Linux - 进程地址空间
前言
首先,我们先要对 内存当中存储 各个数据之间的 结构要有一个 大概的了解:

各个区当中存储的数据使用类型不同,所以,这些数据在使用方式上是有差别的。比如下面这个例子:

在C 语言当中我们不能直接对 上述的 str 这个字符指针直接进行解引用修改,因为,此时这个 str 指向的是 "hello Linux!" 这个字符串的手字符地址,管理的是这个 常量字符串,而常量字符串是存储在 字符常量区当中的,在这个 字符常量区当中的 数据,在初始化创建之后是不能再进行修改的。
所以上述的 *str = "H" 这句代码,的意思就是,把 "hello Linux!" 这个字符串当中的首字符修改成 "H" 这个字符,这肯定是不行的,所以会报错。
那么,在上面描述 什么 字符常量区,栈区,堆区等等的这些区的图当中,这些区的整合,这整个是在内存当中存储的吗?
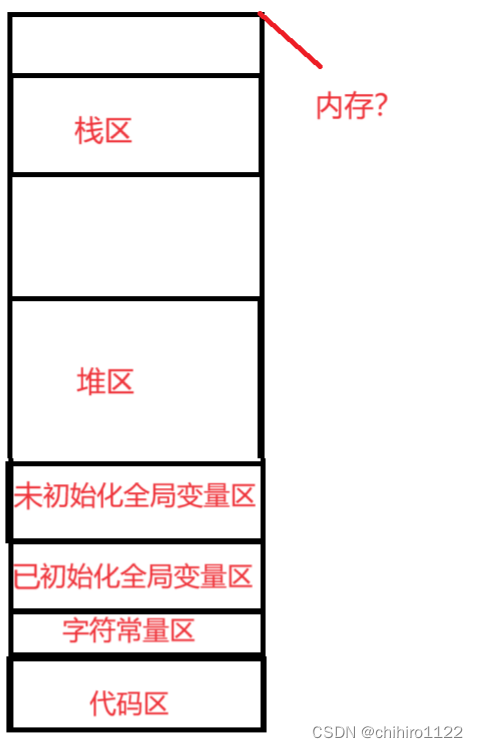
了解这个问题之前,我们先来了解一下,在 C 当中的各种变量在 这些区当中是如何去存储的 :
利用下述的代码,打印出来的地址位置来验证,上述的是否是正确 的:

打印:
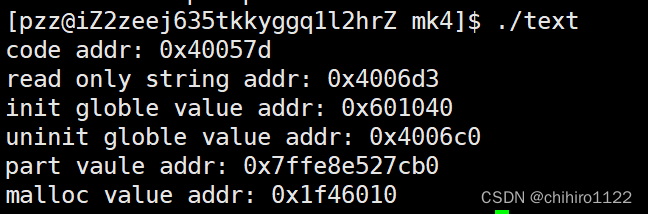
对应的 区空间如下图所示:

我们发现,其中的地址大小,其实是按照上述的图来划分存储的,如果你仔细观察,可以发现,其中的 地址,是按照 从下往上地址是 逐渐增长的。
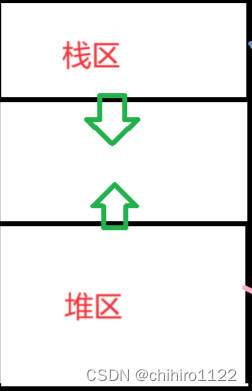
而在 栈区和 堆区当中,中间有一块空着的空间,这块空间其实是有点大的,而,两个区 的 数据是对向生长的:
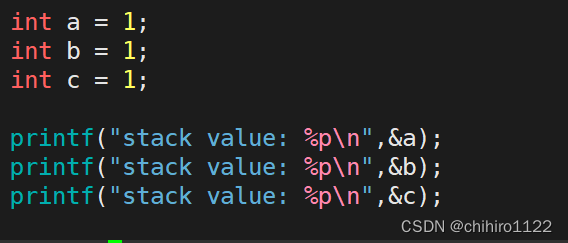
我们可以验证,如下所示是在栈区当中存储的 局部变量的地址,可以发现是,越在后创建的变量,地址越小:
输出:

你可以发现,我们是按照开始对 局部变量的定义顺序来 打印的 地址,你可以发现,这个地址是从上往下依次递减的。所以,我们就证明了 在栈区当中的 数据是往低地址方向来开辟空空间的。
所以,按照栈这个数据结构的存储数据的方式,先来的 数据先入栈,是在栈底位置的;而 后来的数据 后入栈,就是往 栈顶方向来开辟空间的,当然就是 后来的数据地址小啊。
同样的,还可以证明堆区当中存储 :

输出:

你可以发现,我们打印 堆上开辟空间,这些空间的起始地址,是按照定义顺序来打印的 ,而打印的地址的是按照从上往下,地址一次增大 。至此也就证明了,在堆当中的空间是往高地址来开辟空间的 。
所以,我们才会说,堆 和 栈之间是有一大片空间的,而 堆 和 栈是开辟空间的方向是 对向的。
那么为什么要这样做呢?其实,这样可以方式 栈 和 堆开辟空间过多,而占用到 过多的内存资源,栈 和 堆能开辟的最多空间资源就是 堆 和栈 之间的 那一段 空间。而通过上述对 堆 和 栈区的首地址打印,我们发现,其实这段空间之间的差距看上去还是蛮大的:

因为上述使用的系统是 64 位的,所以差别就更大了。同样,就算是 X86 的机器,差别也很大。
首先,我们知道全局变量是一直存在的,全局变量的声明周期是整个程序。不会随着程序当中的某一函数的返回,而释放。
我们把 已初始化的全局变量区 和 未初始化的全局变量区,这个两个区称为 全局数据区。只要是这个程序的地址空间存在,那么这个 全局数据区当中的数据就会释放。
这里也就衍生出一个语法,当我们在某一个函数当中 定义一个 static 的变量的时候,这个 static的变量不会随着 这个函数的 返回而释放,这个 static 变量的 声明周期是整个程序。但是 static 变量在初始化之后就不能在修改了。
那么,static 变量是如何做到上述,本函数释放,但是 static 变量不会释放的呢?
其实,是因为 ,static 变量,在编译之时已经被编译到全局数据区了。
也就是说,static 本身已经是一个 全局变量了,但是,static 变量是在函数体当中定义的,所以,static 变量被迫只能在 本函数体当中被使用。也就是说,static变量的 作用域 是在本函数当中,但是 ,static的声明周期 是在 全局的。
通过上述对于 全局变量的描述,相信你对全局的 概念有了一些了解,现在我们看看下面这个例子,我们使用 fork()函数来 创建出一个子进程,然后在子进程循环 和 父进程循环当中打印出 同一个 全局变量的 值 和 地址:
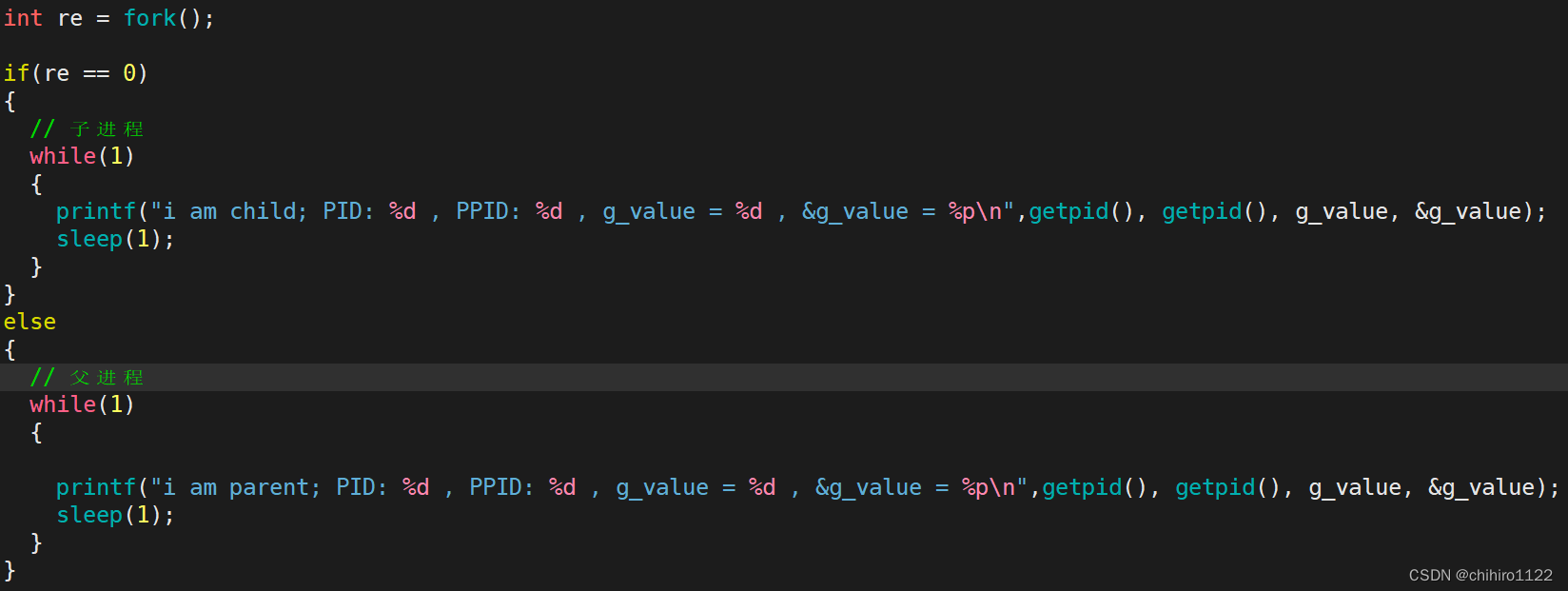
我们把 g_value 这个全局变量的 值 和 地址,在父进程和子进程当中的值都打出来:

发现 子父进程 g_value 的值和 地址都是一样的,这个我们先不看,当我们在子进程当中,把 g_value 的值修改了,但是在 父进程当中不进行修改,那么会影响到父进程吗?

如上所示,我们对子进程的代码做如上处理,父进程代码不做处理,当在子进程当中修改到 g_value 的时候,打印结果如下:

如上所示,子进程的 g-value 修改到了 200,但是 父进程却还是0 。其实这个还不是最怪的,因为 ,进程之间是要独立的。在子进程修改其中的变量之前,父子进程读取的是一个变量,但是,如果子进程对某一个变量进行了修改,那么,就会发生写时拷贝,只是多拷贝一个 相同的变量地址空间,给 子进程自己用,此时相当于是 父子进程使用的是同名的两个变量。
但是,奇怪的是,上述子父进程打印的 g_value 变量的地址是一样的啊,但是,访问出的值却是不一样的。他是怎么做到的呢?
所以,如果上述的地址是一个物理地址,那么是绝对不可能出现上述的情况的。所以,这个地址绝对不是一个物理地址。要不然,如果是一个物理地址的话,两个进程读取同一块空间的数据,读取的数据会不一样呢?
其实,这个地址,是 线性地址(虚拟地址)。
我们在 C/C++ 当中使用的地址其实都不是物理地址,他只是一个映射在 物理地址 的 线性地址。
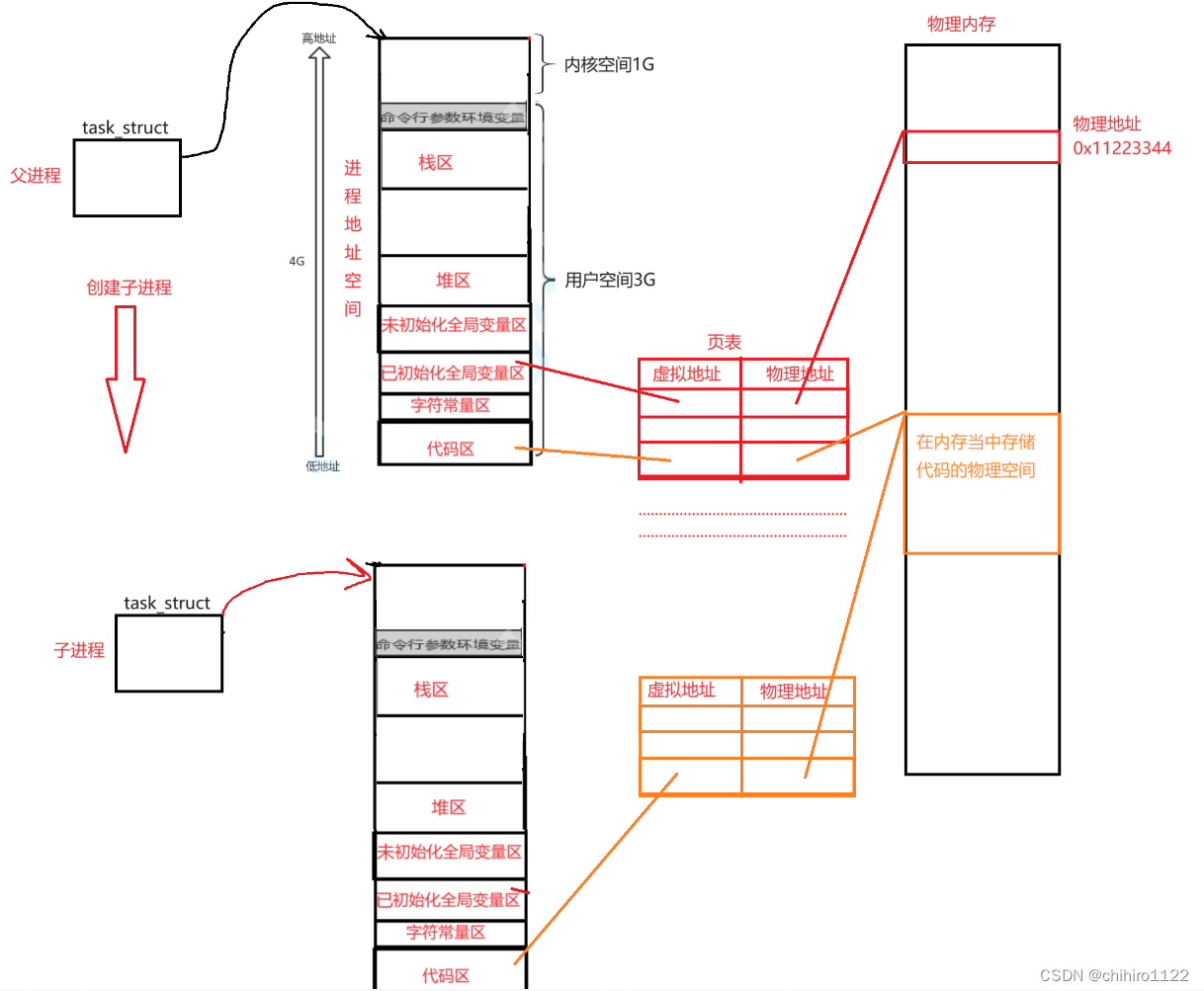
进程地址空间
父进程和子进程之间在虚拟地址和物理地址之间的映射关系

现在我们把前言 当中所说的 这个结构称之为 进程地址空间。
你可能对上述的结构比较熟悉,可能知道他是C/C++ 的 内存当中排布。实际上,这个是有 更官方的 名字叫做 进程地址空间的。
既然叫做进程地址空间,说明,这个空间应该是属于一个进程的,在 Linux 当中管理一个 进程,是通过 管理 操作系统给 这个进程创建的 PCB 对象来管理的,所以,进程的 进程地址空间 的 起始地址是存储在 PCB 当中的。方便操作系统 通过 PCB 来查找到 这个进程地址空间。

而,在 C/C++ 当中我们使用的指针,我们看到的都是 上述从 0000.....0000 到 FFFF.....FFFF 这个地址,其实这个地址只是一个虚拟地址,这个地址是映射在内存当中的。
具体如何映射,其实在内存当中吗,存储的有 页表这个 数据结构,这个页表是 K-V 的方式来存储数据的。
而 K-V 代表的就是 虚拟地址 和 物理地址的映射关系,比如在 全局数据区当中创建了一个 全局变量,那么这个变量,我们如果取地址的话,看到是这个变量的虚拟地址,这个虚拟地址在页表当中存储着,同时这个虚拟地址映射着一个物理地址,这个物理地址就是实际在内存当中存储这个 变量的数据所在空间。

同样的,如使用 父进程来创建出一个子进程的话,操作系统同样会帮这个子进程来创建出属于 子进程 自己的 PCB 结构体,而且,其中的数据,如果是和父进程 共有的,都是按照 父进程当中变量数据当做模版来创建的;如果是,子进程私有的,那么就会进行初始化。
在子进程被创建出来之后,每一个进程都需要有一个 进程地址空间,被创建出的 子进程 也不例外。所以,子进程也要拷贝一份 地址空间给自己。同时,页表也要拷贝一份,或者是使用同一张页表,但是,子进程也是有自己的独立的数据的,所以,还是需要自己的 页表。
这里,应该就理解了 ,为什么子进程和 父进程共享一个 代码,因为 就算是是两个地址空间,但是,其中代码区的虚拟地址,在页表当中 映射的是 和 父进程一样的 代码的物理地址。(此时你应该就理解了,为子进程和父进程之间可以有共享的 代码,和大部分的共享的数据,但是子进程还有自己的 独有的数据,供子进程自己来维护)
同理,子父进程之间既然可以共享 代码,那么两者之间也是可以共享 变量地址空间的。如果子进程没有修改此变量的话,那么子父进程访问的是同一块变量的空间。如果子进程修改了变量的值的话,那么就会发生写时拷贝,在内存当中为子进程新拷贝一块空间,这块空间供子进程使用。
其实,如果子进程不对变量进行修改的话,子父进程访问同一块空间,其实和 浅拷贝有些类似;如果,发生修改,相当于发生了深拷贝,操作系统为子进程新开辟了一块空间,供子进程使用。
那么,相信在前言当中,对于 子父进程 访问同一地址,但是打印的数据却不一样的这个现象,你已经有所眉目了。没错,我们打印在屏幕上的这个地址,不是在内存当中存储的物理地址,而是自己的进程地址空间对应的 虚拟地址。
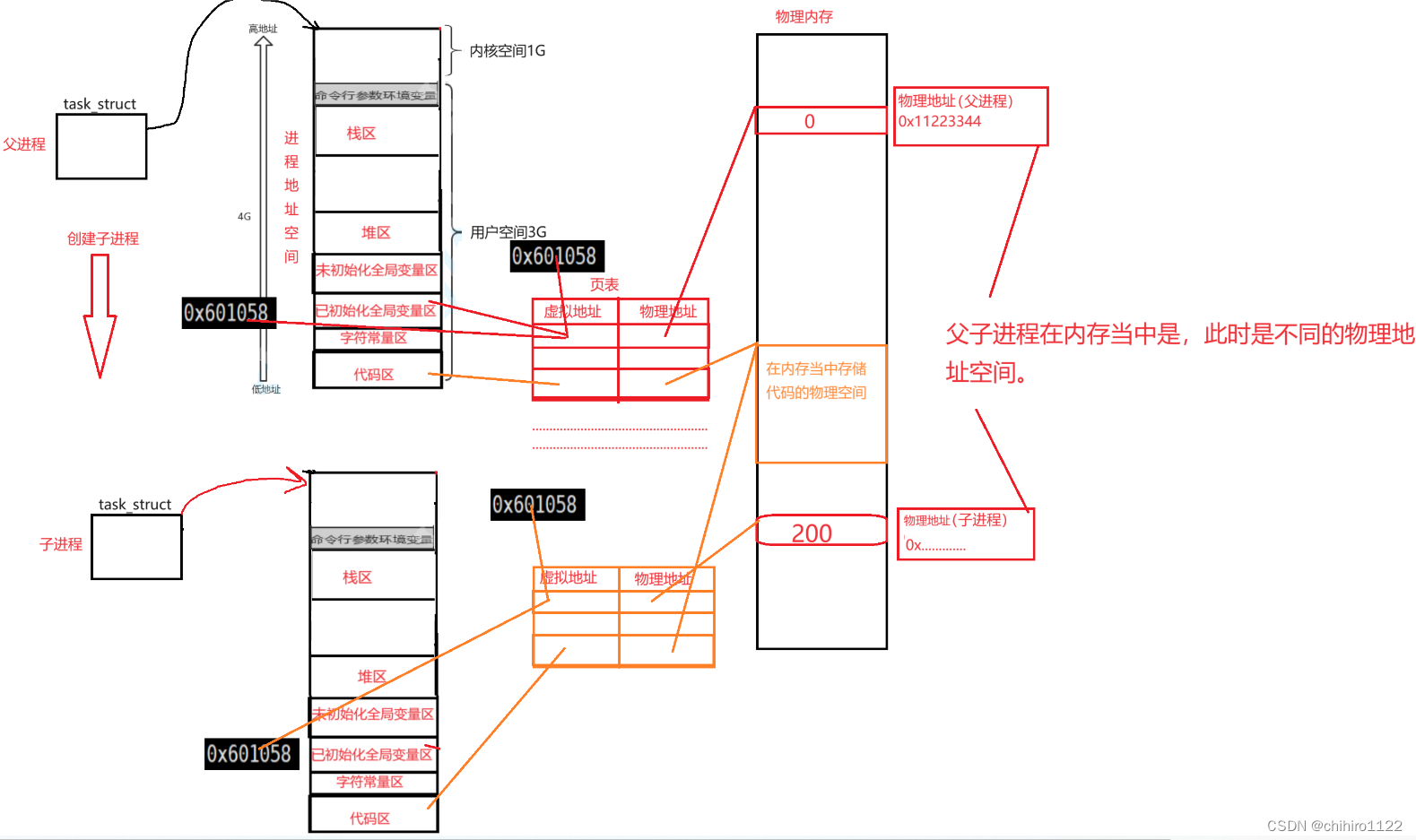
向上述,子进程的 变量 空间的值是200,其实刚开始不是200,因为要修改之前,实现在父进程的这个变量的值的基础之上来进行拷贝的,所以刚开始是 0,在子进程对这个值进行修改之后,这个变量的值就变成 200了。
通过页表映射的方式,就实现了,看似是同一个虚拟地址,实际上打印结果不一样的结果。其实这两个进程的虚拟地址是不一样的,一个是 父进程当中的虚拟地址,一个是 子进程当中的虚拟地址。两虚拟地址,在各自的 页表当中的映射的是不同的 物理地址。
什么是地址空间?什么是进程地址空间
地址空间的本质,其实是以进程的视角,来对内存进行划分的,其实也就是我们说的在 内存当中的离散存储。
在计算机当中有很多的 设备,把这些各种设备连接起来,那么设备和设备之间,内存和外设之间,cpu和内存之间,一定要做到数据的交互。那么这些个设备要进行数据的通讯,就要用“线”来连接起来。这些“线”实际上可以划分成三类:地址总线,数据总线,控制总线。
cpu 和 内存之间连线的叫做系统总线;内存和外设之间连接叫做 IO总线。我们需要这些先,把数据从一个设备拷贝到另一个设备当中。在 32 位机器当中,cpu 和 内存是通过总线直接相连的。
每一根相连的总线,有两个信息,就是 0/1 。在内存当中就可以更具每一根总线上不同的信息,来得到不同的 数据,也就得到不同的地址。
在内存当中有一个 可以更具cpu 通过总线发出的不同信息,解析出地址的设备,可以理解为 地址寄存器。在 32 位机器当中,这个机器就会根据总线的当中给出的不同信息。总线通过给触发器给一个电脉冲,这个触发器就可以给某一个存储单元当中充一个强电频。不充电就没有电流。
所以,在地址寄存器当中,可以理解为总线就是给这个设备充放电。其中,有电时候就是高电频(1);没电就是 低电频或者没电频(0)。
所以,地址寄存器就可以从总线给出的信息当中解析出地址。其实就是告诉内存,此时cpu是要访问哪一个地址处的数据。
所以,从总线当中 0/1 数据,其实就是 高低电频,是cpu在对内存充放电,内存当中可以读取这个高低电频,就是把这些高低电频所代表的二进制数据,进行组合,形成了物理地址。识别到当前是要访问哪一个地址上述数据,这就转换成了物理地址。
那么,像上述的 32 位的寄存器,就是有 32 个比特级别的存储单元,其实就是一个一个的触发器。
其实,内存在接收到cpu 发来的地址,从这个地址当中读取到数据吗,要发送到 cpu 当中只是,实际上也是 内存 给 cpu 充电的过程。cpu 当中寄存器就可以识别到 这种不同组合的 高低电频。cpu 就可以识别这些 0/1 数据了。
本质上,在各个设备之间的数据拷贝的过程,就是一个设备给另一个设备充放电的过程。
所以,如果是 32 位 的机器,总线就有 32 根,这32 根 可以表示的数据个数 就是 2^32 次方个。
我们把 地址总线排列组合形成的地址范围(如上 32 位机器 是 [0 , 2^32])。我们把这个范围叫做 地址空间。就是一段数据范围。
通俗一点来说,就是一个进程,在最极限的访问情况下,这个进程能访问的物理内存的最大空间范围。
比如,现在有两个进程,管理一个内存的当中的空间的使用,是有各一个对象来专门维护的,在这个 对象当中,是有类似的两个 维护这个进程的 地址空间的两个指针(也可能是指向 这个数组空间的某个下标变量)。
把 内存的地址空间,分隔成大小不一的,多个区域,我们把这个操作称之为 -- 区域划分。
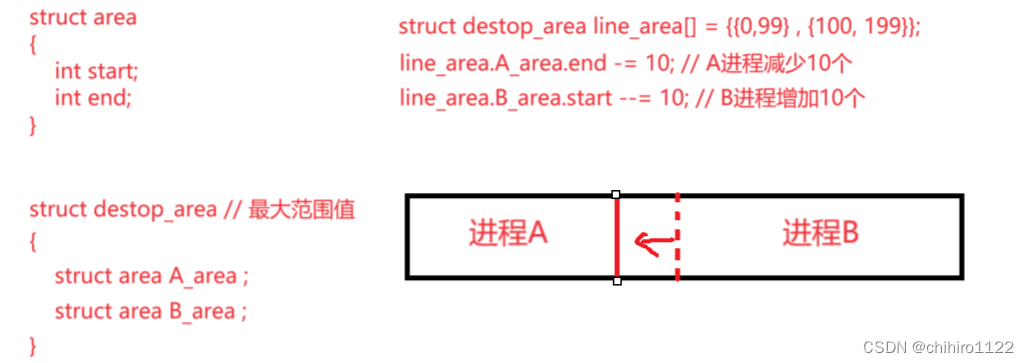
比如,下面这两个进程 A 和 B:

上述是把每一个 进程 的起始地址和 终止地址划分得比较清楚 的,当然,如果嫌麻烦,还可以直接定义一个 destop_area 结构体对象,在这个结构体对象当中直接存储 各个进程的 起始地址和 终止地址:

有了上述结构体对象来维护 各个 进程的地址空间大小,那么,当我们想要修改某一个 进程 的进程大小的话,就可以直接修改,在 这个结构体对象当中的 对应进程的指针指向来修改:
假设,现在是 A 要腾出空间给 B 来使用的话,我们就可以这样做:
上诉是 操作系统给这个进程分配了一个 空间供这个 进程使用,这个空间当中的任何一个位,都是可以供这个进程任意使用的。比如:可以在第一个地址位置开始存储一个 int 类型的变量,在 第10个地址处,存储了一个 double 类型的变量;
也就是说,在这个范围之内,连续的空间当中,每一个最小单位都可以有地址,这个地址可以被这个进程正常使用。
所以,什么是地址空间呢?
进程地址空间,本质上是一个描述进程可视范围的大小,在地址空间内,一定要存在各种区域的划分,对现行地址进行类似 start 和 end 方式的维护。
每一个进程都要有自己的 进程地址空间的,所以,操作系统要管理这个进程,除了来创建这个进程的 PCB 对象,还要创建一个维护 这个进程的 进程地址空间的 结构体。
所以,所谓地址空间本质是一个内核当中的 一个 结构体对象,这个对象类似于 PCB 对象一样,是要被 操作系统来管理的 。和上述说明的 如果 管理 进程地址空间一样,对进程的地址空间进行先描述,在组织。
但是,不可能直接像上述一样,只使用两个指针来维护这个进程,通过前言当中的描述,我们还发现,一个进程当中不是仅仅一个 空间怎么简单,其中还有 比如 全局数据区,代码区,栈区,堆区等等。
这些进程地址空间当中的各种区,也不是仅仅存储在一个连续的空间当中的,很多情况都是离散存储的,当我们想要找到一个 进程当中的 某一个区当中的某一些数据的话,只需要通过页表,对应的 虚拟地址 和 物理地址的键值对来找到某一个数据所在地址。
所以,地址空间想要维护这个一个 进程 当中离散存储的 各个区的话,就要使用多个指针来维护这些区在 内存(物理地址)当中存储的 起始地址和 终止地址:
struct mm_struct
{long code_start;long code_end;long readonly_start;long readonly_end;long init_start;long init_end;long uninit_startlong uninit_end;long heap_start;long heap_end;long stack_start;long stack_end;
}像上述的 就是一个 进程地址空间当中,使用结构体维护的方式,在这个进程的PCB 当中,一定是有一个 指针,或者是直接由上述的一个结构体对象:
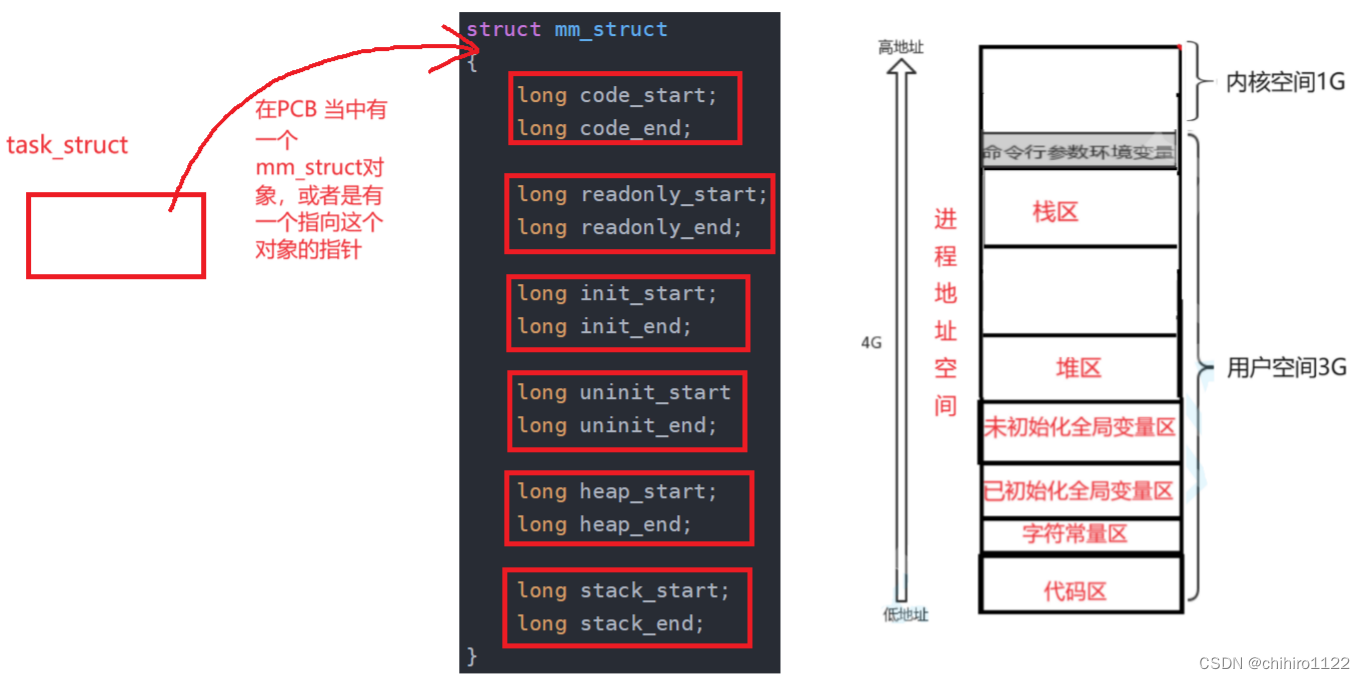
通过这种方式,知道 这个进程的 各个区 在内存当中是如何存储的 。
我们把这个 mm_struct 这个结构体对象,称之为 -- 进程地址空间。
而且,不要忘记了,在这个结构体当中维护的 各个区的连续空间当中,每一个 最小单位都可以有地址,这个地址可以被 这个进程 直接使用。
为什么要有进程地址空间?
你可以很明显的认识到,在现实当中使用计算机,我们的很多进程是基本不可能吧全部的内存占用完的,因为内存相对于 进程 来说还是蛮大的。
那么,对于进程来说,他就可以认为是 内存都是供我使用的,进程以为整个内存都是他的,但是实际上,内存当中的空间很大,内存可以给很多个进程分配空间。所以,而 进程使用的空间大小是相对于 总内存资源来说是很少的,所以,对于进程来说,很多时候,只要是 内存资源够用的话,进程基本上都是有求必应的。进程就会想当然的以为,整个内存资源都是够我使用的。
但是,就算内存相对于 进程来说是一个 无私的富二代,进程向 内存 讨要资源之时,基本都是给的,但是,富二代也是有最大资源的,他的前也不是大风刮来的 ,总是有限的。所以,不排除有进程 像申请特别多的资源,以至于 内存都不能给予的情况。
但是,这种情况一般内存是不给申请资源的,而且这种情况很少,一般进程的需求都是有求必应的。
我们知道,在内存当中,为了能够更好的利用空间,而且更高效的访问空间,那么,每一个进程的各个存储数据的区域,不是直接存储在一个 连续的 地址空间当中的;而是,离散式的存储各个区的数据。所以,在内存当中,对于数据的存储是没有规律的,在进程看来是冗余的。所以,为了进程更好的在内存当中访问自己的数据,就有了 进程地址空间,这个存储各个 区 在内存当中的 起始地址 和 终止地址的两个地址的 变量。
如果让进程直接访问到 内存当中的资源,那么进程是有可能会访问越界的,进程奔溃了都是小事, 修改到其他进程的数据才是大事。但是在进程地址空间 和 页表管理的内存空间当中,不仅仅是虚拟地址映射到 内存的 物理地址,解决 内存存储复杂的问题;而且,还会存储这个 进程的 各个区当中 有多少可以使用的 空间资源。这样不仅可以更好的管理的进程对内存空间的使用,而且还有效的防止了访问越界修改到其他资源的问题。
有了 进程地址空间 和 页表之后,如果 当前你在 进程地址空间当中访问的 虚拟地址还没有申请,或者是,申请了,但是在页表当中没有对应的映射关系,又或者是,映射的物理地址,是只读的,不能修改,那么都是不能够访问这个物理空间的。
所以,增加的进程地址空间,可以让我们在访问内存的时候,增加一个 由 虚拟地址 向 物理地址的转换,看似是麻烦了,其实在进程看来更加统一了;而且,在转换的过程当中,可以对访问的 虚拟地址 或者 是 物理地址进行检查,如果如果有异常的访问,就会拦截,该请求不会到达物理空间。依次来保护内存物理地址空间。
而且,有了 进程地址空间之后,在进程的视角看来,整个内存空间,就是 这个进程所使用 的 进程地址空间 的排列布局。这样的话,在进程看来,不管内存当中的资源如何进行分布,在进程而言都是 进程自己的 地址空间的 排列布局。其中的数据,虽然是虚拟地址,但是有页表,可以通过页表来找到这个 这个虚拟地址 对应 的 物理地址,从而在 内存当中找到这个 这个数据在内存当中存储的位置。
所以,不管是父进程,还是子进程,还是各种的兄弟进程,在他们看来,对于内存当中资源,是归自己所有的,而且,排列布局也是按照 自己的 进程地址空间来排列布局的。
关于页表
在上述章节当中我们多次提到了 页表这个概念,那么页表究竟是什么呢?
页表的作用在上述也说过了,就是那来 把 虚拟地址 映射到 物理地址的,那么操作系统是如何访问这个页表的呢?这个页表是存储在哪儿的呢?
其实,在cpu 当中有一个 寄存器 -- cr3(在 x86 机器当中)这个寄存器,这个cr3 寄存器 当中存储的是 页表的起始地址。
所以,当前正在运行的 进程 对应页表,可以通过这个 cr3 寄存器来找到。
如果某一时刻,某一个进程的被切换走了,在进程再次切换回cpu 运行之时,是不用担心找不到这个页表,一定可以找到。因为,在 cr3 这个寄存器当中存储的 页表地址,本质上其实是 属于这个进程的 硬件上下文。也就是说,如果进程被切换走了,进程是要把自己的上下文带走的,那么这个 cr3 寄存器当中存储的 内容也是要被 进程带走的。当进程切换回来的时候,就会把自己进程对应的 上下文重新加载到内存,或者是 寄存器当中。所以,根本不用担忧。
(在上述所说 cr3 寄存器当中存储的 页表地址,是物理地址。很正常,这些是属于靠硬件上的信息了,如果上诉保存 页表地址也是虚拟地址的话,就套娃了,无限循环了)
在上述也说过,通过页表,可以知道当前要访问物理地址空间,在 进程地址空间当中的权限是,只读权限,比如 字符常量区;还是可读可写的。
所以,在页表当中,还有一个 关键字,叫做标识符,这个标识符就表示了,当前访问的物理地址空间的访问权限是什么。

比如上述的 0x1111 这个虚拟地址,如果对这个地址的数据进行修改的话,操作系统识别到你想访问这个地址的数据,但是页表显示这个 地址的数据是只读的。所以,直接拦截这个操作继续执行。现在,这个进程相当于是进行了一次非法操作,操作系统直接干掉这个进程。
所以,页表可以给我们提供一个很好的访问权限管理。
所以,现在你应该明白了,为什么代码是只读的,字符常量区是只读的?
你知道了 代码是只读的,那么请问:代码是如何做到通过修改写入到物理内存,而且,我们在编写代码之时,肯定不是一下就编写成功,满足要求的。肯定是经过了很多次修改的,那么为什么我们可以修改代码。写代码?
实际上,你也搞清楚,我们在写代码和修改代码的过程当中是在哪里进行的操作,没错是直接在物理内存当中直接进行操作;那么物理空间是没有 访问权限 这个概念的,更没有权限控制这个概念。你想写就写,想读就读,cpu可以直接对物理内存空间进行读写。
这些权限的概念是在 虚拟地址当中才有的,实际上,这些权限是在页表当中的映射之时才会起作用。为什么字符常量区 只读,不可写,是因为,字符常量区的 虚拟地址 和 物理地址 在页表当中的 标志符 是 只读。
所以,操作系统才能拦截你对 字符常量区当中的数据继续修改的操作。当前进行修改操作的进程才会挂掉。
关于 Linux 当中 进程挂起状态 的判断(末尾介绍 区分 Linux 当中的 进程管理 和 内存管理)
在之前的文章当中描述过,如果当前操作系统管理的内存资源已经快满了,就把 一些 进程的 数据和代码 这些 换出 到外设(比如是磁盘)当中,当 排队轮到这个进程执行之时,才把 外设 当中的 代码 和数据 换入 到 内存当中。
注意,换出的不是 页表,不是PCB,更不是地址空间。而是 代码和数据。
Linux - 进程状态 - Linux 当中的进程状态是如何维护的?-CSDN博客
但是! 挂起确实是一种进程的状态,但是在 Linux 当中,是没有具体的状态来表示的挂起这个状态的,比如:有运行状态,僵尸状态,死亡状态,阻塞状态(挂起状态就是对阻塞状态的一种优化)等等,但是在 Linux 当中就是没有具体的状态,来表示 挂起状态。
那么,Linux 操作系统是如何来识别 进程的 挂起状态的呢?换言之,操作系统是怎么知道 这个进程的 代码和数据在不在 内存当中呢?
平时我们在玩一些大型的游戏,那么这些游戏动则 50G,70G 甚至 100+。内存肯定是不能 一次选哪个加载这么多的 数据到内存当中的,所以,一般这种大文件,都是分批进行加载处理的。一块一块的,根据时间片等等信息,进行处理。
在分批处理的过程当中,因为代码是一行一行执行的,那么可能就会出现,当前的 很大部分的数据,没有在这一调度数据的时间片之内,使用的到,只是使用少部分的数据,那么就会发生我们所说的,没有正常去使用传入内存的数据。这其实是一种浪费时间和空间的事情。
所以,实际上,操作系统对于可执行文件的加载的策略,其实是 --- 惰性加载的方式。
也就是,操作系统承诺对某一个进程,多少多少的内存空间来使用,但是实际上,是这个进程实际当中真正使用多少的内存空间,就给申请多少空间给这个进程使用。
所以,为实现上述效果,和区分 进行的 挂起状态,在页表当中还有一个 标识符,这个标识符就表示当前 这一虚拟地址 所维护的 代码或者数据是否被加载到内存当中。
所以,有了这个标识符,当这个进程想通过这个 虚拟地址访问到物理地址的话,先要看这个 虚拟值的 在上述的标识符位置 是 0 还是 1,如果 已经加载到内存,那么就直接用过物理地址访问;如果没有加载到内存,那么就会发生 --- 缺页中断。
缺页中断 简单说就是 找到对应的 可执行程序,把这个可执行程序当中的 代码 或者 数据加载到内存当中。然后把这个加载到内存当中的物理地址,填充到 页表当中 对应 虚拟地址 映射的 物理地址处。
(其实,子进程发生写时拷贝也是通过上述的却也中断的过程来判断是否要进行 写时拷贝的。)
所以,其实理论上 操作系统是可以实现 ,当一个进程在运行之时,只给这个进程 的PCB,页表,进程地址空间等等用于维护这个进程的结构体等等都创建好,但是对于这个进程的代码和数据都不进行加载,当这个进程需要什么哪一些代码和数据的时候,再发生 缺页中断,来实现对这个进程的 惰性加载。
就可以实现,边使用变加载的。
但是上述是极端情况,实际使用当中,是基本不会发生上述极端情况的。操作系统怎么说都会先把一部分的代码和数据先加载到 内存当中。运行这个进程 之前 操作系统还要预读一下这个可执行进程的格式等等。因为,在创建地址空间,页表当中的数据之时,也是要根据可执行程序当中的格式,数据来做参考的。
进程再被创建之时,是先创建内核数据结构呢?还是先加载对应的可执行程序呢?
是要先创建内核数据结构,在这基础之上,再去加载对应的可执行程序。
而,对于再分发生缺页中断时,外存当中的数据,怎么加载到内存当中?加载到内存当中什么位置》把这个内存物理地址填充到页表当中是怎么填充的?什么时候填充?加载的数据是可执行程序的那一部分呢?加载多少数据呢?
这些问题,其实都是由操作系统来做的,这个具体操作被称之为 -- Linux内存管理模块。不是本篇博客的设计范围,所以这里只是提一嘴。
所以,站在进程的视角,进程在自己被切换,调度的时候,根本就不管自己的数据啊,PCB对象等等这些是在内存上如何进行存储,进程是不管的,他只管自己的运行之时,所要处理的事情。
所以,Linux 在把这些处理方式分两种,一种是 进程管理,另一种是 内存管理。
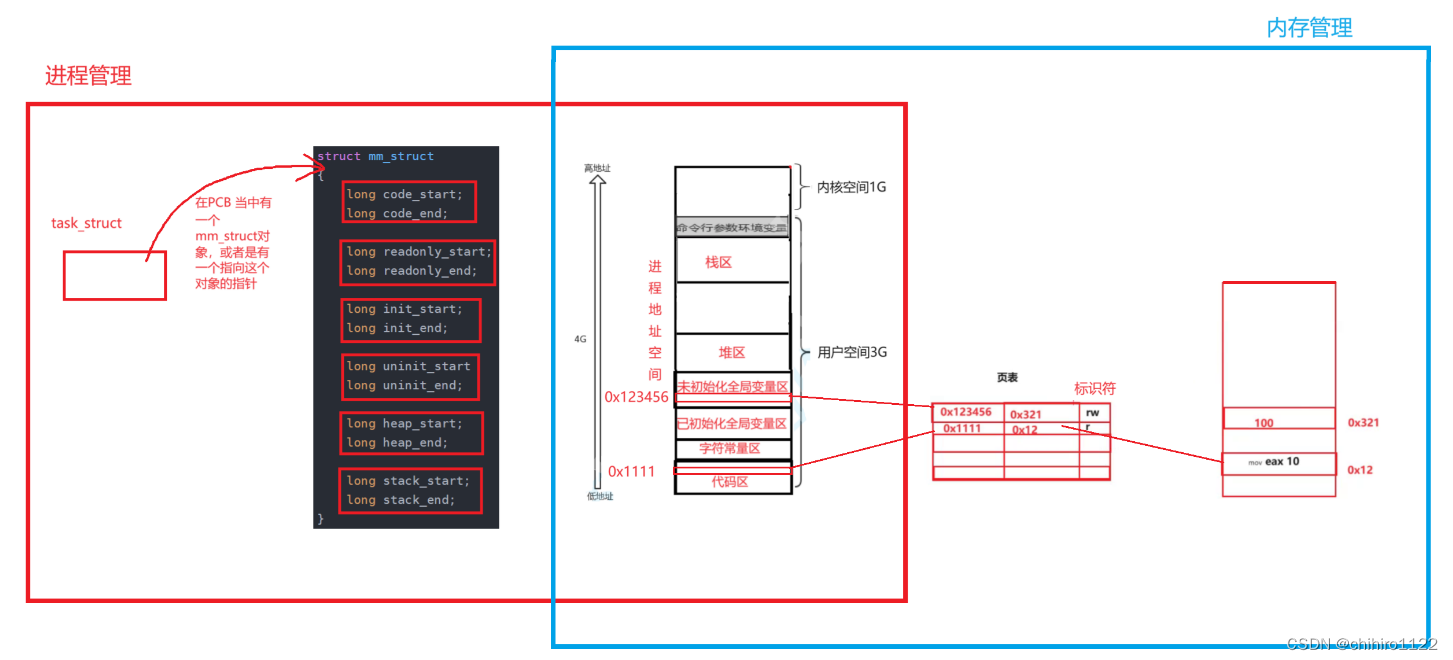
进程管理模块 和 内存管理模块之间的 解耦合
所以,就是有了进程地址空间 和 页表的存在,才有了 Linux 当中的 进程管理模块 和 内存管理模块之间的 解耦合的实现!!!
进程想要申请空间,不需要面对内存,通过操作系统出面,像内存进行申请即可,两个模块各做各的事情,不再出现强耦合的情况。
否则,如果进程直接和 内存物理地址相连,那么当 内存管理模块 或者 进程管理模块出现差错,两者之间都会互相影响。
所以,现在的进程组成,(task_struct && mm_struct && 页表) + 程序的代码和数据。
那么是不是就意味着,当在发生进程切换的时候,进程的 PCB ,进程地址空间,页表都要进行切换呢?
其实,在切换 PCB之时, 这个 PCB 所匹配的地址空间自动被切换,因为 PCB 指向对应的地址空间。又因为,存储页表地址的寄存器 -- cr3,属于进程上下文,所以页表地址的这个上下文被切换,那么页表也就自动被切换了。所以,归根结底,只要进程的上下文一被切换,那么上述的三个数据都要被切换。
为什么进程之间是独立的?(页表存在的意义)
那么为什么各个进程之间都是独立的,发生解耦了呢?其实是因为,就算是 不同进程当中 访问同一个虚拟地址,也就说就算两个进程访问的虚拟地址是一样的,但是,在两个页表当中 ,同一个 虚拟地址 映射的 物理地址也是不一样的,所以,访问的物理地址也就是不一样的,访问的数据也是不一样的。所以,进程之间就不会发生强耦合关系,进程之间就是独立的。
父子进程访问代码虽然是一样的,但是数据区访问的数据是不一样的,那这个不就是解耦了吗?那么,其中某一个进程一旦异常了,那么这个进程就要释放自己的 PCB ,进程地址空间,页表,还要单独开辟的空间。但是,和另一个进程共同使用的空间是不会释放的。这不就又解耦了吗?
所以,此时,对于进程来说,外存当中数据,加载到内存当中什么位置,加载多少,就不重要了。因为有页表映射,所以,在数据存储到内存当中什么位置,通过页表映射就可以了。内存当中存储数据可以是乱序的,离散存储;但是在 虚拟地址当中 这个地址可以是连续的,这就叫以同一的视角来访问进程的数据和代码,就可以把无序变有序,这就是页表所存在的意义。
相关文章:
Linux - 进程地址空间
前言 首先,我们先要对 内存当中存储 各个数据之间的 结构要有一个 大概的了解: 各个区当中存储的数据使用类型不同,所以,这些数据在使用方式上是有差别的。比如下面这个例子: 在C 语言当中我们不能直接对 上述的 str…...

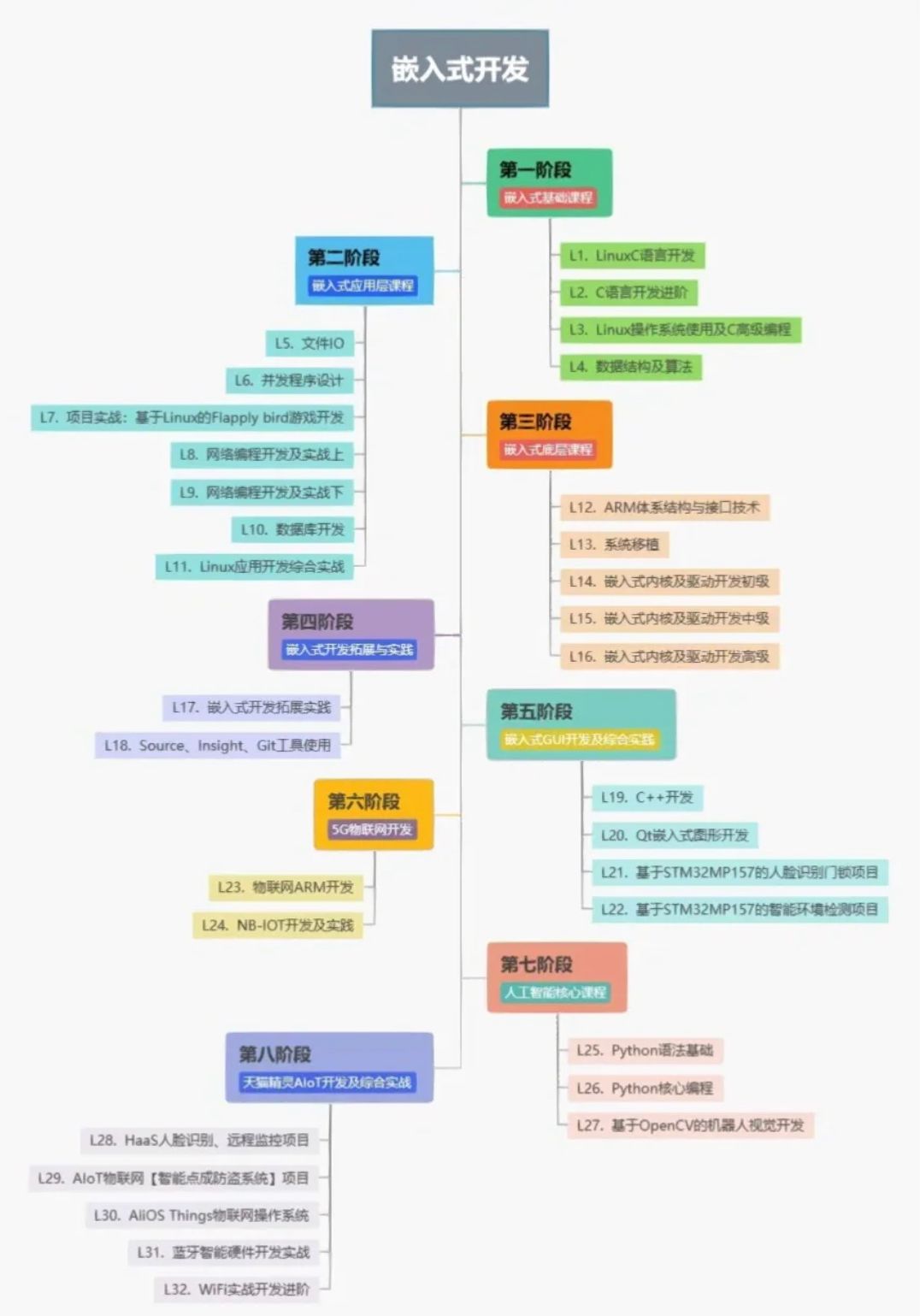
系统架构设计师-第16章-嵌入式系统架构设计理论与实践-软考学习笔记
嵌入式系统( Embedded System) 是为了特定应用而专门构建的计算机系统,其架构是随着嵌入式系统的逐步应用而发展形成的。嵌入式软件架构的设计与嵌入式系统的体系架构是密不可分的。因此,本常首先介绍嵌入式系统硬件相关知识(系统特征、硬件组…...

pod进阶
目录 资源限制 CPU 资源单位 内存 资源单位 实例 健康检查 探针的三种规则: Probe支持三种检查方法: 示例1:exec方式 示例2:httpGet方式 示例3:tcpSocket方式 示例4:就绪检测 扩展 资源限制 当定…...
#NOT_SUPPORTED)
系列四十七、Spring的事务传播行为案例演示(七)#NOT_SUPPORTED
一、演示Spring的传播行为(NOT_SUPPORTED) 1.1、StockServiceImplNOT_SUPPORTED /*** Author : 一叶浮萍归大海* Date: 2023/10/30 15:43* Description: 演示NOT_SUPPORTED的传播行为* 外部不存在事务:不开启新的事务* 外部存在…...

54.RabbitMQ快速实战以及核心概念详解
MQ MQ:MessageQueue,消息队列。这东西分两个部分来理解: 队列,是一种FIFO 先进先出的数据结构。 消息:在不同应用程序之间传递的数据。将消息以队列的形式存储起来,并且在不同的应用程序之间进行传递&am…...

Qt TreeView 设置节点不可编辑
目录 1. 创建treeview 2、节点不可编辑 3、设置logo 4、实例代码 1. 创建treeview //声明模型 QStandardItemModel *model;//创建4行,1列的模型 model new QStandardItemModel(4,1);//添加标题 model->setHeaderData(0, Qt::Horizontal, tr("Tree View…...

python django获取某个角色的某个数据和——例如:获取所有订单的应付金额总和
model关系如下: class Order(models.Model):订单product models.ForeignKey(Product, on_deletemodels.SET_NULL, blankTrue, nullTrue, verbose_name"产品")no models.CharField(max_length50, blankTrue, nullTrue, verbose_name订单编号, db_indexT…...
如何在React项目中引用less
安装less npm install less less-loader --save-dev暴露 webpack 文件 利用 npx create-react-app 搭建的 React 项目,默认隐藏 webpack 配置文件,引入 less 需要修改 webpack 配置文件,因此我们需要执行命令暴露 webpack 配置文件。 请先将…...
NUXT前端服务端渲染技术框架
服务端渲染又称SSR(Server Side Render)实在服务端完成页面的内容,而不是在客户端通过AJAX获取数据 优势:更好的SEO,由于搜索引擎爬虫抓取工具可以直接查看完全渲染的页面 Nuxt.js是一个基于Vue.js的轻量级应用框架&a…...

力扣每日一题90:子集
题目描述: 给你一个整数数组 nums ,其中可能包含重复元素,请你返回该数组所有可能的子集(幂集)。 解集 不能 包含重复的子集。返回的解集中,子集可以按 任意顺序 排列。 示例 1: 输入&#x…...

「linux基础」上传代码到github/gitee
一、在gitee创建一个仓库 1.创建仓库 2.获取仓库地址 二、克隆仓库文件到linux中 1.查看Linux中是否安装git:git --version 如果没有,在root下使用指令 yum install -y git 安装。 2.使用 git clone 仓库地址,克隆仓库文件到linux中 三、第…...

Hafnium总体考虑
安全之安全(security)博客目录导读 目录 一、安全世界构建平台 二、安全分区调度 三、平台拓扑...

C#__对Json文件的解析和序列化
Json: 存储和交换文本信息的语法。(类似XML,语法独立) 一种轻量级的数据交换格式。(更小,更快,更易解析) 语法规则: 数据在键值对里面,数据由逗号分隔开。 …...
如果一定要在C++和JAVA中选择,是C++还是java?
如果一定要在C和JAVA中选择,是C还是java? 计算机专业的同学对这个问题有疑惑的,- 定要看一下这个回答! 上来直接给出最中肯的建议: 如果你是刚刚步入大学的大一时间非常充裕的同学,猪学长强烈建议先学C/C.因为C 非常 最近很多…...

如何运行深度学习项目代码
运行项目代码是第一步哦! 配环境 使用anaconda环境; conda 环境 按照项目提示的README.md,安装指定版本的python; 当然新版python会兼容旧版,也就是你的环境下python版本比它高也不要紧; 但是更新的pyt…...

C语言 每日一题 day9
求最大值及其下标 本题要求编写程序,找出给定的n个数中的最大值及其对应的最小下标(下标从0开始)。 输入格式 : 输入在第一行中给出一个正整数n(1 < n≤10)。第二行输入n个整数,用空格分开。 输出格式 …...
通讯网关软件032——利用CommGate X2OPC实现OPC客户端访问Modbus TCP设备
本文介绍利用CommGate X2OPC实现OPC客户端连接Modbus TCP设备。CommGate X2OPC是宁波科安网信开发的网关软件,软件可以登录到网信智汇(http://wangxinzhihui.com)下载。 【案例】如下图所示,SCADA系统上位机、PLC、设备具备Modbus TCP通讯接口ÿ…...
[计算机提升] 查看系统软件
3.1 查看系统软件 此处系统软件为系统安装后自带的一些软件、工具等。包括:管理工具、系统工具、轻松使用工具、附件等。 方法一:通过菜单打开系统软件 1、点击左下角windows菜单键,在弹出的菜单中,任一点击一个字母(示例中为C)&…...

【mysql】单表数据量过大解决方案
文章目录 背景问题方案数据库冷热数据分离方案 背景 包装码表单表数据量很大,造成查询瓶颈;目前单表数据量达到3000w,单表字段数16 问题 索引膨胀,查询耗时长,影响正常CRUD … 方案 ● 分区 按日期…范围&#x…...
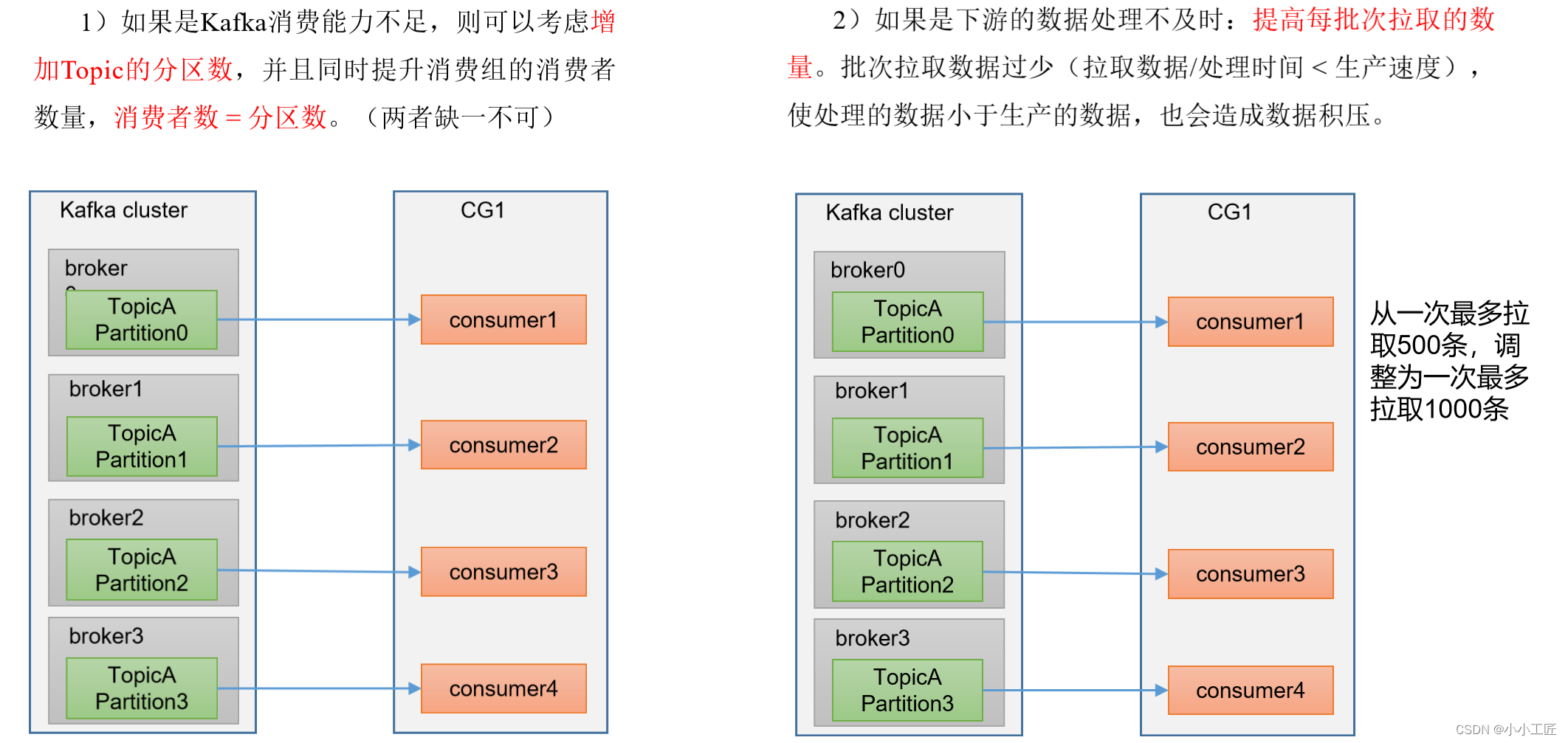
Kafka - 3.x 消费者 生产经验不完全指北
文章目录 生产经验之Consumer事务生产经验—数据积压(消费者如何提高吞吐量) 生产经验之Consumer事务 Kafka引入了消费者事务(Consumer Transactions)来确保在消息处理期间维护端到端的数据一致性。这使得消费者能够以事务的方式…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

Lombok 的 @Data 注解失效,未生成 getter/setter 方法引发的HTTP 406 错误
HTTP 状态码 406 (Not Acceptable) 和 500 (Internal Server Error) 是两类完全不同的错误,它们的含义、原因和解决方法都有显著区别。以下是详细对比: 1. HTTP 406 (Not Acceptable) 含义: 客户端请求的内容类型与服务器支持的内容类型不匹…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

基于当前项目通过npm包形式暴露公共组件
1.package.sjon文件配置 其中xh-flowable就是暴露出去的npm包名 2.创建tpyes文件夹,并新增内容 3.创建package文件夹...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

【JavaSE】绘图与事件入门学习笔记
-Java绘图坐标体系 坐标体系-介绍 坐标原点位于左上角,以像素为单位。 在Java坐标系中,第一个是x坐标,表示当前位置为水平方向,距离坐标原点x个像素;第二个是y坐标,表示当前位置为垂直方向,距离坐标原点y个像素。 坐标体系-像素 …...