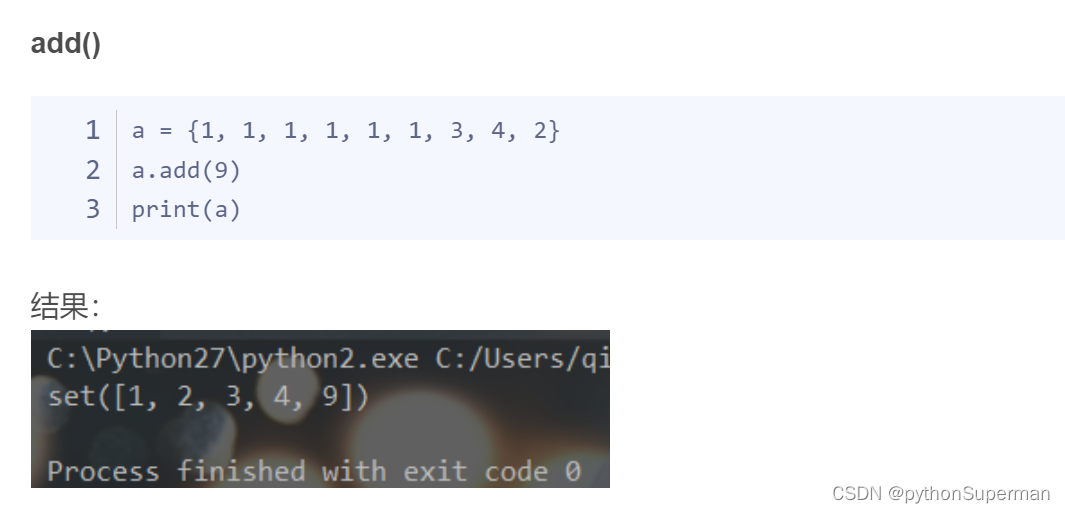
Hadoop MapReduce
目录
- 1.1 MapReduce介绍
- 1.2 MapReduce优缺点
- MapReduce实例进程
- 阶段组成
- 1.3 Hadoop MapReduce官方示例
- 案例:评估圆周率π(PI)的值
- 案例:wordcount单词词频统计
- 1.4 Map阶段执行流程
- 1.5 Reduce阶段执行流程
- 1.6 Shuffle机制
1.1 MapReduce介绍
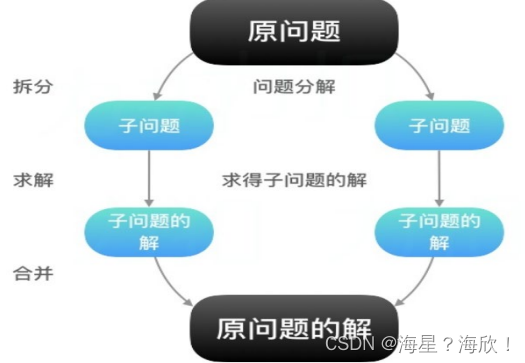
MapReduce的思想核心是“先分再合,分而治之”。
所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,然后把各部分的结果组成整个问题的最终结果。
- Map第一阶段,负责“拆分”:即把复杂的任务分解为若干个“简单的子任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系
拆分前提: 可并行计算+没有依赖关系 - Reduce第二阶段,负责“合并”:即对map阶段的结果进行全局汇总。
- MapReduce借鉴了函数式语言中的思想,用Map和Reduce两个函数提供了高层的并行编程抽象模型。
map: 对一组数据元素进行某种重复式的处理;
reduce: 对Map的中间结果进行某种进一步的结果整理 - MapReduce最大的亮点在于通过抽象模型和计算框架把需要做什么(业务问题)与具体怎么做(技术问题)分开了,为程序员提供一个抽象和高层的编程接口和框架。
程序员仅需要关心其应用层的具体计算问题,仅需编写少量的处理应用本身计算问题的业务程序代码 - Hadoop MapReduce是一个分布式计算框架。
分布式计算是一种计算方法,和集中式计算是相对的
1.2 MapReduce优缺点
优点:
- 易于编程:Mapreduce框架提供了用于二次开发的接口
- 良好的扩展性:当计算机资源不能得到满足的时候,可以通过增加机器来扩展它的计算能力。
- 高容错性:Hadoop集群是分布式搭建和部署得,任何单一机器节点宕机了,它可以把上面的计算任务转移到另一个节点上运行,不影响整个作业任务得完成
- 适合海量数据的离线处理:可以处理GB、TB和PB级别得数据量
局限性:MR主要是在离线计算领域
- 实时计算性能差。MapReduce主要应用于离线作业,无法作到秒级或者是亚秒级得数据响应
- 不能进行流式计算:流式计算特点是数据是源源不断得计算,并且数据是动态的;而MapReduce作为一个离线计算框架,主要是针对静态数据集得,数据是不能动态变化得
MapReduce实例进程
一个完整的MapReduce程序在分布式运行时有三类
- MRAppMaster:负责整个MR程序的过程调度及状态协调
- MapTask:负责map阶段的整个数据处理流程
- ReduceTask:负责reduce阶段的整个数据处理流程
阶段组成
- 一个MapReduce编程模型中只能包含一个Map阶段和一个Reduce阶段,或者只有Map阶段;
- 不能有诸如多个map阶段、多个reduce阶段的情景出现;
- 如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序串行运行
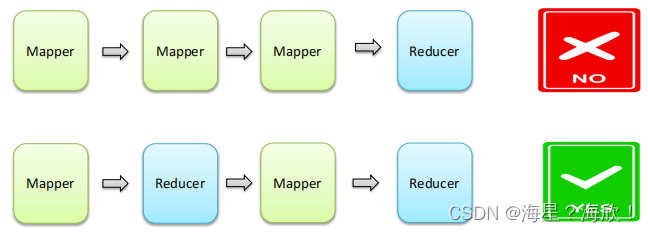
- 整个MapReduce程序中,数据都是以kv键值对的形式流转的
1.3 Hadoop MapReduce官方示例
- 一个最终完整版本的MR程序需要用户编写的代码和Hadoop自己实现的代码整合在一起才可以
- 由于MapReduce计算引擎天生的弊端(慢),当下企业中直接使用率已经很少了,所以在企业中工作很少涉及到MapReduce直接编程,但是某些软件的背后还依赖MapReduce引擎
- 但是后续的新的计算引擎比如Spark,当中就有MapReduce深深的影子存在
案例:评估圆周率π(PI)的值
蒙特卡洛方法计算,在平面上随机撒点
node1上:
jps #验证Hadoop是否启动
start-all.sh #启动Hadoopcd /export/server/hadoop-3.3.0/ #进入Hadoop安装包
cd share/
ll
cd hadoop/
ll
cd mapreduce/
ll
#可以看到一个jar文件
hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 2 2
#调用hadoop-mapreduce-examples-3.3.0.jar文件
#后面三个参数:pi表示MapReduce程序执行圆周率计算任务
#指定map阶段运行的任务task次数,并发度,这里是2;、
#每个map任务取样的个数,这里是2。
打开yarn页面:http://node1:8080/
案例:wordcount单词词频统计
统计文件中,每个单词出现的总次数
WordCount算是大数据计算领域经典的入门案例,相当于Hello World。
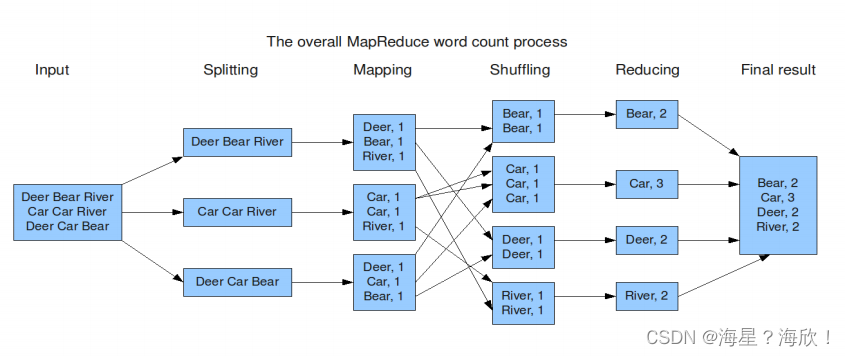
流程:
-
map阶段的核心:把输入的数据经过切割,全部标记1,因此输出就是<单词,1>。
splite后进入map。因为MR数据类型都要求是keyvalue类型 -
shuffle阶段核心:经过MR程序内部自带默认的排序分组等功能,把key相同的单词会作为一组数据构成新的kv对
根据key把他们分组,放在一起 -
reduce阶段核心:处理shuffle完的一组数据,该组数据就是该单词所有的键值对。对所有的1进行累加求和,就是单词的总次数
操作:
- 准备数据:
1.txt中存放要统计的内容
打开node1:9870进入Hadoop (要先在node1上start-all.sh启动)
在Hadoop上创建目录input,然后上传1.txt - 运行官方示例:
官方实例位于Hadoop中mapReduce中
hadoop jar hadoop-mapreduce-examples-3.3.0.jar wordcount /input /outer
#依旧调用hadoop-mapreduce-examples-3.3.0.jar文件
#后面三个参数:wordcount表示执行单词统计任务;
#指定输入文件的路径
#指定输出结果的路径(该路径不能已存在);
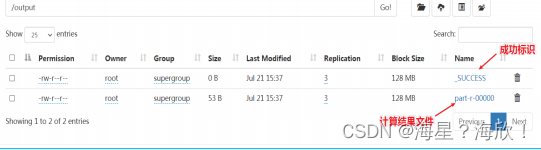
- 查看结果
打开hdfs,点进去ouput,有一个success是成功运行的标识文件,另一个文件显示输出结果
1.4 Map阶段执行流程
Map阶段执行过程:
- 第一阶段:把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。
默认Split size = Block size(128M),每一个切片由一个MapTask处理。(getSplits)
栗子:两个文件,文件a(300M)和文件b(200M),需要3+2个切片,5个MapTask处理 - 第二阶段:对切片中的数据按照一定的规则读取解析返回<key,value>对。
默认是按行读取数据。key是每一行的起始位置偏移量,value是本行的文本内容。(TextInputFormat) - 第三阶段:调用Mapper类中的map方法处理数据。
- 第四阶段:按照一定的规则对Map输出的键值对进行分区partition。默认不分区,因为只有一个reducetask。分区的数量就是reducetask运行的数量。
- 第五阶段:Map输出数据写入内存缓冲区,达到比例溢出到磁盘上。溢出spill的时候根据key进行排序sort。默认根据key字典序排序。
每次结果直接写入磁盘,io次数特别多,所以选择缓冲一下。类似水流打开冲击地面压力大,选择用一个杯子来缓冲,水杯接满一次倒地上一次,载接满再到地上
缓冲区满了—即溢出spill - 第六阶段:对所有溢出文件进行最终的merge合并,成为一个文件。最后合并成一个文件
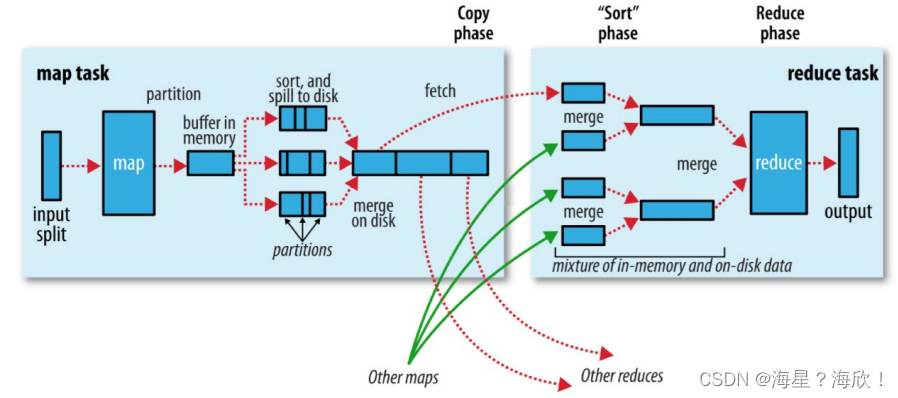
input输入
split切片,几个block数据块几个切片,
memory buffer:缓冲区
spill 溢写:同时sort排序
merge合并成一个文件
1.5 Reduce阶段执行流程
- 第一阶段:ReduceTask会主动从MapTask复制拉取属于需要自己处理的数据。
map运行完后就把数据放在自己运行的本地,是reduce主动出击 - 第二阶段:把拉取来数据,全部进行合并merge,即把分散的数据合并成一个大的数据。再对合并后的数据排序
map阶段有多个maptask,数据从三个地方拉过来,所以需要合并 - 第三阶段是对排序后的键值对调用reduce方法。键相等的键值对调用一次reduce方法。最后把这些输出的键值对写入到HDFS文件中。
copy — 合并排序 — 分组处理reduce
1.6 Shuffle机制
-
Shuffle的本意是洗牌、混洗的意思,把一组有规则的数据尽量打乱成无规则的数据
-
而在MapReduce中,Shuffle更像是洗牌的逆过程,指的是将map端的无规则输出按指定的规则“打乱”成具有一定规则的数据,以便reduce端接收处理
shuffle让数据有序 -
一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。处于下面红框中:
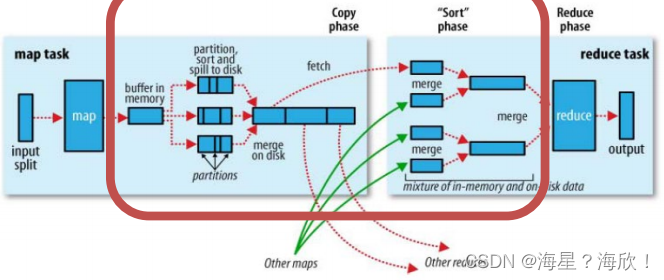
shuffle机制:是核心,但导致慢,慢的原因:数据在内存、磁盘之间的多次往复
- Shuffle是MapReduce程序的核心与精髓,是MapReduce的灵魂
- Shuffle也是MapReduce被诟病最多的地方所在。MapReduce相比较于Spark、Flink计算引擎慢的原因,跟Shuffle机制有很大的关系。
- Shuffle中频繁涉及到数据在内存、磁盘之间的多次往复
相关文章:
Hadoop MapReduce
目录1.1 MapReduce介绍1.2 MapReduce优缺点MapReduce实例进程阶段组成1.3 Hadoop MapReduce官方示例案例:评估圆周率π(PI)的值案例:wordcount单词词频统计1.4 Map阶段执行流程1.5 Reduce阶段执行流程1.6 Shuffle机制1.1 MapReduc…...
时间复杂度和空间复杂度详解
有一堆数据需要排序,A要使用快速排序,B要使用堆排序,A认为自己的代码更高效,B也认为自己的代码更高效,在这种情况下,怎么来判断谁的代码更好一点呢?这时候就有了时间复杂度和空间复杂度。 目录 …...

【C++】面向对象---封装
【C】面向对象—封装 1.封装的意义 封装是C面向对象三大特性之一 封装的意义: 将属性和行为作为一个整体,表现生活的事物将属性和行为加以权限控制 封装意义一: 在设计类的时候,属性和行为写在一起,表现事物 语…...

Docker简介
一、介绍容器虚拟化技术(带环境安装的一种解决方案)打破程序即应用的观念,透过镜像image将作业系统核心除外,运用应用程序所需要的运行环境,由上而下打包,达到应用程序跨平台间的无缝接轨运作。Docker是基于…...
量化学习(一)数据获取
试验环境 windows10 AnacondaPyCharm(小白参考文章:https://coderx.com.cn/?p14) VM中安装MySQL5.7(设置utf8及相应配置优化) 关于复权 小白参考文章:https://zhuanlan.zhihu.com/p/469820288 数据来源 AK…...

java并发编程讨论:锁的选择
java并发编程 线程堆栈大小 单线程的堆栈大小默认为1M,1000个线程内存就占了1G。所以,受制于内存上限,单纯依靠多线程难以支持大量任务并发。 上下文切换开销 ReentrantLock 2个线程交替自增一个共享变量,使用ReentrantLock&…...

大数据框架之Hadoop:MapReduce(三)MapReduce框架原理——ReduceTask工作机制
1、ReduceTask工作机制 ReduceTask工作机制,如下图所示。 (1)Copy阶段:ReduceTask从各个MapTask上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阈值,则写到磁盘上,否则直…...

Nginx的介绍、安装与常用命令
前言:传统结构上(如下图所示)我们只会部署一台服务器用来跑服务,在并发量小,用户访问少的情况下基本够用但随着用户访问的越来越多,并发量慢慢增多了,这时候一台服务器已经不能满足我们了,需要我们增加服务…...

less基础
一、less介绍 1、介绍 是css预处理语言,让css更强大,可以实现在less里面定义变量函数运算等 2、less默认浏览器不识别 less转成csS (框架: less/sass 框架的内置了转码less-css) 3、使用语法 1.创建less文件xxx.less 后缀.less 2. less编译成css 再引入…...
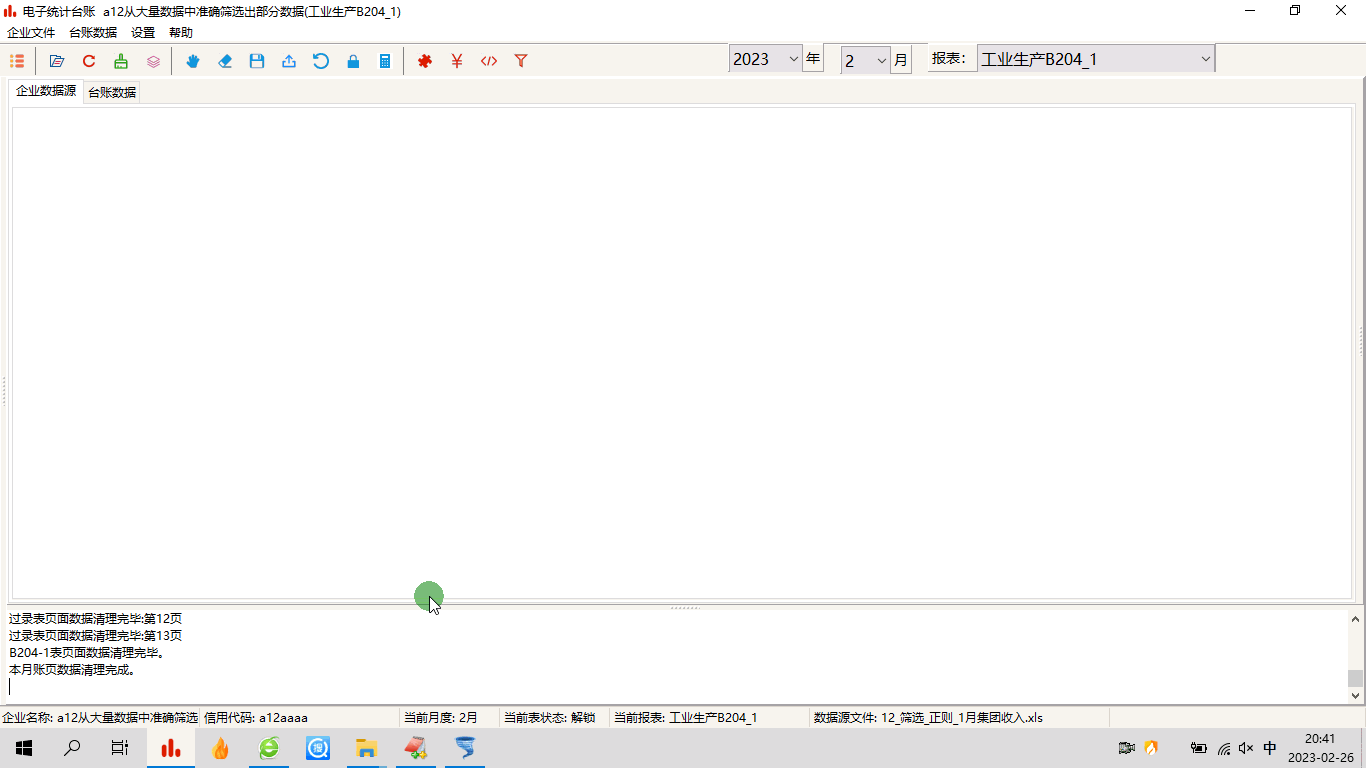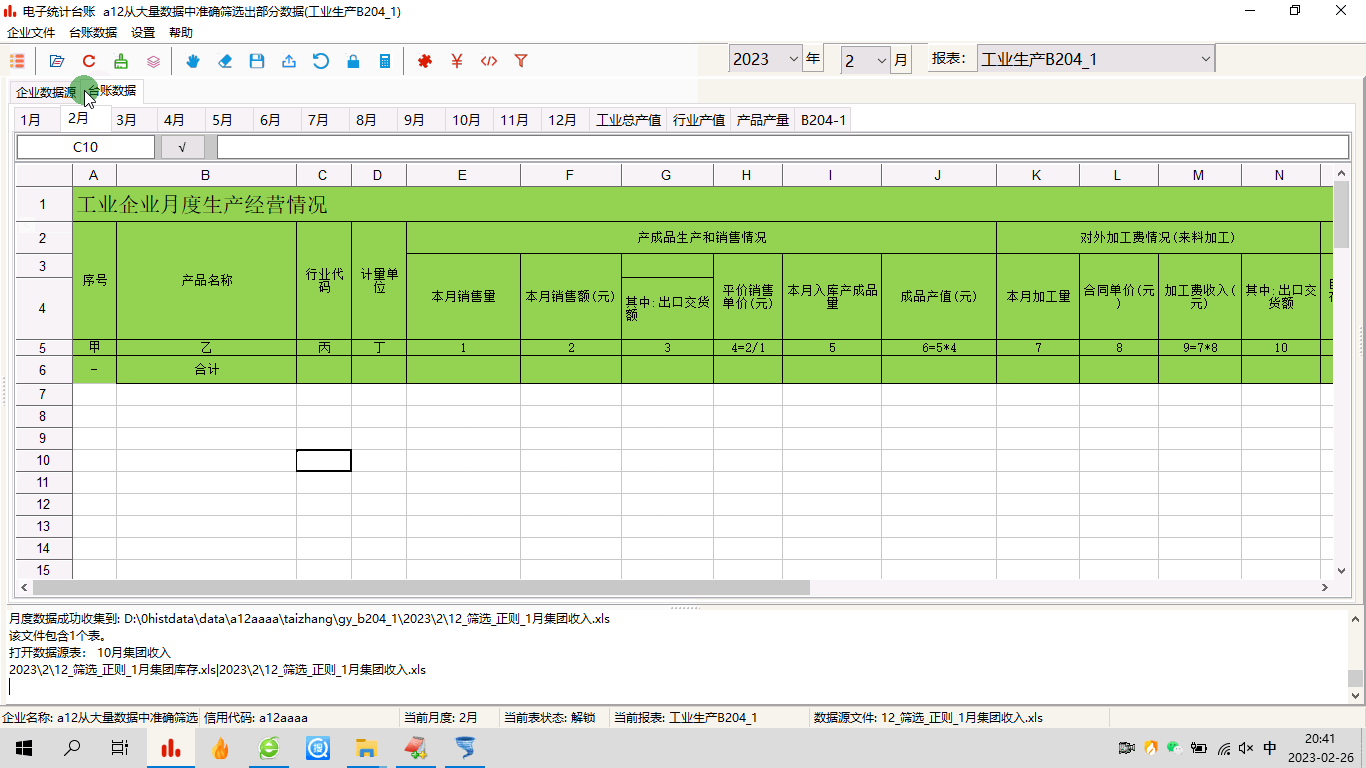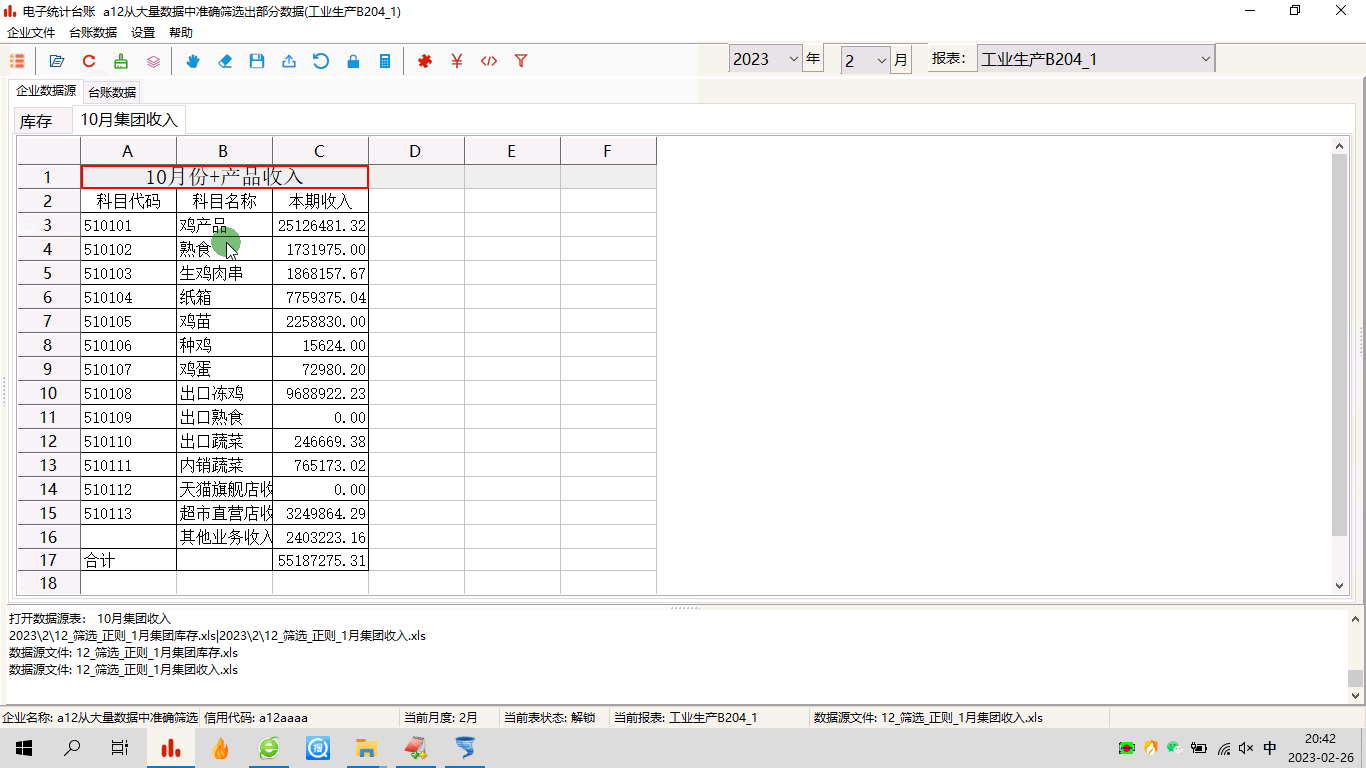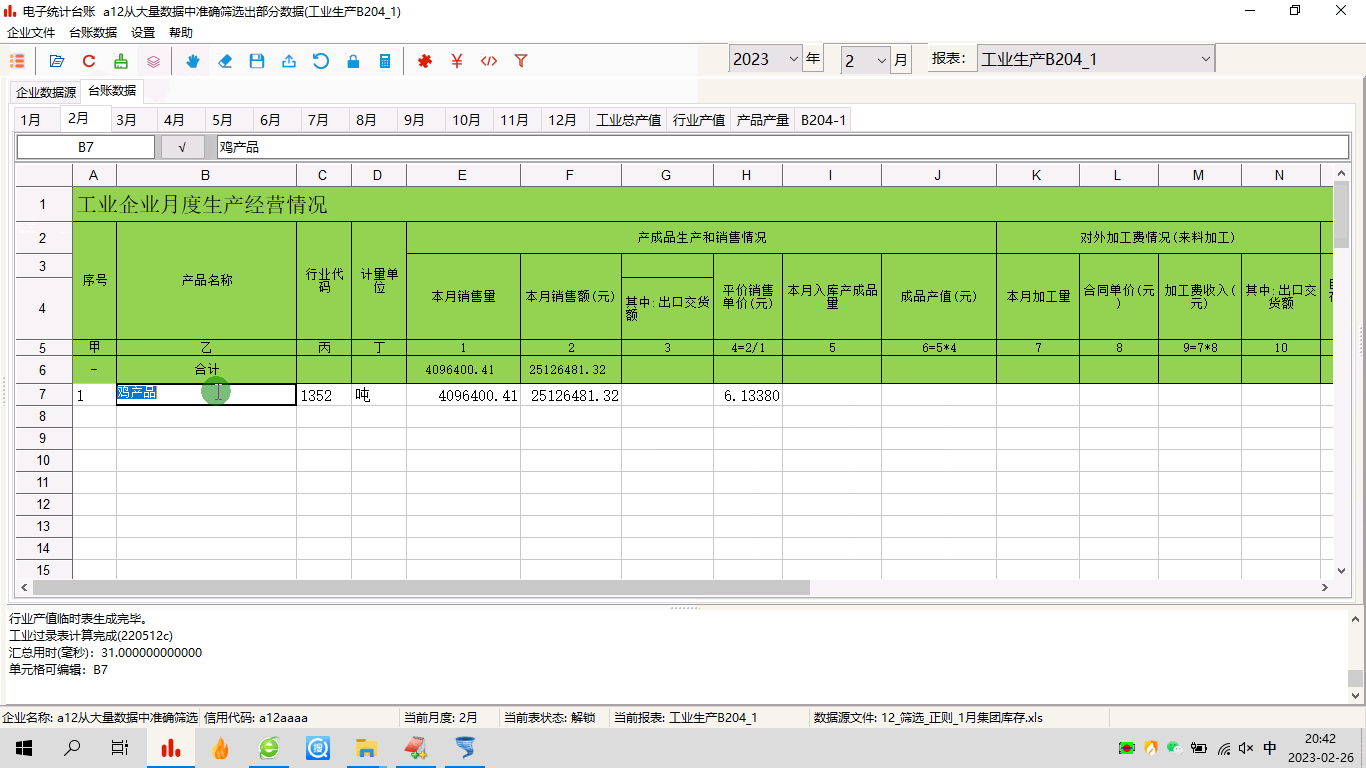
电子统计台账:海量数据中导入特定行,极力减少键盘编辑工作量
1 前言从事企业统计工作的小伙伴,本来已经够忙的了,现在又要加上什么电子台账这种鬼任务,而且居然还要每月来一次,简直不能忍。如果非要捏着鼻子忍了,那么有什么办法,减轻工作量?2 问题的提出有…...
ChatGPT是如何训练得到的?通俗讲解
首先声明喔,我是没有任何人工智能基础的小白,不会涉及算法和底层原理。 我依照我自己的简易理解,总结出了ChatGPT是怎么训练得到的,非计算机专业的同学也应该能看懂。看完后训练自己的min-ChatGPT应该没问题 希望大牛如果看到这…...

刷题28-有效的变位词
32-有效的变位词 解题思路: 注意变位词的条件,当两个字符串完全相等或者长度不等时,就不是变位词。 把字符串中的字符映射成整型数组,统计每个字符出现的次数 注意数组怎么初始化: int [] s1new int[26]代码如下&a…...

JavaWeb中异步交互的关键——Ajax
文章目录1,Ajax 概述1.1 作用1.2 同步和异步1.3 案例1.3.1 分析1.3.2 后端实现1.3.3 前端实现2,axios2.1 基本使用2.2 快速入门2.2.1 后端实现2.2.2 前端实现2.3 请求方法别名3,JSON3.1 概述3.2 JSON 基础语法3.2.1 定义格式3.2.2 代码演示3.2.3 发送异步…...
python爬虫常见错误
python爬虫常见错误前言python常见错误1. AttributeError: WebDriver object has no attribute find_element_by_id1. 问题描述2. 解决办法2. selenium:DeprecationWarning: executable_path has been deprecated, please pass in1. 问题描述2. 解决办法3. 下载了包…...

AI_Papers周刊:第三期
CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理 2023.02.20—2023.02.26 文摘词云 Top Papers Subjects: cs.CL 1.LLaMA: Open and Efficient Foundation Language Models 标题:LLaMA:开放高效的基础语言模型 作者&#…...

在win7上用VS2008编译skysip工程
在win7上用VS2008编译skysip工程 1. 安装vs2008及相应的补丁包,主要包含以下安装包: 1.1 VS2008TeamSuite90DayTrialCHSX1429243.iso 1.2 VS2008SP1CHSX1512981.iso 1.3 VS90sp1-KB945140-CHS.exe 2. 安装Windows SDK: 6.0.6001.18000.367-KRMSDK_EN.zip 例如安装路径为…...

python 数据结构习题
旋转图像给定一个nn的二维矩阵表示一个图像。将图像顺时针旋转90度。你必须在原地旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要使用另一个矩阵来旋转图像。例如,给定matrix[[1,2,3],[4,5&#x…...
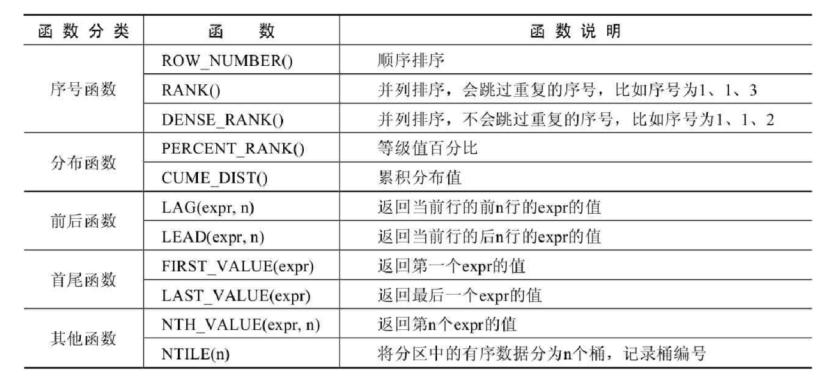
18、MySQL8其它新特性
文章目录1 MySQL8新特性概述1.1 MySQL8.0 新增特性1.2 MySQL8.0移除的旧特性2 新特性1:窗口函数2.1 使用窗口函数前后对比2.2 窗口函数分类2.3 语法结构2.4 分类讲解1 序号函数2 分布函数3 前后函数4 首尾函数5 其他函数2.5 小 结3 新特性2:公用表表达式…...

【Android笔记79】Android之接口请求库Retrofit的介绍及使用
这篇文章,主要介绍Android之接口请求库Retrofit的介绍及使用。 目录 一、Retrofit接口请求库 1.1、什么是Retrofit 1.2、Retrofit的使用 (1)引入依赖...
蓝桥杯 考勤打卡
问题描述 小蓝负责一个公司的考勤系统, 他每天都需要根据员工刷卡的情况来确定 每个员工是否到岗。 当员工刷卡时, 会在后台留下一条记录, 包括刷卡的时间和员工编号, 只 要在一天中员工刷过一次卡, 就认为他到岗了。 现在小蓝导出了一天中所有员工的刷卡记录, 请将所有到岗…...

Chapter03-Authentication vulnerabilities
文章目录 1. 身份验证简介1.1 What is authentication1.2 difference between authentication and authorization1.3 身份验证机制失效的原因1.4 身份验证机制失效的影响 2. 基于登录功能的漏洞2.1 密码爆破2.2 用户名枚举2.3 有缺陷的暴力破解防护2.3.1 如果用户登录尝试失败次…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

基于ASP.NET+ SQL Server实现(Web)医院信息管理系统
医院信息管理系统 1. 课程设计内容 在 visual studio 2017 平台上,开发一个“医院信息管理系统”Web 程序。 2. 课程设计目的 综合运用 c#.net 知识,在 vs 2017 平台上,进行 ASP.NET 应用程序和简易网站的开发;初步熟悉开发一…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...

屋顶变身“发电站” ,中天合创屋面分布式光伏发电项目顺利并网!
5月28日,中天合创屋面分布式光伏发电项目顺利并网发电,该项目位于内蒙古自治区鄂尔多斯市乌审旗,项目利用中天合创聚乙烯、聚丙烯仓库屋面作为场地建设光伏电站,总装机容量为9.96MWp。 项目投运后,每年可节约标煤3670…...

【算法训练营Day07】字符串part1
文章目录 反转字符串反转字符串II替换数字 反转字符串 题目链接:344. 反转字符串 双指针法,两个指针的元素直接调转即可 class Solution {public void reverseString(char[] s) {int head 0;int end s.length - 1;while(head < end) {char temp …...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...