【MySql】10- 实践篇(八)
文章目录
- 1. 用动态的观点看加锁
- 1.1 不等号条件里的等值查询
- 1.2 等值查询的过程
- 1.3 怎么看死锁?
- 1.4 怎么看锁等待?
- 1.5 update 的例子
- 2. 误删数据后怎么办?
- 2.1 删除行
- 2.2 误删库/表
- 2.3 延迟复制备库
- 2.4 预防误删库 / 表的方法
- 2.4.1 账号分离
- 2.4.2 制定操作规范
- 2.5 rm 删除数据
- 3. 为何有kill不掉的语句?
- 3.1 收到 kill 以后,线程做什么?
- 3.2 关于客户端的误解
1. 用动态的观点看加锁
加锁规则。这个规则中,包含了两个“原则”、两个“优化”和一个“bug”:
- 原则 1:加锁的基本单位是 next-key lock。next-key lock 是前开后闭区间。
- 原则 2:查找过程中访问到的对象才会加锁。
- 优化 1:索引上的等值查询,给唯一索引加锁的时候,next-key lock 退化为行锁。
- 优化 2:索引上的等值查询,向右遍历时且最后一个值不满足等值条件的时候,next-key lock 退化为间隙锁。
- 一个 bug:唯一索引上的范围查询会访问到不满足条件的第一个值为止。
基于下面这个表 t:
CREATE TABLE `t` (`id` int(11) NOT NULL,`c` int(11) DEFAULT NULL,`d` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `c` (`c`)
) ENGINE=InnoDB;insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);
1.1 不等号条件里的等值查询
看下这个例子,分析一下这条查询语句的加锁范围:
begin;
select * from t where id>9 and id<12 order by id desc for update;
利用上面的加锁规则,这个语句的加锁范围是主键索引上的 (0,5]、(5,10]和 (10, 15)。也就是说,id=15 这一行,并没有被加上行锁。
加锁单位是 next-key lock,都是前开后闭区间,但是这里用到了优化 2,即索引上的等值查询,向右遍历的时候 id=15 不满足条件,所以 next-key lock 退化为了间隙锁 (10, 15)。
查询语句中 where 条件是大于号和小于号,这里的“等值查询”又是从哪里来的呢?这里先拆解一下加锁过程
图 1 索引 id 示意图

- 首先这个查询语句的语义是 order by id desc,要拿到满足条件的所有行,优化器必须先找到“第一个 id<12 的值”。
- 这个过程是通过索引树的搜索过程得到的,在引擎内部,其实是要找到 id=12 的这个值,只是最终没找到,但找到了 (10,15) 这个间隙。
- 然后向左遍历,在遍历过程中,就不是等值查询了,会扫描到 id=5 这一行,所以会加一个 next-key lock (0,5]。
也就是说,在执行过程中,通过树搜索的方式定位记录的时候,用的是“等值查询”的方法。
1.2 等值查询的过程
这个语句的加锁范围是什么?
begin;
select id from t where c in(5,20,10) lock in share mode;
先来看这条语句的 explain 结果
图 2 in 语句的 explain 结果

可以看出,这条 in 语句使用了索引 c 并且 rows=3,说明这三个值都是通过 B+ 树搜索定位的。
在查找 c=5 的时候,先锁住了 (0,5]。但是因为 c 不是唯一索引,为了确认还有没有别的记录 c=5,就要向右遍历,找到 c=10 才确认没有了,这个过程满足优化 2,所以加了间隙锁 (5,10)。
同样的,执行 c=10 这个逻辑的时候,加锁的范围是 (5,10] 和 (10,15);
执行 c=20 这个逻辑的时候,加锁的范围是 (15,20] 和 (20,25)。
这条语句在索引 c 上加的三个记录锁的顺序是:先加 c=5 的记录锁,再加 c=10 的记录锁,最后加 c=20 的记录锁。
这些锁是“在执行过程中一个一个加的”,而不是一次性加上去的。
有另外一个语句,是这么写的:
select id from t where c in(5,20,10) order by c desc for update;
间隙锁是不互锁的,但是这两条语句都会在索引 c 上的 c=5、10、20 这三行记录上加记录锁。
这里需要注意一下,由于语句里面是 order by c desc, 这三个记录锁的加锁顺序,是先锁 c=20,然后 c=10,最后是 c=5。
也就是说,这两条语句要加锁相同的资源,但是加锁顺序相反。当这两条语句并发执行的时候,就可能出现死锁。
1.3 怎么看死锁?
图 3 是在出现死锁后,执行 show engine innodb status 命令得到的部分输出。
这个命令会输出很多信息,有一节 LATESTDETECTED DEADLOCK,就是记录的最后一次死锁信息。
图 3 死锁现场
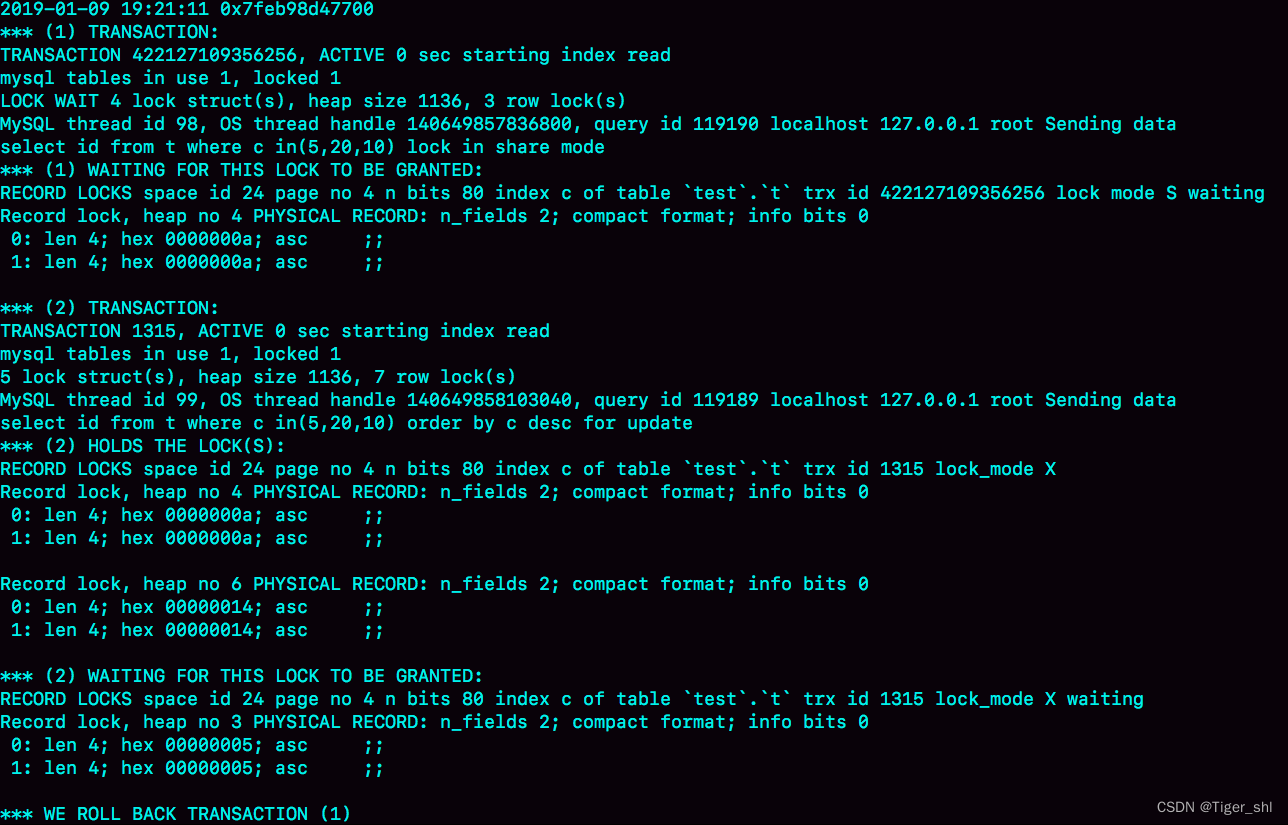
这图中的几个关键信息:
- 这个结果分成三部分:
- (1) TRANSACTION,是第一个事务的信息;
- (2) TRANSACTION,是第二个事务的信息;
- WE ROLL BACK TRANSACTION (1),是最终的处理结果,表示回滚了第一个事务。
- 第一个事务的信息中:
- WAITING FOR THIS LOCK TO BE GRANTED,表示的是这个事务在等待的锁信息;
- index c of table
test.t,说明在等的是表 t 的索引 c 上面的锁; - lock mode S waiting 表示这个语句要自己加一个读锁,当前的状态是等待中;
- Record lock 说明这是一个记录锁;
- n_fields 2 表示这个记录是两列,也就是字段 c 和主键字段 id;
- 0: len 4; hex 0000000a; asc ;; 是第一个字段,也就是 c。值是十六进制 a,也就是 10;
- 1: len 4; hex 0000000a; asc ;; 是第二个字段,也就是主键 id,值也是 10;
- 这两行里面的 asc 表示的是,接下来要打印出值里面的“可打印字符”,但 10 不是可打印字符,因此就显示空格。
- 第一个事务信息就只显示出了等锁的状态,在等待 (c=10,id=10) 这一行的锁。
- 当然,既然出现死锁了,就表示这个事务也占有别的锁,但是没有显示出来。别着急,从第二个事务的信息中推导出来。
- 第二个事务显示的信息
- “ HOLDS THE LOCK(S)”用来显示这个事务持有哪些锁;
- index c of table
test.t表示锁是在表 t 的索引 c 上; - hex 0000000a 和 hex 00000014 表示这个事务持有 c=10 和 c=20 这两个记录锁;
- WAITING FOR THIS LOCK TO BE GRANTED,表示在等 (c=5,id=5) 这个记录锁。
从上面这些信息中,我们就知道:
- “lock in share mode”的这条语句,持有 c=5 的记录锁,在等 c=10 的锁;
- “for update”这个语句,持有 c=20 和 c=10 的记录锁,在等 c=5 的记录锁。
因此导致了死锁。这里可以得到两个结论:
- 由于锁是一个个加的,要避免死锁,对同一组资源,要按照尽量相同的顺序访问;
- 在发生死锁的时刻,for update 这条语句占有的资源更多,回滚成本更大,所以 InnoDB 选择了回滚成本更小的 lock in share mode 语句,来回滚。
1.4 怎么看锁等待?
图 4 delete 导致间隙变化

可以看到,由于 session A 并没有锁住 c=10 这个记录,所以 session B 删除 id=10 这一行是可以的。但是之后,session B 再想 insert id=10 这一行回去就不行了。
看一下此时 show engine innodb status 的结果
图 5 锁等待信息

几个关键信息:
- index PRIMARY of table
test.t,表示这个语句被锁住是因为表 t 主键上的某个锁。 - lock_mode X locks gap before rec insert intention waiting 这里有几个信息:
- insert intention 表示当前线程准备插入一个记录,这是一个插入意向锁。为了便于理解,你可以认为它就是这个插入动作本身。
- gap before rec 表示这是一个间隙锁,而不是记录锁。
- 那么这个 gap 是在哪个记录之前的呢?接下来的 0~4 这 5 行的内容就是这个记录的信息。
- n_fields 5 也表示了,这一个记录有 5 列:
- 0: len 4; hex 0000000f; asc ;; 第一列是主键 id 字段,十六进制 f 就是 id=15。所以,这时我们就知道了,这个间隙就是 id=15 之前的,因为 id=10 已经不存在了,它表示的就是 (5,15)。
- 1: len 6; hex 000000000513; asc ;; 第二列是长度为 6 字节的事务 id,表示最后修改这一行的是 trx id 为 1299 的事务。
- 2: len 7; hex b0000001250134; asc % 4;; 第三列长度为 7 字节的回滚段信息。可以看到,这里的 acs 后面有显示内容 (% 和 4),这是因为刚好这个字节是可打印字符。
- 后面两列是 c 和 d 的值,都是 15。
因此,就知道了,由于 delete 操作把 id=10 这一行删掉了,原来的两个间隙 (5,10)、(10,15)变成了一个 (5,15)。
session A 执行完 select 语句后,什么都没做,但它加锁的范围突然“变大”了;
所谓“间隙”,其实根本就是由“这个间隙右边的那个记录”定义的。
1.5 update 的例子
图 6 update 的例子

session A 的加锁范围是索引 c 上的 (5,10]、(10,15]、(15,20]、(20,25]和 (25,supremum]。
注意:根据 c>5 查到的第一个记录是 c=10,因此不会加 (0,5]这个 next-key lock。
之后 session B 的第一个 update 语句,要把 c=5 改成 c=1,可以理解为两步:
- 插入 (c=1, id=5) 这个记录;
- 删除 (c=5, id=5) 这个记录。
按照上一节说的,索引 c 上 (5,10) 间隙是由这个间隙右边的记录,也就是 c=10 定义的。所以通过这个操作,session A 的加锁范围变成了图 7 所示的样子:
图 7 session B 修改后, session A 的加锁范围
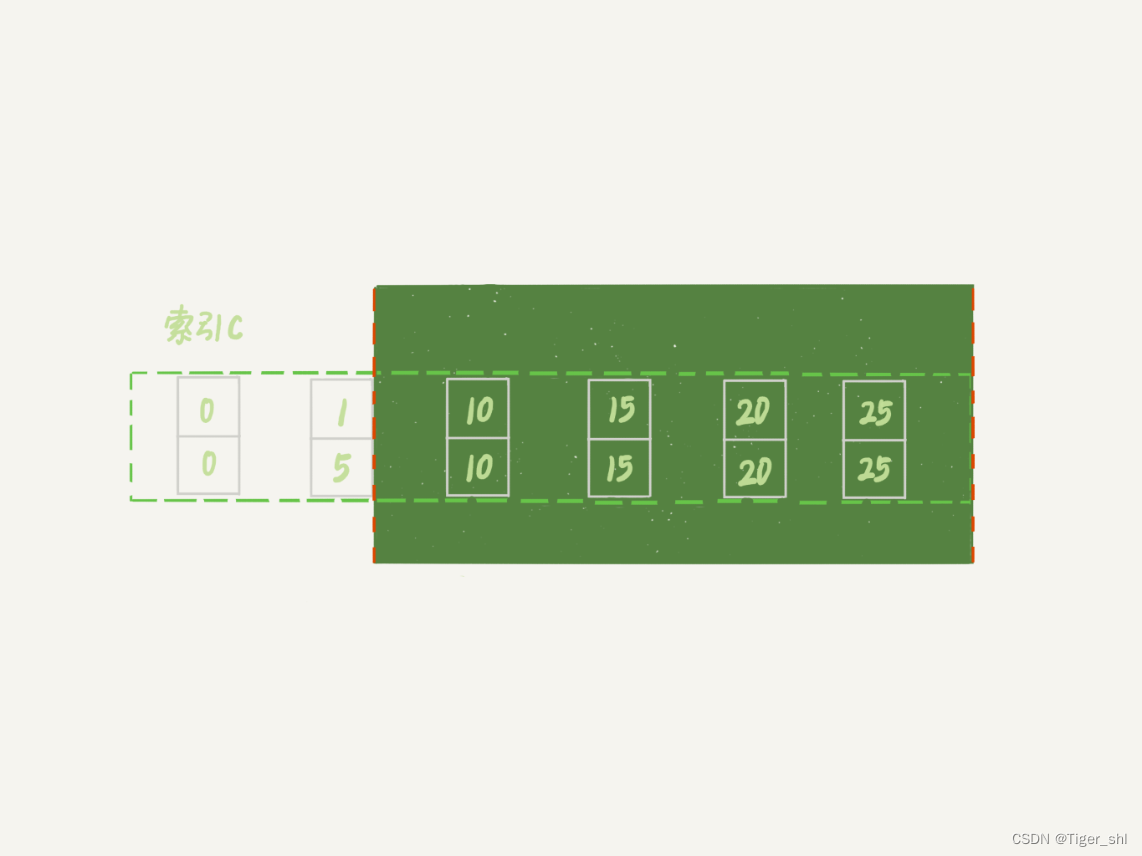
接下来 session B 要执行 update t set c = 5 where c = 1 这个语句了,一样地可以拆成两步:
- 插入 (c=5, id=5) 这个记录;
- 删除 (c=1, id=5) 这个记录。
第一步试图在已经加了间隙锁的 (1,10) 中插入数据,所以就被堵住了。
思考
一个空表有间隙吗?这个间隙是由谁定义的?怎么验证这个结论呢?
一个空表就只有一个间隙。
在空表上执行:begin; select * from t where id>1 for update;
这个查询语句加锁的范围就是 next-key lock (-∞, supremum]。
验证方法
复现空表的 next-key lock

show engine innodb status 部分结果

2. 误删数据后怎么办?
先对和 MySQL 相关的误删数据,做下分类:
- 使用 delete 语句误删数据行;
- 使用 drop table 或者 truncate table 语句误删数据表;
- 使用 drop database 语句误删数据库;
- 使用 rm 命令误删整个 MySQL 实例。
2.1 删除行
使用 delete 语句误删了数据行,可以用 Flashback 工具通过闪回把数据恢复回来。
原理是:
修改 binlog 的内容,拿回原库重放。而能够使用这个方案的前提是,需要确保 binlog_format=row 和 binlog_row_image=FULL。
具体恢复数据时,对单个事务做如下处理:
- 对于 insert 语句,对应的 binlog event 类型是 Write_rows event,把它改成 Delete_rows event 即可;
- 同理,对于 delete 语句,也是将 Delete_rows event 改为 Write_rows event;
- 而如果是 Update_rows 的话,binlog 里面记录了数据行修改前和修改后的值,对调这两行的位置即可。
如果误操作不是一个,而是多个,会怎么样呢?比如下面三个事务:
(A)delete ...
(B)insert ...
(C)update ...
要把数据库恢复回这三个事务操作之前的状态,用 Flashback 工具解析 binlog 后,写回主库的命令是:
(reverse C)update ...
(reverse B)delete ...
(reverse A)insert ...
也就是说,如果误删数据涉及到了多个事务的话,需要将事务的顺序调过来再执行。
需要说明的是,不建议你直接在主库上执行这些操作。
恢复数据比较安全的做法,是恢复出一个备份,或者找一个从库作为临时库,在这个临时库上执行这些操作,然后再将确认过的临时库的数据,恢复回主库。
这是因为,一个在执行线上逻辑的主库,数据状态的变更往往是有关联的。可能由于发现数据问题的时间晚了一点儿,就导致已经在之前误操作的基础上,业务代码逻辑又继续修改了其他数据。所以,如果这时候单独恢复这几行数据,而又未经确认的话,就可能会出现对数据的二次破坏。
不止要说误删数据的事后处理办法,更重要是要做到事前预防。有以下两个建议:
- 把 sql_safe_updates 参数设置为 on。这样一来,如果我们忘记在 delete 或者 update 语句中写 where 条件,或者 where 条件里面没有包含索引字段的话,这条语句的执行就会报错。
- 代码上线前,必须经过 SQL 审计。
设置了 sql_safe_updates=on,如果真的要把一个小表的数据全部删掉,应该怎么办呢?
如果确定这个删除操作没问题的话,可以在 delete 语句中加上 where 条件,比如 where id>=0。
但是,delete 全表是很慢的,需要生成回滚日志、写 redo、写 binlog。
所以,从性能角度考虑,你该优先考虑使用 truncate table 或者 drop table 命令。
2.2 误删库/表
这种情况下,要想恢复数据,就需要使用全量备份,加增量日志的方式了。这个方案要求线上有定期的全量备份,并且实时备份 binlog。
在这两个条件都具备的情况下,假如有人中午 12 点误删了一个库,恢复数据的流程如下:
- 取最近一次全量备份,假设这个库是一天一备,上次备份是当天 0 点;
- 用备份恢复出一个临时库;
- 从日志备份里面,取出凌晨 0 点之后的日志;
- 把这些日志,除了误删除数据的语句外,全部应用到临时库。
流程的示意图如下所示:
图 1 数据恢复流程 -mysqlbinlog 方法
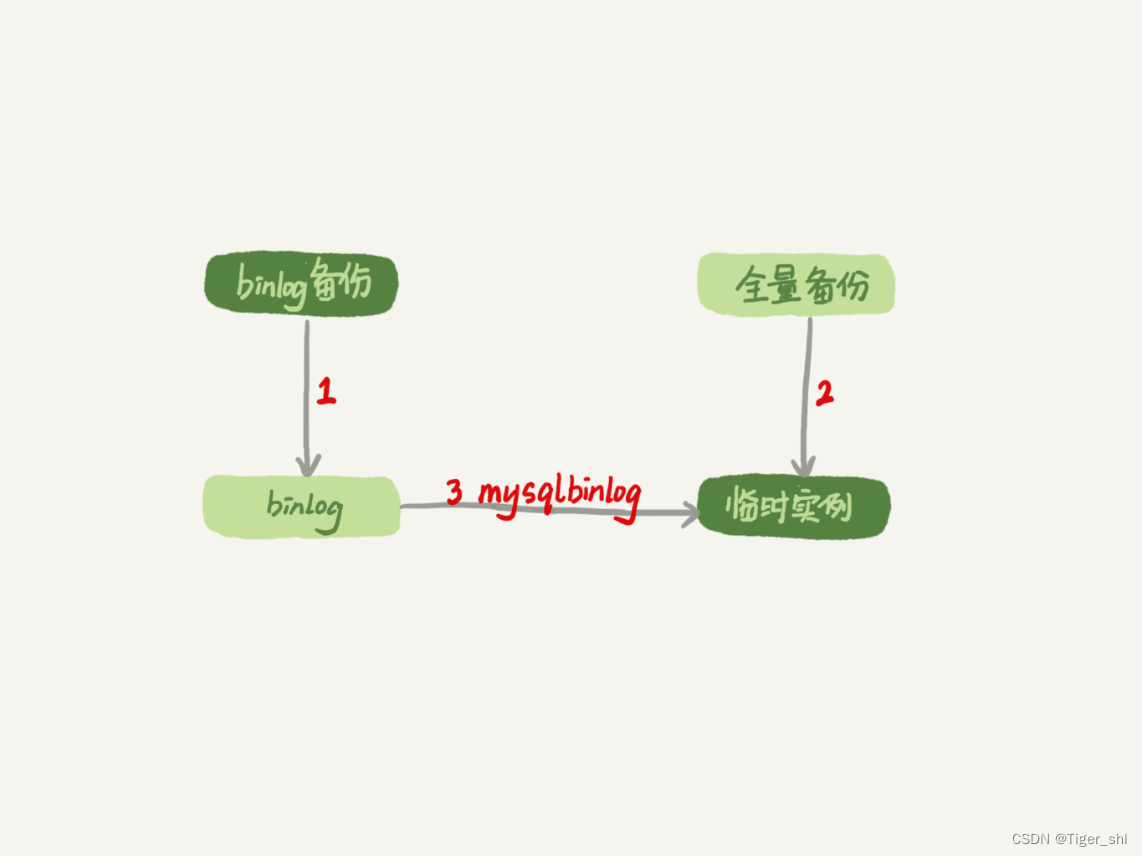
说明:
- 为了加速数据恢复,如果这个临时库上有多个数据库,可以在使用 mysqlbinlog 命令时,加上一个–database 参数,用来指定误删表所在的库。这样,就避免了在恢复数据时还要应用其他库日志的情况。
- 在应用日志的时候,需要跳过 12 点误操作的那个语句的 binlog:
- 如果原实例没有使用 GTID 模式,只能在应用到包含 12 点的 binlog 文件的时候,先用–stop-position 参数执行到误操作之前的日志,然后再用–start-position 从误操作之后的日志继续执行;
- 如果实例使用了 GTID 模式,就方便多了。假设误操作命令的 GTID 是 gtid1,那么只需要执行 set gtid_next=gtid1;begin;commit; 先把这个 GTID 加到临时实例的 GTID 集合,之后按顺序执行 binlog 的时候,就会自动跳过误操作的语句。
不过,即使这样,使用 mysqlbinlog 方法恢复数据还是不够快,主要原因有两个:
- 如果是误删表,最好就是只恢复出这张表,也就是只重放这张表的操作,但是 mysqlbinlog 工具并不能指定只解析一个表的日志;
- 用 mysqlbinlog 解析出日志应用,应用日志的过程就只能是单线程。
一种加速的方法是,在用备份恢复出临时实例之后,将这个临时实例设置成线上备库的从库,这样:
- 在 start slave 之前,先通过执行change replication filter replicate_do_table = (tbl_name) 命令,就可以让临时库只同步误操作的表;
- 这样做也可以用上并行复制技术,来加速整个数据恢复过程。
过程的示意图如下所示:
图 2 数据恢复流程 -master-slave 方法
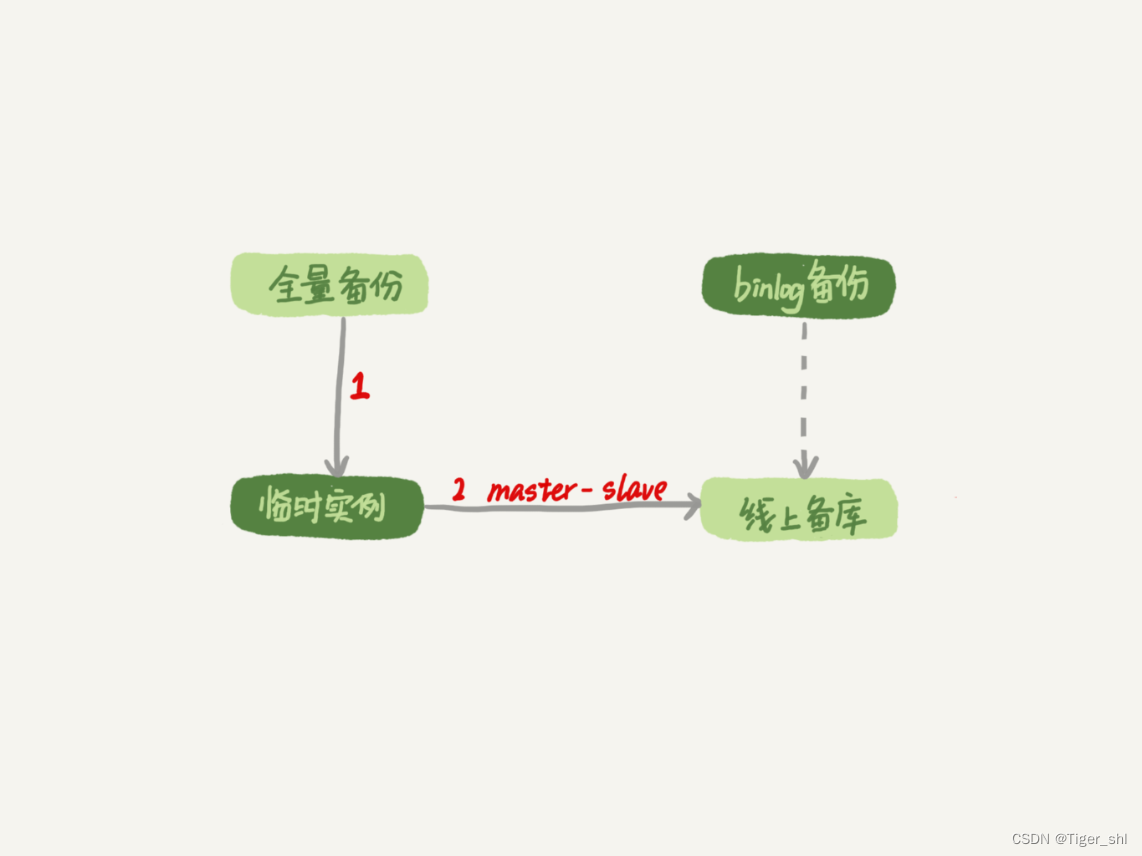
图中 binlog 备份系统到线上备库有一条虚线,是指如果由于时间太久,备库上已经删除了临时实例需要的 binlog 的话,我们可以从 binlog 备份系统中找到需要的 binlog,再放回备库中。
假设,发现当前临时实例需要的 binlog 是从 master.000005 开始的,但是在备库上执行 show binlogs 显示的最小的 binlog 文件是 master.000007,意味着少了两个 binlog 文件。这时,我们就需要去 binlog 备份系统中找到这两个文件。
把之前删掉的 binlog 放回备库的操作步骤,是这样的:
- 从备份系统下载 master.000005 和 master.000006 这两个文件,放到备库的日志目录下;
- 打开日志目录下的 master.index 文件,在文件开头加入两行,内容分别是 “./master.000005”和“./master.000006”;
- 重启备库,目的是要让备库重新识别这两个日志文件;
- 现在这个备库上就有了临时库需要的所有 binlog 了,建立主备关系,就可以正常同步了。
不论是把 mysqlbinlog 工具解析出的 binlog 文件应用到临时库,还是把临时库接到备库上,这两个方案的共同点是:误删库或者表后,恢复数据的思路主要就是通过备份,再加上应用 binlog 的方式。
就是说,这两个方案都要求备份系统定期备份全量日志,而且需要确保 binlog 在被从本地删除之前已经做了备份。
但是,一个系统不可能备份无限的日志,还需要根据成本和磁盘空间资源,设定一个日志保留的天数。
建议
不论使用上述哪种方式,都要把这个数据恢复功能做成自动化工具,并且经常拿出来演练。
- 虽然“发生这种事,大家都不想的”,但是万一出现了误删事件,能够快速恢复数据,将损失降到最小,也应该不用跑路了。
- 如果临时再手忙脚乱地手动操作,最后又误操作了,对业务造成了二次伤害,那就说不过去了。
2.3 延迟复制备库
虽然可以通过利用并行复制来加速恢复数据的过程,但是这个方案仍然存在“恢复时间不可控”的问题。
如果一个库的备份特别大,或者误操作的时间距离上一个全量备份的时间较长,比如一周一备的实例,在备份之后的第 6 天发生误操作,那就需要恢复 6 天的日志,这个恢复时间可能是要按天来计算的。
有什么方法可以缩短恢复数据需要的时间呢?
如果有非常核心的业务,不允许太长的恢复时间,我们可以考虑搭建延迟复制的备库。
这个功能是 MySQL 5.6 版本引入的。
一般的主备复制结构存在的问题是,如果主库上有个表被误删了,这个命令很快也会被发给所有从库,进而导致所有从库的数据表也都一起被误删了。
延迟复制的备库是一种特殊的备库,通过 CHANGE MASTER TO MASTER_DELAY = N 命令,可以指定这个备库持续保持跟主库有 N 秒的延迟。
比如把 N 设置为 3600,这就代表了如果主库上有数据被误删了,并且在 1 小时内发现了这个误操作命令,这个命令就还没有在这个延迟复制的备库执行。
这时候到这个备库上执行 stop slave,再通过之前介绍的方法,跳过误操作命令,就可以恢复出需要的数据。
这样的话,就随时可以得到一个,只需要最多再追 1 小时,就可以恢复出数据的临时实例,也就缩短了整个数据恢复需要的时间。
2.4 预防误删库 / 表的方法
2.4.1 账号分离
这样做的目的是,避免写错命令。比如:
- 我们只给业务开发同学 DML 权限,而不给 truncate/drop 权限。而如果业务开发人员有 DDL 需求的话,也可以通过开发管理系统得到支持。
- 即使是 DBA 团队成员,日常也都规定只使用只读账号,必要的时候才使用有更新权限的账号。
2.4.2 制定操作规范
这样做的目的,是避免写错要删除的表名。比如:
- 在删除数据表之前,必须先对表做改名操作。然后,观察一段时间,确保对业务无影响以后再删除这张表。
- 改表名的时候,要求给表名加固定的后缀(比如加 _to_be_deleted),然后删除表的动作必须通过管理系统执行。并且,管理系删除表的时候,只能删除固定后缀的表。
2.5 rm 删除数据
对于一个有高可用机制的 MySQL 集群来说,最不怕的就是 rm 删除数据了。只要不是恶意地把整个集群删除,而只是删掉了其中某一个节点的数据的话,HA 系统就会开始工作,选出一个新的主库,从而保证整个集群的正常工作。
这时,要做的就是在这个节点上把数据恢复回来,再接入整个集群。
现在不止是 DBA 有自动化系统,SA(系统管理员)也有自动化系统,所以也许一个批量下线机器的操作,会让你整个 MySQL 集群的所有节点都全军覆没。
应对这种情况,建议只能是说尽量把备份跨机房,或者最好是跨城市保存。
小结
- 预防远比处理的意义来得大;
- 定期检查备份的有效性也很有必要;
- 可以使用show grants 命令查看账户的权限,如果权限过大,可以建议 DBA 同学给你分配权限低一些的账号。
3. 为何有kill不掉的语句?
MySQL 中有两个 kill 命令:
- 一个是 kill query + 线程 id,表示终止这个线程中正在执行的语句;
- 一个是 kill connection + 线程 id,这里 connection 可缺省,表示断开这个线程的连接,当然如果这个线程有语句正在执行,也是要先停止正在执行的语句的。
在使用 MySQL 的时候,使用了 kill 命令,却没能断开这个连接。再执行 show processlist 命令,看到这条语句的 Command 列显示的是 Killed。我们就来讨论一下这个问题。
其实大多数情况下,kill query/connection 命令是有效的。比如,执行一个查询的过程中,发现执行时间太久,要放弃继续查询,这时我们就可以用 kill query 命令,终止这条查询语句。
还有一种情况是,语句处于锁等待的时候,直接使用 kill 命令也是有效的。我们一起来看下这个例子:
图 1 kill query 成功的例子
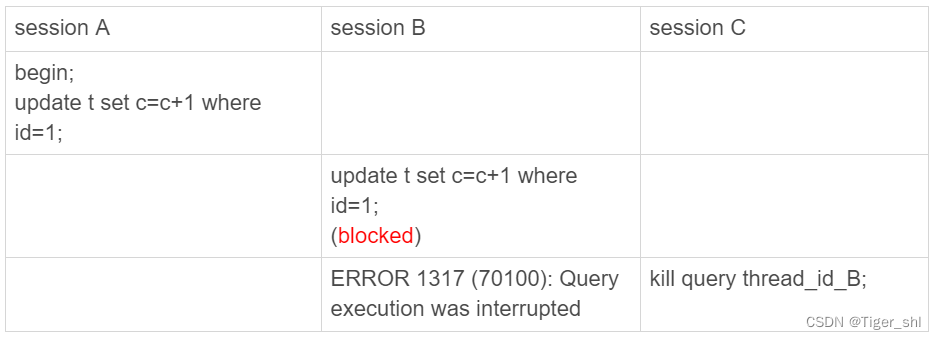
看到,session C 执行 kill query 以后,session B 几乎同时就提示了语句被中断。
3.1 收到 kill 以后,线程做什么?
session B 是直接终止掉线程,什么都不管就直接退出吗?显然,这是不行的。
当对一个表做增删改查操作时,会在表上加 MDL 读锁。所以,session B 虽然处于 blocked 状态,但还是拿着一个 MDL 读锁的。如果线程被 kill 的时候,就直接终止,那之后这个 MDL 读锁就没机会被释放了。
kill 并不是马上停止的意思,而是告诉执行线程说,这条语句已经不需要继续执行了,可以开始“执行停止的逻辑了”。
实现上,当用户执行 kill query thread_id_B 时,MySQL 里处理 kill 命令的线程做了两件事:
- 把 session B 的运行状态改成 THD::KILL_QUERY(将变量 killed 赋值为 THD::KILL_QUERY);
- 给 session B 的执行线程发一个信号。
为什么要发信号呢?
因为像图 1 的我们例子里面,session B 处于锁等待状态,如果只是把 session B 的线程状态设置 THD::KILL_QUERY,线程 B 并不知道这个状态变化,还是会继续等待。发一个信号的目的,就是让 session B 退出等待,来处理这个 THD::KILL_QUERY 状态。
这里隐含了这么三层意思:
- 一个语句执行过程中有多处“埋点”,在这些“埋点”的地方判断线程状态,如果发现线程状态是 THD::KILL_QUERY,才开始进入语句终止逻辑;
- 如果处于等待状态,必须是一个可以被唤醒的等待,否则根本不会执行到“埋点”处;
- 语句从开始进入终止逻辑,到终止逻辑完全完成,是有一个过程的。
再看一个 kill 不掉的例子
innodb_thread_concurrency 不够用的例子。首先,执行 set global innodb_thread_concurrency=2,将 InnoDB 的并发线程上限数设置为 2;然后,执行下面的序列:
图 2 kill query 无效的例子

可以看到:
- sesssion C 执行的时候被堵住了;
- 但是 session D 执行的 kill query C 命令却没什么效果,
- 直到 session E 执行了 kill connection 命令,才断开了 session C 的连接,提示“Lost connection to MySQL server during query”,
- 但是这时候,如果在 session E 中执行 show processlist,你就能看到下面这个图
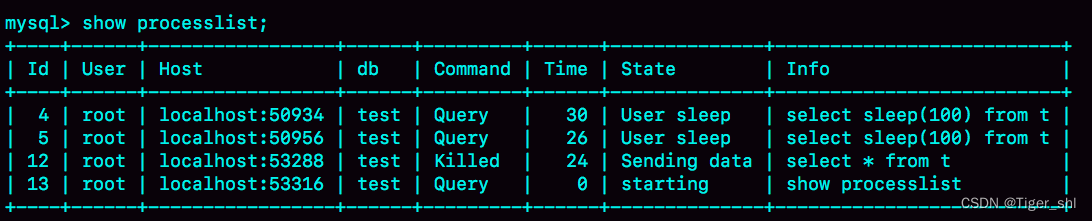
这时候,id=12 这个线程的 Commnad 列显示的是 Killed。也就是说,客户端虽然断开了连接,但实际上服务端上这条语句还在执行过程中。
为什么在执行 kill query 命令时,这条语句不像第一个例子的 update 语句一样退出呢?
在实现上,等行锁时,使用的是 pthread_cond_timedwait 函数,这个等待状态可以被唤醒。但是,在这个例子里,12 号线程的等待逻辑是这样的:每 10 毫秒判断一下是否可以进入 InnoDB 执行,如果不行,就调用 nanosleep 函数进入 sleep 状态。
也就是说,虽然 12 号线程的状态已经被设置成了 KILL_QUERY,但是在这个等待进入 InnoDB 的循环过程中,并没有去判断线程的状态,因此根本不会进入终止逻辑阶段。
当 session E 执行 kill connection 命令时,是这么做的:
- 把 12 号线程状态设置为 KILL_CONNECTION;
- 关掉 12 号线程的网络连接。因为有这个操作,所以你会看到,这时候 session C 收到了断开连接的提示。
为什么执行 show processlist 的时候,会看到 Command 列显示为 killed 呢?其实,这就是因为在执行 show processlist 的时候,有一个特别的逻辑:
如果一个线程的状态是KILL_CONNECTION,就把Command列显示成Killed。
其实,即使是客户端退出了,这个线程的状态仍然是在等待中。
那这个线程什么时候会退出呢?
只有等到满足进入 InnoDB 的条件后,session C 的查询语句继续执行,然后才有可能判断到线程状态已经变成了 KILL_QUERY 或者 KILL_CONNECTION,再进入终止逻辑阶段。
小结一下:
这个例子是 kill 无效的第一类情况,即:线程没有执行到判断线程状态的逻辑。跟这种情况相同的,还有由于 IO 压力过大,读写 IO 的函数一直无法返回,导致不能及时判断线程的状态。
另一类情况是,终止逻辑耗时较长。这时候,从 show processlist 结果上看也是 Command=Killed,需要等到终止逻辑完成,语句才算真正完成。
这类情况,比较常见的场景有以下几种:
- 超大事务执行期间被 kill。这时候,回滚操作需要对事务执行期间生成的所有新数据版本做回收操作,耗时很长。
- 大查询回滚。如果查询过程中生成了比较大的临时文件,加上此时文件系统压力大,删除临时文件可能需要等待 IO 资源,导致耗时较长。
- DDL 命令执行到最后阶段,如果被 kill,需要删除中间过程的临时文件,也可能受 IO 资源影响耗时较久。
如果直接在客户端通过 Ctrl+C 命令,是不是就可以直接终止线程呢?
不可以。其实在客户端的操作只能操作到客户端的线程,客户端和服务端只能通过网络交互,是不可能直接操作服务端线程的。
而由于 MySQL 是停等协议,所以这个线程执行的语句还没有返回的时候,再往这个连接里面继续发命令也是没有用的。实际上,执行 Ctrl+C 的时候,是 MySQL 客户端另外启动一个连接,然后发送一个 kill query 命令。
3.2 关于客户端的误解
第一个误解:如果库里面的表特别多,连接就会很慢。
图 4 连接等待

每个客户端在和服务端建立连接的时候,需要做的事情就是 TCP 握手、用户校验、获取权限。但这几个操作,显然跟库里面表的个数无关。
但实际上,正如图中的文字提示所说的,当使用默认参数连接的时候,MySQL 客户端会提供一个本地库名和表名补全的功能。为了实现这个功能,客户端在连接成功后,需要多做一些操作:
- 执行 show databases;
- 切到 db1 库,执行 show tables;
- 把这两个命令的结果用于构建一个本地的哈希表。
在这些操作中,最花时间的就是第三步在本地构建哈希表的操作。所以,当一个库中的表个数非常多的时候,这一步就会花比较长的时间。也就是说,感知到的连接过程慢,其实并不是连接慢,也不是服务端慢,而是客户端慢。
图中的提示也说了,如果在连接命令中加上 -A,就可以关掉这个自动补全的功能,然后客户端就可以快速返回了。除了加 -A 以外,加–quick(或者简写为 -q) 参数,也可以跳过这个阶段
第二个误解:–quick 是一个更容易引起误会的参数。
是不是觉得这应该是一个让服务端加速的参数?但实际上恰恰相反,设置了这个参数可能会降低服务端的性能。
MySQL 客户端发送请求后,接收服务端返回结果的方式有两种:
- 一种是本地缓存,也就是在本地开一片内存,先把结果存起来。如果用 API 开发,对应的就是 mysql_store_result 方法。
- 另一种是不缓存,读一个处理一个。如果用 API 开发,对应的就是 mysql_use_result 方法。
MySQL 客户端默认采用第一种方式,而如果加上–quick 参数,就会使用第二种不缓存的方式。
采用不缓存的方式时,如果本地处理得慢,就会导致服务端发送结果被阻塞,因此会让服务端变慢。
既然这样,为什么要给这个参数取名叫作 quick 呢?这是因为使用这个参数可以达到以下三点效果:
- 第一点,就是前面提到的,跳过表名自动补全功能。
- 第二点,mysql_store_result 需要申请本地内存来缓存查询结果,如果查询结果太大,会耗费较多的本地内存,可能会影响客户端本地机器的性能;
- 第三点,是不会把执行命令记录到本地的命令历史文件。
思考
如果碰到一个被 killed 的事务一直处于回滚状态,你认为是应该直接把 MySQL 进程强行重启,还是应该让它自己执行完成呢?为什么呢?
因为重启之后该做的回滚动作还是不能少的,所以从恢复速度的角度来说,应该让它自己结束。
如果这个语句可能会占用别的锁,或者由于占用 IO 资源过多,从而影响到了别的语句执行的话,就需要先做主备切换,切到新主库提供服务。
切换之后别的线程都断开了连接,自动停止执行。接下来还是等它自己执行完成。这个操作属于我们在文章中说到的,减少系统压力,加速终止逻辑。
来自林晓斌《MySql实战45讲》
相关文章:
【MySql】10- 实践篇(八)
文章目录 1. 用动态的观点看加锁1.1 不等号条件里的等值查询1.2 等值查询的过程1.3 怎么看死锁?1.4 怎么看锁等待?1.5 update 的例子 2. 误删数据后怎么办?2.1 删除行2.2 误删库/表2.3 延迟复制备库2.4 预防误删库 / 表的方法2.4.1 账号分离2.4.2 制定操…...
【三方登录-Apple】iOS 苹果授权登录(sign in with Apple)之开发者配置一
记录一下sign in with Apple的开发者配置 前言 关于使用 Apple 登录 使用“通过 Apple 登录”可让用户设置帐户并使用其Apple ID登录您的应用程序和关联网站。首先使用“使用 Apple 登录”功能启用应用程序的App ID 。 如果您是首次启用应用程序 ID 或为新应用程序启用应用程序…...

可视化 | 数据可视化降维算法梳理
文章目录 📚数据描述🐇iris🐇MNIST 📚PCA🐇算法流程🐇图像描述 📚Kernel-PCA🐇算法流程🐇图像描述 📚MDS🐇算法流程🐇图像描述 &#…...
分布式:一文吃透分布式事务和seata事务
目录 一、事务基础概念二、分布式事务概念什么是分布式事务分布式事务场景CAP定理CAP理论理解CAPCAP的应用 BASE定理强一致性和最终一致性BASE理论 分布式事务分类刚性事务柔性事务 三、分布式事务解决方案方案汇总XA规范方案1:2PC第一阶段:准备阶段第二…...

Java架构师前沿技术
目录 1 导学2 信息物理系统2.1CPS的体系架构2.2 CPS的技术体系3 人工智能4 机器人5 边缘计算6 数字李生体7 云计算7.1 云计算的部署模式8 大数据想学习架构师构建流程请跳转:Java架构师系统架构设计 1 导学 2 信息物理系统 信息物理系统(CPS)是控制系统、嵌入式系统的扩展与…...

OpenCV ycrcb颜色空间
Opencv中有一个Ycrcb的选项,这个选项其实是Yuv444packet. 下面代码从文件中获取到一个yuv444planar的文件,通过手动转换,将其转为YcrCb,然后进行颜色空间csc. 所以可以确定这是一个packet的存储格式 def yuv444p_2_bgr8_opencv(…...
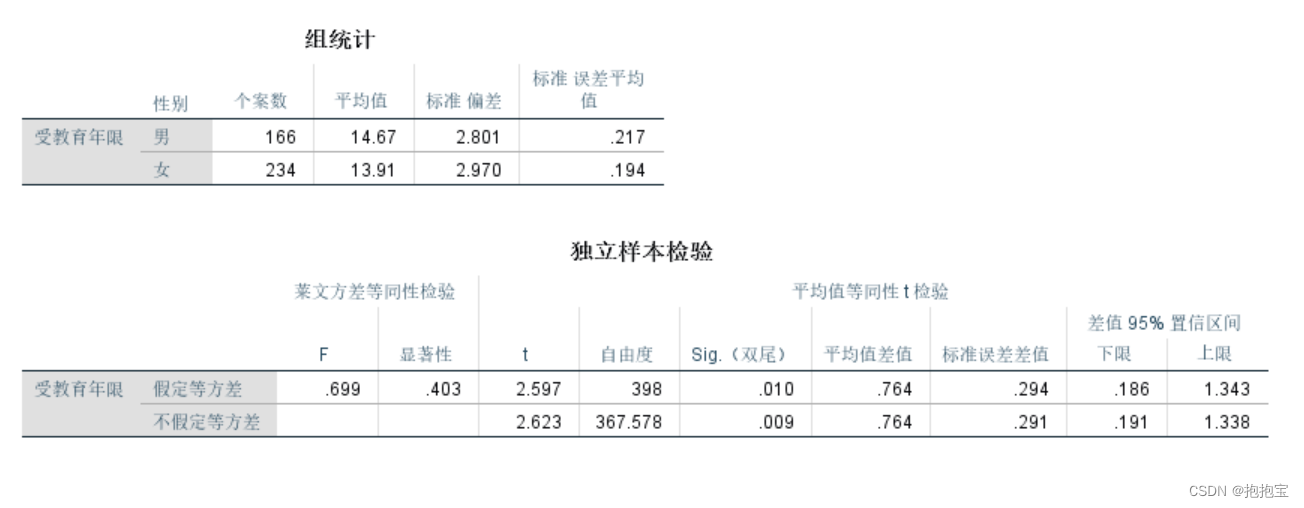
SPSS两独立样本t检验
前言: 本专栏参考教材为《SPSS22.0从入门到精通》,由于软件版本原因,部分内容有所改变,为适应软件版本的变化,特此创作此专栏便于大家学习。本专栏使用软件为:SPSS25.0 本专栏所有的数据文件请点击此链接下…...

视频格式高效转换:MP4视频批量转MKV格式的方法
随着数字媒体技术的不断发展,视频格式转换已经成为了我们日常工作中不可或缺的一部分。不同的视频格式适用于不同的场景和设备,因此将视频从一种格式转换为另一种格式往往是我们必须完成的任务。在本文中,我们将重点介绍如何运用云炫AI智剪高…...
0028Java程序设计-智能农场监控报警系统设计与实现
文章目录 摘要目 录系统设计开发环境 摘要 我国是一个以农业为主的国家,在当今社会信息化迅速发展的背景下,将信息技术与农业相融合是必然的趋势。现代信息技术在农业生产中的运用,主要体现在两个领域:一是传感器技术;…...
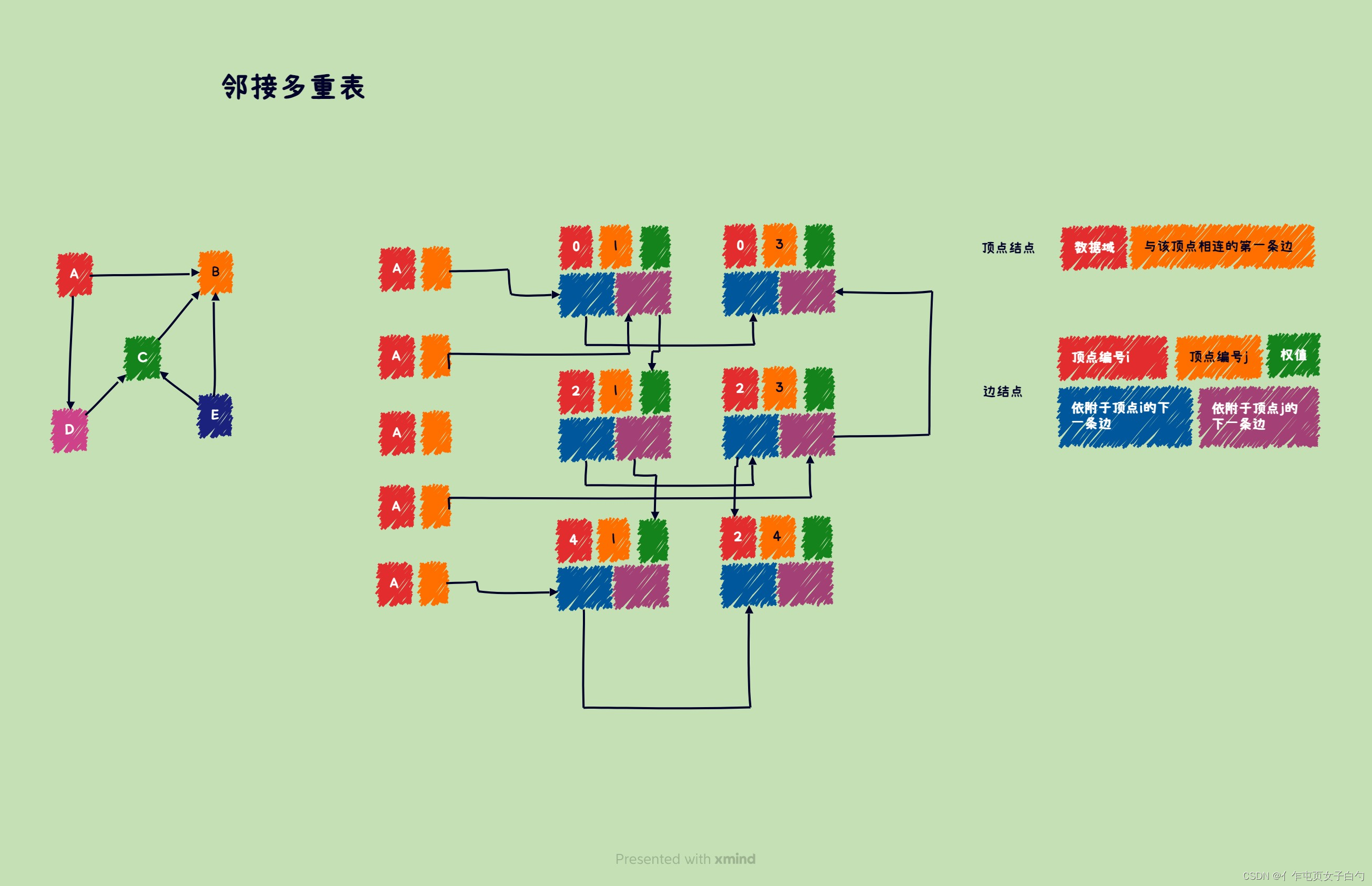
数据结构和算法——用C语言实现所有图状结构及相关算法
文章目录 前言图的基本概念图的存储方式邻接矩阵邻接表十字链表临界多重表 图的遍历最小生成树普里姆算法(Prim)克鲁斯卡尔算法(Kruskal) 最短路径BFS求最短路径迪杰斯特拉算法(Dijkstra)弗洛伊德算法&…...

JavaScript一些数据类型介绍
JavaScript一些数据类型介绍 1)数字类型(Number):可以表示整数和浮点数,例如:42、3.14159。 var x 42; // x 的类型是 Number var y 3.14159; // y 的类型是 Number2)字符串类型(…...

正向代理和反向代理与负载均衡
自存用 什么是反向代理,反向代理与正向代理的区别 一文帮你梳理清楚「正向代理和反向代理的区别与联系」 什么是反向代理服务器 正向代理为用户服务,给用户换个ip使其能访问其他网站 反向代理为服务器服务,使用户访问特定网站服务器。反向代…...

制造执行系统(MES)的核心功能是什么?
“一般来讲,制造执行系统(MES)的功能模块包括过程监控,质量管理,设备监控,计划执行等功能模块。” 为了深入探讨MES的核心功能,本文将从以下3个方面展开说明: 首先,从概…...
uniapp如何使用mumu模拟器
模拟器安装 下载地址:MuMu模拟器 模拟器相关设置 1.在设置-显示中选中手机版,设置手机分辨率 2.设置-关于手机-版本号快速点击,将其设置为开发者模式 3.选择多开器 4.打开hbuilderx,找到adb设置 5.配置adb路径及端口号&#x…...
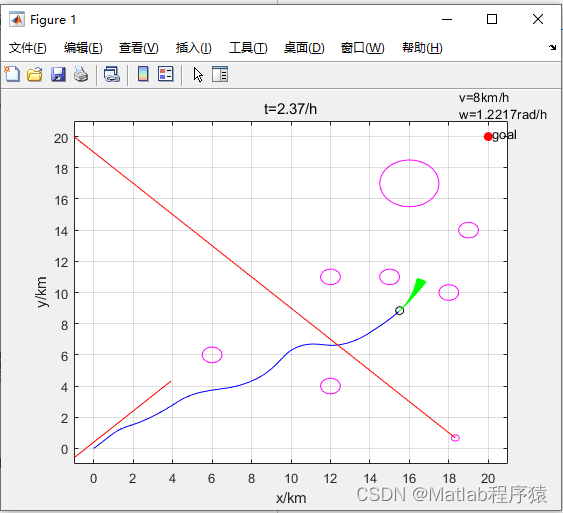
【MATLAB源码-第64期】matlab基于DWA算法的机器人局部路径规划包含动态障碍物和静态障碍物。
操作环境: MATLAB 2022a 1、算法描述 动态窗口法(Dynamic Window Approach,DWA)是一种局部路径规划算法,常用于移动机器人的导航和避障。这种方法能够考虑机器人的动态约束,帮助机器人在复杂环境中安全、…...
阿里云国际版和国内版的区别是什么,为什么很多人喜欢选择国际版?
阿里云国际版和国内版区别如下: 谈到区别,我们不妨先来对比下相同点与不同点,才能清晰明确的知道二者区别 下面先介绍不同点: 面向市场更广泛 阿里云国际版主要是面向国际(全球)客户的,而国内…...

监听redis过期业务处理
配置类: package com.testimport org.springframework.beans.factory.annotation.Autowired; import org.springframework.cache.annotation.CachingConfigurerSupport; import org.springframework.cache.annotation.EnableCaching; import org.springframework.c…...

计算机网络与技术——数据链路层
😊计算机网络与技术——数据链路层 🚀前言☃️基本概念🥏封装成帧🥏透明传输🥏差错检测 ☃️点对点协议PPP🥏PPP协议的特点🥏PPP协议的帧格式🔍PPP异步传输时透明传输(字…...
UE5 Android下载zip文件并解压缩到指定位置
一、下载是使用市场的免费插件 二、解压缩是使用市场的免费插件 三、Android路径问题 windows平台下使用该插件没有问题,只是在Android平台下,只有使用绝对路径才能进行解压缩,所以如何获得Android下的绝对路径?增加C文件获得And…...
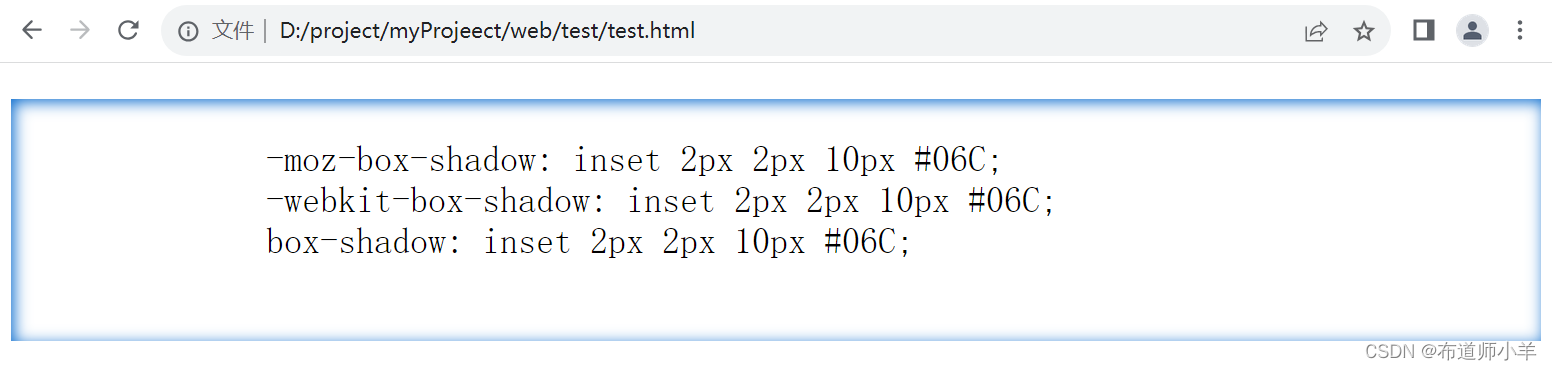
CSS3盒模型
CSS3盒模型规定了网页元素的显示方式,包括大小、边框、边界和补白等概念。2015年4月,W3C的CSS工作组发布了CSS3基本用户接口模块,该模块负责控制与用户接口界面相关效果的呈现方式。 1、盒模型基础 在网页设计中,经常会听到内容…...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

七、数据库的完整性
七、数据库的完整性 主要内容 7.1 数据库的完整性概述 7.2 实体完整性 7.3 参照完整性 7.4 用户定义的完整性 7.5 触发器 7.6 SQL Server中数据库完整性的实现 7.7 小结 7.1 数据库的完整性概述 数据库完整性的含义 正确性 指数据的合法性 有效性 指数据是否属于所定…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...

苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...