pytorch:Model模块专题
一、说明
关于pytorch使用中,模块扮演重要校色,大部分功能不能密集展现,因此,我们这个文章中,将模块的种种功能详细演示一遍。
二、模块
PyTorch使用模块来表示神经网络。模块包括:
-
有状态计算的构建块。PyTorch 提供了一个强大的模块库,使定义新的自定义模块变得简单,允许 轻松构建复杂的多层神经网络。
-
与 PyTorch 的 autograd 系统紧密集成。模块使为 PyTorch 的优化器指定要更新的可学习参数变得简单。
-
易于使用和转换。模块易于保存和恢复,在 CPU/GPU/TPU 设备、修剪、量化等。
本说明介绍模块,适用于所有 PyTorch 用户。由于模块是 PyTorch 的基础, 本说明中的许多主题在其他说明或教程中进行了详细说明,并链接到其中许多文档 这里也提供了。
-
一个简单的自定义模块
-
模块作为构建块
-
使用模块进行神经网络训练
-
模块状态
-
模块初始化
-
模块挂钩
-
高级功能
-
分布式训练
-
性能分析
-
通过量化提高性能
-
通过修剪提高内存使用率
-
参数化
-
使用 FX 转换模块
-
2.1 一个简单的自定义模块
首先,让我们看一下 PyTorch 模块的一个更简单的自定义版本。 此模块对其输入应用仿射变换。
import torch
from torch import nnclass MyLinear(nn.Module):def __init__(self, in_features, out_features):super().__init__()self.weight = nn.Parameter(torch.randn(in_features, out_features))self.bias = nn.Parameter(torch.randn(out_features))def forward(self, input):return (input @ self.weight) + self.bias
这个简单的模块具有模块的以下基本特征:
-
它继承自基模块类。所有模块都应子类化,以便与其他模块可组合。
-
它定义了计算中使用的一些“状态”。在这里,状态由随机初始化和定义仿射的张量组成 转型。由于其中每个都定义为 ,因此它们已为模块注册,并且将自动跟踪并从调用中返回 到 。参数可以是 考虑了模块计算的“可学习”方面(稍后会详细介绍)。请注意,模块 不需要有状态,也可以是无状态的。
weightbias -
它定义了一个执行计算的 forward() 函数。对于此仿射变换模块,输入 与参数矩阵相乘(使用速记符号)并添加到参数中以生成输出。更一般地说,模块的实现可以执行任意 涉及任意数量的输入和输出的计算。
weight@biasforward()
这个简单的模块演示了模块如何将状态和计算打包在一起。此模块的实例可以是 构造和调用:
m = MyLinear(4, 3)
sample_input = torch.randn(4)
m(sample_input)
: tensor([-0.3037, -1.0413, -4.2057], grad_fn=<AddBackward0>)
请注意,模块本身是可调用的,调用它调用其函数。 此名称参考了适用于每个模块的“正向传递”和“向后传递”的概念。 “前向传递”负责应用模块表示的计算 到给定的输入(如上面的代码片段所示)。“向后传递”计算的梯度为 模块输出相对于其输入,可用于通过梯度“训练”参数 下降方法。PyTorch 的 autograd 系统会自动处理这种向后传递计算,因此它 不需要为每个模块手动实现一个函数。培训过程 通过连续的正向/向后传递的模块参数在模块的神经网络训练中有详细介绍。forward()backward()
模块注册的完整参数集可以通过调用 或 进行迭代。 其中后者包括每个参数的名称:
for parameter in m.named_parameters():print(parameter)
: ('weight', Parameter containing:
tensor([[ 1.0597, 1.1796, 0.8247],[-0.5080, -1.2635, -1.1045],[ 0.0593, 0.2469, -1.4299],[-0.4926, -0.5457, 0.4793]], requires_grad=True))
('bias', Parameter containing:
tensor([ 0.3634, 0.2015, -0.8525], requires_grad=True))
通常,模块注册的参数是模块计算的方面,应该是 “学会了”。本说明的后面部分将介绍如何使用 PyTorch 的优化器之一更新这些参数。 然而,在我们开始之前,让我们首先研究一下模块是如何相互组合的。
2.2 模块作为构建块
模块可以包含其他模块,使其成为开发更复杂功能的有用构建块。 最简单的方法是使用该模块。它使我们能够链接在一起 多个模块:
net = nn.Sequential(MyLinear(4, 3),nn.ReLU(),MyLinear(3, 1)
)sample_input = torch.randn(4)
net(sample_input)
: tensor([-0.6749], grad_fn=<AddBackward0>)
Note that Sequential automatically feeds the output of the first module as input into the ReLU, and the output of that as input into the second module. As shown, it is limited to in-order chaining of modules with a single input and output.MyLinearMyLinear
In general, it is recommended to define a custom module for anything beyond the simplest use cases, as this gives full flexibility on how submodules are used for a module’s computation.
For example, here’s a simple neural network implemented as a custom module:
import torch.nn.functional as Fclass Net(nn.Module):def __init__(self):super().__init__()self.l0 = MyLinear(4, 3)self.l1 = MyLinear(3, 1)def forward(self, x):x = self.l0(x)x = F.relu(x)x = self.l1(x)return x
该模块由两个“子模块”或“子模块”(和)组成,它们定义了 神经网络,用于模块方法中的计算。立即的 模块的子模块可以通过调用 或 进行迭代:l0l1forward()
net = Net()
for child in net.named_children():print(child)
: ('l0', MyLinear())
('l1', MyLinear())
要更深入地了解直接子模块,并递归遍历模块及其子模块:
class BigNet(nn.Module):def __init__(self):super().__init__()self.l1 = MyLinear(5, 4)self.net = Net()def forward(self, x):return self.net(self.l1(x))big_net = BigNet()
for module in big_net.named_modules():print(module)
: ('', BigNet((l1): MyLinear()(net): Net((l0): MyLinear()(l1): MyLinear())
))
('l1', MyLinear())
('net', Net((l0): MyLinear()(l1): MyLinear()
))
('net.l0', MyLinear())
('net.l1', MyLinear())
有时,模块需要动态定义子模块。 和模块在这里很有用;他们 从列表或字典中注册子模块:
class DynamicNet(nn.Module):def __init__(self, num_layers):super().__init__()self.linears = nn.ModuleList([MyLinear(4, 4) for _ in range(num_layers)])self.activations = nn.ModuleDict({'relu': nn.ReLU(),'lrelu': nn.LeakyReLU()})self.final = MyLinear(4, 1)def forward(self, x, act):for linear in self.linears:x = linear(x)x = self.activations[act](x)x = self.final(x)return xdynamic_net = DynamicNet(3)
sample_input = torch.randn(4)
output = dynamic_net(sample_input, 'relu')
对于任何给定模块,其参数由其直接参数以及所有子模块的参数组成。 这意味着调用和将 递归包含子参数,允许方便地优化网络内的所有参数:
for parameter in dynamic_net.named_parameters():print(parameter)
: ('linears.0.weight', Parameter containing:
tensor([[-1.2051, 0.7601, 1.1065, 0.1963],[ 3.0592, 0.4354, 1.6598, 0.9828],[-0.4446, 0.4628, 0.8774, 1.6848],[-0.1222, 1.5458, 1.1729, 1.4647]], requires_grad=True))
('linears.0.bias', Parameter containing:
tensor([ 1.5310, 1.0609, -2.0940, 1.1266], requires_grad=True))
('linears.1.weight', Parameter containing:
tensor([[ 2.1113, -0.0623, -1.0806, 0.3508],[-0.0550, 1.5317, 1.1064, -0.5562],[-0.4028, -0.6942, 1.5793, -1.0140],[-0.0329, 0.1160, -1.7183, -1.0434]], requires_grad=True))
('linears.1.bias', Parameter containing:
tensor([ 0.0361, -0.9768, -0.3889, 1.1613], requires_grad=True))
('linears.2.weight', Parameter containing:
tensor([[-2.6340, -0.3887, -0.9979, 0.0767],[-0.3526, 0.8756, -1.5847, -0.6016],[-0.3269, -0.1608, 0.2897, -2.0829],[ 2.6338, 0.9239, 0.6943, -1.5034]], requires_grad=True))
('linears.2.bias', Parameter containing:
tensor([ 1.0268, 0.4489, -0.9403, 0.1571], requires_grad=True))
('final.weight', Parameter containing:
tensor([[ 0.2509], [-0.5052], [ 0.3088], [-1.4951]], requires_grad=True))
('final.bias', Parameter containing:
tensor([0.3381], requires_grad=True))
It’s also easy to move all parameters to a different device or change their precision using to():
# Move all parameters to a CUDA device
dynamic_net.to(device='cuda')# Change precision of all parameters
dynamic_net.to(dtype=torch.float64)dynamic_net(torch.randn(5, device='cuda', dtype=torch.float64))
: tensor([6.5166], device='cuda:0', dtype=torch.float64, grad_fn=<AddBackward0>)
更一般地说,任意函数可以递归地应用于模块及其子模块: 使用该函数。例如,将自定义初始化应用于参数 模块及其子模块:
# Define a function to initialize Linear weights.
# Note that no_grad() is used here to avoid tracking this computation in the autograd graph.
@torch.no_grad()
def init_weights(m):if isinstance(m, nn.Linear):nn.init.xavier_normal_(m.weight)m.bias.fill_(0.0)# Apply the function recursively on the module and its submodules.
dynamic_net.apply(init_weights)
这些例子展示了如何通过模块组合和方便地形成复杂的神经网络 数据处理。为了允许使用最少的样板快速轻松地构建神经网络,PyTorch 在命名空间中提供执行常见神经的大型高性能模块库 网络操作,如池化、卷积、损失函数等。
在下一节中,我们将给出一个训练神经网络的完整示例。
有关更多信息,请查看:
-
PyTorch 提供的模块库:torch.nn
-
定义神经网络模块:PyTorch: Custom nn Modules — PyTorch Tutorials 2.1.0+cu121 documentation
2.3 使用模块进行神经网络训练
一旦网络建成,就必须对其进行训练,并且其参数可以使用PyTorch的参数之一轻松优化。 优化器来自 :
# Create the network (from previous section) and optimizer
net = Net()
optimizer = torch.optim.SGD(net.parameters(), lr=1e-4, weight_decay=1e-2, momentum=0.9)# Run a sample training loop that "teaches" the network
# to output the constant zero function
for _ in range(10000):input = torch.randn(4)output = net(input)loss = torch.abs(output)net.zero_grad()loss.backward()optimizer.step()# After training, switch the module to eval mode to do inference, compute performance metrics, etc.
# (see discussion below for a description of training and evaluation modes)
...
net.eval()
...
在这个简化的示例中,网络学习简单地输出零,因为任何非零输出都会根据 通过用作损失函数来达到其绝对值。虽然这不是一项非常有趣的任务, 培训的关键部分包括:
-
将创建一个网络。
-
创建一个优化器(在本例中为随机梯度下降优化器),并且网络的 参数与之关联。
-
训练循环...
-
获取输入,
-
运行网络,
-
计算损失,
-
将网络参数的梯度归零,
-
调用 loss.backward() 来更新参数的梯度,
-
调用 optimizer.step() 将梯度应用于参数。
-
运行上述代码片段后,请注意网络的参数已更改。特别是,检查 的值参数显示其值现在更接近 0(正如预期的那样):l1weight
print(net.l1.weight)
: Parameter containing:
tensor([[-0.0013],[ 0.0030],[-0.0008]], requires_grad=True)
请注意,上述过程完全是在网络模块处于“训练模式”时完成的。模块默认为 训练模式,可以使用 和 在训练模式和评估模式之间切换。它们的行为可能有所不同,具体取决于它们所处的模式。例如,模块在训练期间维护未更新的运行均值和方差 当模块处于评估模式时。一般来说,模块在训练期间应该处于训练模式 并且仅切换到评估模式进行推理或评估。下面是自定义模块的示例 两种模式之间的行为不同:BatchNorm
class ModalModule(nn.Module):def __init__(self):super().__init__()def forward(self, x):if self.training:# Add a constant only in training mode.return x + 1.else:return xm = ModalModule()
x = torch.randn(4)print('training mode output: {}'.format(m(x)))
: tensor([1.6614, 1.2669, 1.0617, 1.6213, 0.5481])m.eval()
print('evaluation mode output: {}'.format(m(x)))
: tensor([ 0.6614, 0.2669, 0.0617, 0.6213, -0.4519])
训练神经网络通常很棘手。有关更多信息,请查看:
-
使用优化器:PyTorch: optim — PyTorch Tutorials 2.1.0+cu121 documentation。
-
神经网络训练:Neural Networks — PyTorch Tutorials 2.1.0+cu121 documentation
-
自动刻度简介:A Gentle Introduction to torch.autograd — PyTorch Tutorials 2.1.0+cu121 documentation
2.4 模块状态
在上一节中,我们演示了训练模块的“参数”或计算的可学习方面。 现在,如果我们想将训练好的模型保存到磁盘,我们可以通过保存它(即“状态字典”)来实现:state_dict
# Save the module
torch.save(net.state_dict(), 'net.pt')...# Load the module later on
new_net = Net()
new_net.load_state_dict(torch.load('net.pt'))
: <All keys matched successfully>
模块包含影响其计算的状态。这包括但不限于 模块的参数。对于某些模块,具有影响模块的参数之外的状态可能很有用 计算,但不可学习。对于这种情况,PyTorch 提供了“缓冲区”的概念,两者都是“持久”的。 和“非持久性”。以下是模块可以具有的各种类型的状态的概述:state_dict
-
参数:计算的可学习方面;包含在
state_dict -
缓冲区:计算的不可学习方面
-
持久缓冲区:包含在(即保存和加载时序列化)
state_dict -
非持久性缓冲区:不包含在 中(即未被序列化)
state_dict
-
作为使用缓冲区的激励示例,请考虑一个维护运行平均值的简单模块。我们想要 运行均值的当前值被视为模块的一部分,因此它将 在加载模块的序列化形式时恢复,但我们不希望它是可学习的。 此代码段演示如何使用来实现此目的:state_dict
class RunningMean(nn.Module):def __init__(self, num_features, momentum=0.9):super().__init__()self.momentum = momentumself.register_buffer('mean', torch.zeros(num_features))def forward(self, x):self.mean = self.momentum * self.mean + (1.0 - self.momentum) * xreturn self.mean
现在,运行平均值的当前值被视为模块的一部分,并且在从磁盘加载模块时将正确恢复:state_dict
m = RunningMean(4)
for _ in range(10):input = torch.randn(4)m(input)print(m.state_dict())
: OrderedDict([('mean', tensor([ 0.1041, -0.1113, -0.0647, 0.1515]))]))# Serialized form will contain the 'mean' tensor
torch.save(m.state_dict(), 'mean.pt')m_loaded = RunningMean(4)
m_loaded.load_state_dict(torch.load('mean.pt'))
assert(torch.all(m.mean == m_loaded.mean))
如前所述,通过将缓冲区标记为非持久性,可以将缓冲区排除在模块之外:state_dict
self.register_buffer('unserialized_thing', torch.randn(5), persistent=False)
持久和非持久缓冲区都受到应用在以下设备上的模型范围设备/dtype 更改的影响:
# Moves all module parameters and buffers to the specified device / dtype
m.to(device='cuda', dtype=torch.float64)
可以使用 或 迭代模块的缓冲区。
for buffer in m.named_buffers():print(buffer)
以下类演示了在模块中注册参数和缓冲区的各种方法:
class StatefulModule(nn.Module):def __init__(self):super().__init__()# Setting a nn.Parameter as an attribute of the module automatically registers the tensor# as a parameter of the module.self.param1 = nn.Parameter(torch.randn(2))# Alternative string-based way to register a parameter.self.register_parameter('param2', nn.Parameter(torch.randn(3)))# Reserves the "param3" attribute as a parameter, preventing it from being set to anything# except a parameter. "None" entries like this will not be present in the module's state_dict.self.register_parameter('param3', None)# Registers a list of parameters.self.param_list = nn.ParameterList([nn.Parameter(torch.randn(2)) for i in range(3)])# Registers a dictionary of parameters.self.param_dict = nn.ParameterDict({'foo': nn.Parameter(torch.randn(3)),'bar': nn.Parameter(torch.randn(4))})# Registers a persistent buffer (one that appears in the module's state_dict).self.register_buffer('buffer1', torch.randn(4), persistent=True)# Registers a non-persistent buffer (one that does not appear in the module's state_dict).self.register_buffer('buffer2', torch.randn(5), persistent=False)# Reserves the "buffer3" attribute as a buffer, preventing it from being set to anything# except a buffer. "None" entries like this will not be present in the module's state_dict.self.register_buffer('buffer3', None)# Adding a submodule registers its parameters as parameters of the module.self.linear = nn.Linear(2, 3)m = StatefulModule()# Save and load state_dict.
torch.save(m.state_dict(), 'state.pt')
m_loaded = StatefulModule()
m_loaded.load_state_dict(torch.load('state.pt'))# Note that non-persistent buffer "buffer2" and reserved attributes "param3" and "buffer3" do
# not appear in the state_dict.
print(m_loaded.state_dict())
: OrderedDict([('param1', tensor([-0.0322, 0.9066])),('param2', tensor([-0.4472, 0.1409, 0.4852])),('buffer1', tensor([ 0.6949, -0.1944, 1.2911, -2.1044])),('param_list.0', tensor([ 0.4202, -0.1953])),('param_list.1', tensor([ 1.5299, -0.8747])),('param_list.2', tensor([-1.6289, 1.4898])),('param_dict.bar', tensor([-0.6434, 1.5187, 0.0346, -0.4077])),('param_dict.foo', tensor([-0.0845, -1.4324, 0.7022])),('linear.weight', tensor([[-0.3915, -0.6176],[ 0.6062, -0.5992],[ 0.4452, -0.2843]])),('linear.bias', tensor([-0.3710, -0.0795, -0.3947]))])
有关更多信息,请查看:
-
保存和加载:Saving and Loading Models — PyTorch Tutorials 2.1.0+cu121 documentation
-
序列化语义:Serialization semantics — PyTorch main documentation
-
什么是州字典?What is a state_dict in PyTorch — PyTorch Tutorials 2.1.0+cu121 documentation
2.5 模块初始化
默认情况下,在 期间初始化 提供的模块的参数和浮点缓冲区 模块实例化为 CPU 上的 32 位浮点值,使用确定为 对于模块类型,历史上表现良好。对于某些用例,可能需要使用不同的初始化 dtype、设备(例如 GPU)或初始化技术。
例子:
# Initialize module directly onto GPU.
m = nn.Linear(5, 3, device='cuda')# Initialize module with 16-bit floating point parameters.
m = nn.Linear(5, 3, dtype=torch.half)# Skip default parameter initialization and perform custom (e.g. orthogonal) initialization.
m = torch.nn.utils.skip_init(nn.Linear, 5, 3)
nn.init.orthogonal_(m.weight)
请注意,上面演示的设备和 dtype 选项也适用于注册的任何浮点缓冲区 对于模块:
m = nn.BatchNorm2d(3, dtype=torch.half)
print(m.running_mean)
: tensor([0., 0., 0.], dtype=torch.float16)
虽然模块编写者可以使用任何设备或 dtype 来初始化其自定义模块中的参数,但好的做法是 使用,并且默认情况下也是如此。或者,您可以提供充分的灵活性 在自定义模块的这些区域,通过遵守上面演示的约定,所有模块都遵循:dtype=torch.floatdevice='cpu'
-
提供一个构造函数 kwarg,该构造函数适用于模块注册的任何参数/缓冲区。
device -
提供一个构造函数 kwarg,适用于注册的任何参数/浮点缓冲区 模块。
dtype -
仅对 模块的构造函数。请注意,这只需要使用 ;有关说明,请参阅此页面。
torch.nn.init
有关更多信息,请查看:
-
跳过模块参数初始化:Skipping Module Parameter Initialization — PyTorch Tutorials 2.1.0+cu121 documentation
2.6 模块挂钩
在 使用模块的神经网络训练中,我们演示了一个模块的训练过程,它迭代 执行向前和向后传递,每次迭代更新模块参数。实现更多控制 在这个过程中,PyTorch提供了“钩子”,可以在向前或向后执行任意计算。 传递,如果需要,甚至可以修改传递的完成方式。此功能的一些有用示例包括 调试、可视化激活、深入检查梯度等。可以将钩子添加到模块中 你还没有自己编写,这意味着这个功能可以应用于第三方或 PyTorch 提供的模块。
PyTorch 为模块提供了两种类型的钩子:
-
前向钩子在前向传递期间调用。可以使用 和 为给定模块安装它们。 这些钩子将分别在调用转发函数之前和调用之后调用。 或者,这些钩子可以全局安装到具有类似和功能的所有模块上。
-
向后钩子在向后传递期间调用。它们可以与 和 一起安装。 当计算了此模块的向后时,将调用这些钩子。将允许用户访问输出的梯度 而将允许用户访问渐变 输入和输出。或者,可以为带有 和 的所有模块全局安装它们。
所有钩子都允许用户返回一个更新的值,该值将在整个剩余的计算中使用。 因此,这些钩子可用于沿常规模块向前/向后执行任意代码,或者 修改一些输入/输出,而无需更改模块的功能。forward()
下面是一个演示向前和向后钩子用法的示例:
torch.manual_seed(1)def forward_pre_hook(m, inputs):# Allows for examination and modification of the input before the forward pass.# Note that inputs are always wrapped in a tuple.input = inputs[0]return input + 1.def forward_hook(m, inputs, output):# Allows for examination of inputs / outputs and modification of the outputs# after the forward pass. Note that inputs are always wrapped in a tuple while outputs# are passed as-is.# Residual computation a la ResNet.return output + inputs[0]def backward_hook(m, grad_inputs, grad_outputs):# Allows for examination of grad_inputs / grad_outputs and modification of# grad_inputs used in the rest of the backwards pass. Note that grad_inputs and# grad_outputs are always wrapped in tuples.new_grad_inputs = [torch.ones_like(gi) * 42. for gi in grad_inputs]return new_grad_inputs# Create sample module & input.
m = nn.Linear(3, 3)
x = torch.randn(2, 3, requires_grad=True)# ==== Demonstrate forward hooks. ====
# Run input through module before and after adding hooks.
print('output with no forward hooks: {}'.format(m(x)))
: output with no forward hooks: tensor([[-0.5059, -0.8158, 0.2390],[-0.0043, 0.4724, -0.1714]], grad_fn=<AddmmBackward>)# Note that the modified input results in a different output.
forward_pre_hook_handle = m.register_forward_pre_hook(forward_pre_hook)
print('output with forward pre hook: {}'.format(m(x)))
: output with forward pre hook: tensor([[-0.5752, -0.7421, 0.4942],[-0.0736, 0.5461, 0.0838]], grad_fn=<AddmmBackward>)# Note the modified output.
forward_hook_handle = m.register_forward_hook(forward_hook)
print('output with both forward hooks: {}'.format(m(x)))
: output with both forward hooks: tensor([[-1.0980, 0.6396, 0.4666],[ 0.3634, 0.6538, 1.0256]], grad_fn=<AddBackward0>)# Remove hooks; note that the output here matches the output before adding hooks.
forward_pre_hook_handle.remove()
forward_hook_handle.remove()
print('output after removing forward hooks: {}'.format(m(x)))
: output after removing forward hooks: tensor([[-0.5059, -0.8158, 0.2390],[-0.0043, 0.4724, -0.1714]], grad_fn=<AddmmBackward>)# ==== Demonstrate backward hooks. ====
m(x).sum().backward()
print('x.grad with no backwards hook: {}'.format(x.grad))
: x.grad with no backwards hook: tensor([[ 0.4497, -0.5046, 0.3146],[ 0.4497, -0.5046, 0.3146]])# Clear gradients before running backward pass again.
m.zero_grad()
x.grad.zero_()m.register_full_backward_hook(backward_hook)
m(x).sum().backward()
print('x.grad with backwards hook: {}'.format(x.grad))
: x.grad with backwards hook: tensor([[42., 42., 42.],[42., 42., 42.]])
三、高级功能
PyTorch 还提供了几个更高级的功能,旨在与模块配合使用。所有这些功能 可用于自定义编写的模块,但需要注意的是,某些功能可能需要模块才能符合 到特定的约束,以便得到支持。深入讨论这些功能以及相应的 要求可以在下面的链接中找到。
分布式训练
PyTorch 中存在各种分布式训练方法,都可以使用多个 GPU 扩展训练。 以及跨多台机器的培训。查看分布式培训概述页面 有关如何使用这些的详细信息。
性能分析
PyTorch Profiler 可用于识别 模型中的性能瓶颈。它测量并输出 内存使用情况和花费的时间。
通过量化提高性能
将量化技术应用于模块可以通过利用较低的 位宽大于浮点精度。在此处查看 PyTorch 提供的各种量化机制。
通过修剪提高内存使用率
大型深度学习模型通常参数化过度,导致内存使用率高。为了解决这个问题,PyTorch 提供模型修剪机制,这有助于减少内存使用量,同时保持任务准确性。修剪教程描述了如何使用 修剪技术 PyTorch 根据需要提供或定义自定义修剪技术。
参数化
对于某些应用程序,在模型训练期间约束参数空间可能是有益的。例如 强制执行学习参数的正交性可以提高 RNN 的收敛性。 PyTorch 提供了一种机制 应用诸如此类的参数化,以及 进一步允许定义自定义约束。
使用 FX 转换模块
PyTorch 的 FX 组件提供了一种灵活的转换方式 模块通过直接在模块计算图上运行。这可用于以编程方式生成或 为各种用例操作模块。要探索 FX,请查看这些使用 FX 进行卷积 + 批量范数融合和 CPU 性能分析的示例。
相关文章:

pytorch:Model模块专题
一、说明 关于pytorch使用中,模块扮演重要校色,大部分功能不能密集展现,因此,我们这个文章中,将模块的种种功能详细演示一遍。 二、模块 PyTorch使用模块来表示神经网络。模块包括: 有状态计算的构建块。…...

Spring更加简单的读取和存储对象
前言:在上篇文章中,小编写了一个Spring的创建和使用的相关博客:Spring的创建和使用-CSDN博客,但是,操作/思路比较麻烦,那么本文主要带领大家走进:Spring更加简单的读取和存储对象! 本…...

Webpack5 系列:Babel 的配置
1.前言 本篇将介绍对于项目中 JS 文件的处理。 2.babel-loader 2-1.依赖安装 npm install -D babel-loader babel/core babel/preset-env2-2.Loader 配置 webpack.config.js module: {rules: [{test: /\.?js$/,exclude: /node_modules/,use: {loader: babel-loader}}] }…...
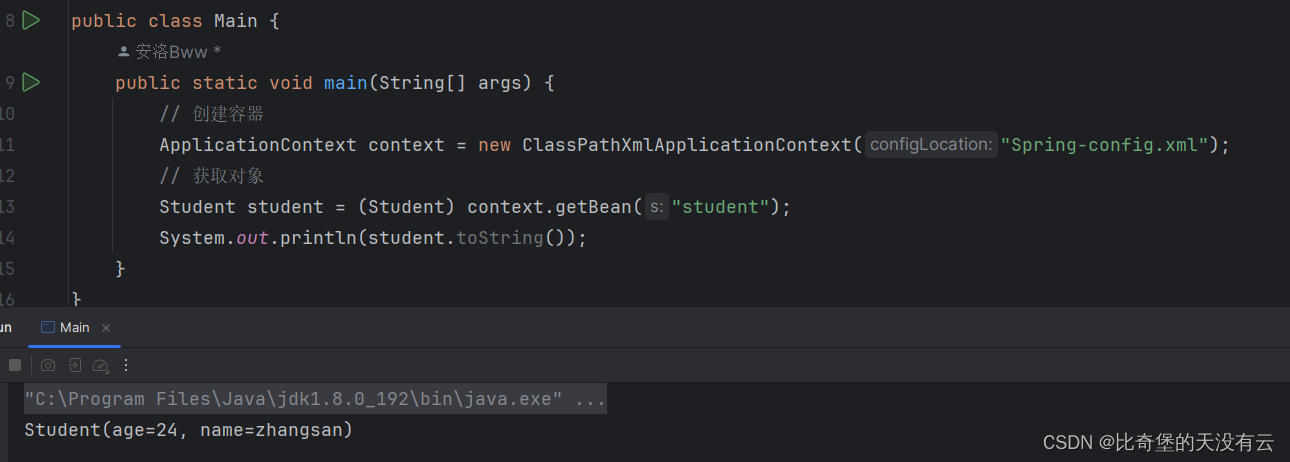
【Spring】DI依赖注入,Lombok以及SpEL
文章目录 1.什么是DI依赖注入2. set方法注入3. ref属性4. 有参构造方法注入5. Lombok6. SpEL 1.什么是DI依赖注入 依赖注入(Dependency Injection,简称DI)是一种设计模式,也是Spring框架的核心概念之一。其基本思想是将程序中的各…...
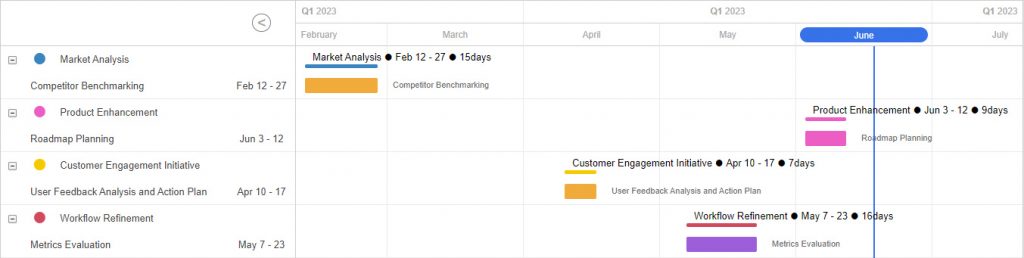
甘特图组件DHTMLX Gantt用例 - 如何自定义任务、月标记和网格新外观
dhtmlxGantt是用于跨浏览器和跨平台应用程序的功能齐全的Gantt图表。可满足项目管理应用程序的所有需求,是最完善的甘特图图表库。 本文将为大家揭示DHTMLX Gantt自定义的典型用例,包括自定义任务、网格的新外观等,来展示其功能的强大性&…...

auto自动类型推导总结
auto 自动推导的规则很多、很细,当涉及移动语义、模板等复杂的规则时,很容易绕进去。因此,在使用 auto 进行自动推导时,牢记以下几点: auto 推导出的是 “值类型”,不会是 “引用类型”。auto 可以和 cons…...

透视2023,如何看清中国SaaS的未来之路?
导读:什么是更适合中国市场的SaaS道路? 如果用一个关键词概括2023年的SaaS产业,很多人会想到:难。 在过去一年时间内,SaaS产业投融资环境巨变,一级市场投融资笔数和金额骤减。根据IT桔子数据,20…...

分类预测 | Matlab实现KOA-CNN-LSTM-selfAttention多特征分类预测(自注意力机制)
分类预测 | Matlab实现KOA-CNN-LSTM-selfAttention多特征分类预测(自注意力机制) 目录 分类预测 | Matlab实现KOA-CNN-LSTM-selfAttention多特征分类预测(自注意力机制)分类效果基本描述程序设计参考资料 分类效果 基本描述 1.Mat…...
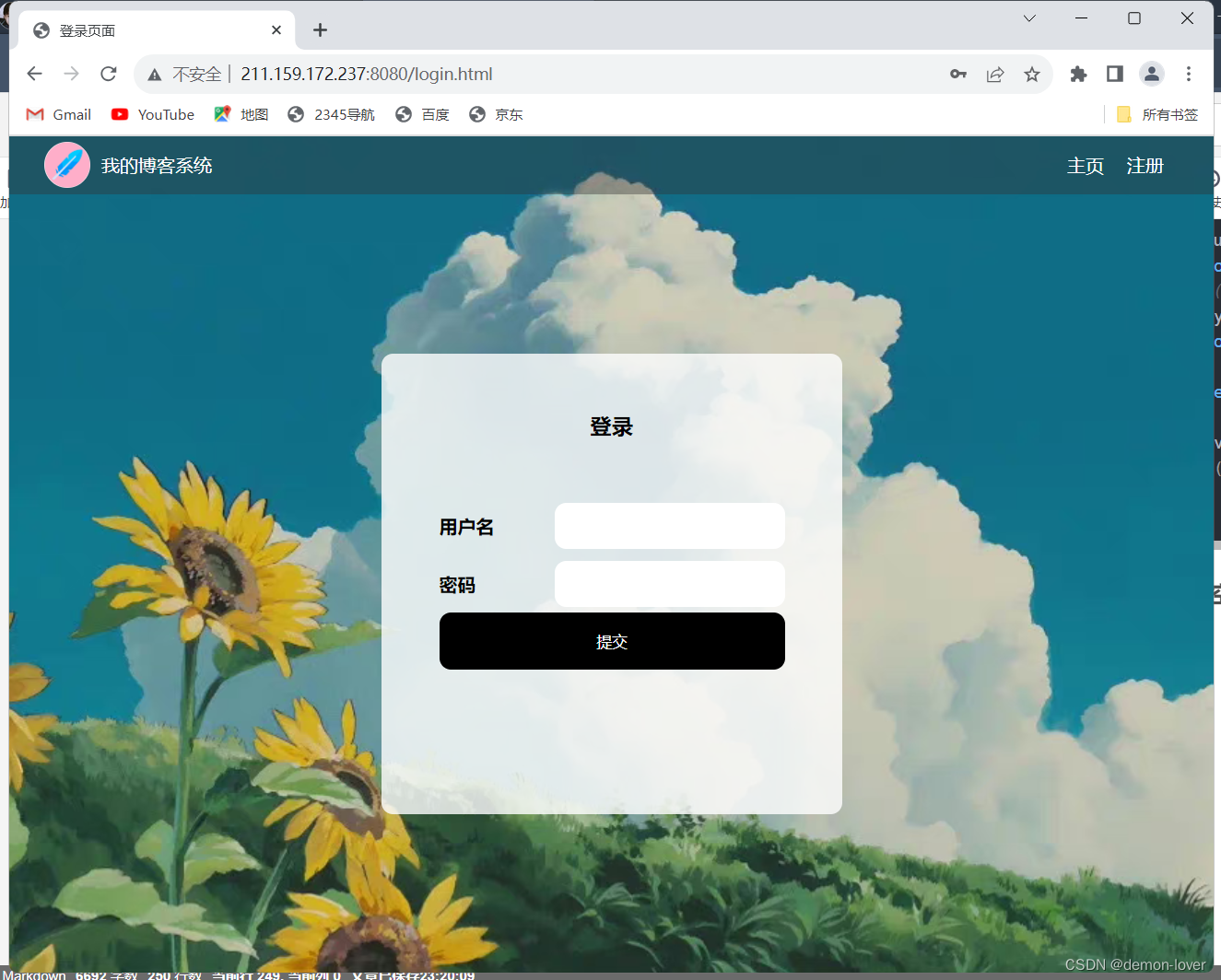
博客系统-项目测试
自动化博客项目 用户注册登录验证效验个人博客列表页博客数量不为 0 博客系统主页写博客 我的博客列表页效验 刚发布的博客的标题和时间查看 文章详情页删除文章效验第一篇博客 不是 "自动化测试" 注销退出到登录页面,用户名密码为空 用户注册 Order(1)Parameterized…...

Inspeckage,动态分析安卓 APP 的 Xposed 模块
前提 我在不久前写过《 APP 接口拦截与参数破解》的博文;最近爬取APP数据时又用到了相关技术,故在此详细描述一下 Inspeckage 的功能。(环境准备本文不再赘述) 功能 在电脑上访问 http://127.0.0.1:8008 就可以看到 inspeckage…...
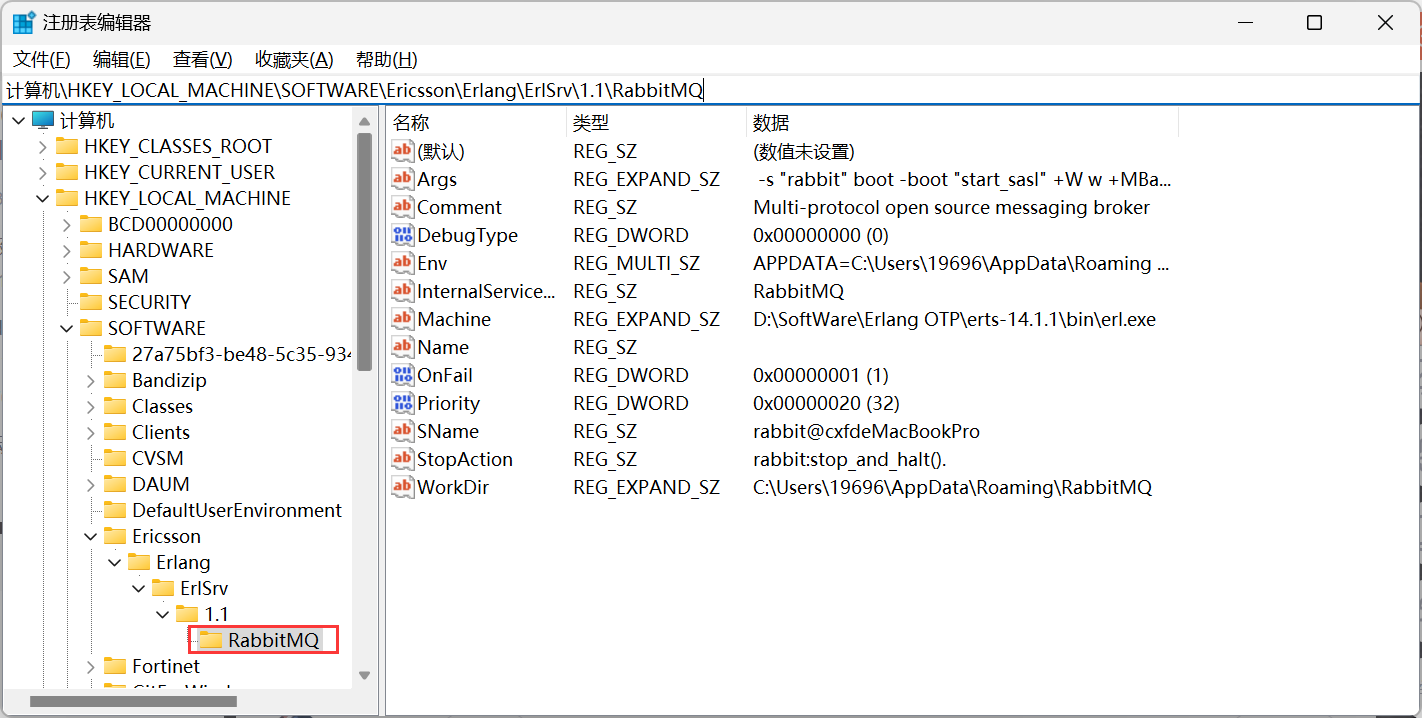
Windows详细安装和彻底删除RabbitMQ图文流程
RabbiitMQ简介 RabbitMQ是实现了高级消息队列协议(AMQP:Advanced Message Queue Protocol)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用Erlang语言编写的,而聚类和故障转移是构建在开放…...

自定义表单规则
const checkF (rule, value, callback) > { if (!value || value ) { callback(new Error(请输入XXXX)); } else { var params new URLSearchParams(); params.append(参数名, value); axios.post(url, params).then(operation > { if (operation && operatio…...

Spring 中 Bean 的作用域有哪些?Spring 中有哪些方式可以把 Bean 注入到 IOC 容器?
Spring 框架里面的 IOC 容器,可以非常方便的去帮助我们管理应用里面的Bean 对象实例。我们只需要按照 Spring 里面提供的 xml 或者注解等方式去告诉 IOC 容器,哪些 Bean需要被 IOC 容器管理就行了。 生命周期 既然是 Bean 对象实例的管理,那意…...

【01低功耗蓝牙开发】
低功耗蓝牙 低功耗蓝牙背后有个基本的概念:任何事物都有状态。状态可以是任何东西,如温度,电池状态等越简单的系统越便宜,开发更迅速,包含更少的错误,更加强健。一种技术想要获得成功必须降低成本。服务器…...

【Java 进阶篇】Java BeanUtils 使用详解
Java中的BeanUtils是一组用于操作JavaBean的工具,它允许你在不了解JavaBean的具体内部结构的情况下,访问和修改其属性。本文将详细介绍Java BeanUtils的使用,包括如何获取和设置JavaBean的属性,复制属性,以及如何处理嵌…...
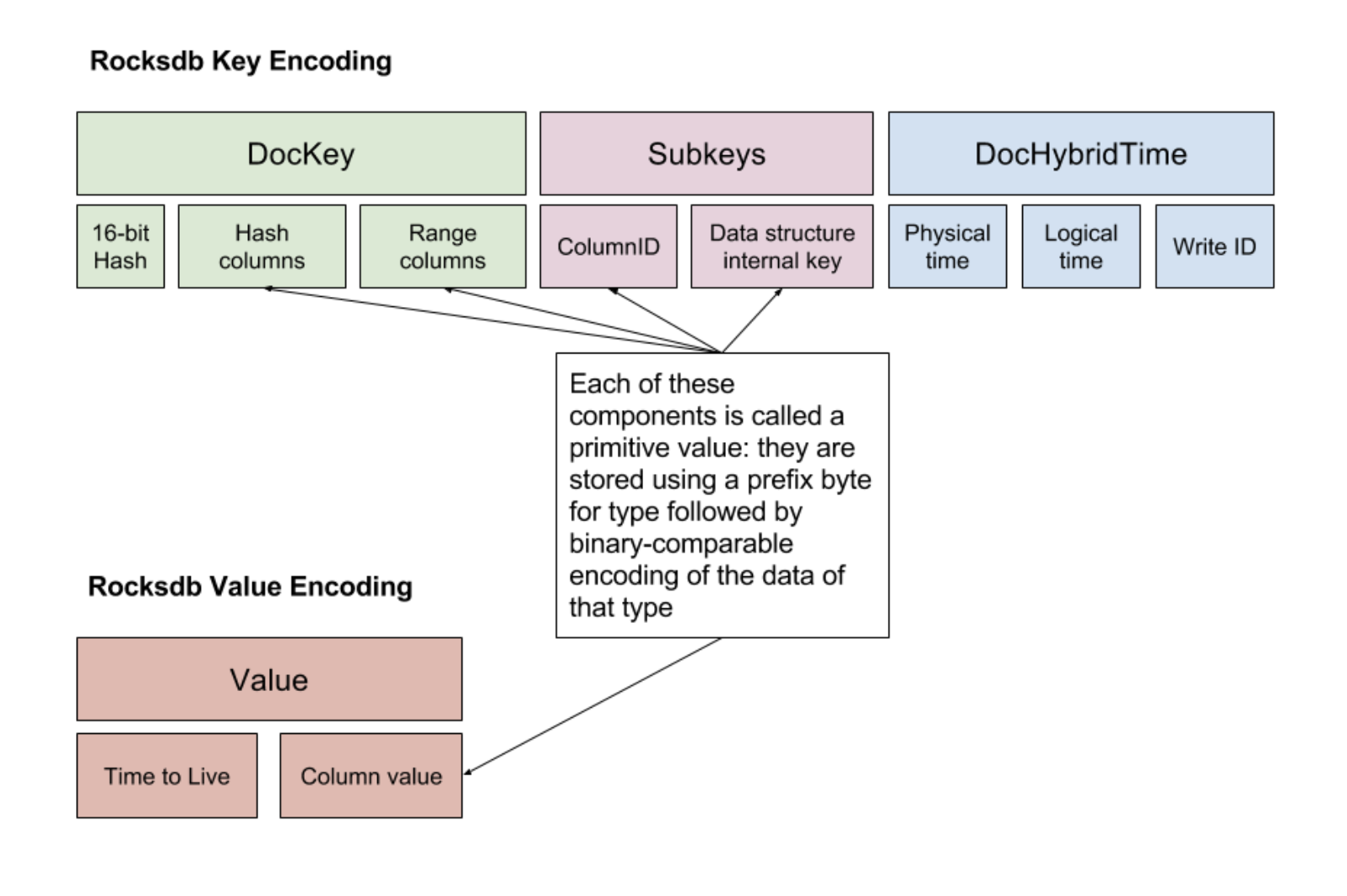
YugaByteDB -- 全新的 “PostgreSQL“ 存储层
文章目录 0 背景1 架构1.1 Master1.2 TServer1.3 Tablet 2 读写链路2.1 DDL2.2 DML2.3 事务 3 KEY 的设计4 Rocksdb 在 YB 中的一些实践总结 0 背景 YugaByteDB 的诞生也是抓住了 spanner 推行的NewSQL 浪潮的尾巴,以 PG 生态为基础 用C实现的 支持 SQL 以及 CQL 语…...

众佰诚:抖音上做生意卖什么好
随着科技的发展,越来越多的人开始利用网络平台进行创业。抖音作为目前最火的短视频平台之一,也成为了许多人选择的创业渠道。那么,在抖音上做生意卖什么好呢? 首先,我们可以考虑一些具有创新性和独特性的产品。例如,手…...

【Redis】环境配置
环境配置 Linux版本: Ubuntu 22.04.2 LTS 下载redis sudo apt install redis 启动redis redis-server 输入redis-server启动redis竟然报错了,原因是redis已经启动,网上大多数的解决方案如下: ps -ef | grep -i redis 查询redi…...

设计交换机原理图前应先理清的框图
一、系统布局图 需重点考虑“外壳、电源、风扇、主板(包含MAC、CPU、PHY)、指示灯、管理网口/串口、电口/光口等连接器”在整机中的大致位置,在系统布局图中予以体现。 二、系统框图 (1)电源整体框图; &…...
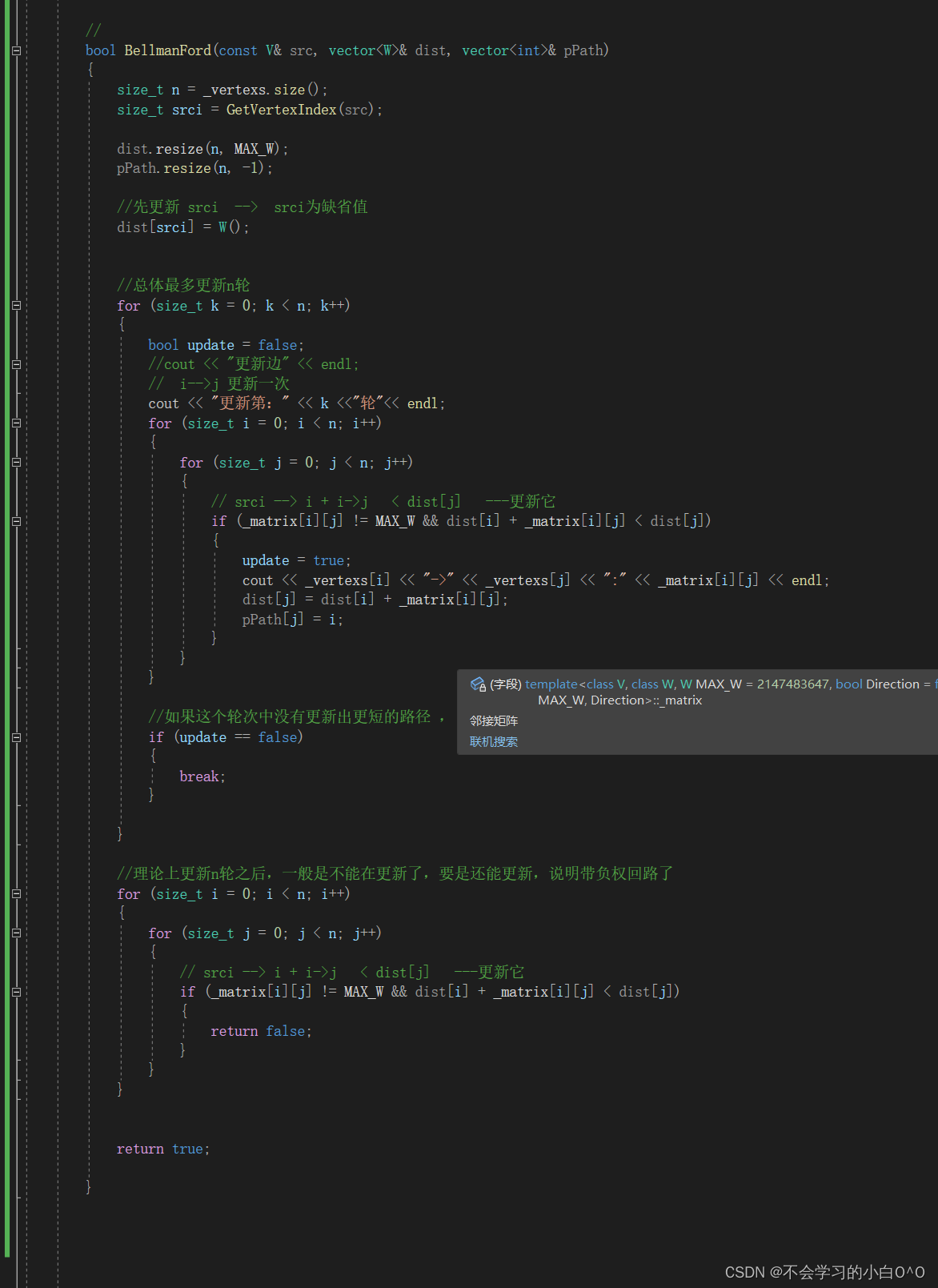
Bellman-ford 贝尔曼-福特算法
Bellman-ford算法可以解决负权图的单源最短路径问题 --- 它的优点是可以解决有负权边的单源最短路径问题,而且可以判断是否负权回路 它也有明显的缺点,它的时间复杂度O(N*E)(N是点数 , E是边数)…...
:手搓截屏和帧率控制)
Python|GIF 解析与构建(5):手搓截屏和帧率控制
目录 Python|GIF 解析与构建(5):手搓截屏和帧率控制 一、引言 二、技术实现:手搓截屏模块 2.1 核心原理 2.2 代码解析:ScreenshotData类 2.2.1 截图函数:capture_screen 三、技术实现&…...

PPT|230页| 制造集团企业供应链端到端的数字化解决方案:从需求到结算的全链路业务闭环构建
制造业采购供应链管理是企业运营的核心环节,供应链协同管理在供应链上下游企业之间建立紧密的合作关系,通过信息共享、资源整合、业务协同等方式,实现供应链的全面管理和优化,提高供应链的效率和透明度,降低供应链的成…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

Ascend NPU上适配Step-Audio模型
1 概述 1.1 简述 Step-Audio 是业界首个集语音理解与生成控制一体化的产品级开源实时语音对话系统,支持多语言对话(如 中文,英文,日语),语音情感(如 开心,悲伤)&#x…...

网络编程(UDP编程)
思维导图 UDP基础编程(单播) 1.流程图 服务器:短信的接收方 创建套接字 (socket)-----------------------------------------》有手机指定网络信息-----------------------------------------------》有号码绑定套接字 (bind)--------------…...

html-<abbr> 缩写或首字母缩略词
定义与作用 <abbr> 标签用于表示缩写或首字母缩略词,它可以帮助用户更好地理解缩写的含义,尤其是对于那些不熟悉该缩写的用户。 title 属性的内容提供了缩写的详细说明。当用户将鼠标悬停在缩写上时,会显示一个提示框。 示例&#x…...

android RelativeLayout布局
<?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"android:gravity&…...

【Veristand】Veristand环境安装教程-Linux RT / Windows
首先声明,此教程是针对Simulink编译模型并导入Veristand中编写的,同时需要注意的是老用户编译可能用的是Veristand Model Framework,那个是历史版本,且NI不会再维护,新版本编译支持为VeriStand Model Generation Suppo…...

云原生周刊:k0s 成为 CNCF 沙箱项目
开源项目推荐 HAMi HAMi(原名 k8s‑vGPU‑scheduler)是一款 CNCF Sandbox 级别的开源 K8s 中间件,通过虚拟化 GPU/NPU 等异构设备并支持内存、计算核心时间片隔离及共享调度,为容器提供统一接口,实现细粒度资源配额…...
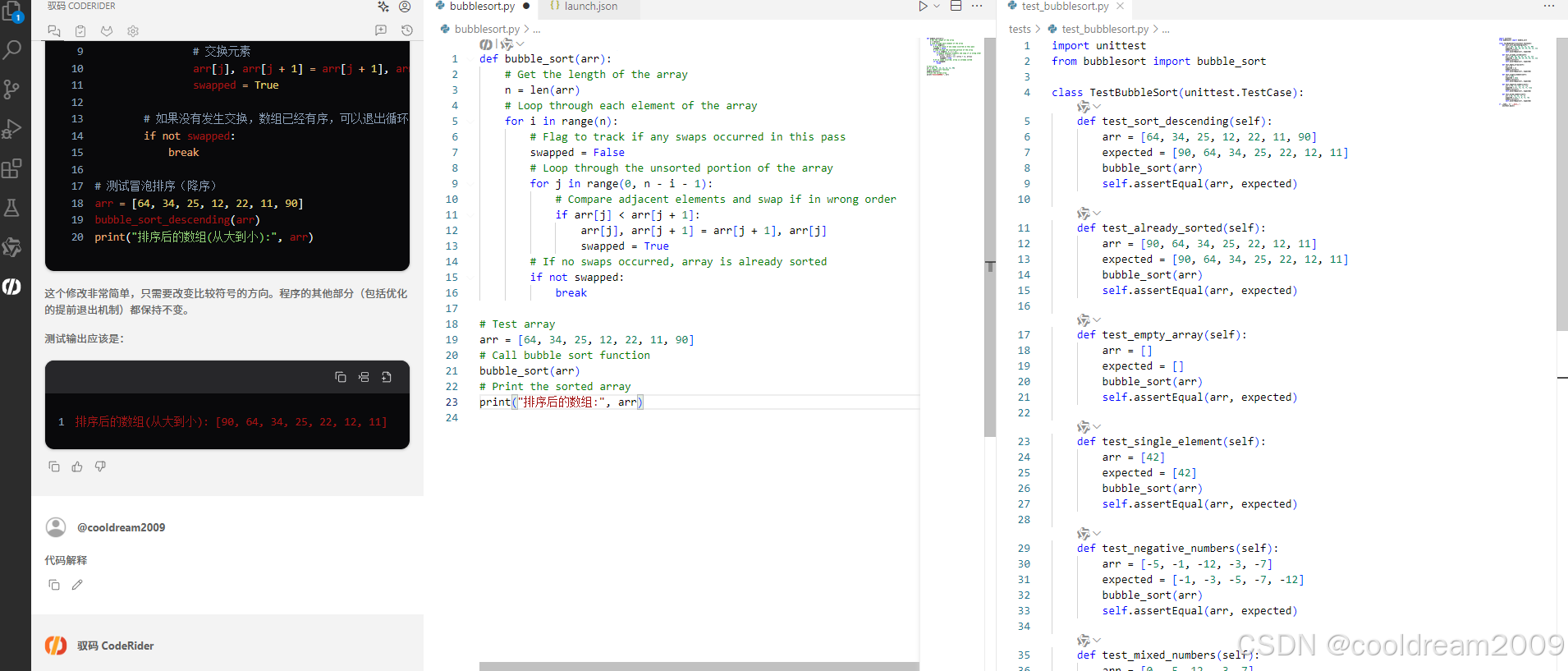
在 Visual Studio Code 中使用驭码 CodeRider 提升开发效率:以冒泡排序为例
目录 前言1 插件安装与配置1.1 安装驭码 CodeRider1.2 初始配置建议 2 示例代码:冒泡排序3 驭码 CodeRider 功能详解3.1 功能概览3.2 代码解释功能3.3 自动注释生成3.4 逻辑修改功能3.5 单元测试自动生成3.6 代码优化建议 4 驭码的实际应用建议5 常见问题与解决建议…...