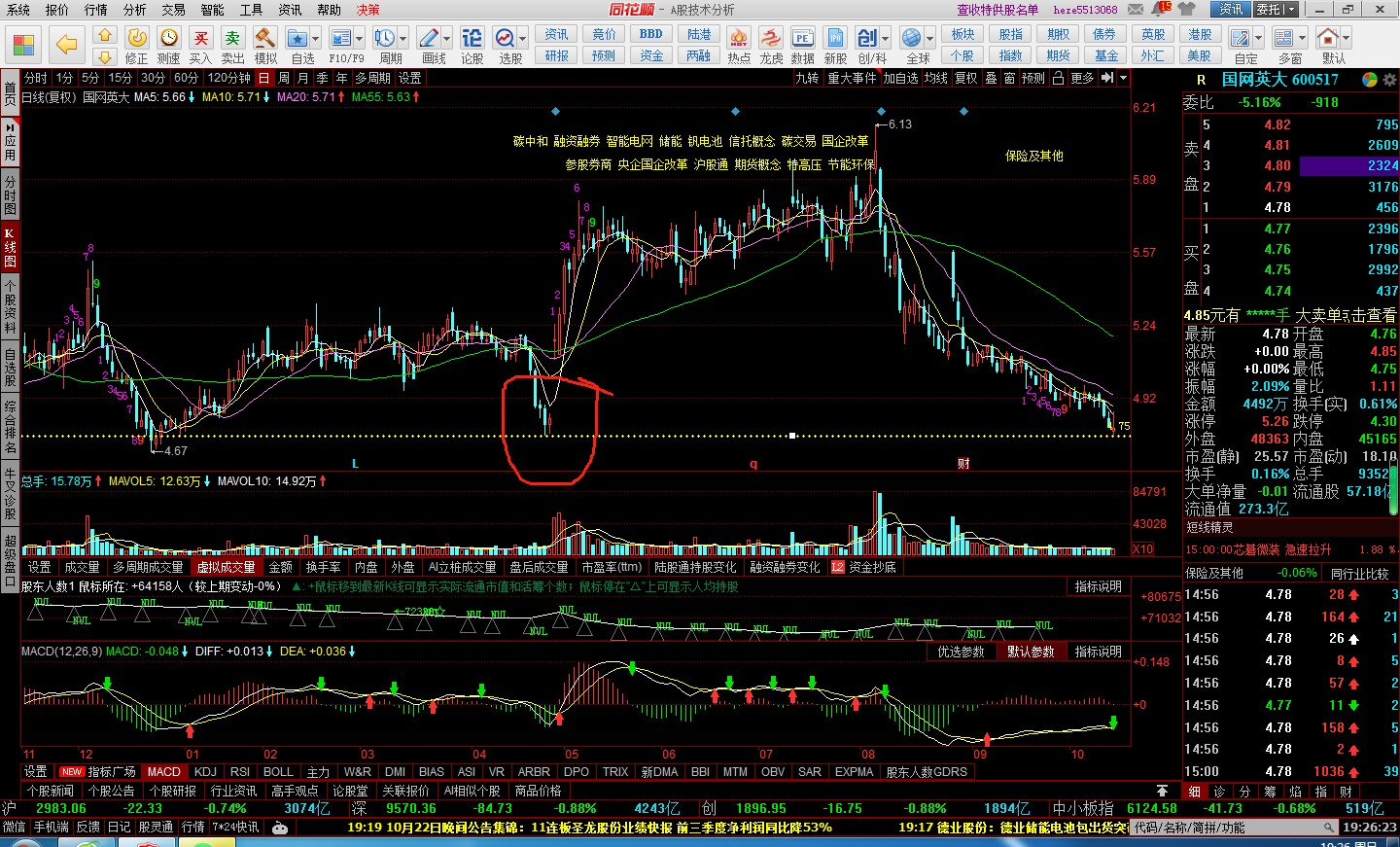
文章目录 1. 股票分析2. 技巧分析3. 分析技巧21. 股票分析 这张图片显示了一个股票交易软件的界面。以下是根据图片内容的一些解读: 股票代码: 图片右上角显示的代码是“600517”,这是股票的代码。 图形解读: 该图展示了股票的日K线图。其中,蜡烛图表示每日的开盘、收盘、最…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

理解 MCP 工作流:使用 Ollama 和 LangChain 构建本地 MCP 客户端
🌟 什么是 MCP? 模型控制协议 (MCP) 是一种创新的协议,旨在无缝连接 AI 模型与应用程序。 MCP 是一个开源协议,它标准化了我们的 LLM 应用程序连接所需工具和数据源并与之协作的方式。 可以把它想象成你的 AI 模型 和想要使用它…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台
🎯 使用 Streamlit 构建支持主流大模型与 Ollama 的轻量级统一平台 📌 项目背景 随着大语言模型(LLM)的广泛应用,开发者常面临多个挑战: 各大模型(OpenAI、Claude、Gemini、Ollama)接口风格不统一;缺乏一个统一平台进行模型调用与测试;本地模型 Ollama 的集成与前…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

【网络安全】开源系统getshell漏洞挖掘
审计过程: 在入口文件admin/index.php中: 用户可以通过m,c,a等参数控制加载的文件和方法,在app/system/entrance.php中存在重点代码: 当M_TYPE system并且M_MODULE include时,会设置常量PATH_OWN_FILE为PATH_APP.M_T…...

深入理解Optional:处理空指针异常
1. 使用Optional处理可能为空的集合 在Java开发中,集合判空是一个常见但容易出错的场景。传统方式虽然可行,但存在一些潜在问题: // 传统判空方式 if (!CollectionUtils.isEmpty(userInfoList)) {for (UserInfo userInfo : userInfoList) {…...