量化学习(一)数据获取
试验环境
windows10
Anaconda+PyCharm(小白参考文章:https://coderx.com.cn/?p=14)
VM中安装MySQL5.7(设置utf8及相应配置优化)
关于复权
小白参考文章:https://zhuanlan.zhihu.com/p/469820288
数据来源
AKShare官方文档:https://www.akshare.xyz/index.html
接口介绍
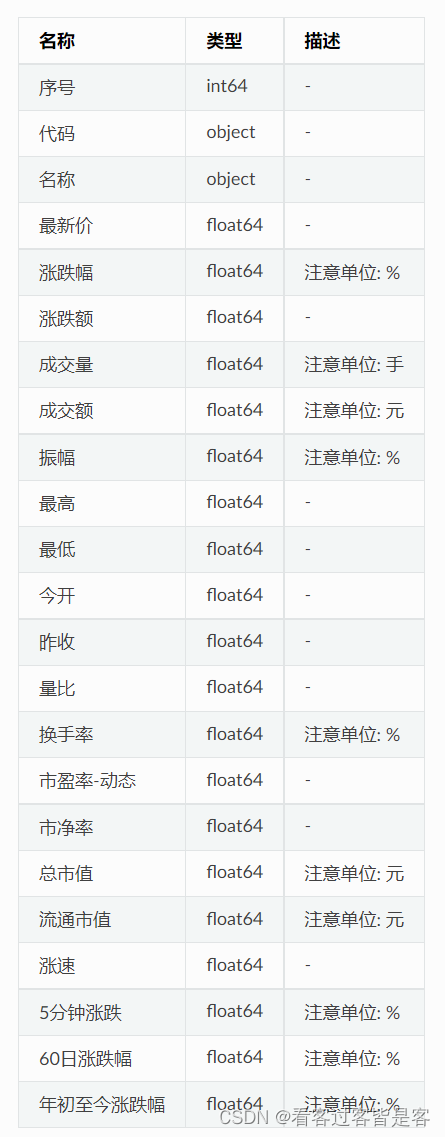
一、东财实时行情数据
描述:东方财富网-沪深京 A 股-实时行情数据;
接口:stock_zh_a_spot_em;
目标地址:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
限量:单次返回所有沪深京 A 股上市公司的实时行情数据;描述: 东方财富-沪深京 A 股日频率数据; 历史数据按日频率更新, 当日收盘价请在收盘后获取
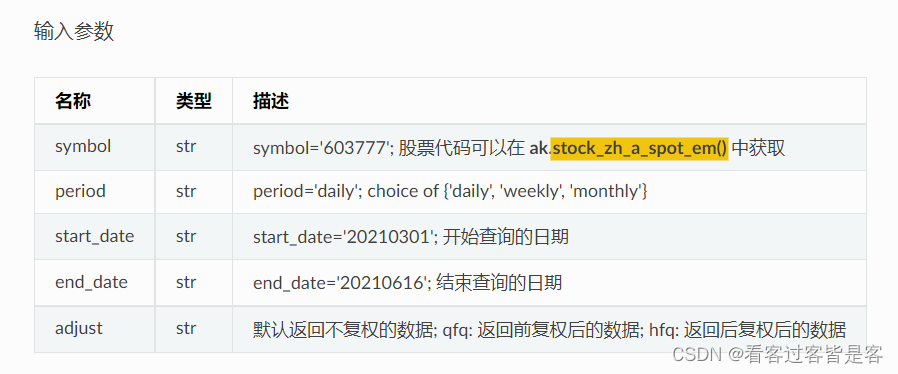
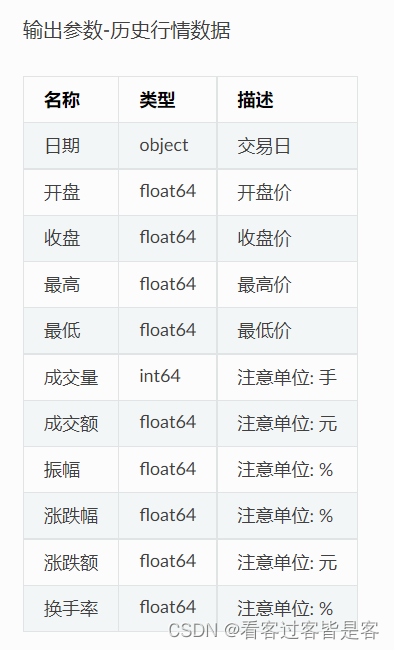
接口: stock_zh_a_hist;
目标地址:http://quote.eastmoney.com/concept/sh603777.html?from=classic(示例);
限量:单次返回指定沪深京 A 股上市公司、指定周期和指定日期间的历史行情日频率数据;
测试
# -*- coding: utf-8 -*-# 按 Shift+F10 执行或将其替换为您的代码。
# 按 双击 Shift 在所有地方搜索类、文件、工具窗口、操作和设置。
### 导包
import akshare as ak
import pandas as pd
import os### 设置工作路径
mypath=r"E:\PycharmProjects\pythonProject"
stock_zh_spot_df = ak.stock_zh_a_spot_em() ## 获取实时数据
stock_zh_spot_data=stock_zh_spot_df[stock_zh_spot_df['名称']!=''] ## 去除名称为空值的数据
codes_names=stock_zh_spot_data[['代码','名称']]
codes_names.to_csv(os.path.join(mypath+'\\'+'111.csv'),encoding='utf_8_sig') ## 数据导出为csv文件
print(codes_names)length=len(codes_names)
all_data = pd.DataFrame([])
for i in range(length):try:data_df = ak.stock_zh_a_hist(symbol=codes_names['代码'][i], period="daily", start_date="20230224", adjust="qfq") ## 日度数据,前复权data_df['stock_id']=codes_names['代码'][i]all_data=all_data.append(data_df)# print(all_data)except:KeyError()all_data.to_csv(os.path.join(mypath + '\\'+ 'All_Data.csv'), encoding='utf_8_sig') ## 数据导出为csv文件
# all_data.to_csv(os.path.join(mypath+'\\'+'All_Data.txt'),sep="\t",index=True) ## 数据导出为txt文件获取股票列表写入数据库
import akshare as ak
import sqlalchemy
import pandas as pddef create_mysql_engine():"""创建数据库引擎对象:return: 新创建的数据库引擎对象"""# 引擎参数信息host = '192.168.9.110'user = 'root'passwd = 'A_quant88'port = '3306'db = 'quant'# 创建数据库引擎对象mysql_engine = sqlalchemy.create_engine('mysql+pymysql://{0}:{1}@{2}:{3}'.format(user, passwd, host, port),poolclass=sqlalchemy.pool.NullPool)# 如果不存在数据库db_quant则创建mysql_engine.execute("CREATE DATABASE IF NOT EXISTS {0} ".format(db))# 创建连接数据库db_quant的引擎对象db_engine = sqlalchemy.create_engine('mysql+pymysql://{0}:{1}@{2}:{3}/{4}?charset=utf8'.format(user, passwd, host, port, db),poolclass=sqlalchemy.pool.NullPool)# 返回引擎对象return db_enginedef get_stock_codes(date=None, update=False):"""获取指定日期的A股代码列表若参数update为False,表示从数据库中读取股票列表若数据库中不存在股票列表的表,或者update为True,则下载指定日期date的交易股票列表若参数date为空,则返回最近1个交易日的A股代码列表若参数date不为空,且为交易日,则返回date当日的A股代码列表若参数date不为空,但不为交易日,则打印提示非交易日信息,程序退出:param date: 日期,默认为None:param update: 是否更新股票列表,默认为False:return: A股代码的列表"""# 创建数据库引擎对象engine = create_mysql_engine()# 数据库中股票代码的表名table_name = 'stock_codes'# 数据库中不存在股票代码表,或者需要更新股票代码表if table_name not in sqlalchemy.inspect(engine).get_table_names() or update:# 查询股票数据stock_zh_spot_df = ak.stock_zh_a_spot_em() ## 获取实时数据stock_zh_spot_data = stock_zh_spot_df[stock_zh_spot_df['名称'] != ''] ## 去除名称为空值的数据codes_names = stock_zh_spot_data[['代码', '名称']]print(codes_names)# 将股票代码写入数据库codes_names.to_sql(name=table_name, con=engine, if_exists='replace', index=False, index_label=False)# 返回股票列表return codes_names['代码'].tolist()# 从数据库中读取股票代码列表else:# 待执行的sql语句sql_cmd = 'SELECT {} FROM {}'.format('代码', table_name)# 读取sql,返回股票列表return pd.read_sql(sql=sql_cmd, con=engine)['代码'].tolist()if __name__ == '__main__':stock_codes = get_stock_codes()# print(stock_codes)获取股票历史数据
import akshare as ak
import sqlalchemy
import datetime
import pandas as pddef create_mysql_engine():"""创建数据库引擎对象:return: 新创建的数据库引擎对象"""# 引擎参数信息host = '192.168.9.110'user = 'root'passwd = 'A_quant88'port = '3306'db = 'quant'# 创建数据库引擎对象mysql_engine = sqlalchemy.create_engine('mysql+pymysql://{0}:{1}@{2}:{3}'.format(user, passwd, host, port),poolclass=sqlalchemy.pool.NullPool)# 如果不存在数据库db_quant则创建mysql_engine.execute("CREATE DATABASE IF NOT EXISTS {0} ".format(db))# 创建连接数据库db_quant的引擎对象db_engine = sqlalchemy.create_engine('mysql+pymysql://{0}:{1}@{2}:{3}/{4}?charset=utf8'.format(user, passwd, host, port, db),poolclass=sqlalchemy.pool.NullPool)# 返回引擎对象return db_enginedef get_stock_codes(date=None, update=False):"""获取指定日期的A股代码列表若参数update为False,表示从数据库中读取股票列表若数据库中不存在股票列表的表,或者update为True,则下载指定日期date的交易股票列表若参数date为空,则返回最近1个交易日的A股代码列表若参数date不为空,且为交易日,则返回date当日的A股代码列表若参数date不为空,但不为交易日,则打印提示非交易日信息,程序退出:param date: 日期,默认为None:param update: 是否更新股票列表,默认为False:return: A股代码的列表"""# 创建数据库引擎对象engine = create_mysql_engine()# 数据库中股票代码的表名table_name = 'stock_codes'# 数据库中不存在股票代码表,或者需要更新股票代码表if table_name not in sqlalchemy.inspect(engine).get_table_names() or update:# 查询股票数据stock_zh_spot_df = ak.stock_zh_a_spot_em() ## 获取实时数据stock_zh_spot_data = stock_zh_spot_df[stock_zh_spot_df['名称'] != ''] ## 去除名称为空值的数据codes_names = stock_zh_spot_data[['代码', '名称']]print(codes_names)# 将股票代码写入数据库codes_names.to_sql(name=table_name, con=engine, if_exists='replace', index=False, index_label=False)# 返回股票列表return codes_names['代码'].tolist()# 从数据库中读取股票代码列表else:# 待执行的sql语句sql_cmd = 'SELECT {} FROM {}'.format('代码', table_name)# 读取sql,返回股票列表return pd.read_sql(sql=sql_cmd, con=engine)['代码'].tolist()def create_data(stock_codes, period = "daily",start_date = '20230214', end_date = datetime.date.today().strftime('%Y%m%d'),adj = 'hfq'):"""下载指定日期内,指定股票的日线数据:param stock_codes: 待下载数据的股票代码:param from_date: 日线开始日期1990-12-19:param to_date: 日线结束日期:param adjustflag: 复权选项 1:后复权 2:前复权 3:不复权 默认为前复权:return: None"""# 下载股票循环for code in stock_codes:print('正在下载{}...'.format(code))# 下载日线数据data_df = ak.stock_zh_a_hist(symbol=code, period=period, start_date=start_date, end_date=end_date,adjust=adj) ## 日度数据,后复权print(data_df)if __name__ == '__main__':stock_codes = get_stock_codes()create_data(stock_codes)# print(stock_codes)多线程获取股票历史数据
import akshare as ak
import sqlalchemy
import datetime
import multiprocessing
import pandas as pddef create_mysql_engine():"""创建数据库引擎对象:return: 新创建的数据库引擎对象"""# 引擎参数信息host = '192.168.9.110'user = 'root'passwd = 'A_quant88'port = '3306'db = 'quant'# 创建数据库引擎对象mysql_engine = sqlalchemy.create_engine('mysql+pymysql://{0}:{1}@{2}:{3}'.format(user, passwd, host, port),poolclass=sqlalchemy.pool.NullPool)# 如果不存在数据库db_quant则创建mysql_engine.execute("CREATE DATABASE IF NOT EXISTS {0} ".format(db))# 创建连接数据库db_quant的引擎对象db_engine = sqlalchemy.create_engine('mysql+pymysql://{0}:{1}@{2}:{3}/{4}?charset=utf8'.format(user, passwd, host, port, db),poolclass=sqlalchemy.pool.NullPool)# 返回引擎对象return db_enginedef get_stock_codes(date=None, update=False):"""获取指定日期的A股代码列表若参数update为False,表示从数据库中读取股票列表若数据库中不存在股票列表的表,或者update为True,则下载指定日期date的交易股票列表若参数date为空,则返回最近1个交易日的A股代码列表若参数date不为空,且为交易日,则返回date当日的A股代码列表若参数date不为空,但不为交易日,则打印提示非交易日信息,程序退出:param date: 日期,默认为None:param update: 是否更新股票列表,默认为False:return: A股代码的列表"""# 创建数据库引擎对象engine = create_mysql_engine()# 数据库中股票代码的表名table_name = 'stock_codes'# 数据库中不存在股票代码表,或者需要更新股票代码表if table_name not in sqlalchemy.inspect(engine).get_table_names() or update:# 查询股票数据stock_zh_spot_df = ak.stock_zh_a_spot_em() ## 获取实时数据stock_zh_spot_data = stock_zh_spot_df[stock_zh_spot_df['名称'] != ''] ## 去除名称为空值的数据codes_names = stock_zh_spot_data[['代码', '名称']]# print(codes_names)# 将股票代码写入数据库codes_names.to_sql(name=table_name, con=engine, if_exists='replace', index=False, index_label=False)# 返回股票列表return codes_names['代码'].tolist()# 从数据库中读取股票代码列表else:# 待执行的sql语句sql_cmd = 'SELECT {} FROM {}'.format('代码', table_name)# 读取sql,返回股票列表return pd.read_sql(sql=sql_cmd, con=engine)['代码'].tolist()def create_data(stock_codes, period = "daily",start_date = '20230224', end_date = datetime.date.today().strftime('%Y%m%d'),adj = 'hfq'):"""下载指定日期内,指定股票的日线数据:param stock_codes: 待下载数据的股票代码:param from_date: 日线开始日期1990-12-19:param to_date: 日线结束日期:param adjustflag: 复权选项 1:后复权 2:前复权 3:不复权 默认为前复权:return: None"""# 下载股票循环for index,code in enumerate(stock_codes):print('({}/{})正在创建{}...'.format(index + 1, len(stock_codes), code))try:data_df = ak.stock_zh_a_hist(symbol=code, period=period, start_date=start_date, end_date=end_date,adjust=adj) ## 日度数据,后复权print(data_df)if data_df.empty:continueexcept Exception as e:print(e)# 将数值数据转为float型,便于后续处理convert_list = ['开盘','收盘','最高','最低','成交量','成交额','振幅','涨跌幅','涨跌额','换手率']data_df[convert_list] = data_df[convert_list].astype(float)def get_code_group(process_num, stock_codes):"""获取代码分组,用于多进程计算,每个进程处理一组股票:param process_num: 进程数:param stock_codes: 待处理的股票代码:return: 分组后的股票代码列表,列表的每个元素为一组股票代码的列表"""# 创建空的分组code_group = [[] for i in range(process_num)]# 按余数为每个分组分配股票for index, code in enumerate(stock_codes):code_group[index % process_num].append(code)return code_groupdef multiprocessing_func(func, args):"""多进程调用函数:param func: 函数名:param args: func的参数,类型为元组,第0个元素为进程数,第1个元素为股票代码列表:return: 包含各子进程返回对象的列表"""# 用于保存各子进程返回对象的列表results = []# 创建进程池with multiprocessing.Pool(processes=args[0]) as pool:# 多进程异步计算for codes in get_code_group(args[0], args[1]):results.append(pool.apply_async(func, args=(codes, *args[2:],)))# 阻止后续任务提交到进程池pool.close()# 等待所有进程结束pool.join()return resultsdef create_data_mp(stock_codes, process_num=6,period = "daily",start_date='20230224', end_date=datetime.date.today().strftime('%Y%m%d'), adj='hfq'):"""使用多进程创建指定日期内,指定股票的日线数据,计算扩展因子:param stock_codes: 待创建数据的股票代码:param process_num: 进程数:param from_date: 日线开始日期:param to_date: 日线结束日期:param adjustflag: 复权选项 1:后复权 2:前复权 3:不复权 默认为前复权:return: None"""multiprocessing_func(create_data, (process_num, stock_codes, period,start_date, end_date, adj))if __name__ == '__main__':stock_codes = get_stock_codes()# print(stock_codes)# create_data(stock_codes)create_data_mp(stock_codes)# print(stock_codes)多线程获取股票历史数据录入数据库
import akshare as ak
import sqlalchemy
import datetime
import multiprocessing
import pandas as pddef create_mysql_engine():"""创建数据库引擎对象:return: 新创建的数据库引擎对象"""# 引擎参数信息host = '192.168.9.110'user = 'root'passwd = 'A_quant88'port = '3306'db = 'quant'# 创建数据库引擎对象mysql_engine = sqlalchemy.create_engine('mysql+pymysql://{0}:{1}@{2}:{3}'.format(user, passwd, host, port),poolclass=sqlalchemy.pool.NullPool)# 如果不存在数据库db_quant则创建mysql_engine.execute("CREATE DATABASE IF NOT EXISTS {0} ".format(db))# 创建连接数据库db_quant的引擎对象db_engine = sqlalchemy.create_engine('mysql+pymysql://{0}:{1}@{2}:{3}/{4}?charset=utf8'.format(user, passwd, host, port, db),poolclass=sqlalchemy.pool.NullPool)# 返回引擎对象return db_enginedef get_stock_codes(date=None, update=False):"""获取指定日期的A股代码列表若参数update为False,表示从数据库中读取股票列表若数据库中不存在股票列表的表,或者update为True,则下载指定日期date的交易股票列表若参数date为空,则返回最近1个交易日的A股代码列表若参数date不为空,且为交易日,则返回date当日的A股代码列表若参数date不为空,但不为交易日,则打印提示非交易日信息,程序退出:param date: 日期,默认为None:param update: 是否更新股票列表,默认为False:return: A股代码的列表"""# 创建数据库引擎对象engine = create_mysql_engine()# 数据库中股票代码的表名table_name = 'stock_codes'# 数据库中不存在股票代码表,或者需要更新股票代码表if table_name not in sqlalchemy.inspect(engine).get_table_names() or update:# 查询股票数据stock_zh_spot_df = ak.stock_zh_a_spot_em() ## 获取实时数据stock_zh_spot_data = stock_zh_spot_df[stock_zh_spot_df['名称'] != ''] ## 去除名称为空值的数据codes_names = stock_zh_spot_data[['代码', '名称']]# print(codes_names)# 将股票代码写入数据库codes_names.to_sql(name=table_name, con=engine, if_exists='replace', index=False, index_label=False)# 返回股票列表return codes_names['代码'].tolist()# 从数据库中读取股票代码列表else:# 待执行的sql语句sql_cmd = 'SELECT {} FROM {}'.format('代码', table_name)# 读取sql,返回股票列表return pd.read_sql(sql=sql_cmd, con=engine)['代码'].tolist()def create_data(stock_codes, period = "daily",start_date = '20230223', end_date = datetime.date.today().strftime('%Y%m%d'),adj = 'hfq'):"""下载指定日期内,指定股票的日线数据:param stock_codes: 待下载数据的股票代码:param from_date: 日线开始日期1990-12-19:param to_date: 日线结束日期:param adjustflag: 复权选项 1:后复权 2:前复权 3:不复权 默认为前复权:return: None"""# 创建数据库引擎对象engine = create_mysql_engine()# 下载股票循环for index,code in enumerate(stock_codes):print('({}/{})正在创建{}...'.format(index + 1, len(stock_codes), code))try:data_df = ak.stock_zh_a_hist(symbol=code, period=period, start_date=start_date, end_date=end_date,adjust=adj) ## 日度数据,后复权convert_list = ['开盘', '收盘', '最高', '最低', '成交量', '成交额', '振幅', '涨跌幅', '涨跌额', '换手率']data_df[convert_list] = data_df[convert_list].astype(float)# 写入数据库table_name = '{}'.format(code)data_df.to_sql(name=table_name, con=engine, if_exists='replace', index=True, index_label='id')if data_df.empty:continueexcept Exception as e:print(e)# 将数值数据转为float型,便于后续处理def get_code_group(process_num, stock_codes):"""获取代码分组,用于多进程计算,每个进程处理一组股票:param process_num: 进程数:param stock_codes: 待处理的股票代码:return: 分组后的股票代码列表,列表的每个元素为一组股票代码的列表"""# 创建空的分组code_group = [[] for i in range(process_num)]# 按余数为每个分组分配股票for index, code in enumerate(stock_codes):code_group[index % process_num].append(code)return code_groupdef multiprocessing_func(func, args):"""多进程调用函数:param func: 函数名:param args: func的参数,类型为元组,第0个元素为进程数,第1个元素为股票代码列表:return: 包含各子进程返回对象的列表"""# 用于保存各子进程返回对象的列表results = []# 创建进程池with multiprocessing.Pool(processes=args[0]) as pool:# 多进程异步计算for codes in get_code_group(args[0], args[1]):results.append(pool.apply_async(func, args=(codes, *args[2:],)))# 阻止后续任务提交到进程池pool.close()# 等待所有进程结束pool.join()return resultsdef create_data_mp(stock_codes, process_num=6,period = "daily",start_date='20230223', end_date=datetime.date.today().strftime('%Y%m%d'), adj='hfq'):"""使用多进程创建指定日期内,指定股票的日线数据,计算扩展因子:param stock_codes: 待创建数据的股票代码:param process_num: 进程数:param from_date: 日线开始日期:param to_date: 日线结束日期:param adjustflag: 复权选项 1:后复权 2:前复权 3:不复权 默认为前复权:return: None"""multiprocessing_func(create_data, (process_num, stock_codes, period,start_date, end_date, adj))if __name__ == '__main__':stock_codes = get_stock_codes()create_data_mp(stock_codes)# print(stock_codes)相关文章:
量化学习(一)数据获取
试验环境 windows10 AnacondaPyCharm(小白参考文章:https://coderx.com.cn/?p14) VM中安装MySQL5.7(设置utf8及相应配置优化) 关于复权 小白参考文章:https://zhuanlan.zhihu.com/p/469820288 数据来源 AK…...

java并发编程讨论:锁的选择
java并发编程 线程堆栈大小 单线程的堆栈大小默认为1M,1000个线程内存就占了1G。所以,受制于内存上限,单纯依靠多线程难以支持大量任务并发。 上下文切换开销 ReentrantLock 2个线程交替自增一个共享变量,使用ReentrantLock&…...

大数据框架之Hadoop:MapReduce(三)MapReduce框架原理——ReduceTask工作机制
1、ReduceTask工作机制 ReduceTask工作机制,如下图所示。 (1)Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直…...

Nginx的介绍、安装与常用命令
前言:传统结构上(如下图所示)我们只会部署一台服务器用来跑服务,在并发量小,用户访问少的情况下基本够用但随着用户访问的越来越多,并发量慢慢增多了,这时候一台服务器已经不能满足我们了,需要我们增加服务…...

less基础
一、less介绍 1、介绍 是css预处理语言,让css更强大,可以实现在less里面定义变量函数运算等 2、less默认浏览器不识别 less转成csS (框架: less/sass 框架的内置了转码less-css) 3、使用语法 1.创建less文件xxx.less 后缀.less 2. less编译成css 再引入…...
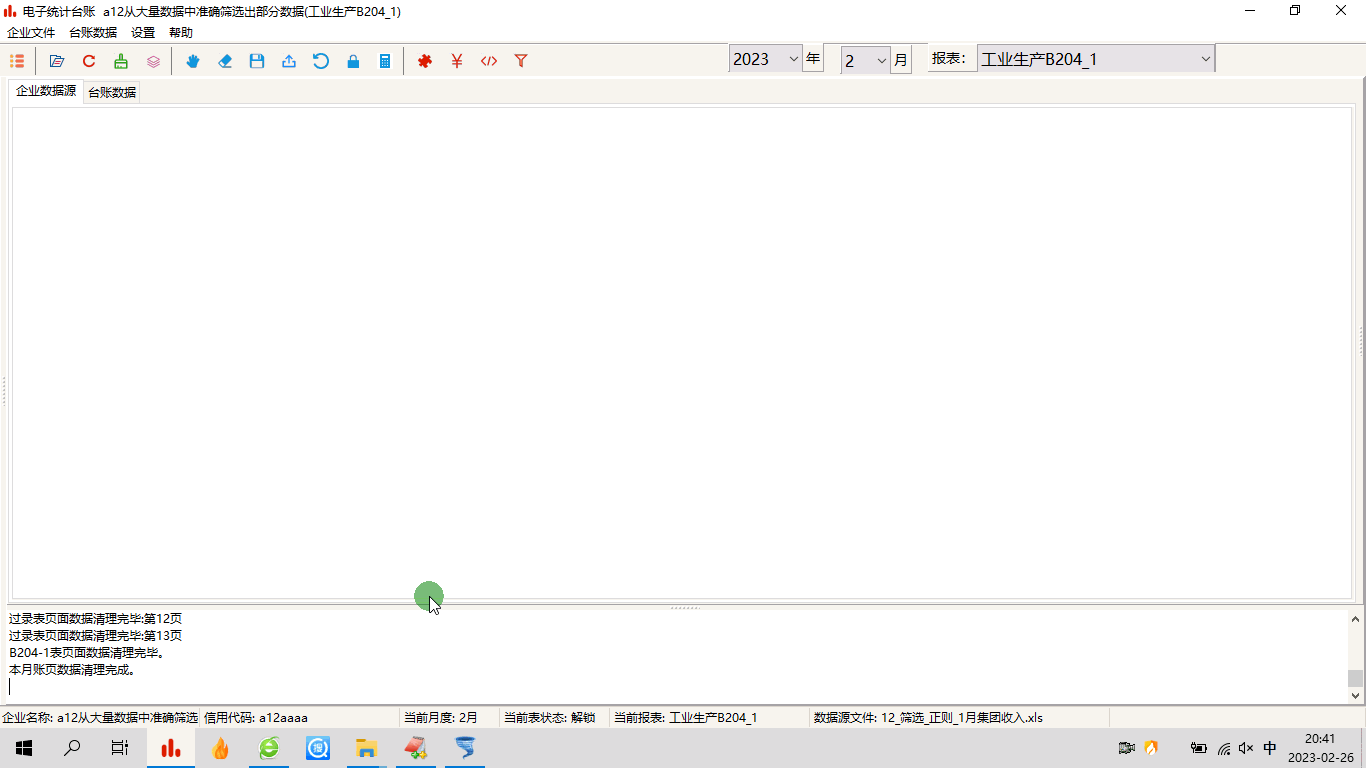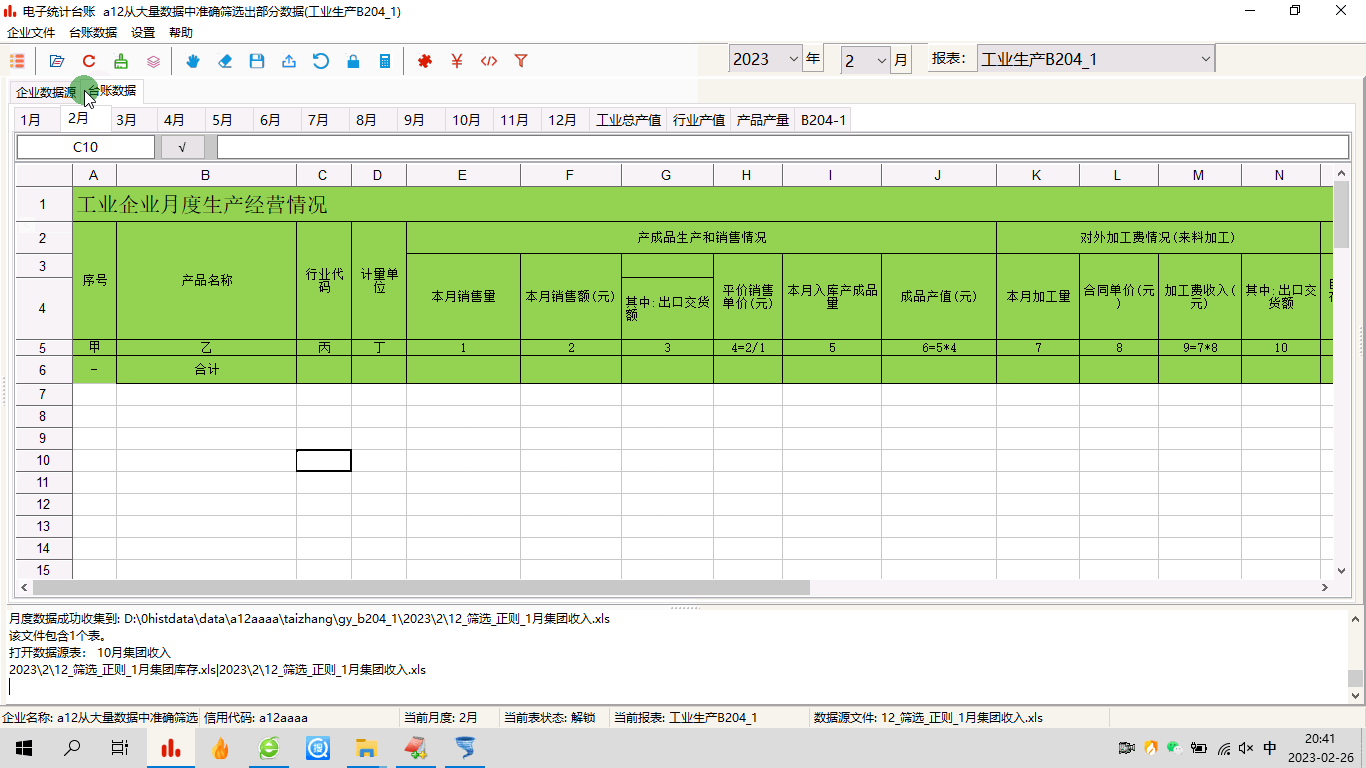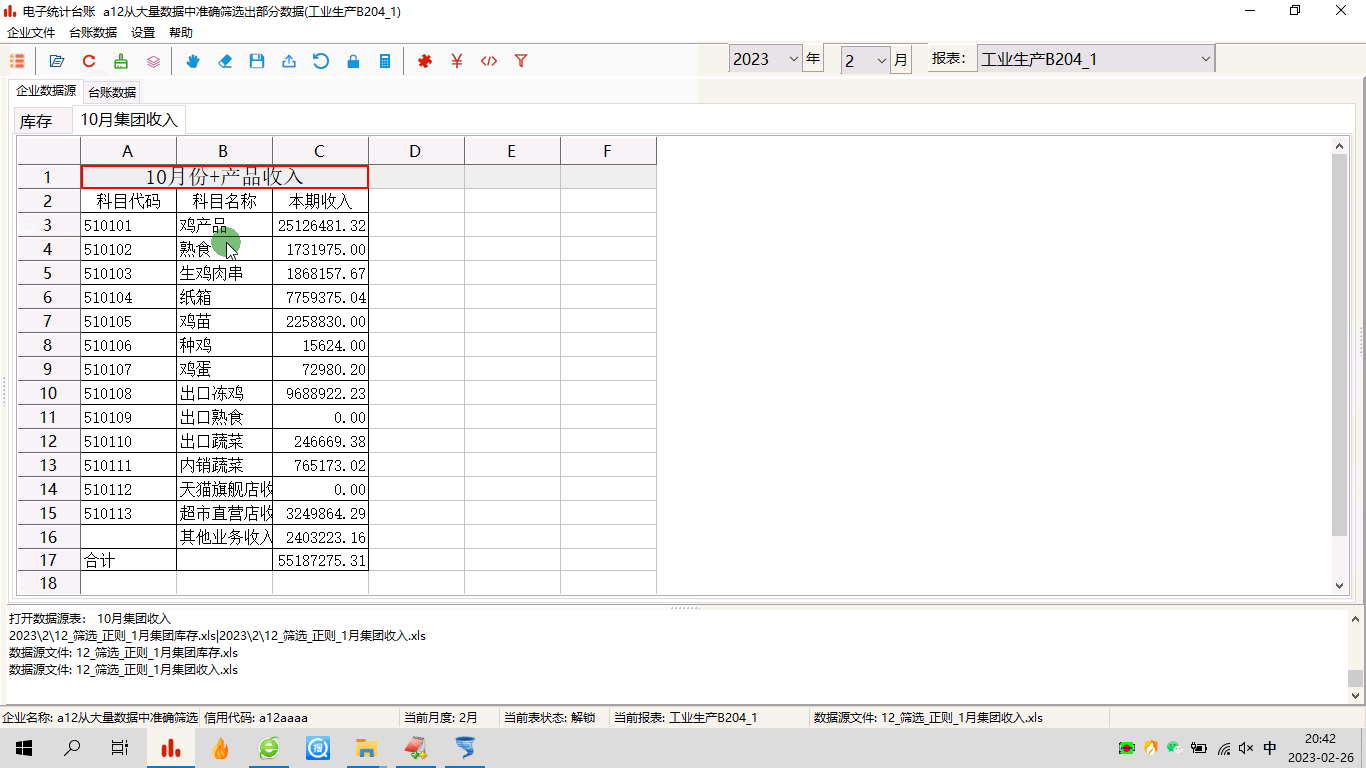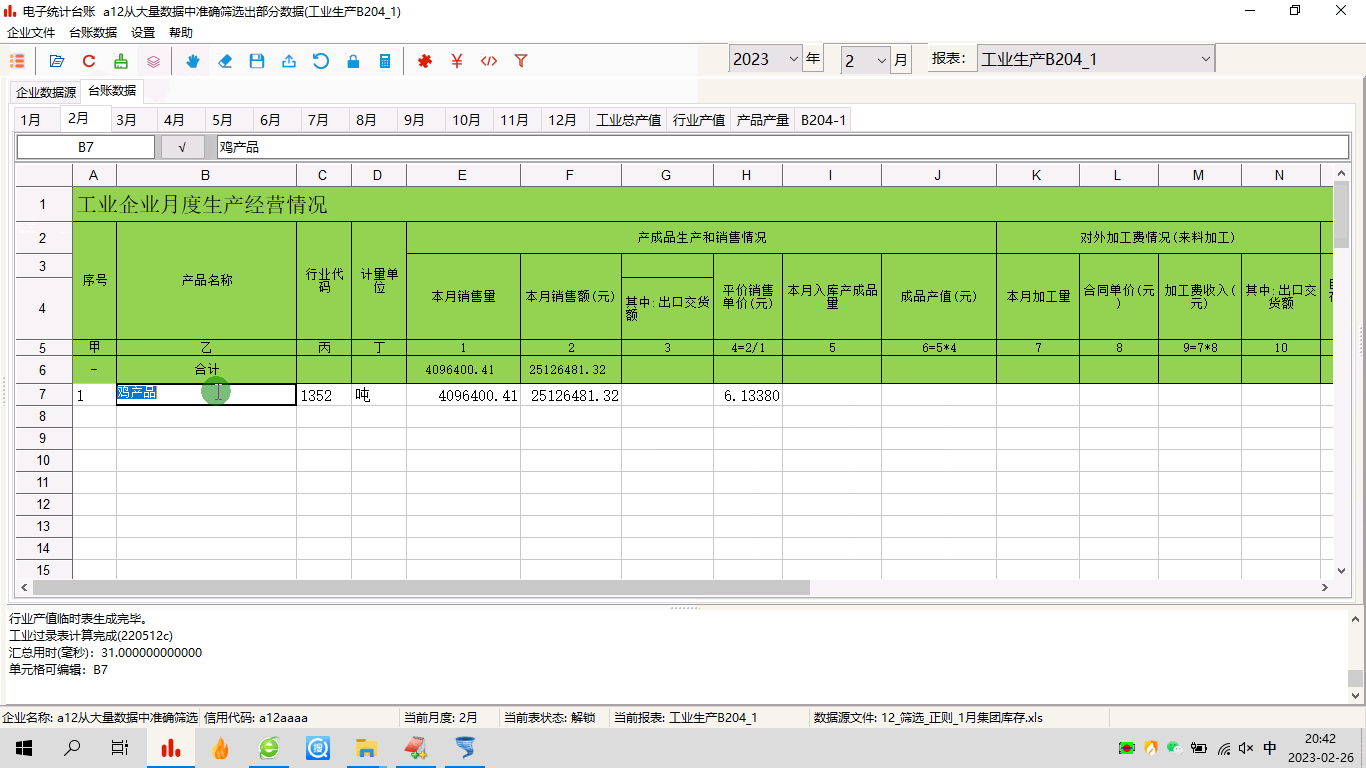
电子统计台账:海量数据中导入特定行,极力减少键盘编辑工作量
1 前言从事企业统计工作的小伙伴,本来已经够忙的了,现在又要加上什么电子台账这种鬼任务,而且居然还要每月来一次,简直不能忍。如果非要捏着鼻子忍了,那么有什么办法,减轻工作量?2 问题的提出有…...
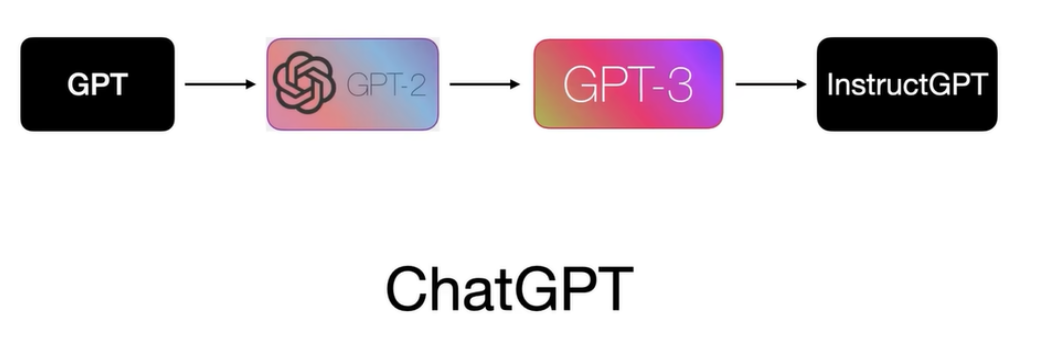
ChatGPT是如何训练得到的?通俗讲解
首先声明喔,我是没有任何人工智能基础的小白,不会涉及算法和底层原理。 我依照我自己的简易理解,总结出了ChatGPT是怎么训练得到的,非计算机专业的同学也应该能看懂。看完后训练自己的min-ChatGPT应该没问题 希望大牛如果看到这…...

刷题28-有效的变位词
32-有效的变位词 解题思路: 注意变位词的条件,当两个字符串完全相等或者长度不等时,就不是变位词。 把字符串中的字符映射成整型数组,统计每个字符出现的次数 注意数组怎么初始化: int [] s1new int[26]代码如下&a…...

JavaWeb中异步交互的关键——Ajax
文章目录1,Ajax 概述1.1 作用1.2 同步和异步1.3 案例1.3.1 分析1.3.2 后端实现1.3.3 前端实现2,axios2.1 基本使用2.2 快速入门2.2.1 后端实现2.2.2 前端实现2.3 请求方法别名3,JSON3.1 概述3.2 JSON 基础语法3.2.1 定义格式3.2.2 代码演示3.2.3 发送异步…...
python爬虫常见错误
python爬虫常见错误前言python常见错误1. AttributeError: WebDriver object has no attribute find_element_by_id1. 问题描述2. 解决办法2. selenium:DeprecationWarning: executable_path has been deprecated, please pass in1. 问题描述2. 解决办法3. 下载了包…...

AI_Papers周刊:第三期
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 2023.02.20—2023.02.26 文摘词云 Top Papers Subjects: cs.CL 1.LLaMA: Open and Efficient Foundation Language Models 标题:LLaMA:开放高效的基础语言模型 作者&#…...

在win7上用VS2008编译skysip工程
在win7上用VS2008编译skysip工程 1. 安装vs2008及相应的补丁包,主要包含以下安装包: 1.1 VS2008TeamSuite90DayTrialCHSX1429243.iso 1.2 VS2008SP1CHSX1512981.iso 1.3 VS90sp1-KB945140-CHS.exe 2. 安装Windows SDK: 6.0.6001.18000.367-KRMSDK_EN.zip 例如安装路径为…...

python 数据结构习题
旋转图像给定一个nn的二维矩阵表示一个图像。将图像顺时针旋转90度。你必须在原地旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要使用另一个矩阵来旋转图像。例如,给定matrix[[1,2,3],[4,5&#x…...
18、MySQL8其它新特性
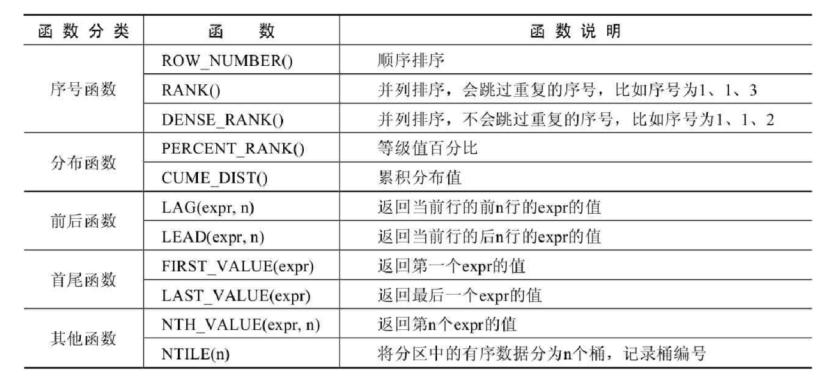
文章目录1 MySQL8新特性概述1.1 MySQL8.0 新增特性1.2 MySQL8.0移除的旧特性2 新特性1:窗口函数2.1 使用窗口函数前后对比2.2 窗口函数分类2.3 语法结构2.4 分类讲解1 序号函数2 分布函数3 前后函数4 首尾函数5 其他函数2.5 小 结3 新特性2:公用表表达式…...

【Android笔记79】Android之接口请求库Retrofit的介绍及使用
这篇文章,主要介绍Android之接口请求库Retrofit的介绍及使用。 目录 一、Retrofit接口请求库 1.1、什么是Retrofit 1.2、Retrofit的使用 (1)引入依赖...
蓝桥杯 考勤打卡
问题描述 小蓝负责一个公司的考勤系统, 他每天都需要根据员工刷卡的情况来确定 每个员工是否到岗。 当员工刷卡时, 会在后台留下一条记录, 包括刷卡的时间和员工编号, 只 要在一天中员工刷过一次卡, 就认为他到岗了。 现在小蓝导出了一天中所有员工的刷卡记录, 请将所有到岗…...
逻辑回归
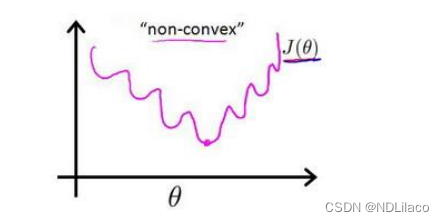
逻辑回归 在分类问题中,要预测的变量y为离散值(y0~1),逻辑回归模型的输出变量范围始终在 0 和 1 之间。 训练集为 {(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))}\{(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),...,(x^{(m)},y^{(m)})\} {…...
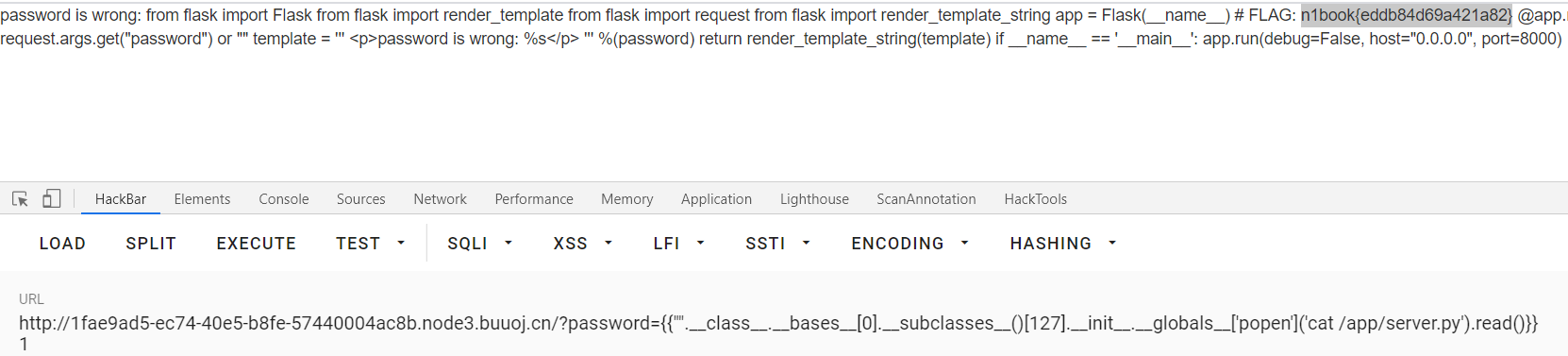
CTFer成长之路之Python中的安全问题
Python中的安全问题CTF 1.Python里的SSRF 题目提示 尝试访问到容器内部的 8000 端口和 url path /api/internal/secret 即可获取 flag 访问url: http://f5704bb3-5869-4ecb-9bdc-58b022589224.node3.buuoj.cn/ 回显如下: 通过提示构造payload&…...
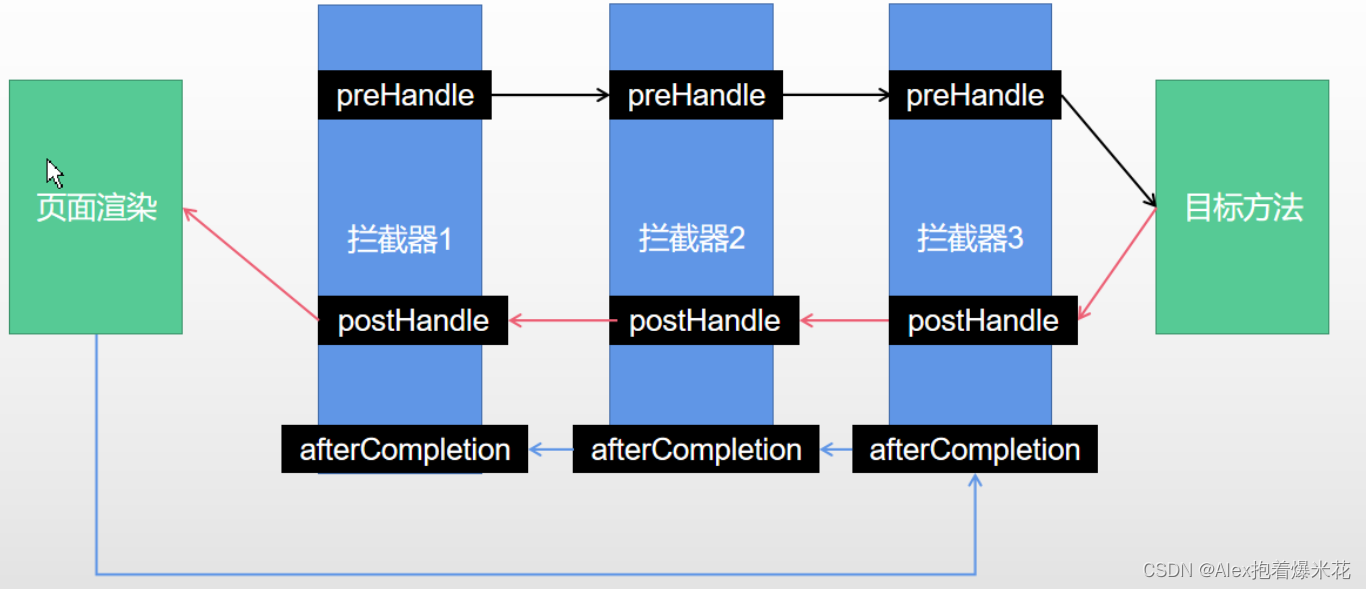
SpringBoot知识快速复习
Spring知识快速复习启动器自动装配ConfigurationImport导入组件Conditional条件装配ImportResource导入Spring配置文件ConfigurationProperties配置绑定Lombok简化开发dev-toolsyaml请求和响应处理静态资源规则与定制化请求处理-Rest映射请求处理-常用参数注解使用请求处理-Ser…...
SpringBoot+React博客论坛系统 附带详细运行指导视频
文章目录一、项目演示二、项目介绍三、项目运行截图四、主要代码一、项目演示 项目演示地址: 视频地址 二、项目介绍 项目描述:这是一个基于SpringBootReact框架开发的博客论坛系统。首先,这是一个前后端分离的项目,文章编辑器…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

【单片机期末】单片机系统设计
主要内容:系统状态机,系统时基,系统需求分析,系统构建,系统状态流图 一、题目要求 二、绘制系统状态流图 题目:根据上述描述绘制系统状态流图,注明状态转移条件及方向。 三、利用定时器产生时…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

HarmonyOS运动开发:如何用mpchart绘制运动配速图表
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在运动类应用中,运动数据的可视化是提升用户体验的重要环节。通过直观的图表展示运动过程中的关键数据,如配速、距离、卡路里消耗等,用户可以更清晰…...

scikit-learn机器学习
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可: # Also add the following code, # so that every time the environment (kernel) starts, # just run the following code: import sys sys.path.append(/home/aistudio/external-libraries)机…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...

作为测试我们应该关注redis哪些方面
1、功能测试 数据结构操作:验证字符串、列表、哈希、集合和有序的基本操作是否正确 持久化:测试aof和aof持久化机制,确保数据在开启后正确恢复。 事务:检查事务的原子性和回滚机制。 发布订阅:确保消息正确传递。 2、性…...

论文阅读笔记——Muffin: Testing Deep Learning Libraries via Neural Architecture Fuzzing
Muffin 论文 现有方法 CRADLE 和 LEMON,依赖模型推理阶段输出进行差分测试,但在训练阶段是不可行的,因为训练阶段直到最后才有固定输出,中间过程是不断变化的。API 库覆盖低,因为各个 API 都是在各种具体场景下使用。…...

数据结构:递归的种类(Types of Recursion)
目录 尾递归(Tail Recursion) 什么是 Loop(循环)? 复杂度分析 头递归(Head Recursion) 树形递归(Tree Recursion) 线性递归(Linear Recursion)…...

Vue3中的computer和watch
computed的写法 在页面中 <div>{{ calcNumber }}</div>script中 写法1 常用 import { computed, ref } from vue; let price ref(100);const priceAdd () > { //函数方法 price 1price.value ; }//计算属性 let calcNumber computed(() > {return ${p…...